47

What is Apache Flink?
• Project undergoing incubation in the Apache Software Foundation
• Originating from the Stratosphere research project started at TU Berlin in 2009
• http://flink.incubator.apache.org
• 58 contributors (doubled in ~ 4 months)
• Has a cool squirrel for a logo
2

What is Apache Flink?
3
Master
Worker
Worker
Flink Cluster
Analytical Program
Flink Client &Optimizer

This talk
• Introduction to Flink
• Flink from a user perspective
• Tour of Flink internals
• Flink roadmap and closing
4

Open Source Data Processing Landscape
55
MapReduce
Hive
Flink
Spark Storm
Yarn Mesos
HDFS
Mahout
Cascading
Tez
Pig
Data processing engines
App and resource management
Applications
Storage, streams KafkaHBase
Crunch
…

6
Common API
StorageStreams
Hybrid Batch/Streaming Runtime
HDFS Files S3
ClusterManager
YARN EC2 Native
Flink Optimizer
Scala API(batch)
Graph API („Spargel“)
JDBC RedisRabbit
MQKafkaAzure …
JavaCollections
Streams Builder
Apache Tez
Python API
Java API(streaming)
Apache MRQL
Ba
tch
Stre
am
ing
Java API(batch)
LocalExecution

Flink APIs
7
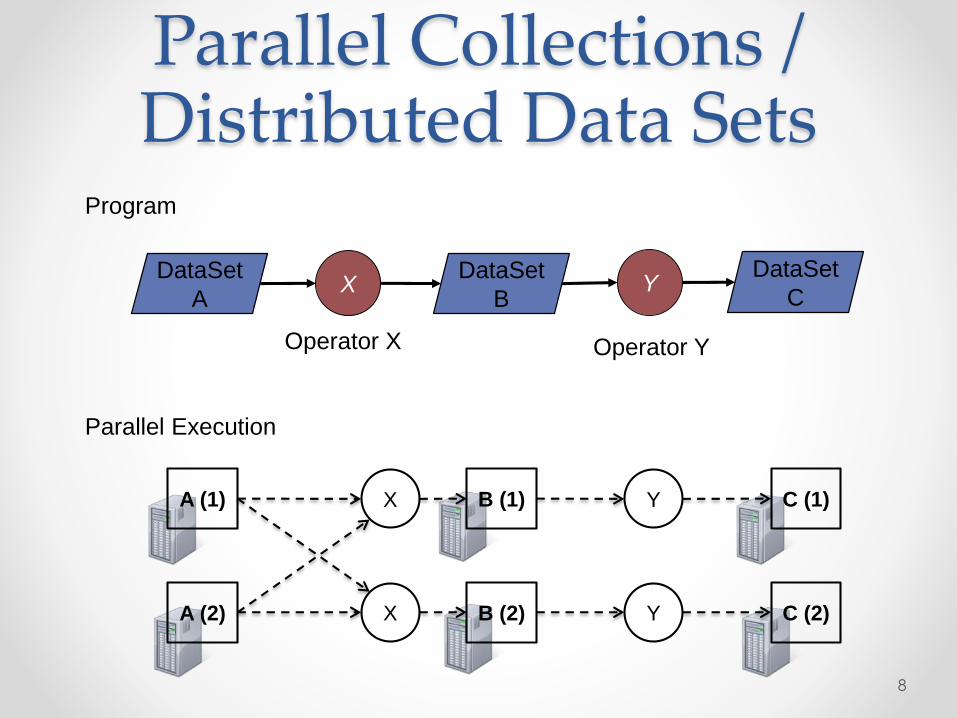
Parallel Collections / Distributed Data Sets
8
DataSet
A
DataSet
B
DataSet
C
A (1)
A (2)
B (1)
B (2)
C (1)
C (2)
X
X
Y
Y
Program
Parallel Execution
X Y
Operator X Operator Y

