223
Spin Locks and Contention Companion slides for The Art of Multiprocessor Programming by Maurice Herlihy & Nir Shavit
| Date post: | 03-Jan-2016 |
| Category: |
Documents |
| Upload: | stewart-lewis |
| View: | 231 times |
| Download: | 1 times |

Spin Locks and Contention
Companion slides forThe Art of Multiprocessor
Programmingby Maurice Herlihy & Nir Shavit

Art of Multiprocessor Programming 2
Focus so far: Correctness and Progress
• Models– Accurate (we never lied to you)
– But idealized (so we forgot to mention a few things)
• Protocols– Elegant– Important– But naïve

Art of Multiprocessor Programming 3
New Focus: Performance
• Models– More complicated (not the same as complex!)
– Still focus on principles (not soon obsolete)
• Protocols– Elegant (in their fashion)
– Important (why else would we pay attention)
– And realistic (your mileage may vary)

Art of Multiprocessor Programming 4
Kinds of Architectures
• SISD (Uniprocessor)– Single instruction stream– Single data stream
• SIMD (Vector)– Single instruction– Multiple data
• MIMD (Multiprocessors)– Multiple instruction– Multiple data.

Art of Multiprocessor Programming 5
Kinds of Architectures
• SISD (Uniprocessor)– Single instruction stream– Single data stream
• SIMD (Vector)– Single instruction– Multiple data
• MIMD (Multiprocessors)– Multiple instruction– Multiple data.
Our space
(1)
Art of Multiprocessor Programming 6
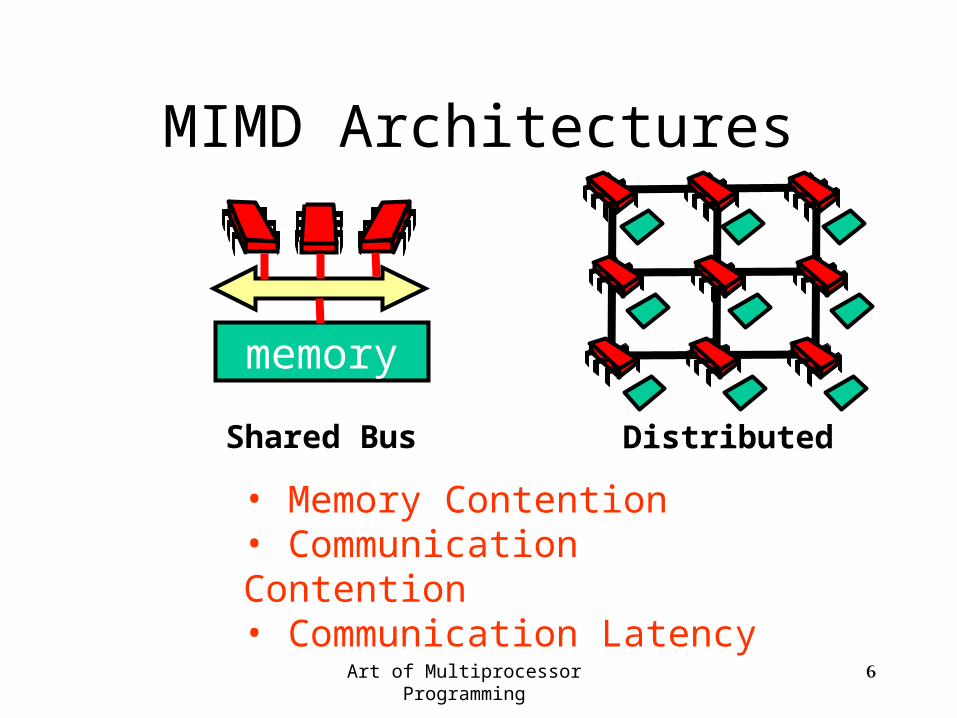
MIMD Architectures
• Memory Contention• Communication Contention • Communication Latency
Shared Bus
memory
Distributed

Art of Multiprocessor Programming 7
Today: Revisit Mutual Exclusion
• Think of performance, not just correctness and progress
• Begin to understand how performance depends on our software properly utilizing the multiprocessor machine’s hardware
• And get to know a collection of locking algorithms…
(1)

Art of Multiprocessor Programming 8
What Should you do if you can’t get a lock?
• Keep trying– “spin” or “busy-wait”– Good if delays are short
• Give up the processor– Good if delays are long– Always good on uniprocessor
(1)

Art of Multiprocessor Programming 9
What Should you do if you can’t get a lock?
• Keep trying– “spin” or “busy-wait”– Good if delays are short
• Give up the processor– Good if delays are long– Always good on uniprocessor
our focus

Art of Multiprocessor Programming 10
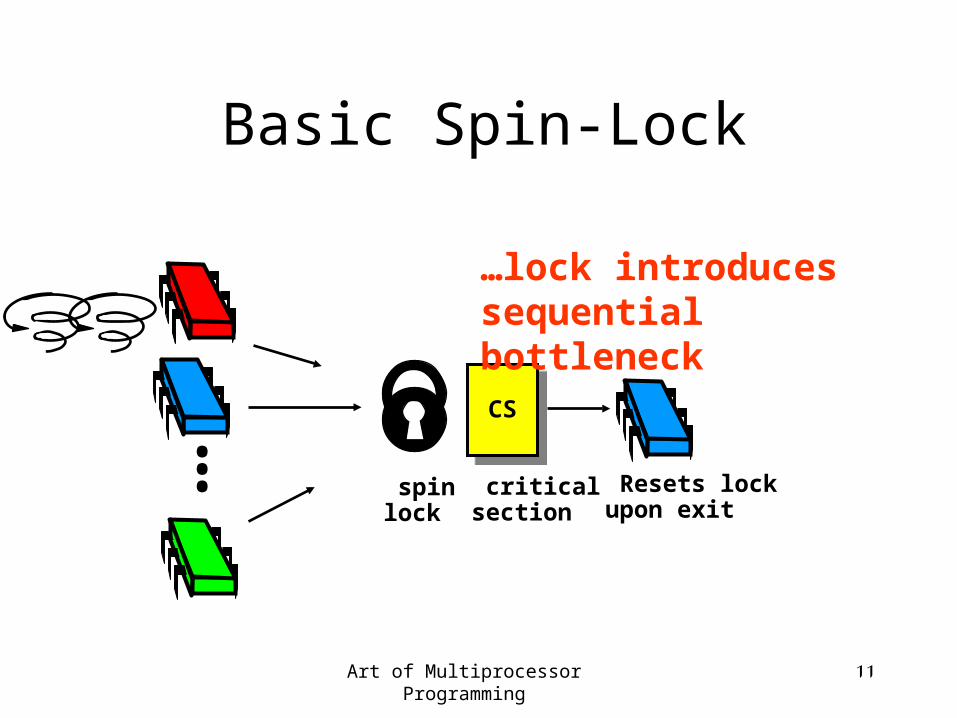
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...
Art of Multiprocessor Programming 11
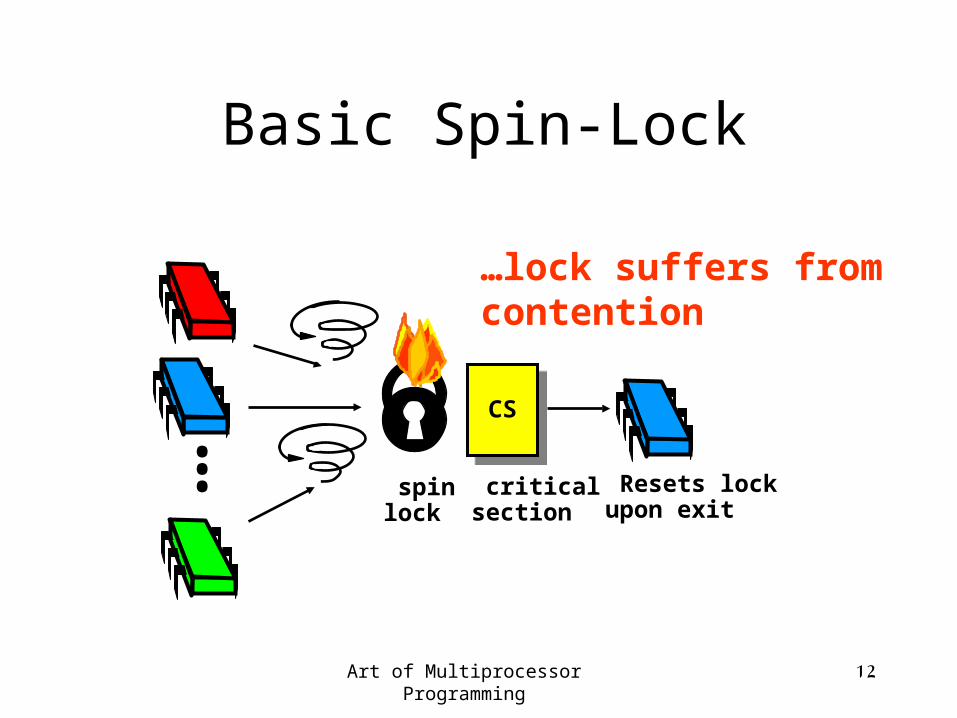
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...
…lock introduces sequential bottleneck
Art of Multiprocessor Programming 12
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...
…lock suffers from contention

Art of Multiprocessor Programming 13
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...Notice: these are distinct phenomena
…lock suffers from contention

Art of Multiprocessor Programming 14
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...
…lock suffers from contention
Seq Bottleneck no parallelism
Art of Multiprocessor Programming 15
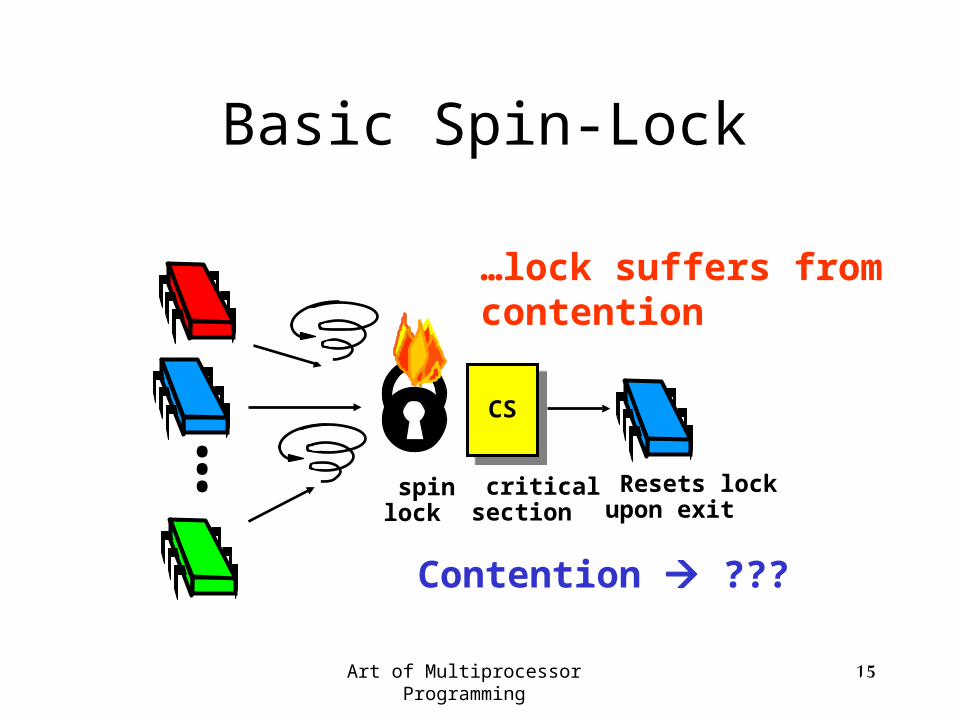
Basic Spin-Lock
CS
Resets lock upon exit
spin lock
critical section
...Contention ???
…lock suffers from contention

Art of Multiprocessor Programming 16
Review: Test-and-Set
• Boolean value• Test-and-set (TAS)
– Swap true with current value– Return value tells if prior value was
true or false
• Can reset just by writing false• TAS aka “getAndSet”

Art of Multiprocessor Programming 17
Review: Test-and-Set
public class AtomicBoolean { boolean value; public synchronized boolean getAndSet(boolean newValue) {
boolean prior = value; value = newValue; return prior; }}
(5)

Art of Multiprocessor Programming 18
Review: Test-and-Set
public class AtomicBoolean { boolean value; public synchronized boolean getAndSet(boolean newValue) {
boolean prior = value; value = newValue; return prior; }}
Packagejava.util.concurrent.atomic

Art of Multiprocessor Programming 19
Review: Test-and-Set
public class AtomicBoolean { boolean value; public synchronized boolean getAndSet(boolean newValue) {
boolean prior = value; value = newValue; return prior; }}
Swap old and new values

