Statistical Approaches to Inverse Problems. DIIG seminars on inverse problems Insight and Algorithms Niels Bohr Institute Copenhagen, Denmark 27-29 May 2002 (Revised 13 May 2003) P.B. Stark Department of Statistics University of California Berkeley, CA 94720-3860 - PowerPoint PPT Presentation
Statistical Approaches to Inverse Problems DIIG seminars on inverse problems Insight and Algorithms Niels Bohr Institute Copenhagen, Denmark 27-29 May 2002 (Revised 13 May 2003) P.B. Stark Department of Statistics University of California Berkeley, CA 94720-3860 www.stat.berkeley.edu/~stark
Transcript
Statistical Approaches to Inverse Problems
DIIG seminars on inverse problems Insight and Algorithms
Niels Bohr InstituteCopenhagen, Denmark
27-29 May 2002(Revised 13 May 2003)
P.B. Stark
Department of Statistics
University of California
Berkeley, CA 94720-3860
www.stat.berkeley.edu/~stark
AbstractIt is useful to distinguish between the intrinsic uncertainty of an inverse problem and the uncertainty of applying any particular technique to “solve” the inverse problem. The intrinsic uncertainty depends crucially on the prior constraints on the unknown (including prior probability distributions in the case of Bayesian analyses), on the forward operator, on the statistics of the observational errors, and on the nature of the properties of the unknown one wishes to estimate. I will try to convey some geometrical intuition for uncertainty, and the relationship between the intrinsic uncertainty of linear inverse problems and the uncertainty of some common techniques applied to them.
References & Acknowledgements
Donoho, D.L., 1994. Statistical Estimation and Optimal Recovery, Ann. Stat., 22, 238-270.
Donoho, D.L., 1995. Nonlinear solution of linear inverse problems by wavelet-vaguelette decomposition, Appl. Comput. Harm. Anal.,2, 101-126.
Evans, S.N. and Stark, P.B., 2002. Inverse Problems as Statistics, Inverse Problems, 18, R1-R43 (in press).
Stark, P.B., 1992. Inference in infinite-dimensional inverse problems: Discretization and duality, J. Geophys. Res., 97, 14,055-14,082.
Stark, P.B., 1992. Minimax confidence intervals in geomagnetism, Geophys. J. Intl., 108, 329-338.
Created using TexPoint by G. Necula, http://raw.cs.berkeley.edu/texpoint
– Forward and Inverse Problems—applied perspective
– Statistical point of view
– Some connections
• Notation; linear problems; illustration
– Example: geomagnetism from satellite observations
– Example: seismic velocity from (p) and x(p)
– Example: differential rotation of the Sun from normal mode splitting
• Identifiability and uniqueness
– Sketch of identifiablity and extremal modeling
– Backus-Gilbert theory
– Example: solar differential rotation
– Example: seismic velocity in Earth’s core
Outline, contd.
• Decision Theory
– Decision rules and estimators
– Comparing decision rules: Loss and Risk
– Strategies; Bayes/Minimax duality
– Mean distance error and bias
– Illustration: Regularization
– Illustration: Minimax estimation of linear functionals
– Example: Gauss coefficients of the magnetic field
• Distinguishing Models: metrics and consistency
Inverse Problems as Statistics
• Measurable space X of possible data.
• Set of possible descriptions of the world—models.
• Family P = {P : 2 } of probability distributions on X, indexed by models .
•Forward operator P maps model into a probability measure on X .
Data X are a sample from P.
P is whole story: stochastic variability in the “truth,” contamination by measurement error, systematic error, censoring, etc.
Models• Set usually has special structure.
• could be a convex subset of a separable Banach space T. (geomag, seismo, grav, MT, …)
• Physical significance of generally gives P reasonable analytic properties, e.g., continuity.
Forward Problems in GeophysicsComposition of steps:
– transform idealized description of Earth into perfect, noise-free, infinite-dimensional data (“approximate physics”)
– censor perfect data to retain only a finite list of numbers, because can only measure, record, and compute with such lists
– possibly corrupt the list with measurement error.
Equivalent to single-step procedure with corruption on par with physics, and mapping incorporating the censoring.
Inverse Problems
Observe data X drawn from distribution Pθ for some unknown . (Assume contains at least two points; otherwise, data superfluous.)
Use data X and the knowledge that to learn about ; for example, to estimate a parameter g() (the value g(θ) at θ of a continuous G-valued function g defined on ).
