88
Dave Stokes MySQL Community Manager [email protected] @Stoker SQL For SQL For Programmers Programmers
| Date post: | 17-Jul-2015 |
| Category: |
Technology |
| Upload: | dave-stokes |
| View: | 88 times |
| Download: | 6 times |

2
Data Is the New Middle Manager – WSJ April 20thData Is the New Middle Manager – WSJ April 20th
Startups are keeping head counts low, and even eliminating management positions, by replacing them with a surprising substitute for leaders and decision-makers: data.
“Every time people come to me and ask for new bodies it turns out so much of that can be answered by asking the right questions of our data and getting that in front of the decision-makers,” says James Reinhart, CEO of online secondhand clothing store thredUP. “I think frankly it’s eliminated four to five people who would [otherwise] pull data and crunch it,” he adds.

3
Data Is the New Middle Manager – WSJ April 20thData Is the New Middle Manager – WSJ April 20th
In the past, says Mr. Bien, companies were beset by “data bread lines,” in which managers had all the data they needed, but their staffers had to get in line to get the information they needed to make decisions. In the world of just a few years ago, in which databases were massively expensive and “business intelligence” software cost millions of dollars and could take months to install, it made sense to limit access to these services to managers. But no more.
The result isn’t really “big data,” just more data, more readily available

4
What We Will Cover
What We Will CoverSQL
5 W's
NoSQL5 W's
When to Pick one of the above over the other
Data
What We Will Not CoverInstallation and
Operations of a database
CodingData analysis,
architecture, dashboards
5
The Problem with ProgrammersThe Problem with Programmers
Your are up to date on the latest version of your language of choice

6
The Problem with ProgrammersThe Problem with Programmers
Your are up to date on the latest version of language of choiceThe latest version of Javascript – no problemo!
7
The Problem with ProgrammersThe Problem with Programmers
Your are up to date on the latest version of language of choiceThe latest version of Javascript – no problemo!Frameworks – you know two or three or more – plus the ones you wrote yourself

8
The Problem with ProgrammersThe Problem with Programmers
Your are up to date on the latest version of language of choiceThe latest version of Javascript – no problemo!Frameworks – you know two or three or more – plus the ones you wrote yourself
But roughly 2-3% have had any training in Structured Query Language (SQL)

9
So what is SQL?!?!??!?!??!??!
http://en.wikipedia.org/wiki/SQL
SQL (/ˈɛs kjuː ˈɛl/ or /ˈsiːkwəl/; Structured Query Language) is a special-purpose programming language designed for managing data held in a relational database management system (RDBMS), or for stream processing in a relational data stream management system (RDSMS).Originally based upon relational algebra and tuple relational calculus, SQL consists of a data definition language and a data manipulation language. The scope of SQL includes data insert, query, update and delete, schema creation and modification, and data access control.

10
Oh Crap!!!
He Said 'relational algebra' and 'tuple relational calculus'!

11
Run Away!!!

12
Relational algebra
http://en.wikipedia.org/wiki/Relational_algebra
Relational algebra is a family of algebra with a well-founded semantics used for modelling the data stored in relational databases, and defining queries on it.
To organize the data, first the redundant data and repeating groups of data are removed, which we call normalized. By doing this the data is organized or normalized into what is called first normal form (1NF). Typically a logical data model documents and standardizes the relationships between data entities (with its elements). A primary key uniquely identifies an instance of an entity, also known as a record.

13
Relation Algebra Continued
Once the data is normalized and in sets of data (entities and tables), the main operations of the relational algebra can be performed which are the set operations (such as union, intersection, and cartesian product), selection (keeping only some rows of a table) and the projection (keeping only some columns). Set operations are performed in the where statement in SQL, which is where one set of data is related to another set of data.
14
So Why was SQL Developed
Very Expensive to store data

15
So Why was SQL Developed
Very Expensive to store dataSQL minimal redundanciesAncient disks, memory, systems

16
So Why was SQL Developed
Very Expensive to store dataSQL minimal redundanciesAncient disks, memory, systems
Easy logicAND, OR, XORGive me all the customers who paid off their balance
last month AND those customers with a balance of less than $10
Procedural

17
Data Architecture at the heart of SQL
Minimal duplicationsLogical layoutRelations between tablesData Normalization

18
Database Normalization Forms
1nf– No columns with repeated or similar data– Each data item cannot be broken down further– Each row is unique (has a primary key)– Each filed has a unique name
2nf– Move non-key attributes that only depend on part of the
key to a new table● Ignore tables with simple keys or no no-key attributes
3nf– Move any non-key attributes that are more dependent
on other non-key attributes than the table key to a new table.
● Ignore tables with zero or only one non-key attribute

19
In more better English, por favor!
3NF means there are no transitive dependencies.
A transitive dependency is when two columnar relationships imply another relationship. For example, person -> phone# and phone# -> ringtone, so person -> ringtone
– A → B– It is not the case that B → A– B → C
20
And the rarely seen 4nf & 5nf
You can break the information down further but very rarely do you need to to 4nf or 5nf

21
So why do all this normalization?
http://databases.about.com/od/specificproducts/a/normalization.htm
Normalization is the process of efficiently organizing data in a database. There are two goals of the normalization process: eliminating redundant data (for example, storing the same data in more than one table ) and ensuring data dependencies make sense (only storing related data in a table). Both of these are worthy goals as they reduce the amount of space a database consumes and ensure that data is logically stored.

22
Example – Cars
Name Gender Color Model
Heather F Blue Mustang
Heather F White Challenger
Eli M Blue F-type
Oscar M Blue 911
Dave M Blue Mustang
There is redundant information across multiple rows but each
row is unique

