Some Problems in Symmetric and Asymmetric Cryptography A thesis submitted for the partial fulfillment of the degree of Doctor of Philosophy in Mathematics By SANTOSH KUMAR YADAV Under the supervision of Prof. Sunder Lal and Prof. S. C. Arora DEPARTMENT OF MATHEMATICS DR. B. R. AMBEDKAR UNIVERSITY, AGRA (FORMERLY AGRA UNIVERSITY) 2010
Transcript
Some Problems in Symmetric and Asymmetric Cryptography
A thesis submitted for the partial fulfillment of the degree of
Doctor of Philosophy in
Mathematics
By SANTOSH KUMAR YADAV
Under the supervision of
Prof. Sunder Lal and Prof. S. C. Arora
DEPARTMENT OF MATHEMATICS DR. B. R. AMBEDKAR UNIVERSITY, AGRA
(FORMERLY AGRA UNIVERSITY) 2010
*Sanskrit verse dating back to the pre-Christian era
Dedicated to my
Teachers, Friends, Students
and
Family Members
DECLARATION
I do hereby declare that the present research work has been carried out
by me under the supervision of Prof. Sunder Lal and Prof. S. C. Arora. This
work has not been submitted elsewhere for any other degree, diploma,
fellowship or any other similar title.
Santosh Kumar Yadav Research Scholar
CERTIFICATE
This is to certify that the thesis entitled “Some Problems in Symmetric
and Asymmetric Cryptography” submitted to Dr. B.R.Ambedkar University,
Agra for the degree of Doctor of Philosophy by Mr. Santosh Kumar Yadav,
is a bonafide record of research work done by him under our supervision. To
the best of our knowledge, this thesis has not previously formed the basis for
the award to any candidate of any degree, diploma, fellowship or any other
similar title and the work has not been submitted to any university or
institution, for the award of any other degree.
S. C. ARORA SUNDER LAL (Co-supervisor) (Supervisor) Professor Professor of Mathematics, and Department of Mathematics Pro-Vice Chancellor University of Delhi Dr. B.R. Ambedkar University Delhi-110007 Agra-282002
ACKNOWLEDGEMENTS I am grateful to my supervisors Prof. Sunder Lal, Professor and Pro-
Vice Chancellor of Dr. B.R. Ambedkar University, Agra and Prof. S.C.Arora,
Professor, Department of Mathematics, University of Delhi, Delhi who spared
their valuable time in guiding me for my research work. They encouraged me
throughout the research work. I am short in words to express their contribution
to this thesis through criticism, suggestions and discussion.
My sincere thanks are to Prof. M. N. Hoda (Bharti Vidyapeeth
University), Prof. A.K. Saini (G.G.S.I.P. University) and Prof. K.K.
Bhardwaj (JNU, Delhi) who supported me during my M. Phil work and
encouraged me for my Ph. D. work.
I am deeply thankful to Prof. R.K. Shrivastava (Head, Department of
Mathematics, Dr. B. R. Ambedkar University, Agra), Dr. Sanjeev Kumar
(Department of Mathematics, Dr. B. R. Ambedkar University, Agra) and my
friends Mr. Kuldeep Bhardwaj (Dr. B. R. Ambedkar University, Agra), and
Mr. Navneet Singh Rana (Delhi).
I am deeply indebted to the mathematicians, computer scientists and
authors whose work I have freely used during my research work. Staff
members and the Library staff of ‘The Institution of Electronics and
Telecommunication Engineers’ New Delhi deserve my thanks for their
constant support for reference titles and study material.
I am short of words to express my feelings for my family members
especially my wife Seema and my children Akshita and Ayan for their
emotional support.
I would fail in my duty if I do not thank to my type setter Mr. Yusuf for
type setting work of the thesis.
Santosh Kumar Yadav
LIST OF FIGURES
Page No.
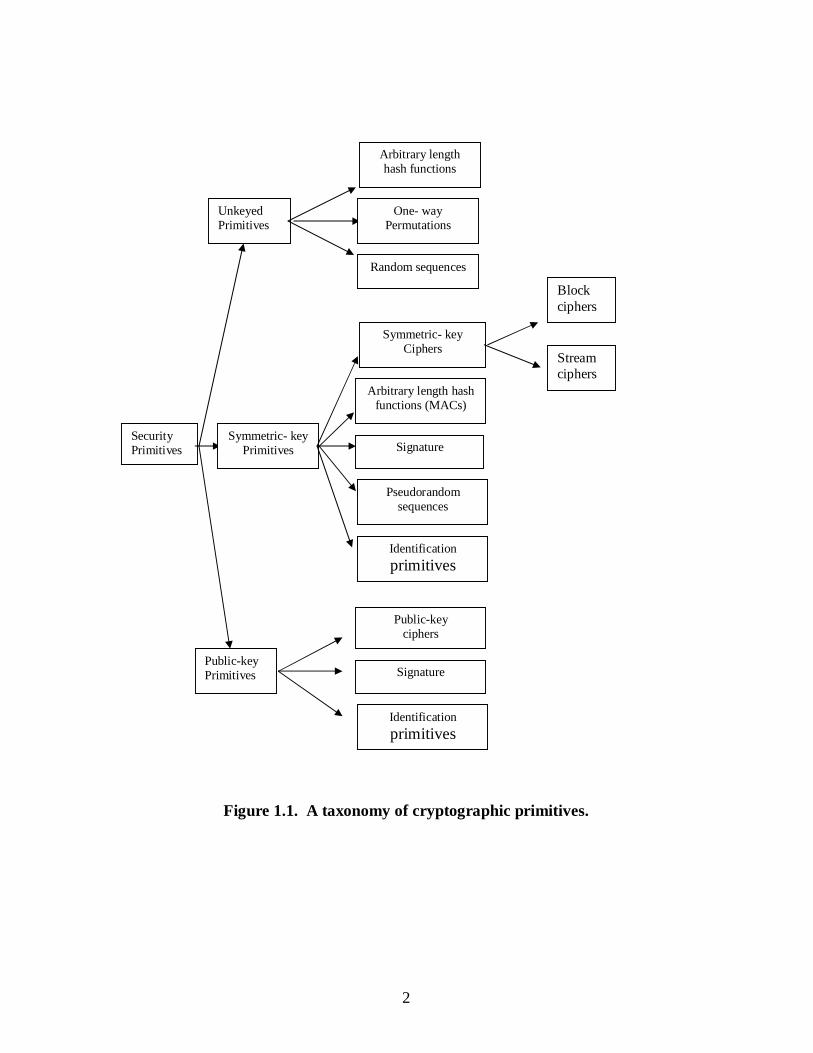
1. A taxonomy of cryptographic primitives 2
2. Communication using symmetric key cryptography (k = d= e) 7
3. Encryption and decryption using two different keys 7
4. Communication using public key cryptography 8
5. A signing and verification function for a digital signature 10
6. ECB Mode 18
7. CBC Mode 19
8. A 5-bit CFB Mode 20
9. OFB Mode 21
10. CTR Mode 22
11. A binary additive stream cipher 25
12. Simplified Classification of Hash Function 29
13. Difference propagation in last round of MD4 32
14. MQ -trapdoor (S, P, T) in HFE 84
15. HFE for encryption o the message M with ciphertext (y, r) 86
16. Signature with MQ , using the HFE trapdoor 88
17. To Process a vote 100
18. An Onion 104
19. A Teller 105
20. Three Tellers anonymising mix 106
21. A vote processed by three Tellers 107
22. Information posted by the sequence of three Tellers 107
23. Auditing Telleri 109
LIST OF TABLES & ALGORITHMS
Page No.
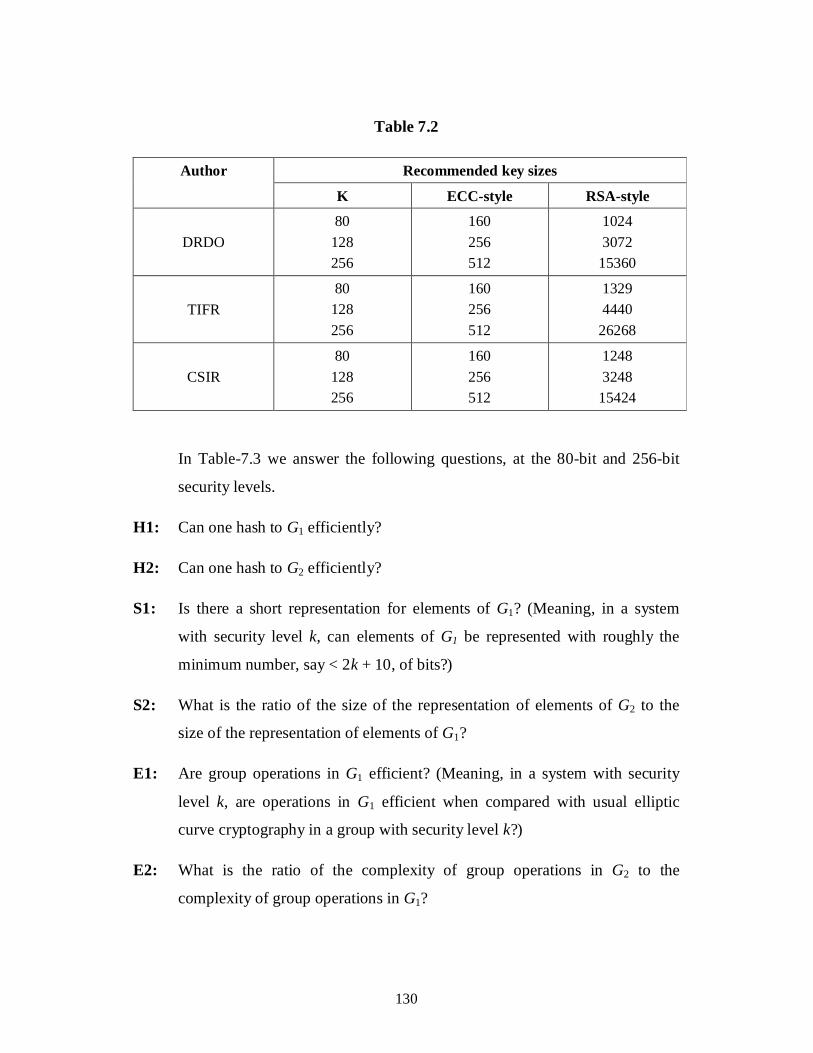
1. Properties of the types of pairing groups 128
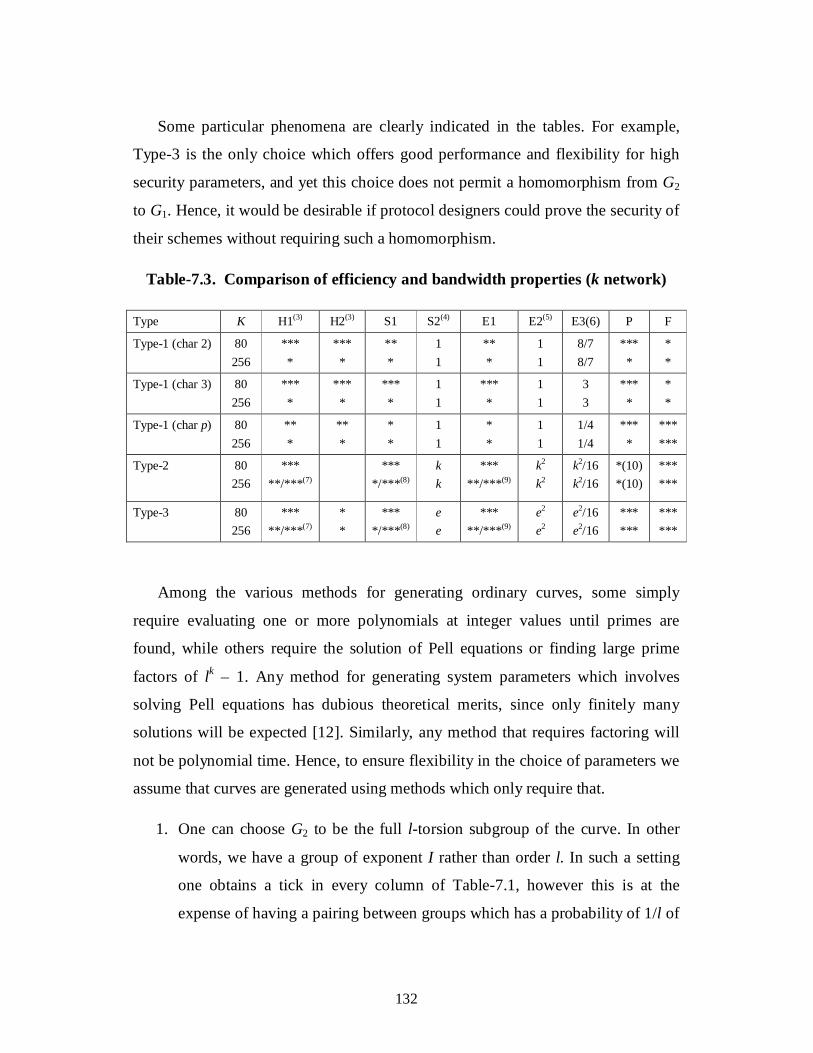
2. Comparison of efficiency and bandwidth properties (k network) 132
3. MAC ALGORITHMS 32
4. The XL Algorithm 34
5. Gröbner Bases Algorithms 35
6. The Buchberger algorithm 36
7. The F4 and F5 Algorithms 37
8. ECDSA-Signature Algorithm 47
9. ECDSA–Signature Verification Algorithm 48
CONTENTS
Page No.
Chapter 1 1-15 INTRODUCTION TO CRYPTOGRAPHY 1.1. CRYPTOGRAPHY 1 1.2. BASIC TERMINOLOGY AND CONCEPTS 3 1.3. INFORMATION SECURITY 5 1.4. CRYPTOLOGY AND ITS TERMS 6 1.5. SYMMETRIC AND ASYMMETRIC CRYPTOGRAPHY 6 1.6. DIGITAL SIGNATURES 8 1.7. SYMMETRIC- KEY VS. PUBLIC-KEY CRYPTOGRAPHY 10 1.8. ABSTRACT OF THE THESIS 13
2.6 MESSAGE DIGESTS (HASH FUNCTION) 29 2.6.1 The Joux attack on SHA-0 30 2.6.2 Special Pattern Attack 31
2.7 MAC ALGORITHMS 32 2.7.1. Block Cipher based 33 2.7.2. Hash Function based 33 2.7.3. Universal hash function based 34
2.8 FORMAL ALGORITHMS 34 2.8.1 The XL Algorithm and Variants 34
2.8.2 Gröbner Bases algorithms 35 2.8.3 The Buchberger algorithm 36 2.8.4 The F4 and F5 algorithms 37
2.9 CONCLUDING REMARKS 40 REFERENCES 40
Chapter 3 43-82 MATHEMATICAL TOOLS OF ASYMMETRIC CRYPTOGRAPHY 3.0 OVERVIEW 43 3.1 INTRODUCTION 43 3.2 CURVE BASED CRYPTOSYSTEMS 44 3.3 SOME BASIC DEFINITIONS 44
3.3.1 Group Operation 45 3.4 LATTICE BASED CRYPTOGRAPHY 48
3.4.1 Minkowski Theorem 50 3.4.2 The Ajtai-Dwork Cryptosystem 51
3.5. THE NTRU CRYPTOSYSTEM 52 3.5.1 Primitives of NTRU 54 3.5.2 NTRU and Lattice Reduction 58 3.5.3 NTRU Security 60
3.6 XTR, SUBGROUP AND TORUS-BASED CRYPTOGRAPHY 63 3.6.1 XTR 63 3.6.2 CEILDH 75 3.6.3 Asymptotically Optimal Torus-Based Cryptography 76 3.6.4 Some Important Theorems 77
3.7 CONCLUDING REMARKS 79 REFERENCES 80
Chapter 4 83-93 ON MULTIVARIATE SYSTEM IN ASYMMETRIC CRYPTOGRAPHY 4.0 OVERVIEW 83 4.1 INTRODUCTION 83 4.2 HIDDEN FIELD EQUATIONS 84 4.3 ENCRYPTION AND DECRYPTION OF MESSAGES USING THE
PRIVATE KEY 85 4.4 MESSAGE SIGNATURE 87 4.5 PUBLIC KEY: GENERATION AND ENCRYPTION 89
4.6 CONCLUDING REMARKS 91 REFERENCES 91
Chapter 5 94-111 CRYPTOGRPHIC VOTER -VERIFIABILITY: A PRACTICAL APPROACH 5.0 OVERVIEW 94 5.1 INTRODUCTION 94 5.2 DIGITAL VOTER-VERIFIABILITY 95 5.3 PRÊT Á VOTER 96 5.4 SINGLE TRANSFERABLE VOTE AND THE ELECTION SETUP 97 5.5 PRESENTATION OF EXAMPLE 98 5.5.1 To Process Votes 98 5.5.2 To Introduce the Voter 100 5.6 TO CHECK THE CONSTRUCTION OF THE BALLOT FORMS 100
5.6.1 To Cast the Vote 102 5.7 MATHEMATICAL DETAILS 102
5.7.1 Cryptographic Seeds and Offsets 103 5.7.2 To Construct Onions 103
5.8 WHAT TELLERS DO? 104 5.9 TO CHECK ON THE AUTHORITY 108 5.10 TO CHECK THE VOTE RECORDING DEVICES 108 5.11 TO CHECK THE TELLERS 109 5.12 ERROR HANDLING/ RECOVERY STRATEGIES 110 5.13 CONCLUDING REMARKS 110
REFERENCES 111 Chapter 6 112-124 PROVABLE SECURITY AND CRYPTOGRAPHY: SOME BASIC PROBLEMS 6.0 OVERVIEW 112 6.1 INTRODUCTION 112 6.2 PROVABLE SECURITY: SOME BASIC PROBLEMS 113
6.2.1 Shannon’s Theory of Security and Symmetric Cryptography 113 6.2.2 The Reduction Theory of Security and Asymmetric Cryptography 114 6.2.3 Formal Security Models 114 6.2.4 Small Inconsistencies: Concrete Vs. Asymptotic Security 115 6.2.5 Can we detect simulation? 117
6.3 THE RANDOM ORACLE MODEL: APPLICATION 118
6.4 RANDOM ORACLE AND ZERO-KNOWLEDGE PROTOCOLS 120 6.5 CONCLUDING REMARKS 122
4. Lynette I, Mallete, and Stephyen H. Holdin. Authentication and its Privacy effects, IEEE Internet Computing pp. 54-58. Nov.-Dec. 2003.
5. A. J. Menezes, P. C. Van Oorschot, and S.A. Vanstone. Handbook of Applied Cryptography, CRC Press, 1997.
6. Bruce Schneier. Applied Cryptography: Protocols, Algorithms and Source Code in C, 2nd ed., John Wiley & Sons, 1995.
7. W. Stallings.Cryptography and Network Security: Principles and Practice, 3rd ed., PHI, 2003.
8. Douglas R. Stinson: Cryptography: Theory and Practice, 2nd ed. Chapman and Hall/CRC 2002.
9. Santosh Kumar Yadav, Sunder Lal, and Kuldeep Bhardwaj. Cryptographic Protocols: Security and Composition. GLA Institute of Technology, Mathura, Conference Proceedings, Feb. 23-24, 2008, pp.1.
16
Chapter 2
PERSPECTIVES OF SYMMETRIC CRYPTOGRAPHY
2.0 OVERVIEW
In this chapter we discuss some important algorithms used for encryption
and decryption in symmetric cryptography. Along with algorithms we also
discuss some cryptanalysis methods. A common method of cryptanalysis is
algebraic method. Algebraic attacks have received a lot of attention of the
cryptographic community in the last few years. These attacks have been
considered against the hidden field equation (HFE) cryptosystem as well as a
number of LFSR-based stream ciphers. However, there has not been much
progress in assessing whether they can be effective against block ciphers. The
main reason for this is its computational complexity. While for most methods
of cryptanalysis it is quite straightforward to perform experiments on reduced
versions of the cipher to understand how the attack might perform, this has not
been the case for algebraic attacks on block ciphers. It has been suggested that
a possible direction to test the effectiveness of the main algorithms in solving
the systems of algebraic equations is the introduction of toy examples of
symmetric ciphers. However it is not an easy task to design small versions that
can replicate the main cryptographic and algebraic properties of the cipher.*
2.1 INTRODUCTION
Symmetric cryptographic algorithms (or secret-key algorithms), require a
key to be shared between sender and receiver and is simultaneously kept secret.
Sharing and still keeping secret is not an easy task. In public key or asymmetric
key cryptography keys are not shared. Keys are split into two parts, public and * The present chapter is based on author’s paper “Perspectives of Symmetric Cryptography”
presented in INDIACOM’09 (A national Conference on Computing for National Development) published in Proceedings pp. 211-216.
17
secret. Public keys are put in a public register and therefore are known to
everybody, secret keys are never shared. From outside, this gives the
impression that symmetric techniques become obsolete after the invention of
public-key cryptography in the mid 1970's. This, however, is not the case
Symmetric techniques are still widely used. In fact public key systems are used
to share keys and the shared keys are then used as keys for symmetric
algorithms. The reason for using such hybrid system is that symmetric
algorithms achieve some major functionalities as high-speed or low-cost
encryption, fast authentication, and efficient hashing. Symmetric algorithms are
being used in GSM mobile phones, in credit cards, in WLAN connections [27], etc.
Symmetric ciphers are classified into block ciphers and stream ciphers. In
block ciphers, plain text is divided into blocks of fixed length and algorithms
are applied to each block separately. In stream ciphers transformation takes
place bit wise.
2.2 BLOCK CIPHERS
A block cipher can be described as a keyed pseudo-random permutation of
the 0, 1 n set of n-bit blocks. The most usual block lengths for existing block
ciphers are n = 64 and 128 bits. Historically, block ciphers have been more
prominent than stream ciphers in open standards (DES, Triple-DES, AES) [27].
They are used in many cryptographic applications such as home banking, e-
mail, authentication, key distribution and in recent standards for encryption on
mobile telephony, in hard disk encryption, and so forth. Stream ciphers are
preferred for selected applications with high performance for low power
requirements.
Some well known block ciphers are: (i) DES [19, 27]
(ii) Triple DES [27]
18
(iii) AES [2]
(iv) FEAL [16, 27]
(v) IDEA [27]
(vi) SAFER [28]
(vii) RCS [27]
(viii) LOKI’91 [28]
Some well known modes of applying block ciphers are:
(i) ECB Mode: The electronic codebook mode is the simplest mode in
which plaintext is handled. Here one block is handled at a time and each
block of plaintext is encrypted using the same key. The ECB method is
ideal for a short amount of data, This mode of operation has the
following properties:
Figure 2.1. ECB Mode
(a) Identical plaintext (under the same key) results in identical
ciphertext.
19
(b) Chaining dependencies: blocks are enciphered independently of
other blocks.
(c) Error propagation; One or more bit error in a single ciphertext
block effect decipherment of that block only.
(ii) CBC Mode: Cipher Block Chaining mode is used to overcome the
security deficiencies of ECB. In this technique the same plaintext block,
if repeated, produces different ciphertext blocks. In this mode, the input
of the encryption algorithm is the XOR of the current plaintext block
and the preceding ciphertext block. The same key is used for each block.
The cipher-block chaining mode of operation involves use of an n-bit
initialization vector. It has the following properties:
Figure 2.2. CBC Mode
(a) Identical plaintexts: Firstly plaintext block results in different
ciphertext.
20
(b) Chaining dependencies: Proper decryption of a correct ciphertext
block requires a correct preceding ciphertext block.
