Software Pipelining for Stream Programs on Resource Constrained Multi-core Architectures IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEM 2012 Authors: Haitao Wei, Junqing Yu, Huafei Yu, Mingkang Qin, Guang R. Gao Chih-Sheng Lin
Transcript
Software Pipelining for Stream Programs on Resource Constrained Multi-core Architectures
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEM 2012Authors: Haitao Wei, Junqing Yu, Huafei Yu, Mingkang Qin, Guang R. Gao
Chih-Sheng Lin
2
Outline•Introduction•Background
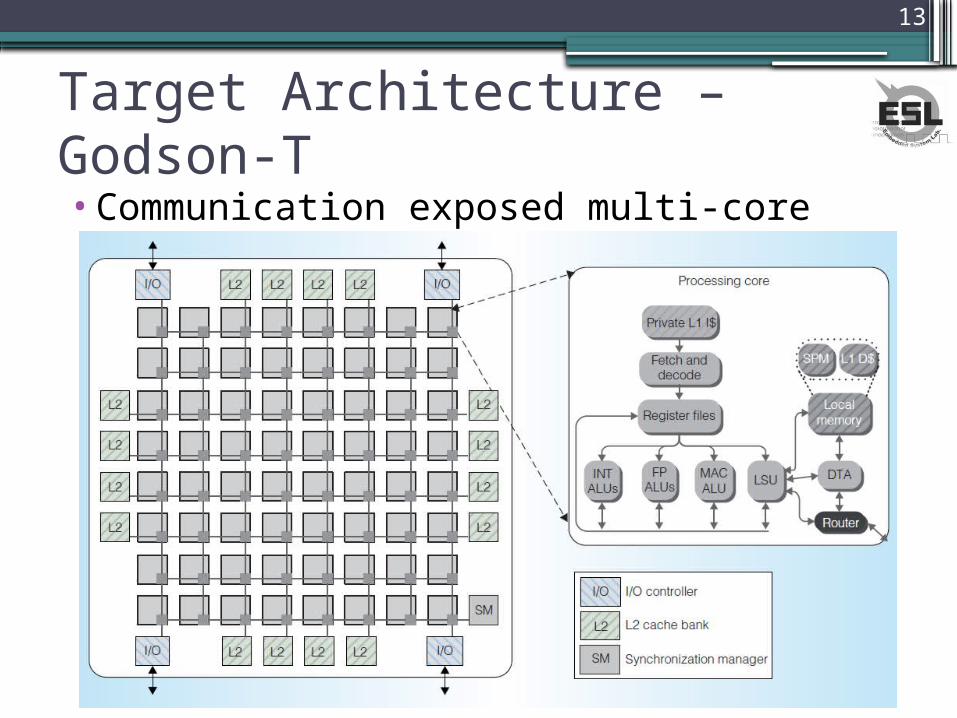
▫DFBrook Stream Language▫Architecture – Godson-T
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
3
Outline•Introduction•Background
▫DFBrook Stream Language▫Architecture – Godson-T
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
4
Multi-core Architectures•Multi-core architectures have become the
mainstream solution and industry standard from servers to desktop platforms and handheld devices▫IBM’s Cell, Nvidia’s GPU, ICT’s Godson,
MIT’s raw
•Multi-core processor▫increases the computation ability▫pushes the performance burden to the
compiler and programmer to effectively exploit the coarse-grained parallelism across the cores
5
Stream Programming Model•The stream programming model is an
approach!
•Stream languages▫StreamIt, Brook, CUDA, SPUR and Cg▫are motivated by applications in media
processing domains▫are based on synchronous dataflow (SDF) or
regular stream flow graphs (RSFG)
6
Regular Stream Flow Graph (RSFG)
•Node▫a computation task (actor)▫has an independent instruction stream and
address space▫fire repeatedly in a periodic schedule
•Arc(Edge)▫the communication (flow of data) between
nodes▫through the communication channel
7
Software Pipelining•Software pipelining
▫an efficient method to exploit the coarse-grained parallelism in stream programs
▫takes whole program as a loop and periodic schedule as iteration of the loop
•Stream programs can be easily and naturally mapped to communication-exposed multi-core architecture▫but the gains through parallel execution can be
overshadowed by the cost of communication and synchronization
8
Software Pipelining (Cont.)•The performance metric of software
pipelining▫the initiation rate of successive iteration
•Rate optimal schedule▫The schedule with the maximum initiation rate
(minimum initiation interval)
•Resource limitations▫Processor capability, the size of memory with
each PE, interconnect bandwidth and direct memory access (DMA)
9
Goal
•To orchestrate an efficient software pipelining schedule which obtains optimal computation rate while minimize the communication cost and satisfying the resource constraints under the system
10
CMRO and ROMC•CMRO (Communication Minimized Rate-
