16
The Evolution of a Backend Data Platform Internet of Things Expo June 2016

The Evolution of a Backend Data Platform
Internet of Things Expo
June 2016
First some context
What is Fuze?
• A Unified Communications as a Service
provider (UCaaS)
• Provide voice, video, web collaboration,
messaging, contact center, and data
analytics services to enterprise customers.
• We replace on-prem pbx, video, and
messaging infrastructure with a global
cloud service.
• 800 employees, 1M users
Who am I?
• Derek Yoo
• CTO and co-founder of Fuze (10 years).
• Responsible for technology and product
strategy.
• Interested in building scalable cloud
platforms.
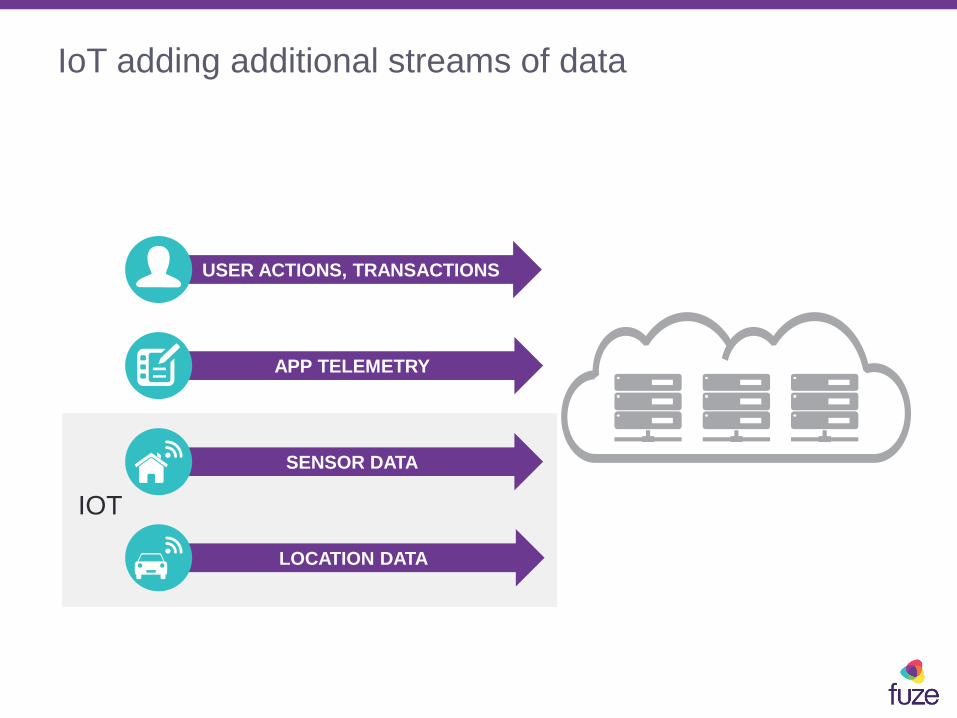
IoT adding additional streams of data
USER ACTIONS, TRANSACTIONS
SENSOR DATA
APP TELEMETRY
LOCATION DATA
IOT
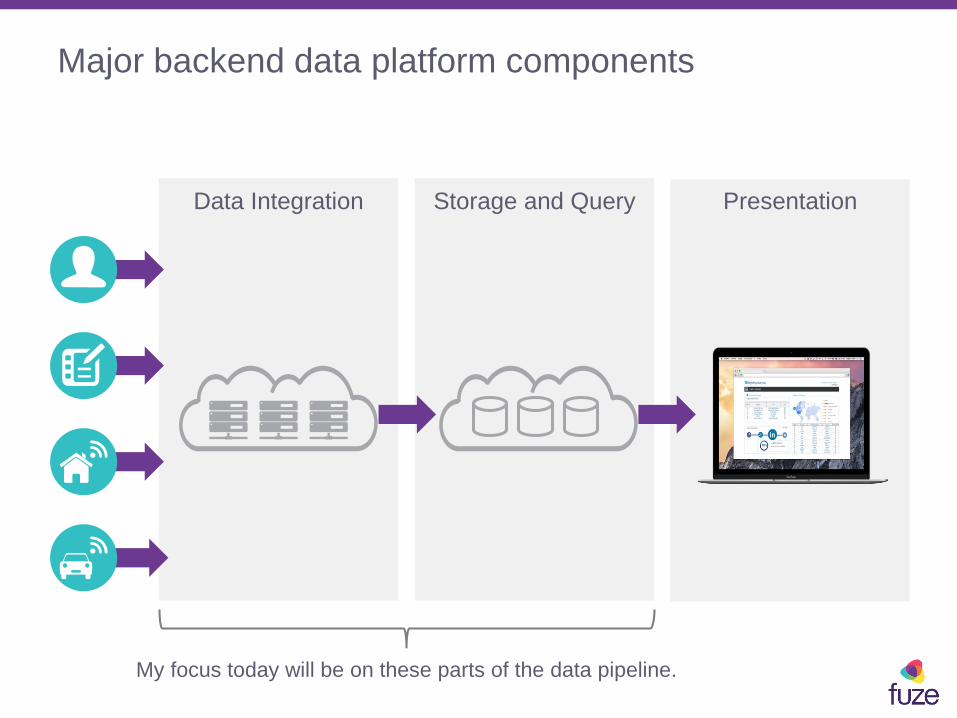
Major backend data platform components
My focus today will be on these parts of the data pipeline.
Data Integration Storage and Query Presentation
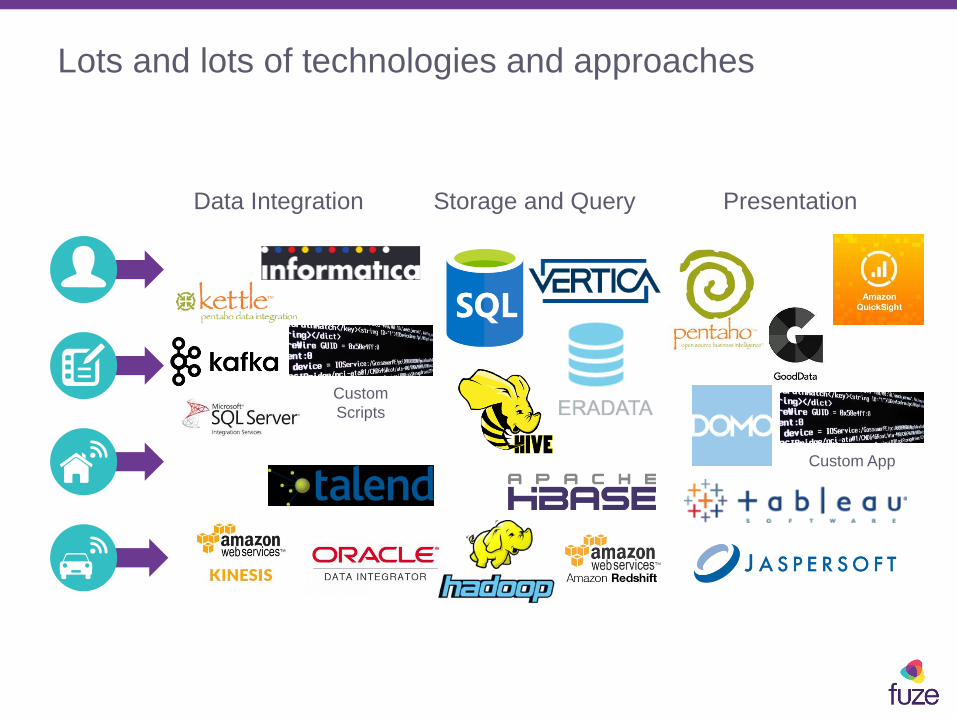
Lots and lots of technologies and approaches
Custom
Scripts
Custom App
Data Integration Storage and Query Presentation

Let me show you how ourbackend data platform has evolved
over time as we have scaled.
I hope you can draw insightsfrom this story to apply to your
own data initiatives.
