29
Stephan Vogel - Machine Transl ation 1 Statistical Machine Translation Word Alignment Stephan Vogel MT Class Spring Semester 2011
| Date post: | 24-Dec-2015 |
| Category: |
Documents |
| Upload: | eleanor-sherman |
| View: | 238 times |
| Download: | 3 times |

Stephan Vogel - Machine Translation 1
Statistical Machine Translation
Word Alignment
Stephan Vogel
MT ClassSpring Semester 2011

Stephan Vogel - Machine Translation 2
Overview
Word alignment – some observations Models IBM2 and IBM1: 0th-order position model HMM alignment model: 1st-order position model IBM3: fertility IBM4: plus relative distortion

Stephan Vogel - Machine Translation 3
Alignment Example
Observations: Mostly 1-1 Some 1-to-many Some 1-to-nothing Often monotone Not always clear-cut
English ‘eight’ is a time German has ‘acht Uhr’ Could also leave ‘Uhr’
unaligned

Stephan Vogel - Machine Translation 4
Evaluating Alignment
Given some manually aligned data (ref) and automatically aligned data (hyp) links can be Correct, i.e. link in hyp matches link in ref: true positive (tp) Wrong, i.e. link in hyp but not in ref: false positive (fp) Missing, i.e. link in ref but not in hyp: false negative (fn)
Evaluation measures Precision: P = tp / (tp + fp) = correct / links_in_hyp
Recall: R = tp / (tp + fn) = correct / links_in_ref
Alignment Error Rate: AER = 1 – F = 1 – 2tp / (2tp +fp +fn)

Stephan Vogel - Machine Translation 5
Sure and Possible Links
Sometimes it is difficult for human annotators to decide Differentiate between sure and possible links
En: Det Noun - Ch: Noun, don’t align Det, or align to NULL? En: Det Noun - Ar: DetNoun, should Det be aligned to DetNoun?
Alignment Error Rate with sure and possible links (Och 2000) A = generated links S = sure links (no finding a sure link is an error) P = possible links (putting a link which is not possible is an error)
||||1 AER
|| Recall
||Precision
SA
SAPA
S
SA
A
PA

Stephan Vogel - Machine Translation 6
Word Alignment Models
IBM1 – lexical probabilities only IBM2 – lexicon plus absolut position IBM3 – plus fertilities IBM4 – inverted relative position alignment IBM5 – non-deficient version of model 4
HMM – lexicon plus relative position
BiBr – Bilingual Bracketing, lexical probabilites plus reordering via parallel segmentation
Syntactical alignment models
[Brown et.al. 1993, Vogel et.al. 1996, Och et al 2000, Wu 1997, Yamada et al. 2003, and many others]

Stephan Vogel - Machine Translation 7
GIZA++ Alignment Toolkit
All standard alignment models (IBM1 … IBM5, HMM) are implemented in GIZA++
This toolkit was started (as GIZA) at John Hopkins University workshop 1998
Extended and improved by Franz Josef Och Now used by many groups Known problems:
Memory when training on large corpora Writes many large files (depends on your parameter setting)
Extensions for large corpora (Qin Gao) Distributed GIZA: run on many machines, I/O bound Multithreaded GIZA: run on one machine, multiple cores

Stephan Vogel - Machine Translation 8
Notation
Source language f: source (French) word J: length of source sentence j: position in source sentence (target position) : source sentence
Target language e: target (English) word I: length of target sentence i: position in target sentence (source position) : target sentence
Alignment: relation mapping source to target positions i=aj: position i of ei which is aligned to j : whole alignment
IiI eeee ......11
JjJ ffff ......11
JjJ aaaa ......11

Stephan Vogel - Machine Translation 9
SMT - Principle
Translate a ‘French’ stringinto an ‘English’ string
Bayes’ decision rule for translation:
Why this inversion of the translation direction? Decomposition of dependencies: makes modeling easier Cooperation of two knowledge sources for final decision
Note: IBM paper and GIZA call e source and f target
JjJ ffff ......11
IiI eeee ......11
)}|Pr(){Pr(maxarg
)}|{Pr(maxarg
111
1
11
1
1
IJI
i
JI
i
I
efee
fee
e

Stephan Vogel - Machine Translation 10
Alignment as Hidden Variable
‘Hidden alignments’ to capture word-to-word correspondences Mapping A subset of [1, …, J]x[1, …, I] Number of connections: J * I (each source word with each target word Number of alignments: 2JI (each connection yes/no)
Summation over all alignments
To many alignments, summation not feasible
)|,Pr()|Pr( 01IJ efef

Stephan Vogel - Machine Translation 11
Restricted Alignment
Each source word has one connection Alignment mapping becomes function: j -> i = aj
Number of alignments is now: IJ
Sum over all alignments: Not possible to enumerate In some situations full summation
possible through Dynamic Programming In other situations: take only best alignment
and perhaps some alignments closeto the best one

