Page 1
Solution Guide
SPLUNK ENTERPRISE ON VxRACK FLEX FOR MACHINE DATA ANALYTICS
Modular, Rack-Scale, Hyper-Converged Infrastructure Validation by Splunk and Dell EMC
May 2017
Abstract
This solution guide describes how Dell EMC and Splunk jointly tested and validated
that a VxRack FLEX hyper-converged infrastructure with Isilon storage meets or
exceeds the performance required for a virtualized Splunk Enterprise environment.
H16010
This document is not intended for audiences in China, Hong Kong, and Taiwan.
Page 2
Copyright
2 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
The information in this publication is provided as is. Dell Inc. makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose.
Use, copying, and distribution of any software described in this publication requires an applicable software license.
Copyright © 2017 Dell Inc. or its subsidiaries. All Rights Reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Intel, the Intel logo, the Intel Inside logo and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries. Other trademarks may be the property of their respective owners. Published in the USA May 2017 Solution Guide H16010.
Dell Inc. believes the information in this document is accurate as of its publication date. The information is subject to change without notice.
Page 3
Contents
3 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Contents
Chapter 1 Executive Summary 5
Business case ........................................................................................................ 6
Solution overview ................................................................................................... 6
Key results .............................................................................................................. 7
Audience ................................................................................................................. 7
We value your feedback ......................................................................................... 7
Chapter 2 Solution Architecture 8
Overview ................................................................................................................. 9
Dell EMC VxRack FLEX architecture ................................................................... 11
Isilon ..................................................................................................................... 12
VMware vSphere .................................................................................................. 12
Dell EMC ScaleIO ................................................................................................. 13
Splunk Enterprise ................................................................................................. 14
Chapter 3 Splunk Enterprise Deployment Design and Consideration 16
Overview ............................................................................................................... 17
Compute design ................................................................................................... 17
Network design ..................................................................................................... 17
Storage design ..................................................................................................... 18
Virtualization design ............................................................................................. 20
Splunk Enterprise design ...................................................................................... 21
Chapter 4 Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention 26
Overview ............................................................................................................... 27
Implementation ..................................................................................................... 27
Use case summary ............................................................................................... 44
Chapter 5 Splunk Enterprise Clustered Infrastructure for 500 GB/day Data Indexing Volume with 90-Day Retention 45
Overview ............................................................................................................... 46
Implementation ..................................................................................................... 46
Use case summary ............................................................................................... 47
Chapter 6 Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing Volume with 90-Day Retention 48
Overview ............................................................................................................... 49
Page 4
Contents EMC Confidential [delete if not required]
4 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Implementation ..................................................................................................... 49
Use case summary ............................................................................................... 51
Chapter 7 Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention 52
Overview ............................................................................................................... 53
Implementation ..................................................................................................... 53
Use case summary ............................................................................................... 60
Chapter 8 Validated Configurations for Splunk Enterprise 61
Overview ............................................................................................................... 62
Splunk-validated sizing configurations ................................................................. 62
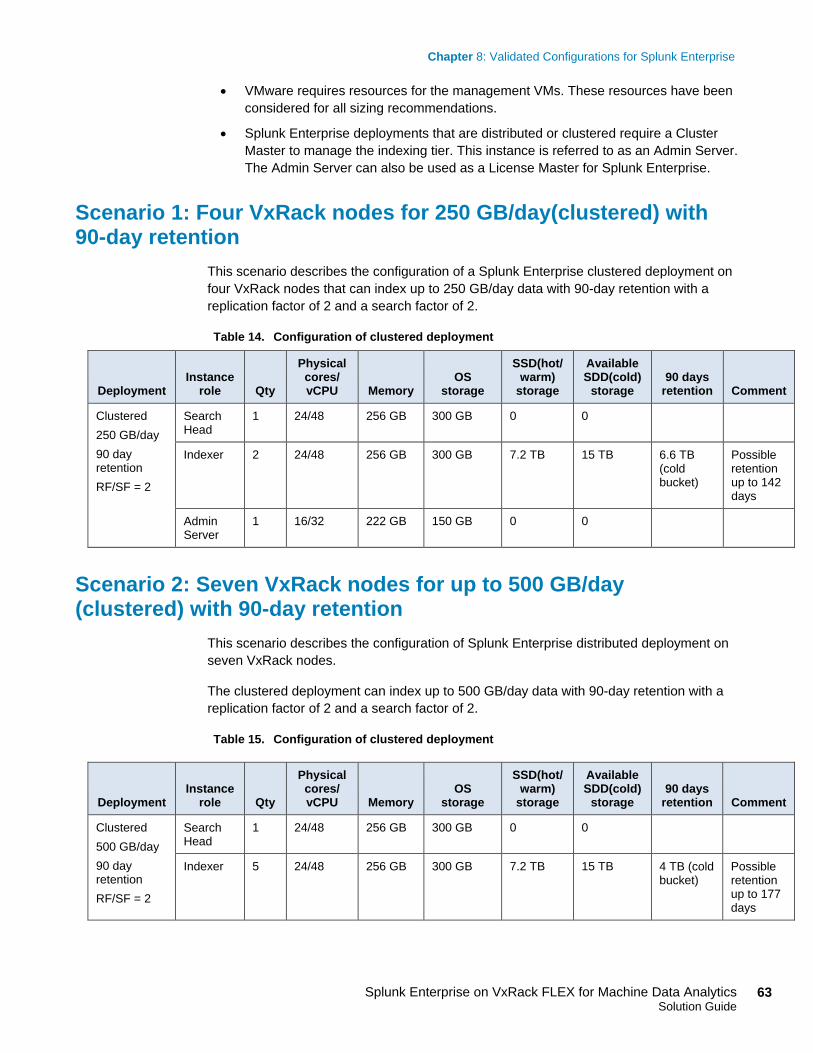
Scenario 1: Four VxRack nodes for 250 GB/day(clustered) with 90-day retention ......................................................................................................... 63
Scenario 2: Seven VxRack nodes for up to 500 GB/day (clustered) with 90-day retention ......................................................................................................... 63
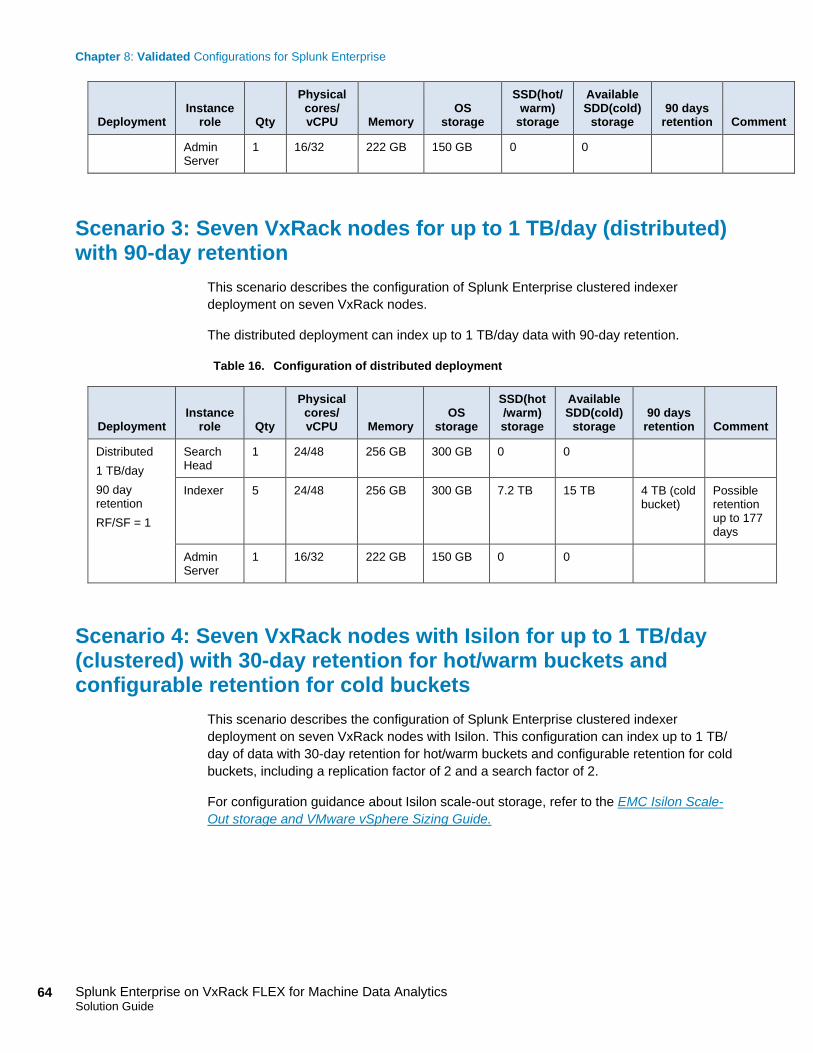
Scenario 3: Seven VxRack nodes for up to 1 TB/day (distributed) with 90-day retention ......................................................................................................... 64
Scenario 4: Seven VxRack nodes with Isilon for up to 1 TB/day (clustered) with 30-day retention for hot/warm buckets and configurable retention for cold buckets ........................................................................................................... 64
Summary .............................................................................................................. 65
Chapter 9 Conclusion 66
Summary .............................................................................................................. 67
Findings ................................................................................................................ 67
Conclusion ............................................................................................................ 67
Chapter 10 References 68
Dell EMC documentation ...................................................................................... 69
VMware documentation ........................................................................................ 69
Splunk Enterprise documentation ......................................................................... 69
Page 5
Chapter 1: Executive Summary
5 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 1 Executive Summary
This chapter presents the following topics:
Business case ....................................................................................................... 6
Solution overview ................................................................................................. 6
Key results ............................................................................................................ 7
Audience ............................................................................................................... 7
We value your feedback ....................................................................................... 7
Page 6
Chapter 1: Executive Summary
6 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Business case
Operational Intelligence (OI) is the use of near real-time data collection and business
analytics to deliver visibility and insight into business operations. Every physical server
and virtual machine, along with all the network equipment and storage devices that
support them, produces constant streams of data. When this IT operational data can be
intelligently combined with real-time user and usage analysis, organizations can:
Identify their most valuable customers
Segment a product’s most popular features by user demographic
Expose where, when, and how customers use or consume your product
Highlight problem areas that yield insights toward positive change
Splunk Enterprise makes it simple to collect, analyze, and act on the untapped value of
Big Data that is generated by technology infrastructure, security systems, and business
applications—giving the insights to drive operational performance and business results. At
least 80 of the Fortune 100 companies and more than 13,000 enterprises across diverse
industries use Splunk Enterprise to drive key insights.
Dell EMC™ and Splunk have partnered to provide a comprehensive list of standardized
hardware and software configurations that provide non-disruptive scalability and
performance that fit today’s organizational need for digital transformation. When paired
together, Dell EMC and Splunk combine the analytics provided by the Splunk platform
with the cost-effective, scalable, and flexible infrastructure of Dell EMC to deliver OI.
Solution overview
This solution describes the factors to consider in the design of a Splunk Enterprise
deployment using Dell EMC VxRack™ System FLEX with Isilon™ storage. We
demonstrate the use of VMware virtualization for all server resources following Splunk’s
documented virtualization best practices. Chapter 2 provides a description of the
technology used in this solution. Chapter 10 lists links to more extensive background
material.
Chapter 3 provides details about the deployment, design, and configuration of Splunk
Enterprise on the Dell EMC hyper-converged infrastructure VxRack FLEX. Chapter 4
describes the steps that we implemented in our lab testing of four types of deployment
configurations that are typical of many customer use case scenarios, as shown in Table 1:
Page 7
Chapter 1: Executive Summary
7 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Table 1. Scenario descriptions
Daily ingest (GB/day)
Retention (days)
Deployment type Splunk services
250 GB/day 90-day Splunk Enterprise Clustered One search head, two indexers, and one admin server
500 GB/day 90-day Splunk Enterprise Clustered One search head, five indexers, and one admin server
1 TB/day 90-day Splunk Enterprise Distributed One search head, five indexers, and one admin server
1 TB/day > 90-day Splunk Enterprise Clustered One search head, one admin server, and five indexers using Isilon storage to provide configurable retention for Splunk cold buckets
Key results
This solution demonstrates how Splunk Enterprise can be deployed in a completely
virtualized configuration with the VxRack FLEX coupled with Isilon scale-out network-
attached storage (NAS) for high performance analysis of hot/warm data and cost-effective
extended term retention of cold data. VMware virtualization software improves
management of systems resources and can easily, efficiently, and cost-effectively scale to
support enterprise-level machine data analytics and real-time operational intelligence.
VxRack FLEX and Isilon are proven building blocks for creating a Software-Defined Data
Center (SDDC) that help you achieve your data center modernization goals using
virtualization, standardization, and automation.
Audience
This guide is intended for IT administrators, storage administrators, virtualization
administrators, system administrators, IT managers, and those who evaluate, acquire,
manage, maintain, or operate Splunk Enterprise environments.
We value your feedback
Dell EMC and the authors of this document welcome your feedback on this solution and
the solution documentation. Contact [email protected] with your
comments.
Dell EMC: Kirankumar Bhusanurmath, James Shen, Tao Guo, Phil Hummel, Reed
Tucker
Splunk: Jenny Hollfelder
Page 8
Chapter 2: Solution Architecture
8 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 2 Solution Architecture
This chapter presents the following topics:
Overview ................................................................................................................ 9
Dell EMC VxRack System FLEX architecture .................................................. 11
Isilon .................................................................................................................... 12
VMware vSphere ................................................................................................. 12
Dell EMC ScaleIO ................................................................................................ 13
Splunk Enterprise ............................................................................................... 14
Page 9
Chapter 2: Solution Architecture
9 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
The following reference architecture describes a Dell EMC hyper-converged infrastructure
VxRack FLEX with Isilon storage for a virtualized Splunk Enterprise environment. Dell
EMC and Splunk jointly tested and validated this reference architecture to meet or exceed
the performance of Splunk Enterprise running on Splunk’s reference hardware.
