26
Interac(ve Queries on Compressed RDD Succinct Spark Rachit Agarwal AMPLab [email protected] TwiEer: @_ragarwal_
| Date post: | 21-Apr-2017 |
| Category: |
Data & Analytics |
| Upload: | spark-summit |
| View: | 1,399 times |
| Download: | 1 times |

Interac(veQueriesonCompressedRDD
SuccinctSpark
RachitAgarwalAMPLab
TwiEer:@_ragarwal_
Nosecondaryindexes,nodatascans,nodatadecompression
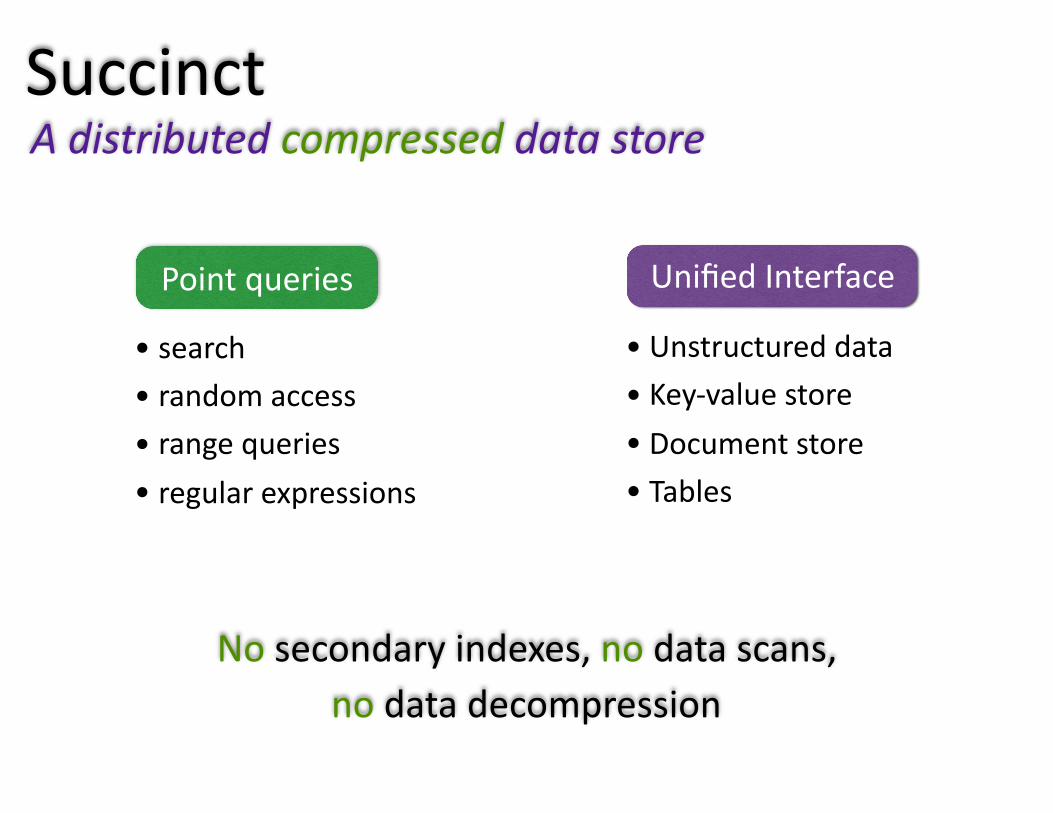
AdistributedcompresseddatastoreSuccinct
Pointqueries
• search• randomaccess• rangequeries• regularexpressions
UnifiedInterface
• Unstructureddata• Key-valuestore• Documentstore• Tables

