89
Aquatic Bacteria Diagnosis Frank O’Hanlon September 2011 - i -

Aquatic Bacteria Diagnosis
Frank O’Hanlon
September 2011
Dissertation submitted in partial fulfilment for the degree of
Master of Science in Information Technology
Department of Computing Science and Mathematics
School of Natural Sciences
University of Stirling
- i -

Abstract
The Institute of Aquaculture seeks IT expertise and insight to oversee the automation of its
bacteriological diagnosis technique using information collated by the Institute from samples
supplied by clients of the Institute’s diagnostic consultancy service. This will be packaged in
a manner readily usable by the academics of the Institute.
The intention is to construct a product which will capture this diagnostic technique and
allow academics of the Institute opportunity to swiftly conduct their diagnosis via a simple
GUI. The package will be local to the final system, relying on no aspects beyond the user’s
system.
Diagnosis has the form of successively narrowing possibilities within a knowledge base
to determine which bacteriological culture most closely resembles an input. Facility to gain
insight from the data, such as determination of the minimum set of tests to fully best discrim-
inate between remaining cultures, is desired. Embedding costs particular to each test and
factoring these into further recommendations required to pinpoint/move-towards-a-singular
diagnosis is sought.
Automation of the known techniques has been achieved, with significant progress made
on determining, by brute force, the set of tests which are required or recommended to best
distinguish or match the considered culture to one (or some) in the knowledge base. An ef-
fective, if unadorned, user interface has been implemented with avenues opened both in code
and in discussion as to how functionality may be improved and extended. Finally, sugges-
tions are made as to other vectors which may be considered in implementation.
- ii -

Attestation
I comprehend the nature of plagiarism and the ramifications breach of University policy may
have.
I affirm that the project herein is my own work, informed only through frank and
open discussion, by the research and reading conducted in the course of preparation,
implementation and review of this project. Sources and references are identified with further
inspiration and influence being drawn only with the fullest integrity.
Signature Date
- iii -

Acknowledgements
It is my foremost pleasure to humbly thank Dr Andrea Bracciali for his insight, input and
patience in supervision of this project. I would additionally thank the alumnus Ms Christine
Gannon for her immense hospitality during the course of the project and additional thanks to
those whose financial support ensured this project was possible; alumnus Mr Joseph
O'Hanlon, Ms Betty-Helen McMeikan and the Students Awards Agency for Scotland.
Further thanks goes to Dr Mags Crumlish for proposing the task and providing invaluable
insight throughout.
- iv -

Table of Contents
Abstract................................................................................................................................ii
Attestation...........................................................................................................................iii
Acknowledgements.............................................................................................................iv
Table of Contents.................................................................................................................v
List of Figures...................................................................................................................viii
1 Introduction.....................................................................................................................1
1.1 Scope and Objectives..............................................................................................1
1.2 Background to Diagnosis........................................................................................4
1.3 Technical Needs......................................................................................................7
1.4 Technologies and Relevance...................................................................................7
1.5 Overview of Tools & Technology...........................................................................8
1.6 Executive Summary................................................................................................8
2 Background & Foundations..........................................................................................10
2.1 Existing Products and Contemporary Work..........................................................10
2.2 Data Structures & Non-trivial Optimisation.........................................................12
2.3 Proposed Implementation......................................................................................15
2.3.1 A0: Activate Diagnostor...................................................................................15
2.3.2 A1: Enter Test Input.........................................................................................16
2.3.3 A2: Move Back................................................................................................16
2.3.4 A3: Reset..........................................................................................................16
2.3.5 A4: Conduct Diagnosis....................................................................................16
2.3.6 A5: Select a Cost Preference (unimplemented)...............................................16
2.3.7 A6: Exit Diagnostor.........................................................................................16
2.3.8 Other Cases & Function...................................................................................17
2.3.9 Sample Story-Board & Class Diagram............................................................17
2.4 Nature of the Underlying Data..............................................................................18
2.5 Capturing the Expert Insight.................................................................................20
2.6 Initial & Established Brief.....................................................................................21
3 Specification & Solution...............................................................................................22
3.1 Requirements.........................................................................................................22
3.1.1 Notes on Long-term Requirements..................................................................22
3.1.2 Requirements of the Project.............................................................................23
- v -

3.2 Assumptions..........................................................................................................24
3.3 Data Cleaning & Manipulation.............................................................................25
3.4 Review of Algorithms...........................................................................................26
3.4.1 The Diagnosis Algorithm.................................................................................26
3.4.2 Recommendation Algorithm............................................................................26
3.4.3 Recommendations with Cost Algorithm..........................................................27
4 Implementation & Function..........................................................................................28
4.1 Solution Achieved: A Working Core.....................................................................28
4.2 Walk-Through: Use of the Mk0 Diagnostor..........................................................29
4.3 Towards Developer Testing...................................................................................34
4.3.1 Extremes & Boundary Testing.........................................................................34
4.3.2 Notable Errors & Malfunctions........................................................................35
5 Evaluation.....................................................................................................................36
5.1 Critical Review of the Mk0 Diagnostor................................................................36
5.2 What was not achieved..........................................................................................36
5.3 Deployment Solution.............................................................................................37
5.4 Reflection on User Feedback................................................................................37
6 Conclusion....................................................................................................................39
6.1 Approach...............................................................................................................39
6.2 Deployment...........................................................................................................39
6.3 Future Work..........................................................................................................39
6.3.1 Expanding the Diagnostor................................................................................40
6.3.1.1 Incorporation of Costs into the Recommendation Algorithm.................40
6.3.1.2 Reading/Writing to a free-standing Knowledge Base..............................40
6.3.1.3 Proper representation of all test options (beyond positive/negative).......40
6.3.1.4 Non-linear entry of test inputs..................................................................40
6.3.1.5 Controlling Level of Detail......................................................................41
6.3.1.6 Development of the Diagnostor by other means......................................41
6.3.2 Applying IT solutions to the Institute’s knowledge resources.........................41
6.4 Concluding Remarks.............................................................................................42
References..........................................................................................................................43
Bibliography.......................................................................................................................44
Appendix A: Installation Guide..........................................................................................45
On Maintenance.............................................................................................................45
Appendix B: User Introduction..........................................................................................46
Under the Bonnet...........................................................................................................46
- vi -

Appendix C: User Guide....................................................................................................47
Appendix D: Legal Note – Institute of Aquaculture & Data Protection............................48
Appendix E: Questionnaire................................................................................................49
Appendix F: Questionnaire Responses..............................................................................50
- vii -

List of Figures
Figure 1. Sample Knowledge Base.......................................................................................2
Figure 2. Example Test Results............................................................................................2
Figure 3. Matching for culture C1........................................................................................3
Figure 4. Matching for culture C2........................................................................................3
Figure 5. apiweb glimpse #1 [4].........................................................................................10
Figure 6. Demonstration input screen from apiweb [4]......................................................11
Figure 7. Demonstration output of apiweb [4]...................................................................11
Figure 8. Extract from: F psychrophilum biochemical database.xls..................................12
Figure 9. Sample of the embedded Knowledge Base.........................................................12
Figure 10. Back from the Drawing Board........................................................................14
Figure 11. Sample Storyboards........................................................................................17
Figure 12. Proposed Class Diagram.................................................................................18
Figure 13. Figure 1Class Diagram Solution.....................................................................22
Figure 14. Initial GUI View..............................................................................................29
Figure 15. Seven Inputs Entered.......................................................................................30
Figure 16. All 26th in!......................................................................................................31
Figure 17. Diagnosis and Recommendations...................................................................32
Figure 18. Figure 2 Raw KB............................................................................................32
Figure 19. No Matches.....................................................................................................33
Figure 20. Singular Match................................................................................................33
Figure 21. The Trivial Case..............................................................................................35
- viii -

1 Introduction
Herein serves as a review of the problem, established and informed by discussion and feed-
back with the Institute of Aquaculture.
1.1 Scope and Objectives
From the outset, four particular objectives have been in mind with regards to the diagnosis
package, which is henceforth referred to as the Diagnostor.
These objectives are outlined as follows:
I. Use inputs supplied by user to achieve diagnosis
II. Maintain and add to the knowledge base
III. Functional user interface
IV. Advise further tests to narrow diagnosis
Two additional functionalities had been originally considered but were largely dropped as
core concerns:
V. Implement Administrator and Inquirer user-types.
VI. Alter the accuracy of any given diagnosis.
To give these four principles some context, it is sensible to first consider the mechanical
aspect of diagnosis itself, as conducted by the Institute.
Consider that Figure 1 represents a condensed ‘knowledge base’ held by the Institute. Its
rows identify a given culture, its columns correspond to biochemical (and other) tests
conducted by the Institute on each culture. Thus each individual cell marked by a test and a
culture corresponds to the result of a specific test on a specific culture1.
1 Strictly speaking, the complexity of the KB supplies by the institute is almost exactly this. The column ‘Culture’ is subdivided to the Genus name, Flavobacterium psychrophilum, whilst also being appended with a strain ID. There is some nuance involved here but it is covered later when discussing Data Cleaning & Manipulation.
- 1 -

Figure 1. Sample Knowledge Base
The Institute will then receive samples2 and begin the process of conducting their suite of
regular tests on the sample. There are six tests, known as primary tests, that are conducted to
identify the genus of the bacteria sample considered, these are conducted in advance of all
other (e.g. biochemical, molecular) tests3. Further to this, the suite considered originally is
composed of twenty further tests, meaning twenty-six tests in total are utilised in the analysis.
The tests results for such samples can be readily encapsulated as in Figure 2:
Figure 2. Example Test Results
So, for a given sample, say, the culture C1, it is seen that only tests 1, 2 and 3 have been
conducted. The remainder are as-yet unknown4. Similarly, culture C2 has only tests 1,2,6 and
7, with C3 having tests 2-5. By visual inspection it is relatively easy to check these samples
against the KB. Allowing that “/?” can mean a test can be either “+” or ”–“, Figures 4 and 5
plainly demonstrate the ‘match’ mechanism visually for cultures C1 and C2. ( Examining the
KB for C3 you will see that its supplied tests do not wholly match anything in the sample KB
seen in Figure 1.)
2 It is rare that the Institute receives actual test results directly from a customer; for the most part actual, living samples are collected and tested.
3 These tests are, Gram, Shape, Oxidase, Motility and Fermentation. For Gram and Oxidase, they have positive/negative result forms, whereas those remaining have their values being more elaborate still, e.g. shape is, for Flavobacterium psychrophilum,
4 As the institute typically conducts the entire suit of tests, this aspect is introduced somewhat arbitrarily, to allow for the case that only some tests are conducted, even if this is not common or would represent only a transitory state in the Institute’s information. (E.g. if still waiting for the other test results to be obtained.)
- 2 -

