SimMatrix: SIMulator for MAny -Task computing execution fabRIc at eXascales. Ke Wang Data-Intensive Distributed Systems Laboratory Computer Science Department Illinois Institute of Technology February 14 th , 2012. Acknowledgements. DataSys Laboratory Dr. Ioan Raicu - PowerPoint PPT Presentation
44
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales Ke Wang Data-Intensive Distributed Systems Laboratory Computer Science Department Illinois Institute of Technology February 14 th , 2012
Transcript
SimMatrix: SIMulator for MAny-Task computing
execution fabRIc at eXascales
Ke WangData-Intensive Distributed Systems Laboratory
Computer Science DepartmentIllinois Institute of Technology
February 14th, 2012
Acknowledgements
• DataSys Laboratory• Dr. Ioan Raicu• Juan Carlos Hernández
Munuera, MS 2011 • Hui Jin, Tonglin Li• Paper submission:
– Ke Wang, Ioan Raicu. “SimMatrix: Exploring Many-Task Computing through Simulations at Exascales”, under review at ACM HPDC 2012SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 2
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 3
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 4
Distributed Systems
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 5
0
50
100
150
200
250
300
2004 2006 2008 2010 2012 2014 2016 2018
Nu
mb
er
of
Co
res
0
10
20
30
40
50
60
70
80
90
100
Ma
nu
fac
turi
ng
Pro
ce
ss
Number of CoresProcessing
Pat Helland, Microsoft, The Irresistible Forces Meet the Movable Objects, November 9th, 2007
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 11
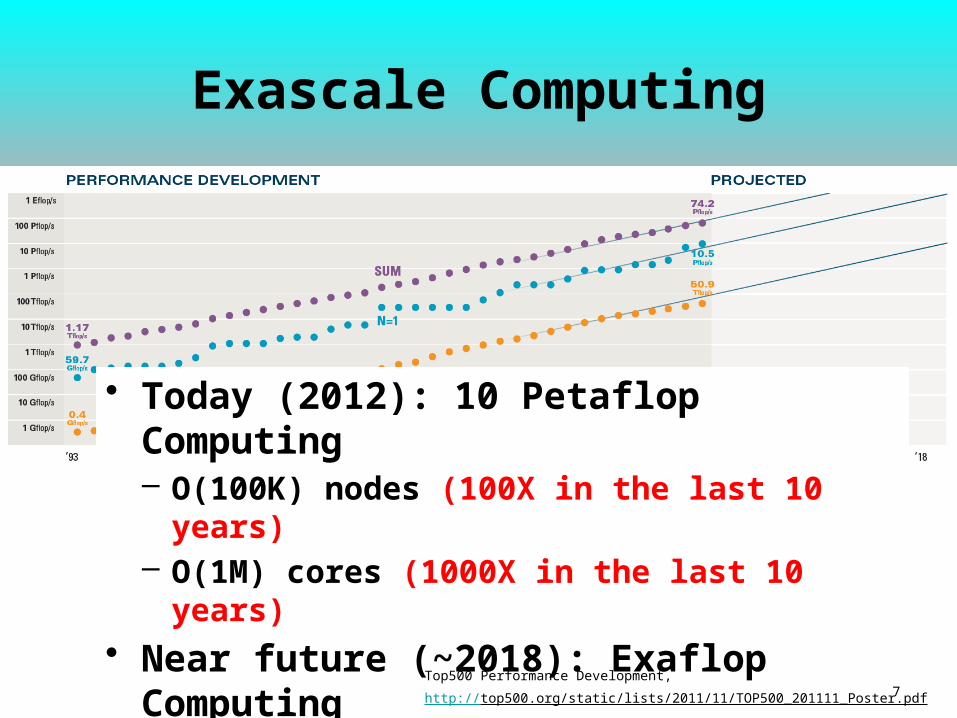
Long-Term Aims
• Address major exascale computing challenges:– Concurrency– Resilience– I/O and Memory– Heterogeneity
• Explore techniques to enable MTC at exascales• Design, Analyze, and Implement a distributed data-aware
execution fabric (MATRIX) supporting HPC/MTC workloads• Integrate MATRIX with parallel programming systems (e.g.