Interactivepointqueries
Randomaccess
Search
RangeQueries
RegularExpressions
Aggregatequeries
Updates
Graphqueries
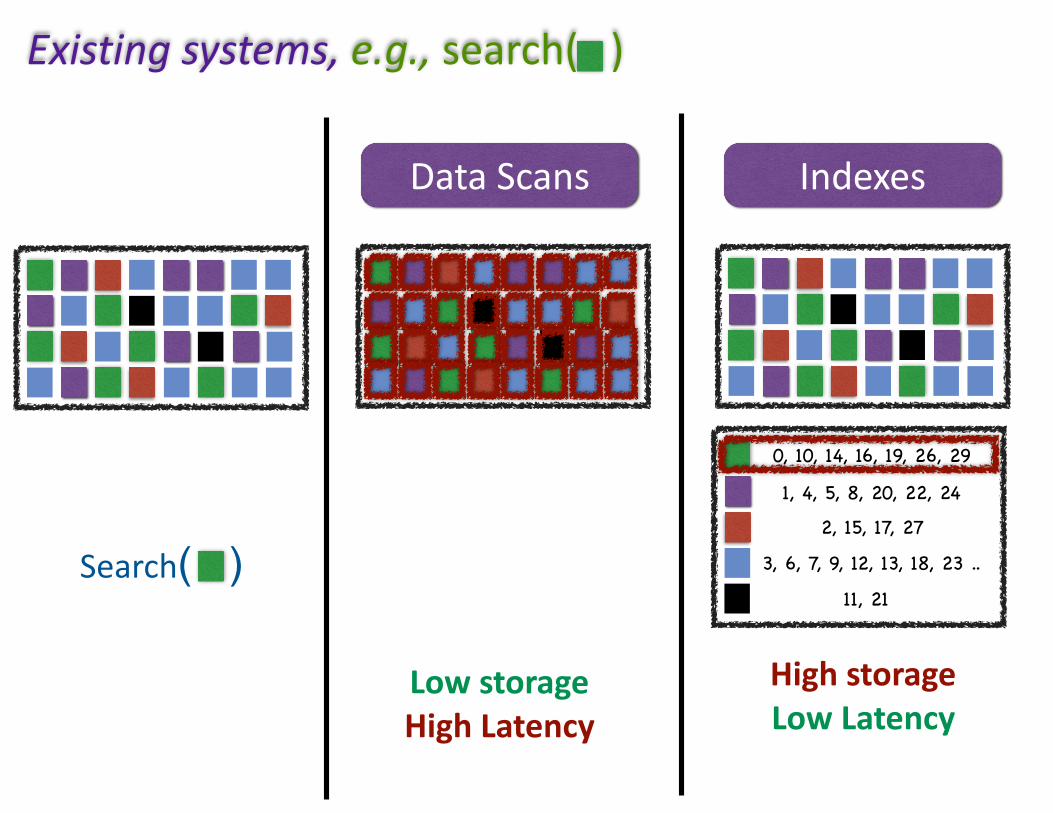
0, 10, 14, 16, 19, 26, 29
1, 4, 5, 8, 20, 22, 24
2, 15, 17, 27
3, 6, 7, 9, 12, 13, 18, 23 ..
11, 21
DataScans Indexes
LowstorageHighLatency
HighstorageLowLatency
Existingsystems,e.g.,search()
Search( )
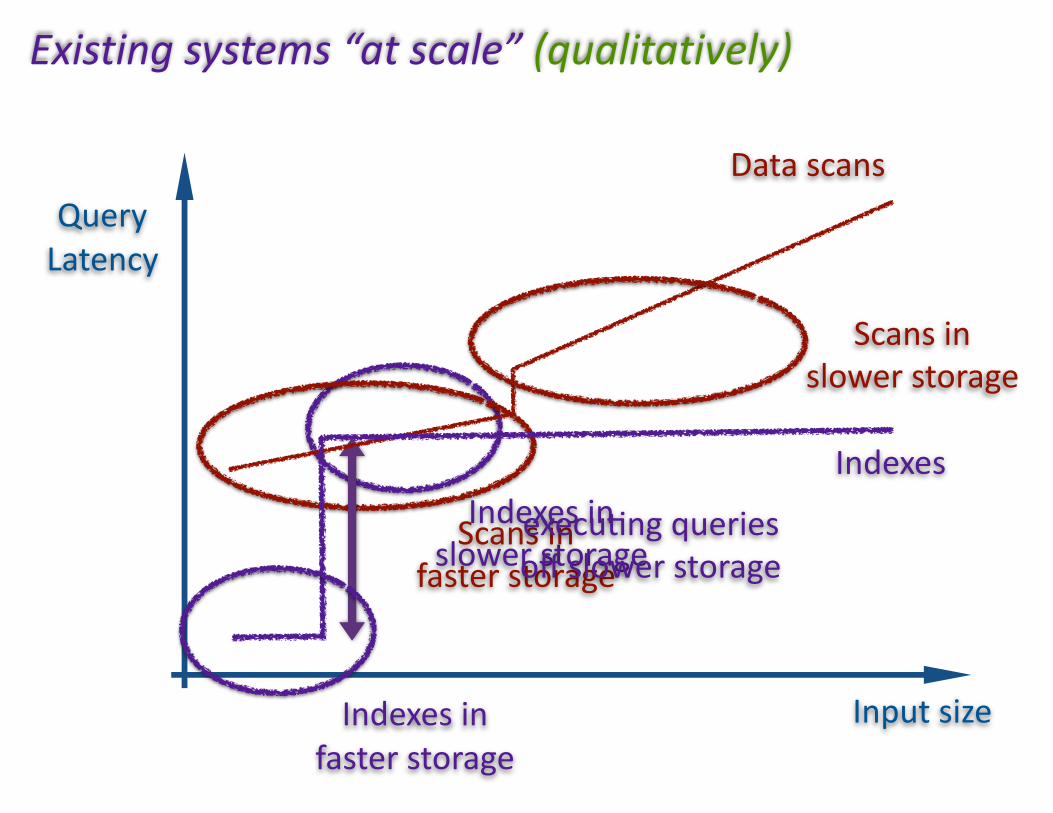
IndexesinslowerstorageScansin
fasterstorageexecu(ngqueriesoffslowerstorage
Inputsize
QueryLatency