(c) Error propagation: A single bit error in one ciphertext block affect
decryption of succeeding blocks.
(d) Error recovery: It is self-synchronizing or ciphertext auto key.
(iii) CFB Mode: The cipher feedback mode is used when the CBC mode
processes plaintext n-bits at a time. A stream cipher eliminates the need
to pad a message to be an integral number of locks. It can also operate in
real time. If a character stream is being transmitted, each character can
be encrypted and transmitted immediately using a character-oriented
stream cipher. It has the following properties:
Figure 2.3. A 5-bit CFB Mode
(a) Identical plaintext: As per CBC encryption changing the results in
the same plaintext input being enciphered to a different output
(c) Error propagation: One or more bit errors in any single r-bit
ciphertext block affects the decipherment of that and next ciphertext
blocks.
(d) Error recovery: It is self-synchronizing similar to CBC, but requires
ciphertext blocks to recover.
(iv) OFB Mode: The output feedback mode of operation may be used for
applications is which all error propagations must be avoided. It is similar
to CFB, and allows encryption of various block sizes, differs in that the
output of the encryption block function serves as the feedback.
(b) Decryption
Figure 2.4. OFB Mode
22
The main advantage of the OFB mode is that the bit errors in transmission do
not propagate.
OFB mode is more vulnerable to a message stream modification attach than
CFB.
(v) CTR Mode
In this mode, a counter, equal to the plaintext block size is used. The
interest in counter mode (CTR) has increased recently with applications to
ATM (asynchronous transfer mode) network security and IP Security. In this
mode the counter is initialized to some value dn then incremented by 1 for
each subsequent block (modulo 2b, where b is the block size). For encryption,
the counter is encrypted and then XORed with the plaintext block to produce
the ciphertext block. The following are the advantages of CTR mode:
Figure 2.5. CTR Mode
23
Hardware efficiency
Software efficiency
Preprocessing
Random access
Provable security
Simplicity
2.3 BLOCK CIPHERS CRYPTANALYSIS
Main cryptanalytic methods for block ciphers are differential cryptanalysis
and linear cryptanalysis. Other than these, several methods that have been
discovered are higher order differential attacks, truncated differential attacks,
interpolation attacks, integral (saturation) attacks [3], impossible differential,
boomerang and rectangle attacks. These are assumed to be more effective than
usual differential techniques. Other attacks such as chi-square, partitioning, and
stochastic cryptanalysis [2], as well as attacks against key schedules, such as
sliding attacks and related key attacks can offer other avenues for the
cryptanalyst. Although formal proofs of security against these attacks have not
been systematically developed for exiting block ciphers, their existence is
generally taken into account by the designers of block ciphers. The algorithm
AES can be reasonable conjectured to resist these attacks techniques. While the
only assertion one has for now is that there exits no feasible shortcut attack on
AES. Moreover, the AES uses several algebraic structures. Hence it cannot be
entirely precluded that further use of advanced algebraic techniques such as the
use of Gröbner basis computations, probabilistic interpolation, and quadratic
approximations might not establish weakness in AES.
The AES algorithm is a simple and elegant design and it is secure against
attacks known to date; the security of AES could also be validated by studying
in more depth and basic AES structure (SPN Network) and by trying to
24
establish its soundness by further investigating pseudo-randomness and super-
pseudo-randomness of generic constructions following the AES approach [20].
Another line of research may be to investigate and develop new attacks that
exploit the algebraic structures present within the AES. The security of a
cryptographic algorithm with fixed parameters such as AES can only degrade
over time as the state of the art in cryptanalysis develops. However,
fundamental research is required to investigate the effectiveness of newer
mathematical techniques like algebraic attacks and probabilistic interpolation
attacks.
Among the basic elementary building blocks used to construct block cipher,
only the S-boxes design and the overall structure (Feistel scheme, Misty
scheme, etc.) have been extensively analysed. Other building blocks such as the
linear part of S/P networks, the key schedule, and the use of uniform rather
than hybrid round structures have been much less investigated until now.
2.4 STREAM CIPHERS
Stream ciphers are another important class of symmetric encryption
algorithm. They encrypt individual characters of a plaintext message one at a
time using an encryption transformation which varies with time.
We often refer to any stream cipher producing one output bit on each clock as
a classical stream cipher design. However, other system ciphers are word-oriented
and may encrypt the plaintext as bytes or larger units of data. In a binary additive
stream cipher the keystream, the plaintext, and the ciphertext are sequences of
binary digits. The output sequence of the keystream generator 1 2, ,z z is
added bitwise to the plaintext 1 2, ,m m producing the ciphertext 1 2, ,c c the
keystream generator to initialize through a secret key k, and hence, each k will
correspond to an output sequence.
25
Since the key is shared between the sender and the receiver, the receiver can
decrypt by adding the output of the keystream generator to the ciphertext and
obtain the message sequence, see Figure 2.6.
1 2, ,z z
1 2, ,m m 1 2, ,c c
Figure 2.6. A binary additive stream cipher
2.4.1 Synchronous stream ciphers [19]
A synchronous stream cipher is one in which the keystream is generated
independently of the plaintext message and of the ciphertext. The design goal
for a synchronous stream cipher is to produce a secure keystream. Here we are
typically concerned about two types of attacks:
Key recovery attacks: The cryptanalyst tries to recover the secret key k
Distinguishing attack: The cryptanalyst tries to determine whether any
arbitrarily selected keystream 1 2, nz z , ,z has been generated by a
given stream cipher or whether it is a truly random sequence. If we can
build a distinguisher, i.e. a box that implements some algorithm, to
correctly answer the above question with high probability, then we have
a distinguishing attack.
2.4.2 LFSR-based designs
Linear feedback shift registers are used in many of the keystream
generators because of the following reasons:
(i) LFSRs are well suited to hardware implementation.
keystream generator
26
(ii) They can produce sequence of large period.
(iii) They can produce sequence with good statistical properties.
(iv) Because of their structure, they can be readily analyzed using algebraic
techniques.
Many stream ciphers are built around the Linear Feedback Shift Register.
Within this class of ciphers there are a variety of design approaches.
The idea of the combiner generator is to destroy the inherent linearity in
LFSRs by using several LFSRs in parallel. The outputs from these n parallel
LFSRs 1, , nu u are combined by f a combining function which is a
nonlinear Boolean function. The output from this nonlinear function is the
keystream and the output symbol at time instant t is denoted by .tz This
symbol is calculated as 1 2, , , nt t t tz f u u u where 1
tu denotes the output bit
from LFSR i at time instant t.
It is possible to consider the constituent sequences 1, , nu u as being
formed from successive states of a single LFSR [19]. In this case the combing
function f is known as a filter function and the corresponding stream cipher
as a filter generator. In both the case of the combination and the filter function
however, it is possible to set out certain desirable properties of the function
f so as to (hopefully) derive secure keystream generation. However as new
attacks are developed, it is likely that new design criteria may need to be added.
2.4.3 Table driver stream ciphers
Table driven cipher belongs to another major class of stream cipher design.
RC4 is a classic example of such ciphers. While some weaknesses in the output
function of RC4 have been noted, table-driver stream ciphers can offer
significant performance advantages. Their design has little in common with
27
LFSR-based design and so, as a result, are often immune to classical LFSR-
based analysis. However they can become susceptible to dedicated attacks.
Other types of underlying components have also been proposed, such as T-
functions. FCSRs (Feedback with Carry Shift Registers) or some families of
NFSRs (Nonlinear Feedback Shift Registers) New research result on these
building blocks have been obtained recently.
2.5. STREAM CIPHER CRYPTANALYSIS
LFSRs are used widely in stream cipher design. Exploiting the algebraic
properties of the shift register is very popular cryptanalysis tool. Consequently
the use of linear complexity, the Berlekamp-Massey algorithm, the linear
complexity profile, and other advance but related topics in the analysis of
stream ciphers is well-known.
2.5.1. Divide and conquer attacks
Divide and conquer attack is a powerful attack. However, it relies on the
fact that the keystream generator is built out of several, rather weak,
components. Suppose that we have nonlinear combiner generator consisting of
n different LFSRs and that these LFSRs have lengths 1 2, , , .nL L L Then the
total number of different possible initialization values of these LFSRs is
1(2 1)iLni . However, if we assume that some individual component register
leaks into the keystream produced then one may try to break the keystream
generator one component at a time. Thus under a known keystream attack and
under the assumption that we have sufficiently many keystream bits, we might
be able to identity the correct initial state of most 1(2 1)i
n Li
trials which is
much less than 1(2 1)iLni we might have expected. While the exact
property exploited to identity the component LFSR might vary from cipher to
cipher, there are a variety of design principles that might be employed to
28
protect the cipher against a range of divide- and conquer attacks. It is also
noteworthy that divide-and-conquer attacks may also apply to the combination
of NFSRs [2].
2.5.2. Correlation Attacks
This is another attack which exploits the correlation between sequence and
one of the constituent components. Basic versions of LFSR based stream
ciphers are found to be vulnerable to correlation attacks. These techniques
introduced by Siegenthaler enable to distinguish the correct initial state from a
wrong one since the sequence generated by a wrong initial state is assumed to
be statistically independent of the keystream. Fast correlation attacks were
introduced by Meier and Staffelbach in 1988. They avoided the need to
examine all possible initializations of the target LFSR by using the keystream.
They require the knowledge of a longer segment of the keystream. In practice,
the most efficient fast correlation attacks are able to recover the initial state of a
target LFSR of length 60 for an error-probability p = 0.4 in a few hours on a
PC with around 106 bits of keystream [5].
2.5.3 Algebraic attacks
The basic idea behind the algebraic attack is to set up a system of equations
including key bits and output bits and then to solve this system to recover key
or keystream information. A system of linear equations may be solved by
Gaussian elimination method or any other known method. However, a cipher
may contain a non-linear part. In this case the equations will be non-linear. If
the system of equations is clearly defined then the equation set can be solved
using techniques such as linearization, or other methods such as Gröbner bases.
However, since the complexity of solving such equations grows exponentially
with the degree of the equations, the cryptanalysis may try to identity low
degree equations. A variety of techniques have been proposed to help the
cryptanalyst. The fast algebraic attack was introduced in 2003. The idea was to
29
reduce the degree in the equations using an additional pre-computations step. In
spite of some limitations to algebraic attacks they have been very effective in
the analysis of several stream ciphers to date [29].
2.6 MESSAGE DIGESTS (HASH FUNCTION)
A hash function is an easy to compute function h which compresses an
input x of arbitrary finite bit length, to an output h(x) of fixed length n.
Figure 2.7. Simplified Classification of Hash Function
Hash functions, also known as message digests, are important
cryptographic primitives. The selection of a secure hash function is necessary
to create a secure digital signature scheme. Here, security means a high level of
collision resistance. Below we discuss some methods of attack on hash
function based systems.
We denote the message blocks by 0 1, , kX X X where in most
cases k = 16. The values resulting from the message expansion which are used
30
in the step operation are denoted by Wi, and iX s denotes the rotation (cyclic
shift) of Xi by s bits.
We denote the (new) value of the register changed in step i by iR . For
example the step operation of SHA-0 [6] and SHA-1 [7] then can be described
as follows:
1 5 2 3 45 2 , 2, 2i i i i i i i iR R R R R R K W
2.6.1 The Joux Attack on SHA-0 [6, 7]
Chaubaud and Joux use an approach with differences. Their idea to
find collisions for the original function is to look for messages which have the
same difference propagation in the original function as in the linearized
function Clearly, this cannot be true for every message, but it is possible to
deduce conditions from the difference patterns which described for which
actual register values the differences propagation is the same.
Joux [6, 7] suggested some refined randomized search to find actual
collisions: They start, by repeatedly choosing random values for X0 and
computing the first step until all the conditions for R0 are fulfilled. Then they
do the same with lX , the second step and lR and so on up to X14, the 15-th step
and R14. This can be done step by step, as the values 0 , , i lR R are not
influenced by Xi for i 15.
After having found this (first 15 words of a message conforming to the first
15 steps) they only choose random values for X15. This does not change the
output difference pattern for first 15 steps, but produces a nearly random
behaviour for the remaining steps [15]. Of course, we can construct at most 232
different messages by choosing only X15 and hence, after a certain number of
(unsuccessful) tries for X15 one has to start from the beginning again by
choosing new (random) 0 14, ,X X .
31
2.6.2 Special Pattern Attack [7]
Wang et al. [7] start by looking for a difference pattern as in the Joux
attack, but in their attack the search for an appropriate difference pattern is
divided into two separate parts: finding a useful input differences pattern to
have a 'nice' differential behaviour in some parts (e.g. in the last round), and
then find an appropriate output difference pattern for the remaining steps.
For example, in the MD4-attack the input pattern is chosen such that
randomly chosen messages conform to the differences pattern in the last (i.e.
third) round with a probability of ¼. This can be done by looking at the step
operation and choosing the input differences such that they cancel each after
only a few steps. For example, the step operation of the last round of MD4 can
be described by the following equation (for step i.)
4 1 2 3( )i i i i i i i iR R R R R W K s
Thus, if we induce a (modular) difference of 216 into X12 which is used as
W35 in step 35, we can see that in this step the value in the brackets produces
also a difference of 216 (if we suppose that in the steps before there have been
zero output difference in the Ri) Then by the rotation by s35=15 bits, this
modular difference is rotated to either a difference of 231 or 231+1, depending
on one of the carry bits [19]. Hence, with a probability of ½ (depending on the
actual values of the registers) the modular difference in R36 is 231. The
advantage of using this special modular difference is that it implies also an -
difference of 231 in 35R . Thus in the next step
36 32 35 34 33 36 36( ) 3R R R R R W K
It follows that the operation 35 34 33R R R results in difference of
again 231 by choosing a difference 231 or 228 for X2 = W36 we then get a
difference 238 in the brackets (the "231"s cancel as we compute module 232)
32
which is again rotated to a difference 231 in R36 with a probability of ½. Similar
considerations can be done for the following steps to produce zero difference.
The complete difference propagation up to the collision in step 41 is illustrated
in Figure 2.8
4 1, 2 3( )i i i i i i i iR R R R R W K s
31 28
Pr .1/ 231 16
Pr.1/ 231 31 2 2
31 31
35 : 2 2
36 : 2 2
37 : 2 2
i 15
i 3
i
3138 : 2
i
312 3139 : 2
i
312 3140 : 2
i
312 41:
i
Figure 2.8. Difference propagation in last round of MD4
By this consideration the complete input difference pattern is determined.
To determine the complete difference it remains to find an output pattern for
the first rounds which can be fulfilled given this input pattern. Wang et al. do
this similarly to what we just described by simply considering the step
operation and the modular differences in the registers.
Using such techniques Wang et al. found the differential patterns together
with a set of conditions on the register values (similar to those in the
Chabaud/Joux attack) which were used to find the actual collisions.
2.7 MAC ALGORITHMS
MAC algorithms compute a short string as a complex function of a message
and a secret key. The recipient shares a secret key with the sender. On receipt
33
of the message, he recomputed the MAC value. If it is correct, he is convinced
that the message originated from the particular sender and that it has not been
tampered with during the transmission. Indeed. If an opponent modifies the
message, the MAC value will no longer be correct. Moreover, the opponent
does not know the secret key, so he is not able to predict how the MAC value
should be modified [12, 13].
The main security properties of a MAC algorithm is that one should not be
able to forge MAC values, that is, to predict values on new messages without
knowing the secret key. A second requirement is that it should be
computationally infeasible to recover the MAC key by exhaustive search.
2.7.1. Block Cipher Based
The most popular MAC algorithms are variants of CBC-MAC which are
based on a block cipher.
There exists several security proofs for CBC-MAC and variants (Bellare,
Krawcays and Rogaway, Petrank and Rackoff, Vaudenay, Maurer, Black and
Rogaway). Most of these proofs reduce the security of CBC-MAC to the
assumption that the underlying block cipher is a pseudo-random function.
Moreover, the best advantage an attacker has to break the system that can be shown
in this case is on the order of q2.m2/2n, with q the number of chosen text, m the
number of blocks in each message, and n the block length of the block cipher.
If CBC-MAC is used with a pseudo-random function, the best known
attack by Preneel and van Oorschot has advantage q2.m/2n. If CBC-MAC is
used with a pseudo-random permutation (as this is done in practice) the best
known attack by Preneel and van Oorschot has advantage q2/2n.
2.7.2. Hash Function based
The security of HMAC, EHMAC and ENMAC is based on a set of non-
standard assumptions, such as pseudo-randomness properties in the presence of
34
secret initialization vectors and collision-resistance or weak-collision-resistance
with secret IVs. These assumptions should be studied for reduced-round versions
of popular hash algorithms such as MD5, SHA1 and RIPEMD-160, Also,
collisions and near-collisions have been found on several hash functions recently.
For how many rounds of these functions can one break the HMAC
construction?
Do near-collisions endanger of the HMAC construction at all? Are more
efficient primitives such as EHMAC or ENMAC at risk?
2.7.3. Universal hash function based
Universal hash functions today are either moderately efficient (in between
HMAC-SHA-1 or HMAC-MDS) with a rather short key, or extremely efficient
(UMAC) with a rather long key [23].
Can we improve the trade-off, that is, develop constructions that are
extremely fast in software yet have modest keys (say less than 64
bytes)?
2.8 FORMAL ALGORITHMS
2.8.1 The XL Algorithm and Variants
The linearization method work, when the number of linearly independent
(LI) equations in the system is approximately the same as the number of terms
in the system. A number of techniques have been proposed to generate enough
LI equations in the contrary case. The XL algorithm (Standing for eXtended
Linearization) aims at introducing new rows to the matrix iLM by
multiplication of the original equations by monomials of prescribed degree.
More specifically, the following matrix MXL is constructed.
35
... X ...
1X f ... 1,c ...
= MXL,
1
mX f ... 1,ic
...
where the set of the rows is constructed from all products 1,j
jX f c X ,
where and jf are such that deg 1
jX f D, D being a parameter of the
algorithm. The hope is that at least one univariate equation (say in 1X ) will
appear after the Gaussian elimination on MXL.
2.8.2 Gröbner Bases Algorithms
Gröbner bases algorithms are perhaps the best known technique for solving
polynomial systems. These algorithms return a basis for the ideal derived from
the set of equations, which can then be used to obtain the solutions of the
system [13].
Let be a monomial order, i.e. a total order on the set of monomials
, nX which is compatible with multiplication. Then the set of terms
c X of a polynomial 1, , nf c X k X X
can be ordered with
respect to and the notion of leading term LT f , leading monomial LM f
and leading coefficient LC f of the polynomial f are all well defined.
Let 1, , nI k X X be an ideal and let LM I = {LM f : fI} be the set
of leading monomials of polynomials in I. A Gröbner basis of the total I is a set
1, , lG g g I such that:
36
1
( ) , , .l
ni
i
LM I LM g X
In other works, G is a Gröbner basis of I if the leading term of any
polynomial in I is divisible by the leading term of some polynomial of G. One
can show that every non-empty ideal 1, , nI k X X .
There is also the notion of a Gröbner basis of degree D of an ideal (denoted
by GD), which has the property that the leading monomial of every polynomial
in I of degree < Divisible by the leading monomial of a polynomial of GD. It
can be shown that there exits D large enough such that GD is a Gröbner basis of I.
Gröbner bases algorithms are powerful tools for solving systems of
polynomial equations. In most cases, when the Gröbner basis is found, the
solution is also found. For most cryptographic applications, we will have a
system with unique solution, say 1 2, , nna a F , and the ideal is radical. Then
the reduced Gröbner basis of I is 1 1, , n nX a X a .
2.8.3. The Buchberger algorithm
The Buchberger algorithm is the classical algorithm for computing the
Gröbner basis of an ideal I. It is based on a generalization of the Euclidean
division of polynomials in one variable to the multivariate case. More
precisely, given a monomial order, there exists an algorithm division
1 1, , , , , ,l lf f f g g r with the following properties:
1 1 l lf f g f g
can be computed by the following algorithm (Buchberger algorithm):
Initialize: 1, , lG f f
Loop
1. Combine every pair ,i jf f canceling leading terms, to get ,i jS f f
(The S-polynomials);
37
2. Compute the remainders of the ,i jS f f by G;
3. Augment G with the non-zero remainders.
Until all remainders are zero.
Return G.
We can show that this algorithm terminates and computes a Grobner basis
of the ideal generated by 1, , lf f . It is a fact that most S-polynomials
generated in step 1 will reduce to zero, and therefore many useless
computations leading to zero remainder are performed. The algorithm can be
modified to include Buchberger's criteria [17], which are a perioi conditions on
the pairs ,i jf f to detect the ones whose S-polynomial will have a remainder
equal to zero, and therefore discard them from Steps 1, 2 of the algorithm.
While a great proportion of pairs will be discarded by the criteria, still many S-
polynomial constructed will reduce to zero, as experience in reported
implementations.
The complexity of the Buchberger algorithm is closely related to the total
degree of the intermediate polynomials that are generated during the running of
algorithm.
2.8.4. The F4 and F5 Algorithms
The F4 algorithm is a matrix version of the Buchberger algorithm. To
introduce the idea, we first depict the Euclidean division for univariate
polynomials
1 0 1 0and ,d dd df f X f X f g g X g X g
with d' < d as matrix reduction algorithm. Consider the following:
38
Xd Xd-1 X0
f fd fd-1 ... f0
Xd-d'g gd' gd'-1
... g0
Xd-d'-1g 0 gd' gd'-1
... g0 ......(1)
Xd-d'-2g 0 0 gd' gd'-1
... g0
g 0 0 0 0 gd' gd'-1
... g0
Then successive reduction of the first row by the remaining rows (row
echelon reduction by elementary row operations) give the remainder of f by g.
Similarly the multivariate division algorithm can be written in a matrix fashion.
The above mentioned algorithms are related. In fact, let M denotes the
Macaulay matrix with an infinite number of rows and columns, defined as:
... X ...
iX f ... 1,c ...
= M,
jX f ... ,jc
...
for all monomials X, X of unbound degree. The MXL matrix of XL algorithm
in degree D is therefore just a finite sub-matrix of the Macaulay matrix,
corresponding to all monomials of degree less than or equal to D. Performing
Gaussian elimination on the Macaulay matrix is equivalent to running the
Buchberger algorithm. This fact is closely related to the behaviour of XL
algorithm, and shows that XL algorithms terminates for a degree D if and only
39
if it terminates in degree D for the lexicographical ordering concerning F4, we
can see that
... X ...
iX f ... 1,c
...
= 4FM
jX f ... , jc ...
is constructed only from pairs ,i jf f originating from the previous iteration of
the algorithm, and which are not discarded by the Buchberger criteria. It shows
that 4FM is a very small sub-matrix of the matrix MXL constructed by XL.
Using an XL description as an 4F algorithm, is proven that a slightly modified
XL computes a Gröbner basis. For efficiency reasons, Buchberger [12] suggests
to translate 5F to an algorithm in 4F fashion. As current records in computing,
Gröbner bases were obtained using variants of the 4F algorithm, we try to
develop an 5F variant based on linear algebra techniques similar as those
employed in 4F . Such a hybrid version specialized for fields of characteristic
two, called 5 2F , was also used by Courtois [15] to break first HFE challenge.
The 4F algorithm benefits from transforming the reduction of polynomials
to the problem of reducing a matrix over the coefficient ring to row echelon
form. Efficiently solving large systems of linear equations over finite fields is a
difficult, but well-studied problem, which arises for instance in index-calculus
methods for computing discrete algorithms. This translation enables the use of
efficient sparse linear algebra techniques to speed up the reduction.
40
The major feature of 5F is that it prevents all reduction to zero caused by
principal syzygies and by the syzygies caused by new polynomials.
