This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Syntia: Synthesizing the Semantics of Obfuscated Code Tim Blazytko, Moritz Contag, Cornelius Aschermann, and Thorsten Holz, Ruhr-Universität Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/blazytko
Transcript
This paper is included in the Proceedings of the 26th USENIX Security SymposiumAugust 16–18, 2017 • Vancouver, BC, Canada
ISBN 978-1-931971-40-9
Open access to the Proceedings of the 26th USENIX Security Symposium
is sponsored by USENIX
Syntia: Synthesizing the Semantics of Obfuscated Code
Tim Blazytko, Moritz Contag, Cornelius Aschermann, and Thorsten Holz, Ruhr-Universität Bochum
Current state-of-the-art deobfuscation approaches operateon instruction traces and use a mixed approach of sym-bolic execution and taint analysis; two techniques thatrequire precise analysis of the underlying code. However,recent research has shown that both techniques can easilybe thwarted by specific transformations.
As program synthesis can synthesize code of arbitrarycode complexity, it is only limited by the complexity ofthe underlying code’s semantic. In our work, we proposea generic approach for automated code deobfuscationusing program synthesis guided by Monte Carlo TreeSearch (MCTS). Specifically, our prototype implementa-tion, Syntia, simplifies execution traces by dividing theminto distinct trace windows whose semantics are then“learned” by the synthesis. To demonstrate the practicalfeasibility of our approach, we automatically learn the se-mantics of 489 out of 500 random expressions obfuscatedvia Mixed Boolean-Arithmetic. Furthermore, we synthe-size the semantics of arithmetic instruction handlers intwo state-of-the art commercial virtualization-based ob-fuscators (VMProtect and Themida) with a success rateof more than 94%. Finally, to substantiate our claim thatthe approach is generic and applicable to different usecases, we show that Syntia can also automatically learnthe semantics of ROP gadgets.
1 Introduction
Code obfuscation describes the process of applying anobfuscating transformation to an input program to obtainan obfuscated copy of the program. Said copy should bemore complex than the input program such that an analystcannot easily reason about it. An obfuscating transfor-mation is further desired to be semantics-preserving, i. e.,it must not change observable program behavior [12].Code obfuscation can be leveraged in many applicationdomains, for example in software protection solutions
to prevent illegal copies, or in malicious software to im-pede the analysis process. In practice, different kinds ofobfuscation techniques are used to hinder the analysisprocess. Most notably, industry-grade obfuscation solu-tions are typically based on Virtual Machine (VM)-basedtransformations [38, 55, 57, 58], which are considered oneof the strongest obfuscating transformations available [2].While these protections are not perfect and in fact arebroken regularly, attacking them is still a time-consumingtask that requires highly specific domain knowledge ofthe individual Virtual Machine implementation. Conse-quently, for example, this gives game publishers a head-start in which enough revenue can be generated to stayprofitable. On the other hand, obfuscated malware staysunder the radar for a longer time, until concrete analysisresults can be used to effectively defend against it.
To deal with this problem, prior research has exploredmany different approaches to enable deobfuscation ofobfuscated code. For example, Rolles proposes staticanalysis to aid in deobfuscation of VM-based obfuscationschemes [44]. However, it incorporates specific imple-mentation details an attacker has to know a priori. Further,static analysis of obfuscated code is notoriously knownto be intractable in the general case [12]. Hence, recentdeobfuscation proposals have shifted more towards dy-namic analysis [13, 61, 62]. Commonly, they producean execution trace and use techniques such as (dynamic)taint analysis or symbolic execution to distinguish input-dependent instructions. Based on their results, the pro-gram code can be reduced to only include relevant, input-dependent instructions. This effectively strips the obfus-cation layer. Even though such deobfuscation approachessound promising, recent work proposes several ways toeffectively thwart underlying techniques, such as sym-bolic execution [2]. For this reason, it suggests itself toexplore distinct techniques that may be leveraged for codedeobfuscation.
In this paper, we propose an approach orthogonal toprior work on approximating the underlying semantics
USENIX Association 26th USENIX Security Symposium 643
of obfuscated code. Instead of manually analyzing theinstruction handlers used in virtualization-based (VM) ob-fuscation schemes in a complex and tedious manner [44]or learning merely the bytecode decoding (not the seman-tics) of these instruction handlers [53], we aim at learningthe semantics of VM-based instruction handlers in an auto-mated way. Furthermore, our goal is to develop a genericframework that can deal with different use cases. Natu-rally, this includes constructs close to obfuscation, suchas Mixed Boolean-Arithmetic (MBA), different kinds ofVM-based obfuscation schemes, or even analysis of codechunks (so called gadgets) used in Return-oriented Pro-gramming (ROP) exploits.
To this extend, we explore how program synthesis canbe leveraged to tackle this problem. Broadly speaking,program synthesis describes the task of automatically con-structing programs for a given specification. While thereexists a variety of program synthesis approaches [21], wefocus on SMT-based and stochastic program synthesis inthe following, given its proven applicability to problemdomains close to trace simplification and deobfuscation.SMT-based program synthesis constructs a loop-free pro-gram based on first-order logic constraints whose satisfia-bility is checked by an SMT solver. For component-basedsynthesis, components are described that build the instruc-tion set of a synthesized program; for instance, compo-nents may be bitwise addition or arithmetic shifts. Thecharacteristics of a well-formed program such as the inter-connectivity of components are defined and the semanticsof the program are described as a logical formula. Then,an SMT solver returns a permutation of the componentsthat forms a well-encoded program following the previ-ously specified intent [22,24], if it is satisfiable, i. e., sucha permutation does exist.
Instead of relying on a logical specification of programintent, oracle-guided program synthesis uses an input-output (I/O) oracle. Given the outputs of an I/O oraclefor arbitrary program inputs, program synthesis learnsthe oracle’s semantics based on a finite set of I/O sam-ples. The oracle is iteratively queried with distinguishinginputs that are provided by an SMT solver. Locatingdistinguishing inputs is the most expensive task in this ap-proach. The resulting synthesized program has the sameinput-output behavior as the I/O oracle [24]. Contrary toSMT-based approaches that only construct semanticallycorrect programs, stochastic synthesis approximates pro-gram equivalence and thus remains faster. In addition, itcan also find partial correct programs. Program synthesisis modeled as heuristic optimization problem, where thesearch is guided by a cost function. It determines, forinstance, output similarity of the synthesized expressionand the I/O oracle for same inputs [50].
As program synthesis is indifferent to code complex-ity, it can synthesize arbitrarily obfuscated code and is
only limited by the underlying code’s semantic complex-ity. We demonstrate that a stochastic program synthesisalgorithm based on Monte Carlo Tree Search (MCTS)achieves this in a scalable manner. To show feasibilityof our approach, we automatically learned the semanticsof 489 out of 500 MBA-obfuscated random expressions.Furthermore, we synthesize the semantics of arithmeticinstruction handlers in two state-of-the art commercialvirtualization-based obfuscators with a success rate ofmore than 94%. Finally, to show applicability to areasmore focused on security aspects, we further automati-cally learn the semantics of ROP gadgets.
Contributions In summary, we make the followingcontributions in this paper:
• We introduce a generic approach for trace simpli-fication based on program synthesis to obtain thesemantics of different kinds of obfuscated code. Wedemonstrate how Monte Carlo Tree Search (MCTS)can be utilized in program synthesis to achieve ascalable and generic approach.
• We implement a prototype of our method in a toolcalled Syntia. Based on I/O samples from assemblycode as input, Syntia can apply MCTS-based pro-gram synthesis to compute a simplified expressionthat represents a deobfuscated version of the input.
• We demonstrate that Syntia can be applied in sev-eral different application domains such as simplify-ing MBA expressions by learning their semantics,learning the semantics of arithmetic VM instructionhandlers and synthesizing the semantics of ROP gad-gets.
2 Technical Background
Before presenting our approach to utilize program syn-thesis for recovering the semantics of obfuscated code,we first review several concepts and techniques we usethroughout the rest of the paper.
2.1 ObfuscationIn the following, we discuss several techniques thatqualify as an obfuscating transformation, namelyvirtualization-based obfuscation, Return-oriented Pro-gramming and Mixed Boolean-Arithmetic.
2.1.1 Virtualization-based Obfuscation
Contemporary software protection solutions such as VM-Protect [58], Themida [38], and major game copy protec-tions such as SecuROM base their security on the concept
644 26th USENIX Security Symposium USENIX Association
5b 60 97 84 66 d8 aa 11 22
Bytecode
handler_add8
handler_mul16
handler_not8
…
handler_sub32
Handler Table
Fetch
Decode
Execute
VM Entryswitch from native
to VM context
Native Codecorresponds to
handler_exit
Figure 1: The Fetch–Decode–Execute cycle of a VirtualMachine. Native code calls into the VM, upon whichstartup code is executed (VM entry). It performs the con-text switch from native to VM context. Then, the nextinstruction is fetched from the bytecode stream, mappedto the corresponding handler using the handler table (de-coding) and, finally, the handler is executed. The processrepeats for subsequent VM instructions in the bytecodeuntil the exit handler is executed, which returns back tonative code.
of Virtual Machine-based obfuscation (also known asvirtualization-based obfuscation [44]).
Similar to system-level Virtual Machines (VMs) thatemulate a whole system platform, process-level VMs em-ulate a foreign instruction set architecture (ISA). Thecore idea is to translate parts of a program, e. g., a func-tion f containing intellectual property, from its nativearchitecture—say, Intel x86—into a custom VM-ISA. Theobfuscator then embeds both the bytecode of the virtual-ized function (its instructions encoded for the VM-ISA)along with an interpreter for the new architecture intothe target binary whilst removing the function’s origi-nal, native code. Every call to f is then replaced withan invocation of the interpreter. This effectively thwartsany naive reverse engineering tool operating on the nativeinstruction set and forces an adversary to analyze the inter-preter and re-translate the interpreted bytecode back intonative instructions. Commonly, the interpreter is heavilyobfuscated itself. As VM-ISAs can be arbitrarily complexand generated uniquely upon protection time, this processis highly time-consuming [44].