Figure 3. Matching for culture C1
Figure 4. Matching for culture C2
Very briefly: C1 matches a singular culture in the KB, Culture A. C2, however, could be
culture A or culture B: more tests must be conducted to discover which it is!5
In essence, however, it is this simple ‘by eye’ manual inspection by which the academics of
the Institute have been making their diagnoses. This, plainly, is a somewhat trivial and tedious
exercise in pattern matching: humans can easily make mistakes or, worse, get bored and dis-
tracted. Better, surely, to utilise everyone’s mechanical silicon-based friends whose innate abil-
ities are much better suited to such an endeavour.
To that end the primary objectives are then clearly:
I. Obtain inputs from the user to obtain a diagnosis to one of three possibilities:
i. Single match, as for sample culture C1
ii. Multiple matches, as for sample culture C2
iii. No matches in the knowledge base, as for sample C3.
II. Maintain and add to the knowledge base allowing academics to keep their records up
to date.6
5 It is expedient here to note that in the case of Culture C2, distinguishing whether it matches to A or to B (or to nothing our KB knows of) offers the options of tests 3, 4 and 5. However, the result for test 4 and 5 are the same: - for A, + for B, this is a minor aspect of a much larger problem in concocting the recommended tests given by the Diagnostor: several tests may offer the same information, so only one of those ‘equivalent’ tests need be conducted to narrow within the KB. (Note, trivially, for only two possibilities, only one test is needed to be conducted. A hypothetical test 8 could be considered which may have, like tests 1 & 2, + and + for both A and B: conducting this mystery test 8 would be fruitless for the endeavour!)
- 3 -

III. Functional user interface to speedily and intelligibly enact user desires and convey
results.
IV. Advise further tests to narrow diagnosis in the case I.ii corresponding to culture C2.
1.2 Background to Diagnosis
Now that the problem is set, it is worth establishing the real-world context and need underpin-
ning this project.
The Institute of Aquaculture offers a commercial diagnostic consultancy service
worldwide[1]. They offer a wide range of services, notably in taking aquatic samples, typically
fish, on behalf of their clients and in doing so apply a 'suite' of twenty standard tests. The
sampling is typically enacted to check for the presence (and then diagnosis) of specific
bacteria strains7. There are six particular tests whose results will, for the bulk of the Institute's
work, constrain the given sample to a specific, particular genus. Within this genus, the
aforementioned suite of twenty tests can then distinguish to a particular strain.
The Institute conducts these tests themselves on campus. Once the results are collected the
academic in question will then 'compute' the results by hand: literally observing the tabled
results and checking them off one by one. This can be considered a tedious job, one which is
readily handled by information technology8, hence the request for computing insight into
resolving the issue.
Moreover, it is noted that this diagnostic service is a commercial endeavour. As with most
such endeavours, there is a manifest interest in reducing costs and efficiently using resources.
It is doubtless the case that the Institute's academics are a valuable resource and, therefore, so
6 It should be re stated that this objective was not achieved in the project and is therefore only given cursory treatment and exploration.
7 As noted in 1.1, the Institute identifies bacteria cultures first by six Primary Tests, which reliably identify the given Genus, whilst then conducting a suite of secondary tests which aide in the pinpointing of which Strain is being handled. This hinges on the scientific classification of organisms in biology. By the International Code of Zoological Nomenclature[2] there are seven nested classes here listed in increasing specificity: Kingdom, phylum/division, class, order, family, genus, species. In this manner, when Strain is discussed, it of course refers to a sub-member of a species of bacteria.
8 Pattern matching is well covered in IT. Most users will be intimately familiar with crtl+f ‘Find’ searches within a document; the what is desired within this project, by encapsulating that which the academics already do (but faster), is to extract information from a given KB and set of inputs and combine these sources in such a way as to readily facilitate the application of whichever pattern matching method is most desired. Though, of course, human cognitive ability in pattern matching is still rather readily more advanced/complex, as the still efficacious CAPTCHA tests show, such advanced aspects are not utilised in the task at hand.
- 4 -

is their time. If a package could be developed which would minimise the time an academic
spends on any given consulting diagnosis, then there is a clear benefit to be reaped.
There are further benefits relating to this focus, prominently: the potential to reduce the
costs as offered to the clients: if the process of diagnostic consultancy consumes less of the
Institute's resources, it is possible that the cost of offered services may be reduced.
Alternatively, or indeed additionally, there is the likelihood of increased throughput on the part
of the Institute. It would require the time taken to compute the diagnosis to be a significant
concern, of course, which is not strictly given, but if the specific details of the proposed
Diagnostor bear fruit (especially the ability to recommend only the minimal further tests
necessary to achieve a diagnosis within a KB), then it is not at all inconceivable that this could
improve efficiency overall.
The Institute of Aquaculture has collected a large and comprehensive bacteriological
knowledge base which constitutes a very desirable resource. As will be discussed in Section
2.1, it is the case that modern commercial diagnostic packages are both expensive and ill-
suited to the Institute’s purpose: they have their own knowledge base and their own routine for
managing the consulting of it. As this is the case, the Institute has a clear interest in trimming
time spent by its academics in unnecessarily computing diagnoses when there are other
approaches which may be both quicker and, potentially, more reliable9.
Through discussion with the Institute, it is plain that there are several primary factors
involved in the diagnosis process. The first and most involved is the actual cultivating of
cultures, the application of the tests in correct manner and the collection of the results. This
'labour time' is an accepted part of the process and is not something that is within the remit of
the project. Nevertheless, arbitrary data has been formed to illustrate how simply connecting
the knowledge of the time spent on each individual test could be incorporated into the
Diagnostor and factored into some of the decisions which, without it, may be made on other
information or, indeed, wholly arbitrarily (see section 3.3: Data Cleaning and Manipulation).
Concluding that consideration, there are two other factors concerned with the process. The
first follows tangentially to the first's labour costs: the delay involved. Cultivating cultures to a
suitable point where test results can be achieved is likely an involved process. Though
typically the established suite of packages is conducted as routine by the Institute, it is not
unthinkable that, given some redundancy in which tests are needed, corners could be rightfully
9 A major feature of the early development of the Diagnostor was musing on the nature of the knowledge base and how it was maintained by the Institute. Though the Diagnostor fails to accommodate the maintenance of the KB, that remains an outstanding IT problem for further work in this field: the KB must be managed in a sensible manner with fairly rigorous standards applied throughout so as to encourage capitalisation and exploitation of the information resources they have assembled for themselves.
- 5 -

cut if the redundancy is not desired. Though it is repeated elsewhere, it is best to be secure on
this point:
Consider two hypothetical tests, Alpha-Ted and Beta-Dougal. If, having conducted
and diagnosed for several preceding tests, the knowledge base allows it to be
diagnosed to a selection of, say, four cultures, these two tests remain to be conducted.
But, both Alpha-Ted and Beta-Dougal, make the same predictions! E.g. if a particular
culture is indeed to be diagnosed, both Alpha-Ted and Beta-Dougal will give the same
result when conducted, regardless of which culture is actually present.
Or, more bluntly, both Alpha-Ted and Beta-Dougal will allow the same level of
discrimination between the four cultures. (Unless, trivially, they eliminate: none of the
four cultures match the input, meaning the input doesn't match our existing
knowledge.) Only one is needed to ‘best’ distinguish between the four cultures.
This problem and proposed solutions are discussed in more detail later, but it serves to
illustrate a pressing point with regards to the diagnosis process: though the tests Alpha-Ted
and Beta-Dougal remain to be tested, they are not both required to arrive at the best answer the
knowledge base could yield. That is the central issue arising from the redundancy of tests:
once some new knowledge is obtained about a client's sample, the already-assembled
knowledge base can be seen to allow improved efficiency.
A final concern raised by the diagnosis process is, essentially, an ethical one. Diagnosis of
bacteria, whilst so far regarded as a scientific endeavour with some commercial ramifications,
is highly important to the well-being of the ecosystems where these bacteria dwell. Though
commonly the Institute deals with farmed-fish populations (certainly that is the relevance of
the base this project worked with primarily: Flavobacterium psychrophilum), where disease-
causing bacteria can cause havoc, there is a wider health interest beyond the immediate well-
being of the fish; notably those dependent on it. Austin and Austin, 1993 support the serious
repercussions of this view:
“It is apparent that most attention has been devoted to diseases of farmed fish species.
Perhaps not unnaturally the reasons reflect the high value of the stock, and he serious eco-
nomic importance of losses attributable to bacterial fish pathogens” [3]
Though it hardly needs stating: the efficient, concise and reliable diagnosis of potentially
harmful bacteria (and the attendant knowledge gained in general) will surely go some way to
improving the quality of life of all those concerned; the web of concern spreads, even if at
least by gossamer tangibility.
- 6 -

1.3 Technical Needs
The package utilised previously by the Institute is the clinical diagnostic apiweb product
which was offered by bioMériux[4]. The Institute has long since disavowed itself of this
service, notably because the interface was purportedly clunky, unclear and generally offering
too many options beyond their own concern. That said, it suffices as a typical complaint:
existing clinical diagnostic tools are not suited to the Institute's particular needs.
1.4 Technologies and Relevance
As best can be surmised, the apiweb interface is precisely that, a web-hosted interface
which allows communion with, perhaps, a PHP script which in turn consults the relevant data-
base sustained at server-side, or likely separate from the client. Though a web-hosted mechan-
ism was considered (and indeed is still entirely viable: the diagnostic algorithms can surely be
translated to similar functioning SQL queries), the decision to focus on a user’s desktop ap-
plication seemed most sensible.
The choice of programming languages to be considered was quickly narrowed to Java and
Python: Java for simple expedience and familiarity, Python for its reputed strength in handling
and manipulating high-level data structures. Though progress was made in learning Python,
some setbacks and delays, notably in obtaining the relevant data, meant that progress was
largely made unguided and somewhat unfocussed whilst other aspects of the project were
being established.
Both Java and Python offer ready portability, Java was held to as being most widely
accessible and the most convenient to begin with. With elaboration (see sections 2 & 3) made
on the potential design ‘in the long run’, it was then plain that initial progress on a Diagnostor
to provide to the Institute would have to constitute a ‘proof of concept’ or ‘core’ to any larger
project tool. Design considerations supported this, leading to the somewhat poorly organised
three classes assembled which constitute the Diagnostor and effective KB.
As this is thought to be a core module, a further strength in the selection of Java is thought
to be the relative neatness with which prior-familiarity would allow code to be prepared. In the
case that the Diagnostor proves useful and attractive, which is indeed what is hoped, further
development from this basic package should be easily facilitated.
Tangentially, it is also worth noting the rejection of other more potent mechanisms for
matching and analysis: as the method already used for diagnoses by the Institute is so simple,
proper exploration of, say, case based learning or more detailed techniques, such as composing
the Institute’s KB into something upon which data mining techniques may be applied were
largely dismissed early on as being particularly fanciful given the relative simplicity of the
problem. Though they are potent and applied to more general diagnosis problems, it was clear
- 7 -

