Page 1
SAND: A Fault-Tolerant Streaming
Architecture for Network Traffic Analytics
Qin Liu, John C.S. Lui 1
Cheng He, Lujia Pan, Wei Fan, Yunlong Shi 2
1The Chinese University of Hong Kong
2Huawei Noah’s Ark Lab
1
Page 3
Motivation
Network traffic arrives in a streaming fashion, and should beprocessed in real-time. For example,
1. Network traffic classification
2. Anomaly detection
3. Policy and charging control in cellular networks
4. Recommendations based on user behaviors
3
Page 4
Challenges
1. A stream processing system must sustain high-speednetwork traffic in cellular core networks
I existing systems: S4 [Neumeyer’10], Storm 1 ...I implemented in Java: heavy processing overheadsI cannot sustain high-speed network traffic
2. For critical applications, it is necessary to providecorrect results after failure recovery
I high hardware costI cannot provide “correct results” after failure recoveryI at-least-once vs. exactly-once
1http://storm.incubator.apache.org/4
Page 5
Challenges
1. A stream processing system must sustain high-speednetwork traffic in cellular core networks
I existing systems: S4 [Neumeyer’10], Storm 1 ...I implemented in Java: heavy processing overheadsI cannot sustain high-speed network traffic
2. For critical applications, it is necessary to providecorrect results after failure recovery
I high hardware costI cannot provide “correct results” after failure recoveryI at-least-once vs. exactly-once
1http://storm.incubator.apache.org/4
Page 6
Contributions
Design and implement SAND in C++:
• high performance on network traffic
• a new fault tolerance scheme
5
Page 8
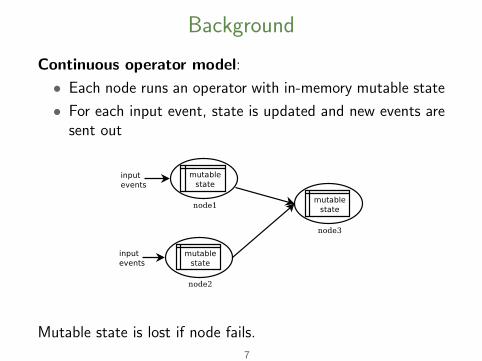
Background
Continuous operator model:
• Each node runs an operator with in-memory mutable state
• For each input event, state is updated and new events aresent out
Mutable state is lost if node fails.
7
Page 9
Example: AppTracker
• AppTracker: traffic classification for cellular networktraffic
• Output traffic distribution in real-time:
Application Distribution
HTTP 15.60%Sina Weibo 4.13%
QQ 2.56%DNS 2.34%
HTTP in QQ 2.17%
8
Page 10
Example: AppTracker
Under the continuous operator model:
• Spout: capture packets from cellular network
• Decoder: extract IP packets from raw packets
• DPI-Engine: perform deep packet inspection on packets
• Tracker: track the distribution of application levelprotocols (HTTP, P2P, Skype ...)
9
Page 12
Architecture of SAND
One coordinator and multiple workers.Each worker can be seen as an operator.
11
Page 13
Coordinator
Coordinator is responsible for
• managing worker executions
• detecting worker failures
• relaying control messages among workers
• monitoring performance statistics
Zookeeper cluster provides fault tolerance and reliablecoordination service.
12
Page 14
WorkerContain 3 types of processes:
• The dispatcher decodes streams and distributes them tomultiple analyzers
• Each analyzer independently processes the assignedstreams
• The collector aggregates the intermediate results from allanalyzers
The container daemon
• spawns or stops the processes
• communicates with the coordinator13
Page 15
Communication Channels
Efficient communication channels:
• Intra-worker: a lock-free shared memory ring buffer
• Inter-worker: ZeroMQ, a socket library optimized forclustered products
14
Page 16
Fault-Tolerance
15
Page 17
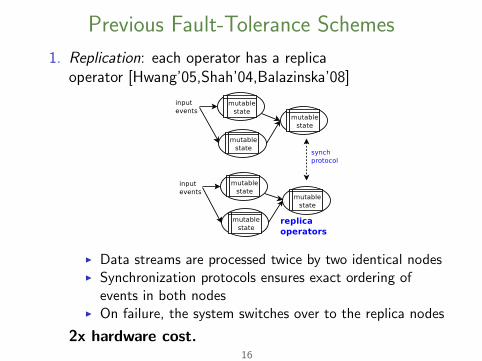
Previous Fault-Tolerance Schemes
1. Replication: each operator has a replicaoperator [Hwang’05,Shah’04,Balazinska’08]
I Data streams are processed twice by two identical nodesI Synchronization protocols ensures exact ordering of
events in both nodesI On failure, the system switches over to the replica nodes
2x hardware cost.16
Page 18
Previous Fault-Tolerance Schemes
2. Upstream backup with checkpoint [Fernandez’03,Gu’09]:I Each node maintains backup of the forwarded events
since last checkpointI On failure, upstream nodes replay the backup events
serially to the failover node to recreate the state
Less hardware cost. It’s hard to provide correct results afterrecovery.
