IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014 2323 Surfing the Network for Ranking by Multidamping Giorgos Kollias, Efstratios Gallopoulos, and Ananth Grama Abstract—PageRank is one of the most commonly used techniques for ranking nodes in a network. It is a special case of a family of link-based rankings, commonly referred to as functional rankings. Functional rankings are computed as power series of a stochastic matrix derived from the adjacency matrix of the graph. This general formulation of functional rankings enables their use in diverse applications, ranging from traditional search applications to identification of spam and outliers in networks. This paper presents a novel algorithmic (re)formulation of commonly used functional rankings, such as LinearRank, TotalRank and Generalized Hyperbolic Rank. These rankings can be approximated by finite series representations. We prove that polynomials of stochastic matrices can be expressed as products of Google matrices (matrices having the form used in Google’s original PageRank formulation). Individual matrices in these products are parameterized by different damping factors. For this reason, we refer to our formulation as multidamping. We demonstrate that multidamping has a number of desirable characteristics: (i) for problems such as finding the highest ranked pages, multidamping admits extremely fast approximate solutions; (ii) multidamping provides an intuitive interpretation of existing functional rankings in terms of the surfing habits of model web users; (iii) multidamping provides a natural framework based on Monte Carlo type methods that have efficient parallel and distributed implementations. It also provides the basis for constructing new link-based rankings based on inhomogeneous products of Google matrices. We present algorithms for computing damping factors for existing functional rankings analytically and numerically. We validatevarious benefits of multidamping on a number of real datasets. Index Terms—Ranking, Graph algorithms, Markov processes, Mining methods and algorithms, Personalization, Web mining, Monte Carlo 1 I NTRODUCTION T HE problem of ranking nodes in a network, based on the link structure, has been an important topic in sociometrics and bibliometrics for over 50 years [1]–[3]. Interest in this topic has vastly increased with the advent of the Web and social media, and the important role of ranking algorithms, such as PageRank, which introduced content-neutral ranking of web pages (nodes). These meth- ods generally rely on a stochastic matrix encoding the hyperlink structure, and its convex combination with a suit- ably chosen matrix of unit rank. This matrix is often called the “Google matrix” 1 G(μ), where μ ∈ [0, 1] is a parameter, called “damping factor” see Section 2 and [5], [6]. Using this matrix representation, ranking algorithms typically compute a nonnegative “ranking vector” (which is often referred to by the algorithm used to compute it, for e.g., the PageRank vector). Nodes in the network are 1. Sometimes referred to as parametric Google matrix [4]. • G. Kollias and A. Grama are with the Department of Computer Science and Center for Science of Information, Purdue University, West Lafayette, IN 47907 USA. E-mail: {gkollias, ayg}@cs.purdue.edu. • E. Gallopoulos is with the Computer Engineering and Informatics Department, University of Patras, Patras GR-26500, Greece. E-mail: [email protected]. Manuscript received 20 Aug. 2012; revised 26 Dec. 2012; accepted 3 Jan. 2013. Date of publication 14 Jan. 2013; date of current version 31 July 2014. Recommended for acceptance by T. Sellis. For information on obtaining reprints of this article, please send e-mail to: [email protected], and reference the Digital Object Identifier below. Digital Object Identifier 10.1109/TKDE.2013.15 ranked based on the order specified by the correspond- ing values in the ranking vector. The most commonly used methods for computing the PageRank vector rely on eigen- vector or linear-system solution-based approaches; see [7], [8]. The conceptualization of the PageRank of a node as the normalized aggregation of the PageRanks of all of its neigh- bors naturally leads to the power method for computing a dominant eigenvector (i.e., the eigenvector correspond- ing to the dominant eigenvalue) of the Google matrix. This eigenvector computation can be equivalently expressed as the solution of a linear system. It is worth noting that for any constant μ, the Google matrix is a transition probability matrix and the PageRank vector is the stationary distribu- tion for the corresponding homogeneous Markov chain (if one exists). In addition to these commonly used approaches there are two other formulations that are of relevance here. First, the “random surfer” who, in the words of Brin and Page ([5]) “is given a web page at random and keeps clicking on links, never hitting ‘back’ but even- tually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank.” Second, the “functional rankings”, pro- posed by Baeza-Yates, Boldi and Castillo in [9], [10], which quantify the importance of each node based on incom- ing paths of varying lengths. Functional rankings compute ranking vectors using a power series, whose coefficients are values of a suitably chosen, decreasing, “damping function”. 1041-4347 c 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
Transcript
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014 2323
Surfing the Network for Ranking byMultidamping
Giorgos Kollias, Efstratios Gallopoulos, and Ananth Grama
Abstract—PageRank is one of the most commonly used techniques for ranking nodes in a network. It is a special case of a family oflink-based rankings, commonly referred to as functional rankings. Functional rankings are computed as power series of a stochasticmatrix derived from the adjacency matrix of the graph. This general formulation of functional rankings enables their use in diverseapplications, ranging from traditional search applications to identification of spam and outliers in networks. This paper presents anovel algorithmic (re)formulation of commonly used functional rankings, such as LinearRank, TotalRank and Generalized HyperbolicRank. These rankings can be approximated by finite series representations. We prove that polynomials of stochastic matrices can beexpressed as products of Google matrices (matrices having the form used in Google’s original PageRank formulation). Individualmatrices in these products are parameterized by different damping factors. For this reason, we refer to our formulation asmultidamping. We demonstrate that multidamping has a number of desirable characteristics: (i) for problems such as finding thehighest ranked pages, multidamping admits extremely fast approximate solutions; (ii) multidamping provides an intuitive interpretationof existing functional rankings in terms of the surfing habits of model web users; (iii) multidamping provides a natural frameworkbased on Monte Carlo type methods that have efficient parallel and distributed implementations. It also provides the basis forconstructing new link-based rankings based on inhomogeneous products of Google matrices. We present algorithms for computingdamping factors for existing functional rankings analytically and numerically. We validate various benefits of multidamping on anumber of real datasets.
Index Terms—Ranking, Graph algorithms, Markov processes, Mining methods and algorithms, Personalization, Web mining,Monte Carlo
1 INTRODUCTION
THE problem of ranking nodes in a network, basedon the link structure, has been an important topic in
sociometrics and bibliometrics for over 50 years [1]–[3].Interest in this topic has vastly increased with the adventof the Web and social media, and the important role ofranking algorithms, such as PageRank, which introducedcontent-neutral ranking of web pages (nodes). These meth-ods generally rely on a stochastic matrix encoding thehyperlink structure, and its convex combination with a suit-ably chosen matrix of unit rank. This matrix is often calledthe “Google matrix”1 G(μ), where μ ∈ [0, 1] is a parameter,called “damping factor” see Section 2 and [5], [6].
Using this matrix representation, ranking algorithmstypically compute a nonnegative “ranking vector” (whichis often referred to by the algorithm used to compute it,for e.g., the PageRank vector). Nodes in the network are
1. Sometimes referred to as parametric Google matrix [4].
• G. Kollias and A. Grama are with the Department of Computer Scienceand Center for Science of Information, Purdue University, West Lafayette,IN 47907 USA. E-mail: {gkollias, ayg}@cs.purdue.edu.
• E. Gallopoulos is with the Computer Engineering and InformaticsDepartment, University of Patras, Patras GR-26500, Greece.E-mail: [email protected].
Manuscript received 20 Aug. 2012; revised 26 Dec. 2012; accepted 3 Jan.2013. Date of publication 14 Jan. 2013; date of current version 31 July 2014.Recommended for acceptance by T. Sellis.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference the Digital Object Identifier below.Digital Object Identifier 10.1109/TKDE.2013.15
ranked based on the order specified by the correspond-ing values in the ranking vector. The most commonly usedmethods for computing the PageRank vector rely on eigen-vector or linear-system solution-based approaches; see [7],[8]. The conceptualization of the PageRank of a node as thenormalized aggregation of the PageRanks of all of its neigh-bors naturally leads to the power method for computinga dominant eigenvector (i.e., the eigenvector correspond-ing to the dominant eigenvalue) of the Google matrix. Thiseigenvector computation can be equivalently expressed asthe solution of a linear system. It is worth noting that forany constant μ, the Google matrix is a transition probabilitymatrix and the PageRank vector is the stationary distribu-tion for the corresponding homogeneous Markov chain (ifone exists).
In addition to these commonly used approaches thereare two other formulations that are of relevance here.First, the “random surfer” who, in the words of Brinand Page ([5]) “is given a web page at random andkeeps clicking on links, never hitting ‘back’ but even-tually gets bored and starts on another random page.The probability that the random surfer visits a page isits PageRank.” Second, the “functional rankings”, pro-posed by Baeza-Yates, Boldi and Castillo in [9], [10], whichquantify the importance of each node based on incom-ing paths of varying lengths. Functional rankings computeranking vectors using a power series, whose coefficientsare values of a suitably chosen, decreasing, “dampingfunction”.
