26
HUAWEI TECHNOLOGIES CO., LTD. Spark SQL on HBASE Spark Meet-up Tech Talks Yan Zhou/Bing Xiao March 25, 2015

HUAWEI TECHNOLOGIES CO., LTD.
Spark SQL on HBASE
Spark Meet-up Tech Talks
Yan Zhou/Bing Xiao
March 25, 2015

HUAWEI TECHNOLOGIES Co., Ltd.
Lead architect of Huawei Big Data Platform
Apache Pig committer
ex-Hadooper @ Yahoo!
15+ years of experience in DB, OLAP, distributed computing fields.
About me
Page ‹2›

HUAWEI TECHNOLOGIES Co., Ltd.
A Fortune Global 500, Private Company
Annual growth at 15% (revenue up to $46 Billion in 2014)
More than $6.5 Billion investment on R&D
Transition from telecom-equipment manufacturer to a leader of ICT
(information and communications technology)
Big data and open source are part of company-wide strategies
About Huawei
Page ‹3›
HUAWEI TECHNOLOGIES Co., Ltd.
Spark SQL on HBase
o Motivations
o Data Model
o SQL Semantics
o Performance
o Value Proposition
Demo
Roadmap
Q/A
Agenda
Page ‹4›

HUAWEI TECHNOLOGIES Co., Ltd.
Driven by use cases in verticals
including telco
Telco Data is unique & complex
Flexible data organization for various
types of queries: range, ad-hoc,
interactive, DW
Stay in tune: planned sessions in
future events
Customer & Billing Data
• Well Structured
• TB
Session Signaling Data:• Multi-Device generated
• Hundreds TB-PB
• Real-Time Biz Oriented
MR/CHR Data:• Semi-structured & Nested
• PB
• Location-centered Data
xDR Data:
• 1~10PB each month
Network Raw Data
• Unstructured
• TB/Sec
• Linear Growth with
Biz
CRM
Billing
Signaling Data
MR/CHR Type Data
xDR Data
Network Raw Data
Note:In a typical network of ~30M subscribers and the data flow around 1TB/Sec.
Page ‹5›
Motivations