Components. The (VM) context holds internal vari-ables of the VM-ISA such as general-purpose registers orthe virtual instruction pointer. It is initialized by sequencecalled VM entry, which handles the context switch fromnative code to bytecode.
After initialization, the VM dispatcher fetches and de-codes the next instruction and invokes the corresponding
handler function by looking it up in a global handler table(depicted in Figure 1). The latter maps indices, obtainedfrom the instruction’s bytecode in the decoding step, tohandlers addresses. In its most simple implementation,all handler functions return to a central dispatching loopwhich then dispatches the next handler. Eventually, exe-cution flow reaches a designated handler, VM exit, whichperforms the context switch back to the native processorcontext and transfers control back to native code.
Custom ISA. The design of the target VM-ISA is en-tirely up to the VM designer. Still, to maximize theamount of handlers an analyst has to reverse engineer,VMs often opt for reduced complexity for the individualhandlers, akin to the RISC design principle. To exemplify,consider the following Intel x86 code:
It favors many small, simple handlers over fewer morecomplicated ones.
Bytecode Blinding. In order to prevent global analysisof instructions, the bytecode bc of each VM instruction isblinded based on its instruction type, i. e., its correspond-ing handler h, at protection time. Likewise, each han-dler unblinds the bytecode before decoding its operands:(bc,vm_key)← unblindh(blinded_bc,vm_key).
The routine is parameterized for each handler h andupdates a global key register in the VM context. Conse-quently, instruction decoding can be flow-sensitive: Anadversary is unable to patch a single VM instruction with-out re-blinding all subsequent instructions. This, in turn,requires her to extract the unblinding routines from ev-ery handler involved. The individual unblinding routinescommonly consist of a combination of arithmetic andlogical operations.
Handler Duplication. In order to easily increase anal-ysis complexity, common VMs duplicate handlers such
USENIX Association 26th USENIX Security Symposium 645
that the same virtual instruction can be dispatched by mul-tiple handlers. In presence of bytecode blinding, thesehandlers’ semantics only differ in the way they unblindthe bytecode, but perform the same operation on the VMcontext.
Architectures. In his paper about interpretation tech-niques, Klint denotes the aforementioned concept usinga central decoding loop as the “classical interpretationmethod” [28]. An alternative is proposed by Bell withThreaded Code (TC) [4]: He suggests inlining the dis-patcher routine into the individual handler functions suchthat handlers execute in a chained manner, instead ofreturning to a central dispatcher. Nevertheless, the dis-patcher still indexes a global handler table.
In Klint’s paper, however, he describes an extension ofTC, Direct Threaded Code (DTC). As in the TC approach,the dispatcher is appended to each handler. The handlertable, though, is inlined into the bytecode of the instruc-tion. Each instruction now directly specifies the addressof its corresponding handler. This way, in presence ofbytecode blinding, not all handler addresses are exposedimmediately, but only those used on a certain path in thebytecode.
Attacks. Several academic works have been publishedthat propose novel attacks on virtualization-based obfus-cators [13, 44]. Section 6.3 discusses and classifies them.In addition, it draws a comparison to our approach.
2.1.2 Return-oriented Programming
In Return-oriented Programming (ROP) [30, 52], shell-code is expressed as a so-called ROP chain, a list ofreferences to gadgets and parameters for those. In thepreliminary step of an attack, the adversary makes esppoint to the start of the chain, effectively triggering thechain upon function return. Gadgets are small, generalinstruction sequences ending on a ret instruction; otherflavors propose equivalent instructions. Concrete valuesare taken from the ROP chain on the stack. As an example,consider the gadget pop eax; ret: It takes the value ontop of the stack, places it in eax and, using the ret instruc-tion, dispatches the next gadget in the chain. By placingan arbitrary immediate value imm32 next to this gadget’saddress in the chain, an attacker effectively encodes theinstruction mov eax, imm32 in her ROP shellcode. De-pending on the gadget space available to the attacker, thistechnique allows for arbitrary computations [39, 51].
Automated analysis of ROP exploits is a desirable goal.However, its unique structure poses various challengescompared to traditional shellcode detection. In their pa-per, Graziano et al. outline them and propose an analysisframework for code-reuse attacks [19]. Amongst others,
they mention challenges such as verbosity of the gadgets,stack-based chaining, lack of immediates, and the distinc-tion of function calls and regular control flow. Further,they stress how an accurate emulation of gadgets is im-portant for addressing these challenges. Considering theaforementioned challenges, at its core, Return-orientedProgramming can be seen as an albeit weaker flavor ofobfuscated code. In particular, the chained invocation ofgadgets is reminiscent of handlers in VM-based obfusca-tion schemes following the threaded code principle.
In addition to its application to exploitation, ROP hasseen other fields of applications such as rootkit devel-opment [59], software watermarking [34], steganogra-phy [33], and code integrity verification [1], which rein-forces the importance of automatic ROP chain analysis.
2.1.3 Mixed Boolean-Arithmetic
Zhou et al. propose transformations over Boolean-arithmetic algebras to hide constants by turning theminto more complex, but semantically equivalent expres-sions, so called MBA expressions [14, 63]. In Section 6.2,we provide details on their proposal of MBA expressionsand show how our approach is still able to simplify them.
2.2 Trace Simplification
Due to the complexity of static analysis of obfuscatedcode, many deobfuscation approaches proposed recentlymake use of dynamic analysis [13,19,19,53,62]. Notably,they operate on execution traces that record instructionaddresses and accompanying metadata, e. g., register con-tent, along a concrete execution path of a program. Sub-sequently, trace simplification is performed to strip theobfuscation layer and simplify the underlying code. De-pending on the approach, multiple traces are used for sim-plification or one single trace is reduced independently.
Coogan et al. [13] propose value-based dependenceanalysis of a trace in order to track the flow of valuesinto system calls using an equational reasoning system.This allows them to reduce the trace to those instructionsrelevant to the previously mentioned value flow.
Graziano et al. [19] mainly apply standard compilertransformations such as dead code elimination or arith-metic simplifications to reduce the trace.
Yadegari et al. [62] use bit-level taint analysis to iden-tify instructions relevant to the computation of outputs.For subsequent simplification, they introduce the notionof quasi-invariant locations with respect to an execution.These are locations that hold the same value at every usein the trace and can be considered constants when per-forming constant propagation. Similarly, they use severalother compiler optimizations and adapt them to make use
646 26th USENIX Security Symposium USENIX Association
TreePolicy
DefaultPolicy
Selection Expansion Simulation Backpropagation
Figure 2: Illustration of a single MCTS round (taken fromBrowne et al. [5]).
of information about quasi-invariance to prevent over-simplification.
2.3 Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) is a stochastic, best-first tree search algorithm that directs the search towardsan optimal decision, without requiring much domainknowledge. The algorithm builds a search tree throughreinforcement learning by performing random simula-tions that estimate the quality of a node [5]. Hence,the tree grows asymmetrically. MCTS has had sig-nificant impact in artificial intelligence for computergames [16, 35, 49, 56], especially in the context of Com-puter Go [17, 54].
In an MCTS tree, each node represents a game state; adirected link from a parent node to its child node repre-sents a move in the game’s domain. The core algorithmiteratively builds the decision tree in four main steps thatare also illustrated in Figure 2: (1) The selection stepstarts at the root node and successively selects the most-promising child node, until an expandable leaf (i. e., anon-terminal node that has unvisited children) is reached.(2) Following, one or more unvisited child nodes areadded to the tree in the expansion step. (3) In the sim-ulation step, node rewards are determined for the newnodes through random playouts. For this, consecutivegame states are randomly derived until a terminal state(i. e., the end of the game) is reached; the game’s outcomeis represented by a reward. (4) Finally, the node rewardsare propagated backwards through the selected nodes tothe root in the backpropagation step. The algorithm ter-minates if either a specified time/iteration limit is reachedor an optimal solution is found [5, 8].
Selecting the most-promising child node can be treatedas a so called multi-armed bandit problem, in which agambler tries to maximize the sum of rewards by choosingone out of many slot machines with an unknown probabil-ity distribution. Applied to MCTS, the Upper Confidence
Bound for Trees (UCT) [5,17,29] provides a good balancebetween exploration and exploitation. It is obtained by
X j +C
√lnnn j
, (1)
where X j represents the average reward of the childnode j, n the current node’s number of visits, n j the visitsof the child node and C the exploration constant. Theaverage reward is referred to as exploitation parameter:if C is decreased, the search is directed towards nodeswith a higher reward. Increasing C, instead, leads to anintensified exploration of nodes with few simulations.
2.4 Simulated AnnealingSimulated Annealing is a stochastic search algorithm thathas been used to effectively solve NP-hard combinatorialproblems [27]. The main idea of Simulated Annealing isto approximate a global optimum by iteratively improvingan initial candidate and exploring the local neighborhood.To avoid a convergence to local optima, the search isguided by a falling temperature T that decreases the prob-ability of accepting worse candidates over time [25]; inthe following, we assume that a falling temperature de-pends on a decreasing loop counter.
Figure 3: Simulated Annealing approximates a globaloptimum (the darkest area in the map).