that capturing the expert’s own method would be the primary concern; progression beyond
that could wait.
1.5 A View of Tools & Technology
Broadly, only the Java Virtual Machine is particularly required to engage the Diagnostor. It
was developed primarily in Eclipse, though BlueJ was used on odd occasion. As the KB was,
unfortunately, hardwritten into the code of the Diagnostor’s KBBoundary class, there is evid-
ence of the facility in the code, allowing any who follow in these footsteps to see the prepara-
tions made for allowing the KB to be read, say, from a .csv file. As there was (what is thought
to be a minor) hiccough in the road to establishing the file reader and writer aspects, the Dia-
gnostor as it stands is very much a stand-alone package.
Of the potential complexities afoot, it was found that most of the academic hurdles could
indeed be solved with effectively simple IT concepts: single- and two-dimensional arrays, in-
teger, string and Boolean data types, nesting of arrays and the correct arrangement of paramet-
ers. Though this leads to some unwieldy or inelegant code in places, it is nonetheless effective
and, with application of good software development practices in indentation and sensible nam-
ing conventions and so forth10, it is hoped to be readily extended. The text “Data Structures
with Java” was very widely consulted in this regard[5].
1.6 Project Summary
With the problem of diagnosis of aquatic bacteria established, the aim of a maintainable KB
accessed through a GUI, which is queried and offering advice for further tests based on the
knowledge (and input) given having been presented, the Diagnostor itself falls under inspec-
tion.
The elements of the KB are held as identified Strains with fully complete tests listed for
them. Further to this each strain has a name (in this case “Flavobacterium Psychrophilum”)
and a Strain ID. The KB supplied by the institute has been padded with hypothetical (and ar-
bitrary) cost values, notably for Financial, Delay and Labour concerns. The test ‘columns’ are
headed by their test name and have each one of the three respective costs as well as a result for
that test corresponding to each strain held in the KB. The KB is held directly in the KBBound-
ary.java file as the maintainable aspect of the Diagnostor has not been achieved.
10 It is mused that the most perplexing of the names are those of the objects afoot in the Diagnostor. The instance of the Archive class we’re concerned with is denoted “biscuityKnowledge”. This stems from Swede Mason’s “Masterchef Synesthesia”[6] which interfered with progress from time to time, any time the word ‘base’ was considered. That is: that buttery biscuit base.
- 8 -

The approach taken is to accurately discern and model the process of diagnosis conducted
by the Institute’s academics and produce a GUI which should greatly speed up that process.
As such, inputs can be taken in the form “?”, “+” or “-“ relating to whether a given test is
unknown/undeclared, positive or negative. For the twenty-six tests (six primary, twenty bio-
chemical/molecular) an input is declared and diagnosis is conducted. The GUI is then updated
to correspond to the three possibilities: single match, multiple match or no match. This has
been achieved.
The algorithm for determining which recommendations are to be given transpired to be a
non-trivial problem in optimisation and, as such, the progress which has been made, indeed
discerning the precise problem and the computing complexity required to achieve it is viewed
as a particular (albeit partial) success of the Diagnostor.
It is delivered as a Java application, ran in suitable environment such as Eclipse. Design
notes and consideration accounting for the form, nature and decisions made will be covered in
more technical depth in the remainder of this report.
The Diagnostor is far from a complete package suitable for ready exploitation by the Insti-
tute, but it stands as a ready package, a genuine proof of concept that with further development
and consideration it could be expanded to prove a functional and viable tool. In essence, it is a
satisfactory demonstration of the efficacy of the approach, its nature and realisations readily
reapplied to alternative deployments as necessary or desired.
- 9 -

2 Background & Foundations
It is noted that existing tools are either ill-suited or not easily reapplied to the problems faced
by the Institute for Aquaculture.
2.1 Existing Products and Contemporary Work
The Institute for Aquaculture’s concern is, unsurprisingly, aquaculture. Though many bacteria
are flung widely in nature, being essentially ever-present, the established packages are tailored
too closely to mammalian and, more specifically, human bacterial strains. Though they can
provide some information, their tests are conducted in, for aquaculture purposes, overwhelm-
ingly the wrong environment. Temperatures and pressures in water will be distinctly separate,
it is asserted by the Institute, that many bacteria give widely different responses when subject
to different environments; in effect the tests conducted and the knowledge assembled is not
widely useful in its reapplication to the aquaculture environments of concern to the Institute.
Figure 5. apiweb glimpse #1 [4]
As can be seen in Figure 5, this product the apiweb, which the Institute had previously used
is operating on a largely different level and accessing a differently formatted KB: the dimen-
sionality and variation needed to cluster profiles as in Fig. 5 is indeed significantly more com-
plex than needs discussing, apiweb is thus already offering a complexity which is wholly un-
- 10 -

necessary. (This is compounded by the database used being likely invalid for the aquaculture
environment.)
Figure 6. Demonstration input screen from apiweb[4]
Figure 7. Demonstration output of apiweb[4]
- 11 -

Figures 6 and 7 give an indication to the nature of the process involved in using apiweb:
use by a non-specialist is not obvious given the problem already outlined. Though it is shakily
inferred, it does support the idea related by the Institute that the product was not exactly well-
suited to their purposes.
2.2 Data Structures & Non-trivial Optimisation
It is worth considering the manner in which the KB was to be stored and utilised within the
Diagnostor. Though supplied as an Excel-prepared database of the form:
Figure 8. Extract from: F psychrophilum biochemical database.xls
Enzymes Control alk C4 C8Culture recoded id neg pos var var
Flavobacterium psychrophilum 1 - + + +Flavobacterium psychrophilum 1a - + + +Flavobacterium psychrophilum 1b - + + +
It was hoped that, by converting to .csv format the file could be read directly. As has been
noted before, this was not achieved within the project and instead it was hardwired as a two-
dimensional String data type array (albeit padded with some extra information, see Section 3.3
for further information):
Figure 9. Sample of the embedded Knowledge Base
Care was taken to ensure that the kbProxy was dimensionally correct, that the length of all
its rows and all its columns were consistent (as variation in these, though permitted in Java,
would require detailed fine-tuning in the management of sizes as they progress through the
Diagnostor). This kbProxy is held in the KBBoundary class, where it would be intuitively ex-
pected that any KB being read from outside the Diagnostor itself would enter into it.
As the KB is now principally encoded as an NxM array, loosely corresponding to N cul-
tures and M tests (strictly these are slightly larger, as the costs, names, IDs and so forth must
be padded in suitable places). However, the immediate intent was then to vivisect the kbProxy
and translate it into several smaller, ostensibly relational, knowledge bases:
Names corresponding to the tests. 26-long 1D array String
Names corresponding to the cultures. 74-long 1D array String
- 12 -

IDs corresponding to the cultures. 74-long 1D array String
Each of the costs for the tests. 3x26 2D array Integer
The cultures and their test results. 74*26 2D array Boolean11
Non-rectangular options for tests 26*variable array12 String?
As the data structure discussed is primarily arrays, this raises some other considerations.
Foremost is the manner of organisation and managing the associations of these arrays. It is
clearly seen that the two main ‘keys’ for the knowledge base would, discursively, be ‘Tests’
and ‘Cultures’. Provided the indices for these are tracked and that the padding/management of
the arrays is adhered to consistently (and is not so esoteric as to be unmanageable by anyone
else who observes the inner workings of the Diagnostor; that they are managed as intuitively
as possible), then these structures will be well managed.
Similarly, when it came to considering a GUI, use of the names corresponding to tests to be
input, the names of cultures (when reporting diagnosis) and so forth was particularly useful:
again, allowing for consistency and intelligible inference based on consistent use of indices
was well rewarded.
A second consideration on the point of arrays is that this effectively disallows some poten-
tially more intriguing data structures.
As the method of diagnosis is effectively similar to classification, the temptation was there
implement a class which itself not only analyses the KB, but essentially dissects it and uses the
components to form wholly new data structures, such as a manner of decision tree which
might be applied to the entire dataset. In that way, any queries input by the user might take the
form of progression through a tree rather than being forced to input (or skip by use of “?”)
each and every test. Close analysis of the KB given clearly shows that many of the tests are
not entirely relevant once you have some matches established, as such the KB does lend itself
towards this perhaps innovative system.
11 This is enforced by choice in this instance of the Diagnostor. In the KBBoundary class the method actually used in our solution translates from textual input, including non-binary values like “l” (rod shaped) or “pig yellow” (a culture’s appearance at 15⁰C). As the entries in the source KB are uniform, this core process of the Diagnostor simply treats these values as “+”, or, strictly: True. (Where “-“ corresponds to False.)
12 This is never implemented in the Diagnostor: the fifth ‘row’ of the array kbProxy is assiduously avoided. A mechanism of splitting each element was entertained, as noted by the internal separator ‘;’, e.g. as “+,-“, “l;o”, “WG;?”, thus allowing the potential options to be ‘read’ from the inbound KB. This is of particular use in the Primary Tests whose values are not always simply positive/negative, but which can be quite varied. Standardising for, or at very least comprehending the nuance and working around these and incorporating them is a surely important, but was not explored in this instance of the Diagnostor.
- 13 -

As the project’s KB has been formed from only one of the Institute’s data sets, that is the
database “F psychrophilum biochemical database.xls” supplied, the decision was taken early
on to stick to the ‘crude’ method of manipulating arrays; the potential nuance of further sets
was not known and, as had additionally been committed to early on, the intent was to first rep-
licate and automate the existing method conducted by the academics. As such, tree approaches
(and even the use of lists rather than arrays) were largely dismissed, mainly because it was ex-
pected that brute force and arrays, simple tools, would be quite sufficient for the task.
This optimism confidence was, perhaps, misplaced. It became apparent rather quickly that
the idea of determining the set of ‘recommended tests’ needed to narrow a multiple-match res-
ult would be a non-trivial optimisation problem. Though, for effectively small numbers and
low dimensions, the problem is still managed by brute-force, it is not exactly efficient. Or aes-
thetically pleasing, as Figure 10 indicates.
Figure 10. Back from the Drawing Board
Figure 10 relates a brief glimpse of the method of determining recommendations. It hinges
on narrowing the knowledge base: knowing that, once some tests are input, those aspects can
be neglected and that, having made a diagnosis to more than several cultures (S1,S5, S7 & S8
in Fig.10), the possibilities for remaining unconducted tests can be used to inform progress.
That said, in such cases some tests will not be useful, the possible answers, if conducted, could
be fruitless, they could all be “+” (as the case for Test 3 when compared against S1,S5,S7 &
- 14 -

