Text Analysis: Methods for Searching, Organizing, Labeling and Summarizing Document Collections Danny Dunlavy Computer Science and Informatics Department (1415) Sandia National Laboratories July 16, 2008 CSRI Student Seminar Series SAND2008-4999P
Transcript
Text Analysis:Methods for Searching, Organizing,
Labeling and Summarizing Document Collections
Danny DunlavyComputer Science and Informatics Department (1415)
Sandia National Laboratories
July 16, 2008CSRI Student Seminar Series
SAND2008-4999P
Outline
• Introduction
• Motivational Problems
• Data
• Analysis Pipeline
• Transformation, Analysis, and Post-processing
• Hybrid Systems
• Examples
• Conclusions
Introduction
• Knowledge discovery– Goal of text analysis– Data → information → knowledge
• Challenges– Too much information to process manually– Data ambiguity
• Word sense, multilingual, errors, weak signals
– Heterogeneous data sources– Interpretability
• Goals of this talk– Exposure to research in text analysis at Sandia– Focus on methods based on mathematical principles
Example 1: Information Retrieval
Problem: ambiguous queries lead to information overload and topic confusion
Solutions: optimization, linear algebra, machine learning, and probabilistic modeling
[G. Salton, A. Wong, and C. S. Yang (1975), "A Vector Space Model for Automatic Indexing," Comm. ACM, 18(11), 613–620.]
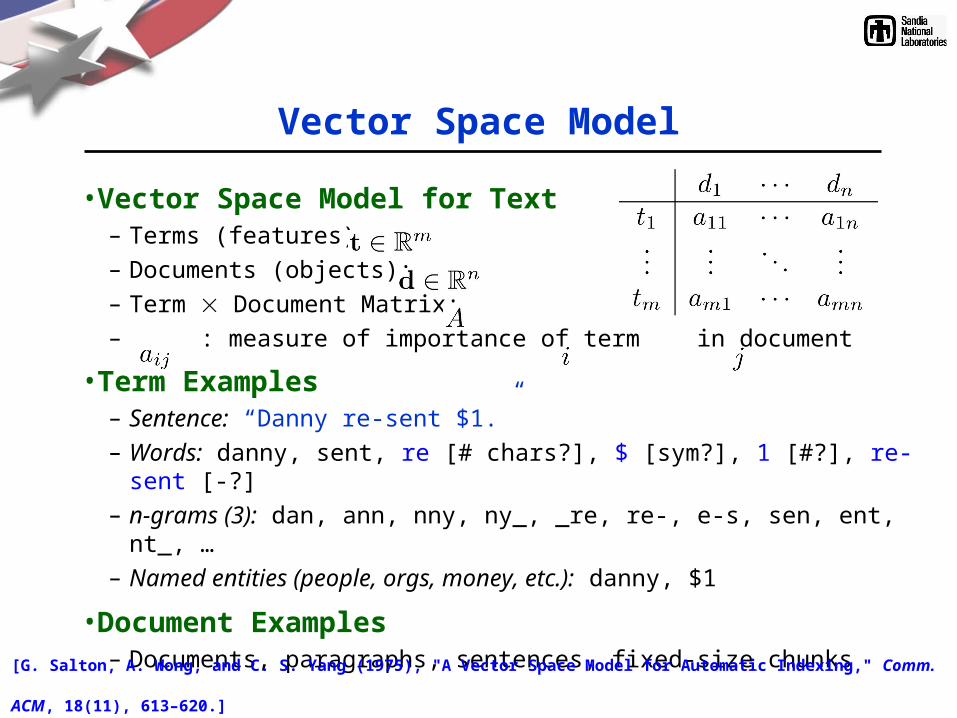
Feature Weighting
Term Document Matrix Scaling:
Feature Extraction: Dimension Reduction
• Goal: find new, smaller set of features (dimensions) that best captures variability, correlations, or structure in the data
• Methods– Principal component analysis (PCA)
• Eigenvalue decomposition of covariance matrix of
• Pre-processing: mean of each feature is 0
– Singular value decomposition of– Local Linear Embedding (LLE)
• Express points as combinations of neighbors and embed points into lower dimensional space (preserving neighbors)
– Multidimensional scaling• Preserve pairwise distances in lower dimensional space
– ISOMAP (nonlinear)• Extends MDS to use geodesic distances on a weighted graph
Analysis Tasks in This Talk
• Information retrieval– Goal: find documents most related to a query– Challenges: pseudonyms, synonyms, stemming, errors– Methods: LSA (later), boolean search, probabilistic retrieval
• Clustering– Goal: find a set of partitions that best separates groups of like objects– Challenges: distance metrics, number of clusters, uniqueness– Methods: k-means (later), agglomerative, graph-based
• Summarization– Goal: find a compact representation of text with same meaning– Challenges: single- vs. multi-document summaries, subjectivity– Methods: HMM+QR (later), probabilistic
• Classification– Goal: predict labels/categories of data instances (documents)– Challenges: data overfitting, – Methods: HEMLOCK (S. Gilpin, later), decision trees, naïve bayes, SVM
Other Analysis Tasks
• Machine translation• Speech recognition• Cross language information retrieval• Word sense disambiguation
– Determining sense of ambiguous words from context
• Lexical acquisition– Filling in gaps in dictionaries build from text corpora
• Concept drift detection– Change in general topics in streaming data
• Association analysis– Discovering novel relationships hidden in text
• TITAN: customizable front-ends to analysis pipelines
• YALE: required parameters vs. complete set of parameters
• Performance, Verification & Validation– Tests for independent systems and overall system– Compatible test data and benchmarks– Analysis of parameter dependencies across individual systems
Hybrid System Example
Query, Cluster, Summarize
Motivation
• Query– methods plasma physics
• Retrieval– General: Google, 7.8106 of >2.51010 documents
– Targeted: arXiv, 9,000 of >403,000 documents
• Problems– Too much information
– Redundant information
– Results: link, title, abstract, snippet (?), etc.