Figure 3 illustrates this process on the example of find-ing the darkest area in a given map. Starting in an initialstate (s0), the algorithm always accepts a candidate thathas a better score than the current one (green arrows). Ifthe score is worse, we accept the worse candidate withsome probability (the red arrow from s2 to s3) that de-pends on the temperature (loop counter) and how muchworse the candidate is. The higher the temperature, themore likely the algorithm accepts a significantly worsecandidate solution. Otherwise, the candidate is discarded(e. g., the crossed out red arrow at s4); in this case, we pickanother one in the local neighborhood. This allows thealgorithm to escape from local optima while the tempera-ture is high; for low temperatures (loop counters closer to0), it mainly accepts better candidate solutions. The algo-rithm terminates after a specified number of iterations.
USENIX Association 26th USENIX Security Symposium 647
Figure 4: Dissecting a given trace (a) into several tracewindows (b). The trace windows can be used to recon-struct a (possibly disconnected) control-flow graph (c).
3 Approach
Given an instruction trace, we dissect the instruction traceinto trace windows (i. e., subtraces) and aim at learningtheir high-level semantics which can be used later onfor further analysis. In the following, we describe ourapproach which is divided into three distinct parts:
1. Trace Dissection. The instruction trace is partitionedinto unique sequences of assembly instructions in a(semi-)automated manner.
2. Random Sampling. We derive random input-outputpairs for each trace window. These pairs describethe trace window’s semantics.
3. Program Synthesis. Expressions that map all pro-vided inputs to their corresponding outputs are syn-thesized.
3.1 Trace Dissection
The choice of trace window boundaries highly impactslater analysis stages. Most notably, it affects synthesisresults: if a trace window ends at an intermediary com-putation step, the synthesized formula is not necessarilysuccinct or meaningful at all, as it includes spurious se-mantics.
Yet, we note how trace dissection of ROP chains andVM handlers lends itself to a simple heuristic. Namely,we split traces at indirect branches. In the ROP case, thisdescribes the transition between two gadgets (commonly,on a ret instruction), whereas for VM handlers it distin-guishes the invocation of the next handler (cf. Section 6.3).Figure 4 illustrates the approach. Given concrete tracewindow boundaries, we can reconstruct a control-flowgraph consisting of multiple connected components. Atrace window then describes a particular path through aconnected component.
3.2 Random SamplingThe goal of random sampling is to derive input-outputrelations that describe the semantics of a trace window.This happens in two steps: First, we determine the inputsand outputs of the trace window. Then, we replace theinputs with random values and obverse the outputs.
Generally speaking, we consider register and memoryreads as inputs and register and memory writes as outputs.For inputs, we apply a read-before-write principle: inputsare only registers/memory locations that are read beforethey have been written; for outputs, we consider the lastwrites of a register/memory location as output.
Following this principle, the code above has three in-puts and two outputs: The inputs are the memory read M0in line 1, rcx (line 2) and rdx (line 4). The two outputsare o0 (line 2) and o1 (line 4).
In the next step, we generate random values and ob-verse the I/O relationship. For instance, we obtain theoutputs (7,14) for the input tuple (2,5,7); for the inputs(1,7,10), we obtain (8,18).
By default, we use register locations as well as memorylocations as inputs and outputs. However, we support theoption to reduce the inputs and outputs to either register ormemory locations. For instance, if we know that registersare only used for intermediate results, we may ignorethem since it reduces the complexity for the synthesis.
3.3 SynthesisThis section demonstrates how we synthesize the seman-tics of assembly code; we discuss the inner workings ofour synthesis approach in the next section.
After we obtained the I/O samples, we combine thedifferent samples and synthesize each output separately.These synthesis instances are mutually independent andcan be completely parallelized.
To exemplify, for the I/O pairs above, we search anexpression that transforms (2,5,7) to 7 and (1,7,10) to 8for o0; for o1, the expression has to map (2,5,7) to 14 and(1,7,10) to 18. Then, the synthesizer finds o0 =M0+rcxand o1 = M0 +rcx+ rdx.
4 Program Synthesis
In the last section, we demonstrated how we obtain I/Osamples from assembly code and apply program synthesisto that context. This section describes our algorithm indetail; we show how we find an expression that mapsall inputs to their corresponding outputs for all observed
648 26th USENIX Security Symposium USENIX Association
samples. We use Monte Carlo Tree Search, since it hasbeen proven to be very effective when working on infinitedecision trees without requiring much domain knowledge.
We consider program synthesis as a single-player gamewhose purpose is to synthesize an expression whose input-output behavior is as close as possible to given I/O sam-ples. In essence, we define a context-free grammar thatconsists of terminal and non-terminal symbols. (Partially)derived words of the grammar are game states; the gram-mar’s production rules represent the moves of the game.Terminal nodes are expressions that contain only terminalsymbols; these are end states of the game.
Given a maximum number of iterations and I/O sam-ples, we iteratively apply the four MCTS steps (cf. Sec-tion 2.3), until we find a solution or we reach the timeout.Starting with a non-terminal expression as root node, weselect the most-promising expandable node. A node isexpandable, if there still exist production rules that havenot been applied to this node. We choose a productionrule randomly and expand the selected node. To evaluatethe quality of the new node, we perform a random play-out: First, we randomly derive a terminal expression bysuccessively applying random production rules. Then, weevaluate the expressions based on the inputs from the I/Opairs and compare the output similarity. The similarityscore is the node reward. A reward of 1 ends the synthe-sis, since the input-output behavior is the same for theprovided samples. Finally, we propagate the reward backto the root.
In the following, we give details on node selection, ourgrammar, random playouts and backpropagation. Finally,we discuss the algorithm configuration and parametertuning. To demonstrate the different steps of our approach,we use the following running example throughout thissection:
Example 1 (I/O relationship). Working with bit-vectors ofsize 3 (i. e., modulo 23), we observe for an expression withtwo inputs and one output the I/O relations: (2,2)→ 4and (4,5)→ 1. A synthesized expression that maps theinputs to the corresponding outputs is f (a,b) = a+b.
4.1 Node SelectionSince we have an infinite search space for program syn-thesis, node selection must be a trade-off between ex-ploration and exploitation. The algorithm has to ex-plore different nodes such that several promising andnon-promising candidates are known. On the other hand,it has to follow more promising candidates to find deeperexpressions. As described in Section 2.3, the UCT (cf.Equation 1) provides a good balance between exploitationand exploration for many MCTS applications.
However, we observed that it does not work for our usecase: if we set the exploration constant C to a higher value
(focus on exploration), it does not find deeper expressions;if we set C to a lower value, MCTS gets lost in deepexpressions. To solve this problem, we use an adaptionof UCT that is known as Simulated Annealing UCT (SA-UCT) [47]. The main idea of SA-UCT is to use thecharacteristics of Simulated Annealing (cf. Section 2.4)and apply it to UCT. SA-UCT is obtained by replacingthe exploration constant C by a variable T with
T =CN− i
N, (2)
where N is the maximum number of MCTS iterationsand i the current iteration. Then, SA-UCT is defined as
X j +T
√lnnn j
. (3)
T decreases over time, since N−iN converges to 0 for
increasing values of i. As a result, MCTS places theemphasis on exploration in the beginning; the more Tdecreases, the more the focus shifts to exploitation.
4.2 GrammarGame states are represented by sentential forms of acontext-free grammar that describes valid expressionsof our high-level abstraction. We introduce a terminalsymbol for each input (which corresponds to a variablethat stores this input) and each valid operator (e. g., ad-dition or multiplication). For every data type that can becomputed we introduce one non-terminal symbol (in ourrunning example, we only use a single non-terminal valueU that represents an unsigned integer). The productionrules describe how we can derive expressions in our high-level description. Since the sentential forms representpartial expressions, we will use the term expression todenote the (partial) expression that is represented by agiven sentential form. Sentences of the grammar are finalstates in the game since they do not allow any furthermoves (derivations). They represent expressions that canbe evaluated. We represent expressions in Reverse PolishNotation (RPN).
Example 2. The grammar in our previous example hastwo input symbols V = {a,b}, since each I/O sample hastwo inputs. If the grammar supports addition and mul-tiplication O = {+,∗}, there are four production rules:R = {U →U U + |U U ∗ | a | b}. An unsigned integerexpression U can be mapped to an addition or multipli-cation of two such expressions or a variable. The finalgrammar is ({U},Σ =V ∪O,R,U).
Synthesis Grammar. Our grammar is designedto synthesize expressions that represent the se-mantics of bit-vector arithmetic, especially for
USENIX Association 26th USENIX Security Symposium 649
U
U U * U U +
U b + U U U + + U a +
U U * a + b a +
U U U * +
a b
Figure 5: An MCTS tree for program synthesis that growstowards the most-promising node b a +, the right-mostleaf in layer 3.
the x86 architecture. For every data type (U8,U16, U32 and U64), we define the set of operationsas O = {+,−,∗,/s,/,%s,%,∧,∨,⊕,�,�,�a,−1,¬,sign_ext, zero_ext, extract, ++, 1}, where theoperations are binary addition, subtraction, multiplication,signed/unsigned division, signed/unsigned remainder,bitwise and/or/xor, logical left shift, logical/arithmeticright shift as well as unary minus and complement.The unary operations sign_ext and zero_ext extendsmaller data types to signed/unsigned larger data types.Conversely, the unary operator extract transformslarger data types into smaller data types by extracting therespective least significant bits. Since the x86 architectureallows register concatenation (e. g., for division), weemploy the binary operator ++ to concatenate twoexpressions of the same data type. Finally, to synthesizeexpressions such as increment and decrement, we use theconstant 1 as niladic operator. The input set V consistsof |V | = n variables, where n represents the number ofinputs.
Tree Structure. The sentential form U is the root nodeof the MCTS tree. Its child nodes are other expressionsthat are produced by applying the production rules to asingle non-terminal symbol of the parent. The expressiondepth (referred to as layer) is equivalent to the number ofderivation steps, as depicted in Figure 5.
