20
SemSearch: A Search Engine for the Semantic Web Yuangui Lei, Victoria Uren, Enrico Motta Knowledge Media Institute The Open University EKAW 2006 Presented by Jungyeon, Yang
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | donna-wright |
| View: | 212 times |
| Download: | 0 times |

SemSearch: A Search Engine for the Semantic Web
Yuangui Lei, Victoria Uren, Enrico Motta
Knowledge Media Institute
The Open University
EKAW 2006
Presented by Jungyeon, Yang

Copyright 2008 by CEBT
Outline
Research background
SemSearch overview
Query interface
Search process
Implementation & examples
Conclusions

Copyright 2008 by CEBT
Research background
Semantic search: extending traditional search with the semantic web technology
Exploiting the explicit meaning of documents (i.e., ontology-based metadata)
Current semantic search tools
Form-based, e.g., SHOE, Magnet
QA-based, e.g., AquaLog, ORAKEL
Keyword-based, e.g., TAP, Squiggle, DOSE

Copyright 2008 by CEBT
Support for ordinary end users
Form-based tools Forms are intuitive Issues: knowledge overhead; scalability
QA-based tools Easy to use Issue: heavy NLP.
Keyword-based tools Easy to post queries; quick response Issue: typically one keyword only; general knowledge of
the problem domain required

Copyright 2008 by CEBT
The goal of our search engine
Hide the complexity of semantic search from end users:
Low barrier to access: easy to post queries
– Avoiding the form-based routine
Dealing with relatively complex queries
– Supporting multiple keywords
Precise and self-explanatory results:
– Results satisfy user queries
– Results are easy to understand
Quick response
– Avoiding linguistic processing

Copyright 2008 by CEBT
SemSearch Architecture
Google-like User Interface Layer
Semantic Query Layer
Formal Query Language Layer (SPARQL, SERQL, etc.)
Semantic Data Layer
End users
Semantic entity indexing en-gineSemantic entity search engine
Formal query construction en-gineQuery engineRanking en-
gine
Google-like query interface
Text Search Layer

Copyright 2008 by CEBT
The Google-like query interface
Extending the traditional keyword search languages by allow-ing the specification of: The queried subject (the type of expected search results) The combination of keywords
Three operations are used: Operator “:” captures the query subject “and”/”or” specifies the combination of keywords
Query formats: One keyword: finding entities that have relations with the keyword
match Multiple keywords: “subject:keyword1 and/or keyword2 and/or
keyword3”, e.g., “<news: phd students>”, <paper: john and en-rico>
Advantages: More flexible than form-based query interface More powerful than state-of-art keyword-based semantic search
interfaces
Copyright 2008 by CEBT
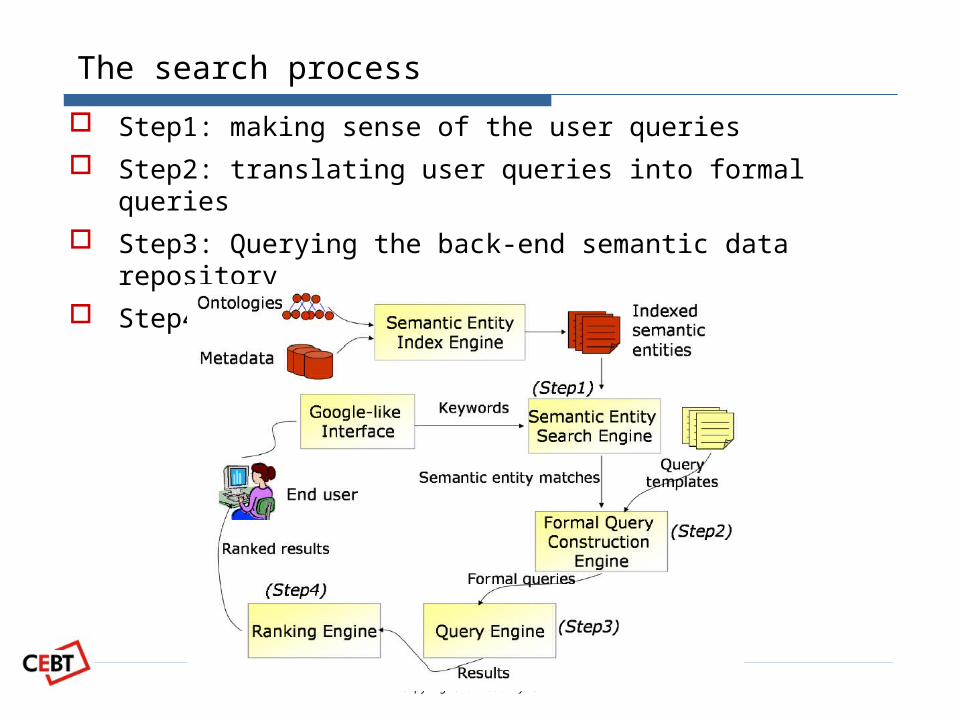
The search process
Step1: making sense of the user queries Step2: translating user queries into formal queries Step3: Querying the back-end semantic data repository Step4: Ranking the querying results