The VxRack FLEX hyper-converged platform complements Dell EMC converged
infrastructure systems. It is a software-defined architecture with integrated compute,
networking, software-defined storage, and virtualization layers. Each self-contained unit
includes a Dell™ PowerEdge™ server and networking, and is well-suited for use cases
that require a highly scalable infrastructure. It has a flexible, modular design that meets
the scalability, performance, and efficiency requirements of modern data centers.
Figure 1 and Figure 2 show how we deployed two reference architectures. These
architectures represent Splunk instances as virtual machines on a VMware vSphere 6.0
cluster following Splunk’s documented virtualization best practices. In the storage layer,
VxRack FLEX leverages Dell EMC ScaleIO™ technology to build a software-defined
storage area network (SAN) on groups of local attached disks. This configuration provides
rapid read and write disk I/O and low latency through the use of an all-flash and hybrid
array.
Figure 1. Splunk Enterprise on VxRack FLEX reference architecture
Note: For an explanation of the hot/warm and cold bucket concepts, refer to Splunk core
architecture.
Reference
architecture
Page 10
Chapter 2: Solution Architecture
10 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 2 shows a reference architecture similar to Figure 1, but with different Splunk
bucket locations. ScaleIO defined storage is used to store all virtual machines and Splunk
hot/warm buckets, while Isilon storage is used to store the Splunk cold bucket for long-
term data retention.
Figure 2. Splunk Enterprise on VxRack FLEX with Isilon reference architecture
Table 2 lists the hardware components in this solution.
Table 2. Hardware configuration
Component Hardware
Dell PowerEdge R630 High-Density Flash: Dense SSD-High Capacity
2 Intel® Xeon® Processors E5-2680 v4
512 GB RAM
10 x 3.84 TB SSD
Switch 10 GbE Cisco Nexus
Isilon X410 2 Intel Xeon Processors 2.0 GHz per node
128 GB RAM per node
3.2 TB SSD storage
64 TB HDD storage
2 x 10 GbE SFP+ per node
2 x 1 GbE per node
Hardware
components
Page 11
Chapter 2: Solution Architecture
11 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Table 3 lists the versions of software in this solution.
Table 3. Software configuration
Software Version
Splunk Enterprise 6.5.0
Splunk Universal Forwarder 6.5.0
RedHat Linux 64-bit 6.7
VMware vSphere Enterprise 6.0
VMware vCenter Server 6.0 Update 2
DELL EMC Vision™ Intelligent Operations 3.30
DELL EMC ScaleIO 2.0.0.2
Dell EMC VxRack FLEX architecture
VxRack FLEX is a rack-scale hyper-converged infrastructure built on PowerEdge servers
and ScaleIO software-defined storage. Customers benefit from the extreme application
performance and scalability offered by this platform. Direct-attached storage (DAS) is
virtualized into a shared pool of block storage, similar to SAN storage. This makes it easy
to achieve extreme scale: over 1,000 nodes. As part of the DELL EMC VxRack System
family, it is the only hyper-converged infrastructure that provides extreme scale. VxRack
FLEX achieves this extreme scale without compromising data center performance, high
availability, resiliency, or security.
ScaleIO provides the software-defined block storage virtualization layer. DAS storage on
servers within the VxRack FLEX is virtualized into a shared network-based block storage
that is similar to SAN storage. Customers can start with a minimum of four nodes and
rapidly add more nodes based on their business needs. ScaleIO optimizes resource
allocation with performance that scales linearly.
The VxRack System is powered by Intel Xeon processors and integrated with Dell
PowerEdge Servers to enable additional use cases while providing more flash capacity.
More than 20 configurations are available, providing the flexibility to add compute-heavy,
storage-heavy, or balanced configurations (in both all-flash and hybrid models) as needed
to match workload requirements. The latest Intel Broadwell processors also provide 40
percent more CPU performance without increasing footprint or cost. With Dell PowerEdge
integration, the VxRack System now delivers the entire hyper-converged stack, from
software through servers, enabling organizations to rapidly deploy Infrastructure as a
Service and/or Private Cloud architectures on top of a rack-scale hyper-converged
system.
Many solutions do not initially include a software-defined network (SDN); however, adding
one after the fact can be disruptive to clients and administrators. Under-investing in the
initial network design makes it difficult to react to performance declines in the
environment. Components that are often left out of the initial design are the physical top-
of-rack switches, and the SDN software technologies.
Software
components
Storage
components
Compute
components
Networking
components
Page 12
Chapter 2: Solution Architecture
12 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
The VxRack FLEX encompasses support for both physical and virtual networking.
Physical networking consists of a leaf-spine topology with top-of-rack (ToR) and spine
switches. Each physical rack contains two ToR switches, which control network traffic and
redundancy, and a management switch for out-of-band connectivity. With scale-out across
multiple racks, east-west traffic is fully self-contained. Connectivity between racks is
provided by using the two inter-rack spine switches.
When designing a network, oversubscription, spine density, switch ports, high density, low
density, and wire rates are technical details that must be considered. The VxRack FLEX
was designed with industry best practices already applied. Best-in-class Cisco Nexus Top
of Rack (ToR) and Spine switches provide 10 GbE or 40 GbE IP connectivity between
VxRack FLEX and the external network for superior performance. Unlike other solutions in
the market, where network bottlenecks limit the scale of hyper-converged infrastructures,
the 10 GbE network switches within the VxRack FLEX eliminate these restrictions and
provide a path for future growth.
Isilon
The Isilon X-Series is a flexible and comprehensive storage product that provides large
capacity and high performance. The VxRack FLEX supports Isilon storage.
Isilon storage uses intelligent software to scale data across a large number of commodity
hardware units, enabling explosive growth in performance and capacity. The product's
revolutionary storage architecture, the OneFS™ operating system (OS), offers a single
clustered file system.
OneFS provides value by incorporating parallelism at a deep level in the OS. Virtually, the
system is distributed across multiple hardware units. This parallelism allows OneFS to
scale in every dimension as the infrastructure is expanded. By providing multiple
redundancy levels, the system has no single point of failure. As a result, OneFS can grow
to a multi-petabyte scale while providing greater reliability than traditional systems.
OneFS runs on Isilon scale-out (NAS hardware, ensuring that Isilon benefits from the
ever-improving cost and efficiency curves of commodity hardware. OneFS allows you to
add hardware to or remove hardware from the cluster at any time. The data is protected
from hardware changes. This feature alleviates the cost and burden of data migrations
and hardware refreshes.
VMware vSphere
VMware vSphere is a widely adopted virtualization platform. The technology increases
server utilization so that a firm can consolidate its servers and spend less on hardware,
administration, energy, and floor space. The vSphere platform enables its installations to
respond to user requests reliably while giving administrators the tools to respond to their
changing needs.
The components of particular importance in this solution are vSphere ESXi and vCenter.
Page 13
Chapter 2: Solution Architecture
13 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
VMware vSphere ESXi is a bare-metal hypervisor. It is installed directly on a physical
server, and partitions that server into multiple virtual machines. An ESXi host refers to the
physical server.
VMware vSphere ESXi hosts and their resources are pooled together into clusters that
contain the CPU, memory, network, and storage resources that are available for allocation
to the virtual machines.
VMware vCenter Server is management software that runs on a virtual or physical server
to oversee multiple ESXi hypervisors as a single cluster. An administrator can interact
directly with vCenter Server or use vSphere Client to manage virtual machines from a
browser window anywhere in the world. For example, the administrator can capture the
detailed blueprint of a known, validated configuration—a configuration that includes
networking, storage, and security settings—and then deploy that blueprint to multiple ESXi
hosts.
Dell EMC ScaleIO
ScaleIO is a software-only solution that uses existing servers' local disks and local area
network (LAN) to create a virtual SAN that has all the benefits of external storage—but at
a fraction of the cost and complexity. ScaleIO utilizes the existing local storage devices
and turns them into shared block storage. For many workloads, ScaleIO storage is
comparable to, or better than external shared-block storage.
ScaleIO is designed and implemented with enterprise-grade resilience. Furthermore, the
software features an efficient distributed self-healing process that overcomes media and
server failures, without requiring administrator involvement.
Figure 3 shows the architecture for ScaleIO.
Figure 3. ScaleIO hyper-converged architecture
VMware vSphere
ESXi
VMware vSphere
vCenter
Page 14
Chapter 2: Solution Architecture
14 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Splunk Enterprise
Splunk Enterprise is a software platform that enables you to collect, index, and visualize
machine-generated data gathered from different sources in your IT infrastructure. These
sources include applications, networking devices, host and server logs, mobile devices,
and more.
Splunk turns silos of data into operational insights and provides end-to-end visibility
across your IT infrastructure to enable faster problem solving and informed, data-driven
decisions.
Figure 4 provides a graphic overview of Splunk system architecture. A Splunk Enterprise
instance can perform the role of a search head, an indexer, or both in small deployments.
When the daily ingest rate or search load exceeds the sizing recommendations for a
combined instance environment, Splunk Enterprise scales horizontally by adding
additional indexers and search heads. For more information, refer to the Splunk Capacity
Planning Manual.
Figure 4. Splunk architecture overview
When a Splunk Enterprise indexer receives data, the indexer parses the raw data into
distinct events that are based on the timestamp of the event and writes them to the
appropriate index. Splunk implements a form of storage tier involving hot/warm and cold
buckets of data to optimize performance for newly indexed data and to provide an option
to keep older data for longer periods on higher capacity storage.
Newly indexed data lands in a hot bucket, where it is actively read and written by Splunk.
When the number of hot buckets is reached, or when the size of the data in the hot
buckets exceeds the specified threshold, the hot bucket is rolled to a warm bucket. Warm
buckets reside on the same tier of storage as hot buckets and are read-only. It is
important that the storage that is identified for hot/warm data is your fastest storage tier
because it has the biggest impact on the performance of your Splunk Enterprise
deployment.
Splunk core
architecture
Page 15
Chapter 2: Solution Architecture
15 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
When the number of warm buckets or volume size is exceeded, data is rolled into a cold
bucket, which can optionally reside on another tier of storage. Cold data may reside on an
NFS mount if the latency is less than 5 ms (ideally) and not more than 200 ms. NAS
technologies offer an acceptable blend of performance and lower cost per TB, making
them a good choice for longer-term retention of cold data.
Data can also be archived or frozen, but is no longer searchable by Splunk search heads.
Manual user action is required to bring the data back into Splunk Enterprise buckets to be
searchable. While you might choose to use frozen buckets to meet compliance retention
requirements, this paper shows how Isilon’s massive scalability and competitive cost of
ownership can empower you to retain more data in the cold bucket, where it remains
searchable. Figure 5 provides more details about Splunk bucket concepts.
Figure 5. Splunk Index Buckets
Page 16
Chapter 3: Splunk Enterprise Deployment Design and Consideration
16 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 3 Splunk Enterprise Deployment Design and Consideration
This chapter presents the following topics:
Overview .............................................................................................................. 17
Compute design ................................................................................................. 17
Network design ................................................................................................... 17
Storage design .................................................................................................... 18
Virtualization design .......................................................................................... 20
Splunk Enterprise design .................................................................................. 21
Page 17
Chapter 3: Splunk Enterprise Deployment Design and Consideration
17 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
This chapter provides details about the deployment, design, and configuration of Splunk
Enterprise on the Dell EMC hyper-converged infrastructure VxRack FLEX. This solution
covers four types of deployment for the different user scenarios:
Scenario 1: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data
Indexing volume with 90-day Retention – One search head, two indexers, and one
admin server
Scenario 2: Splunk Enterprise Clustered Infrastructure for 500 GB/day Data
Indexing volume with 90-day Retention – One search head, five indexers, and one
admin server
Scenario 3: Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing
volume with 90-day Retention – One search head, five indexers, and one admin
server
Scenario 4: Splunk Enterprise Clustered Infrastructure for 1 TB/day Data Indexing
volume with > 90-day Retention – One search head, one admin server, and five
indexers using Isilon to provide configurable retention for Splunk cold buckets
Compute design
Table 4 shows the details of the compute design of four types of Splunk Enterprise
deployments on VxRack FLEX.
Table 4. Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing volume with 90-day Retention
Instance role Physical cores/vCPUs Memory
Search Head 24/48 256 GB
Indexer 24/48 256 GB
Admin Server 16/32 222 GB
Network design
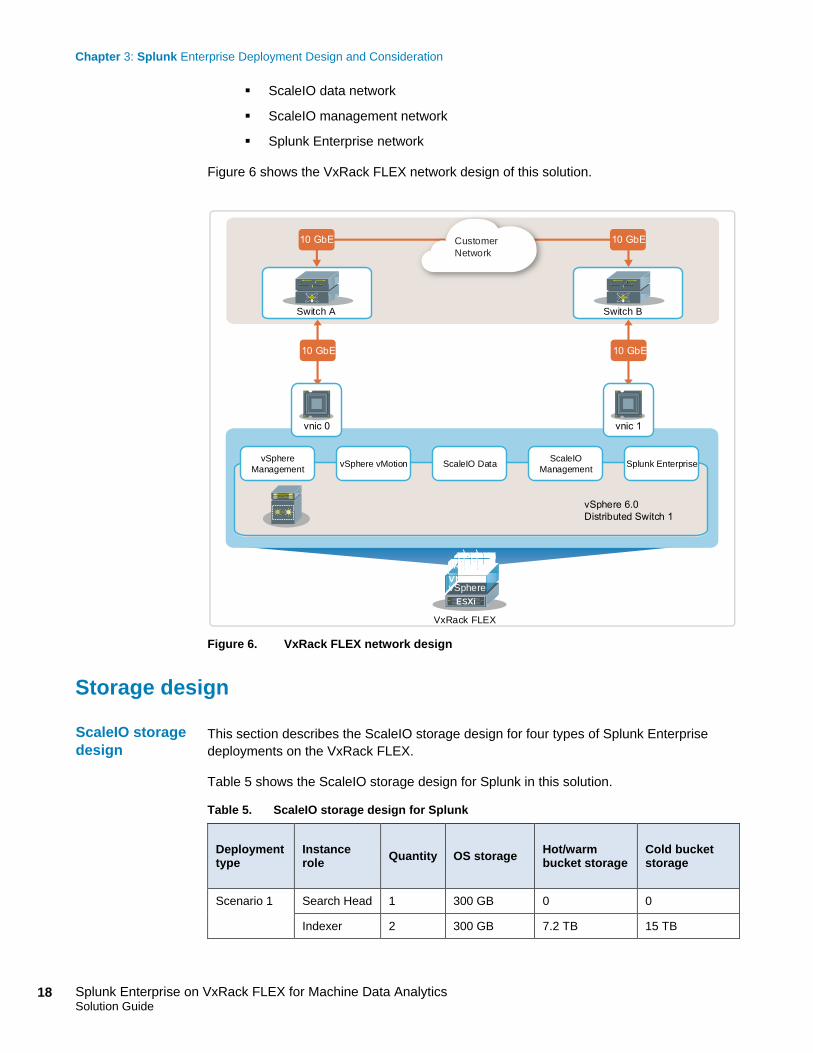
The VxRack FLEX is delivered ready to deploy and attach to any 10 GbE network
infrastructure using IPv4 and IPv6. As a best practice, Dell EMC recommends using dual
ToR switches to eliminate the switch as a single point of failure. In this solution, we
designed the VxRack FLEX network as follows:
Use virtual local area networks (VLANs) to logically group devices on different
network segments or subnetworks.