23
2nf – split into tables
Name Gender
Heather F
Eli M
Oscar M
Dave M
Color Model Owner
Blue Mustang Heather
White Challenger Heather
Blue F-type Eli
Blue 911 Oscar
Blue Mustang Dave
Split data into two tables – one for owner data and one for car data
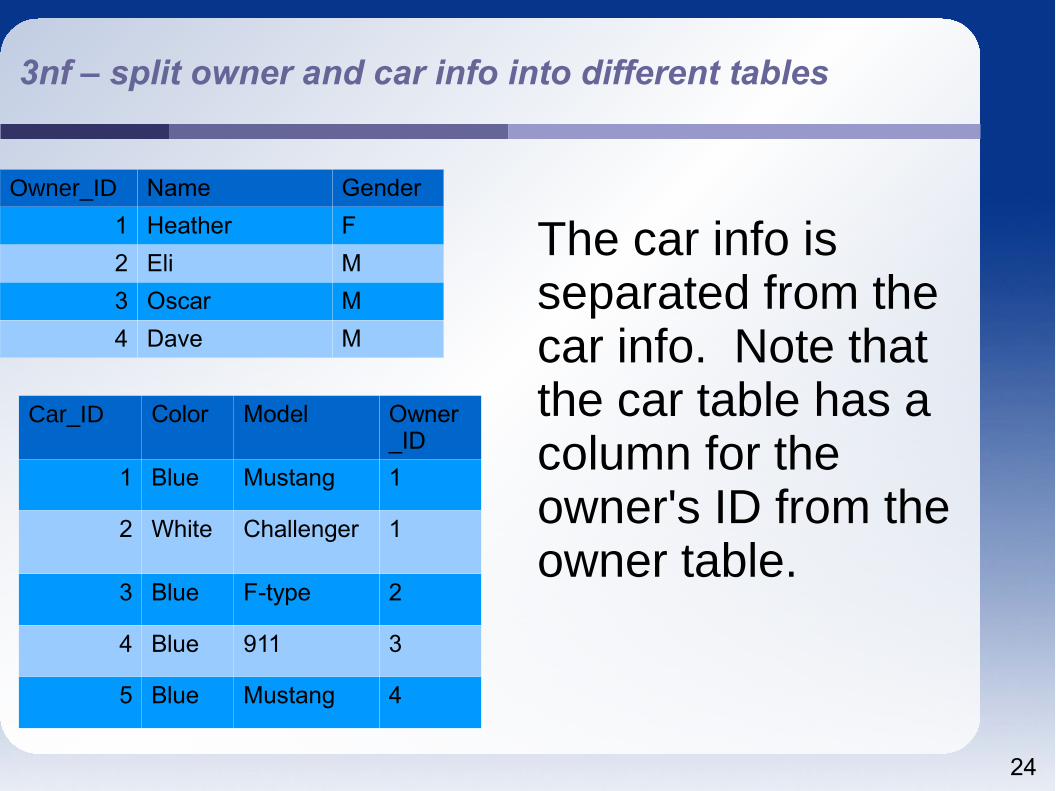
24
3nf – split owner and car info into different tables
Car_ID Color Model Owner_ID
1 Blue Mustang 1
2 White Challenger 1
3 Blue F-type 2
4 Blue 911 3
5 Blue Mustang 4
The car info is separated from the car info. Note that the car table has a column for the owner's ID from the owner table.
Owner_ID Name Gender
1 Heather F
2 Eli M
3 Oscar M
4 Dave M
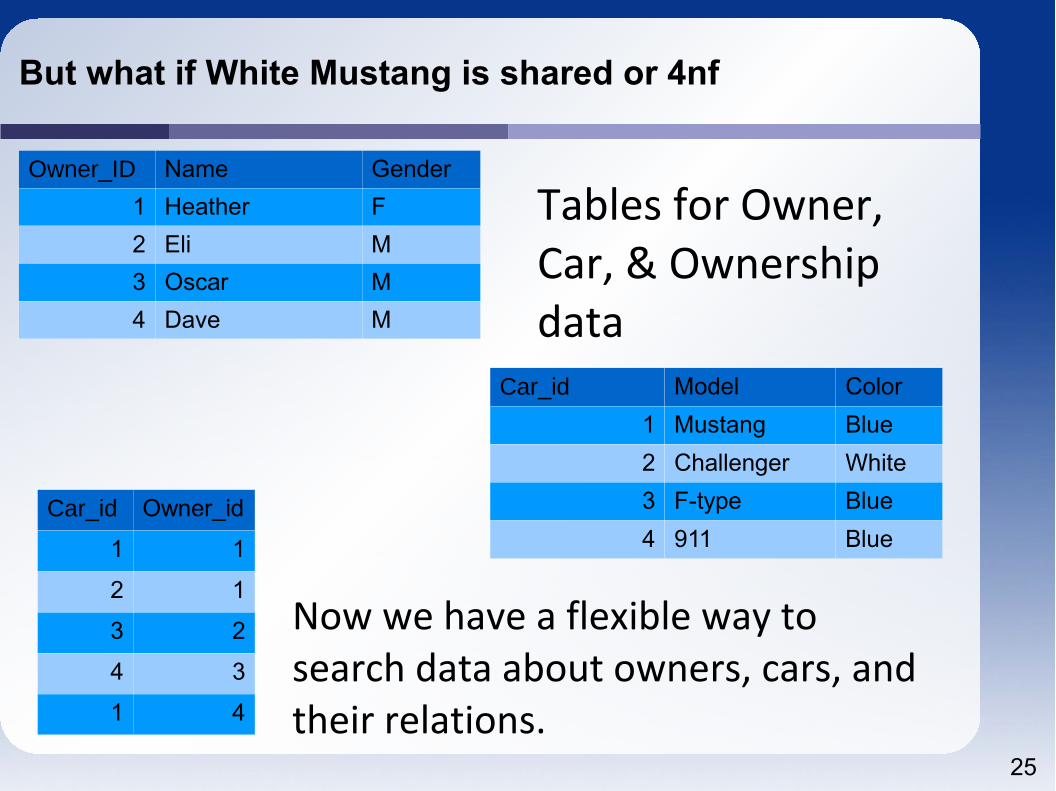
25
But what if White Mustang is shared or 4nf
Owner_ID Name Gender
1 Heather F
2 Eli M
3 Oscar M
4 Dave M
Car_id Model Color
1 Mustang Blue
2 Challenger White
3 F-type Blue
4 911 BlueCar_id Owner_id
1 1
2 1
3 2
4 3
1 4
Tables for Owner, Car, & Ownership data
Now we have a flexible way to search data about owners, cars, and their relations.
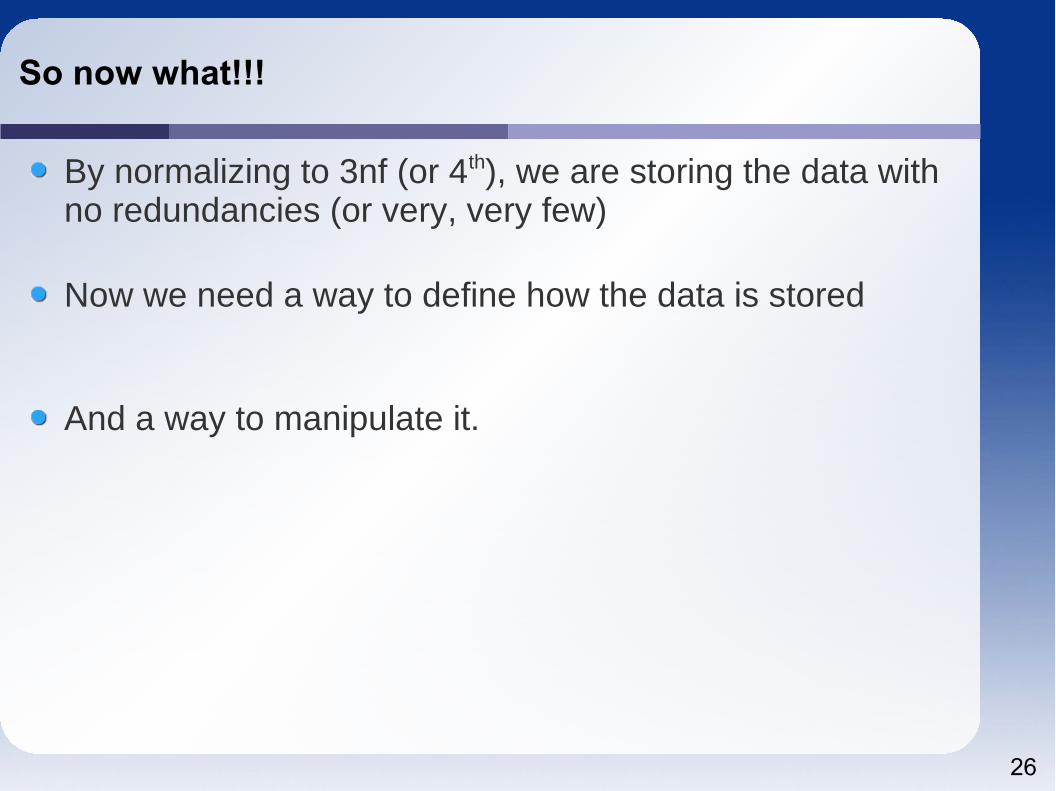
26
So now what!!!
By normalizing to 3nf (or 4th), we are storing the data with no redundancies (or very, very few)
Now we need a way to define how the data is stored
And a way to manipulate it.

27
SQL
SQL is a declarative language made up of– DDL – Data Definition Language– DML – Data Manipulation Language
SQL was one of the first commercial languages for Edgar F. Codd's relational model, as described in his influential 1970 paper, "A Relational Model of Data for Large Shared Data Banks." --Wikipedia
– Codd, Edgar F (June 1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM (Association for Computing Machinery) 13 (6): 377–87. doi:10.1145/362384.362685. Retrieved 2007-06-09.

28
Cod versus Codd

29
SQL is declarative
Describe what you want, not how to processHard to look at a query to tell if it is efficient by just looksOptimizer picks GPS-like best route
– Can pick wrong – traffic, new construction, washed out roads, and road kill! Oh my!!
You can not examine a syntactically correct SQL query by itself to determine if it is a good query.