Datascans
Indexes
Scansinslowerstorage
Indexesinfasterstorage
Existingsystems“atscale”(qualitatively)
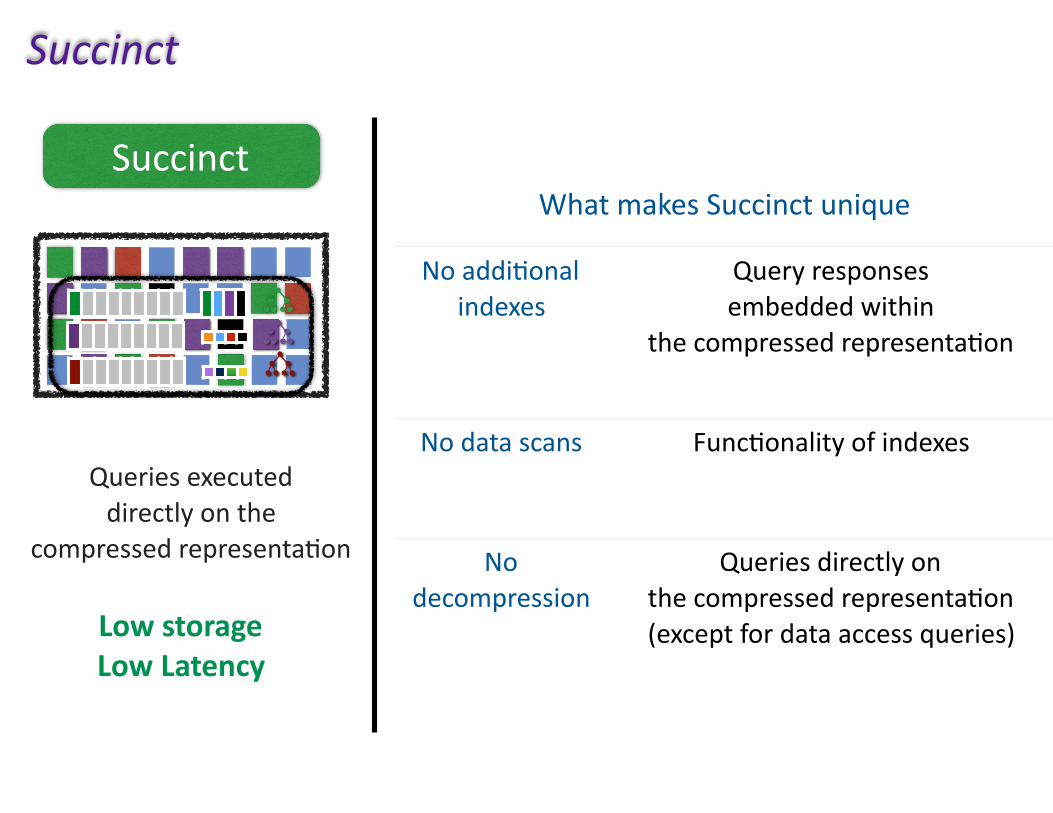
Succinct
LowstorageLowLatency
Queriesexecuteddirectlyonthe
compressedrepresenta(on
WhatmakesSuccinctunique
Noaddi(onalindexes
Queryresponsesembeddedwithin
thecompressedrepresenta(on
Nodatascans Func(onalityofindexes
Nodecompression
Queriesdirectlyonthecompressedrepresenta(on(exceptfordataaccessqueries)
Succinct
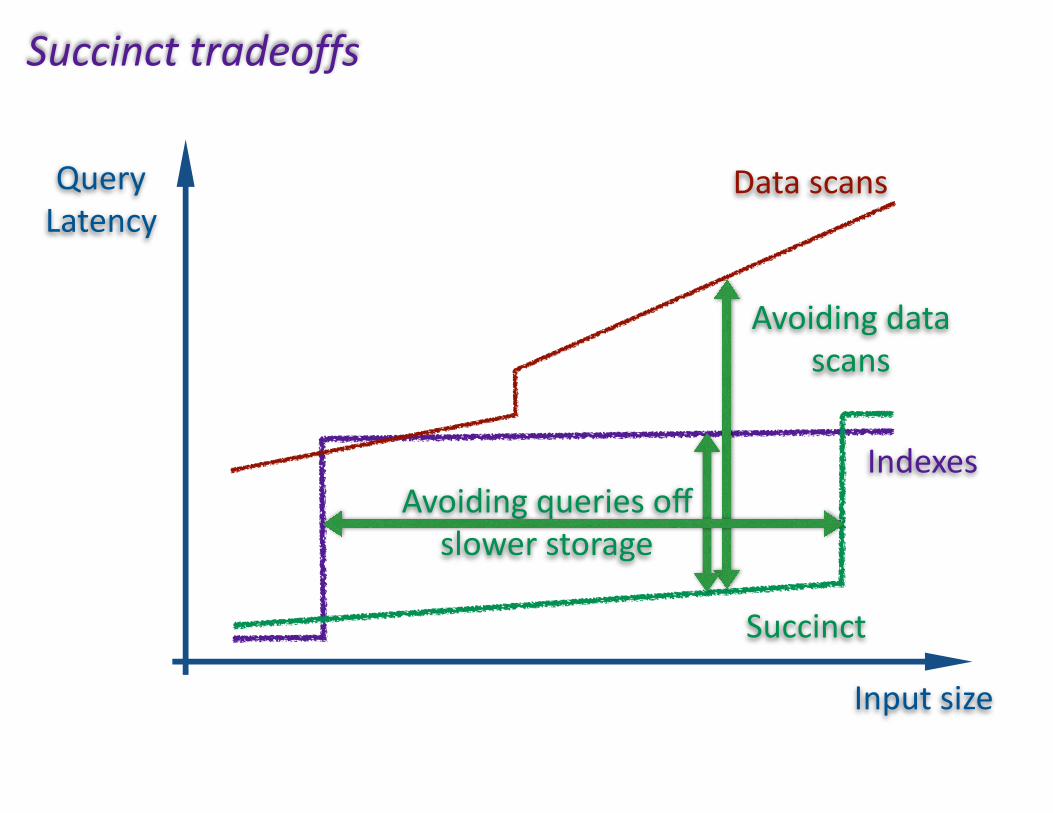
