38
Spark Streaming-as-a- Service with Kafka and YARN Jim Dowling KTH Royal Institute of Technology, Stockholm Senior Researcher, SICS CEO, Logical Clocks AB
| Date post: | 13-Apr-2017 |
| Category: |
Technology |
| Upload: | jim-dowling |
| View: | 164 times |
| Download: | 2 times |

Spark Streaming-as-a-Service with Kafka and YARN
Jim DowlingKTH Royal Institute of Technology, StockholmSenior Researcher, SICSCEO, Logical Clocks AB

Spark Streaming-as-a-Service in Sweden
• SICS ICE: datacenter research environment• Hopsworks: Spark/Flink/Kafka/Tensorflow/Hadoop• -as-a-service
– Built on Hops Hadoop (www.hops.io)– >130 active users
Hadoop is not a cool kid anymore!

Hadoop’s Evolution
2009 2016
?
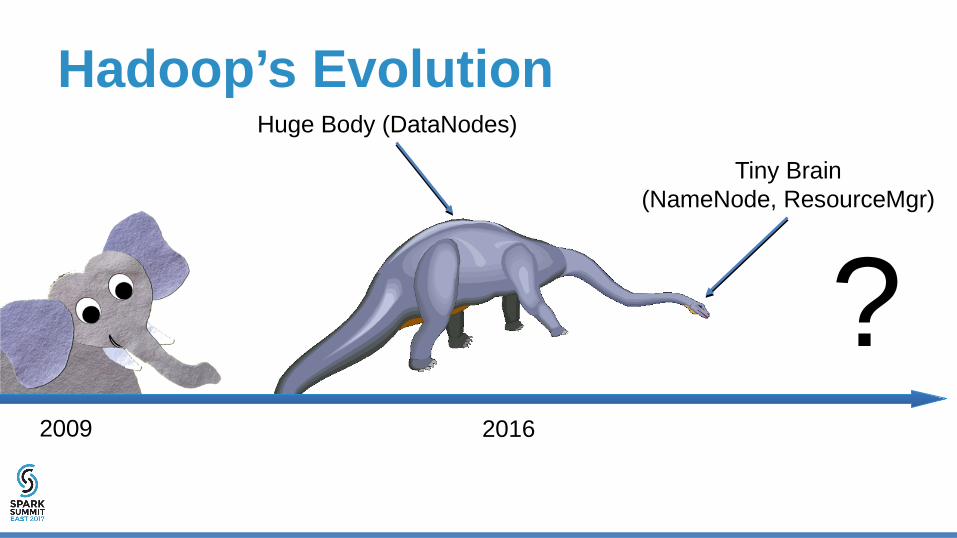
Hadoop’s Evolution
2009 2016
?Tiny Brain
(NameNode, ResourceMgr)
Huge Body (DataNodes)