Use separate vSphere distributed switches and port groups to isolate the network
communication for each of these networks:
vSphere management network
vSphere vMotion network
Page 18
Chapter 3: Splunk Enterprise Deployment Design and Consideration
18 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
ScaleIO data network
ScaleIO management network
Splunk Enterprise network
Figure 6 shows the VxRack FLEX network design of this solution.
V
M
V
M
V
M
vSphere
Customer
Network
Switch A
vSphere
ManagementvSphere vMotion
Switch B
ScaleIO DataScaleIO
ManagementSplunk Enterprise
VxRack FLEX
Figure 6. VxRack FLEX network design
Storage design
This section describes the ScaleIO storage design for four types of Splunk Enterprise
deployments on the VxRack FLEX.
Table 5 shows the ScaleIO storage design for Splunk in this solution.
Table 5. ScaleIO storage design for Splunk
Deployment type
Instance role
Quantity OS storage Hot/warm bucket storage
Cold bucket storage
Scenario 1 Search Head 1 300 GB 0 0
Indexer 2 300 GB 7.2 TB 15 TB
ScaleIO storage
design
Page 19
Chapter 3: Splunk Enterprise Deployment Design and Consideration
19 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Deployment type
Instance role
Quantity OS storage Hot/warm bucket storage
Cold bucket storage
Admin Server
1 150 GB 0 0
Scenario 2 Search Head 1 300 GB 0 0
Indexer 5 300 GB 7.2 TB 15 TB
Admin Server
1 150 GB 0 0
Scenario 3 Search Head 1 300 GB 0 0
Indexer 5 300 GB 7.2 TB 15 TB
Admin Server
1 150 GB 0 0
Scenario 4 Search Head 1 300 GB 0 0
Indexer 5 300 GB 7.2 TB Configurable
Admin Server
1 150 GB 0 0
In this solution, a four-node Isilon X410 cluster provides configurable retention for cold
buckets for Scenario 4. The detailed configuration of Isilon nodes and Isilon storage
design for Splunk are shown in Table 6 and Table 7.
Table 6. Isilon node configuration
CPU CPU cores RAM SSD capacity HDD capacity Network
Two Intel Xeon Processors 2.0 GHz
8 cores 128 GB 3.2 TB 64 TB 2 x 10 GbE
2 x 1 GbE
Table 7. Isilon storage design for Splunk
Deployment type Instance role Quantity Indexer cold bucket storage
Scenario 4 Indexer 5 Configurable
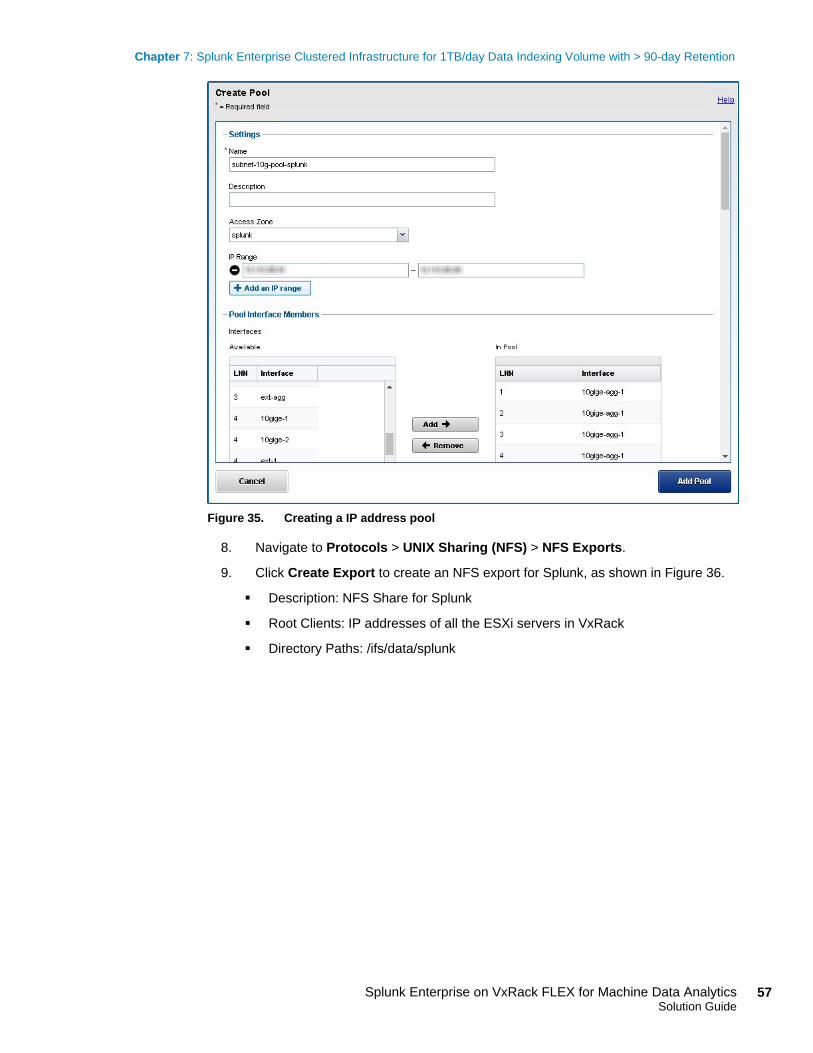
For the overall Isilon configuration, we followed these best practices:
Enabled SmartPools settings across all four Isilon nodes and used an SSD as L3
cache for metadata read acceleration
Enabled SmartConnect to provide automatic client connection load balancing and
failover capabilities
Enabled SmartCache for write performance
Optimized for concurrent access for data access pattern
Used 10 Gb/s external network for data connection
Isilon storage
design
Page 20
Chapter 3: Splunk Enterprise Deployment Design and Consideration
20 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Increased network MTU to 9000 (Jumbo Frames)
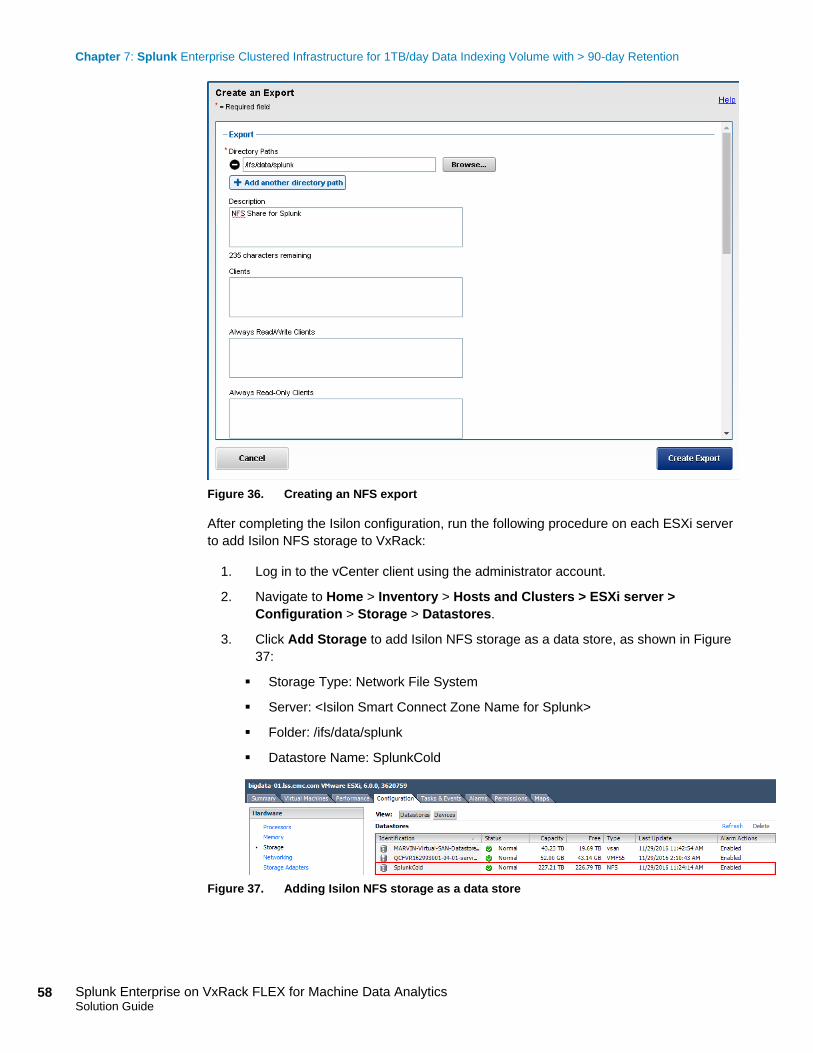
Splunk and Dell EMC recommend that NFS storage, including Isilon, is only used for cold
and frozen data, never for hot/warm data. For details about system requirements, see the
Splunk Enterprise Installation Manual.
Virtualization design
VxRack FLEX delivers virtualization, compute, and storage in a scalable, easy to manage,
hyper-converged infrastructure appliance. It deeply integrates VMware vSphere
virtualization software that delivers an industry-leading virtualization platform to provide
application virtualization with a highly available, resilient, efficient on-demand
infrastructure.
For details about the configuration of the virtual machines that are used in this solution,
refer to Compute design.
This solution implements the following Dell EMC and VMware best practices to provide
optimal performance for all Splunk Enterprise virtual machines running on the VxRack
FLEX:
Create a vSphere HA cluster to provide a virtualized, high-availability Splunk Enterprise environment that is easy to use and cost-effective.
Use a single virtual socket for each virtual machine. With virtual Non-Uniform Memory Access (NUMA) topology, a single virtual socket that has fewer virtual CPU cores than the physical CPU cores of a socket in the physical ESXi host is recommended.
Use a VMware Paravirtual SCSI controller to increase throughput with significant CPU utilization reduction in the SAN environment.
Use a VMware VMXNET3 network adapter to optimize network performance.
Use Thick Provision Eager Zeroed disk provisioning to optimize virtual disk performance.
Install VMware tools in the guest OS to improve virtual machine (VM) performance.
Set the VM advance parameters numa.vcpu.preferHT to “true” for enabling hyper-
threading with NUMA in ESXi.
For more information, refer to Performance Best Practices for VMware vSphere 6.0.
Virtual machine
configuration
Virtualization
configuration
Page 21
Chapter 3: Splunk Enterprise Deployment Design and Consideration
21 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Splunk Enterprise design
Figure 7 shows the Splunk Enterprise Cluster Infrastructure deployment with one search
head and two indexers. This type of deployment targets clients with these characteristics:
Requires high data availability
Indexing data volume is up to 250 GB/day with 90-day retention
Splunk Enterprise Clustered Infrastructure for 250GB/day Data Indexing volume
with 90-day Retention
Indexer Cluster: 1 master node, 1 search head, 2 indexer peer nodes,
replication factor = 2, search factor = 2
Two indexer peers
One search head One master node
Figure 7. Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing volume with 90-day Retention
Figure 8 shows the Splunk Enterprise Cluster Infrastructure deployment with one search
head and five indexers. Using Isilon, this type of deployment targets clients with these
characteristics:
Requires high data availability
Indexing data volume is up to 500 GB/day with 90-day retention
Splunk
Enterprise
deployment
design
Page 22
Chapter 3: Splunk Enterprise Deployment Design and Consideration
22 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Splunk Enterprise Clustered Infrastructure for 500GB/day Data Indexing volume with 90-day
Retention
Indexer Cluster: 1 master node, 1 search head, 5 indexer peer nodes,
replication factor = 2, search factor = 2
Five indexer peers
One search head One master node
Figure 8. Splunk Enterprise Clustered Infrastructure for 500 GB/day Data Indexing volume with 90-day Retention
Figure 9 shows the Splunk Enterprise Distributed Infrastructure deployment with one
search head and five indexers. This type of deployment targets clients with these
characteristics:
Indexing data volume is up to 1 TB/day with 90-day retention
Page 23
Chapter 3: Splunk Enterprise Deployment Design and Consideration
23 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Splunk Enterprise Distributed Infrastructure for 1TB/day Data Indexing volume with
90-day Retention
Indexer Cluster: 1 master node, 1 search head, 5 indexer peer nodes,
replication factor = 1, search factor = 1
Five indexer peers
One search head One master node
Figure 9. Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing volume with 90-day Retention
Figure 10 shows the Splunk Enterprise Cluster Infrastructure deployment design with one
search head and five indexers. Using Isilon, the VxRack FLEX nodes can provide
configurable retention for Splunk cold buckets. This type of deployment targets clients with
these characteristics:
Requires high data availability
Indexing data volume is up to 1 TB/day with 90-day retention
Page 24
Chapter 3: Splunk Enterprise Deployment Design and Consideration
24 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing volume with > 90-day
Retention
Indexer Cluster: 1 master node, 1 search head, 5 indexer peer nodes,
replication factor = 2, search factor = 2
Five indexer peers
One search head One master node
Figure 10. Splunk Enterprise Clustered Infrastructure for 1 TB/day Data Indexing volume with > 90-day Retention
In this solution, we implement the following Linux configuration parameter settings to
provide optimal Splunk Enterprise performance:
Change tuned profile to virtual-host in RHEL 6.X. This profile decreases the
swappiness of virtual memory and enables more aggressive writeback of dirty
pages. It tunes the system settings for high throughput and low latency.