30
SQL is made up of two parts
Data Definition Language (DDL)– For defining data structures
● CREATE, DROP, ALTER, and RENAME
Data Manipulation Language (DML)For using data
● Used to SELECT, INSERT, DELETE, and UPDATE data
31
DDL
Useful commands– DESC[ribe] table– SHOW CREATE TABLE table–

32
The stuff in the parenthesis
CHAR(30) or VARCHAR(30) will hold strings up to 30 character long.
– SQL MODE (more later) tells server to truncate or return error if value is longer that 30 characters
–
INT(5) tells the server to show five digits of data
DECIMAL(5,3) stores five digits with two decimals, i.e. -99.999 to 99.999
FLOAT(7,4) -999.9999 to 999.9999
33
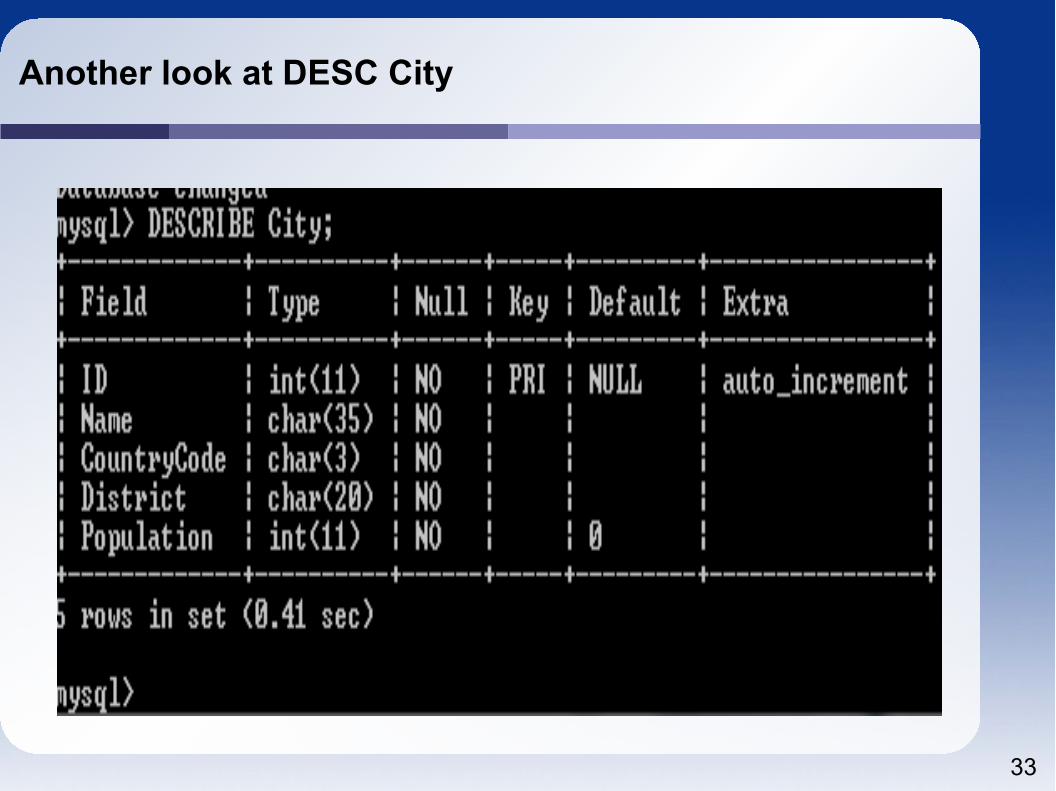
Another look at DESC City
34
NULL No Value
Null is used to indicate a lack of value or no data– Gender : Male, Female, NULL
Nulls are very messy in B-tree Indexing, try to avoidMath with NULLs is best avoided
35
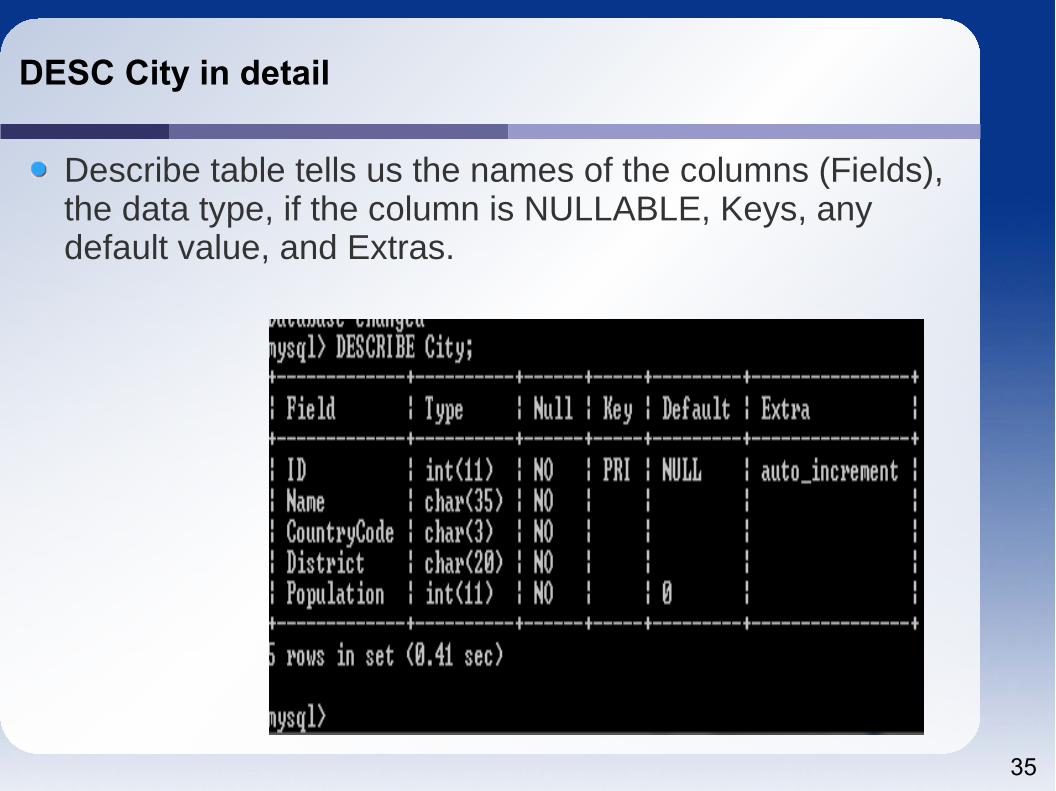
DESC City in detail
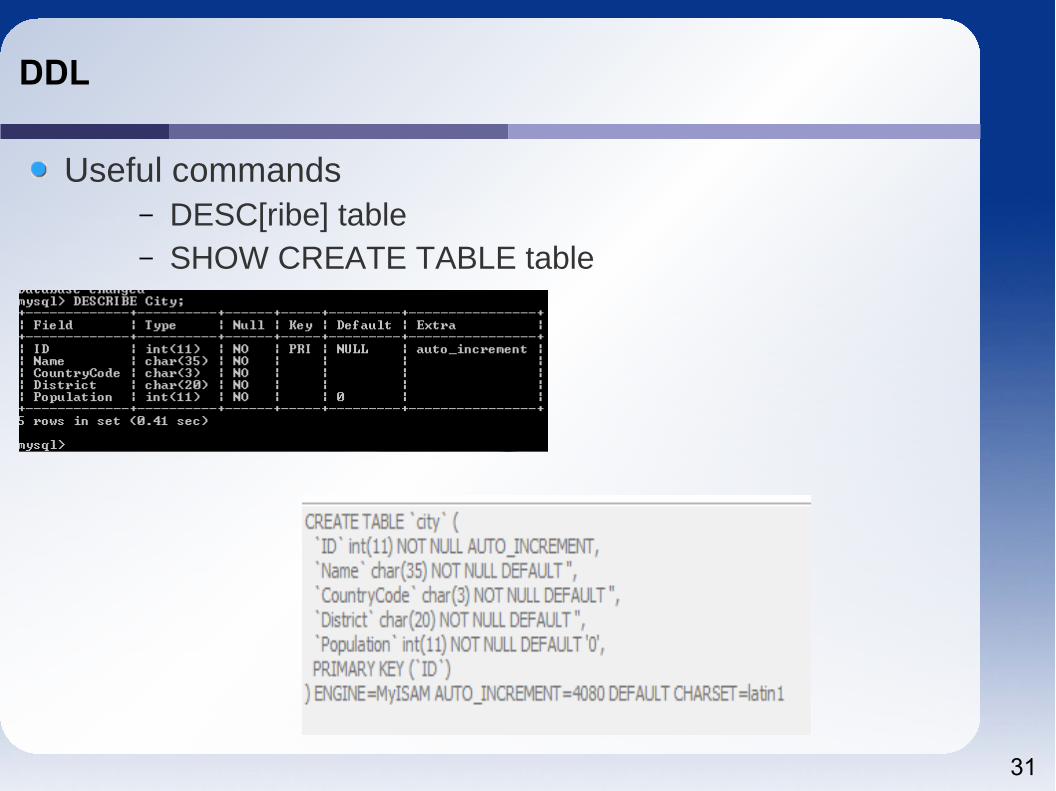
Describe table tells us the names of the columns (Fields), the data type, if the column is NULLABLE, Keys, any default value, and Extras.
36
Data Types
Varies with vendorUsually have types for text, integers, BLOBs, etc.Refer to manual
37
MySQL World Database
http://dev.mysql.com/doc/index-other.htmlUsed in MySQL documentation, books, on line tutorials, etc.Three tables
– City– Country– Country Language
38
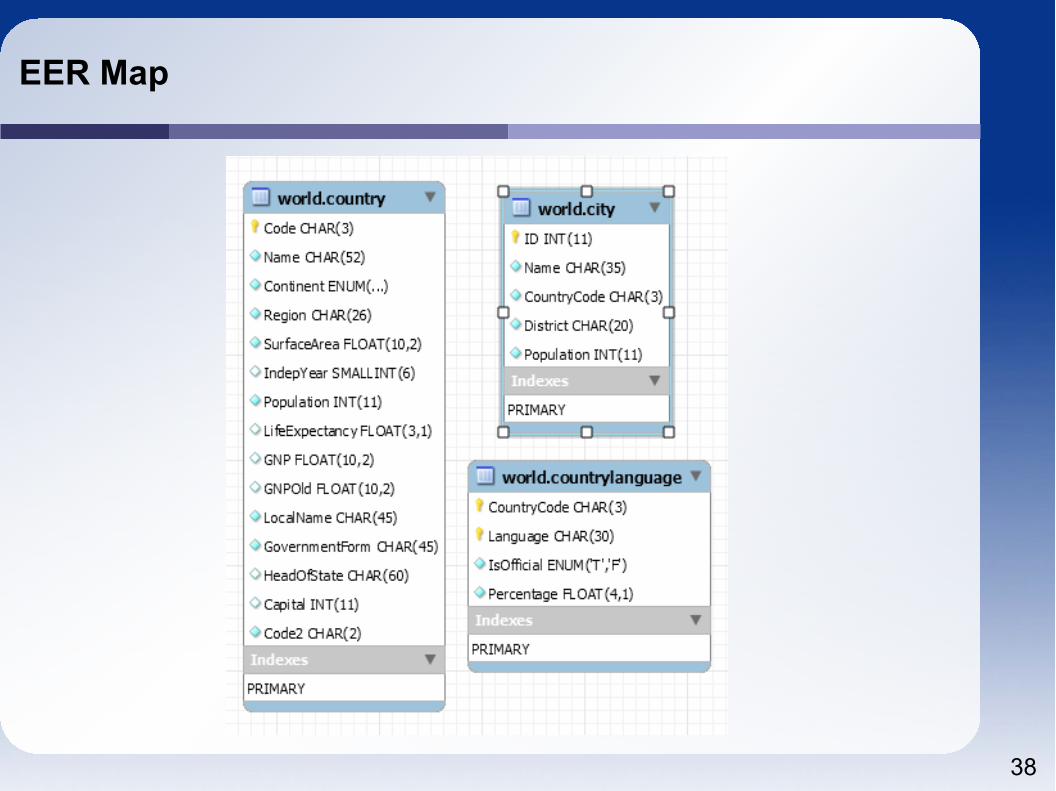
EER Map
39
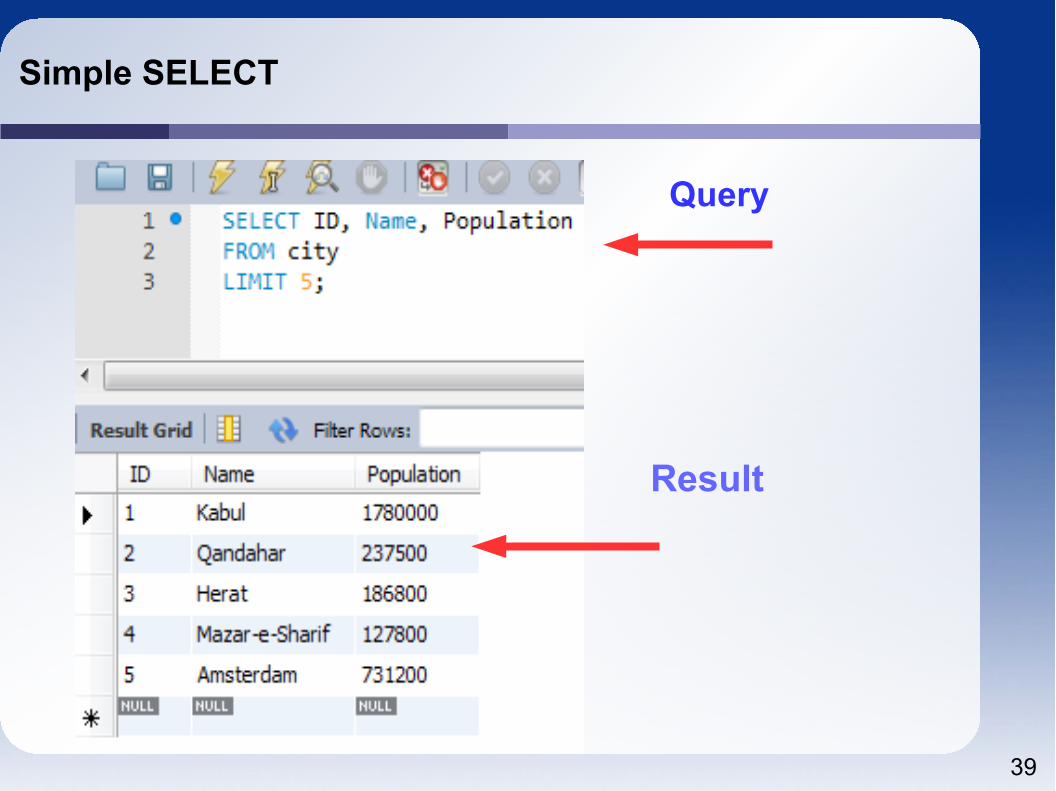
Simple SELECT
Query
Result