S8). The steps involved are conceptually a tad difficult, but already strongly hint that only a
vague familiarity with discrete mathematics could be crippling or, at best, embarrassing in
formalising this aspect of the problem...
First the ‘profile’ for each remaining test (the results for each diagnosed culture) must be
determined, then it must be analysed for homogeneity. If it is not homogeneous then it should
be grouped (if possible) with other tests...because some tests might yield the same possible an-
swers (and thus be said to be “equally discriminating” for the cultures we’re still considering
to narrow down)! And, once they are grouped together, only one need be selected from each
group for the recommendation.
But, before conducting the analysis, the number of groups of equally discriminating tests
and the number of discriminating tests themselves (if any) are not readily known.13
2.3 Proposed Implementation
Though a hope was made early on in conceptual development to allow for two user types, an
Administrator (who could manipulate the KB as well as consult the Diagnostor) and an In-
quirer (who could only consult the Diagnostor, without executive ability to alter the KB), the
inability to manage direct access of a stand-alone KB separate from the Diagnostor itself
meant this was swiftly relegated from concern. As such, the Actor for conventional purposes is
now a generic Inquirer, someone who has the ability to access the Diagnostor’s functions via
the graphic user interface, but who is effectively separated from the KB.
It is then viable to consider the possible use cases of such an Inquirer.
Actor: Inquirer
2.3.1 A0: Activate Diagnostor
The Inquirer is able to commence the running of the program, then to be allowed access to the
initial GUI and further options.
2.3.2 A1: Enter Test Input
The Inquirer, for most stages of the GUI except when all inputs have been assembled (e.g.
after inputting the final test value), will have the option to select a suitable input value for a
13 There are alluring corollaries here: that the possible groups can never be greater than the number of tests involved (and even at most, equal numbers, each group would contain only one test), also that homogeneous tests can be safely discarded – either they will support the diagnosis without narrowing, or they will invalidate the diagnosis and say that the KB has no knowledge of such a strain.
- 15 -

test (which will be sequentially entered). By pressing the button, they will communicate their
choice to the GUI which will store it properly. At each stage a test input is added to set I[t] (in-
puts with each value corresponding to a specific test).
2.3.3 A2: Move Back
Except in the very first state, the Inquirer will have the ability to ‘move back one step’ in the
entry of data via the GUI. This will prompt the correct update of the GUI.
2.3.4 A3: Reset
At any stage, the Inquirer may reset the GUI and the Diagnostor to its initial state as if no in-
puts had been entered and, if diagnosis has been conducted, as if none had been undertaken.
2.3.5 A4: Conduct Diagnosis
The Inquirer, having assembled a complete set of choices for set I[t], effects a diagnosis which
submits this set to the Diagnostor’s innards which consult the KB, narrow and returns the set
M, which relates the result of the diagnosis14 along with any recommendations.
2.3.6 A5: Select a Cost Preference (unimplemented)
Prior to the conduction of a diagnosis, the Inquirer may select which of three costs (financial,
labour or delay) is of concern, this will influence the manner in which any recommendations
are selected for return to the Inquirer via the updated GUI.
2.3.7 A6: Exit Diagnostor
Simple functionality allows the Inquirer to close the Diagnostor interface. In a more extended
version, this exit might prompt a warning of, say, partially input cultures to be added to the
KB. As such functionality was not explored, in the end, the exit use-case is simply to end the
Inquirer’s interface with the Diagnostor.
2.3.8 Other Cases & Function
As consideration was given to other possible implementations and functions which remain de-
sirable features in a more developed Diagnostor, there are other use cases which can be noted
for posterity:
a) Begin the introduction of a new culture to the KB
b) Select a new value as part of a new culture being added
14 As before, this will be one of three possibilities: single match, multiple match or no match.
- 16 -

c) ‘Writing’/saving a new strain’s data to the KB
d) Discard an in-progress entry (see discussion in ‘Exit Diagnostor’ case)
e) Begin the introduction of a new test to the KB, etc.
2.3.9 Sample Story-Board & Class Diagram
Early in the design process, some effort was made to anticipate a long-term view of the Dia-
gnostor project. The pertinent surviving records of that era of development demonstrate the
conceptualisation of a more nuanced GUI, involving interaction more common to a nice web-
site or well adapted Flash presentation, as crudely seen in Fig. 11; as the GUI was not deemed
an overwhelmingly pressing aspect of this project, development on that front flagged signific-
antly, though the concept still remains viable for further expansion (especially in light of test
users’ feedback).
Figure 11. Sample Storyboards
In terms of structure, it presents some significant departures from the actually implemented
version, but it does inform the vision underpinning the Diagnostor with aims beyond Mk0.
- 17 -

Another holdover from before implementation is the early Class Diagram proposals. Once
decision was taken to focus on making the Diagnostor only the ‘core’ of a wider system, ad-
herence to Class Diagram and sequence diagrams stemming from the prior outlined Use Cases
significantly dropped. Nevertheless, the ethos underpinning UML was held firmly in mind, al-
beit making for very conscious awareness of how poorly jointed the final implementation ac-
tually became. Nevertheless, as it elaborates the design process and is useful in comparing the
initial ideas to those that held through development, we now see in Fig 12 one of the earliest
yet detailed class diagrams, poorly noted as it is15.
Figure 12. Proposed Class Diagram
Significantly with Fig. 12, it is worth noting that some of the functions are indeed still
present in the Mk0 Diagnostor. The user boundary and GUI have been fused into the Primer.-
java class, whilst the bulk of information exhibited by the Data Controller and Algorithm
classes are actually contained in the Archive.java class. The KBBoundary held over as expec-
ted, though with a more elaborate format which is notably more thorough than that seen here.
2.4 Nature of the Underlying Data
The given biochemical tests all have the form, in the original data set, of “+” or “–“ entries.
The arbitrarily added Primary Test data (-, l , - etc) begins in a less helpful way but is forced to
15 A key lesson surely obvious to most is that if a significant scribble is hastily made on a busy train, it should at first opportunity be updated and formalised; not left as an untidy future reference.
- 18 -

fit to the “+”/”-“ standard for our purposes. This, plainly, (and as seen in the view of the api-
web tool) is not necessarily the whole story. Biochemical test data may take the form of, say,
visual inspection of applied solutions for colour change or any variety of particular tests. It is
not difficult to imagine many variety methods of test output, both qualitative (e.g. colour
change, information by inspection) or quantitative (measure of mass, molarity etc).With this in
mind it is plain that the database supplied is not likely the whole story. Indeed, beyond the
scope of the Diagnostor, but reflecting part of the use to which it is expected to be applied,
there is some cause for concern on the validity of casually associating the presence of an or-
ganism to any given conclusion on cause of disease:
“A question mark hangs over the significance of some organisms to fish pathology – are
they truly pathogens or chance contaminants”[7]
Whilst it is prudent not to overstate any importance to the Diagnostor’s ability to match in-
put to the KB, it is worth a moment’s speculation as to what, computationally, could be done
with more fulsome raw data and better understanding of the cogitative problems facing the
field of aquatic biology. Certainly, as late as 1993, authors note:
“The ubiquity of bacteria in the aquatic environment where they play a major role in
both synthetic and degradative processes, makes the task of the fish bacteriologist far from
straight forward. The lack of more than a vestigial taxonomic framework, leading to very
incomplete understanding of the relationships between the various groups associated with
fish diseases or spoilage, makes the logical study or classification problematical. A full un-
derstanding of cultural requirements, biochemical properties and antigenic and genetic
characteristics is being developed only gradually” [8]
Within the last two decades,, at least, it seems the state of their art is indeed hampered. In
collusion with what has been said regarding diagnostic tools available to the institute, it would
appear that aquatic bacteriology is lagging in comparison to its more glamorous peers; human
and mammalian bacteriology.
Considering that conjecture, briefly, with a knowledge base such as the Institute possess,
ready and able for worldwide consultancy, there is possibility that the data underlying the set
on which this Diagnostor has already been prepared, may yield more interesting and poten-
tially more powerful classification mechanisms.16 Of course, it is also entirely possible that the
16 It was considered during development that a mechanism capable of handling only partial matches may prove to be a useful research tool. Though only receiving a tepid response when proposed, mainly due to its speculative nature, it is noted for posterity. By selecting, say, a k-value for a diagnosis, a threshold to which the diagnosis must adhere accurately. E.g. if a k-value of 0.2 is selected, then only one in five of the supplied tests need be matched accurately. This could be immensely less efficient. In discussions with the Institute it was touched upon the high accuracy typically required only uncommonly deviates significantly lower than, say 98% accuracy. Implementing some variation over very high accuracy and, perhaps, along with the use of ‘raw’
- 19 -

data possessed is insufficient or that the information systems methods mused on would be in-
appropriate to the task.
As it is known that the data is well divided such that Genus can readily be established from
the Primary tests: Gram, Shape, Oxidase, Motility, Fermentation and the inspection of
appearance on the selective agar the culture is cultivated upon (at 15⁰C), it is already possible
to assert a stratification to the diagnosis process. Though the Diagnostor does not reflect this, it
is something that has been consciously remembered throughout development and study: the
first six tests (strictly, the first seven including the ‘control’ test, which is always negative in
the present Diagnsotor’s case) all give specific, unchanging results for F. Psychrophilum.17
2.5 Capturing the Expert Insight
The nature of the method for diagnosis was largely determined quite quickly. As has been de-
scribed, the knowledge base takes the form of positive and negative values for some biochem-
ical tests, with more complex results allowed for the Primary tests.
Once an academic in the institute is in possession of a set of test results, it is then their lot
to, by hand, begin matching off the results against those in the tables. For F. Psychrophilum it
is such that there are only several dozen cultures and twenty individual biochemical tests. It is
inferred that, as this is only one genus’ worth of bacterial strains, that there is a measure of
‘narrowing it down’ before even this process of ‘consulting the tables’ was begun.
Human concentration and tolerance for tedious or fine tasks is not infinite and it is easily
imagined that the academic’s mental prowess might well be spent elsewhere when a well pre-
pared machine may conduct it exceedingly quickly. This was the primary drive to this: aca-
demics are capable of doing this, but there is no real expertise involved beyond first preparing
and arranging the tables; all else is tedium. The prospect of deeper analysis of the data was
only introduced by the author, though ultimately set aside in favour of development of the Dia-
gnostor as remains to be seen.
data (numeric or qualitative) rather than +/- values may allow such an endeavour to be better explored. Unfortunately as it is not immediately obviously a productive avenue, it was, again, largely dismissed.
17 Those results are: Gram – Negative; Shape – Long filamentous rods; Oxidase – positive; Motility – weakly gliding; Fermentation – oxidation; Appearance on selective agar at 15*C – as yellow pigmented bacteria. Additionally there is the control which is always negative. When input into the Diagnostor, this run of six results (plus control, for seven) for F. Psychrophilum would be as “-, +, +, +, +, +, -“.
- 20 -

