Page 1
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Sequence Classificationwith emphasis on Hidden Markov Models and Sequence Kernels
Andrew M. White
September 29, 2009
Andrew M. White Sequence Classification
Page 2
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 3
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 4
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Examples
Biological Sequence Analysis
Ï genes
Ï proteins
Temporal Pattern Recognition
Ï speech
Ï gestures
Semantic Analysis
Ï handwriting
Ï part-of-speech detection
Andrew M. White Sequence Classification
Page 5
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Examples
Biological Sequence Analysis
Ï genes
Ï proteins
Temporal Pattern Recognition
Ï speech
Ï gestures
Semantic Analysis
Ï handwriting
Ï part-of-speech detection
Andrew M. White Sequence Classification
Page 6
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Examples
Biological Sequence Analysis
Ï genes
Ï proteins
Temporal Pattern Recognition
Ï speech
Ï gestures
Semantic Analysis
Ï handwriting
Ï part-of-speech detection
Andrew M. White Sequence Classification
Page 7
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Sequential Data
Characteristics
Ï an example of structured data
Ï exhibit sequential correlation, i.e., nearby values are likely to berelated
Why not just use earlier techniques?
Ï difficult to find appopriate features
Ï structural information is important
Andrew M. White Sequence Classification
Page 8
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Example Framework
Speech Recognition
Ï goal: identify individual phonemes (the building blocks ofspeech, sounds like “ch” and “t” )
Ï source data:Ï quantized speech waveformsÏ tagged phonemes as sequence of values
Ï multiple classes, each:Ï has hundreds to thousands of sequencesÏ sequences vary in length
Andrew M. White Sequence Classification
Page 9
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Example Framework
Speech Recognition
Ï goal: identify individual phonemes (the building blocks ofspeech, sounds like “ch” and “t” )
Ï source data:Ï quantized speech waveformsÏ tagged phonemes as sequence of values
Ï multiple classes, each:Ï has hundreds to thousands of sequencesÏ sequences vary in length
Andrew M. White Sequence Classification
Page 10
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Example Framework
Speech Recognition
Ï goal: identify individual phonemes (the building blocks ofspeech, sounds like “ch” and “t” )
Ï source data:Ï quantized speech waveformsÏ tagged phonemes as sequence of values
Ï multiple classes, each:Ï has hundreds to thousands of sequencesÏ sequences vary in length
Andrew M. White Sequence Classification
Page 11
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 12
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Methods for Sequence Classification
Generative Models
Ï Hidden Markov ModelsÏ Stochastic Context-Free GrammarsÏ Conditional Random Fields
Discriminative Methods
Ï Kernel Methods (incl. SVMs)Ï Max-margin Markov Networks
Andrew M. White Sequence Classification
Page 13
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Methods for Sequence Classification
Generative Models
Ï Hidden Markov ModelsÏ Stochastic Context-Free GrammarsÏ Conditional Random Fields
Discriminative Methods
Ï Kernel Methods (incl. SVMs)Ï Max-margin Markov Networks
Andrew M. White Sequence Classification
Page 14
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Methods for Sequence Classification
Generative Models
Ï Hidden Markov ModelsÏ Stochastic Context-Free GrammarsÏ Conditional Random Fields
Discriminative Methods
Ï Kernel Methods (incl. SVMs)Ï Max-margin Markov Networks
Andrew M. White Sequence Classification
Page 15
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 16
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Markov Models
HOME
OFFICE CAFE
HOME
OFFICE CAFE
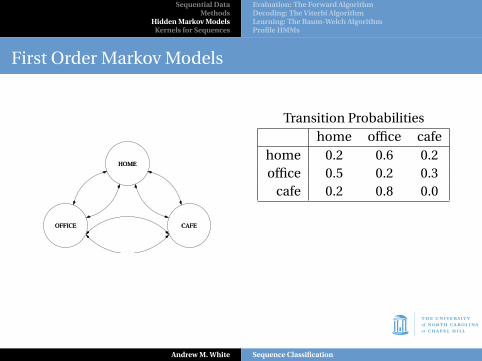
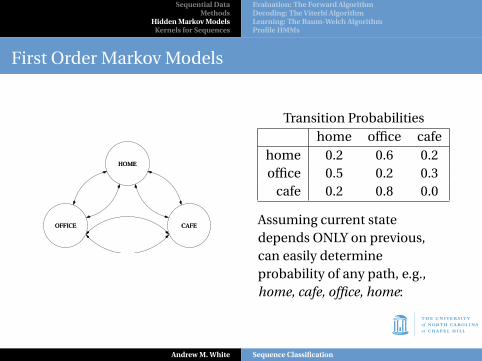
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Assuming current statedepends ONLY on previous,can easily determineprobability of any path, e.g.,home, cafe, office, home:
P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
.