2.9 CONCLUDING REMARKS
There are two families of basic cryptographic algorithms: symmetric
algorithms, and public-key algorithm. Symmetric techniques are still widely
used because this can achieve high speed, low cost encryption, fast
authentication and efficient hashing. In modern perspective, we find symmetric
algorithms in GSM mobile phones, in credit cars, in WLAN connection, and
symmetric cryptology is a very active research area.
This chapter gives a brief introduction to some research trends in
symmetric cryptography. We discuss some aspects of symmetric cryptography
that can be used to solve the problems of the status of work with regard to
different types of symmetric algorithms, including block ciphers, stream
ciphers, hash functions and MAC algorithms, the recently proposed algebraic
attacks on symmetric primitives and the design criteria for symmetric ciphers.
Here we review recent progress and problems concerning different types of
symmetric primitives. One recent advance has been in cryptanalysis of secure
hash functions and MAC algorithms. We also focus on algorithms for solving
algebraic systems, which lie at the core of the recently proposed algebraic
attacks against block and stream ciphers.
REFERENCES
1. F. Armkencht. Improving fast algebraic attacks. In Fast Software Encryption – FSE 2004, LNCS, # 3017, pp. 65-82. Springer-Verlag, 2004.
2. F. Arnault, and T. P. Berger, F-FCSR: design of a new class of stream ciphers. In Fast Software Encryption – FSE 2005, LNCS, # 3557, pp. 83-97. Springer-Verlag, 2005.
3. M. Bellare, J. Kilian, and P. Rogaway. The security of cipher block chaining. In Advances in Cryptology – CRYPTO'94, LNCS, # 839, pp. 341-358. Springer-Verlag, 1994.
41
4. M. Bellare, R. Guerin, and P. Rogaway, XOR MACs: New Methods for Messagve Authentication Using Finite Pseudorandom Functions. In Advances in Cryptology, CRYPTO'95, LNCS, # 963, pp. 15-26. Springer-Verlag, 1995.
5. M. Bellare, R. Canetti, and H. Krawczyk, Keying hash functions for message authentication. In Advances in Cryptology – CRYPT'96, LNCS, # 1109, pp. 1-15, Springer-Verlag, 1996.
6. E. Biham, and R. Chen. Near-Collision of SHA-0. In Advances in Cryptology – CRYPTO'94, LNCS, # 3152, pp. 290-305. Springer-Verlag, 1994.
7. E. Biham, R. Chen, A. Joux, P. Carribault, C. Lemuet, and W. Jalby. Collisions on SHA-0 and reduced SHA-1. In Advances in Cryptology – EUROCRYPTO 2005, LNCS, # 3494, pp. 19-35. Springer-Verlage, 2005.
8. E. Biham, and A. Shamir. Differential cryptanalysis of DES- like cryptosystems. In Advances in Cryptology – CRYPTO'90, LNCS # 537, pp. 2-21. Springer-Verlag, 1991.
9. Biryukov, and A. Shamir. Cryptanalytic time-memory-data trade-offs for stream ciphers. In Advances in Cryptology – ASIACRYPTO 2000, LNCS, # 1976, pp. 1-14. Springer-Verlag, 2000.
10. Biryukov S. Mukhopadhyay, and P. Sarkar. Improved time-memory trade-offs with multiple data. In Selected Areas in Cryptography – SAC 2005, LNCS, # 3496, pp. 30-37, Springer Verlag, 2005.
11. Buchberger. A criterion for detecting unnecessary reductions in the construction of Gröbner basis. In Symbolic and Algebraic Computation, EUROSAM'79, An International Symposium on Symbolic and Algebraic Computation, LNCS, # 72, Springer Verlag, 1979.
12. Buchberger. Gröbner bases: An algorithmic method in polynomial ideal theory. In Multidimensional Systems Theory. LNCS, # 3329 pp. 28-31.
13. Cid, and G. Leuretn. An analysis of the XSL algorithm. In Advances in Cryptology-ASIACRYPT 2005, LNCS, # 3788, pp. 333-352, Springer Verlag, 2005.
14. Cid, S. Murphy, and M. Robshaw. Small Scale Variants of the AES. In Fast Software Encryption – FES 2005, LNCS, # 3557, pp. 145-162. Springer-Verlag, 2005.
15. N. T. Courtois. The security of hidden field equations (HFE). In Progress in Cryptology – CT-RSA 2001: The Cryptographers' Track at RSA Conference 2001. LNCS, # 2020, pp. 201-206, Springer-Verlag, 2001.
16. N. T. Courtois. Higher order correlation attacks, XL algorithm and cryptanalysis of toyocrypt. In Information Security and Cryptology – ICISC 2002: 5th International Conference, LNCS, # 2587, pp. 208-215. Springer-Verlag, 2002.
42
17. N. T. Courtois, A. Klimov, J. Patarin, and A. Shamir. Efficient algorithms for solving over defined systems of multivariate of polynomial equations. In Advances in Cryptology – EUROCRYPT 2000, LNCS, # 1807, pp. 1-7, Springer-Verlag, 2000.
18. N. T. Courtois, and J. Patarin. About the XL algorithm over GF(2). In Topics in Cryptology-CT-RSA 2003: The Cryptographers' Track at the RSA Conference 2003, LNCS, # 2612, pp. 141-157, Springer-Verlag, 2003.
19. N. T. Courtois, and J. Pieprzyk, Cryptanalysis of block ciphers with overdefined systems of equations. In Advances in Cryptology-ASIACRYPT 2002, LNCS, # 2501, pp. 267-287. Springer-Verlag, 2002.
20. T. Jakobsen. Cryptanalysis of block ciphers with probabilistic non-linear relations of low degree. In Advances in Cryptology-CRTYPTO'98, LNCS, # 1462, pp. 212-222. Springer-Verlag, 1998.
21. T. Jakobsen, and L. R. Knudsen. The interpolation attack on block ciphers. In Fast Software Encryption 97, LNCS, # 1267, pp. 201-207, Springer-Verlag, 1997.
22. T. Kasami. The weight enumerators for several classes of subcodes of the second order Binary Reed-Muller codes. Information and Control, 18: 369-394, 1971.
23. J. D. Key, T. P. McDonough, and V. C. Mavron. Information sets and partial permutation decoding for codes from finite geometries. Finite Fields and Their Applications, 2005, pp. 14-22.
24. Klapper, and M. Goresky. Feedback shift registers, 2-adic span and combiners with memory. Journal of Cryptology, 10(2), pp. 281-292, 1997.
25. Klimov, and A. Shamir. A new class of invertible mappings. In CHES 2002, LNCS, # 2523, pp. 47-483. Springer-Verlag, 2002.
26. Klomov, and A. Shamir. Cryptographic applications of t-functions. In Selected Areas in Cryptography – SAC 2003, LNCS, # 3006, Springer-Verlag, 2004.
27. W. Stallings. Cryptography and Network Security, Fourth Edition PHI, New Delhi, 2007.
28. D. R. Stinson, Cryptography, Theory and Practice, Second edition, Chapman & Hall/CRC, 2005.
29. Santosh Kumar Yadav, and Sunder Lal. On Algebraic Immunity of Functions: A Cryptographic Problem. Accepted IEEE, Mathematics Research Forum, Nigeria Region.
43
Chapter 3
MATHEMATICAL TOOLS OF ASYMMETRIC CRYPTOGRAPHY
3.0 OVERVIEW
The aim of this chapter is to discuss some mathematical tools used for
asymmetric encryption algorithms beyond the RSA public key cryptosystem.
There are millions of products which are based on RSA Cryptography.
Mumford representation, group operation, Cantor’s algorithm, ECDSA-
signature algorithm and signature verification algorithm etc. are some
important tools for asymmetric cryptography. Recently lattice based systems
and NTRU cryptosystems have been added to the list of mathematical tools of
asymmetric cryptography.* Some such tools have been introduced and analyzed
in the present chapter.
3.1 INTRODUCTION
Since the introduction of RSA some 35 years ago, several cryptosystems
based on elliptic and hyper elliptic curves, algebraic codes, multivariate
quadratic equations, and polynomial factorization such as NTRU, have been
proposed. These cryptosystems have one or more advantages over RSA, with
respect to speed, key length availability of protocols, ease of set-up and
implementation. The RSA system has been shown to provide less security than
initially believed specially with moderate key length. Hence, alternative
systems are being invented and used [13].
The need for ever increasing levels of security together with the
improvements of techniques for factoring integers and solving the discrete
* The present chapter is based on author’s paper “Mathematical Tools of Asymmetric Cryptography”,
presented in ICRTMA’09 at Jamia Millia Islamia University, Delhi and extended abstract published in Proceedings pp.6.
44
logarithm problem in finite fields has led to increase in key size to the tune of
1000 bits or even more. For elliptic curve cryptosystems, and lattice based
cryptosystems there are no known sub-exponential attacks. This means that, as
security demands increase, the lengths of the key sizes for ECC or for lattice-
based cryptography increase much slower than the key sizes for RSA or for
cryptosystems based on the DLP in finite fields. Since there is an obvious
correlation between key size and performance for a given cryptosystem, it is
clear that RSA could soon become impractical, and that alternative systems
will offer better performance and security at the same time. As a matter of fact,
implementing high-security RSA is becoming a technological challenge.
3.2 CURVE BASED CRYPTOSYSTEMS
Systems based on the discrete logarithm problem in the Jacobian of curves
over finite fields were suggested in 1985 by Miller and Koblitz independently.
Since then a lot of research has been done towards efficient implementations of
curve based cryptography. Elliptic curves cryptosystems are widely studied
because of their security properties. Special curves for which the Tate pairing
can be computed efficiently have also been used by Boneh and Franklin for
ID-based cryptography. Hyper elliptic curves which were not considered
competitive enough as compared to elliptic curves because of the difficulty of
finding suitable curves and their poor performance, have also been used to
construct efficient and secure ID-based cryptosystems [26].
3.3 SOME BASIC DEFINITIONS
Definition 3.3.1: Let K be a field. The projective curve defined by the affine
equation.
2: ( ) ( ), , [ ], deg( ) 2 1, deg( )C y h x y f x f h K x f g h g (1)
45
is a hyper elliptic curve of genus g if there is no point P C K over the
algebraic closure K such that both partial derivatives vanish simultaneously.
Example 3.3.1: An elliptic curve, i.e. a curve of genus 1, over F2 is given by
2 3 2 1y xy x x
as the only point for which the partial derivative with respect to y vanishes in
(0, 1) and it does not satisfy the partial derivative with respect to x.
According to this definition we subsume elliptic curves as curves of genus 1
under hyper elliptic curves.
3.3.1 Group Operation
Let
2 3 21 3 2 4 6: + + = + + +E y a xy a y x a x a x a
be an elliptic curve defined over a field K.
We define the group operation on two points as follows:
Let ( , ),= P PP x y ( , ),= Q QQ x y and ( , ).R RP Q R x y Then
1 3( , ),P P PP x y a x a
21 2 1 3( , ( ) ),P Q P Q P QP Q a a x x x x y a x a
where
2
2 4 1
1 3
if ,
3 2 if .2
P Q
P Q
P P P
P P
y yP Q
x x
x a x a a y P Qy a x a
(2)
46
If char(K) = 2, one can either achieve 1 41, 0= =a a or 1 20, 0= =a a and
otherwise one gets 1 3 0= =a a and for char(K) 3 additionally 2 0.=a For
each of these cases addition formulae are simplified and become faster than the
general formulas stated in (2) Additionally, for each case there are other
representations of the curve which allow to implement the group arithmetic
without inversions. Usual choices are =q pF F a prime field with 1602>p and
2 pq F F with p a prime > 160 and for these choices the formulas are
optimized for efficient scalar multiplication.
Elliptic Curve Cryptography
ECC is the counterpart of modular multiplication in RSA and multiple
addition is the counterpart of modular exponentiation. To form a cryptosystem
using elliptic curves, we find a hard problem corresponding to factoring the
product of two primes or taking the discrete algorithm.
We consider the equation (discrete problem of EC)
Q = kP, where , ,pQ P E a b , and k < p
Analog of Diffie-Hellman key exchange shows the following:
(i) Pick a large integer q, which is either a prime number p or an integer of the
form 2m and elliptic curve parameters a and b for equation
2 3mod mod .y p x ax b p
This defines the elliptic group of point , .qE a b (ii) Pick a base point 1 1, in ,pG x y E a b whose order is very large value n. The order n of a point G on an elliptic curve is the smallest positive integer n such that . ,qnG O E a b
47
and G are parameters of the cryptosystem known to all participants.
A key exchange between users A and B can be accomplished as follows:
1. A selects an integer An less than n. This is A’s private-key. A then
generates a public-key ;A AP n G the public-key is a point in , .qE a b
2. B similarly selects a private-key Bn and computes a public-key .BP
3. A generates the secret key .A BK n P
B generates the secret key .B AK n P
Two calculations in steps 3 produce the result because
.A B A B B A B An P n n G n n G n P
To break this scheme, an attacker would need to be able to compute k given G
and kG, which is too hard.
ECDSA – Signature Algorithm
In: message m, entity A with private key d and public key Q = [d]P, domain
parameter D.
Out: A’s signature (r, s) on m.
1. Select a random or pseudorandom integer k, 1 1.k
2. Compute [k] 1 1( , )=P x y and 1=r x mod . If r = 0 goto step 1.
3. Compute 1 mod-k .
4. Compute e = SHA-1 (m).
5. Compute e = 1( )mod .- +k e dr If s = 0 goto step 1.
6. A’s signature for the message m is (r, s).
Clearly the hash function SHA-1 can be replaced by any other hash function.
48
ECDSA – Signature Verification Algorithm
In: A’s signature (r, s) on message m and A’s public key [ ] ,=Q d P domain
parameters D.
Out: Acceptance or Rejection of signature.
1. Verify that r and s are integers in the interval [1, 1].-
2. Compute e = SHA-1(m).
3. Compute w = s-1 mod .
4. Compute u1 = ew mod and u2 = rw mod .
5. Compute 1 2[ ] [ ] .X u P u Q If ,X P then reject signature.
Otherwise compute 1 mod ,=v x where 1 1( , ).=X x y
6. Accept the signature if and only if v = r.
The scheme works correctly as
1 1 11 2( ) modk s e dr s e s dr we wrd u u d
and thus
1 2 1 2[ ] [ ] ( ) [ ]u P u Q u u d P k P
and so v = r as required.
3.4 LATTICE BASED CRYPTOGRAPHY
Several cryptographic schemes based on the hardness of lattice problems
have been proposed. These schemes attracted interest for at least three reasons:
49
1. There are very few public-key cryptosystems which are based on problems
different from integer factorization (RSA) or the discrete logarithm
problem (ElGamal).
2. Some of these schemes offer encryption/decryption rates asymptotically
higher than classical schemes.
3. Lattice problems have better complexity than their classical counterparts. It
is therefore assumed that the lattice-based schemes might survive the
quantum computation era.
A lattice is a discrete (additive) subgroup of .n In particular, any
subgroup of n is a lattice, such lattices are called integer lattices.
Equivalently a lattice consists of all integral linear combinations of a set of
linearly independent vectors, that is,
1
| ,d
i i ii
L n b n
where the 'ib s are linearly independent over . Such a set of vectors 'ib s is
called a lattice basis. All the bases have the same number dim(L) of elements,
called the dimension (or rank) of the lattice.
Since a lattice is discrete, it has a shortest non-zero vector: the Euclidean
norm of such a vector is called the lattice first minimum, denoted by 1( )L or
|| || .L We will use || ||L to denote the first minimum for the infinity norm.
More generally, for all 1 dim( ),i L Minkowski’s thi minimum ( )i L is
defined as the minimum of 1max || ||j i jv over all i linearly independent
lattice vectors 1,..., .iv v L There always exist linearly independent lattice
vectors 1,..., dv v reaching the minima, i.e., is || || ( ).i iv L However, for
dim( ) 4,L such vectors do not necessarily form a lattice basis, and for
50
dim( ) 5,L there may not even exist a lattice basis reaching the minima. For
this reason there exist several notions of basis reduction in high dimension,
without any “optimal” one, The lattice gap is defined as the ratio 2 1( ) ( )L L
between the first two minima.
Minkowski’s Convex Body Theorem guarantees the existence of short
vectors in lattices. Further, any d-dimensional lattice L satisfies 1/|| || vol( ) ,dL L which is perhaps the best possible bound. It follows that
1/|| || vol( ) ,dL d L which is not optimal, but shows that the value
1/1( ) vol( ) dL L is bounded when L runs over all d-dimensional lattices. The
supremum of 2 2 /1( ) vol( ) dL L is denoted by d and is called Hermite’s
constant of dimension d. Exact value of Hermite’s constant is only known for
8.d
3.4.1 Minkowski Theorem
For all d-dimensional lattices L and all :r d
1
vol .r
r dri d
i
L L
For any lattice L of ,n one defines the dual lattice (also called polar lattice) of L as:
* span( ) : , , .L x L y L x y
If 1( ,..., )db b is a basis of L, then the dual family * *1( ,..., )db b is a basis of *L
(the dual family if the unique linearly independent family of span(L) such that * *( ,..., )i jb b is equal to l if i = j, and to 0 otherwise). Thus, * *( ) =L L and
*vol( )vol( ) 1.L L The transference theorems relate the successive minima of
a lattice and its dual lattice. The first transference theorem states that:
51
*1 1( ) ( ) .dL L
A more difficult transference theorem ensures that for all 1 :r d
*1( ) ( ) .r d rL L d (Constant)
3.4.2 The Ajtai-Dwork Cryptosystem
Description: The Ajtai-Dwork cryptosystem [1] works in ,n with some
finite precision depending on n.
The private key is a uniformly chosen vector u in the n-dimensional unit
ball. One then defines a distribution uH of points a in a large n-dimensional
cube such that the dot product ,a u is very close to .
The public key is obtained by picking w1,…, wn, v1,..., vm (where m = n3)
independently at random from the distribution uH , subject to the constraint
that the parallelepiped w spanned by the wi's is not flat. Thus, the public key
consists of a polynomial number of points close to a collection of parallel
affine hyper-planes, which is kept secret.
The scheme is mainly of theoretical purpose, as encryption is bit-by-bit. To
encrypt a '0', one randomly selects b1, …, bm in {0, 1}, and reduces 1
mi ii
b v
modulo the parallelepiped w. The ciphertext of '1' is just a randomly chosen
vector in the parallelepiped w. To decrypt a ciphertext x with the private key u,
one computes , .x u If is sufficiently close to , then x is decrypted as
'0', and otherwise as '1'. Thus, an encryption of '0' will always be decrypted as
'0', and an encryption of '1' has a small probability to be decrypted as '0'.
Security: The Ajtai-Dwork cryptosystem received wide attention due to a
surprising security proof based on worst-case assumptions. One can show that
any probabilistic algorithm which distinguishes encryptions of a '0' from
52
encryptions of a '1' with some polynomial advantage can be used to solve SVP
in any n-dimensional lattice for which the gap 2 1/ is larger than n8. It is
known that the problem of decrypting ciphertexts is unlikely to be NP-hard.
A cryptanalysis can attack to recover the secret key as follows: One knows
that each ,iv u is close to some unknown integer vi. It can be shown that any
sufficiently short linear combination of the vi's give information on the vi's.
More precisely, if i iiv is sufficiently short and the i 's are sufficiently
small, then 0.i iiv Note that the vi's are disclosed if enough such equations
are found. And each vi gives an approximate linear equation satisfied by the
coefficients of the secret by u. Thus, one can compute a sufficiently good
approximation of u from the vi's. To find the vi's, we produce many short
combinations i iiv with small i 's, using lattice reduction. Theoretically
there exist enough such combinations. Experiments showed that the assumption
was reasonable in practice.
3.5. THE NTRU CRYPTOSYSTEM
Let denote the ring of integers and q the integers modulo q. We shall
represent. The elements of q in the symmetric interval 2, 2q q . For a
positive integer N, we identify the set N (resp. )Nq with the ring of
polynomials P(N) = [ ] 1NX X (resp. ( ) [ ] 1 ),Nq qP N X X by
1
0 1 10
( , ,..., ) .N
iN i
if f f f f X
Here, the modulus q may not necessarily be prime and hence q may not be a
field.
53
Two polynomials , ( )f g P N are multiplied by the cyclic convolution
product which will be denoted by * to distinguish it from the multiplication in
or [ ].X Let ,= *h f g then the thk -coefficient kh of h is given by
1
0 1 mod
0 .k n
k i k i i n k i i jki i k i j k N
h f g f g f g f g k N
This is the ordinary polynomial product in ( ),qP N and is both commutative
and associative. The symmetric representation of q ensures that the product
of two polynomials with coefficients of small absolute value will again be a
polynomial with small coefficients.
The multiplicative group of units in ( )qP N we shall denote by *qP (N) and
the inverse polynomial of *( )qf P N is denoted by 1qf .
We will also require a “small” element of P(N) which is relatively prime to
q, which we shall dente by p. Typically p is chosen to be equal to one of
2, 3, or 2 + X.
Reduction modulo p when p is equal to 2 or 3 is conducted in the standard way
to produce a representative either in the set {0, 1} or the set {-1, 0, 1}. When
p = 2 + X a slightly nonstandard reduction is carried out, signified by the use of
p = 2 + X rather than p = X + 2. By writing 2 + X we are signifying that the
term 2 is of higher priority than X in the reduction. The reduction of a
polynomial modulo 2 + X proceeds by rewriting each integer n = 2a + b
as (-X)a + b. Hence, we rewrite 2 as – X as opposed to the more standard
rewriting of X as – 2. As an example of these two different types of reduction
consider.
4 6 2 (mod 2) 6+ + + =X X X
54
4 46 2 (mod 2 ) 3( ) ( )X X X X X X X
4 23X X X
4 2 24 2X X X X X
4 2 2 2( ) ( )X X X X X X X
22= +X X
3X X
3 32X X X
4 3 .= + +X X X
It is easily seen that reduction modulo 2 + X always leads to a polynomial with
coefficients in {0, 1}.
We now define ( )pP N to be the elements in P(N) reduced modulo p, the
multiplicative group of units in ( )pP N we shall denote by * ( )pP N and the
inverse polynomial of *( )pf P N is denoted by 1.pf
3.5.1 Primitives of NTRU
We choose public parameters N, p and q as above with p and q relatively
prime, and q > p. The value of q is chosen to lie between N/2 and N and chosen
to aid computation. For the “recommended” security parameter N=251 we may
choose q=128 or q=127 so as to aid in reduction modulo q.
Other required parameters are various pairs of integers 1 2( , )d d which are
used to define several families of trinary polynomials of ( )qP N as follows: Let
1 2( , )d dL denote the set of polynomials in ( ),qP N with 1d coefficients equal
to 1, 2d coefficients equal to –1 and all other coefficients set to zero. These
55
sets are used to define three sets of polynomials ,f gL L and .rL In literature
three common choices for these sets are as follows:
Choice A
This is the choice used in earlier academic papers on the NTRU system, where
( , 1), ( , )f f f g g gd d d d L L L L and ( , ).r r rd dL L
for certain parameters ,f gd d and rd dependent on the security parameter N.
Choice B
This choice is one adopted in the standard .We have
11 11 : ( ,0) ,f fp f f d L L
( ,0),g gdL L ( ,0),r rdL L
for certain parameters ,f gd d and .rd Here we note with this choice of f
computing 1pf is easy.