2.6 Initial & Established Brief
After elucidation of the problem through contact with the Institute, the path and immediate re-
mit of the project as easily determined:
To construct an information system which will act upon a knowledge base (ideally access-
ing and maintaining it, though not yet realised) through which diagnostic consultancy will
be performed by Institute academics.
Primary function is to enact accurate diagnosis with rapidity.
Diagnosis is to, at least initially, take form as matching that practiced by academics.
A desktop application ultimately to be held within (a few) machines in the institute.
As other clinical diagnostic software is available (but ill suited) there exists potential long-
term for commercial use: The package should be prepared with mind to potential further
extension beyond whatever is achieved in the short term.
- 21 -

3 Specification & Solution
The solution given is referred to as the Diagnostor.
It is a Java application composed of three classes:
Primer in Primer.java, Archive in Archive.java and
KBBoundary in KBBoundary.java18. As can be
seen in Fig. 13, they are rather simply organised
with respect to one another.19
Figure 13. Figure 1Class Diagram Solution
3.1 Requirements
3.1.1 Notes on Long-term Requirements
As has been mentioned, there is potential for long term production on the Diagnostor, it is a
project which is of value to the Institute and, further to that, there is possibility of commer-
cialisation.
With that in mind, there are concerns both towards the modularity and form of the product.
The GUI as established has been prepared with little mind to aesthetics, rather the functional-
ity and concision of the display was paramount. As the GUI is handled in the Primer.java
class, it is noted that a sustained, long term implementation of the Diagnostor will highly
likely see an independent GUI class formed, especially if further use-cases which have been
considered are implemented.
Moreover, throughout the project is was therefore doubly important to hold to good soft-
ware development practices in the event that, regardless of the outcome of the project, the Dia-
gnostor may be picked up by another developer for further exploration or utilisation by the In-
stitute.
18 Some methods which are not utilised in the implementation, but which were developed and still persist within the KBBoundary.java file were heavily informed, as a starting point, by discussion at DANIWEB[9]
19 It is noted, as off completion of development, that the classes Archive and Primer are somewhat bulging. They are effectively ready to be decomposed into four separate branches, one each governing: Primer becoming a dedicated user boundary and a GUI operator, whilst Archive would separate out to become a data controller and an actual diagnostics operator which would hold the computational ‘power’ offered by the Diagnostor.
- 22 -

3.1.2 Requirements of the Project
The Institute of Aquaculture seeks a desktop application which will allow the user to conduct
diagnoses (to specific bacterial strains) by providing the system with a set of bio-chemical test
results as input. On top of the six Primary test values, these biochemical test results individu-
ally take one of three forms: Positive, negative and unknown.
The application has four primary functions:
I. The application will furnish the user with the ability to input these tests and obtain a
diagnosis.
II. To return recommendations of which other tests would be conducted as a means to
further narrow a diagnosis (e.g. in the case of multiple matches). 20
III. Further to the above: group and distinguish between equally discriminatory tests21.
IV. The ability to maintain the KB and also to extend it by introducing new strains and
their attendant test results.22
Diagnosis will be conducted by algorithm which compares the input test results with the estab-
lished Knowledge Base provided by the Institute of Aquaculture. Additional information is ar-
bitrarily generated for demonstration purposes in the event that such information is not avail-
able.23
The nature of the Knowledge Base was intended to be maintained via a simple .csv file.
Embedded within will, primarily, be the tests (and test names) along with the respective results
for each identified strain.
The most pertinent aspect of the KB, the results, were organised as follows:
KB[i] = [Genus, Strain, TP1, ... , TP6, TS1, ... , TSn]
20 It is important to bear in mind that it is possible for a diagnosis to match multiple strains completely without ability to further discriminate. Two distinct strains may yield the same results for all tests.
21 If one is to decide between four strains matching your original input, and the results known for these strains in a choice of four as-yet unknown (not yet conducted) tests are: t1(+,+,+,+), t2(+,+,-,-), t3(-,+,+,+) and t4(-,+,+,+). The selection mechanism would do well to recognise that t1 would yield no discriminatory information, whilst t2 would most significantly determine between strains. However, t3 and t4 are equally discriminatory, and only one of them is required to offer the attainable information relevant to distinguishing between these strains.
22 Again, this requirement has not been met.
23 This specifically pertains to costs: it may be instructive to demonstrate potential savings/direction based on availability of resources to users in a management capacity.
- 23 -

For each strain, i, in the knowledge base, it will properly embed the data of TP1, the result
for Primary Test 1, TP2, the result for Primary Test 2 etc. These are distinguished from the
strain tests 1 through n which, once genus is established, begin identification within the genus,
e.g. determining which strains. In this manner, a strain will ideally be identified first by genus
then narrowed to a strain.
Bear in mind the concerns given coherency and duplication within the knowledge base: the
knowledge base is concerned with biological facts, the enforcement of idealised rules
concerning uniqueness of entries and full spanning quality of the KB is thus avoided., The
hope is merely to capture the processes of the experts; they can cope with the complexity and
overlap of strains associated to a culture, therefore so will the Diagnostor.
3.2 Assumptions
For the Diagnostor proper, the assertion of some clear assumptions for which the entire pro-
ject hinges may be made:
The Knowledge Base aspires to completeness. All entries have full, unambiguous results
noted and all entries will obey this. 24
All 2D arrays will be rectangular so as to facilitate ready navigation and reading.
Cultures in the KB are not necessarily coherent. It is possible for two such distinct strains
to be represented by cultures possessing the same assortment of values.
It is possible for strains to be identified by more than one profile. The tests do not enforce
uniqueness.
Diagnosis is conducted one sample at a time.25
A match is valid if all known and specified tests given as input are correctly identified to
strains(s) in the KB. 26
24 This can be altered. It is possible to accommodate incomplete entries, to work with partial information. Awaiting confirmation from Dr Crumlish on the generality of such assumptions
25 If reading of inputs were automated and file-reading were enacted, this need not always apply: many test results for many samples could be fed into a more advanced version of the Diagnostor at once, with the GUI affording relatively easy navigation of many results, but not for this version of the Diagnostor!
26 As mentioned previously, this could conceivably be altered: a user may elect for, say, ‘only 80% of inputs’ to qualify for the diagnosis, given some reason for the uncertainty. Moreover, output could be a scale of ‘most accurate matches’ down to yet a lower threshold (even as far as simply ordering the KB with ‘most accurate matches’ given first.) Similarly, it could be conceived that rather than returning ‘matches’, the returned set could be those for which it is noted not to be. These are, by this assumption, excluded from this version of the Diagnostor.
- 24 -

o A match is not returned if the given inputs do not wholly match at least one of the
strain cultures held in the KB.
3.3 Data Cleaning & Manipulation
The original .xls data file received from the Institute is noted to have the form seen in Figure
8. Though readily translated to a .csv file, the nature of the planned analysis of elements of
aforementioned data structures meant that the contents of each and every cell had to be care-
fully checked to ensure it adhered to the expected format. Notably, a large amount of the
entries in the .xls file had been slightly padded as follows “ + “ instead of “+”; whilst this
white space is innocuous on visual inspection (albeit very faintly untidy when inconsistently
applied), it could wreak havoc if not checked when entered into the KB.27
Though was given early on to the possibility of some parser-mechanism which would
check the entries being read in via the KBBoundary to ensure formatting, though as this func-
tionality itself was never properly enacted, the need for a parser at such point was never
probed deeper. Nevertheless, trimming whitespace from Strings is effectively a trivial matter
in Java, albeit one that could incur further problems if overzealously or carelessly applied.
Trimming white-space and separating read-in lines on selected tokens is one thing; detect-
ing whether a String’s contents are at all sensible, in the case of hypothetical ‘other’ options
for Primary tests, is not necessarily a trivial matter at all. To some extents fortunately, this was
sidestepped by the decision to treat only for Boolean test results when reading in the results
section of the KB. This lessens the potency of the Diagnostor, certainly, but it does allow for
ready testing of functionality.
27 Though the principle concern is indicated to be reading it into the system, it did present a task, in the end, when the author mistakenly accessed a pre-cleaning version of the data set when attempting to hard-write it into the code. The author had made significant progress in re-cleaning it before the realisation of the mistake had occurred! Hardly time consuming, but somewhat vexing...
- 25 -

3.4 Review of Algorithms
At this stage it serves well to review the plan of the algorithms alluded to until now.
3.4.1 The Diagnosis Algorithm
Client tests input I[t] to be checked against knowledge base KB[r,t]
Note M which will hold matched results
ForAll t {IF isMatch(I,KB[r]) THEN
add KB[r] to M} return M
DefN: isMatch(I, KB[r]) = {True: forall t. IF ( (I[t] == KB[r,t] ) OR (I[t] = ‘?’) )False: Otherwise}
IF (M is empty)@ user: “No matches found for your test results.”
ELSE IF (M is only one entry)@user: “Unique match found. Details...”
ELSE IF (M is many)@user: “Multiple possible matches found.”FOR each entry in M
@user: “<detail of each entry>”
3.4.2 Recommendation Algorithm
As noted, the process for solving the recommendations task rapidly became complex and,
though the concept was pinned down in advance, proved to be particularly vexing in its imple-
mentation.
Discursive description:
1. Consider only tests which were unspecified in the original input
2. Compose new KB’ of M and the unspecified tests.
3. Note characteristic profiles for the tests:
a. Each test’s profile
b. Whether the test is homogeneous
4. Group tests by distinct profiles (e.g. partitioning the set of tests into disjoint subsets)
5. Eliminate subsets whose profiles are homogeneous as they do not discriminate fur-
ther.
- 26 -

