34
Search Trees
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| Upload: | mary-fletcher |
| View: | 220 times |
| Download: | 3 times |

Search Trees

Introduction
In order to handle spatial data efficiently, as required in CAD and Geo-data applications, a database system needs an index mechanism that will help it retrieve data items quickly according to their spatial locations
R-Trees

R-Tree Index Structure
An R-tree is a height-balanced tree similar to a B-tree with index records in its leaf nodes containing pointers to data objects
Leaf nodes in an R-tree contain index record entries of the form (I, tuple-identifier) where tuple-identifier refers to a tuple in the database and I is an n-dimensional rectangle
Non-leaf nodes contain entries of the form (I, child-pointer) where child-pointer is the address of a lower node in the R-tree and I covers all rectangles in the lower node’s entries
R-Trees

Properties of R-TreeEvery leaf node contains between
m(<=M/2) and M index records unless it is the root
For each index record (I, tuple-identifier) in a leaf node, I is the smallest rectangle that spatially contains the n-dimensional data object represented by the indicated tuple
Every non-leaf node has between m and M children unless it is the root
For each entry (I, child-pointer) in a non-leaf node, I is the smallest rectangle that spatially contains the rectangles in the child node
The root node has at least two children unless it is a leaf and all leaves appear on the same level
R-Trees
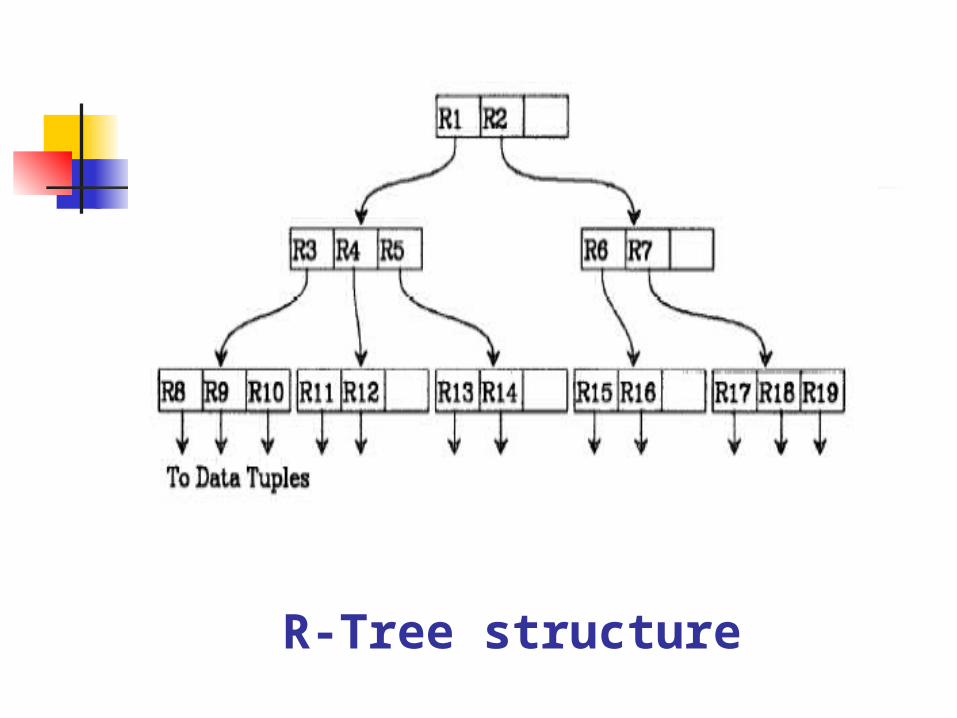
R-Tree structure
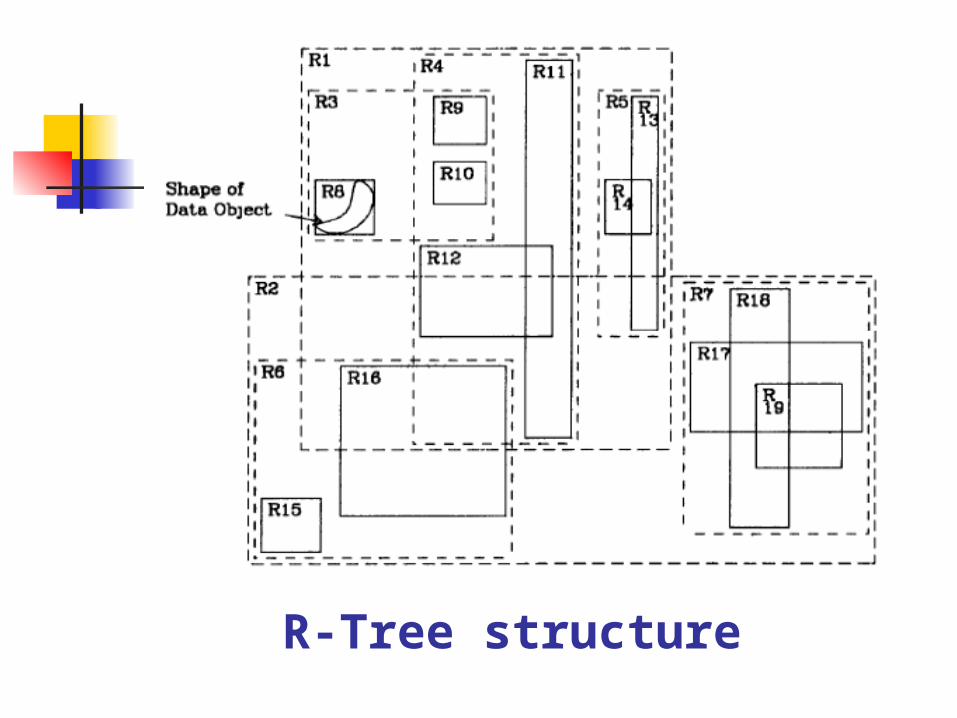
R-Tree structure

