42
SUPPORT FOR ADVANCED COMPUTING IN PROJECT CHRONO Dan Negrut Vilas Associate Professor NVIDIA CUDA Fellow Simulation-Based Engineering Lab University of Wisconsin-Madison December 9, 2015

SUPPORT FOR ADVANCED COMPUTING IN PROJECT CHRONO
Dan NegrutVilas Associate Professor
NVIDIA CUDA FellowSimulation-Based Engineering Lab
University of Wisconsin-Madison
December 9, 2015

Acknowledgement
• Funding for Project Chrono comes from US Army TARDEC• Ends in September 2016
• [looking for organizations to partner with for transfer of technology and joint projects]
MaGIC Fall 2015 2

Overview
• Part 1: discussion of two trends in computing
• Part 2: how we position Chrono to accommodate future trends in computing
MaGIC Fall 2015 3

The Price of 1 Gflop/second
• 1961: • Combine 17 million IBM-1620 computers
• At $64K apiece, when adjusted for inflation, this would cost $8.3 trillion
• 2000:• About $1,000
• 2015:• 8 cents
MaGIC Fall 2015 4
[wikipedia]

“The inside of a computer is as dumb as hell but it goes like mad.”
--Richard Feynman
5MaGIC Fall 2015

Adopting a Positive Outlook
“The inside of a computer goes like mad but needs some hand holding.”
6MaGIC Fall 2015

First Trend Discussed Here: Memory Speed
• 3D Memory – A major breakthrough
7MaGIC Fall 2015

Basic Fact, Speed of Execution: Math Doesn’t Matter
MaGIC Fall 2015 8
void someFunction(double* a, double* b, unsigned int arrSize){
double dummy[3];
dummy[0] = sin(a[1]);dummy[1] = log(fabs(a[2])) + sqrt(2.+dummy[0]);dummy[2] = cos(b[1]) + exp(b[0]);a[0] = dummy[1];b[0] = dummy[2];
// and so on...}
void someFunction(double* a, double* b, unsigned int arrSize){
double dummy[3];
dummy[0] a[1]dummy[1] a[2]dummy[2] b[1] and b[0]
// and so on...}

Why Math Operations Don’t Count
• Memory speed almost always dictates performance of computation
• One transaction to GPU global memory: 400 clock cycles
• 32 fused multiply-add operations; i.e., 64 operations: 1 clock cycle
𝑐 = 𝛼 × 𝑐 + 𝑏
• Bottom line: 100X more expensive to move data where is needed
9MaGIC Fall 2015

Memory Speed: Hard Nut to Crack
• Historically, memory speed increasing at a rate of approx. 1.07/year
• Historically, processors improved at faster rates• 1.25/year (1980-1986)
• 1.52/year (1986-2004)
• 1.20/year (2004-2010)
• Growing gap between memory speed and processing speed
10MaGIC Fall 2015

Memory Speed:Widening of the Processor-DRAM Performance Gap
Courtesy of Elsevier, Computer Architecture, Hennessey and Patterson, fourth edition
1111MaGIC Fall 2015

3D Stacked Memory[future looks quite bright]
SK Hynix’s High Bandwidth Memory (HBM) Developed by AMD and SK Hynix
12
1st Generation (HBM1) introduced in AMD Fiji GPUs 1GB & 128GB/s per stack
AMD Radeon R9 Fury X: had four stacks 4GB & 512GB/s
2nd Generation (HBM2) will be used in NVIDIA Pascal and AMD Arctic Island GPUs 2 GB & 256GB/s bandwidth per stack
NVIDIA Pascal reported to have 1TB/s memory bandwidth
MaGIC Fall 2015
[AMD]

13
3D Stacked Memory[ leap in technology ]
OLD EMERGING
MaGIC Fall 2015
[AMD]