Copyright 2008 by CEBT
Making sense of user queries
Finding out the semantic meaning of keywords
Class, (e.g., the keyword “phd students”)
Relation, (e.g., “author”)
Instance, (e.g., “Enrico”, ”KMi director”)
Method: text search
labels (rdfs:label)
Short literals also used in the case of instances matching
– When searching for “KMi director”, the instances can be picked up.
Two components in the search engine
The semantic entity index engine
The semantic entity search engine

Copyright 2008 by CEBT
Translating user queries into formal queries
The search engine takes as input the semantic matches of user search terms
The search engine takes outputs an appropriate formal query according to the semantic meanings of keywords
One user query Each keyword
multiple matches SEARCH ENGINE
multiple formal queries.

Copyright 2008 by CEBT
Simple user queries
There are only two keywords involved: <subject : keyword>
Fixed number of combination types
Subject match Keyword match Example
Class Class <news: phd students>
Property <news: author>
Instance <news: chief scientist>
Instance Property <victoria:author>
Instance <victoria:yuangui>
Property Instance <member: x-media>
Property <member: author>
• The SeRQL query templates are defined

Copyright 2008 by CEBT
select {Is}, {R}, {Ik} from {Is} rdf:type {Cs}, {Ik} rdf:type {Ck}, {Is} R {Ik} unionselect {Is}, {R}, {Ik} from {Is} rdf:type {Cs}, {Ik} rdf:type {Ck}, {Ik} R {Is}
A template example
Pattern: Subject -> Class Cs; Keyword -> Class Ck Results: <Is,Relation,Ik> associated with exploratory
links. Example: news stories about phd students
<news “KMi success”, mentions-person, Tom-Heath>
A simplified template in Sesame SeRQL:

Copyright 2008 by CEBT
Complex user queries
< subject: keyword1 and/or keyword2 and/or… >
Instances of the subject which either have relations with all the keywords or have relations with some of the keywords.
Operational problem the number of combination gets big when there are many
keywords involved and there are lots of matches for each keyword.
Rules for combination reduction: Only considering the subject keyword as class entities Choosing the closest matches to the keyword as possible Choosing the most specific class match among the class
matches.

Copyright 2008 by CEBT
Query construction In SeRQL
Three building blocks– Head block: what needs to be retrieved, i.e., <Is, r, Ikx>
– Body block: how to retrieve the triples
– Condition block: conditions need to be satisfied
Union block : in order to cover bidirectional relations
SELECT DISTINCTlabel(ArtefactTitle), MuseumName
FROM{Artefact} arts:created_by {} arts:first_name {"Rem-
brandt"},{Artefact} arts:exhibited {} dc:title {MuseumName},{Artefact} dc:title {ArtefactTitle}
WHEREisLiteral(ArtefactTitle) ANDlang(ArtefactTitle) = "en" ANDlabel(ArtefactTitle) LIKE "*night*"

Copyright 2008 by CEBT
Query construction algorithm
No
No
Adding query blocks for class-property relations retrieval
YesAdding query blocks for class-class re-
lations retrieval
Yes
Adding blocks for class-instance rela-tions retrieval
Has keyword match?
Yes
Initializing the query blocks
Composing queries using the blocks
No
Is class?
Is property?
Is instance?Yes
No

Copyright 2008 by CEBT
Simple query example

Copyright 2008 by CEBT
Refinement support

Copyright 2008 by CEBT
Complex query example

Copyright 2008 by CEBT
Conclusions
A keyword-based semantic search engine has been de-veloped Google-like query interface Supporting relatively complex queries Providing relatively quick response

Copyright 2008 by CEBT
Opinions
Pros Google-like query interface (intuitive) Supporting relatively complex queries
Cons Limitation of the target data form. (RDF) Ranking Simple semantic matching
Issues Finding out the semantic meaning of keyword Storage modeling Strategy of the semantic match between keyword and se-
mantic entity

