Disable Transparent Huge Pages (THP) to avoid the degradation of Splunk
Enterprise performance on RHEL 6.X. For more information, refer to Transparent
huge memory pages and Splunk performance.
Disable SELinux, so that enhanced system security does not add overhead to the
performance.
Increase the maximum number of open file descriptors and processes by
configuring ulimit to avoid the “Too Many Open Files” exception. Table 8 shows the
recommended values.
Splunk
Enterprise Linux
configuration
Page 25
Chapter 3: Splunk Enterprise Deployment Design and Consideration
25 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Table 8. Recommended ulimit values
System-wide resources Ulimit invocation Recommended minimum value
Open files ulimit -n 8,192
User processes ulimit -u 1,024
Data segment size ulimit -d 1,073,741,824
Tune the kernel to optimize the network for high throughput over a 10 Gb Ethernet
by adding the following command string to /etc/sysctl.conf:
net.ipv4.tcp_timestamps=0
net.ipv4.tcp_sack=1
net.core.netdev_max_backlog=250000
net.core.rmem_max=4194304
net.core.wmem_max=4194304
net.core.rmem_default=4194304
net.core.wmem_default=4194304
net.core.optmem_max=4194304
net.ipv4.tcp_rmem=4096 87380 4194304
net.ipv4.tcp_wmem=4096 65536 4194304
net.ipv4.tcp_low_latency=1
Page 26
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
26 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 4 Splunk Enterprise Clustered Infrastructure for 250 GB/day
Data Indexing Volume with 90-Day Retention
This chapter presents the following topics:
Overview .............................................................................................................. 27
Implementation ................................................................................................... 27
Use case summary ............................................................................................. 44
Page 27
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
27 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
In this chapter, we will show the Splunk Enterprise clustered infrastructure for 250 GB/day
data indexing volume with 90-day retention on VxRack FLEX with four nodes. Each
VxRack node is installed with Splunk Enterprise binaries and assigned one search head,
two indexers, and one admin server role. We optimize the design for both high
performance and data retention capability using VxRack for the storage of hot/warm and
cold buckets in Splunk Enterprise.
Implementation
Table 9 lists the process flow for the Splunk Enterprise clustered infrastructure for 250
GB/day data indexing volume with 90-day retention on VxRack with four nodes.
Table 9. Process flow for Splunk Enterprise clustered infrastructure for 250 GB/day data indexing volume with 90-day retention implementation
Step Action Description
1 Implementing VxRack infrastructure
Implement a four-node VxRack infrastructure.
2 Preparing ScaleIO volumes
Prepare the ScaleIO volumes that are used for Splunk disks, including hot/warm and cold buckets.
3 Creating Splunk VM template
Prepare the VM template that is used for indexer/search head and forwarder. Tune it according to Splunk’s recommendation.
4 Deploying indexer cluster master
Deploy one master instance for the indexer cluster.
5 Deploying peer nodes Deploy two Splunk indexer instances and add them into the indexer cluster as peer nodes.
6 Deploying search head Deploy one search head instance for the indexer cluster.
7 Configuring master as forwarder
Configure the cluster master as one forwarder of the indexer cluster and connect directly to the peer nodes.
8 Deploying forwarder Deploy one universal forwarder instance.
9 Configuring indexer discovery
Configure the indexer discovery to connect the universal forwarder to the indexer cluster.
10 Validating implementation Validate the implementation of Splunk.
Implement a four-node VxRack cluster. This is a Dell EMC internal process. Contact your
Dell EMC or partner representative when planning to implement your VxRack cluster.
Follow these steps to prepare volumes on ScaleIO.
1. Log in to the ScaleIO GUI.
2. Navigate to Frontend > Volumes.
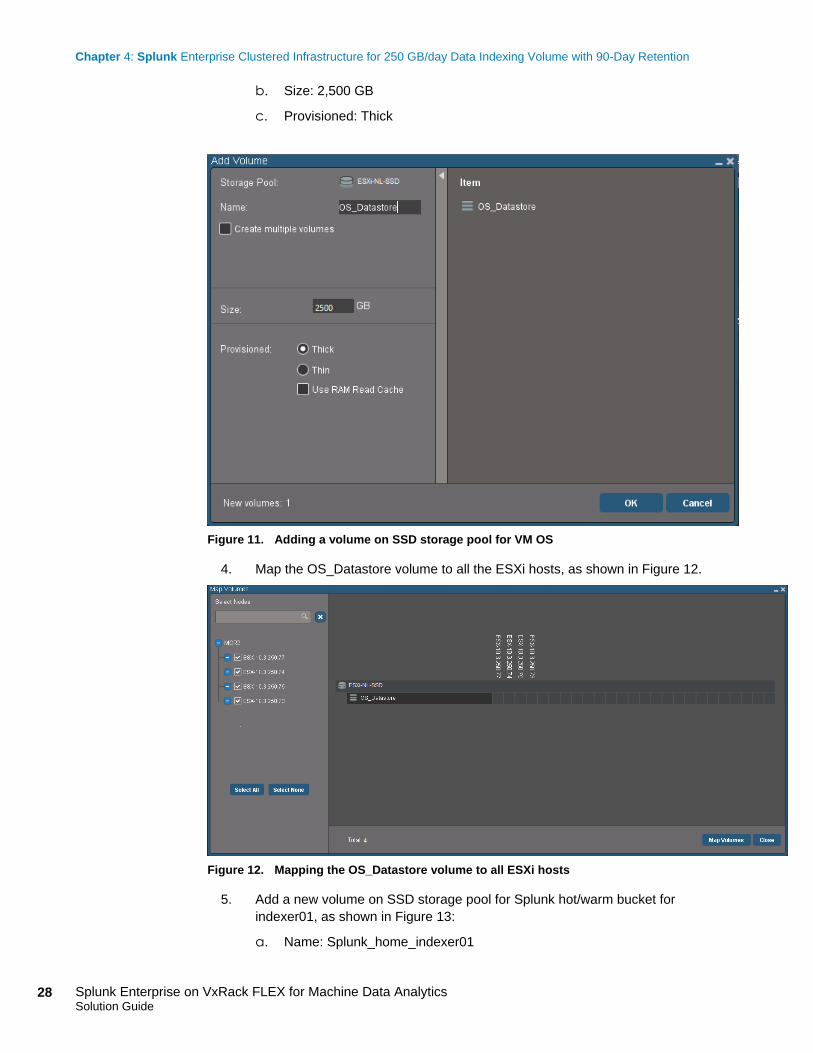
3. Add a new volume on SSD storage pool for the VM OS, as shown in Figure 11.
a. Name: OS_Datastore
Implementing
the VxRack
infrastructure
Preparing
ScaleIO volumes
Page 28
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
28 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Size: 2,500 GB
c. Provisioned: Thick
Figure 11. Adding a volume on SSD storage pool for VM OS
4. Map the OS_Datastore volume to all the ESXi hosts, as shown in Figure 12.
Figure 12. Mapping the OS_Datastore volume to all ESXi hosts
5. Add a new volume on SSD storage pool for Splunk hot/warm bucket for
indexer01, as shown in Figure 13:
a. Name: Splunk_home_indexer01
Page 29
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
29 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Size: 7,200 GB
c. Provisioned: Thick
Figure 13. Adding a new volume on SSD storage pool for Splunk hot/warm bucket for indexer01
6. Map the Splunk_home_indexer01 volume to all the ESXi hosts, as shown in
Figure 14.
Figure 14. Mapping the Splunk_home_indexer01 volume to all ESXi hosts
7. Similarly, create Splunk_home_indexer02 SSD storage pool for a second indexer
and map the volume to all ESXi hosts.
Page 30
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
30 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
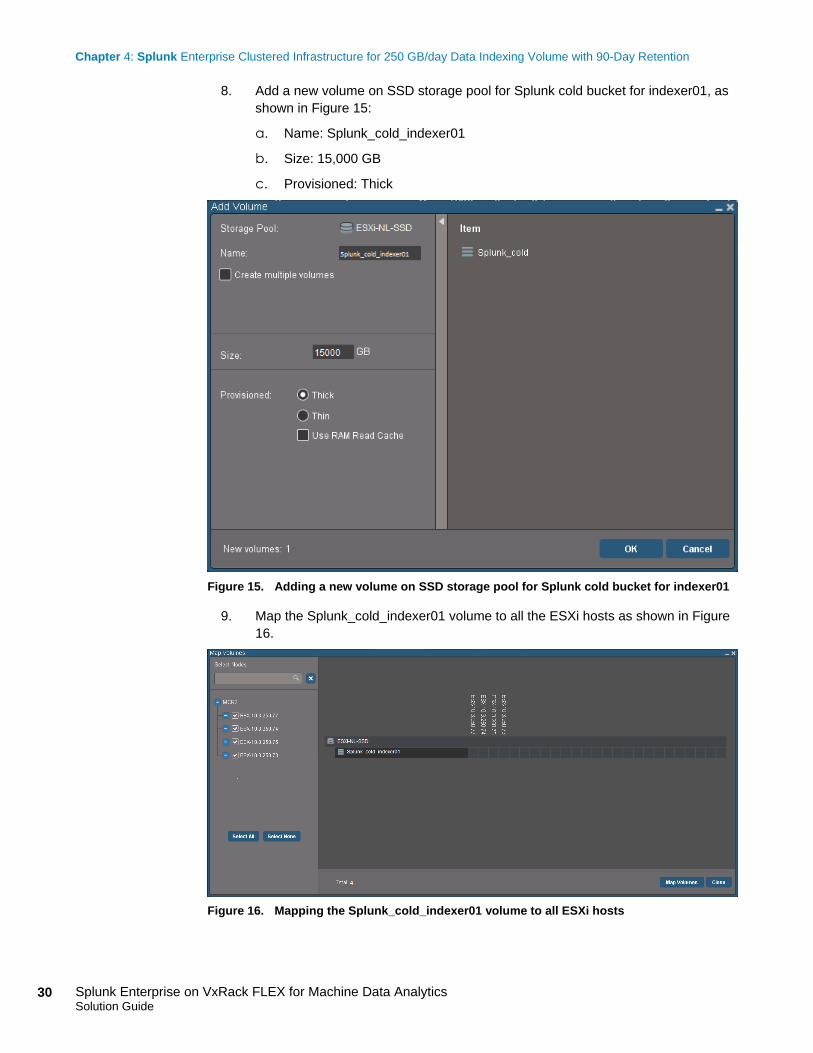
8. Add a new volume on SSD storage pool for Splunk cold bucket for indexer01, as
shown in Figure 15:
a. Name: Splunk_cold_indexer01
b. Size: 15,000 GB
c. Provisioned: Thick
Figure 15. Adding a new volume on SSD storage pool for Splunk cold bucket for indexer01
9. Map the Splunk_cold_indexer01 volume to all the ESXi hosts as shown in Figure
16.
Figure 16. Mapping the Splunk_cold_indexer01 volume to all ESXi hosts
Page 31
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
31 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
10. Similarly, create Splunk_cold_indexer02 SSD storage pool for a second Indexer
and map the volume to all ESXi hosts.
11. Log in to vCenter vSphere client.
12. Navigate to Home > Inventory > Hosts and Clusters > ScaleIO cluster > any
ESX host > Configuration > Datastores.
13. Add storage to create OS datastore, Splunk_home_indexer01 datastore, and
Splunk_cold_indexer01 datastore, using the ScaleIO volumes we just created, as
shown in Figure 17.
Figure 17. Add storage to create OS datastore, Splunk_home_indexer01 datastore, and Splunk_cold_indexer01 datastore
14. Similarly, add storage to Splunk_home_indexer02 datastore and
Splunk_cold_indexer02 datastore, using the ScaleIO volumes created for second
indexer.
Follow these steps to create a VM template and tune it according to Splunk’s
recommendation. We will use the template to deploy a Splunk indexer/search head and a
Splunk forwarder.
1. Log in to the vCenter client and deploy one VM with RHEL 6.7 OS.
2. Log in to the Linux VM deployed in step 1 using the root account.
3. Disable the firewall to allow Splunk instances on different hosts to communicate
with each other correctly:
service iptables stop
chkconfig iptables off
4. Disable SELinux, so that enhanced system security does not add overhead to
Splunk’s performance:
vi /etc/selinux/config
SELINUX=disabled
5. Disable THP to avoid the degradation of Splunk Enterprise performance on RHEL
6.X:
vi /etc/grub.conf
transparent_hugepage=never
Creating a
Splunk VM
template
Page 32
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
32 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
6. Change the tuned profile to virtual-host in RHEL 6.X for high throughput and low
latency storage access:
yum install -y tuned
chkconfig tuned on
tuned-adm profile virtual-host
7. Tune the kernel to optimize the network for high throughput over a 10 Gb Ethernet
by adding the following command string to /etc/sysctl.conf:
vi /etc/sysctl.conf
net.ipv4.tcp_timestamps=0
net.ipv4.tcp_sack=1
net.core.netdev_max_backlog=250000
net.core.rmem_max=4194304
net.core.wmem_max=4194304
net.core.rmem_default=4194304
net.core.wmem_default=4194304
net.core.optmem_max=4194304
net.ipv4.tcp_rmem=4096 87380 4194304
net.ipv4.tcp_wmem=4096 65536 4194304
net.ipv4.tcp_low_latency=1
8. Increase the maximum number of open file descriptors and processes by
configuring ulimit to avoid the “Too Many Open Files” exception:
vi /etc/security/limits.conf
root - nofile 65536
root - nproc 65536
vi /etc/security/limits.d/90-nproc.conf
root - nofile 65536
root - nproc 65536
9. Remove the NIC's MAC address runtime mapping file:
rm -f /etc/udev/rules.d/70-persistent-net.rules
10. Shut down the server:
shutdown -P now
Export the Open Virtualization Format (OVF) template for the Splunk VM template.