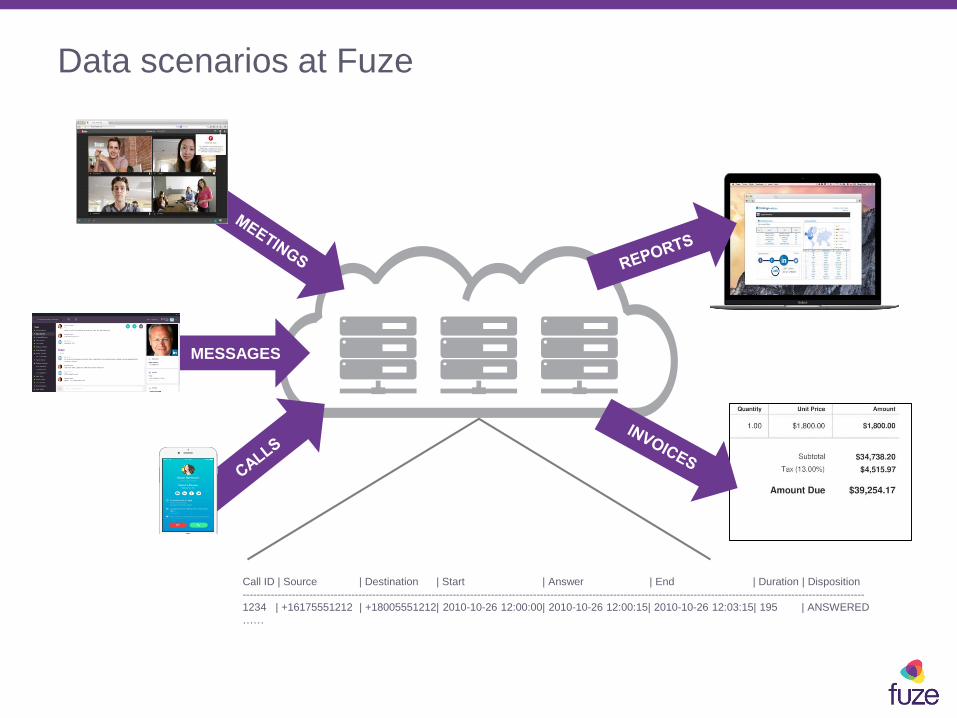
Data scenarios at Fuze
MESSAGES
Call ID | Source | Destination | Start | Answer | End | Duration | Disposition
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1234 | +16175551212 | +18005551212| 2010-10-26 12:00:00| 2010-10-26 12:00:15| 2010-10-26 12:03:15| 195 | ANSWERED
……
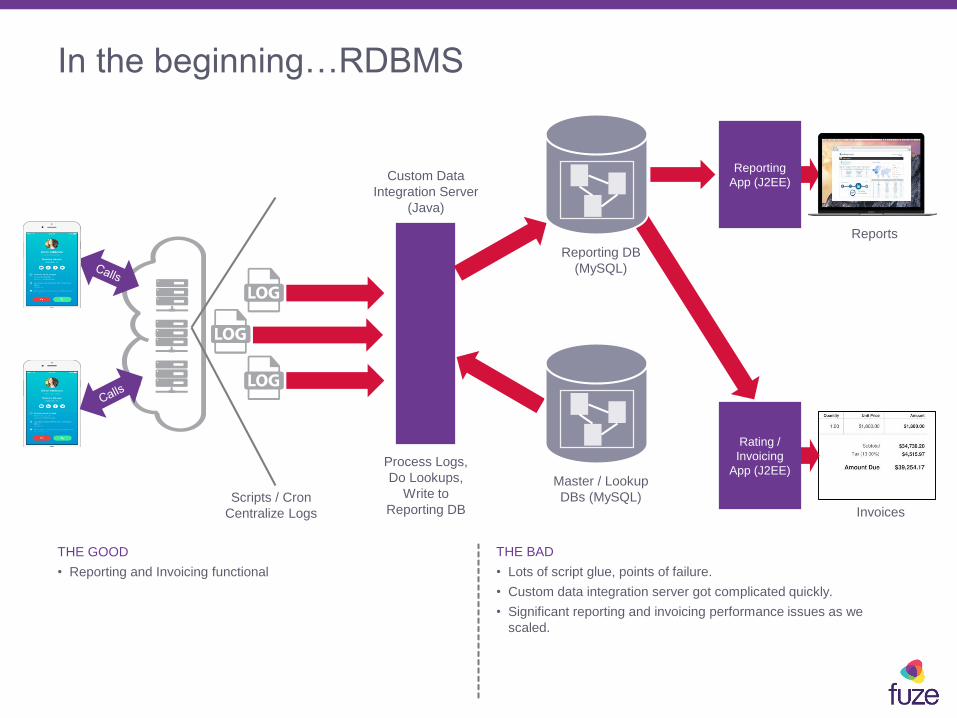
In the beginning…RDBMS
THE GOOD
• Reporting and Invoicing functional
THE BAD
• Lots of script glue, points of failure.