17
Page 19
Why is it hard?
• Stateful continuous operators tightly integrate“computation” with “mutable state”
• Makes it harder to define clear boundaries whencomputation and state can be moved around
18
Page 20
Checkpointing
• Need to coordinate checkpointing operation on eachworker
• 1985: Chandy-Lamport invented an asynchronoussnapshot algorithm for distributed systems
• A variant algorithm was implemented within SAND
19
Page 21
Checkpointing Protocol
• Coordinator initiates a global checkpoint by sendingmarkers to all source workers
• For each worker w ,I on receiving a data event E from worker u
I if marker from u has arrived, w buffers EI else w processes E normally
I on receiving a marker from worker uI if all markers have arrived, w starts checkpointing
operation
20
Page 22
Checkpointing Operation
On each worker:
• When a checkpoint starts, the worker creates childprocesses using fork
• The parent processes then resume with the normalprocessing
• The child processes write the internal state to HDFS,which performs replication for data reliability
21
Page 23
Output Buffer
Buffer output events for recovery:
• Each worker records output data events in its outputbuffer, so as to replay output events during failurerecovery
• When global checkpoint c is finished, data in outputbuffers before checkpoint c can be deleted
22
Page 24
Failure Recovery
F
a
b
c
d
e
f
g
h
DF
PF
• F : failed workers
• DF : downstream workers of F
• F ∪ DF : rolled back to the most recent checkpoint c
• PF : the upstream workers of F ∪ DF
• Workers in PF replay output events after checkpoint c
23
Page 26
Experiment 1
• Testbed: one quad-core machine with 4GB RAM
• Dataset: packet header trace; 331 million packetsaccounting for 143GB of traffic
• Application: packet counter
System Packets/s Payload Rate Header Rate
Storm 260K 840Mb/s 81.15Mb/sBlockmon 2.7M 8.4Gb/s 844.9Mb/s
SAND 9.6M 31.4Gb/s 3031.7Mb/s
• 3.7X and 37.4X compared to Blockmon [Simoncelli’13]and Storm
25
Page 27
Experiment 2
• Testbed: three 16-core machines with 94GB RAM
• Dataset: a 2-hour network trace (32GB) collected from acommercial GPRS core network in China in 2013
• Application: AppTracker
26
Page 28
Experiment 2
0
200
400
600
800
1000
1200
0 2 4 6 8 10 12
Thro
ughput
(Mb/s
)
Number of Analyzers
Interval 2sInterval 5s
Interval 10sNo Fault-Tolerance
• Scale out by running parallel workers on multiple servers
• Negligible overheads
27
Page 29
Experiment 3
0
200
400
600
800
1000
0 10 20 30 40 50 60
Thr
ough
put
(Mb/
s)
Time (seconds)
Interval 5sInterval 10s
t1 t2 t3 t4 t5
• Recover in order of seconds
• Recovery time is in proportion to checkpointing interval
28
Page 30
Conclusion
• Present a new distributed stream processing system fornetwork analytics
• Propose a novel checkpointing protocol that providesreliable fault tolerance for stream processing systems
• SAND can operate at core routers level and can recoverfrom failure in order of seconds
29
Page 31
Thank you!Q & A
30





























![MillWheel: Fault-Tolerant Stream Processing at Internet Scalestatic.googleusercontent.com/media/research.google.com/... · 2020-03-03 · Streaming SQL systems [1] [2] [5] [6] [21]](https://static.documents.pub/doc/80x56/5ed36d38c0c9044a864b0e97/millwheel-fault-tolerant-stream-processing-at-internet-2020-03-03-streaming-sql.jpg)
