Stephan Vogel - Machine Translation 12
Empty Position (Null Word)
Sometimes a word has no correspondence Alignment function aligns each source word to one target
word, i.e. cannot skip source word Solution:
Introduce empty position 0 with null word e0
‘Skip’ source word fj by aligning it to e0
Target sentence is extended to: Alignment is extended to:
IiI eeee ......00
JjJ aaaa ......00

Stephan Vogel - Machine Translation 13
Translation Model
Sum over all alignment
3 probability distributions: Length:
Alignment:
Lexicon:
),,|Pr(),|Pr()|Pr(
),|,Pr()|Pr(
)|,Pr(
011010
0110
011
IJJIJI
IJJI
IJJ
eJafeJaeJ
eJafeJ
eaf
Ja
IJJ eafef0
)|,Pr()|Pr( 011
)|Pr( 0IeJ
J
j
Ijj
IJ eJaaeJa1
01
101 ),,|Pr(),|Pr(
J
j
IJjj
IJJ eJaffeJaf1
011
1011 ),,,|Pr(),,|Pr(

Stephan Vogel - Machine Translation 14
Model Assumptions
Decompose interaction into pairwise dependencies Length: Source length only dependent on target length (very
weak)
Alignment: Zero order model: target position only dependent on source
position
First order model: target position only dependent on previous target position
Lexicon: source word only dependent on aligned word
)|()|Pr( 0 IJpeJ I
),,|(),,|Pr( 01
1 IJjapeJaa jIj
j
)|(),,,|Pr( 011
1 jajIJj
j efpeJaff
),,|(),,|Pr( 101
1 IJaapeJaa jjIj
j

Stephan Vogel - Machine Translation 15
Mixture Model
Interpretation as mixture model by direct decomposition
Again, simplifying model assumptions applied
J
j
I
iij
J
j
I
i
Ij
J
j
Ij
IJ
efpIJjipIJp
eJifpIJp
eJfpIJpef
1 1
1 11
1111
)|(),,|()|(
),|,()|(
),|()|()|Pr(

Stephan Vogel - Machine Translation 16
Training IBM2
Expectation-Maximization (EM) Algorithm Define posterior weight (i.e. sum over column =
1)
Lexicon probabilities
Alignment probabilities
'
);'(
);()|(
)|(),(),();(
f
s j i
sj
si
sj
efA
efAefp
fipeeffefA
'
),,;'(
),,;(),,|(
)|(),(),(),,;(
i
s
sj
ss
IJjiB
IJjiBIJjip
fipJJIIIJjiB
'' )|(),,|'(
)|(),,|()|(
i
si
sjss
si
sjss
efpIJjip
efpIJjipfip
count how oftenword pairs arealigned Turn counts into
probabilities

Stephan Vogel - Machine Translation 17
IBM1 Model
Assume uniform probability for position alignment
Alignment probability
In training: only collect counts for word pairs
IJIjip
1),,|(
J
j
I
iijJ
J
j
I
iij
IJ
efpI
IJp
efpIJjipIJpef
1 1
1 111
)|(1
)|(
)|(),,|()|()|Pr(

Stephan Vogel - Machine Translation 18
Training for IBM1 Model – Pseudo Code
# Accumulation (over corpus)For each sentence pair For each source position j Sum = 0.0 For each target position i Sum += p(fj|ei) For each target position i Count(fj,ei) += p(fj|ei)/Sum
# Re-estimate probabilities (over count table)For each target word e Sum = 0.0 For each source word f Sum += Count(f,e) For each source word f p(f|e) = Count(f,e)/Sum
# Repeat for several iterations

Stephan Vogel - Machine Translation 19
HMM Alignment Model
Idea: relative position model
Source
Target
Entire word groups (phrases)are moved with respect tosource position

Stephan Vogel - Machine Translation 20
HMM Alignment
First order model: target position dependent on previous target position(captures movement of entire phrases)
Alignment probability:
Maximum approximation:
),,|(),,|Pr( 101
1 IJaapeJaa jjIj
j
J
j
a
J
jajjj
IJ efpIaapIJpef1 1
111 )|(),|()|()|Pr(
J
jajjj
a
IJ
jJefpIaapIJpef
1111 )|(),|(max)|()|Pr(
1

Stephan Vogel - Machine Translation 21
Viterbi Training on HMM Model
# Accumulation (over corpus)# find Viterbi pathFor each sentence pair For each source position j For each target position i Pbest = 0; t = p(fj|ei) For each target position i’ Pprev = P(j-1,i’) a = p(i|i’,I,J) Pnew = Pprev*t*a if (Pnew > Pbest) Pbest = Pnew
BackPointer(j,i) = i’
# update countsi = argmax{ BackPointer( J, I ) }For each j from J downto 1 Count(f_j, e_i)++ Count(i,iprev,I,J)++ i = BackPoint(j,i)
# renormalize…
Pprev
a = p(i | i’,I,J)
t = p(fj | ei)
Pnew=Pprev*a*t