Example: Geomagnetism
Geomagetic model parametrization
Geomagnetic inverse problem
Geophysical Inverse Problems
• Inverse problems in geophysics often “solved” using applied math methods for Ill-posed problems (e.g., Tichonov regularization, analytic inversions)
• Those methods are designed to answer different questions; can behave poorly with data (e.g., bad bias & variance)
• Inference construction: statistical viewpoint more appropriate for interpreting geophysical data.
Elements of the Statistical View
Distinguish between characteristics of the problem, and characteristics of methods used to draw inferences.
One fundamental property of a parameter:
g is identifiable if for all η, Θ,
{g(η) g()} {P P}.
In most inverse problems, g(θ) = θ not identifiable, and few linear functionals of θ are identifiable.
Deterministic and Statistical Connections
Identifiability—distinct parameter values yield distinct probability distributions for the observables—similar to uniqueness—forward operator maps at most one model into the observed data.
Consistency—parameter can be estimated with arbitrary accuracy as the number of data grows—related to stability of a recovery algorithm—small changes in the data produce small changes in the recovered model.
quantitative connections too.
More Notation
Let T be a separable Banach space, T * its normed dual.
Write the pairing between T and T *
<•, •>: T * x T R.
Linear Forward ProblemsA forward problem is linear if
• Θ is a subset of a separable Banach space T
• X = Rn, X = (Xj)j=1n
• For some fixed sequence (κj)j=1n of elements of T*,
Xj = h j, i + j, 2 ,
where = (j)j=1n is a vector of stochastic errors whose
distribution does not depend on θ.
Linear Forward Problems, contd.
•Linear functionals {κj} are the “representers”
•Distribution Pθ is the probability distribution of X. Typically, dim(Θ) = ; at least, n < dim(Θ), so estimating θ is an underdetermined problem.
Define
K : T Rn
(<κj, θ>)j=1n .
Abbreviate forward problem by X = Kθ + ε, θ Θ.
Linear Inverse Problems
Use X = Kθ + ε, and the constraint θ Θ to estimate or draw inferences about g(θ).
Probability distribution of X depends on θ only through Kθ, so if there are two points
θ1, θ2 Θ such that Kθ1 = Kθ2 but
g(θ1)g(θ2),
then g(θ) is not identifiable.
Ex: Sampling w/ systematic and random error
Observe
Xj = f(tj) + j + j, j = 1, 2, …, n,
• f 2 C, a set of smooth of functions on [0, 1]
• tj 2 [0, 1]
• |j| 1, j=1, 2, … , n
• j iid N(0, 1)
Take = C £ [-1, 1]n, X = Rn, and = (f, 1, …, n).
Then P has density
(2)-n/2 exp{-j=1n (xj – f(tj)-j)2}.
R
X = Rn
Sketch: Identifiability
KX = K
K
g()
PP = P
g() g()
{P = P} ; {g() = g()}, so g not identifiable
{P = P} ; { = }, so not identifiable
g cannot be estimated with bounded bias
Backus-Gilbert Theory
Let = T be a Hilbert space.
Let g 2 T = T* be a linear parameter.
Let {j}j=1n µ T*. Then:
g() is identifiable iff g = ¢ K for some 1 £ n matrix .
If also E[] = 0, then ¢ X is unbiased for g.
If also has covariance matrix = E[T], then the MSE of ¢ X is ¢ ¢ T.
R
X = Rn
Sketch: Backus-Gilbert
KX = K
g() = ¢ K
P
¢ X
Example: Differential solar rotation• Stellar oscillations known since late
1700s.
• Sun's oscillation observed in 1960 by Leighton, Noyes, Simon. Explained as trapped acoustic waves by Ulrich, Leibacher, Stein, 1970-1.
Source: SOHO-SOI/MDI website
Formal error bars inflated by 200. Hill et al., 1996. Science 272, 1292-1295
Then 1×n matrix Λ s.t. the restriction of ğ to Ť is the restriction of Λ.K to Ť.
Backus-Gilbert++: Sufficient Conditions
Suppose g = (gi)i=1m is an Rm-valued parameter that can be written
as the restriction to Θ of Λ.K for some m×n matrix Λ.
Then
1. g is identifiable.
2. If E[ε] = 0, Λ.X is an unbiased estimator of g.
3. If, in addition, ε has covariance matrix Σ = E[εεT], the covariance matrix of Λ.X is Λ.Σ.ΛT whatever be Pθ.
Decision RulesA (randomized) decision rule
δ: X M1(A)
x δx(.),
is a measurable mapping from the space X of possible data to the collection M1(A) of probability distributions on a separable metric space A of actions.