HUAWEI TECHNOLOGIES Co., Ltd.
NOSQL Key-Value data store on Hadoop
Following Google BigTable model
Emerging platform for scale-out relational data stores on Hadoop:
o Splice Machines
o Trafodion (HP)
o Apache Phoenix (Salesforce)
o Kylin (eBay)
M/R and API-based data access interfaces only
Page ‹6›
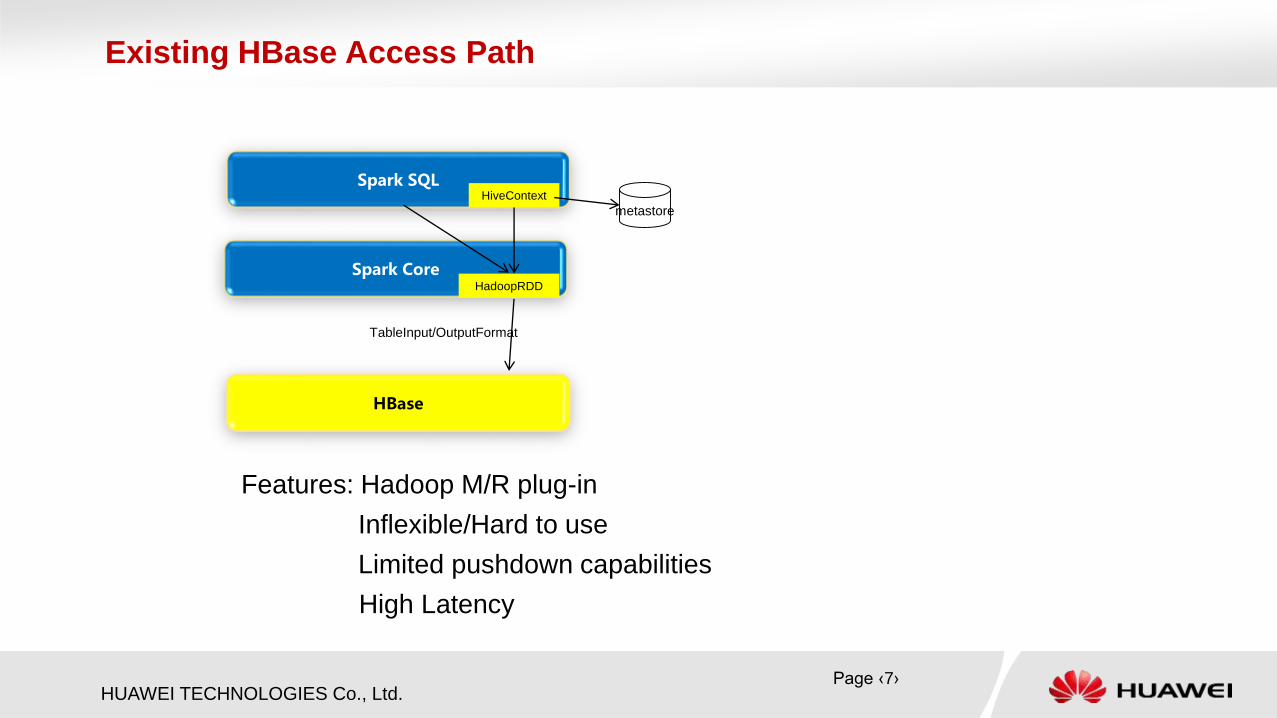
What is HBase?
HUAWEI TECHNOLOGIES Co., Ltd.
Spark Core
Spark SQL
Existing HBase Access Path
HadoopRDD
TableInput/OutputFormat
Features: Hadoop M/R plug-in
Inflexible/Hard to use
Limited pushdown capabilities
High Latency
HiveContext
metastore
Page ‹7›
HBase
HUAWEI TECHNOLOGIES Co., Ltd.
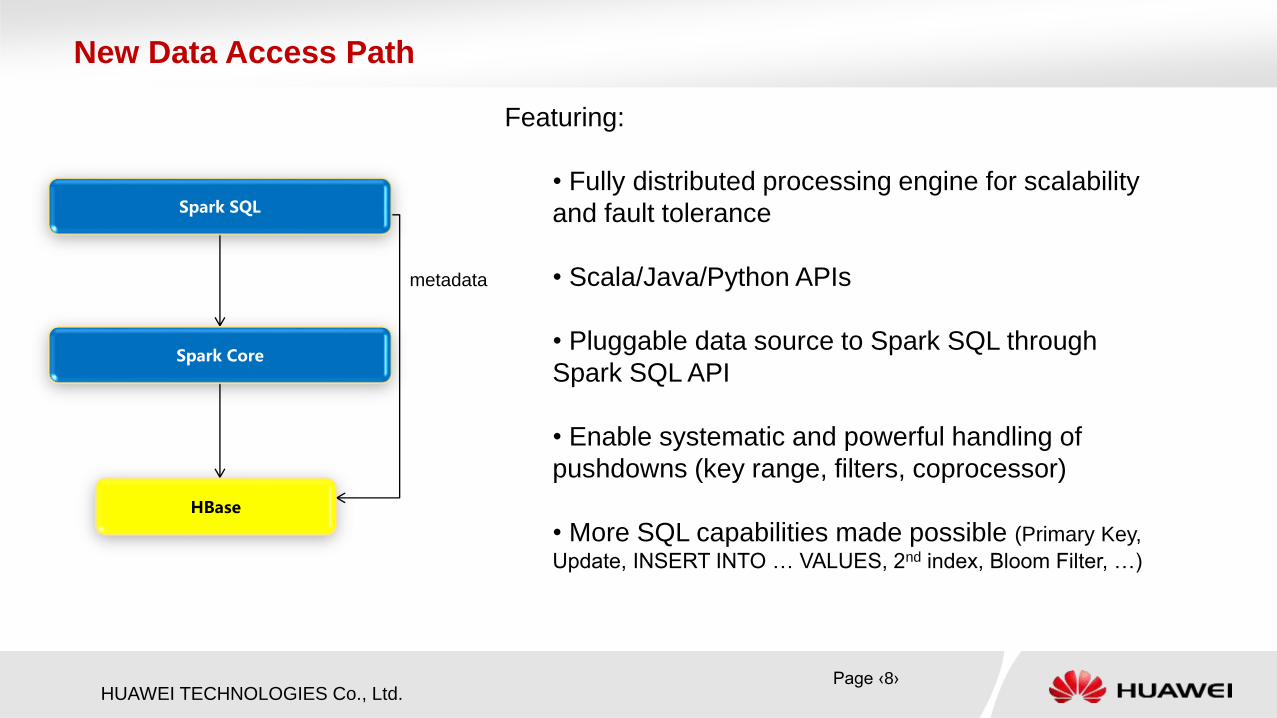
New Data Access Path
metadata
Featuring:
• Fully distributed processing engine for scalability
and fault tolerance
• Scala/Java/Python APIs
• Pluggable data source to Spark SQL through
Spark SQL API
• Enable systematic and powerful handling of
pushdowns (key range, filters, coprocessor)
• More SQL capabilities made possible (Primary Key,
Update, INSERT INTO … VALUES, 2nd index, Bloom Filter, …)
Page ‹8›
Spark SQL
Spark Core
HBase