• Custom data integration server got complicated quickly.
• Significant reporting and invoicing performance issues as we
scaled.
Reports
Reporting
App (J2EE)
Invoices
Rating /
Invoicing
App (J2EE)
Scripts / Cron
Centralize Logs
Reporting DB
(MySQL)
Custom Data
Integration Server
(Java)
Process Logs,
Do Lookups,
Write to
Reporting DB
Master / Lookup
DBs (MySQL)
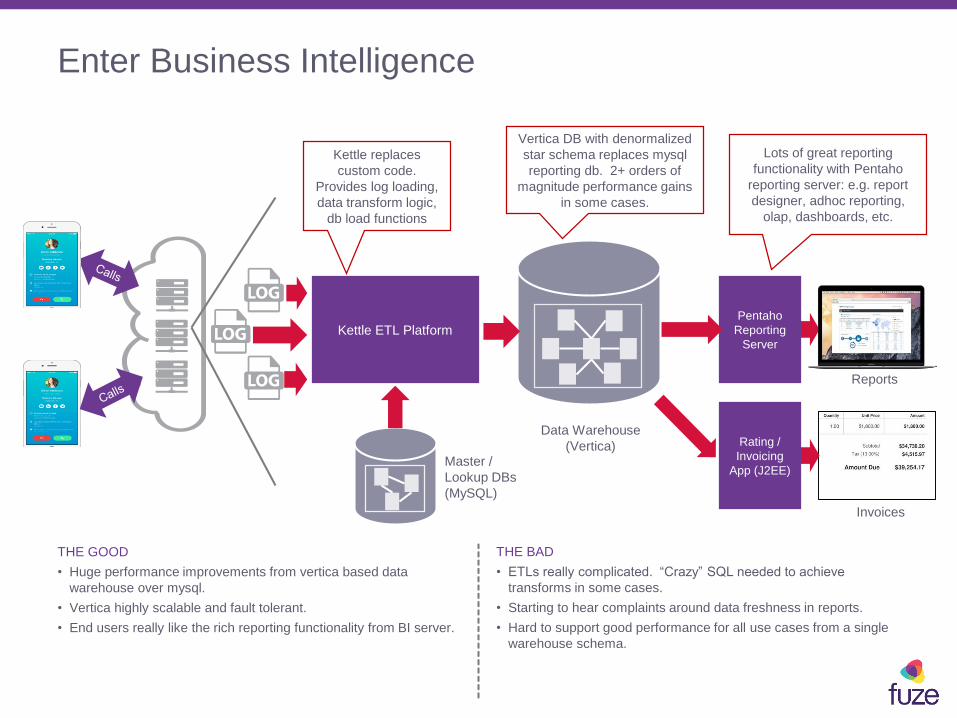
Enter Business Intelligence
THE GOOD
• Huge performance improvements from vertica based data
warehouse over mysql.
• Vertica highly scalable and fault tolerant.
• End users really like the rich reporting functionality from BI server.
THE BAD
• ETLs really complicated. “Crazy” SQL needed to achieve
transforms in some cases.
• Starting to hear complaints around data freshness in reports.
• Hard to support good performance for all use cases from a single
warehouse schema.
Reports
Pentaho
Reporting
Server
Invoices
Rating /
Invoicing
App (J2EE)Master /
Lookup DBs
(MySQL)
Data Warehouse
(Vertica)
Kettle ETL Platform
Kettle replaces
custom code.
Provides log loading,
data transform logic,
db load functions
Vertica DB with denormalized
star schema replaces mysql
reporting db. 2+ orders of
magnitude performance gains
in some cases.