Build out Hadoop’s Brain with External Weakly Consistent MetaData Services
Google-Glass Approach to Intelligence
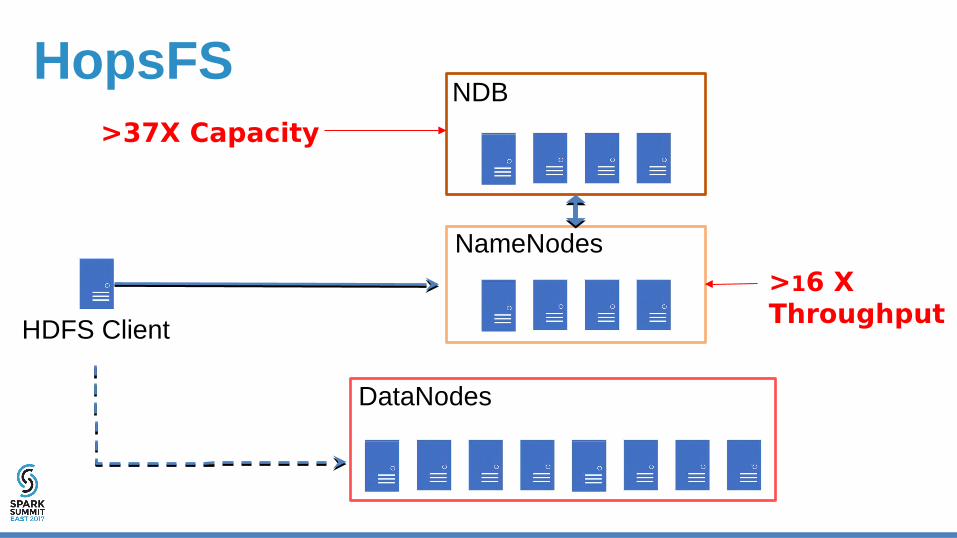
NameNodes
NDB
HDFS Client
DataNodes
>37X Capacity
>16 XThroughput
HopsFS
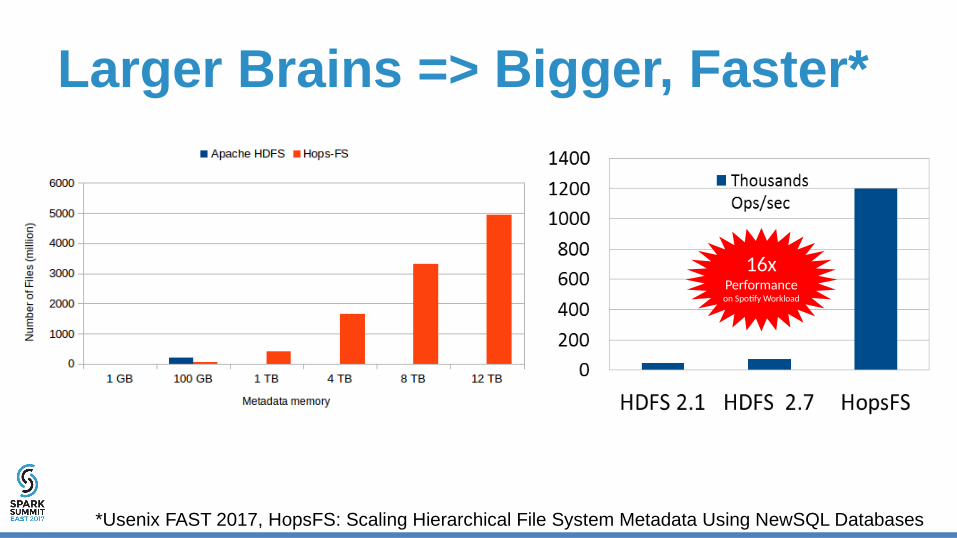
Larger Brains => Bigger, Faster*
16xPerformance on Spotify Workload
*Usenix FAST 2017, HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases
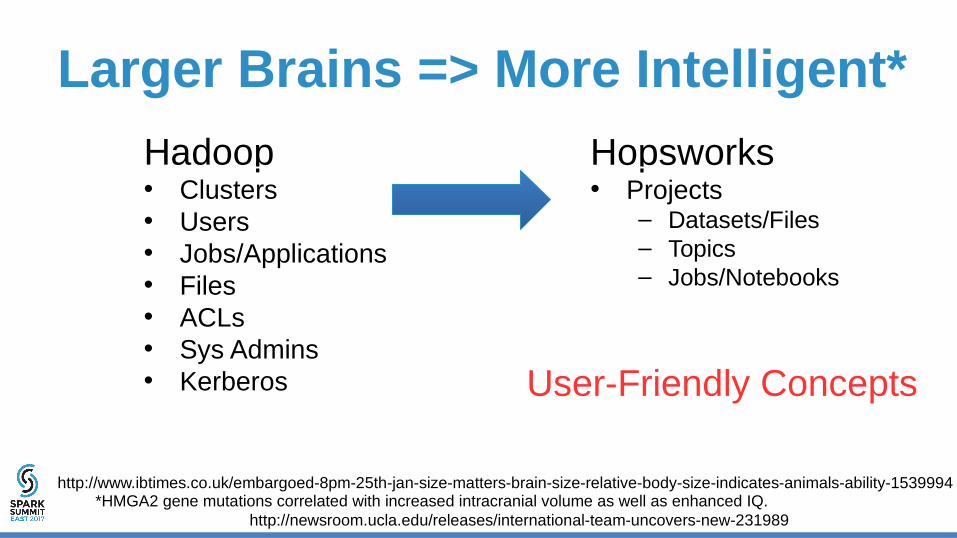
Hopsworks• Projects
– Datasets/Files– Topics– Jobs/Notebooks
Hadoop• Clusters• Users• Jobs/Applications• Files• ACLs• Sys Admins• Kerberos
