SIGMOD 2006 Context-sensitive ranking Rakesh Agrawal Microsoft Search Labs Ralf Rantzau IBM Silicon Valley Lab Evimaria Terzi University of Helsinki & Microsoft Search Labs Work done largely while the authors were in IBM Almaden
Transcript
SIGMOD 2006
Context-sensitive ranking
Rakesh Agrawal Microsoft Search Labs
Ralf Rantzau IBM Silicon Valley Lab
Evimaria Terzi University of Helsinki &Microsoft Search Labs
Work done largely while the authors were in IBM Almaden
SIGMOD 2006
The curse of abundance:Too many data and too many answers
• Query shopping.com for a digital camera:
• Query Froogle for a tennis racquet:
SIGMOD 2006
Ranking query results
• Algorithms for ranking web pages have been quite successful ([BP’98,Kleinberg98])
– Key idea: Exploit the graph of hyperlinks between web pages
• Can we take similar approach for ranking database query results?
– Need for a graph structure that accurately describes the relationships between tuples in the database
- Past attempts: schema and key constraints or queries [BHP’04, BHNCS’02, GMT’04]
But are these graphs natural or do they reflect design optimization decisions?
• Pairwise preferences in ML literature [CSS’97]• Preferences as partial orders [Kieβling’02]• Preferences as first-order formulas [Chomiki’03]
SIGMOD 2006
Contextual preferences
Genre (G)
Actor (A)
Title (T) Language (L)
t1 Drama Kidman Birth English
t2 Drama Cruz Vanilla Sky English
t3 Sci-Fi Reeves Matrix English
t4 Comedy Cruz Sin noticias de Dios
Spanish
t5 Comedy Aniston Rumor has it… English
• P1={G=Drama > G=Sci-Fi | L=English}
• P2={A=Kidman > A=Reeves | L = English}
• P3={T=matrix > T=Birth | L=English }
t1>t3|En and t2>t3|En
t1>t3|En
t3>t1|En
Genre (G)
Actor (A)
Title (T) Language (L)
t1 Drama Kidman Birth English
t2 Drama Cruz Vanilla Sky English
t3 Sci-Fi Reeves Matrix English
t4 Comedy Cruz Sin noticias de Dios
Spanish
t5 Comedy Aniston Rumor has it… English
t1 t2
t3
2/3
1/3
1
1/2
1/2t1 t2
t3
SIGMOD 2006
Obtaining preferences
• Users provide preferences voluntarily – in the same way users rate products and services
• Preferences can be automatically collected via browser plug-ins or taskbars (with user permission)
• Preferences can be learned from past data
• Preferences can also be learned from the data (e.g., using association-rule mining)
Preferences are obtained from various sources and can contain cycles and contradictions, which are resolved
democratically
SIGMOD 2006
Overview
Question:How to incorporate users preferences when ranking query results?
Approach:• Accumulate contextual preferences of the form i1>i2|X
• Order the answer tuples such that the preferences are maximally respected, giving higher weight to those preferences whose contexts have closer match to the query
SIGMOD 2006
Issues
• How to define similarity between a query and a context ? – See paper for the distance function.
• Can we create orders in an offline step and use their information at query time ?
• Should we save all orders?
• How to combine the saved orders while answering queries ?