Example 3. The root node U is an expression of layer 0.Its children are a, b, U U +, and U U ∗, where a and b areterminal expressions of layer 1. Assuming that the right-most U in an expression is replaced, the children of U U +are U b+, U a+, U U U + +, and U U U ∗ +. To obtainthe layer 3 expression b a +, the following derivationsteps are applied: U ⇒U U +⇒U a +⇒ b a +.
To direct the search towards outer expressions, we re-place the top-most-right-most non-terminal. If we, in-
+
U3*
U2U1
Figure 6: The left-most U in U3 U2 U1 ∗ + is the top-most-right-most non-terminal in the abstract syntax tree.(The indices are provided for illustrative purposes only.)
stead, substitute always the right-most non-terminal only,then the search would be guided towards most-promisingsubexpressions. If the expression is too nested, the syn-thesizer would find the partial subexpression but not thewhole expression. The top-most-right-most derivation isillustrated in Figure 6, which shows the abstract syntaxtree (AST) of an expression.
Example 4. The expression (U +(U ∗U)) is representedas U U U ∗ +. If we successively replace the right-mostU, the algorithm is unlikely to find expressions such as((a+b)+(b∗ (b∗a))), since it is directed into the subex-pression with the multiplication. Instead, replacing thetop-most-right-most non-terminal directs the search to thetop-most addition and then explores the subexpressions.
4.3 Random PlayoutOne of the key concepts of MCTS are random playouts.They are used to determine the outcome of a node; thisoutcome is represented by a reward. In the first step,we randomly apply production rules to the current node,until we obtain a terminal expression. To avoid infinitederivations, we set a maximum playout depth. This max-imum playout depth defines how often a non-terminalsymbol can be mapped to rules that contain non-terminalsymbols; at the latest we reached the maximum, we mapnon-terminals only to terminal expressions. This happensin a top-most-right-most manner. Afterwards, we evaluatethe expression for all inputs from the I/O samples.
Example 5. Assuming a maximum playout depth of 2and the expression U U ∗, the first top-most-right-most Uis randomly substituted with U U ∗, the second one withU U +. After that, the remaining non-terminal symbolsare randomly replaced with variables: U U ∗⇒U U U ∗∗⇒U U + U U ∗ ∗⇒ ·· · ⇒ a a + b a ∗ ∗. A randomplayout for U U + is a b b + +.
For the I/O sample (2,2)→ 4, we evaluate g(2,2) = 0for g(a,b) = ((a+a)∗(b∗a)) mod (28) and h(2,2) = 6for h(a,b) = (a+(b+b)) mod 28.
We set terminal nodes to inactive after their evaluation,since they already are end states of the game; there isno possibility to improve the node’s reward by randomplayouts. As a result, MCTS will not take these nodes
650 26th USENIX Security Symposium USENIX Association
into account in further iterations. The node’s reward isthe similarity of the evaluated expressions and the out-puts from the I/O samples. We describe in the followingsection how to measure the similarity to the outputs.
4.4 Measuring Similarity of OutputsTo measure the similarity of two outputs, we compare val-ues with different metrics: arithmetic distance, Hammingdistance, count leading zeros, count trailing zeros, countleading ones and count trailing ones. While the numericdistance is a reliable metric for arithmetic operations, itdoes not work well with overflows and bitwise operations(e. g., xor and shifts). In turn, the Hamming distance ad-dresses these operations since it states in how many bitstwo values differ. Finally, the leading/trailing zeros/onesare strong indicators that two values are in the same range.We scale each result between a value of 0 and 1. Since thedifferent metrics compensate each other, we set the totalsimilarity reward to the average reward of all metrics.
Example 6. Considering I/O pair (2,2)→ 4, the out-put similarities for g and h (as defined in Example 5)are similarity(4,0) and similarity(4,6). Limiting to themetrics of Hamming distance and count leading ze-ros (clz), we obtain hamming(4,0) = hamming(4,6) =0.67, clz(4,0) = 0 and clz(4,6) = 1.0. Therefore, theaverage similarities are similarity(4,0) = 0.335 andsimilarity(4,6) = 0.835. Related to the random play-outs, the evaluated node U U + has a higher rewardthan U U ∗.
During a random playout, we calculate the similarityfor all I/O samples. The final node reward is the averagescore of all similarity rewards. A reward of 1 finishes pro-gram synthesis, since the evaluated expression producesexactly the outputs from the I/O samples.
4.5 BackpropagationAfter obtaining a score by random playout, we do thefollowing for the selected node and all its parents, up tothe root: (1) We update the node’s average reward. Thisreward is averaged based on the node’s and its successors’total number of random playouts. (2) If the node is fullyexpanded and its children are all inactive, we set the nodeto inactive. (3) Finally, we set the current node to itsparent node.
4.6 Expression SimplificationSince MCTS performs a stochastic search, synthesized ex-pressions are not necessary in their shortest form. There-fore, we apply some basic standard expression simplifi-cation rules. For example, if the synthesizer constructs
integer values as ((1� 1)� (1 + (1� 1))), we canreduce them to the value 16.
4.7 Algorithm Configuration
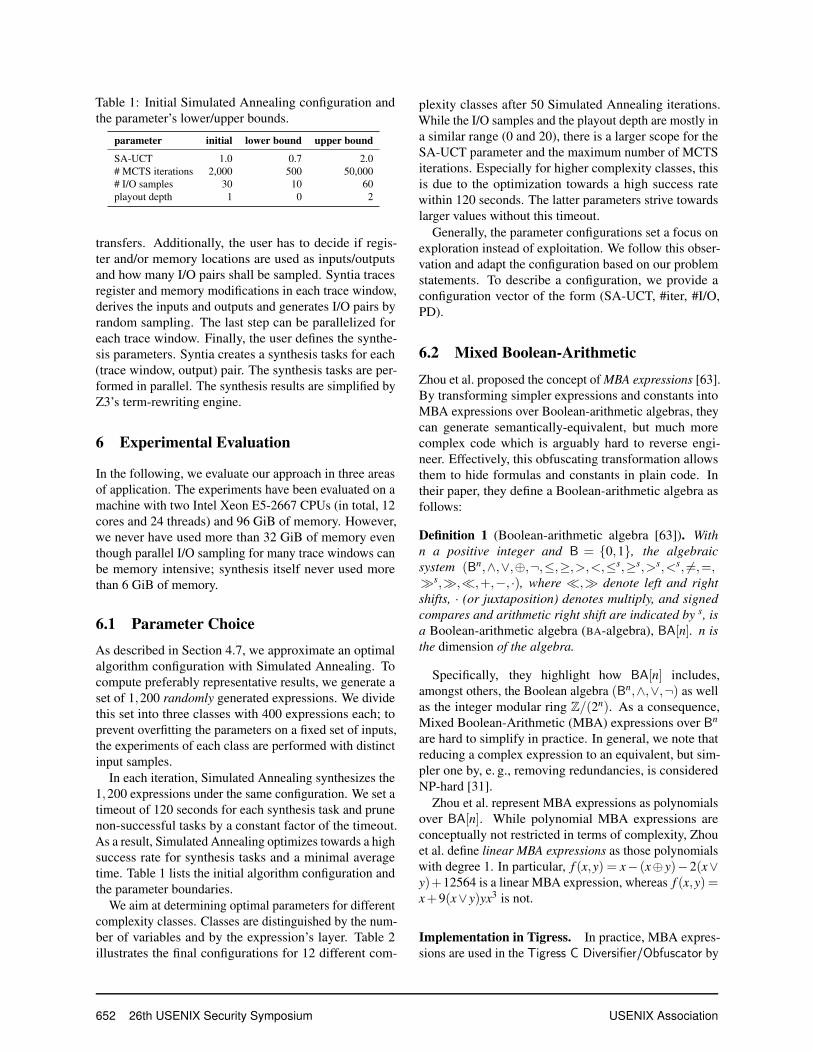
Two main factors define the algorithm’s success that can-not be influenced by the user: the number of input vari-ables and the complexity (e. g., depth) of the expressionto synthesize. Contrary, there exist four parameters thatcan be configured by a user to improve the effectivenessand speed: the initial SA-UCT value, the number of I/Osamples, the maximum number of MCTS iterations andthe maximum playout depth.
The SA-UCT parameter T configures the trade-off be-tween exploration and exploitation and depends on themaximum number of MCTS iterations; if the maximumnumber of MCTS iterations is low, the algorithm focuseson exploiting promising candidates within a small periodof time. The same holds for small initial values of T .
A large number of variables or a higher expressiondepth requires more MCTS iterations. Besides the maxi-mum number of MCTS iterations, the maximum playoutdepth provides more accuracy since it is more probableto hit deeper expressions or more influencing variableswith deeper playouts. On the other hands, deeper playoutshave an impact on the execution time.
Since random playouts are performed for every nodeand for every I/O pair, the number of I/O samples has asignificant impact on the execution time. In addition, iteffects the number of false positives, since there are lessexpressions that have the same I/O behavior for a largernumber of I/O samples. Finally, the MCTS synthesis ismore precise since the different node rewards are expectedto be informative.
Since the search space for finding good algorithm con-figurations for different complexity classes is large, weapproximate an optimal solution by Simulated Annealing.We present the details and results in Section 6.1.
5 Implementation
We implemented a prototype implementation of our ap-proach in our tool Syntia, which is written in Python. Fortrace generation and random sampling, we use the Uni-corn Engine [43], a CPU emulator framework. To analyzeassembly code (e. g., trace dissection), we utilize the dis-assembler framework Capstone [42]. Furthermore, weuse the SMT solver Z3 [36] for expression simplification.