Stephan Vogel - Machine Translation 22
HMM Forward-Backward Training
Gamma : Probability to emit fj when in state i in sentence s
Sum over all paths through (j,i)
iaa
J
jajjj
sj
jJ
jefpIaapi
, 1''1''
1
')|(),|()(
j
i

Stephan Vogel - Machine Translation 23
HMM Forward-Backward Training
Epsilon: Probability to transit from state i’ into i Sum over all paths through (j-1,i’) and (j,i), emitting fj
iaiaa
J
jajjj
jjJ
jefpIaapii
,', 1''1''
11
')|(),|(),'(
j-1
i
j

Stephan Vogel - Machine Translation 24
Forward Probabilities
Defined as:
Recursion:
Initial condition:
)|(),'|()'()(1'
1 ij
I
ijj efpIiipii
iaa
j
jajjjj
jj
jefpIaapi
, 1''1''
1
')|(),|()(
)|(),0|()( 10 iefpIipi
j
i

Stephan Vogel - Machine Translation 25
Backward Probabilities
Defined as:
Recursion:
Initial condition:
)|(),|'()'()( 11'
1 ij
I
ijj efpIiipii
iaa
J
jjajjjj
jJj
jefpIaapi
, ''1'' )|(),|()(
'
1)(0 I
j
i

Stephan Vogel - Machine Translation 26
Forward-Backward
Calculate Gamma and Epsilon with Alpha and Beta:
Gammas:
Epsilons:
I
ij
j
ii
ii
1'
)()'(
)()(
iijijj
jijj
iefpIiipi
iefpIiipiii
~,'
~~1
1
)~
()|(),'~
|~
()'~
(
)()|(),'|()'(),'(

Stephan Vogel - Machine Translation 27
Parameter Re-Estimation
Lexicon probabilities
Alignment probabilities:
S
s
J
eej
sj
S
s
J
eeffj
sj
s
i
s
ij
i
i
efp
1 1
1,1
)(
)(
)|(
S
s
J
j
sj
S
s
J
j
sj
s
s
i
ii
iip
1 1
1 1
)(
),'(
)'|(

Stephan Vogel - Machine Translation 28
Forward-Backward Training – Pseudo Code
# Accumulation
For each sentence-pair {
Forward. (Calculate Alpha’s)
Backward. (Calculate Beta’s)
Calculate Xi’s and Gamma’s.
For each source word {
Increase LexiconCount(f_j|e_i) by Gamma(j,i).
Increase AlignCount(i|i’) by Epsilon(j,i,i’).
}
}
# Update
Normalize LexiconCount to get P(f_j|e_i).
Normalize AlignCount to get P(i|i’).
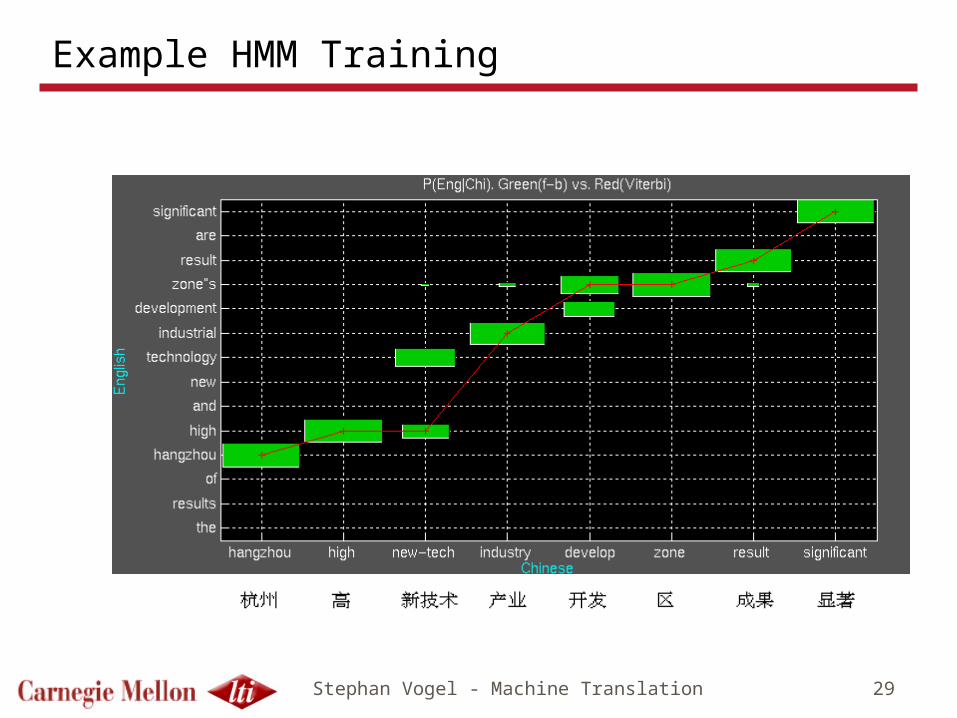
Stephan Vogel - Machine Translation 29
Example HMM Training

