3D Stacked Memory
14
• More power efficient
• Electrons move shorter distances• Less power wasted moving data
• Smaller memory footprint• More memory can be packed into space
MaGIC Fall 2015
[AMD]
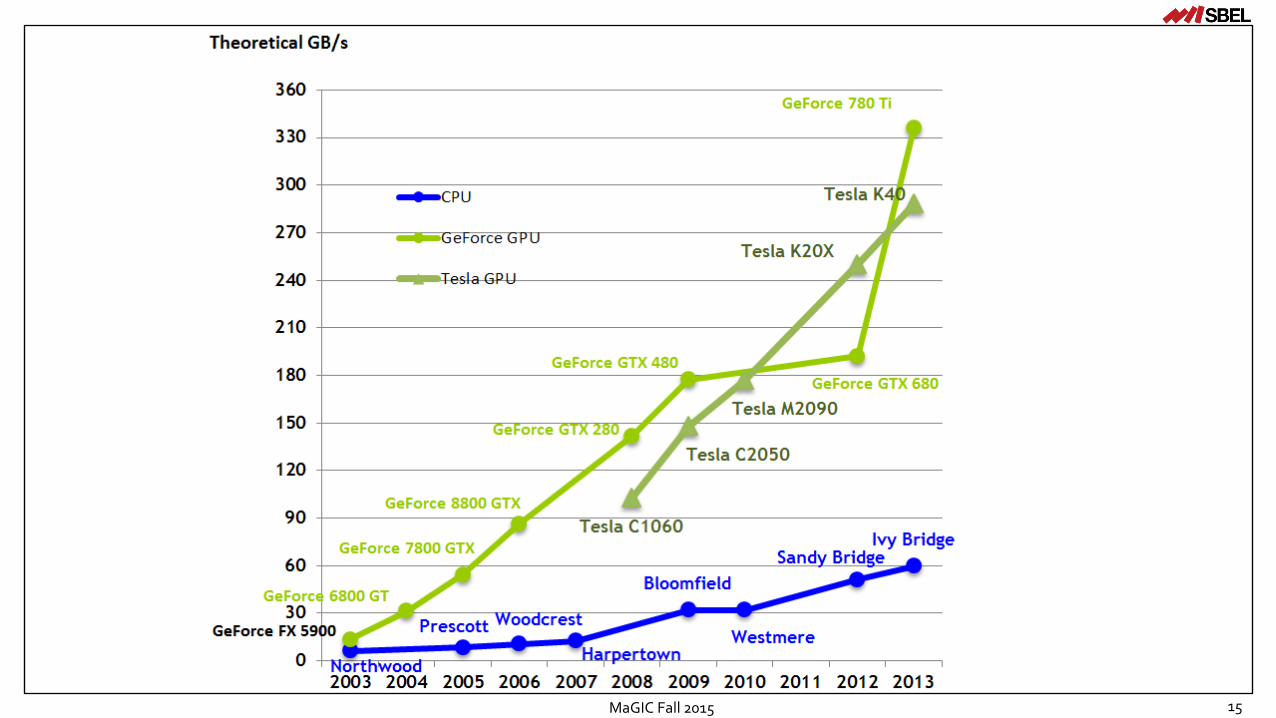
15MaGIC Fall 2015

Memory Speeds in a CPU-GPU System
16
System Memory
GPU cores
GPU Memory
50-100
GB/s
8-16 GB/s
100-240
GB/s
CPU Core
6GB/sInfiniband
to Next
Node
80GB/s
Latency:
High
Latency:
Medium
Latency:
Medium Low
Latency:
Low
Latency:
Rel.Low
16MaGIC Fall 2015
Cache

Second Trend Discussed Here: Moore’s Law
• Number of transistors per unit area has been steadily going up
• ILP and Clock Speed have stagnated
17MaGIC Fall 2015

Intel Roadmap, and Relevance to Us
• 2013 – 22 nm Tick: Ivy Bridge – Tock: Haswell
• 2015 – 14 nm Tick: Broadwell – Tock: Skylake
• 2016 – 14nm “Refresh” Kaby Lake
• 2017 – 10 nm Tick: Cannonlake (delayed to 2nd Half 2017)
• 2019 – 7 nm
• 2021 – 5 nm
• 2023 – ??? (carbon nanotubes?)
• Happening now: Moore’s law moving from 18-24 month cycle to 24-30 month cycle for the first time in 50 years
18MaGIC Fall 2015