Inputsize
QueryLatency
Indexes
Succinct
Avoidingdatascans
Avoidingqueriesoffslowerstorage
Datascans
Succincttradeoffs
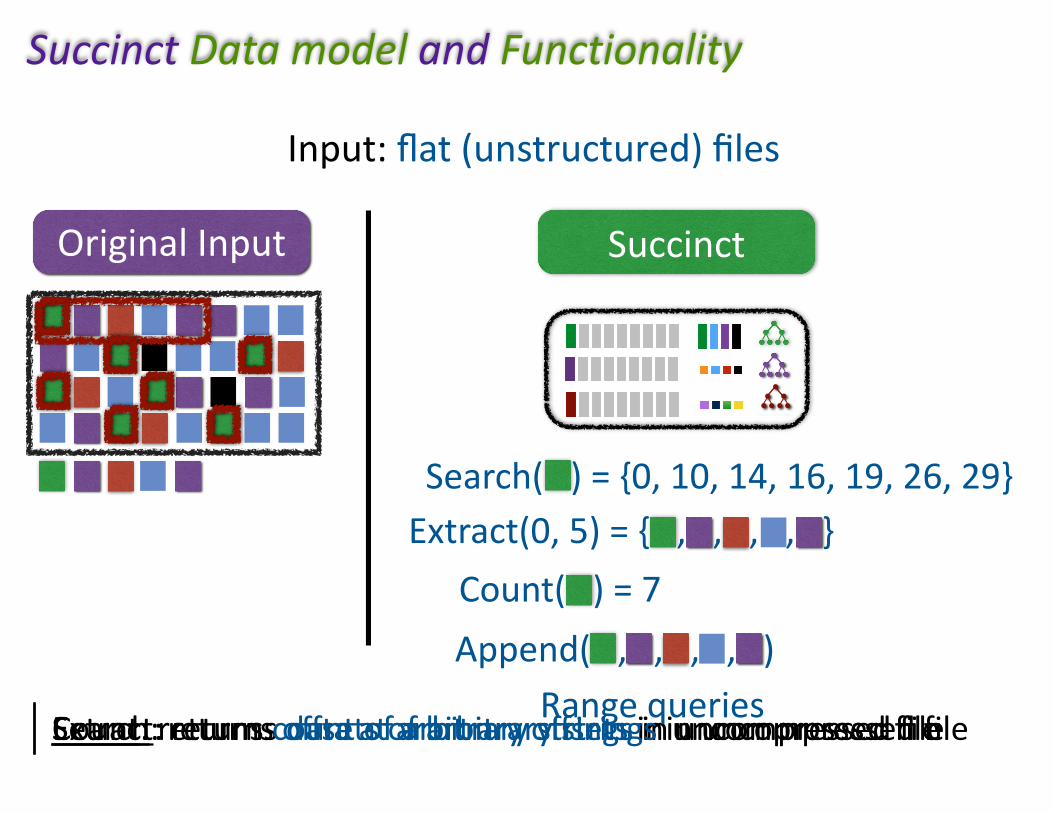
OriginalInput
Extract:returnsdataatarbitraryoffsetsinuncompressedfileCount:returnscountofarbitrarystringsinuncompressedfile
Succinct
Search()={0,10,14,16,19,26,29}Extract(0,5)={,,,,}
Count()=7
Search:returnsoffsetsofarbitrarystringsinuncompressedfile
Input:flat(unstructured)files
Append(,,,,)Rangequeries
SuccinctDatamodelandFunctionality