Algorithm SearchGiven an R-tree whose root node is T, find all index records whose rectangles overlap a search rectangle SS1 [Search subtrees] If T is not a leaf, check each entry E to determine whether EI overlaps S. For all overlapping entries, invoke Search on the tree whose root node is pointed to by EpS2 [Search leaf node] If T is a leaf, check all entries E to determine whether EI overlaps S. If so, E is a qualifying record
R-Trees …. contd

Algorithm InsertL1 [Find position for new record] Invoke ChooseLeaf to select a leaf node L in which to place EL2 [Add record to leaf node] If L has room for another entry, install E. Otherwise invoke SplitNode to obtain L and LL containing E and all the old entries of LL3 [Propagate changes upward] Invoke AdjustTree on L, also passing LL if a split was performedL4 [Grow tree taller] If node split propagation caused the root to split, create a new root whose children are the two resulting nodes
R-Trees …. contd

Algorithm ChooseLeafCL1 [Initialize] Set N to be the root node
CL2 [Leaf check] If N is a leaf, return NCL3 [Choose subtree] If N is not a leaf, let F be the entry in N whose rectangle FI needs least
enlargement to include EI. Resolve ties by choosing the entry with the rectangle of
smallest area.CL4 [Descend until a leaf is reached] Set N to be the child node pointed to by Fp and repeat from CL2
R-Trees …. contd

Algorithm AdjustTreeAT1 [Initialize] Set N=L. If L was spilt previously, set NN to be the resulting second nodeAT2 [Check if done] If N is the root, stopAT3 [Adjust covering rectangle in parent entry] Let P be the parent node of N, and let En be N’s entry in P. Adjust EnI so that it tightly encloses all entry rectangles in NAT4 [Propagate node split upward] If N has a partner NN resulting from an earlier split, create a new entry Enn with EnnP pointing to NN and EnnI enclosing all rectangles in NN. Add Enn to P if there is room. Otherwise, invoke SpiltNode to produce P and PP containing Enn and all P’s old entries
… contd
R-Trees …. contd

Algorithm AdjustTree … contdAT5 [Move up to next level] Set N=P and set NN=PP if a split occurred. Repeat from AT2
R-Trees …. contd

Algorithm DeletionD1 [Find node containing record] Invoke FindLeaf to locate the leaf node L containing E. Stop if the record was not found.D2 [Delete record] Remove E from LD3 [Propagate changes] Invoke CondenseTree, passing LD4 [Shorten tree] If the root node has only one child after the tree has been adjusted, make the child the new root
R-Trees …. contd