HUAWEI TECHNOLOGIES Co., Ltd.
Logical Data Model the same as Spark SQL: relational and type system.
Physical Data Model:
• Support of composite primary keys
• HBase rowkey of byte representation of composite primary keys
• Logical non-key columns mapped onto <column family, column qualifier>
• Persistent metadata on a special HBase table
• Presplit tables supported
Data Models
Page ‹9›

HUAWEI TECHNOLOGIES Co., Ltd.
Based on Spark SQL syntax, plus …
DDL:
• CREATE TABLE table_name (col1 TYPE1, col2 TYPE2, …, PRIMARY KEY (col7, col1, col3))
MAPPED BY (hbase_tablename, COLS=[col2=cf1.cq11, col4=cf1.cq12, col5=cf2.cq21,
col6=cf2.cq22])
•ALTER TABLE table_name ADD/DROP column …
DML:
• INSERT … INTO VALUES …
Bulk Loading:
• LOAD DATA [PARALLEL] INPATH filePath [OVERWRITE] INTO TABLE tableName [FIELDS
TERMINATED BY char]
SQL Semantics
Page ‹10›

HUAWEI TECHNOLOGIES Co., Ltd.
Precise partition pruning and partition-specific multidimensional predicate
pushdowns based on partial evaluation of filter boolean expressions for queries
Query Optimization Approach
=> Itemid > 300 AND amount < 30
=> customer=‘John’ AND itemid < 100 AND amount > 200
E.g. a sales table with <customer, itemid> as a 2-dimensional primary key
SELECT * from sales WHERE ((customer=‘Joe’ AND itemid > 300 AND amount < 30) OR
(customer=‘John’ AND itemid < 100) AND amount > 200)
The existing partitions/regions are:
1. (, ‘Ashley’)
2. [‘Ashley’, “Iris”)
3. [(‘Joe’, 10), (‘Joe’, 100)),
4. [(‘Joe’, 200), (‘Joe’, 1000))
5. [‘John’, ‘York’)
6. [‘York’, )
The algorithms are generic and applicable to other organized data sets like
hash-partitioned Hive tables as well.
Suitable for interactive ad hoc queries
Page ‹11›
for scan range for filtering

HUAWEI TECHNOLOGIES Co., Ltd.
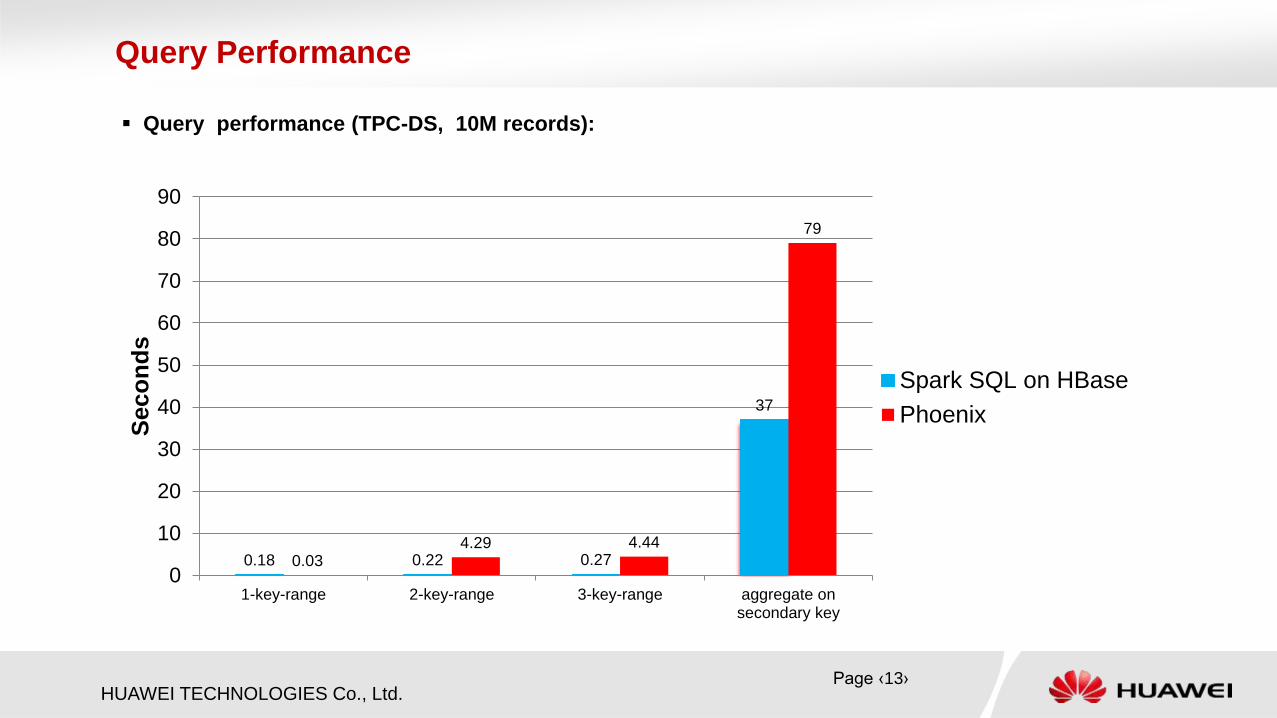
Queries (TPC-DS, 10M records):
Query Performance
Page ‹12›
SQL Query SparkSQL
on HBase(Seconds)
Phoenix(Seconds)
1-key-range select count(1) from store_sales where
(ss_item_sk = 99 and ss_ticket_number > 1000);
0.18 0.03
2-key-range select count(1) from store_sales where
(ss_item_sk = 99 and ss_ticket_number > 1000) or
(ss_item_sk = 5000 and ss_ticket_number < 20000);
0.22 4.29
3-key-range select count(1) from store_sales where
(ss_item_sk = 99 and ss_ticket_number > 1000) or
(ss_item_sk = 5000 and ss_ticket_number < 20000) or
(ss_item_sk = 28000 and ss_ticket_number <= 10000);
0.27 4.44
Aggregate on
the secondary
key
select count(1) from store_sales group by ss_ticket_number; 37 79
• Cluster:
o 1 master + 6 slaves with 48GB/node
o Xeon 2.4G 16 cores
HUAWEI TECHNOLOGIES Co., Ltd.
Query performance (TPC-DS, 10M records):
Query Performance
0.18 0.22 0.27
37
0.034.29 4.44
79
0
10
20
30
40
50
60
70
80
90
1-key-range 2-key-range 3-key-range aggregate onsecondary key
Seco
nd
s
Spark SQL on HBase
Phoenix
Page ‹13›

