96
IBM Tivoli Netcool Performance Manager 1.3.2 Wireline Component Document Revision R2E1 SNMP Formula Language Reference Guide

IBM Tivoli Netcool Performance Manager 1.3.2Wireline ComponentDocument Revision R2E1
SNMP Formula Language ReferenceGuide
���

NoteBefore using this information and the product it supports, read the information in “Notices” on page 83.
© Copyright IBM Corporation 2011, 2012.US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contractwith IBM Corp.

Contents
Preface . . . . . . . . . . . . . . . vAudience . . . . . . . . . . . . . . . vTivoli Netcool Performance Manager - WirelineComponent. . . . . . . . . . . . . . . v
Chapter 1. Language Basics . . . . . . 1Glossary of Terms . . . . . . . . . . . . 1Variables. . . . . . . . . . . . . . . . 2
Built-In Variables . . . . . . . . . . . . 2Input Variables . . . . . . . . . . . . 3Persistent Variables . . . . . . . . . . . 5Temporary Variables . . . . . . . . . . . 7
Operators . . . . . . . . . . . . . . . 7Mathematical Conventions. . . . . . . . . 7Binary Operators . . . . . . . . . . . . 8Table Operations . . . . . . . . . . . . 9
Chapter 2. Functions. . . . . . . . . 13Aggregation Functions. . . . . . . . . . . 13
Aggregation (Across Dimensions) . . . . . . 14Manipulation . . . . . . . . . . . . . 17
Common Functions. . . . . . . . . . . . 23Abs . . . . . . . . . . . . . . . . 23Delta . . . . . . . . . . . . . . . 23Diff . . . . . . . . . . . . . . . . 24Int . . . . . . . . . . . . . . . . 24Last . . . . . . . . . . . . . . . . 24Not . . . . . . . . . . . . . . . . 25Round . . . . . . . . . . . . . . . 25
Conversion Functions . . . . . . . . . . . 26asIp . . . . . . . . . . . . . . . . 26asMac . . . . . . . . . . . . . . . 26asString . . . . . . . . . . . . . . 27asNumber . . . . . . . . . . . . . . 27replace . . . . . . . . . . . . . . . 28
Filtering Functions . . . . . . . . . . . . 29BottomN . . . . . . . . . . . . . . 29Distrib . . . . . . . . . . . . . . . 30Distrib . . . . . . . . . . . . . . . 32Filter . . . . . . . . . . . . . . . 33FirstN . . . . . . . . . . . . . . . 34If . . . . . . . . . . . . . . . . . 34LastN . . . . . . . . . . . . . . . 35TopN . . . . . . . . . . . . . . . 36
SNMPSet Functions . . . . . . . . . . . 36OidSet . . . . . . . . . . . . . . . 36
Verify Functions . . . . . . . . . . . . . 37Ensure . . . . . . . . . . . . . . . 37
Chapter 3. Common formula structure 39Comments in formulas . . . . . . . . . . 39OIDVAL Expression Line . . . . . . . . . . 39
Example . . . . . . . . . . . . . . 39
OIDINST Expression Line . . . . . . . . . 40Example . . . . . . . . . . . . . . 40
Dim Section . . . . . . . . . . . . . . 41Def Section . . . . . . . . . . . . . . 42Result Line . . . . . . . . . . . . . . 42
Discovery . . . . . . . . . . . . . . 43Collection . . . . . . . . . . . . . . 43Default Return Form . . . . . . . . . . 43Example . . . . . . . . . . . . . . 43
Chapter 4. Writing Discovery Formulas 45Discovery Formula Structure . . . . . . . . 45
Dim Section . . . . . . . . . . . . . 45Def Section . . . . . . . . . . . . . 45OID Gathering Section. . . . . . . . . . 48Result Line Section . . . . . . . . . . . 48
Merging . . . . . . . . . . . . . . . 51Application . . . . . . . . . . . . . 52Merge Rules . . . . . . . . . . . . . 52Understanding the inventory_subelements.txt file 56
Match Formulas . . . . . . . . . . . . . 59Example: RADIUS_Acc_Server_Match Formula 59
SNMP Get and GetNext Optimization . . . . . 59Example . . . . . . . . . . . . . . 60
Chapter 5. Writing Collection Formulas 61Collection Formula Structure . . . . . . . . 61
Dim Section . . . . . . . . . . . . . 61Def Section . . . . . . . . . . . . . 61OID Gathering Section. . . . . . . . . . 63Result Line Section . . . . . . . . . . . 64
Lite Formulas. . . . . . . . . . . . . . 64The Scheduler . . . . . . . . . . . . . 65CME Formulas . . . . . . . . . . . . . 66Formula Synchronization . . . . . . . . . . 67
Syntax . . . . . . . . . . . . . . . 68Understanding Scope . . . . . . . . . . 69Listing Semaphores . . . . . . . . . . . 71
Collection of Probe Results over Adjustable TimePeriods . . . . . . . . . . . . . . . . 72
About Collection Intervals . . . . . . . . 72Required Formulas . . . . . . . . . . . 72Required Tasks . . . . . . . . . . . . 73Scope and the Collection of Probe Results . . . 74Setting a Collection Interval . . . . . . . . 75
Collection Libraries . . . . . . . . . . . . 78
Chapter 6. Generic Formulas . . . . . 81
Notices . . . . . . . . . . . . . . 83
Trademarks. . . . . . . . . . . . . 87
© Copyright IBM Corp. 2011, 2012 iii

iv IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Preface
This guide provides detailed information about the SNMP formula language usedby the technology packs for Tivoli Netcool Performance Manager.
AudienceThe intended audience is application engineers who need to modify the formulasused by the technology packs.
Tivoli Netcool Performance Manager - Wireline ComponentIBM® Tivoli Netcool Performance Manager consists of a wireline component(formerly Netcool/Proviso) and a wireless component (formerly Tivoli® Netcool®
Performance Manager for Wireless).
Tivoli Netcool Performance Manager - Wireline Component consists of thefollowing subcomponents:v DataMart is a set of management, configuration, and troubleshooting GUIs. The
Tivoli Netcool Performance Manager System Administrator uses the GUIs todefine policies and configuration, and to verify and troubleshoot operations.
v DataLoad provides flexible, distributed data collection and data import of SNMPand non-SNMP data to a centralized database.
v DataChannel aggregates the data collected through Tivoli Netcool PerformanceManager DataLoad for use by the Tivoli Netcool Performance ManagerDataView reporting functions. It also processes online calculations and detectsreal-time threshold violations.
v DataView is a reliable application server for on-demand, web-based networkreports.
v Technology Packs extend the Tivoli Netcool Performance Manager system withservice-ready reports for network operations, business development, andcustomer viewing.
The following figure shows the different Tivoli Netcool Performance Managermodules.
© Copyright IBM Corp. 2011, 2012 v

Tivoli Netcool Performance Manager documentation consists of the following:v Release notesv Configuration recommendationsv User guidesv Technical notesv Online help
The documentation is available for viewing and downloading on the informationcenter at http://publib.boulder.ibm.com/infocenter/tivihelp/v8r1/topic/com.ibm.netcool_pm.doc/welcome_tnpm.html.
vi IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 1. Language Basics
The IBM Tivoli Netcool Performance Manager: SNMP Formula Language Referenceprovides detailed information about the formula language used by the technologypacks for Tivoli Netcool Performance Manager.
The intended audience is application engineers who need to modify the formulasused by the technology packs.
This chapter documents the basics of the formula language.
Glossary of TermsA list of the terms used in this guide.
This guide uses the following terms:
Collection formulaUsed in the Tivoli Netcool Performance Manager Request Editor to collectinformation (polling) about various devices in the network and theirresources.
Complex formulaA specific class of formula that uses all the formula language features.Discovery formulas can be complex.
Discovery formulaUsed with the Tivoli Netcool Performance Manager Inventory Tool duringthe process of discovering and analyzing devices in the network. Alsoknown as an inventory formula.
ElementA managed node or host.
FormulaA calculation performed against raw SNMP or Bulk data. It is acombination of OIDs, functions, and standard mathematical operations.
Lite formulaA specific class of formula that only uses a subset of formula features,which enables a collector to optimize the calculations. For performancereasons, all collection formulas should be translated into lite formulas.
MetadataConfiguration data. Metadata changes slowly.
Metric Collected data values. From the database perspective, a metric is a singledata value, identified by the IDs of the subelement (the Resource ID orRID) and formula (the Metric ID or MID) used to collect it, and the time atwhich it was collected. From the reporting perspective, a metric is a datavalue shown in a report. This is usually a set of database metrics,aggregated over time using a statistical function like average or maximum.A report metric can be aggregated across a set of subelements.
© Copyright IBM Corp. 2011, 2012 1

MIB (Management Information Base)A definition of the management information that can be read from andpossibly written to the management interface of an SNMP-compliantdevice.
OID The basic information that an SNMP agent can provide. An OID is typedand indexed within a MIB table. In a MIB table, each row corresponds to adifferent instance of the information represented in the table.
ResourceAn element or subelement (in practice, always a subelement; any manageditem).
SubelementA subcomponent of an element (physical or logical object), such as port,interface, virtual circuit, or DLCI.
VariableAn internal container for a set of temporary results. Variables can beproduced and populated as the result of an expression and used in otherexpressions. Variables can be persisted between executions of the sameformula and/ between different formulas.
VariablesThis section describes the available classes of variables.v Built-in variables.v Input variables.v Persistent variables.v Temporary variables.
Built-In VariablesBuilt-in variables allow access to attributes used by the collector to access the SNMPagent on a device.
They are used only in discovery formulas.
Usage: % <Variable_name>
Example: %HOSTNAME
Variables:v RCOMMUNITY -- This is the read community passed by the calling application.
Typically, the calling application will not force any value, relying on thecollector's configuration for the SNMP communities. Therefore, this variable isvery often empty.
v USEDRCOMMUNITY -- This is the read community that the collector used tocommunicate with the device. This is either the forced community passed by thecalling application, or (when empty) the community configured in Tivoli NetcoolPerformance Manager for that device. This value is never empty; there is alwaysa default (catchall) read community.
v WCOMMUNITY -- This is the write community that the collector used tocommunicate with the device. This is either the forced community passed by thecalling application, or (when empty) the community configured in Tivoli NetcoolPerformance Manager for that device. This value is never empty; there is alwaysa default (catchall) write community.
2 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

v USEDWCOMMUNITY -- This is the write community that the collector used tocommunicate with the device. This is either the forced community passed by thecalling application, or (when empty) the community configured in Tivoli NetcoolPerformance Manager for that device. This value is never empty; there is alwaysa default (catchall) write community.
v HOSTNAME -- The name of the host.v HOSTLONGNAME -- The long name of the host.v HOSTUSEDNAME -- The name of the host actually used.v HOSTIP -- The IP address of the host.
Input VariablesInput variables (I x , where x is an integer starting with 1) represent input values fora formula.
You can set values for input variables using either the Formula Editor or theResource Editor.
The instance is specified as a string that contains a list of attribute name/valuepairs. Each attribute represents one particular index column in a MIB and theindex used to access a particular OID. Because an OID might require several indexentries to specify an unambiguous location, the instance string can contain severalindex/value pairs. The values are mapped to input variables based on theirposition in the instance string. The first value is mapped to %I1 , the second valueto %I2 , and so on.
Consider the following examples:ifIndex<3>
Defines a single index. The name ifindex is ignored and the value 3 is mapped to%I1 .port<5>dlci<112>
Defines a double index structure. The first value (5), which identifies a port, ismapped to %I1 . The second value (112), which identifies a DLCI number, ismapped to %I2 .
Once indexes from the instance strings have been mapped to input variables, youcan assign mnemonic names to these variables (such as %Interface instead of %I1 ),so the expression lines in the formulas are easier to understand.
Input Variables with Multiple DimensionsBased on the complexity of the MIB table, multiple index columns (input variables)might be required to get a single result.
The frCircuitTable is an example of this situation.
The frCircuitTable has two index columns: the interface number ( frCircuitIfIndex )and the DLCI number ( frCircuitDlci ). Multiple DLCIs can share the same interfacenumber.
The device configuration is as follows:
Chapter 1. Language Basics 3

frCircuitState.2.201 = 2 (active)
frCircuitState.2.202 = 2 (active)
frCircuitState.4.401 = 3 (inactive)
You could use a single input variable that would have no special type and wouldcontain both the interface number and the DLCI number, or use two separate inputvariables (both typed as integer ) for each of these numbers. It is always moreefficient and more predictable to have well-defined, typed variables. This ensurescorrect key matching in the response-matching mechanism, which enables you touse dimension operations. In this case, the formula contains an explicit typedefinition: I1 as Integer and I2 as Integer . Each input variable is also assigned analias name: I1 is Interface and I2 is Dlci . You can use either the input numbers ornames, but you must use only one form -- all names or all numbers -- in a givenformula expression.
Therefore:Dim I1 as Integer default * name Interface;
Dim I2 as Integer default * name Dlci;
V1 = frCircuitState.%Interface.%Dlci;
The following result is produced in memory:
V1 =
%Interface %Dlci frCircuitState
2 201 2
2 202 2
4 401 3
The SNMP GetNext on the frCircuitState OID returns three results. The formularesponse-matching mechanism detects that responses are valid for values of I1 inthe {2, 4} set and for values of I2 in the {201, 202, 401} set. The mechanism thenbuilds three key values and stores the three associated result values {2, 2, 3} in theV1 variable. The stored variable has three keys:1. (Interface = 2; Dlci= 201)
2. (Interface = 2; Dlci= 202)
3. (Interface = 4; Dlci= 401)
The stored values in V1 are:
Based on the number of required dimensions to build a unique key, you mustprovide two replacement values ( Interface and Dlci ) to access a single result row.
4 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Persistent VariablesBy default, values assigned to a formula's variables are no longer retrievable at theend of formula execution.
However, the values of persistent variables can be used by different executions ofthe same formula and between different formulas.
Persistent variables are useful in the following situations:v Sharing filter results between a discovery formula and a merge formula.
For example, a discovery formula scans thousands of resources, and it builds afilter that retains only 50 of the resources in order to discover some propertiesfor these selected resources. Subsequently, a merge formula is executed to add anumber of properties to the same selected resources. Instead of re-scanning thethousands of resources to apply the same filter, the merge formula can access ashared variable that contains the filtered list of resources created by thediscovery formula. The merge formula then only needs to scan just thoseresources to get the additional properties.See See Writing Discovery Formulas, for information on discovery formulas.
v Sharing unique indexes between formulas.For example, a timestamp value is used in combination with a MIB object ID toidentify a particular instance of an activity involving an object -- in this case,when the object was last reset in the MIB table. Other formulas know the OID ofthe object, but they cannot know the exact time the object was last reset. Toallow other formulas to use the complete index value (OID plus timestamp), theformula that resets the object creates a persistent variable containing the resettime. Subsequent formulas can then construct the index for the reset activity bycombining the OID of the object with the timestamp retrieved from thepersistent variable.See See Collection of Probe Results over Adjustable Time Periods, forinformation on a use case for this type of persistent variable.
SyntaxSyntax rules.
Any formula that assigns a value to a persistent variable or reads a persistentvariable must contain the following line:UsingvariableNamescopescopeValue;
Where:v variableName is any user-defined name for the variable. The name can include
only letters and digits. It must start with a capital letter and must not start witha digit.
v scopeValue defines the scope within which the variable retains its value. Validvalues (case insensitive) are:– global . The variable persists in all formulas associated with the collector.
There is only one instance of that variable in the entire collector. The samevalue is seen by all formulas.
– element . The variable persists in all formulas associated with a givenelement. There is one instance of that variable per element. A formula applied
Chapter 1. Language Basics 5

on element 1, and a formula applied on element 2 will access differentinstances, and see different values for the same variable name.
– subelement . The variable persists in all formulas associated with a givensub-element. There is one instance of that variable per subelement. A formulaapplied on subelement 1, and a formula applied on subelement 2 will accessdifferent instances, and see different values for the same variable name.
See See Understanding Scope, for more information about scope.
Example:
The following example allows a formula to either read or assign a value to thepersistent variable LastIpSlaUpdate in subelement scope:Using LastIpSlaUpdate Scope subelement;
Persistent variables are assigned values and are referenced in formulas in the sameway as non-persistent variables -- for example:v Assigning a value to a variable: LastIpSlaUpdate = some_expresssion;
v Referencing a variable: %LastIpSlaUpdate
SynchronizationTo ensure a formula that reads a persistent variable executes after the formula thatassigns a value to the variable, you may need to synchronize the execution of theformulas.
Synchronization is achieved using the keywords Signal and Wait . For moreinformation, see See Formula Synchronization.
Persistent Variables ListYou can use the VarsDump utility to list the persistent variables in a running SNMPcollector.
The VarsDump utility takes one of the following arguments:v global -- Lists all persistent variables in Global scope.v element -- Lists all persistent variables in Element scope.v subelement -- Lists all persistent variables in SubElement scope.v all -- Lists all persistent variables in Global, Element, and SubElement scope.
For example, the following command lists all the persistent variables stored in arunning SNMP collector:$ ./contribs/dialogTest2 VarsDump all
Example output:Dumping Variables.
@@ Global variables
@@ Per Element variables
@@ Per SubElement variables
## SubElement ID 200035777
-- Var ’LastIpSlaUpdate’
## SubElement ID 200035778
6 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