Larger Brains => More Intelligent*
*HMGA2 gene mutations correlated with increased intracranial volume as well as enhanced IQ.http://newsroom.ucla.edu/releases/international-team-uncovers-new-231989
User-Friendly Concepts
http://www.ibtimes.co.uk/embargoed-8pm-25th-jan-size-matters-brain-size-relative-body-size-indicates-animals-ability-1539994
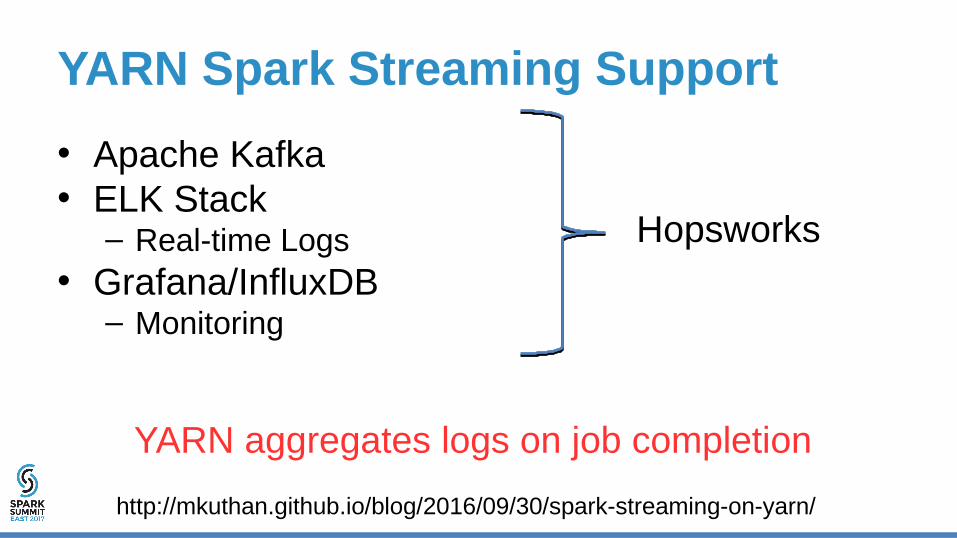
YARN Spark Streaming Support
• Apache Kafka• ELK Stack
– Real-time Logs• Grafana/InfluxDB
– Monitoring
Hopsworks
YARN aggregates logs on job completion
http://mkuthan.github.io/blog/2016/09/30/spark-streaming-on-yarn/

