UPPSALA UNIVERSITET Nationalekonomiska institutionen Examensarbete magisteruppsats Master's Thesis Vårterminen 2007 The Forecasting Power of Economic Growth Models Author: Andreas Bryhn Supervisor: Johan Lyhagen
Transcript
UPPSALA UNIVERSITET Nationalekonomiska institutionen Examensarbete magisteruppsats Master's Thesis Vårterminen 2007
The Forecasting Power of Economic Growth Models
Author: Andreas Bryhn Supervisor: Johan Lyhagen
Abstract
High forecasting power is essential for understanding scientific relationships. In economics,
forecasting power may be decisive for the success or failure of a particular policy. The
forecasting power of economic growth models is investigated in this study. Regressions from
one dataset including the gross domestic product (GDP), GDP growth, trade openness, the
quality of public institutions and secondary education generate insufficient forecasting power
with respect to growth. Furthermore, the International Monetary Fund's one-year growth
forecasts are compared to outcome. Forecasts for 1999-2006 were found to be significantly
different from outcome during 7 years out of 8. The forecast error slightly exceeded 1
percentage unit, which is similar to results from earlier studies on forecast error and equal to
the forecast/hindcast error from a simple multivariate model constructed from historical
growth data. Possible reasons behind poor forecast quality are discussed, including the
tradition to build models using assumptions from irrefutable theoretical constructs.
Sammanfattning
Hög prognoskraft är nödvändigt för förståelsen av vetenskapliga samband. Inom
nationalekonomin kan prognoskraften vara avgörande för huruvida en viss ekonomisk politik
kommer att lyckas eller misslyckas. Ekonomiska tillväxtmodellers prognoskraft undersöks i
denna studie. Regressioner från ett dataset som innehåller bruttonationalprodukten, tillväxten
hos densamma, öppenhet för handel, offentliga institutioners kvalitet, samt andel
gymnasieutbildade, genererar otillräcklig prognoskraft med avseende på tillväxt. Vidare
jämförs Internationella Valutafondens ettårsprognoser med utfall. Prognoser för 1999-2006
var signifikant skilda från utfall under 7 år av 8. Prognosfelet uppgick till drygt 1
procentenhet, vilket motsvarar resultat från tidigare studier av prognosfel, liksom prognosfelet
från en enkel, flervariabelsmodell som är baserad på historiska tillväxtdata. Möjliga
anledningar till den låga prognoskvaliteten diskuteras, däribland traditionen att bygga
modeller med hjälp av antaganden från teoretiska konstruktioner som inte kan falsifieras.
1
TABLE OF CONTENTS
Page
1. INTRODUCTION
2. METHODS AND DATA
2.1. Statistical methods and considerations
2.2. The Gallup dataset
2.3. The IMF dataset
3. RESULTS
3.1. Cross-country growth regressions
3.2. The IMF's growth forecasts
4. DISCUSSION
5. CONCLUSIONS
REFERENCES
3
5
5
6
6
7
7
9
13
17
18
2
1. INTRODUCTION
Forecasting the future has been a highly desirable goal for humans ever since the Stone Age.
With the emergence and growth of science, our forecasting methods have improved
considerably, as forecasting power has become a fundamental part and a distinguishing
feature of scientific knowledge. The ability to make accurate forecasts of important goal
variables is essential for the understanding of scientific relationships, particularly with respect
to causality (Blaug, 1980; DeLurgio, 1998; Fildes and Stekler, 2002). High forecasting power
is necessary but not sufficient for causal analysis in economics, because strongly correlated
variables may have an external, cointegrating causal factor (Clements and Hendry, 1999).
Nevertheless, without high forecasting power, economists will have poor quantitative
knowledge about the effect of their suggested policies on, e. g., economic growth. Insufficient
forecasting power may therefore result in disappointing and expensive policy failure.