-- Var ’LastIpSlaUpdate’
## SubElement ID 200036278
-- Var ’LastIpSlaUpdate’
## SubElement ID 200036279
-- Var ’LastIpSlaUpdate’
Variables are organized by their assigned scope (Global, Element, or SubElement).In the example above, there are no persistent variables with Global or Elementscope.
Temporary VariablesIt is not mandatory to use temporary variables in a formula.
In fact, IBM recommends that you not use temporary variables in a collectionformula, because collection formulas with temporary variables are consideredcomplex and perform poorly compared to lite formulas.
You can name a temporary variable whatever you want, as long as the name startswith a capital letter and does not match any built-in or input variables. Inaddition, no variable names can be included within another variable name becausethe results will be unpredictable. For example, you cannot have both Abcd andAbcdef as variable names. The string %Abcdef could be interpreted as %(Abcdef) or%(Abcd)ef , meaning the content of the variable Abcdef or the content of thevariable Abcd , followed by the two characters ef .
The following example shows temporary variables used in a complex discoveryformula:DeviceName = OIDVAL(sysName.0,once);
DeviceLocation = OIDVAL(sysLocation.0,once);
%DeviceName index"<NULL>||%DeviceName||location<%DeviceLocation>IPDevice<true>||";
OperatorsThe operators supported by the formula language.
Mathematical ConventionsThe formula language uses standard priority rules between operators.
Expressions are evaluated from left to right, respecting parentheses andmathematical precedence rules. You can use parentheses to alter priority or toincrease readability.
Chapter 1. Language Basics 7
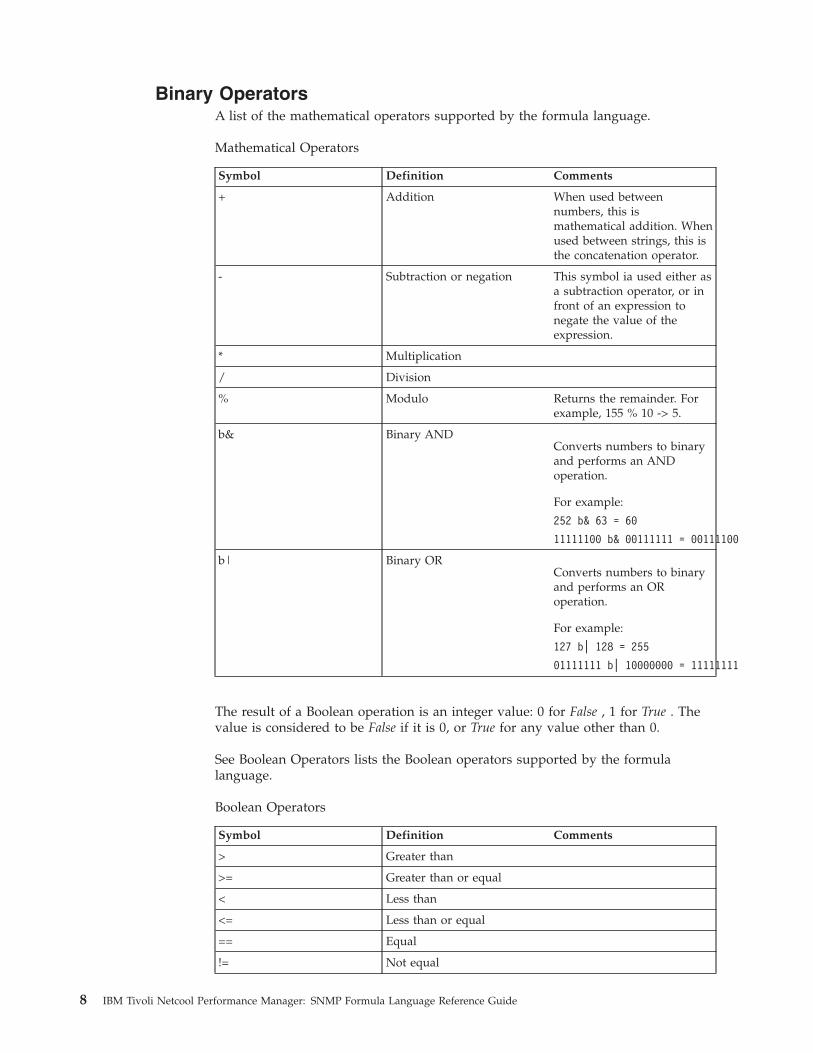
Binary OperatorsA list of the mathematical operators supported by the formula language.
Mathematical Operators
Symbol Definition Comments
+ Addition When used betweennumbers, this ismathematical addition. Whenused between strings, this isthe concatenation operator.
- Subtraction or negation This symbol ia used either asa subtraction operator, or infront of an expression tonegate the value of theexpression.
* Multiplication
/ Division
% Modulo Returns the remainder. Forexample, 155 % 10 -> 5.
b& Binary ANDConverts numbers to binaryand performs an ANDoperation.
For example:
252 b& 63 = 60
11111100 b& 00111111 = 00111100
b| Binary ORConverts numbers to binaryand performs an ORoperation.
For example:
127 b| 128 = 255
01111111 b| 10000000 = 11111111
The result of a Boolean operation is an integer value: 0 for False , 1 for True . Thevalue is considered to be False if it is 0, or True for any value other than 0.
See Boolean Operators lists the Boolean operators supported by the formulalanguage.
Boolean Operators
Symbol Definition Comments
> Greater than
>= Greater than or equal
< Less than
<= Less than or equal
== Equal
!= Not equal
8 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide
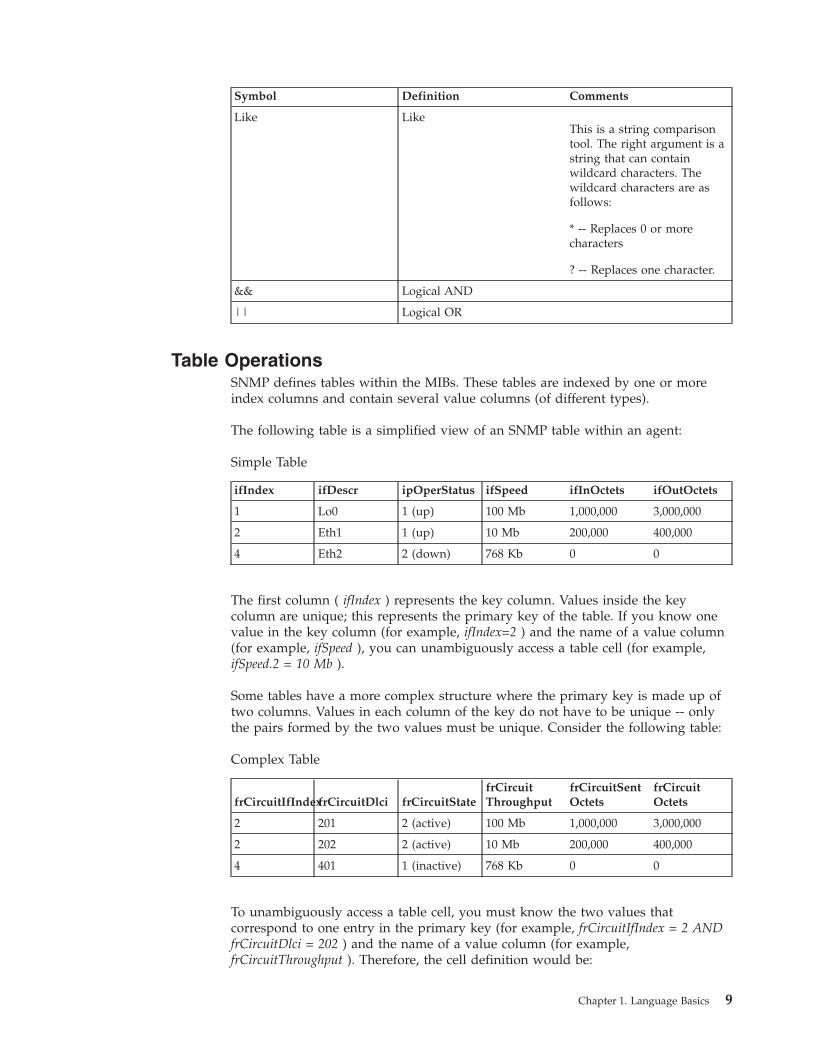
Symbol Definition Comments
Like LikeThis is a string comparisontool. The right argument is astring that can containwildcard characters. Thewildcard characters are asfollows:
* -- Replaces 0 or morecharacters
? -- Replaces one character.
&& Logical AND
|| Logical OR
Table OperationsSNMP defines tables within the MIBs. These tables are indexed by one or moreindex columns and contain several value columns (of different types).
The following table is a simplified view of an SNMP table within an agent:
Simple Table
ifIndex ifDescr ipOperStatus ifSpeed ifInOctets ifOutOctets
1 Lo0 1 (up) 100 Mb 1,000,000 3,000,000
2 Eth1 1 (up) 10 Mb 200,000 400,000
4 Eth2 2 (down) 768 Kb 0 0
The first column ( ifIndex ) represents the key column. Values inside the keycolumn are unique; this represents the primary key of the table. If you know onevalue in the key column (for example, ifIndex=2 ) and the name of a value column(for example, ifSpeed ), you can unambiguously access a table cell (for example,ifSpeed.2 = 10 Mb ).
Some tables have a more complex structure where the primary key is made up oftwo columns. Values in each column of the key do not have to be unique -- onlythe pairs formed by the two values must be unique. Consider the following table:
Complex Table
frCircuitIfIndexfrCircuitDlci frCircuitStatefrCircuitThroughput
frCircuitSentOctets
frCircuitOctets
2 201 2 (active) 100 Mb 1,000,000 3,000,000
2 202 2 (active) 10 Mb 200,000 400,000
4 401 1 (inactive) 768 Kb 0 0
To unambiguously access a table cell, you must know the two values thatcorrespond to one entry in the primary key (for example, frCircuitIfIndex = 2 ANDfrCircuitDlci = 202 ) and the name of a value column (for example,frCircuitThroughput ). Therefore, the cell definition would be:
Chapter 1. Language Basics 9

frCircuitThroughput.2.202 = 10 Mb
The formula language provides a way to retrieve pieces of these SNMP tables, onecolumn at a time, and either manipulate them or store them in temporaryvariables. When pieces are retrieved, the full corresponding primary key is alsoretrieved and kept with the retrieved value.
For example, using See Simple Table, ifSpeed.%I1; where I1 = *; would retrieve:
I1 ifSpeed
1 100 Mb
2 10 Mb
4 768 Kb
Note that the name of the variable that is used to specify the scope of the retrieval(in this example, %I1 ) becomes the name of the key column. Because the retrievalis done on a single column, there can only be one result ( IfSpeed ) column, butthere can be several key ( I1 ) values. Throughout this guide, a result table like thisis called a vector because it contains only one column besides the key column.
Pieces of the table can then be:v Combined with operators to produce new valuesv Filtered or sortedv Truncated using aggregationv Displayed, returned, or used to populate properties during the discovery phase
Combination RulesThe formula language simplifies the writing of tables by implementing built-inbehavior for table combinations that follows a set of simple rules.
When two tables, A and B, of arbitrary size and key structure are combined:v The resulting product is another table whose key structure is the Cartesian
product of the key structures of A and B, with a single value column that is theresult of the operation performed between the value columns of A and B.
v If the operation on the values is not possible, the corresponding key entry isdropped from the result.
v Whenever the two tables share one (or several) common key column names, animplicit JOIN is performed on the tables, based on the values of the commonkey columns. When the JOIN is performed, if one table does not have amatching value, the combination is dropped from the result.
These combination rules are illustrated in the examples that follow.
Example 1
Tables A and B represents constants.
They do not have a primary key column and contain only one cell. The result ofthe combination of A and B is also a constant ( Ab ).
10 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Example 2
Table A has a primary key named I1 of type integer and table B is a constant.
The result of the combination of A and B is a table with the same key structure astable A.
Example 3
Tables A and B share the same key structure. (a primary key named I1 of typeinteger ).
Therefore, an implicit JOIN is performed, and only results for which tableA.I1 =tableB.I1 are kept. The result of the combination is a table with the same keystructure as A or B, but with only common keys.
Note that line I1=4 from table A has no matching line in table B. Therefore, value Cof table A is not included in the result.
Example 4
Tables A and B do not share the same key structure; one table's key is larger thanthe other.
The key structure of the result will contain all the key columns ( I1 and I2 ) fromtables A and B. Because tables A and B share key column I1 , an implicit tableA.I1 =tableB.I1 is performed.
Note that line I1=4 from table A has no matching line in table B. Therefore, value Cof table A is not included in the result.
Chapter 1. Language Basics 11

Example 5
Tables A and B do not share the exact same key structure; both tables have extrapieces in their keys.
The key structure of the result will contain all the key columns ( I1 , I2 , and I3 )from tables A and B. Because tables A and B share key column I1 , an implicittableA.I1 = tableB.I1 is performed.
12 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 2. Functions
This section describes the formula language functions, grouped alphabetically byfunctional type.
Aggregation FunctionsThe purpose of aggregation functions is to alter (reduce) the key structure of atable, so operations between the resulting table and a third table are possible.
Because the key structure is altered and the resulting key must still be unique, it isvery likely that several values (lines) must be condensed into a single one. To dothis, you use aggregation functions.
Suppose that you have the following table, with the key structure I1 , I2 :
I1 I2 Value
1 101 100
1 102 400
2 103 200
2 104 500
3 105 300
You want to "remove" I2 from the key structure. You cannot simply drop thecolumn because it would leave you with duplicate values in column I1 -- and oneof the basic rules is that the primary key cannot contain duplicate values. As shownin the following figure, you need to "slice" the table, so that each slice contains allthe lines that share the same remaining key:
For each slice, the aggregation operator is applied to the values within the slice.
This enables you to drop the I2 key, yielding the following results:
I1 Value
1 500
2 700
3 300
© Copyright IBM Corp. 2011, 2012 13

The aggregation functions can be divided into two categories:v Aggregation (Across Dimensions)v Manipulation
Aggregation (Across Dimensions)These functions change the dimension set of the result. They can reduce along oneor all dimensions at the same time and perform aggregation operations on theresult side.
The formula language supports the following aggregation functions.
See Sum for an example of using the aggregation functions.
AveThis Ave aggregation function.
PurposeKeeps the average value of all the values to aggregate.
SyntaxAve (Dimensions, Expression)
Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
Expression The expression used for the returned values.
ConcatThe Concat aggregation function.
PurposeConsiders each value as a string, and concatenates all strings in theaggregation set.
SyntaxConcat (Dimensions, Expression)
Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
14 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Expression The expression used for the returned values.
CountThe Count aggregation function.
PurposeReturns the number of values in the aggregations set.
SyntaxCount (Dimensions, Expression)
Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
Expression The expression used for the returned values.
MaxThe Max aggregation function.
PurposeKeeps only the largest value of all the values to aggregate.
SyntaxMax (Dimensions, Expression)
Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
Expression The expression used for the returned values.
MinThe Min aggregation function.
PurposeKeeps only the smallest value of all the values to aggregate.
SyntaxMin (Dimensions, Expression)
Chapter 2. Functions 15

Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
Expression The expression used for the returned values.
SumThe Sum aggregation function.
PurposeSums all the values to aggregate.
SyntaxSum (Dimensions, Expression)
Dimensions The dimension to be used for theaggregation. It can be either one dimensionor all dimensions (*). Aggregating using alldimensions produces a single result,regardless of the size of the initial Expressionresult set, and the result will be withoutdimensions (like a numerical constant).Aggregating using one dimension removesthat dimension from the Expression result setby grouping all result lines that share theexact same dimension set and values (exceptfor the specified dimension).
Expression The expression used for the returned values.
Example
For V01 set to the following values:
You can remove all dimensions using the Sum aggregation. This produces asingle result value, without dimensions, which will be the sum of all
values.
16 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

If you remove dimension I1 using Sum , the only remaining dimension willbe I2 . In this case, there are three possible values for I2 -- 1, 2, or 3:v For I2=1 , aggregate [I1=1] -> 10 + [I1=2] -> 40 -> Result is 50v For I2=2 , aggregate [I1=1] -> 20 + [I1=2] -> 50 -> Result is 70v For I2=3 , aggregate [I1=1] -> 30 + [I1=2] -> 60 -> Result is 90
V02 = Sum (I1, %V01) produces:
ManipulationManipulation functions enable you to manipulate the dependencies betweenvariables. They are much more commonly used than the aggregation functions.
The formula language supports the following manipulation functions.
AddForMissingThis AddForMissing manipulation function.
PurposeIncreases the number of lines by adding new, unique key values and acorresponding value (either a default value or a value taken from anothertable).
SyntaxAddForMissing (expression,reference_vector [, default_replacement])
expression The table to add values to
reference_vector The reference table to use for the list of keys
default_replacement The default value to use when a new linehas to be added to the expression table
Description
For example, suppose two tables have been obtained from two columns ofthe same, original SNMP table. Because the original SNMP table wasincomplete (had "holes"), the resulting two tables do not have samenumber of lines. Operations between these tables would (possibly) furtherreduce the size.
Using the AddForMissing function ensures that both tables have the samenumber of lines, by adding new key values when keys are missing fromone table, when compared to the other.
Suppose that table A is the table you want to modify. Table B is consideredthe reference table , and provides the list of key values that you wantincluded in table A. For every line added to table A, the correspondingvalue will be either a default value (if provided as the third argument tothe function), or the corresponding value for that key, from table B.
If table A is:
Chapter 2. Functions 17

