33
Text Analytics Summit Text Analytics Evaluation Tom Reamy Chief Knowledge Architect KAPS Group Knowledge Architecture Professional Services http://www.kapsgroup.com
| Date post: | 29-Dec-2015 |
| Category: |
Documents |
| Upload: | maud-mcbride |
| View: | 219 times |
| Download: | 1 times |

Text Analytics SummitText Analytics
Evaluation
Tom ReamyChief Knowledge Architect
KAPS Group
Knowledge Architecture Professional Services
http://www.kapsgroup.com

2
Agenda
Features, Varieties, Vendors Evaluation Process
– Start with Self-Knowledge – Text Analytics Team – Features and Capabilities – Filter
Proof of Concept/Pilot– Themes and Issues– Case Study
Conclusion

3
KAPS Group: General
Knowledge Architecture Professional Services Virtual Company: Network of consultants – 8-10 Partners – SAS, SAP, FAST, Smart Logic, Concept Searching, etc. Consulting, Strategy, Knowledge architecture audit Services:
– Taxonomy/Text Analytics development, consulting, customization– Technology Consulting – Search, CMS, Portals, etc.– Evaluation of Enterprise Search, Text Analytics– Metadata standards and implementation– Knowledge Management: Collaboration, Expertise, e-learning– Applied Theory – Faceted taxonomies, complexity theory, natural
categories

4
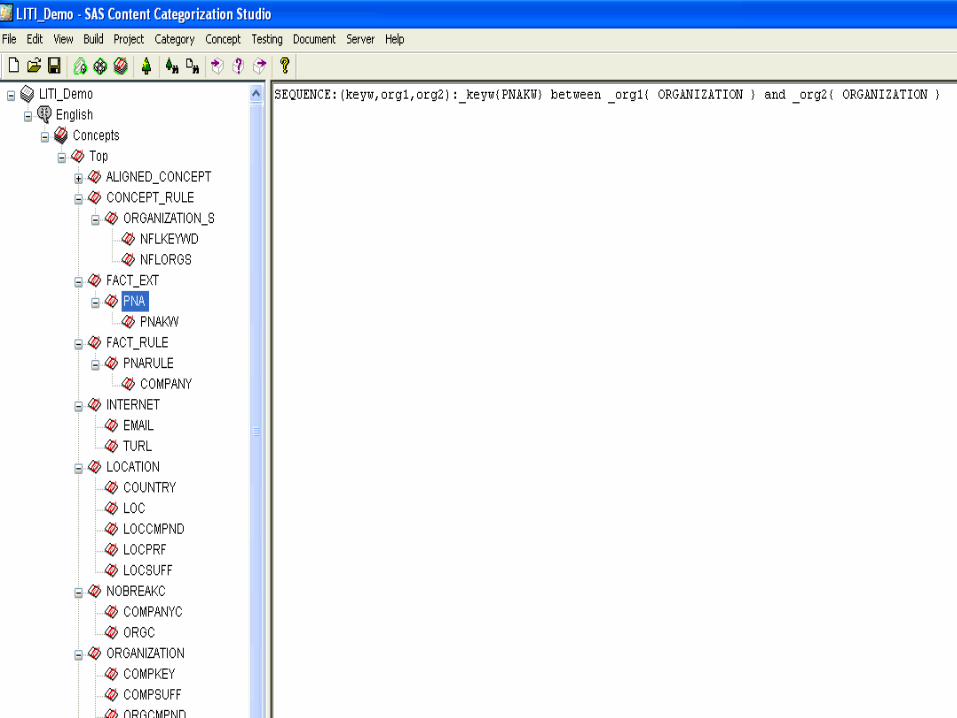
Introduction to Text AnalyticsText Analytics Features Noun Phrase Extraction
– Catalogs with variants, rule based dynamic– Multiple types, custom classes – entities, concepts, events– Feeds facets
Summarization– Customizable rules, map to different content
Fact Extraction– Relationships of entities – people-organizations-activities– Ontologies – triples, RDF, etc.
Sentiment Analysis– Statistical, rules – full categorization set of operators