2324 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
Functional rankings are of interest because they gen-eralize the notion of PageRank, while offering additionalflexibility. They can be used in diverse applications such asspam detection. Spirin and Han in their survey [11], iden-tify the seminal role of functional rankings in link-basedspam detection algorithms based on label propagation.However, since functional rankings are defined in powerseries form, they provide only limited interpretability ofthe rankings. Conversely, when designing functional rank-ings for specific applications, it is harder to design suitablepolynomials directly based on prior insight. Motivated bythese considerations, we study alternate formulations offunctional rankings that lend themselves more naturallyto interpretation, design of ranking schemes, and investi-gate their performance for specific ranking problems. Wesummarize our major contributions and conclusions asfollows:
• Using stochasticity properties, it is shown that func-tional rankings can be represented as inhomoge-neous products of Google matrices. Here, inhomo-geneity refers to the fact that each Google matrix inthe product is constructed from the same matrix ofnetwork links, but with different damping factors.This representation of functional rankings is referredto as “multidamping”. Multidamping provides a nat-ural alternate framework for expressing ranking vec-tors. This framework has a number of advantages:(i) it allows interpretation of functional rankings interms of surfer behavior, and conversely, given surferbehavior, it allows intuitive design of multidamp-ing formulations; (ii) it facilitates design of very fastapproximation algorithms; and (iii) it allows compu-tation of rankings in massively parallel/ distributedenvironments. Algorithms for computing dampingfactors from the polynomial coefficients of functionalrankings are derived in this paper.
• Damping factors for several published functionalrankings (LinearRank, TotalRank and GeneralizedHyperbolic Rank) are computed. This allows inter-pretation of the functional rankings as randomsurfers, with time-dependent transition probabilities.
• It is shown that the formulation in terms of inho-mogeneous products can be used to compute topranked nodes in the network extremely quickly(orders of magnitude faster than ranking computa-tions using traditional power methods). Specifically,the interpretation/ implementation of multidampingas concurrent random surfer processes enables appli-cation of Monte Carlo methods. It follows that thesecomputations may be embedded into the crawleritself, facilitating large-scale parallel and distributedimplementations.
The rest of the paper is organized as follows: Section 3provides an overview of the matrix based formulationof functional rankings and their series representation. InSection 4, the notion of multidamping is introduced andits associated theory is developed. Furthermore, damp-ing factors for several known functional rankings arederived and the behavior of these rankings is interpreted.Section 5 describes the features and desirable properties
of multidamping. Numerical experiments over large graphinstances that support our findings are presented inSection 6.
2 NOTATION AND BASIC CONCEPTS OFLINK-BASED RANKING
Unless noted otherwise, we denote matrices by uppercase latin letters, vectors (assumed in column form) bylower case latin, and scalars by lower case greek letters.We denote by ej, the jth vector in the canonical basis(the jth element of the vector is one; all others are zero)and by e the vector of all ones. The dimension of thesevectors is determined by the context within which theyare used. Unless otherwise noted, stochastic matrices areassumed to be column stochastic (i.e., a matrix whosecolumns are stochastic vectors – nonnegative elements thatsum to 1).
Assuming a web graph of n pages (nodes) with deg(i)denoting the out-degree of node i, the matrix of hyper-links (or simply, link matrix) is the adjacency matrix of theweb graph, and is denoted by A. In practice, this matrixis typically constructed by processing data retrieved bycrawlers. Elements of this adjacency matrix αij = 1 if andonly if page i points to page j, otherwise αij = 0. We con-struct a corresponding transition matrix P with elementsπij = αij/deg(i) when deg(i) �= 0, and zero otherwise (dan-gling pages). Here, deg(i) = ∑
j αij is the outdegree of pagei. From these definitions, we construct the stochastic matrixS: = P�+wd�, where d is the dangling indicator vector whosenonzero elements are δi = 1 if and only if deg(i) = 0 and wis some stochastic vector. The Google matrix G(μ) is thenthe stochastic, nonnegative matrix G(μ): = μ S+(1−μ) v e�.Here, the stochastic vector v is referred as personalization orteleportation vector. It is frequently chosen to be 1
n e, but moreinterestingly chosen depending on the user surfing habits;its choice can also be driven by some trust metric to combatspam [11]. The rank-one matrix H: = v e� is the teleportationmatrix. The largest eigenvalue of G(μ), for μ ∈ (0, 1), is 1and this is also the eigenvalue of largest modulus (see [12],[13]). From stochasticity, a left eigenvector is along e, whilefrom Perron-Frobenius theory, there exists a nonnegativeright eigenvector x so that, when normalized (‖x‖1 = 1),limk→∞ Gk = xe�; see [14].
For a random web surfer about to visit the next page,the damping factor μ ∈ [0, 1] is the probability of choosinga link-accessible page. Alternately, with probability 1 − μ,the random surfer makes a transition to a node selectedfrom among all nodes based on the conditional probabili-ties in vector v. The probabilistic interpretation of μ playsan important role in our exposition. The value of μ alsoaffects the convergence of iterative methods for comput-ing PageRank – after all, it was introduced (with valuesstrictly smaller than 1 - it is reported that Google initiallyused μ = 0.85 [8]) so as to enable the power method forcomputing the eigenvector (PageRank) to converge. As μapproaches 1, ill-conditioning slows the convergence of thepower method [15], [16]. Various studies also show thatdamping factors not too close to 1 are preferable, not onlybecause of convergence, but also because they provide moremeaningful rankings [17]–[20].
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2325
3 MATRIX-BASED FORMULATION OF RANKINGSAND SERIES REPRESENTATION
PageRank is frequently described in terms of one of thefollowing characterizations:i) As a normalized eigenvector:
xPR: = xe�x
, where Gx = x. (1)
ii) As the normalized solution of a linear system:
xPR: = x, where (I − μ S) x = (1 − μ)v. (2)
Characterizations (1) and (2) are equivalent in exactarithmetic, thus we use the same notation for both vec-tors. With respect to their computation, for problem sizesthat are typical in web ranking applications, the simplestiterative methods are often used. The power method for(1) (applied in an early exposition of PageRank; see [6])and classical relaxation methods for (2). In fact, the appli-cation of more sophisticated numerical approaches remainsan exception rather than the rule.
3.1 Functional RankingsMatrix S is stochastic hence the spectral radius ρ(μS) is lessthan 1, therefore the PageRank vector in relation (2) can beexpressed by means of the convergent Neumann series,
xPR = (1 − μ)
∞∑
j=0
μjSjv, (3)
Characterization (3) is not only an algebraic relation; it alsoprovides information related to paths contributing to therankings, a notion dating back to Katz [1]. This is not sur-prising, if one recalls that the elements of the kth power ofan adjacency matrix count the number of paths of length kbetween graph nodes [21]. This has also been noted in sev-eral studies of link-based rankings, including PageRank [9],[22]–[25]. These investigations have led to alternate rankingschemes. Of particular interest here is the approach in [9],[10], which generalizes the series representation (3) as:
xdf : =∞∑
j=0
ψ(j)Sjv (4)
Here, ψ is a suitably selected function termed damping func-tion, and the resulting ranking is referred to as functional.Intuitively ψ(j) is used as an attenuation factor to the con-tribution of any path of length j entering an arbitrary graphnode. Relation (4) is used as a template for a general rank-ing vector based on ψ . For example, the damping functionψ(j) = (1 − μ)μj generates the usual PageRank vector,while the choice ψ(j) = 1
(j+1)(j+2) generates another ranking,called TotalRank, introduced by Boldi in [26]. We reviewthe damping functions and corresponding functional rank-ings that have been proposed in the literature (e.g. [9]) inSection 4.2.
In the rest of this paper, we also refer to the valuesψ(j) that are the coefficients of the power series as damp-ing coefficients. Please note that these damping coefficientsare different from the damping factors used to constructparameterized Google matrices.
There exist some natural constraints on ψ . Clearly,it must be selected so that the power series converges.Another constraint is that the coefficients must sum to one.Functional rankings that satisfy these constraints are calledwell-defined and normalized [9, Theorem 1]. Notwithstandingthese (mild) constraints, well-defined and normalized func-tional rankings define a rich class of ranking vectors. On theother hand, it is worth noting that the series representationaccumulates rank at a node by summing contributions of allpaths of any length j leading to it, essentially necessitatinga global view of the graph. Moreover, other than the con-straints mentioned above, the choice of ψ and the resultingcoefficients in the power series do not lend themselves toa clear interpretation, and appear more as arbitrary atten-uation functions. The framework developed in this paperhelps to restore interpretability to functional rankings.
Please observe, also, that any practical implementationof an iterative method based on any of (1), (2) or (3) to com-pute PageRank must terminate. For (3), this corresponds toa cutoff, hence a finite series. This aspect was noted byBoldi et al. [18], [27] and used to investigate methods forcomputing PageRank for different values of the dampingfactor. Similarly, practical implementations of general func-tional rankings must be approximated by a finite numberof terms in the above template.
