200
BIG DATA ANALYTICS & DATA WAREHOUSING Breakthrough Insight
| Date post: | 20-Aug-2015 |
| Category: |
Technology |
| Upload: | atidan |
| View: | 975 times |
| Download: | 0 times |

BIG DATA ANALYTICS & DATA WAREHOUSING Breakthrough Insight

THE FANTASTIC 12 OF 2012
4 3 2 1
11 12 10 9
8 5 7 6

SCALABLE DATA WAREHOUSING & ANALYTICS GAIN SCALE & FLEXIBILITY FOR MASSIVE SCALE AT LOW COST




SOFTWARE SQL Server 2012: Self-build Data Warehouse
Ideal for custom data marts or small to mid-sized data
warehouses
Proven technology
Most integrated out-of-the-box BI solution with no extra fees
Control costs with no hardware vendor lock-in
Large partner ecosystem
Blazing-fast performance with xVelocity in-memory
technologies
Support for up to 256 logical cores
Table partitioning scales to 15,000 partitions

REFERENCE ARCHITECTURES Fast Track Data Warehouse: Guided-build DW (Balanced Optimizations)
Tuned and optimized for data warehousing
Eliminate guesswork to build HW box and balance CPU, IO, Storage
with SW
Next-generation performance with xVelocity
Required 9’s of availability
All the features of SQL Server 2012
xVelocity in-memory technologies for performance
AlwaysOn for mission critical availability
Latest generation of hardware
Best practices guide to build HW, install, configure, tune SW
Choice of storage with traditional HDDs or SSDs
Choose from 7 industry-standard hardware vendors including HP, Dell,
IBM, EMC, Cisco, Nimbus, XIO
Configurations as low as $8K per TB
Scale from 5 to 95 TB
Major components of BI and EIM included in purchase

APPLIANCES Parallel Data Warehouse: Pre-built DW (Massive Scale at Low Cost)
Handles midrange - largest data warehousing scale requirements
Fastest time to solution (plug and play) – shipped to your door HW + SW pre-tested, integrated, configured
Hardware pre-built (SAN, switches, cables, drives, adapters, CPU)
Out-of-the-box integration with Microsoft BI solution
Interoperable with Informatica, Microstrategy, SAP BO
Unstructured or semi-structured data from various sources
80-600+ TB with up to 4 full racks from under $12K per TB
0-80 TB half racks available
Highest level of co-engineering with open, industry standard HW
partners
Integrated premier support for entire appliance (HW + SW)
22 Intel Westmere procs / rack; 132 physical cores / rack
Massively Parallel Processing (MPP) for most powerful distributed
computing and scale
Connector to Apache Hadoop with SQOOP (SQL to Hadoop)



FASTEST TIME TO SOLUTION AT LOWEST COST Lowest Total Cost of Ownership
Save hundreds of thousands on new license and maintenance
costs migrating to SQL Server
Save 450% on ongoing administration cost than leading vendors
Get deployed immediately with choice of form factors
Deploy on open industry hardware without vendor lock-in that your IT staff already knows
Choice of form factors – Reference Architectures or Appliances
Co-developed with HW – pre-tested, pre-configured, pre-tuned
Open industry standard hardware – Intel x86
Installs 4x faster – than other leading vendors
Lowest cost of ownership – maintenance, IT staffing, installation,
configuration, operations
Lowest cost of acquisition – price/performance



FAST TRACK DATA WAREHOUSE Accelerate your data warehouse road map
Benefits Tuned and optimized for data warehousing
Rapid deployment
Complete out-of-the-box BI solution with no extra fees
Blazing-fast performance with ColumnStore Index
Choice of storage with traditional HDDs or SSDs
Key Features Configurations as low as $11K per TB
Scale from 4 to 80 TB
Choose from 11 industry-standard hardware vendors
including Dell, HP, Bull, IBM, EMC & more
All the features of SQL Server 2012


FAST TRACK 4.0 – THROUGHPUT & CAPACITY

LATEST HARDWARE FROM MAJOR VENDORS Choice, Flexibility, And Value

DOUBLING OF THROUGHPUT IN BENCHMARK TEST SQL Server 2012 Columnstore Indexes
Test System Fast Track Data Warehouse 3.0 HP DL380 reference architecture
SQL Server 2008 R2
20 TB data warehouse
2.4 GB/s throughput on 1TB benchmark schema
Configuration Changes Upgrade to SQL Server 2012
Apply ColumnStore indexes to benchmark schema
No query changes
No hardware changes