Kafka Self-Service UI
Manage & Share• Topics• ACLs• Avro Schemas
Manage & Share• Topics• ACLs• Avro Schemas
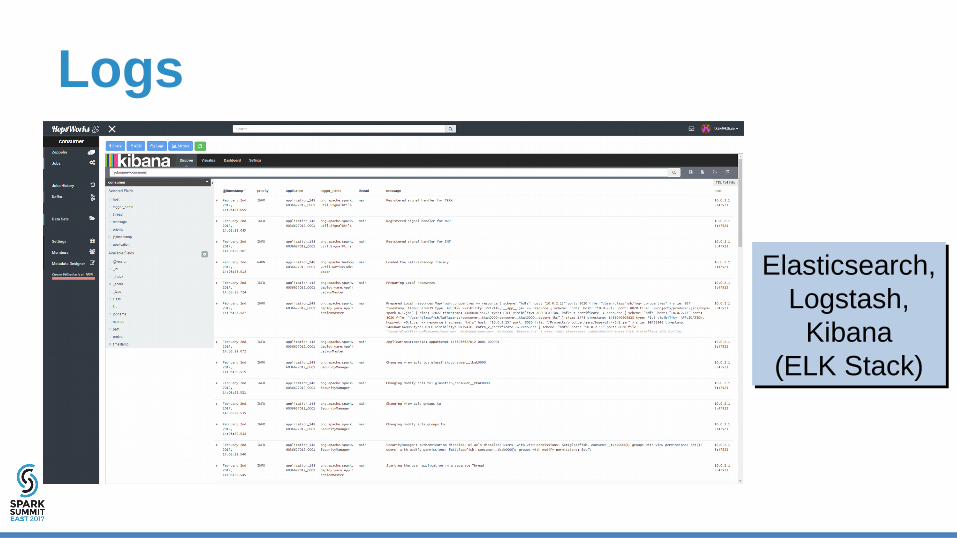
Logs
Elasticsearch, Logstash,
Kibana(ELK Stack)
Elasticsearch, Logstash,
Kibana(ELK Stack)
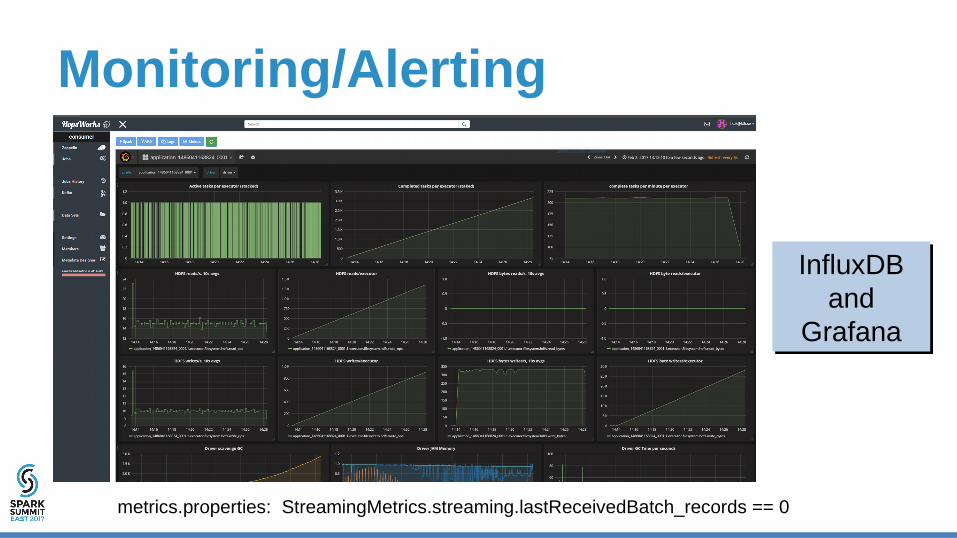
Monitoring/Alerting
InfluxDB and
Grafana
InfluxDB and
Grafana
metrics.properties: StreamingMetrics.streaming.lastReceivedBatch_records == 0
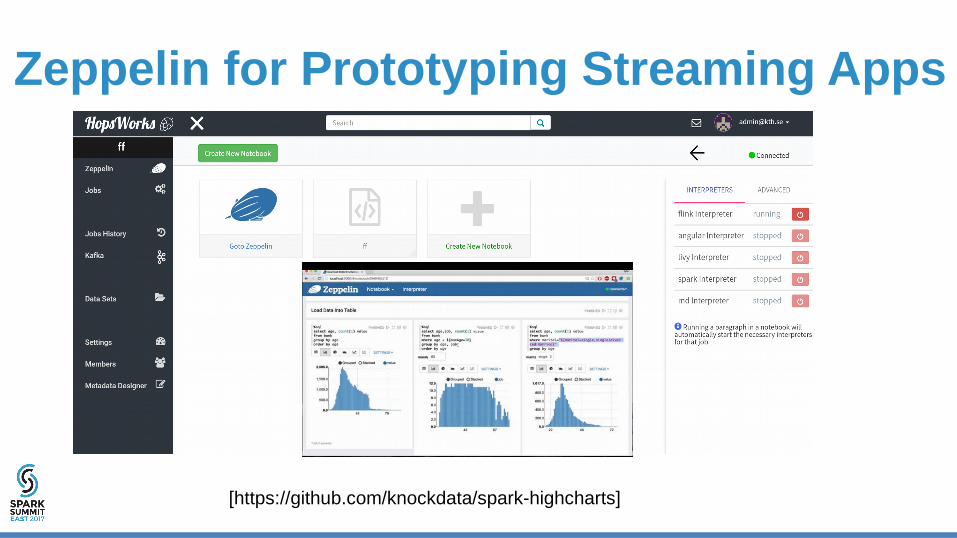
Zeppelin for Prototyping Streaming Apps
[https://github.com/knockdata/spark-highcharts]