Supported,buttraded-offinfavorofpointqueriesoncompresseddata
• Preprocessingtime
• CPU(dataaccess)
• Sequentialscanthroughput
• “In-place”updates
Whatdowelose?
Succincttradeoffs

Nosecondaryindexes,nodatascans,nodatadecompression
AdistributedcompresseddatastoreSuccinct
Pointqueries
• search• randomaccess• rangequeries• regularexpressions
UnifiedInterface
• Unstructureddata• Key-valuestore• Documentstore• Tables

Withallthepowerfulqueriesonvalues,documents,columns
• Unstructureddata
• Key-valuestores(Voldemort,Dynamo)
• Documentstore(Elasticsearch,MongoDB)
• Tables(Cassandra,BigTable)
• Andmanymore….
UnifiedInterface
SuccinctDataModel:FlatFileInterface

Search(Column1,)Search()
SuccinctFlatFileInterface:Unification
Wherearewe?
• Succinct• SuccinctSpark
Wherearewegoing?
• Industrycollabora(on• Succinct++
AdistributedcompresseddatastoreSuccinct

• System(prototyped&tested)
• Asalibrary
• C++,Java,Scala
• foreaseofintegration
• Allfunctionalitiessupported
Succinct
Succinct:Wherearewe?

• ASparkpackage
• Enablesnewfunctionalities
• Documentstores
• Pointqueries
• Fasterfilters
• CompressedRDDs:Morein-memory
• DataframesAPInotsomature
QueriesoncompressedRDDs
SuccinctSpark
Succinct:Wherearewe?