40
Join two tables
To get a query that provides the names of the City and the names of the countries, JOIN the two tables on a common data between the two columns (that are hopefully indexed!)
41
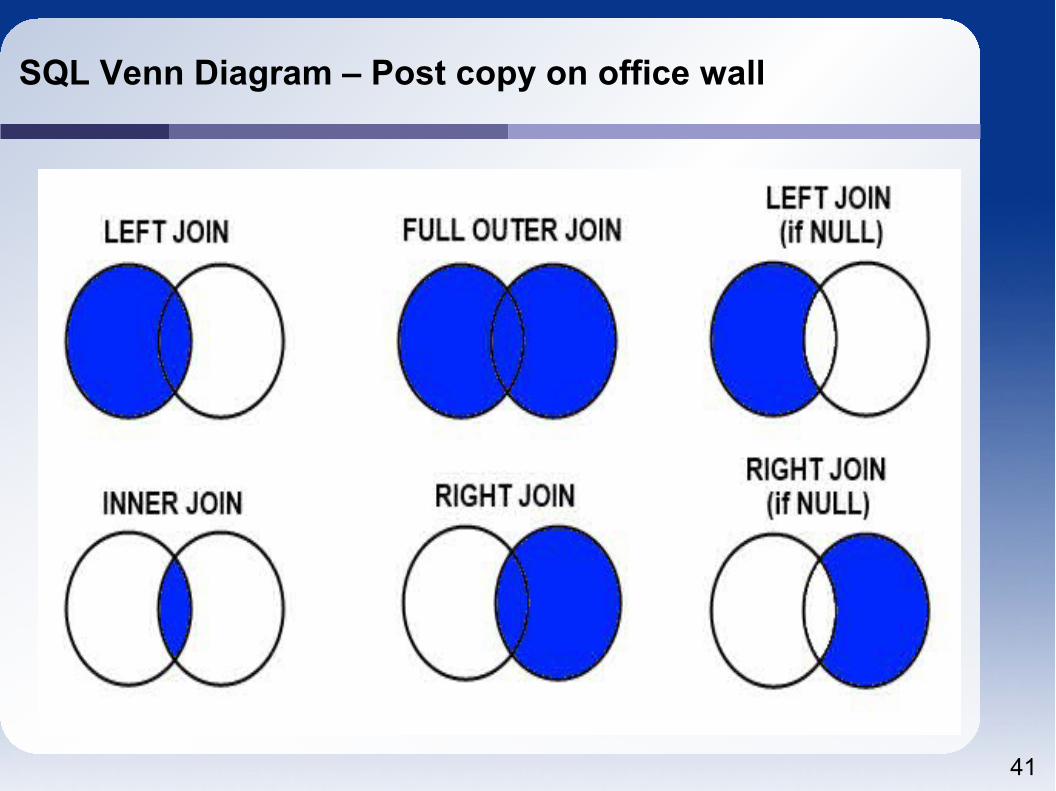
SQL Venn Diagram – Post copy on office wall
42
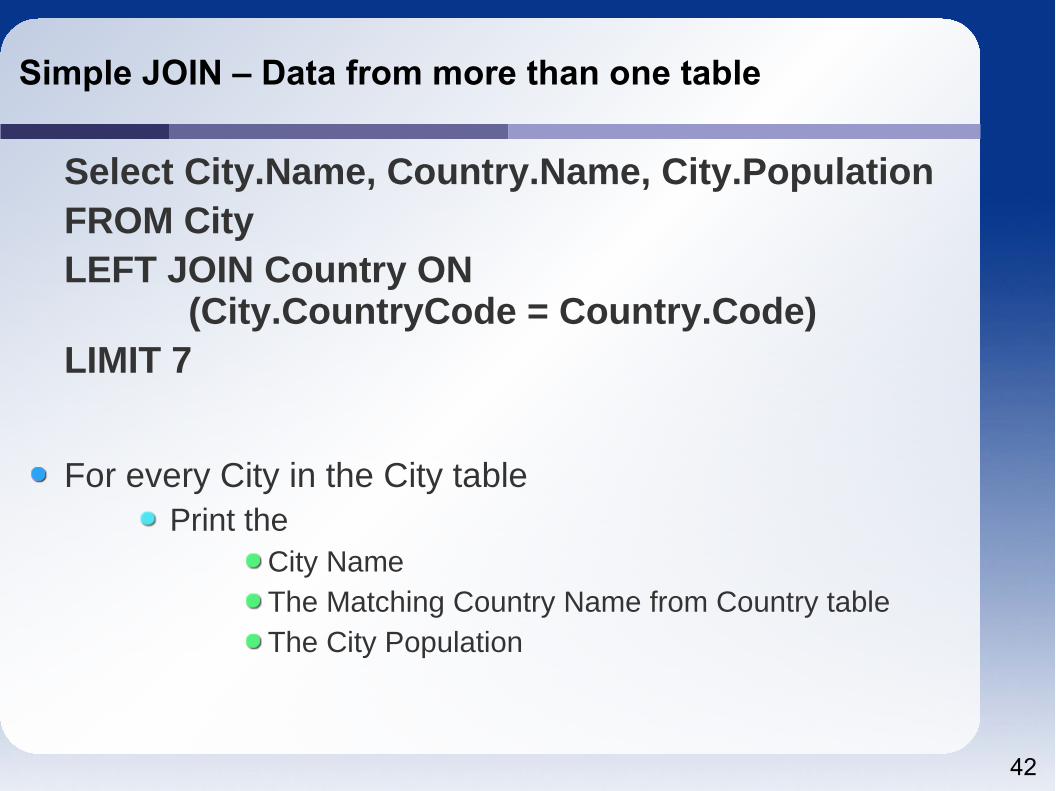
Simple JOIN – Data from more than one table
Select City.Name, Country.Name, City.PopulationFROM CityLEFT JOIN Country ON (City.CountryCode = Country.Code)LIMIT 7
For every City in the City tablePrint the
City NameThe Matching Country Name from Country tableThe City Population

