44
The Entity-Relationship Model IS698 Min Song
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | jayla-moseley |
| View: | 217 times |
| Download: | 3 times |

The Entity-Relationship Model
IS698
Min Song

Overview of Database Design
Conceptual design: (ER Model is used at this stage.) What are the entities and relationships in the
enterprise? What information about these entities and
relationships should we store in the database? What are the integrity constraints or business
rules that hold? A database `schema’ in the ER Model can be
represented pictorially (ER diagrams). Can map an ER diagram into a relational schema.

ER Model Basics
Entity: Real-world object distinguishable from other objects. An entity is described (in DB) using a set of attributes.
Entity Set: A collection of similar entities. E.g., all employees. All entities in an entity set have the same set of
attributes. (Until we consider ISA hierarchies, anyway!)
Each entity set has a key. Each attribute has a domain.
Employees
ssnname
lot

ER Model Basics (Contd.)
Relationship: Association among two or more entities. E.g., Attishoo works in Pharmacy department.
Relationship Set: Collection of similar relationships. An n-ary relationship set R relates n entity sets E1 ...
En; each relationship in R involves entities e1, ..., en. Same entity set could participate in different
relationship sets, or in different “roles” in same set.
lot
dname
budgetdid
sincename
Works_In DepartmentsEmployees
ssn
Reports_To
lot
name
Employees
subor-dinate
super-visor
ssn

Cartesian or Cross-Products A tuple <a1,a2,…,an> is just a list with n elements in
order. A binary tupe <a,b> is called an ordered pair. Given two sets A,B, we can form a new set A x B
containing all ordered pairs <a,b> such that a is a member of A, b is a member of B.
In set notation: A x B = {<a,b> | a in A, b in B}. Example: {1,2,3} x {x,y} =
{<1,x>,<1,y>,<2,x>,<2,y>,<3,x>,<3,y>}

A Formal Treatment of Relation: The Cross Product
Let E1, E2, E3 be three entity sets. A relationship among E1, E2, E3 is a
tuple in E1 x E2 x E2. A relationship set, or relation, is a set
of relationships. So if R is a relation among E1, E2, E3, then R is a subset of E1 x E2 x E3.

Key Constraints
Consider Works_In: An employee can work in many departments; a dept can have many employees.
In contrast, each dept has at most one manager, according to the key constraint on Manages.
Many-to-Many1-to-1 1-to Many Many-to-1
dname
budgetdid
since
lot
name
ssn
ManagesEmployees Departments

Participation Constraints Does every department have a manager?
If so, this is a participation constraint: the participation of Departments in Manages is said to be total (vs. partial). Every did value in Departments table must appear in
a tuple of the Manages relation.
lot
name dnamebudgetdid
sincename dname
budgetdid
since
Manages
since
DepartmentsEmployees
ssn
Works_In

Weak Entities
A weak entity can be identified uniquely only by considering the primary key of another (owner) entity. Owner entity set and weak entity set must participate in a
one-to-many relationship set (one owner, many weak entities).
Weak entity set must have total participation in this identifying relationship set.
lot
name
agepname
DependentsEmployees
ssn
Policy
cost