DOUBLING OF THROUGHPUT IN BENCHMARK TEST SQL Server 2012 Columnstore Indexes Cont...
SQL Server 2012 ColumnStore Index Scenario Apply ColumnStore Index to benchmark schema
No query changes
No Hardware changes


cMLC* $/GB NOW SUPERIOR TO SAS HDD FOR DW

eMLC* IS COMPETITIVE EVEN AT $6/GB LIST



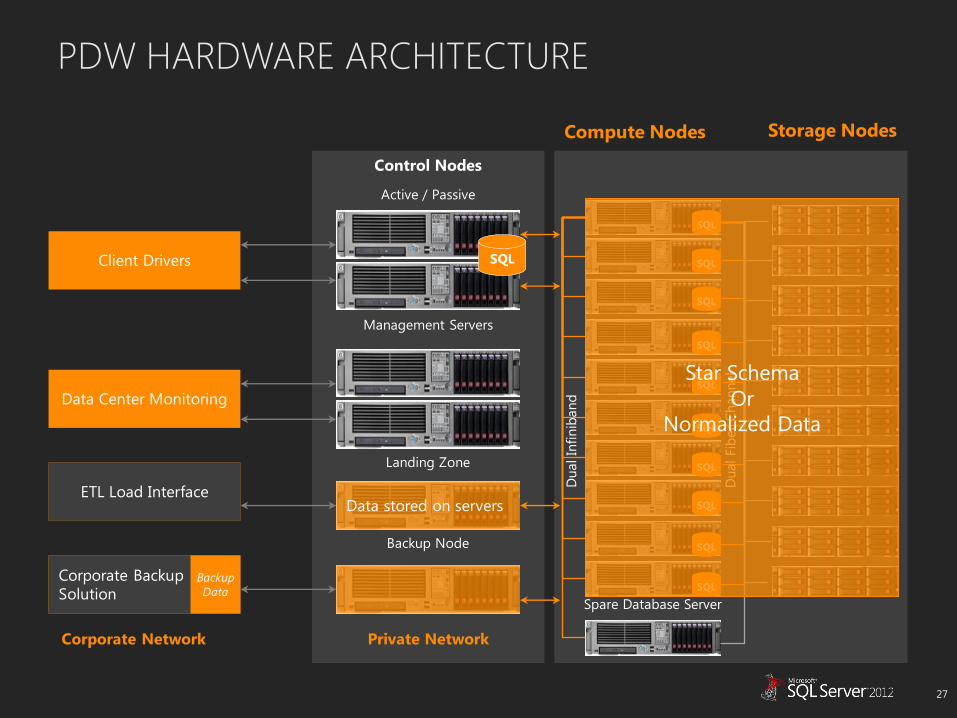

LOGICAL ARCHITECTURE

CONTROL NODE


MANAGEMENT NODE

MANAGEMENT NODE

LANDING ZONE


BACKUP NODE

BACKUP NODE

“PDW NODE”

COMPUTE NODES

STORAGE NODES
Dual fiber channel controllers Active/Active
Provides fault tolerance


STORAGE NODE – PHYSICAL FILE LAYOUT

DATA STRATEGIES IN PDW

DATA LAYOUT APPROACHES
Replicated: A table structure that exists as a full copy within each discrete PDW Node.
Distributed: A table structure that is hashed on a single column and uniformly distributed across all nodes on the appliance. Each distribution is a separate physical table in the DBMS.
Shared Nothing: The ability to design a schema of both distributed and replicated tables to minimize data movement between nodes. Small sets of data can be more efficiently stored in full (replicated).
Certain set operations (i.e., single-node operations) are more efficient against full sets
of data.