Flexible Pipelines
9
Reduce
Join
Map
Reduce
Map
Iterate
Source
Sink
Source
Map, FlatMap, MapPartition, Filter, Project, Reduce, ReduceGroup, Aggregate, Distinct, Join, CoGoup, Cross, Iterate, Iterate Delta, Iterate-Vertex-Centric

DataSet<String> text = env.readTextFile(input);
DataSet<Tuple2<String, Integer>> result = text
.flatMap((str, out) -> {
for (String token : value.split("\\W")) {
out.collect(new Tuple2<>(token, 1));
})
.groupBy(0)
.aggregate(SUM, 1);
Word Count, Java API
10

Word Count, Scala API
11
val input = env.readTextFile(input);
val words = input flatMap { line => line.split("\\W+") }
val counts = words groupBy { word => word } count()

12

Beyond Key/Value Pairs
13
DataSet<Page> pages = ...;
DataSet<Impression> impressions = ...;
DataSet<Impression> aggregated =
impressions
.groupBy("url")
.sum("count");
pages.join(impressions).where("url").equalTo("url")
.print()
// outputs pairs of matching pages and impressions
class Impression {
public String url;
public long count;
}
class Page {
public String url;
public String topic;
}
// outputs pairs of pages and impressions

Distributed architecture
14
val paths = edges.iterate (maxIterations) { prevPaths: DataSet[(Long, Long)] =>val nextPaths = prevPaths
.join(edges)
.where(1).equalTo(0) {(left, right) => (left._1,right._2)
}.union(prevPaths).groupBy(0, 1).reduce((l, r) => l)
nextPaths}
Client
Optimization and
translation to data
flow
Job Manager
Scheduling,
resource
negotiation, …
Task Manager
Data node
me
mo
ry
heap
Task Manager
Data node
me
mo
ry
heap
Task Manager
Data node
me
mo
ry
heap

What’s new in Flink
15

Dependability
16
JVM
Heap
Flink ManagedHeap
Network Buffers
UnmanagedHeap
(next version unifies network buffersand managed heap)
User Code
Hashing/Sorting/Caching
• Flink manages its own memory
• Caching and data processing happens in a dedicated memory fraction
• System never breaks theJVM heap, gracefully spills
Shuffles/Broadcasts

Operating onSerialized Data
• serializes data every time Highly robust, never gives up on you
• works on objects, RDDs may be stored serializedSerialization considered slow, only when needed
• makes serialization really cheap: partial deserialization, operates on serialized form Efficient and robust!
17

Operating onSerialized Data
Microbenchmark
• Sorting 1GB worth of (long, double) tuples
• 67,108,864 elements
• Simple quicksort
18

Memory Management
19
public class WC {
public String word;
public int count;
}
emptypage
Pool of Memory Pages
• Works on pages of bytes, maps objects transparently• Full control over memory, out-of-core enabled• Algorithms work on binary representation• Address individual fields (not deserialize whole object)• Move memory between operations

Beyond Key/Value Pairs
20
DataSet<Page> pages = ...;
DataSet<Impression> impressions = ...;
DataSet<Impression> aggregated =
impressions
.groupBy("url")
.sum("count");
pages.join(impressions).where("url").equalTo("url")
.print()
// outputs pairs of pages and impressions
class Impression {
public String url;
public long count;
}
class Page {
public String url;
public String topic;
}
// outputs pairs of pages and impressions

