Sequence analysis June 19, 2007 Learning objectives-Understand the concept of sliding window programs. Understand difference between identity, similarity and homology. Understand difference between global alignment and local alignment. Appreciate that amino acids structures may be similar. Workshop-Perform sliding window to compute %GC as a function of position in sequence.
Transcript
Sequence analysis
June 19, 2007
Learning objectives-Understand the concept of sliding window programs. Understand difference between identity, similarity and homology. Understand difference between global alignment and local alignment. Appreciate that amino acids structures may be similar.
Workshop-Perform sliding window to compute %GC as a function of position in sequence.
Sliding window (1)
This refers to the number of characters looked at, during one particular time.
Below is a sequence shown three times with different window lengths
GCATATGCGCATATCCCGTCAATACCA
GCATATGCGCATATCCCGTCAATACCA
GCATATGCGCATATCCCGTCAATACCA
4
5
6
Sliding window (2)
A "window" can be defined as a span of a certain number of residues (nucleotides or amino acids). One calculates some value for the residues in that window. Once the calculation is completed, the program shifts the window and the process repeats itself until the end of the sequence is reached.
A simple example is to calculate the %GC content within a window. Then move the window one nucleotide and repeat the calculation.
Sliding window (3)
If the window is too small it is difficult to detect the trendof the measurement. If too large you could miss meaningfuldata.
Large window size
Small window size
%GC
%GC
Number in sequence
Number in sequence
Sliding window (4)
Dot Plots
A T G C C T A G
A T G C C T A G
**
**
**
**
**
**
**
*
*
Window = 1
Note that 25% ofthe table will befilled due to randomchance. 1 in 4 chanceat each position
Dot Plots with window = 2
A T G C C T A GA T G C C T A G
**
**
**
*
Window = 2The larger the windowthe more noise canbe filtered
What is thepercent chance thatyou will receive a match randomly? Onein (four)2
Chou-Fasman Rules (Mathews, Van Holde, Ahern)Amino Acid -Helix -Sheet Turn Ala 1.29 0.90 0.78 Cys 1.11 0.74 0.80 Leu 1.30 1.02 0.59 Met 1.47 0.97 0.39 Glu 1.44 0.75 1.00 Gln 1.27 0.80 0.97 His 1.22 1.08 0.69 Lys 1.23 0.77 0.96 Val 0.91 1.49 0.47 Ile 0.97 1.45 0.51 Phe 1.07 1.32 0.58 Tyr 0.72 1.25 1.05 Trp 0.99 1.14 0.75 Thr 0.82 1.21 1.03 Gly 0.56 0.92 1.64 Ser 0.82 0.95 1.33 Asp 1.04 0.72 1.41 Asn 0.90 0.76 1.23 Pro 0.52 0.64 1.91 Arg 0.96 0.99 0.88
Favors-Helix
Favors-Sheet
FavorsTurns
Chou-Fasman-the first sliding window programs to predict protein secondary structure
First widely used procedureIf propensity in a window of six residues (for a helix) is above a certain threshold the helix is chosen as secondary structure.If propensity in a window of five residues (for a beta strand) is above a certain threshold then beta strand is chosen.Each classification is extended until the average propensity in a 4 residue window falls below a value.Output-helix, strand or turn.
Chou&Fasman structure prediction
Chou & Fasman [Biochemistry 13(2):222-245 (1974)]. By studying a number of proteins whose structures were known, they were able to determine stretches of amino acids that could serve to form an -helix or a -sheet. These amino acids are called helix formers or sheet formers and can have different strengths for forming their structures. Once these nucleation sites are determined, adjacent amino acids are examined to see if the structure can be extended in either or both directions. Values for some amino acids allow extension, other amino acids do not. Some amino acids are categorized as helix breakers, or sheet breakers. A string of these will terminate the current structure. This method is about 60-65% accurate.
Kyte-Doolittle Hydropathy
– Another sliding window routine [J. Mol. Biol. 157:105-132 (1982)]. They determine a "hydropathy scale" for each amino acid based on empirical observations.
1. Identity: Quantity that describes how muchtwo sequences are alike in the strictest terms.2. Similarity: Quantity that relates how much two amino acid sequences are alike.3. Homology: a conclusion drawn from datasuggesting that two genes share a commonevolutionary history.