Andrew M. White Sequence Classification
Page 17
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Markov Models
HOME
OFFICE CAFE
HOME
OFFICE CAFE
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Assuming current statedepends ONLY on previous,can easily determineprobability of any path, e.g.,home, cafe, office, home:
P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
.
Andrew M. White Sequence Classification
Page 18
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Markov Models
HOME
OFFICE CAFE
HOME
OFFICE CAFE
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Assuming current statedepends ONLY on previous,can easily determineprobability of any path, e.g.,home, cafe, office, home:
P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
.
Andrew M. White Sequence Classification
Page 19
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Markov Models
HOME
OFFICE CAFE
HOME
OFFICE CAFE
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Assuming current statedepends ONLY on previous,can easily determineprobability of any path, e.g.,home, cafe, office, home:
P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
.Andrew M. White Sequence Classification
Page 20
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
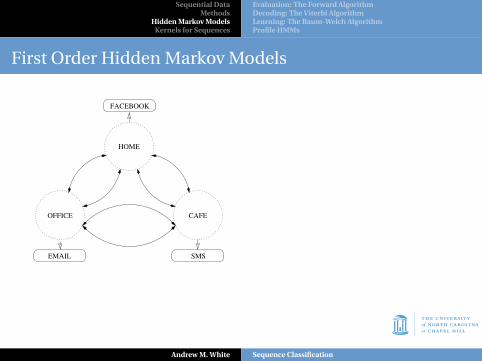
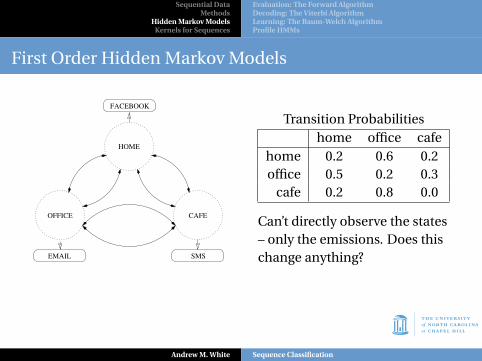
First Order Hidden Markov Models
HOME
OFFICE CAFE
EMAIL SMS
FACEBOOK
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Can’t directly observe the states– only the emissions. Does thischange anything?
In this case, no.
P(FSEF) = P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
Andrew M. White Sequence Classification
Page 21
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Hidden Markov Models
HOME
OFFICE CAFE
EMAIL SMS
FACEBOOK
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Can’t directly observe the states– only the emissions. Does thischange anything?
In this case, no.
P(FSEF) = P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
Andrew M. White Sequence Classification
Page 22
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Hidden Markov Models
HOME
OFFICE CAFE
EMAIL SMS
FACEBOOK
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Can’t directly observe the states– only the emissions. Does thischange anything?
In this case, no.
P(FSEF) = P(HCOH) = P(C|H)P(O|C)P(H|O) = (0.2)(0.8)(0.5) = 0.08
Andrew M. White Sequence Classification
Page 23
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
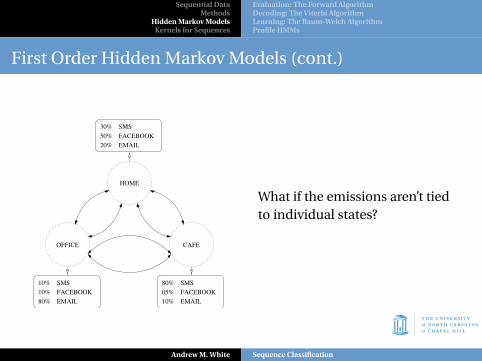
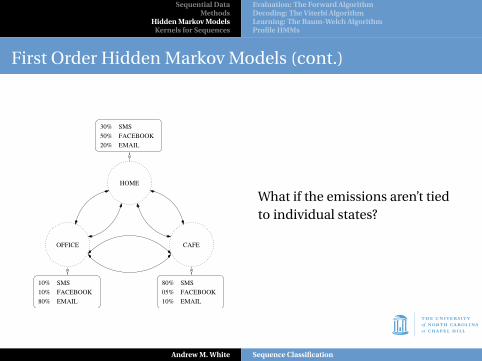
First Order Hidden Markov Models (cont.)