IfyouarealreadyusingSpark
Newfunc(onali(es
Documentstore,Key-Valuestore
searchondocuments,values
Fasteropera(onsintoRDDs
randomaccess,filters
avoidscans
Morein-memory CompressedRDDs nodecompressionoverheads
SuccinctSpark
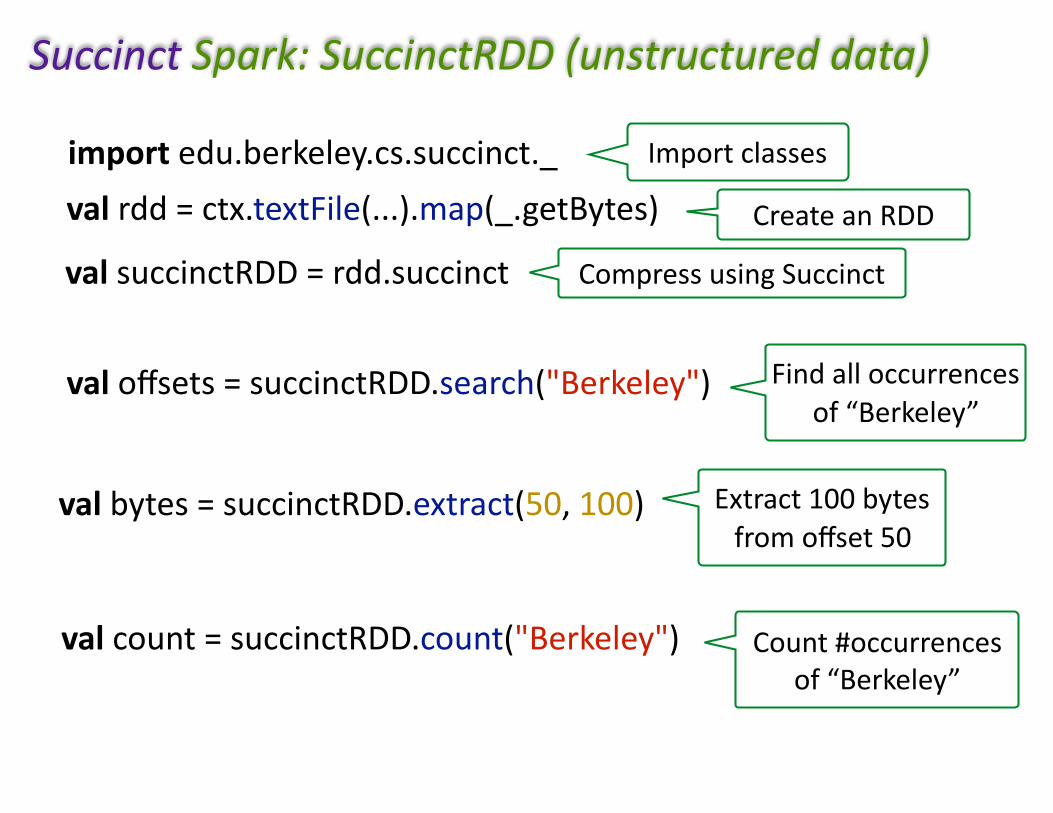
importedu.berkeley.cs.succinct._valrdd=ctx.textFile(...).map(_.getBytes)
valbytes=succinctRDD.extract(50,100)
valcount=succinctRDD.count("Berkeley")
valoffsets=succinctRDD.search("Berkeley")
Importclasses
CreateanRDD
Extract100bytesfromoffset50
Count#occurrencesof“Berkeley”
Findalloccurrencesof“Berkeley”
valsuccinctRDD=rdd.succinct CompressusingSuccinct
SuccinctSpark:SuccinctRDD(unstructureddata)
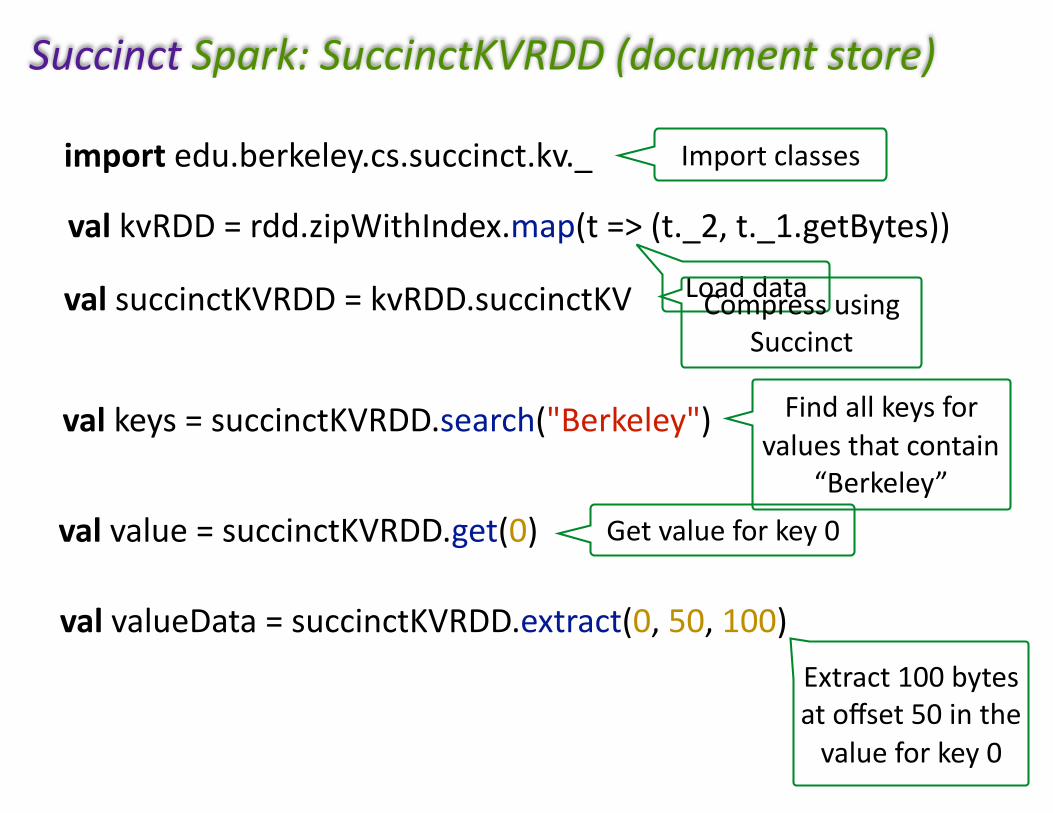
importedu.berkeley.cs.succinct.kv._
valkvRDD=rdd.zipWithIndex.map(t=>(t._2,t._1.getBytes))
valvalue=succinctKVRDD.get(0)
valvalueData=succinctKVRDD.extract(0,50,100)
valkeys=succinctKVRDD.search("Berkeley")
Importclasses
Loaddata
Getvalueforkey0
Extract100bytesatoffset50inthevalueforkey0
Findallkeysforvaluesthatcontain
“Berkeley”
valsuccinctKVRDD=kvRDD.succinctKV CompressusingSuccinct
SuccinctSpark:SuccinctKVRDD(documentstore)