Algorithm FindLeafFL1 [Search subtrees] If T is not a leaf, check each entry F in T to determine if FI overlaps EI. For each such entry invoke FindLeaf on the tree whose root is pointed to by Fp until E is found or all entries have been checkedD2 [Search leaf node for record] If T is a leaf, check each entry to see if it matches E. If E is found return T
R-Trees …. contd

Algorithm CondenseTreeCT1 [Initialize] Set N=L. Set Q, the set of eliminated nodes, to be emptyCT2 [Find parent entry] If N is the root, go to CT6. Otherwise let P be the parent of N, and let En be N’s entry in PCT3 [Eliminate under-full node] If N has fewer than m entries, delete En from P and add N to set QCT4 [Adjust covering rectangle] If N has not been eliminated, adjust EnI to tightly contain all entries in N
… contd
R-Trees …. contd

Algorithm CondenseTree … contdCT5 [Move up one level in the tree] Set N=P and repeat from CT2CT6 [Re-insert orphaned entries] Re-insert all entries of nodes in set Q. Entries from eliminated leaf nodes are re-inserted in tree leaves as described in Algorithm Insert, but entries from higher-level nodes must be placed higher in the tree, so that leaves of their dependent subtrees will be on the same level as leaves of the main tree
R-Trees …. contd

Algorithm Quadratic SplitQS1 [Pick first entry for each group] Apply PickSeeds to choose two entries to be the first elements of the groups. Assign each to a group.QS2 [Check if done] If all entries have been assigned, stop. If one group has so few entries that all the rest must be assigned to it in order for it to have the minimum number m, assign them and stop.QS3 [Select entry to assign] Invoke PickNext to
choose the next entry to assign. Add it to the group whose covering rectangle will have to be enlarged least to accommodate it. Resolve ties by adding the entry to the group with smaller area, then to the one with fewer entries, then to either. Repeat from QS2
R-Trees …. contd

Algorithm PickSeedsPS1 [Calculate inefficiency of grouping entries together] For each pair of entries E1 and E2, compose a rectangle J including E1I and E2I. Calculate d=area(J)-area(E1I)-area(E2I).PS2 [Choose the most wasteful pair] Choose the pair with the largest d
R-Trees …. contd

Algorithm PickNextPN1 [Determine cost of putting each entry in each group] For each entry E not yet in a group, calculate d1=the area increase required in the covering rectangle of Group 1 to include E1. Calculate d2 similarly for Group 2.PN2 [Find entry with greatest preference for one
group] Choose any entry with the maximum difference between d1 and d2
R-Trees …. contd

Why GiSTExtensible both in data types supported
and in the queries applied on this data
Allows new data types to be indexed in a manner that supports the queries natural to the data type
Unifies previously disparate structures for currently common data types
Example B+ and R trees can be implemented as
extensions to GiST. Single code base for indexing multiple dissimilar applications
Generalized Search Tree (GiST)

DefinitionA GiST is a balanced multi-way tree of
variable fan-out between kM and M Where k is the fill factor
With the exception of the root node that can have fan-out from 2 to M
Leaf nodes: (p,ptr)ptr: Identifier of some tuple of the
DBNon-leaf nodes: (p,ptr)
ptr: Pointer to another tree nodeand p: Predicate used as a search
key
GiST …. contd
2
12k
M

PropertiesEvery node contains between kM and M
index entries unless it is the root.For each index entry (p,ptr) in a leaf
node, p holds for the tuple For each index entry (p,ptr) in a non-leaf
node, p is true when instantiated with the values of any tuple reachable from ptr
The root has at least two children unless it is a leaf
All leaves appear on the same level
GiST …. contd

GiST MethodsKey Methods
The methods the user can specify to configure the GiST. The methods encapsulate the structure and behavior of the object class used for keys in the tree
Tree MethodsProvided by the GiST, and may
invoke the required key methods
GiST …. contd

GiST Key Methods … contdE is an entry of the form (p,ptr) , q is a
query, P a set of entries
Consistent(E,q) returns false if p^q guaranteed unsatisfiable, true otherwise.
Union(P) returns predicate r that holds for all predicates in P
Compress(E) returns (p’,ptr).Decompress(E) returns (r,ptr) where
pr. This is a lossy compression as we do not require pr
GiST …. contd