Optimal)▫minimizes the communication cost at optimal
computation rate▫formulated as an unified Integer Linear
Programming (ILP) problem•ROMC (Rate-Optimal with Memory
Constraints)▫formulated as an unified integer quadratic
programming problem▫transformed to an ILP problem by using stage
adjustment optimization
11
Outline•Introduction•Background
▫DFBrook Stream Language▫Architecture – Godson-T
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
12
DFBrook Steam Language•DFBrook: extension of Brook for SDF
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
15
CMRO Schedule – Problem Definition
•Stream Graph ▫: set of nodes (actors)▫: set of edges
•Schedule▫a sequence of actor firings (executing)▫Steady state schedule: a stream graph can
execute infinite number of times with finite buffers
• Instance: each firing of some actor•Repetition vector : the min number of
times that each actor must execute in a steady state schedule
16
CMRO Schedule – Problem Definition (Cont.)•Each stream graph has a corresponding data dependency graph (DDG) ▫Node , where , ▫Edge , where , and
17
Example of Stream Graph and DDG
Stream Graph
Data Dependency Graph
18
CMRO Problem
•Given a stream graph and a multi-core architecture , construct a software pipelining schedule that achieves the optimal computation rate within the constraints of while minimizing the communication cost
19
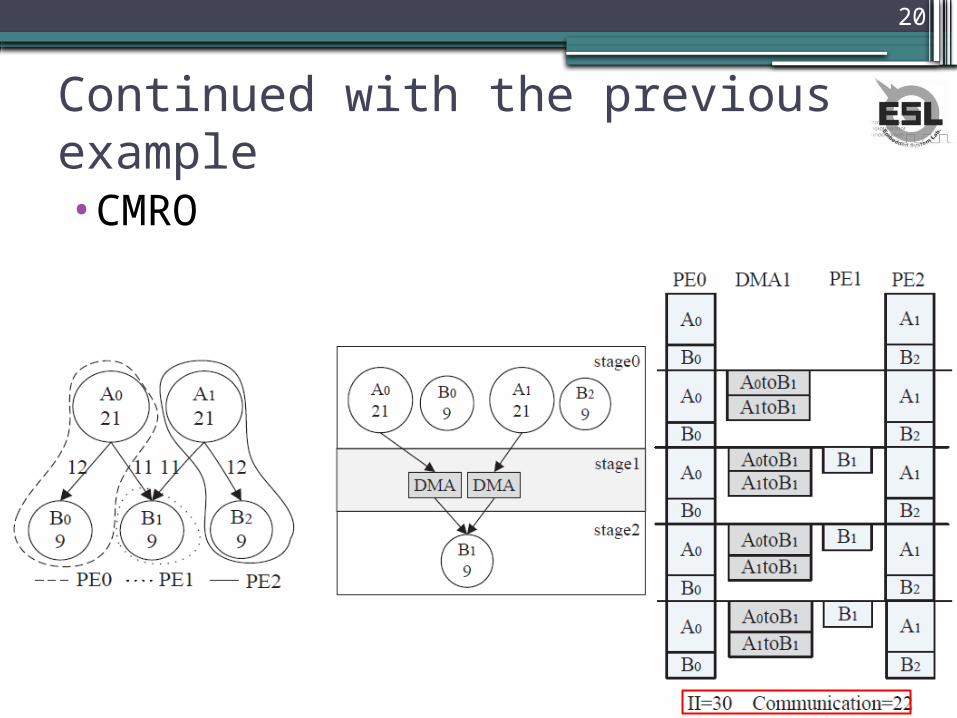
Continued with the previous example•SGMS (Stream Graph Modulo Schedule)
▫lacks the consideration of communication
20
Continued with the previous example•CMRO
21
ILP Formulation - Space
•Given a stream graph
•Each instance of each kernel is assigned to exactly one PE
(1)
22
ILP Formulation - Space(Cont.)•All the workload assigned to a PE is
constrained to be complete in a specified (Initiation Interval)
▫the execution time of kernel
23
ILP Formulation - Space(Cont.)
•For each edge
•DMA transfer is not introduced between two connected instances if they are on the same PE
24
ILP Formulation - Space(Cont.)
•All the data transfer workload assigned to a DMA will not be larger than the specified
▫: the data transfer workload between and
25
ILP Formulation - Time
•The concept stage is adopted for scheduling instance nodes and edges in time dimension
▫: the stage number for each instance ▫: the stage number which is assigned to
each edge
26
ILP Formulation – Time(Cont.)
•The stage assignment constraints
27
ILP Formulation for CMRO Problem
28
Rate-Optimal Schedule with Memory Constraints (ROMC)
•Given a stream graph and a multi-core architecture , construct a software pipelining schedule that achieves the optimal computation rate within the memory constraints of
29
ROMC(Cont.)