Choice C
This is also a choice adopted in the standards, but produces polynomials
slightly larger than those in Choice B. In this case we have
1 2 31 : ( ,0) ,if i fp f f f f d L L
( ,0),g gdL L
: ( ,0) .ir i rr d 1 2 3L r r + r L
for certain parameters 1 2 3 1 2 3, , , , , and .f f f g r r rd d d d d d d
56
In a public key encryption algorithm we need three sub-procedures: A key
generation algorithm, an encryption algorithm and a decryption algorithm.
These procedures in the context of the NTRU algorithm are as follows.
Key Creation
The generation of public/private keys then proceeds as follows:
1. Choose random ff L and .ggL
2. Compute 1 ( )q qf P N and 1 ( )*p pf P N , if they exist
3. If one of these inverses does not exist choose a new f. Otherwise f serves as
the secret key.
4. Publish the polynomial
1 (mod )qh p f g q (3)
as the public key.
Let 0 1 1, ,..., ( ).N qf f f f P N Then
1 1 0 1 1, ,..., , ,..., , ( ).iN i N i N N i Nf x f f f f f i
Thus, if f is the secret key of NTRU, then ( )if x is also a secret key for any
integer i > 1.
Note that for parameter Choice’s B and C we have 1 1pf and so we do
not have to compute this value.
Encryption
NTRU encryption is a probabilistic algorithm. To encrypt a plaintext m,
(which we identify as a polynomial in ( )),pP N we perform the following steps.
57
1. Chose random .r rL
2. Compute
( ; ) (mod ).he m r r h m q (4)
Decryption
Given a ciphertext e and a private key f, (and hence 1qf and 1)pf , decryption
is performed as follows:
Step 1:
First we compute
1
(mod )(mod )
(mod )q
a e f qr p f g f m f qp r g m f q
(5)
to get an element of P(N).
Step 2:
We now switch to reduction modulo p by computing
1 1 1
1
(mod )
(mod )
(mod ).
p p p
p
a f p r g f m f f p
m f f pm p
(6)
and recover the plaintext ( ).pm P N Note that for parameter Choices B and C
we have 1 1,pf = and therefore the above calculation simplifies to
(mod )a m p
58
Notice, that the message lies in ( ),pP N whilst the ciphertext lies in ( ).qP N In
practice q is chosen fairly larger than p and so this leads to a large expansion
rate for a message. With typical values for p and q one can have that the
ciphertext is seven to eight times larger than the underlying plaintext. In
practice this is not so much a problem since public key encryption is mainly
used to transmit short session keys rather than encrypt actual messages. A
similar expansion happens in practice for RSA, where to encrypt a 128 bit
session key one embeds it into an RSA message block of over 1024 bits.
3.5.2 NTRU and Lattice Reduction
Here the public key is a polynomial ( )qh P N and the private key is given
by two “small” polynomials f and g such that
1 (mod ).h f g q
We call two polynomials u and v “a” factorisation of ( ),qh P N if
u h v holds in ( ).qP N The security of NTRU is based on the following
complexity assumption:
Assumption:
Given a polynomial ( ) [ ] 1Nqh P N X X with 1 ,qh f g where
the coefficients of the secret keys of f and g are small compared to q. For
appropriate choices of N it is hard to recover one of the polynomials f or g from
h or find two polynomials u, v with small coefficients such that
(mod ).u h v q
There are no statements about the hardness of the above polynomial
factorisation problem in complexity theory, but from the following heuristic
argument it appears to be a difficult problem: Every polynomial ( )qu P N
59
coprime modulo q to 1,NX has an inverse in ( )qP N and therefore gives a
solution to the factorisation problem. Thus there are | ( ) | NqP N q possible
factorisations of which only those with small l2-norm are useful for decryption.
Up to now, there are no polynomial time algorithms known to solve this
problem. But because the secret polynomials f and g have small l2-norm lattice
based attacks on the public key h might be a good strategy, if the polynomial
factorisation problem can be translated into a lattice problem. So consider the
set of vectors
2( , ) : (mod ), , .N NL u v u h v q u v
The set L forms a lattice in 2 ,N which clearly contains the vector (f, g). Thus,
if we could find a basis for L then finding short vectors in L might return (f, g).
Coppersmith and Shamir developed a basis for what will be called the NTRU
Lattice .NTL It is spanned by the row vectors of the (2N × 2N)-matrix
0 1 1
1 2 0
1 0 2
0 00 0
0 0,(
0 0 0 0 00 0 0 0 0
0 0 0 0 0
N
N NNT
h h hh h h
h h hL
qq
q
).
Notice that this lattice is not the same as L. However, Coppersmith and Shamir
showed, if 0 1( ,..., )Nu u u -= and 0 1( ,...., )Nv v v -= is an arbitrary factorization
of ( ),qh P N then the NTRU Lattice NTL contains the vector ( ),u v with
0 1 2 2 1( ) ( , , ,..., , ).N Nu u u u u us - -= Thus, in particular ( ), .NTf g L
60
Although the vector ( ),f g is not known to be the shortest vector in the
NTRU Lattice, Coppersmith and Shamir proved that shorter vectors correspond
to alternative private keys. Since current algorithms to find the shortest vector
in a given lattice are exponential in time with respect to the dimension, they are
(for appropriate parameter choices) no threat for the security of NTRU [7,28].
3.5.3 NTRU Security
As the NTRU system may provide imperfect decryption some interesting
issues in the development of the NTRU algorithm have cropped up. Before
discussing those, let us recall that the public key system means the following:
Given a message space M there is a triplet of algorithms , K D , where:
1. 1 ,kK the key-generation algorithm, is a probabilistic algorithm which on
input of a security parameter k produces a pair (pk, sk) of matching
public and private keys.
2. ( ; ),pk m r the encryption algorithm, which returns a ciphertext
{0,1}*c C corresponding to the plaintext mM , using a random bit
string r according to the public key pk.
3. ( )sk yD , the decryption algorithm, is a deterministic algorithm which on
input of the secret key sk and an arbitrary yC returns a message xM
or . If is returned, then y is an invalid ciphertext i.e. y is not in the
range of pk . In other words there exists no mM and r with
( ; ).pky m r
4. For any k the following holds: For all (pk, sk) which can be output of
1 ,kK and all mM that if ( ; ),pkc m r for any r, then ( ) .sk c mD
61
Some notable points here are the following:
The security parameter k in the key generation function is the parameter
used to measure the security of the scheme. In an RSA scheme k is the bit
length of the modulus, whilst in an elliptic curve based scheme k is the
base-2 logarithm of the size of the elliptic curve group. For NTRU the
value of k is given by the parameter N. We note that security parameters of
two different schemes are not comparable [28].
Non-probabilistic algorithms such as textbook RSA are considered insecure
under modern security definitions. We therefore allow probabilistic
encryption algorithms, for example ElGamal
The last property guarantees that if a plaintext m is encrypted using pk and
the resulting ciphertext is subsequently decrypted using skD , then the
original plaintext m results. This property holds for all the standard public
key algorithms such as textbook RSA, however it does not hold for NTRU
as we have already remarked.
According to the third property it may happen that for an invalid yC , i.e.
a ciphertext which cannot be obtained from a valid encryption, the
decryption algorithm returns a message xM . Thus, we call a public key
scheme restricted, if for every invalid yC the symbol is returned.
If the fourth property is violated, as it is in NTRU, i.e. there exists a
public/private key pair (pk, sk) and a message nonce pair (m, r) for which
( ( ; )) ,sk pk m r m D
62
then the public key cryptosystem is called imperfect. If we are given an
imperfect scheme, we refer to a valid ciphertext ( ; )pkc m r with
sk c mD as indecipherable with respect to m, otherwise we call the valid
ciphertext decipherable sk c mD
We describe the main ideas of the two DCA attacks against the NTRU
primitive. Here the adversary is given the public key h along with access to the
DC oracle.
(A) First attack: We assume that the adversary has freedom to choose
( )pm P N and .rrL The adversary then recovers the private key in
three stages:
Step1. Find ( , ) ( )p rm r P N L which lead to an indecipherable ciphertext
: ( , ) ,pkc m r pr g m f e.g. ( ) .sk c mD Thus there exists at
least one coefficient of c outside the interval ( 2, 2].q q
Step2. Using the (m, r) found in Step 1 one then finds a message ( )pm P N
with ( ( , ))sk pk m r m D such that if any nonzero bit of m is set to zero
then ( , )pk m r is decipherable.
It follows that : ( , )pkc m r pr g m f has coefficients in
2, ( 2 ) 1 .q q In addition m should satisfy the condition that
exactly one of the coefficients of c is in the set 2, ( 2) 1 ,q q
whereas the rest of the coefficients lies in the interval
( 2) 2, ( 2 ) 1 .q q
The message m is deduced form m by successively setting coefficients
to zero. If m = 0 or the condition does not hold, then we return to Step 1.
63
Step3. The coefficients j if - of the private key f can be determined by setting
the thi coefficient of m to -1, 0 and 1 respectively and checking whether
the corresponding ciphertext ( , )pk m r is decipherable.
Practical results show that one is very likely to find pairs (m, r) which
lead to a successful completion of Step 2 and 3.
(B) Second Attack: Here we assume that the adversary has freedom to
choose ( ),pm P N but rrL must be selected at random. This time
the polynomial g is recovered. Once g has been determined the private
key f can be found by solving the system of linear equation.
0 1 1
1 2 0
1 0 2
N
N N
h h hh h h
h h h
0
1
1N
ff
f
=
0
1
1
(mod ).
N
gg
q
g
Step1. The first stage of this attack is the same as for the last DCA attack, so
suppose we are given a tuple ( , ) ( )p rm r P N L which leads to an
indecipherable ciphertext [25].
Step2. Randomly search ( , ),r rr d dL such that ( , )m r is indecipherable.
Step3. Analyse the distribution of 1’s and -1’s in all the 'r s found in Step 2 to
recover the nonzero coefficients of g. If not all nonzero coefficients are
found then go back to Step 2.
3.6 XTR, SUBGROUP AND TORUS-BASED CRYPTOGRAPHY
3.6.1 XTR
The cryptosystems discussed in this section are all based on the DLP
(discrete logarithm problem) in a finite field and are based on the ideal of
64
working in a cycle subgroup G of the multiplicative subgroup of a finite field
,nqF [26] in such a way that the following properties hold.
1. Working in G is very efficient (the subgroup must be small, but also
large enough that Pollard rho attacks in it be ineffective).
2. The security of the system depends on the difficulty of solving the DL in
the full finite field nqF (the subgroup should not be contained in a
proper subfield of nqF ).
3. There is compact representation of the elements of G which is much
shorter than the representation of all the elements of nqF ( )n elements
of qF should suffice to represent the elements of G, except in some
cases where a few additional bits may be necessary.
XTR (or ‘ECSTR’: Efficient and Compact Subgroup Trace Representation) is a
cryptographic primitive that makes use of traces to represent and calculate
powers of elements of a subgroup of a finite field. The LUC cryptosystem uses
the trace over qF to represent elements of the order p + 1 subgroup of 2 .pF
Compared to the XTR uses the trace over 2pF to represent elements of the
order 2p – p + 1 subgroup of 6 ,pF thereby achieving a factor 3 size reduction.
We discuss classical XTR as under.
Let p and q be primes with p2(mod 3) and q dividing 2p p + 1 with a
small cofactor, and let g be a generator of the order q subgroup 2 1p pG
- + of 6p
F
(and thus g ) is interesting for cryptographic purposes because it cannot be
embedded in a proper subfield of 6 .p
F
65
For p and q of appropriate sizes the discrete logarithm problem in g is as
hard as the discrete logarithm problem in 6pF . Thus, for cryptographic
purposes working in g gives the same security as working in 6pF . For p and
q of about 170 bits the security is at least equivalent to 1024-bit RSA or 170-bit
ECC. In XTR elements of g are represented by their trace over 2pF . The
trace of h g equals the sum of its conjugates h, 2 1 ,p ph h -= and
4p ph h-= over 2pF . Thus, conjugates over 2p
F have the same trace as over
2pF , which implies that in XTR no distinction is made between a particular
element of g and its conjugates over 2pF . This has no real effect on difficulty
of the discrete logarithm problem in XTR. Before stating a precise result, we
introduce some notation: We say that problem A is (a, b)-equivalent to
problem B , if any instance of problem A (or B ) can be solved by at most
a (or b) calls to an algorithm solving problem B (or A ). As usual, DL
stands for discrete logarithm, DH for Diffie-Hellman and the DHD Problem is
the Diffie-Hellman Decision Problem: the XTR variants are defined in the
obvious ways but with the traces of the elements of g .
Theorem 3.6.1 The following equivalences hold:
1. The XTR-DL problem is (1, 1) – equivalent to the DL problem in g .
2. The XTR-DH problem is (1, 2) – equivalent to the DH problem in g .
3. The XTR-DHD problem is (3, 2) – equivalent to the DHD problem in g .
66
Facts: We collect here the computational costs of some operations.
1. Identities involving traces of powers, with ,u v :
(a) pu up uc c c- = = (so that negations and p-th powers can be computed for
free, cf. 1a).
(b) 2p
u v u v v u v u vc c c c c c+ - -= - + (which can be computed in four
multiplications in ,pF based on Facts 1a ad 1d).
(c) If 1 ,uc c= then vc denotes the trace of the v-th power uvg of ,ug so
that .uv vc c=
2. Computing traces of powers, with u ;
(a) 22 2 p
u u uc c c takes two multiplications in .pF
(b) 2 1 1 1 1p
u u u uc c c c c c takes four multiplications in .pF
(c) 2 1 1 1 1p p p
u u u u uc c c c c c takes four multiplications in .pF
(d) 2 1 1 1 1p p
u u u uc c c c c u c takes four multiplications in .pF
XTR single exponentiation. Let 1 1,S c and 1 2 0, ,..., {0,1}r rv v v be given, let
y = 1 and e = 0 (so that 2e + 1 = y; the values y and e are included for
expository purposes only). To compute 2 1vS + with 1
02
ri
ii
v v
do the
following for i = r – 1, r – 2,...,0 in succession:
If 0,iv = then compute 2 1yS - based on yS and 1,c replace yS by 2 1yS -
(and thus 2 1eS + by 2(2 ) 1eS + since if 2 1e y+ = then 2(2 ) 1 4 1e e+ = +
2 1y= - ), replace y by 2y – 1, and e by 2e.
67
Else if 1,iv = then compute 2 1yS + based on yS and 1,c replace yS by
2 1yS + (and thus 2 1eS + by 2(2 1) 1eS + + since if 2 1e y+ = then
2(2 1) 1 4 3 2 1),e e y+ + = + = + replace y by 2y + 1, and e by 2e +1.
XTR double exponentiation. Let 2, , , , ,k k ka b c c c- - and c be given with
0 < a and b < q. To compute bk ac + do the following.
1. Let u = k, v = , d = b, e = a, ,u kc c= ,u v kc c- -= 2 2 ,u v kc c- -=
,rc c= and f = 0.
2. As long as d and e are both even, replace d by d/2, e by e/2 and f by
1.f +
3. As long as d e replace 2 ,( , , , , , , )u uv u v vd e u v c c c c- by the 8-tuple given
below:
(a) If d > e then
i. if 4 ,d e then ( , , , , , , , ).u v v v u ue d e u v u c c c c+ -- +
ii. else if d is even. then 2 2 2( ), , 2 , , , , , .2 u u v u v vd e u v c c c c
iii. else if de mod 3 then 3 2 2, , 3 , , , , , .3 u u v u v u v
d e e u u v c c c c
iv. else if 3 is even. then 2 2 2( ), , 2 , , , , , .2 v v u v u ue d v u c c c c
v. else (d and e odd), then 2 2, , 2 , , , , , .2 u u v v u v
d e e u u v c c c c
68
(b) Else (if e > d)
i. if 4 ,e d then , , , , , , , .u v u u v vd e d u v v c c c c
ii. else if e is even, then 2 2 2( ), , 2 , , , , , .2 v v u v u ue d v u c c c c
iii. else if e0 mod 3 then 3 3 3 2, , 3 , , , , , .3 v v u v u ue d v u c c c c
iv. else if ed mod 3 then 3 2 2, , 3 , , , , , .3 v v u u u u v
e d e v u v c c c c
v. else if d is even, then 2 2 2( ), , 2 , , , , , .2 u u v u v vd e u v c c c c
vi. else (d and e odd). then 2 2, , 2 , , , , , .2 v v u u u v
e d d v u v c c c c
4. Apply Fact (1b) to 2, , ,u uv u vc c c - and ,vc to compute 1 .u vc c +=
5. Apply Algorithm “XTR single exponentiation” to 1 1 1 13, , 2 ,pS c c c
1,c and the binary representation of d, resulting in ( )d d u vc c += [1(c)].
6. Compute 2 ( )f d u vc + based on ( )d u vc + by applying fact (2a) f times.
Improved XTR single exponentiation. Let u and 1c be given, with 0 < u < q.
To compute ,uc we do the following.
1. Let a = round 3 5
2u
and b = u –a (where round (x) is the integer
closest to x). As a result 1 5/ ,
2b a
the golden ratio.
69
2. Let 1,k = = 1 ,kc c c= = 0 3,kc c- = = 2 1 1p
kc c c- -= = (cf. Fact (1a)).
3. Apply the XTR double exponentiation algorithm to 2, , , , , ,k k ka b c c c c- -
resulting in ,bk a uc c+ = as desired,
XTR-DH Key agreement [9]. Let p, q, ( )Tr g be shared XTR public key data.
If Seema and Ayan want to agree on a secret key k they do the following.
1. Seema selects a random integer [2, 3],a q computes
1 1( ) ( ), ( ), ( )a a aa p
S Tr g Tr g Tr g Tr g 32F
using the XTR single exponentiation algorithm with n a= and
( )c Tr g= , and sends 2( )apTr g F to Ayan.
2. Ayan receives ( )aTr g from Seema, selects a random integer
[2, 3],b q computes
1 1( ) ( ), ( ), ( )b b bb p
S Tr g Tr g Tr g Tr g 32F
using the XTR single exponentiation algorithm with n b= and
( )c Tr g= , and sends 2( )bpTr g F to Seema.
3. Seema receives ( )bTr g from Ayan, computes
1 1( ) ( ), ( ), ( )a b a bb aba p
S Tr g Tr g Tr g Tr g 32F
using the XTR single exponentiation algorithm with n a= and
( )bc Tr g= , determines the secret key K based on 2( )abpTr g F .
70
4. Ayan compute
32
( 1) ( 1)( ) ( ), ( ), ( )a a b ab a bb p
S Tr g Tr g Tr g Tr g F
using the XTR single exponentiation algorithm with n b= and
( )ac Tr g= , determines the secret key K based on 2( )abpTr g F .
The communication and computational overhead of the XTR-DH key
agreement are both about one third of traditional implementations of the Diffic-
Hellman protocol that are based on subgroups of multiplicative groups of finite
fields, and that achieve the same level of security.
XTR-ElGamal encryption [28]. Let p, q, ( )Tr g be XTR public key data,
either owned (and made public) by Seema or shared by all parties.
Furthermore, let ( )kTr g be a value computed and made public by Seema, for
some integer k selected (and kept secret) by Seema. Given
( ), , ( ), ( ) ,kp q Tr g Tr g Ayan can encrypt a message M intended for Seema as
follows.
1. Ayan selects at random [2, 3]b q and applies the XTR single
exponentiation algorithm to n b= and ( )c Tr g= to compute
32
1 1( ) ( ), ( ), ( ) .b b bb p
S Tr g Tr g Tr g Tr g F
2. Ayan applies the XTR single exponentiation algorithm to n b= and
( )kc Tr g= to compute
32
( 1) ( 1)( ) ( ), ( ), ( ) .k b k bk b kb p
S Tr g Tr g Tr g Tr g F
3. Ayan determines a symmetric encryption key k based on 2( ) .bkpTr g F
71
4. Ayan uses an agreed upon symmetric encryption method with key k to
encrypt M, resulting in the encryption E.
5. Ayan sends ( )( ),bTr g E to Seema.
XTR-ElGamal decryption [28]. Using her knowledge of k, Seema decrypts
the message ( )( ),bTr g E encrypted using XTR–ElGamal encryption as
follows.
1. Seema applies the XR single exponentiation algorithm to n k= and
( )bc Tr g= to compute
32
( 1) ( 1)( ) ( ), ( ), ( ) .b b k bk b kk p
S Tr g Tr g Tr g Tr g F
2. Seema determines symmetric encryption key k based on 2( ) .bkpTr g F
3. Seema uses the agreed upon symmetric encryption method with key k to
decrypt E, resulting in the encryption M.
The communication and computational overhead of XTR-based ElGamal
encryption and decryption are both about one third of traditional
implementations of the ElGamal encryption and decryption protocols that are
based on subgroups of multiplicative groups of finite fields, and that achieve
the same level of security.
Field Arithmetic [2]. Let p be prime with 2p (mod 9). Then p generates 9
and 6 39( ) 1x x x is irreducible in *
pF Let z denote a root of 9( ),x then
2 6, ,...,z z z is a basis for 6pF over *pF
72
Let 5 1
60.i
i pia a z
F From (mod 9)n nz z and thus 2pz z= it follows
with 9 ( ) 0z that
2 3 4 5 64 0 3 5 1 3 2( ) .pa a z a a z a z a z a z a z
Thus, thp powering costs 1.A In a similar way it follows that 3p -th powering
costs 12 .A For multiplication in 6pF Karatsuba’s trick is used, allowing the
multiplication to be done with 18 multiplications instead of 36. In fact, one can
even reduce the number of modular reductions to just 6. Squaring follows by
replacing the 18 multiplications by squaring, but it can be
done substantially faster by observing that
22 4 2 50 1 0 1 0 1 0 1 12 ,G G z G z G G G G z G G G z
with 0 1, pG G zF of degree two. Computing this requires then a total of 12
multiplications (here, the number of modular reductions needed is just 6, too,
as in the multiplication case). For squaring and multiplication several additions
in pF are necessary, too.
Lemma 3.6.1 Let 6, pa bF with 2 mod 9 .p
1. Computing pa or 5pa costs one field addition in .pF
2. Computing 2 3, ,p pa a or 4pa costs two field additions in .pF
3. Computing 2a costs 12 multiplications in .pF
4. Computing ab costs 18 multiplications in .pF
73
Subgroup Arithmetic [22]. Let 5 1
60.i
i pia a z
F membership of one of
the three proper subfields of 6pF is characterized by one of the equations
ipa a= for 1,2,3.i = Specifically, paF if and only if pa a= which is
equivalent to the system of linear equations
0 1 2 3 4 5( , , , , , )a a a a a a 4 0 3 5 1 3 2( , , , , , ).a a a a a a a
The solution 0 1 3 4 0a a a a= = = = and 2 5a a= is not surprising since 3 61 0,z z+ + = so an element pcF takes the form 3 6.cz cz Similarly,
2paF if and only if 2 ,pa a= which is equivalent to 3 62 5 ,a a z a z= + and
3paF if and only if 3pa a= or
2 3 4 5 63 4 3 4 5 3 4 5( ) ( ) .a a a z a a z a z a z a z a z
Let us turn our attention to the subgroup 2 1p pG - + of 6.p*F The 2 1p pG - +
membership condition 2 1 1p pa is equivalent to 2 ,p pa a a= which can be
verified at a cost of, essentially, a single 6pF -multiplication. From 3 1pa a-= it
follows that inversion in 2 1p pG
costs two additions in .pF
Computing 52 1
0p p i
iia a a v z
symbolically produces
2 20 1 0 2 4 4 3 5;v a a a a a a a
21 0 1 2 3 0 3 3 2 4 1 52 ;v a a a a a a a a a a a
22 0 1 3 1 5 2 5 52 ;v a a a a a a a a (7)
23 1 2 3 1 4 4 0 5 3 52 ;v a a a a a a a a a a
24 0 1 2 3 0 3 4 52 ;v a a a a a a a a
25 2 2 1 3 0 4 3 4 2 52 .v a a a a a a a a a a
74
If 2 1,
p pa G
then 0iv = for 0 6i and the resulting six relations can
be used to significantly reduce the cost of squaring in 2 1p pG
. Let
0 1 5( , ,..., )V v v v= be the vector consisting of the 'iv s . Then for any
6 6 matrix M, we have that 2 2.( . )Ta M V a if 2 1,
p pa G
because
in that case V is the all-zero vector. Carrying out this computation
symbolically, involving the expressions for the 'iv s for a particular choice of
M yields a method for computing squares in 2 1p pG
using only 6
multiplications, which is optimal.