CREATING A DISTRIBUTED TABLE

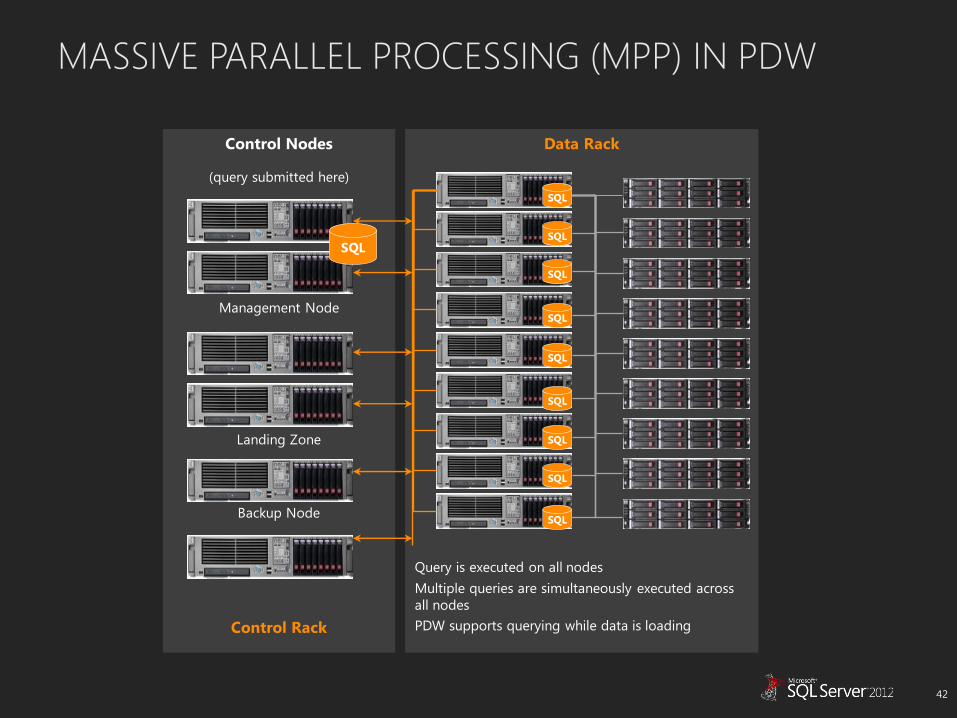
PDW SOFTWARE ARCHITECTURE


DSQL – DISTRIBUTION INCOMPATIBILITY
A DSQL query that requires redistribution of data between DBMS instances within an appliance to create the result set.
Common examples of incompatible SQL: When a distribution key is not used in join or grouping functions applied
against distributed tables
When a replicated table outer-joins with a distributed table



POWER OF PDW


INTEGRATION WITH PDW
SQL Server – Remote Table Copy Only MPP-to-SMP supported
Must be co-located and on same Infiniband network
Requires Infiniband HCA card in SQL Server or Fast Track server
Sample transfer rate to 4-socket 24-core server
300 – 600 MB per second including compression factor
SSAS – PDW ADO.NET driver
SSIS – PDW ADO.NET driver
SSRS – PDW ADO.NET driver
MPP-to-MPP integration requires SSIS
Remote Table Copy is not available for Non-SQL Server databases



WHAT IS NEW IN PDW APPLIANCE UPDATE 3 (AU3)


