52
TCP Servers: Offloading TCP/IP Processing in Internet Servers Liviu Iftode Department of Computer Science University of Maryland and Rutgers University
| Date post: | 23-Dec-2015 |
| Category: |
Documents |
| Upload: | michael-richards |
| View: | 224 times |
| Download: | 2 times |

TCP Servers: Offloading TCP/IP Processing in Internet Servers
Liviu IftodeDepartment of Computer Science
University of Maryland and Rutgers University

2
My Research: Network-Centric Systems
TCP Servers and Split-OS [NSF CAREER] Migratory TCP and Service Continuations Federated File Systems Smart Messages [NSF ITR-2] and Spatial
Programming for Networks of Embedded Systems
http://discolab.rutgers.edu

3
Networking and Performance
C C C
S S
D D D
WAN
SAN
Internet Servers
Storage Networks
IP NetworkTCP
IP or not IP ?TCP or not TCP?
The transport-layer protocol must be efficient

4
The Scalability Problem
0
100
200
300
400
500
600
700
300 350 400 450 500 550 600 650 700 750
Offered load (requests/s)
Th
rou
gh
pu
t (r
eq
ue
sts
/s)
Dual Processor
Uniprocessor
Apache web server on 1 Way and 2 Way 300 MHz Intel Pentium II SMP repeatedly accessing a static16 KB file

5
Network Processing
71%
Other system calls9%
User space20%
Breakdown of CPU Time for Apache

6
The TCP/IP Stack
RECEIVE
copy_to_application_buffers
TCP_receive
IP_receive
software_interrupt_handler
hardware_interrupt_handler
packet_in
SEND
copy_from_application_buffers
TCP_send
IP_send
packet_scheduler
setup_DMA
APPLICATION
SYSTEM CALLS
KERNEL
packet_out

7
Breakdown of CPU Time for Apache
TCP Send45%
Other system calls9%
User space20%
TCP Receive 7%
IP Send0%
IP Receive0%
Software Interrupt Processing
11%
Hardware Interrupt Processing
8%

8
Serialized Networking Actions
RECEIVE
copy_to_application_buffers
TCP_receive
IP_receive
software_interrupt_handler
hardware_interrupt_handler
packet_in
SEND
copy_from_application_buffers
TCP_send
IP_send
packet_scheduler
setup_DMA
packet_out
APPLICATION
SYSTEM CALLS
Serialized Operations

9
TCP/IP Processing is Very Expensive
Protocol processing can take up to 70% of the CPU cycles For Apache web server on uniprocessors [Hu
97] Can lead to Receive Livelock [Mogul 95]
Interrupt handling consumes a significant amount of time Soft Timers [Aron 99]
Serialization affects scalability

10
Outline Motivation TCP Offloading using TCP Server TCP Server for SMP Servers TCP Server for Cluster-based Servers Prototype Evaluation

11
TCP Offloading Approach Offload network processing from application
hosts to dedicated processors/nodes/I-NICs Reduce OS intrusion
network interrupt handling context switches serializations in the networking stack cache and TLB pollution
Should adapt to changing load conditions Software or hardware solution?

12
The TCP Server Idea
TCP/IPApplication
OS
FAST COMMUNICATION
Host Processor TCP Server
SERVER
CLIENT

13
TCP Server Performance Factors
Efficiency of the TCP server implementation event-based server, no interrupts
Efficiency of communication between host(s) and TCP server non-intrusive, low-overhead
API asynchronous, zero-copy
Adaptiveness to load

14
TCP Servers for Multiprocessor Systems
TCP ServerApplication
Host OS
SHARED MEMORY
CPU 0 CPU N
CLIENT
Multiprocessor (SMP) Server

15
TCP Servers for Clusters with Memory-to-Memory Interconnects
TCP ServerApplication
MEMORY-to-MEMORY INTERCONNECT
Host
CLIENT
Cluster-based Server

16
TCP Servers for Multiprocessor Servers

17
SMP-based Implementation
Network and Clock Interrupts
Disk & OtherInterrupts
TCP ServerApplication
Host OS
IO APIC
Interrupts

18
SMP-based Implementation (cont’d)
SHARED QUEUE
TCP ServerApplication
Host OS
ENQUEUESEND REQUEST
DEQUEUEAND EXECUTESEND REQUEST

19
TCP Server Event-Driven Architecture
Shared Queue
Monitor
Dispatcher
NIC
Send Handler
ReceiveHandler
Asynchronous Event Handler
From Application Processors To Application Processors