Initially, Syntia expects a memory dump, a start andan end address as input. Then, it emulates the programand outputs the instruction trace. Then, the user has theopportunity to define its own rules for trace dissection;otherwise, Syntia dissects the trace at indirect control
USENIX Association 26th USENIX Security Symposium 651
transfers. Additionally, the user has to decide if regis-ter and/or memory locations are used as inputs/outputsand how many I/O pairs shall be sampled. Syntia tracesregister and memory modifications in each trace window,derives the inputs and outputs and generates I/O pairs byrandom sampling. The last step can be parallelized foreach trace window. Finally, the user defines the synthe-sis parameters. Syntia creates a synthesis tasks for each(trace window, output) pair. The synthesis tasks are per-formed in parallel. The synthesis results are simplified byZ3’s term-rewriting engine.
6 Experimental Evaluation
In the following, we evaluate our approach in three areasof application. The experiments have been evaluated on amachine with two Intel Xeon E5-2667 CPUs (in total, 12cores and 24 threads) and 96 GiB of memory. However,we never have used more than 32 GiB of memory eventhough parallel I/O sampling for many trace windows canbe memory intensive; synthesis itself never used morethan 6 GiB of memory.
6.1 Parameter ChoiceAs described in Section 4.7, we approximate an optimalalgorithm configuration with Simulated Annealing. Tocompute preferably representative results, we generate aset of 1,200 randomly generated expressions. We dividethis set into three classes with 400 expressions each; toprevent overfitting the parameters on a fixed set of inputs,the experiments of each class are performed with distinctinput samples.
In each iteration, Simulated Annealing synthesizes the1,200 expressions under the same configuration. We set atimeout of 120 seconds for each synthesis task and prunenon-successful tasks by a constant factor of the timeout.As a result, Simulated Annealing optimizes towards a highsuccess rate for synthesis tasks and a minimal averagetime. Table 1 lists the initial algorithm configuration andthe parameter boundaries.
We aim at determining optimal parameters for differentcomplexity classes. Classes are distinguished by the num-ber of variables and by the expression’s layer. Table 2illustrates the final configurations for 12 different com-
plexity classes after 50 Simulated Annealing iterations.While the I/O samples and the playout depth are mostly ina similar range (0 and 20), there is a larger scope for theSA-UCT parameter and the maximum number of MCTSiterations. Especially for higher complexity classes, thisis due to the optimization towards a high success ratewithin 120 seconds. The latter parameters strive towardslarger values without this timeout.
Generally, the parameter configurations set a focus onexploration instead of exploitation. We follow this obser-vation and adapt the configuration based on our problemstatements. To describe a configuration, we provide aconfiguration vector of the form (SA-UCT, #iter, #I/O,PD).
6.2 Mixed Boolean-Arithmetic
Zhou et al. proposed the concept of MBA expressions [63].By transforming simpler expressions and constants intoMBA expressions over Boolean-arithmetic algebras, theycan generate semantically-equivalent, but much morecomplex code which is arguably hard to reverse engi-neer. Effectively, this obfuscating transformation allowsthem to hide formulas and constants in plain code. Intheir paper, they define a Boolean-arithmetic algebra asfollows:
Definition 1 (Boolean-arithmetic algebra [63]). Withn a positive integer and B = {0,1}, the algebraicsystem (Bn,∧,∨,⊕,¬,≤,≥,>,<,≤s,≥s,>s,<s, 6=,=,�s,�,�,+,−, ·), where �,� denote left and rightshifts, · (or juxtaposition) denotes multiply, and signedcompares and arithmetic right shift are indicated by s, isa Boolean-arithmetic algebra (BA-algebra), BA[n]. n isthe dimension of the algebra.
Specifically, they highlight how BA[n] includes,amongst others, the Boolean algebra (Bn,∧,∨,¬) as wellas the integer modular ring Z/(2n). As a consequence,Mixed Boolean-Arithmetic (MBA) expressions over Bn
are hard to simplify in practice. In general, we note thatreducing a complex expression to an equivalent, but sim-pler one by, e. g., removing redundancies, is consideredNP-hard [31].
Zhou et al. represent MBA expressions as polynomialsover BA[n]. While polynomial MBA expressions areconceptually not restricted in terms of complexity, Zhouet al. define linear MBA expressions as those polynomialswith degree 1. In particular, f (x,y) = x− (x⊕ y)−2(x∨y)+12564 is a linear MBA expression, whereas f (x,y) =x+9(x∨ y)yx3 is not.
Implementation in Tigress. In practice, MBA expres-sions are used in the Tigress C Diversifier/Obfuscator by
652 26th USENIX Security Symposium USENIX Association
Table 2: Parameter choices for different complexity classes that depend on the expression layer and the number ofvariables. The parameters are the SA-UCT parameter (SA), the maximum number of MCTS iterations (# iter), thenumber of I/O samples (# I/O) and the playout depth (PD).
# variables
2 5 10 20
layer SA # iter # I/O PD SA # iter # I/O PD SA # iter # I/O PD SA # iter # I/O PD
Collberg et al. [9] which uses the technique to encode inte-ger variables and expressions in which they are used [11].Further, Tigress also supports common arithmetic encod-ings to increase an expression’s complexity, albeit notbased on MBAs [10].
For example, the rather simple expression x+ y+ z istransformed into the layer 23 expression (((x⊕y)+((x∧y)� 1))∨ z)+ (((x⊕ y)+ ((x∧ y)� 1))∧ z) using itsarithmetic encoding option. In a second transformationstep, Tigress encodes it into a linear MBA expression oflayer 383 (omitted due to complexity). Such expressionsare hard to simplify symbolically.
Evaluation Results. We evaluated our approach to sim-plify MBA expressions using Syntia. As a testbed, webuilt a C program which calls 500 randomly generatedfunctions. Each of these random functions takes 5 in-put variables and returns an expression of layer 3 to 5.Then, we applied the arithmetic encoding provided byTigress, followed by the linear MBA encoding. The re-sulting program contained expressions of up to 2,821layers, the average layer being 156. The arithmetic encod-ing is applied to highlight that our approach is invariantto the code’s increased symbolic complexity and is onlyconcerned with semantical complexity.
Based on a concrete execution trace it can be observedthat the 500 functions use, on average, 5 memory inputs(as parameters are passed on the stack) and one registeroutput (the register containing the return value). Table 3shows statistics for the analysis run using the configura-tion vector (1.5,50000,50,0). The first two componentsindicate a strong focus on exploration in favor of exploita-tion; due to the small number of synthesis tasks, we used50 I/O samples to obtain more precise results.
The sampling phases completed in less than two min-utes. Overall, the 500 synthesis tasks were finishedin about 34 minutes, i. e., in 4.0 seconds per expres-sion. We were able to synthesize 448 out of 500 expres-sions (89.6%). The remaining expressions are not founddue to the probabilistic nature of our algorithm; after 4subsequent runs, we synthesized 489 expressions (97.8%)in total.
Table 3: Trace window statistics and synthesis perfor-mance for Tigress (MBA), VMProtect (VMP), Themida(flavor Tiger White, TM), and ROP gadgets.
MBA VMP TM ROP
#trace windows 500 12,577 2,448 78#unique windows 500 449 106 78#instructions per window 116 49 258 3#inputs per window 5 2 15 3#outputs per window 1 2 10 2#synthesis tasks 500 1,123 1,092 178
I/O sampling time (s) 110 118 60 17overall synthesis time (s) 2,020 4,160 9,946 829synthesis time per task (s) 4.0 3.7 9.1 4.7
To get a better feeling for this probabilistic behavior, wecompared the cumulative numbers of synthesized MBAexpressions for 10 subsequent runs. Figure 7 shows theresults averaged over 15 separate experiments. On aver-age, the first run synthesizes 89.6% (448 expressions) ofthe 500 expressions. A second run yields 22 new expres-sions (94.0%), while a third run reveals 10 more expres-sions (96.0%). While converging to 500, the number ofnewly synthesized expressions decreases in subsequentruns. Comparing the fifth and the eighth run, we onlyfound 5 new expressions (from 489 to 494). After theninth run, Syntia synthesized 495 (99.0%) of the MBAexpressions.
6.3 VM Instruction HandlerAs introduced in Section 2.1.1, an instruction handler ofa Virtual Machine implements the effects of an atomic in-struction according to the custom VM-ISA. It operates onthe VM context and can perform arbitrarily complex tasks.As handlers are heavily obfuscated, manual analysis of ahandler’s semantics is a time-consuming task.
Attacking VMs. When faced with virtualization-basedobfuscations, an attacker typically has two options. Forone, she can analyze the interpreter and, for each han-dler, extract all information required to re-translate thebytecode back to native instruction. Especially in face ofhandler duplication and bytecode blinding, this requires
USENIX Association 26th USENIX Security Symposium 653
0 2 4 6 8 100
100
200
300
400
500
# synthesis runs
#sy
nthe
size
dex
pres
sion
s
Figure 7: Subsequent synthesis runs increase the numberof synthesized MBA expressions. Each point representsthe average cumulative number of synthesized expres-sions from 15 separate experiments.
her to precisely capture all effects produced by the han-dlers. This includes both the high-level semantics withregard to input and output variables as well as the indi-vidual unblinding routines. In his paper, Rolles discusseshow this type of attack requires complete understandingof the VM and therefore has to be repeated for each virtu-alization obfuscator [44]. Thus, we note that this attackdoes not lend itself easily to full automation. Another ap-proach is to perform analyses on the bytecode level. Theidea is that while an attacker cannot learn the full seman-tics of the original code, the analysis of the interactionof handlers itself reveals enough information about theunderlying code. This allows the attacker to skip detailslike bytecode blinding as she only requires the high-levelsemantics of a handler. Sharif et al. successfully mountedsuch an attack to recover the CFG of the virtualized func-tion [53], but do not take semantics other than virtualinstruction pointer updates into account.