ISA (`is a’) Hierarchies
Contract_Emps
namessn
Employees
lot
hourly_wagesISA
Hourly_Emps
contractid
hours_workedAs in C++, or other PLs, attributes are inherited.If we declare A ISA B, every A entity is also considered to be a B entity. Overlap constraints: Can Joe be an Hourly_Emps as well
as a Contract_Emps entity? (Allowed/disallowed) Covering constraints: Does every Employees entity also
have to be an Hourly_Emps or a Contract_Emps entity? (Yes/no)
Reasons for using ISA: To add descriptive attributes specific to a subclass. To identify entities that participate in a relationship.
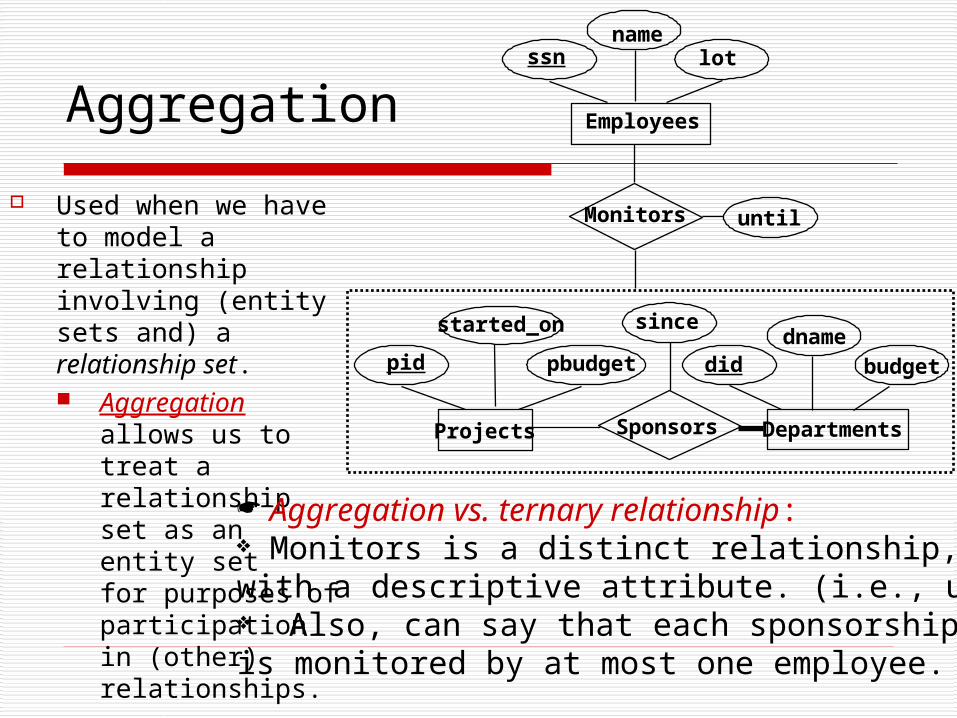
Aggregation
Used when we have to model a relationship involving (entity sets and) a relationship set. Aggregation
allows us to treat a relationship set as an entity set for purposes of participation in (other) relationships.
Aggregation vs. ternary relationship: Monitors is a distinct relationship, with a descriptive attribute. (i.e., until) Also, can say that each sponsorship is monitored by at most one employee.
budgetdidpid
started_on
pbudgetdname
until
DepartmentsProjects Sponsors
Employees
Monitors
lotname
ssn
since

Conceptual Design Using the ER Model
Design choices: Should a concept be modeled as an entity or
an attribute? Should a concept be modeled as an entity or
a relationship? Identifying relationships: Binary or ternary?
Aggregation?

Entity vs. Attribute
Should address be an attribute of Employees or an entity (connected to Employees by a relationship)?
Depends upon the use we want to make of address information, and the semantics of the data:
If we have several addresses per employee, address must be an entity (since attributes cannot be set-valued).
If the structure (city, street, etc.) is important, e.g., we want to retrieve employees in a given city, address must be modeled as an entity (since attribute values are atomic).

Entity vs. Attribute (Contd.)
Works_In4 does not allow an employee to work in a department for two or more periods.
Similar to the problem of wanting to record several addresses for an employee: We want to record several values of the descriptive attributes for each instance of this relationship. Accomplished by introducing new entity set, Duration.
name
Employees
ssn lot
Works_In4
from todname
budgetdid
Departments
dnamebudgetdid
name
Departments
ssn lot
Employees Works_In4
Durationfrom to

Entity vs. Relationship First ER diagram OK if a
manager gets a separate discretionary budget for each dept.
What if a manager gets a discretionary budget that covers all managed depts? Redundancy:
dbudget stored for each dept managed by manager.
Misleading: Suggests dbudget associated with department-mgr combination.
Manages2
name dnamebudgetdid
Employees Departments
ssn lot
dbudgetsince
dnamebudgetdid
DepartmentsManages2
Employees
namessn lot
since
Managers dbudget
ISA
This fixes theproblem!

Binary vs. Ternary Relationships
If each policy is owned by just 1 employee, and each dependent is tied to the covering policy, first diagram is inaccurate.
What are the additional constraints in the 2nd diagram?
agepname
DependentsCovers
name
Employees
ssn lot
Policies
policyid cost
Beneficiary
agepname
Dependents
policyid cost
Policies
Purchaser
name
Employees
ssn lot
Bad design
Better design

Binary vs. Ternary Relationships (Contd.)
Previous example illustrated a case when two binary relationships were better than one ternary relationship.
An example in the other direction: a ternary relation Contracts relates entity sets Parts, Departments and Suppliers, and has descriptive attribute qty. No combination of binary relationships is an adequate substitute: S “can-supply” P, D “needs” P, and D “deals-
with” S does not imply that D has agreed to buy P from S.
How do we record qty?