HUAWEI TECHNOLOGIES Co., Ltd.
Performance optimization for tabular data bulk loading
• late materialization of KeyValue cells
reduction of shuffle data volume
• removal of sorting by reducers
lightweight reducer
more scalable
• best effort to colocate reducers with the region servers
Optional parallel incremental loading after M/R in the bulk loader
Bulk Load Optimization
Page ‹14›
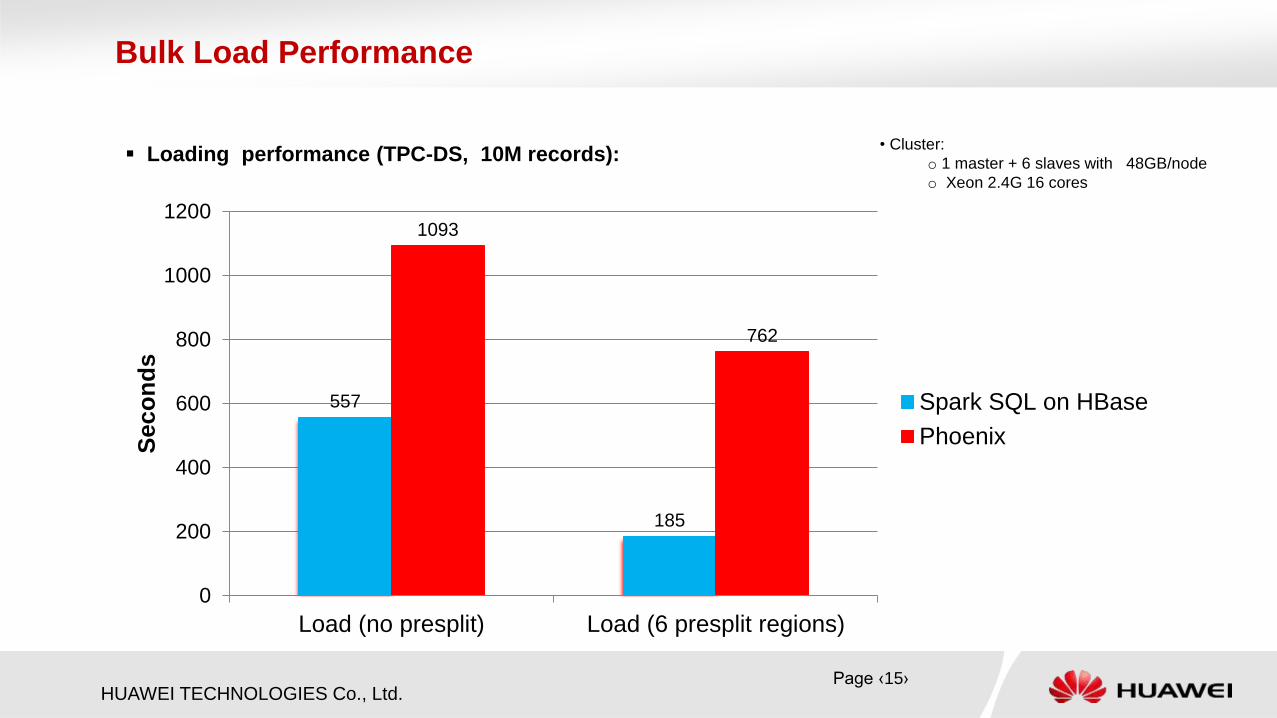
HUAWEI TECHNOLOGIES Co., Ltd.
Loading performance (TPC-DS, 10M records):
Bulk Load Performance
557
185
1093
762
0
200
400
600
800
1000
1200
Load (no presplit) Load (6 presplit regions)
Seco
nd
s
Spark SQL on HBase
Phoenix
Page ‹15›
• Cluster:
o 1 master + 6 slaves with 48GB/node
o Xeon 2.4G 16 cores