Art of Multiprocessor Programming 20
Review: Test-and-Set
AtomicBoolean lock = new AtomicBoolean(false)…boolean prior = lock.getAndSet(true)

Art of Multiprocessor Programming 21
Review: Test-and-Set
AtomicBoolean lock = new AtomicBoolean(false)…boolean prior = lock.getAndSet(true)
(5)
Swapping in true is called “test-and-set” or TAS

Art of Multiprocessor Programming 22
Test-and-Set Locks
• Locking– Lock is free: value is false– Lock is taken: value is true
• Acquire lock by calling TAS– If result is false, you win– If result is true, you lose
• Release lock by writing false

Art of Multiprocessor Programming 23
Test-and-set Lock
class TASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (state.getAndSet(true)) {} } void unlock() { state.set(false); }}

Art of Multiprocessor Programming 24
Test-and-set Lock
class TASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (state.getAndSet(true)) {} } void unlock() { state.set(false); }}
Lock state is AtomicBoolean

Art of Multiprocessor Programming 25
Test-and-set Lock
class TASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (state.getAndSet(true)) {} } void unlock() { state.set(false); }}
Keep trying until lock acquired

Art of Multiprocessor Programming 26
Test-and-set Lock
class TASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (state.getAndSet(true)) {} } void unlock() { state.set(false); }}
Release lock by resetting state to false

Art of Multiprocessor Programming 27
Space Complexity
• TAS spin-lock has small “footprint” • N thread spin-lock uses O(1) space• As opposed to O(n)
Peterson/Bakery • How did we overcome the (n)
lower bound? • We used a RMW operation…

Art of Multiprocessor Programming 28
Performance
• Experiment– n threads– Increment shared counter 1 million
times
• How long should it take?• How long does it take?
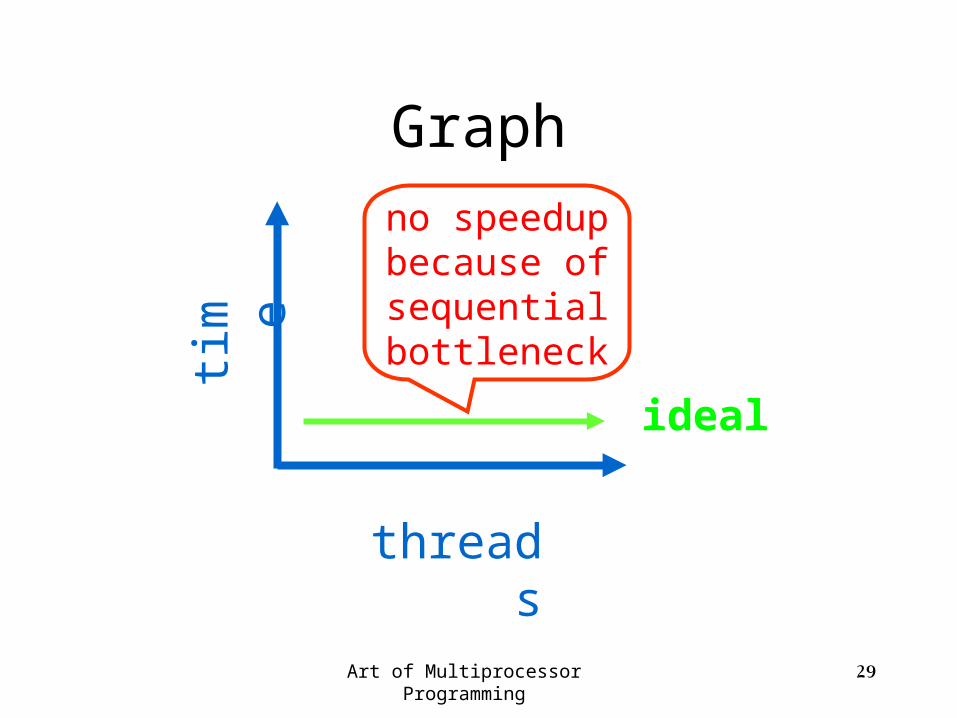
Art of Multiprocessor Programming 29
Graph
ideal
tim e
threads
no speedup because of sequential bottleneck

Art of Multiprocessor Programming 30
Mystery #1ti
m e
threads
TAS lock
Ideal
(1)
What is going on?

Art of Multiprocessor Programming 31
Test-and-Test-and-Set Locks
• Lurking stage– Wait until lock “looks” free– Spin while read returns true (lock
taken)• Pouncing state
– As soon as lock “looks” available– Read returns false (lock free)– Call TAS to acquire lock– If TAS loses, back to lurking

Art of Multiprocessor Programming 32
Test-and-test-and-set Lock
class TTASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (true) { while (state.get()) {} if (!state.getAndSet(true)) return; }}

Art of Multiprocessor Programming 33
Test-and-test-and-set Lock
class TTASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (true) { while (state.get()) {} if (!state.getAndSet(true)) return; }} Wait until lock looks free

Art of Multiprocessor Programming 34
Test-and-test-and-set Lock
class TTASlock { AtomicBoolean state = new AtomicBoolean(false);
void lock() { while (true) { while (state.get()) {} if (!state.getAndSet(true)) return; }}
Then try to acquire it

Art of Multiprocessor Programming 35
Mystery #2
TAS lock
TTAS lock
Ideal
tim e
threads

Art of Multiprocessor Programming 36
Mystery
• Both– TAS and TTAS– Do the same thing (in our model)
• Except that– TTAS performs much better than TAS– Neither approaches ideal

Art of Multiprocessor Programming 37
Opinion
• Our memory abstraction is broken• TAS & TTAS methods
– Are provably the same (in our model)
– Except they aren’t (in field tests)
• Need a more detailed model …

Art of Multiprocessor Programming 38
Bus-Based Architectures
Bus
cache
memory
cachecache

Art of Multiprocessor Programming 39
Bus-Based Architectures
Bus
cache
memory
cachecache
Random access memory (10s of cycles)

Art of Multiprocessor Programming 40
Bus-Based Architectures
cache
memory
cachecache
Shared Bus•Broadcast medium•One broadcaster at a time•Processors and memory all “snoop”
Bus

Art of Multiprocessor Programming 41
Bus-Based Architectures
Bus
cache
memory
cachecache
Per-Processor Caches•Small•Fast: 1 or 2 cycles•Address & state information

Art of Multiprocessor Programming 42
Jargon Watch
• Cache hit– “I found what I wanted in my cache”– Good Thing™

Art of Multiprocessor Programming 43
Jargon Watch
• Cache hit– “I found what I wanted in my cache”– Good Thing™
• Cache miss– “I had to shlep all the way to memory
for that data”– Bad Thing™

Art of Multiprocessor Programming 44
Cave Canem
• This model is still a simplification– But not in any essential way– Illustrates basic principles
• Will discuss complexities later

Art of Multiprocessor Programming 45
Bus
Processor Issues Load Request
cache
memory
cachecache
data

Art of Multiprocessor Programming 46
Bus
Processor Issues Load Request
Bus
cache
memory
cachecache
data
Gimmedata
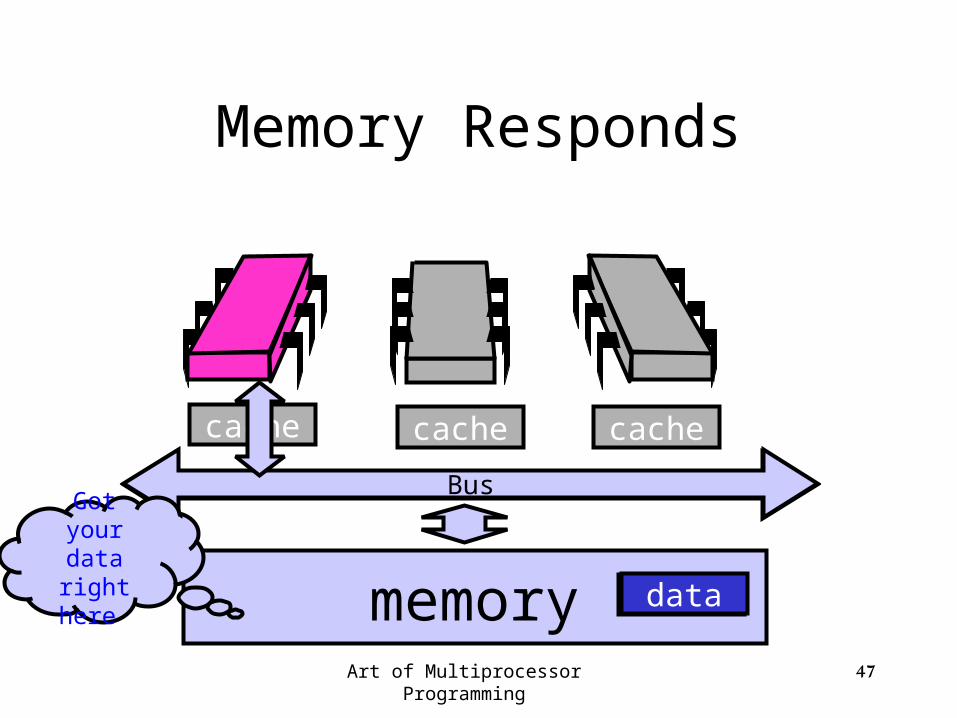
Art of Multiprocessor Programming 47
cache
Bus
Memory Responds
Bus
memory
cachecache
data
Got your data right here data

Art of Multiprocessor Programming 48
Bus
Processor Issues Load Request
memory
cachecachedata
data
Gimmedata
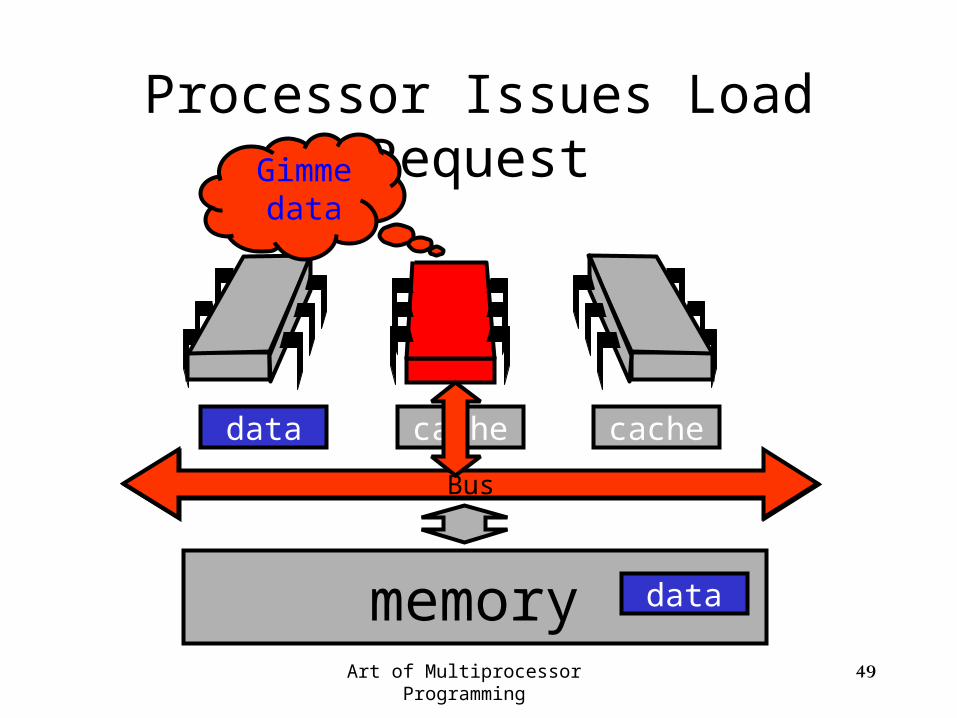
Art of Multiprocessor Programming 49
Bus
Processor Issues Load Request
Bus
memory
cachecachedata
data
Gimmedata

Art of Multiprocessor Programming 50
Bus
Processor Issues Load Request
Bus
memory
cachecachedata
data
I got data

Art of Multiprocessor Programming 51
Bus
Other Processor Responds
memory
cachecache
data
I got data
datadata
Bus

Art of Multiprocessor Programming 52
Bus
Other Processor Responds
memory
cachecache
data
datadata
Bus

Art of Multiprocessor Programming 53
Modify Cached Data
Bus
data
memory
cachedata
data
(1)

Art of Multiprocessor Programming 54
Modify Cached Data
Bus
data
memory
cachedata
data
data
(1)

Art of Multiprocessor Programming 55
memory
Bus
data
Modify Cached Data
cachedata
data

Art of Multiprocessor Programming 56
memory
Bus
data
Modify Cached Data
cache
What’s up with the other copies?
data
data

Art of Multiprocessor Programming 57
Cache Coherence
• We have lots of copies of data– Original copy in memory – Cached copies at processors
• Some processor modifies its own copy– What do we do with the others?– How to avoid confusion?