Follow these steps to deploy one cluster master for the indexer cluster. For more details
about this configuration, refer to Enable the indexer cluster master node in the Splunk
online document Managing Indexers and Clusters of Indexers.
1. Use the Splunk VM template to deploy one VM for the cluster master.
2. Configure the IP and hostname of the VM.
3. Edit the virtual machine settings as follows:
Deploying the
indexer cluster
master
Page 33
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
33 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Memory: 222 GB
CPUs: 32
4. Start Splunk Enterprise:
/opt/splunk/bin/splunk start
5. Configure the Splunk instance name:
/opt/splunk/bin/splunk set servername cluster-
master.bigdata.emc.local
/opt/splunk/bin/splunk set default-hostname cluster-
master.bigdata.emc.local
6. Restart Splunk Enterprise:
/opt/splunk/bin/splunk restart
7. Log in to the Splunk web server using the default credential admin/changeme.
8. Navigate to Settings > Indexer clustering.
9. Click Enable indexer clustering, as shown in Figure 18.
Figure 18. Enabling indexer clustering
10. Choose Master node, as shown in Figure 19.
Figure 19. Choose Master node
Page 34
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
34 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
11. Configure the Replication Factor and Search Factor:
Replication Factor: 2
Search Factor: 2
Note: In the distributed deployment mode, the replication factor and search factor are set to 1.
During indexer clustered deployment choose an adequate replication factor and search factor for
your environment. Dell EMC recommends that you not increase the factors later, after the cluster
contains significant amounts of data.
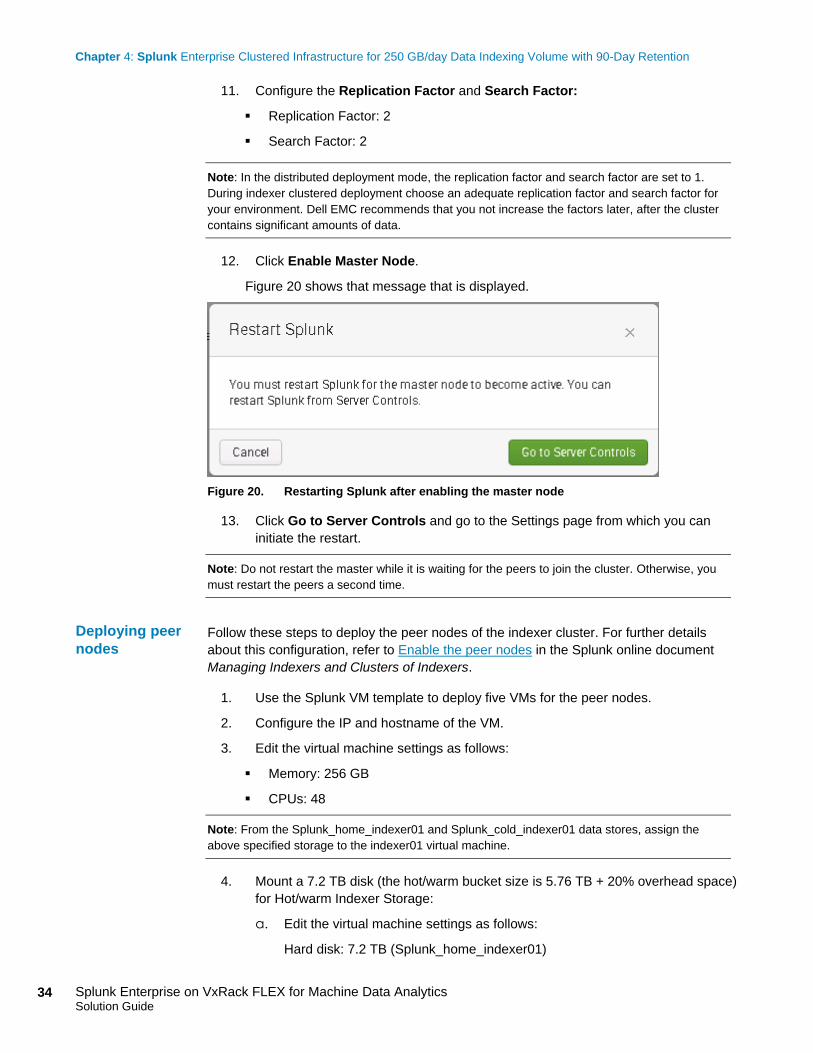
12. Click Enable Master Node.
Figure 20 shows that message that is displayed.
Figure 20. Restarting Splunk after enabling the master node
13. Click Go to Server Controls and go to the Settings page from which you can
initiate the restart.
Note: Do not restart the master while it is waiting for the peers to join the cluster. Otherwise, you
must restart the peers a second time.
Follow these steps to deploy the peer nodes of the indexer cluster. For further details
about this configuration, refer to Enable the peer nodes in the Splunk online document
Managing Indexers and Clusters of Indexers.
1. Use the Splunk VM template to deploy five VMs for the peer nodes.
2. Configure the IP and hostname of the VM.
3. Edit the virtual machine settings as follows:
Memory: 256 GB
CPUs: 48
Note: From the Splunk_home_indexer01 and Splunk_cold_indexer01 data stores, assign the
above specified storage to the indexer01 virtual machine.
4. Mount a 7.2 TB disk (the hot/warm bucket size is 5.76 TB + 20% overhead space)
for Hot/warm Indexer Storage:
a. Edit the virtual machine settings as follows:
Hard disk: 7.2 TB (Splunk_home_indexer01)
Deploying peer
nodes
Page 35
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
35 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Make partitions:
fdisk /dev/sdb
c. Make file systems:
mkfs.ext4 /dev/sdb1
d. Mount to Splunk default database:
mount /dev/sdb1 /mnt/Splunk_home
vi /etc/fstab
/dev/sdb1 /mnt/Splunk_home ext4 defaults 1 1
5. Mount a 15 TB disk (the cold bucket size is 12 TB + 20% overhead space) for
cold Indexer Storage by following these steps:
a. Edit the virtual machine settings as follows:
Hard disk: 15 TB (Splunk_cold_indexer01)
b. Make partitions:
fdisk /dev/sdc
c. Make file systems:
mkfs.ext4 /dev/sdc1
d. Mount to Splunk default database:
mount /dev/sdc1 /mnt/Splunk_cold
vi /etc/fstab
/dev/sdc1 /mnt/Splunk_cold ext4 defaults 1 1
6. Update the indexer indexes.conf file with following parameters to index 250
GB/day with 90-days data retention and storage path properties. Use the Splunk
Storage Sizing tool for configuring the indexes.conf property file.
indexes.conf
# volume definitions
[volume:hotwarm]
path = /mnt/Splunk_home
maxVolumeDataSizeMB = 6039798
[volume:cold]
path = /mnt/Splunk_cold
maxVolumeDataSizeMB = 12582912
# index definition (calculation is based on a single index)
[main]
homePath = volume:hotwarm/defaultdb/db
coldPath = volume:cold/defaultdb/colddb
thawedPath = $SPLUNK_DB/defaultdb/thaweddb
maxWarmDBCount = 4294967295
Page 36
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
36 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
frozenTimePeriodInSecs = 7776000
maxDataSize = auto_high_volume
7. Start Splunk Enterprise:
/opt/splunk/bin/splunk start
8. Configure a Splunk instance name:
/opt/splunk/bin/splunk set servername cluster-
indexer01.bigdata.emc.local
/opt/splunk/bin/splunk set default-hostname cluster-
indexer01.bigdata.emc.local
9. Log in to the Splunk web server using the default credential admin/changeme.
10. Navigate to Settings > Indexer clustering.
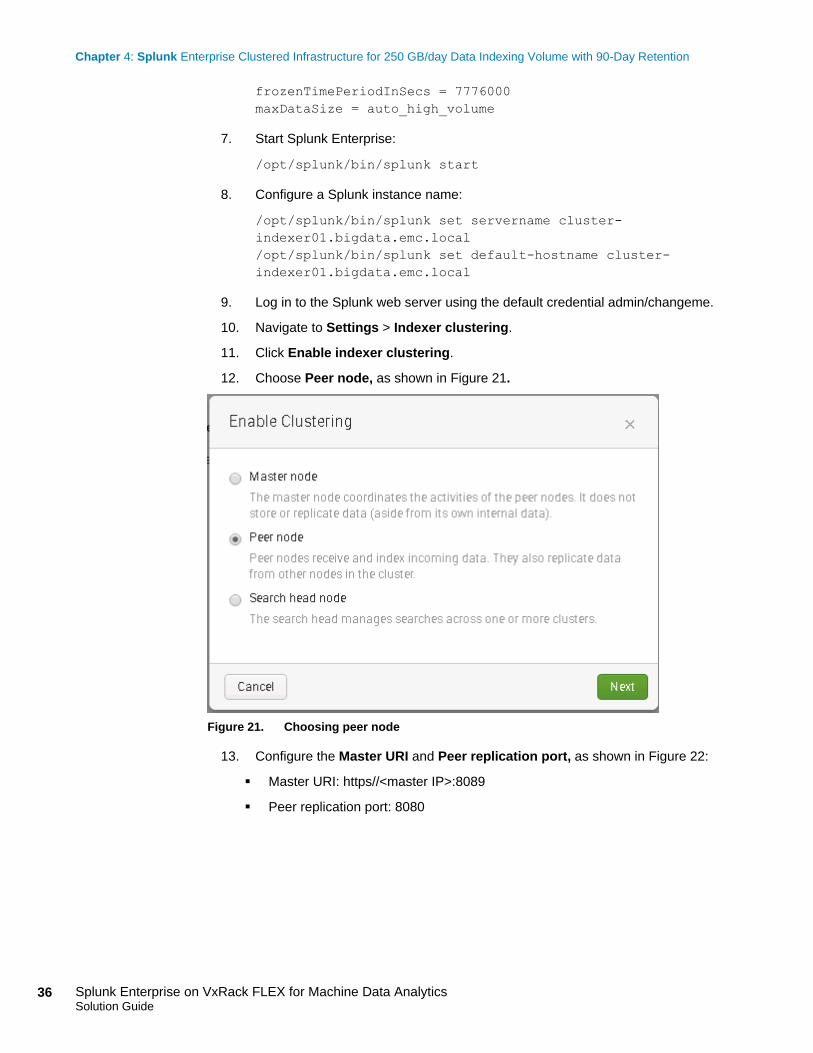
11. Click Enable indexer clustering.
12. Choose Peer node, as shown in Figure 21.
Figure 21. Choosing peer node
13. Configure the Master URI and Peer replication port, as shown in Figure 22:
Master URI: https//<master IP>:8089
Peer replication port: 8080
Page 37
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
37 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 22. Configuring Master URI and peer replication port
14. Click Enable peer node. .
Figure 23 shows that message that is displayed.
Figure 23. Restarting Splunk
15. Click Go to Server Controls and restart the server.
Page 38
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
38 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Note: A warning message is displayed unless you add two indexers into the cluster, as shown in
Figure 24.
Figure 24. Error message if adding less than <repFactor> indexers
Repeat this process on two indexer VMs.
Follow these steps to deploy one search head in the indexer cluster. The cluster master
acts as one search head by default. For further details about this configuration, refer to
Enable the search head in the Splunk online document Managing Indexers and Clusters
of Indexers.