4 MULTIDAMPING
Many studies on computing PageRank are based on char-acterization (1) and thus apply the simple power methodon G. If u is a stochastic vector, the application of k stepsof the power method amounts to using
x: = G(μ)ku (5)
as an approximation to PageRank. As noted earlier, the useof the same μ in every term of the product can be viewed asa stationary or homogeneous Markov process. We extend(5) and introduce the following definition:
Definition 1. Let G(μ) be as above, u a stochastic vector, andconsider a sequence of damping factors M: = (μ1, μ2, . . . , )
where μi ∈ [0, 1), i = 1, 2, . . .. We call the transitionsdescribed by
u → G(μ1)u → · · · → (G(μi) · · · G(μ1))u � (6)
as a multidamping surfing process modeled by M. Whenthe sequence is finite and has only k elements, we referto the process as k-step multidamping, modeled by Mk: =(μ1, . . . , μk).
If the sequence of nonzero damping factors is finite, then,starting from a vector u, and applying the transitions, weobtain
x: = G(μk) · · · G(μ1)u. (7)
Furthermore, when the μj’s are not all equal, themultidamping process above corresponds to a time-inhomogeneous or non-stationary Markov process [28],[29]. Following this terminology, we call products of Googlematrices with different damping factors as inhomogeneous.
2326 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
In product form notation, the matrix product term in (7) iswritten
k∏
j=1
G(μk−j+1) = G(μk) · · · G(μ1).
Note that new terms enter in the multiplication from theleft and since each G(μj) is stochastic, so is their product.Furthermore, when the teleportation matrix H = ve�, mul-tiplies from the left, any stochastic vector (resp. matrix),it returns the vector v (resp. the matrix H). For instance,Hv = v, H2 = H, HG(μ) = H and HS = H. Moreover,(S − H)j = Sj−1(S − H). See also [30, Lemmas 2 and 3]. Thenext theorem, shows that a finite inhomogeneous productof the G(μj)’s, say k of them, can be written as a weightedsum of (S − H)k or of Sk and a rank-one term.
Theorem 1. Let S,H and v be as above. Consider a k-step mul-tidamping process modeled by Mk = {μ1, . . . , μk}. Then theinhomogeneous product of Google matrices can be written inany of the following equivalent forms:
1)
k∏
j=1
G(μk−j+1) = ηk(S − H)k +k−1∑
j=0
ηj(S − H)jH, (8)
where ηj = μk · · ·μk−j+1 with η0 = 1, ηk+1 = 0.2)
k∏
j=1
G(μk−j+1) = ξkSk + E (9)
where E: =(∑k−1
j=0 ξjSjv)
e� so that rank(E) = 1 and
ξk = μk · · ·μ2μ1, (10)ξk−1 = μk · · ·μ2(1 − μ1)
...
ξ1 = μk(1 − μk−1)
ξ0 = 1 − μk.
Proof. The results hold for any k, therefore, we use induc-tion to prove the first part. The result is trivially true fork = 1. Assuming it is true for k − 1, the product of kterms is
G(μk)
k∏
j=2
G(μk−j+1) = (μk(S − H)+ H)k∏
j=2
G(μk−j+1),
so from the induction assumption this equals
(μk(S − H)+ H)
⎛
⎝ηk−1(S − H)k−1 +k−2∑
j=0
ηj(S − H)jH
⎞
⎠ .
Simplifying this, leads to
μkηk−1(S − H)k + μk(S − H)k−2∑
j=0
ηj(S − H)jH + H,
because left multiplication with matrix H zeroes out allterms of the form H(S−H)j. Observe that the coefficients
TABLE 1Functional Rankings and Their Damping Factors Obtained
from Algorithm 1
satisfy ηj = ηj−1μk−j+1. Therefore, the above expressionreadily simplifies to the desired form for k and the firstpart follows. It is worth noting that if we denote theproduct of k Google matrices as k, then the followingrecurrence holds.
k = μj(S − H)k−1 + H. (11)
To prove the second part we can also use (somewhatmore tedious) induction. Instead, it is more instructiveto observe how Eq. (8) can be transformed into Eq. (9).We noted before Theorem 1 that (S − H)j = Sj−1(S − H).Making this substitution in Eq. (8), the expression canbe written as
k∏
j=1
G(μk−j+1) = ηkSk−1(S − H)+
k−1∑
j=1
ηjSj−1(S − H)H + H
= ηkSk − ηkSk−1H +k−1∑
j=1
ηj(Sj − Sj−1H)H + H.
Regrouping terms and from the fact that H2 = H, weobtain
k∏
j=1
G(μk−j+1) = ηkSk +k−1∑
j=0
(ηj − ηj+1)Sj H
Noting that ξj = ηj − ηj+1 Eq. (9) readily follows. Notealso that ξk = ηk.A crucial observation is that we can match coefficients
between this expanded product and the functional rank-ing template (4) so that the two expressions agree, exactlyor approximately. This follows directly, if we multiply theright-hand side of (9) by the stochastic vector v and thenmatch the resulting expression with template (4) on a term-by-term basis. As an example, for the case of LinearRank(see Table 1) for k = 3, the damping coefficients are ξ0 =25 = 1 − 3
5 , ξ1 = 2·34·5 = 3
5 (1 − 24 ), ξ2 = 2·2
4·5 = 35 · 2
4 (1 − 13 ) and
ξ3 = 2·14·5 = 1
3 · 24 · 3
5 . This clearly identifies μ1 = 13 , μ2 = 2
4and μ3 = 3
5 as the corresponding damping factors.In the rest of this paper, we refer extensively to damping
coefficients and factors. Please note that these depend on k,therefore, we label the elements ξ (k)j and μ
(k)j . For concise-
ness of representation, when the context is clear, we leavethe dependence implicit, and omit the superscripts.
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2327
4.1 Multidamping Realization of FunctionalRankings
We first consider the case of a well defined, normalizedfunctional ranking expressed in terms of a finite powerseries. Setting ψ(j) = ξj for the damping coefficients intemplate (4), this yields:
x =k∑
j=0
ξjSjv, wherek∑
j=0
ξj = 1, e�v = 1. (12)
Eq. (12) can also be written as
x = (ξkSk +k−1∑
j=0
ξjSjve�)v.
The operator in parentheses has exactly the series formthat we encountered in Theorem 1 for the k steps ofmultidamping.
The relations in ((10)) can be used to construct recur-rences for generating k damping factors from the k + 1damping coefficients, ξj, defining a functional ranking sothat the vector obtained from the power series for the latterranking is exactly equal to the vector generated by the cor-responding multidamping process. We organize the overallmatching mechanism in the following theorem:
Theorem 2. Given the set of scalars
Zk: = {ξj ≥ 0, j = 0, . . . , k |k∑
j=0
ξj = 1},
for some k, let the matrices G(·),S be as before, v a stochas-tic vector, and write pk(S): = ∑k
j=0 ξjSj. Then, there existsa k-step multidamping process modeled by Mk: = {μj ∈[0, 1), j = 1, . . . , k}, such that
k∏
j=1
G(μk−j+1)v = ξkSkv + pk−1(S)v.
The damping factors in Mk can be computed by means of theforward recurrence
μj = 1 − 1
1 + ρk−j+11−μj−1
, j = 1, . . . , k, (13)
where μ0 = 0 and ρk−j+1 = ξk−j+1ξk−j
.
Proof. Let ξk = μk · · ·μ2μ1. Dividing by parts with thesecond relation in Eqs. (10), we obtain
ρk = μ1
1 − μ1⇒ μ1 = 1 − 1
1 + ρk
with ρk = ξkξk−1
, which proves (13) when j = 1. We pro-ceed similarly for the other terms, dividing the left andright hand side terms of adjacent equations from (10)
ξk−j+1 = (1 − μj−1)μj · · ·μk
ξk−j = (1 − μj)μj+1 · · ·μk
to obtain
ρk−j+1 = 1 − μj−1
1 − μjμj
with ρk−j+1 = ξk−j+1ξk−j
; solving for μj leads to the desiredrelation (13).Theorem 2 demonstrates that it is possible to express
vectors produced by the finite form of the template for func-tional rankings as a finite number of multidamping steps,that is, in product form, where each term is a Google matrix.Observe also that the multidamping process is determinedby the k damping factors, just as the series templatedepends on k + 1 damping coefficients that are constrainedto sum to 1. When k = 1, p1(z) = (1−ξ1)+ξ1z. Therefore, therecurrence (13) returns the coefficients for the usual Googlematrix with a single damping parameter μ = ξ1.
Two basic assumptions affecting both Theorems 1 and 2are, i) finiteness, that is the power series and correspondingmultidamping process consist of a finite number of terms,and ii) normalization, namely that the coefficients of thepower series add to 1. As we subsequently note, with fewexceptions, functional rankings are defined in terms of infi-nite, rather than finite power series. In practice, however,the finite case is much more prevalent since infinite seriesand products are forced to terminate after a finite numberof steps (depending on the desired degree of approxima-tion). Therefore, only a finite number of their terms is takeninto account. When an infinite series is approximated bya finite sum, however, normalization is violated and theranking vectors are no longer stochastic. For example, sim-ple truncation of the power series would make the sums = ∑k
j=0 ξj < 1 because ξj’s are nonnegative. One way torestore normalization, so as to apply Theorem 2 to gen-erate the damping factors, is by means of an “additive”correction:
Definition 2. Let the nonnegative sequence Zk =(ξ0, . . . , ξk−1, ξk) be such that s: = ∑k
j=0 ξj < 1. Thenwe set
add_cor(Zk) : = (ξ0, . . . , ξk−1, ξk + 1 − s).