Art of Multiprocessor Programming 58
Write-Back Caches
• Accumulate changes in cache• Write back when needed
– Need the cache for something else– Another processor wants it
• On first modification– Invalidate other entries– Requires non-trivial protocol …

Art of Multiprocessor Programming 59
Write-Back Caches
• Cache entry has three states– Invalid: contains raw seething bits– Valid: I can read but I can’t write– Dirty: Data has been modified
• Intercept other load requests• Write back to memory before using cache

Art of Multiprocessor Programming 60
Bus
Invalidate
memory
cachedatadata
data
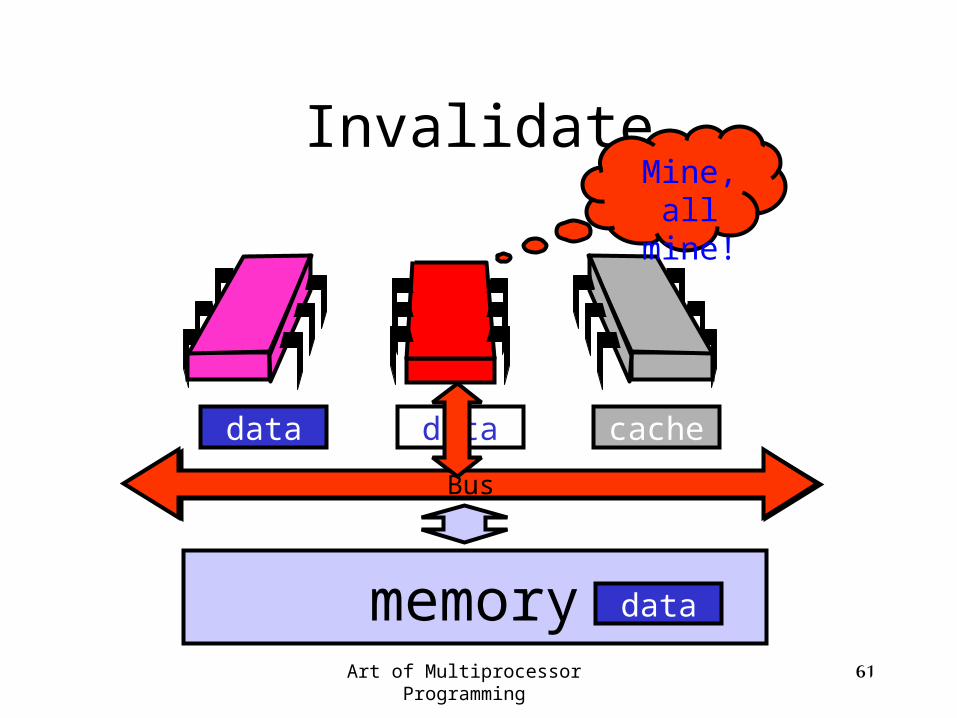
Art of Multiprocessor Programming 61
Bus
Invalidate
Bus
memory
cachedatadata
data
Mine, all mine!

Art of Multiprocessor Programming 62
Bus
Invalidate
Bus
memory
cachedatadata
data
cache
Uh,oh
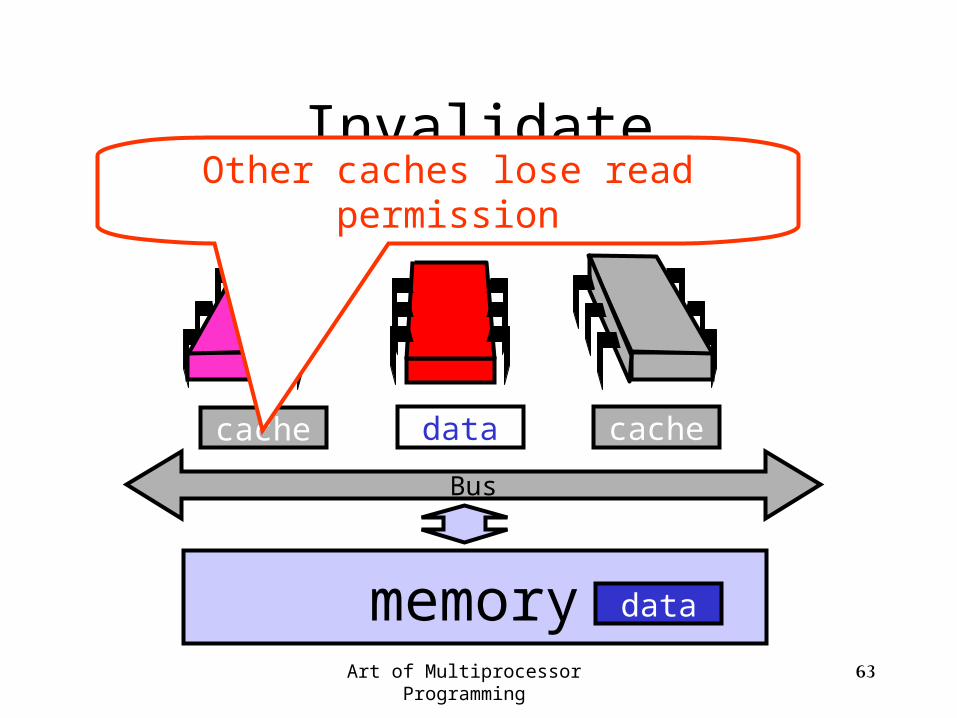
Art of Multiprocessor Programming 63
cache
Bus
Invalidate
memory
cachedata
data
Other caches lose read permission

Art of Multiprocessor Programming 64
cache
Bus
Invalidate
memory
cachedata
data
Other caches lose read permission
This cache acquires write permission

Art of Multiprocessor Programming 65
cache
Bus
Invalidate
memory
cachedata
data
Memory provides data only if not present in any cache, so no need
to change it now (expensive)
(2)
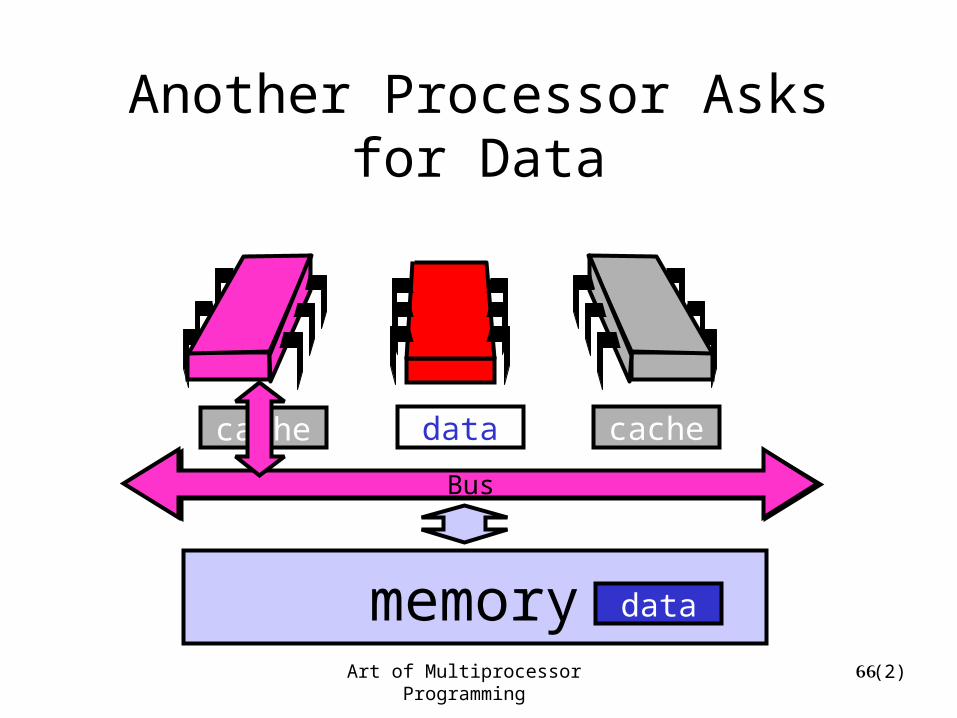
Art of Multiprocessor Programming 66
cache
Bus
Another Processor Asks for Data
memory
cachedata
data
(2)
Bus

Art of Multiprocessor Programming 67
cache data
Bus
Owner Responds
memory
cachedata
data
(2)
Bus
Here it is!

Art of Multiprocessor Programming 68
Bus
End of the Day …
memory
cachedata
data
(1)
Reading OK, no writing
data data

Art of Multiprocessor Programming 69
Mutual Exclusion
• What do we want to optimize?– Bus bandwidth used by spinning
threads– Release/Acquire latency– Acquire latency for idle lock

Art of Multiprocessor Programming 70
Simple TASLock
• TAS invalidates cache lines• Spinners
– Miss in cache– Go to bus
• Thread wants to release lock– delayed behind spinners

Art of Multiprocessor Programming 71
Test-and-test-and-set
• Wait until lock “looks” free– Spin on local cache– No bus use while lock busy
• Problem: when lock is released– Invalidation storm …

Art of Multiprocessor Programming 72
Local Spinning while Lock is Busy
Bus
memory
busybusybusy
busy
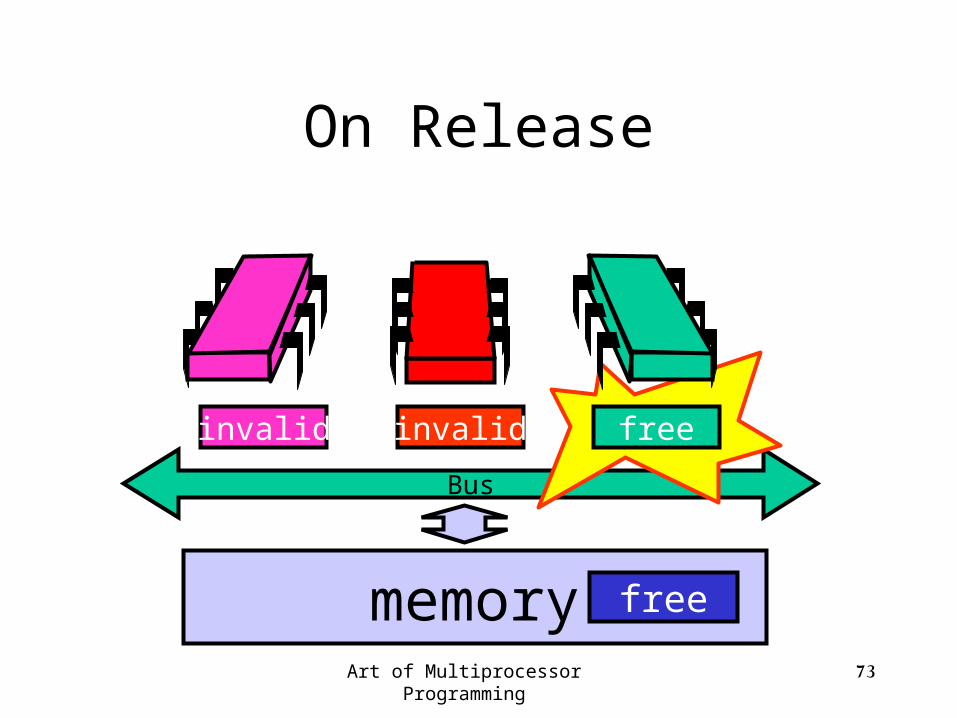
Art of Multiprocessor Programming 73
Bus
On Release
memory
freeinvalidinvalid
free

Art of Multiprocessor Programming 74
On Release
Bus
memory
freeinvalidinvalid
free
miss miss
Everyone misses, rereads
(1)

Art of Multiprocessor Programming 75
On Release
Bus
memory
freeinvalidinvalid
free
TAS(…) TAS(…)
Everyone tries TAS
(1)

Art of Multiprocessor Programming 76
Problems
• Everyone misses– Reads satisfied sequentially
• Everyone does TAS– Invalidates others’ caches
• Eventually quiesces after lock acquired– How long does this take?

Art of Multiprocessor Programming 77
Measuring Quiescence Time
P1
P2
Pn
X = time of ops that don’t use the busY = time of ops that cause intensive bus traffic
In critical section, run ops X then ops Y. As long as Quiescence time is less than X, no drop in performance.
By gradually varying X, can determine the exact time to quiesce.