We recognize the latter approach as promising and notehow Syntia allows us to automatically extract the high-level semantics of arithmetical and logical instructionhandlers. This is achieved by operating on an executiontrace through the interpreter and simplify its individualhandlers—as distinguished by trace window boundaries—using program synthesis. Especially, we highlight how ob-taining the semantics of one handler automatically yieldsinformation about the underlying native code at all pointsof the trace where this specific handler is used to encodeequivalent virtualized semantics.
Evaluation Setup. We evaluated Syntia to learn thesemantics of arithmetic and logical VM instruction han-dlers in recent versions of VMProtect [58] (v3.0.9) andThemida [38] (v2.4.5.0). To this end, we built a programthat covers bit-vector arithmetic for operand widths of 8,16, 32, and 64 bit. Since we are interested in analyzing ef-fects of the VM itself, using a synthetic program does not
distort our results. For verification, we manually reverseengineered the VM layouts of VMProtect and Themida.Note that the commercial versions of both protection sys-tems have been used to obfuscate the program. These areknown to provide better obfuscation strength comparedto the evaluation versions.
We argue that our evaluation program is representativeof any program obfuscated with the respective VM-basedobfuscating scheme. As seen in Section 2.1.1, commoninstructions map to a plethora of VM handlers. Conse-quently, if we succeed in recovering the semantics of theseintegral building blocks, we are at the same time able torecover other variations of native instructions using thesehandlers as well.
This motivates the design of our evaluation program,which aims to have a wide coverage of all possible arith-metic and logical operations. We note that this may not bethe case for real-world test cases, which may not triggerall interesting VM handlers. To this extent, our evalua-tion program is, in fact, more representative than, e. g.,malware samples.
6.3.1 VMProtect
In its current version, VMProtect follows the DirectThreaded Code design principle (cf. Section 2.1.1). Eachhandler directly invokes the next handler based on theaddress encoded directly in the instruction’s bytecode.Hence, reconstructing the handlers requires an instructiontrace. Also, this impacts trace dissection: since VM han-dlers dispatch the next handler, they end with an indirectjump. Unsurprisingly, Syntia could automatically dissectthe instruction trace into trace windows that represent asingle VM handler. As evident from Table 3, there are449 unique trace windows out of a total of 12,577 in theinstruction trace.
Further, VMProtect employs handler duplication. Forexample, the 449 instruction handlers contain 12 instancesperforming 8-bit addition, 11 instances for each of addi-tion (for each flavor of 16-, 32-, 64-bit), nor (8-, 64-bit),left and right shift (32-, 64-bit); amongst multiple others.If Syntia is able to learn one instance in each group, it issafe to assume that it will successfully synthesize the fullgroup, as supported by our results.
Similarly, the execution trace is made up of all possiblehandlers and some of them occur multiple times. Hence,if we correctly synthesize semantics for, e. g., a 64-bitaddition, this immediately yields semantics for 772 tracewindows (6.2% of the full trace, 32.0% of all arithmeticand logical trace windows in the trace). Equivalent rea-soning applies to 16-bit nor operations in our trace (3.6%of the full trace, 18.8% of all arithmetic and logical tracewindows). In total, our results reveal semantics for 19.7%of the full execution trace (2,482 out of 12,577 trace win-
654 26th USENIX Security Symposium USENIX Association
dows). Manual analysis suggests that the remaining tracesemantics mostly consists of control-flow handling andstack operations. These are especially used when switch-ing from the native to the VM context and amount for alarge part of the execution trace.
On average, an individual instruction handler consistsof 49 instructions. As VMProtect’s VM is stack-based,binary arithmetic handlers pop two arguments from thestack and push the result onto the stack. This tremen-dously eases identification of inputs and outputs. There-fore, we mark memory operands as inputs and outputsand use the configuration vector (1.5,30000,20,0) for thesynthesis. The sampling phase finished in less than twominutes. Overall, the 1,123 synthesis tasks completedin less than an hour, which amounts to merely 3.7 sec-onds per task. In total, in our first run, we automaticallyidentified 190 out of 196 arithmetical and logical han-dlers (96.9%). The remaining 6 handlers implement 8-bitdivisions and shifts. Due to their representation in x86assembly code, Syntia needs to synthesize more complexexpressions with nested data type conversions. As theanalysis is probabilistic in nature, we scheduled five moreruns which yielded 4 new handlers. Thus, we are able toautomatically pinpoint 98.9% of all arithmetic and logicalinstruction handlers in VMProtect.
6.3.2 Themida
The protection solution Themida supports three basic VMflavors, namely, Tiger, Fish, and Dolphin. Each flavorcan further be customized to use one of three obfuscationlevels, in increasing complexity: White, Red, and Black.We note that related work on deobfuscation does not di-rectly mention the exact configuration used for Themida.In hopes to be comparable, we opted to use the defaultflavor Tiger, using level White, in our evaluation. UnlikeVMProtect, Tiger White uses an explicit handler tablewhile inlining the dispatcher routine; i. e., it follows theThreaded Code design principle (cf. Section 2.1.1). Con-sequently, trace dissection again yields one trace windowper instruction handler. Even though the central handlertable lists 1,111 handlers, we identified 106 unique tracewindows along the concrete execution trace.
Themida implements a register-based architecture andstores intermediate computations in one of many registeravailable in the VM context. This, in turn, affects theidentification of input and output variables. While in thecase of VMProtect, inputs and outputs are directly takenfrom two slots on the stack, Themida has a significantlyhigher number of potential inputs and outputs (i. e., allvirtual registers in the VM context, 10 to 15 in our case).
Tiger White supports handlers for addition, subtraction,multiplication, logical left and right shift, bitwise oper-ations and unary subtraction; each for different operand
widths. In contrast to VMProtect, handlers are neitherduplicated nor do they occur multiple times in the execu-tion trace. Hence, the trace itself is much more compact,spanning 2,448 trace windows in total; roughly 5 timesshorter than VMProtect’s. Still, Themida’s handlers aremuch longer, with 258 instructions on average.
We ran the analysis using the configuration vector(1.8,50000,20,0). Due to the higher number of in-puts, this configuration—in comparison to the previoussection—sets a much higher focus on exploration as indi-cated by higher values chosen for the first two parameters.Sampling finished in one minute, whereas the synthesisphase took around 166 minutes. At 1,092 synthesis tasks,this amounts to roughly 9.1 seconds per task. Eventually,we automatically learned the semantics of 34 out of 36arithmetic and logical handlers (94.4%). The remaininghandlers (8-bit subtraction and logical or) were not foundas we were unable to complete the sampling phase due tocrashes in Unicorn engine.
6.4 ROP Gadget Analysis
We further evaluated Syntia on ROP gadgets, specifically,on four samples that were thankfully provided by De-bray [62]. They implement bubble sort, factorials, Fi-bonacci, and matrix multiplication in ROP. To have alarger set of samples, we also used a CTF challenge [41]that has been generated by the ROP compiler Q [51] andanother Fibonacci implementation that has been generatedwith ROPC [39].
Syntia automatically dissected the instruction tracesinto 156 individual gadgets. Since many gadgets useexactly the same instructions, we unified them into 78unique gadgets. On average, a gadget consists of 3 instruc-tions with 3 inputs and 2 outputs (register and memorylocations).
Due to the small numbers of inputs and synthesis tasks,we chose the configuration vector (1.5,100000,50,0) thatsets a very strong focus on exploration while acceptinga higher running time. Especially, we experienced botheffects for the maximum number of MCTS iterations.
Syntia synthesized partial semantics for 97.4% of thegadgets in less than 14 minutes; in total, we were suc-cessful in 163 out of the 178 (91.5%) synthesis tasks.Our synthesis results include 58 assignments, 17 binaryadditions, 5 ternary additions, 4 unary minus, 4 binarysubtractions, 4 register increments/decrements, 2 binarymultiplications and 1 bitwise and. In addition, we found68 stack pointer increments due to ret statements. Theresults do not include larger constants or operations suchas ror as they are not part of our grammar.
USENIX Association 26th USENIX Security Symposium 655
7 Discussion
In the following, we discuss different aspects of programsynthesis for trace simplification and MCTS-based pro-gram synthesis. Furthermore, we point out limitations ofour approach as well as future work.
Program Synthesis for Trace Simplification. Currentresearch on deobfuscation [13, 53, 61, 62] operates oninstruction traces and uses a mixed approach consistingof symbolic execution [61] and taint analysis [60]; twoapproaches that require a precise analysis of the under-lying code. While techniques exist that defeat taint anal-ysis [6, 48], recent work shows that symbolic executioncan similarly be attacked [2].
Program synthesis is an orthogonal approach that oper-ates on a purely semantical level as opposed to (binary)code analysis; it is oblivious to the underlying code con-structs. As a result, syntactical aspects of code complexitysuch as obfuscation or instruction count do not influenceprogram synthesis negatively. It is merely concerned withthe complexity of the code’s semantics. The only excep-tion where code-level artifacts matter is the generationof I/O samples; however, this can be realized with smalloverhead compared to regular execution time using dy-namic binary instrumentation [37, 40].
Commonly, instruction traces contain repetitions ofunique trace windows that can be caused by loops orrepeated function calls to the same function. By synthe-sizing these trace windows, the synthesized semanticspertain for all appearances on the instruction trace; themore frequently these trace windows occur in the trace,the higher the percentage of known semantics in the in-struction trace. We stress how VM-based obfuscationschemes do this to the extreme: a relatively small numberof unique trace windows are used over the whole trace.