I1 Value
1 A1
2 A2
And table B is:
I1 Value
1 B1
2 B2
4 B3
The result of the call AddForMissing (%A, B, 'myDefaultValue') would be:
I1 Value
1 A1
2 A2
4 myDefaultValue
Compare this to the result of the call AddForMissing (%A, B)
I1 Value
1 A1
2 A2
4 B3
Example
This example is taken from the IETF_IF discovery formula. The code has toset up a name for the interface. If possible, use ifName because this objectprovides the best interface name. But ifName is not always supported, inwhich case the formula has only ifDescr to use as the interface name. It isalso possible that a given SNMP agent supports ifName for some of theinterfaces it manages, but not for all of them.
The code is as follows:Dim I1 AS Integer Default * NAME I1;V001 = OIDINST(ifAdminStatus.%I1 == 1);...V104 = OIDVAL(ifDescr.%V001);V106 = OIDVAL(ifName.%V001);V004 = OIDVAL(AddForMissing(%V106,V104));
The result set for V104 contains entries for all interfaces that supportifDescr : this will be all interfaces managed by the agent.
The result set for V106 contains entries for all interfaces that supportifName . This result set might have fewer entries than the one for V104 , ifnot all interfaces support ifName .
The AddForMissing() function compares the result sets in V104 and V106 .All entries in V106 are included in the final output. Wherever V104 has anentry but V106 does not, the entry from V104 is copied into the output.The final result set stored in V004 will be a blend of all the entries from theV106 result set, augmented by entries from the V104 result set. The result
18 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

set output by AddForMissing() and stored in V004 will always be at least aslong as the result set in the reference vector ( V104 ).
Note: This method works only because V104 and V106 are both indexedby V001 .
Alternative Approach
Before AddForMissing() was added to the discovery formula language, itwas possible to achieve the same effect using multiple return lines from thediscovery formula. The return line from the code above would look likethis: %V002 Index "... InterfaceName<%V004> ..."
Omitting AddForMissing() and V004 , you could get the same output usingthe following code:%V002 Index "...InterfaceName<%V106> ..."
%V002 Index "...InterfaceName<%V104> ..."
With this construction, all the values of V002 that also have a result forV106 will be returned by the first line and removed from the result set.Entries that exist for V002 and V104 , but not for V106 , are returned bythe second return line.
Either approach works in simple cases but as the complexity of theformula increases, AddForMissing() has an advantage. If there are severalindependent properties that must be set, more return lines are needed tohandle the various cases and the formula becomes more and more difficultto understand.
ExpandThis Expand manipulation function.
PurposePerforms complex combinations between two tables by joining them usingone table's values to match another table's keys. (All other combinationmatching is always done between keys).
SyntaxExpand (Dimension, Expression)
Dimension The name of the index column to bereplaced with its ancestors
Expression The expression to use for the returnedvalues
Description
Suppose that you have two tables, A and B. Table A's values serve as keysin table B. Calling Expand() on table B will convert its key structure so thatit becomes compatible with table A (for standard combination rules).
Chapter 2. Functions 19

Every time a temporary variable is created (for example, V1 = ifDescr.%I1 ),you can add that variable to a "dependency tree", as shown in the
following figure:
The dependency relation is the name of the key columns for a given table.
Many variables can be created, all from the same original SNMP table, andall sharing the same key name ( I1 ):
Because V1 , V2 , and V3 share the same key, they can be combined usingany operator. Thinking visually, you can say that all variables that aredisplayed at the same depth can be freely combined together.
The values in V1 can be used in another SNMP table as keys to accessspecific attributes. You would use a line similar to:
V4 = someAttribute.%V1
The updated dependency tree would look like this:
However, now table V4 cannot be combined freely with table V2 or V3because the key for V4 is expressed by V1 , whereas the key for V2 and V3is expressed by I1 .
The expand() function will "realign" table V4 by expanding the definition ofV1 and reconnecting V4 directly to V1 's ancestor. Use the following call:
V5 = Expand (V1, %V4);
This call creates the table V5 , whose values are copied from table V4 andwhose key structure is expressed by I1 , enabling you to combine it freelywith table V2 or V3 .
20 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

The following figure shows the updated dependency tree:
Example
The discovery formula must create VLAN subelements (slot and port), andassociate the interface information in property settings. The link betweenthe Interface table and the VLAN table is through the portIfIndex column inthe VLAN table; it defines an ifIndex number in the Interface table.
The VLAN table is as follows (in these tables, shading is used for theprimary key):
slot port portIfIndex portDuplex vlanPortOperStatus
1 5 1
2 9 2
The Interface table is as follows:
ifIndex ifSpeed ifAdminStatus ifOperStatus ifName
1 1
2 6
The formula looks something like this:Dim I1 as integer Default * name Slot;Dim I2 as integer Default * name Port;
V02 = OIDVAL (portIfIndex.%I1.%I2);V07 = OIDVAL (expand(V02, ifOperStatus.%V02));%V02 index "...%V07...%V02...%I1....%I2...."
V02 = OIDVAL(portIfIndex.%I1.%I2) produces the following:
Without the Expand() , V07 = OIDVAL(ifOperStatus.%V02) would produce:
Chapter 2. Functions 21

This would cause the return line to produce nothing because V07 and V02have different dimensions and therefore no matchable values.
With the Expand() function, V07 = OIDVAL(expand(V02, ifOperStatus.%V02))produces:
Because V02 and V07 are both dimensioned by I1
+ I2 , the result line produces values.
IndexAsValueThis IndexAsValue manipulation function.
Purpose
Provides a replacement and enhancement over the OIDINST() function.When a table is returned with a composite key structure (where severalcolumns are combined to compose the key), the IndexAsValue() functionenables you to extract only one column of the key, and store that partialkey's value inside the value field of the table.
This functionality is useful for some SNMP MIBs when some columns thatcompose the key of an SNMP table are not directly accessible (permissionsare set to not-accessible), and the only way to get the key entries is tobrowse another column of that table.
SyntaxIndexAsValue (Dimension, Expression)
Dimension The dimension (for example, I2 )
Expression The expression to use for the returnedvalues (for example, %V1 )
ExampleDim I1 AS DisplayString Default * NAME VpnVrfName;Dim I2 AS DisplayString Default * NAME VPNDestinationNetwork;Dim I3 AS DisplayString Default * NAME VPNRouteMask;Dim I4 AS Integer Default * NAME IfIndex;Dim I5 AS DisplayString Default * NAME VPNNextHop;V1 = OIDVAL (mplsVpnVrfRouteIfIndex.%I1.%I2.%I3.%I4.%I5);V2 = OIDVAL (AsString(IndexAsValue (I1, %V1)));V3 = OIDVAL (AsIp(IndexAsValue (I2, %V1)));V4 = OIDVAL (AsIp(IndexAsValue (I5, %V1)));%V1 index "ifIndex<%V1>||- N/A||VpnVrfName<%V2>VPNDestinationNetwork<%V3>VPNNextHop<%V4>"
The results are as follows:162.1.2.100:ifIndex<0>||- N/A||VpnVrfName<ACME>VPNDestinationNetwork<0.0.0.0>VPNNextHop<172.20.125.253>:0162.1.2.100:ifIndex<4>||-N/A||VpnVrfName<ACME>VPNDestinationNetwork<162.1.1.100>VPNNextHop<172.20.125.253>:4162.1.2.100:ifIndex<0>||-N/A||VpnVrfName<ACME>VPNDestinationNetwork<162.1.1.102>VPNNextHop<162.1.1.202>:0162.1.2.100:ifIndex<10>||-N/A||VpnVrfName<ACME>VPNDestinationNetwork<162.1.2.100>VPNNextHop<0.0.0.0>:10
22 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Common FunctionsThe common functions supported by the formula language.
AbsThis Abs common function.
PurposeReturns the absolute value of the specified value.
SyntaxAbs(x)
x The value whose absolute value you want tofind.
ExampleAbs(-10) -> 10
DeltaThis Delta common function.
Purpose
Returns the difference between the current value of x and its previousvalue.
If x is of type Counter and the difference is negative, the collector assumesa counter rollover and adds MAX_INT to the value. Every other casewhere the difference is negative is rejected and no value is returned.
This function is used exclusively in collection formulas.
Syntaxdelta (x)
x The value whose delta value you want tofind
Description
If delta() of a MIB object with counter syntax is negative, it is notconsidered a problem. The SNMP collector loads the MIBs and knows theMAX_INT for the counter (2^32 or 2^64). When the new measurement isless than the old measurement, the value for delta() is:(MAX_INT - old_value) + new value
If the new value is less than the old value because of an SNMP agentrestart (or other counter reset), the formula language invalidates that result.
Because a TimeTicks object should never have a negative delta, the formulalanguage invalidates anything that contains a negative time delta. Thisfeature ensures that agent restarts are not treated as counter rollovers.Therefore, any counter-based delta collection formula should also includedistrib() on a delta of sysUpTime , which is in TimeTicks .
Exampledistrib(delta(sysUpTime.0), "default:1") * delta(mibCounter.%I1)
100 * (delta(mibCounter.%I1)) / (distrib(delta(sysUpTime.0), "==0:1, default:*"))
Chapter 2. Functions 23

The second example needs sysUpTime for the rate calculation. The ==0:case in the distrib() is defense against a device that updates sysUpTime soinfrequently that it has the same value on two consecutive polls. This willreturn a "rollover spike" on reboot: delta(mibCounter.%I1) .
Protection is not required ( mibCounter.%I1 ), although it would be astrange formula that used the raw value of a counter object.
DiffThis Diff common function.
Purpose
Returns the difference between the current value of x and its previousvalue.
This is the same as Delta() , except there is no control of the type and theresult can be either positive or negative.
SyntaxDiff (x)
x The value whose difference value you wantto find
IntThis Int common function.
Purpose
Converts the specified number to the closest lower integer.
SyntaxInt (x)
x The value whose absolute value you want tofind
ExampleInt(5/3) -> 1
LastThis Last common function.
Purpose
Returns the value of x computed during the previous execution of theformula.
SyntaxLast (x)
x The last computed value for x
24 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

NotThis Not common function.
Purpose
Negation operator. Value 0 is transformed to 1; values other than 0 aretransformed to 0.
SyntaxNot (x)
x The value to negate
ExampleNot(5) -> 0
RoundThis Round common function.
Purpose
Returns a number rounded to the nearest multiple of significance. This isuseful because division alone will truncate its answer towards zero.
SyntaxRound (number [, significance])
number The value to round.
significance The multiple to which you want to round.The default value is 1, which means thenumber will be rounded to the closestinteger.
Description
For example, you could round network traffic in bytes to the closest valuein Kb:Round (valueInBytes, 1024)/1024
You could round a percentage value to the closest even number:Round (percentageValue, 2)99.2 -> 10095.1 -> 96101.02 -> 100
When the input is exactly between two possible rounded values, the higherone is returned. For example:Round (2.5) = 3Round (-2.5) = -2
If the input is an exact multiple of significance, no rounding occurs.
Examples
Example Action Result
Round(2.5, 1) Rounds 2.5 up to the nearestvalue of 1
3
Chapter 2. Functions 25

Round(-2.5, 2) Rounds -2.5 up to the nearestmultiple of 2
-2
Round(1.52, 0.1) Rounds 1.5 down to thenearest multiple of 0.1
1.5
Round(0.234, 0.01) Rounds 0.234 down to thenearest multiple of 0.01
0.23
Round(1548, 10) Rounds 1548 up to thenearest multiple of 10
1550
Conversion FunctionsThe conversion functions supported by the formula language.
asIpThe asIp conversion function.
Purpose
Represents the specified value as a clean IP address.
Syntaxaslp(x)
x The value for which you want a clean IPaddress
Description
The argument can be four numbers (prefixed by the number 4) or fourASCII characters. They are translated to the same format: 1.2.3.4 or A.B.C.D.
asMacThe asMac conversion function.
Purpose
Represents the specified value as a clean MAC address.
SyntaxasMac (x)
x The value for which you want a clean MACaddress
Description
The argument can be six numbers (with or without a prefix of the number6). It is translated to the format 0x000000000000 .
26 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

asStringThe asString conversion function.
Purpose
Converts the OID path to its object name.
SyntaxAsString (OIDVAL)
OIDVAL The OID path to convert
ExampleDim I1 AS DisplayString Default *NAME VpnVrfName;
Dim I2 AS DisplayString Default *NAME VPNDestinationNetwork;
Dim I3 AS DisplayString Default *NAME VPNRouteMask;
Dim I4 AS Integer Default * NAMEIfIndex;
Dim I5 AS DisplayString Default * NAME VPNNextHop;
V1 = OIDVAL(mplsVpnVrfRouteIfIndex.%I1.%I2.%I3.%I4.%I5);
V2 = OIDVAL (AsString (IndexAsValue(I1, %V1)));
V3 = OIDVAL (AsIp (IndexAsValue (I2, %V1)));
V4 = OIDVAL (AsIp (IndexAsValue (I5,%V1)));
%V1 index "ifIndex<%V1>||-N/A||
VpnVrfName<%V2>VPNDestinationNetwork<%V3>VPNNextHop<%V4>"
The results are as follows:162.1.2.100:ifIndex<0>||- N/A||
VpnVrfName<ACME>VPNDestinationNetwork<0.0.0.0>VPNNextHop<172.20.125.253>:0162.1.2.100:ifIndex<4>||-N/A||
VpnVrfName<ACME>VPNDestinationNetwork<162.1.1.100>VPNNextHop<172.20.125.253>:4
162.1.2.100:ifIndex<0>||-N/A||
VpnVrfName<ACME>VPNDestinationNetwork<162.1.1.102>VPNNextHop<162.1.1.202>:0
162.1.2.100:ifIndex<10>||-N/A||
VpnVrfName<ACME>VPNDestinationNetwork<162.1.2.100>VPNNextHop<0.0.0.0>:10
asNumberThe asNumber conversion function.
Purpose
Converts an OID of type OCTET STRING to a numeric value.
SyntaxasNumber (OIDVAL)
OIDVAL The OCTET STRING value to convert.
Chapter 2. Functions 27

Description
The asNumber() function takes a value stored in an OID of type OCTETSTRING and converts it to a numeric value so that arithmetic operationscan be performed.
Note: Tivoli Netcool Performance Manager does not support arithmeticoperations on string objects.
Example
The following example shows how to use the asNumber() function withinan SNMP formula to multiply the value stored in ifDescr (an OID of typeOCTET STRING ) by the value 8:DIM I1 Integer Default * Name ifIndex;.
.
.
IfCorrectedIndex = asNumber ( ifDescr.%I1 ) * 8;
.
.
.
The arithmetic operation (multiply by the value 8) is permitted on thestring object ifDescr because the asNumber() function converts it to anumeric value.
replaceThe replace conversion function.
Purpose
The SNMP collector provides basic string manipulation support permittingstring replacement. A string within a variable or expression can be replacedwith a different string.
Syntaxreplace (aVariableOrExpression, what,with)
aVariableOrExpression A variable or expression.
what A string within the variable or expression.
with A string to replace the what string.
Description
Replaces instances of the what string inside aVariableOrExpression with thewith string.
Example
The following simple formula example:Def useQuotedStrings No;
V1=sysName.0 ;
28 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

V2=sysDescr.0 ;
V3=ifNumber.0 ;
%V1 index"name<%V1>descr<%V2>number<%V3>"’
Produces output similar to the following:qarouter1:name<QAROUTER1>descr<CiscoIOS Software, C2600 Software (C2600-ENTBASEK9-M), Version 12.4(5a),RELEASE SOFTWARE (fc3)\0D\0ATechnical Support:http://www.cisco.com/techsupport\0D\0ACopyright (c) 1986-2006 byCisco Systems, Inc.\0D\0ACompiled Fri 13-Jan-06 19:18 byalnguyen>number<2>:QAROUTER1
To replace the ( ) in the sysDescr with [ ] we can use the followingreplacements:Def useQuotedStrings No;V1=sysName.0 ;V2=replace( replace( sysDescr.0, "(", "[" ) , ")" , "]" ) ;V3=ifNumber.0 ;%V1 index "name<%V1>descr<%V2>number<%V3>"’
Giving the following result:qarouter1:name<QAROUTER1>descr<CiscoIOS Software, C2600 Software [C2600-ENTBASEK9-M], Version 12.4[5a],RELEASE SOFTWARE [fc3]\0D\0ATechnical Support:http://www.cisco.com/techsupport\0D\0ACopyright [c] 1986-2006 byCisco Systems, Inc.\0D\0ACompiled Fri 13-Jan-06 19:18 byalnguyen>number<2>:QAROUTER1
Filtering FunctionsThe purpose of filtering functions is to reduce the number of lines a table has;filtering does not affect the structure of the key. Filtering is done on either the linenumber or the value.
The formula language supports the following filtering functions:
BottomNThe BottomN filtering function.
Purpose
Sorts all results in the result set based on their values and keeps only thespecified number of results with the lowest values.
SyntaxBottomN (N, expression)
N The number of values to return
expression The returned values
Example
Chapter 2. Functions 29

For V1 set to the following values:
BottomN (2, %V1) returns the following lines:I1 = 3 -> (int) 10I1 = 2 -> (int) 20
DistribThe Distrib filtering function.
Purpose
Converts ranges of values into other values.
SyntaxDistrib (expression, format_string)
expression The expression. This can be any combinationof OIDs and operators.
format_stringA quoted list of condition/value pairs.
The overall syntax of the format string is "pair , pair , ...". All the pairs in the formatstring are separated by commas.
A pair is condition:value , where:
v Valid conditions are <N , <=N , ==N , >N, >=N , and !=N , where N is a number. Inaddition, the condition can be default ,which is always true and returns a valuewhen none of the preceding conditionsare met. If you specify default , it must bein the last pair in the format string.
v The value can be either a number or astring. There are no quotes around value ,which makes the colon and commacharacters invalid in a string value . Thecollector does not enforce it, but it is alsoinvalid to mix numeric and string valuesin the same format string. This canproduce unexpected results. value can alsobe specified as an asterisk (*). This returnsthe value of expression and is often usedwith the default condition.
Description
This function performs a range transformation of each result line. Theoriginal intent of this function was to replace a large set of possible inputvalues with a small set of results. For example if expression is between 0and 60%, you could have quality = 1 for values between 0 to 60%; quality =2 for values between 61 and 80%; and quality = 3 for values over 81%.
30 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