Summary of Conceptual Design Conceptual design follows requirements analysis,
Yields a high-level description of data to be stored ER model popular for conceptual design
Constructs are expressive, close to the way people think about their applications.
Basic constructs: entities, relationships, and attributes (of entities and relationships).
Some additional constructs: weak entities, ISA hierarchies, and aggregation.
Note: There are many variations on ER model.

Summary of ER (Contd.)
Several kinds of integrity constraints can be expressed in the ER model: key constraints, participation constraints, and overlap/covering constraints for ISA hierarchies. Some constraints (notably, functional
dependencies) cannot be expressed in the ER model. (e.g., z = x + y)
Constraints play an important role in determining the best database design for an enterprise.

Summary of ER (Contd.)
ER design is subjective. There are often many ways to model a given scenario! Analyzing alternatives can be tricky, especially for a large enterprise. Common choices include: Entity vs. attribute, entity vs. relationship,
binary or n-ary relationship, whether or not to use ISA hierarchies, and whether or not to use aggregation.
Ensuring good database design: resulting relational schema should be analyzed and refined further. FD information and normalization techniques are especially useful.

Chapter 3Data Storage and Access Methods
Title: Operating System Support for Database ManagementAuthor: Michael StonebrakerPages: 217—223

Problem Definition Apparent disconnect between DBMS performance
goals and operating system design and implementation.
Services provided by OS are inadequate and sub-optimal.
Paper evaluates the following services: Buffer pool management File system Interprocess communication Consistency control Paged virtual memory

Contributions
Demonstrates OS services are too slow or inappropriate for DBMS tasks.
Attempts to make OS designers aware of and more sensitive to DBMS needs.

Key Concepts Buffer Pool Management
OS has a fixed buffer pool that handles all I/O UNIX uses LRU replacement strategy, which may
not be ideal for a DBMS Large performance overhead to pull a block into
the buffer. Approx. 5000 instructions for 512 bytes
No good prefetch strategy. UNIX does not implement a selected force out
buffer manager where the DBMS can dictate the order of the commits

Key Concepts The File System
UNIX implements its file system as character arrays and forces the DBMS to implement its own higher level objects.
Tree Structured File Systems UNIX implements 2 service using trees
Keeping track of blocks in a given file Hierarchical directory structure
DBMS adds a third tree to support keyed access One tree with all 3 kinds of information is more
efficient.

Key Concepts Scheduling Process Management and
Interprocess Communication Performance
Task switches are inevitable Processes have a great deal of state information
making task switches expensive Critical Sections
Buffer pool is a shared data segment. Problems arise if OS deschedules a DB process
holding a lock on the buffer pool. Server model
OS needs to provide a message facility for multiple processes to message a single process.
Server must do its own scheduling and multitasking.

Key Concepts Consistency Control
Many Operating Systems can only place locks at the file level.
DBMS prefer finer granularity. When DBMS implement its own buffer pool,
crash recovery by the operating system would be impossible.
Paged Virtual Memory Large files may not be able to be stored in
memory Binding chunks of the file into user space may
incur a performance loss.

Validation Content is mostly informational.
Based off previous papers and existing implementations of current systems.
Examples are cited primarily from the UNIX OS and the Ingres DBMS.
Issues could be biased and may not be common or applicable to all OS and DBMS combinations.

Assumptions Presents the topic as one that is applicable
to across a number of DBMS and OS
Author constrains his examples to UNIX and Ingres.
Paper was written in 1981. Operating Systems have advanced considerably since then. His points may no longer be applicable.

Changes if Rewritten Today Increase the diversity of operating systems
and DBMS
Add industry perspective. Are the problems Stonebraker presents really a problem for DBMS designers?
Quantify claims by providing statistical analysis of performance hits.