Based on the above, we construct Algorithm 1, whichimplements the multidamping framework to compute func-tional rankings defined using the template (4). Specifically,to compute the damping factors Mk from a finite setof coefficients Zk, we first check and restore, if needed,the normalization condition by applying the correction inDefinition 2. We then generate Mk using Theorem 2. Finally,we apply the multidamping process to generate the exactor approximate functional ranking.
2328 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
Note that ζ (2) = π2/6. Only the values of sequences Mk for k = 1, . . . , 4 are displayed.
We finally note that convergence and normalization ofthe series defining the functional rankings affect the damp-ing coefficients Zk, and thus the damping factors Mk. For
instance, it can be shown that −1 < μj+1 − μj ≤ (1−μj)2
2−μj.
Please see [30] for more details.
4.2 Linear, Total and Generalized HyperbolicFunctional Rankings and Multidamping
We now consider functional rankings that have been pro-posed in the literature, in particular LinearRank, TotalRankand Generalized Hyperbolic Rank, and derive their multi-damping formulations. Table 1 presents the series represen-tation for each (finite or infinite) ranking, from which onemay obtain damping coefficients. The last column in thetable contains the damping factors Mk. These are derivedby using symbolic, as well as numerical implementations ofAlgorithm 1 applied to the damping coefficients. For com-pleteness, we also include corresponding PageRank (abbrv.PR) damping coefficients and parameters. Note that ζ(β) isthe Riemann zeta function.
We note several interesting aspects of the multi-damping formulations in Table 1. In LinearRank (abbrv.LR) [9], weights decrease linearly and k acts as a cut-off.Consequently, paths longer than k are not considered. First,note that the values of Zk depend on k. In fact, there is adifferent set of coefficients for every value of k. It can beshown in this case that damping factors are strictly increas-ing, bounded by 1 and the relation linking the dampingfactors for successive values of k is Mk+1 = (Mk, μk+1).
Boldi et al. proposed TotalRank (abbrv. TR) to addressthe problem of identifying the best damping factor inPageRank [26]. By averaging over all possible dampingfactors in (0, 1), so that
xTR =∫ 1
0xPR(μ)dμ,
TR provides “equal opportunity” to the damping fac-tors. Even greater generality could be provided by usingsome form of weighted averaging. As noted in Section 4.1,a practical computation of TR would use only a finitesubsequence of Z of chosen length to provide an accept-able approximation. In contrast to LR, the damping factorsequences for any given k are decreasing.
General Hyperbolic Rank (GHR), generalizes TR byusing a parameter β to control the effect of longer pathson ranking (with small β’s actually favoring contributionof longer paths) [9]. It is easy to see that each term of thecorresponding ranking vector is a Dirichlet series. Table 2presents the damping factors as computed from recurrence(13). Note that the sequences of damping factors behave asthose in TR for successive values of k.
4.3 Eigenvalues in MultidampingTo better understand the effect of the multidamping frame-work, we investigate the eigenvalues of product of theGoogle factors G(μj).
Theorem 3. Given Google matrices G(μj): = μjS+(1−μj)ve�and a sequence of k damping factors Mk: = (μ1, . . . , μk)
all in (0, 1) and define GMk : = G(μk) · · · G(μ1), then if{1, λ2, . . . , λn} are the eigenvalues of S, then the eigenvaluesof
∏kj=1 G(μj) are {1, λk
2∏k
j=1 μj, . . . , λkn∏k
j=1 μj}. Moreover,the eigenvalues are independent of the ordering of the Googlematrix terms in the product.
Proof. For the first part, note that from stochasticity ofS, e is a left eigenvector corresponding to the largest(unit) eigenvalue, therefore the maximum eigenvalue of∏k
j=1 μjSk + pk−1(S)ve� is
k∏
j=1
μj + e�pk−1(S)v =k∑
j=0
ξj = 1
from the properties of the {ξj}. From a theoremof Brauer the remaining eigenvalues are unaf-fected by this rank-one perturbation, so they are{λk
2∏k
j=1 μj, . . . , λkn∏k
j=1 μj} [31]. Observe that if wedenote by ξk the coefficient of the highest power of theseries representation for the product of Google matrices,then ξk = ∏k
j=1 μj. The second part follows triviallyfrom the formulas. It is worth noting that this is unlikethe case of products of (three or more) general matrices,where the eigenvalues depend on the ordering of theproduct terms.It is worth noting that if all the μjs are equal, then the
above theorem reaffirms that the eigenvalues of a singleGoogle matrix, G(μ) are {1, μλ2, . . . , μλn} [12], [13].
Observe that multidamping facilitates definition of newranking methods based on suitable choice of a sequenceof damping factors Mk. One of these choices is to con-struct a “cyclic” ranking process by repeated applicationsof the matrix that corresponds to any given finite sequenceof damping values, all in (0, 1), so that their product isless than 1. According to the above theorem, the secondeigenvalue of the corresponding (stochastic) product oper-ator GMk would be smaller than 1, and therefore, in thelimit, the process would converge to a stochastic vector inthe direction of the eigenvector corresponding to its largesteigenvalue (which is 1). This vector could then be used forranking.
5 FEATURES AND BENEFITS OF MULTIDAMPING
Using the multidamping formulations, we faithfully com-pute functional rankings, that is (in exact arithmetic), theuse of the expression
∏kj=1 G(μk−j+1)v (product of k terms)
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2329
to approximate the ranking vector is equivalent to the useof the series
∑kj=0 ξjSj (as a sum of k + 1 terms, assuming
normalized ξj’s).This also means that the convergence properties of any
functional ranking are retained in multidamping. Beforeshowing how these properties reflect on the factors Mk, wereview the patterns for the coefficients Zk. Rapidly decreas-ing Zk sequences imply that satisfactory approximations ofconvergence can be attained in a small number of steps.Conversely, remote neighborhoods of a graph node are stillexpected to have non-negligible contributions to the node’sranking value. Plots 1(a), 1(b) and 1(c) show the logarithmsof the values of Zk for a number of functional rankings fork = 50 (note that the plots use different scalings). The lastelement in each sequence Zk indicates the magnitude of theresidual in the infinite series representation of their trueranking vector (with the exception of LR with coefficientssumming to 1 for any k). Practically, the smaller the valueξk, the closer the vector computed by the functional rankingscheme at this step is to its “true” convergence point.
Plots 1(a), 1(b), and 1(c) also illustrate the fact that TRand GHR (for small β) have slow convergence rates com-pared to PR (with μ = 0.85). Only GHR for large β canapproximate its ranking better than PR for the same k.
On this issue, however, we observe that slow conver-gence for small β of GHR or TR can be an advantage inspam detection applications. The idea is that link farms canonly produce localized spamming. Consequently, since PRhas comparatively large coefficients in the first rank diffu-sion hops (large ξj for small j), it is more vulnerable to spam.Therefore, trading convergence rate for robustness is a prac-tical motivation for functional rankings other than PR, thusmaking them excellent candidates for multidamping.
5.1 Functional Rankings as Surfing ProcessesThe most evident advantage of multidamping is directinterpretation. As noted in Section 1, G(μ) = μ S + (1 −μ) v e� encodes the two options for one-hop transition arandom surfer has: Jumping, with probability μ, to one ofthe immediate neighbor nodes, as dictated by the normal-ized linkage information contained in S, or teleporting, withprobability 1 −μ and conditioned by the probability vectorv, to any node in the graph. It follows that the k-term prod-uct G(μk) · · · G(μ2) G(μ1) models k consecutive transitionsfor this surfer, initially at node v0. More specifically, withprobability μ1, the surfer follows the link structure by visit-ing one of v0’s neighbors or teleporting to any graph nodewith the complementary probability 1 − μ1; let v1 be thelanding node. In the second step, with probability μ2 thesurfer chooses one of v1’s neighbors as the transition target,or teleports, and so on. Therefore, a multidamping factor μican be interpreted as the probability that the surfer jumpsto an immediate neighbor at the ith step of the session. Thesequence of damping factors can thus be considered as anencoding of the behavior of random surfers, quantifyinghow their attitudes in following existing links at the pagesvisited varies over “time” (increasing i).
These random surfers can be used eventually to obtainthe corresponding functional ranking. So one advantage isthat, unlike power series, the product form obtained from
Fig. 1. Plots (a–c) show the series coefficients ξj ’s (in log scale) succes-sively for LR, PR(μ = 0.85) and TR, GHR (β = 4.5) versus the numberof steps j = 0, . . . , 50. Plots (d–f) show the corresponding damping fac-tors μ’s. Note that ξ ’s are decreasing in all cases, but the monotonicityof the multidamping coefficients μ’s depends on the rate of ξ ’s decreaseand can be either increasing (LR), constant (PR) or decreasing(TR,GHR).
multidamping readily lends itself to the random surferinterpretation. As we see next, multidamping also helpsextract a more refined understanding of the damping coeffi-cients of the series themselves and a way to classify variousrankings.