The Distrib() function can be used for other purposes as well. It is theclosest thing the formula language has to a conditional statement. You canuse it as a filter to avoid formula errors if a calculation could do somethingillegal (such as dividing by zero.)
Each line of the expression result set is treated independently, and allconditions are evaluated in order from left to right. As soon as a conditionis true for a given line of the result set, its value is replaced by the valuefrom the condition/value pair and no more conditions are evaluated forthat line. If after evaluating all conditions there are no matches, the resultline is discarded from the expression result set -- which enables Distrib() toact as a filter.
For example, with the format string "<5:0, <95:*, <110:100":
v Any value less than 5 is replaced by 0.v Values from 5 to 94 are returned unchanged.v Values from 95 to 109 are replaced by 100.v Values greater than or equal to 110 are discarded.
As another example, suppose you want to translate ifSpeed into a string fordisplay purposes. ( ifSpeed is taken from the IETF_IF discovery formula.)
The process is as follows:
1. Convert ifSpeed into reasonable units (kilobits/second,megabits/second, and so on) by dividing it by the largest reasonablefactor:Factor = distrib
(ifSpeed.%I1,"<1000:1, <1000000:1000, <1000000000:1000000,default:1000000000")
ReadableSpeed = ifSpeed.%I1/%Factor
2. Specify the format string to use for the units:Units = distrib (ifSpeed.%I1,"<1000:bps, <1000000:Kbps, <1000000000:Mbps,
default:Gbps")
3. Display the readable speed:DisplaySpeed = %ReadableSpeed + ""+ %Units
Example
For V1 set to the following values:
Distrib (%V1, ">40:3, >20:2, default:1") returns the following lines:I1 = 1 -> (int) 2I1 = 2 -> (int) 1I1 = 3 -> (int) 1I1 = 4 -> (int) 2I1 = 5 -> (int) 3
Chapter 2. Functions 31

DistribThe Distrib filtering function.
Purpose
Converts ranges of values into other values.
SyntaxDistrib (expression, format_string)
expression The expression. This can be any combinationof OIDs and operators.
format_stringA quoted list of condition/value pairs.
The overall syntax of the format string is "pair , pair , ...". All the pairs in the formatstring are separated by commas.
A pair is condition:value , where:
v Valid conditions are <N , <=N , ==N , >N, >=N , and !=N , where N is a number. Inaddition, the condition can be default ,which is always true and returns a valuewhen none of the preceding conditionsare met. If you specify default , it must bein the last pair in the format string.
v The value can be either a number or astring. There are no quotes around value ,which makes the colon and commacharacters invalid in a string value . Thecollector does not enforce it, but it is alsoinvalid to mix numeric and string valuesin the same format string. This canproduce unexpected results. value can alsobe specified as an asterisk (*). This returnsthe value of expression and is often usedwith the default condition.
Description
This function performs a range transformation of each result line. Theoriginal intent of this function was to replace a large set of possible inputvalues with a small set of results. For example if expression is between 0and 60%, you could have quality = 1 for values between 0 to 60%; quality =2 for values between 61 and 80%; and quality = 3 for values over 81%.
The Distrib() function can be used for other purposes as well. It is theclosest thing the formula language has to a conditional statement. You canuse it as a filter to avoid formula errors if a calculation could do somethingillegal (such as dividing by zero.)
Each line of the expression result set is treated independently, and allconditions are evaluated in order from left to right. As soon as a conditionis true for a given line of the result set, its value is replaced by the valuefrom the condition/value pair and no more conditions are evaluated forthat line. If after evaluating all conditions there are no matches, the resultline is discarded from the expression result set -- which enables Distrib() toact as a filter.
For example, with the format string "<5:0, <95:*, <110:100":
32 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

v Any value less than 5 is replaced by 0.v Values from 5 to 94 are returned unchanged.v Values from 95 to 109 are replaced by 100.v Values greater than or equal to 110 are discarded.
As another example, suppose you want to translate ifSpeed into a string fordisplay purposes. ( ifSpeed is taken from the IETF_IF discovery formula.)
The process is as follows:
1. Convert ifSpeed into reasonable units (kilobits/second,megabits/second, and so on) by dividing it by the largest reasonablefactor:Factor = distrib
(ifSpeed.%I1,"<1000:1, <1000000:1000, <1000000000:1000000,default:1000000000")
ReadableSpeed = ifSpeed.%I1/%Factor
2. Specify the format string to use for the units:Units = distrib (ifSpeed.%I1,"<1000:bps, <1000000:Kbps, <1000000000:Mbps,
default:Gbps")
3. Display the readable speed:DisplaySpeed = %ReadableSpeed + ""+ %Units
Example
For V1 set to the following values:
Distrib (%V1, ">40:3, >20:2, default:1") returns the following lines:I1 = 1 -> (int) 2I1 = 2 -> (int) 1I1 = 3 -> (int) 1I1 = 4 -> (int) 2I1 = 5 -> (int) 3
FilterThe Filter filtering function.
Purpose
Keeps only the lines of the result set that have a value of True ( != 0 ). Theexpression is usually a Boolean expression with a result of 1 or 0.
SyntaxFilter (expression)
expression The range of values to convert
Example
Chapter 2. Functions 33

For V1 set to the following values:
Filter (%V1 > 30) returns the following lines:I1 = 1 -> (int) 40I1 = 5 -> (int) 50
FirstNThe FirstN filtering function.
Purpose
Keeps only the first N results of a result set. The order is the returnedorder from the SNMP device.
SyntaxFirstN (N, expression)
N The number of values to return
expression The returned values
Example
For V1 set to the following values:
FirstN (2, %V1) returns the following lines:I1 = 1 -> (int) 40I1 = 2 -> (int) 20
IfThe If filtering function.
Purpose
Performs conditional branching. The function returns results from one tableor another, based on the specified condition.
The collector works in two phases for formula execution -- first collectingall possible OIDs from the device, then executing the formula content.Therefore, for If() , three tables (test, ifTrue, and ifFalse) will be filled withvalues before the test is executed. This might turn into an expensiveoperation when in order to return a single value, three values are polled.
34 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

SyntaxIf (booleanExpression,expressionIfTrue [, expressionIfFalse])
booleanExpression A mathematical expression, or a reference toa temporary variable, that provides aBoolean result.
expressionIfTrue An expression, or a reference to a temporaryvariable, that has the same key structure andsize as booleanExpression . For each line inbooleanExpression that evaluates to true , If()returns the value at the corresponding keyin expressionIfTrue .
expressionIfFalse [Optional] An expression, or a reference to atemporary variable, that has the same keystructure and size as booleanExpression . Foreach line in booleanExpression that evaluatesto false , If() returns the value at thecorresponding key in expressionIfFalse .
Example
Suppose that you want to test the interface type: if it is `ethernet', returnthe ifName . Otherwise, return the ifDescr field.
Use the following call:Dim I1 as integer default * name Interface;FinalName = IF (ifType.%Interface == `ethernet’, ifName.%Interface, ifDescr.%Interface);
LastNThe LastN filtering function.
Purpose
Keeps only the last N results of a result set. The order is the returned orderfrom the SNMP device.
SyntaxLastN (N, expression)
N The number of values to return
expression The returned values
Example
For V1 set to the following values:
LastN (3, %V1) returns the following lines:
Chapter 2. Functions 35

I1 = 3 -> (int) 10I1 = 4 -> (int) 30I1 = 5 -> (int) 50
TopNThe TopN filtering function.
Purpose
Sorts all results in the result set based on their values and keeps only thespecified number of results with the highest values.
SyntaxTopN (N, expression)
N The number of values to return
expression The returned values
Example
For V1 set to the following values:
TopN (3, %V1) returns the following lines:I1 = 5 -> (int) 50I1 = 1 -> (int) 40I1 = 4 -> (int) 30
SNMPSet FunctionsSNMPSet functions enable SNMPSet commands to be issued from within theformula language.
The formula language supports the following SNMPSet functions:
OidSetThe OidSet filtering function.
Purpose
Issues an SNMPSet command to set a value in a specified MIB object.
SyntaxOidSet(oid.instance, valueToWrite)
oid.instance The fully qualified OID of the object toupdate.
valueToWrite The value to write into the OID. The valuemust be a constant (number or string).Expressions and variable names are notsupported.
36 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Example
The following example is based on the MIB CISCO-RTTMON-MIB . It setsthe MIB OID rttMonCtrlOperState to a value of 7 (restart) for a probe Idindicated by the contents of variable %I2 .OidSet(rttMonCtrlOperState.%I2, 7);
Verify FunctionsVerify functions confirm that an expression is true before proceeding with aformula.
The formula language supports the following verify functions:
EnsureThe Ensure filtering function.
Purpose
Ensures that a condition is met before proceeding with a formula.
This function verifies that an expression is true.
If the expression is not true, the function will pause the formula executionfor a given time ( shortDelay ), and resume execution at the lineimmediately preceding the Ensure command.
The loop can occur up to maxRepeats times, for a total delay of shortDelay *maxRepeats .
SyntaxEnsure (expression , shortDelay ,maxRepeats)
expression Boolean expression to evaluate. A result hasto be produced, and that result must bedifferent than zero, for the Ensure( )condition to pass. Each time the expressionis false, a pause will be executed, and theformula execution will resume at the linepreceding the Ensure( ) condition.
shortDelay Optional. Duration in milliseconds of thedelay to apply, before re-executing the linethat precedes the Ensure( ) condition. Defaultvalue is 20.
maxRepeats Optional. Maximum number of iterations,whilst the expression is false.
Example
This example demonstrates how the function works. It is not a meaningfulcollection formula.
The following example ensures that the time difference between twoconsecutive pollings of sysUpTime , is at least 500 milliseconds.Time1msec=sysUpTime.0 * 10 ;Time2msec=sysUpTime.0 * 10 ;ensure ( %Time2 - %Time1 > 500 ,300 , 3)
Chapter 2. Functions 37

The Ensure ( ) condition will fail twice. On the first occasion the timedifference is ~0 milliseconds. On the second occasion after a wait of 300milliseconds, the difference is ~300 milliseconds. On the third occasion(after 2 waits of 300 milliseconds each) the difference is ~600 milliseconds,the condition becomes true.
Example 2
In this example an Ensure( ) condition is needed in an IPSLA Reset formulato give enough time to the router to create the MIB entries for newstatistics, immediately after the SNMPSet command.
In this case a short wait, and a small number of repeats are sufficient.Wait IPSLA Scope subElement;Using LastIpSlaUpdate ScopesubElement;Dim I0 as Integer default * nameLastWrite;Dim I1 as Integer default * nameUnused;Dim I2 as Integer default * nameProbeIndex;OidSet( rttMonCtrlOperState.%I2, 7);LastIpSlaUpdate= Max(*, IndexAsValue(I0, rttMonStatsTotalsElapsedTime.%I2.I0)) ;Ensure( %LastIpSlaUpdate > 0 , 30, 4 )
38 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 3. Common formula structure
This chapter describes the common structure for formulas.
Comments in formulasHow to add comments to a formula.
To add comments to a formula:1. Put each comment on a separate line.2. Start each line with a pound sign (#).3. End each line with a semi-colon (;).
For example:# This is a comment;
Do not include commas or semi-colons within the body of the comment. TheSNMP collector parses the text inside the comments and might become confusedby punctuation and special characters. Restrict yourself to very simple commentsor none at all.
OIDVAL Expression LineThe OIDVAL expression line executes an expression (based on an OID or statisticvariable) and stores the result in a temporary variable. Dimensions of thetemporary variable reflect the dimensions of the expression.
The declaration uses the following syntax:Vn = OIDVAL(<Expression>);
In the syntax, Expression is an OID, a STAT variable, or mathematical operations.
ExampleOIDVAL expression line example.Dim I1 as integer default 2;V1 = OIDVAL(ifInOctets.%I1/ifSpeed.%I1 * 100.0);
The OID query results are as follows:
© Copyright IBM Corp. 2011, 2012 39

The result of 1000/512 * 100.0 is as follows:
OIDINST Expression LineThe OIDINST expression line is mainly used in discovery formulas to filter asubset of indexes from a large set.
The declaration uses the following syntax:Vn = OIDINST(<Boolean expression> [, Validity]);
In this syntax:v Expression : An OID, STAT variable, or mathematical operation with a Boolean
result.v Validity : Obsolete.
You might see the validity value "once" in old discovery formulas, but it no longerdoes anything useful. Similarly, the Validity clause used in OIDVAL expression isalso obsolete.
ExampleThe OIDINST expression line example.
Consider the following example:Dim I1 as integer default * NAME interface;V1 = OIDINST(ifAdminStatus.%I1 == 1);
The IfAdminStatus value is returned as an integer. For example, 1 = up, 2 = down,and so on.
The SNMP query results are as follows:
The Boolean expression comparison results are as follows:
The OIDINST stores all keys with a result other than 0 in the V1 vector. Therefore,two keys ( I1 = 1 , and I1 = 3 ) are stored. V1 will be constructed with no dimension
40 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

and multiple values, as follows:
You can use the V1 variable in another expression line, exactly in the same way asan I x variable.
You can use the OIDINST operator with a vector having more than one dimension(such as retrieving objects from a MIB table with multiple index columns). In thiscase, all substitution values are concatenated, separated by the dot character. Typesof each dimension are lost and the resulting type of V1 variables is string ; this is thedefault type when no explicit type is declared. As previously stated, not usingexplicit types has more side-effects than benefits.
You should not use the OIDINST operator when there is more that one dimensionbecause the individual dimensions are lost.
The following example shows why you should not use OIDINST when more thanone dimension exists:V1 = OIDINST(dlciStatus.%I1.%I2 like "up")
Two keys ( I1 = 1 , I2 = 101 and I1 = 2 , I2 = 103 ) are selected.
Because more than one dimension is involved, the keys are transformed to 1.101
and 2.103 . V1 is set to:
On the next substitution, using the V1 value you will lose the <interface>.<dlci>information because the type is string and each dimension is no longer accessible.
Dim SectionThe Dim section declares types and default values for input variables of theformula.
You must declare the type of input values. The Dim declarations, if present, mustappear before anything else in the formula.
The declaration uses the following syntax:Dim {input number} AS {type} [Default {default value}] [Name{mnemonic name}];
The valid types are as follows:v Integer
v IPAddress
v Gauge
v Counter
Chapter 3. Common formula structure 41

v MacAddress
v OctetString
v DisplayString
v Timeticks
Default instances can be a comma-separated list of values, or the wildcardcharacter (*) to indicate that all instances should be used. Spaces are not allowed ina list of values for an input variable.
The following declarations are valid:Integer 3
List of integers 1,3,6,9,8,109
Interval 4-59
List of integers and intervals 1,3,6,9,8-96,109,200-250
Character string "This is a STRING"Pointer to a string 128.3.56.7
Wildcard *
For example:DEF SaveAlias 2212;
Dim I1 AS Integer Default * Name Interface;
8 * delta(ifInOctets.%I1) * distrib(delta(sysUptime.0),"default:1") *
distrib(delta(ifLastChange.%I1), "==0:1")
Def SectionThe Def directives go at the top of the formula, immediately after the Dimstatements.
Result LineThe result lines in a formula are located at the end of the formula, after all variableassignments.
A result line defines the format of the information sent back to the callingapplication. Execution of a result line in a formula results in the creation inmemory of one or more value lines. Each line contains the name of the device thathas been queried, a result value (number or string), and an instance number forthe result (0 if the result is not indexed, or a number corresponding to values ofdimensions of that result).
42 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

DiscoveryIn the case of a discovery formula, the expected format is a long string composedof four fields separated by double pipes ("||").
Each field of that string represents a part of a subelement being discovered. It ispossible for a discovery formula to specify several result lines and for each resultline to generate multiple value lines.
CollectionIn the case of a collection formula, the expected format for a result is a singlevalue.
Therefore, it is invalid for a collection formula to specify more than one result line,and it is also invalid for that result line to generate more than one value line.
Default Return FormBy default, the format of the instance string is deduced by the collector from thelist of dimensions contained in the result vector.
If the result is Res [I1 , I2] , a string " %I1.%I2 " is used for constructing theinstance field. The usual order is I xx variables ordered by increasing numbers,then V xx variables in increasing number order.
The returned instance is used:v In standard collections for matching the result with the instance field of the
subelement.v In discovery formulas for sending back the complete description of each
subelement. This is done using a user-defined instance string.
ExampleThe Result Line example.V1 = OIDVAL(ifInOctets.%I1 + ifOutOctets.%I1);%V1 <- This is the result line, which will output the content of the V1 vector.
Testing this formula yields the following:Information:Expression: compiling ’V1=OIDVAL(ifInOctets.%I1 +ifOutOctets.%I1)’
...
Information:Expression: compiling ’%V1’ ...Information:Running Formula ...Information:Executing: OIDVAL(ifInOctets.%I1 + ifOutOctets.%I1) ...
Debug:OIDVAL( ): list of all SNMP values returned ...Debug:192.168.64.29:ifInOctets.1:0
Debug:192.168.64.29:ifOutOctets.1:0
Debug:192.168.64.29:ifInOctets.2:2329703221
Debug:192.168.64.29:ifOutOctets.2:1621920323
Information:Partial result for var V1 ...
Information:V1([H1=192.168.64.29] [I1=1]) = [float] 0
Information:V1([H1=192.168.64.29] [I1=2]) = [float] 3951623544
Chapter 3. Common formula structure 43