Debugging Spark with Dr. Elephant
• Analyzes Spark Jobs for errors and common using pluggable heuristics
• Doesn’t show killed jobs
• No online support for streaming apps yet

Integration as Microservices in Hopsworks
• Project-based Multi-tenancy
• Self-Service UI
• Simplifying Spark Streaming Apps

Proj-All
Proj-X
Projects in Hopsworks•
Proj-42
Shared TopicTopic /Projs/My/Data
CompanyDB

User roles
18
Data Owner- Import/Export data- Manage Membership- Share DataSets, Topics
Data Scientist- Write and Run code
Self-Service Administration – No Administrator Needed

Notebooks, Data sharing and Quotas
• Zeppelin Notebooks in HDFS, Jobs launcher UI.
• Sharing is not Copying– Datasets/Topics
• Per-Project quotas– Storage in HDFS– CPU in YARN (Uber-style Pricing)
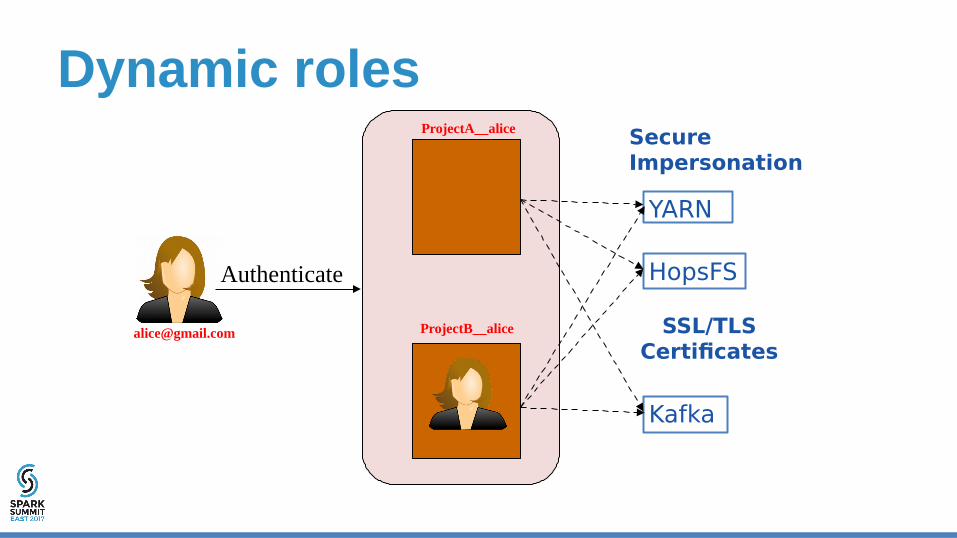
Dynamic roles
ProjectA
Authenticate
ProjectB
HopsFS
YARN
Kafka
SSL/TLSCertificates
Secure Impersonation
ProjectA__alice
ProjectB__alice

Look Ma, no Kerberos• Each project-specific user issued with a SSL/TLS
(X.509) certificate for both authentication and encryption.
• Services also issued with SSL/TLS certificates.– Same root CA as user certs

Simplifying Spark Streaming Apps
• Spark Streaming Applications need to know– Credentials
• Hadoop, Kafka, InfluxDb, Logstash– Endpoints
• Kafka Broker, Kafka SchemaRegistry, ResourceManager, NameNode, InfluxDB, Logstash
• The HopsUtil API hides this complexity.– Location/security transparent Spark applications

Secure Streaming App with Kafka
Developer
1.Discover: Schema Registry and Kafka/InfluxDB/ELK Endpoints2.Create: Kafka Properties file with certs and broker details3.Create: Producer/Consumer using Kafka Properties
4.Download: the Schema for the Topic from the Schema Registry5.Distribute: X.509 certs to all hosts on the cluster6.Cleanup securely
These steps are replaced by calls to the HopsUtil API
Operations
https://github.com/hopshadoop/hops-kafka-examples

Streaming Producer in HopsWorks
JavaSparkContext jsc = new JavaSparkContext(sparkConf);String topic = HopsUtil.getTopic(); //Optional
SparkProducer producer = HopsUtil.getSparkProducer();
Map<String, String> message = …sparkProducer.produce(message);