Lemma 3.6.2 Let 2 1p pG
be the order 2 1p p- + subgroup of 6p
*F with
2 mod 9p and let 2 660 1 5 pa a z a z a z F with 9( ) 0.z
1. The element a is in pF if and only if 3 62 2 .a a z a z= +
2. The element a is in 2pF if and only if 3 62 5 .a a z a z= +
3. The element a is in 3pF if and only if
23 4 3 4( ) ( )a a a z a a z 3 4 5 6
5 3 4 5 .a z a z a z a z+ + + +
4. The element a is in 2 1p pG
if and only if in relations 0iv = for
0 6.i This can be checked at a cost of essentially 18
multiplications in ,pF where in fact only 6 modular reductions need to
be performed.
5. Computing 1a- for 21p p
a G
costs two additions.
6. Computing 2a for 2 1p pa G
costs essentially 6 multiplications in *
pF
75
3.6.2 CEILDH [23] is essentially a compression/decompression mechanism
for representing elements of the cyclotonic group 2 61.pp p
G
F it is based on
the observation that the field elements of 6pF lying in this subgroup can be
viewed as the 6pF -rational points on the algebraic torus 6T . Using this
perspective, Rubin and Silverberg showed that by exploiting birational maps
from 6T to two-dimensional affine space, one can efficiently represent its
elements with just two elements of *pF matching the compression afforded by
XTR.
The Torus ( )n pT F
Let pF be the prime field consisting of p elements. Let be the Euler
-function, and let n be the thn cyclotonic polynomial. We write ,p nG for
the subgroup of npF of order ( ),n p and let ( )n
pFA denote n-dimensional
affine space over ,pF i.e. the variety whose points lie in npF .
More formally, one can define algebraic torus as follows:
Definition. Let pk = F and .npL F Define the torus nT to be the intersection
of the kernels of the norm maps / ,L FN for all subfields :k F L
/( ) : ker[ ].n L Fk F L
T k N
The dimension of nT is ( ).n Since ( )n pT F is a subgroup of npF the group
operation is just ordinary multiplication in the larger field. The following
lemma provides some essential properties of .nT
76
Lemma 3.6.3
1. ,( ) .n p p nT GF
2. # ( ) ( ).n p nT pF
3. If ( )n ph T F is an element of prime order not dividing n, then h does
Since nT is known to be rational only for special values of n, the above ideas
do not lead to an optimal compression factor of / ( )n n in general. Woodruff
[29] overcome this problem in the case where several elements of nT are to be
compressed. They construct a bijection:
| , ( / ) 1 | , ( / ) 1: ( ) ( ) .d dn q d n p n d d n n dq qT X X
F F F
Specializing their map to the case 30n = gives
10 15 2 3 5 30530 ( ) ,q q q q q q q q qT F F F F F F F F F
which can be reinterpreted as an “almost bijection”
32 4030 ( ) ( ) ( ).q q qT A AF F F
We can use this map to achieve an asymptotic compression factor of 30/8.
Indeed, to compress m elements of 30 ( ),qT F one can compress an element x
and split its image into 81 ( )qy A F and 32
2 ( ).qy A F Then 1y forms the
affine input of the next compression. In the end, 8 32m + elements of qF are
77
used to represent m elements of 30 ( ),qT F Observe that heir map comes from
the equation
6 10 15 2 3 5 3030( )( 1)( 1)( 1)( 1) ( 1)( 1)( 1)( 1),x x x x x x x x x
relating the order of all the different component groups of domain and range.
Since these groups are cyclic, one can map to and from their products as long
as the orders of the component groups are coprime. For the map above there
are some small primes that occur in the order of several component groups, but
van Dijk and Woodruff are able to isolate and handle them separately.
3.6.4 Some Important Theorems
Theorem 3.6.2 If p is a prime, q is a prime power, a is a positive integer, qa is
not divisible by p, and gcd ( ), ( ) 1,ap aq q then
/( ) ( ) (Re )( ) ( ).ppap q a q q a q a qqT T s T T F FF F F F
Theorem 3.6.3 If n is square-free and m is a divisor of n, then
| , 1 | , 1
( ) ( ) ( ).d dn m m
n n n nd dm md m md
x x x
Theorem 3.6.4 If n is square-free and m is a divisor of n, then there is an
efficiently computable bijection (with an efficiently computable inverse)
| , 1 | , 1
( ) ( ) ( ).d dn q m mq qn n n nd dm md m md
T T T
F F F
In case m = 1 then it is most useful in the theorem, if mT is rational, then
theorem gives “almost bijections” between mT and ( ) ,mA and we have
( , ) ( ) ( , )D m n n D m nnT A A
78
where | , 1
( , ) ( )n ndm md
D m n m d
and ~ denotes efficient “almost bijections”. The smaller D(m, n) is , the better
for our applications. Given the current state of knowledge about the rationality
of the torus ,mT we take m with at most two prime factors. Ideally, m = 6. We
can also take m = 2. When m = 6, then Equation
2 1030T A A and 10
24 722
.T A A
As a comparison with the original bijection for n = 30 which requires 8m + 32
elements of qF to represent m elements in 30 ( ),qT F we see that this provides a
considerable improvement.
Theorem 3.6.5 If 1 kn p p is a product of 2k distinct primes, then
3
1 1 2
1
2
( ) ( ) ( ).p pi k
k
i
kp p
n p p p pi
x x x
Applying this to 210 2 3 5 7,n one can similarly show
7 35210 30 6 6( ) ( ) ( ) ( ).q q q qT T T T F F F F
Now since 26 ,T A we obtain 14 70
210 30 .T T A A Using 2 1030T A A
now gives
22 10 12 2 12 14 70210 210 210 30 210 30( ) ,T T T T T T A A A A A A A
so 22 70210 .T A A
More generally, the above reasoning shows that if 1 k
n p p (square-
free), then
79
2 3 1 31 2( ) ( ) ( ) ,n np p p p n p p p p
uT A A
which for 6 | n gives
/ 3 ( ) / 3,n n n
nT A A (8)
Using Equation (8), we can compress m elements of ( )n qT F down to just
( 1) ( ) / 3m n n elements of qF by either sequential or tree-based chaining.
Our new map saves a significant amount of communication in applications
where many group elements are transmitted. For instance for compression can
be used to agree on a sequence of keys using Diffe-Hellman. Other applications
include verifiable secret sharing, electronic voting and mix-nets, and private
information retrieval.
In our applications we compress many elements. This is done by using part
of the output of the n-th element as the affine input for the compression of the
(n + 1)-st element. This sequential chaining is simple, but has the drawback of
needing to decompress all elements in order to obtain the first element.
Alternatively, one can use trees to allocate the output of previous
compressions. For instance, the output of the first compressions is split into
five pieces, which are subsequently used as the affine input when compressing
elements two through six. The output of the second compression is used to
compress elements seven through twelve, etc. When compressing m elements,
decompressing a specific element now takes O (log m) atomic decompressions
on average.
3.7 CONCLUDING REMARKS
Curve-based cryptosystems are one of the most versatile alternatives to
RSA. They are based on very well investigatory problems, and their security is
fairly well understood. They can be used in a extremely broad range of
80
protocols and offer very good speed. There has been also extensive research in
securing implementations.
Lattice-based systems and NTRU offer, in principle, very good speed, They
are also expected to survive the development of fairly sized quantum
computers, because they are based on problems for which no quantum
algorithm is known for the general case. It is difficult to create instances which
are secure even under a classical computing model. Moreover, the complexity
of the classical lattice reduction algorithm is not well understood.
XTR, subgroup – and Torus-based cryptography is an attempt to revive
classical ElGamal cryptography over finite field by exploiting the group
structure with special properties. Security is fairly well understood. However
quantum computing would render them obsolete, their performance is a bit
slower than that of elliptic curves, and the existence of sub-exponential
classical algorithms for DLP in finite fields make these systems shortly-lived.
REFERENCES
1. M. Ajtai, and C. Dwork. A Public-Key Cryptosystem with Worst-Case/ Average-Case Equivalence. In Proc. of 2996 STOC. pp.284-293 ACM 1997.
2. M. Ajtai, R. Kumar, and D. Sivakumar. A sieve algorithm for the shortest lattice vector problem. In Proc. 33rd STOC, pp. 601-610, ACM, 2001.
3. P. D. Bangert. The Word and Conjugacy Problems in Bn. A thesis submitted in Oxford, 2003.
4. D. J. Bernstein. Circuits for Integer Factorization: a Proposal. Manuscript, 2001.
5. J. Birman, K. Koo, and S. Lee. A new approach to the word problem in the braid groups, Adv. in Math. 139 (1998) 322-353.
6. J. Birman, K. Koo, and S. Lee. The infimum, supremum, and geodesic length of a braid conjugacy class, Adv. in Math. 164 (2001) 41-56
7. Consortium for Efficient Embedded Security. Efficient embedded security standards, 1: Implementaation aspects of NTRU and NSS, Version 1, 2002.
81
8. J. Chcon. J. Han, J. Kang, K. Ko, S. Lee, and C. Park. New public key cryptosystem using braid groups. In Proceedings of CRYPTO 2000, LNCS, # 1880, 166-184. Springer-Verlag, 2000.
9. P. Dchornoy. A fast method for comparing braids, Adv. in Math. 123 (1997) 205-235.
10. P. Dchornoy. Braid-based cryptography. Contemp. Math. 360 (2004) 5-33.
11. P. Dchornoy, M. Girault, and H. Sibert. Entity authentication schemes using braid word reduction, Proc. Internat. Workshop on Coding and Cryptography, 153-164, Versailles, 2003.
12. G. Gaubatz, J. P. Kaps, E. Ozturk, and B. Sunar. State of the art in ultra-low power public key cryptography for wireless sensor networks. In Pervasive Computing and Communications Workshops, 2005. PerCom 2005 Workshops, Third IEEE International Conference on, pages 146-150, 2005.
13. A. Kahate. Cryptography and Network Security. TMH 2003.
14. B. Schneier, Applied Cryptography, Wiley, 2nd ed. 1996.
15. C. P. Schnoor. Factoring integers and computing discrete logarithms via Diophantine approximatin. In Proc. Of Eurocrypto ’91. LNCS, # 547, 171-181. IACR, Springer-Verlag, 1991.
16. C. P. Schnorr, and M. Euchner. Lattice basis reduction: improved practical algorithms and solving subset sub problems. Math. Programming, 66:181-199, 1994.
17. C. P. Schnorr, and H. H. Horner. Attacking the Chor-Rivest cryptosystem by improved lattice reduction. In Proc. Of Eurocrypt ’95, LNCS, # 921, 1-12. IACR, Springer-Verlag, 1995.
18. A. Shamir, and E. Tromer. Factoring large numbers with the TWIRL device. In Proceedings of Crypto 2003. LNCS, # 2729, 1-26. Springer-Verlag, 2003.
19. A. Shamir, and E. Tromer. On the cost of factoring RSA-1024. RSA CryptoBytes, Vol. 6 no. 2, 10-19, 2003.
20. P. W. Shor. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM Journal on Computing, 26, 1484-1509, 1997.
21. V. Shoup. OAEP Reconsidered. Advances in cryptology- CRYPTO 2001, LNCS, # 2139, 239-259. Springer-Verlag 2001.
22. V. Shoup. Number Theory C++ Library (NTL) version 3.6. Available at http://www.shoup.net/ntl/.
23. C. Stahlke. Point compression on Jacobians of hyper elliptic curves over Fq. preprint, 2004
82
24. F. Vercauteren. Computing Zeta Functions of Curves over Finite Fields Ph.D. thesis, katholiede Universiteit Leuven, November 2003. Available at http://www.csbris.ac.uk/frederik/.
25. VAM 3 Side-Channel Attacks and Security. State of the art of ema and fault attacks. Technical report. VAMPIRE in ECRYPT, 2005.
26. A. Weng. Konstruktion kryptographisch geeigneter Kurven mit Komplexer multiplication. Ph.D thesis, Universitat Gesamthochschule Essen, 2001.
27. Santosh Kumar Yadav, and Kuldeep Bhardwaj, NTRU implementation : An algorithmic approach, Accepted for INDIACom10. 4th National Conference on Computers for Nation Development.
28. Santosh Kumar Yadav, Sunder Lal, and Kuldeep Bhardwaj On NTRU Cryptosystems and L3 Algorithm: A Problem: Accepted for International Journal of Applied Maths, IAEng, Hong-Kong.
29. A. Woodruff. Torus-based Cryptography: Some facts. LNCS, # 549, pp. 82-89, Springer-Verlag, 1992.
83
Chapter 4
ON MULTIVARIATE SYSTEM IN ASYMMETRIC CRYPTOGRAPHY
4.0 OVERVIEW
In this chapter our aim is to discuss the problem of multivariate system in
asymmetric cryptography with the help of Directional, Propagation and Key
generations. In this system Polynomial time quantum algorithms can be used to
solve the problems in asymmetric cryptography. With the help of hidden field
equations we find a trapdoor for multivariate quadratic problem.*
4.1 INTRODUCTION
We have seen that the security of public key cryptosystems centres on the
difficulty of solving certain classes of problem. The RSA scheme relies on the
difficult of factoring large numbers, while for the ElGamal and Elliptic Curve
schemes the difficulty of solving discrete logarithms provide the basis. Given
that the security of these public key schemes rely on such a small number of
problems that are currently considered hard, research on new schemes that are
based on other classes of problems is worthwhile. Such work provides a greater
diversity that forces cryptanalysts to expand additional effort by concentration
on a completely new type of problem. In addition, important results on the
potential weaknesses of existing public key schemes are emerging. Techniques
for factorisation and solving discrete logarithm continually improve.
Polynomial time quantum algorithms can be used to solve both problems. This
stresses the importance of research into new algorithms for asymmetric
encryption and signature schemes [14, 18].
* This chapter is based on the author’s paper “On Multivariate System in Asymmetric Cryptography”
presented at ETCSIT’09 Conference at Pooja Bhagavat Memorial Maharajana P.G. Centre, Mysore-16, Karnataka and published in the Proceedings, pp.29.
84
4.2 HIDDEN FIELD EQUATIONS
HFE is based on polynomials over finite fields and extension fields. The
general idea is to use a polynomial over an extension field as a private key and
a vector of polynomials over the underlying finite field as public key. HFE also
uses private affine transformations to hide the extension field and the private
polynomial. This way HFE provides a trapdoor for an MQ-problem (system of
Multivariate Quadratic equations) [1].
Mathematical Background: Figure 4.1 gives an outline of the structure of
HFE. S and T represent two affine transformations and P is the private
polynomial. Hence, the private key is represented by the triple (S, P, T).
Input r
x = (x1,..., xn)
Private: S
x
Public:
Private P (p1, ..., pn)
y
Private T
output y
Figure 4.1. MQ -trapdoor (S, P, T) in HFE
85
The polynomials (p1,..., pn) are the public key. These public polynomials as
well as the private affine transformations S and T are over, a finite field with
cardinality q = | F |. The private polynomial P is defined over E , an extension
field of F generated by the irreducible polynomial i(x) of degree n.
4.3 ENCRYPTION AND DECRYPTION OF MESSAGES USING
THE PRIVATE KEY
The private polynomial P (with degree d) over E is an element of
E [x]. To keep the public polynomials small, the private polynomial P must
have the property that its terms are at most quadratic over F . In the case of
E = GF(2n) this means that the powers have Hamming weight at most 2. In
symbols:
P : F E
( ) ihiP x c x
, , , ,i i i jc h d h h i j E
0
0
0, (constant term), (linear terms)
, , (quadratic terms)
ai
b c
h q a
q q b c
Since the affine transformations S and T are over F it is necessary to transfer
the message M from E to nF in order to encrypt it. This done by regarding M
as a vector with n components (x1,..., xn) nF .
86
Plaintext M
side computation: redundancy r
x = (x1,..., xn)
Private: S
x
Public:
Private P (p1,..., pn)
y
Private T
y
Figure 4.2. HFE for encryption o the message M with ciphertext (y, r)
Thus we no longer think about the extension field as a field but as an n-
dimensional vector-space over F with the rows of the identity matrix I as basis
of nF . To encrypt (x1,..., xn) we first apply S, resulting in x. At this point x is
transferred from nF to E so we can apply the private polynomial P which is
over E . The result is denoted as yE . Once again y is transferred to the
vector 1( ,..., )ny y , the transformation T is applied and the final output yE is
produced from 1( ,..., ) .nny y F
87
To decrypt y, the above steps are done in reverse order. This is possible if
the private key (S, P, T) is known. The crucial step in the deciphering is not the
inversion of S and T, but rather the computation of the solutions of P(x) =
y. As P has agree d there are up to d different solutions X : =
1{ ,..., }dx x E for this equation. Addition of redundancy to the message M
provides an error-correcting effect that makes it possible to select the right M
from the set of solution X. This redundancy is added at the first step.
Another way of circumventing this problem would be to take the
polynomial P bijective. Unfortunately.
4.4 MESSAGE SIGNATURE
In addition to encryption / decryption, HFE can also be used for signing a
message M. As for decryption, we assume that without the trapdoor (S, P, T) it
is computationally not feasible to obtain a solution 1( ,..., )nx x for the system of
equations
1 1 1
2 2 1
1
( ,..., )( ,..., )
( ,..., ).
n
n
n n n
y p x xy p x x
y p x x
where 1( ,..., )np p are quadratic polynomials in the variables 1,..., nx x . In Figure
4.3, we follows this notation, so the input for signature generation is denoted
with y, while the output is called x. In addition, the message M consists of t
elements from F , i.e., M = (M1, ...., Mt) 1F . The vector r = (r1,..., rj) jR F is
randomly chosen (see below).
88
input y = (M1,..., Mt) || (r1,..., rj)
private : T
Public discarded
y p1 pt+1
private : P
x pt pt+f
private : S
signature x
Figure 4.3. Signature with MQ , using the HFE trapdoor
If one knows the private key k = (S, P, T), the problem of finding a solution
x for given y, reduces to find a solution to the equation P(x) = y where the
polynomial P E [x] has degree d. This is feasible. Unfortunately for HFE.
P(x) is usually not a surjection and therefore : ( ) .y P x y x E Keeping
this in mind, we cannot find a solution 1( ,..., )nx x for each MQ -problem with a
HFE trapdoor. So from a practical point of view, if we do not succeed in
finding a solution x for a certain y in P(x) = y, we have to try another y until
we obtain a result x. In HFE, the number of y-values we have to try is small.
For a special system such as Quartz [1], we expect to find a solution for one
given y with probability 11e
, i.e., approx. 60%. However, as Quartz tries up
to 128 different values for y for a given message, the overall probability for not
finding any solution drops to approx. 2185 and is therefore negligible.
89
For signature generation [6], we assume that the message tM F and
n t f . Here, f N is the number of free input variables for the MQ -
problem. So y = (M1,...,Mt) || (r1,...,rf) where || denotes the concatenation
function and (r1,...,rf) fR F is chosen uniformly at random. The parameter f
has to be selected according to the field size of F . As the parameters in the
Quartz scheme are F = GF(2), and f = 7, there are 27 = 128 different y-values
for each given message M. In general, we have qf different y-values for a given
message M. If we can solve the corresponding P(x) = y for one of these qf
different y-values, we publish the corresponding x = S1(x) as the signature of
M. See Fig. 4.3 for the overall structure of a signature scheme.
Anybody who wants to verify that the message m = (m1,...,mt) was signed
by the owner of the private key K = (S, P, T) with x = (x1,..., xn), uses the public
key, that is, k = (p1, ..., pt) and compares (denoted ? ):
1 1 1 ? ( ,..., )nM p x x
2 2 1 ? ( ,..., )nM p x x
1 ? ( ,..., )t t nM p x x
If all t equations are satisfied, the signature is valid. Otherwise, it is not. Note
that only t of the m = t + f public equations are necessary to verify a signature,
the equations pt+1 ... pt+f equations can be discarded
4.5 PUBLIC KEY: GENERATION AND ENCRYPTION
We begin with a description of polynomial interpolation for fields
(2)GFF . The key generation for (2)GFF is slightly different, we deal
with this case later in this section. For HFE, we want to obtain polynomials
over F as the public key which has the form
90
1 , , .1 1
( ,..., )i n i j k j k i j j ij k n j n
p x x x x x
,
for 1 i m and , , ,, ,i i j i j k F (constant, linear, and quadratic terms). To
compute these polynomials pi, we use polynomial interpolation, i.e., we need
the output of these polynomials for several inputs. To do so, we exploit that the
private key K = (S, P, T) yields the same values as the public key [1].
Therefore, we evaluate the function T(P(S(x))) for several values of x:
0n F is the 0 vector;
:1nj j n F , is a vector with its jth coefficient 1, the others 0;
, :1nj k j k n F is a vector with its jth and kth coefficient 1, the
others 0.
These 1 + n + n(n 1)/2 = n(n + 1)/2 + 1 vectors yield the required
coefficients, as we see below:
0( ( )) iiT P S
, , ,( ( ))j i i j i j jiT P S
2, , ,( ( )) , where , 0.1j i i j i j ji
T P a a a a a S F
, , , , , , , ,( ( ))j k i i j i j j i k k i j kiT P S .
The values for , , ,,i i j i j k are obtained by
0: ( ( ))i iT P S
, ,1: ( ( ) ) ( ( )) (1 )
( 1)i j j j j ii iT P S a aT P a
a a
S
91
, , ,: ( ( ) ))i j j i j j iiT P S
, , , , , ,: ( ( ) , ))i j k j i j j i j i k iiT P k S .
This yields the public polynomials 1( ,..., )i np x x for 1 i m in the case
(2)GFF .
To adapt the algorithm TO (2)GFF , we observe that x2 = x over GF(2),
i.e., all squares in only one variable become linear factors instead. Therefore,
we can skip all terms with , ,i j j , i.e., all quadratic terms in 2jx for
1 j n. We can also take another point of view: as there is no element
a GF(2) : a 0, 1, we could not evaluate ( ( ))j iT P aS .
4.6 CONCLUDING REMARKS
Multivariate quadratic systems can be used to construct both secure and
efficient public key schemes. Their main problem is the key size, which can
easily go to reveal hundreds of kilobytes. In particular, promising are the
Unbalanced Oil and Vinegar (UOV) schemes. The attacks known so far against
UOV are basically exponential – in particular they do not fall to the same kind
of attacks that have plaques earlier schemes like HFE. Hence, it is necessary a
very high workload for breaking system with reasonably small parameters.
REFERENCES
1. N. T. Courtois, M. Daum, and P. Felke. “On the security of HFe, HFEv-and Quartz”. In Public Key Cryptography – PKC 2003, LNCS 2567, 337-350. Springer, 2002. http://eprint.eacr.org/2002/138.
2. N. T. Courtois, L. Goubin, W.Meier, and J. D. Tacier. “Solving underdefined systems of multivariate quadratic equation”. In Public Key Cryptography – PKC 2002, LNCS 2274, 211 – 227. Springer, 2002.