Lots of great reporting
functionality with Pentaho
reporting server: e.g. report
designer, adhoc reporting,
olap, dashboards, etc.
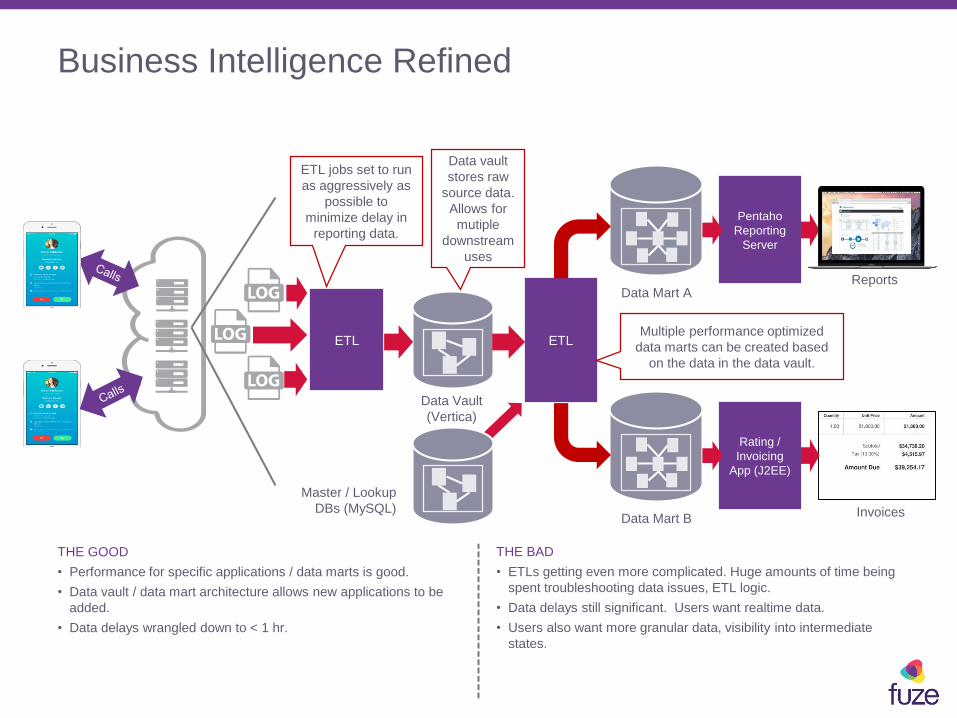
Business Intelligence Refined
THE GOOD
• Performance for specific applications / data marts is good.
• Data vault / data mart architecture allows new applications to be
added.
• Data delays wrangled down to < 1 hr.
THE BAD
• ETLs getting even more complicated. Huge amounts of time being
spent troubleshooting data issues, ETL logic.
• Data delays still significant. Users want realtime data.
• Users also want more granular data, visibility into intermediate
states.
Reports
Pentaho
Reporting
Server
Data Mart A
Invoices
ETLMultiple performance optimized
data marts can be created based
on the data in the data vault.
Rating /
Invoicing
App (J2EE)
Data Mart B
Master / Lookup
DBs (MySQL)
Data Vault
(Vertica)
ETL
ETL jobs set to run
as aggressively as
possible to
minimize delay in
reporting data.
Data vault
stores raw
source data.
Allows for
mutiple
downstream
uses

Making our reporting real-time
THE GOOD
• A few seconds delay before data shows up in reports.
• Java / Scala way better for complex logic than SQL.
THE BAD
• Have to port ETL logic from SQL to Java.
• Challenging to fix data problems (the source data can’t be
replayed).
Reports
Pentaho
Reporting
Server
Vertica
Kafka
Instrument feature
environment to
emit events in
addition to logs.
Storm writes processed
events into Vertica tables.
Data
Stream
Processing
(Storm)
Events go to a Kafka
queue. Event
producers can submit
as many events as they
have. Services
interested in event scan
pull them off the queue
at their own pace.
Storm provides stream
processing of events from
the kafka queue. Think of
it as stream ETL.