Streaming Consumer in HopsWorks
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf,Durations.seconds(2));
String topic = HopsUtil.getTopic(); //OptionalString consumerGroup = HopsUtil.getConsumerGroup(); //Optional
SparkConsumer consumer = HopsUtil.getSparkConsumer(jssc);
JavaInputDStream<ConsumerRecord<String, byte[]>> messages = consumer.createDirectStream();jssc.start();

Less code to write
https://github.com/hopshadoop/hops-kafka-examples
Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);props.put(SCHEMA_REGISTRY_URL, restApp.restConnect);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, org.apache.kafka.common.serialization.StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, io.confluent.kafka.serializers.KafkaAvroSerializer.class);props.put("producer.type", "sync");props.put("serializer.class","kafka.serializer.StringEncoder");props.put("request.required.acks", "1");props.put("ssl.keystore.location","/var/ssl/kafka.client.keystore.jks")props.put("ssl.keystore.password","test1234")props.put("ssl.key.password","test1234")ProducerConfig config = new ProducerConfig(props);String userSchema = "{\"namespace\": \"example.avro\", \"type\": \"record\", \"name\": \"User\"," + "\"fields\": [{\"name\": \"name\", \"type\": \"string\"}]}";Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(userSchema);GenericRecord avroRecord = new GenericData.Record(schema);avroRecord.put("name", "testUser");Producer<String, String> producer = new Producer<String, String>(config);ProducerRecord<String, Object> message = new ProducerRecord<>(“topicName”, avroRecord );producer.send(data);
Lots of Hard-Coded Endpoints Here!
SparkProducer producer = HopsUtil.getSparkProducer();Map<String, String> message = …sparkProducer.produce(message);
Massively Simplified Code for Secure Spark Streaming/Kafka
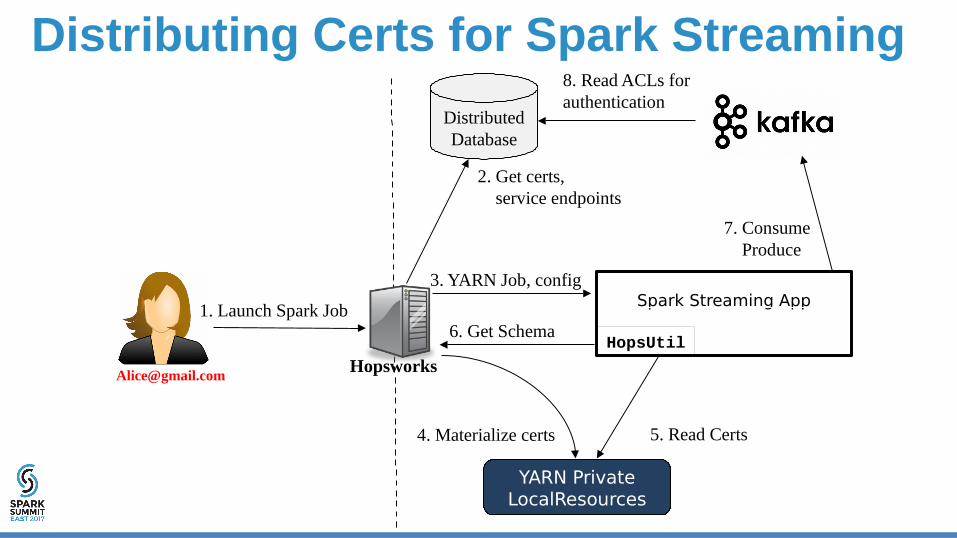
Distributing Certs for Spark Streaming
1. Launch Spark Job
Distributed Database
2. Get certs, service endpoints
YARN Private LocalResources
Spark Streaming App
4. Materialize certs
3. YARN Job, config
6. Get Schema
7. Consume Produce
5. Read Certs
HopsworksHopsUtil
8. Read ACLs for authentication
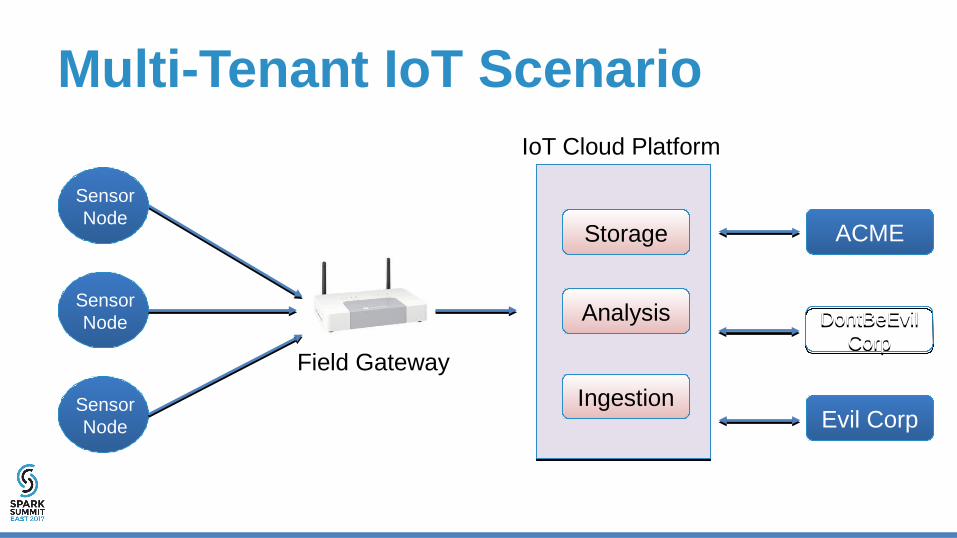
Multi-Tenant IoT Scenario
Sensor Node
Sensor Node
Sensor Node
Sensor Node
Sensor Node
Sensor Node
Field Gateway
StorageStorage
AnalysisAnalysis
IngestionIngestion
ACMEACME
Evil CorpEvil Corp
IoT Cloud Platform
DontBeEvil Corp
DontBeEvil Corp
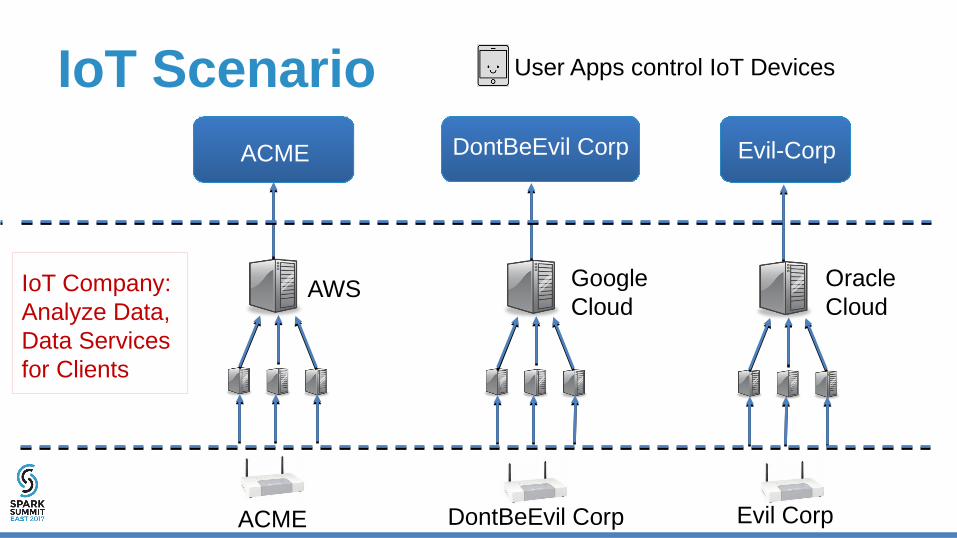
IoT Scenario
ACME DontBeEvil Corp Evil-Corp
AWS Google Cloud
OracleCloud
User Apps control IoT Devices
IoT Company:Analyze Data,Data Services for Clients
ACME DontBeEvil Corp Evil Corp