•Considerations▫All the buffers used for an instance are
allocated statically in the memory of the processor where the instance is assigned to
▫In the software pipelining schedule, multiple buffers are introduced to keep up with the distance in the stages between two connected instances
30
Example of Buffer Allocation Schemes
Number of buffers =
Number of buffers in PE0 = Number of buffers in PE1 =
31
ROMC(Cont.)•The total buffer usage of PE should be no
larger than the memory’s capability
▫ : the buffer size for storing tokens of edge ▫ : the amount of local memory in PE
32
Solving ROMC Problem
In Step2:
33
Solving ROMC Problem
34
Stage Assignment and Adjustment Optimization Process
35
Stage Assignment and Adjustment Optimization Process(Cont.)
Key:The stage of DMA-node can be adjusted to reduced the buffer usage of victim processors
36
Buffer Usage Calculation
The number of input buffers in each PE’s memory
37
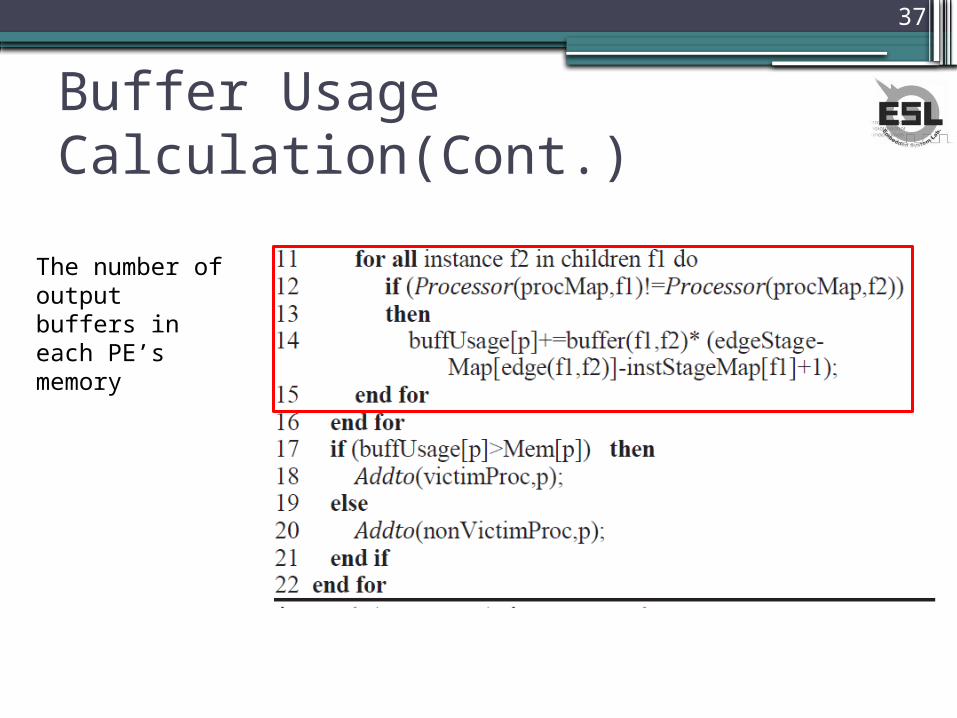
Buffer Usage Calculation(Cont.)
The number of output buffers in each PE’s memory
38
Stage Adjustment Optimization
39
Stage Adjustment Optimization(Cont.)
40
Stage Adjustment Optimization(Cont.)
41
Outline•Introduction•Background
▫DFBrook Stream Language▫Architecture – Godson-T
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
42
Experiment Infrastructure and Methodology•Scheduler
▫implemented by DFBrook to generate codes for the software pipelining schedules
ROMC Schedule Performance• Number of processors = 9• MinMem = 16KB for all benchmarks• MaxMem = 512KB for imgsmth, Gauss and aveMotion;
32KB for others
46
ROMC vs Conservative Estimate Method (CEM)• *: both of the two schedulers can find a feasible solution• +: only ROMC finds a solution while the solution by CEM
is unable to meet the memory constraints
47
Scalability (over single processor)
48
ROMC ILP Solving Time (in CPU seconds)•In 70% of the cases, ROMC scheduler can
obtain an optimal solution in less than 6 minutes
49
CMRO ILP Solving Time
50
CMRO Performance Improvement
51
Outline•Introduction•Background
▫DFBrook Stream Language▫Architecture – Godson-T
•Software Pipelining Scheduling with Resource Constraints
•Experiments and Evaluation•Related Works•Conclusion
52
Related Works
•The schedule of stream graph▫Ptolemy: model of computation and
scheduling on SDF▫Regular Stream Flow Graph (RSFG) can




























































![Pipelining & Parallel Processing - ics.kaist.ac.krics.kaist.ac.kr/ee878_2018f/[EE878]3 Pipelining and Parallel Processing.pdf · Pipelining processing By using pipelining latches](https://static.documents.pub/doc/80x56/5d40e26d88c99391748d47fb/pipelining-parallel-processing-icskaistackricskaistackree8782018fee8783.jpg)