EMAIL
SMS10%
10%
80%
FACEBOOK
EMAIL
SMS
FACEBOOK
80%
10%
05%
EMAIL
SMS
FACEBOOK
30%
50%
20%
HOME
OFFICE CAFE
What if the emissions aren’t tiedto individual states?
Andrew M. White Sequence Classification
Page 24
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Hidden Markov Models (cont.)
EMAIL
SMS10%
10%
80%
FACEBOOK
EMAIL
SMS
FACEBOOK
80%
10%
05%
EMAIL
SMS
FACEBOOK
30%
50%
20%
HOME
OFFICE CAFE
What if the emissions aren’t tiedto individual states?
Andrew M. White Sequence Classification
Page 25
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
First Order Hidden Markov Models (cont.)
Transition Probabilitieshome office cafe
home 0.2 0.6 0.2office 0.5 0.2 0.3
cafe 0.2 0.8 0.0
Emission Probabilitiessms facebook email
home 0.3 0.5 0.2office 0.1 0.1 0.8
cafe 0.8 0.1 0.1Now we have to look at all possible state sequences which couldhave generated the given observation sequence.
Andrew M. White Sequence Classification
Page 26
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
The Three Canonical Problems of Hidden Markov Models
Evaluation
Given: parameters, observation sequenceFind: P( observation sequence | parameters )
Decoding
Given: parameters, observation sequenceFind: most likely state sequence
Learning
Given: observation sequence(s)Find: parameters
Andrew M. White Sequence Classification
Page 27
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
The Three Canonical Problems of Hidden Markov Models
Evaluation
Given: parameters, observation sequenceFind: P( observation sequence | parameters )
Decoding
Given: parameters, observation sequenceFind: most likely state sequence
Learning
Given: observation sequence(s)Find: parameters
Andrew M. White Sequence Classification
Page 28
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
The Three Canonical Problems of Hidden Markov Models
Evaluation
Given: parameters, observation sequenceFind: P( observation sequence | parameters )
Decoding
Given: parameters, observation sequenceFind: most likely state sequence
Learning
Given: observation sequence(s)Find: parameters
Andrew M. White Sequence Classification
Page 29
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Notation
For now, consider a single observation sequence
O = o1o2...oT
and an associated (unknown) state sequence
Q = q1q2...qT .
Denote the transition probabilities:
aij = P( transition from node i to node j )
Similarly, the emission probabilities:
bjk = P( emission of symbol k from node j )
Andrew M. White Sequence Classification
Page 30
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Notation
For now, consider a single observation sequence
O = o1o2...oT
and an associated (unknown) state sequence
Q = q1q2...qT .
Denote the transition probabilities:
aij = P( transition from node i to node j )
Similarly, the emission probabilities:
bjk = P( emission of symbol k from node j )
Andrew M. White Sequence Classification
Page 31
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Notation
For now, consider a single observation sequence
O = o1o2...oT
and an associated (unknown) state sequence
Q = q1q2...qT .
Denote the transition probabilities:
aij = P( transition from node i to node j )
Similarly, the emission probabilities:
bjk = P( emission of symbol k from node j )
Andrew M. White Sequence Classification
Page 32
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Assumptions
We have two big assumptions to make:
Markov Assumption
Current state depends only on the previous state.
Independence Assumption
Current emission depends only on the current state.
Andrew M. White Sequence Classification
Page 33
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Assumptions
We have two big assumptions to make:
Markov Assumption
Current state depends only on the previous state.
Independence Assumption
Current emission depends only on the current state.
Andrew M. White Sequence Classification
Page 34
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Assumptions
We have two big assumptions to make:
Markov Assumption
Current state depends only on the previous state.
Independence Assumption
Current emission depends only on the current state.