In general, the synthesis results may not be precise se-mantics since we approximate them based on I/O samples.If these do not reflect the full semantics, the synthesismisses edge cases. For instance, we sometimes cannotdistinguish between an arithmetic and a logical right shiftif the random inputs are no distinguishing inputs. Wepoint out that this is not necessarily a limitation, since ahuman analyst might still get valuable insights from theapproximated semantics.
As future work, we consider improving trace simplifi-cation by a stratified synthesis approach [23]. The mainidea is to incrementally synthesize larger parts of the in-struction trace based on previous results and successivelyapproximate high-level semantics of the entire trace. Fur-ther, we note that the work by Sharif et al. [53] is comple-mentary to our synthesis approach and would also allowus to identify control flow. Likewise, extending the gram-
mar by control-flow operations is another viable approachto tackle this limitation.
MCTS-based Program Synthesis. Compared to SMT-based program synthesis, we obtain candidate solutions,even if the synthesizer does not find an exact result. Thisis particularly beneficial for applications such as deob-fuscation, since a human analyst can sometimes infer thefull semantics. We decided to utilize MCTS for programsynthesis since it has been proven very effective whenoperating on large search trees without domain knowl-edge. However, our approach is not limited to MCTS,other stochastic algorithms are also applicable.
Drawn from the observations made in Section 6, weinfer that the MCTS approach is much more effectivewith a configuration that focuses on exploration instead ofexploitation. The SA-UCT parameter ensures that pathswith a higher reward are explored in-depth in later stagesof the algorithm. We still try to improve explorationstrategies, for instance with Nested Monte Carlo TreeSearch [35] and Monte Carlo Beam Search [7].
Limitations. In general, limits of program synthesisapply to our approach as well. Non-determinism and pointfunctions—Boolean functions that return 1 for exactly oneinput out of a large input domain—cannot be synthesizedpractically. This also holds for semantics that have strongconfusion and diffusion properties, such as cryptographicalgorithms. These are inherently very complex, non-linearexpressions with a deep nesting level. Our approach isalso limited by the choice of trace window boundaries;ending a trace window in intermediate computation stepsmay produce formulas that are not meaningful at all.
8 Related Work
We now review related work for program synthesis, MonteCarlo Tree Search and deobfuscation. Furthermore, wedescribe how our work fits into these research areas.
Program Synthesis. Gulwani et al. [22] introduced anSMT-based program synthesis approach for loop-free pro-grams that requires a logical specification of the desiredprogram behavior. Building on this, Jha et al. [24] re-placed the specification with an I/O oracle. Upon gener-ation of multiple valid program candidates, they derivedistinguishing inputs that are used for subsequent oraclequeries. They demonstrated their use case by simplifyinga string obfuscation routine of MyDoom. Godfroid andTaly [18] used an SMT-based approach to learn the formalsemantics of CPU instruction sets; for this, they use theCPU as I/O oracle.
656 26th USENIX Security Symposium USENIX Association
Schkufza et al. [50] proved that stochastic programsynthesis often outperforms SMT-based approaches. Thisis mostly due to the fact that common SMT-based ap-proaches effectively enumerate all programs of a givensize or prove their non-existence. On the other hand,stochastic approaches focus on promising parts of thesearch space without searching exhaustively. Schkufzaet al. use this technique for stochastic superoptimizationon the basis of their tool STOKE. Recent work by Heuleet al. [23] demonstrates a stratified approach to learn thesemantics of the x86-64 instruction set, based on STOKE.Their main idea is to re-use synthesis results to synthe-size more complex instructions in an iterative manner.To the best of our knowledge, STOKE is the only otherstochastic synthesis tool that is able to synthesize low-level semantics. By design, their code only produces Intelx86 code.
In our case, stochastic techniques have additional prop-erties that are not achieved by previous tools: we obtainpartial results that are often already “close” to a real solu-tion and might be helpful for a human analyst who triesto understand obfuscated code. Furthermore, we can en-code arbitrary complex function symbols in our grammar(e. g., complex encoding schemes or hash functions); acharacteristic that is not easily reproduced by SMT-basedapproaches.
In the context of non-academic work, Rolles appliedsome of the above mentioned SMT-based approaches toreverse engineering and deobfuscation [45]. Amongstothers, he learned obfuscation rules by adapting peepholesuperoptimization techniques [3] and extracted metamor-phic code using an oracle-guided approach. In his recentwork, he performs SMT-based shellcode synthesis [46].
Monte Carlo Tree Search. MCTS has been widelystudied in the area of AI in games [16, 35, 49, 56]. Ruijlet al. [47] combine Simulated Annealing and MCTS byintroducing SA-UCT for expression simplification. Limand Yoo [32] describe an early exploration on how MCTScan be used for program synthesis and note that it showscomparable performance to genetic programming. Weextend the research of MCTS-based program synthesis byapplying SA-UCT and introducing node pruning. For oursynthesis approach, we designed a context-free grammarthat learns the semantics of Intel x86 code.
Deobfuscation. Rolles provides an academic analysisof a VM-based obfuscator and outlines a possible attackon such schemes in general [44]. He proposes usingstatic analysis to re-translate the VM’s bytecode back intonative instructions. This, however, requires minute analy-sis of each obfuscator and hence is time-consuming andprone to minor modifications of the scheme. Kinder is
also concerned with (static) analysis of VMs [26]. Specif-ically, he lifts a location-sensitive analysis to be usablein presence of virtualization-based obfuscation schemes.His work highlights how the execution trace of a VM,while performing various computations, always exhibitsa recurring set of addresses. As seen in Section 6, our ap-proach actually benefits from this side effect. In contrast,Sharif et al. [53] analyze VMs in a dynamic manner andrecord execution traces. In contrast to the work of Rolles,their goal is not to re-translate, but to directly analyze thebytecode itself. Specifically, they aim to reconstruct partsof the underlying code’s control flow from the bytecode.This approach is closest to our work as we are, in turn,mostly concerned with arithmetic and logical semanticsof a handler.
More recent results include work by Coogan et al. [13]as well as Yadegari et al. [62]. Both approaches seek to de-obfuscate code based on execution traces by further mak-ing use of symbolic execution and taint tracking. The for-mer approach is focused on the value flow to system callsto reduce a trace whereas Yadegari et al. propose a moregeneral approach and aim to produce fully deobfuscatedcode. However, to counteract symbolic execution-baseddeobfuscation approaches, Banescu et al. propose novelobfuscating transformations that specifically target theirdeficiencies [2]. For one, they propose a construct akinto random opaque predicates [12] that deliberately ex-plodes the number of paths through a function. A secondtechnique preserves program behavior of the obfuscatedprogram for specific input invariants only, effectively in-creasing the input domains and thus the search space forsymbolic executors.
Guinet et al. present arybo, a framework to simplifyMBA expressions [20]. In essence, they perform bit-blasting and use a Boolean expression solver that triesto simplify the expression symbolically. Eyrolles [15]describes a symbolic approach that uses pattern matching.Furthermore, she suggests improvements of current MBA-obfuscated implementations that impede these symbolicdeobfuscation techniques [14]. To this effect, we alsoargue that symbolic simplification is inherently limitedby the complexity of the input expression. However, wedemonstrated that a synthesis-based approach allows fine-tuned simplification, irrespective of syntactical complex-ity, while producing approximate intermediate results.
9 Conclusion
With our prototype implementation of Syntia we haveshown that program synthesis can aid in deobfuscationof real-world obfuscated code. In general, our approachis vastly different in nature compared to proposed deob-fuscation techniques and hence may succeed in scenarioswhere approaches requiring precise code semantics fail.
USENIX Association 26th USENIX Security Symposium 657
Acknowledgments
We thank the reviewers for their valuable feedback. Thiswork was supported by the German Research Foundation(DFG) research training group UbiCrypt (GRK 1817) andby ERC Starting Grant No. 640110 (BASTION).
References[1] ANDRIESSE, D., BOS, H., AND SLOWINSKA, A. Parallax: Im-
plicit Code Integrity Verification using Return-Oriented Program-ming. In Conference on Dependable Systems and Networks (DSN)(2015).
[2] BANESCU, S., COLLBERG, C., GANESH, V., NEWSHAM, Z.,AND PRETSCHNER, A. Code Obfuscation against Symbolic Exe-cution Attacks. In Annual Computer Security Applications Con-ference (ACSAC) (2016).
[3] BANSAL, S., AND AIKEN, A. Automatic Generation of PeepholeSuperoptimizers. In ACM Sigplan Notices (2006).
[4] BELL, J. R. Threaded Code. Communications of the ACM (1973).
[5] BROWNE, C. B., POWLEY, E., WHITEHOUSE, D., LUCAS,S. M., COWLING, P. I., ROHLFSHAGEN, P., TAVENER, S.,PEREZ, D., SAMOTHRAKIS, S., AND COLTON, S. A Surveyof Monte Carlo Tree Search Methods. IEEE Transactions onComputational Intelligence and AI in Games (2012).
[6] CAVALLARO, L., SAXENA, P., AND SEKAR, R. Anti-Taint-Analysis: Practical Evasion Techniques against Information Flowbased Malware Defense. Secure Systems Lab at Stony BrookUniversity, Tech. Rep (2007).
[7] CAZENAVE, T. Monte carlo beam search. IEEE Transactions onComputational Intelligence and AI in Games (2012).
[8] CHASLOT, G. Monte-Carlo Tree Search. PhD thesis, UniversiteitMaastricht, 2010.
[9] COLLBERG, C., MARTIN, S., MYERS, J., AND NAGRA, J. Dis-tributed Application Tamper Detection via Continuous SoftwareUpdates. In Annual Computer Security Applications Conference(ACSAC) (2012).