43
The Optimizer has to figure out
Select City.Name, Country.Name, City.PopulationFROM CityLEFT JOIN Country ON (City.CountryCode = Country.Code)LIMIT 7
Permission to access database/tab es/columnsSix options for getting data (3 factorial)And process the limit of 7 records
44
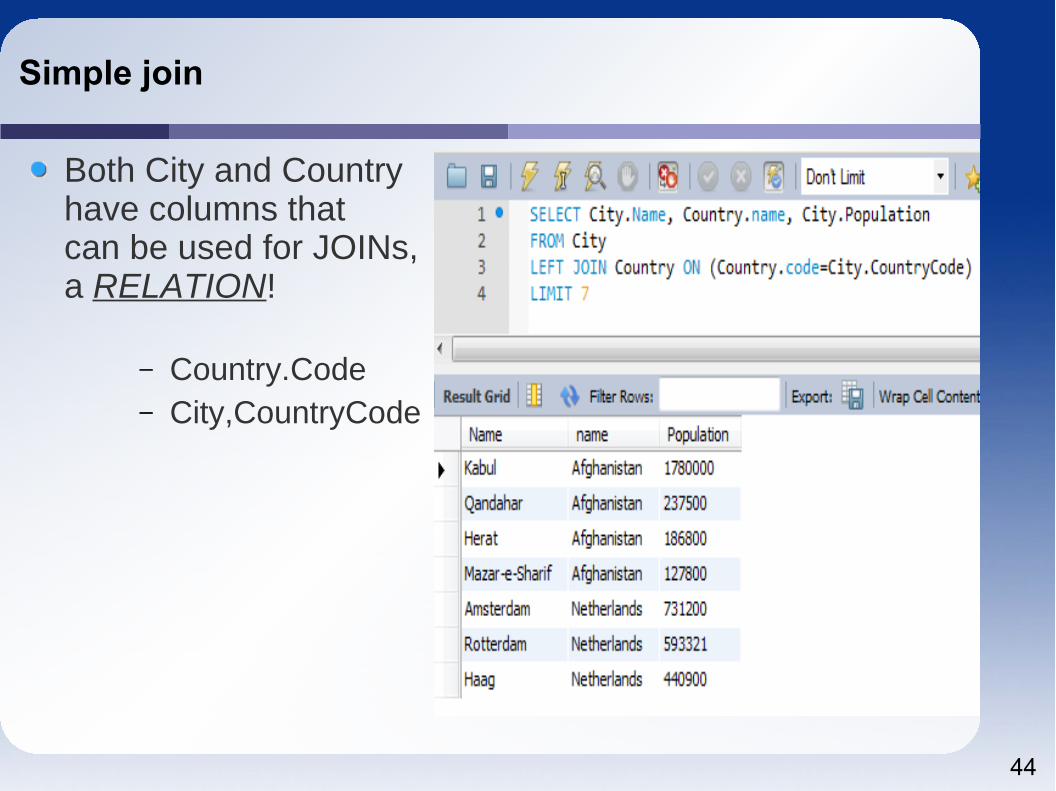
Simple join
Both City and Country have columns thatcan be used for JOINs,a RELATION!
– Country.Code– City,CountryCode

