23
Statistical Methods in Computer Science Data 3: Correlations and Dependencies Ido Dagan
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 220 times |
| Download: | 0 times |

Statistical Methods in Computer Science
Data 3: Correlations and
Dependencies
Ido Dagan

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 2
Connecting Variables
So far: talked about the data reflected by a single variable
Common scientific goal: relate between variables Find out whether a relation exists between values of
variables Find out the strength of this relation Find out the nature of this relation
Our focus here: The relation between two variables e.g., the relation between input size and run-time e.g., the relation between time spent coordinating, and
productivity e.g., the relation between shoe-size and reading skills

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 3
Paired Samples
The starting point for our discussion: Bi-variate data Paired samples, for each X, give its corresponding Y:
<input-size, run-time> <time spent coordinating, productivity> <shoe-size, reading skills>
These paired samples come from the experiment The experiment should record the data to allow us the
desired pairing
Pairing can be implicit, through fields/variables Test at beginning of year, test at end of year: pair by
student

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 4
Tools in identifying bi-variate relations
Visualize: Scatter Diagram (Scatter Plot)
Ordinal variables: Pearson's correlation coefficient, rXY
Spearman's rank-correlation coefficient, rho ()
Categorical variables Dependency tests (Chi-Square – in recitation)
Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 5
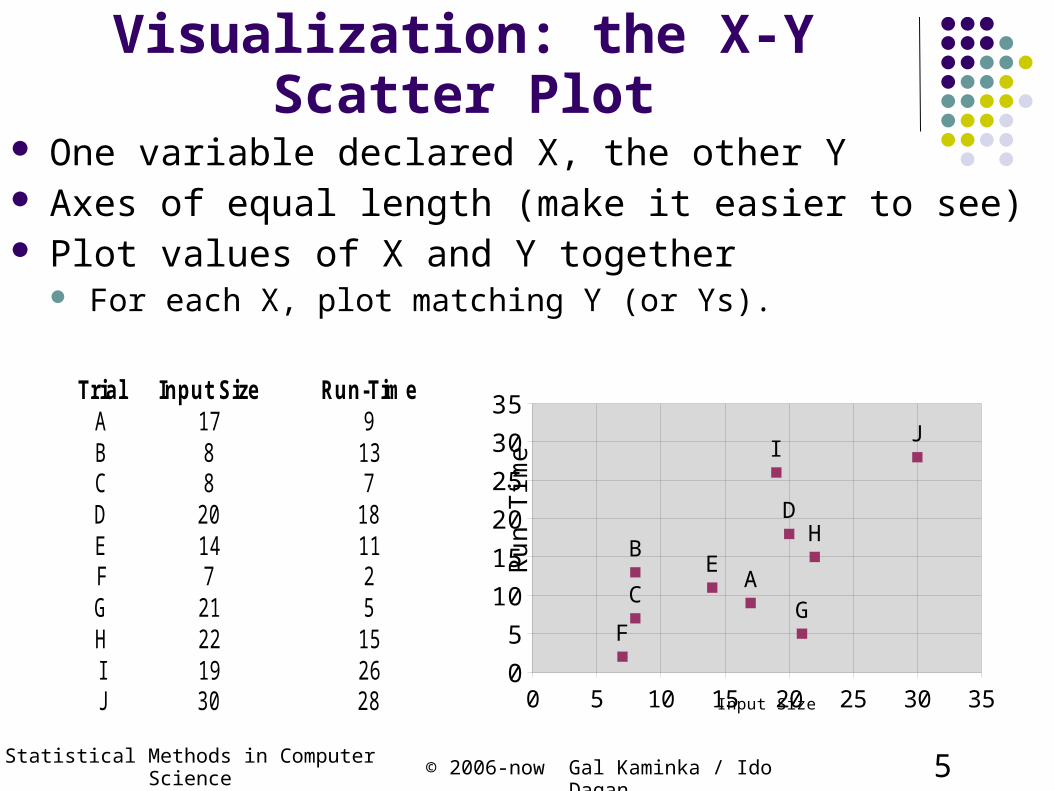
Visualization: the X-Y Scatter Plot
One variable declared X, the other Y Axes of equal length (make it easier to see) Plot values of X and Y together
For each X, plot matching Y (or Ys).
Trial Input Size Run-TimeA 17 9B 8 13C 8 7D 20 18E 14 11F 7 2G 21 5H 22 15I 19 26J 30 28 0 5 10 15 20 25 30 35
0
5
10
15
20
25
30
35
A
F
B
CE
I
D
G
H
J
Input Size
Run T
ime