Andrew M. White Sequence Classification
Page 35
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 36
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation
Under the Markov assumption, for a state sequence Q, can calculatethe probablity of this sequence given the parameters (A,B) =λ:
P(Q|λ) =T∏
t=2P(qt |qt−1) = aq1q2 aq2q3 ...aqT−1qT
Under our independence assumption, can find the probability of anobservation sequence O given a state sequence Q and theparameters (A,B) =λ:
P(O|Q,λ) =T∏
t=1P(ot |qt) = bq1o1 bq2o2 ...bqT−1oT−1 bqT oT
Andrew M. White Sequence Classification
Page 37
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation
Under the Markov assumption, for a state sequence Q, can calculatethe probablity of this sequence given the parameters (A,B) =λ:
P(Q|λ) =T∏
t=2P(qt |qt−1) = aq1q2 aq2q3 ...aqT−1qT
Under our independence assumption, can find the probability of anobservation sequence O given a state sequence Q and theparameters (A,B) =λ:
P(O|Q,λ) =T∏
t=1P(ot |qt) = bq1o1 bq2o2 ...bqT−1oT−1 bqT oT
Andrew M. White Sequence Classification
Page 38
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation
Under the Markov assumption, for a state sequence Q, can calculatethe probablity of this sequence given the parameters (A,B) =λ:
P(Q|λ) =T∏
t=2P(qt |qt−1) = aq1q2 aq2q3 ...aqT−1qT
Under our independence assumption, can find the probability of anobservation sequence O given a state sequence Q and theparameters (A,B) =λ:
P(O|Q,λ) =T∏
t=1P(ot |qt) = bq1o1 bq2o2 ...bqT−1oT−1 bqT oT
Andrew M. White Sequence Classification
Page 39
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation
Under the Markov assumption, for a state sequence Q, can calculatethe probablity of this sequence given the parameters (A,B) =λ:
P(Q|λ) =T∏
t=2P(qt |qt−1) = aq1q2 aq2q3 ...aqT−1qT
Under our independence assumption, can find the probability of anobservation sequence O given a state sequence Q and theparameters (A,B) =λ:
P(O|Q,λ) =T∏
t=1P(ot |qt) = bq1o1 bq2o2 ...bqT−1oT−1 bqT oT
Andrew M. White Sequence Classification
Page 40
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation (continued)
Now we can find the probability of an observation sequence giventhe model:
P(O|λ) =∑Q
P(O|Q,λ)P(Q|λ) =∑Q
bq1o1
T∏t=2
aqt−1qt bqt ot
Note that this does a lot of redundant calculations.
Andrew M. White Sequence Classification
Page 41
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation (continued)
Now we can find the probability of an observation sequence giventhe model:
P(O|λ) =∑Q
P(O|Q,λ)P(Q|λ) =∑Q
bq1o1
T∏t=2
aqt−1qt bqt ot
Note that this does a lot of redundant calculations.
Andrew M. White Sequence Classification
Page 42
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation (continued)
Now we can find the probability of an observation sequence giventhe model:
P(O|λ) =∑Q
P(O|Q,λ)P(Q|λ) =∑Q
bq1o1
T∏t=2
aqt−1qt bqt ot
Note that this does a lot of redundant calculations.
Andrew M. White Sequence Classification
Page 43
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Evaluation (continued)
A trellis algorithm.
We can use dynamic programmingto cache the redundant calculationsby thinking in terms of partialobservation sequences:
αj(t) = P(o1o2...ot ,qt = sj|λ)
We’ll refer to these as the forwardprobabilities for the observationsequence.
Andrew M. White Sequence Classification
Page 44
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Forward algorithm
The forward trellis.
For the first time step we have:
αj(1) = P(o1|q1 = sj) = bjo1
Then we can calculate the forwardprobabilities from the trellis:
αj(t) = P(o1o2...ot ,qt = sj|λ)
= bjot
N∑i=1
aijαi(t −1)
Andrew M. White Sequence Classification
Page 45
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Forward algorithm
The forward trellis.
For the first time step we have:
αj(1) = P(o1|q1 = sj) = bjo1
Then we can calculate the forwardprobabilities from the trellis:
αj(t) = P(o1o2...ot ,qt = sj|λ)
= bjot
N∑i=1
aijαi(t −1)
Andrew M. White Sequence Classification
Page 46
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Forward algorithm (continued)
The forward trellis.
