Studies of the User- Scheduler Relationship Cynthia Bailey Lee Advisor: Allan E. Snavely Department of Computer Science and Engineering San Diego Supercomputer Center University of California, San Diego May 19, 2008
Transcript
Studies of the User-Scheduler Relationship
Cynthia Bailey LeeAdvisor: Allan E. Snavely
Department of Computer Science and Engineering
San Diego Supercomputer Center
University of California, San Diego
May 19, 2008
Introduction The job submission routine:
Edit job script, including resources needed and amount of time requested
Submit job—typically, many questions remain: Did I request enough time? How long will the job wait in the queue?
Eventually, job runs—more questions: I submitted to a ‘high-priority’ queue—was my wait time
actually shorter than if I hadn’t? By how much? Was it worth it?
Is this a satisfying relationship for either party?
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
• Falsified “The Padding Hypothesis” as the sole explanation for users’ inaccurate runtime requests
• Quantified users’ valuation of turnaround by collecting actual users’ utility curves
• Proposed a model for synthetically generating utility functions that draws on patterns seen in the actual user curves
• A genetic algorithm-based scheduler that uses aggregate utility as an explicit objective function
Contributions of This Work
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
“The Padding Hypothesis”
The inaccuracy of users’ requested runtimes, relative to the actual runtime of jobs, is explained by users explicitly “padding”
otherwise accurate runtime estimates in order to avoid the possibility of being killed by the
scheduler.
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Padding Hypothesis
Lessons Learned:
• Users can’t provide information most schedulers ask for, but…
• Maybe they can (and would want to) provide useful information schedulers currently don’t ask for
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
SDSC users were asked to provide a “no-kill”/no-pressure estimate, with prizes for being accurate
Users are able to self-identify as more or less accurate
0%10%20%30%40%50%60%70%80%90%
100%
0 1 2 3 4 5
Confidence Level
Avg
. % A
ccu
racy
changed
not changed
02468
10121416
0% 10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
% Decrease
72
Padding Hypothesis
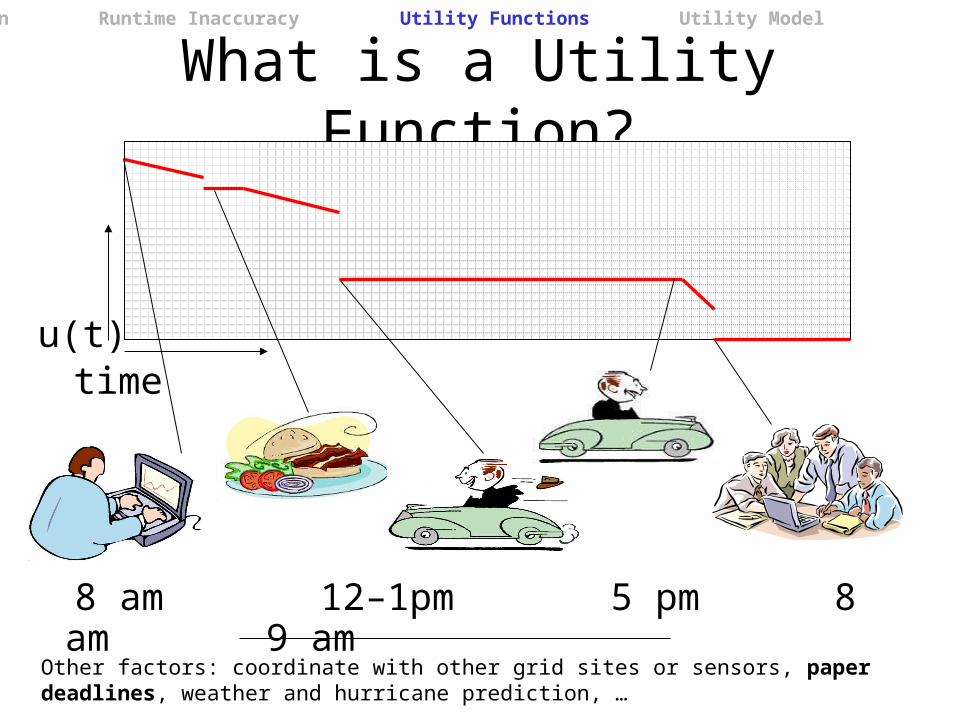
What is a Utility Function?
8 am 12–1pm 5 pm 8 am 9 am
timeu(t)
Other factors: coordinate with other grid sites or sensors, paper deadlines, weather and hurricane prediction, …
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Real Users' Functions
• Randomly-selected users of SDSC systems provided these data points for jobs they were submitting
• Utility is in terms of the SDSC charge unit (“SU”)
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
More Real Users' Functions
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Existing Model
[Used by e.g. Chun and Culler 2002, and Irwin, Grit, Chase 2004]
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Proposed ModelTo use Aggregate Utility, utility
functions needed for all jobs Propose to store function as series of (time,
value) pairs appending each line of Standard
Workload Format, allowing arbitrarily-shaped
functions
Absent real data collected from users for each job, we need a model for synthetic generation...
Job ID Submit Time Req. Time Run Time Nodes ... Utility1 Time Value ...23...
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Modeling Three Distinct Decay Patterns
0 1 2 3 4 5 6 7 8 9 10 11
0
10
20
30
40
50
60
70
80
90
100
110
Expected Linear
Expected Exponential
Step
Time
Util
ity
• Expected Linear
• Expected Exponential
• Step
“Expected” refers to
the fact that each point
is chosen randomly (i.e.