6. For each disjoint subset unified by a distinct, heterogeneous profile, select28 one test
and add that test to set R, the recommendations. (Set R will be a set which should, it is
hoped, offer best best-possible distinction of diagnosed strains.)
7. Return set R of recommendations.
3.4.3 Recommendations with Cost Algorithm
In 3.4.2 above point 6 deals with selection from an ‘equally discriminating subset’. Here it is
wished to conjecture a manner in which this is evaluated based upon asserted cost factors. For
instance: In KB[r,t] there will be an associated pieces: KB[t,c], where c = {d, l, f}, e.g. delay,
labour and finance. These costs are associated to the tests. These are generated arbitrarily for
the purpose of this discussion, but it is assumed that, in the long run, such knowledge could be
obtained properly if desired.
Discursively, interjecting at stage 6 in 3.4.2 and continuing:
1. Access a set, P, of equally discriminating, heterogeneous subsets.
2. Note the discriminator selected by the user D(d,f,l)
3. One-value subsets are trivial and need not be considered further; their sole value is
their recommendation.
4. For non-trivial subsets, they ought be reordered according to corresponding KB[t,D],
e.g. where KB[t1,f] = £10 or KB[t2, d] = 5 hours. Assuming ascending ordering (and
that discriminator D is to be minimised), continue.
5. From each subset in P, select the lowest (first) value to be the recommendation.
As can be seen, this is conceptually not a terribly difficult problem, but it is involved and
enters into the Diagnostor the concept of ordering (or rather: reordering). Until now only lin-
ear searches of mundane (lack of) innovation have been considered, the incorporation of costs
would be a wholly more complex step.
Nevertheless, though costs were embedded into the KB and function is left to properly or-
ganise them, the actual algorithm itself is not actually implemented and little progress was
made to formalising the above to a programmable quality.
28 In the Diagnostor’s actual setup, it is such that for multiple options, the last presented choice is kept as the recommendation: this is mere convenience from a programming perspective. It is a crude implementation: writing each to the set, such that the final one added is the last one written, the other options have been ‘covered’ by successive additions. Hardly a mechanism of genius!
- 27 -

4 Implementation & Function
4.1 Solution Achieved: A Working Core
Strictly, the Diagnostor achieves three of the four aims laid down early on in development:
I. Use inputs supplied by user to achieve diagnosis √
II. Maintain and add to the knowledge base X
III. Functional user interface √
IV. Advise further tests to narrow diagnosis √
The Diagnostor returns accurate diagnoses on F. Psychrophilum as well as correctly identi-
fying tests which can/should be conducted. The GUI is functional and allows intelligible nav-
igation of the input/diagnosis process, though it is far from perfect.
Some progress was made towards incorporating the costs aspect, though these are largely
superficial. The coded algorithm for assembling the recommendations is functional and accur-
ate, but it is unsatisfactory when it comes to projected extension; it can likely be untangled and
streamlined to more intuitive code. But, as noted, it is functional.
The lack of ability to read directly from a file and to maintain the knowledge base is a
severe limitation. It is still thought that the mechanism for this should be somewhat trivial,
though as the problem persisted amidst development in other parts of the project, attempts to
make progress with it (or even divine the nature of the obstacle) were eventually sidestepped
as the solution was not forthcoming and, though it would be useful, was not a critical factor in
the diagnosis/recommendation mechanism itself.
As the belief is retained that solving it should be trivial, it is hoped that, for the benefit of
the Institute, further work on the problem after submission should yield a significant improve-
ment to the product, ideally moving the Diagnostor from a ‘proof of concept’ to a working, al-
most autonomous product.
- 28 -

4.2 Walk-Through: Use of the Mk0 Diagnostor
It is now time to see the Diagnostor in progress. Consider the situation:
You are an academic of the Institute of Aquaculture, having made only cursory examina-
tions and having eager students to assist you, you have swiftly collated the values for the six
Primary tests, the control test and two biochemical tests, the ninth and tenth available tests,
noted as C4 and C8. Both of these returned negative values. You move to your machine and
begin awaken its spirit...
Figure 14. Initial GUI View
As can be seen in Fig. 14, the buttons available are “+”, “-“ and “?” (also “Reset” and the
“Costs” drop-box.) “Back” and “Diagnose!” are as yet unavailable. Confident, the user might
select a button given that they know the first seven tests are always “-+++++-“ for F.
Psychrobilum.
- 29 -

Figure 15. Seven Inputs Entered
And there, for Fig15, can be seen the pleasant, unthreatening entry of the first set of results.
Bolstered by this success, the user may then feel canny enough to enter “?” for Test 8, then “-“
for both tests 9 and 10, C4 and C8! The remainder, 11+, would be “?” too. Doing so...
- 30 -

Figure 16. All 26th in!
Fig. 16 plainly shows the complete diagnosis set entered, albeit with a few mysteries. And
so, once all are entered the choice remains: reset or continue to diagnose. Presuming confid-
ence remains, the user opts to diagnose...
- 31 -

As of Fig. 17 then shows, this choice of inputs yields a diagnosis set M of six results, not-
ably the Flavobacterium psychrophilum of strain ID 18, 28, 40, 41, 70 and 71. Associated to
this set is the set R of recommendations who appear by their test names: cys, N-a Beta glu,
acp, Alpha-glu and Beta-glu.
Figure 17. Diagnosis and Recommendations
And yet, Fig. 18 shows, by direct inspection of a narrowed sample of (eliminating rows as
per the algorithms described) the KB:
Figure 18. Figure 2 Raw KB
- 32 -

That is: the Diagnostor works. It has correctly, for this case, pinpointed the recommendations
exactly as expected. It should be noted, however, that the ‘distinct discriminating subsets’
aforementioned would split as follows: 3:{val, cys}, 4:{try, chr, N-aBeta glu}, 5:{acp}, 6:{np,
alpha-glu} and 7:{Beta-glu}. Selecting the last of each gives the results seen in Fig. 14.
And, for completeness, Fig. 19 corresponds to input which yields no matches (contradict-
ing even one Primary tests is sufficient for this result.) Whilst Fig. 20 shows a singular match
obtained.
Figure 19. No Matches
Figure 20. Singular Match
- 33 -

4.3 Towards Developer Testing
Testing the Diagnostor is an important aspect. Throughout the development effort has been
made to ensure that it is consistent and functional; heavy use of the Java console output was
therefore used. As can be seen in Fig. 18, there is detail and manipulation going on ‘under the
bonnet’ (ideally sans bee) which is both somewhat complicated and largely irrelevant to the
academic using the Diagnostor provided it works. If it were to not work, by giving wrong or
erroneous answers then any potential user who was not the developer would almost be as
quick conducting the whole operation themselves as checking the details as it progresses.
With that in mind, it is hoped that testing throughout the development of the Diagnostor as
it stands has been sufficient to ensure if it is both properly functional and does not offer any
bizarre outputs to the user. Of particular concern, given the sheer number of arrays and de-
pendencies involved in the Diagnostor’s interior working, one would wish to see the limits.
Care has been taken to ensure that array limits are linked to variables, such that if, say, the
size of input were to be changed, everything else would correctly flow: only a few minor de-
tails would need to be changed at this stage. Otherwise, much of the variability is effectively
fixed and, if it works at all, it should be consistent. Due to the nature of the Diagnostor’s exist-
ence as a ‘core’ piece to what is expected to be a larger project, it is with some satisfaction that
it is viewed working stand-alone.
4.3.1 Extremes & Boundary Testing
Consider the check inputs:
All “-“s: Diagnostor correctly yields no matches found, as per Fig. 19.
All “+”s: Diagnostor correctly yields no matches found, as per Fig. 19.
All “?”s: The trivial case, the Diagnostor yields the entire KB as a diagnosis,
with all 16 heterogeneous tests as recommendations, see Fig. 21.
Input of any test set which is non-discriminating (e.g. only the Primary tests and the control, as
“-+++++-“ will yield the result analogous to the trivial case above.
Attempting to return all the way back from the cusp of inputting test 26 (fuc) will
work correctly, though the inputs already in place remain displayed. This is not an error, as
such, but it is something that users may find perplexing: when moving back entered inputs
will not be erased unless specifically overwritten by contradiction. Only selecting ‘reset’ will
properly remove all inputs.
- 34 -

4.3.2 Notable Errors & Malfunctions
The only notable error at present, which is ultimately more of an oversight, is that as the “Dia-
gnose!” button is activated on completing all twenty-six inputs, the “Back” button is also dis-
abled. This is a minor concern, but it is likely something which may skew users and certainly,
in hindsight, seems a baffling decision to have made. As noted, it is surely an interaction over-
sight which remains to be corrected in future versions.
Figure 21. The Trivial Case
- 35 -

5 Evaluation
Wherein the Mk0 Diagnostor is reviewed and assessed by the developer.
5.1 Critical Review of the Mk0 Diagnostor
The Diagnostor works very effectively: for a properly formatted KB it does indeed give the
correct diagnosis and happily yields a correct set of ‘best’ recommendations minimally29 re-
quired to properly distinguish between possible diagnosed strains.
It is regrettable that the Mk0 Diagnostor is not capable of reading directly from a file. Of all
the success displayed, it is effectively a very minimally useful tool. Time saving, certainly, es-
pecially when quickly adapted, but it applies presently to but one genus, that of F. Psychrophi-
lum, hardly an astounding contribution to the progress of microbiological science.
However, it does clearly demonstrate the immense time-saving ability of a wider, more
comprehensive system. Indeed, the mechanisms developed to conduct diagnosis and compute
for the recommendations is a significant achievement, if not a particularly resounding one.
5.2 What was not achieved
As previously noted, the critical failure of the project so far is the lack of functionality in read-
ing directly from ‘outside’ knowledge bases. Perhaps effort to establish this would best have
been applied prior to even accessing the knowledge base supplied by the institute of aquacul-
ture.
Nevertheless, room for functionality is allowed. The KBBoundary.java file has several
methods and a constructor ready to be extended and tweaked to allow this function. Conceptu-
ally, the Mk0 Diagnostor, though complete, is not the ‘ultimate’ finished product: more work
has to be conducted on it.
The Graphic User Interface, though functional and well established, is poorly implemented
in the code, a stand-alone interface linking to an internal Diagnostor which in turn accesses a
knowledge base has been a long-standing vision held in mind in this project. Work on this
front is hoped to be continued after submission, allowing a further separation and partition
function now that the core concept of diagnosis is demonstrated to be effective and achieved.
29 It is widely noted throughout that the terminology used is very relaxed. Formulation of the problem in rigorous, formal terms was beyond the scope of this project, so the idea of a ‘minimal set’ should be understood as a mathematical or set theoretical assertion!
- 36 -