The forecasting power of a model can be estimated by calculating the correlation coefficient
(R2) for the relationship between model forecasts and actual outcome. Two crucial issues in
this context are (1) the relative quality of models; i. e., how much better is, e. g., R2 = 0.9,
compared to R2 = 0.8 in a regression between forecast and outcome, and (2) the lower limit of
acceptability, as measured in R2. If there is a large enough amount of data, a correlation with
R2 very close to 0 can still be significant at high confidence levels, but it will be just as
useless for forecasting as a correlation with R2 = 0, because in both cases, correlations will
describe a beeswarm-like scatterplot from which forecasts will have very high uncertainty.
One widely used lower limit of acceptability regarding R2 and forecasting power was first
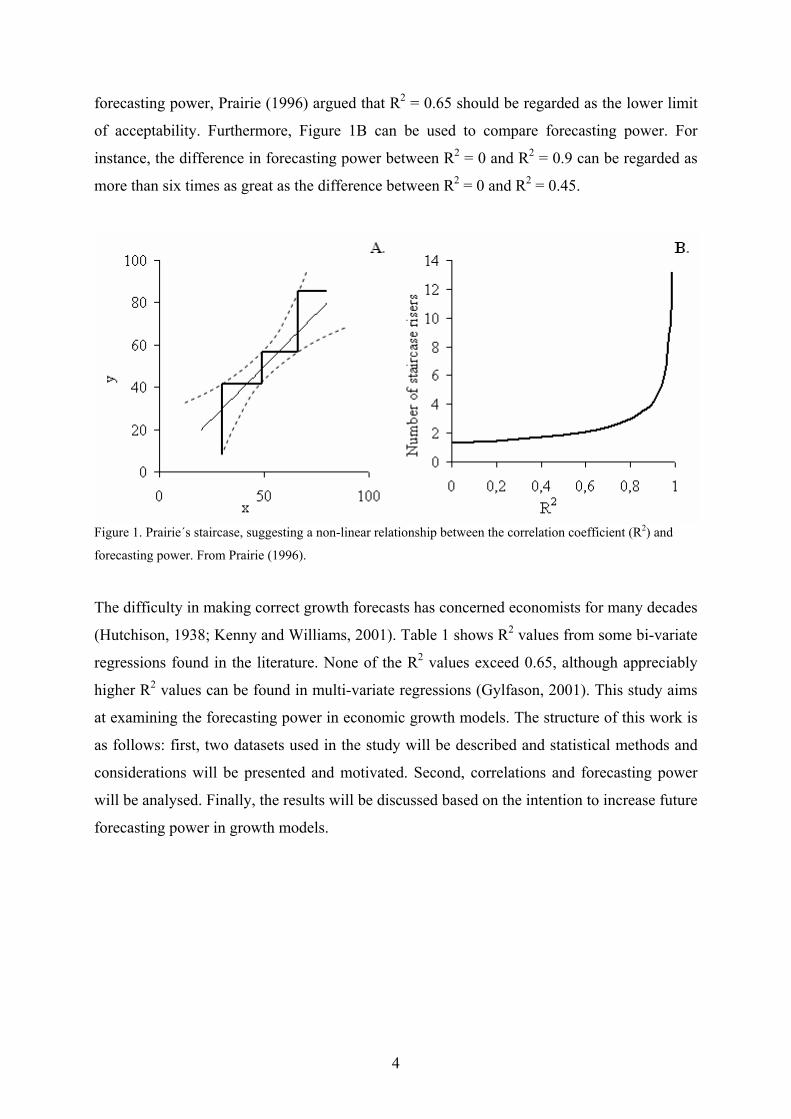
motivated by Prairie (1996), who presented what has become known in the natural sciences as
Prairie's staircase. Prairie's staircase method is illustrated in Figure 1A. A thick, solid line
starts at the lower boundary line of the 95 % confidence level from the regression and is
drawn upwards until it reaches the upper 95 % confidence limit, and is then drawn to the right
until the lower boundary line is reached again. This procedure is repeated so that the thick,
solid line takes the shape of a staircase (Figure 1A). When Prairie (1996) reiterated this
exercise for a large number of correlations, he found a non-linear relationship between R2 and
the number of staircase risers, which is depicted in Figure 1B. According to this figure, the
number of risers is low and fairly constant for R2 values from 0 to about 0.65, after which the
number rises rather dramatically. Using the number of staircase risers as a representation of
3
forecasting power, Prairie (1996) argued that R2 = 0.65 should be regarded as the lower limit
of acceptability. Furthermore, Figure 1B can be used to compare forecasting power. For
instance, the difference in forecasting power between R2 = 0 and R2 = 0.9 can be regarded as
more than six times as great as the difference between R2 = 0 and R2 = 0.45.