1. Use the Splunk VM template to deploy one VM for the search head.
2. Configure the IP and hostname of the VM.
3. Edit the virtual machine settings as follows:
Memory: 256 GB
CPUs: 48
4. Start Splunk Enterprise:
/opt/splunk/bin/splunk start
5. Configure the Splunk instance name:
/opt/splunk/bin/splunk set servername cluster-
searchhead.bigdata.emc.local
/opt/splunk/bin/splunk set default-hostname cluster-
searchhead.bigdata.emc.local
6. Restart Splunk Enterprise:
/opt/splunk/bin/splunk restart
7. Log in to the Splunk web server using the default credential admin/changeme.
8. Navigate to Settings > Indexer clustering.
9. Click Enable indexer clustering.
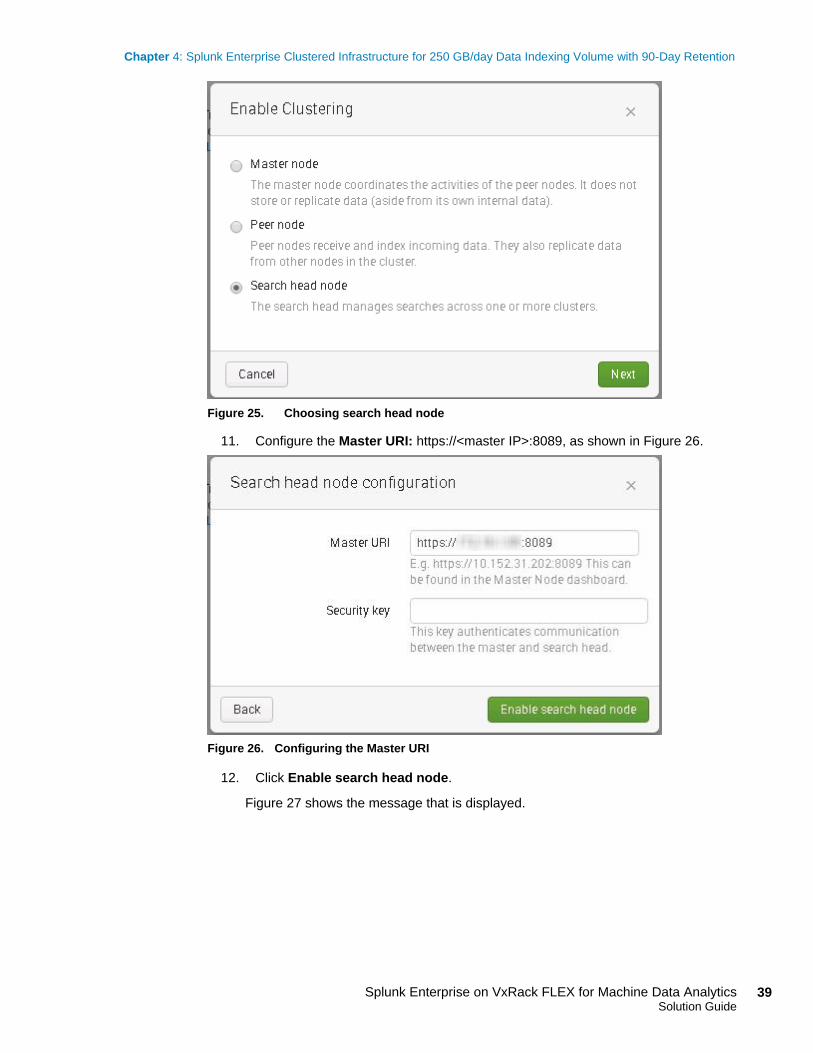
10. Choose Search head node, as shown in Figure 25.
Deploying a
search head
Page 39
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
39 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 25. Choosing search head node
11. Configure the Master URI: https://<master IP>:8089, as shown in Figure 26.
Figure 26. Configuring the Master URI
12. Click Enable search head node.
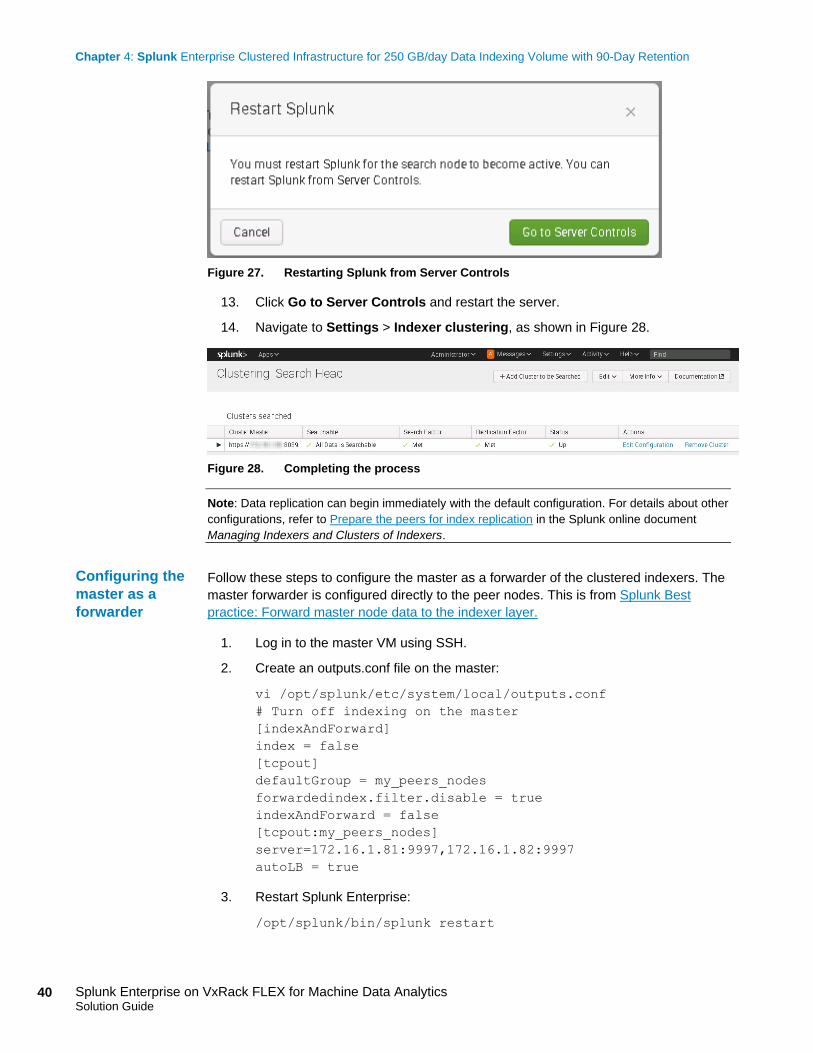
Figure 27 shows the message that is displayed.
Page 40
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
40 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 27. Restarting Splunk from Server Controls
13. Click Go to Server Controls and restart the server.
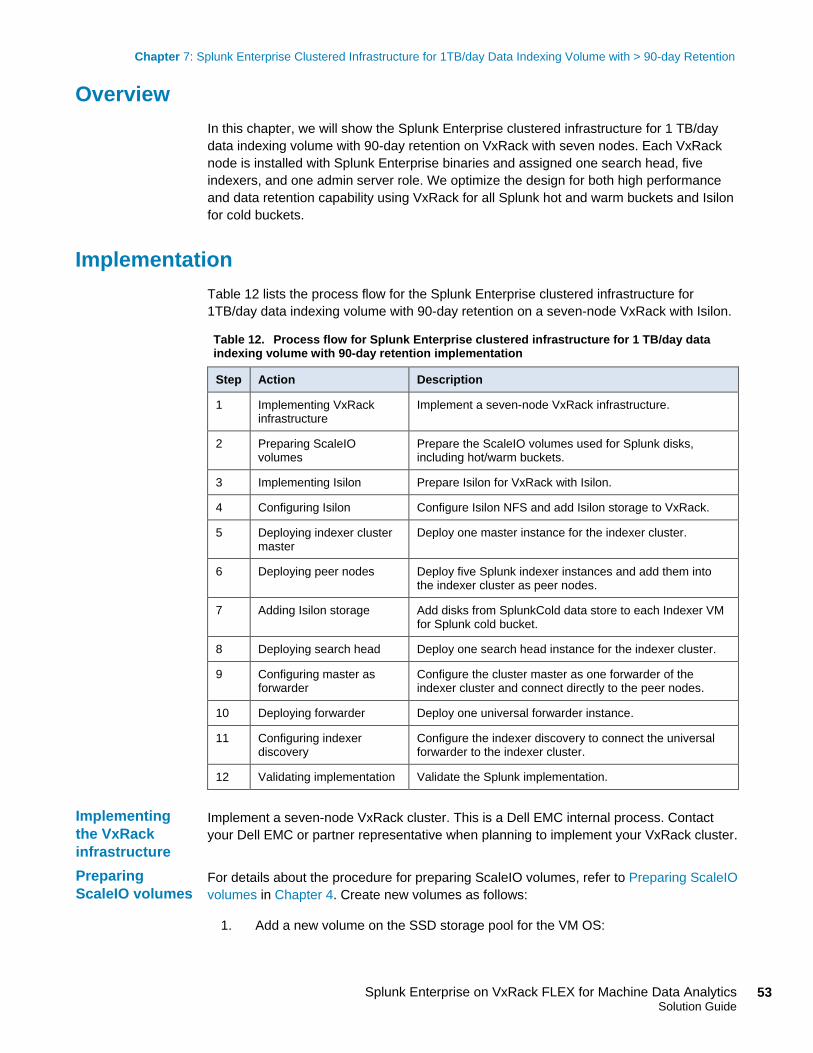
14. Navigate to Settings > Indexer clustering, as shown in Figure 28.
Figure 28. Completing the process
Note: Data replication can begin immediately with the default configuration. For details about other
configurations, refer to Prepare the peers for index replication in the Splunk online document
Managing Indexers and Clusters of Indexers.
Follow these steps to configure the master as a forwarder of the clustered indexers. The
master forwarder is configured directly to the peer nodes. This is from Splunk Best
practice: Forward master node data to the indexer layer.
1. Log in to the master VM using SSH.
2. Create an outputs.conf file on the master:
vi /opt/splunk/etc/system/local/outputs.conf
# Turn off indexing on the master
[indexAndForward]
index = false
[tcpout]
defaultGroup = my_peers_nodes
forwardedindex.filter.disable = true
indexAndForward = false
[tcpout:my_peers_nodes]
server=172.16.1.81:9997,172.16.1.82:9997
autoLB = true
3. Restart Splunk Enterprise:
/opt/splunk/bin/splunk restart
Configuring the
master as a
forwarder
Page 41
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
41 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Follow these steps to deploy one universal forwarder, which will then be connected to the
peer nodes using indexer discovery in the next section.
1. Use the Splunk VM template to deploy one forwarder VM.
2. Configure the IP and hostname of the VM.
3. Start Splunk forwarder:
/opt/splunk/bin/splunk start
4. Configure a Splunk instance name:
/opt/splunk/bin/splunk set servername cluster-
forwarder.bigdata.emc.local
/opt/splunk/bin/splunk set default-hostname cluster-
forwarder.bigdata.emc.local
5. Restart Splunk forwarder:
/opt/splunk/bin/splunk restart
There are several Ways to get data into an indexer cluster. In our implementation, we
followed these steps to use the indexer discovery in this instance, because of the Advantages of the indexer discovery method.
Note: When the forwarder starts for the first time, it gets a list of peers from the master. However,
the list does not persist through a forwarder restart and the forwarder must ask for the list again.
Therefore, do not restart a forwarder while the master is down.
1. Make sure that the receiving port 9997 is open on each indexer by following these
steps:
a. Log in to the web server with the default credential admin/changeme.
b. As shown in Figure 29, navigate to Settings > Forwarding and receiving >
Configure receiving.
Figure 29. Checking receiving port 9997
Note: When using indexer discovery, each peer node can have only one configured receiving port.
2. Enable indexer discovery on the master node by following these steps:
a. Log in to the master VM using SSH.
Deploying the
forwarder
Configuring
indexer
discovery
Page 42
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
42 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Add this stanza to the server.conf file:
vi /opt/splunk/etc/system/local/server.conf
[indexer_discovery]
pass4SymmKey = my_secret
polling_rate = 10
indexerWeightByDiskCapacity = true
Note: : The default polling_rate is 10 (refer to Adjust the frequency of polling). The default value of
indexerWeightByDiskCapacity is false (refer to Use weighted load balancing).
c. Restart Splunk Enterprise.
/opt/splunk/bin/splunk restart
3. Configure the forwarder to use indexer discovery by following these steps:
a. Log in to the forwarder VM using SSH.
b. Add these settings to the outputs.conf file:
vi /opt/splunk/etc/system/local/outputs.conf
[indexer_discovery:master1]
pass4SymmKey = my_secret
master_uri = https://172.16.1.80:8089
[tcpout:group1]
autoLBFrequency = 30
forceTimebasedAutoLB = true
indexerDiscovery = master1
useACK=true
[tcpout]
defaultGroup = group1
c. Restart the Splunk forwarder:
/opt/splunk/bin/splunk restart
Note: For further details about configuration of load balancing on the forwarder, refer to Set up
load balancing in the Splunk online document Forwarding Data.
Follow these steps to validate the implementation of Splunk.
1. Validate the peer nodes on the master using these steps:
a. Log in to the web server of the master using the default credential
admin/changeme.
b. Navigate to Settings > Indexer clustering.
c. Click the Peers tab to verify that the indexers are searchable.
2. Validate the search heads on the master using these steps:
a. Log in to the web server of the master using the default credential
admin/changeme.
Validating the
implementation
Page 43
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
43 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Navigate to Settings > Indexer clustering.
c. Click the Search Heads tab to verify that the search heads are up.
3. Validate the forwarder on the master using these steps:
a. Log in to the web server of the master using the default credential
admin/changeme.
b. Navigate to Settings > Monitoring Console > Forwarders > Forwarders:
Instance.
c. Choose the forwarder in the Instance drop-down list. Click the name of the
forwarder under Status and Configuration to see the five receivers of the
forwarder.
d. Choose the master in the Instance drop-down list and click the master in
Status and Configuration to see the five receivers of the master.
4. Validate forwarders on the indexers by repeating step 3 for each indexer.
5. Validate the forward servers on the forwarder using these steps:
a. Log in to the forwarder VM using SSH.
b. Run this command to verify the five indexers as the forward servers:
/opt/splunk/bin/splunk list forward-server
Note: When we enable load balancing, the active forwards are changed among the three indexers
in the cluster.
6. Validate the cluster master on the search head using these steps:
a. Log in to the web server of the search head using the default credential
admin/changeme.
b. Navigate to Settings > Indexer clustering.
c. Verify that the cluster is searchable in the Cluster searched list, as shown in
Figure 30.
Figure 30. Locate the cluster in the Cluster Searched list
7. Validate the Indexing using these steps:
a. Upload data to the forwarder, as shown in Figure 31.
Page 44
Chapter 4: Splunk Enterprise Clustered Infrastructure for 250 GB/day Data Indexing Volume with 90-Day Retention
44 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 31. Uploading data to the forwarder
Note: Download the Prices.csv.zip file from the Splunk Tutorial.
b. Search for the search head, as shown in Figure 32.
Figure 32. Searching for the search head
8. Verify that the VMs are balanced between the seven ESXi servers.
Use case summary
In this use case, we created a clustered Splunk environment, optimized for both high
performance and data retention capability utilizing VxRack FLEX for the storage of
hot/warm buckets in Splunk Enterprise. We designed and implemented this procedure to
showcase the ease of configuring a clustered Splunk architecture for indexing volume 250
GB/day with 90-day data retention. Sufficient storage space is available on the VxRack
FLEX to update the Splunk data retention policy up to 142 days.