5
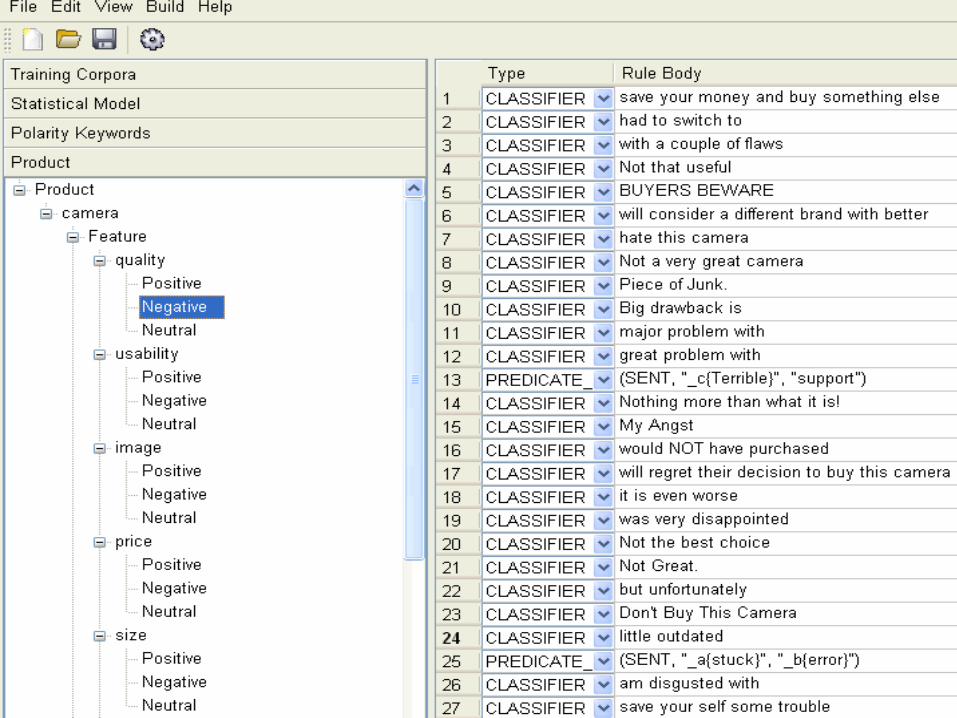
Introduction to Text AnalyticsText Analytics Features Auto-categorization
– Training sets – Bayesian, Vector space– Terms – literal strings, stemming, dictionary of related terms– Rules – simple – position in text (Title, body, url)– Semantic Network – Predefined relationships, sets of rules– Boolean– Full search syntax – AND, OR, NOT– Advanced – NEAR (#), PARAGRAPH, SENTENCE
This is the most difficult to develop Build on a Taxonomy Combine with Extraction
– If any of list of entities and other words

6

7

8
9

10
11

12
Varieties of Taxonomy/ Text Analytics Software
Taxonomy Management– Synaptica, SchemaLogic
Full Platform– SAS-Teragram, SAP-Inxight, Clarabridge, Smart Logic,
Linguamatics, Concept Searching, Expert System, IBM, GATE
Embedded – Search or Content Management– FAST, Autonomy, Endeca, Exalead, etc.– Nstein, Interwoven, Documentum, etc.
Specialty / Ontology (other semantic)– Sentiment Analysis – Lexalytics, Lots of players– Ontology – extraction, plus ontology

Evaluating Taxonomy/Text Analytics Software Start with Self Knowledge
Strategic and Business Context
Info Problems – what, how severe Strategic Questions – why, what value from the taxonomy/text
analytics, how are you going to use it Formal Process - KA audit – content, users, technology, business
and information behaviors, applications - Or informal for smaller organization,
Text Analytics Strategy/Model – forms, technology, people– Existing taxonomic resources, software
Need this foundation to evaluate and to develop
13

Evaluating Taxonomy/Text Analytics Software Start with Self Knowledge
Do you need it – and what blend if so? Taxonomy Management Only
– Multiple taxonomies, languages, authors-editors Technology Environment – Text Mining, ECM, Enterprise Search
– where is it embedded Publishing Process – where and how is metadata being added –
now and projected future– Can it utilize auto-categorization, entity extraction, summarization
Is the current search adequate – can it utilize text analytics? Applications – text mining, BI, CI, Alerts?
14

Design of the Text Analytics Selection Team
Traditional Candidates - IT Experience with large software purchases
– Search/Categorization is unlike other software
Experience with needs assessments– Need more – know what questions to ask, knowledge audit
Objective criteria– Looking where there is light?– Asking IT to select taxonomy software is like asking a construction
company to select the design of your house.
They have the budget– OK, they can play.
15

Design of the Text Analytics Selection Team
Traditional Candidates - Business Owners Understand the business
– But don’t understand information behavior
Focus on business value, not technology– Focus on semantics is needed
They can get executive sponsorship, support, and budget.– OK, they can play
16

Design of the Text Analytics Selection Team
Traditional Candidates – Library, KM, Data Analysis Understand information structure
– But not how it is used in the business
Experts in search experience and categorization– Suitable for experts, not regular users
Experience with variety of search engines, taxonomy software, integration issues
– OK, they can play
17

Design of the Text Analytics Selection Team
Interdisciplinary Team, headed by Information Professionals
Relative Contributions– IT – Set necessary conditions, support tests– Business – provide input into requirements, support project– Library – provide input into requirements, add understanding
of search semantics and functionality
Much more likely to make a good decision Create the foundation for implementation
18

Evaluating Text Analytics Software – Process
Start with Self Knowledge Eliminate the unfit
– Filter One- Ask Experts - reputation, research – Gartner, etc.• Market strength of vendor, platforms, etc.• Feature scorecard – minimum, must have, filter to top 3
– Filter Two – Technology Filter – match to your overall scope and capabilities – Filter not a focus
– Filter Three – Focus Group one day visit – 3-4 vendors Deep pilot (2) / POC – advanced, integration, semantics Focus on working relationship with vendor.
19