5.3 Deployment Solution
A primary feature of user response to testing is that the Mk0 Diagnostor is not a stand-alone
application. Though this is readily accepted by the developers, it is unfortunately not so useful
for the clients or those who originally sought IT support in the institute.
Although it is effective, this presents ready consideration for future development. The self-
contained nature of the project means it is somewhat easier to deploy and demonstrate, with
setup amount merely to configuring a suitable environment (e.g. installing Eclipse, BlueJ, see
Appendix A). This is a sorry situation, but hardly insurmountable.
Though by no means outside the scope of this project, it was ultimately outside the pro-
ject’s reach: the work put in to even beginning the Diagnostor project, conceiving it and under-
standing the Institute’s requirements (as well as the time spent in acquiring the sample know-
ledge base originally) meant that only a certain amount could feasibly be implemented.
Settlement for a skeletal core, or perhaps more accurately a stand-alone ‘brain in a jar’ that
is the Mk0 is a suitable compromise. It sets a vital organ into place and demonstrates an effect-
ive core concept with a clear ability. In many respects this depth first approach cuts straight to
the heart of the initial problem, though it is hamstrung by its lack of immediate reapplication
to even slightly different problems. (See On Maintenance in Appendix A for further discus-
sion of reapplication of the Mk0 Diagnostor directly.)
5.4 Reflection on User Feedback
Appendices E & F reflect user feedback as exposed to Appendices B, C and E, along with use
of the actual Mk0 Diagnostor. Unfortunately several other questionnaires which had been as-
sembled have since been lost, but their knowledge remains.
It is almost unanimously said that the Interface is seriously flawed. User feedback clearly
exhibited the short sightedness and lack of perception involved in the creation of the User
Guide and Installation Guide (Appendices B and A respectively), even though most users
never saw the latter!
As has been apparent, it is developer expertise which has been key in allowing the test
users any hope of ensuring the Diagnostor’s proper functioning. The most damning criticism
is, perhaps, how far from obvious what it is supposed to do is. Though this is not directly from
our contact within the Institute who has unfortunately not yet been available for trialling it, it
marks a serious consideration for tweaking and improving the Mk0 even before initial deploy-
ment after submission.
- 37 -

Having said the above, it is also the case that users were indeed mildly impressed by the
functionality of the Mk 0 Diagnostor: that it quickly and readily achieves a diagnosis. Though
hardly a remarkable achievement given technology as it stands, as a very specific replication
of the function previously conducted at length by academics, it does appear to meet that de-
mand well.
Most pressingly, the user evaluation highlights the unfinished nature of the Mk0. Lacking a
trouble-free GUI (many users note the remaining clumsiness/tediousness of the method of in-
put), multiple functions (such as adding to the knowledge base or manipulating it) and even a
thoroughly organised, intuitive structure of code, the Diagnostor plainly has serious flaws.
Nevertheless, these are acknowledged and to some extents anticipated: the design of the GUI
was never intended to be a significant portion, merely one facilitating function and demon-
strating room for expansion.
To this extent, the lesson of the feedback is clear: that mechanically sound as the Dia-
gnostor appears, it is still some distance from a well formed product; it is a working core, but
requires more and better formed layers to allow successful adoption.
- 38 -

6 Conclusion
6.1 Approach
Strictly, there were some fundamental errors and oversights in this approach, as well as a par-
ticular, resounding success.
Clear progress has been made in aiding the information technological plight of the Institute
of Aquaculture. Comprehending the situation facing their diagnostic consultancy was key to
even beginning work on this problem and, as can be seen in Sections 1 & 2, this has been well
explored, with insight gained into potential developments in many other directions beyond
simply aiding in automating/augmenting their diagnostic process.
This aspect was a significant point of the first half of the time spent on the project. Along-
side it was spent many hours considering the longer term design of the project. Though the
GUI is functional, it is not expected to remain as part of the Primer.java class, indeed it is a
critical oversight early in development that meant it remained within that! (Time was not
available to undo that error, alas.)
In many respects, the project transpired to be somewhat larger than the scope of one sum-
mer project, certainly given its approach. Starting from the ground-up, designing and holding
the diagnostic software internally in a Java project consumed much time and brainpower, but
nevertheless was deemed necessary (and vindicated) by clearly implementing of the perhaps
slightly less clear, more ephemeral vision of the Diagnsotor held initially.
6.2 Deployment
As noted, the Diagnostor as a stand-alone piece is both useful, with regards to
demonstration and supporting the concept that yes indeed, the diagnostic technique of the
Institute can be readily augmented with a little IT insight. That said, its lack of interface with a
dynamic knowledge base is a critical failure, one which it is hoped will be rectified so as to
fully allow the Institute well realised, readily used augmentation in its Diagnostic Consultancy.
6.3 Future Work
Several aspects have been noted throughout this project as avenues for future work, these can
be distinguished in two primary ways. First those that pertain to the Diagnostor, secondly
those that pertain to the Institute’s IT plight more broadly.
- 39 -

6.3.1 Expanding the Diagnostor
6.3.1.1 Incorporation of Costs into the Recommendation Algorithm.
The commented-out code:
Compose subCosts[][]; prepSub2D(subCosts, costsBase2, numbTestsRemaining, noCosts,trivialCase, setM, setTs);
and the method
organiseProfiles (int testLim, int[][] subTestSource, int[] mapTar-get, int[] subTarget, int[] testsSet) {...
form an excellent and ready starting point for any such further implementation, given the
algorithm conjectured in Section 3.4.3. Though not requested in the requirements elaborated
by the Institute, pairing such information accurately could be made to be an effective organisa-
tional tool.
6.3.1.2 Reading/Writing to a free-standing Knowledge Base.
Critically the Mk0 Diagnostor only functions with respect to F. Psychrophilum. This is an em-
barrassingly small capacity.
6.3.1.3 Proper representation of all test options (beyond positive/negative).
Limited somewhat in development by only having access to the F. Psychrophilum KB, future
development will seek to capture the nuance and possibility allowed by the Primary tests,
making determination of genus something that the Diagnostor itself may achieved, or poten-
tially allowing both the Diagnostor to do so on its own, or to allow the user to override this
and make the selection themselves. There are many possibilities in how this might be imple-
mented.
6.3.1.4 Non-linear entry of test inputs.
Consideration was given early on to non-linear entry, but with the indication that the Institute
conducts the biochemical tests as part of a suite of standard tests, this linear approach was kept
for convenience, e.g. the option to simply select the ‘name’ of the test (for example C8, Beta-
glu or Fermentation) and then be presented with options relevant only to that test. With large
tests inputs it may be unwieldy, but testing and inspection of a wider knowledge base would
readily inform any decisions made here even from the very outset.
- 40 -

6.3.1.5 Controlling Level of Detail
Currently the Mk0 only offers the strain name and ID as diagnosis and the test name as recom-
mendations: though suited for a well informed academic, it is not all that it could be.
Allowing for the option of adjusting the level of detail given in a response (what the
expected results of a test would be), perhaps giving the results in a more (or less) conversa-
tional manner, allowing the tabling of information and so forth are all aspects that a client may
well request, expect, demand or simply be pleased to see appear: nuance that an IT developer
may understand and perceive, but that a client might overlook or ignore as it is not precisely
what they need at any given time.
In essence, with the information available, the Diagnostor could be made to allow users
more intuitive exploration of the knowledge base and the mechanisms available, not just the
mechanical “input-mystery-output” process with which people may settle.
6.3.1.6 Development of the Diagnostor by other means
The mechanism and principle inherent in the Mk 0 Diagnostor is not restricted to Java by any
means. Much of the work is essentially language independent. Expansion and formalisation of
the algorithms, conducting analysis based on efficiency and potential for automation is cer-
tainly a valid starting point. With that in mind a great many approaches could be undertaken.
A web-hosted PHP script which interfaces with a KB held at the Institute as a relational
database might well be efficacious, though it has certain security ramifications that are not as
prominent as with a desktop Java application. Alternatively the production of a mobile phone
App which is provided for use by Institute’s academics might well be a novel solution too.
There are many possibilities and the enterprising student or developer may indeed wish to con-
sult the Institute with such ideas.
6.3.2 Applying IT solutions to the Institute’s knowledge resources
As has been discussed previously, the Institute is host to a large collection of knowledge which
is not widely available; so much so that they reject other diagnostic software available because
it is unable to incorporate their own knowledge sufficiently in a way that is better (albeit with
more time consumed) handled by their own academics inspecting by eye!
The Diagnostor is only one possible solution. Though conceived as potentially via Python,
though ultimately implemented in Java, there are many other deployment mechanisms. Above
are noted simple conjectures for translating the Diagnostor to other formats, such as a phone
App or a web-based service, there are more fundamentally different possibilities too.
- 41 -

The application of case-based learning or indeed data mining to the Institute’s knowledge
may be feasible, should they be prepared to participate in an endeavour such as that. Auto-
mated reasoning may well offer more direct progress in Aquacultural studies, albeit by inter-
disciplinary application of more commonly Computer Science solutions.
6.4 Concluding Remarks
In brief, it is pleasing to note that the Mk0 Diagnostor does indeed work. It is a small step in
development, using basic techniques and only minimally complicated data structures to
achieve a task. It is hoped that the form of the code is readily intelligible for any who might
use it to expand the Diagnostor beyond its currently somewhat limited capacity.
Nevertheless, it stands as a stunted testament indicating many plausible and attractive op-
tions for the future. It is a step in the right direction and a way-marker for any who might pro-
gress in the same direction. With only some more development focus and input, it could be ex-
panded readily to something very easily used by the academics of the Institute for Aquacul-
ture, perhaps more broadly useful not only as a diagnostic aide, but if the cost aspects were
factored in, as a management tool able to fully begin increasing efficiency beyond the simple
matter of the diagnostic process itself.
Knowing it was hoped that the final stage would be more advanced, it is not with too heavy
a heart that one may view the Diagnostor. Detailed inspection of the code may reveal some un-
wieldy statements and easily improved structures; it is hoped that such improvements are not
too blatant or too embarrassing for the developer. The effort and insight fed into the project
feel well rewarded in seeing that it is indeed effective.
Though the recommendations offered by the Diagnostor are the result of brute force, it is
reassuring to know that they are nonetheless well formed. As the complexity of the recom-
mendation process became clear, it bolstered resolve in development: the task was set and the
challenge accepted. It is not a general solution and there is a capacity for oversight provided
by it (the Diagnostor makes no mention of the population of each ‘non-homogeneous distinct
subset’ merely that a selection has been made and it presents the user with that selection: it
may have been the only choice!), but it is felt that this is an acceptable trade-off for the speed
with which the Diagnostor achieves its result over the more elaborate and time consuming ap-
proaches conducted by experts in optimisation, or even by the lay working to their own un-
guided tune.
With three of the four aims achieved, it is difficult not to view the Diagnostor as only 75%
achieved. Still, it is encouragement for future development and a foundation or inspiration for
further study, a cliché perhaps, but a justly founded one.
- 42 -