PDW AU3 OFFERS HIGH VALUE TO CUSTOMERS



AU3 SHELL DB ENABLES COST BASED OPTIMIZATION
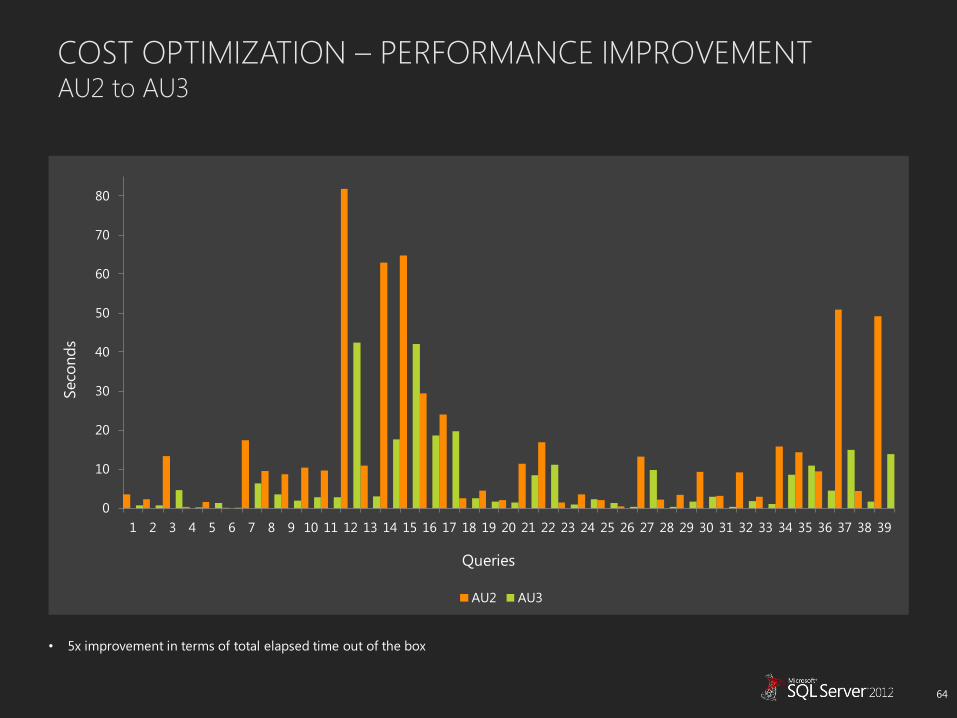
COST OPTIMIZATION – PERFORMANCE IMPROVEMENT AU2 to AU3
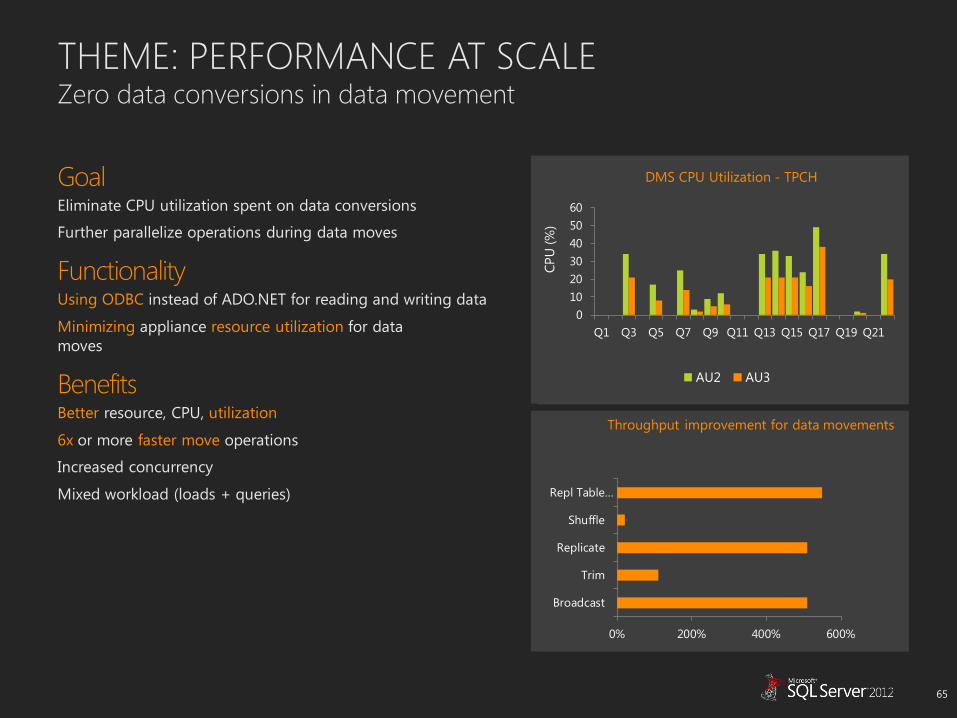
THEME: PERFORMANCE AT SCALE Zero data conversions in data movement
AU2 AU3




UPDATING STATISTICS ON PDW


7
2






BI SCENARIO: PDW AS A ‘DATA HUB’
MPP ‘data hub’ Fast and parallel feeding of data marts (DMs) via Infiniband
CREATE REMOTE TABLE AS SELECT
Aggregation abilities avoids ETL overhead in existing systems
No need for indexes
No need to maintain indexed/materialized views (summary tables)



EXAMPLE AGGREGATED TABLE:

QUERYING AND DATA ANALYSIS BEST PRACTICES Observed data analysis pattern




Dimensional properties to change









PDW KEYS

ADDING INFINIBAND TO SSAS

MAX NUMBER OF CONNECTIONS
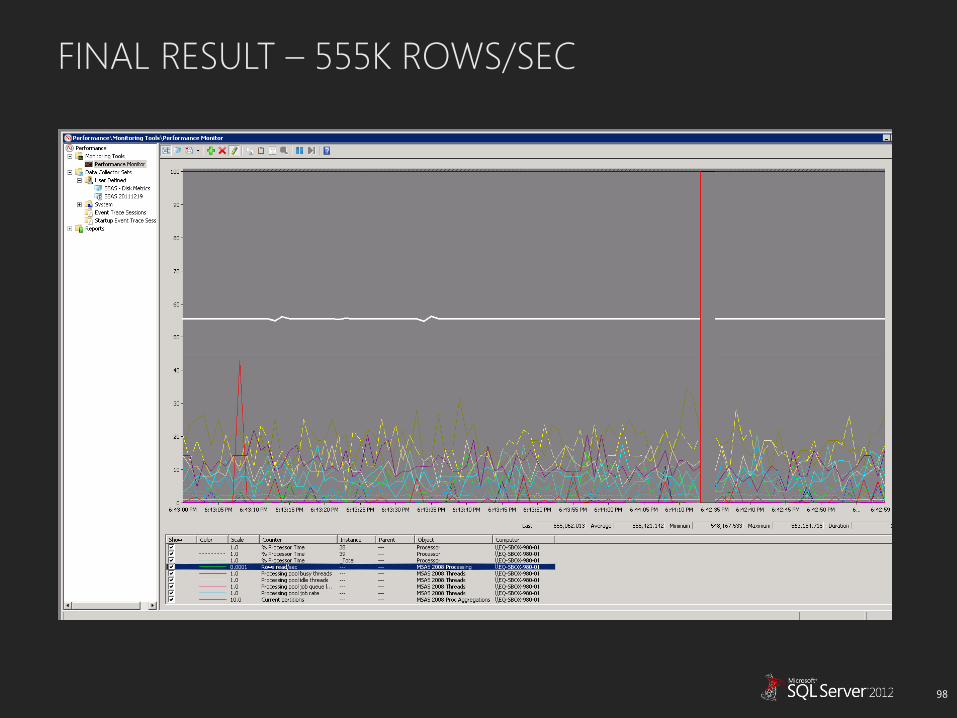
FINAL RESULT – 555K ROWS/SEC

PDW KEYS




CUSTOMER SUCCESSES – CONT’D How are customers using PDW for BI ?
Data Volume 36 TB data warehouse analyzing data from transactional and
clickstream sources
Business need to expand to 7 year data window
(currently 1 year data)
Requirements Scalability - growing data volume does not affect performance
Performance and ad-hoc analysis for interactive querying
by users
BI Integration with Microsoft BI stack - SSAS and SSRS
AU3 Feedback SSAS cubes worked ‘out-of-box’
Performance an order of magnitude faster than existing system
(~30x on an expanded data set)

HP BUSINESS DATA WAREHOUSE APPLIANCE


HP HARDWARE
Server HP ProLiant DL370 G6 x 5670 (4U)
2x Westmere processors (12 cores)
96 GB of RAM
Storage 24 x internal SFF SAS disks
2 x Smart Array controllers and SAS expander
2 TB physical user storage (up to 8 TB compressed)


SYSTEM VERIFICATION

WINDOWS MOUNT POINT VERIFICATION

DATABASE CONFIGURATION

SYSTEM CENTER OPERATIONS MANAGER Appliance Management Pack
Extents Fragmentation TOP 20 large tables
Fragmentation Thresholds
Avg Fragment Size in pages > 400 : Green
Avg Fragment Size in pages 300-400: Yellow
Avg Fragment Size in pages <300: Red
Critical State added to the monitor's states
Show Extents Fragmentation diagnostic task in Monitor's history
Show Extents Fragmentation task in Knowledge Base link and in State
Adverse configuration changes Lock Pages in memory Startup Option
Even growth DB files in Filegroup
Increase Extents Number in Database
Autogrow increment <5% or < 100mb
…more…

DIAGNOSTIC TASK AND MONITOR HISTORY Fragmentation
1
1
2

DIAGNOSTIC TASK AND MONITOR HISTORY Fragmentation (Details)



APPLIANCE DISK LAYOUT

CONFIGURE APPLIANCE & DOMAIN

CONFIGURE SQL

SETUP COMPLETE

FACTORY RESET

MDW APPLIANCE MANAGEMENT PACK Monitoring
Extents Fragmentation TOP 20 large tables
Fragmentation Thresholds
Avg Fragment Size in pages > 400 : Green
Avg Fragment Size in pages 300-400: Yellow
Avg Fragment Size in pages <300: Red
Critical State added to the monitor's states
Show Extents Fragmentation diagnostic task in Monitor's history
Show Extents Fragmentation task in Knowledge Base link and in State
Adverse configuration changes Lock Pages in memory Startup Option
Even growth DB files in Filegroup
Increase Extents Number in Database
Autogrow increment <5% or < 100mb
…more…