20
Dispatcher
Kernel thread executing at the highest priority level in the kernel
Schedules different handlers based using input from the monitor
Executes an infinite loop and does not yield the processor No other activity can execute on the TCP
Server processor

21
Asynchronous Event Handler (AEH)
Handles asynchronous network events Interacts with the NIC Can be an Interrupt Service Routine or a
Polling Routine Is a short running thread
Has the highest priority among TCP server modules
The clock interrupt is used as a guaranteed trigger for the AEH when polling

22
Send and Receive Handlers
Scheduled in response to a request in the Shared Memory queues
Run at the priority of the network protocol
Interact with the Host processors

23
Monitor Observes the state of the system queues
and provides hints to the Dispatcher to schedule
Used for book-keeping and dynamic load balancing
Scheduled periodically or when an exception occurs Queue overflow or empty Bad checksum for a network packet Retransmissions on a connection
Can be used to reconfigure the set of TCP servers in response to load variation

24
TCP Servers for Cluster-based Servers

25
Cluster-based Implementation
VI Channels
TCP ServerApplication
TUNNELSOCKET REQUEST
DEQUEUE AND EXECUTESOCKET REQUEST
Host
Socket Stub

26
SAN
TCP Server Architecture
NIC - WAN
Eager Processor
(To Host)
TCP/IP Provider
VI ConnectionHandler
RequestHandler
Socket CallProcessor
ResourceManager

27
Sockets and VI Channels Pool of VI’s created at initialization
Avoid cost of creating VI’s in the critical path Registered memory regions associated with
each VI Send and receive buffers associated with socket Also used to exchange control data
Socket mapped to a VI on the first socket operation All subsequent operations on the socket
tunneled through the same VI to the TCP server

28
Socket Call Processing
Host library intercepts socket call Socket call parameters are tunneled to the TCP
server over a VI channel TCP server performs socket operation and returns
results to the host Library returns control to the application immediately
or when the socket call completes (asynchronous vs synchronous processing).

29
Design Issues for TCP Servers
Splitting of the TCP/IP processing Where to split?
Asynchronous event handling Interrupt or polling?
Asynchronous API Event scheduling and resource allocation Adaptation to different workloads

30
Prototypes and Evaluation

31
SMP-based Prototype
Modified Linux – 2.4.9 SMP kernel on Intel x86 platform to implement TCP server
Most parts of the system are kernel modules, with small inline changes to the TCP stack, software interrupt handlers and the task structures
Instrumented the kernel using on-chip performance monitoring counters to profile the system

32
Evaluation Testbed Server
4-Way 550MHz Intel Pentium II Xeon system with 1GB DRAM and 1MB on chip L2 cache
Clients 4-way SMPs 2-Way 300 MHz Intel Pentium II system with 512
MB RAM and 256KB on chip L2 cache NIC : 3-Com 996-BT Gigabit Ethernet Server Application: Apache 1.3.20 web
server Client program: sclients [Banga 97]
Trace driven execution of clients

33
Trace Characteristics
Logs Number of files
Average file size
Number of
requests
Average reply size
Forth 11931 19.3 KB 400335 8.8 KB
Rutgers 18370 27.3 KB 498646 19.0 KB
Synthetic
128 16.0 KB 50000 16.0 KB

34
SEND
copy_from_application_buffers
TCP_send
IP_send
packet_scheduler
setup_DMA
packet_out
Splitting TCP/IP Processing
RECEIVE
copy_to_application_buffers
TCP_receive
IP_receive
software_interrupt_handler
interrupt_handler
packet_in
APPLICATION
SYSTEM CALLSAPPLICATIONPROCESSORS
DEDICATEDPROCESSORS
C1
C3 C2

35
Implementations
ImplementationInterrupt processing
(C1)
Receive Bottom
(C2)
Send Bottom
(C3)
Avoiding Interrupts
(S1)
SMP_BASE
SMP_C1C2
SMP_C1C2S1
SMP_C1C2C3
SMP_C1C2C3S1

36
Throughput
0
500
1000
1500
2000
2500
3000
3500
4000
4500
Un
ipro
cess
or
SM
P_b
ase_
4pro
cess
ors
SM
P_C
1C2_
1ser
ver
SM
P_C
1C2_
2ser
vers
SM
P_C
1C2C
3_1s
erve
r
SM
P_C
1C2C
3_2s
erve
rs
SM
P_C
1C2S
1_1s
erve
r
SM
P_C
1C2S
1_2s
erve
rs
SM
P_C
1C2C
3S1_
1ser
ver
SM
P_C
1C2C
3S1_
2ser
vers
Th
rou
gh
pu
t (r
equ
ests
/s)
Forth
Rutgers
Synthetic