Figure 1. Prairie´s staircase, suggesting a non-linear relationship between the correlation coefficient (R2) and
forecasting power. From Prairie (1996).
The difficulty in making correct growth forecasts has concerned economists for many decades
(Hutchison, 1938; Kenny and Williams, 2001). Table 1 shows R2 values from some bi-variate
regressions found in the literature. None of the R2 values exceed 0.65, although appreciably
higher R2 values can be found in multi-variate regressions (Gylfason, 2001). This study aims
at examining the forecasting power in economic growth models. The structure of this work is
as follows: first, two datasets used in the study will be described and statistical methods and
considerations will be presented and motivated. Second, correlations and forecasting power
will be analysed. Finally, the results will be discussed based on the intention to increase future
forecasting power in growth models.
4
Table 1. Correlations between some x-variables and GDP growth or GDP per capita growth as a y-variable. x-variable Correlation sign R2 Reference Fertility - 0.61 Perotti, 1996 Liquid liabilities + 0.55 King and Levine, 1993 Private loans + 0.50 King and Levine, 1993 Investment + 0.35 Levine and Renelt, 1992 Natural resources - 0.28 Gylfason, 2001 Inequality - 0.22 Persson and Tabellini, 1994 Savings + 0.20 Levine and Zervos, 1998 Education + 0.17 Gylfason, 2001 Telecommunications + 0.17 Bougheas et al., 2000 Black market - 0.14 Levine and Renelt, 1992 Revolutions and coups - 0.13 Levine and Renelt, 1992 Bank credit + 0.12 Levine and Zervos, 1998 Paved roads + 0.11 Bougheas et al., 2000 War casualties - 0.10 Easterly et al., 1993 Inflation - 0.08 Carkovic and Levine, 2002 Government size + 0.06 Carkovic and Levine, 2002 Marginal tax + 0.03 Perotti, 1996 Trade + 0.02 Dollar and Kraay, 2001 Welfare spending + 0.01 Perotti, 1996 GDP + ≈ 0 Barro, 1996
2. METHODS AND DATA
2.1. Statistical methods and considerations
Relationships were analysed with single, and forward stepwise multiple, linear regression.
Stepwise multiple regression makes it possible to distinguish the strongest co-varying
parameter, followed by all other parameters that may add additional explanatory power to the
regression. Several potential x-variables can all show strong individual correlations with the
y-variable that they are being used to forecast, although these individual correlations may not
be additive if the x-variables are also correlated with each other. Multi-variate models may
take such co-variation between x-variables into account if they are developed with stepwise
multiple regression techniques (DeLurgio, 1998). Criteria for x-variables to be used to
forecast the various y-variables were (1) they had to correlate significantly with y-variables
individually as well as within the multiple regression and (2) these correlations had to be of
the same sign; i.e., an x-variable that was positively correlated with a y-variable was excluded
5
if its contribution in the multiple regression was negative, and vice versa. These criteria are
not commonly used in econometrics (DeLurgio, 1998) and their relevance will therefore be
discussed later in this paper. Changes in linear slopes were detected with a trend shift analysis
method from Rodionov and Overland (2005). This method consists of a downloadable
application to Microsoft Excel and makes it possible to detect at which points a trend changes
at a specified significance level, given that the trend changes at all. Statistical significance
was always determined at the 95 % confidence level, since Figure 1 is defined at that level.