Information:Executing: Expression %V1 ...
Debug:Expression: list of all SNMP values returned ...
Debug:Merging results into current result set (init size = 0) withindex
mask =’%I1’
Debug:[1] 0
Debug:[H1=192.168.64.29] [I1=1] ==> result at index ’1’
Debug:[2] 3951623544
Debug:[H1=192.168.64.29] [I1=2] ==> result at index ’2’192.168.64.29 = 1:0192.168.64.29 = 2:3951623544
The formula has been tested against an element, without specifying a specificinstance number. Therefore, all instances available (in this case, 1 and 2) have beencollected.
The number of value lines returned by the execution of that formula is driven bythe size of the vector V1 . This vector has two entries in its dictionary: Interface 1and Interface 2. Therefore, two value lines are produced. The index format for theresult lines is automatically produced by parsing the dependencies of thevalue/vector used to drive the results. The H1 part is ignored because the multiplehosts formula is not supported.
In the previous example, the index format was expressed using variations of %I1only. If you had defined the V1 vector using more than one dimension ( I1 and I2), the index format would have been " %I1.%I2 ". The results are displayed asfollows:{Device name} = {instance}: {value}
192.168.64.29 = 1:0
192.168.64.29 = 2:3951623544
44 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 4. Writing Discovery Formulas
This section describes how to write discovery formulas.
The discovery implementation consist of several steps.v At discovery time, capabilities of each subelement are detected and stored in
specific properties (either one property name for each capability, a singleproperty containing a list of capabilities, or a mix of both).
v Specific grouping rules are applied inside the subelement collection tree to groupsubelements that have common capabilities.
v Requests (also known as "collections") are deployed against part or all thecreated groups. Formulas used in each request use OIDs that have previouslybeen validated during the discovery phase. For example, a formula thatcomputes the traffic using 64-bit counters is deployed only against a subgroupthat contains interfaces that have 64-bit counters. Regular traffic formulas thatuse 32-bit counters should be deployed only against subgroups with 32-bitinterfaces. At discovery time, because a capability is either 64 or 32, asubelement will end up in a single collection group.
v If properties and capabilities of an interface change over time, another discoveryrun will catch the change and update the property. This change will force aregrouping of that subelement to place it into the "new" group. The collectionformula then moves to the proper collection group when the collector does a"resync" of its model.
Discovery Formula StructureA discovery formula has the following structure:
Dim SectionThe Dim section declares types and default values for input values of the formula.
You must declare the type of the input value if it is anything other than Integer .For detailed information about the Dim section and the supported data types.
Def SectionThe Def directives go at the top of the formula, immediately after the Dimstatements.
The Def directives include:v Def AllowCreationOfSEv Def MaxLinesv Def UseQuotedStrings
Def AllowCreationOfSEThe AllowCreationOfSE directive is a merge formula used when the resources to bediscovered have all the characteristics of some general subelement type, but havesome special additional characteristics.
For example, interfaces on Riverstone routers are regular interfaces and can bediscovered using the IETF_IF discovery formula. But physical interfaces on these
© Copyright IBM Corp. 2011, 2012 45

devices have the special quality that ifName can be used as the invariant for thesesubelements. Because you do not want to repeat all the logic of the IETF_IFformula just to add the invariant, you can use a merge formula instead.
The syntax is as follows:Def AllowCreationOfSE 0;
There probably is a variant of this directive with 1 instead of 0, but it is nevernecessary or used: in practice, the the 0 variant is the only one you will see. This isan indication that this formula is actually a merge formula, which is a special typeof discovery formula.
Example:
The Def AllowCreationOfSE example.
The Riverstone_IF formula is:Dim I1 AS Integer Default * NAME I1;Def AllowCreationOfSE 0;V9 = OIDINST(ifAdminStatus.%I1 == 1);V1 = OIDINST(ifConnectorPresent.%V9 like "true" format clean);V2 = OIDVAL(ifName.%V1);%V2 index"If<%V1>||-UNSPECIFIED||Invariant<Riverstone_PhysIF>||%V2";
Like the IETF_IF formula, this formula filters out any interface with ifAdminStatus!= 1 . But what if someone changes the IETF_IF formula to be even morerestrictive? This formula could potentially create interface subelements with noneof the right properties and a label of "UNSPECIFIED". The AllowCreationOfSEdirective prevents this from happening.
Def MaxLinesThe DISMAN_Ping_Match formula determines whether the device has any Pingtests configured for it, and returns a true/false result.
The match formula retrieves the first row of the ping Ctrl Row Status column. Ifthe formula gets a response, it returns that value ( true ). If there are no rows inping Ctrl Row Status , the formula returns no result ( false ).
The MaxLines directive prevents the formula from retrieving all the rows in theping Ctrl Row Status column.
The DISMAN_Ping_Match formula is defined as follows:Def MaxLines 1;pingCtlRowStatus.%I1;
Def UseQuotedStringsUsed primarily for discovery formulas, the UseQuotedStrings directive sets thedefault behavior of the collector for displaying strings.
If UseQuotedStrings is set to yes ( True ), which is the default value, all strings aredisplayed within a pair of double quotes. Otherwise, strings are not delimited bydouble quotes.
The syntax is as follows:Def UseQuotedStrings {yes|no};
46 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

It is often necessary to include this directive to prevent property values being setas quoted strings. If quotes are allowed to become part of the property value, theproperty generally becomes more difficult to display and work with.
Alternatively, you can explicitly include literal quotes by escaping them with abackslash character, as in:juniAddressPoolName<\"%V1\">
ExampleERX VR element discovery formula to handle the VR community string:
Dim I1 as Integer default *;
Def UseQuotedStrings no;
V1=OIDINST(usdRouterRowStatus.%I1 > 0);
V2=OIDVAL(usdRouterName.%V1);
V3=OIDVAL(sysName.0);
V4=OIDVAL(sysDescr.0);
%V2 index"NULL||%HOSTNAME||ipAddress<%HOSTIP>IP.name<%HOSTNAME_%V2>rCommunity<%USEDRCOMMUNITY@%V2>sysDescr<%V4>physAddress<%HOSTNAME:%V2>sysName<%V3:%V2>||%V3/%V2";
Example:
The Def UseQuotedStrings example
The IP Address Pool discovery formula is defined as follows:Def UseQuotedStrings No;
Dim I1 AS Integer Default * NAME Instance;
V1 = OIDVAL (juniAddressPoolName.%I1);
%V1 index "ERXAddressPool<%I1>||Pool%V1||juniAddressPoolName<%V1>DeviceVendor<Juniper>||";
In the V1 = OIDVAL... line, V1 is set to the name of an address pool (juniAddressPool ); in the next line, it is returned as the value of the propertyjuniAddressPoolName<%V1>.
The IP Address Pool formula returns property values such as the following:Dialup 508 PoolBband 483 Pool
Without the UseQuotedStrings directive, the values would be enclosed in quotes, asfollows:"Dialup 508 Pool""Bband 483 Pool"
Clearly, you do not want the values enclosed in quotes if the values are used togenerate subelement groups. Similarly, the quoted names do not look good whendisplayed in reports.
Chapter 4. Writing Discovery Formulas 47

OID Gathering SectionThe OID gathering section explains how SNMP values are retrieved from a device,and how the results are stored in a temporary variable (vector).
Storing a raw OID in a temporary vector:V1 = OIDVAL (ifDescr.%I1)
Saves the following in memory:V1([H1=192.168.64.29] [I1=1]) = [float] "lo0"
V1([H1=192.168.64.29] [I1=2]) = [float] "hme0"
Storing the result of an expression in a temporary vector:V2 = OIDVAL (ifSpeed.%I1/1E6)
Saves the following in memory:V2([H1=192.168.64.29] [I1=1]) = [float] 10V2([H1=192.168.64.29] [I1=2]) = [float] 100
Getting a list of indexes that satisfy a condition:V3 = OIDINST (ifOperStatus.%I1 == "up" format clean);
Saves in memory a vector without dimensions:V3( ) = [float] 1V3( ) = [float] 2
Using another vector's values to drive a collection:V4 = OIDVAL (ifDescr.%V3)
Saves in memory:V4([H1=192.168.64.29] [V3=1]) = [float] "lo0"V4([H1=192.168.64.29] [V3=2]) = [float] "hme0"
Result Line SectionYou can use the result line, with a custom INDEX format string, to definecharacteristics of a subelement to add to the database.
Note: If you use multiple result lines, priority rules apply (top to bottom).
A result line has the following form:%V1 index "...%Vxx... || ...%Vxx...||...%Vxx...||...%Vxx... "
%V1 is the variable that drives the size of the result set. The collector loopsthrough all the values of the variable %V1 and substitutes every time it is possible,all the V xx variables used in the index line with their corresponding values. If a Vxx variable has no appropriate value, no result is produced and the current resultof the variable V1 is omitted.
Field DefinitionsA result line contains four fields:1. The subelement instance string. This is the string to be transmitted to each
collection formula when that subelement is deployed for collection.2. The custom label of the subelement.
48 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

3. The property list for the subelement. This is a list of pairs {propertyname}{property value} .
4. (Optional) The invariant of the subelement. The invariant is used during thesynchronization process to detect a change of element properties, including theinstance string (the first field).
All fields are separated by "||" tokens.
Example:
The field definitions example.
The 1213_IF formula for discovering 1213 interface subelements is as follows:Dim I1 AS Integer Default * NAME If;V1 = OIDVAL(ifType.%I1 format clean, once);V2 = OIDVAL(sysLocation.0, once);V3 = OIDVAL(ifSpeed.%I1, once);V4 = OIDVAL(int(%V3/1000000), once);V5 = OIDVAL(ifAdminStatus.%I1 format clean, once);%V1 index "If<%I1>||IF: %I1(%V4Mbps)||type<%V1>location<%V2>physicalCapacity<%V3>status<%V5>siteID<IP:%H1ifIndex:%I1>||";
Assuming two interfaces, this formula produces the following subelements:
Subelement #1:
Host 192.168.64.29
Instance If <1>
Label IF: 1 (10 Mbps)
Propertiestype -> softwareLoopback
location -> "System administrators office"
physicalCapacity -> 10000000
status -> up
siteID -> IP:192.168.64.29ifIndex:1
Invariant {empty}
Subelement #2:
Host 192.168.64.29
Instance If <2>
Label IF: 2(100 Mbps)
Propertiestype -> ethernetCsmacd
location -> "System administrators office"
physicalCapacity -> 100000000
status -> up
siteID -> IP:192.168.64.29ifIndex:2
Chapter 4. Writing Discovery Formulas 49

Invariant {empty}
Use cases and implementationA set of use case examples and implementation specifics.
Procedure1. Discover a small section of a large MIB table.
For performance reasons, you must discover a small section of a large MIBtable. There is no sense in querying the entire table when the number ofdesired results in the table is considerably smaller than the size of the table. Todo this, do a single scan of the table, extracting all indexes that satisfy acondition, then use the list of indexes to directly access other objects in thetable.ExampleFor the Juniper ERX Technology Pack, only interfaces of type DS1 areconsidered. IfIndex values corresponding to valid DS1 interfaces are stored inV1 and reused everywhere in the formula so you do not have to scan the hugeifTable for every OID.The formula is as follows:Dim I1 AS Integer Default * NAME Interface;
V1 = OIDINST(dsx1IfIndex.%I1);
V2 = OIDVAL(ifDescr.%V1);
V3 = OIDVAL(ifSpeed.%V1);
V4 = OIDVAL(ifType.%V1 format clean);
V5 = OIDVAL(usdIfType.%V1 format clean);
V6 = OIDVAL(ifAlias.%V1);
%V3 index "Interface<%V1>||Name %V2 Index%V1||physicalCapacity<%V3>type<%V4>usdIfType<%V5>ifAlias<%V6>||";
2. Browsing a table that requires multiple indexes.The following example is from the CISCO_MPLS_LSP formula. The tablerequires four index numbers. The formula is as follows:Dim I1 AS Integer Default * Name TunIndex;
Dim I2 AS Integer Default * Name TunInstance;
Dim I3 AS Integer Default * Name LsrInID;
Dim I4 AS Integer Default * Name LsrOutID;
V1=OIDVAL(sysName.0,once);
V2=OIDVAL(sysLocation.0,once);
V3=OIDVAL(mplsTunnelName.%I1.%I2.%I3.%I4);
V4=OIDVAL(mplsTunnelDescr.%I1.%I2.%I3.%I4);
V5=OIDVAL(mplsTunnelIfIndex.%I1.%I2.%I3.%I4);
%V3 index"TunIndex<%I1>TunInstance<%I2>LsrInID<%I3>LsrOutID<%I4>||CiscoLSP:%V3||hostName<%V1>location<%V2>name<%V3>description<%V4>siteID<IP:%H1ifIndex:%V5>||";
3. Generate default values for OIDs that do not respond (property detection).This scenario explains the use of a formula to discover interfaces with varyingspeeds (64, 32, or 0) for both inbound and outbound traffic. There are ninepossibilities, so nine result lines describe each combination.ExampleDim I1 AS Integer Default * NAME If;
50 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

V1 = OIDVAL (ifIndex.%I1);
V2 = OIDVAL (filter (ifHCInOctets.%I1 >0));
V3 = OIDVAL (filter (ifInOctets.%I1 >0));
V5 = OIDVAL (filter (ifHCOutOctets.%I1 > 0));
V6 = OIDVAL (filter (ifOutOctets.%I1 > 0));
%V2+%V5 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out64>||";
%V2+%V6 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out32>||";
%V3+%V5 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out64>||";
%V3+%V6 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out32>||";
%V2 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out0>||";
%V3 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out0>||";
%V5 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out64>||";
%V6 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out32>||";
%V1 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out0>||";
The following is a rewrite of the formula using the AddForMissing() function:Dim I1 AS Integer Default * NAME If;
V1 = OIDVAL (ifIndex.%I1);
V2 = OIDVAL (distrib (ifHCInOctets.%I1, ">0:64"));-> support Inbound 64;
V3 = OIDVAL (distrib (ifInOctets.%I1, ">0:32"));-> support Inbound 32;
V4 = OIDVAL (AddForMissing (AddForMissing(%V2, V3), V1, 0));-> Inbound speed;
V5 = OIDVAL (distrib (ifHCOutOctets.%I1, ">0:64"));-> support Outbound 64;
V6 = OIDVAL (distrib (ifOutOctets.%I1, ">0:32"));-> support Outbound 32;
V7 = OIDVAL (AddForMissing (AddForMissing(%V5, V6), V1, 0));-> Outbound speed;
%V1 index"If<%I1>||-UNSPECIFIED_LABEL||Octets<in%V4.out%V7>||";
MergingThe formula language stores OID values in variables.
There are two possible results returned from an OID query:v Response received -- A response has been provided for a given interface index
and a property has to be filled with the value.v No response received -- No response has been provided for a given interface
index and a property has to be filled with a default value.
If each OID query required two result lines, this would consume a lot of space. Aformula body size is limited to 4000 characters; this is based on a database storage
Chapter 4. Writing Discovery Formulas 51

setting. If 2 n required result lines takes more than 4000 bytes, the formula cannotbe saved. Even under the limit of 4000 bytes, a formula with many lines is difficultto read and debug.
The solution is to break a large formula into several smaller formulas. The main, ortop-level, formula discovers the subelement and some basic properties, and a seriesof expansion formulas defines and populates additional properties. There is nolimit to the number of expansion formulas allowed. The goal is to create a uniquesubelement as a result of the execution of several discovery formulas.
This method simplifies formula writing by allowing you to split the formula bytechnology, such as an IF using RFC1213, an IF using RFC2233, and so on -- allcontributing to create a complete IF subelement. Several discovery formulas runsequentially and the result is a merged subelement with all its required properties.
ApplicationTo accomplish this property merge configuration, a common key is required.
The key is a pair: Element Name and Sub-element instance field (which is theunique key in the database). If the execution of a discovery formula produces asubelement for which the key already exists, all the fields of that subelement willbe merged with the existing ones. Additionally, logic needs to be put in to placefor values that already exist as a result of a previous execution of the discoveryformula, and for which a new value is provided by the latest discovery.
The merge is applied on all three fields: Sub-Element Label, Properties, andInvariant. Properties will be treated one by one, and keyed by name.
The following terms are used in the merge rules:v Base formula -- The first discovery formula that defines or creates a subelement
and some base propertiesv Expansion formula -- All other formulas that enrich an already existing
subelement
Merge RulesThe following rules are used when merging subelements:1. When a formula defines a value for a Sub-Element Label, Property, and
Invariant that is not defined, the value is immediately assigned to theSub-Element Label, Property, and Invariant of that subelement.
2. When a formula defines a value for a Sub-Element Label, Property, andInvariant that is already defined, the merge process is used.At the beginning of the three fields, a tag or special character indicates mergingpreferences. The tag is removed for file output.The absence of a tag results in default merging behavior; this assumes the +behavior. A Sub-Element Label, Property, and Invariant cannot start with aspecial character (*, +, or -).There are three special characters:
* The value always overwrites the previouscontent.
+ The value overwrites the previous contentonly if the previous content was missing orempty.
52 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

- The value overwrites the previous contentonly if the previous content was missing.
The following table summarizes the effect of the special characters:
* Current
+ Current (Thisrepresents thedefault behavior ifthe special characteris missing.) - Current
Previous content ismissing
Current Current Current
Previous content isempty
Current Current Previous
Previous content isdefined ( "Defined"means it exists andthe content is notempty.)
Current Previous Previous
1.2.
3. The inventory_subelements.txt filev All expansion formulas should use the same family name as their base
formula. This is not a requirement for the feature, but it helps inunderstanding the inventory_subelements.txt file.
v If a match formula is used for a base formula, all the associated expansionformulas should use the same matching rules.
v No expansion formulas should define the family to cancel -- only the baseformula should do that. This is not a requirement, but it improves readabilityof the inventory_subelements.txt file.
4. The Sub-Element Label fieldThe general rule is that no expansion formula should rewrite the originalSub-Element Label name provided by the base formula. However, theexpansion formula needs to define the Sub-Element Label field (the second one)because it's mandatory in the formula language syntax. Therefore, theSub-Element Label field should contain a word prefixed by "-" to indicate that arewrite is not selected. IBM suggests that you use "-UNSPECIFIED_LABEL" soif there is a problem and the creation of a subelement uses the expansionformula label, it will be easy to spot.
Example 1The Merge example.V1=OIDVAL(indexAsValue (I1, firstN(1, filter (not(ifPhysAddress.%I1like "") &&
not(ifPhysAddress.%I1 like "6.0.0.0.0.0.0")))));
V2=OIDVAL (concat(V1,ifPhysAddress.%V1 format clean));
V9=OIDINST (dot3StatsIndex.%I1);
V8=OIDVAL (concat(V9,firstN(1, ifPhysAddress.%V9 format clean)));
V3=OIDVAL (sysName.0);
V4=OIDVAL (sysDescr.0);
V5=OIDVAL (ifNumber.0);
Chapter 4. Writing Discovery Formulas 53