A non-randomized decision rule is a randomized decision rule that, to each x X, assigns a unit point mass at some value
a = a(x) A.
Why randomized rules?
• In some problems, have better behavior.
• Allowing randomized rules can make the set of decisions convex (by allowing mixtures of different decisions), which makes the math easier.
• If the risk is convex, Rao-Blackwell theorem says that the optimal decision is not randomized. (More on this later.)
Example: randomization natural
Coin has chance 1/3 of landing with one side showing; chance 2/3 of the other showing. Don’t know which side is which.
Want to decide whether P(heads) = 1/3 or 2/3.
Toss coin 10 times. X = #heads.
Toss fair coin once. U = #heads.
Use data to pick the more likely scenario, but if data don’t help, decide by tossing a fair coin.
Estimators
An estimator of a parameter g(θ) is a decision rule for which the space A of possible actions is the space G of possible parameter values.
ĝ=ĝ(X) is common notation for an estimator of g(θ).
Usually write non-randomized estimator as a G-valued function of x instead of a M1(G)-valued function.
Comparing Decision Rules
Infinitely many decision rules and estimators.
Which one to use?
The best one!
But what does best mean?
Loss and Risk
• 2-player game: Nature v. Statistician.
• Nature picks θ from Θ. θ is secret, but statistician knows Θ.
• Statistician picks δ from a set D of rules. δ is secret.
• Generate data X from Pθ, apply δ.
• Statistician pays loss L(θ, δ(X)). L should be dictated by scientific context, but…
• Risk is expected loss: r(θ, δ) = EL(θ, δ(X))
• Good rule has small risk, but what does small mean?
Strategy
Rare that one has smallest risk 8
• is admissible if not dominated (if no estimator does at least as well for every , and better for some .
• Minimax decision minimizes r() ´ supr(θ, δ) over D
• Minimax risk is r* ´ inf 2 D r(δ)
• Bayes decision minimizes
r() ´ sr(,)(d) over D
for a given prior probability distribution on
• Bayes risk is r* ´ inf 2 D r().
Minimax is Bayes for least favorable prior
If minimax risk >> Bayes risk, prior π controls the apparent uncertainty of the Bayes estimate.
Pretty generally for convex D, concave-convexlike r,
Common Risk: Mean Distance Error (MDE)
Let dG denote the metric on G, and let ĝ be an estimator of g.
MDE at θ of ĝ is
MDEθ(ĝ, g) = E d(ĝ(X), g(θ)).
When metric derives from norm, MDE is called mean norm error (MNE).
When the norm is Hilbertian, MNE2 is called mean squared error (MSE).
Shrinkage
Suppose X » N(, I) with dim() = d ¸ 3.
X not admissible for for squared-error loss (Stein, 1956).
Dominated by S(X) = X(1 – /( + ||X||2)) for small and big .
James-Stein better: JS(X) = X(1-/||X||2), for 0 < · 2(d-2).
Better if take positive part of shrinkage factor: JS
+(X) = X(1-/||X||2)+, for 0 < · 2(d-2). Not minimax, but close.
Implications for Backus-Gilbert estimates of d¸ 3 linear functionals.
9 extensions to other distributions; see Evans & Stark (1996).
Bias
When G is a Banach space, can define bias at θ of ĝ:
biasθ(ĝ, g) = E [ĝ - g(θ)]
(when the expectation is well-defined).
• If biasθ(ĝ, g) = 0, say ĝ is unbiased at θ (for g).
• If ĝ is unbiased at θ for g for every θ, say ĝ is unbiased for g. If such ĝ exists, say g is unbiasedly estimable.
• If g is unbiasedly estimable then g is identifiable.
Example: Bounded Normal Mean
Observe X » N (, ). Know a priori 2 [-, ].
Want to estimate g(
Let (¢) be the standard normal density.Let (¢) be the standard normal cumulative distribution function.
Suppose we elect to use squared-error loss:
L(, ) = ( - )2
r(, ) = E L(, (X)) = E ( - (X))2
r() = sup 2 r(, ) = sup 2 E ( - (X))2
r = inf 2 D sup 2 E ( - (X))2
Risk of X for bounded normal meanConsider simple estimator (X) = X.
EX = , so X is unbiased for , and is unbiasedly estimable.
r(, X) = E ( – X)2 = Var(X) = .
Consider Bayesian prior to capture the constraint 2 [-, ]:
» = U[-, ], the uniform distribution on the interval [-, ].
r(X) = s- r(, X) (d) = s-
£ (2)-1 d = .