92
3. N. T. Courtois, L. Goubin, and J. Patarin. Quartz: Primitive specification and supporting documentation, 2000. https://www.cosic.esat.kuleuven.ac.be/nessie/workshop/submissions/quartz.zip,15 pages.
4. N. T. Courtois, L. Goubin, and J. Patarin. SFlash: Primitive specification and supporting documentation, 2000.https://www.cosic.esat.kuleuven.ac.be/ nessie/workshop/submissions/sflash.zip, 10 pages.
5. N. T. Courtois, L. Goubin, and J. Patarin. Quartz: Primitive specification (second revised version), October 2001. https://www.cosic.esat.\kuleuven.ac.be/nessie/workshop/submissions/quartzv21-b.zip, 18 pages.
6. N. T. Courtois, L. Goubin, and J. Patarin. SFlashv3, a fast symmetric signature scheme Revised Specification of SFlash, version 3.0, October 17th 2003. Print Report 2003/21, http://eprint.iacr.org/, 14 pages.
7. N. T. Courtois, A. Klimov, J. Patarin, and A. Shamir. “Efficient algorithms for solving over defined systems of multivariate polynomial equations”. In Advances in Cryptology-EUROCRYPT 2000. LNCS # 1807. 392-407. Springer-Verlag. 2000. Extended Version: http://www.minrank. org/xlfull.pdf.
8. N. T. Courtois. “The security of Hidden Field Equations(HFE)”. In The Cryptographer’s Track of RSA Conference 2001, LNCS, # 2020, pp. 266-281, Springer-Verlag, 2001. http://www.minrank.org/hfesec. {ps|dvi|pdf|}.
9. M. Daum. Das Cryptosystem HFE and quadraticshe Gleichungssysteme iiber endlichen Korpern. Diplomarbeit, Universitat Dortmund, August 2001. http://homepage.ruhr-unibochum.de/Magnus.Daum/HFE.{ps.zip|pdf}
10. J. C. Faugere. HFE challenge 1 broken in 96 hours. Announcement that appeared in news://sci.crypt, 19th of April 2002.
11. J. C. Faugere. “A new efficient algorithm for computing Gröbner bases without reduction to zero(F5)”. In International Symposium on Symbolic and Algebraic Computation-ISSC 2002, pages 75-83. ACM Press, July 2002
12. J. C. Faugere. “Algebraic cryptanalysis of (HFE) using Grobner bases”. Technical report, institute National de Rechereche en informatique et en Automatique, February 2003. http://www.inria.fe/rrrt/rr-4738.html, 19pages
13. G. Gaubatz, J. P. Kaps, E. Ozturk, and B. Sunar. “State of the art in ultra-low power public key cryptography for wireless sensor networks”. In Pervasive Computing and Communications Workshops, 2005. PerCom 2005 Workshops, Third IEEE International Conference on, pages 146-150, 2005.
14. A. Kahate. Cryptography and Network Security. TMH 2003.
93
15. T. Matusumato, and H. Imai. “Public Quadratic polynomial-tuples for efficient signature verification and message-encryption”. In Advance in Cryptology- EUROCRYPT 1988, LNCS, # 330, 449-545. Springer-Verlag, 1988.
16. A. J. Mcnezes, P. C. van Oorschot, and S.A. Vanstone. Handbook of Applied Cryptography. CRC Press, 1996. ISBN 0-8493-8523-7, online-version:http:// www.cacr.math.uwaterloo.ca.hac/
17. T. Moh. “A public key system with signature and master key function”. Communications in Algebra, 27(5): 2207-2222, 1999. Electronic version at http://citeseer/moh99public.html.
18. B. Schneier, Applied Cryptography, Wiley, 2nd ed. 1996.
94
Chapter 5
CRYPTOGRPHIC VOTER -VERIFIABILITY: A PRACTICAL APPROACH
5.0 OVERVIEW
In this chapter, we evaluate some voter verifiability techniques with the
help of key-management. The ancient Greeks investigated the use of technical
devices to provide trustworthy voting system and avoid the need to trust voting
officials. An important issue here is to provide the voters complete confidence
that their vote have been accurately recorded and counted whilst at the same
time guaranteeing the secrecy of their vote. We present here an election scheme
that to allow voters to verify that their vote is accurately included in the
tabulation. The scheme provides a high degree of transparency whilst ensuring
the secrecy of votes. Assurance is derived from close auditing of all the steps of
the vote recording and counting process with minimal dependence on the
system components. Thus, assurance arises from verification of the election
rather than having to place trust in the correct behavior of components of
voting system. In particular, care needs to be taken to ensure that ballot forms
used for checking cannot be reused to cast real votes.*
5.1 INTRODUCTION
In the democratic system of government, the process of recording and
counting votes would be the target of manipulation and corruption. The earliest
generation i.e. Greeks used several devices to provide trustworthy voting
system to avoid the need to trust voting officials. There is, however, a
challenge till today to provide voters complete confidence that their vote would
* The present chapter is based on author’s paper “Cryptographic Voter -Verifiability: Practical Approach” presented in WORLDCOMP’08, July 14-17, 2008 at Las Vegas Nevada, USA and published in Proceedings of the Int. Conf. on Security & Management (SAM’08), pp. 15-21.
95
be accurately recorded and counted whilst at the same time by guaranteeing the
secrecy of their vote. For the traditional paper ballot system, the handling of the
ballot boxes and counting process must be trusted that the boxes are not lost or
manipulated and that the counting process is accurate. With the sincere efforts
various observers can be introduced to the process which helps to spread the
dependence but does not eliminate the problem so far.
In modern perspective so many precautions are made to provide accuracy
With many of the touch screen, DRE, devices widely used in the US
presidential elections, the voter at the best gets some form of acknowledgement
of the way they cast their vote. After that process they can hope that their vote
will be accurately included in the final telly. Here we discuss voter verifiability
process with more suitable techniques.
5.2 DIGITAL VOTER-VERIFIABILITY
Chaum [3] presented a digital voting scheme which enables voter
verification. It provides each voter confidence that their vote has been
accurately included in the vote telly. This system has the following
characteristics:
It provides the voter with a receipt showing their vote in encrypted form.
It enables the voter to confirm in the booth that her intended vote is
correctly encoded in the receipt, and that the vote has not been revealed
outside the booth.
It has a number of tellers who perform an anonymising mix on the batch
of encrypted ballot receipts with all intermediate steps of the tellers
processing posted to the web bulleting board.
It performs random checks on all steps of the process to ensure that, any
attempt to corrupt the vote option and counting will be detected with
high probability.
96
The vote is in encrypted form to ensure that there is no way to prove to a
third party of voting. Voter can visit the web bulletin board and check that his
encrypted ballot receipt has been correctly posted.
5.3 PRÊT Á VOTER
Visual cryptography is used to encrypt the receipts and perform the
decryption in the polling booth. The column process is used in representation
of votes i.e. ballot forms with the candidates or voting options listed in one
column, and the voter choices entered in the adjacent column. To maintain the
trust in components, decryption process in the booth is made transparent and
does not depend on the intercession of any hardware or software devices to
detect corruption.
Peter Y. A. Ryan [6] introduced the idea of encoding the vote in terms of
two aligned strips, one of them carrying the candidate or option list in
randomized order which is independent for each ballot form and the other strip
carries the voter choice. According to this system, the voter was invited to
choose between the two strips and to retain one as the receipt. This was an
introduction of a certain asymmetry with both cryptographic and psychological
implications. We also introduce in this system some ballot forms which are
generated and printed in advance. To avoid the asymmetry in the choice
between left and right columns of the existing scheme, we use the tellers in an
oracle mode to enable the checks on the well-formed ness of the ballot forms.
This is in addition to the usual use of the tellers to perform the anonymising
mix during the tallying phase. Besides allowing independent auditing
authorities to perform random checks, this also opens up the possibility of
various checking modes, including enabling the voters to cast a dummy vote
and have the tellers return the decryption to them as a check on the construction
of the ballot forms.
97
The scheme presented here provides a number of appealing aspects, notably:
Voters will find the vote casting process quite familiar.
Cryptographic commitments are generated before voter choices are known.
Voter checks on the correct construction of the ballot forms are
supplemented by random audits. Thus voters are able to contribute to the
verification of the vote capture process but are not dependent on the voters
being sufficiently diligent.
Checks on the correct construction of the ballot forms are performed before
votes are cast. This simplifies the recovery strategies.
The vote recording devices in the booth do not learn the voters’ choices.
This neatly avoids any threats of such devices leaking the voters’ choices.
The scheme is conceptually much simpler that others have proposed. This
increases the chance of voter acceptance.
The current scheme shows considerable flexibility, and could readily be
adapted to different electoral requirements.
5.4 SINGLE TRANSFERABLE VOTE AND THE ELECTION SETUP
In this system, we appoint a number of tellers. Each teller is assigned to
secret/public key pairs which are publicized and certified further.
A large number of ballot forms are created by an authority, significantly
more than required for the electorate. These will have a familiar appearance: a
left hand column listing the candidates or options and a right hand column into
which the voter can insert her selection. This might just be an X in one cell for
a single choice election or a ranking for a Single Transferable Vote (STV)
system. Thus, for a four candidate race, a typical ballot form might look like:
98
Nihilist Buddhist Anarchist Alchemist Onion
The order in which the candidates are listed will be randomized for each
ballot, that is, for any given ballot; the candidate order shown should be totally
unpredictable. The onion contains the information allowing the ordering to be
reconstructed, buried cryptographically under the public keys of the tellers.
The exact details of the voting procedure can be varied according to the
details of the election and according to the perceived nature of threats to which
the system is exposed. For simplicity of presentation we outline one simple
procedure. Others procedure are possible and indeed one of the advantages of
this scheme is that it appears to be significantly more flexible than previous
variants.
5.5 PRESENTATION OF EXAMPLE
To deal with a simple election system in which each voter selects exactly
one candidate. We use cyclic shifts of the candidate ordering.
5.5.1. TO PROCESS VOTES
We consider that there are four candidates and those are given in a base ordering:
Anarchist
Alchemist
Nihilist
Buddhist
Since we consider only cyclic shifts in this example, there are four possible
candidate lists. These will be numbered from 0 to 3 according to the offset
99
from the base candidate list. Ballot forms will be generated with random
offsets.
We adopt a numbering convention for the candidates from 0 to 3 as
indicated. Thus a vote for Anarchist will be encoded as 0, for Alchemist as 1
etc. This numerical representation is purely for the machine manipulations and
need not trouble the voter.
We consider the following ballot form:-
Buddhist Anarchist Alchemist Nihilist Qqkr3c
This has an offset of 1. Thus the onion- Qqkr3c-encodes the value 1. Let
the system is to process a vote for Nihilist. This would be represented by a
mark in the Nihilist box:
Buddhist Anarchist Alchemist Nihilist X Qqkr3c
Once the voter has marked their choice, the left hand column that shows the
candidate ordering is detached and destroyed, to leave a ballot receipt of the form:
X Qqkr3c
Such right hand strips showing the position of an X and an onion value
constitute the ballot receipts.
100
This is now fed into the voting device, presumably an optical character
reader, which transmits the information on the strip, the position of the X (as a
numerical value 0, 1, 2 or 3) and the value of the onion, to the tellers. The
tellers use their secret keys to perform the decryption of the onion and provide
the decrypted vote value corresponding to the vote in the base ordering. In this
case the process yields the offset1, so the vote value is the position of the vote
(3) with the appropriate offset removed, yielding candidate
3 1 2 : Nihilist.
This process is illustrated in the figure 5.1. A more detailed will be provided later.
LH strip RH strip processed base
RH strip ordering
Figure 5.1. To Process a vote
5.5.2. TO INTRODUCE THE VOTER
Our voter Arue first authenticates herself and registers at the polling station.
She is invited to select, at random, a pair of ballot forms. Of these, she will
choose one with which to cast her vote. The other will be used for a simple
check to test the veracity of the onions and the vote extraction process, after
which it can be discarded.
5.6 TO CHECK THE CONSTRUCTION OF THE BALLOT FORMS
Correct construction of the ballot forms has the following steps:-
a) Single dummy vote. b) Multiple or ranked dummy vote.
Tellers
X Qqkr3c
Buddhist Anarchist Alchemist Nihilist
X
Anarchist Alchemist Nihilist Buddhist
101
c) Given the onion value, the tellers return the candidate ordering.
d) Return the seed and run a checking algorithm for the well-formedness.
In the first, Arue would cast a dummy vote in exactly the same way that she
will later cast her real vote in the booth. Thus, she could put a cross against a
random selection and send the receipt off the tellers. They decrypt the onion
and return what they believe was the vote cast. If the onion was correctly
constructed, this should of course agree with the dummy vote Arue selected.
Psychologically this is an interesting possibility: assuming that the check
succeeds, it should provide the voter with some assurance that when they come
to cast their real vote, it will also be correctly counted. On the other hand it
might undermine their confidence that the secrecy of their vote will be assured.
It should also be noted that the singly dummy vote provides a rather weak
check on the ballot form construction, checking only part of the construction.
The second mode seeks to rectify this by allowing the voter to cast several
dummy votes, either in series or in parallel by making a ranking selection. In
the later case, given the receipt the tellers should return what they believe to be
the candidate ranking chosen by the voter. This provides a more complete
check on the construction of the ballot form. Both of these suffer the drawback
that the voter is expected to make random choices. People are notoriously bad
at making random choices.
The third mode is perhaps the most satisfactory. It provides a complete
check on the ballot form but does not require the voter to make any random
selections. Here, given the onion value, the tellers should return what they
believe to be the candidate ordering as shown on the ballot form.
NOTE. The first three modes are vulnerable to collusion attacks. If the authority that
generated the forms is in collusion with one of the tellers there is the possibility of
corrupting forms without detection by these modes. For example, the authority could
102
flip a pair of candidates on the ballot forms. The colluding teller performs the
corresponding flip during the checking phase, but not during the tallying phase.
The last checking mode is not vulnerable to such collusions and so is more
rigorous. It therefore appears to be most suitable for the auditing authorities. It
could also be made available to voters, but it seems less intuitive and so
perhaps less reassuring to the voters. Investigating the psychological aspects of
these checking modes from a voter perspective will be investigated in future work.
5.6.1 TO CAST THE VOTE
We check the vote of Arue which has succeeded. Confidently, the ballot
forms have been correctly constructed and hence that onion on her real ballot
form also corresponds correctly to the offset of the candidate list. Arue enters a
booth with her ‘real’ ballot form. She marks her X in the usual way. Suppose
that she decides to vote for the “Buddhist” candidate:-
Nihilist Buddhist X Anarchist Alchemist elrg38
She now removes the left hand strip (for shredding), and feeds the right
hand strip into the voting device, which reads the position of Arue’s X, and the
value of the onion. The device then returns the right hand strip to Arue for her
to retain as the ballot receipt.
X Elrg38
5.7. MATHEMATICAL DETAILS
To construct the Ballot Forms.
103
5.7.1 Cryptographic Seeds and Offsets
For each ballot form, the authority will generate a unique, random seed. If
there are k tellers (numbered 0 to k – 1), this seed will be made up of a
sequence of 2k values that we will call the germs:
0 1 2 2 1Seed: , , , , kg g g g
Each of these germs should be drawn from some modest size field, perhaps
232. Thus, for k = 3 say, the seed values will then range over 2192. These
numbers can be adjusted to achieve whatever cryptographic strength is required.
The offset for the candidate list is now calculated from these germ values as
follows. First a publically known cryptographic hash function is applied to each
of the germs and the result taken modulo v, where v is the size of the candidate list:
: hash mod , 0,1,2, , 2 1.i id g v i k
The cyclic offset that will be applied to the candidate list on this form is
now computed as the (mod v) sum of these values:
2 1
0: (mod ).
k
ii
d v
5.7.2 To Construct Onions
Each teller performs accordingly, has two independent secret/public key
pairs assigned to it. Teller i will have public keys PKT2i and PKT2i+1, and
corresponding secret keys. The onion is formed by nested encryption of the
germs under these public keys, and is given by:
2 1 2 2 1 0 0 T0 T1 T2 3 T2 2 T2 1, , , , ,D PK PK PK PK PK .k k k k kg g g g
104
We introduce a little more notation to denote the intermediate layers of the
onions. D0 will be a random, nonce-like value, unique to each onion. The
further layers are defined as follows:
Di+1 := {gi , Di} PKTi Onion := D2k
D2k D2k-1 D3 D2 D1
Figure. 5.2 An Onion
5.8. WHAT TELLERS DO?
Primarily, tellers perform an anonymising mix and decryption on the batch
of encrypted ballot receipt posted to the web bulletin board. This ensures that
the decrypted votes that emerge at the end of mix cannot be linked back to the
encrypted receipts which are input to process.
The first, left hand column, of the bulletin board shows the receipts in
exactly the same form as the printed receipts held by the voters. The voters can
check this column to verify that their receipt has been accurately posted. An
easy way to do this would be to search on the string representing the onion
value and check that the X appears in the correct box, i.e., as shown on the
voter’s receipt.
The information in the first, left hand column of the bulletin board is then
passed to the first teller Tellerk-1, for processing. There is no shuffling of the
information when it is passed to the teller. The position of the X on the voting
g2k-1
g2k-2 …
g2
g1
g0 D0
105
slip is encoded as an integer r, and the correctness of this encoding can be
simply and publically verified.
The tellers will subsequently manipulate the numerical representations of
the receipts, i.e., pairs of the form (ri, Di ), where ri is an element of Zv and Di is
an ith level onion. The initial value of r2k is the encoding of the position of the
X as originally placed by Anne on her receipt.
Each column (apart from the first, which contains the actual receipts) shows
only the simplified, digital representation: a pair (r2k, D2k ) consisting of a value
r from Zv and the value D of the onion layer.
Each teller accepts an input column of votes (r, D) from the previous teller,
and then carries out two manipulations, to produce a middle column of votes
and an output column of votes. The output column produced by the teller is
then passed to the next teller in the chain.
Thus for each of the (r2i , D2i) pairs in the batch in the input column, Telleri-1 will:
Telleri+1 Telleri Telleri-1
Figure 5.3. A Teller
Apply its first secret key, SKT2i-1 to strip off the outer layer of the onion
D2i to reveal the enclosed germ 2 1ig and the enclosed onion D2i-1.
g2i-1, D2i-1 : = {D2i}SKT2i-1
Apply the hash function to the germ value and take the result (mod v) to
recover d2i-1 :
106
2 1 2 1: hash modi id g v
Subtract d2i-1 from r2i (mov v) to obtain a new r value r2i-1:
2 1 2 2 1: modi i ir r d v
form the new pair ( r2i-1, D2i-1)
Telleri-1 now repeats this process on the contents of the middle column
using its second secret key, SKT2i-2 to obtain a new set of (r2i-2, D2i-2) pairs. It
will apply a second secret shuffle, independent of the previous one, to this
batch of new pairs. The resulting transformed and shuffled (r2i-2, D2i-2) pairs are
now posted to the output column on the bulletin board, and passed on to the
next teller, Telleri-2. The value of any of the intermediate r values is thus given by:
2 1 2 21
: modi
k k k ik
r r d v
Ballots Votes
Teller2 Teller1 Teller0
Figure 5.4. Three Tellers anonymising mix
To see this, observe that the candidate list on each form is shifted by the
(mod v) sum of the d values, i.e. . Thus, the initial r value is the candidate
value plus modulo v. For each ballot pair, the tellers will have subtracted out
the d values from the initial r value, thus canceling the original shift of the
candidate list and so recovering the original candidate value.
107
Thus:
2
0 2 2 21
: mod mod .k
k k i ki
r r d v r v
Consider the example of Arue’s vote again. The form she used to cast her
vote had an offset of 2 and her X was in the second box, value 1. Hence the
initial value of r2k was 1 in her case. The tellers will in effect compute:
2
0 21
: mod 4 1 2 mod 4 3.k
k ii
r r d
Thus the final r value r0 = 3 does indeed translate to a vote for
“Buddhist” in the base ordering . The encryption of the vote can thus be
thought of as a (co-variant) transformation of the frame of reference,
decryption to the corresponding (contra-variant) transformation.
Ballots
Votes
Teller2 Teller1 Teller0
Figure 5.5. A vote processed by three Tellers
Ballots Votes
Teller2 Teller1 Teller0
Figure 5.6. Information posted by the sequence of three Tellers
Ni
Bu X An
Al
n
An Al Ni x Bu
108
5.9. TO CHECK ON THE AUTHORITY
Firstly, editors select a random sample of forms to check. This can be done
before, during and after (on unused forms) the election period. For each
selected ballot form they perform the following mode 4 check:
- A digital copy of the onion is sent to the tellers.
- The tellers strip off layers of encryption using their private player’s keys to
reveal the germs.
- These germ values are returned to the auditors.
- Given the germs values, and knowing the public keys of the tellers, the
auditors are able to reconstruct the values of the onion and can check that
this agrees with the values printed on the form.
- They now recomputed the offset value as the (mod v) sum of the hashes of
the germs.
- They can now check that the offset applied to the candidate list shown on
the form agreed with the values obtained above.
5.10. TO CHECK THE VOTE RECORDING DEVICES
Once voting has closed, all ballot receipts should be posted to the bulletin
board. The material posted to the bulletin board should be publically available
in read only mode. Thus any voter can visit the board and confirm that their
receipt appears correctly in the input column.
If their receipt does not appear, or appears in corrupted form (in particular,
if the position of the X is incorrect), then this should be reported. The voters
have their receipt to prove to an official if their receipt does not appear
correctly. In practice all ballot forms would probably have a digital signature to
prevent attempts to fake receipts.
109
5.11. TO CHECK THE TELLERS
For each teller an auditing authority goes down the middle column and
randomly assigns R or L to each (r, D) pair. For pairs assigned an R, the
auditor requires the teller to reveal the outgoing link (to the right) to the
corresponding pair in the next column along with the corresponding germ
value. For all pairs assigned an L, the auditor requires the teller to reveal the
incoming link (form the left) along with the germ value.
This way of selecting links ensures that, for any given teller, no complete
routes across the two shuffles performed by that teller are revealed by the audit
process. Hence no ballot receipt can be traced across the two mixes performed
by any given teller. Each ballot transformed has a 50/50 chance of begin audited.
This is illustrated in Figure 5.7, with the selected links included. The
remaining links are not revealed. For each teller the auditor performs such a
random audit. Given the property that there are no full links revealed across
any tellers’s mixes, the L/R selection can be made quite independently for each
teller. This is the rationale for making each teller perform two mixes.
Suppose that for a revealed link the pair has been transformed thus:
ri , Di ri-1 , Di-1
Knowing this and the corresponding germ value gi-1 (which the teller is
required to provide for each revealed link), it can be checked that the following hold:
Di =gi-1, Di-1PKTi-1
From Telleri+1 Telleri to Telleri-1
Figure 5.7. Auditing Telleri
LLRLRRRL
110
5.12. ERROR HANDLING/ RECOVERY STRATEGIES
Let us consider the error handling strategy for a failed voter checks. The
first step for the official is to confirm that there is a real disagreement. Arue
will have both parts of the dummy ballot form so she can prove which way she
casted her dummy vote and she has the printout for the tellers. The official can
thus establish that the problem is genuine and not just a case of voter error.
If the problem is real, the official should now run further, mode 4 checks:
use the tellers as an oracle to extract the seed value to reconstruct the onion
value and candidate list offset. If these values agree with those shown on the
ballot, then it is fair to conclude that the form was correctly constructed by the
authority. The error must then lie with the decryption of the vote performed by
the tellers.