HUAWEI TECHNOLOGIES Co., Ltd.
Combined capabilities of Spark, SparkSQL and HBase
o Spark Dataframe supported
More traditional DBMS capabilities made possible on HBase
Basis to build a highly performing and concurrent distributed big data SQL
system
Optimized bulk loader for tabular data sets
Performance excellence
Value Proposition
Page ‹16›

HUAWEI TECHNOLOGIES Co., Ltd.
Source repo: https://github.com/Huawei-Spark/hbase/
emails: [email protected], [email protected]
Team members:
Bo Meng, Xinyun Huang, Wang Fei, Stanley Burnitt, Shijun(Ken) Ma, Jacky
Li, Stephen Boesch
Plus our Big Data Teams in India and Hangzhou, China
Project Info
Join us …
o Comments, tryouts, and contributions are more than welcome
o Open for Joint development in next phase project(s)
o We are hiring: Big Data Engineers/Spark Fans
Page ‹17›

HUAWEI TECHNOLOGIES Co., Ltd.
Environment
Hardware: 9-node (1 master + 8 slaves) blades
Software: Linux Enterprise Server 11.1
Data set: TPC-DS 10M records
Indexed-range query vs. full scan query through use of the DataFrame
Join between a Hbase table with an in-memory side table through use of Dataframe
Partial Evaluation
• Schema = (id : Int, age: Int)
• The row to be partially evaluated on is: ([1,5), null)
• Predicate 1: (id < 1) OR (age > 30) => (age > 30)
• Predicate 2: (id < 6) OR (age > 30) => True
Demo
Page ‹18›

HUAWEI TECHNOLOGIES Co., Ltd.
Targeting Spark 1.4
Coprocessor/Custom Filter
Filter/Partitions from CAST values in predicates
Latency reduction: Spark-3306 for external resource management
Optimizations of Sorting/Aggregation/Join on primary keys
Support of salting, timestamp, dynamic columns, nested data type, …
Views and materialized views
Future Plan
Page ‹19›