The first observation is that sequences M of increasingdamping factors μj imply users who become more focusedas time progresses, on following the links of the pages theyvisit. On the other hand, the loss of interest in followinglinks over a surfing session manifests itself in sequences ofdecreasing damping factors. Using the terminology of Brinand Page, the web surfer “gets bored” in this case.
For the functional rankings under consideration, andeach k, we identify three patterns of sequences Mk thatdepend on the rate of decrease of the damping coeffi-cients Zk in the series representation. Note that the latteralways decreases (with the exception of the last one afternormalization), whereas this is not the case for Mk.
• Linear decay of Zk as in LR, for each k, generates anincreasing sequence Mk.
• Exponential decay of Zk, as in PR, is related to surferswith fixed interest, generating constant sequencesMk.
• Quadratic decay of Zk, as in TR, and general hyperbolicdecay, as in GHR, are related to surfers succes-sively losing their interest, generating decreasing Mksequences.
The plots in Fig. 1 illustrate these findings. It followsthat ranking strategies can be compared on the basis oftheir induced random surfer properties as quantified by thedamping factors M’s.
It is important to observe that this insight into randomsurfer behavior is a consequence of the multidamping fac-torization into products of Google matrices. It would havebeen impossible to accomplish this with standard polyno-mial factorization of pk(S), since the resulting factors wouldnot be Google matrices. In fact, they would only be relaxedstochastic (in the sense that a scalar multiple is stochastic) of
2330 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
the form S−σjI, with possibly complex shifts σj. Moreover,rank accumulation at a node necessitates a global view ofthe graph and is attenuated by: i) the product of degreesof intermediate nodes, incorporated into the normalizationof Sj terms, and ii) the additional damping coefficients ξj.On the contrary, the product representation suggests a localneighborhood view. All a surfer needs to proceed with itsith transition is the probability μi. Most importantly, in bothviews, ξ ’s and μ’s basically perturb the effect of purelysticking to the underlying link structure, as captured inS. The ξ ’s, however, do not have a clear enough inter-pretation, but appear as arbitrary attenuation functions. Bycomparison, the values of the damping factors can be linkedto the evolution of the assumed surfing habits of modelusers: Varying these habits will naturally suggest alternate,more suitable, functional rankings for the respective userpopulation.
5.2 Computational Cost and Parallelism inFunctional Ranking Through Monte CarloMethods
Avrachenkov et al. (see [32]–[34], along with otherresearchers [35]–[37]), have shown that it is possible toapproximate the PageRank vector using probabilistic algo-rithms based on a random surfer interpretation. Specifically,Avrachenkov et al. [32] derive: (i) a Monte Carlo-type algo-rithm that computes, with high probability, a PageRankvector approximation with relative error at most 0.1 aftera couple of hundred of iterations, and (ii) excellent resultsfor highly-ranked pages after a single Monte Carlo iteration(i.e. the workload of n random surfers). In [33], a fractionof a Monte Carlo iteration is shown to provide satisfactoryapproximation to the set of top − k ranked nodes in thecase of a personalized setting, i.e. for surfers initiated at aspecific seed node.
In addition to this reduced computational cost of approx-imation, an important benefit of the Monte Carlo approachis that it is inherently parallel. Random surfers hop acrossnodes independently, and thus can be implemented bymapping them to the (lightweight) execution primitiveof the underlying computational platform (i.e. a softwarethread/hardware core). For example on a multicore system,threads/surfers sharing the graph structure, equipped withthe suitable sequence Mk and started from various nodeswill mark the nodes they visit, the ranking value estimatorof a node simply emerging as the relative frequency of vis-its. This inherently parallel and synchronization-free proce-dure provides an alternative to the parallel implementationof deterministic, iterative ranking procedures, such as thepower method, which are built over sparse matrix-vectormultiplication kernels (matvecs) on distributed matrices(see also [38] for recent work on distributed randomizedalgorithms for computing PageRank).
Given the aforementioned advantages of a Monte Carlobased approach for PageRank it is natural to ask whether itcan be extended to the broader class of functional rankings,and what the associated benefits would there be? The multi-damping framework provides the vehicle for this extension:Casting functional rankings in the form of multidampingenables their interpretation as equivalent random surfer
TABLE 3Datasets
processes and the application of Monte Carlo methods toapproximate the relevant functional ranking vectors. Wedemonstrate these ideas in greater detail in the context ofreal networks, and quantify the performance improvementsin Section 6.1.
6 VALIDATION AND APPLICATIONS
We have argued that multidamping formulations facil-itate interpretation and design of ranking functions, aswell as enable fast Monte-Carlo-based algorithms. In thisSection, we validate our claims based on representativeresults from two groups of experiments. The first group isbased on serial implementations and is aimed at validatingthe multidamping framework. Following this, numericalexperiments in the second group (Section 6.1) are used tovalidate various aspects of the random surfer model, mostnotably its approximation properties using parallel surfers.
For our experiments, we use the datasets shownin Table 3. These datasets are available fromhttp://law.dsi.unimi.it/datasets.php, as part of theWebGraph [39] framework. We implement core function-ality in Java, primarily leveraging WebGraph libraries. Forthe second group of experiments, we also make extensiveuse of built-in multithreading capabilities of our computingplatform. In both cases, in order to get the final, executablecodes, we scripted resulting class libraries in Python.
Fig. 2 shows results from the application of Algorithm 1for TR and GHR (for values β = 2.0, 3.5). In each case, weset x(201) (i.e., the iterate after 201 steps) as the “true” func-tional ranking xdf, and we computed log10 ‖x(k) − xdf‖1 forsteps k = 5, 15, 25, . . . , 195. It is evident that as k increases,all sequences converge to the true functional ranking vec-tor. These results, confirm that multidamping simulationsare faithful (see Section 5).
6.1 Fast Rank Approximations by MultidampingTo evaluate the use of multidamping in acceleratingapproximate computations of functional rankings, we firstsummarize the findings of Avrachenkov et al. [32], whichwe significantly generalize to the broad class of functionalrankings. To analyze the performance of the Monte Carloapproach versus the classical power method, the notion ofthe “expected length” of a Monte Carlo run is used. It isfound that one iteration of Monte Carlo would be fasterthan one iteration of the power method if the expectedlength were smaller than the ratio between the number ofedges and the number of nodes (see [32]), that is the averagenode outdegree, say 〈d〉, of the graph.
The PageRank model induces a geometric distributionfor the probability of node visits by the random surfer, so
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2331
Fig. 2. log10 ‖x(k) − xdf‖1 for steps k = 5, 15, 25, . . . ,195 for TR andGHR (β = 2.0, β = 3.5) for in-2004.
Fig. 3. Random surfer for k -step multidamping over Mk =(μ1, . . . , μk ).
that the probability that a surfer teleports after j = 0, . . .steps is (1 − μ)μj. It follows that the average length ofthe path traversed by the random surfer for PageRank isgiven by:
〈lPR〉 = (1 − μ)
∞∑
j=0
(j + 1)μj = 11 − μ
. (14)
For μ = 0.85, this is ∼ 6.7 [32, p. 898]. Observe that thelengths become larger for μ closer to 1, and it is usefulto note that in order for the expected path length to bebounded by β, the value of μ must be less than (β − 1)/β.
We use the multidamping formulation to compute theaverage path length for functional rankings. The generalprocess can also be represented by in Fig. 3, if we inter-pret the downward looking tree branches correspond tothe process stopping with probability (1 − μk)μk−1 · · ·μ1.Specifically, from Theorem 1 (formulas (8) and (9)), for mul-tidamping formulations of k steps of functional ranking,emerges the following approximation for the expected pathlength:
k−1∑
j=0
(j + 1)(1 − μj+1
)j∏
i=1
μi. (15)
Since μLRj = j
j+2 and μTRj = k−j+1
k−j+2 for j = 1, . . . , k, we suc-
cessively obtain 〈lLRk 〉 = 2k
k+2 and 〈lTRk 〉 = k
2 . This implies thatfor the modest values of k(∼ 10) we opt for, in the paral-lel random surfer experiments described below, 〈lLR
k ∼ 10) yield average path lengths of around 3.4.It is instructive to consider in more detail the above
results for the case of TotalRank. Recall that this rankingwas obtained by averaging PageRank-generated rankingsover all possible damping factors in (0, 1); see [26] andSection 4.2 above. It follows that simulating TotalRank asa surfing processes would necessitate the initiation of acollection of a potentially infinite number of PageRanksurfers from graph nodes, i.e., ideally for all possible valuesof μ ∈ (0, 1). This is not practical, while it is evident that thesurfers corresponding to values of μ close to 1, contributeexcessively high path lengths - intuitively as the probability1 − μ of stopping for a surfer tends to 0, the surfer wouldsurf for ever (see also Equation (14). This would eventuallydrive the average path length to very large values. Instead,with the introduction of a single TotalRank surfer basedon the damping factors Mk, as opposed to a collection ofan infinite number of PageRank surfers, the realization ofthe inherently parallel surfing process becomes practical. Itis also worth noting that the expected path length has aconsistent behavior – as shown above, it varies as k
2 , alsoyielding large values for large number of steps k. Finally, wenote one more aspect of this result, based on our proposedinterpretation of a TotalRank surfer as having the propertyof following the link structure with high probability dur-ing a long series of initial edge traversals, as seen in Fig. 1.This implies low probability for stopping during this sameperiod and, consequently, large average path length.