Beyond Key/Value Pairs
Why not key/value pairs
• Programs are much more readable ;-)
• Functions are self-contained, do not need to set key for successor)
• Much higher reusability of data types and functions
o Within Flink programs, or from other programs
21
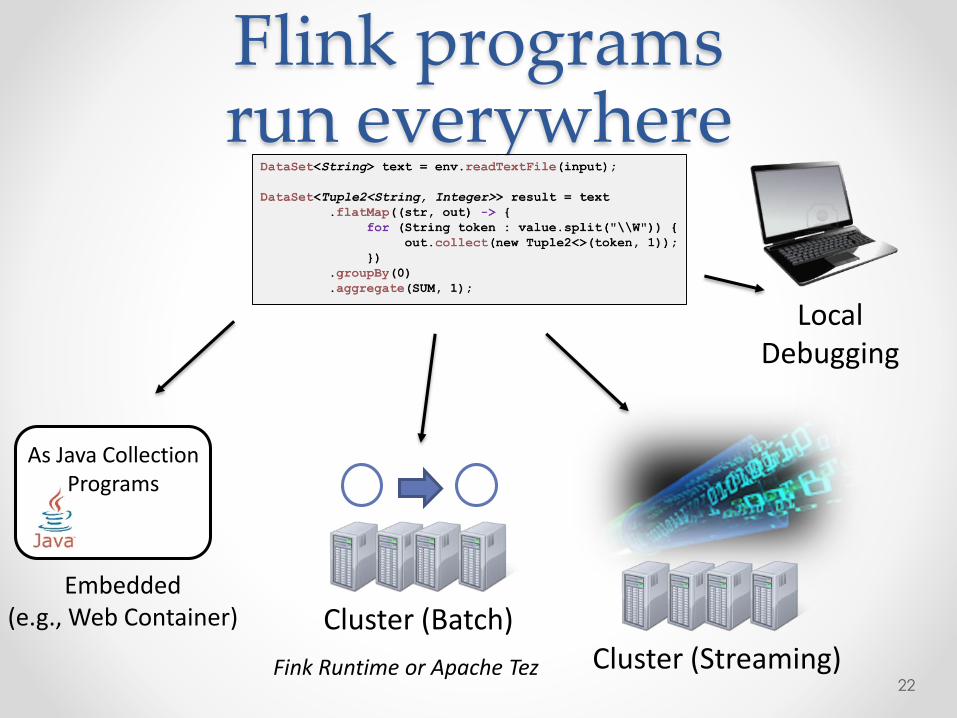
Flink programsrun everywhere
22
Cluster (Batch)Cluster (Streaming)
LocalDebugging
Fink Runtime or Apache Tez
As Java CollectionPrograms
Embedded(e.g., Web Container)

Upcoming Streaming API
23

Streaming Throughput
24

Migrate Easily
Flink supports out-of-the-box supports
• Hadoop data types (writables)
• Hadoop Input/Output Formats
• Hadoop functions and object model
25
Input Map Reduce Output
DataSet DataSet DataSetRed Join
DataSet Map DataSet
OutputS
Input