Finally, the probability of the fullobservation sequence is the sum ofthe forward probabilities at the lasttime-step:
P(O|λ) =N∑
j=1αj(T)
Andrew M. White Sequence Classification
Page 47
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 48
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Viterbi Algorithm
Kevin Snow will present details of the Viterbi algorithm in the nextclass.
Andrew M. White Sequence Classification
Page 49
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 50
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Baum-Welch algorithm
Given an observation sequence, how do we estimate theparameters of the HMM?
Ï transition probabilities:
aij = expected number of transitions from state i to state j
expected number of transitions from state i
Ï emission probabilities:
bjk =expected number of emissions of symbol k from state j
expected number of emissions from state j
This is another Expectation-Maximization algorithm.
Andrew M. White Sequence Classification
Page 51
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Baum-Welch algorithm
Given an observation sequence, how do we estimate theparameters of the HMM?
Ï transition probabilities:
aij = expected number of transitions from state i to state j
expected number of transitions from state i
Ï emission probabilities:
bjk =expected number of emissions of symbol k from state j
expected number of emissions from state j
This is another Expectation-Maximization algorithm.
Andrew M. White Sequence Classification
Page 52
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Baum-Welch algorithm
Given an observation sequence, how do we estimate theparameters of the HMM?
Ï transition probabilities:
aij = expected number of transitions from state i to state j
expected number of transitions from state i
Ï emission probabilities:
bjk =expected number of emissions of symbol k from state j
expected number of emissions from state j
This is another Expectation-Maximization algorithm.
Andrew M. White Sequence Classification
Page 53
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: the Baum-Welch algorithm
Given an observation sequence, how do we estimate theparameters of the HMM?
Ï transition probabilities:
aij = expected number of transitions from state i to state j
expected number of transitions from state i
Ï emission probabilities:
bjk =expected number of emissions of symbol k from state j
expected number of emissions from state j
This is another Expectation-Maximization algorithm.
Andrew M. White Sequence Classification
Page 54
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Baum-Welch as Expectation-Maximization
Remember, the sequence of states for the observation sequence isour hidden variable.
Expectation
Given
Ï an observation sequence O
Ï an estimate of the parameters λ
we can find the expectation of the log-likelihood for the observationsequence over the possible state sequences.
MaximizationThen we maximize this expectation over all possible λ.
Baum et al proved that this procedure converges to a localmaximum.
Andrew M. White Sequence Classification
Page 55
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Baum-Welch as Expectation-Maximization
Remember, the sequence of states for the observation sequence isour hidden variable.
Expectation
Given
Ï an observation sequence O
Ï an estimate of the parameters λ
we can find the expectation of the log-likelihood for the observationsequence over the possible state sequences.
MaximizationThen we maximize this expectation over all possible λ.
Baum et al proved that this procedure converges to a localmaximum.
Andrew M. White Sequence Classification
Page 56
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs: Baum-Welch as Expectation-Maximization
Remember, the sequence of states for the observation sequence isour hidden variable.
Expectation
Given
Ï an observation sequence O
Ï an estimate of the parameters λ
we can find the expectation of the log-likelihood for the observationsequence over the possible state sequences.
MaximizationThen we maximize this expectation over all possible λ.
Baum et al proved that this procedure converges to a localmaximum.
Andrew M. White Sequence Classification
Page 57
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 58
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Profile HMMs
Left-Right HMMs
Ï special type of HMMs
Ï links only go in one direction
Ï no circular routes involving more than one node
Ï specialized start and end nodes
Profile HMMs
Ï special type of Left-Right HMMs
Ï has special delete states which don’t emit symbols
Ï consists of sets of match, insert, and delete states
Andrew M. White Sequence Classification
Page 59
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Profile HMM (continued)
Di
Mi
Ii
S E
Figure: Topology of a Profile HMM
Andrew M. White Sequence Classification
Page 60
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs in our Example Framework
Recall the framework for classifying phonemes.