Page 45
Chapter 5: Splunk Enterprise Clustered Infrastructure for 500 GB/day Data Indexing Volume with 90-Day Retention
45 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 5 Splunk Enterprise Clustered Infrastructure for 500 GB/day
Data Indexing Volume with 90-Day Retention
This chapter presents the following topics:
Overview .............................................................................................................. 46
Implementation ................................................................................................... 46
Use case summary ............................................................................................. 47
Page 46
Chapter 5: Splunk Enterprise Clustered Infrastructure for 500 GB/day Data Indexing Volume with 90-Day Retention
46 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
In this chapter, we will show how to scale the Splunk Enterprise clustered infrastructure
from two indexers to five indexers to handle 500 GB/day data indexing volume with 90-
day retention on VxRack FLEX by adding three more nodes for indexers. The 3 new
VxRack nodes are installed with Splunk Enterprise binaries and assigned indexer roles.
We optimize the design for both high performance and data retention capability using
VxRack for the storage of hot/warm and cold buckets in Splunk Enterprise.
Implementation
Table 10 lists the process flow for scaling a Splunk Enterprise clustered infrastructure for
500 GB/day data indexing volume with 90-day retention on VxRack with seven nodes.
Table 10. Process flow for scaling Splunk Enterprise clustered infrastructure for 500 GB/day data indexing volume with 90-day retention implementation
Step Action Description
1 Implementing VxRack infrastructure
Add three VxRack nodes into the infrastructure.
2 Preparing ScaleIO volumes
Prepare the ScaleIO voumes that are used for Splunk disks, including hot/warm and cold buckets.
3 Adding new peer nodes Deploy three Splunk indexer instances and add them into the indexer cluster as peer nodes.
4 Validating implementation Validate the Splunk implementation.
Scaling a VxRack infrastructure is a Dell EMC internal process. Contact your Dell EMC or
partner representative when planning to expand your VxRack cluster.
For details about the procedure for preparing ScaleIO volumes, refer to Preparing ScaleIO
volumes in Chapter 4.
Create new volumes as follows:
1. Add three new volumes on the SSD storage pool for the hot/warm buckets for the
three indexers:
a. Name: Splunk_home_indexer03, Splunk_home_indexer04 and
Splunk_home_indexer05
b. Size: 7,200 GB
c. Provisioned: Thick
2. Add three new volumes on the SSD storage pool for the cold buckets for the three
new indexers:
a. Name: Splunk_cold_indexer03, Splunk_cold_indexer04 and
Splunk_cold_indexer04
Implementing
the VxRack
infrastructure
Preparing
ScaleIO volumes
Page 47
Chapter 5: Splunk Enterprise Clustered Infrastructure for 500 GB/day Data Indexing Volume with 90-Day Retention
47 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Size: 15,000 GB
c. Provisioned: Thick
3. Map the ScaleIO volumes to all the ESXi hosts.
4. Log in to vCenter vSphere client.
5. Navigate to Home > Inventory > Hosts and Clusters > ScaleIO cluster > any
ESX host > Configuration > Datastores.
6. Create six new datastores:
a. Splunk_home_indexer03
b. Splunk_home_indexer04
c. Splunk_home_indexer05
d. Splunk_cold_indexer03
e. Splunk_cold_indexer04
f. Splunk_cold_indexer05
Note: All other steps for preparing ScaleIO volumes are the same as in Chapter 4.
To expand the Splunk indexer cluster, we added three new peer nodes. For detailed steps
about how to deploy three new peer nodes, refer to Deploying peer nodes in Chapter 4
and use the six new datastores created in the previous step for hot/warm and cold
buckets.
For details about the procedure for validating the implementation, refer to Validating
implementation in Chapter 4.
Use case summary
In this use case, we deployed the three new Splunk Indexers and added them to the
existing indexer cluster to expand the Splunk clustered infrastructure. We added three
more VxRack nodes and installed Splunk indexers to create a cluster of five peer nodes,
optimized for both high performance and data retention capabilities. We utilized VxRack
for the storage of hot/warm and cold buckets in Splunk Enterprise. We designed and
implemented this procedure to showcase the ease of configuration of a clustered Splunk
architecture for indexing volumes of up to 500 GB/day with 90-day data retention.
Sufficient storage space is available on the VxRack to update the Splunk data retention
policy up to 177 days.
Adding new peer
nodes
Validating the
implementation
Page 48
Chapter 6: Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing Volume with 90-Day Retention
48 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 6 Splunk Enterprise Distributed Infrastructure for 1 TB/day Data
Indexing Volume with 90-Day Retention
This chapter presents the following topics:
Overview .............................................................................................................. 49
Implementation ................................................................................................... 49
Use case summary ............................................................................................. 51
Page 49
Chapter 6: Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing Volume with 90-Day Retention
49 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
In this chapter, we will show the Splunk Enterprise distributed infrastructure for 1 TB/day
data indexing volume with 90-days retention on VxRack with seven nodes. Each VxRack
node is installed with Splunk Enterprise binaries and assigned one search head, five
indexers, and one admin server role. We optimize the design for both high performance
and data retention capability using VxRack for the storage of hot/warm and cold buckets
in Splunk Enterprise.
Implementation
Table 11 lists the process flow for the Splunk Enterprise distributed infrastructure for 1
TB/day data indexing volume with 90-day retention on VxRack with seven nodes.
Table 11. Process flow for Splunk Enterprise distributed infrastructure for 1 TB/day data indexing volume with 90-day retention implementation
Step Action Description
1 Implementing VxRack infrastructure
Implement a seven nodes VxRack infrastructure.
2 Preparing ScaleIO volumes
Prepare the ScaleIO volumes that are used for Splunk disks, including hot/warm and cold buckets.
3 Deploying admin server Deploy one master instance as admin server for the indexer cluste.r
4 Deploying indexer Deploy five Splunk indexer instances.
6 Deploying search head Deploy one search head instance.
7 Configuring admin server as forwarder
Configure the admin server as one forwarder and connect directly to the indexers.
8 Deploying forwarder Deploy one universal forwarder instance.
9 Configuring indexer discovery
Configure the indexer discovery to connect the universal forwarder to the indexers.
10 Validating implementation Validate the Splunk implementation.
Implement a seven-node VxRack cluster. This is a Dell EMC internal process. Contact
your Dell EMC or partner representative when planning to implement your VxRack cluster.
For details about the procedure for preparing ScaleIO volumes, refer to Preparing ScaleIO
volumes in Chapter 4. Create new volumes as below.
1. Add a new volume on SSD storage pool for VMs’ OS:
a. Name: OS_Datastore
b. Size: 2,000 GB
c. Provisioned: Thick
2. Add a new volume on SSD storage pool for Splunk hot/warm buckets:
a. Name: Splunk_home
Implementing
the VxRack
infrastructure Preparing
ScaleIO volumes
Page 50
Chapter 6: Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing Volume with 90-Day Retention
50 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
b. Size: 36,000 GB
c. Provisioned: Thick
3. Add a new volume on SSD storage pool for Splunk cold buckets:
a. Name: Splunk_cold
b. Size: 75,000 GB
c. Provisioned: Thick
4. Map the ScaleIO volumes to all the ESXi hosts.
5. Log in to vCenter vSphere client.
6. Navigate to Home > Inventory > Hosts and Clusters > ScaleIO cluster > any
ESX host > Configuration > Datastores.
7. Create Splunk_home datastore and Splunk_cold datastore.
Note: All other steps for preparing ScaleIO volumes are the same as in Chapter 4, other than the
sizes of the volumes.
Dell EMC recommends the admin server for the Splunk distributed environment. The
procedure for deploying an admin server is the same as deploying an indexer cluster
master, but it will not make any index replication.
Replication Factor: 1
Search Factor: 1
For details about the procedure for deploying indexer cluster master, refer to Deploying
indexer cluster master in Chapter 4.
For details about the procedure for deploying five indexers, refer to Deploying peer nodes
in Chapter 4.
For details about the procedure for deploying a search head, refer to Deploying search
head in Chapter 4.
For details about the procedure for configuring the admin server as the forwarder, refer to
Configuring master as forwarder in Chapter 4.
For details about the procedure for deploying the forwarder, refer to Deploying forwarder
in Chapter 4.
For details about the procedure for configuring indexer discovery, refer to Configuring
indexer discovery in Chapter 4.
For details about the procedure for validating implementation, refer to Validating
implementation in Chapter 4.
Deploying the
admin server
Deploying an
indexer
Deploying a
search head
Configuring the
admin server as
the forwarder
Deploying the
forwarder
Configuring
indexer
discovery
Validating the
implementation
Page 51
Chapter 6: Splunk Enterprise Distributed Infrastructure for 1 TB/day Data Indexing Volume with 90-Day Retention
51 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Use case summary
In this use case, we deploy the new distributed Splunk environment on seven VxRack
nodes and install Splunk indexers, optimized for both high performance and data retention
capability utilizing VxRack for the storage of hot/warm and cold buckets in Splunk
Enterprise. Designed and implemented procedure to showcase the ease of configuration
of a distributed Splunk architecture for indexing volume 1 TB/day with 90-days data
retention.
Page 52
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
52 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 7 Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day
Retention
This chapter presents the following topics:
Overview .............................................................................................................. 53
Implementation ................................................................................................... 53
Use case summary ............................................................................................. 60
Page 53
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
53 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
In this chapter, we will show the Splunk Enterprise clustered infrastructure for 1 TB/day
data indexing volume with 90-day retention on VxRack with seven nodes. Each VxRack
node is installed with Splunk Enterprise binaries and assigned one search head, five
indexers, and one admin server role. We optimize the design for both high performance
and data retention capability using VxRack for all Splunk hot and warm buckets and Isilon
for cold buckets.
Implementation
Table 12 lists the process flow for the Splunk Enterprise clustered infrastructure for
1TB/day data indexing volume with 90-day retention on a seven-node VxRack with Isilon.
Table 12. Process flow for Splunk Enterprise clustered infrastructure for 1 TB/day data indexing volume with 90-day retention implementation
Step Action Description
1 Implementing VxRack infrastructure
Implement a seven-node VxRack infrastructure.
2 Preparing ScaleIO volumes
Prepare the ScaleIO volumes used for Splunk disks, including hot/warm buckets.
3 Implementing Isilon Prepare Isilon for VxRack with Isilon.
4 Configuring Isilon Configure Isilon NFS and add Isilon storage to VxRack.
5 Deploying indexer cluster master
Deploy one master instance for the indexer cluster.
6 Deploying peer nodes Deploy five Splunk indexer instances and add them into the indexer cluster as peer nodes.
7 Adding Isilon storage Add disks from SplunkCold data store to each Indexer VM for Splunk cold bucket.
8 Deploying search head Deploy one search head instance for the indexer cluster.
9 Configuring master as forwarder
Configure the cluster master as one forwarder of the indexer cluster and connect directly to the peer nodes.
10 Deploying forwarder Deploy one universal forwarder instance.
11 Configuring indexer discovery
Configure the indexer discovery to connect the universal forwarder to the indexer cluster.
12 Validating implementation Validate the Splunk implementation.
Implement a seven-node VxRack cluster. This is a Dell EMC internal process. Contact
your Dell EMC or partner representative when planning to implement your VxRack cluster.
For details about the procedure for preparing ScaleIO volumes, refer to Preparing ScaleIO
volumes in Chapter 4. Create new volumes as follows:
1. Add a new volume on the SSD storage pool for the VM OS:
Implementing
the VxRack
infrastructure
Preparing
ScaleIO volumes
Page 54
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
54 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
a. Name: OS_Datastore
b. Size: 2,000 GB
c. Provisioned: Thick
2. Add a new volume on the SSD storage pool for Splunk hot/warm buckets:
a. Name: Splunk_home
b. Size: 36TB
c. Provisioned: Thick
3. Map the ScaleIO volumes to all the ESXi hosts.
4. Log in to the vCenter vSphere client.
5. Navigate to Home > Inventory > Hosts and Clusters > ScaleIO cluster > any
ESX host > Configuration > Datastores.
6. Increase storage size of Splunk_home datastore.
Note: All other steps for preparing ScaleIO volumes are the same as in Chapter 4, other than the
sizes of the volumes.
Implementing an Isilon storage array is a Dell EMC internal process. Contact your Dell
EMC representative when planning to set up your Isilon storage.
Follow these steps to configure Isilon NFS for the VxRack cluster:
1. Log in to the Isilon OneFS web service using the root account.
2. Navigate to Cluster Management > Network Configuration.
3. Click More > Add Subnet of groupnet0 to create a subnet, as shown in Figure
33.
Implementing
Isilon
Configuring
Isilon
Page 55
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
55 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 33. Creating a subnet
4. Navigate to Access > Access Zones.
5. Click Create an access zone to create an access zone for Splunk, as shown in
Figure 34.
Page 56
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
56 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 34. Creating an access zone
6. Navigate to Cluster Management > Network Configuration.
7. Click More > Add Pool of subnet-10g to create an IP address pool, as shown in
Figure 35.
Page 57
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
57 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 35. Creating a IP address pool
8. Navigate to Protocols > UNIX Sharing (NFS) > NFS Exports.
9. Click Create Export to create an NFS export for Splunk, as shown in Figure 36.
Description: NFS Share for Splunk
Root Clients: IP addresses of all the ESXi servers in VxRack
Directory Paths: /ifs/data/splunk
Page 58
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
58 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Figure 36. Creating an NFS export
After completing the Isilon configuration, run the following procedure on each ESXi server
to add Isilon NFS storage to VxRack:
1. Log in to the vCenter client using the administrator account.
2. Navigate to Home > Inventory > Hosts and Clusters > ESXi server >
Configuration > Storage > Datastores.