Little tuning or configuration required
• Requires no memory thresholds to configureo Flink manages its own memory
• Requires no complicated network configso Pipelining engine requires much less memory for data exchange
• Requires no serializers to be configuredo Flink handles its own type extraction and data representation
• Programs can be adjusted to data automaticallyo Flink’s optimizer can choose execution strategies automatically
26
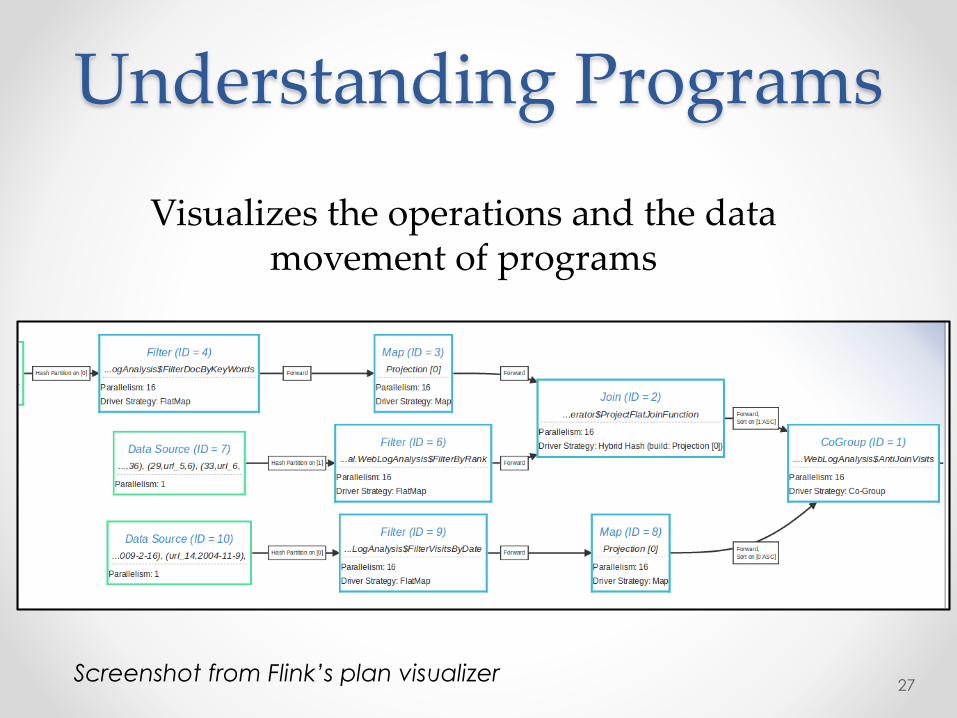
Understanding Programs
27
Visualizes the operations and the data movement of programs
Analyze after execution
Screenshot from Flink’s plan visualizer

Understanding Programs
28
Analyze after execution (times, stragglers, …)

Understanding Programs
29
Analyze after execution (times, stragglers, …)

Iterations in other systems
30
Step Step Step Step Step
ClientLoop outside the system
Step Step Step Step Step
ClientLoop outside the system

Iterations in Flink
31
Streaming dataflowwith feedback
map
join
red.
join
System is iteration-aware, performs automatic optimization
Flink

Automatic Optimization for Iterative Programs
32
Caching Loop-invariant DataPushing work„out of the loop“
Maintain state as index

Flink Roadmap
What is the community currently working on?
• Flink has a major release every 3 months,with >=1 big-fixing releases in-between
• Finer-grained fault tolerance
• Logical (SQL-like) field addressing
• Python API
• Flink Streaming , Lambda architecture support
• Flink on Tez
• ML on Flink (e.g., Mahout DSL)
• Graph DSL on Flink
• … and more33

34

35
http://flink.incubator.apache.org
github.com/apache/incubator-flink
@ApacheFlink

Engine comparison
36
Paradigm
Optimization
Execution
API
Optimization
in all APIs
Optimization
of SQL queriesnone none
DAG
Transformations
on k/v pair
collections
Iterative
transformations
on collections
RDDCyclic
dataflows
MapReduce on
k/v pairs
k/v pair
Readers/Writers
Batch
sorting
Batch
sorting and
partitioning
Batch with
memory
pinning
Stream with
out-of-core
algorithms
MapReduce

DataSet<Order> large = ...
DataSet<Lineitem> medium = ...
DataSet<Customer> small = ...
DataSet<Tuple...> joined1 = large.join(medium).where(3).equals(1)
.with(new JoinFunction() { ... });
DataSet<Tuple...> joined2 = small.join(joined1).where(0).equals(2)
.with(new JoinFunction() { ... });
DataSet<Tuple...> result = joined2.groupBy(3).aggregate(MAX, 2);
Example: Joins in Flink
37
Built-in strategies include partitioned join and replicated join with local sort-merge or hybrid-hash algorithms.
⋈⋈
γ
large medium
small