• 5xAmazonEC2servers,30GBRAMeach
• Wikipediadataset,40GB
• Spark,Elasticsearch
• searchqueries
• #occurrences1-10k
SuccinctEvaluation

Take-away:SuccinctSpark2.75xfasterthanElas(cSearchwhilebeing2.5xmorespaceefficient(datafitsinmemoryforallsystems)
SuccinctSparkEvaluation(searchlatency)

SuccinctSparknowsupportsRegularExpressions!
valmatches=succinctRDD.regexSearch("William.*Clinton")
FindallmatchesfortheRegEx
“William.*Clinton”
valmatchKeys=succinctKVRDD.regexSearch("William.*Clinton")
FindallkeysforvaluesthatcontainmatchesfortheRegEx“William.*Clinton”
SuccinctRDD
SuccinctKVRDD
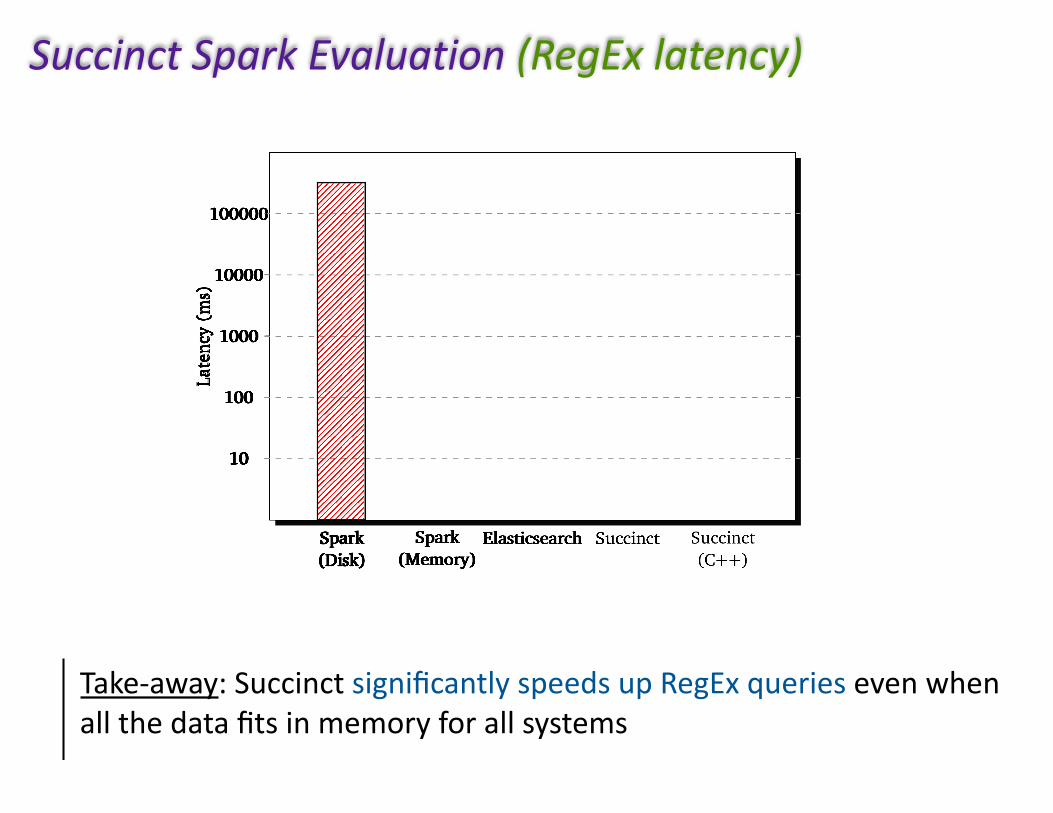
Take-away:SuccinctsignificantlyspeedsupRegExqueriesevenwhenallthedatafitsinmemoryforallsystems
SuccinctSparkEvaluation(RegExlatency)
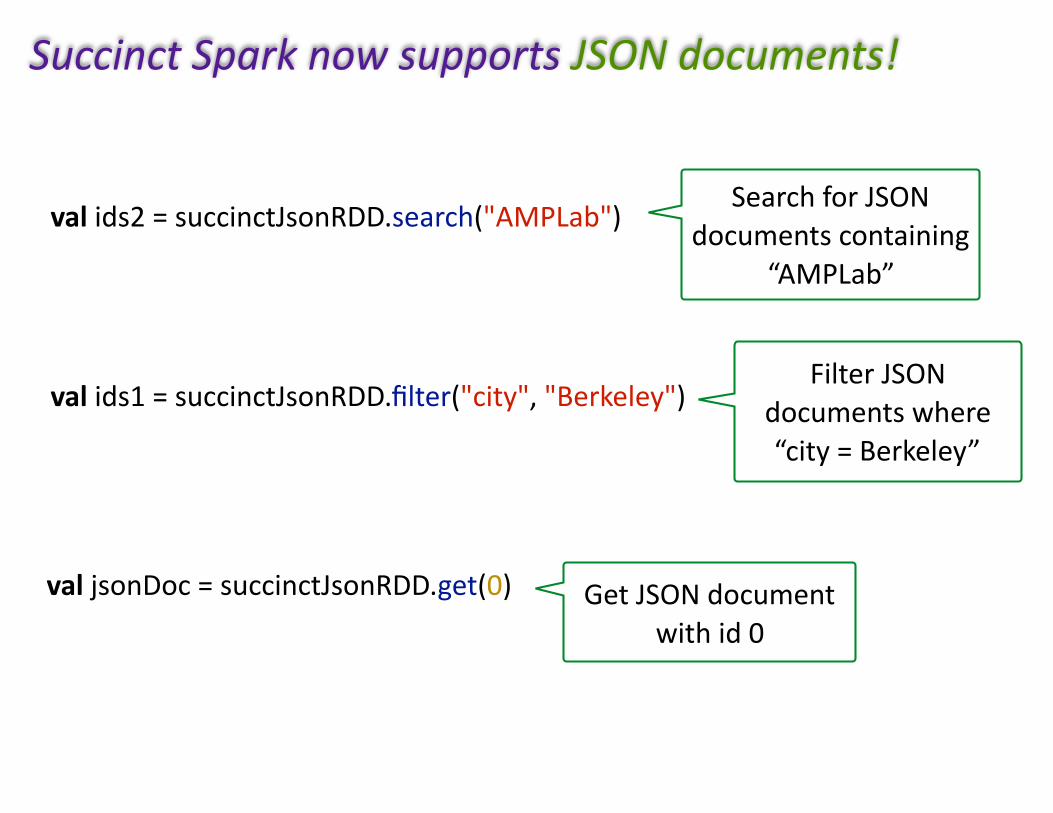
valjsonDoc=succinctJsonRDD.get(0)
valids1=succinctJsonRDD.filter("city","Berkeley")
valids2=succinctJsonRDD.search("AMPLab")
GetJSONdocumentwithid0
FilterJSONdocumentswhere“city=Berkeley”
SearchforJSONdocumentscontaining
“AMPLab”
SuccinctSparknowsupportsJSONdocuments!

• Moretesting,benchmarking
• SuccinctSparkDataframes
• Newfunctionalities
Where are we going?
Queriesoncompressedandencrypteddata
• BlowFish
• SuccinctEncryption
• SuccinctGraphs
Newfunctionalities
Succinct
BlowFish
Indexes
Queriesoncompressedgraphs
Storage
QueryLatency

ANDMANYMORE!
succinct.cs.berkeley.edu

![Rectal drug delivery system [RDDS]](https://static.documents.pub/doc/80x56/587aa8501a28abed218b4e75/rectal-drug-delivery-system-rdds.jpg)

![Distributed graph queries over models@run.time for runtime … · 2020-02-03 · data distribution service (RDDS [35]). RDDS is an exten-sion for the DDS standard [50] of the Object](https://static.documents.pub/doc/80x56/5ed726b0c30795314c174a2d/distributed-graph-queries-over-modelsruntime-for-runtime-2020-02-03-data-distribution.jpg)
![Go green rachit]](https://static.documents.pub/doc/80x56/588584731a28ab84668b4a05/go-green-rachit.jpg)