3. Click Add Storage to add Isilon NFS storage as a data store, as shown in Figure
37:
Storage Type: Network File System
Server: <Isilon Smart Connect Zone Name for Splunk>
Folder: /ifs/data/splunk
Datastore Name: SplunkCold
Figure 37. Adding Isilon NFS storage as a data store
Page 59
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
59 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
For details about the procedure for deploying the indexer cluster master, refer to
Deploying indexer cluster master in Chapter 4.
For details about the procedure for deploying peer nodes, refer to Deploying peer nodes
in Chapter 4. Assign storage space from Splunk_home datastore and SplunkCold
datastore as described below to the Indexer virtual machines.
1. Mount only the 7.2 TB disk from Splunk_home datastore for hot/warm bucket.
2. Mount SplunkCold datastore from Isilon as described in Adding Isilon storage.
3. After Isilon storage is added, update the index.conf file.
Follow these steps to add disks from the SplunkCold data store on each Indexer VM:
1. Log in to the vCenter client using the administrator account.
2. Click Indexer VM and Edit virtual machine settings.
3. Click Add Hardware to run the wizard:
Device Type: Hard Disk
Disk: Create a new virtual disk
Capacity/Disk Size: Configurable
Location/Specify a data store or data store cluster: SplunkCold
Follow these steps to prepare Splunk cold buckets using Isilon disks on VMs.
1. Log in to the indexer using SSH.
2. Make a partition on the newly provisioned Isilon virtual disk:
fdisk /dev/sdc
3. Make a file system on the partition:
mkfs.ext4 /dev/sdc1
4. Mount the Isilon virtual disk to a separate mount point.
mkdir -p /data/isilon
mount /dev/sdc1 /data/isilon
vi /etc/fstab
/dev/sdc1 /data/isilon ext4 defaults 1 1
5. Update the indexer indexes.conf file with following parameters to index 1 TB/day
with 90 days data retention and storage path properties. Use the Splunk Storage
Sizing tool to configure the indexes.conf property file.
indexes.conf
# volume definitions
[volume:hotwarm]
path = /mnt/Splunk_home
Deploying the
indexer cluster
master
Deploying peer
nodes
Adding Isilon
storage
Page 60
Chapter 7: Splunk Enterprise Clustered Infrastructure for 1TB/day Data Indexing Volume with > 90-day Retention
60 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
[volume:cold]
path = /data/isilon
# index definition (calculation is based on a single index)
[main]
homePath = volume:hotwarm/defaultdb/db
coldPath = volume:cold/defaultdb/colddb
thawedPath = $SPLUNK_DB/defaultdb/thaweddb
homePath.maxDataSizeMB = 7200000
coldPath.maxDataSizeMB = [configurable]
maxWarmDBCount = 4294967295
maxHotSpanSecs = 2592000
frozenTimePeriodInSecs = 7776000
maxDataSize = auto_high_volume
6. Ensure that the directory for the coldPath exists.
mkdir –p /data/isilon/defaultdb/colddb
7. Restart Splunk Enterprise:
/opt/splunk/bin/splunk restart
For details about the procedure for deploying a search head, refer to Deploying search
head in Chapter 4).
For details about the procedure for configuring the master as a forwarder, refer to
Configuring the master as a forwarder.
For details about the procedure for deploying the forwarder, refer to Deploying forwarder.
For details about the procedure for configuring indexer discovery, refer to Configuring
indexer discovery.
For details about the procedure for validating the implementation, refer to Validating
implementation.
Use case summary
This use case explains the design and implementation procedure for integrating Isilon into
the Splunk multi-instance 1 TB/day with > 90-day retention deployment. This solution
enables a clustered Splunk Enterprise environment for high performance and large
capacity data retention capabilities, using VxRack for hot/warm buckets and Isilon for cold
buckets.
Deploying a
search head
Configuring the
master as a
forwarder
Deploying the
forwarder
Configuring
indexer
discovery
Validating the
implementation
Page 61
Chapter 8: Validated Configurations for Splunk Enterprise
61 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 8 Validated Configurations for Splunk Enterprise
This chapter presents the following topics:
Overview .............................................................................................................. 62
Splunk-validated sizing configurations ............................................................ 62
Scenario 1: Four VxRack nodes for 250 GB/day(clustered) with 90-day retention ....................................................................................................... 63
Scenario 2: Seven VxRack nodes for up to 500 GB/day (clustered) with 90-day retention ................................................................................................ 63
Scenario 3: Seven VxRack nodes for up to 1 TB/day (distributed) with 90-day retention ................................................................................................ 64
Scenario 4: Seven VxRack nodes with Isilon for up to 1 TB/day (clustered) with 30-day retention for hot/warm buckets and configurable retention for cold buckets ........................................................................................... 64
Summary ............................................................................................................. 65
Page 62
Chapter 8: Validated Configurations for Splunk Enterprise
62 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Overview
In this chapter, we provide the Splunk validated configuration for Dell EMC to meet or
exceed the performance of Splunk’s documented reference hardware.
Splunk-validated sizing configurations
Splunk validated the following configurations for Dell EMC to meet or exceed the
performance of Splunk’s documented reference hardware:
Scenario 1: Four VxRack nodes for 250 GB/day(clustered) with 90-day retention
Scenario 2: Seven VxRack nodes for 500 GB/day (clustered) with 90-day retention
Scenario 3: Seven VxRack nodes for up to 1 TB/day (distributed) with 90-day
retention
Scenario 4: Seven VxRack nodes with Isilon for up to 1 TB/day (clustered) with 30-
day retention for hot/warm buckets and configurable retention for cold buckets
These configurations represent typical uses in the current marketplace.
Chapter 2 lists the attributes of the VxRack FLEX. Table 13 describes the physical
characteristics of the VxRack FLEX tested by Splunk in the four scenarios.
For Scenarios 1, 2, 3, and 4 we used the VxRack FLEX with R630 nodes with memory
and disk group configurations to provide a cost-optimized, highly available infrastructure
solution.
Table 13. VxRack with R630 nodes
Components High-density flash: dense SSD-high capacity
Processor cores (per node) 28
Processors (per node) 2x E5-2680v4
Memory/RAM (per node) 512 GB
SSD (per node) 10x3.84 TB
HDD (per node) None
DAS Cache No
Splunk implemented these best practices in designing the configurations that were used in
the four scenarios:
When hyper-threading is enabled, allocate the equivalent number of physical cores
(for example, for 32 physical cores allocate 64 vCPUs).
Splunk Enterprise is resource-intensive. For best performance, do not overcommit
vCPU or memory for Splunk instances.
VxRack FLEX
description
General VxRack
FLEX
configuration
guidance for
Splunk
Enterprise
Page 63
Chapter 8: Validated Configurations for Splunk Enterprise
63 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
VMware requires resources for the management VMs. These resources have been
considered for all sizing recommendations.
Splunk Enterprise deployments that are distributed or clustered require a Cluster
Master to manage the indexing tier. This instance is referred to as an Admin Server.
The Admin Server can also be used as a License Master for Splunk Enterprise.
Scenario 1: Four VxRack nodes for 250 GB/day(clustered) with 90-day retention
This scenario describes the configuration of a Splunk Enterprise clustered deployment on
four VxRack nodes that can index up to 250 GB/day data with 90-day retention with a
replication factor of 2 and a search factor of 2.
Table 14. Configuration of clustered deployment
Deployment Instance
role Qty
Physical cores/ vCPU Memory
OS storage
SSD(hot/ warm)
storage
Available SDD(cold)
storage 90 days
retention Comment
Clustered
250 GB/day
90 day retention
RF/SF = 2
Search Head
1 24/48 256 GB 300 GB 0 0
Indexer 2 24/48 256 GB 300 GB 7.2 TB 15 TB 6.6 TB (cold bucket)
Possible retention up to 142 days
Admin Server
1 16/32 222 GB 150 GB 0 0
Scenario 2: Seven VxRack nodes for up to 500 GB/day (clustered) with 90-day retention
This scenario describes the configuration of Splunk Enterprise distributed deployment on
seven VxRack nodes.
The clustered deployment can index up to 500 GB/day data with 90-day retention with a
replication factor of 2 and a search factor of 2.
Table 15. Configuration of clustered deployment
Deployment Instance
role Qty
Physical cores/ vCPU Memory
OS storage
SSD(hot/warm)
storage
Available SDD(cold)
storage 90 days
retention Comment
Clustered
500 GB/day
90 day retention
RF/SF = 2
Search Head
1 24/48 256 GB 300 GB 0 0
Indexer 5 24/48 256 GB 300 GB 7.2 TB 15 TB 4 TB (cold bucket)
Possible retention up to 177 days
Page 64
Chapter 8: Validated Configurations for Splunk Enterprise
64 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Deployment Instance
role Qty
Physical cores/ vCPU Memory
OS storage
SSD(hot/warm)
storage
Available SDD(cold)
storage 90 days
retention Comment
Admin Server
1 16/32 222 GB 150 GB 0 0
Scenario 3: Seven VxRack nodes for up to 1 TB/day (distributed) with 90-day retention
This scenario describes the configuration of Splunk Enterprise clustered indexer
deployment on seven VxRack nodes.
The distributed deployment can index up to 1 TB/day data with 90-day retention.
Table 16. Configuration of distributed deployment
Deployment Instance
role Qty
Physical cores/ vCPU Memory
OS storage
SSD(hot/warm) storage
Available SDD(cold)
storage 90 days
retention Comment
Distributed
1 TB/day
90 day retention
RF/SF = 1
Search Head
1 24/48 256 GB 300 GB 0 0
Indexer 5 24/48 256 GB 300 GB 7.2 TB 15 TB 4 TB (cold bucket)
Possible retention up to 177 days
Admin Server
1 16/32 222 GB 150 GB 0 0
Scenario 4: Seven VxRack nodes with Isilon for up to 1 TB/day (clustered) with 30-day retention for hot/warm buckets and configurable retention for cold buckets
This scenario describes the configuration of Splunk Enterprise clustered indexer
deployment on seven VxRack nodes with Isilon. This configuration can index up to 1 TB/
day of data with 30-day retention for hot/warm buckets and configurable retention for cold
buckets, including a replication factor of 2 and a search factor of 2.
For configuration guidance about Isilon scale-out storage, refer to the EMC Isilon Scale-
Out storage and VMware vSphere Sizing Guide.
Page 65
Chapter 8: Validated Configurations for Splunk Enterprise
65 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Table 17. Configuration of clustered deployment
Deployment Instance
role Qty
Physical cores/ vCPU Memory
OS storage
SSD (hot/
warm) storage
Available SDD
(cold) storage
HDD (cold) storage
Clustered
1 TB/day
Hot/Warm 30 day retention
Cold(configuarable)
RF/SF = 2
Search Head
1 24/48 256 GB 300 GB 0 0
Indexer 5 24/48 256 GB 300 GB 7.2 TB 15 TB configurable
Admin Server
1 16/32 222 GB 150 GB 0 0
Summary
The configuration flexibility of Splunk Enterprise software together with the modular scale-
out features of the VxRack platform provide an integrated technology solution for
analyzing machine-generated Big Data across a wide range of data ingestion rates and
customer use case scenarios. The depth of the partnership between Splunk and Dell EMC
has produced a set of jointly tested and validated systems that customer can implement
with confidence. These systems will meet current needs and flexibly scale when the need
arises.
Page 66
Chapter 9: Conclusion
66 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 9 Conclusion
This chapter presents the following topics:
Summary ............................................................................................................. 67
Findings ............................................................................................................... 67
Conclusion .......................................................................................................... 67
Page 67
Chapter 9: Conclusion
67 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Summary
For many organizations, two of the most important goals are expanding the scope of data
available for improving Operational Intelligence and lowering the cost of IT operations.
Splunk Enterprise provides a complete end-to-end software solution for data ingestion
from almost any source, powerful indexing, and robust reporting and ad hoc query
capability – all from a single platform. Splunk and Dell EMC have proven that deploying
Splunk Enterprise on the appropriate configuration of VxRack FLEX will meet or exceed
the performance requirements for a broad range of customer scenarios. VxRack FLEX
and Isilon systems meet the needs for virtualization, standardization, and automation
required to lower IT operational costs for both Splunk as well as most other enterprise
workload demands.
Findings
The flexible design of the Splunk Enterprise platform and Dell EMC’s VxRack and Isilon
platforms provides end-to-end data management and analytics that can be used for many
different use cases and scaling needs. The solutions described in this document are
widely applicable, cost-effective, and provide varied implementation and support options
for the analytics that drives better insights and improved Operational Intelligence.
Conclusion
The ongoing dedicated partnership between Splunk and Dell EMC makes investing in new
or expanded machine data analytics less risky and more cost-effective for businesses of
all sizes. The Dell EMC systems together with Splunk Enterprise configurations described
in this document give prospective customers the information needed to find the right
investment options and necessary skills to confidently commit to meeting their goals for
improving Operational Intelligence and data center modernization.
Page 68
Chapter 10: References
68 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Chapter 10 References
This chapter presents the following topics:
Dell EMC documentation ................................................................................... 69
VMware documentation ..................................................................................... 69
Splunk Enterprise documentation .................................................................... 69
Page 69
Chapter 10: References
69 Splunk Enterprise on VxRack FLEX for Machine Data Analytics Solution Guide
Dell EMC documentation
The following documentation on EMC.com or EMC Online Support provides additional
and relevant information. Access to these documents depends on your login credentials. If
you do not have access to a document, contact your Dell EMC representative.
EMC Isilon Scale-Out Storage and VMware vSphere Sizing Guide
Dell EMC ScaleIO data sheet
Dell EMC VxRack System FLEX data sheet
Dell EMC VxRack System data sheet
Dell EMC VxRack System FLEX store page
VMware documentation
The following documentation on the VMware website provides additional and relevant
information:
Performance Best Practices for VMware vSphere 6.0
Splunk Enterprise documentation
The following documentation on the Splunk documentation website provides additional
and relevant information:
Splunk Installation Manual
Splunk Capacity Planning Manual
Transparent huge memory pages and Splunk performance
Managing Indexers and Clusters of Indexers
Distributed Search
Forwarding Data