DataSet<Tuple...> large = env.readCsv(...);
DataSet<Tuple...> medium = env.readCsv(...);
DataSet<Tuple...> small = env.readCsv(...);
DataSet<Tuple...> joined1 = large.join(medium).where(3).equals(1)
.with(new JoinFunction() { ... });
DataSet<Tuple...> joined2 = small.join(joined1).where(0).equals(2)
.with(new JoinFunction() { ... });
DataSet<Tuple...> result = joined2.groupBy(3).aggregate(MAX, 2);
Automatic Optimization
38
Possible execution 1) Partitioned hash-join
3) Grouping /Aggregation reuses the partitioningfrom step (1) No shuffle!!!
2) Broadcast hash-join
Partitioned ≈ Reduce-sideBroadcast ≈ Map-side
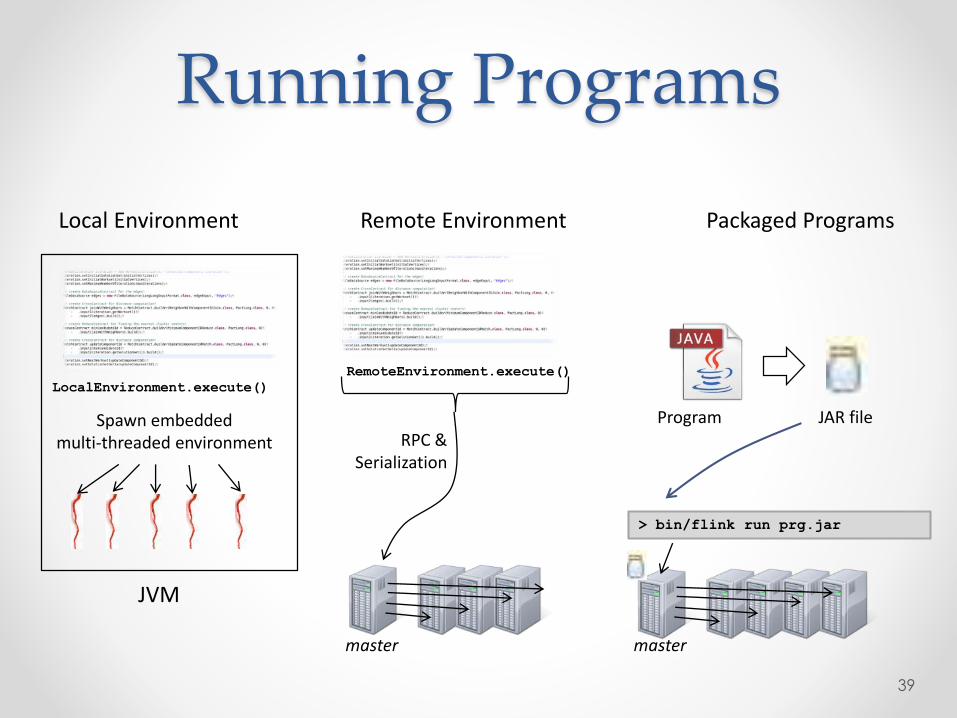
Running Programs
39
> bin/flink run prg.jar
Packaged ProgramsRemote EnvironmentLocal Environment
Program JAR file
JVM
master master
RPC &Serialization
RemoteEnvironment.execute()
LocalEnvironment.execute()
Spawn embeddedmulti-threaded environment

Iterative Programs
40

Why Iterative Algorithms
• Algorithms that need iterationso Clustering (K-Means, Canopy, …)
o Gradient descent (e.g., Logistic Regression, Matrix Factorization)
o Graph Algorithms (e.g., PageRank, Line-Rank, components, paths, reachability, centrality, )
o Graph communities / dense sub-components
o Inference (believe propagation)
o …
• Loop makes multiple passes over the data
41

Iterations in other systems
42
Step Step Step Step Step
ClientLoop outside the system
Step Step Step Step Step
ClientLoop outside the system

Iterations in Flink
43
Streaming dataflowwith feedback
map
join
red.
join
System is iteration-aware, performs automatic optimization
Flink