Art of Multiprocessor Programming 78
Quiescence Time
Increses linearly with the number of processors for bus architectureti
m e
threads

Art of Multiprocessor Programming 79
Mystery Explained
TAS lock
TTAS lock
Ideal
tim e
threads
Better than TAS but still
not as good as ideal
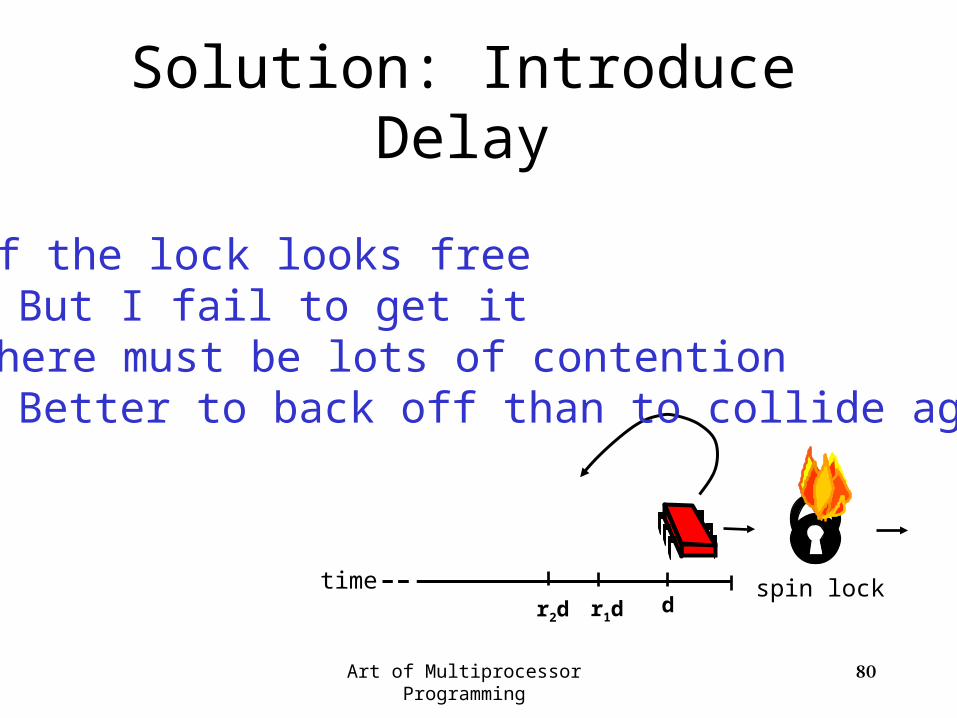
Art of Multiprocessor Programming 80
Solution: Introduce Delay
spin locktimedr1dr2d
• If the lock looks free• But I fail to get it
• There must be lots of contention• Better to back off than to collide again

Art of Multiprocessor Programming 81
Dynamic Example: Exponential Backoff
timed2d4d spin lock
If I fail to get lock– wait random duration before retry– Each subsequent failure doubles
expected wait

Art of Multiprocessor Programming 82
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}}

Art of Multiprocessor Programming 83
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}} Fix minimum delay

Art of Multiprocessor Programming 84
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}} Wait until lock looks free

Art of Multiprocessor Programming 85
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}} If we win, return

Art of Multiprocessor Programming 86
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}}
Back off for random duration

Art of Multiprocessor Programming 87
Exponential Backoff Lock
public class Backoff implements lock { public void lock() { int delay = MIN_DELAY; while (true) { while (state.get()) {} if (!lock.getAndSet(true)) return; sleep(random() % delay); if (delay < MAX_DELAY) delay = 2 * delay; }}}
Double max delay, within reason

Art of Multiprocessor Programming 88
Spin-Waiting Overhead
TTAS Lock
Backoff lock
tim e
threads

Art of Multiprocessor Programming 89
Backoff: Other Issues
• Good– Easy to implement– Beats TTAS lock
• Bad– Must choose parameters carefully– Not portable across platforms

Art of Multiprocessor Programming 90
Idea
• Avoid useless invalidations– By keeping a queue of threads
• Each thread– Notifies next in line– Without bothering the others

Art of Multiprocessor Programming 91
Anderson Queue Lock
flags
next
T F F F F F F F
idle

Art of Multiprocessor Programming 92
Anderson Queue Lock
flags
next
T F F F F F F F
acquiring
getAndIncrement

Art of Multiprocessor Programming 93
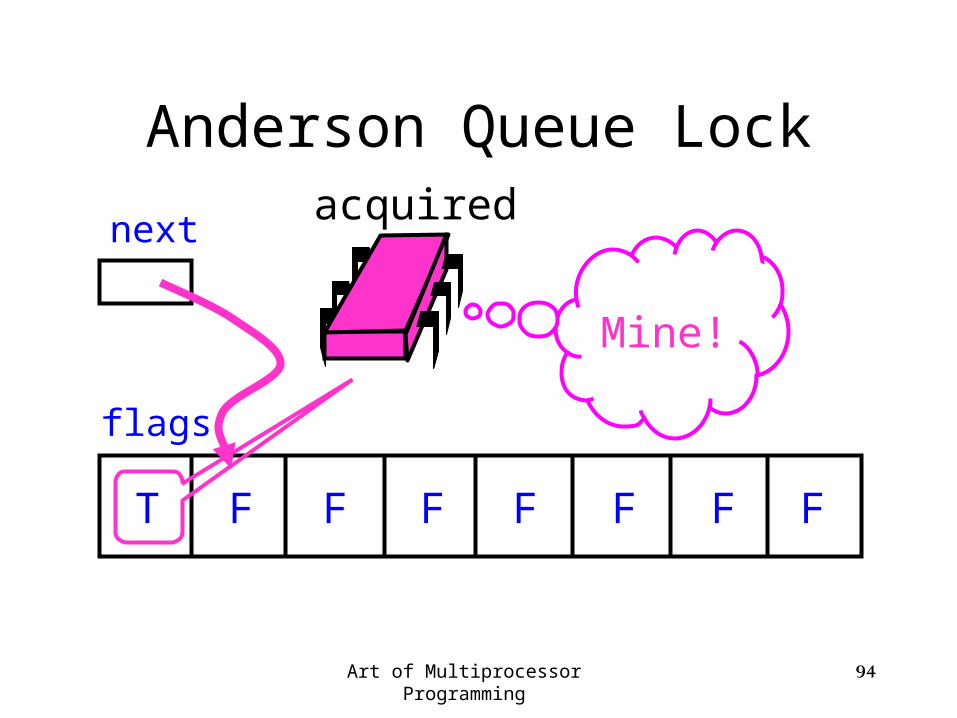
Anderson Queue Lock
flags
next
T F F F F F F F
acquiring
getAndIncrement
Art of Multiprocessor Programming 94
Anderson Queue Lock
flags
next
T F F F F F F F
acquired
Mine!

Art of Multiprocessor Programming 95
Anderson Queue Lock
flags
next
T F F F F F F F
acquired acquiring

Art of Multiprocessor Programming 96
Anderson Queue Lock
flags
next
T F F F F F F F
acquired acquiring
getAndIncrement
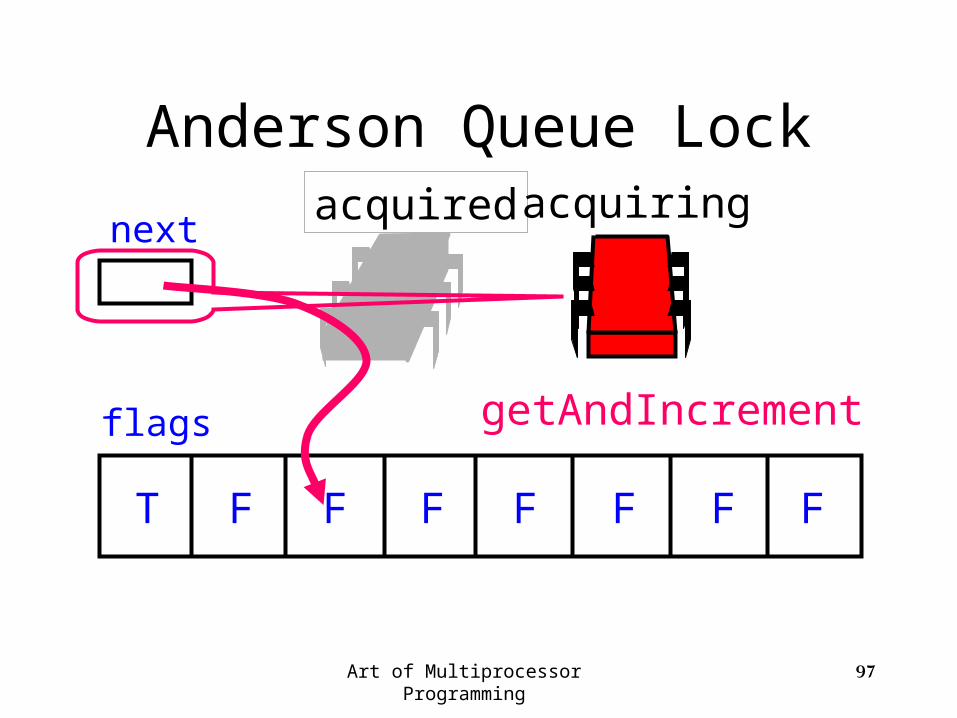
Art of Multiprocessor Programming 97
Anderson Queue Lock
flags
next
T F F F F F F F
acquired acquiring
getAndIncrement

Art of Multiprocessor Programming 98
acquired
Anderson Queue Lock
flags
next
T F F F F F F F
acquiring

Art of Multiprocessor Programming 99
released
Anderson Queue Lock
flags
next
T T F F F F F F
acquired
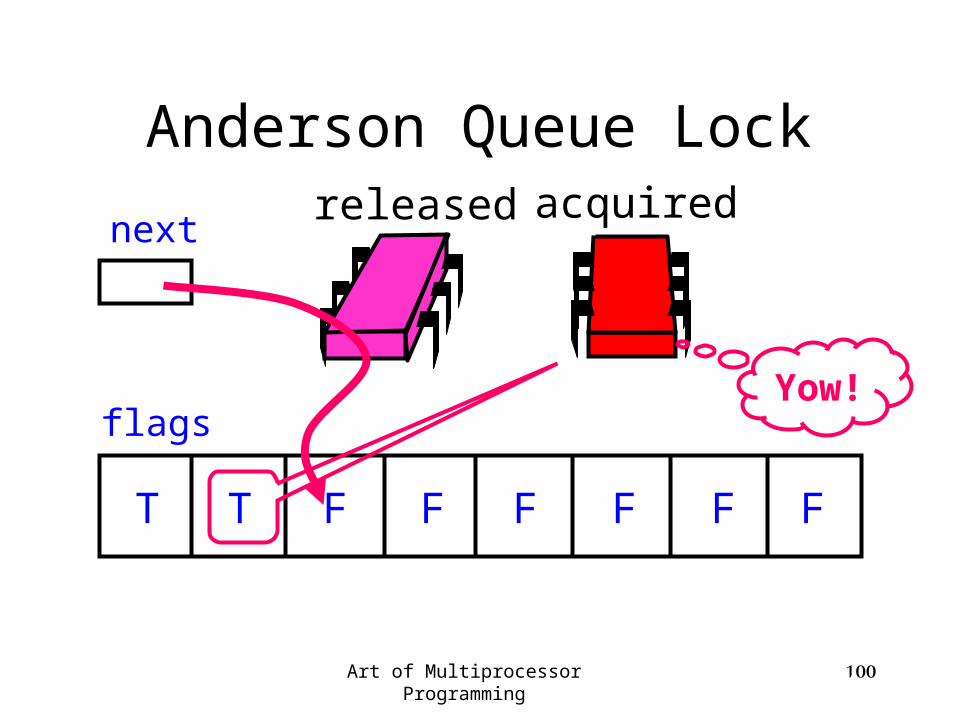
Art of Multiprocessor Programming 100
released
Anderson Queue Lock
flags
next
T T F F F F F F
acquired
Yow!