Generative HMM classifier for speech recognition
Ï for each phoneme, train a (profile) HMM using Baum-WelchÏ for each test example:
Ï score using the Forward algorithm for each HMMÏ classify according to whichever HMM scores highest
Andrew M. White Sequence Classification
Page 61
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
HMMs in our Example Framework
Recall the framework for classifying phonemes.
Generative HMM classifier for speech recognition
Ï for each phoneme, train a (profile) HMM using Baum-WelchÏ for each test example:
Ï score using the Forward algorithm for each HMMÏ classify according to whichever HMM scores highest
Andrew M. White Sequence Classification
Page 62
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Generative vs. Discriminative
HMMs as Generative Models
Ï can treat an HMM as a generator for a distribution
Ï build an individual HMM for each class of interest
Ï can give probability of an example given the model
Kernel Methods as Discriminative Models
Ï model pairs of classes
Ï find discriminant functions
Andrew M. White Sequence Classification
Page 63
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Evaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Generative vs. Discriminative
HMMs as Generative Models
Ï can treat an HMM as a generator for a distribution
Ï build an individual HMM for each class of interest
Ï can give probability of an example given the model
Kernel Methods as Discriminative Models
Ï model pairs of classes
Ï find discriminant functions
Andrew M. White Sequence Classification
Page 64
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 65
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Kernels for Sequences
Fixed-length Subsequence Kernels
Based on counting common subsequences of a fixed length.
Ï p-spectrum kernelsÏ fixed-length subsequences kernelÏ gap-weighted subsequences kernel
All-subsequences Kernel
Based on counting all common contiguous or non-contiguoussubsequences.
Andrew M. White Sequence Classification
Page 66
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 67
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
p-Spectrum Kernels
Ï counts number of common (contiguous) subsequences oflength p
Ï useful where contiguity is important structurally
φ ar at ba cabar 1 0 1 0bat 0 1 1 0car 1 0 0 1cat 0 1 0 1
K bar bat car catbar 2 1 1 0bat 1 2 0 1car 1 0 2 1cat 0 1 1 2
Andrew M. White Sequence Classification
Page 68
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
p-Spectrum Kernels
Ï counts number of common (contiguous) subsequences oflength p
Ï useful where contiguity is important structurally
φ ar at ba cabar 1 0 1 0bat 0 1 1 0car 1 0 0 1cat 0 1 0 1
K bar bat car catbar 2 1 1 0bat 1 2 0 1car 1 0 2 1cat 0 1 1 2
Andrew M. White Sequence Classification
Page 69
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
p-Spectrum Kernels
Ï counts number of common (contiguous) subsequences oflength p
Ï useful where contiguity is important structurally
φ ar at ba cabar 1 0 1 0bat 0 1 1 0car 1 0 0 1cat 0 1 0 1
K bar bat car catbar 2 1 1 0bat 1 2 0 1car 1 0 2 1cat 0 1 1 2
Andrew M. White Sequence Classification
Page 70
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
Fixed-Length Spectrum Kernels
Ï counts common (non-contiguous) subsequences of a givenlength
Ï allows insertions/deletions with no penalties
φ aa ar at ba br btbaa 1 0 0 2 0 0bar 0 1 0 1 1 0bat 0 0 1 1 0 1
K baa bar batbaa 3 2 2bar 2 3 1bat 2 1 3
Andrew M. White Sequence Classification
Page 71
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
Fixed-Length Spectrum Kernels
Ï counts common (non-contiguous) subsequences of a givenlength
Ï allows insertions/deletions with no penalties
φ aa ar at ba br btbaa 1 0 0 2 0 0bar 0 1 0 1 1 0bat 0 0 1 1 0 1
K baa bar batbaa 3 2 2bar 2 3 1bat 2 1 3
Andrew M. White Sequence Classification
Page 72
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
Fixed-Length Spectrum Kernels
Ï counts common (non-contiguous) subsequences of a givenlength
Ï allows insertions/deletions with no penalties
φ aa ar at ba br btbaa 1 0 0 2 0 0bar 0 1 0 1 1 0bat 0 0 1 1 0 1
K baa bar batbaa 3 2 2bar 2 3 1bat 2 1 3
Andrew M. White Sequence Classification
Page 73
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Fixed-Length Subsequence Kernels (continued)
Gap-Weighted Subsequences Kernel
Ï interpolates between fixed-length and p-spectrum kernels
Ï allows weighting of the importance of contiguity
φ aa ar at ba br btbaa λ2 0 0 λ2 +λ3 0 0bar 0 λ2 0 λ2 λ3 0bat 0 0 λ2 λ2 0 λ3
Andrew M. White Sequence Classification
Page 74
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 75
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
All-Subsequences Kernel
All-subsequences Kernel
Ï counts number of common subsequences of any lengthÏ contiguous and non-contiguous subsequences considered
Andrew M. White Sequence Classification
Page 76
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Methods
Hidden Markov ModelsEvaluation: The Forward AlgorithmDecoding: The Viterbi AlgorithmLearning: The Baum-Welch AlgorithmProfile HMMs
Kernels for SequencesFixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Andrew M. White Sequence Classification
Page 77
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Variations of Sequences for Kernels
Character Weights
different inserted characters result in different values
Soft Matching
two different characters can match with penalty
Gap-number Weighting
weight number of gaps instead of gap lengths
For details, see Shawe-Taylor and Christianini, 2004.