SIGMOD 2006
Problem decomposition
[Problem 1]: For every context X build an order τX (Ordering)
[Problem 2]: Given a set of orders Tm = {τ1,…, τm} find ℓ representative orders Tℓ (ClusterOrders)
• Assign each of the input orders to one of the representatives (the closest)
• Associate with each representative σ a set of contexts Yσ
[Problem 3]: Provide top-k results for the query Q– respecting the representative orders and– weight respect according to the similarity between
query and contexts (Querying)
SIGMOD 2006
Problem 1: The Ordering problem
For a given context X and a set of preferences PX over the tuples D={t1,…,tn} find an ordering τ of D such that
)Agree(maxarg ' Xτ',P
t1 t2
t3
1/2
1/2
2/3
1/3
1
t1 t2
t3
t2
t1
t3
Agree = 1 +1/2 = 2/3 = 13/6
SIGMOD 2006
Problem 2: The ClusterOrders problem
Given m orders Tm={τ1,…,τm} , each corresponding to a single concept Xi, find ℓ representative orders Tℓ such that cost(Tℓ) is minimized where
and
We use the standard Spearman footrule and Kendall tau distances for comparing orderings
mT
TdT
),()(Cost
),(min),( dTdmT
SIGMOD 2006
The ClusterOrders problem: Example
a
b
c
d
e
f
a
b
c
d
e
f
a
b
c
d
e
f
f
e
d
c
b
a
f
e
d
c
b
a
a
b
c
d
e
f
f
e
d
c
b
a
Cost(τ1) = 2
0 1 1 0 1
Cost(τ2) = 1
Cost(τ1, τ2) = 2+1=3
SIGMOD 2006
Problem 3: The Querying problem
Provide top-k results for query Q respecting the representative orders and weighting respect using the corresponding set of contexts
SIGMOD 2006
Problem decomposition
[Problem 1]: For every context X build an order τX (Ordering)
[Problem 2]: Given a set of orders Tm = {τ1,…, τm} find ℓ representative orders Tℓ (ClusterOrders)
• Assign each of the input orders to one of the representatives (the closest)
• Associate with each representative σ a set of contexts Yσ
[Problem 3]: Provide top-k results for the query Q– respecting the representative orders and– weight respect according to the similarity between
query and contexts (Querying)
SIGMOD 2006
Constructing orders from preferences [Problem1]
• Problem is NP-hard; need for heuristics • PickPerm algorithm : pick a random permutation, inverse it
and pick the best of the two
t1 t2
t3
1/2
1/2
2/3
1/3
1
t1 t2
t3
t2
t3
t1
A = 11/6
t1
t3
t2
A = 5/6
t2
t3
t1
[ Inspired by the 2-approximation algorithm for finding the maximum acyclic subgraph of a given graph ]
SIGMOD 2006
Greedy algorithm [CSS’97]
• At the i-th iteration pick the i-th element of the output permutation
• At each iteration pick the tuple t with the highest s_val(t) = OutDegree(t)-InDegree(t)
in the remaining preference graph
t1 t2
t3
1/2
1/2
2/3
1/3
1
t1 t2
t3
1/3
2/3
1/3
t1
t3
1
-4/3
t2
1/3
-1/3
t2
t1
t2
t1
t3
SIGMOD 2006