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 6
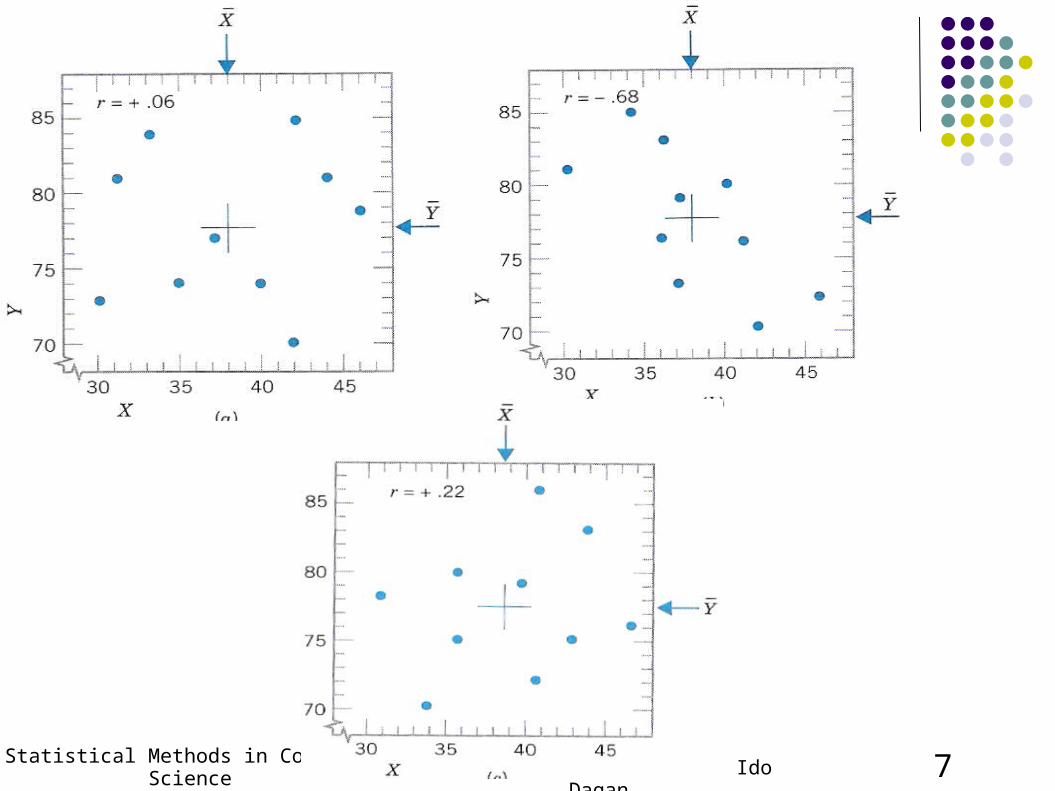
Is there a relation? We see that in general, there is some relation here:
Lower X => lower Y Higher X => higher Y
But how can we recognize this systematically? From “Statistical Reasoning”, Minium, King, and Bear 1993
Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 7

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 8
Reminder: Variance
Sum of squares Shorthand for: Sum of squared deviations from the mean
And normalizing for the size of the sample
o This is called the variance of the sampleo Distribution/Population variance is denoted
by , defined relative to μ
2XXi=SSX
N
XXi=
N
SS=S X 2
2
2

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 9
Covariance
Positive correlation: Lower X <=> Lower Y Negative correlation: Lower X <=> Higher Y
How do we transform this into a measure?
Intuition: Multiply pairs, and sum the results positive X positive = positive; negative X negative =
positive, ....Covariance sign determined by accumulative values from
points in 1st & 3rd quartiles vs. 2nd & 4th big X small = small, big X big = big
N
YyXx=YX,Cov ii