References
Note: As little work is widely available on clinical diagnostic tools, largely due to their com-
mercial nature, much work on the Mk0 Diagnostor has been conducted ‘from scratch’, though
it is hardly innovative enough to be considered remarkably original.
[1] University of Stirling, Institute of Aquaculture, Integrated Health Management ‘Con-
sultancy Home’, http://www.aqua.stir.ac.uk/diagnostic/, September 2011.
[2] International Code of Zoological Nomenclature, supported online by the John Spedan
Lewis Trust, http://www.nhm.ac.uk/hosted-sites/iczn/code/, September 2011
[3] B.A. Austin & D.A. Austin, Bacterial Fish Pathogens: Disease in Farmed and Wild Fish,
Second Edition, Ellis Horwood, 1993
[4] bioMerieux’s apiweb application, http://www.biomerieux-diagnostics.com/servlet/srt/bio/
clinical-diagnostics/dynPage?doc=CNL_PRD_CPL_G_PRD_CLN_12, September 2011
[5] John R. Hubbard. Schaum’s Outline of Data Structures with Java, Second Edition. The
McGraw Hill Companies Inc., 2007.
[6] Masterchef Synesthesia, http://www.wordmagazine.co.uk/content/masterchef-synesthesia-
or-i-like-the-buttery-biscuit-bass, September 2011
[7] B.A. Austin & D.A. Austin, Bacterial Fish Pathogens: Disease in Farmed and Wild Fish,
Fourth Edition, Praxis Publishing Ltd., UK, 2007
[8] V. Inglis, R.J. Roberts, Niall R. Bromage, Bacterial Diseases of Fish, First Edition, Black-
well Scientific Publications, 1993.
[9] DANIWEB, IT Discussion Community, www.daniweb.com/software_development/java/
threads/17262
- 43 -

Bibliography
Throughout the project, many works were consulted in general, offering a guiding inspiration
and insight to the course of the project.
Generally Consulted Texts
David Avison & Guy Fitzgerald, Information Systems Development: Methodologies,
Techniques and Tools, Third Edition, McGraw-Hill Publishing, 2003
A Chetwynd and P. Diggle, Discrete Mathematics, Butterworth-Heinemann, 2003
Robert J. McEliece, Robert B. Ash, Carol Ash, Introduction to Discrete Mathematics,
International Edition, McGraw-Hill Book Company, 1989
Steven S. Skiena, The Algorithm Design Manual, Springer-Verlag, New York Inc.,
1998
Widely Consulted Web Resources & Sites
Java Samples, http://java-samples.com/, last accessed September 2011
Stack Overflow, http://stackoverflow.com/, last accessed September 2011
Oracle’s Java Technical Documentation, http://download.oracle.com/javase/, last ac-
cessed September 2011
Other Resources
Course notes and material from University of Stirling ITNPs 11, 21, 62 & 92 and Uni-
versity of St Andrews CS1002, MT2002, MT3501 & PH4030.
- 44 -

Appendix A: Installation Guide
1. Download & install Java: http://www.java.com/en/download/
2. Download & install a code compiler:
http://www.bluej.org/download/download.html
(Only if a Java development environment has
not been prepared. If Eclipse or Dreamweaver
available, those make more sense.)
3. Load project into editing environment
4. Run the project (BlueJ specific: right click on the
box entitled Primer, click on “public static void
main” )
5. Witness the GUI appear onscreen.
Note: The KB is hardwired into the code at this time.
On Maintenance
It is worth noting that the Mk0 Diagnostor has no active facility for expanding its knowledge
base or receiving updates to it. Presently this is only achievable by directly altering the repres-
entation held prominently as “private String kbPRoxy[][] =...” in the class’ file KBBoundary.-
java . Artefact code is leftover demonstrating attempts to allow reading directly from a file,
but it is not functional.
This is terribly unwieldy, but it is possible. If this is done then the corresponding variables
noted beneath it, e.g.:
final private int name row = 0, nameBuffer =2,...
must be ensured to be correct alongside a modified KB. Finally, the initialisation variables in
class file Archive.java must also be checked for correct correspondence, notably:
final int noTests = 26;
Though cumbersome, an expected extension to the Diagnostor will to allow loading directly
from .csv file.
- 45 -

Appendix B: User Introduction
Welcome to the Mk0 Diagnostor.
The purpose of this information system is to present an interface and mechanism for which
an academic concerned with, say, disease causing bacteria in farmed fish populations may dia-
gnose a test sample by comparison with an established knowledge base.
By receiving, sequentially, the real-world results for so-called Primary and biochemical
tests, the Diagnostor then feeds this information into its interior. Within, the information sup-
plied by the user is analysed and compared against a preferred information set, known as the
knowledge base.
The Diagnostor will return the information gained from this comparison and analysis to the
two output fields visible in the Diagnostor. The upper of these two will show the results of the
actual diagnosis, i.e. the strains (if any) which fit the results given by a user.
The second of these will display the recommended tests which are needed to best distin-
guish precisely which strain is being considered if there is more than one.
Under the Bonnet
Throughout use and trial of the Mk0, you will find it offers some insight into the nature of the
F. Psychrophilum knowledge base with which it is concerned. If you feel confident in access-
ing the Java editing environment, you will notice that the console output also has some under-
lying facility which shows the activity of the internal workings, particularly the binary-repres-
entation and classification process of the recommendation-determination process.
There are “System.out.println” lines which have been commented out but which still
persist within the code to aid this exploration. In Archive.java, the method private void organ-
iseProfiles(int, int[][], int[], int[], int[]) has a particularly insightful such point.
- 46 -

Appendix C: User Guide
Welcome to the Mk0 Diagnostor. I hope you enjoy your science!
Operating the Diagnostor is a simple process:
1. Activate the Diagnostor, you
may wish to look for the fol-
lowing in Eclipse:
2. Know the details which you
wish to enter.30 There are
twenty-six separate tests, though many will likely be entered as “?”.
For demonstration, try Test 9 and10; C4 and C8 as “-“. “?” for the rest.
3. Click the option to be entered for test one (in the F.psych. case always “Gram” which has
value: “-”), by clicking on the relevant option.
You should find the Diagnostor updates to the next test, with the diagnostic set line
reading:
4. Progress through the tests, entering unknown/unspecified ones as '?'. This is a sequential
process, but you can move back in the sequence by utilising the “Back” button. You may
restart the entire process by selecting “Reset” in the lower corner.
5. After entering the relevant tests, you will arrive at the following setup:
You should feel comfortable with pressing “Diagnose!”
6. Reap the rewards from the output!
30 For Flavobacterium psychrophilum, the first six tests are always entered as “-,+,+,+,+,+,+” and the seventh test, the control test, is known to be always “-”. These can be entered also as “?” which gives the same results; but entering anything aside from this (e.g. test 1: +) will yield no results for this KB.
- 47 -
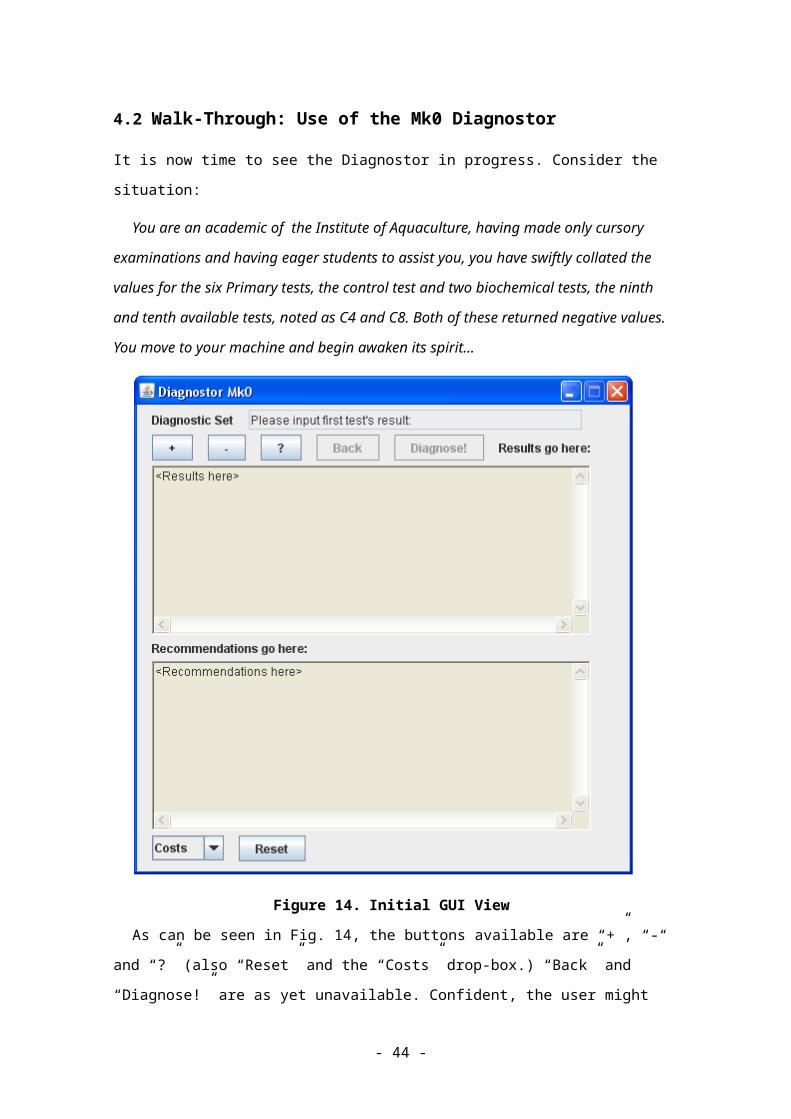
Appendix D: Legal Note – Institute of Aquaculture & Data
Protection
The data handled in the M0 Diagnostor has been released confidentially by the Institute of
Aquaculture, part of the School of Natural Sciences at the University of Stirling. This informa-
tion is legally protected and should only be handled by those authorised by the Institute of
Aquaculture.
The information is assembled so as to ensure the anonymity of the clients of the Institute;
this had been conducted prior to its provision for this project. Care has been taken to ensure
that this confidentiality is upheld.
- 48 -

Appendix E: Questionnaire
Greetings!
I hope you have found use of the Diagnostor a pain-free experience. I would be greatly in-
debted if you would complete this for feedback and reference purposes. The scale is ‘1-5’ as in
‘Poor to Great’.
Q. Zero How useful did you find the User Guide?
Q. One How well do you comprehend the purpose of the Diagnostor?
Q. Two How did you find the output from the Diagnostor?
Q. Three The Diagnostor was <?> to use?
Q. Four Did you find the Diagnostor met your expectations?
Q. Five How professional do you feel the Diagnostor is?
Q. Six How useful do you feel it would be (if you had to diagnose bacteria
regularly)?
And, if you would be kind/critical enough, I would enjoy any (cruel) feedback on the aes-
thetic and usability of the Diagnostor. If you have comments on the design of the interface, I
would be keen to hear your thoughts...
Finally, if you have suggestions for any functional aspects of the Diagnostor, or indeed, any
criticisms in general, I would be grateful to receive them...
Your Name:
Contact Detail:
- 49 -

Appendix F: Questionnaire Responses
- 50 -

- 51 -

