The preceding example serves as an illustration of theinsights offered by the multidamping framework, here fora large number of steps k. In the next Section, we focuson the methods for rapid approximation enabled by ourapproach.
We can now draw a correspondence between the com-putational cost for a single classical iterative step, imple-mented as a sparse matvec and that of the random surfermodel based on multidamping. To facilitate comparisons,cost is counted in terms of edge traversals. During eachsparse matvec in the iteration of the power method, eachnode “consumes” values through each of its inbound links,and produces a result by summing their contributions.Therefore, the average cost of one iterative step is of theorder n〈d〉. On average, a single node uses 〈d〉 edges toupdate its rank value at each iteration (where 〈d〉 is the aver-age in-degree in graphs of interest). Therefore, the averagecost of one iterative step is n〈d〉.
Let us call microstep, the activity of a single surfer tocompletion, hence a microstep requires 〈lk〉 edge traversals.It follows that the computational cost of running one surferinitiated at each of the n nodes is n〈lk〉 edge traversals, i.e.,n microsteps or n surfers running to completion. Therefore,as in the PageRank case analyzed in [32], this cost is equalor smaller to one sparse matvec depending on whether 〈lk〉is smaller or larger than 〈d〉.
Considering these values, we note that for web graphssuch as the ones used (Table 3), 〈d〉 is in the range (9, 24);see also [40], [41] for experimental evidence of slightlysmaller values for 〈d〉 in web graphs. Within the multi-damping framework, a random surfer performs on average〈lk〉 transitions (i.e., edge traversals) to completion (for a
2332 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
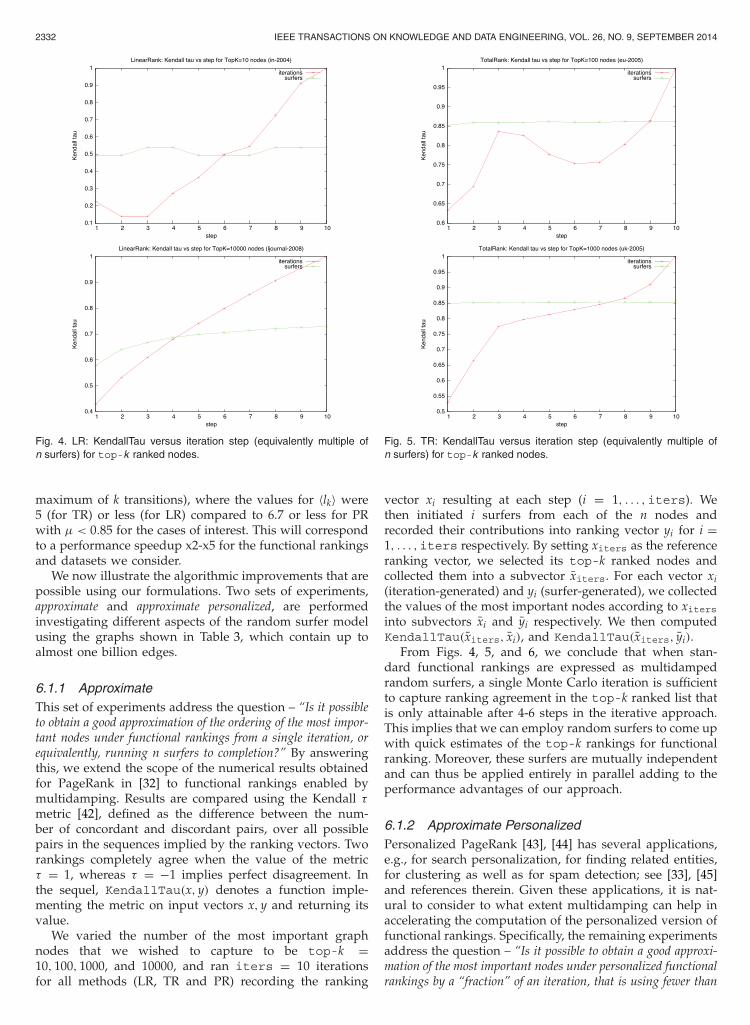
Fig. 4. LR: KendallTau versus iteration step (equivalently multiple ofn surfers) for top-k ranked nodes.
maximum of k transitions), where the values for 〈lk〉 were5 (for TR) or less (for LR) compared to 6.7 or less for PRwith μ < 0.85 for the cases of interest. This will correspondto a performance speedup x2-x5 for the functional rankingsand datasets we consider.
We now illustrate the algorithmic improvements that arepossible using our formulations. Two sets of experiments,approximate and approximate personalized, are performedinvestigating different aspects of the random surfer modelusing the graphs shown in Table 3, which contain up toalmost one billion edges.
6.1.1 ApproximateThis set of experiments address the question – “Is it possibleto obtain a good approximation of the ordering of the most impor-tant nodes under functional rankings from a single iteration, orequivalently, running n surfers to completion?” By answeringthis, we extend the scope of the numerical results obtainedfor PageRank in [32] to functional rankings enabled bymultidamping. Results are compared using the Kendall τmetric [42], defined as the difference between the num-ber of concordant and discordant pairs, over all possiblepairs in the sequences implied by the ranking vectors. Tworankings completely agree when the value of the metricτ = 1, whereas τ = −1 implies perfect disagreement. Inthe sequel, KendallTau(x, y) denotes a function imple-menting the metric on input vectors x, y and returning itsvalue.
We varied the number of the most important graphnodes that we wished to capture to be top-k =10, 100, 1000, and 10000, and ran iters = 10 iterationsfor all methods (LR, TR and PR) recording the ranking
Fig. 5. TR: KendallTau versus iteration step (equivalently multiple ofn surfers) for top-k ranked nodes.
vector xi resulting at each step (i = 1, . . . ,iters). Wethen initiated i surfers from each of the n nodes andrecorded their contributions into ranking vector yi for i =1, . . . ,iters respectively. By setting xiters as the referenceranking vector, we selected its top-k ranked nodes andcollected them into a subvector xiters. For each vector xi(iteration-generated) and yi (surfer-generated), we collectedthe values of the most important nodes according to xitersinto subvectors xi and yi respectively. We then computedKendallTau(xiters, xi), and KendallTau(xiters, yi).
From Figs. 4, 5, and 6, we conclude that when stan-dard functional rankings are expressed as multidampedrandom surfers, a single Monte Carlo iteration is sufficientto capture ranking agreement in the top-k ranked list thatis only attainable after 4-6 steps in the iterative approach.This implies that we can employ random surfers to come upwith quick estimates of the top-k rankings for functionalranking. Moreover, these surfers are mutually independentand can thus be applied entirely in parallel adding to theperformance advantages of our approach.
6.1.2 Approximate PersonalizedPersonalized PageRank [43], [44] has several applications,e.g., for search personalization, for finding related entities,for clustering as well as for spam detection; see [33], [45]and references therein. Given these applications, it is nat-ural to consider to what extent multidamping can help inaccelerating the computation of the personalized version offunctional rankings. Specifically, the remaining experimentsaddress the question – “Is it possible to obtain a good approxi-mation of the most important nodes under personalized functionalrankings by a “fraction” of an iteration, that is using fewer than
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2333
Fig. 6. PR: KendallTau versus iteration step (equivalently multiple ofn surfers) for top-k ranked nodes.
n surfers?” Personalization is realized by the selection ofa specific “seed node” to launch the random surfers. Thisimportant issue, for the case of PageRank, was the centraltopic in [33]. Parameters for these experiments were set tobe iters = 10, someIters = 3, freq = 10, top-k = 30.
We first ran maxIters = 50 iterations for methods LR,TR, PR, recorded the final ranking vectors and computedthe corresponding induced node orderings. We then var-ied a parameter top-pc (top-percentage) to take values0, 20, 50% and 80% and for each constructed a correspond-ing set seeds consisting of all nodes in the graph forwhich top-pc graph nodes had larger ranking values.For instance, the rank of every seed node in set seedsfor top-pc = 20% will be higher than 80% of the graphnodes.
Next, for each seed node s in set seeds we ran i =1, 2, . . . ,iters iterations of the power method for all func-tional rankings using v = es as personalization vector, that isteleporting only towards the seed. These personalized rank-ings were then relabeled, from x(s)i to x(s)t , setting t = i×n.Effectively, this mapped the value of the iteration index, i,of the power method, to the number, t, of computationallyequivalent random surfers started in order to facilitate com-parisons between the ranking vector iterates generated bythe power method and the Monte Carlo runs.