– Ordering of results (meaning of “best” match?)
Problems to Solve
• QCS (Query, Cluster, Summarize)– Unstructured text parsing (common representation)
– Data fusion (cleaning, assimilating, normalizing)
– Natural language processing (sentences, POS)
– Document retrieval (ranking)
– High-dimensional clustering (data organization)
– Automatic text summarization (data reduction)
– Data representation/visualization (multiple perspectives)
QueryLatent Semantic Analysis (LSA)
• SVD:
• Truncated SVD:
• Query scores (query as new “doc”):
• LSA Ranking:
term
s
documentsd1 d2 dn
t2
t1
tm
…d3 d4
.
.
. Truncated SVD
term
s
concepts documents
con
cep
ts
singular values
[Deerwester, S. C., et al. (1990). Indexing by latent semantic analysis. J. Am. Soc. Inform. Sci. 41 (6), 391–407.]
d1 : Hurricane. A hurricane is a catastrophe.
d2 : An example of a catastrophe is a hurricane.
d3 : An earthquake is bad.
d4 : Earthquake. An earthquake is a catastrophe.
d1 : Hurricane. A hurricane is a catastrophe.
d2 : An example of a catastrophe is a hurricane.
d3 : An earthquake is bad.
d4 : Earthquake. An earthquake is a catastrophe.
1011catastrophe
2100earthquake
0012hurricane
d4d3d2d1
0catastrophe
0earthquake
1hurricane
qA
.30.15.60.59catastrophe
.92.96.02-.03earthquake
.11-.11.78.78hurricane
d4d3d2d1
A2
00.71.89qTA .11–.78.78qTA2
Removestopwords
normalization only rank-2 approximation
captures link to doc 4
LSA Example 1
.450.71.45catastrophe
.89100earthquake
00.71.89hurricane
d4d3d2d1
A
LSA Example 2
∆policy∆planning∆politics∆tomlinson∆1986oSport in Society: policy, Politics and Culture, ed A. Tomlinson (1990) oPolicy and Politics in Sport, PE and Leisure eds S. Fleming, M. Talbot and A. Tomlinson (1995) oPolicy and Planning (II), ed J. Wilkinson (1986) oPolicy and Planning (I), ed J. Wilkinson (1986) oLeisure: Politics, Planning and People, ed A. Tomlinson (1985)
∆parker∆lifestyles∆1989∆partoWork, Leisure and Lifestyles (Part 2), ed S. R. Parker (1989) oWork, Leisure and Lifestyles (Part 1), ed S. R. Parker (1989)
[Leisure Studies of America Data: 97 documents, 335 terms]
ClusterGeneralized Spherical K-Means (gmeans)
• The Players– Documents:
– Partition/Disjoint Sets:
– Concept vectors (centroids):
• The Game– Maximize
• The Rules– Adaptive, but bounded k
– Similarity Estimation
– First variation (stochastic perturbation)[Dhillon, I. S., et al. (2002). Iterative clustering of high dimensional text data augmented by local search. Proc. IEEE ICDM.]
SummarizeHidden Markov Model + Pivoted QR
• Single Document Summarization– Mark summary sentences in training documents– Build probabilistic model
• Impact– Available in ThreatView 1.2.0+ directly or through ParaText™ server– Plans to interface to LSAView, OverView (1424), Sisyphus (1422)
ParaText™ Server (PTS)
Artifact DB
PTS PTS PTS
Reader
P0 P1 Pk
Parser
Matrix
SVD
Reader
Parser
Matrix
SVD
Reader
Parser
Matrix
SVD
Parallel Pipeline
Matrices DB
HPC Resource (cluster, multicore server, etc.)