Cloud-Native Analytics Solution
ACME S3S3[Authorization]
GCSGCS
OracleOracleIoT Company
Each customer needs its own Analytics Infrastructure
Each customer needs its own Analytics Infrastructure
Spark Streaming App
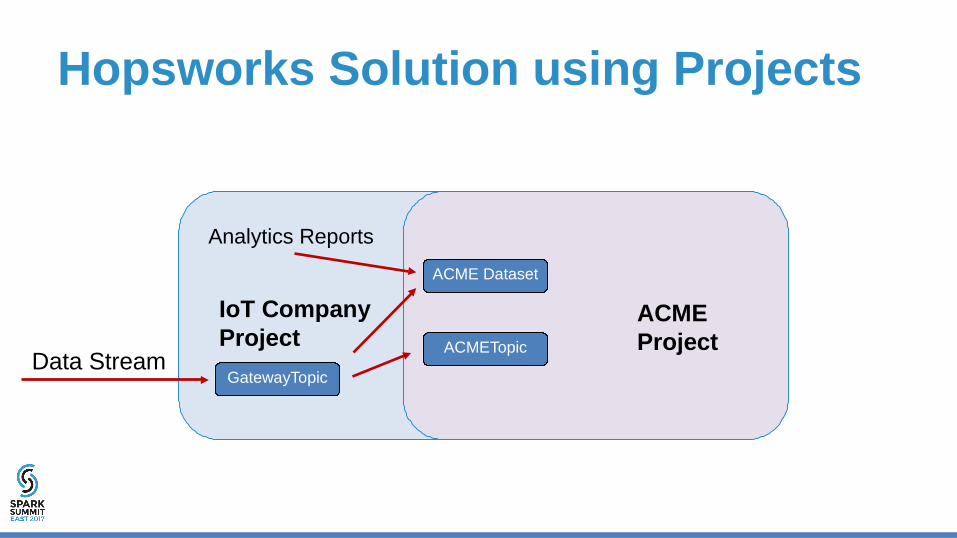
IoT CompanyProject
GatewayTopic
Hopsworks Solution using Projects
ACMEProjectACMETopic
ACME Dataset
Data Stream
Analytics Reports

Hopsworks Solution
ACME
Spark Streaming App
[Authorized]
ACMEDatasetACMEDataset
ACME Topic
ACME Analytics Reports
ACME Analytics Reports
Spark Batch Job
ACME Project

Karamel/Chef for Automated Installation
Google Compute Engine BareMetal

DEMO

Hops Roadmap
• HopsFS– HA support for Multi-Data-Center– Small files, 2-Level Erasure Coding
• HopsYARN– Tensorflow with isolated GPUs
• Hopsworks– P2P Dataset Sharing– Jupyter, Presto, Hive

Summary
• Hops is a new distribution of Hadoop– Tinker-friendly and open-source.
• Hopsworks provides first-class support for Spark-Streaming-as-a-Service – With support services like Kafka, ELK Stack,
Zeppelin, Grafana/InfluxDB.

Hops Team
Jim Dowling, Seif Haridi, Tor Björn Minde, Gautier Berthou, Salman Niazi, Mahmoud Ismail, Theofilos Kakantousis, Ermias Gebremeskel, Antonios Kouzoupis, Alex Ormenisan, Roberto Bampi, Fabio Buso, Fanti Machmount Al Samisti, Braulio Grana, Adam Alpire, Zahin Azher Rashid, Robin Andersso, ArunaKumari Yedurupaka, Tobias Johansson, August Bonds, Tiago Brito, Filotas Siskos.
Active:
Alumni:
Vasileios Giannokostas, Johan Svedlund Nordström,Rizvi Hasan, Paul Mälzer, Bram Leenders, Juan Roca, Misganu Dessalegn, K “Sri” Srijeyanthan, Jude D’Souza, Alberto Lorente, Andre Moré, Ali Gholami, Davis Jaunzems, Stig Viaene, Hooman Peiro, Evangelos Savvidis, Steffen Grohsschmiedt, Qi Qi, Gayana Chandrasekara, Nikolaos Stanogias, Daniel Bali, Ioannis Kerkinos, Peter Buechler, Pushparaj Motamari, Hamid Afzali, Wasif Malik, Lalith Suresh, Mariano Valles, Ying Lieu.
Hops

Thank You.We totally understand it’s going to be America First Spark Streaming first, but can we take this chance to say Hopsworks second!
http://www.hops.io@hopshadoop
Hops

