Master /
Lookup
DBs
(MySQL)
Events
Reports
Pentaho
Reporting
Server
Vertica
Data
Stream
Processing
(Storm)
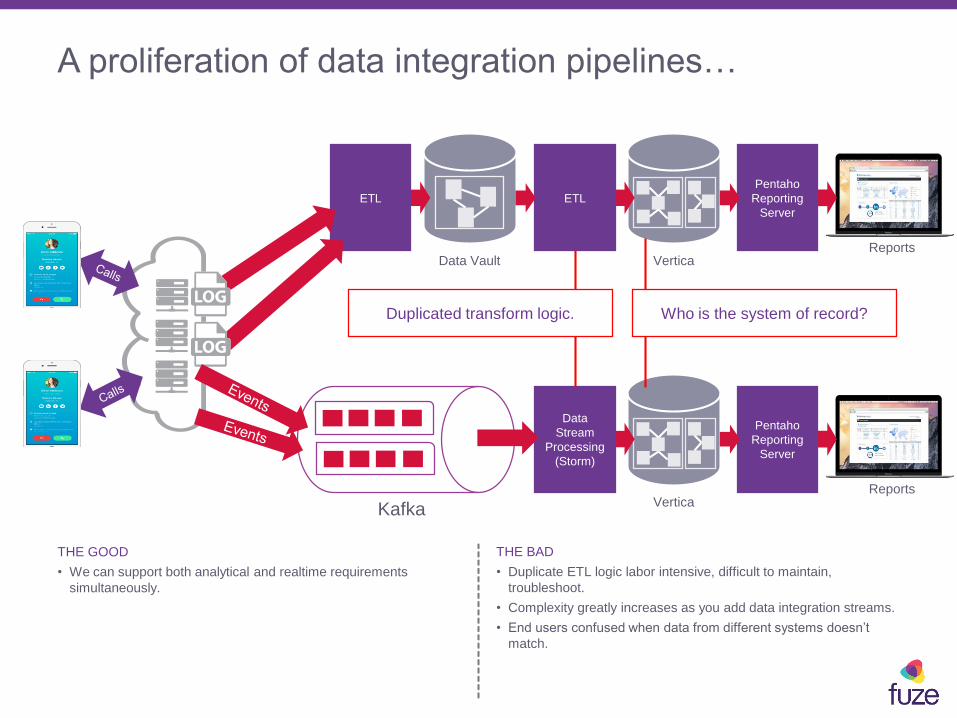
A proliferation of data integration pipelines…
THE GOOD
• We can support both analytical and realtime requirements
simultaneously.
THE BAD
• Duplicate ETL logic labor intensive, difficult to maintain,
troubleshoot.
• Complexity greatly increases as you add data integration streams.
• End users confused when data from different systems doesn’t
match.
Reports
Pentaho
Reporting
Server
Vertica
ETL
Data Vault
ETL
Kafka
Who is the system of record?Duplicated transform logic.

Towards a lambda architecture?
THE GOOD
• Single source for data reduces complexity, makes branching and
merging possible.
• Should provide the best of both worlds: data accuracy and
summarization from batch, timeliness from realtime.
THE BAD
• Duplicate ETL logic still labor intensive, difficult to maintain,
troubleshoot.
• The single reporting engine only covers a subset of the query
scenarios well.
Reports
Impala
HDFS
Reporting
App
Kafka
Data Stream
Processing (Storm)
Batch Processing
(ETL,
MapReduce)HDFS
Batch layer provides the
source of truthStore all raw data in Hadoop
Consolidate source
data into Kafka.
Speed layer integrates near
realtime data to the reporting
system. This data is replaced by
batch data when it arrives.
This is the system of record.