GiST Key Methods … contdPenalty(E1,E2): returns domain
specific penalty for inserting E2 into the subtree rooted at E1. Typically the penalty metric is representation of the increase of size from E1.p to Union(E1,E2).
PickSplit(P): M+1 entries, splits P into two sets of entries P1,P2, each of the size kM. The choice of the minimum fill factor is controlled here
GiST …. contd

GiST Tree MethodsSearch Controlled by the Consistent
Method.Insert Controlled by the Penalty and
PickSplit.Delete Controlled by the Consistent
GiST …. contd

Example
New (q,ptr)
Penalty = m Penalty = nm < n
Penalty =i Penalty = j j < i
Full.. Then split according to PickSplit
(p,ptr) (p,ptr) (p,ptr)
(p,ptr) (p,ptr)
(p,ptr) (p,ptr)
R
(p,ptr) (p,ptr) (p,ptr) (p,ptr)(q,ptr) (p,ptr) (p,ptr)
New (q,ptr)

GiST Over Z (B+ Trees)
GiST Over Polygons in R2 (R Trees)
Applications

p here is on the form Contains([xp,yp),v)Consistent(E,q) returns true if
If q= Contains([xq,yq),v): (xp<yq)^(yp>xq)
If q= Equal (xq,v): xp xq <yp
Union(P) returns [Min(x1,x2,…,xn),MAX(y1,y2,….,yn)).
B+ Trees Using GiST

Penalty(E,F)If E is the leftmost pointer on its node, returns
MAX(y2-y1,0)If E is the rightmost pointer on its node, returns
MAX(x1-x2,0)Otherwise, returns MAX(y2-y1,0)+MAX(x1-x2,0)
PickSplit(P) let the first entries in order to go to the left node and the remaining in the right node.
B+ Trees Using GiST … contd

Compress(E) if E is the leftmost key on a non-leaf node return 0 bytes otherwise, returns E.p.x
Decompress(E) If E is the leftmost key on a non-leaf node let
x= - otherwise let x=E.p.xIf E is the rightmost key on a non-leaf node let
y= . If E is other entry in a non-leaf node, let y = the value stored in the next key. Otherwise, let y = x+1
B+ Trees Using GiST … contd

The key here is in the form (xul,yul,xlr,ylr)
Query predicates are:Contains ((xul1,yul1,xlr1,ylr1), (xul2,yul2,xlr2,ylr2))
Returns true if (xul1 xul2) ^( yul1 yul2) ^ ( xlr1
xlr2) ^ ( ylr1 ylr2)
Overlaps ((xul1,yul1,xlr1,ylr1), (xul2,yul2,xlr2,ylr2))
Returns true if (xul1 xlr2) ^( yul1 ylr2) ^ ( xul2
xlr1) ^ ( ylr1 yul2)
Equal ((xul1,yul1,xlr1,ylr1), (xul2,yul2,xlr2,ylr2))
Returns true if (xul1= xul2) ^( yul1= yul2) ^ ( xlr1=
xlr2) ^ ( ylr1= ylr2)
R-Trees Using GiST

Consistent(E,q) p contains (xul1,yul1,xlr1,ylr1), and q is either
Contains, Overlap or Equal (xul2,yul2,xlr2,ylr2)
Returns true if Overlaps ((xul1,yul1,xlr1,ylr1), (xul2,yul2,xlr2,ylr2))
Union(P) returns coordinates of the maximum bounding rectangles of all rectangles in P.
R-Trees Using GiST … contd

Penalty(E,F)Compute q= Union(E,F) and return area(q) –
area(E.p)PickSplit(P)
Variety of algorithms are provided to best split the entries in a over-full node
R-Trees Using GiST … contd

Compress(E)Form the bounding rectangle of E.p
Decompress(E)The identity function
R-Trees Using GiST … contd
















![Speculative Transaction Processing in Geo-Replicated Data ... · over geographically-scattered data centers (geo-replication) [12, 27, 29]. Geo-replication allows services to remain](https://static.documents.pub/doc/80x56/5f87a873775bc660232f36a9/speculative-transaction-processing-in-geo-replicated-data-over-geographically-scattered.jpg)