MDW APPLIANCE DIAGRAM VIEW

DIAGNOSTIC TASK AND MONITOR HISTORY - FRAGMENTATION
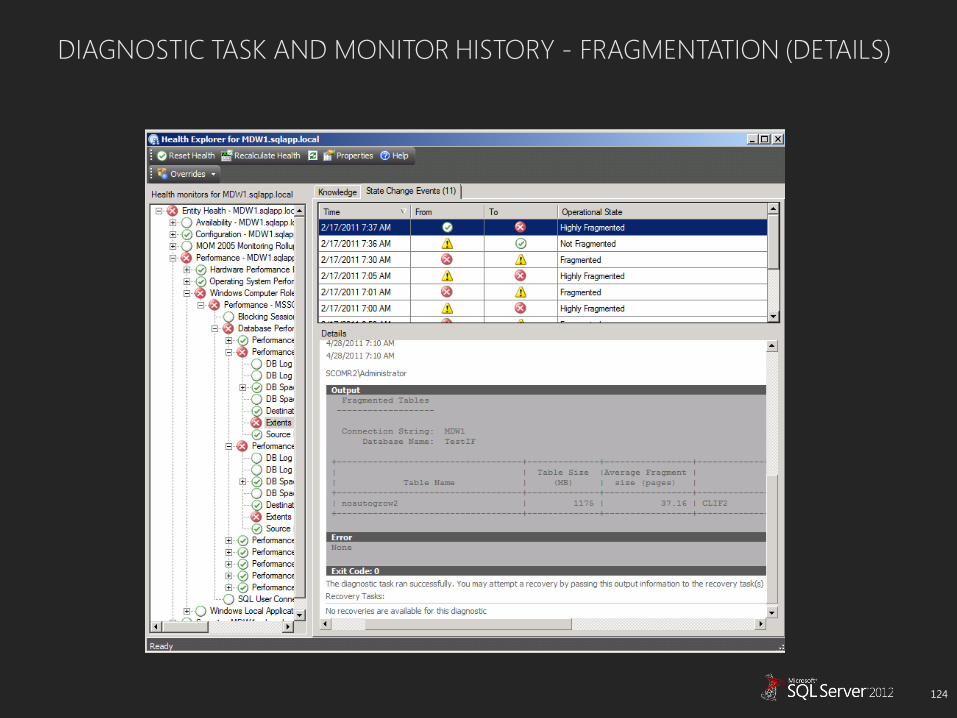
DIAGNOSTIC TASK AND MONITOR HISTORY - FRAGMENTATION (DETAILS)


SO HOW DOES IT WORK? First, store the data

SO HOW DOES IT WORK? Second, take the processing to the data

HOW DO WE STORE BIG DATA?

HOW DO WE PROCESS BIG DATA?

MAPREDUCE – WORKFLOW
A Map Reduce job usually splits
the input data-set into independent
chunks which are processed by the
map tasks in a completely parallel
manner
The framework sorts the outputs
of the maps, which are then input
to the reduce tasks; the framework
shuffles the output of maps to be
reduced
The framework takes care of
scheduling tasks, monitoring them
and re-executes the failed tasks

HADOOP ARCHITECTURE & NEW PROGRAMMING

THE HADOOP ECOSYSTEM (SIMPLIFIED)

MICROSOFT’’S APPROACH TO BIG DATA Insights to all users by activating new types of data

HADOOP ON …

BIG DATA: ENTERPRISE-READY Integrated with Leading DW Performance and Scale
Benefits Simplicity and manageability of Windows for Hadoop
Enterprise-class security
High performance with consistently high throughput of data
Integration with Enterprise Data Warehouse
Key Features Integration with key enterprise components such as System Center
and Active Directory
Hadoop-based service on Windows Azure and Windows Server
Integration with enterprise-level BI solution through new Hadoop
connectors for SQL Server and PDW

BIG DATA: CONNECTED TO THE WORLD’S DATA Combines Internal and External Data and Services
Benefits Stronger customer relationships using social media
Wider marketplace for sharing and collaboration
Enriched analytics within the application using Bing models
Extended analytics with smart mining algorithms
Key Features Integration with third-party data and services
(U.S. stock sentiment)
Integration with Azure Marketplace Services
(Microsoft Translator service)
Rich web data and mining models used on Bing
Integration with social media (Microsoft codename ‘Social Analytics’)