Andrew M. White Sequence Classification
Page 78
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Variations of Sequences for Kernels
Character Weights
different inserted characters result in different values
Soft Matching
two different characters can match with penalty
Gap-number Weighting
weight number of gaps instead of gap lengths
For details, see Shawe-Taylor and Christianini, 2004.
Andrew M. White Sequence Classification
Page 79
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Variations of Sequences for Kernels
Character Weights
different inserted characters result in different values
Soft Matching
two different characters can match with penalty
Gap-number Weighting
weight number of gaps instead of gap lengths
For details, see Shawe-Taylor and Christianini, 2004.
Andrew M. White Sequence Classification
Page 80
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Variations of Sequences for Kernels
Character Weights
different inserted characters result in different values
Soft Matching
two different characters can match with penalty
Gap-number Weighting
weight number of gaps instead of gap lengths
For details, see Shawe-Taylor and Christianini, 2004.
Andrew M. White Sequence Classification
Page 81
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequence Kernels in our Example Framework
Recall the framework for classifying phonemes.
Discriminative SVM classifier for speech recognition
Ï for each pair of phonemes, train a binary classifier using asequence kernel
Ï for each test example:Ï each binary classifier votes for a labelÏ classify according to whichever label receives the most votes
Andrew M. White Sequence Classification
Page 82
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequence Kernels in our Example Framework
Recall the framework for classifying phonemes.
Discriminative SVM classifier for speech recognition
Ï for each pair of phonemes, train a binary classifier using asequence kernel
Ï for each test example:Ï each binary classifier votes for a labelÏ classify according to whichever label receives the most votes
Andrew M. White Sequence Classification
Page 83
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Ï can be treated differently from feature-vector data
Ï provides structurally important information
Hidden Markov Models
Ï generative models of sequencesÏ assume:
Ï state t depends only on state t −1Ï emission t depends only on state t
Kernels for Sequences
Ï discriminative approach
Ï many different kernels
Andrew M. White Sequence Classification
Page 84
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Ï can be treated differently from feature-vector data
Ï provides structurally important information
Hidden Markov Models
Ï generative models of sequencesÏ assume:
Ï state t depends only on state t −1Ï emission t depends only on state t
Kernels for Sequences
Ï discriminative approach
Ï many different kernels
Andrew M. White Sequence Classification
Page 85
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
Sequential Data
Ï can be treated differently from feature-vector data
Ï provides structurally important information
Hidden Markov Models
Ï generative models of sequencesÏ assume:
Ï state t depends only on state t −1Ï emission t depends only on state t
Kernels for Sequences
Ï discriminative approach
Ï many different kernels
Andrew M. White Sequence Classification
Page 86
Sequential DataMethods
Hidden Markov ModelsKernels for Sequences
Fixed-Length Subsequence KernelsAll-Subsequences KernelVariations
References
Phil Blunsom.Hidden markov models, 2004.
Lawrence R. Rabiner.A tutorial on hidden markov models and selected applicationsin speech recognition.In Proceedings of the IEEE, pages 257–286, 1989.
John Shawe-Taylor and Nello Cristianini.Kernel Methods for Pattern Analysis.Cambridge University Press, Cambridge, United Kingdom,2004.
Andrew M. White Sequence Classification