We then initiated iters × n surfers from each seeds ∈ seeds for all methods. Note that running these surfersto completion would demand similar computational work-load as iters steps of the power method. We then sampledfreq ranking vectors per Monte Carlo iteration; a new suchranking vector is recorded each time an additional numberof n
freq surfers terminates. Based on this, we denote by I(s)
the set of the top-k nodes in the final iteration-generated
Fig. 7. LR: Number of shared top-k nodes as a function of the numberof microsteps (i.e. number of surfers, where 1 iteration=n surfers).
ranking vector x(s)t=iters×n. This was the reference set forthis experiment.
Next, for the first j = 1, . . . ,someIters iterations ofthe power method, the top-k nodes were recorded in setsI(s)t=j×n. We also recorded the corresponding sets S(s)t oftop-k nodes at the termination of t surfers, for t = j n
freqwith j = 1, 2, . . . ,freq×someIters. These were the top-knode sets computed by the surfing process; thus, freqsuch sets were collected per iteration. Finally, we computedthe cardinalities |I(s)t ∩ I(s)| and |S(s)t ∩ I(s)| in order toobtain how many top-k nodes were common between thereference set I(s) and all available sets I(s)t and S(s)t .
We show the number of these shared top-k nodes vs.microsteps in Figs. 7, 8, and 9 for graphs from Table 3.The plots show that a fraction of the resources neededfor a single iteration (i.e., fewer than n surfers) is suffi-cient to capture most of the nodes in the top-k rankedlist for a node acting as the personalization seed. This wasenabled by the multidamping framework, which cast func-tional rankings such as LR, TR as well as PR as randomsurfers.
Interestingly, even the first ranking vector generated bythe single-node seeded random surfers, yields a satisfac-tory approximation of its reference top-k list of nodes.Observe that this vector is computed in a fraction 1
freq of apower method iteration. The fact that in these experimentsfreq=10, 〈d〉 > 〈lk〉, and that 3-5 iterations were neededfor the power method to achieve an approximation of sim-ilar quality, imply the potential for at least two orders ofmagnitude speedup in approximating personalized top-kranked nodes by random surfers. Since a general person-alization vector is a linear combination of seed contribu-tions (usually a small support vector) this means that one
2334 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
Fig. 8. TR: Number of shared top-k nodes as a function of the numberof microsteps (i.e. number of surfers, where 1 iteration=n surfers).
Fig. 9. PR: Number of shared top-k nodes as a function of the numberof microsteps (i.e. number of surfers, where 1 iteration=n surfers).
can employ random surfers in parallel to rapidly obtainestimates of top-k personalized rankings for functionalrankings.
7 ADDITIONAL REMARKS ON RELATED WORK
Functional rankings were first studied for their potentialto approximate standard PageRank by suitably optimizingover their parameters in [9], [10]. One functional ranking,Truncated Rank, has been proposed by Beccheti et al. tocombat spam [46]. An early report on Markovian rank-ing emphasizing on simulations can be found in [36]. Aninteresting connection between Monte Carlo methods asdeveloped in [32] and algorithms for hitting times in graphsis discussed in [47]. Avrachenkov et al. in [32] proved thatthe expected value of the Monte Carlo estimator for thePageRank vector equals the corresponding ranking vector.Fogaras et al. [37], [48] provide a proof of the sharp con-centration of the samples around the expected value basedon the Chernoff inequality. A similar result is derived byBahmani et al. [49], also extending the theoretical results forthe personalization case. An early version of our work waspresented at a Dagstuhl seminar [30].
Our arguments in Section 6.1 also justify the use of theseemingly counter-intuitive notion of a fraction of an itera-tion that is implicit in the discussion of [33]. There, it wasargued that the computation requires fewer than n surfers,started from a particular set of seed nodes. As noted in theIntroduction, we refrained from discussing matters relatedto algorithms other than the power method for comput-ing PageRank as well as from considering the effects offinite precision arithmetic. Please see [14], [50] and refer-ences therein regarding these matters. We finally note thatTheorem 1 extends the generalized Sherman-Morrison for-mula of [18, Lemma 1], and earlier results of Bernstein andvan Loan for the effect of rank-1 modifications of matricesto their rational functions (see [51]).
8 CONCLUSION
In this paper we presented the general concept of multi-damping. We theoretically show that practical functionalrankings can be formulated as multistep multidamping pro-cesses. This formulation has several advantages – it directlyresults in interpretable rankings providing new insights,extends Monte Carlo-type estimators to functional rank-ings, thus significantly reducing their computational cost,and lends itself naturally to highly efficient parallel imple-mentations. Numerical experiments establish the suitabilityof the random surfer realization of multidamping for thefast, parallel identification of the most important rankednodes both in the generic as well as in personalized case.
In continuing work, we undertake a systematic study ofthese approximation schemes in distributed settings; pro-totypes for cluster environments are currently availableand their performance optimization is work in progress.Additionally, leveraging the theoretical apparatus of theinhomogeneous Markov chain and nonnegative stochasticmatrix product literature, we intend to explore poten-tial applications of new rankings based on syntheticallygenerated sequences of damping factors Mk.
ACKNOWLEDGMENTS
The authors would like to sincerely acknowledge the com-ments and concerns of the reviewers, which served to
KOLLIAS ET AL.: SURFING THE NETWORK FOR RANKING BY MULTIDAMPING 2335
enhance the quality of the manuscript significantly. Theywould also like to thank D. Szyld for his comments on thiswork. This work was supported in part by the US NationalScience Foundation grants DBI-0835677, DMS-0800568 andin part by the Center for Science of Information (CSoI), anNSF Science and Technology Center, under grant agreementCCF-0939370.
REFERENCES
[1] L. Katz, “A new status index derived from sociometric analysis,”Psychometrika, vol. 18, no. 1, pp. 39–43, 1953.
[2] N. Friedkin, “Theoretical foundations for centrality measures,”Amer. J. Sociol., vol. 96, no. 6, pp. 1478–1504, 1991.
[4] R. Horn and S. Serra-Capizzano, “A general setting for the para-metric Google matrix,” Internet Math., vol. 3, no. 4, pp. 385–411,2006.
[5] S. Brin and L. Page, “The anatomy of a large-scale hypertextualweb search engine,” Comput. Netw. ISDN Syst., vol. 33, no. 1–7,pp. 107–117, 1998.
[6] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRankcitation ranking: Bringing order to the web,” Stanford Univ.,Stanford, CA, USA, Tech. Rep. 1999-66, 1999.
[7] S. Kamvar, Numerical Algorithms for Personalized Search in Large-Scale Self-Organizing Information Networks. Princeton, NJ, USA:Princeton University Press, 2010.
[8] A. Langville and C. Meyer, Google’s PageRank and Beyond: TheScience of Search Engine Rankings. Princeton, NJ, USA: PrincetonUniversity Press, 2006.
[9] R. Baeza-Yates, P. Boldi, and C. Castillo, “Generalizing PageRank:Damping functions for link-based ranking algorithms,” inProc. ACM SIGIR, 2006, pp. 308-315 [Online]. Available:citeseer.ist.psu.edu/baeza-yates06generalizing.html
[10] R. Baeza-Yates, P. Boldi, and C. Castillo, “Generic damping func-tions for propagating importance in link-based ranking,” InternetMath., vol. 3, no. 4, pp. 445–478, 2006.
[11] N. Spirin and J. Han, “Survey on web spam detection: Principlesand algorithms,” ACM SIGKDD Explor. Newslett., vol. 13, no. 2,pp. 50–64, 2012.
[12] L. Eldén, “A note on the eigenvalues of the Google matrix,” Dep.Math., Linköping Univ., Linköping, Sweden, Tech. Rep. 0401177v1[math.RA], 2004.
[13] T. Haveliwala and S. Kamvar, “The second eigenvalue of theGoogle matrix,” Stanford Univ., Stanford, CA, USA, Tech. Rep.2003-20, Mar. 2003.
[14] I. Ipsen and R. Wills, “Mathematical properties and analysis ofGoogle’s PageRank,” Bol. Soc. Esp. Mat. Apl., vol. 34, pp. 191–196,Mar. 2006.
[15] C. Brezinski and M. Redivo-Zaglia, “Rational extrapolation for thePageRank vector,” Math. Comput., vol. 77, no. 263, pp. 1585–1598,2008.
[16] S. Serra-Capizzano, “Jordan canonical form of the Google matrix:A potential contribution to the PageRank computation,” SIAM J.Matrix Anal. Appl., vol. 27, no. 2, pp. 305–312, 2005.
[17] K. Avrachenkov, N. Litvak, and K. Pham, “Distribution ofPageRank mass among principle components of the web,” in Proc.5th WAW, Berlin, Germany, 2007.
[18] P. Boldi, M. Santini, and S. Vigna, “PageRank as a function ofthe damping factor,” in Proc. Int. Conf. WWW, Chiba, Japan, 2005,pp. 557–566.