Evaluating Text Analytics SoftwareFeature Checklist and Score
Basic Features, Taxonomy Admin– New, copy, rename, delete, merge, node relationships– Scope Notes, spell check, versioning, node ID– Analytical reports – structure, application to documents
Usability, user documentation, training Visualization – taxonomy structure Language support API/SDK, Import-Export – XML & SKOS Standards, security, access roles & rights Clustering – taxonomy node generation, sentiment
20

Initial Evaluation Example Outcomes
Filter One:– Company A, B – sentiment analysis focus, weak categorization– Company C – Lack of full suite of text analytics– Company D – business concerns, support– Open Source – license issues– Ontology Vendors – missing categorization capabilities
4 Demos– Saw a variety of different approaches, but – Company X – lacking sentiment analysis, require 2 vendors– Company Y – lack of language support, development cost
21

Evaluating Taxonomy SoftwarePOC
Quality of results is the essential factor 6 weeks POC – bake off / or short pilot Real life scenarios, categorization with your content Preparation:
– Preliminary analysis of content and users information needs– Set up software in lab – relatively easy– Train taxonomist(s) on software(s)– Develop taxonomy if none available
Six week POC – 3 rounds of development, test, refine / Not OOB Need SME’s as test evaluators – also to do an initial categorization of
content
22

Evaluating Taxonomy SoftwarePOC
Majority of time is on auto-categorization and/or sentiment Need to balance uniformity of results with vendor unique capabilities –
have to determine at POC time Risks – getting software installed and working, getting the right content,
initial categorization of content Elements:
– Content– Search terms / search scenarios– Training sets– Test sets of content
Taxonomy Developers – expert consultants plus internal taxonomists
23

Evaluating Taxonomy SoftwarePOC: Test Cases
Auto-categorization to existing taxonomy – variety of content Clustering – automatic node generation Summarization Entity extraction – build a number of catalogs – design which
ones based on projected needs – example privacy info (SS#, phone, etc.)
– Entity example –people, organization, methods, etc. Sentiment – Best Buy phones Evaluate usability in action by taxonomists Integration – with ontologies Output – XML, API’s
24

Evaluating Taxonomy SoftwarePOC - Issues
Quality of content Quality of initial human categorization Normalize among different test evaluators Quality of taxonomists – experience with text analytics software and/or
experience with content and information needs and behaviors Quality of taxonomy
– General issues – structure (too flat or too deep)– Overlapping categories – Differences in use – browse, index, categorize
Categorization essential issue is complexity of language– Good sentiment is based on categorization
Entity Extraction essential issue is scale and disambiguation
25

Case Study: Telecom Service
Company History, Reputation Full Platform –Categorization,
Extraction, Sentiment Integration – java, API-SDK,
Linux Multiple languages Scale – millions of docs a day Total Cost of Ownership Ease of Development - new
Vendor Relationship – OEM,
etc.
Expert Systems IBM SAS - Teragram Smart Logic
Option – Multiple vendors – Sentiment & Platform
26

POC Design Discussion: Evaluation Criteria
Basic Test Design – categorize test set– Score – by file name, human testers
Categorization – Call Motivation– Accuracy Level – 80-90%– Effort Level per accuracy level
Sentiment Analysis– Accuracy Level – 80-90%– Effort Level per accuracy level
Quantify development time – main elements Comparison of two vendors – how score?
– Combination of scores and report
27

Text Analytics POC OutcomesCategorization Results
SAS IBM
Recall-Motivation 92.6 90.7
Recall-Actions 93.8 88.3
Precision – Mot. 84.3
Precision-Act 100
Uncategorized 87.5
Raw Precision 73 46
28

Text Analytics POC OutcomesVendor Comparisons
Categorization Results – both good, edge to SAS on precision– Use of Relevancy to set thresholds
Development Environment– IBM as toolkit provides more flexibility but it also increases
development effort
Methodology – IBM enforces good method, but takes more time
– SAS can be used in exactly the same way
SAS has a much more complete set of operators – NOT, DIST, START
29

Text Analytics POC OutcomesVendor Comparisons - Functionality
Sentiment Analysis – SAS has workbench, IBM would require more development
– SAS also has statistical modeling capabilities
Entity and Fact extraction – seems basically the same– SAS and use operators for improved disambiguation –
Summarization – SAS has built-in– IBM could develop using categorization rules – but not clear that
would be as effective without operators
Conclusion: Both can do the job, edge to SAS
30

POC and Early Development: Risks and Issues
CTO Problem –This is not a regular software process Semantics is messy not just complex
– 30% accuracy isn’t 30% done – could be 90% Variability of human categorization Categorization is iterative, not “the program works”
– Need realistic budget and flexible project plan Anyone can do categorization
– Librarians often overdo, SME’s often get lost (keywords) Meta-language issues – understanding the results
– Need to educate IT and business in their language
31

Conclusion
Start with self-knowledge – what will you use it for?– Current Environment – technology, information
Basic Features are only filters, not scores Integration – need an integrated team (IT, Business, KA)
– For evaluation and development POC – your content, real world scenarios – not scores Foundation for development, experience with software
– Development is better, faster, cheaper Categorization is essential, time consuming Sentiment / VOC without categorization will fail
32

Questions?
KAPS Group
Knowledge Architecture Professional Services
http://www.kapsgroup.com

