45
Transactions – ACID
Transactions are often needed to enure the quality of data
Bank Account Example
The ability to roll back actions
Set check points and roll back to these intermediate points
ACIDAtomicityConsistencyIsolationDurability

46
What happens when you send a query?
Server receives the queryThe user is authenticated for permissions
– Database, table, and/or column level
SyntaxOptimizer
– Statistics on data– Cost model
● Pick cheapest option (DISK I/O)– Changing in the future
Get the dataSorting/Grouping/etcData returned

47
EXPLAIN
EXPLAIN is pre pended to the query to show the results from the optimizer

48
VISUAL Explain
MySQL WorkbenchMySQL 5.6/5.7

49
Optimizer Trace
{ "query_block": { "select_id": 1, "cost_info": { "query_cost": "5779.32" }, "nested_loop": [ { "table": { "table_name": "City", "access_type": "ALL", "rows_examined_per_scan": 4079, "rows_produced_per_join": 4079, "filtered": 100, "cost_info": { "read_cost": "68.72", "eval_cost": "815.80", "prefix_cost": "884.52", "data_read_per_join": "286K" }, "used_columns": [ "Name", "CountryCode", "Population" ] } }, { "table": { "table_name": "Country", "access_type": "eq_ref", "possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"Code"
],
"key_length": "3",
"ref": [
"world.City.CountryCode"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 4079,
"filtered": 100,
"cost_info": {
"read_cost": "4079.00",
"eval_cost": "815.80",
"prefix_cost": "5779.32",
"data_read_per_join": "1M"
},
"used_columns": [
"Code",
"Name"
For the folks who have to eek out the last 1% of performance.

50
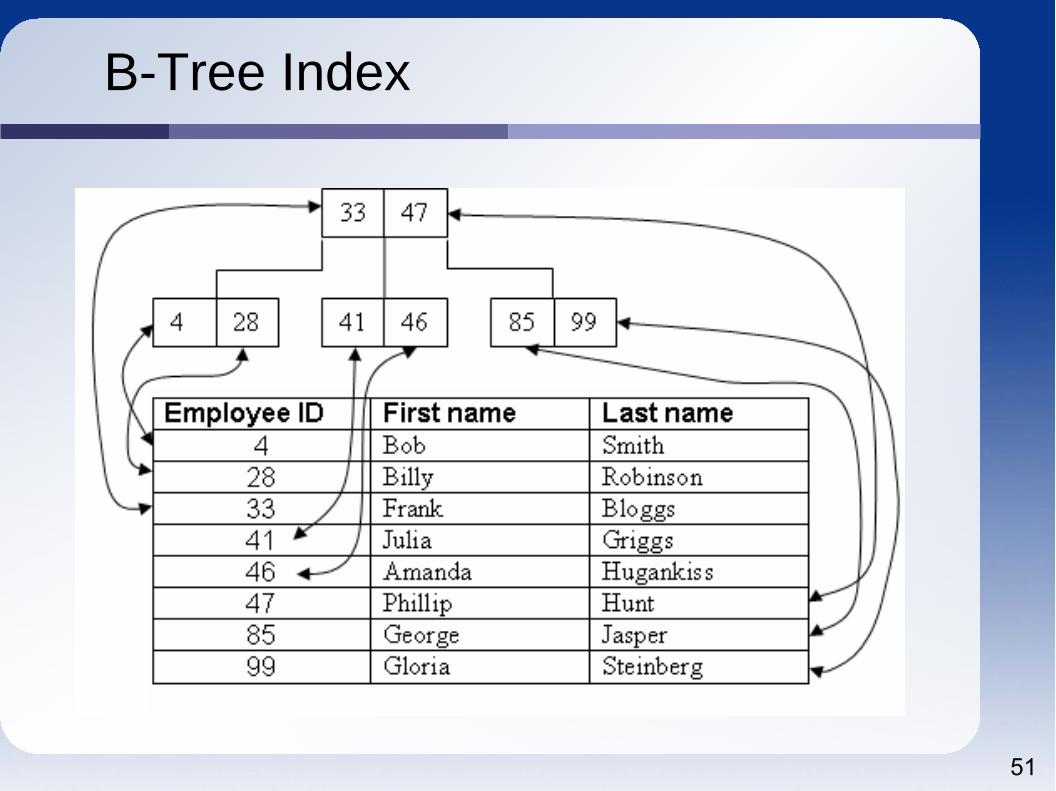
Indexes in a Nutshell
Indexes provide direct access to record desired
Primary KeyMoose example
Cardinality is the measure of number of variants in indexed column(s)
Higher the better
General rulesKeep as short as
possibleIndex any column
used for joins
OverheadInserts, updates,
deletes need processing
Maintenance
Too many as worse than too fewCan be used to 'cover' multiple columns
Can sometimes 'drag' result with index
51
B-Tree Index

52
Where SQL Gets Hard to Optimize
Goal:A list of the top 100
customers (from 10 million) by sales
'All I want is a 100 rows, why does the server look at all customers?'
?

53
Where SQL Gets Hard to Optimize
Goal:A list of the top 100
customers (from 10 million) by sales
'All I want is a 100 rows, why does the server look at all customers?'
It has to perform a full table scan before it can sort the top 100!

54
N+1 Problem
Goal:List of all customers
with positive account balances and their credit ratings
Usually the query is written to get all customers with balances and then separate queries to each credit rating → each customer query also generates three more queries
?

55
N+1 Problem
Goal:List of all customers
with positive account balances and their credit ratings
Usually the query is written to get all customers with balances and then separate queries to each credit rating → each customer query also generates three more queries
Better queryReduce the number
of queries
Data ArchitectureKeep credit data in
customer record
56
Ordering/Sorting → temporary tables
Goal:List of all customers
ordered by state, by zipcode, area-code, last name, first name, and customer id number
?
57
Ordering/Sorting → temporary tables
Goal:List of all customers
ordered by state, by zip code, area-code, last name, first name, and customer id number
All the sorting takes time, memory, maybe temporary disk spaceIndexes on data may help

58
Object Relation Manager
ORMs try to map SQL, a declarative language, to Objects.May produce less than optimal SQLobject-relational impedance mismatchExtra layer to maintain/debug/support
Most use Prepared Statements to facilitate queries
Often easier to write SQL from the beginning

59
NoSQL
So if SQL is so great, why is there NoSQL???
Not all data relationalFriend of Friend of
your friends 'Facebook query'
Graphical data
Structure of dataDocument databases
No Structure in the dataMay have no idea of
data structure but want to capture all of it
Amorphous data

60
http://en.wikipedia.org/wiki/NoSQL
A NoSQL (often interpreted as Not only SQL) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. Motivations for this approach include simplicity of design, horizontal scaling, and finer control over availability. The data structures used by NoSQL databases (e.g. key-value, graph, or document) differ from those used in relational databases, making some operations faster in NoSQL and others faster in relational databases. The particular suitability of a given NoSQL database depends on the problem it must solve.

61
http://en.wikipedia.org/wiki/NoSQL
NoSQL databases are increasingly used in big data and real-time web applications. NoSQL systems are also called "Not only SQL" to emphasize that they may also support SQL-like query languages. Many NoSQL stores compromise consistency (in the sense of the CAP theorem) in favor of availability and partition tolerance. Barriers to the greater adoption of NoSQL stores include the use of low-level query languages, the lack of standardized interfaces, and huge investments in existing SQL. Most NoSQL stores lack true ACID transactions

62
http://en.wikipedia.org/wiki/Big_data
Big data is a broad term for data sets so large or complex that traditional data processing applications are inadequate. Challenges include analysis, capture, curation, search, sharing, storage, transfer, visualization, and information privacy. The term often refers simply to the use of predictive analytics or other certain advanced methods to extract value from data, and seldom to a particular size of data set.