[10] COLLBERG, C., MARTIN, S., MYERS, J., AND ZIMMER-MAN, B. Documentation for Arithmetic Encodings inTigress. http://tigress.cs.arizona.edu/transformPage/docs/encodeArithmetic.
[11] COLLBERG, C., MARTIN, S., MYERS, J., AND ZIMMERMAN,B. Documentation for Data Encodings in Tigress. http://tigress.cs.arizona.edu/transformPage/docs/encodeData.
[12] COLLBERG, C., THOMBORSON, C., AND LOW, D. Manufactur-ing Cheap, Resilient, and Stealthy Opaque Constructs. In ACMSymposium on Principles of Programming Languages (POPL)(1998).
[13] COOGAN, K., LU, G., AND DEBRAY, S. Deobfuscationof Virtualization-obfuscated Software: A Semantics-Based Ap-proach. In ACM Conference on Computer and CommunicationsSecurity (CCS) (2011).
[14] EYROLLES, N. Obfuscation with Mixed Boolean-Arithmetic Ex-pressions: Reconstruction, Analysis and Simplification Tools. PhDthesis, Université de Versailles Saint-Quentin-en-Yvelines, 2017.
[15] EYROLLES, N., GOUBIN, L., AND VIDEAU, M. Defeating MBA-based Obfuscation. In ACM Workshop on Software PROtection(SPRO) (2016).
[16] FINNSSON, H. Generalized Monte-Carlo Tree Search Extensionsfor General Game Playing. In AAAI Conference on ArtificialIntelligence (2012).
[17] GELLY, S., KOCSIS, L., SCHOENAUER, M., SEBAG, M., SIL-VER, D., SZEPESVÁRI, C., AND TEYTAUD, O. The Grand Chal-lenge of Computer Go: Monte Carlo Tree Search and Extensions.Communications of the ACM (2012).
[18] GODEFROID, P., AND TALY, A. Automated Synthesis of Sym-bolic Instruction Encodings from I/O Samples. In ACM SIGPLANNotices (2012).
[19] GRAZIANO, M., BALZAROTTI, D., AND ZIDOUEMBA, A. ROP-MEMU: A Framework for the Analysis of Complex Code-ReuseAttacks. In ACM Symposium on Information, Computer and Com-munications Security (ASIACCS) (2016).
[20] GUINET, A., EYROLLES, N., AND VIDEAU, M. Arybo: Ma-nipulation, Canonicalization and Identification of Mixed Boolean-Arithmetic Symbolic Expressions. In GreHack Conference (2016).
[21] GULWANI, S. Dimensions in Program Synthesis. In Proceedingsof the 12th international ACM SIGPLAN symposium on Principlesand practice of declarative programming (2010).
[22] GULWANI, S., JHA, S., TIWARI, A., AND VENKATESAN, R.Synthesis of Loop-free Programs. ACM SIGPLAN Notices (2011).
[23] HEULE, S., SCHKUFZA, E., SHARMA, R., AND AIKEN, A. Strat-ified synthesis: Automatically Learning the x86-64 InstructionSet. In ACM SIGPLAN Conference on Programming LanguageDesign and Implementation (PLDI) (2016).
[24] JHA, S., GULWANI, S., SESHIA, S. A., AND TIWARI, A. Oracle-guided Component-based Program Synthesis. In ACM/IEEE 32ndInternational Conference on Software Engineering (2010).
[25] KIM, D.-W., KIM, K.-H., JANG, W., AND CHEN, F. F. Unre-lated Parallel Machine Scheduling with Setup Times using Simu-lated Annealing. Robotics and Computer-Integrated Manufactur-ing (2002).
[26] KINDER, J. Towards Static Analysis of Virtualization-ObfuscatedBinaries. In IEEE Working Conference on Reverse Engineering(WCRE) (2012).
[27] KIRKPATRICK, S., GELATT, C. D., AND VECCHI, M. P. Opti-mization by Simulated Annealing. Science (1983).
[28] KLINT, P. Interpretation Techniques. Software, Practice andExperience (1981).
[29] KOCSIS, L., AND SZEPESVÁRI, C. Bandit based Monte-CarloPlanning. In European Conference on Machine Learning (2006).
[30] KRAHMER, S. x86-64 Buffer Overflow Exploits and the BorrowedCode Chunks Exploitation Technique, 2005.
[31] LIBERATORE, P. The Complexity of Checking Redundancy ofCNF Propositional Formulae. In International Conference onAgents and Artificial Intelligence (2002).
[32] LIM, J., AND YOO, S. Field Report: Applying Monte Carlo TreeSearch for Program Synthesis. In International Symposium onSearch Based Software Engineering (2016).
[33] LU, K., XIONG, S., AND GAO, D. RopSteg: Program Steganog-raphy with Return Oriented Programming. In ACM Conference onData and Application Security and Privacy (CODASPY) (2014).
[34] MA, H., LU, K., MA, X., ZHANG, H., JIA, C., AND GAO, D.Software Watermarking using Return-Oriented Programming. InACM Symposium on Information, Computer and CommunicationsSecurity (ASIACCS) (2015).
[35] MARC, SEBAG, M., SILVER, D., SZEPESVÁRI, C., AND TEY-TAUD, O. Nested Monte-Carlo Search. Communications of theACM (2012).
[36] MICROSOFT RESEARCH. The Z3 Theorem Prover. https://github.com/Z3Prover/z3.
658 26th USENIX Security Symposium USENIX Association
[39] PAKT. ROPC: A Turing complete ROP compiler. https://github.com/pakt/ropc.
[40] PEWNY, J., GARMANY, B., GAWLIK, R., ROSSOW, C., ANDHOLZ, T. Cross-architecture Bug Search in Binary Executables.In IEEE Symposium on Security and Privacy (2015).
[42] QUYNH, N. A., DI, T. S., NAGY, B., AND VU, D. H. CapstoneEngine. http://www.capstone-engine.org.
[43] QUYNH, N. A., AND VU, D. H. Unicorn – The Ultimate CPUEmulator. http://www.unicorn-engine.org.
[44] ROLLES, R. Unpacking Virtualization Obfuscators. In USENIXWorkshop on Offensive Technologies (WOOT) (2009).
[45] ROLLES, R. Program Synthesis in Reverse Engineer-ing. http://www.msreverseengineering.com/blog/2014/12/12/program-synthesis-in-reverse-engineering, 2014.
[46] ROLLES, R. Synesthesia: A Modern Approach to ShellcodeGeneration. http://www.msreverseengineering.com/blog/2016/11/8/synesthesia-modern-shellcode-synthesis-ekoparty-2016-talk, 2016.
[47] RUIJL, B., VERMASEREN, J. A. M., PLAAT, A., AND VAN DENHERIK, H. J. Combining Simulated Annealing and Monte CarloTree Search for Expression Simplification. In International Con-ference on Agents and Artificial Intelligence (2014).
[48] SARWAR, G., MEHANI, O., BORELI, R., AND KAAFAR, D. Onthe Effectiveness of Dynamic Taint Analysis for Protecting againstPrivate Information Leaks on Android-based Devices. Nicta(2013).
[49] SCHADD, M. P., WINANDS, M. H., TAK, M. J., ANDUITERWIJK, J. W. Single-player Monte-Carlo Tree Search forSameGame. Knowledge-Based Systems (2012).
[50] SCHKUFZA, E., SHARMA, R., AND AIKEN, A. Stochastic Su-peroptimization. ACM SIGPLAN Notices (2013).
[51] SCHWARTZ, E. J., AVGERINOS, T., AND BRUMLEY, D. Q:Exploit Hardening Made Easy. In USENIX Security Symposium(2011).
[52] SHACHAM, H. The Geometry of Innocent Flesh on the Bone:Return-into-libc without Function Calls (on the x86). In ACMConference on Computer and Communications Security (CCS)(2007).
[53] SHARIF, M., LANZI, A., GIFFIN, J., AND LEE, W. AutomaticReverse Engineering of Malware Emulators. In IEEE Symposiumon Security and Privacy (2009).
[54] SILVER, D., HUANG, A., MADDISON, C. J., GUEZ, A.,SIFRE, L., VAN DEN DRIESSCHE, G., SCHRITTWIESER, J.,ANTONOGLOU, I., PANNEERSHELVAM, V., LANCTOT, M.,ET AL. Mastering the Game of Go with Deep Neural Networksand Tree Search. Nature (2016).
[55] SONY DADC. SecuROM Software Protection. https://www2.securom.com/Digital-Rights-Management.68.0.html.
[56] SZITA, ISTVÁN AND CHASLOT, GUILLAUME AND SPRONCK,PIETER. Monte-Carlo Tree Search in Settlers of Catan. In Ad-vances in Computer Games (2009).
[59] VOGL, S., PFOH, J., KITTEL, T., AND ECKERT, C. PersistentData-only Malware: Function Hooks without Code. In Symposiumon Network and Distributed System Security (NDSS) (2014).
[60] YADEGARI, B., AND DEBRAY, S. Bit-level Taint Analysis. InIEEE International Working Conference on Source Code Analysisand Manipulation (2014).
[61] YADEGARI, B., AND DEBRAY, S. Symbolic Execution of Obfus-cated Code. In ACM Conference on Computer and Communica-tions Security (CCS) (2015).
[62] YADEGARI, B., JOHANNESMEYER, B., WHITELY, B., ANDDEBRAY, S. A Generic Approach to Automatic Deobfuscation ofExecutable Code. In IEEE Symposium on Security and Privacy(2015).
[63] ZHOU, Y., MAIN, A., GU, Y. X., AND JOHNSON, H. InformationHiding in Software with Mixed Boolean-Arithmetic Transforms.In International Workshop on Information Security Applications(WISA) (2007).
USENIX Association 26th USENIX Security Symposium 659