%V2 index"NULL||%HOSTNAME||ipAddress<%HOSTIP>rCommunity<%USEDRCOMMUNITY>sysName<\"%V3\"
>sysDescr<\"%
V4\">ifNumber<%V5>physAddress<%V2>||\"%V3\"/%V5/%V2";
%V8 index"NULL||%HOSTNAME||ipAddress<%HOSTIP>rCommunity<%USEDRCOMMUNITY>sysName<\"%V3\"
>sysDescr<\"%
V4\">ifNumber<%V5>physAddress<%V8>||\"%V3\"/%V5/%V8";
The two result lines will be merged to create only one answer. If the first linefound a valid ifPhysAddress in the ifTable , the result will use %V2 . If that fails, thecall returns the answer found through the dot3StatsTable (which is stored in V8 ).
Example 2This example shows how to use the expansion formulas seen in theinventory_subelements.txt file.
The following examples implement:v Octet capability detection: inbound and outbound; 64, 32, or undefinedv Packets capability detection: 64, 32, or undefinedv Custom invariant, either from MIB II ifDescr or RFC2233 ifName
v Customer-specific key, and properties
inventory_subelements.txt#{FAMILY} |{Elem. FAMILY}|{sysObjId Mask} |{Match Formula}|{I}|{Discovery Formula} |{I}|{cancel FAMILY};[{...};]|1213_Device |Generic~Agent |1.3.6.1 |NULL|<*>|AP~1213_Device |<*>| |1213_IF |Generic~Agent |1.3.6.1 |NULL|<*>|AP~1213_IF |<*>| |2233_IF |Generic~Agent |1.3.6.1|AP~2233_IF_match|<*>|AP~2233_IF |<*>|1213_IF;|2233_IF(Exp) |Generic~Agent |1.3.6.1|AP~2233_IF_match|<*>|AP~2233_HCOctets_Support |<*>||2233_IF(Exp) |Generic~Agent |1.3.6.1|AP~2233_IF_match|<*>|AP~2233_HCPackets_Support|<*>||1213_IF(Exp) |Generic~Agent |1.3.6.1 |NULL|<*>|AP~1213_IF_Invariant |<*>||2233_IF(Exp) |Generic~Agent |1.3.6.1|AP~2233_IF_match|<*>|AP~2233_IF_Invariant |<*>||1213_IF(Exp) |Generic~Agent |1.3.6.1 |NULL|<*>|Custom~CUSTOMER_KEY |<*>||
1213_IF Discovery FormulaDim I1 AS Integer Default * NAME If;V1 = OIDVAL(ifType.%I1 format clean, once);V2 = OIDVAL(sysLocation.0, once);V3 = OIDVAL(ifSpeed.%I1, once);V4 = OIDVAL(int(%V3/1000000), once);V5 = OIDVAL(ifAdminStatus.%I1 format clean, once);V6 = OIDVAL(ifDescr.%I1, once);
%V1 index "If<%I1>||IF %I1(%V4Mbps)||type<%V1>location<%V2>physicalCapacity<%V3>status<%V5>||";
2233_IF Discovery FormulaDim I1 AS Integer Default * NAME If;V1 = OIDVAL(ifType.%I1 format clean, once);V2 = OIDVAL(sysLocation.0, once);V3 = OIDVAL(ifSpeed.%I1, once);
54 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

V4 = OIDVAL(int(%V3/1000000), once);V5 = OIDVAL(ifName.%I1 format clean, once);V6 = OIDVAL(ifAdminStatus.%I1 format clean, once);V7 = OIDVAL(ifAlias.%I1 format clean, once);V8 = OIDVAL(ifDescr.%I1, once);
%V1 index "If<%I1>||IF: %I1 (%V5)(%V4Mbps)||type<%V1>location<%V2>physicalCapacity<%V3>name<%V5>status<%V6>||";
2233_HCOctets_Support Discovery formulaDim I1 AS Integer Default * NAME If; V1 = OIDVAL(ifIndex.%I1);V2 = OIDVAL(filter(ifHCInOctets.%I1 >0));V3 = OIDVAL(filter(ifInOctets.%I1 >0));V5 = OIDVAL(filter(ifHCOutOctets.%I1 > 0));V6 = OIDVAL(filter(ifOutOctets.%I1 > 0));%V2+%V5 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out64>||";%V2+%V6 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out32>||";%V3+%V5 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out64>||";%V3+%V6 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out32>||";%V2 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in64.out0>||";%V3 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in32.out0>||";%V5 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out64>||";%V6 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out32>||";%V1 index "If<%I1>||-UNSPECIFIED_LABEL||Octets<in0.out0>||";
2233_HCPackets_Support Discovery FormulaDim I1 AS Integer Default * NAME If;V1 = OIDVAL (ifSpeed.%I1);V2 = OIDVAL (filter ((ifHCInUcastPkts.%I1 + ifHCInMulticastPkts.%I1+ ifHCInBroadcastPkts.%I1) > 0) );V3 = OIDVAL (filter ((ifInUcastPkts.%I1+ ifOutUcastPkts.%I1 +ifInNUcastPkts.%I1 + ifOutNUcastPkts.%I1) > 0));%V2 index "If<%I1>||-UNSPECIFIED_LABEL||Packets<64>||";%V3 index "If<%I1>||-UNSPECIFIED_LABEL||Packets<32>||";%V1 index "If<%I1>||-UNSPECIFIED_LABEL||Packets<no>||";
1213_IF_Invariant Discovery Formula# provide ifDescr and ifType as default invariant;Dim I1 AS Integer Default * NAME If;V1 = OIDVAL(ifType.%I1 format clean, once);V2 = OIDVAL(ifDescr.%I1, once);%V1 index "If<%I1>||-UNSPECIFIED_LABEL||||%V1-%V2";
2233_IF_Invariant Discovery formula# provide invariant based on ifName when non empty;Dim I1 AS Integer Default * NAME If;V1 = OIDVAL (filter (not (ifName.%I1 like "")), once);V2 = OIDVAL (ifName.%I1, once);%V1 index "If<%I1>||-UNSPECIFIED_LABEL||||*%V2";
CUSTOMER_KEY Discovery FormulaDim I1 AS IPAddress Default * NAME I1;V01=OIDVAL (ipAdEntAddr.%I1);V02=OIDVAL (ipAdEntIfIndex.%I1);V09=OIDVAL (expand(V02, ifDescr.%V02));%V09 index"If<%V02>||-UNSPECIFIED_LABEL||CustomerKEY<%V09>HPKEY<%V09>IP@<%V01>||";
Example 3This formula is included as an example of how to create an Inventory formula thatincludes an invariant field.
Chapter 4. Writing Discovery Formulas 55

The formula is an expansion formula; it relies on the IETF_IF formula to discoverthe basic attributes of the subelement and adds only the attributes specific to aRiverstone interface subelement.Line 1 Dim I1 AS Integer Default * NAME I1;Line 2 V9 = OIDINST(ifAdminStatus.%I1 == 1);Line 3V1 = OIDINST(ifConnectorPresent.%V9 like "true" formatclean);Line 4 V2 = OIDVAL(ifName.%V1);Line 5 %V2 index"If<%V1>||-UNSPECIFIED||Invariant<Riverstone_PhysIF>||%V2";
In this code:v Line 2 repeats the filter on ifAdminStatus that is used in IETF_IF . This ensures
that Riverstone_IF does not create subelements for interfaces that IETF_IF filteredout. Any such subelements would be created without all the attributes set byIETF_IF and would not work properly. If you change the filter in IETF_IF , thisfilter must be changed to match it.
v In line 3, the invariant on Riverstone interfaces applies only to physicalinterfaces, so this line applies another filter to eliminate all logical interfaces.
v In line 5, the Instance attribute (If<%V1>) must be set to exactly the same valueas the Instance set by IETF_IF . The Label attribute (-UNSPECIFIED) is set byIETF_IF and should not be overwritten by this formula. The leading "-" indicatesthat the value given here should be used only if the attribute has not been set byanother formula. The value "UNSPECIFIED" is intended to make it obvious thatthe attribute has been set from an unexpected source. If a subelement everappears in the database with the Label attribute set to this value, something hasgone wrong. If you want to have a more specific Label set for all Riverstonephysical interfaces, you can put a different value in this field. In this case, besure to put "*" as the first character to indicate that this value should overwriteany previous value (the "*" will be removed by the subelement merge code).
Understanding the inventory_subelements.txt fileThe inventory_subelements.txt file contains the list of rules used by the discovery.
The file is located in PVM/conf directory.
When you create new discovery formulas, you must edit this file to create newrules. You must edit the file before the new discovery formula can be used by theinventory tool, but you do not need to edit this file before a new collection formulacan be used.
Each row (one per family) of the file is executed for every IP address that respondsduring discovery. To prevent conflicting definitions for any one subelement (fromtwo or more different rows), any row can be set to override one or more otherrows.
Excerpt and Explanation of inventory_subelements.txt#{FAMILY}|{Elem. FAMILY}|{sysObjId Mask}|{Match Formula}|{I}|
{Discovery Formula}|{I}|{cancel FAMILY};[{...};]|1213_Device|Generic~Agent|1.3.6.1|NULL|<*>|AP~1213_Device|<*>| |1213_Device|Generic~Agent|1.3.6.1.4.1.9|NULL|<*>|AP~Cisco~Cisco_Device|<*>| |
The following table explains the file excerpt:
FAMILY The new subelement is assigned to thisfamily.
56 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Elem. FAMILYThe element family.
The element family is defined in the fileinventory_elements.txt .
The element family specified in theinventory_subelements.txt file must match oneof the element families defined in inventory_elements.txt .
sysObjId MaskThe sysObjectID.
The inventory tool checks to see if thesysObjectID of each element matches thesysObjectID specified here. If they match,the tool checks to see if there is an entry forthe match formula. If the element matchesboth entries, the inventory tool runs thespecified match formula.
Only a partial match for the sysObjectID isrequired. DataMart includes genericformulas that specify 1.3.6.1 as thesysObjectID -- which is not an exact matchfor anything, but it is a partial match foreverything. Because only a partial match forthe sysObjectID is required, these genericformulas can be used against every elementencountered by the inventory tool. Anyvendor-specific formula will contain a morespecific sysObjectID that will match onlythat vendor's sysObjectID.
Match FormulaThe path to the formula used to distinguishbetween different elements with the samesysObjectID. This formula is no longerrequired in most cases; the SNMP formulalanguage has been enhanced to handle thissituation from within a single formula. Use`NULL' for this field if a match formula isnot required.
The path is a location within the AliasInstance and Label Inventory directory, withtilde (~) as the path separator. The matchformula name cannot contain any spaces --use underscores instead.
Instance The instance specification used by the matchformula. If a match formula is not required,enter the value ` <*> ' for this field.
Chapter 4. Writing Discovery Formulas 57
Discovery FormulaThe path to the formula used to define asubelement's name, label, and properties. Itmust retrieve all inputs on a particularinstance for a subelement to be generated. Inother words, if any part of the discoveryformula fails, the subelement will not begenerated.
The path is a location within the AliasInstance and Label Inventory directory, withtilde (~) as the path separator. The discoveryformula name cannot contain any spaces --use underscores instead.
NOTE: Although the discovery formulamust succeed for a row to "pass" andgenerate a subelement definition, FAMILYcancellations will execute regardless ofdiscovery formula success. Use a matchformula to prevent unwanted cancellationsfrom occurring.
cancel FAMILYEnsures that only a single row passes forcertain subelement types. This field containsa semicolon-separated list of family names.If instances exist that have a family name inthe cancel list, those instances are cancelledor removed, leaving only the instancescreated by this row.
NOTE: This list must end with a semicolon,even if it contains only a single entry.
If you leave this field blank, the samesubelement can appear under two differentgroups -- the vendor-specific group and ageneric group.
For example:
1315_FR_DLC_SNMP-CIR|Generic~Agent|1.3.6.1|AP~1315_FR_DLC_Match|<*>|AP~1315_FR_DLC_SNMP-CIR |<*>| |
1315_FR_DLC_noSNMP-CIR|Generic~Agent|1.3.6.1|AP~1315_FR_DLC_Match|<*>|AP~1315_FR_DLC_noSNMP-CIR|<*>| |
Cisco_FR_DLC_SNMP-CIR|Generic~Agent|1.3.6.1|AP~Cisco_FR_DLC_Match|<*>|AP~Cisco_FR_DLC_SNMP-CIR|<*>|1315_FR_DLC_SNMP-CIR;|
The instances discovered byAP~1315_FR_DLC_SNMP-CIR will bediscarded. The instances discovered byAP~Cisco_FR_DLC_SNMP-CIR will beadded.
58 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Match FormulasA match formula looks and behaves like a collection formula, but is used as anadjunct to a discovery formula.
Unlike a collection formula, the value returned by a match formula is irrelevant:the only important thing is whether the formula returns a value.
You use a match formula to avoid running an expensive discovery formula whenthere is no chance that it will return anything. A match formula could be used to:v Distinguish between devices that are similar but different. For example, the
sysObjId Mask "1.3.6.1.4.1.9" will match Cisco Catalyst devices as well as Ciscorouters. If you have a discovery formula for resources that occur only oncatalysts, running that formula against every Cisco router would be a waste oftime. A match formula should be used to quickly answer the question "Is this acatalyst?".
v Find out whether a particular feature is enabled on a device. For example, manytypes of router can be configured to run Ping (latency) tests, but in any givennetwork only a few routers are likely to be configured this way. A matchformula is the most efficient way to find those few.
Example: RADIUS_Acc_Server_Match FormulaConsider the RADIUS_Acc_Server_Match formula:radiusAccServTotalRequests.0
In this formula, it does not matter how many total requests there are -- even avalue of zero means true . If the MIB object is supported at all, the device isrunning a Radius Accounting server.
SNMP Get and GetNext OptimizationSNMP GetNext is used when a table browse is required.
This is always true when the input variable for a MIB object is set to all available(*). GetNext is a rather inefficient method of retrieving information. A packet issent and returned across the network for each line of a table. If several objectsfrom the same table are used in the same line of the formula, they are submitted inthe same GetNext request. If the table is large or the network is slow, it will take along time to do a full browse of the table.
SNMP GetBulk is a lot more efficient but returns the entire table column. It mightbe inefficient to grab the entire column when only a few lines are usable.
SNMP Get is used when the instance value of an object is known in advance --such as when a table has already been scanned and all instance values have beenstored in a temporary variable (using OIDINST). The temporary variable can thenbe used to drive the rest of the discovery formula. In this case, a collector knowsthe list of instances to query and builds efficient multi-varbind PDUs. It is possibleto put 20 OIDs in a single Get request, in which case getting responses from atable of 100 rows requires only five request/response message pairs (compared to100 request/response pairs using GetNext ).
However, there are situations in which GetNext can be more efficient. It is fairlyunusual, but some SNMP agents implement the IF-MIB with a lot of "holes" forifTable/ifXTable when specific interfaces do not support specific counters. In this
Chapter 4. Writing Discovery Formulas 59

case, many of the multi-varbind Get s will generate errors: the collector then has torecover from the error by removing OIDs from the request and retrying. This isvery inefficient.
ExampleThis example uses GetNext to browse the entire ifTable/ifXTable twice.
Only in the return line does it filter the result set down to just the interfaces thatare "up".V001 = OIDINST(ifAdminStatus.%I1 == 1);V002 = OIDVAL(ifHCOutUcastPkts.%I1 + ifHCOutMulticastPkts.%I1 +ifHCOutBroadcastPkts.%I1);
%V001 index .... %V002 ......
This example uses GetNext to establish which interfaces are "up", and stores thatlist of instances in V001 . The example then uses the filtered instance list in V001 tosupply index values for the rest of the formula. This version is far more efficientthan the first version -- until it encounters a table with a lot of holes.V001 = OIDINST(ifAdminStatus.%I1 == 1);V002 = OIDVAL(ifHCOutUcastPkts.%V001 + ifHCOutMulticastPkts.%V001 +ifHCOutBroadcastPkts.%V001);...%V001 index .... %V002 ...
60 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 5. Writing Collection Formulas
This chapter describes how to write collection formulas.
A collection formula is designed to be applied against a subelement to produce aresult (almost always a number, but occasionally a string) that will be saved to thedatabase. Because collection formulas are executed on a regular basis (pollingperiod) and applied on a larger scale than inventory formulas, they must be assimple as possible. The first concern for a collection formula is efficiency , beforereadability or cosmetics.
Collection Formula Structure
A collection formula has the following structure:v Dim Sectionv Def Sectionv OID Gathering Sectionv Result Line Section
Dim SectionThe Dim section declares types and default values for input values of the formula.
You must declare the type of the input value if it is anything other than Integer.
Def SectionThe Def directives go at the top of the formula, immediately after the Dimstatements.
The Def directives include:v Def DefaultNoRespResultv Def DefaultResultv Def SaveAliasv Def UseQuotedStrings
Def DefaultNoRespResultSpecifies a number to be returned by a formula.
This is useful if no SNMP data (at all) can be retrieved from the agent.
The syntax is as follows:Def DefaultNoRespResult {number};
If partial data is retrieved or a mathematical error occurs, the value specified byDefaultNoRespResult will not be used -- the DefaultResult value will be usedinstead.
© Copyright IBM Corp. 2011, 2012 61