Chapter 3: Data Storage and Access Methods
Title: The R* Tree: An Efficient and Robust Access Method for Points and Rectangles
Authors: N. Beckmann, H. Kriegel, R. Schneider and B. Seeger
Pages: 207-216

The R* Tree: An Efficient and Robust Access Method for Points and Rectangles
Problem Problem Statement Why is this problem important? Why is this problem hard?
Approaches Approach description, key concepts Contributions (novelty, improved) Assumptions

Problem Statement – R* Tree Given
Data containing points and rectangles Spatial queries (point, range query, insert, delete)
Find - An Access Method (Data Structure) A hierarchical organization of rectangles Example from wikipedia
Objectives Efficiency of spatial queries
Constraints Balanced tree Each node is a disk page and has >= m (min # of entries)
entries. Root has at least two children unless it is a leaf Efficiency metric = number of disk-pages accessed

Why is this problem important?
Multi-dimensional Applications Large geographic data. e.g., Map objects like
countries occupy regions of non-zero size in two dimension.
Common real world usage: “Find all museums within 2 miles of my current location".
CAD …
Many DBMS servers support spatial indices Orcale, IBM DB2, …

Why is this problem Hard? B-tree split methods ineffective in 2-dimensions
Ex. Sorting
Size variation across data Rectangles Large rectangles limit split options!
Non-uniform data distribution over space
Dynamic Access Method Insertions and deletions Overlapping directory rectangles => multiple search paths

Novelty of Contribution Related Work
Traditional one-dimensional indexing structures (e.g., hash, B-tree) are not appropriate for range search
B+ tree Represents sorted data in a way that allows for
efficient insertion and removal of elements. Dynamic, multilevel index with maximum and
minimum bounds on the number of keys in each node.
Leaf nodes are linked together as a linked list to make range queries easy.

Novelty of Contribution Related Work
R-tree R-tree is a foundation for spatial access method A complex spatial object is represented by
minimum bounding rectangles while preserving essential geometric properties
Over-lapping regions Heuristic: minimize the area of each enclosing
rectangle in the inner nodes.

Principles of R-tree
Reference: A Guttman ‘R-tree a dynamic index structure for spatial searching’, 1984
Height-balanced tree similar to a B-tree with index records in its leaf nodes containing pointers to data objects.
Heuristic Optimization: minimize the area of each enclosing rectangle in the inner nodes.

Performance Parameters beyond R-tree (Q1) The area covered by a directory rectangle should be minimized.
(Q2) The overlap between directory rectangles should be minimized.
(Q3) The margin of a directory rectangle should be minimized.
(Q4) Storage utilization should be optimized.
Intuitions: Reduce overlap between sibling nodes. Reduce traversal of multiple branches for point query Reinsert old data changes entries between neighboring nodes and thus
decreases overlap. Due to more restructuring, less splits occur

Difference between R-tree and R*-tree
Minimization of area, margin, and overlap is crucial to the performance of R-tree / R*-tree.
The R*-tree attempts to reduce the tree, using a combination of a revised node split algorithm and the concept of forced reinsertion at node overflow. This is based on the observation that R-tree structures are highly susceptible to the order in which their entries are inserted, so an insertion-built (rather than bulk-loaded) structure is likely to be sub-optimal. Deletion and reinsertion of entries allows them to "find" a place in the tree that may be more appropriate than their original location. Improve retrieval performance

Example
R1
R2
R3
R5
R4
R1
R2
R3
R5
R4
R1
R2
R3
R5
R4
Preferred by R-tree
Preferred by R*-tree

Validation Methodology
Methodology Experiments with simulated workloads Evaluation of design decisions
Results R*-tree outperforms variants of R-tree
and 2-level grid file. R*-tree is robust against non-uniform
data distributions.

Summary Paper’s focus
R*-tree – implementations and performance
Ideas Heuristic Optimizations (pp. 208)
Reduction of area, margin, and overlap of the directory rectangles
Better Storage Utilization (pp 211) Forced Reinsertion (splits can be prevented)
Experimental comparison Using many data distributions

Assumptions, Rewrite today Assumptions
Indexing data in two-dimensional space Bulk load and bulk reorganization not available Concurrency control and recovery costs are negligible
Reinserts during split!
Rewrite today Bulk-load of rectangles Compare with newer methods
R+ tree (disjoint sibling), Hilbert-R-tree Analytical results
Formally compare R*-tree with alternatives

