Automatic Optimization for Iterative Programs
44
Caching Loop-invariant DataPushing work„out of the loop“
Maintain state as index

Unifies various kinds of Computations
45
ExecutionEnvironment env = getExecutionEnvironment();
DataSet<Long> vertexIds = ...
DataSet<Tuple2<Long, Long>> edges = ...
DataSet<Tuple2<Long, Long>> vertices = vertexIds.map(new
IdAssigner());
DataSet<Tuple2<Long, Long>> result = vertices .runOperation(
VertexCentricIteration.withPlainEdges(
edges, new CCUpdater(), new CCMessager(), 100));
result.print();
env.execute("Connected Components");
Pregel/Giraph-style Graph Computation
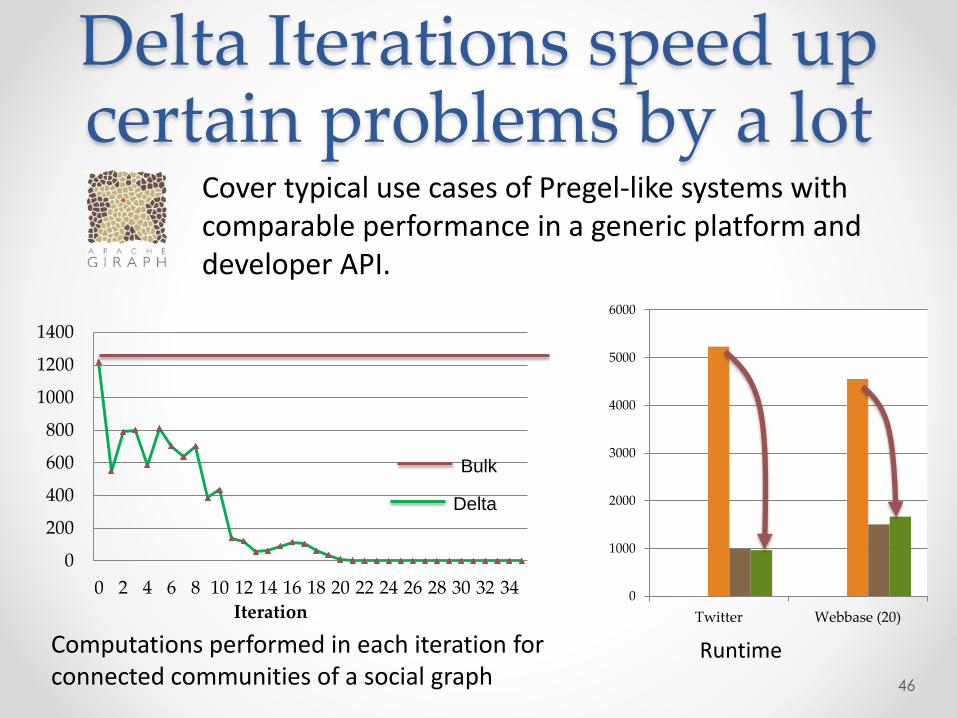
Delta Iterations speed up certain problems by a lot
46
0
200
400
600
800
1000
1200
1400
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34
Iteration
Bulk
Delta
0
1000
2000
3000
4000
5000
6000
Twitter Webbase (20)
Computations performed in each iteration for connected communities of a social graph
Runtime
Cover typical use cases of Pregel-like systems with comparable performance in a generic platform and developer API.

What is Automatic Optimization
47
Run on a sampleon the laptop
Run a month laterafter the data evolved
Hash vs. SortPartition vs. BroadcastCachingReusing partition/sortExecution
Plan A
ExecutionPlan B
Run on large fileson the cluster
ExecutionPlan C


















![Accumulo Summit 2015: Alternatives to Apache Accumulo's Java API [API]](https://static.documents.pub/doc/80x56/55a5e4141a28ab37368b4765/accumulo-summit-2015-alternatives-to-apache-accumulos-java-api-api.jpg)