Art of Multiprocessor Programming 101
Anderson Queue Lock
class ALock implements Lock { boolean[] flags={true,false,…,false}; AtomicInteger next = new AtomicInteger(0); int[] slot = new int[n];

Art of Multiprocessor Programming 102
Anderson Queue Lock
class ALock implements Lock { boolean[] flags={true,false,…,false}; AtomicInteger next = new AtomicInteger(0); int[] slot = new int[n];
One flag per thread

Art of Multiprocessor Programming 103
Anderson Queue Lock
class ALock implements Lock { boolean[] flags={true,false,…,false}; AtomicInteger next = new AtomicInteger(0); int[] slot = new int[n];
Next flag to use

Art of Multiprocessor Programming 104
Anderson Queue Lock
class ALock implements Lock { boolean[] flags={true,false,…,false}; AtomicInteger next = new AtomicInteger(0); ThreadLocal<Integer> mySlot;
Thread-local variable

Art of Multiprocessor Programming 105
Anderson Queue Lock
public lock() { mySlot = next.getAndIncrement(); while (!flags[mySlot % n]) {}; flags[mySlot % n] = false;}
public unlock() { flags[(mySlot+1) % n] = true;}

Art of Multiprocessor Programming 106
Anderson Queue Lock
public lock() { mySlot = next.getAndIncrement(); while (!flags[mySlot % n]) {}; flags[mySlot % n] = false;}
public unlock() { flags[(mySlot+1) % n] = true;} Take next slot

Art of Multiprocessor Programming 107
Anderson Queue Lock
public lock() { mySlot = next.getAndIncrement(); while (!flags[mySlot % n]) {}; flags[mySlot % n] = false;}
public unlock() { flags[(mySlot+1) % n] = true;} Spin until told to go

Art of Multiprocessor Programming 108
Anderson Queue Lock
public lock() { myslot = next.getAndIncrement(); while (!flags[myslot % n]) {}; flags[myslot % n] = false;}
public unlock() { flags[(myslot+1) % n] = true;} Prepare slot for re-use

Art of Multiprocessor Programming 109
Anderson Queue Lock
public lock() { mySlot = next.getAndIncrement(); while (!flags[mySlot % n]) {}; flags[mySlot % n] = false;}
public unlock() { flags[(mySlot+1) % n] = true;}
Tell next thread to go
Art of Multiprocessor Programming 110
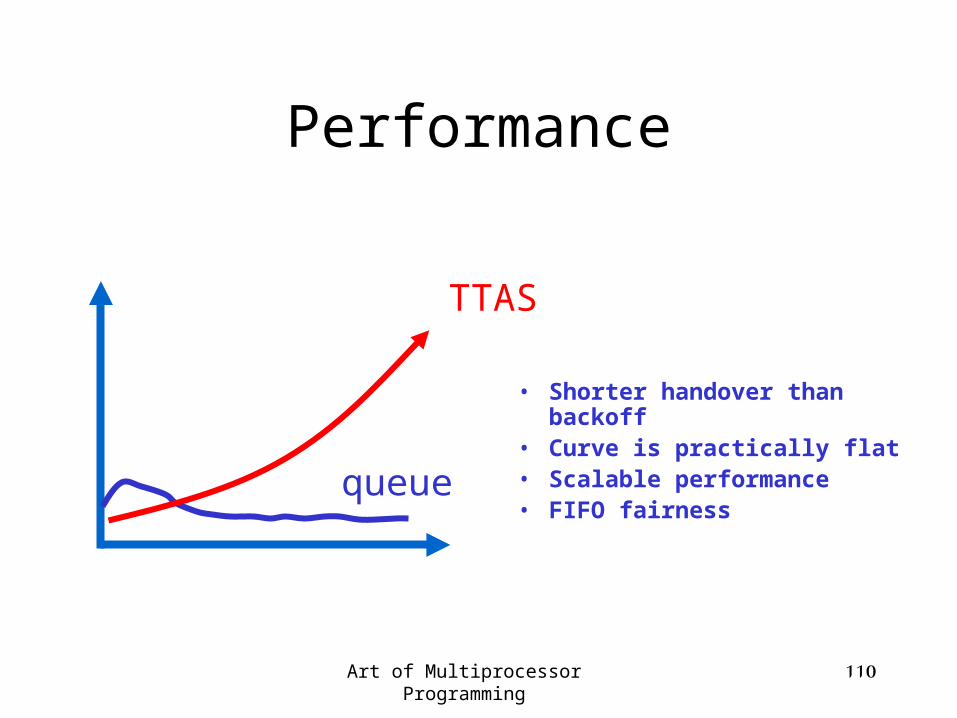
Performance
• Shorter handover than backoff
• Curve is practically flat• Scalable performance• FIFO fairness
queue
TTAS

Art of Multiprocessor Programming 111
Anderson Queue Lock
• Good– First truly scalable lock– Simple, easy to implement
• Bad– Space hog– One bit per thread
• Unknown number of threads?• Small number of actual contenders?

Art of Multiprocessor Programming 112
CLH Lock
• FIFO order• Small, constant-size overhead per
thread

Art of Multiprocessor Programming 113
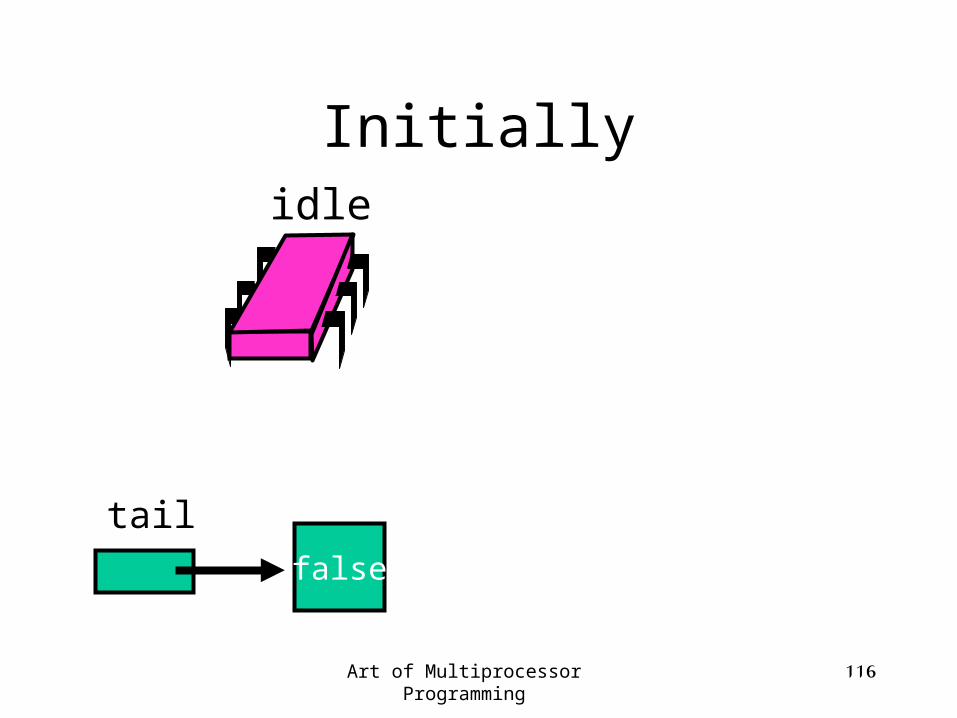
Initially
false
tail
idle

Art of Multiprocessor Programming 114
Initially
false
tail
idle
Queue tail

Art of Multiprocessor Programming 115
Initially
false
tail
idle
Lock is free
Art of Multiprocessor Programming 116
Initially
false
tail
idle

Art of Multiprocessor Programming 117
Purple Wants the Lock
false
tail
acquiring

Art of Multiprocessor Programming 118
Purple Wants the Lock
false
tail
acquiring
true

Art of Multiprocessor Programming 119
Purple Wants the Lock
falsetail
acquiring
true
Swap

Art of Multiprocessor Programming 120
Purple Has the Lock
false
tail
acquired
true
Art of Multiprocessor Programming 121
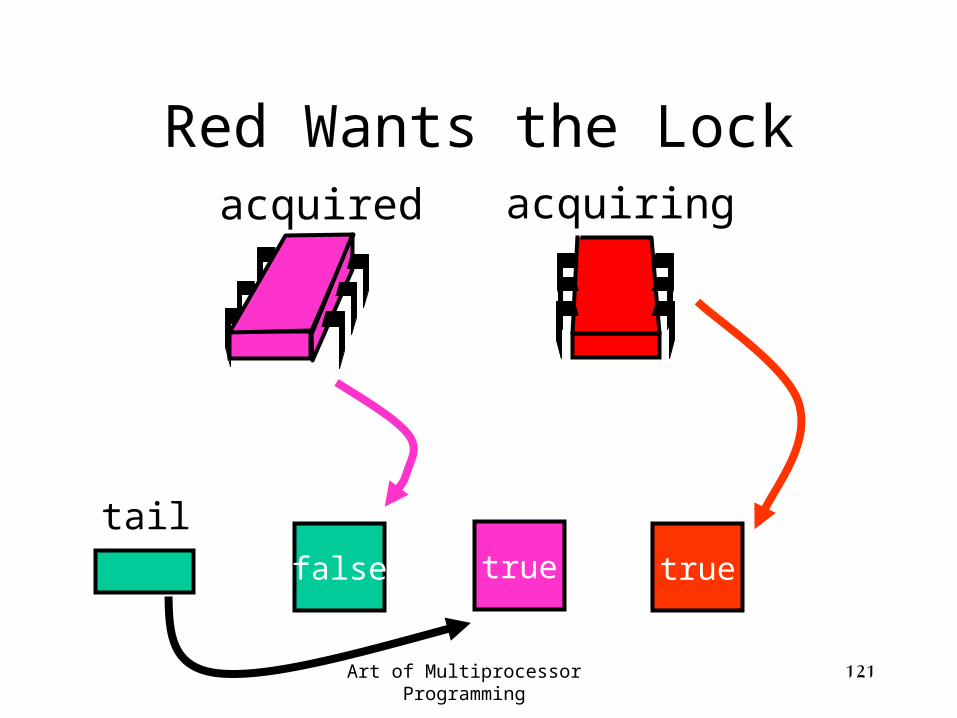
Red Wants the Lock
false
tail
acquired acquiring
true true

Art of Multiprocessor Programming 122
Red Wants the Lock
false
tail
acquired acquiring
true
Swap
true

Art of Multiprocessor Programming 123
Red Wants the Lock
false
tail
acquired acquiring
true true

Art of Multiprocessor Programming 124
Red Wants the Lock
false
tail
acquired acquiring
true true

Art of Multiprocessor Programming 125
Red Wants the Lock
false
tail
acquired acquiring
true true
Implicitely Linked list

Art of Multiprocessor Programming 126
Red Wants the Lock
false
tail
acquired acquiring
true true
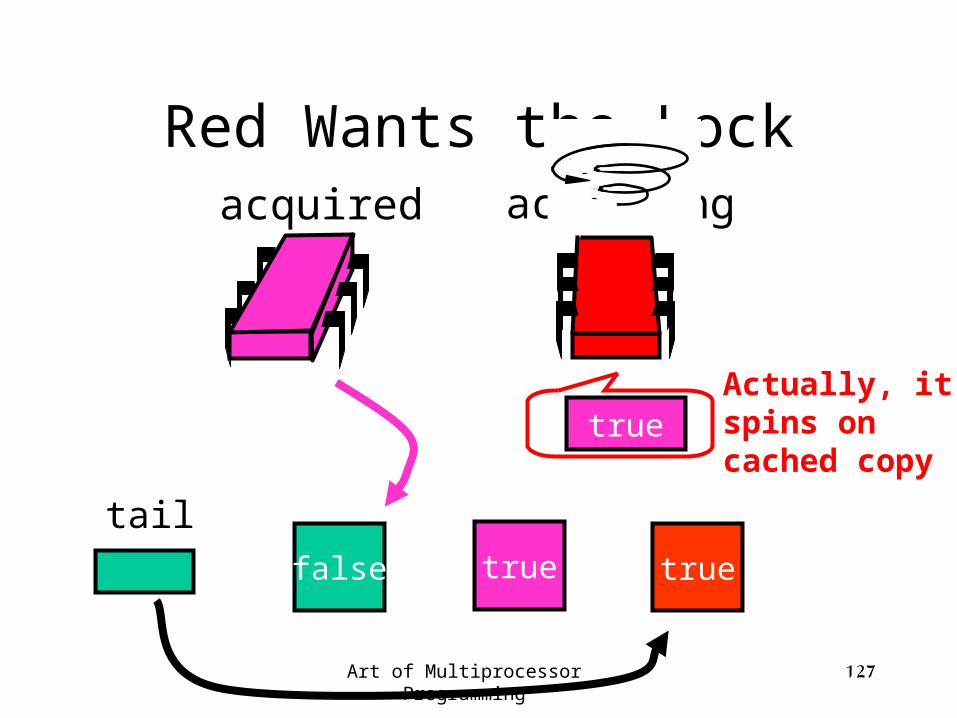
Art of Multiprocessor Programming 127
Red Wants the Lock
false
tail
acquired acquiring
true true
trueActually, it spins on cached copy

Art of Multiprocessor Programming 128
Purple Releases
false
tail
release acquiring
false true
falseBingo
!