In this example, frequentist risk of X equals Bayes risk of X for uniform prior .
X is not the best: Truncation
Easy to find an estimator better than X from both frequentist and Bayes perspectives.
Truncation estimate T
T is biased, but has smaller MSE than X, whatever be 2 is the constrained maximum likelihood estimate.)
Risk of T
f(x|
0
0
x
T
P(X < -)
Minimax Estimation of BNM
Truncation estimate better than X, but not minimax.
Clear that r* ¸ min(1, 2): MSE(X) = 1, and r(0) = 2.
Minimax MSE estimator is a nonlinear shrinkage estimator.
Minimax MSE risk is 2/(1+2).
Bayes estimation of BNMPosterior density of given x is
Posterior Mean• The mean of the posterior density minimizes the Bayes risk,
Philip B. Stark:Philip B. Stark:Philip B. Stark:Philip B. Stark:
R
X = Rn
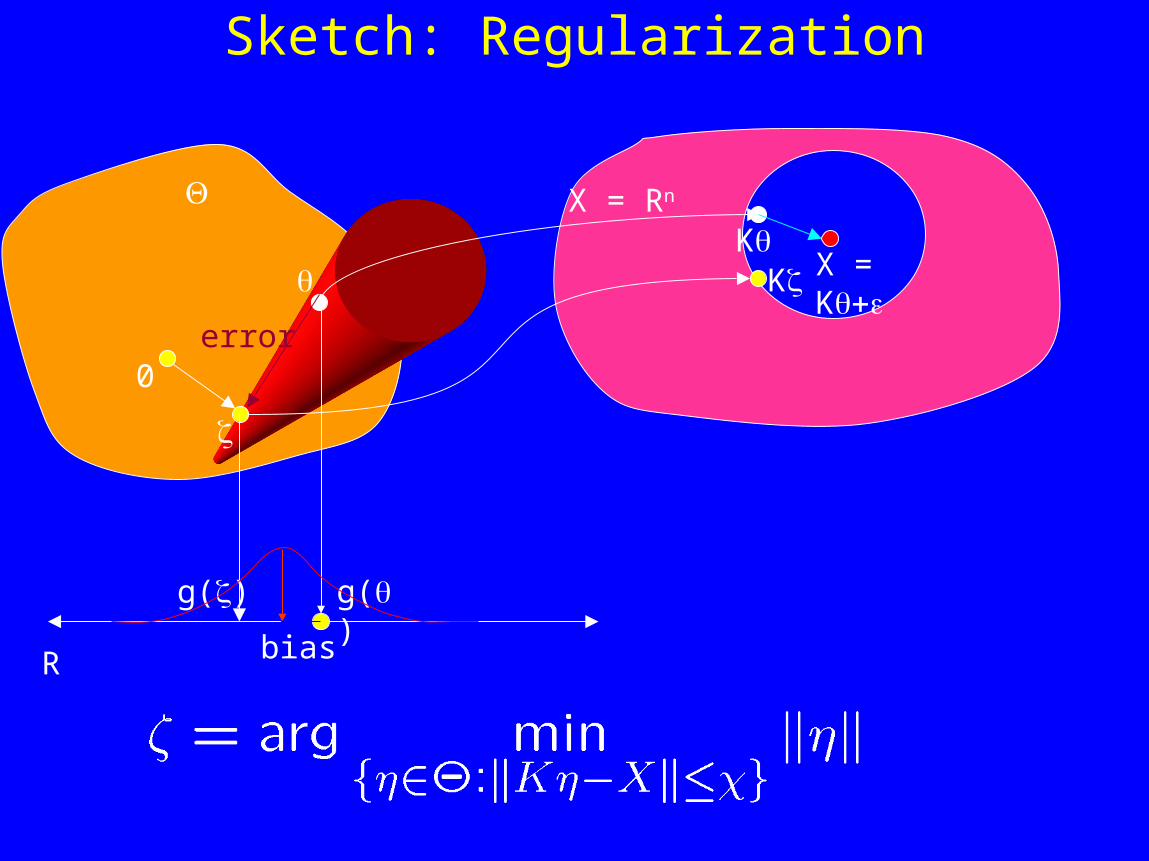
Sketch: Regularization
K
X = KK
g()
0error
g()
bias
Consistency of “Occam’s Inversion”• Common approach: minimize norm (or other regularization
functional) subject to mean data misfit · 1.
• Sometimes called Occam’s Inversion (Constable, Parker and Constable): simplest hypothesis consistent with the data.