Transistor Densities Still Going Up
• Although not as fast as before, transistor densities are still going up
• Consequence: lots of cores in one chip
• CPU Cores: 18 today, probably 32 in two-three years
• GPU Scalar Processors: 3,000 today (Maxwell), probably 4,500 in two years (Pascal)
• Intel Xeon Phi : 61 today, very likely close to 200 in two years
19MaGIC Fall 2015

Parallel Computing: Some Black Spots
• More transistors = More computational units
• 2015 Vintage: • 18-core Xeon Haswell-EX E7 8890 V3 – 5.6 billion transistors ($7200)
• Black silicon: owing to high density and power leaks, not able to fully power these chips…• Black silicon: transistors that today don’t get used and are dead weight
• Dennard’s scaling started to break down at the end of last decade
• Dennard’s law is the secrete sauce for Moore’s law
MaGIC Fall 2015 20

Lots of Cores: There’s More Than Meets the Eye
• Solutions rarely scale beyond 20 cores when using shared memory• Cache coherence and NUMA slow things down
• I have 32 cores and only see the net effect of 20 of them ???
• What if I have one workstation with four sockets; i.e, 128 cores – can I only scale up to 20 ???
• It looks like that – shared memory solutions don’t scale well
MaGIC Fall 2015 21

Scaling, with Lots of Cores: Via Distributed Memory
• To scale, a different parallel programming paradigm needed: distributed memory
• Distributed memory eliminates cache coherence issues• Also good since you can solve very large problems – lots of memory available to user
• Why not always do this?• Distributed memory solution calls for major code re-write
• If not implemented well, distributed memory solution has high data access latencies
• 1000X higher than accessing memory on a workstation
MaGIC Fall 2015 22

Distributed Memory, Good for Long Run Though
• Five to six years from now, it’s not clear what will replace Moore’s law
• No technology yet to continue past steady increase in core count• Can’t improve anymore speeds by use of more cores on one workstation
• Distributed memory is the path towards running by drawing on multiple workstations• Called “nodes”
MaGIC Fall 2015 23

Project Chrono Goal
• Solve one billion degrees of freedom by the time we get together in December 2016
MaGIC Fall 2015 24

Positioning Chrono for Advanced Computing
Cluster Group of nodescommunicating through fast interconnect
Node Group of processorscommunicating through shared memory
Coprocessors/Accelerators Special compute devicesattached to the local node through special interconnect
Socket Group of corescommunicating through shared cache
Core Group of functional unitscommunicating through registers
Hyper-Threads Group of thread contexts sharing functional units
Superscalar Group of instructions sharing functional units
Pipeline Sequence of instructions sharing functional units
Vector Single instruction using multiple functional units
25
[Intel]We have little to no control
We have full control
MaGIC Fall 2015

HPC in Computational Dynamics: Is MPI the Way to Go?
• Applications are getting more sophisticated• Multi-scale, multi-module, multi-physics
• The traditional approach based on MPI not attractive• Working on 100s of nodes is run of the mill in HPC
• Load imbalance emerges as a big issue for some apps
26MaGIC Fall 2015

MaGIC Fall 2015 27

MaGIC Fall 2015 28

29MaGIC Fall 2015

30MaGIC Fall 2015

MPI or Charm++ ?
• Charm++ is a generalized approach to writing parallel programs• An alternative to the likes of MPI, Chapel, UPC, etc.
• Charm++, three facets• A style of writing parallel programs
• An ecosystem that facilitates the act of writing parallel programs
• Debugger, profiler, ability to define own load balancing, etc.
• A runtime system
31MaGIC Fall 2015

Charm++ Attribute: Overdecomposition
• Decompose the work units & data units into many more pieces than execution units• Cores/Nodes/..
• Why do this?• Central idea: oversubscription of the hardware
• Hide memory latency w/ useful execution
• This oversubscription idea is a general tenet
• Done by the GPU
32MaGIC Fall 2015

Charm++ Attribute: Migratability
• Make the work and data units on previous slide migratable at runtime• That is, the programmer or runtime can move them from execution unit (PE, from processing element) to execution
unit• From PE to PE, that is
• Consequences for the app-developer• Communication must now be addressed to logical units with global names, not to physical processors
• But this is a good thing
• Consequences for the runtime system (RTS)• Must keep track of where each unit is
• Naming and location management
33MaGIC Fall 2015