Def DefaultResultSpecifies the number returned by a formula.
The syntax is as follows:Def DefaultResult {number};
This directive is useful if either no SNMP data was available or a mathematicalerror occurred. For example, if a formula is to return "dropped packets" as apercentage of "total packets", it will fail and return no result if there is no traffic.That will cause a gap in the report graphs and make it look as if the formula is notworking (or the SNMP agent is not responding). The DefaultResult directive can beused to make the formula return zero in such cases.
Def SaveAliasSpecifies an alternate ID for storage.
The syntax is as follows:Def SaveAlias {FormulaID};
Every metric (data value) stored in the database is identified by the three IDs -- theID of the formula that produced the metric, the ID of the subelement the metric isattached to, and a timestamp. The SaveAlias declaration enables you to change theformula ID used on metrics produced by the formula. The FormulaID given in theSaveAlias declaration is the ID of a generic formula. There are two rules governingwhat you can use:1. The generic formula must exist in the formula table.2. The generic formula must be the same data type as the specific formula ( float
or string ).
Although there is nothing in Tivoli Netcool Performance Manager to enforce theserules, failure to follow them will result in unexpected or no results, or an errormessage.
Generic formulas are used to insert a level of indirection into the formulalanguage, which enables you to use different collection formulas in differentcircumstances, depending on the capabilities of the resource.
ExampleCisco CPU Utilization % Formula defined using the Cisco privateMIB
Juniper CPU Utilization % Formula defined using the Juniperprivate MIB
Id 100 CPU Utilization % Generic formulaId 201 Cisco CPU Utilization % SaveAlias = 100Id 301 Juniper CPU Utilization % SaveAlias = 100
Metrics produced by both specific formulas are stored with the ID (100) of thegeneric formula called CPU Utilization % .
Although this example seems plausible in theory, it turns out to be completelyunworkable in practice. CPU utilization on one network device is presented as asingle number, on another each card in the device has its own CPU utilization, ona third three different utilizations are available (averaged over 1, 5, and 15minutes), and so on. Even if two devices measure CPU utilization in the same way,
62 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

they have nothing else in common, so there are separate reporter sets for the two.It almost never makes sense to "alias" any formula that uses objects from a device'sprivate MIB.
Def UseQuotedStringsUsed primarily for discovery formulas, the UseQuotedStrings directive sets thedefault behavior of the collector for displaying strings.
If UseQuotedStrings is set to yes ( True ), which is the default value, all strings aredisplayed within a pair of double quotes. Otherwise, strings are not delimited bydouble quotes.
The syntax is as follows:Def UseQuotedStrings {yes|no};
It is often necessary to include this directive to prevent property values being setas quoted strings. If quotes are allowed to become part of the property value, theproperty generally becomes more difficult to display and work with.
Alternatively, you can explicitly include literal quotes by escaping them with abackslash character, as in:juniAddressPoolName<\"%V1\">
ExampleERX VR element discovery formula to handle the VR community string:
Dim I1 as Integer default *;
Def UseQuotedStrings no;
V1=OIDINST(usdRouterRowStatus.%I1 > 0);
V2=OIDVAL(usdRouterName.%V1);
V3=OIDVAL(sysName.0);
V4=OIDVAL(sysDescr.0);
%V2 index"NULL||%HOSTNAME||ipAddress<%HOSTIP>IP.name<%HOSTNAME_%V2>rCommunity<%USEDRCOMMUNITY@%V2>sysDescr<%V4>physAddress<%HOSTNAME:%V2>sysName<%V3:%V2>||%V3/%V2";
OID Gathering SectionA collection formula can contain several lines with temporary variables like adiscovery formula, but these lines make the formula perform slowly and should beavoided.
An efficient collection formula is a formula that has only one result line. Collectionformulas should be lite formulas, not complex formulas.
Here is a sample lite formula:Dim I1 As Integer Default * Name Interface;Delta (ifInOctets.%I1)/delta (sysUpTime.0)/100)
Here is a sample complex formula:V1=OIDVAL(ifInOctets.%I1);%V1 index ...
Chapter 5. Writing Collection Formulas 63

Result Line SectionA result line defines the format of the information that will be sent back to thecalling application.
Execution of a result line in a formula results in the creation in memory of one ormore value lines. Each line contains the name of the device that was queried, aresult value (number or string), and an instance number for the result (0 if theresult is not indexed, or a number corresponding to values of dimensions of thatresult).
A collection formula is expected to return only one result line for a subelement. Iftwo result lines are produced, they will be discarded by the CME as duplicates.
Because only one result is produced, the instance number is not really used for acollection formula. The instance is already defined in the subelement instance fieldand does not need to be repeated. Therefore, the instance field of a collectionformula is ignored, making the INDEX keyword useless.
Example
Here is a sample result line for a lite formula:DEF SaveAlias 2212;Dim I1 AS Integer Default * NAME Interface;8 * delta(ifInOctets.%I1) * distrib(delta(sysUpTime.0),"default:1") * distrib(delta(ifLastChange.%I1), "==0:1")
Lite FormulasRules for Lite formulas.
Lite formulas have the following rules:1. There should be only one calculation line.2. There should be no intermediate variables (V x ).3. A target must define all instance values before execution -- there cannot be any
input variables with a default value of "*".4. All OID type formulas are considered to be lite formulas.5. Each formula is analyzed the first time it is used. If the formula is found to be
complex, a performance warning is issued in the pvmd.log file.6. Lite formulas are marked as ServiceFormLite in the Scheduler.
Example 1
Consider the following formula:V1=oidval(xxxxx.%I1);%V1
To improve performance, replace it with:xxxxx.%I1;
Example 2
Consider the following formula:V1=oidval (OID1.%I1);V2=oidval (OID2.%I1);
64 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

%V1 + %V2
To improve performance, replace it with:OID1.%I1 + OID2.%I2
Example 3
Even if an OID is listed several times in the same expression, this OID is polledonly once.
Consider the following formula:V1=oidval(xxxxx.%I1);Delta (OID1.%I1/%V1) + delta (OID2.%I1/%V1)
To improve performance, replace it with:Delta (OID1.%I1/xxxxx.%I1) + delta (OID2.%I1/xxxxx.%I1)
Example 4
Even if the expression is very complicated, with a lot of OIDs and calls to distrib() ,it is always more efficient to use a single line and avoid the use of temporaryvariables.
For example:Def DefaultNoRespResult 0;
100*(abs((((1+(distrib(ifOperStatus.%I1,"==1:1,==2:-1,==3:-1")))/2)*(delta(sysUpTime.0)))-((delta(sysUpTime.0)-(sysUpTime.0-(ifLastChange.%I1)))*(abs (delta(distrib(ifOperStatus.%I1,"==1:1,==2:-1,==3:-1")))/2))))/delta(sysUpTime.0)
Example 5
Sometimes it is more powerful to make a formula without a filter.
Consider the following formula:V1=oidinst (ifOperStatus.%I1 == ’up’);IfOutOctets.%V1/sysUpTime.0;
To improve performance, replace it with:(IfOutOctets.%I1/sysUpTime.0) * distrib (ifOperStatus.%I1 == ’up’,"==1:1")
The number of OIDs does not matter, but the number of PDUs does.
The SchedulerUsing statGet (found in the dataload/bin directory) or the Collector InformationGUI, you can view all the requests inside the Scheduler.
If formulas are marked as ServiceForm , you can probably improve the performanceby changing the formula syntax.
Chapter 5. Writing Collection Formulas 65

CME FormulasCME formulas are written in the Smalltalk coding language.
An explanation of the Smalltalk language is beyond the scope of this guide.
The examples that follow show simple and complex CME formulas, and provide aquick introduction to the Smalltalk language.
Simple Example
GenericID Name Smalltalk Code
2208 InboundThroughput (bps)HC
| result newTimeStamp deltaTime |
timeStamp = nil
ifTrue: [timeStamp := inOctets date + timeOffset]
ifFalse: [newTimeStamp := inOctets date + timeOffset.
deltaTime := newTimeStamp - timeStamp.
timeStamp := newTimeStamp.
deltaTime = 0
ifFalse: [result := inOctets * 8/deltaTime]].
self setOutputMetricRecordDate: timeStamp.
^result
Complex Example
The statements that begin `self system logInfo:' are for debugging: they cause textmessages to be output to the DataChannel log file ( datachannel_home /log/proviso.log). This example is complex because the second component of the response input isa timestamp coded into an octet string. Tivoli Netcool Performance Managercannot handle octet strings, so by the time it reaches the CME, this part ofresponse is a period-delimited text string, where each string component representsa single octet, coded as a decimal number.
66 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

GenericID Name Smalltalk Code
2408 Ping ResponseTime (msec)
"response comes from SNMP formula Ping Response Time.lastTime is a variable.testInterval is set to property testActivationFrequency(which is really pingCtlFrequency)."| substrings timestamp timeFields yr mon day hr min sec |self system logInfo: #GRAEMEA text: (’input formula value
is ’, response asString).substrings := response value findToken: $_.(substrings size ~= 2)
ifTrue: [^self error: ’response is not twounderscore-delimited strings’].
timeFields := (substrings at: 2) tokensBasedOn: $. .((timeFields size = 9) and: [(timeFields at: 1)
asNumber = 8])ifFalse: [^self error: ’bad timestamp format’].
yr := (timeFields at: 2) asNumber * 256 + (timeFields at: 3)asNumber.mon := (timeFields at: 4) asNumber.day := (timeFields at: 5) asNumber.hr := (timeFields at: 6) asNumber.min := (timeFields at: 7) asNumber.sec := (timeFields at: 8) asNumber."Ignore the deciseconds value in octet 8 (timeField 9)"timestamp := PvTimestamp
fromDate: (Date newDay: day monthNumber: monyear: yr)
andTime: (Time new hours: hr minutes: minseconds: sec).
"Check & return nil if timestamp is old. There must betestInterval between tests."lastTime = nil
ifTrue: [lastTime := timestamp].self system logInfo: #GRAEMEB text: (’lastTime starts at ’,lastTime asString, ’ timestamp is ’, timestamp asString).(timestamp asSeconds) < ((lastTime asSeconds) + (testIntervalvalue asNumber))
ifTrue: [^nil].self system logInfo: #GRAEMED text: (’returning value ’,((substrings at: 1) copyWithoutAll: ’"’)).lastTime := timestamp.^((substrings at: 1) copyWithoutAll: ’"’) asNumber
Formula SynchronizationThere may be occasions when you need to ensure that formulas execute in aparticular sequence.
For example:v When formulas use a persistent variable - the formula that assigns a value to the
variable must execute before the formula that reads the variable.v When formulas either read or reset values in a MIB table - the read formula
must execute before the reset formula executes.
Synchronization is achieved using a semaphore scheme, managed with thekeywords Wait and Signal :v Wait -- A formula containing this keyword will not execute until a
pre-configured number of formulas containing the Signal keyword execute.
Chapter 5. Writing Collection Formulas 67

v Signal -- When a formula containing this keyword is executed, the number ofsignals issued is incremented by one. When the number of signals issued reachesa pre-configured quota, the semaphore is raised, and the formula containing theWait keyword executes.
After the formula containing the Wait keyword executes, the semaphore quota isreset to 0.
The Signal and Wait keywords should appear near the beginning of the formula.
The synchronization scheme does not determine the execution order of theformulas containing Signal keywords, nor is there any way to predict the executionorder of those formulas. The synchronization scheme only guarantees that aformula containing the Wait keyword will be blocked until the pre-configurednumber of formulas containing the Signal keyword finish executing.
SyntaxSyntax for a synchronized formula.
A synchronized formula must contain one of the following lines:SignalsemaphoreNamescopescopeValue;
WaitsemaphoreNamescopescopeValue;
Where:v semaphoreName is any user-defined name for the semaphore. The name can
include only letters and digits. It must start with a capital letter and must notstart with a digit.
v
All formulas that participate in a particular synchronization scheme must usethe same semaphore name, names are case sensitive.
v scopeValue defines the scope within which formulas that reference the samesemaphore name are synchronized. Valid values (case insensitive):– global . All formulas associated with the collector that use the same
semaphore name are synchronized.– element . All formulas associated with a given element that use the same
semaphore name are synchronized.– subelement . All formulas associated with a given sub-element that use the
same semaphore name are synchronized.
Examples (based on the MIB CISCO-RTTMON-MIB ):Wait IPSLA scope subelement;Signal IPSLA scope subelement;
68 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Understanding ScopeSynchronization scope plays an important role in the performance of the TivoliNetcool Performance Manager collector, it determines not only the order in whichformulas are executed, but the length of time between formula execution.
The narrowest scope that is appropriate should be used. For example, if you aresynchronizing formulas that use a persistent variable, and the variable only needsto be shared among formulas associated with a particular sub-element, usesubelement scope, not element or global scope.
IllustrationsSynchronization scope illustrations.
Figure 2 below illustrates unsynchronized formulas, and Figures 3 through 5illustrate synchronized formulas within different scopes. Each figure is a simplifiedrepresentation of a collector that collects data from two elements, with eachelement having two sub-elements.
In Figure 2, four unsynchronized formulas (represented by blue arrows) arerunning independently of each other. One formula is deployed for each of the foursub-elements. The length of each arrow represents the running time of the formula.The start and end times of the formulas are arbitrary, and are for illustrationpurposes only.
Figure 3 shows the deployment of a second formula for each of the sub-elements.Each new formula (in brown) reads a persistent variable that is assigned a value inthe old formula (in blue).
To ensure that the assignment formulas finish executing before the read formulasbegin executing, the formulas must be synchronized. To achieve synchronization,the assignment formulas are updated with Signal keywords, and the read formulasare updated with Wait keywords, as follows:v Line added to assignment formulas (blue):
Signal Semaphore1 scope global;
v Line added to read formulas (brown):v Wait Semaphore1 scope global;
Figure 1. Unsynchronized Formulas Running Independently of Each Other
Chapter 5. Writing Collection Formulas 69

The synchronization scope is global. Therefore, throughout the entire collector ,none of the formulas containing Wait keywords can begin executing until allformulas containing Signal keywords have completed executing.
See Synchronized Formulas in Element Scope shows the use of element scopeinstead of global scope. With element scope, the assignment formulas (blue) andread formulas (brown) are synchronized within a given element, but not acrossdifferent elements.
The time intervals between the execution of the assignment and read formulas forthe first element are unchanged from the global scope illustration, but the intervalsare shorter for the second element.
See Synchronized Formulas in Subelement Scope shows the use of subelementscope instead of element scope. With subelement scope, the assignment formulas(blue) and read formulas (brown) are synchronized within a given sub-element, butnot across different sub-elements.
Figure 2. Synchronized Formulas in Global Scope
Figure 3. Synchronized Formulas in Element Scope
70 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Because there is no dependency between the formulas deployed for onesub-element and the formulas deployed for any other, the time interval betweenthe execution of the assignment formula and the read formula in the same scope isminimal.
Listing Semaphores
You can use the LockDump utility to list the semaphores in a running SNMPcollector. The LockDump utility takes one of the following arguments:v global -- Lists all semaphores in Global scope.v element -- Lists all semaphores in Element scope.v subelement -- Lists all semaphores in SubElement scope.v all -- Lists all semaphores in Global, Element, and SubElement scope.
For example, the following command lists all the semaphores used in a runningSNMP collector:$ ./contribs/dialogTest2 LockDump all
Example output:Dumping Locks.@@ Global Locks@@ Per Element Locks@@ Per SubElement Locks## SubElement ID 200035778
-- Lock ’IPSLA’ [Blocked] 0/2 Signaled by (ID1021, ID1043)## SubElement ID 200036278
-- Lock ’IPSLA’ [Blocked] 0/2 Signaled by (ID1024, ID1043)## SubElement ID 200036279
-- Lock ’IPSLA’ [Blocked] 0/2 Signaled by (ID1020, ID1043)
The semaphores (referenced as "Locks") are organized by the associatedsynchronization scope (Global, Element, or SubElement). In this example, there arethree instances of the semaphore IPSLA . There are no semaphores associated withGlobal or Element scope. Each of the three semaphore instances is currently in ablocked state (the associated reset formula is blocked from executing).
To display information about a signal issued to a semaphore, use the statGet utility(found in the dataload/bin directory) -- for example:
Figure 4. Synchronized Formulas in Subelement Scope
Chapter 5. Writing Collection Formulas 71