Swift, Charm++, MapReduce) and with the FusionFS distributed file system
• Prove that MTC applications can scale to exascales
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 12
This Work’s Contributions
• Explore techniques to enable MTC to scale to exascales– Design, Analyze, and Implement a discrete-event
simulator (SimMatrix) enabling the study of MATRIX at extremely large scales (e.g. exascales)
– Identified work stealing as a viable technique to achieve load balance at exascales
– Provide evidence that work stealing is scalable by identifying optimal parameters affecting the performance of work stealing
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 13
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 14
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales
OverviewJob Scheduling Systems
• Efficiently manage the distributed computing power of workstations, servers, and supercomputers in order to maximize job throughput and system utilization.– Load balancing is critical
• Different scheduling strategies– Centralized scheduling hinders the scalability– Hierarchical scheduling has long job turnaround time – Distributed scheduling is a promising approach at exascales
• Work Stealing – a distributed scheduling strategy – Starved processors steal tasks from overloaded ones– Various parameters affect performance:
• Number of tasks to steal• Number of neighbors• Static or Dynamic random neighbors
15
SimMatrix Architecture
Client
Submit tasks
Submit tasks
ClientArbitrary Node
Figure 1: Simulation architectures; the left part is the centralized one with a single dispatcher connecting all nodes, the right part is the homogeneous distributed topology with each node having the same number of cores and neighbors
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 16
Dispatcher
Simulations
• Continuous time simulations– Abandoned the idea of creating a separate thread
per simulated node: we found that on our 48-core system with 256GB of memory, we were limited to 32K threads
• Discrete event simulations– The only viable approach (today) to explore
scheduling techniques at exascales (millions of nodes and billions of cores)
– Created a unique object per simulated node, and converted any behavior to an event
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 17
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 18
At the Heart of SimMatrixGlobal Event Queue
Figure 2: Event State Transition DiagramSimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 19
• All events are inserted to the queue, sorted based on the occurrence time ascending
• Handle the first event, advance the simulation time and update the event queue
• Implemented as red-black tree based “TreeSet” in Java, which ensures Θ(log ) 𝑛time for insert & remove
Simulator Features
• Node load information– Nested hash maps provides extremely fast
performance at large scales• Dynamic Task Submission
– Aims to reduce the memory foot-print• Dynamic Poll interval
– Exponential backoff to reduce the number of messages and increase speed of simulation
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 20
Implementation
• SimMatrix is developed in JAVA– Sun 64-bit JDK version 1.6.0_22– 1500 lines of code– Code accessible at:
– The ratio between the ideal simulation time of completing a given workload and the real simulation time. The ideal simulation time is calculated by taking the average task execution time multiplied by the number of tasks per core.
• Load Balancing– We adopted the coefficient variance of the number of tasks finished by each
node as a measure the load balancing. The smaller the coefficient variance, the better the load balancing is. It is calculated as the standard-deviation/average in terms of number of tasks finished by each node.
• Scalability– Total number of tasks, number of nodes, and number of cores supported.
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 24
Workloads
• Synthetic workloads: – Uniform distributions with different average task
lengths, such as 10s (ave_10), 100s (ave_100), 1000s (ave_1000), 5000s (ave_5000), 10000s (ave_10000), and 100000s (ave_100000); also all tasks of 1 sec each (all_1)
• Realistic application workloads: – General MTC workload from 2008-2009 trace of
173M tasks; average task length 64±486s (mtc_64), using Gamma Distribution
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 25
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales
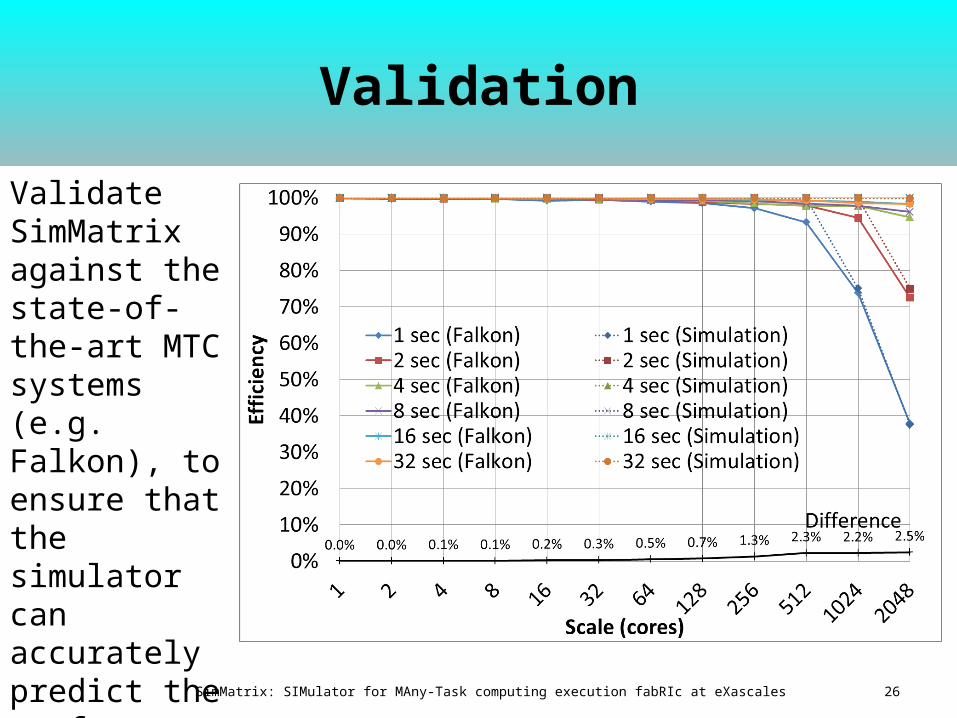
Validation
Validate SimMatrix against the state-of-the-art MTC systems (e.g. Falkon), to ensure that the simulator can accurately predict the performance of current petascale systems. 26
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales
Comparing Work Stealing to Falkon’s Naïve Distributed Scheduler
27
Fine grained workloads:• 2% 99.3%
efficiency increase
Coarse grained workloads:• 99%
99.999% efficiency increase
Scalability1M Nodes and 10B tasks
Memory consumption• <13 KB/task• <200 GB
CPU Time• <90 us/task• <260 hours
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 28
Scalability1M Nodes and 10B tasks
Efficiency• 90%+
Co-variance• <0.06• Load
imbalance of <600 tasks from 10K tasks per node
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 29
Work Stealing ParametersNumber of Tasks to Steal
30
Stealing half of neighbor’s work is best
strategy!0%
10%20%30%40%50%60%70%80%90%
100% No. of Tasks to Stealsteal_1steal_2steal_logsteal_sqrtsteal_half
No. of Nodes
Effici
ency
Work Stealing ParametersNumber of Neighbors (Static)
31
Requires linear number of neighbors for good
performance!