Purpose of finding differences and similarities of amino acids in two proteins.
Infer structural information
Infer functional information
Infer evolutionary relationships
Modular nature of proteins (cont. 1)
Exon 1a Exon 2a
Duplication of Exon 2a
Exon 1a Exon 2a Exon 2a
Exchange with Gene B
Gene A
Gene A
Gene A
Gene B
Exon 1a Exon 2a Exon 3 (Exon 2b from Gene B)
Exon 1b Exon 2b Exon 3 (Exon 2a from Gene A)
Exon 1b Exon 2b Exon 2bGene B
Evolutionary Basis of Sequence Alignment (Cont. 1)
Why are there regions of identity?
1) Conserved function-residues participate in reaction.
2) Structural (For example, conserved cysteine residues that form a disulfide linkage)
3) Historical-Residues that are conserved solely due to a common ancestor gene.
One is mouse trypsin and the other is crayfish trypsin.They are homologous proteins. The sequences share 41% identity.
Evolutionary Basis of Sequence Alignment (Cont. 2)
Note: it is possible that two proteins share a high degree of similarity but have two different functions. For example, human gamma-crystallin is a lens protein that has no knownenzymatic activity. It shares a high percentage of identity withE. coli quinone oxidoreductase. These proteins likely had acommon ancestor but their functions diverged.
Analogous to railroad car and diner function.
Modular nature of proteins
The previous alignment was global. However, many proteins do not display global patterns of similarity. Instead, they possess local regions of similarity.
Proteins can be thought of as assemblies of modular domains. It is thought that this may, in some cases, be due to a process known as exon shuffling.
Identity Matrix
Simplest type of scoring matrix
LICA
1000L
100I
10C
1A
Similarity
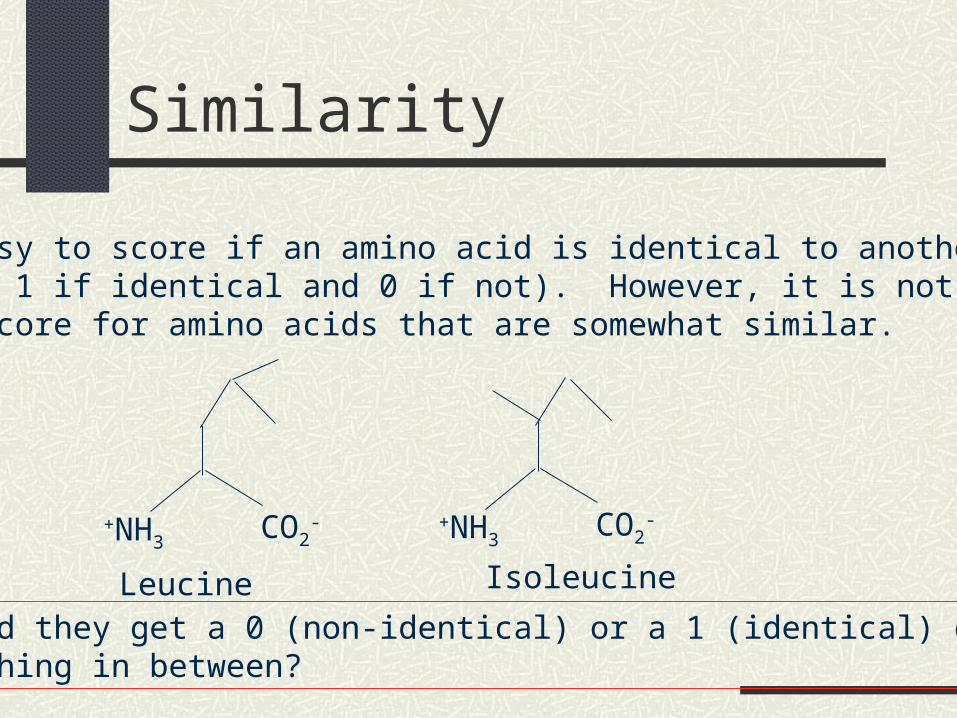
It is easy to score if an amino acid is identical to another (thescore is 1 if identical and 0 if not). However, it is not easy togive a score for amino acids that are somewhat similar.
+NH3CO2
- +NH3CO2
-
Leucine Isoleucine
Should they get a 0 (non-identical) or a 1 (identical) orSomething in between?