BIG DATA: INSIGHTS FOR EVERYONE Analytics to All Users Through Familiar Tools
Benefits Analyze Hadoop data in Excel
Reduced time-to-solution
Predictive analysis on Hadoop
Quick-start BI for corporate solutions
Key Features Hive Add-in for Excel
Hive ODBC driver for SQL Server Data Mining tools
Integration of Hive and Microsoft BI tools such as
PowerPivot and Power View

BIG DATA: OPEN AND FLEXIBLE Develop Once, Deploy On-Premises or in the Cloud
Benefits Deployment choice on-premises or in the cloud
Compatibility with Hadoop
Simplified programming with deployment using
a web browser
Key Features New JavaScript libraries
Rich ecosystem of open source partners, including
Hortonworks, Cloudera, and Karmasphere
Integration with .NET

MICROSOFT HADOOP STRATEGY


HADOOP ON WINDOWS

APACHE HADOOP AS A SERVICE ON AZURE

BIG DATA CUSTOMERS

WEB / SOCIAL


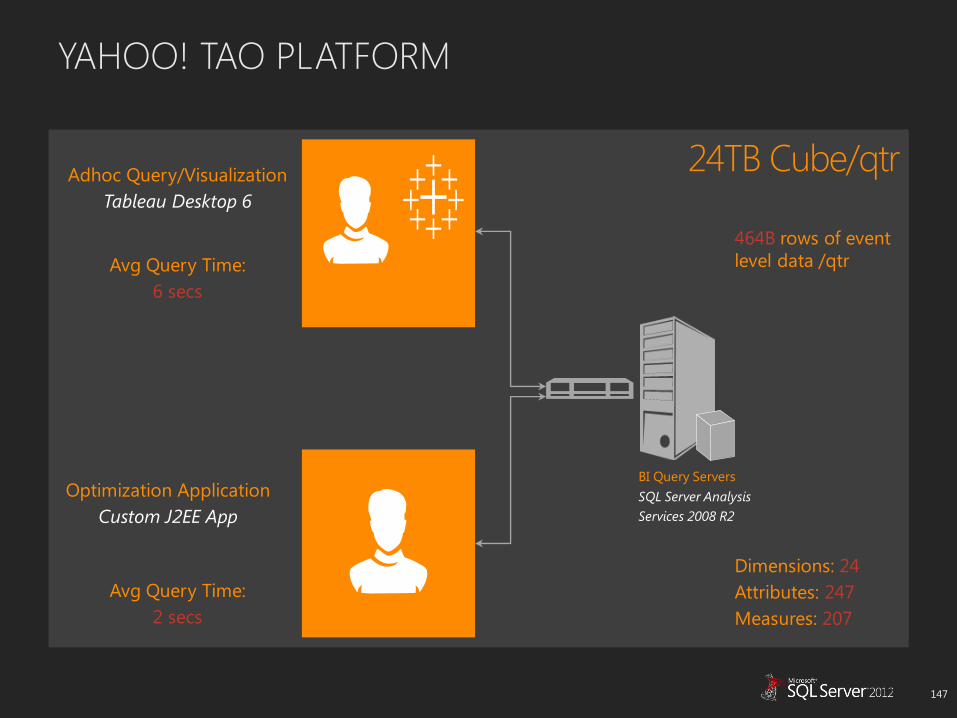
YAHOO! TAO PLATFORM


KLOUT’S BIG DATA PROBLEM


EVENT TRACKER ARCHITECTURE
insights3:9003/track/{"project":”plusK","event":”spend”, "ks_uid":123456,”type":”add_topic"}
SELECT { [Measures].[Counter], [Measures].[PreviousPeriodCounter]} ON COLUMNS, NON EMPTY CROSSJOIN ( exists([Date].[Date].[Date].allmembers, [Date].[Date].&[2012-05-19T00:00:00]:[Date].[Date].&[2012-06-02T00:00:00]), [Events].[Event].[Event].allmembers ) DIMENSION PROPERTIES MEMBER_CAPTION ON ROWS FROM [ProductInsight] WHERE ({[Projects].[Project].[plusK]})
event_log tstamp string project string event string session_id bigint ks_uid bigint ip string json_keys array<string> json_values array<string> json_text string dt string hr string
{ "project":"plusK", "event":"spend", "session_id":"0", "ip":"50.68.47.158", "kloutId":“123456", “cookie_id":”123456", "ref":"http://klout.com/", "type":"add_topic", "time":"1338366015" } will be saved in HDFS at: /logs/events_tracking/2012-05-30/0100