HUAWEI TECHNOLOGIES Co., Ltd.
Earliest Corporate sponsor of AMP Lab & its projects including Spark
One of Leading contributors to Spark: 10 & 11 contributors in Spark 1.2 & 1.3
releases
Highlighted contributions of New features : Power Iteration Clustering
represents the first use of GraphX routines within MLLIB; ORCFiles Support;
FP-Growth
Bring Spark & Apps on top of Spark into leading telcos globally as Spark is
cornerstone of Huawei big data vertical solution
Huawei’s Long Term Commitment to Spark & Ecosystem
Page ‹20›
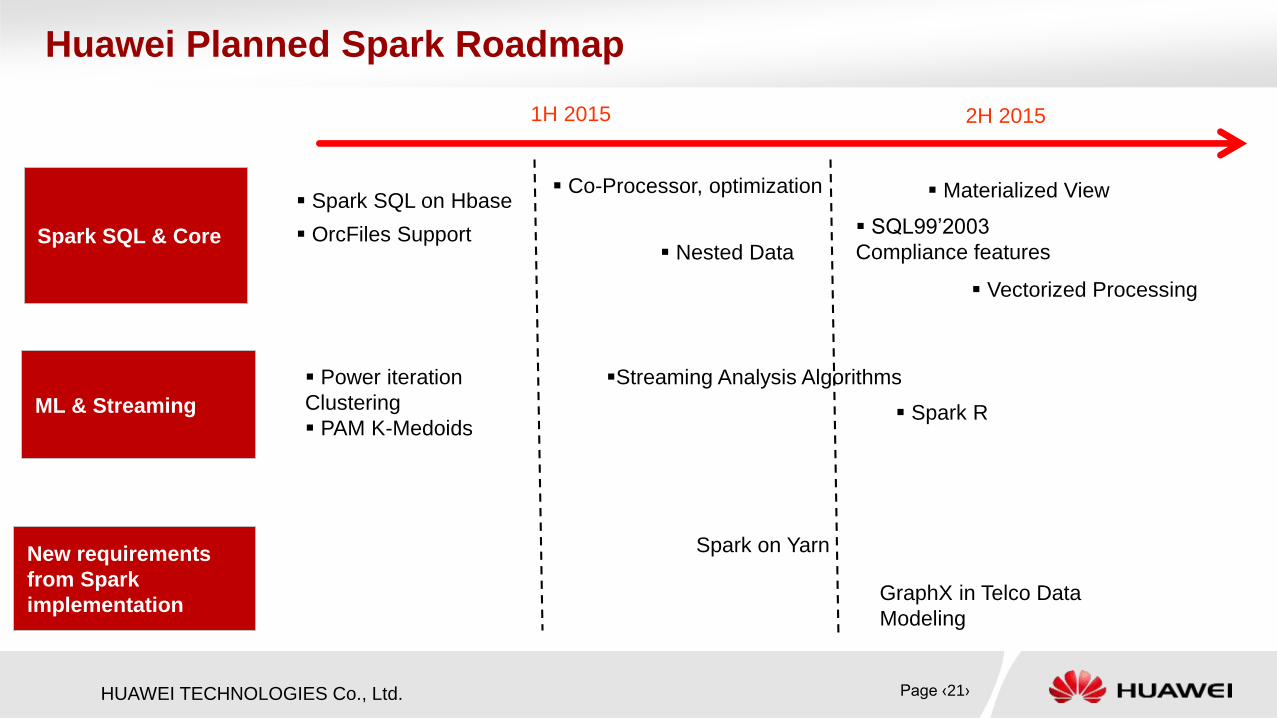
HUAWEI TECHNOLOGIES Co., Ltd.
Huawei Planned Spark Roadmap
Spark SQL & Core
1H 2015
Co-Processor, optimization Spark SQL on Hbase
OrcFiles Support
Vectorized Processing
ML & Streaming
2H 2015
Nested Data
Spark on Yarn
Power iteration
Clustering
PAM K-Medoids
Streaming Analysis Algorithms
New requirements
from Spark
implementation
Materialized View
Spark R
GraphX in Telco Data
Modeling
SQL99’2003
Compliance features
Page ‹21›

HUAWEI TECHNOLOGIES Co., Ltd.
Reynold Xin, Michael Armbrust at Databricks reviewed Spark SQL
on HBase design document and the code, provided feedback and helped
improve the design
Xiangrui Meng at Databricks provided the guidance, reviewed and
modified the code MLLib Power Iteration Clustering algorithm (Spark 1.3
release) & FP-Growth algorithm (Spark 1.3 release)
Huawei Big Data team in India & Hangzhou, China provided the
performance testing/tuning and participated in code development
Acknowledgements
Page ‹22›