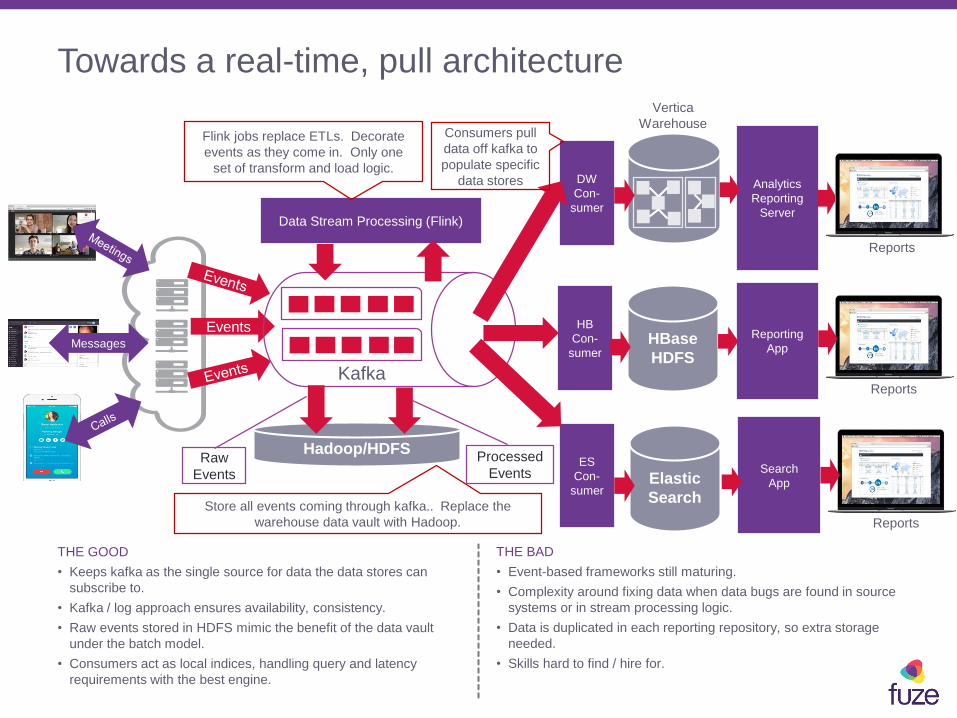
Towards a real-time, pull architecture
THE GOOD
• Keeps kafka as the single source for data the data stores can
subscribe to.
• Kafka / log approach ensures availability, consistency.
• Raw events stored in HDFS mimic the benefit of the data vault
under the batch model.
• Consumers act as local indices, handling query and latency
requirements with the best engine.
THE BAD
• Event-based frameworks still maturing.
• Complexity around fixing data when data bugs are found in source
systems or in stream processing logic.
• Data is duplicated in each reporting repository, so extra storage
needed.
• Skills hard to find / hire for.
Messages
Vertica
Warehouse
HBase
HDFS
Reporting
App
Reports
Analytics
Reporting
Server
Reports
Elastic
Search
Search
App
Reports
DW
Con-
sumer
HB
Con-
sumer
ES
Con-
sumer
Kafka
Events
Data Stream Processing (Flink)
Hadoop/HDFS
Store all events coming through kafka.. Replace the
warehouse data vault with Hadoop.
Flink jobs replace ETLs. Decorate
events as they come in. Only one
set of transform and load logic.
Processed
EventsRaw
Events
Consumers pull
data off kafka to
populate specific
data stores

Concluding thoughts
Takeaways
Make sure you have a clear data strategy and
architecture as part of your IoT project.
Lots of simplification in creating a single data
integration pipeline that consumers can
subscribe to.
Start with a real-time data integration strategy
if possible.
Be prepared to live with multiple query
engines optimized for different use cases.
Some reference points
LinkedIn (Jay Kreps)
https://engineering.linkedin.com/distributed-
systems/log-what-every-software-engineer-
should-know-about-real-time-datas-unifying
https://blog.twitter.com/2015/handling-five-billion-
sessions-a-day-in-real-time

Thinking Phone Networks, Inc.
54 Washburn Ave
Cambridge, MA 02140www.thinkingphones.com
David Laubner
UC PHONE :+1.617.649.1369
Email: [email protected]
Thinking Phone Networks, Inc.
10 Wilson Rd.
Cambridge, MA 02140
Facebook.com/thinkingphones
Thank You!















![LNCS 5154 - Divided Backend Duplication Methodology for ... · Divided Backend Duplication Methodology for Balanced Dual Rail Routing ... as smart-cards [4] ... Divided Backend Duplication](https://static.documents.pub/doc/80x56/5aee27d87f8b9ac62b8b9c1e/lncs-5154-divided-backend-duplication-methodology-for-backend-duplication.jpg)