MC-algorithm
• Reverse the directions of the edges on the preference graph
• Run a random walk (with random restarts) on the reversed graph
• Rank according to the stationary distribution
SIGMOD 2006
Performance
• Data generation– Fix an order on the tuples– Generate preferences that
respect this order– Pc: the probability that a
preference is generated between a pair of tuples
• Observations– For small pc values more
orders are compatible, all algorithms are good
– For large pc values MC and Greedy find the optimal order
SIGMOD 2006
Problem decomposition
[Problem 1]: For every context X build an order τX (Ordering)
[Problem 2]: Given a set of orders Tm = {τ1,…, τm} find ℓ representative orders Tℓ (ClusterOrders)
• Assign each of the input orders to one of the representatives (the closest)
• Associate with each representative σ a set of contexts Yσ
[Problem 3]: Provide top-k results for the query Q– respecting the representative orders and– weight respect according to the similarity between
query and contexts (Querying)
SIGMOD 2006
Reducing the number of orders [Problem 2]
• Finding ℓ representative orders is NP-hard
• Finding ℓ orders from the input ones (good approximation, but still hard)
• Need for heuristics
• Greedy algorithm– Always pick the order (from the input) that introduces the
minimum cost
• Furthest algorithm– Start by picking a random order τ and add it in the output set
of orders Tℓ
– For ℓ-1 iterations pick the order that is furthest away from the orders already in Tℓ
SIGMOD 2006
Refine the representative orders
• Given the set of representative orders Tℓ, assign each input order τЄTm to its closest representative in Tℓ. (partition Tm into ℓ partitions)*
– Discrete refinement: For each partition pick the best representative of the partition
– Continuous refinement: ([DKNS’01]) For each partition find the best representative of the partition
*Notice the resemblance between this problem and Catalog Segmentation problem by [KPR’04]
SIGMOD 2006
Performance
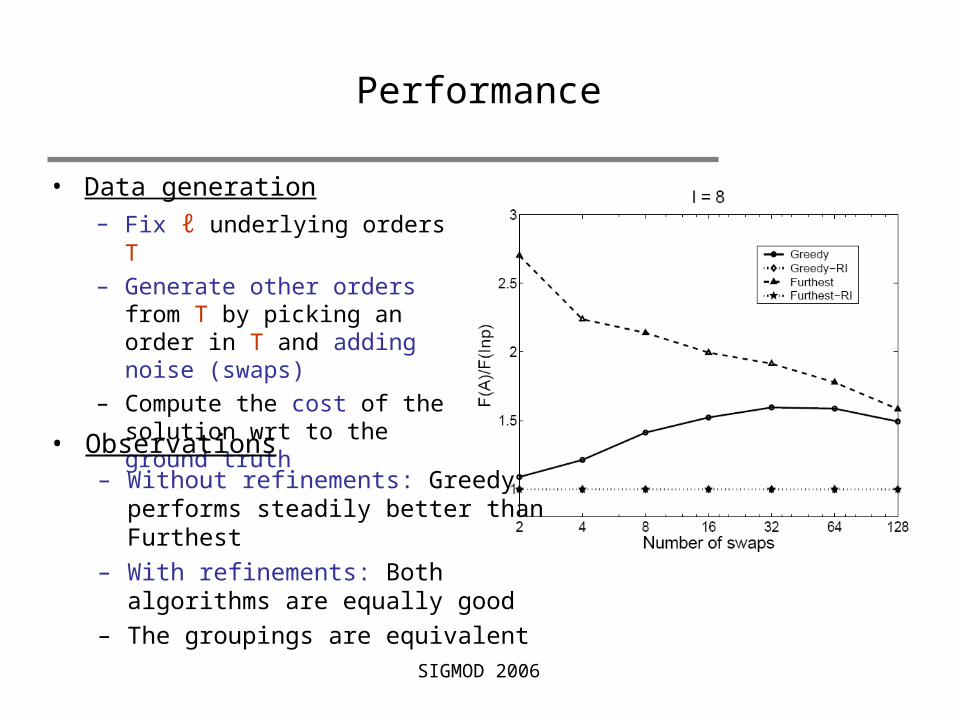
• Data generation– Fix ℓ underlying orders T– Generate other orders
from T by picking an order in T and adding noise (swaps)
– Compute the cost of the solution wrt to the ground truth• Observations
– Without refinements: Greedy performs steadily better than Furthest
– With refinements: Both algorithms are equally good
– The groupings are equivalent
SIGMOD 2006
Problem decomposition
[Problem 1]: For every context X build an order τX (Ordering)
[Problem 2]: Given a set of orders Tm = {τ1,…, τm} find ℓ representative orders Tℓ (ClusterOrders)
• Assign each of the input orders to one of the representatives (the closest)