• In many circumstances, this estimator is inconsistent: as number of data grows, greater and greater chance that the estimator is 0. Allowable misfit grows faster than norm of noise-free data image.
• In common situations, consistency of the general approach requires data redundancy and averaging.
Singular Value Decomposition, Linear Problems• Assume ½ T , separable Hilbert space;
{j}j=1n iid N(0, 2)
{j}j=1n linearly independent
• K is compact: infinite-dimensional null space.Let K*: <n ! T be the adjoint operator to K.
• 9 n triples {(j, xj, j)}j=1n, j 2 T, xj 2 X and j 2 <+, such that
– Kj = j xj,
– K* xj = j j.
• {j}j=1n can be chosen to be orthonormal in T;
{xj}j=1n can be chosen to be orthonormal in X.
• j > 0, 8 j. Order s.t. 1 ¸ 2 ¸ > 0.
• {(j, xj, j)}j=1n are singular value decomposition of K.
Singular Value Weighting•Can write minimum norm model that fits data exactly as
MN(X) = j=1n j
-1 (xj ¢ X) j.
Write = || + ? (span of {} and its orthocomplement)
Bias(MN) = E MN(X) - = ?.
Var MN = E || j=1n j
-1 (xj ¢ ) j ||2 = 2 j=1n j
-2.
Components associated with small j make variance big: noise components multiplied by j
-1.
Singular value truncation: reconstruct using {j} with j ¸ t:
SVT = j=1m j
-1 (xj ¢ X) j, where m = max {k : k > t}.
Mollifies the noise magnification but increases bias.
Bias of SVTBias of SVT bigger than of MNE by projection of onto span {j}j=m+1
n.
Variance of SVT smaller by 2 j = m + 1n j
-2.
With adequate prior information about (to control bias) can exploit bias-variance tradeoff to reduce MSE.
SVT in family of estimators that re-weight the singular functions in the reconstruction:
w = j=1n w(j) (xj ¢ X) j.
Regularization using norm penalty, with regularization parameter , corresponds to
w(u) = u/(u2 + ).
These tend to have smaller norm smaller than maximum likelihood estimate: can be viewed as shrinkage.
Examples of Singular Functions• Linear, time-invariant filters: complex sinusoids
• Circular convolution: sinusoids
• Band and time-limiting: prolate spheroidal wavefunctions
• Main-field geomagnetism: spherical harmonics, times radial polynomials in r-1
• Abel transform: Jacobi polynomials and Chebychev polynomials
See Donoho (1995) for more examples and references.
Minimax Estimation of Linear parameters
• Observe X = K + 2 Rn, with
– 2 µ T, T a separable Hilbert space
– convex
– {i}i=1n iid N(0,2).
• Seek to learn about g(): ! R, linear, bounded on
For variety of risks (MSE, MAD, length of fixed-length confidence interval), minimax risk is controlled by modulus of continuity of g, calibrated to the noise level.
Full problem no harder than hardest 1-dimensional subproblem; reduces to BNM (Donoho, 1994).
Example: Geomagnetism = { 2 l2(w) : l=1
1 wl m=-ll | l
m |2 · q }.
Estimate g() = lm.
Symmetry of and linearity of K, g, let us characterize the modulus:
The problem is to maximize a linear functional of a vector in the intersection of two ellipsoids. In the main-field geomagnetism problem, as the data sampling becomes more uniform over the spherical idealization of a satellite orbit, both the norm (prior information) and the operator K are diagonalized by spherical harmonics.
R
X = Rn
Modulus of Continuity
g() g()
K
K
Distinguishing two modelsData tell the difference between two models and if the L1 distance between P and P is large:
L1 and Hellinger distances
Consistency in Linear Inverse Problems
• Xi = i + i, i=1, 2, 3, … , subset of separable Banach space{i} * linear, bounded on {i} iid
• If restriction to converges to metric compatible with weak topology, can estimate consistently in weak topology.
• For given sequence of functionals {i}, µ rougher consistent estimation easier.
Importance of the Error Distribution
Summary• “Solving” inverse problem means different things to different
audiences.
• Statistical viewpoint is useful abstraction. Physics in mapping PPrior information in constraint .
• There is more information in the assertion » , with supported on , than there is in the constraint 2
• Separating “model” from parameters g() of interest is useful: Sabatier’s “well posed questions.” Many interesting questions can be answered without knowing the entire model.
• Thinking about measures of performance is useful.
• Difficulty of problem performance of specific method.