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 10
From Covariance to Correlation
Big positive Cov(X,Y) means that X, Y grow together Big negative Cov(X,Y) means that X, Y grow
negatively together Problem: How big is big?
This depends on the values of X, Y For instance: Large x (100000) multiplied by small y
(0.00001) Where both x and y are the largest values?
Solution: Pearson's correlation coefficient rXY (or simply, r):
1.0: Perfect positive correlation -1.0: Perfect negative correlation 0: No correlation

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 11
Reminder: z Scores
Key idea: Express all values in units of standard deviation
This allows comparison of values from different distributions But only if shapes of distributions are similar
Example usage: Sequence mining We find the most frequent sequences of any length k What are the most frequent sequences of the entire DB? This is difficult to answer:
There are more short sequences than long ones This can be solved with transforming frequency counts into
their z Scores
XS
XX=z

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 12
Formulas for r
z-Score based formula:
Deviation-score based formula (equivalent):
where Sk denotes the standard deviation of variable k.
n
zz=r i
yx ii
YXYX
iii
SS
YX,Cov=
SnS
YyXx=r

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 13
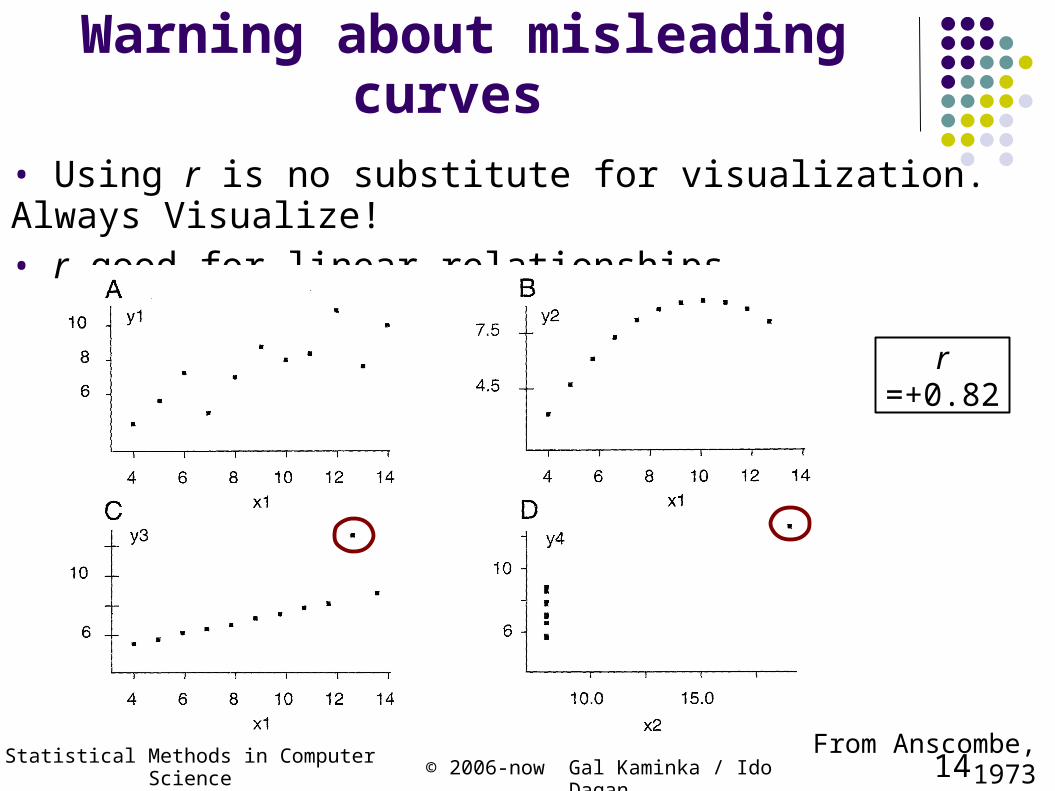
Warning about misleading curves
• Using r is no substitute for visualization. Always Visualize! • r good for linear relationships
r =+0.82
From Anscombe, 1973
Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 14
Warning about misleading curves
• Using r is no substitute for visualization. Always Visualize! • r good for linear relationships
r =+0.82
From Anscombe, 1973