HEALTHCARE
Often a laggard in technology
Yet, application of technology will be revolutionary to understanding the human system
Genomic sequencing brings the promise of understanding human biological systems
Proteomic sequencing brings the promise of building the protein sequences to build customized drugs
Healthcare Incidence Prediction: Heart Attacks and Asthma

UNIVERSITY OF DUNDEE PROTEOMICS

UNIVERSITY OF DUNDEE PROTEOMICS

HEALTHCARE
Key Scenarios Clinical trials: not just examining existing drugs and efficacy, but also potential deviations E.g. Originally Viagra was developed to lower blood pressure and treat Angina; now it
also helps with newborn pulmonary hypertension and altitude sickness
Predicting healthcare incidences issues
Social media campaigns (e.g. advertising drugs)
Pharmaceutical campaign advertising analytics Modeling the consumer, trying to understand their user behavior (why are they
purchasing this medication, how do they feel about their ailment, related behaviors, etc.)

HEALTHCARE: RHIOs

GOVERNMENT & UTILITIES

GOVERNMENT & UTILITIES
Hard to work with (personnel, lengthy engagements, bureaucracy, etc.)
Lots of standards and compliance requirements, and requires a lot of people to engage.
But if you develop the relationship, it often becomes long term
Government engagements include VA, DoD, DoD vendors
Utilities engagements include China Light and Power, Florida Power and Light, Duke Energy, and Toshiba

GOVERNMENT & UTILITIES
Thanks to Greg Morning and Larry Cochrane Evaluating consumer decisions and sentiment for green energy trends
Smart grid load management and targeted marketing (e.g. Smart Cities)
Targeted Marketing and Performance
Utilities Marketplace

EVENT PROCESSING AND REAL TIME

OIL & GAS

OIL & GAS
Seismic Data Processing A lot of this data is processed based on 1950s seismic algorithms
Chevron has a 3000 node Linux cluster just to process this data
Sometimes to process this data, it takes over a year!
Hadoop allows us to have greater degrees of parallelism by firing off multiple map jobs
Next Generation Applications Processing of WITSML data (Wellsite Information Transfer Standard Markup Language XML format) via
Hive XML SerDe
Apply current BI tools to understand and model this data
Apply Stream Insight / Storm to trigger against this information
Data Sharing Scenarios

FINANCIAL

FINANCIAL
Natural extension of web analytics We built a web site, now let’s make some money
Fraud Analytics | Position, Triggers | Targeted Coupon / Payments
Verticals: Financial, Retail, Finance Departments in All Verticals (e.g. How to save money on ordering laboratory supplies for a hospital)
Technology Features: R, HBase, HPC scenarios
On Prem/Cloud: Almost always exclusively onprem due to SoX and other compliance / GRC models






Schema on Read The schema is not defined until data is queried
More exploratory, requires domain knowledge
Goal is to find new value in ambient data
…You don’t know what you don’t know…
Schema on Write The schema is defined before data is loaded
Exposes well-defined metric’s and KPI’s to users
Mature patterns & practices for development
…Show me what I already know…



CLOUD

ON-PREMISE

HYBRID



FINANCIAL RISK


OIL & GAS – WELL-HEAD
Acquire
Manage
Store
Analyze
VisualizeSources
Data Nodes
Name Node Health Node
HDFS Cluster
MapReduce(Java,.Net,
R, etc…)
On-Premise Cloud
Cloud
On-Premise On-Premise
StreamInsight
System CenterOperations Manager
ColdStream
Flu
me
Sqo
op
TeamFoundation Server
Inp
ut
Ad
apte
rs
TelemetryStreams
Active Directory
PigHive Sqoop
SQL ServerParallel Data Warehouse
Azure VNet
IaaS
On-Premise and / or Cloud
(On-Premise Only)
AzureStorage
SSIS
SSAS
PerformancePoint Services Excel Services
LearnedLimits
HotStream
WellheadMetrics
Maint.
Operations
Equip.


EVENT-DRIVEN FEEDBACK









ANALYSIS, CONSUMPTION



1
9
9

© 2011 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.
The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation.
MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.
© 2011 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.
The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation.
MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.






