63
http://en.wikipedia.org/wiki/Big_data 2
Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time. Big data "size" is a constantly moving target, as of 2012 ranging from a few dozen terabytes to many petabytes of data. Big data is a set of techniques and technologies that require new forms of integration to uncover large hidden values from large datasets that are diverse, complex, and of a massive scale

64
Is NoSQL OR Big Data new
NoSQLNo:Key/Value pair
BDBHash
Yes:Map/ReduceGraphical
Big DataNo
Data Warehouses
Large data sets
Yes'Never throw
any data away'
Increased data feeds
“better” analytics

65
When Are You At The Limits of SQL?
Working Set No Longer Fits in Memory Drinking From 'Fire House'Not really OLTP Work Load
Possible Data Warehouse AlternativeAnalysis Tools Do Not Need Transactions
Speed, lack there of …Disk Space Reaching MaximumSegregation of Data
Transactions needed versus No Transaction
Security/SOX/Regulatory needsProject NeedsExploration

66
NoSQL Database Types
Key-ValueData stored as a blobRiak, Memached,
Redis, Berkeley DB, Couchbase …
Document Data stored as XML,
JSON, BSON; Self describing tree structure
Mongo, Couchbase
ColumnStores data vertically,
easy to compressCassandra, Hbase,
Hypertable …Sometimes available
in RDMS
GraphStores Relations
between entities

67
You have you choice of hammers ...
What ARE you trying to solve??
Fully Describe Problem
FeedsOutputsProcesses
Identify ConstraintsTime$StaffSanityPolitical
Intangibles

68

69
Stoker's Categories
Divide and Conquer Relations
RepackageLibrary

70
Divide and Conquer – Data in Manageable Pieces
71
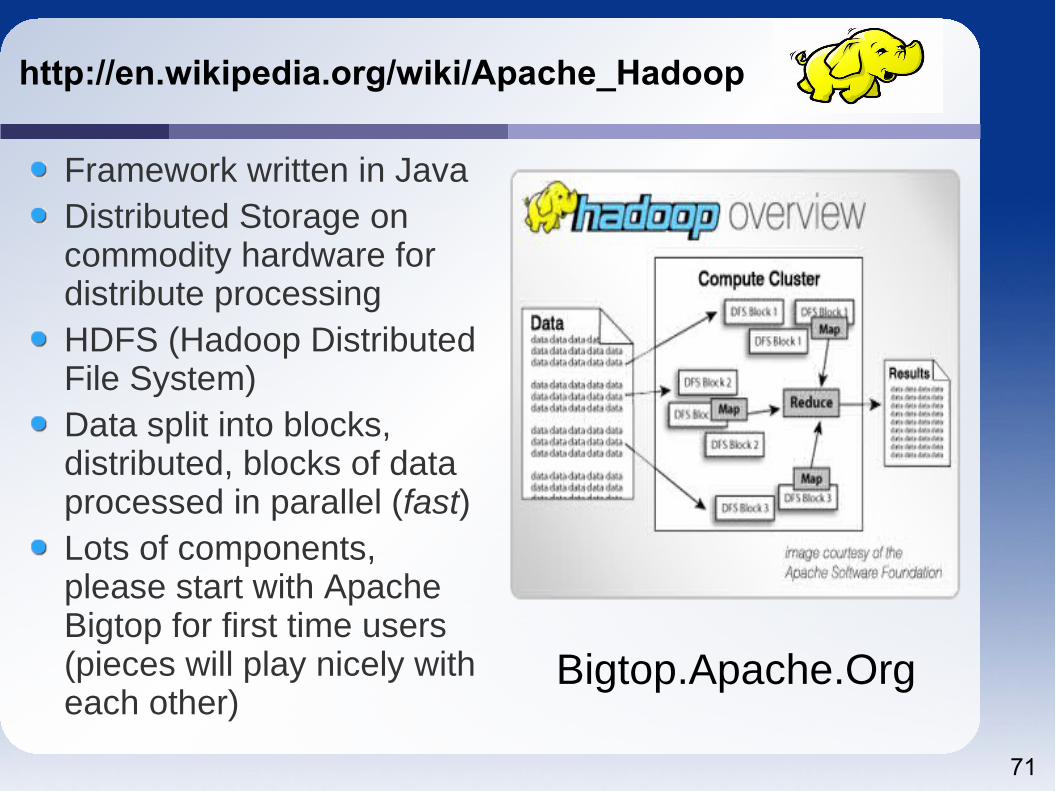
http://en.wikipedia.org/wiki/Apache_Hadoop
Framework written in JavaDistributed Storage on commodity hardware for distribute processingHDFS (Hadoop Distributed File System) Data split into blocks, distributed, blocks of data processed in parallel (fast)Lots of components, please start with Apache Bigtop for first time users (pieces will play nicely with each other)
Bigtop.Apache.Org

72
Map/Reduce http://en.wikipedia.org/wiki/MapReduce
MapReduce is a programming model for processing and generating large data sets with a parallel, distributed algorithm on a cluster …
A MapReduce program is composed of a Map() procedure that performs filtering and sorting (such as sorting students by first name into queues, one queue for each name) and a Reduce() procedure that performs a summary operation (such as counting the number of students in each queue, yielding name frequencies).
73
Relationships – Study the Connections
74
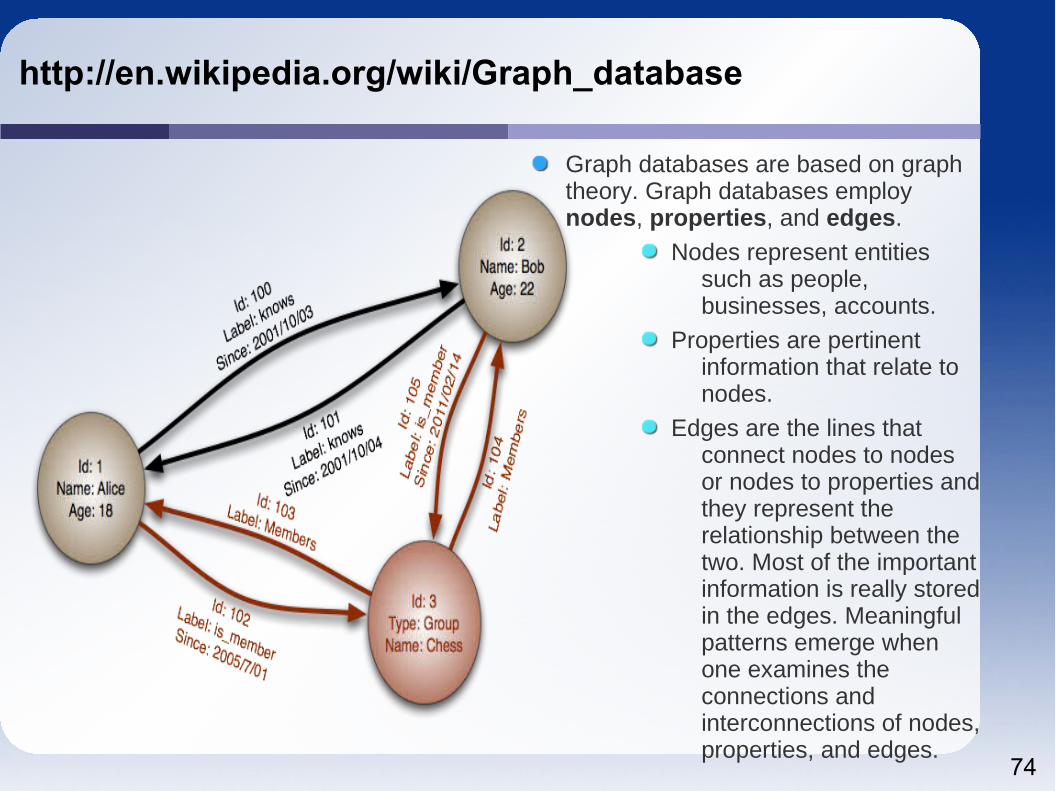
http://en.wikipedia.org/wiki/Graph_database
Graph databases are based on graph theory. Graph databases employ nodes, properties, and edges.
Nodes represent entities such as people, businesses, accounts.
Properties are pertinent information that relate to nodes.
Edges are the lines that connect nodes to nodes or nodes to properties and they represent the relationship between the two. Most of the important information is really stored in the edges. Meaningful patterns emerge when one examines the connections and interconnections of nodes, properties, and edges.