0%10%20%30%40%50%60%70%80%90%
100% No. of Static Neighbors
nb_2nb_lognb_sqrtnb_eighthnb_quarnb_half
No. of Nodes
Effici
ency
Work Stealing ParametersNumber of Neighbors (Dynamic Random)
32
An increasing number of neighbors are needed for 90%+ efficiency, with the largest scales requiring square root neighbors (e.g. 1K
neighbors from 1M nodes!0%10%20%30%40%50%60%70%80%90%
100% No. of Dynamic Random Neighbors
nb_1nb_2nb_lognb_sqrt
No. of Nodes
Effici
ency
Work Stealing ParametersOptimal Parameters Generality
33
The same optimal parameters achieve 90%+ efficiency across many different
workloads!0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100% Different Workloads
ave_1064+/-486ave_100ave_1000
No. of Nodes
Effici
ency
Work StealingThroughput
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 34
Centralized scheduling has severe bottleneck, especially for workload with fine granularity. Distributed scheduling has great scalability, for workload with coarse granularity, there is no obvious upper bound
Load Balancing Visualization1024 Nodes and Ave_5000 Workload
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 35
Good Load Balancing
Square Root Dynamic Neighbors
Starvation
Square Root Static Neighbors
Good Load Balancing
Quarter Static Neighbors
Starvation
2 Static Neighbors
Summary Plot for Distributed Scheduling
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 36
Steady state utilization is ~100% at exascales
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 37
Related Work
• Real Job Scheduling Systems: – Condor (University of Wisconsin), Bradley et al, 2012 – PBS (NASA Ames) , Corbatto et al, 2012 – LSF Batch (Platform Computing of Toronto), 2011– Falkon (University of Chicago), Raicu et al, SC07
• Job Scheduling System Simulators:– simJava (University of Edinburgh), Wheeler et al, 2004 – GridSim (University of Melbourne, Australia), Buyya et al, 2010
• Load Balancing: – Neighborhood averaging scheme, Sinha et al, 1993 – Charm++ (UIUC), Zheng et al, 2011
• Scalable Work Stealing– Dinan et al, SC09– Blumofe et al, Scheduling multithreaded computations by work stealing, 1994
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 38
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 39
Contributions
• Designed, Analyzed, and Implemented a discrete-event simulator (SimMatrix) enabling the study of MTC workloads at exascales
• Identified work stealing as a viable technique to achieve load balance at exascales
• Provided evidence that work stealing is scalable by finding optimal parameters affecting the performance of work stealing– Number of tasks to steal is half– Dynamic random neighbors strategy is required– There must be a squared root number of neighbors
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 40
Outline
• Introduction & Motivation• Long-Term Aims and Contributions• SimMatrix Architecture• Implementation• Evaluation• Related Work• Contributions• Future Work & Conclusion
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 41
Future Work
• Explore work stealing for manycore processors with 1000 cores
• Enhancing the network topology model to allow complex networks
• Insight from SimMatrix will be used to develop MATRIX, a distributed task execution fabric– MATRIX will employ work stealing for distributed load
balancing– MATRIX will be integrated with other projects, such as
Swift (a data-flow parallel programming systems) and FusionFS(a distributed file systems)
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 42
Conclusion
• Exascale systems bring great opportunities in unraveling of significant scientific mysteries
• There are significant challenges to achieve exascales, such as concurrency, resilience, I/O and memory, heterogeneity, and energy
• MTC requires a highly scalable and distributed task/job management system at large scales– Distributed scheduling is likely an efficient way to achieve
load balancing, leading to high job throughput and system utilization
• Work stealing is a scalable method to achieve load balance at exascales given the optimal parameters
SimMatrix: SIMulator for MAny-Task computing execution fabRIc at eXascales 43
• More information:– http://datasys.cs.iit.edu/~kewang/ – http://datasys.cs.iit.edu/projects/SimMatrix/