$ statGet | grep 1021
+ [19] ID 1021,{CAL none (peri=180)(next=2008/01/01 15:48:00)}(P2)ASLEEP:
ServiceForm ...Elmt=qarouter1.usma.ibm.com-6;Metric=ipsla_intervalBetween
Collections;Inst=RTTMon<NULL>Probe<2039>
Collection of Probe Results over Adjustable Time PeriodsThis section describes one possible solution for efficiently collecting aggregatedprobe results from MIB tables over an adjustable collection period.
The solution includes the following features of the Tivoli Netcool PerformanceManager Formula Language:v Persistent variablesv The function OidSet() (see See OidSet)v Formula synchronization
The solution is based on the results of probes generated by Cisco routers andstored in the MIB CISCO-RTTMON-MIB . Similar solutions can be developed fordifferent technologies.
About Collection IntervalsThe Cisco MIB that provides round-trip time monitoring (RTTMON) of IPSLAobjects includes tables that contain aggregations (such as count, max, min, andsum) of probe results accumulated over one hour.
These results are accumulated (aggregated) and stored in tables by the router. Afterone hour, the router resets the tables, and a new collection cycle begins.
The Tivoli Netcool Performance Manager Formula Language allows you to collectaggregated data from tables at a much finer granularity, ranging from everyminute to every 60 minutes, adjustable in one-minute gradations.
This adjustable time period is called a collection interval . The default collectioninterval varies between technology packs.
Unless otherwise specified, the collections and collection intervals described areperformed by the Tivoli Netcool Performance Manager SNMP collector. Provisocollects aggregated probe results from MIB tables. This should not be confusedwith the accumulation, aggregation, and storage of the probe results - theseoperations are performed within the router.
Required FormulasFormulas that enable you to collect probe results.
The following types of formulas enable you to collect probe results for auser-defined collection interval:v Collection formulas. These formulas retrieve a specific type of data -- for
example, maximum jitter or total round-trip time -- that the router hasaccumulated, aggregated, and stored.
v
72 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Typically, you will have multiple collection formulas for collecting the types ofdata you want to monitor.
v Reset formula. This formula clears the results tables where aggregated data for aparticular probe has been stored by the router.
v
A formula that resets a particular table is executed after all associated collectionformulas have finished gathering data for the current collection interval. After allthe data for the current interval has been collected, a new reset-and-collectioncycle can begin for the next collection interval.
Reset and collection formulas are associated by being in the same scope.
Required TasksA list of the tasks that must be performed by Formulas that collect or reset proberesults tables within a given collection interval.
Required Tasks for Collecting Probe Results Within an Adjustable CollectionInterval
Task Function or Keyword Description
Clear theresults tables
OidSet functionReset formulas perform this task after allassociated collection formulas have retrievedprobe results from the MIB tables for the currentcollection interval. This task prepares the tablesfor the collection interval that is about to begin.
Syntax:
OidSet(oid.instance, oidValue);
Example (based on the CISCO-RTTMON-MIB ):
OidSet(rttMonCtrlOperState.%I2, 7);
In the example, the MIB OIDrttMonCtrlOperState is set to a value of 7 (restart)for the probe indicated by the variable %I2 .
Chapter 5. Writing Collection Formulas 73

Task Function or Keyword Description
Synchronizethe formulas
Signal Wait keywordsA reset formula must not execute until all theassociated collection formulas have collectedprobe results for the current time interval.Synchronization between a reset formula and itsassociated collection formulas is achievedthrough the Signal and Wait keywords.
Each collection formula contains a Signalkeyword, and each reset formula contains a Waitkeyword. A reset formula "waits" (executioncannot begin) until each of its associatedcollection formulas has "signaled" (through theSignal keyword in each collection formula) that ithas completed its execution, and therefore, that ithas collected its data for the current interval.
When the expected number of signals has beenreceived (one for each collection formula),execution of the reset formulas can begin. Theexpected number of signals is pre-configured inthe technology pack.
Share thetimestamp forthe currentcollectioninterval amongformulas
Using keywordWhen a reset formula clears a MIB tableassociated with a probe in preparation for thenew collection interval, the formula captures atimestamp value (generated by the router duringthe reset) and assigns it to a variable.
This unique timestamp can be used with theprobe ID to construct a unique OID of an item ofaggregated data for the probe within theparticular collection interval.
Because the timestamp value is assigned to avariable by the reset formula, and the value isrequired by subsequent collection formulas thatcollect data in the new collection interval, thevariable must be persistent.
A variable is declared persistent through theUsing keyword.
Keyword names are not case-sensitive.
Scope and the Collection of Probe Results
To achieve accurate and efficient collection of probe results, two levels of scope areinvolved:v The scope of the synchronization of reset and collection formulasv The scope of the persistent variable that stores the reset timestamp
At either level, scope can be set to global , element , or subelement . .
The following sections describe the two levels of scope within the context of thecollection of probe results.
74 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Scope of Formula Synchronization
After a probe's data has been collected from a MIB table, data for that probe mustnot be collected from the table again until data from all probes within the given scopehas been collected from the tables, and the tables have been reset.
Depending on the length of time between the time a collection formula reads datafrom a table and the time the reset formula resets the table, some data that theprobe collects between the last reading and the reset may be missed.
For example, in See Synchronized Formulas in Global Scope four collectionformulas (blue arrows) for four probes are synchronized within global scope. Noticethe wide gap of time between the ending time of the formula that completes itsexecution first (indicated by Signal 1) and the time the reset formula for the sameprobe is allowed to start. The wider the time gap, the more likely that some datacollected by the probe will be missed.
In See Synchronized Formulas in Element Scope ( element scope) and SeeSynchronized Formulas in Subelement Scope ( subelement scope), the gap betweenthe collection and reset formulas for the same probe narrows as thesynchronization scope narrows.
To reduce the chance of missing data, select the narrowest synchronization scopethat is appropriate for your technology pack. For example, if probe data iscollected on a sub-element basis, use subelement scope.
Scope of Persistent Variables
When multiple collection formulas use a single timestamp value to construct OIDsfor probe results, the scope of the persistent variable that is assigned the timestampmust include:v All collection formulas that gather aggregated results for the probev The reset formula that assigned the timestamp value to the variable
Setting a Collection Interval
Technology packs that support adjustable collection intervals for network proberesults are shipped with a default collection interval. You can change the defaultcollection interval in the DataMart Request Editor, where you associate formulaswith sub-element groups.
You can define the collection interval for a selected formula in the Details area ofthe Collections tab. The current collection interval setting for a formula appears inthe Period= column of the table above the Details area.
All formulas that have a common Signal/Wait semaphore value must be set to thesame collection interval. Additionally, all formulas assigned to the samesub-element group must be set to the same collection interval.
The following illustration shows a group of collection formulas and the associatedreset formula, with each formula having the same collection interval of 3 minutes.
Chapter 5. Writing Collection Formulas 75

For instructions on using the Request Editor to associate formulas with groups andto modify the collection period for a formula, see the IBM Tivoli Netcool PerformanceManger: DataMart Configuration and Operation Guide .
Example
The following example contains seven sample formulas -- one reset formula(ipsla_reset) and six collection formulas -- that demonstrate the synchronizedcollection of IPSLA probe data. The formulas are based on the MIBCISCO-RTTMON-MIB.
Note the following features of these samples:v Only the reset formula uses the OidSet () function. This function clears the probe
results table of data from the previous collection interval.v Only the reset formula contains a Wait keyword, and only the collection
formulas contain Signal keywords. Execution of a formula with a Wait keywordwill not begin until the formulas with Signal keywords have been completed.This prevents the reset of the probe results table from occurring until after alldata has been collected for the current collection interval.
v The user-defined value IPSLA is referenced for the keywords Wait and Signal .This value identifies the set of formulas that operate together to collect proberesults and reset the results table.
v All the formulas operate within subelement scope. Subelement scope is thenarrowest and most efficient scope to use when synchronizing formulas.
v The reset formula assigns a timestamp value to the variable LastIpSlaUpdate .v The Using keyword appears in all formulas. This keyword allows the value of
the LastIpSlaUpdate variable to be shared among all the formulas.v The collection formulas use the value of %LastIpSlaUpdate as part of a unique
identifier of aggregated data for a particular probe and within a particularcollection interval -- for example:
rttMonStatsTotalsElapsedTime.%I2.%LastIpSlaUpdate
76 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

ipsla_resetWait IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I0 as Integer default * name LastWrite;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;OidSet( rttMonCtrlOperState.%I2, 7);LastIpSlaUpdate= Max(*, IndexAsValue( I0,rttMonStatsTotalsElapsedTime.%I2.%I0));Ensure( %LastIpSlaUpdate > 0 , 30 , 4 )
ipsla_totalElapsedSignal IPSLA Scope subelement;Using LastIpSlaUpdate Scope subelement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;rttMonStatsTotalsElapsedTime.%I2.%LastIpSlaUpdate
ipsla_totalsInitiationsSignal IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;rttMonStatsTotalsInitiations.%I2.%LastIpSlaUpdate
ipsla_JitterRttSumSignal IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;rttMonJitterStatsRTTSum.%I2.%LastIpSlaUpdate
ipsla_JitterRttMaxSignal IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;rttMonJitterStatsRTTMax.%I2.%LastIpSlaUpdate
ipsla_JitterRttNumSignal IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;rttMonJitterStatsNumOfRTT.%I2.%LastIpSlaUpdate
ipsla_CaptureCompletionsSignal IPSLA Scope subElement;Using LastIpSlaUpdate Scope subElement;Dim I1 as Integer default * name Unused;Dim I2 as Integer default * name ProbeIndex;
rttMonStatsCaptureCompletions.%I2.%LastIpSlaUpdate.1.1.1
Chapter 5. Writing Collection Formulas 77

Collection LibrariesThe collection library provides a set of interfaces.
The collection library provides the following interfaces:
Library: DEF UseLib RFC1213Interface;
Functions:deviceReachability(Percent)deviceRebootdeviceAvailabilityTime(Seconds)deviceUnknownAvailabilityTime(Seconds)deviceAvailability(Percent)deviceUnknownAvailability(Percent)ifAvailabilityTime(Seconds)ifUnavailabilityTime(Seconds)ifUnknownAvailabilityTime(Seconds)ifAvailability(Percent)ifUnavailability(Percent)ifUnknownAvailability(Percent)
Implementation:
There are two ways to implement the functions defined in the collection library:v Write a new formula that produces results under its own ID and requires a new
report to display the results.v Use a SaveAlias directive. This saves results on the same ID as the previous set
of availability formulas. In this case, new reports are not required, but allcollection requests using the previous set of availability formulas must beremoved and replaced with the new set of formulas to avoid collecting duplicatedata.
Example 1
This formula does not use the collection library:Interface Availability percentage (AP original formula)DEF SaveAlias 2955;Def DefaultNoRespResult 0;Dim I1 AS Integer Default * NAME Interface;100 * abs(delta(sysUpTime.0) * (1 +distrib(ifOperStatus.%I1,"==1:1,==2:-1,==3:-1")) / 2 -delta(sysUpTime.0) / 2 *abs(delta(distrib(ifOperStatus.%I1,"==1:1,==2:-1,==3:-1"))/2 )) /delta(sysUpTime.0)
This formula uses the library:Interface Availability percentage (new formula, using previous ID)DEF UseLib RFC1213Interface;DEF SaveAlias 2955;ifAvailability(Percent)
Example 2
This formula does not use the collection library:Device Availability percentage (AP original, which is mainly adevice
reachability percentage)
Stat("Targets", %H1, "SNMP Availability (%) [last hour]")
78 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

This example uses the library:Device Availability percentage (new formula, using new ID)
DEF UseLib RFC1213Interface;deviceAvailability(Percent)
Chapter 5. Writing Collection Formulas 79

80 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Chapter 6. Generic Formulas
A generic formula is not really a formula at all: it contains no code and does noprocessing. The only purpose of a generic formula is to provide an alternativeformula ID (metric ID) for the metrics produced by a collection formula. A genericformula belongs to a formula group and appears in the formula tree.
Before a generic formula is useful, two conditions must be met:v There must be two collection formulas that produce the same metric. For
example, one formula that uses 32-bit counters and another that uses 64-bitcounters, or one that acquires data using SNMP and another that uses a Bulkdata file.
v There must be a reporter to display the metric, regardless of which specificcollection formula was used to acquire the data.
A generic formula should never be used in a collection request: it contains no codeand cannot produce metrics. A generic formula is used by making it the target of aSaveAlias directive in a collection formula. In fact, a generic formula is not beingused correctly until it is the target of the SaveAlias directive in at least twocollection formulas. This causes the collected metrics to be stored in the databaseusing the ID of the generic formula as the metric ID. Then the generic formula isused in reporters, which will display the collected metrics. It is entirely possible forsome of the subelements shown on a report to be collecting data using onecollection formula whereas other subelements are using another. For the statisticalaggregations to give consistent results in this case, all the collection formulas mustuse the same polling period.
To make this work, the collection grouping structure must include a separategroup for each collection formula and the grouping rules must be arranged toensure that no subelement can belong to more than one of these groups. If thesame subelement is ever used to collect data with more than one collectionformula, duplicate metrics will be collected. DataChannel will reject the duplicates,but in an unpredictable way -- for example, it might not keep all the metrics fromthe same source.
© Copyright IBM Corp. 2011, 2012 81

82 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Notices
This information was developed for products and services offered in the U.S.A.IBM may not offer the products, services, or features discussed in this document inother countries. Consult your local IBM representative for information on theproducts and services currently available in your area. Any reference to an IBMproduct, program, or service is not intended to state or imply that only that IBMproduct, program, or service may be used. Any functionally equivalent product,program, or service that does not infringe any IBM intellectual property right maybe used instead. However, it is the user's responsibility to evaluate and verify theoperation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matterdescribed in this document. The furnishing of this document does not give youany license to these patents. You can send license inquiries, in writing, to:
IBM Director of LicensingIBM CorporationNorth Castle DriveArmonk, NY 10504-1785 U.S.A.
For license inquiries regarding double-byte (DBCS) information, contact the IBMIntellectual Property Department in your country or send inquiries, in writing, to:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan, Ltd.1623-14, Shimotsuruma, Yamato-shiKanagawa 242-8502 Japan
The following paragraph does not apply to the United Kingdom or any othercountry where such provisions are inconsistent with local law:
INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THISPUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHEREXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIEDWARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESSFOR A PARTICULAR PURPOSE.
Some states do not allow disclaimer of express or implied warranties in certaintransactions, therefore, this statement might not apply to you.
This information could include technical inaccuracies or typographical errors.Changes are periodically made to the information herein; these changes will beincorporated in new editions of the publication. IBM may make improvementsand/or changes in the product(s) and/or the program(s) described in thispublication at any time without notice.
Any references in this information to non-IBM Web sites are provided forconvenience only and do not in any manner serve as an endorsement of those Websites. The materials at those Web sites are not part of the materials for this IBMproduct and use of those Web sites is at your own risk.
© Copyright IBM Corp. 2011, 2012 83

IBM may use or distribute any of the information you supply in any way itbelieves appropriate without incurring any obligation to you.
Licensees of this program who wish to have information about it for the purposeof enabling: (i) the exchange of information between independently createdprograms and other programs (including this one) and (ii) the mutual use of theinformation which has been exchanged, should contact:
IBM Corporation2Z4A/10111400 Burnet RoadAustin, TX 78758 U.S.A.
Such information may be available, subject to appropriate terms and conditions,including in some cases payment of a fee.
The licensed program described in this document and all licensed materialavailable for it are provided by IBM under terms of the IBM Customer Agreement,IBM International Program License Agreement or any equivalent agreementbetween us.
Any performance data contained herein was determined in a controlledenvironment. Therefore, the results obtained in other operating environments mayvary significantly. Some measurements may have been made on development-levelsystems and there is no guarantee that these measurements will be the same ongenerally available systems. Furthermore, some measurement may have beenestimated through extrapolation. Actual results may vary. Users of this documentshould verify the applicable data for their specific environment.
Information concerning non-IBM products was obtained from the suppliers ofthose products, their published announcements or other publicly available sources.IBM has not tested those products and cannot confirm the accuracy ofperformance, compatibility or any other claims related to non-IBM products.Questions on the capabilities of non-IBM products should be addressed to thesuppliers of those products.
This information contains examples of data and reports used in daily businessoperations. To illustrate them as completely as possible, the examples include thenames of individuals, companies, brands, and products. All of these names arefictitious and any similarity to the names and addresses used by an actual businessenterprise is entirely coincidental.
COPYRIGHT LICENSE:
This information contains sample application programs in source language, whichillustrate programming techniques on various operating platforms. You may copy,modify, and distribute these sample programs in any form without payment toIBM, for the purposes of developing, using, marketing or distributing applicationprograms conforming to the application programming interface for the operatingplatform for which the sample programs are written. These examples have notbeen thoroughly tested under all conditions. IBM, therefore, cannot guarantee orimply reliability, serviceability, or function of these programs. You may copy,modify, and distribute these sample programs in any form without payment toIBM for the purposes of developing, using, marketing, or distributing applicationprograms conforming to IBM‘s application programming interfaces.
84 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

If you are viewing this information in softcopy form, the photographs and colorillustrations might not be displayed.
Notices 85

86 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide

Trademarks
IBM, the IBM logo, and ibm.com are trademarks or registered trademarks ofInternational Business Machines Corp., registered in many jurisdictions worldwide.Other product and service names might be trademarks of IBM or other companies.A current list of IBM trademarks is available on the Web at “Copyright andtrademark information” at http://www.ibm.com/legal/copytrade.shtml.
Adobe, Acrobat, PostScript and all Adobe-based trademarks are either registeredtrademarks or trademarks of Adobe Systems Incorporated in the United States,other countries, or both.
Cell Broadband Engine and Cell/B.E. are trademarks of Sony ComputerEntertainment, Inc., in the United States, other countries, or both and is used underlicense therefrom.
Intel, Intel logo, Intel Inside, Intel Inside logo, Intel Centrino, Intel Centrino logo,Celeron, Intel Xeon, Intel SpeedStep, Itanium, and Pentium are trademarks orregistered trademarks of Intel Corporation or its subsidiaries in the United Statesand other countries.
IT Infrastructure Library is a registered trademark of the Central Computer andTelecommunications Agency which is now part of the Office of GovernmentCommerce.
ITIL is a registered trademark, and a registered community trademark of the Officeof Government Commerce, and is registered in the U.S. Patent and TrademarkOffice.
Java and all Java-based trademarks and logos are trademarks or registeredtrademarks of Sun Microsystems, Inc. in the United States, other countries,or both.
Linux is a trademark of Linus Torvalds in the United States, other countries, orboth.
Microsoft, Windows, Windows NT, and the Windows logo are trademarks ofMicrosoft Corporation in the United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and othercountries.
Other company, product, and service names may be trademarks or service marksof others.
For trademark attribution, visit the IBM Terms of Use Web site:http://www.ibm.com/legal/us/.
© Copyright IBM Corp. 2011, 2012 87

88 IBM Tivoli Netcool Performance Manager: SNMP Formula Language Reference Guide


����
Printed in USA

