75
Neo4j http://en.wikipedia.org/wiki/Neo4j
Neo4j is an open-source graph database, implemented in Java. The developers describe Neo4j as "embedded, disk-based, fully transactional Java persistence engine that stores data structured in graphs rather than in tables". Neo4j is the most popular graph database.
Grate for studying relationshipsSix Degrees of Kevin Bacon like questions

76
Library – Common Meta Data

77
Document Databases - http://en.wikipedia.org/wiki/MongoDB
MongoDB is one of many cross-platform document-oriented databases. Classified as a NoSQL database, MongoDB eschews the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas (MongoDB calls the format BSON), making the integration of data in certain types of applications easier and fasterInstead of taking a business subject and breaking it up into multiple relational structures, MongoDB can store the business subject in the minimal number of documents. For example, instead of storing title and author information in two distinct relational structures, title, author, and other title-related information can all be stored in a single document called Book, which is much more intuitive and usually easier to work with.

78
Columnar Databases

79
Vertical Data
Compress the heck out of columnVery quick to readGreat for low cardinality data
Fantastic for analytic queries, i.e. MIN, MAX, AVG...May react like more conventional RDMS and be more 'comfortable'

80
So We've Hard The Tour – Now What??

81

82
Hybrids – Best of Both
MySQL NoSQL plug-in for InnoDBJSON data manipulation
PostgreSQLMySQL
SQL on top of HadoopColumnar Databases from RDMS Vendors
83
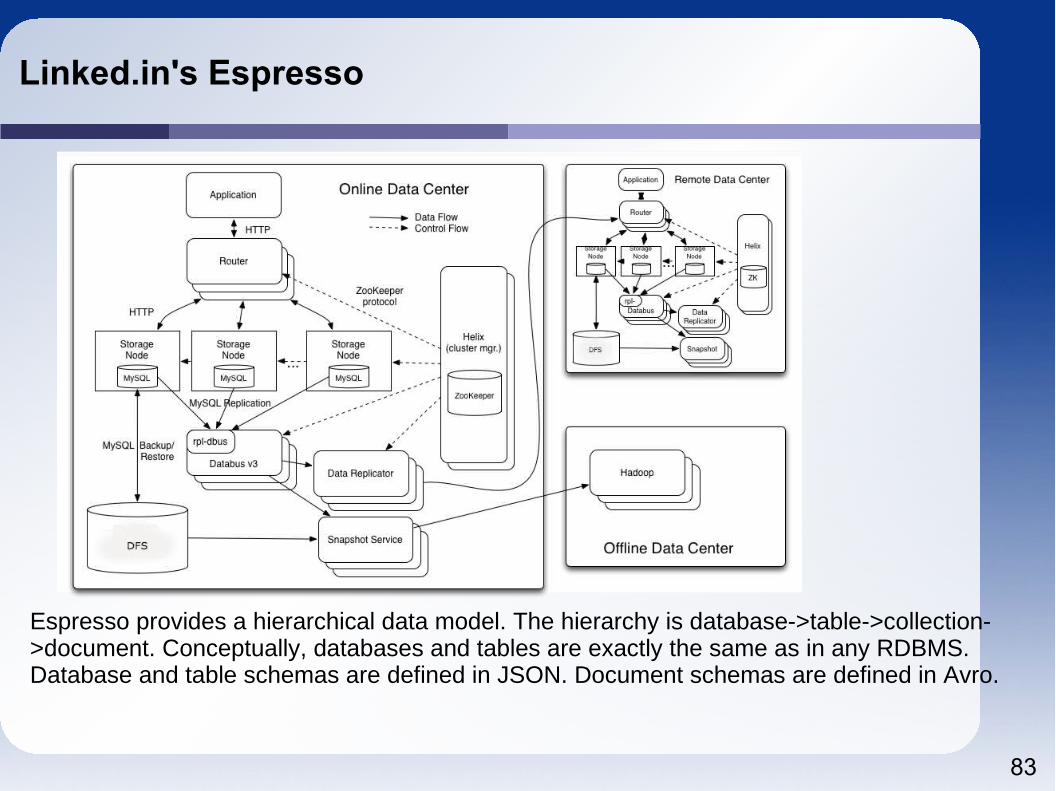
Linked.in's Espresso
Espresso provides a hierarchical data model. The hierarchy is database->table->collection->document. Conceptually, databases and tables are exactly the same as in any RDBMS. Database and table schemas are defined in JSON. Document schemas are defined in Avro.

84
Functional Programming As An Alternative
functional programming is a programming paradigm, a style of building the structure and elements of computer programs, that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data. It is a declarative programming paradigm, which means programming is done with expressions. In functional code, the output value of a function depends only on the arguments that are input to the function, so calling a function f twice with the same value for an argument x will produce the same result f(x) each time. Eliminating side effects
85
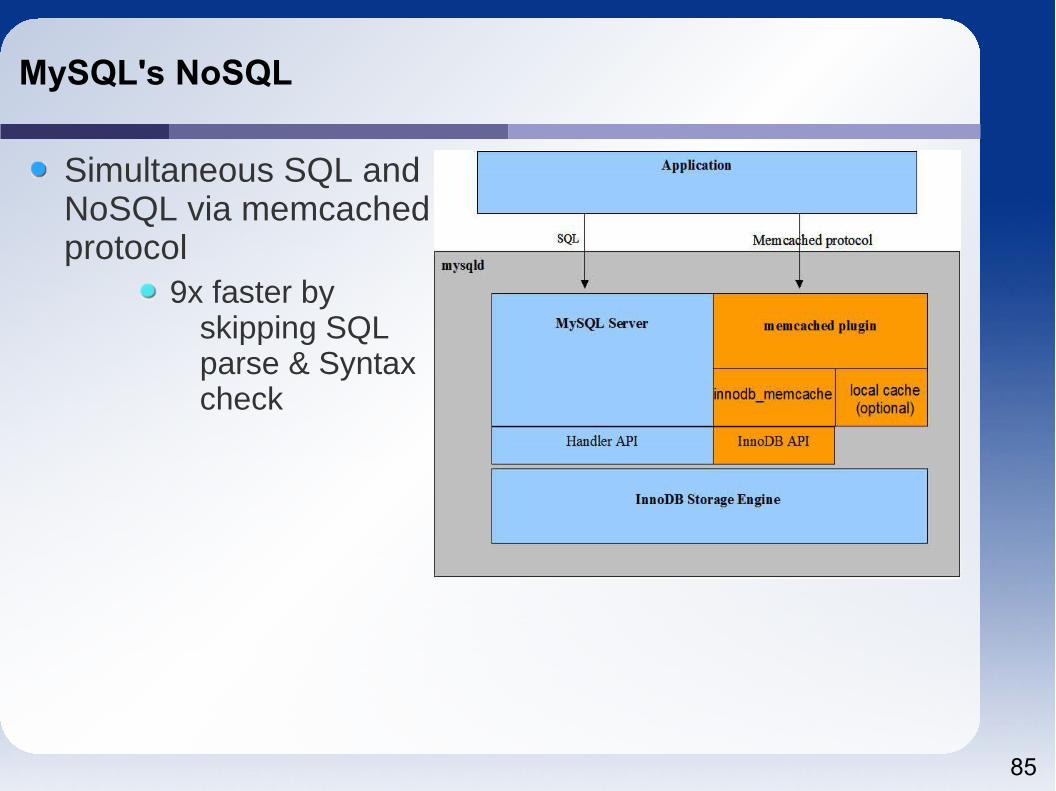
MySQL's NoSQL
Simultaneous SQL and NoSQL via memcached protocol
9x faster by skipping SQL parse & Syntax check

86
Now What?!?!?!

87
Books
SQL Antipatterns -Bill KarwinSQL and Relational Theory -CJ Date

88
Summary & Q&A
Define WHAT you are trying to accomplishSet goals
PerformanceFunctionalitySkills
Do a lot of reading/testing/questioning
[email protected] @StokerSlideshare.net/davestokes or conference web site


