[19] P. Boldi, M. Santini, and S. Vigna, “PageRank: Functional depen-dencies,” ACM Trans. Inf. Syst., vol. 27, pp. 19:1–19:23, Nov. 2009[Online]. Available:http://doi.acm.org/10.1145/1629096.1629097
[20] D. Gleich, P. Constantine, A. Flaxman, and A. Gunawardana,“Tracking the random surfer: Empirically measured teleportationparameters in PageRank,” in Proc. 19th Int. Conf. WWW, Raleigh,NC, USA, 2010, pp. 381–390.
[21] L. Festinger, “The analysis of sociograms using matrix algebra,”Hum. Relat., vol. 2, no. 2, pp. 153–158, 1949.
[23] D. Fogaras, “Where to start browsing the web?” in InnovativeInternet Community Systems, Berlin, Germany: Springer, 2003,LNCS 2877 [Online]. Available:http://www.springerlink.com/content/v3q5d15tp6mbdvd7
[24] J. Miller et al., “Modifications of Kleinberg’s HITS algorithm usingmatrix exponentiation and web log records,” in Proc. 24th SIGIR,New Orleans, LA, USA, 2001, pp. 444–445.
[25] M. Newman, S. Strogatz, and D. Watts, “Random graphs witharbitrary degree distributions and their applications,” Phys. Rev.E, vol. 64, no. 2, pp. 1–17, 2001.
[26] P. Boldi, “Total rank: Ranking without damping,” in Proc. 14thInt. Conf. WWW, Chiba, Japan, 2005, pp. 898–899.
[27] P. Boldi, M. Santini, and S. Vigna, “A deeper investigation ofPageRank as a function of the damping factor,” in Proc. DagstuhlSeminar Web Information Retrieval Linear Algebra Algorithms, 2007.
[28] D. Isaacson and R. Madsen, Markov Chains. Theory andApplications. New York, NY, USA: Wiley, 1976.
[29] E. Seneta, Non-Negative Matrices and Markov Chains. New York,NY, USA: Springer-Verlag, 2006.
[30] G. Kollias and E. Gallopoulos, “Multidamping simulation frame-work for link-based ranking,” in Web Information Retrieval andLinear Algebra Algorithms, A. Frommer, M. Mahoney, and D. Szyld,Eds. Wadern, Germany: IBFI, Schloss Dagstuhl, 2007.
[31] A. Brauer, “Limits for the characteristic roots of a matrix. IV:Applications to stochastic matrices,” Duke Math. J., vol. 19,no. 1,pp. 75–91, 1952.
[32] K. Avrachenkov, N. Litvak, D. Nemirovsky, and N. Osipova,“Monte Carlo methods in PageRank computation: When oneiteration is sufficient,” SIAM J. Numer. Anal., vol. 45, no. 2,pp. 890–904, 2007.
[33] K. Avrachenkov, N. Litvak, D. Nemirovsky, E. Smirnova, andM. Sokol, “Quick detection of top-k personalized PageRank lists,”in Proc. 8th Int. Conf. Algorithms Models Web Graph, Atlanta, GA,USA, 2011, pp. 50–61.
[34] D. Nemirovski, “Monte Carlo methods and Markov chain basedapproaches for PageRank computation,” Ph.D. dissertation, Univ.Nice, Sophia Antipolis, France, 2010.
[35] M. Bianchini, M. Gori, and F. Scarselli, “Inside PageRank,” ACMTrans. Internet Technol., vol. 5, pp. 92–128, Feb. 2005 [Online].Available: http://doi.acm.org/10.1145/1052934.1052938
[36] L. Breyer. (2002). Markovian Page Ranking Distributions: SomeTheory and Simulations [Online]. Available:www.lbreyer.com/preprints.html
[37] D. Fogaras and B. Rácz, “Towards scaling fully personalizedPageRank,” in Proc. Algorithms Models Web-Graph, Rome, Italy,2004, pp. 105–117.
[38] H. Ishii and R. Tempo, “Distributed randomized algorithms forthe PageRank computation,” IEEE Trans. Autom. Control, vol. 55,no. 9, pp. 1987–2002, Sept. 2010.
[39] P. Boldi and S. Vigna, “The webgraph framework I: Compressiontechniques,” in Proc. 13th Int. Conf. WWW, New York, NY, USA,2004, pp. 595–601.
[40] J. Kleinberg, R. Kumar, P. Raghavan, S. Rajagopalan, andA. Tomkins, “The web as a graph: Measurements, models, andmethods,” in Proc. 5th COCOON, vol. 1627. Tokyo, Japan, 1999,pp. 1–17.
[41] A. Broder et al., “Graph structure in the web,” Comput. Netw.,vol. 33, no. 1, pp. 309–320, 2000.
[42] M. Kendall, “A new measure of rank correlation,” Biometrika,vol. 30, no. 1/2, pp. 81–93, 1938.
[43] T. H. Haveliwala, “Topic-sensitive PageRank: A context-sensitiveranking algorithm for web search,” IEEE Trans. Knowl. Data Eng.,vol. 15, no. 4, pp. 784–796, Jul./Aug. 2003.
[44] G. Jeh and J. Widom, “Scaling personalized web search,” in Proc.12th Int. Conf. WWW, New York, NY, USA, May 2003.
[45] J. Cho and U. Schonfeld, “RankMass crawler: A crawler withhigh personalized PageRank coverage guarantee,” in Proc.33rd Int. Conf. VLDB, 2007, pp. 375–386 [Online]. Available:http://dl.acm.org/citation.cfm?id=1325851.1325897
[46] L. Becchetti, C. Castillo, D. Donato, S. Leonardi, and R. Baeza-Yates, “Using rank propagation and probabilistic counting forlink-based spam detection,” in Proc. WebKDD, 2006.
[47] D. Sheldon, “Manipulation of PageRank and Collective HiddenMarkov Models,” Ph.D. dissertation, Cornell Univ., Ithaca, NY,USA, 2010.
2336 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 9, SEPTEMBER 2014
[48] D. Fogaras, B. Rácz, K. Csalogány, and T. Sarlós, “Towards scal-ing fully personalized PageRank: Algorithms, lower bounds, andexperiments,” Internet Math., vol. 2, no. 3, pp. 333–358, 2005.
[49] B. Bahmani, A. Chowdhury, and A. Goel, “Fast incre-mental and personalized PageRank,” Proc. VLDB,vol. 4, no. 3, pp. 173–184, Dec. 2010 [Online]. Available:http://dl.acm.org/citation.cfm?id=1929861.1929864
[50] G. Wu and Y. Wei, “Arnoldi versus GMRES forcomputing PageRank: A theoretical contribution toGoogle’s PageRank problem,” ACM Trans. Inf. Syst.,vol. 28, pp. 11:1–11:28, Jul. 2010 [Online]. Available:http://doi.acm.org/10.1145/1777432.1777434
[51] D. Bernstein and C. Van Loan, “Rational matrix functions andrank-1 updates,” SIAM J. Matrix Anal. Appl., vol. 22, no. 1,pp. 145–154, 2000.
Giorgos Kollias received the B.Sc. degreein physics in 2000, the M.Sc. degree incomputational science from the University ofAthens, Greece, in 2002, and the Ph.D. degreein computer science from the University ofPatras, Greece, in 2009. He is currently aPost-Doctoral Researcher with the Center forScience of Information and the ComputerScience Department at Purdue University, WestLafayette, IN, USA. His current research inter-ests include graph mining applications and paral-
lel/distributed computing, problem solving environments, and dynamicalsystems.
Efstratios Gallopoulos is a Professor inthe Computer Engineering and InformaticsDepartment, University of Patras, Greece. Hiscurrent research interests include scientific com-puting, linear algebra and its applications, par-allel processing, data mining, problem solvingenvironments, and education in computationalscience and engineering. He received the B.Sc.degree in mathematics from Imperial College,London, and the Ph.D. degree in computer sci-ence in 1985 from the University of Illinois at
Urbana-Champaign (UIUC), Urbana-Champaign, IL, USA. He has heldvisiting appointments at INRIA Rennes-Bretagne-Atlantique, Rennes I,Padova, and Purdue and Prior to his current post, he also held researchand faculty positions at UIUC from 1986 to 1996, and at UCSB from1985 to 1986. He was the co-recipient of the 2012 Hypertext Ted NelsonNewcomer Award from ACM SIGWEB, as well as the 1986 NASAGroup Achievement Award. Between 1980 and 1994, he participatedin R&D for the Goodyear Massively Parallel Processor, and was SeniorComputer Scientist at the UIUC Center for Supercomputing Researchand Development, where he developed the cedar vector multiprocessor.
Ananth Grama received the Ph.D. degree fromthe University of Minnesota, Minneapolis, MN,USA, in 1996. He is currently a Professor ofComputer Sciences and Associate Director ofthe Center for Science of Information at PurdueUniversity, West Lafayette, IN, USA. His cur-rent research interests include areas of par-allel and distributed computing architectures,algorithms, and applications. On these topics,he has authored several papers and texts. Heis a member of the American Association for
Advancement of Sciences.
� For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.