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 15
Correlation and Transformations
Mean changes with additions, std dev does not Raise all scores by 10 ==> raise mean by 10, no change
to stddev Mean changes with multiplications, std dev does too
Multiply all scores by 10 ==> multiple mean & std dev by 10.
Pearson's r not affected by any linear transformation, on either X and/or Y Adding = translating points Multiplying = scaling Neither affects relation between the variables.

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 16
Interpreting Correlation
Always visualize! Pearson's coefficient only appropriate for linear relationships
r measures how closely points “hug” a straight line Other measures exist for non-linear relations (Spearman's, eta)
r sensitive to value ranges within the target population Smaller range => smaller r - differences in values are less meaningful
E.g. correlation between age and math skills for a small age range Large absolute r is not necessarily indicative of significance
r is subject to sampling variation: May change from sample to sample, and significance depends on sample size
We will address significance test of r later r is affected by the way some phenomenon is measured (e.g. grades on
different types of scales – grades A,B,… vs. 1-100) Need to report specific conditions for correlation measurements, and
test again under different conditions to see if still correlated

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 17
Correlation and Causation
IMPORTANT: Correlation is not causation!
Example of positive correlations: Grip strength and mathematical skills Shoe size and reading level ...
But shoe sizes does not causes reading level!The results are in kids 6-13!

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 18
Possible Explanations Two correlated variables may be:
Causally related (one causes the other) Affected by the same third variable (that causes both – control variable)
Two uncorrelated variables (according to r) may be: Correlated in highly non-linear fashion (always visualize!)
E.g. a circle around 0 (balanced in all quartiles)
There are specific ways to address these cases Example: Partial correlation
Correlation of a,b, given c Example: Manipulation controls (experiment design)
E.g. measure grip strength vs. math skill separately in different age groups

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 19
Partial Correlation
A test for correlation between a, b, given c intuitively, correlation between a & b remaining after
neutralizing their correlation with c
For instance (“Empirical Methods in AI”, Cohen 1995)
22 11 bcac
bcacabc|ab
rr
rrr=r
rreading ,shoesize=0.7
r reading ,age=0.85
rshoesize ,age=0.8
22 0.810.851
0.80.850.7
=r age|shoesizereading,
= 0.020.53×0.6
=0.020.32
=0.06

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 20
Visualize as well
From “Empirical Methods in AI”, Cohen 1995

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 21
Correlation for ordinal variables
Pearson's coefficient is intended for ratio and interval data
Ordinal data cannot be used as is Here, difference between subsequent values is meaningless Only direction matters (above or below)
Examples: Correlation between military rank of career soldiers and the
time they have been in the army Correlation between user and system ranking of search results
Spearman's rank-correlation (rho, ) addresses thisρ

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 22
Spearman's rho: Step 1
First step: Transform all scores to ranks
First = 1, Second = 2, ..... Ties: Replace with average of intended ranks For instance, for ordinal data:
X = Private Sgt. Sgt. Lt. Capt. Capt. Capt. Maj. Col. Col. General ==>
Xrank = 1 2.5 2.5 4 6 6 6 8 9.5 9.5 11
(2+3)/2 (5+6+7)/3 (9+10)/2

Statistical Methods in Computer Science © 2006-now Gal Kaminka / Ido Dagan 23
Calculating rho: Step 2
• Generally:
• Ranges in [-1,1]• With no ties, can simply use Pearson's r on the ranks with identical
results• May be useful (in addition to r) also for data of numerical scores, when
we don’t trust the scale properties of the scores and rank really matters– E.g. correlation between user and system relevance scores for the ranked pages in
search results
• “Debugging” note: – maintained for averaged ties, as sum of all ranks (for X and Y) = n(n-1)/2
1
61
2
2
nn
YX=ρ=r rankrank
s
0rankrank YX

