Positioning Chrono for Advanced Computing
Cluster Group of nodescommunicating through fast interconnect
Node Group of processorscommunicating through shared memory
Coprocessors/Accelerators Special compute devicesattached to the local node through special interconnect
Socket Group of corescommunicating through shared cache
Core Group of functional unitscommunicating through registers
Hyper-Threads Group of thread contexts sharing functional units
Superscalar Group of instructions sharing functional units
Pipeline Sequence of instructions sharing functional units
Vector Single instruction using multiple functional units
35
[Intel]We have little to no control
We have full control
MaGIC Fall 2015

Positioning Chrono for Advanced Computing
Cluster Group of nodescommunicating through fast interconnect
Node Group of processorscommunicating through shared memory
Coprocessors/Accelerators Special compute devicesattached to the local node through special interconnect
Socket Group of corescommunicating through shared cache
Core Group of functional unitscommunicating through registers
Hyper-Threads Group of thread contexts sharing functional units
Superscalar Group of instructions sharing functional units
Pipeline Sequence of instructions sharing functional units
Vector Single instruction using multiple functional units
36
[Intel]We have little to no control
We have full control
MaGIC Fall 2015

HMMWV on Deformable Terrain. Year: 2012
MaGIC Fall 2015 37

Chrono GPU: HMMWV on Deformable Terrain. Year: 2015
MaGIC Fall 2015 38

HMMWV on Discrete Terrain
• 2012• 300k rigid spheres
• Length of simulation: 15 seconds
• Hardware used: CPU (Intel)
• Multicore, based on OpenMP
• Integration time step: 0.001s
• Velocity Based Complementarity
• 17 seconds per time step
• Simulation time: ~2.5 days
• 2015• ~1.5 million rigid spheres
• Length of simulation: 15 seconds
• Hardware: GPU (NVIDIA)
• Tesla K40X
• Integration time step: 0.0005s
• Position Based Dynamics
• 0.3 seconds per time step
• Simulation time: ~2.5 hours
39
2015 Simulation: although 5X more bodies, runs about 25 times faster
MaGIC Fall 2015

Positioning Chrono for Advanced Computing
Cluster Group of nodescommunicating through fast interconnect
Node Group of processorscommunicating through shared memory
Coprocessors/Accelerators Special compute devicesattached to the local node through special interconnect
Socket Group of corescommunicating through shared cache
Core Group of functional unitscommunicating through registers
Hyper-Threads Group of thread contexts sharing functional units
Superscalar Group of instructions sharing functional units
Pipeline Sequence of instructions sharing functional units
Vector Single instruction using multiple functional units
40
[Intel]We have little to no control
We have full control
MaGIC Fall 2015

4 wide add operation (SSE 1.0)
C++ code__m128 Add (const __m128 &x, const __m128 &y){
return _mm_add_ps(x, y);}
__mm128 z, x, y;x = _mm_set_ps(1.0f,2.0f,3.0f,4.0f);y = _mm_set_ps(4.0f,3.0f,2.0f,1.0f);z = Add(x,y);
“gcc –S –O3 sse_example.cpp”
Assembly__Z10AddRKDv4_fS1_ __Z10AddRKDv4_fS1_:
movaps (%rsi), %xmm0 # move y into SSE register xmm0addps (%rdi), %xmm0 # add x with y and store xmm0
ret # xmm0 is returned as result
41
x3 x1x2 x0
y3 y1y2 y0
= == =
x
y
+ + + + +
=
z1z2 z0z3z
[Hammad] MaGIC Fall 2015

Conclusions, Chrono::HPC
• Moore’s law reaching terminus in six years: distributed memory solutions all we have left
• Looking at “all of the above” opportunities to speed up large simulations in Chrono
• Large simulations in Chrono: billion degree of freedom dynamic systems• Fluid solid interaction
• Granular material (high/low saturation)
• Large nonlinear FEA
• Aiming to present billion DOF simulation in Chrono at Fall 2016 MaGIC meeting
MaGIC Fall 2015 42


