Most won't follow the pattern as cleanly
as shown here)
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Start Values and Deadlines
User-provided priority (queue) from the log controls the starting (maximum) job value
Distribution of actual
wait times from the log
controls the deadline
(when the value goes
to zero) 0 1 2 3 4 5 6 7 8 9 10 11
0
10
20
30
40
50
60
70
80
90
100
110
Time
Util
ity
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Metric: Aggregate Utility
– Reflects administrator's priorities • allocation of funds (“SUs”/Monopoly money) to users at the
beginning of the fiscal [year/quarter/month/etc]
– Reflects users' personal input • how they choose to spend their funds
– Enables more comprehensive evaluation and
comparison of all job scheduling algorithms
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Parallel Job Scheduling Explicitly by Utility
FunctionFinding the best solution is NP-hard
“Tennis Court Scheduling” (human-powered) Still practiced occasionally at most centers (officially and not) -- a
phone call to sys admins gets a job a reservation or to the front of the queue
Custom Heuristics Sort by current value, or a combination of start value and slope
[Chun and Culler 2002; Irwin, Grit, Chase 2004]
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Genetic Algorithm Scheduler
• Individuals:
– permutations of the job queue ordering
• Mutation:
– swap two randomly-selected jobs
• Reproduction:
– zipper-like merging of parents (skip duplicates)
• Fitness: global utility of resulting schedule (approx.)
J1 J2 J3 J4 J5
J1 J2 J3 J4 J5
J1 J2 J3 J4 J5+ = J1 J1 J2 J2 J3
J1 J2 J3 J4 J5
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
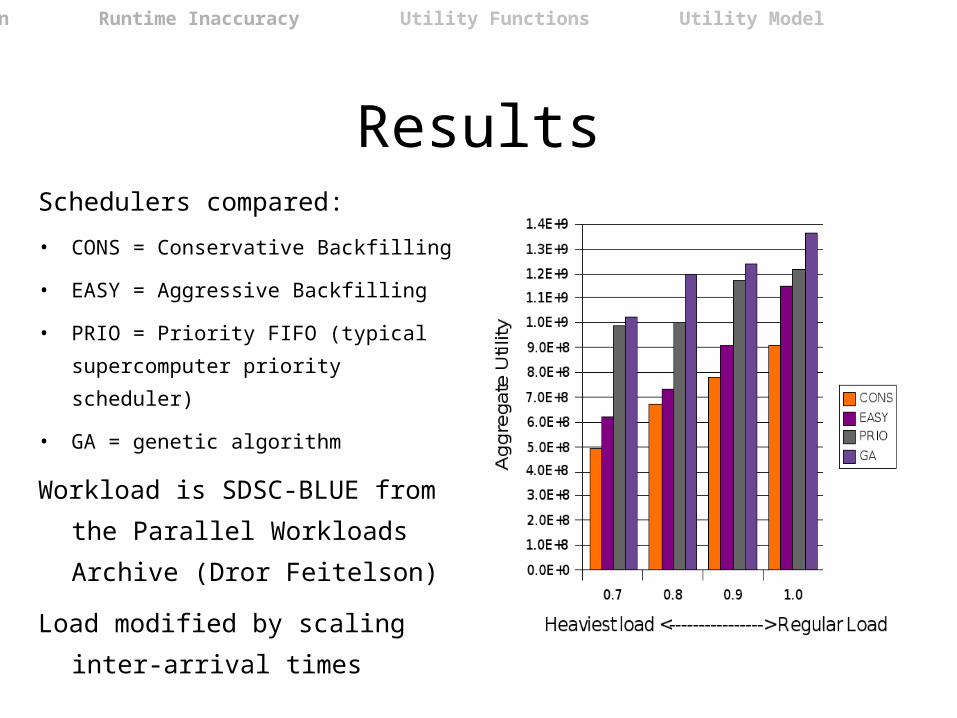
ResultsSchedulers compared:
• CONS = Conservative Backfilling
• EASY = Aggressive Backfilling
• PRIO = Priority FIFO (typical
supercomputer priority scheduler)
• GA = genetic algorithm
Workload is SDSC-BLUE from
the Parallel Workloads
Archive (Dror Feitelson)
Load modified by scaling inter-
arrival times
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Accurate and Inaccurate Runtimes
Normal Load Heavy Load
Many, many more results in the paper...
Introduction Runtime Inaccuracy Utility Functions Utility Model Scheduler
Current & Future Work• Eliciting the Utility Function
– What would this look like in a production environment
– Interview users to better see how they think about the utility
function
• Quantifying the benefit
– What is the additional benefit of providing additional utility
function data points?
– Who benefits? Everyone? Do users who provide more data
points than their peers benefit individually?
Current & Future Work
For more information…• Inaccurate runtime requests survey:
Lee, C., Y. Schwartzman, J. Hardy, A. Snavely. “Are user runtime estimates inherently inaccurate?” Workshop on Job Scheduling Strategies for Parallel Processing, with SIGMETRICS, June 2004.
• Survey collecting SDSC users' utility curves:Lee, C. and A. Snavely. "On the User-Scheduler Dialogue: Studies of User-
Provided Runtime Estimates and Utility Functions." International Journal of High Performance Computing Applications, vol. 20, 2006.
• Genetic algorithm scheduler and model for generating synthetic utility curves:
Lee, C. and A. Snavely. “Precise and Realistic Utility Functions for User-Centric Performance Analysis of Schedulers.” HPDC-16, June 2007.