2.2. The Gallup dataset
The first dataset (CID, 2007) of two used in this study has been described by Gallup et al.
(1999) and was used in regression 1, Table 3 in the same study. It consists of six variables;
average purchasing power parity (PPP) adjusted annual gross domestic product (GDP) per
capita growth between 1965 and 1990 (hereafter called yG), PPP adjusted initial GDP per
capita in 1965 (hereafter referred to as YG), average years of secondary schooling among the
population in 1965 (EduG), the log value of life expectancy (LifeG), openness to international
trade (OpenG), and finally, the quality of public administration (PublG). This dataset was used
in Section 3.1, first to estimate bi-variate correlations with yG, and subsequently, to
quantitatively assess multi-variate correlations with yG using the criteria stated in 2.1. The
dataset was then divided into groups according to the gradient of one variable which was
insignificantly correlated with yG, to investigate whether the effect of such a variable on other
regressions could be estimated without violating the criteria in 2.1.
2.3. The IMF dataset
The second dataset consisted of actual and forecasted data on PPP adjusted GDP growth in 29
advanced economy in 10 of the International Monetary Fund's (IMF) April or May issues of
World Economic Outlook (IMF, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006,
2007). In this work, yt denotes historical IMF data on growth at time t (in years), and it is
worth noting that IMF data are not given as per capita values, as opposed to yG. One-year
growth forecasts (yfort+1) were first compared to the actual outcome (yt+1) in a bi-variate
regression, and the resulting R2 value was compared to R2 values found between historical
data at the time of the forecast and yt+1.
6
A statistical model based on the presented historical data at the time of the forecast was then
used as a baseline from which to evaluate the forecast quality. This statistical model was
developed from a stepwise multiple regression with yt+1 as a y-variable and all historical data
available at the time of the forecast as potential x-variables. The baseline model was based on
the time period 1998 ≤ t ≤ 2004, i. e., on growth outcome from 7 years and 29 OECD
countries. In order to test the criteria in 2.1 by violating them, 100 normal distributed random
variables were added to the data set, allowing all significant x-variables to enter into the
forward stepwise multiple regression with yt+1 as a y-variable. If any of the random variables
would enter, then that would indicate that the criteria in 2.1 could decrease the risk of adding
nonsensical information to the regression.
The stability of the model constants were subsequently studied by omitting data from one year
at the time. Forecasts/hindcasts from the statistical model were tested against yt+1 by using
those model constants which were valid for all years except for the particular
forecast/hindcast year, in order to perform a test against "independent" data in the sense that
they were not used to develop the statistical model. For example, when hindcasting yt+1 for t =
2001, the model constants used were those that were valid for a multiple regression when t =
2001 had been omitted. Furthermore, the baseline model with constants valid for 1998 ≤ t ≤
2004 was tested to forecast yt+1 for t = 2005, a year from which data had previously not been
used at all in the study. These forecasts were compared to the IMF's forecasts (IMF, 2005)
and to the actual outcome (IMF, 2007). Finally, error terms from all forecasts and hindcasts in
this section were studied and compared.
3. RESULTS
3.1. Cross-country growth regressions
Table 2 displays cross-correlations (R2 values) between the six variables in Gallup et al.
(1999), described in Section 2. All correlations carried a positive sign. According to Table 2,
EduG, LifeG, OpenG and PublG were all mutually correlated and also positively correlated with
yG. YG was insignificantly - although, if anything, positively - correlated with yG.
7
Table 2. Cross-correlations (n=75) between six variables described in Section 2 and by Gallup et al., (1999). * =