HUAWEI TECHNOLOGIES Co., Ltd.Page ‹23›
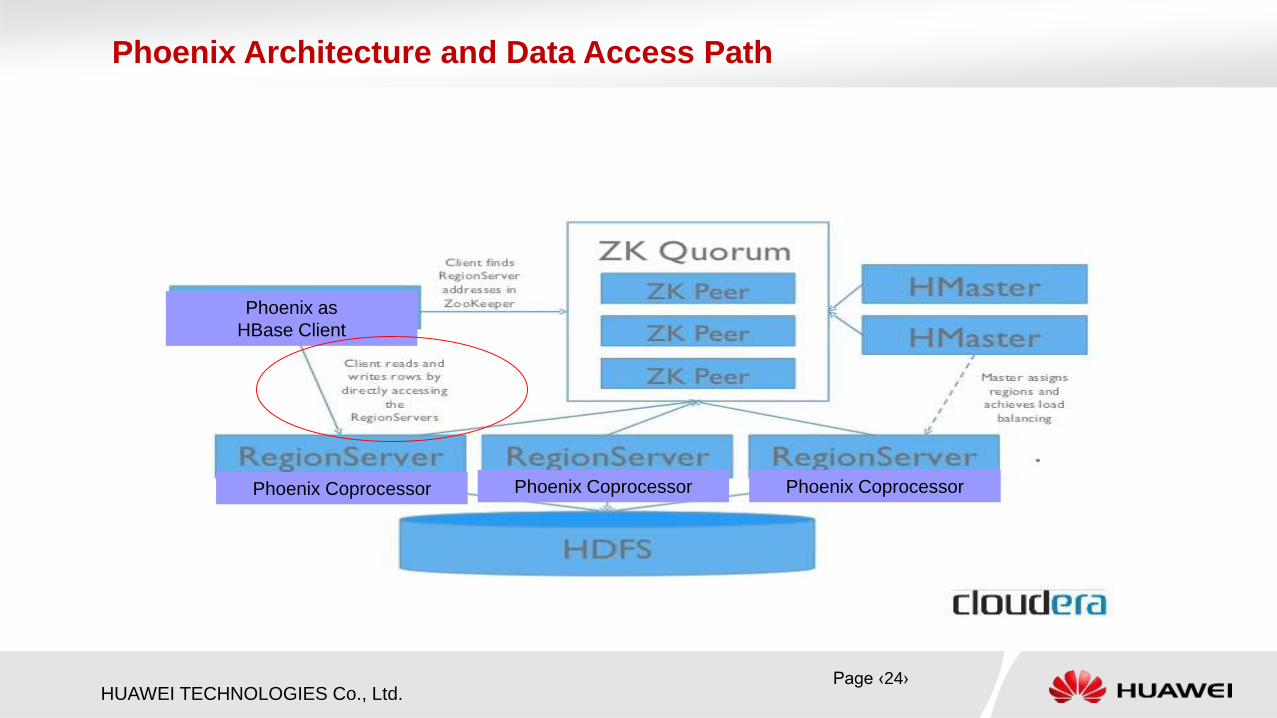
HUAWEI TECHNOLOGIES Co., Ltd.
Phoenix Architecture and Data Access Path
Phoenix Coprocessor Phoenix Coprocessor Phoenix Coprocessor
Phoenix as
HBase Client
Page ‹24›
HUAWEI TECHNOLOGIES Co., Ltd.
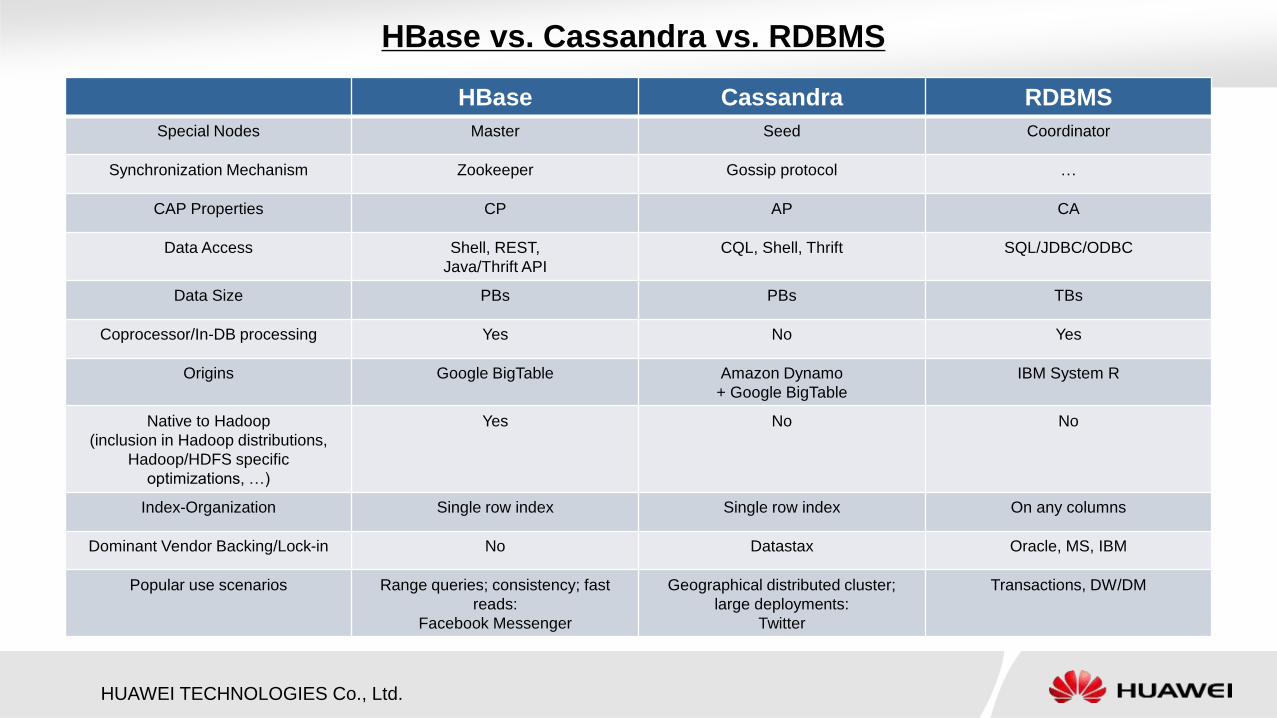
HBase vs. Cassandra vs. RDBMS
HBase Cassandra RDBMS
Special Nodes Master Seed Coordinator
Synchronization Mechanism Zookeeper Gossip protocol …
CAP Properties CP AP CA
Data Access Shell, REST,
Java/Thrift API
CQL, Shell, Thrift SQL/JDBC/ODBC
Data Size PBs PBs TBs
Coprocessor/In-DB processing Yes No Yes
Origins Google BigTable Amazon Dynamo