Art of Multiprocessor Programming 129
Purple Releases
tail
released acquired
true

Art of Multiprocessor Programming 130
Space Usage
• Let– L = number of locks– N = number of threads
• ALock– O(LN)
• CLH lock– O(L+N)

Art of Multiprocessor Programming 131
CLH Queue Lock
class Qnode { AtomicBoolean locked = new AtomicBoolean(true);}

Art of Multiprocessor Programming 132
CLH Queue Lock
class Qnode { AtomicBoolean locked = new AtomicBoolean(true);}
Not released yet

Art of Multiprocessor Programming 133
CLH Queue Lockclass CLHLock implements Lock { AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode = new Qnode(); public void lock() { Qnode pred = tail.getAndSet(myNode); while (pred.locked) {} }}
(3)

Art of Multiprocessor Programming 134
CLH Queue Lockclass CLHLock implements Lock { AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode = new Qnode(); public void lock() { Qnode pred = tail.getAndSet(myNode); while (pred.locked) {} }}
(3)
Tail of the queue

Art of Multiprocessor Programming 135
CLH Queue Lockclass CLHLock implements Lock { AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode = new Qnode(); public void lock() { Qnode pred = tail.getAndSet(myNode); while (pred.locked) {} }}
(3)
Thread-local Qnode

Art of Multiprocessor Programming 136
CLH Queue Lockclass CLHLock implements Lock { AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode = new Qnode(); public void lock() { Qnode pred = tail.getAndSet(myNode); while (pred.locked) {} }}
(3)
Swap in my node

Art of Multiprocessor Programming 137
CLH Queue Lockclass CLHLock implements Lock { AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode = new Qnode(); public void lock() { Qnode pred = tail.getAndSet(myNode); while (pred.locked) {} }}
(3)
Spin until predecessorreleases lock

Art of Multiprocessor Programming 138
CLH Queue LockClass CLHLock implements Lock { … public void unlock() { myNode.locked.set(false); myNode = pred; }}
(3)

Art of Multiprocessor Programming 139
CLH Queue LockClass CLHLock implements Lock { … public void unlock() { myNode.locked.set(false); myNode = pred; }}
(3)
Notify successor

Art of Multiprocessor Programming 140
CLH Queue LockClass CLHLock implements Lock { … public void unlock() { myNode.locked.set(false); myNode = pred; }}
(3)
Recycle predecessor’s
node

Art of Multiprocessor Programming 141
CLH Queue LockClass CLHLock implements Lock { … public void unlock() { myNode.locked.set(false); myNode = pred; }}
(3)
(notice that we actually don’t reuse myNode. Code in book shows how its done.)

Art of Multiprocessor Programming 142
CLH Lock
• Good– Lock release affects predecessor only– Small, constant-sized space
• Bad– Doesn’t work for uncached NUMA
architectures

Art of Multiprocessor Programming 143
NUMA Architecturs
• Acronym:– Non-Uniform Memory Architecture
• Illusion:– Flat shared memory
• Truth:– No caches (sometimes)– Some memory regions faster than
others

Art of Multiprocessor Programming 144
NUMA Machines
Spinning on local memory is fast

Art of Multiprocessor Programming 145
NUMA Machines
Spinning on remote memory is slow

Art of Multiprocessor Programming 146
CLH Lock
• Each thread spin’s on predecessor’s memory
• Could be far away …

Art of Multiprocessor Programming 147
MCS Lock
• FIFO order• Spin on local memory only• Small, Constant-size overhead

Art of Multiprocessor Programming 148
Initially
false
tail false
idle

Art of Multiprocessor Programming 149
Acquiring
false
queuefalse
true
acquiring
(allocate Qnode)

Art of Multiprocessor Programming 150
Acquiring
false
tail false
true
acquired
swap

Art of Multiprocessor Programming 151
Acquiring
false
tail false
true
acquired

Art of Multiprocessor Programming 152
Acquired
false
tail false
true
acquired

Art of Multiprocessor Programming 153
Acquiring
tail
false
acquiredacquiring
trueswap

Art of Multiprocessor Programming 154
Acquiring
tail
acquiredacquiring
true
false

Art of Multiprocessor Programming 155
Acquiring
tail
acquiredacquiring
true
false

Art of Multiprocessor Programming 156
Acquiring
tail
acquiredacquiring
true
false

Art of Multiprocessor Programming 157
Acquiring
tail
acquiredacquiring
true
true
false
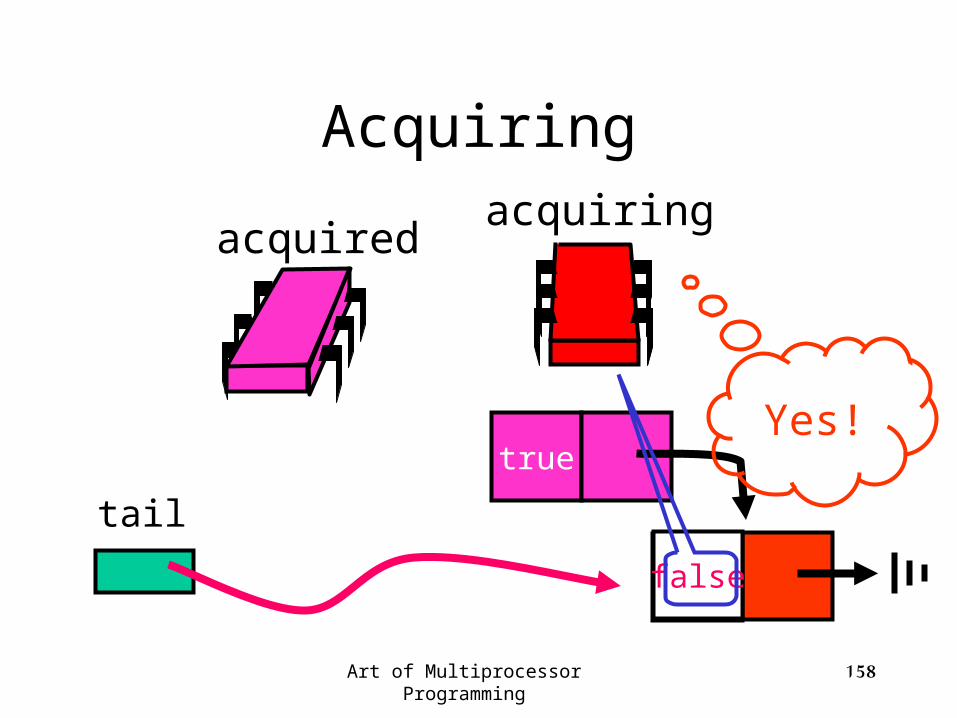
Art of Multiprocessor Programming 158
Acquiring
tail
acquiredacquiring
true
trueYes!
false

Art of Multiprocessor Programming 159
MCS Queue Lock
class Qnode { boolean locked = false; qnode next = null;}

Art of Multiprocessor Programming 160
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void lock() { Qnode qnode = new Qnode(); Qnode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; while (qnode.locked) {} }}}
(3)

Art of Multiprocessor Programming 161
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void lock() { Qnode qnode = new Qnode(); Qnode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; while (qnode.locked) {} }}}
(3)
Make a QNode

Art of Multiprocessor Programming 162
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void lock() { Qnode qnode = new Qnode(); Qnode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; while (qnode.locked) {} }}}
(3)
add my Node to the tail of
queue

Art of Multiprocessor Programming 163
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void lock() { Qnode qnode = new Qnode(); Qnode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; while (qnode.locked) {} }}}
(3)
Fix if queue was non-
empty

Art of Multiprocessor Programming 164
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void lock() { Qnode qnode = new Qnode(); Qnode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; while (qnode.locked) {} }}}
(3)
Wait until unlocked

Art of Multiprocessor Programming 165
MCS Queue Unlockclass MCSLock implements Lock { AtomicReference tail; public void unlock() { if (qnode.next == null) { if (tail.CAS(qnode, null) return; while (qnode.next == null) {} } qnode.next.locked = false;}}
(3)

Art of Multiprocessor Programming 166
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void unlock() { if (qnode.next == null) { if (tail.CAS(qnode, null) return; while (qnode.next == null) {} } qnode.next.locked = false;}}
(3)
Missingsuccessor?

Art of Multiprocessor Programming 167
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void unlock() { if (qnode.next == null) { if (tail.CAS(qnode, null) return; while (qnode.next == null) {} } qnode.next.locked = false;}}
(3)
If really no successor, return

Art of Multiprocessor Programming 168
MCS Queue Lockclass MCSLock implements Lock { AtomicReference tail; public void unlock() { if (qnode.next == null) { if (tail.CAS(qnode, null) return; while (qnode.next == null) {} } qnode.next.locked = false;}}
(3)
Otherwise wait for successor to catch up

Art of Multiprocessor Programming 169
MCS Queue Lockclass MCSLock implements Lock { AtomicReference queue; public void unlock() { if (qnode.next == null) { if (tail.CAS(qnode, null) return; while (qnode.next == null) {} } qnode.next.locked = false;}}
(3)
Pass lock to successor

Art of Multiprocessor Programming 170
Purple Release
false
releasing swap
false
(2)

Art of Multiprocessor Programming 171
Purple Release
false
releasing swap
false
By looking at the queue, I see another
thread is active
(2)

Art of Multiprocessor Programming 172
Purple Release
false
releasing swap
false
By looking at the queue, I see another
thread is active
I have to wait for that thread to finish
(2)
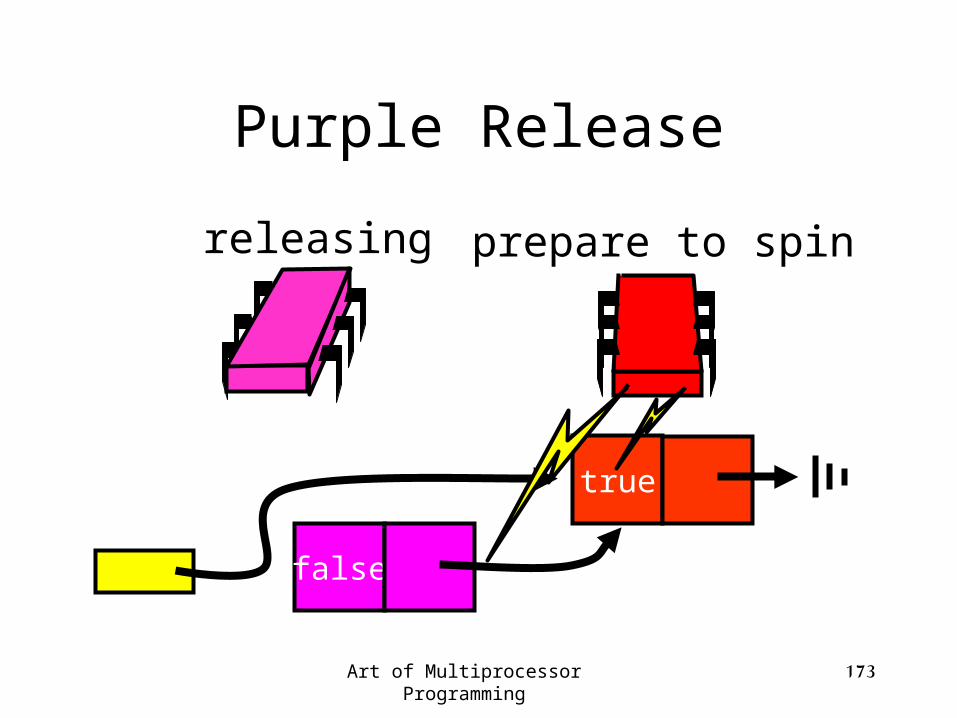
Art of Multiprocessor Programming 173
Purple Release
false
releasing prepare to spin
true
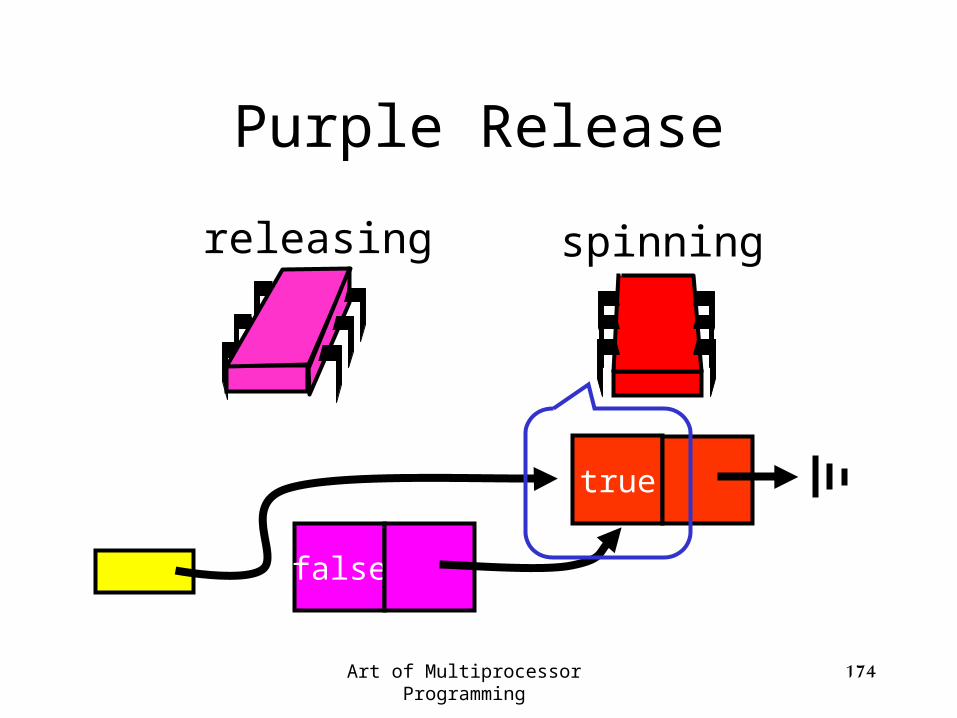
Art of Multiprocessor Programming 174
Purple Release
false
releasing spinning
true