37
CPU Utilization for Synthetic Trace
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
SM
P_
ba
se_
A
SM
P_
ba
se_
D
C1
C2
_1
ser_
A
C1
C2
_1
ser_
D
C1
C2
_2
ser_
A
C1
C2
_2
ser_
D
C1
C2
C3
_1
ser_
A
C1
C2
C3
_1
ser_
D
C1
C2
C3
_2
ser_
A
C1
C2
C3
_2
ser_
D
C1
C2
S1
_1
ser_
A
C1
C2
S1
_1
ser_
D
C1
C2
S1
_2
ser_
A
C1
C2
S1
_2
ser_
D
C1
C2
C3
S1
_1
ser_
A
C1
C2
C3
S1
_1
ser_
D
C1
C2
C3
S1
_2
ser_
A
C1
C2
C3
S1
_2
ser_
D
Idle
User
System
38
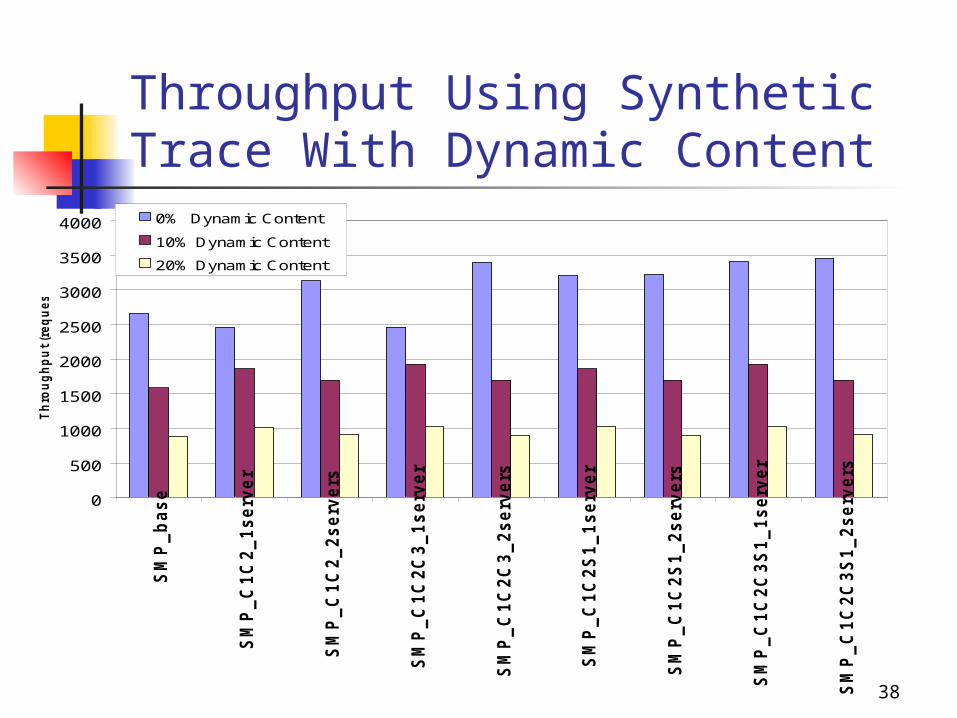
Throughput Using Synthetic Trace With Dynamic Content
0
500
1000
1500
2000
2500
3000
3500
4000
SM
P_
ba
se
SM
P_
C1
C2
_1
se
rve
r
SM
P_
C1
C2
_2
se
rve
rs
SM
P_
C1
C2
C3
_1
se
rve
r
SM
P_
C1
C2
C3
_2
se
rve
rs
SM
P_
C1
C2
S1
_1
se
rve
r
SM
P_
C1
C2
S1
_2
se
rve
rs
SM
P_
C1
C2
C3
S1
_1
se
rve
r
SM
P_
C1
C2
C3
S1
_2
se
rve
rs
Th
rou
gh
pu
t (r
eq
ue
sts
/s)
0% Dynamic Content
10% Dynamic Content
20% Dynamic Content