+ Google BigTable
IBM System R
Native to Hadoop
(inclusion in Hadoop distributions,
Hadoop/HDFS specific
optimizations, …)
Yes No No
Index-Organization Single row index Single row index On any columns
Dominant Vendor Backing/Lock-in No Datastax Oracle, MS, IBM
Popular use scenarios Range queries; consistency; fast
reads:
Facebook Messenger
Geographical distributed cluster;
large deployments:
Transactions, DW/DM
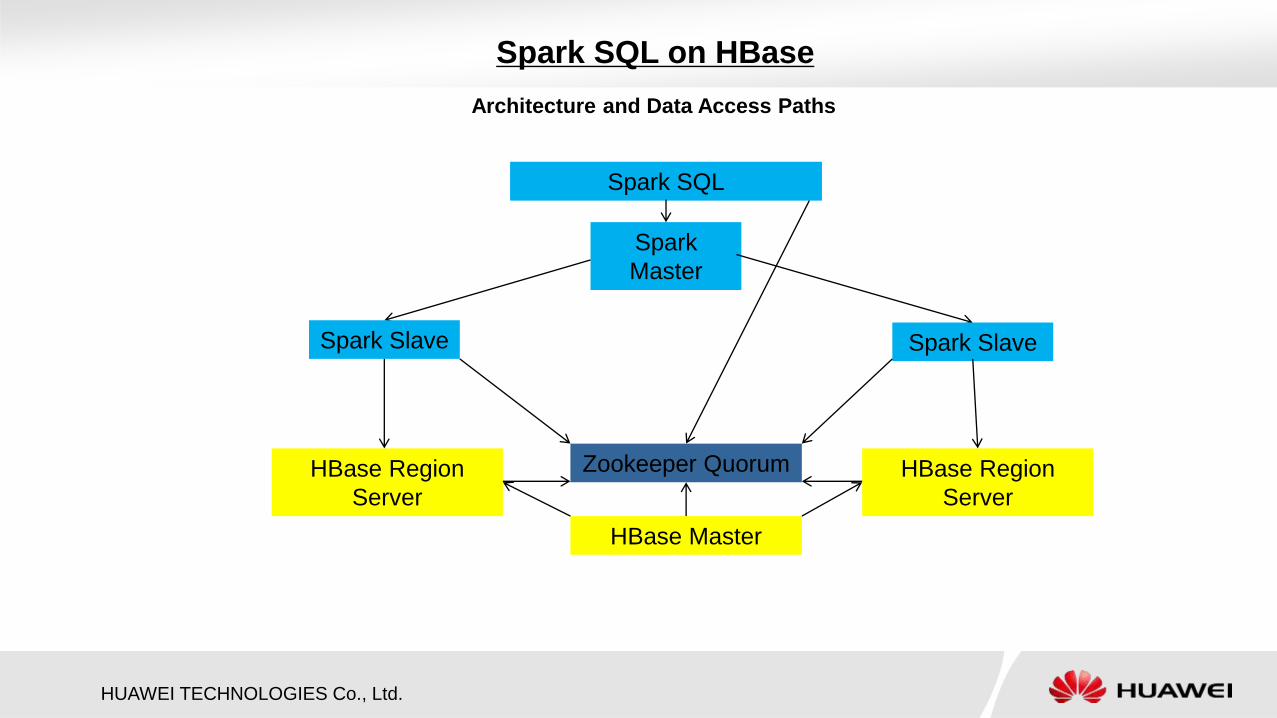
HUAWEI TECHNOLOGIES Co., Ltd.
Spark SQL on HBase
Spark SQL
Spark
Master
HBase Master
Spark Slave Spark Slave
HBase Region
Server
HBase Region
Server
Architecture and Data Access Paths
Zookeeper Quorum

