Art of Multiprocessor Programming 175
Purple Release
false
releasing spinning
truefalse

Art of Multiprocessor Programming 176
Purple Release
false
releasing
true
Acquired lock
false

Art of Multiprocessor Programming 177
Abortable Locks
• What if you want to give up waiting for a lock?
• For example– Timeout– Database transaction aborted by user

Art of Multiprocessor Programming 178
Back-off Lock
• Aborting is trivial– Just return from lock() call
• Extra benefit:– No cleaning up– Wait-free– Immediate return

Art of Multiprocessor Programming 179
Queue Locks
• Can’t just quit– Thread in line behind will starve
• Need a graceful way out

Art of Multiprocessor Programming 180
Queue Locks
spinning
true
spinning
truetrue
spinning

Art of Multiprocessor Programming 181
Queue Locks
spinning
true
spinning
truefalse
locked

Art of Multiprocessor Programming 182
Queue Locks
spinning
true
locked
false
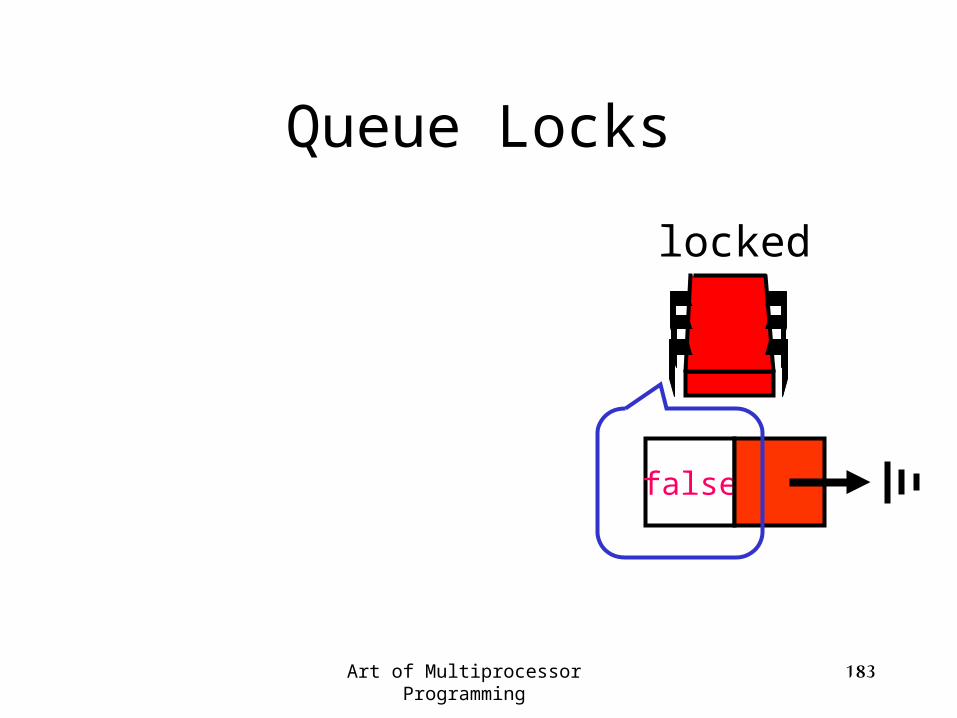
Art of Multiprocessor Programming 183
Queue Locks
locked
false
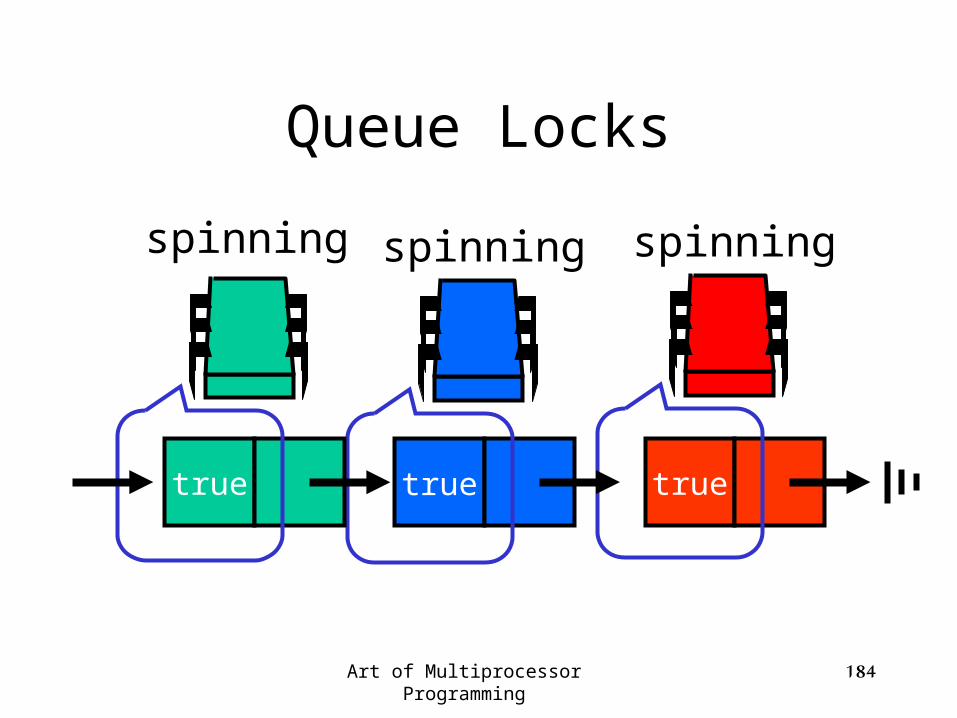
Art of Multiprocessor Programming 184
Queue Locks
spinning
true
spinning
truetrue
spinning

Art of Multiprocessor Programming 185
Queue Locks
spinning
truetruetrue
spinning

Art of Multiprocessor Programming 186
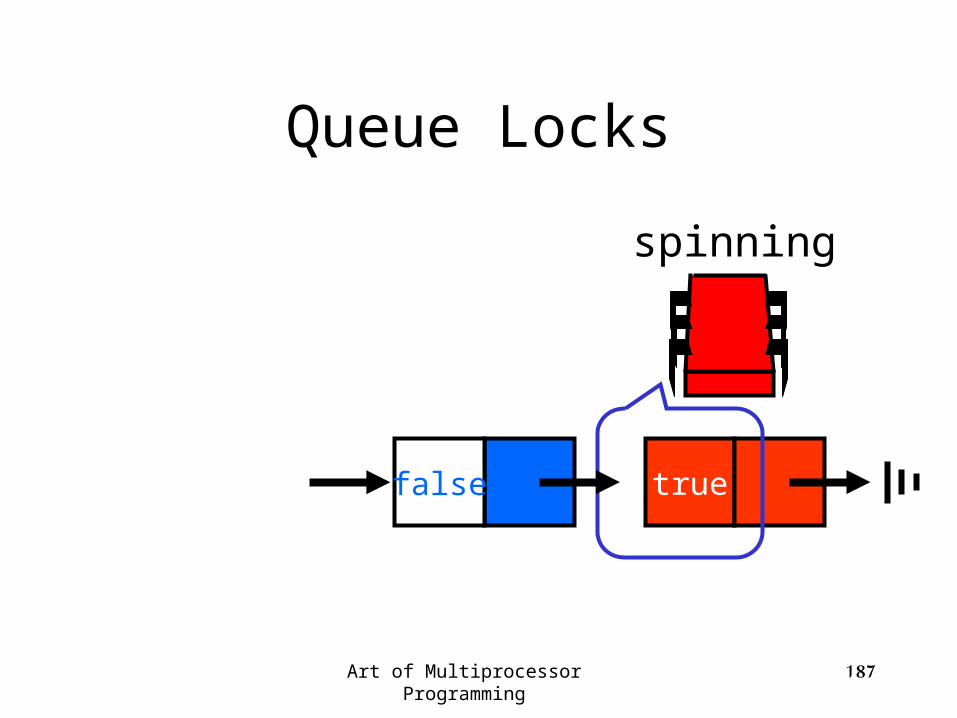
Queue Locks
spinning
truetruefalse
locked
Art of Multiprocessor Programming 187
Queue Locks
spinning
truefalse

Art of Multiprocessor Programming 188
Queue Locks
pwned
truefalse

Art of Multiprocessor Programming 189
Abortable CLH Lock
• When a thread gives up– Removing node in a wait-free way is
hard
• Idea:– let successor deal with it.
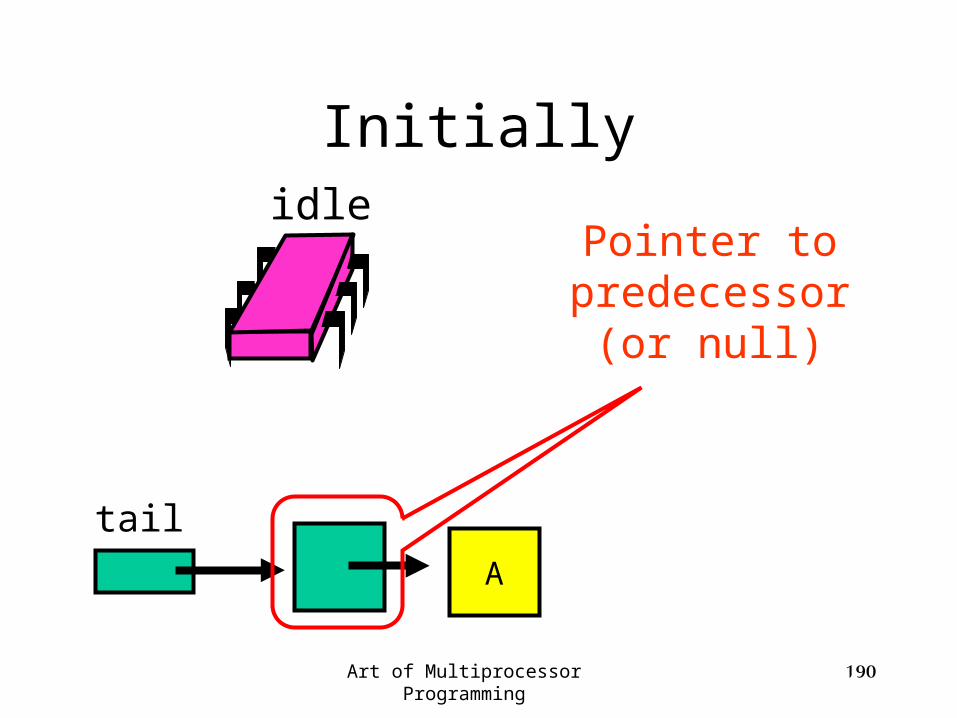
Art of Multiprocessor Programming 190
Initially
tail
idlePointer to
predecessor (or null)
A

Art of Multiprocessor Programming 191
Initially
tail
idleDistinguished available
node means lock is free
A

Art of Multiprocessor Programming 192
Acquiring
tail
acquiring
A

Art of Multiprocessor Programming 193
Acquiringacquiring
A
Null predecessor means lock not
released or aborted