If this check fails, it can mean one of the two things: the form was
incorrectly constructed by the authority, or the form was perhaps actually
correctly formed but the seed value returned by the tellers is incorrect.
Errors have to be diagnosed and collated. Strategies for dealing with
patterns errors must be specified. Thus, if a significant number of ballot forms
were found to be mal-formed, it would lead to doubt would be cast on the
integrity of the authority charged with generating the forms.
5.13 CONCLUDING REMARKS
The analysis presented in this chapter does not constitute an exhaustive,
systematic identification of all the system-based threats to voter-verifiable
schemes. The idea behind voter-verifiability in very abstract term is to provide
the voter, at the time of vote casting, with a unique receipt with their vote in
encrypted form. Once the election has closed, receipts are posted to a scheme.
Web Bulletin Board and votes are invited to check their receipt is accurately
posted and included in the tabulation process. The tabulation, performed by a
111
number of trustees or tellers with appropriate keys, is performed in publicly
verifiable fashion but in such a way as to ensure secrecy, i.e. decrypted votes
cannot be linked back to receipts. Various mechanisms are deployed to ensure
that votes will be correctly encrypted and subsequently decrypted.
This approach has been realized in a number of ways in various
schemes. The Chaum scheme implements receipt encryption using visual
cryptography whilst Neff’s uses ElGamal.
This analysis constitutes a useful first step towards a more systematic
analysis technique for voting system. We have the start of taxonomy of attacks
i.e. classification into subliminal channels, side channels, Kleptographic
channels, social engineering, threats, implementation problems etc.
REFERENCES
1. Robert S. Brumbaugh. Ancient Greek Gadgets and Machines, Thomas Y. Crowell , 1966.
2. Jeremy W. Bryans, and Peter Y. A. Ryan. A dependability Analysis of the Chaum Voting Scheme, Technical Report CS-TR -809, Newcastle University School of Computing Science, 2003.
3. David Chaum. Secret-Ballot Receipts: True Voter-verifiable Elections, IEEE Security and Privacy, Jan/Feb 2004.
4. M. Jakobsson, M. Juels, and R. Rivest. Making Mix Nets Robust for Electronic Voting by Randomised Partial Checking, USENIX’02, 2002.
5. C. Andrew Neff. A verifiable secret suffle and its application to e-voting, ACM-CCS-2001, 2001.
6. Peter Y. A. Ryan. A variant of the Chaum Voter-Verifiable Scheme, Technical Report CS-TR 864, University of Newcastle, October 2004.
7. S. K. Yadav, Sunder Lal, and S. C. Arora. Contourlet Cryptography, I.E.T.E. Vol. 58, pp. 201-208, 2007.
8. S. K. Yadav, Sunder Lal, and Kuldeep Bhardwaj. Multidimensional Cryptography: Latency Free Election Scheme, Proceedings of Indiacom2008, pp. 291-296, Bharti Vidyapeeth University, New Delhi, India.
112
Chapter 6
PROVABLE SECURITY AND CRYPTOGRAPHY: SOME BASIC PROBLEMS
6.0 OVERVIEW
In the following chapter we examine the methods for formally proving the
security of cryptographic techniques. We show that, despite of so many years
of active research, still, there are some basic problems which have yet to be
solved. We also present a new approach to one of the more controversial aspect
of provable security i.e. the random oracle model. We also have discussion on
some problems in Symmetric and Asymmetric Cryptography.*
6.1. INTRODUCTION
In the field of cryptography, the researches on 'Information security' aims
at protection of information from malicious attackers while still allowing
legitimate users to manipulate data freely. It also covers the study of algorithms
and protocols that secure data. For many years the vast majority of
cryptosystems proposed for practical use offered very little in the way of
security guarantees. They were developed in an ad-hoc fashion, following a
cycle in which cryptographic schemes were attached, broken, repaired and
attacked again. Some of these schemes have proven successful beyond the
wildest dreams of their designers; most have fallen, irrevocably broken, by the
wayside.
In this chapter we study these theoretical limitations and some of their
practical implications. We survey some problems in the field of provable
security and focusing on the problems associated with the random oracle * The present chapter is based on author’s paper “Provable Security and Cryptography: Some Basic Problems” presented in Ideal Institute Conference at Ghaziabad and extended abstract published in Proceedings pp. 46.
113
model. Random oracle is a powerful simplifying assumption which allows the
analysis of a cryptosystem by modeling certain parts of its internal structure as
random functions that act in a manner that is unknown to an attacker. We also
present an application of the random oracle model that may shed some light on
its future use within cryptography.
6.2. PROVABLE SECURITY: SOME BASIC PROBLEMS
6.2.1 Shannon’s Theory of Security and Symmetric Cryptography [14]
In a symmetric cryptosystem, a group of privileged users all know the key,
which we assume is not known to the adversary. We always assume that the
attacker knows the encryption also rhythm completely.
Shannon [15] proposed a theory to access the secrecy of symmetric
cryptosystems. This theory was based on his earlier theory of information and
entropy and involved examining the amount of information about a random
message (drawn from some probability distribution) an attacker gains after
being given an encryption of that message. An encryption scheme is said to be
perfect if an attacker gains no information about the message from its
encryption. However, it has been shown that for perfect secrecy to be achieved,
every bit of information in the message must be encrypted using a bit of
information in the key. As an example, consider a perfect block cipher.
Assuming that every n-bit message is equally likely to occur. Shannon’s theory
tells us that we will require n-bit keys. Of course, this result may be more
easily seen by nothing that, when given a cipertext C encrypted using a k-bit
key generated uniformly at random, there exist 2k possible pre-image for C.
Thus if k < n then the attacker will be able to narrow down the number of
possibilities for the message m and so gain information about the message.
Furthermore, these keys are not reusable. If we wish to use the block cipher
twice, then we will be encrypting a total of 2n-bits of message and so require a
114
key of length at least 2n-bits. It is impossible to produce a system that is
perfectly secure for arbitrary length messages.
6.2.2 The Reduction Theory of Security and Asymmetric Cryptography[8]
In an asymmetric cryptosystem, as we mentioned earlier, there exist two
related keys: a public key, which is widely known, and a private key, which is
only known by a single user. We assume that any attacker who wishes to break
the cryptosystem is fully aware of the public key and any algorithms that may
be used as part of the cryptosystem; the only piece of information that is denied
to the attacker is the private key. Typically, asymmetric cryptosystems are
based on the computation of large numerical values and are a lot slower than
their symmetric counterparts.
The nature of the relationship between the public and private keys means
that it is impossible for any asymmetric scheme to achieve a perfect notion of
security. The public key, by definition, must contain enough information to
compute its associated private key. Security is obtained by using large enough
public and private key valves so that, while it may be theoretically possible to
recover the private key from the public key, it is not computationally feasible to
do so. This notion of computational infeasibility led researchers to consider
phrasing security requirements in terms of Turing’s complexity theory [17]
rather than Shannon’s information theoretical approach.
6.2.3 Formal Security Models [10]
A formal security model consists of two definitions: it must specify how an
arbitrary, probabilistic, polynomial-time attacker can interact with legitimate
users of a cryptosystem, and it must state what that attacker should achieve in
order to ‘break’ the cryptosystem. There are two general approaches to formal
security models.
115
The first is the game-based approach. In this style of security model the
attacker interacts with a hypothetical probabilistic algorithm called a
challenger. The challenger generates all the keys used in the system, and may
respond to queries made by the attacker. The game terminates when the
attacker terminates, and we assess whether the attacker has met the condition
for breaking the cryptosystem. If a cryptosystem is to be proven secure, then
we must show that the probability that an arbitrary attacker breaks the
cryptosystem is small. Widely accepted game-based security models have been
proposed for many types of cryptosystem, including digital signatures,
asymmetric encryption and symmetric encryption.
As an example, we will consider the security model for a digital signature
scheme. Consider an arbitrary, probabilistic, polynomial-time attacker. The
challenger generates an asymmetric key pair of the appropriate security level
(as determined by the security parameter). The attacker algorithm is then
executed. It takes the public key and the security parameter as input. During its
execution, the attacker may ask the challenger to produce signatures for
messages of the attacker’s choice. This the challenger does faithfully using the
signing algorithm and the private key. The attacker terminates by outputting a
signature and a message m. The attacker is deemed to have broken the
system if the verification algorithm declares that is a valid signature for the
message m and the attacker did not ask the challenger to sign the message m.
This is a strong notion of security, but does capture many of the real-world
capabilities of an attacker, particularly that they may be able to ‘trick’ a user or
system into signing certain messages of their choice.
6.2.4 Small Inconsistencies : Concrete Vs. Asymptotic Security
Another issue that has caused some controversy among cryptographers is
the definition of ‘small’ in the statement ‘the probability that an attacker can
116
break the system should be small’. The original definition is that the attacker’s
probability should be negligible as a function of the security parameter.
Definition [17]: A function f : N R is negligible if for every
polynomial p there exists a positive integer N(p) such that
1f n p n , for all n > N (p).
It may be true that the probability of breaking a cryptosystem is
asymptotically small, but that does not mean that the scheme is secure for
security parameters that can actually be used. The alternative to the asymptotic
definition is a concrete definition [3].
In a concrete security analysis, we still reduce the security of a
cryptosystem to a well-studied mathematical problem; however, now we
evaluate the security of the scheme based on the quality of the reduction.
Typically, we prove the security of a cryptosystem by considering an arbitrary
attacker that breaks the scheme and showing that we can use such an attacker to
create an algorithm that will solve the underlying problem. A concrete security
proof assumes that the attacker runs in time bounded by a known function t ()
and has an (unknown) success probability (), where is the security
parameter. The reduction allows as to derive an algorithm for solving the
underlying problem in time bounded by t’ (t(), ()) and with a success
probability ’ (t(), ()). We may approximate an upper bound for the success
probability ’ as less than that of the best known algorithm for solving the
underlying problem in time t’ (determined through experimental results). It is
then possible to derive an upper bound for ; and so a lower bound for the
security parameter above which the probability that an attacker breaks the
scheme can be estimated to be below a given security value. Hence, we can
estimate the values of the security parameter for which the scheme is secure.
117
6.2.5 Can we detect simulation?
Cryptographers typically prove the security of a cryptosystem by assuming
the existence of an attacker who can break the cryptosystem and then using that
attacker as a subroutine in a larger algorithm that solves the underlying
problem. The assumption that there exist no efficient algorithms that solve the
underlying problem implies that there are no attackers who can break the
cryptosystem; this is a well-known technique in complexity theory.
Unfortunately, there is a difference between a complexity theoretic reduction
and the kinds of reduction used in proofs of security. In order to construct a
complexity theoretic reduction, one simply has to find a way to phrase on
instance of one problem as an instance of the other problem. This is not true
when reducing the security of a cryptosystem to the difficulty of solving a
mathematical problem.
In a security model, the attacker normally does more than just receive an
instance of the cryptosystem to break. Often, in a security model, the attacker
may also query other entities in the system (for example, the challenger in a
game-based security model or the environment in a simulation-based security
model). These entities compute values and return the results to the attacker, and
are modeled as oracles to which the attacker has access. Thus, in order to prove
the security of a cryptosystem, it is not only necessary to phrase the instance of
the underlying problem as an instance of the problem of breaking the
cryptosystem, it is also necessary to make sure that the responses to the
attacker’s oracle queries are correct. It is the problem of responding to these
oracle queries that typically makes producing security proofs so difficult.
It is frustrating that many security proofs cannot be completed, or require
additional assumptions, owing to the problems associated with correctly
responding to ‘trivial’ oracle queries. A trivial oracle query is one in which the
attacker already knows the response that it should receive from an oracle before
118
it make the query: thus, the query does not help them break the cryptosystem in
any way, but it does allow them to detect whether the oracle is responding
correctly or not.
6. 3. THE RANDOM ORACLE MODEL: APPLICATION
A hash function is a keyless algorithm that takes arbitrary-length inputs
and outputs a fixed-length hash value or hash. There are several properties that
one would expect a hash function to exhibit, including pre-image resistance
(given a random element of the output set, it should be computationally
infeasible to find a pre-image of that element) and collision resistance (it
should be computationally infeasible to find two elements that have the same
hash value). However, there are many more properties that we might require of
a hash function depending on the circumstances. For example, it might be
hoped that if the hash function is evaluated on two related inputs, then the
outputs will appear unrelated.
From a provable security point of view, hash functions present a difficult
problem. They are usually developed using symmetric techniques, either as
stand-alone algorithms or based on the use of a block cipher. Thus it is difficult
to apply the reductionist theory of provable security to them because there are
no natural candidate problems to which we may reduce the security. There are
constructions of hash functions from block ciphers for which it can be proven
that the hash function has certain properties (such as pre-image and collision
resistance) as long as the underlying block cipher is undistinguishable from a
random permutation. However, it is impossible for any publicly-known
function to produce outputs that appear independent when evaluated on two
known inputs.
The random oracle model attempts to overcome our inability to make
strong statements about the security of hash functions by modeling them as
completely random functions about which an attacker has no information. The
119
attacker (and all other parties in the security model) may evaluate such a
random hash function by querying an oracle. The original interpretation of this
simplification was that it heuristically demonstrated that a cryptosystem was
secure up to attacks against the system that may be introduced via the use of a
specific hash function. Equivalently, it was thought that a proof of security in
the random oracle model meant that, with overwhelming probability, the
cryptosystem was secure when instantiated with a randomly chosen hash
function.
The one major difference between the random oracle model and the use of
a hash function selected at random from a random-looking function family is
that in the latter case the attacker is given access to a description of a Turing
machine that can compute the hash function; in the former the attacker is not
given such a description. This led to the cataclysmic result of Canetti et al. [8]
who demonstrated that it was possible to have a scheme that was provably
secure in the random oracle model, and yet insecure when the random oracle
was replaced with any hash function. The trick Canetti et al. employ is to use
knowledge of the Turing machine that computes the hash function like a
password that forces the cryptosystem to release sensitive information (such as
its private key).
As an example, we consider the formal game-based security model for an
asymmetric encryption scheme. In this model, the cryptosystem is represented
as three separate polynomial-time algorithms: a probabilistic key generation
algorithm G that takes as input the security parameter in unary format 1k, and
output a public key pk and a private key sk; a probabilistic encryption
algorithm that takes as input the public key pk and a message m drawn from a
message space M that is defined by the public key, and outputs a ciphertext C,
and a deterministic decryption algorithm D that takes as input the secret key sk
and a ciphertext C, and returns either a message m M or the error symbol .
120
For an arbitrary, probabilistic polynomial-time attacker A = (A1, A2), and a
security parameter k, the security model is as follows:
1. The challenger generates an asymmetric key-pair (pk, sk) = g (1k).
2. The attacker A1 is executed on the input (1k, pk). During its
execution, A1 may query a decryption oracle with a ciphertext C.
This decryption oracle returns D (sk, C) to the attacker. A1 terminates
by outputting distinct equal-length messages (m0, m1) and some state
information state.
3. The challenger randomly selects a bit b {0,1} and computes
C* = (pk, mb).
4. The attacker A2 is executed on the input (C*, state). As before,
during its execution, A2 may query a decryption oracle; however now
we forbid A2 to query the decryption oracle on C*. A2 terminates by
outputting a bit b’.
6.4. RANDOM ORACLE AND ZERO-KNOWLEDGE PROTOCOLS
For game-based security models, all known proofs for the separation
between the random oracle model and the standard (real-world) model are
based on the Canetti et al. trick of passing a (binary) description of the hash
function to the challenger as part of an oracle query. It is therefore natural to
ask whether this is the only way in which is cryptosystem might be provably
secure in the random oracle model, yet insecure when that oracle is instantiated
with any hash function. If so, then an examination of the algorithms of a
cryptosystem might be enough to (heuristically) convince users that this
situation does not occur and therefore that a proof of security in the random
oracle model is sufficient.
One approach to this problem might be to consider an extended version of
the random oracle model in which the attacker is given some form of identifier
121
which uniquely identifies the hash function in use and allows the evaluation of
that hash function on arbitrary inputs, but does not give any information about
the internal structure of the hash function. For example, one may consider
using code obfuscation to disguise the internal workings of the hash function,
or encrypting the hash function and providing the attacker with an oracle that
executes encrypted code. Sadly, this does not appear to work. The former
approach fails because it is impossible to provide sufficiently strong code
obfuscation [4]. The latter approach fails because we may construct schemes
that are provably secure in this ‘encrypted random oracle model’, but insecure
in the standard model. These examples use knowledge of the key used to
decrypt the hash function as a ‘password’ in exactly the same way that Canetti
et al, used the hash function code.
Another interesting point about Canetti et al. [8] style attacks is that they
all make use of the attacker’s ability to make oracle queries in the security
model, for example, decryption oracle queries in the security model for an
asymmetric encryption scheme. We do not know to any example of any
asymmetric encryption scheme that is Indistinguishability under Chosen
Plaintext attack (IND-CPA) secure in the random oracle model, but insecure
when the random oracle is instantiated with any hash function. If such a
cryptosystem (G, E, D) existed and we assume, without loss of generality, that
M = {0,1} for all values of the security parameter, then the protocol for
proving knowledge of [f] reduces to:
1. The verifier computes (pk, sk) = G (1k), generates a random bit
b {0,1} and computes C* = (pk, b). The verifier sends
(1k, pk, C*) to the prover.
2. The prover executes the attacker algorithm that breaks the
encryption scheme and recovers a guess b’ for b. This value is
sent to the verifier.
122
3. The verifier accepts the prover’s claim if b = b’.
This is a zero-knowledge protocol for any honest verifier. Therefore,
either there exists a two-round honest-verifier zero-knowledge protocol
that demonstrates knowledge of [f], or a proof of Indistinguishability
under Chosen Data attack (IND-CDA) security in the random oracle
model is sufficient to guarantee security.
It is clear that neither game based, nor simulation-based, models of
security are entirely adequate. The game based models do not give the security
guarantees that one requires, and the simulation based models cannot be used
to prove the security of certain types of scheme. Since simulation based
security models were developed to overcome the problems in game based
models, it should be hoped that researchers will once return to first principle in
an attempt to produce a comprehensive model for security. We are unaware of
any group attempting to do this, and it is unclear whether this daunting line of
research will be pursued.
6.5 CONCLUDING REMARKS
The next decade will decide whether provable security has a future in
practical cryptography, or whether it will be banished back to the realms of
‘theoretically interesting’ science. This will be largely determined by how well
cryptographers overcome the fundamental problems that we discuss.
A situation exists for the random oracle model; however, in this case we do
not believe the future in quite as black, while it is true that many researchers
are still studying the negative aspects of the Random Oracle model in various
situations. Towards this end, this chapter suggests that separation between the
random oracle model and the standard model is intrinsically linked to certain
problems connected with zero-knowledge proofs.
123
In an interesting twist, it seems possible that the problem of responding to
terminal oracle queries may be connecting to be problem of analyse the zero-
knowledge protocols.
REFERENCES
1. M. Ballare. 1977 Practice – Oriented provable-security: Modern Cryptology in Theory and Practice (ed. I. Damgard). Springer-Verlag Lecture Notes in Computer Science, No. 1561, pp. 1-15.
2. M. Ballare, and A. Palacio. 2004 Towards plaintext-aware public-key encryption without random oracles. Advances in Cryptology – ASIACRYPT 2004, Proc. 10th International Conference on the Theory and Application of Cryptology and Information Security, Jeju Island, Korea, 5-9 December, 2004 (ed. P.J. Lee). Springer-Verlag, LNCS, # 3329, pp. 48-62.
3. B. Barak. 2001 How to do beyond the black-box simulation barrier. Proc. 42nd IEEE Annual Symp. on Foundations of Computer Science, Las Vegas, NV, USA, 14-17 October 2001, pp. 106-115.
4. B. Barak, O. Goldrecih, R. Impagliazzo, S. Rudich, A. Sahai, S. Vadhan, and K. Yang 2001 On the (im) possibility of obfuscating programs. Advances in Cryptology – CRYPTO 2001, Proc. 21st Annual International Cryptology Conference, Santa Barbara, California, USA, 19-23 August 2001 (ed. J. Killan). Springer-Verlag LNCS, No. 2139, pp. 1-18.
5. D. Boneh, and X. Boyen. 2004 Short signatures without random oracles. Advances in Cryptology – EUROCRYPT 2004, Proc. International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2-6 May 2004 (eds. C. Cochin & J. Camenisch). Springer-Verlag, LNCS, # 3027, pp. 56-73.
6. R. Canetti. 2001 Universally composable security: A new paradigm for cryptographic protocols. Proc. 42nd IEEE Annual Symp. on Foundations of Computer Science, Las Vegas, NV, USA, 14-17 October 2001, pp. 136-145.
7. R. Canetti, and M. Fischlin. 2001 Universally composable commitments. Advances in Cryptology – CRYPTO 2001, Proc. 21st Annual International Cryptology Conference, Santa Barbara, CA, USA, 19-23 August 2001 (ed. J. Killian). Springer-Verlag LNCS , # 2139, pp. 19-40.
8. R. Cannetti, O. Goldreich, and S. Halevi. 2004 The random oracle methodology, revisited. J. ACM 51(4), 557-594.
124
9. A. W. Dent. 2002 Adapting the weaknesses of the random oracle model to the generic group model. Advances in Cryptology – ASIACRYPT 2002, Proc. 8th International Conference on the Theory and Application of Cryptology and Information Security, Queenstown, New Zealand, 1-5 December 2002 (ed. Y. Zheng). Springer-Verlag, LNCS, # 2501, pp. 100-109.
10. W. Diffie, and M. E. Hellman. 1976 New directions in cryptography. IEEE Trans. Inf. Th. 22, 644-654.
11. S. Goldwasser, S. Micali, and R. Rivest. 1988 A digital signature scheme secure against adaptive chosen-message attacks. SIAM J. Computing 17(2), 281-308.
12. B. Pfitzmann, and M. Waidner. 2000 Composition and integrity preservation of secure reactive systems. Proc. 7th ACM Conf. Computer and Communications Security, Athens, Greece, 1-4 November 2000, pp. 245-254.
13. C. Rackoff, and D. R. Simon. 1991 Non-interactive zero-knowledge proof of knowledge and chosen ciphertext attack. Advances in Cryptology– CRYPTO ’91, Proc. 11th Annual International Cryptology Conference, Santa Barbara, CA, USA, 11-15 August 1991 (ed. J. Feigenbaum). Springer-Verlag, LNCS, # 576, pp. 433-444.
14. C. E. Shannon. 1948 A mathematical theory of communication. Bell System Technical J. 27, 379-423, 623-656.
15. C. E. Shannon. 1949 Communication theory of secrecy systems. Bell System Technical J. 28, 565-715.
16. V. Shoup. 1997 Lower bounds for discrete logarithms and related problems. Advances in Cryptology – EUROCRYPT ’97, Proc. International Conference on the Theory and Application of Cryptographic Techniques, Konstanz, Germany, 11-15 May 1997 (ed. W. Fumy). Springer-Verlag, LNCS, # 1233, pp. 256-266.
17. A. M. Turing. 1936 On computable numbers, with an application to the Entscheidung-problem. Proc. Lon. Math. Soc. Ser. 242, 230-265.
125
Chapter 7 CRYPTOGRAPHIC PAIRINGS:
A MATHEMATICAL APPROACH
7.0 OVERVIEW
Traditionally, cryptographic pairings were treated as a ‘black box’.
Cryptographers build cryptographic schemes making use of various properties of
pairings. If this approach is considered, then it is easy to make invalid assumption
concerning the properties of pairings. The cryptographic schemes developed may
not be realized in practice, or may not be efficient as we assume. Here we aim to
outline, the basic choice which are available when using pairings in cryptography.