1 or 2DB Servers
XMLHTTP
Master ParaText™
Server
ParaText™ Client
LSAView: Algorithm Analysis/ Development
• LSAView– Analysis and exploration of
impact of informatics algorithms on end-user visual analysis of data
– Aids in discovery process of optimal algorithm parameters for given data and tasks
• Features – Side-by-side comparison of visualizations for two sets of parameters– Small multiple view for analyzing 2+ parameter sets simultaneously– Linked document, graph, matrix, and tree data views– Interactive, zoomable, hierarchical matrix and matrix-difference views– Statistical inference tests used to highlight novel parameter impact
• Impact– Used in developing and understanding ParaText™ and LSALIB algorithms
20 40 60 800
0.5
1
1.5
2
20 40 60 800
0.5
1
1.5
2
20 40 60 800
0.5
1
1.5
2
20 40 60 800
0.5
1
1.5
2
k
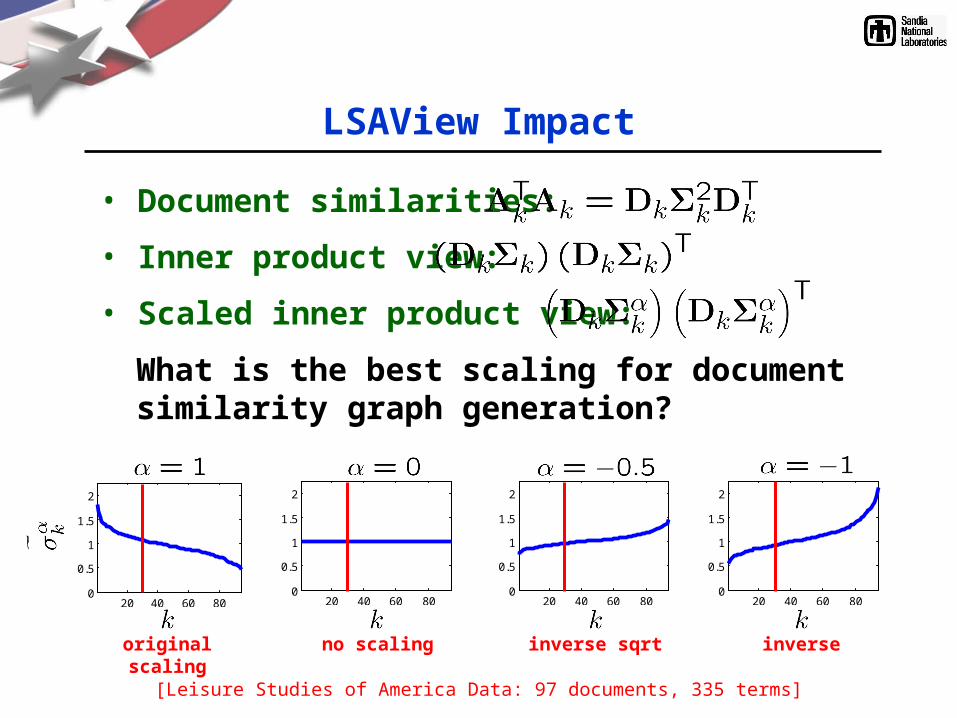
LSAView Impact
• Document similarities:
• Inner product view:
• Scaled inner product view:
What is the best scaling for document similarity graph generation?
original scaling no scaling inverse sqrt inverse
[Leisure Studies of America Data: 97 documents, 335 terms]
E-Mail Classification
• LSN Assistant / Sandia Categorization Framework – Yucca Mountain: categorize e-mail (Relevant, Federal Record, Privileged)– Machine learning library and GUI for document categorization & review– For review of existing categorizations, recommendations for new documents– Balanced learning
• Skewed class distributions
• Importance– Solved important, real problem
• ~400K e-mails incorrectly categorized
– Foundation for LSN Online Assistant• Real-time system for recommendations
• Impact– Dong Kim, lead of DOE/OCRWM LSN certification is “very impressed with the
LSN Assistant Tool and the approach to doing the review.”– Factor of 3 speedup over manual categorization review only
Conclusions
• Text analysis relies heavily upon mathematics– Linear algebra, optimization, machine learning,
probability theory, statistics, graph theory
• Hybrid system development is a challenge– More than just gluing pieces together
• Large-scale analysis is important– Storing and processing large amounts of data
– Scaling algorithms up
– Developing new algorithms for large data
• Useful across many application domains
Collaborations
• QCS
– Dianne O’Leary (Maryland), John Conroy & Judith Schlesinger (IDA/CCS)