19
Science in Data Science Science in Text Mining by Tanay Chowdhury Data Scientist,Zurich North America
| Date post: | 11-Apr-2017 |
| Category: |
Data & Analytics |
| Upload: | tanay-chowdhury |
| View: | 822 times |
| Download: | 1 times |

Science in Data Science Science in Text Mining
by Tanay Chowdhury
Data Scientist,Zurich North America

Word2vec model • Creates the vector representation of every word using one-hot
encoding.
• The displacement vector (the vector between two vectors) describes the relation between two words.
• Comparing displacement vectors helps find similarity. Eg: vqueen−vking=vwoman−vman.
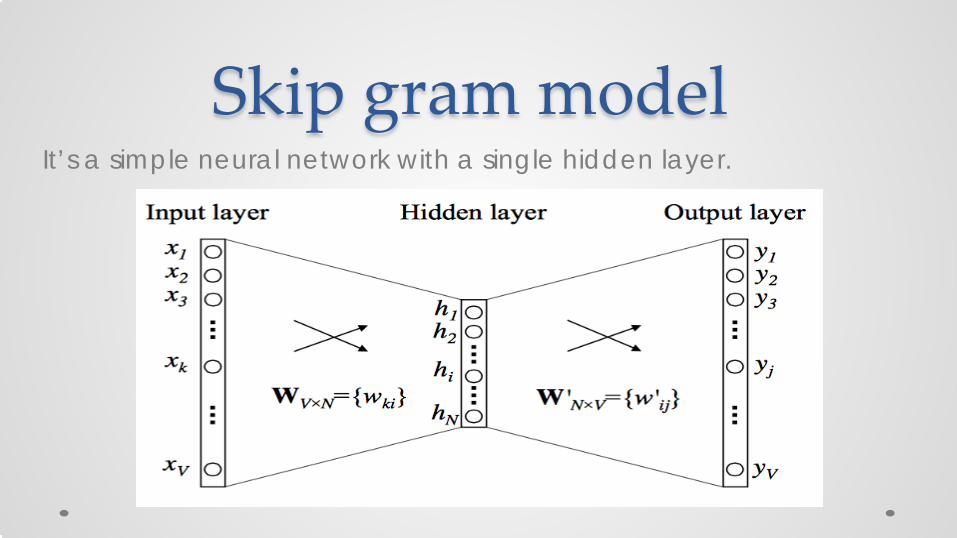
Skip gram model It’s a simple neural network with a single hidden layer.

• For training words w1,w2, . . . ,wt proper position of output word wo for input word wI is found by minimizing the loss function
• Weight update equation using stochastic gradient descent.
• Then back propagation for learning rate is
Skip gram model

Skip gram model If we now re-compute the probability of each word given the input word queen, we see that the probability of king given queen goes up
Softmax regression
Weight update Backpropagation
Example available at : https://github.com/fbkarsdorp/doc2vec/blob/master/doc2vec.ipynb

cbow model

cbow model • If the context C comprises multiple words, instead of copying the
input vector we take the mean of their input vectors as our hidden layer:
• The update functions remain the same except that for the update of the input vectors, we need to apply the update to each word in the context C:
•

Softmax • Softmax regression (or multinomial logistic regression) is a generalization
of logistic regression to the case where we want to handle multiple classes.
• In text classification every word in vocabulary is a label, making it a multiclass problem.
• Hence using softmax regression, we can compute the posterior probability P(wO|wI)

Hierarchical Softmax • It consists of a binary Huffman tree based on word frequencies,
with each word wo as leaf.
• Probability of the path from root to the word causes normalization.
• One N-way normalization is replaced by a sequence of O(logN) local (binary) normalizations, as it is all about traversing subtree with higher probability.
•
“.”makes the result -1
or +1

Negative Sampling
• The objective is to distinguish the target word from draws from the noise distribution using logistic regression, where there are k negative samples for each data sample.
• References • Gutmann and Hyvarinen 2012 . Noise-contrastive estimation of unnormalized statistical models, with
applications to natural image statistics. • Mnih and The 2012. A fast and simple algorithm for training neural probabilistic language models.

Vectoring paragraph
• Paragraph Vector model attempts to learn fixed-length continuous representations from variable-length pieces of text.
• Some of the attempts made in that direction are paragraph2vec,vector averaging and clustering.
• Reference : Le & Mikolov (2014)
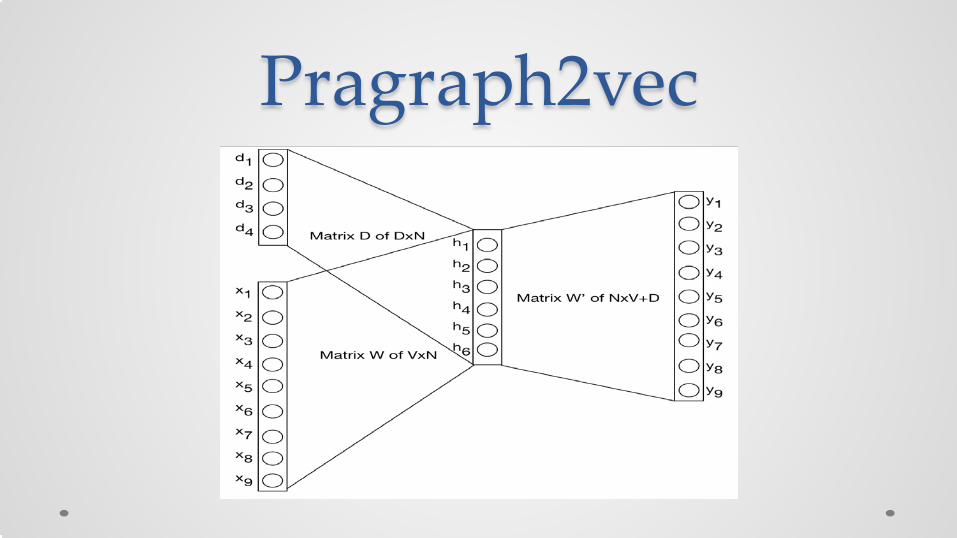
Pragraph2vec

Pragraph2vec
• At each step h is computed by concatenating or averaging a paragraph vector d with a context of word vectors C
• The weight update functions are the same as in Word2Vec except that paragraph vectors also gets updated.

Pragraph2vec • Vector representation of a paragraph with different length
sentence.
Paragraph w/17
different words

Pragraph2vec
Paragraph vector of
dimension 17x3
Document vector of
dimension 5x3
Softmax regression
Weight update

Vector Averaging
• Vector averaging is the simplest technique to get the vector representation for a sentence.
• It calculates the sum of all word vectors and divides that with number of words.
• It’s considered fastest but not so accurate in result.

Clustering method
• It creates predetermined number of cluster of words.
• Synonymous words (mainly adjectives) ends up in same cluster.
• Rather than using bag of words, it uses bag of centroids (counting the occurrence of a word in a certain cluster)then.
• Reference : https://www.kaggle.com/c/word2vec-nlp-tutorial/details/part-3-more-fun-with-word-vectors

Performance comparison
• Paragraph2vec is generally the most accurate one when used in classification algorithm.
• Vector averaging is the fastest but clustering is considered to be decent in terms of accuracy and speed.

Questions

