For each choice the main properties and efficiency issues are summarized. This
chapter deals with simple approach of cryptographic pairings.*
7.1. INTRODUCTION
Many cryptographers in this field treat pairings as a “black box” and then
proceed to build various cryptographic schemes making use of assumed properties
of the pairings. As an approach, it allows one to ignore mathematical and
algorithmic subtleties and focus on purely cryptographic aspects of the research.
However, if this approach is taken, then it is easy for us to make assumptions
concerning the properties of pairings which are not necessarily correct, and hence
develop cryptographic schemes which cannot be realized in practice, or which
cannot be implemented as efficiently as we assume. Some common assumptions of
this type are as follows:
One can efficiently construct two groups associated with the pairing. * This chapter is based on the author’s paper “Cryptographic Pairings: A Mathematical Approach”
presented at Ideal Institute of Technology, Ghaziabad Conference, 2008 and extended abstract published in Proceedings, pp.48.
126
Operation in groups association with the pairing can be efficiently
implemented.
Elements of one or more groups associated with the pairing have a
“short” representation.
One can construct suitable system parameters for pairing-based
cryptosystems in polynomial time for any security level.
The pairing can be computed efficiently.
There are efficiently computable homomorphisms between various
groups associated with the pairing.
7.2 BACKGROUND
There are two forms of pairings used in the cryptography literature. The first are
of the form
e: G1 G1 GT
where G1 and GT are groups of prime order l.
The second form is
e: G1 G2 GT
where G1, G2 and GT are groups of prime order l. We will always use the second
form, and we consider the first form to be just the special case where G2 = G1. Of
course this important special case may yield advantage in practice.
One of the main goals of this chapter is to explore various issues, which arise
depending on the choices of groups and pairing. We comment that the groups G1,
G2, GT and the pairing e(. , .) often form part of the system parameters of a
cryptosystem and may be used by a large number of users. For example, in many
127
identity-based encryption schemes, the trusted authority sets up the system
parameters which includes descriptions of groups and a pairing, and all users’
public keys are defined with respect to these parameters.
It turns out to be appropriate to separate different possible pairing instantiations
into three basic types:
Type-1: G1 = G2;
Type-2: G1 G2 but there is an efficiently computable homomorphism
G2 G1
Type-3: G1 G2 and there are no efficiently computable homomorphism between
G1 and G2.
We should clarify that in all cases, there exist homomorphism between G1 and
G2 (this is trivially true since they are cyclic groups of the same order). The
situation, where G1 G2 but there are efficiently computable homomorphism in
both directions can be re-interpreted as Type-1, so we do not consider it separately.
This distinction into types is relevant for the design of cryptographic schemes.
In particular, the existence of maps between G2 and G1 is sometimes required to get
a security proof to work. There exist many primitives in pairing-based
cryptography whose security proof does not apply if the cryptosystem is
implemented using pairings of the third type.
It is focused on several of the frequently made assumptions about pairings when
they are treated as black boxes.
- We can hash to G2.
- There is a (relatively) short representation for elements of G1.
- There is an efficiently computable homomorphism from G2 to G1.
128
We can generate system parameters (including groups and a pairing) achieving
at least bits of security, where is a security parameter.
We briefly summaries what is possible in Table-7.1, but first we mention
some technical properties of pairing implementations. The Type-1 case G1 = G2 is
implemented using super singular curves. The super singular curves can be
separated into two sub-classes: those over fields of characteristic 2 or 3 (with
embedding degree 4 or 6 respectively), and those over fields of large prime
characteristic (with embedding degree 2). The curves of Type-2 are ordinary and
the homomorphism from G2 to G1 is the trace map. The curves of Type-3 are
ordinary, and G2 is typically taken to be the kernel of the trace map.
Table-7.1. Properties of the types of pairing groups.
Type Hash to G2
Short G1 Homomorphism Poly time generation
1. (small char) 1. (large char)
2. 3.
x
x
x
x
x
7.3 BANDWIDTH CONSIDERATIONS AND EFFICIENCY
Once one has decided, with the help of Table-7.1, whether a proposed scheme
can be implemented, it is natural to ask about the speed and storage requirements of
the system. We discuss these issues in this section. It turns out that these properties
can change as the security level increases. The results depend on specific
implementation details of the relevant group operations and pairing calculation.
It is necessary to discuss, for each of the three types defined above, how to
ensure that an appropriate security level is attained.
129
First we note that all practical pairings are based on the Weil pairing or Tate
pairing on elliptic (or hyper elliptic) curves over finite fields. In this chapter we
restrict to elliptic curves. The groups G1 and G2 are groups of points on the curve
and the group GT is a subgroup of the multiplicative group of a related finite field.
We denote by l the (common) order of these three groups. if q denotes the size of
the field over which our elliptic curve E is defined, then G1 is a subgroup of E(Fq),
G2 is usually a subgroup of E(Fqk), and GT is a subgroup of F*qk. Here k is a
parameter usually called the embedding degree in pairing-based cryptography.
There are then three main parameters that one needs to keep in mind: the base field
size q, the embedding degree k and the group size l.
Secondly, we note that in order to achieve a particular level of security, it is
necessary that the discrete logarithm problems (DLPs) in G1, G2 and GT be
sufficiently hard. Thus we need to consider (as a first step) what minimum sizes we
need for our base field Fq and for our extension field Fqk to be in order to make the
relevant DLPs sufficiently hard. Even this is a complicated question, particularly
with regard to selecting Fqk, as there is a variety of algorithms for solving the DLP,
and these algorithms have complicated asymptotic running times.
Table-7.2, shows roughly equivalent parameter sizes at a variety of security
levels from three different sources, DRDO, TIFR, and CSIR. The first column in
this table shows the security level k. roughly speaking, 2k is the number of basic
operations (block cipher encryptions, say) needed to break a block cipher with a k-
bit key. The second column represents the size of an elliptic curve group needed to
provide k bits of security (again, meaning that 2k basic operations are needed to
solve the DLP in the group). Note the simple relationship between k and the group
size 22k. The third column shows the size of RSA keys needed to provide k bits of
security. This can be roughly equated to the size of field needed to attain a given
level of security for the DLP in Fqk.
130
Table 7.2
Recommended key sizes Author
K ECC-style RSA-style
DRDO 80
128 256
160 256 512
1024 3072
15360
TIFR 80
128 256
160 256 512
1329 4440
26268
CSIR 80
128 256
160 256 512
1248 3248
15424
In Table-7.3 we answer the following questions, at the 80-bit and 256-bit
security levels.
H1: Can one hash to G1 efficiently?
H2: Can one hash to G2 efficiently?
S1: Is there a short representation for elements of G1? (Meaning, in a system
with security level k, can elements of G1 be represented with roughly the
minimum number, say < 2k + 10, of bits?)
S2: What is the ratio of the size of the representation of elements of G2 to the
size of the representation of elements of G1?
E1: Are group operations in G1 efficient? (Meaning, in a system with security
level k, are operations in G1 efficient when compared with usual elliptic
curve cryptography in a group with security level k?)
E2: What is the ratio of the complexity of group operations in G2 to the
complexity of group operations in G1?
131
E3: What is the ratio of the complexity of group operations in GT to the
complexity of group operations in G1?
P: Is the pairing efficient? (Meaning, how does the speed of pairing
computation compare with alternative groups of the same security level?)
F: Is there wide flexibility in choosing system parameters? (Meaning, is it
necessary for all users to share one curve, or is there plenty of freedom for
users to generate their own curves of any desired security level k?)
Question H1, H2, S1, E1, P, and F will be answered by a rating of 0 to 3 stars.
Zero stars means that the operation is impossible, 1 star means the operation is
possible but that there is some significant practical problem with it, 2 stars means
there is a satisfactory solution, 3 stars means the question is answered as well as
could be expected.
For Type-3 curves it is necessary to define the quantity e. Let D be the CM
discriminate used to construct the elliptic curve. If D = 4, then set
gcd ,4 ,e k k
if D = 3, then set
gcd ,6 ,e k k
while if D < - 4, then set
gcd , 2 2.e k k k
Since we have not given absolute times/sizes in the starred columns it is
difficult to compare the various types of pairing groups. This is a deliberate choice
in our part, since the type of pairing group one chooses is dictated more by the
scheme and hence by Table-7.1. Thus Table-7.3 is primarily meant to indicate what
happens as the security level increases for a particular type of curve.
132
Some particular phenomena are clearly indicated in the tables. For example,
Type-3 is the only choice which offers good performance and flexibility for high
security parameters, and yet this choice does not permit a homomorphism from G2
to G1. Hence, it would be desirable if protocol designers could prove the security of
their schemes without requiring such a homomorphism.
Table-7.3. Comparison of efficiency and bandwidth properties (k network)
Type K H1(3) H2(3) S1 S2(4) E1 E2(5) E3(6) P F
Type-1 (char 2) 80 256
*** *
*** *
** *
1 1
** *
1 1
8/7 8/7
*** *
* *
Type-1 (char 3) 80 256
*** *
*** *
*** *
1 1
*** *
1 1
3 3
*** *
* *
Type-1 (char p) 80 256
** *
** *
* *
1 1
* *
1 1
1/4 1/4
*** *
*** ***
Type-2 80 256
*** **/***(7)
*** */***(8)
k k
*** **/***(9)
k2 k2
k2/16 k2/16
*(10) *(10)
*** ***
Type-3 80 256
*** **/***(7)
* *
*** */***(8)
e e
*** **/***(9)
e2 e2
e2/16 e2/16
*** ***
*** ***
Among the various methods for generating ordinary curves, some simply
require evaluating one or more polynomials at integer values until primes are
found, while others require the solution of Pell equations or finding large prime
factors of lk – 1. Any method for generating system parameters which involves
solving Pell equations has dubious theoretical merits, since only finitely many
solutions will be expected [12]. Similarly, any method that requires factoring will
not be polynomial time. Hence, to ensure flexibility in the choice of parameters we
assume that curves are generated using methods which only require that.
1. One can choose G2 to be the full l-torsion subgroup of the curve. In other
words, we have a group of exponent I rather than order l. In such a setting
one obtains a tick in every column of Table-7.1, however this is at the
expense of having a pairing between groups which has a probability of 1/l of
133
being trivial on random non-trivial input elements. In addition such pairing
systems consume more bits to represent the elements in G2 compared to our
other systems.
2. In a number of recent papers, pairings have been used on groups of
composite order where the factors of group order are kept secret. However,
one may note that currently the only known way to generate such groups is
in the Type-1 setting. In addition, such groups necessarily consume greater
bandwidth and computational resources than the “traditional” pairing systems.
3. Hashing into G1 and G2 usually involves multiplication by the cofactor,
though in many cases this will be chosen to be small. In some schemes the
need for this multiplication can be effectively removed by taking care of it
through other operations at a later stage in the operation of a scheme, for
example through the final powering in the Take pairing algorithm. In these
columns it is assumed that the cofactor multiplication is carried out.
4. We assume that G1E(Fq) and G2E(Fqk) and so the standard
representation of elements of G2 will be k times longer than the standard
representation of elements of G1. This memory requirement can be reduced
in the case where G2 is the trace zero subgroup by using twists. This is why
the smaller ratio e appears for Type-3 groups. We assume for Type-3 groups
that the embedding degree k is always even, so e is at most k/2.
5. We assume projective coordinates are used in the group G2, rather than
affine coordinates. This might not be the most efficient in any given
implementation, but also give a rough order of magnitude difference.
As explained in point 4 above, the ratio of the size of elements of G2 to G1
for Type-2, and Type-3 curves is k or e. Since multiplication is quadratic we
make the naïve calculation that the cost of operations in G2 is either k2 or e2
the cost of operations in G1.
134
If one is using pairing friendly fields, which are fields of degree 2 3i jk ,
then the value of k2 (respectively e2 ) can be replaced by 3i5j (respectively
3i25j or 3i15j-1 or 3i15j ).
6. We assume a standard naïve implementation as we only aim to give a rough
estimate. Thus multiplication in Fqk costs k2 – multiplications in Fq,
whereas projective coordinate addition in G1E(Fq) cost roughly
- For Type-1 curves in characteristic 2 at most 14-Fq operations.
- For Type-1 curves in characteristic 3 at most 12-Fq operations.
- For Type-1 curves in characteristic p at most 16-Fq operations.
- For Type-2 and Type-3 curves at most 16-Fq operations.
Hence the ratio of the cost of an operation in Fqk to the cost of an
operation in G1 is k2/16, for Type-2 and Type-3 curves. The values for
Type-1 curves are obtained as 42/14, 62/12 and 22/16.
A similar comment related to pairing friendly fields as in point 5 can also
be applied here.
A common operation in the groups is exponentiation / point
multiplication. Comparing the relative costs of these methods is less
easy, since there are a number of special tricks available, the exact trick
which is used depends on the relative cost of operations in the group, the
amount of available memory, and the size of the exponent / multiplier
being used.
7. When hashing into G1 this will be efficient when k is chosen so that q I,
but when q is much larger than l then this will become progressively more
expensive. Hence, this depends on k and whether curves can be generated
with the correct parameter sizes.
135
8. This too depends on whether q l, and hence depends on the choice of k and
whether cures can be generated with the correct parameter sizes.
9. Again this depends on whether q l curves can be generated with the correct
parameter sizes.
10. One can reduce a Type-2 pairing computation to that of a Type-3 pairing at
the cost of an extra multiplication in G1. One uses the following property of
the pairing, if P G1 and Q G2 in the Type-2 situation then
1, , Tre P Q e P Q Qk
.
Where Tr is the trace function from E(Fpk) down to E(Fp), i.e. the function
The pairing on the right is such that its arguments are values of the pairing in the
Type-3 situation.
7.4 CONCLUDING REMARKS
In the above work we studied the feasibility of pairing based protocols and
application in sensors with limited computational resources using mathematical
fundamentals.
REFERENCES
1. I. Blake, G. Seroussi, and N. P. Smart (eds.). Advances in Elliptic Curve Cryptography. Cambridge University Press, 2005.
2. D. Boneh, and X. Boyen. Efficient selective-ID secure identity-based encryption without random oracles. In Advances in Cryptology – Eurocrypt 2004, Springer-Verlag LNCS, # 3027, 223-238, 2004.
3. D. Bonch, X. Boyen, and H. Shacham. Short group signatures. Advances in Cryptology – CRYPTO 2004, Springer-Verlag LNCS, # 3152, 41-55, 2004.
4. D. Boneh, and M. Franklin. Identity-based encryption from the Weil pairing. Advances in Cryptology – CRYPTO 2001, Springer-Verlag LNCS, # 2139, 213-229, 2001.
136
5. D. Bonch, B. Lynn, and H. Shacham. Short signatures from the Weil pairing. Advances in Cryptology – ASIACRYPT 2001, Springer – Verlag LNCS, # 2248, 514-532, 2001.
6. D. Boneh, B. Lynn, and H. Shacham. Short signatures from the Weil pairing. J. of Cryptology, 17, 297-319, 2004.
7. D. Boneh, and H. Shacham, Group signatures with verifier-local revocation. ACM CCS 2004, 168-177, ACM Press, 2004.
8. L. Chem, and Z. Cheng. Security proof of Sakai-Kasahara’s identity-based encryption scheme. Proceedings of Cryptography and Coding 2005, Springer-Verlag LNCS, # 3796, 442-459, 2005.
9. G. Grey, and H.. G. Ruck. A remark concerning m-divisibility and the discrete logarithm in the divisor class group of curves. Math. Comp. 62, 865-874, 1994.
10. A. Joux. A one round protocol for tripartite Diffie-Hellman. Algorithmic Number Theory Symposium – ANTS IV, Springer-Verlag, LNCS, # 1838, 385-394, 2000.
11. A. K. Lenstra. Key lengths. Handbook of Information Security, Vol. 2, 617-635, Wiley, 2005.
12. F. Luca, and I. Shparlinski. Elliptic curves with low embedding degree. NNCS, # 2025, Springer-Verlag 226-237, 2008.
13. A. J. Menezes. T. Okamota, and S. A. Vastone. Reducing elliptic curve logarithms to logarithms in a finite field. IEEE Trans. Inf. Theory, 39, 1639-1646, 1993.
14. R. Sakai, K. Ohgishi, and M. Kasabara. Cryptosystem based on pairing. The 2000 Symposium on Cryptography and Information Security, Okinawa, Japan, January 2000.
15. R. Sakai, K. Ohgishi, and M. Kasahara. Cryptosystem based on pairing over elliptic curve (in Japanese). The 2001 Symposium on Cryptography and Information Security, Oiso, Japan, January 2001.
16. R. Sakai, and M. Kasahara. ID based cryptosystems with pairing on elliptic curve. Cryptology ePrint Archive, Report 2003/054.2003.
17. N. P. Smart, and F. Vercauteren. On computable isomorphisms in efficient pairing based systems. Cryptology ePrint Archive, Report 2005/116.2005.
18. NIST Recommendation for Key Management Part 1: General. NIST Special Publication 800-57. August, 2005. available from http://csrc/nist.gov./ publications/nistpubs/800-57/SP800-57-Part1.pdf.
19. ECRYPT Yearly Report in Algorithms and Keysizes (2004), March 2005, Available from http://www.ecrypt.eu.org/documents/D.SPA.10-1.1-pdf.
137
APPENDIX-I
LIST OF PUBLICATIONS DURING RESEARCH WORK
1. “Multipath Routing with self healing Tech. for QoS in MANET ” I.E.T.E. Journal of research, Vol. 52 (2004)
2. “Application of Wavelets in Neural Network” INDIACOM 2007 Proceedings, B. V. P. New Delhi.
3. “PKI Services in BSNL” International Conference on Communication Networks, Min. of Information Technology. 2007 in Delhi.
4. “Viscous flow and Boundary Layers in Aerodynamics” Ae. S. I. Technical Journal, Apr. 2004.
5. “Implementing and Developing Cryptographic Protocol” National Conference on Advances in Information Technology, Institute of Engineering & Technology Dr. B.R. Ambedkar University Agra.
6. “Wavelet Theory and Application in Biomedical Science” INDIACOM 2007 Proceedings, B. V. P. New Delhi.
7. “E. Business; Emerging Trends in India” IMS Conference Proceedings GZB.2007 8. “Web Based Requirement of use case tool” Webcom 2007, Galgotia Institute
Conference Proceedings 2007. 9. “JFS and Rijndael algorithm: Projection Protocol” National Conference on
Networking Anand Institute of Tech. Agra. Proceedings 2007. 10. “Modeling in Nanophysics” National Conference on Nano-materials, IIT Delhi
2007 (Dept. of Material Sc.) 11. “Contourlet Cryptography: A better option for pattern Recognition” International
Conference of Industrial and Application Mathematics, 2007. (Jammu University).
University of Jammu 2008. 14. “Multidimensional Cryptography: A Latency Free Election Scheme”. INDIACom
2008.(P. P. 291-296) 15. “Cryptographic protocols: Security and Composition” National Conference on
Advancement Technology – Trends in Networking & Communication; G. L. A. Institute Mathura (2008).
16. “Provable Security and Cryptography: Some Basic Problems” International Conference on Security & Network Technology, Ideal Institute, Ghaziabad (2008).
17. “Cryptographic Pairings: A Mathematical Approach” International Conference on Security & Network Technology, Ideal Institute, Ghaziabad (2008).
18. “Contourlet Cryptography and Image Processing”. International Conference on Security & Network Technology, Ideal Institute, Ghaziabad (2008).
138
19. “Cryptographic Voter Verifiabilits Technique: A Practical Approach” Paper presented and published in proceedings of WorldComp 2008, at Las vegas USA (14 Jun 2008)
20. “Perspectives of Symmetric cryptography”, Published in INDIACOM 2009 Proceedings (PP. 211-216)
21. “Mathematical Tools of Asymmetric Cryptography”, ICRTM 09 (International Conference at Jamia Milia Islamia University) Proceedings.
22. “On False Report Filtering in Sensor Networking: A Cryptographic Approach”, (International Journal of Theoretical & Applied Sciences July – Dec., 2009 Vol. II)
23. “On Multivariate System in Asymmetric Cryptography” (Published in Category 1, For ETCSIT ‘09 Mysore India).
24. “Symmetric Cryptography: A Mathematical Perspective” (Paper accepted in IETE Journal of Research).
25. “On NTRU Cryptosystem and L3 Algorithm: A Problem” (Accepted for publication in IAENG International Journal of Applied Mathematics, Hong Kong).
26. “On Lattice Based Cryptographic Sampling: An Algorithmic Approach” (Accepted for Publication in BVICAM’s International Journal of Information Technology).
27. “An Algebraic Immunity of Functions: A Cryptographic Problem” (Accepted for Publication in IEEE. Nig. Comp. Chap.)
139
APPENDIX-II
LIST OF CONFERENCES AND WORKSHOP PARTICIPATED DURING RESEARCH WORK
(1) Attended 16th Annual Conference of The Jammu Mathematical Society on March
1-3, 2006, Dept. of Mathematics, University of Jammu. (2) Attended INDIACom 2007, National Conference on Computing for Nation
Development and Presented 3 papers on Feb. 23-24, 2007, at Bharti Vidyapeeth, University, New Delhi.
(3) Attended International Congress and 8th Conference of Indian Society of Industrial & App. Mathematics on Certain Emerging Areas in Applicable Maths and 17th Annual Conference of Jammu Mathematical Society at Dept. of Mathematics, University of Jammu and Presented a paper contourlet cryptography: A better description for pattern recognition.
(4) Participated workshop on Mathematical Modeling optimization and their Application on April. 23-27, 2007 at Bharti Vidyapeeth University, New Delhi.
(5) Participated National Conference on Mathematical Modeling Optimization and their Applications on April. 28-29, 2007 at Bharti Vidyapeeth University, New Delhi.
(6) Participated National Workshop on Analysis on Sep. 27-28, 2007, Dept. of Mathematics, University of Delhi, Delhi.
(7) Participated International Conference on Operator theory and Related Areas on Jan. 9-12, 2008, Dept. of Mathematics, University of Delhi, Delhi.
(8) Participated INDIACom 2008, and Presented Three papers on Feb. 8-9, 2008, at Bharti Vidyapeeth University, New Delhi.
(9) Participated National Conference on Advancement of Technologies – Trends in Networking & Communication on Feb. 23-24, 2008, at GLA, I. T. M, Mathura and Presented a paper.
(10) Participated 18th Annual Conference of Jammu Mathematical Society on 29 Feb. 29-2nd March 2008, at Dept. of Mathematics, University of Jammu, Jammu. and Presented a paper.
(11) Participated Workshop of Scientific and Technical vocabulary Commission, MHRD, Govt. of India, at R. K. Puram, New Delhi on March 14-15, 2008.
(12) Participated WorldComp 2008 at Las Vagas USA (on Jul 14-16, 2008) and Presented a paper on Votor Verifiablities technique under category I.
(13) Participated National Conference on Advances in Information Technology on Sep. 16, 2008, at IET, Dr. B. R. A. University Agra. and Presented a paper.
(14) Participated INDIACom’09, 3rd National Conference on computing for Nation Development on Feb. 26-27 at Bharti Vidyapeeth University and Presented a paper on Perspectives of symmetric Cryptography.
140
(15) Participated International Conference on Recent Trends in Mathematics and its Applications (ICRTMA-09) on March 30-31, 2009, Department of Mathematics, Jamia Millia Islamia University, New Delhi and presented a paper entitled Mathematical Tools of Asymmetric Cryptography (Published).
(16) Participated three days workshop during Sep. 14-16, 2009 organized by ILLL, University of Delhi (South Campus) on Mathematical Awareness.