• Associate with each representative σ a set of contexts Yσ
[Problem 3]: Provide top-k results for the query Q– respecting the representative orders and– weight respect according to the similarity between
query and contexts (Querying)
SIGMOD 2006
Problem 3: The Querying problem
• Use variation of the TA algorithms [FLN’02, FKS’03]– Assume k = 2 and query Q such that:
• sim(Q,Y1) = 0.5, sim(Q,Y2) = 0.3, sim(Q,Y3)=0.1
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
0.5 0.3 0.1
SIGMOD 2006
Problem 3: The Querying problem
1. At each sequential accessa. Set the threshold TH to be the aggregate of the
scores seen in this access
TH =0.5*5+0.3*5+0.1*5=4.5
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
0.5 0.3 0.1
SIGMOD 2006
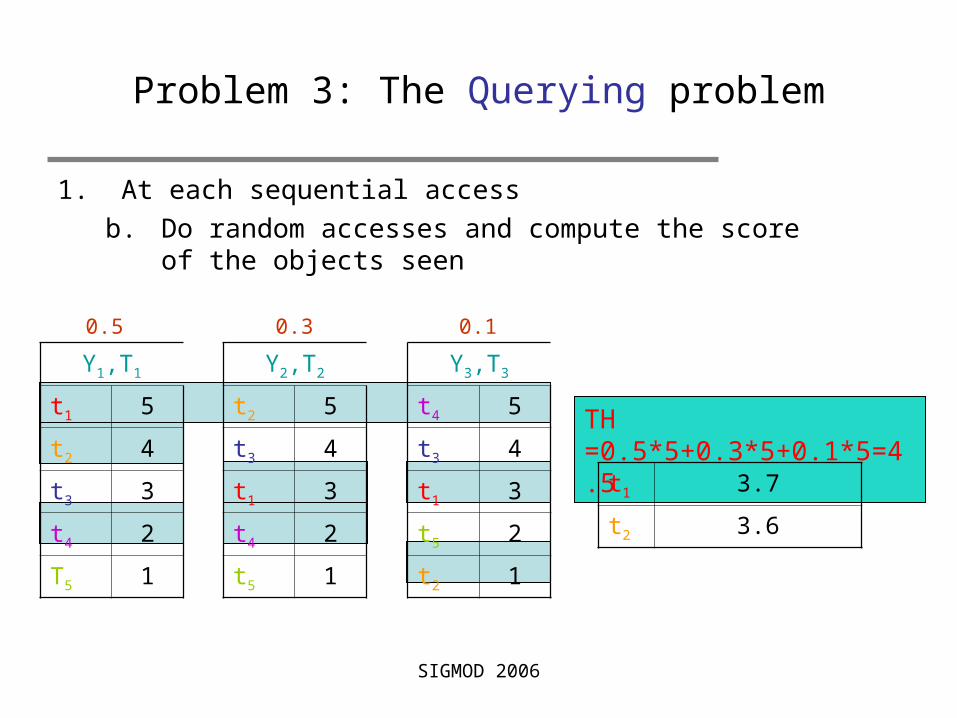
Problem 3: The Querying problem
1. At each sequential accessb. Do random accesses and compute the score of the
objects seen
TH =0.5*5+0.3*5+0.1*5=4.5
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
t1 3.7
t2 3.6
t4 2.1
0.5 0.3 0.1
SIGMOD 2006
Problem 3: The Querying problem
1. At each sequential accessb. Do random accesses and compute the score of the
objects seen
TH =0.5*5+0.3*5+0.1*5=4.5
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
t1 3.7
t2 3.6
0.5 0.3 0.1
SIGMOD 2006
Problem 3: The Querying problem
1. At each sequential accessc. Maintain a list of the top-k objects seen so far
TH =0.5*5+0.3*5+0.1*5=4.5
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
t1 3.7
t2 3.6
0.5 0.3 0.1
SIGMOD 2006
Problem 3: The Querying problem
1. At each sequential accessd. When the scores of the top-k are greater or equal
to the threshold, stop
TH =0.5*4+0.3*4+0.1*4=3.6
Y1,T1
t1 5
t2 4
t3 3
t4 2
T5 1
Y2,T2
t2 5
t3 4
t1 3
t4 2
t5 1
Y3,T3
t4 5
t3 4
t1 3
t5 2
t2 1
t1 3.7
t2 3.6
0.5 0.3 0.1
SIGMOD 2006
Accuracy of top-k results
• IMDB dataset– Automatically generate
preferences via association-rule mining:‘A1=a’ > ‘A1=b’ |X if conf(Xa)>conf(Xb)
– Solk: top-k results obtained after clustering
– Gk: top-k results without clustering
|Sol|
|Sol|),,Accuracy(
kk
kk
G
GkGSol
SIGMOD 2006
Accuracy of top-k results
SIGMOD 2006
Recap
• Notion of contextual preferences
• Use of contextual preferences to order database results
• Use of association rules to obtain contextual preferences
• Experimental validation of the effectiveness of the proposed techniques using both synthetic and real data
SIGMOD 2006
Conclusions and future work
• The framework of contextual preferences is both intuitive and practical
• The framework is easily extended to accommodate for top-k lists and bucket orders
• Scalability of the algorithms needs further investigation