Art of Multiprocessor Programming 194
Acquiringacquiring
A
Swap
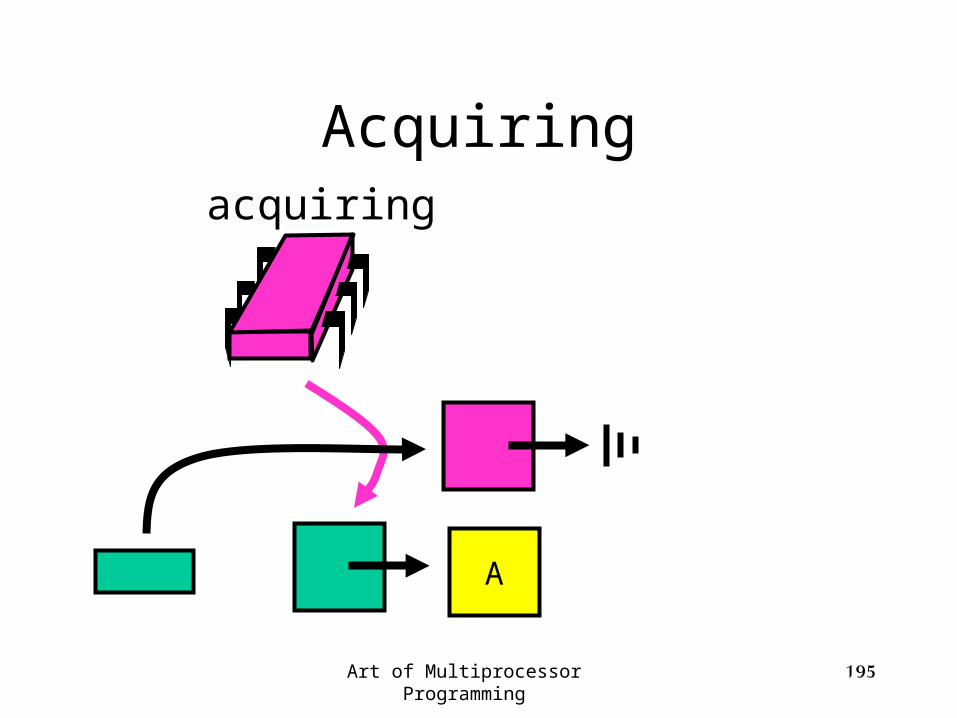
Art of Multiprocessor Programming 195
Acquiringacquiring
A
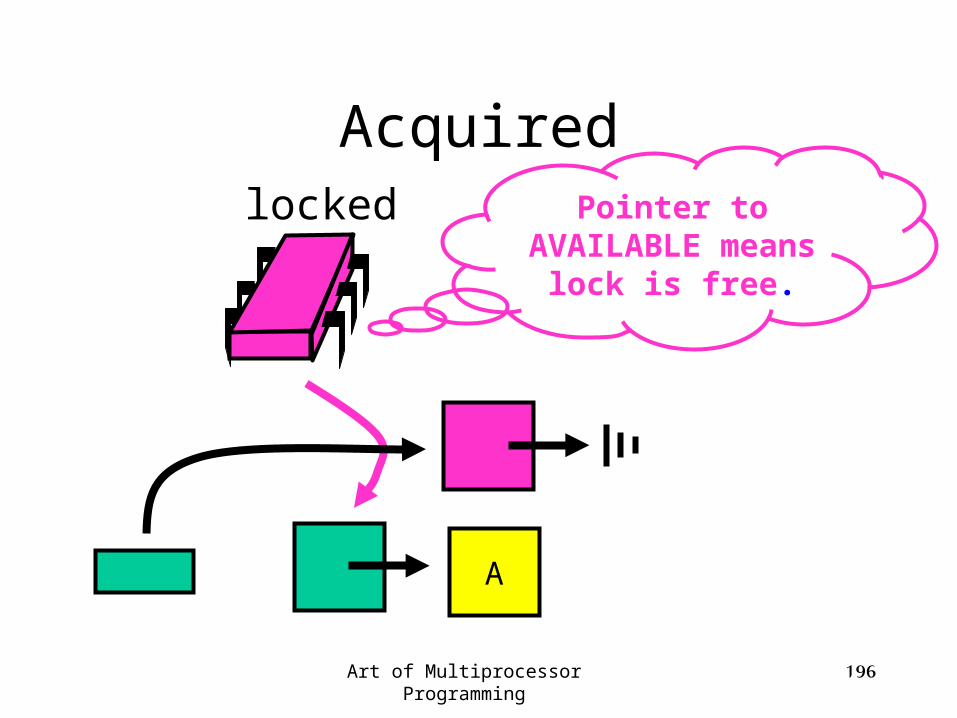
Art of Multiprocessor Programming 196
Acquiredlocked
A
Pointer to AVAILABLE
means lock is free.
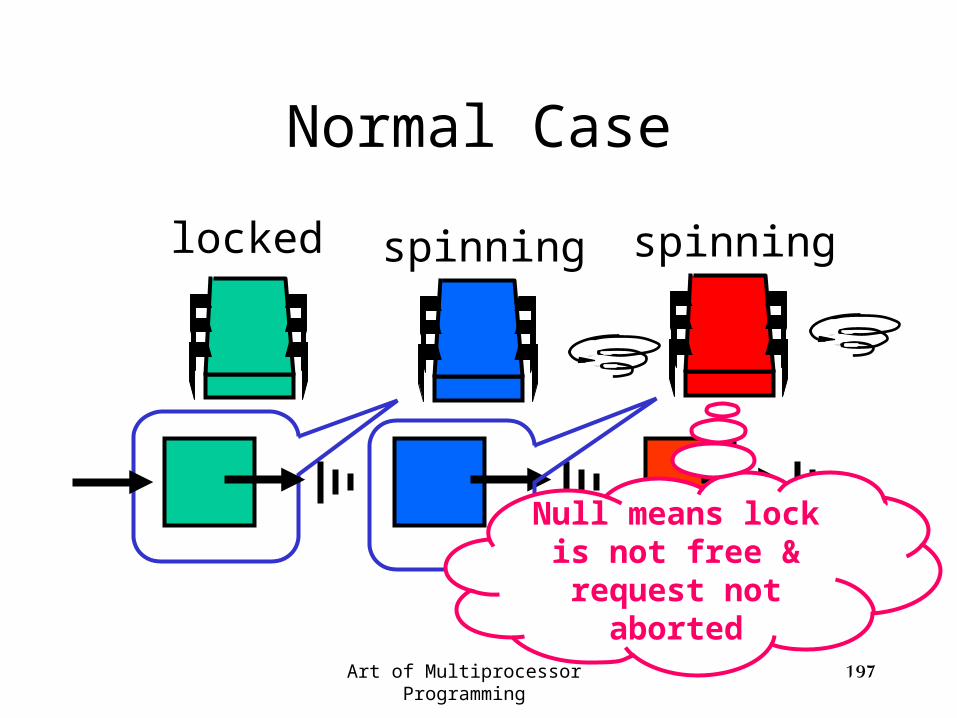
spinningspinninglocked
Art of Multiprocessor Programming 197
Normal Case
Null means lock is not free & request not
aborted

Art of Multiprocessor Programming 198
One Thread Aborts
spinningTimed outlocked

Art of Multiprocessor Programming 199
Successor Notices
spinningTimed outlocked
Non-Null means predecessor
aborted

Art of Multiprocessor Programming 200
Recycle Predecessor’s Node
spinninglocked

Art of Multiprocessor Programming 201
Spin on Earlier Node
spinninglocked

Art of Multiprocessor Programming 202
Spin on Earlier Node
spinningreleased
A
The lock is now mine

Art of Multiprocessor Programming 203
Time-out Lockpublic class TOLock implements Lock { static Qnode AVAILABLE = new Qnode(); AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode;

Art of Multiprocessor Programming 204
Time-out Lockpublic class TOLock implements Lock { static Qnode AVAILABLE = new Qnode(); AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode;
Distinguished node to signify free lock

Art of Multiprocessor Programming 205
Time-out Lockpublic class TOLock implements Lock { static Qnode AVAILABLE = new Qnode(); AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode;
Tail of the queue

Art of Multiprocessor Programming 206
Time-out Lockpublic class TOLock implements Lock { static Qnode AVAILABLE = new Qnode(); AtomicReference<Qnode> tail; ThreadLocal<Qnode> myNode;
Remember my node …

Art of Multiprocessor Programming 207
Time-out Lockpublic boolean lock(long timeout) { Qnode qnode = new Qnode(); myNode.set(qnode); qnode.prev = null; Qnode myPred = tail.getAndSet(qnode); if (myPred== null || myPred.prev == AVAILABLE) { return true; }…

Art of Multiprocessor Programming 208
Time-out Lockpublic boolean lock(long timeout) { Qnode qnode = new Qnode(); myNode.set(qnode); qnode.prev = null; Qnode myPred = tail.getAndSet(qnode); if (myPred == null || myPred.prev == AVAILABLE) { return true; }
Create & initialize node

Art of Multiprocessor Programming 209
Time-out Lockpublic boolean lock(long timeout) { Qnode qnode = new Qnode(); myNode.set(qnode); qnode.prev = null; Qnode myPred = tail.getAndSet(qnode); if (myPred == null || myPred.prev == AVAILABLE) { return true; }
Swap with tail

Art of Multiprocessor Programming 210
Time-out Lockpublic boolean lock(long timeout) { Qnode qnode = new Qnode(); myNode.set(qnode); qnode.prev = null; Qnode myPred = tail.getAndSet(qnode); if (myPred == null || myPred.prev == AVAILABLE) { return true; } ...
If predecessor absent or released, we are
done

Art of Multiprocessor Programming 211
Time-out Lock… long start = now(); while (now()- start < timeout) { Qnode predPred = myPred.prev; if (predPred == AVAILABLE) { return true; } else if (predPred != null) { myPred = predPred; } } …
spinningspinninglocked

Art of Multiprocessor Programming 212
Time-out Lock… long start = now(); while (now()- start < timeout) { Qnode predPred = myPred.prev; if (predPred == AVAILABLE) { return true; } else if (predPred != null) { myPred = predPred; } } …
Keep trying for a while …

Art of Multiprocessor Programming 213
Time-out Lock… long start = now(); while (now()- start < timeout) { Qnode predPred = myPred.prev; if (predPred == AVAILABLE) { return true; } else if (predPred != null) { myPred = predPred; } } …
Spin on predecessor’s prev field

Art of Multiprocessor Programming 214
Time-out Lock… long start = now(); while (now()- start < timeout) { Qnode predPred = myPred.prev; if (predPred == AVAILABLE) { return true; } else if (predPred != null) { myPred = predPred; } } …
Predecessor released lock

Art of Multiprocessor Programming 215
Time-out Lock… long start = now(); while (now()- start < timeout) { Qnode predPred = myPred.prev; if (predPred == AVAILABLE) { return true; } else if (predPred != null) { myPred = predPred; } } …
Predecessor aborted, advance one

Art of Multiprocessor Programming 216
Time-out Lock…if (!tail.compareAndSet(qnode, myPred)) qnode.prev = myPred; return false; }}
What do I do when I time out?

Art of Multiprocessor Programming 217
Time-out Lock…if (!tail.compareAndSet(qnode, myPred)) qnode.prev = myPred; return false; }}
Do I have a successor? If CAS fails: I do have a
successor, tell it about myPred

Art of Multiprocessor Programming 218
Time-out Lock…if (!tail.compareAndSet(qnode, myPred)) qnode.prev = myPred; return false; }}
If CAS succeeds: no successor, simply return
false

Art of Multiprocessor Programming 219
Time-Out Unlockpublic void unlock() { Qnode qnode = myNode.get(); if (!tail.compareAndSet(qnode, null)) qnode.prev = AVAILABLE;}

Art of Multiprocessor Programming 220
public void unlock() { Qnode qnode = myNode.get(); if (!tail.compareAndSet(qnode, null)) qnode.prev = AVAILABLE;}
Time-out Unlock
If CAS failed: exists successor, notify
successor it can enter

Art of Multiprocessor Programming 221
public void unlock() { Qnode qnode = myNode.get(); if (!tail.compareAndSet(qnode, null)) qnode.prev = AVAILABLE;}
Timing-out Lock
CAS successful: set tail to null, no clean up since no
successor waiting

Art of Multiprocessor Programming 222
One Lock To Rule Them All?
• TTAS+Backoff, CLH, MCS, ToLock…• Each better than others in some
way• There is no one solution• Lock we pick really depends on:
– the application– the hardware– which properties are important

Art of Multiprocessor Programming 223
This work is licensed under a Creative Commons Attribution-ShareAlike 2.5 License.
• You are free:– to Share — to copy, distribute and transmit the work – to Remix — to adapt the work
• Under the following conditions:– Attribution. You must attribute the work to “The Art of
Multiprocessor Programming” (but not in any way that suggests that the authors endorse you or your use of the work).
– Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under the same, similar or a compatible license.
• For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to– http://creativecommons.org/licenses/by-sa/3.0/.
• Any of the above conditions can be waived if you get permission from the copyright holder.
• Nothing in this license impairs or restricts the author's moral rights.

