39
Adapting TCP Servers to Changing Workloads
Monitor the queues Identify low and high water marks to change the
size of the processor set Execute a special handler for exceptional events
Queue length lower than the low water mark Set a flag which dispatcher checks Dispatcher sleeps if the flag is set Reroute the interrupts
Queue length higher than the high water mark Wake up the dispatcher on the chosen processor Reroute the interrupts

40
Load behaviour and dynamic reconfiguration

41
Throughput with Dynamic Reconfiguration
0
500
1000
1500
2000
2500
3000
3500
4000
0% 10% 20% 30% 40%
% of CGI requests
Th
rou
gh
pu
t (r
eq
ue
sts
/s)
SMP_base
SMP_C1C2C3_1server
SMP_C1C2C3_2servers
SMP_C1C2C3_Dyn_Reconf

42
Cluster-based Prototype
User-space implementation (bypass host kernel)
Entire socket operation offloaded to TCP Server C1, C2 and C3 offloaded by default
Optimizations Asynchronous processing: AsyncSend Processing ahead: Eager Receive, Eager Accept Avoiding data copy at host using pre-registered
buffers requires different API: MemNet

43
Implementations
Implementation
Kernel Bypassi
ng(H1)
Asynchronous
Processing(H2)
Avoiding Host
Copies(H3)
Processing
Ahead(S2)
Cluster_base
Cluster_C1C2C3H1
Cluster_C1C2C3H1H3
Cluster_C1C2C3H1H2H3
Cluster_C1C2C3H1H2H3S2

44
Evaluation Testbed Server
Host and TCP Server: 2-Way 300 MHz Intel Pentium II system with 512 MB RAM and 256KB on chip L2 cache
Clients 4-Way 550MHz Intel Pentium II Xeon system with
1GB DRAM and 1MB on chip L2 cache NIC: 3-Com 996-BT Gigabit Ethernet Server application: Custom web server
Flexibility in modifying application to use our API Client program: httperf

45
Throughput with Synthetic Trace Using HTTP/1.0
0
100
200
300
400
500
600
700
800
900
400 500 600 700 800 900 1000
Offered Load (requests/sec)
Th
rou
gh
pu
t (r
ep
lie
s/s
ec
)
Cluster_C1C2C3H1H2H3
Cluster_C1C2C3H1H2H3S2
Cluster_C1C2C3H1H3
Cluster_C1C2C3H1
Cluster_base

46
CPU Utilization
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Clu
ste
r_b
as
e
C1
C2
C3
H1
(Ho
st)
C1
C2
C3
H1
(TC
PS
)
C1
C2
C3
H1
H3
(Ho
st)
C1
C2
C3
H1
H3
(TC
PS
)
C1
C2
C3
H1
H2
H3
(Ho
st)
C1
C2
C3
H1
H2
H3
(TC
PS
)
Offered Load(Reqs/sec)
CP
U U
tili
zati
on
(%)
Idle Time
User Time
System Time

47
Throughput with Synthetic Trace Using HTTP/1.1
0
200
400
600
800
1000
1200
1400
800 900 1000 1100 1200 1300
Offered Load (requests/sec)
Th
rou
gh
pu
t (r
ep
lie
s/s
ec
)
Cluster_C1C2C3H1H2H3
Cluster_C1C2C3H1H2H3S2
Cluster_C1C2C3H1H3
Cluster_base

48
Throughput with Real Trace (Forth) Using HTTP/1.0
0
200
400
600
800
1000
1200
800 900 1000 1100 1200 1300
Offered Load (requests/sec)
Th
rou
gh
pu
t (r
ep
lies/s
ec)
Cluster_C1C2C3H1H2H3S2Cluster_C1C2C3H1H2H3Cluster_C1C2C3H1H3Cluster_base

49
Related Work
TCP Offloading Engines Communication Services Platform (CSP)
System architecture for scalable cluster-based servers, using a VIA-based SAN to tunnel TCP/IP packets inside the cluster
Piglet - A vertical OS for multiprocessors Queue Pair IP - A new end point
mechanism for inter-network processing inspired from memory-to-memory communication

50
Conclusions Offloading networking functionality to a set
of dedicated TCP servers yields up to 30% performance improvement
Performance Essentials: TCP Server architecture
event driven polling instead of interrupts adaptive to load
API asynchronous, zero-copy

51
Future Work
TCP Server software distributions Compare TCP Server Architecture with
hardware based offloading schemes Use TCP Servers in Storage Networking

52
Acknowledgements
My graduate students:Murali Rangarajan, Aniruddha Bohra and Kalpana Banerjee
http://discolab.rutgers.edu

















