The Queen’s Tower The Queen’s Tower Imperial College London Imperial College London South Kensington, SW7 South Kensington, SW7 6th Jun 2007 | Ashley Brown Real-Number Real-Number Optimisation: A Optimisation: A Speculative, Profile- Speculative, Profile- Guided Approach Guided Approach PhD Transfer Presentation 6 th June 2007
Transcript
The Queen’s TowerThe Queen’s TowerImperial College LondonImperial College LondonSouth Kensington, SW7South Kensington, SW7
6th Jun 2007 | Ashley Brown
Real-Number Real-Number Optimisation: A Optimisation: A
• Most useful applications use real-number algorithms– Chemical modelling– Weather forecasting– MP3 players– Mobile phones– Etc.
• Science Applications = Double precision floating point– 64-bit or 80-bit floating point ALU
• Embedded Applications = 32-bit fixed point– 32-bit integer ALU
# 2
6th Jun 2007 | Ashley Brown # 3
Introduction: Our FocusIntroduction: Our Focus
• Two distinct sets of requirements
• Embedded systems– High precision often not important (video/audio
processing)– Fixed point implementations possible
• Scientific computation– High precision extremely important– Reduction in precision or conversion to single prec.
must be done with great care– IEEE-754 floating point
6th Jun 2007 | Ashley Brown
What if….?
• What if we could make these applications run faster?
• What if we could shrink the hardware resources needed to run them?
• What if we could do it more aggressively than current methods?
• What if we took up gambling?
6th Jun 2007 | Ashley Brown
Introduction: Avoiding the Safe OptionIntroduction: Avoiding the Safe Option
• Standard formats (e.g. IEEE-754) are good for generality
• But, we can do better– Optimise data format for the job in hand– Use reconfigurable technology to change format on-
the-fly
• Static analysis steps must be conservative
• Formal proofs are also conservative
• We could be more daring!
# 5
6th Jun 2007 | Ashley Brown
Motivation
• Graphics cards have made highly parallel vector processors commodity items
• In the high performance computing world, FPGAs are available as acceleration cards– New Hypertransport cards provide faster communication
channels
• Both provide speed increases if used effectively– But graphics cards only have single-precision f.p.– Simply implementing double precision f.p. on FPGAs
provides no benefits
• Optimise aggressively to provide reduced f.p. capabilities, within needs of application
6th Jun 2007 | Ashley Brown
FPGA Focus
• FPGAs provide a good prototyping platform
• Exploiting reconfiguration may provide further benefits
• Limitations:– Clock-rates are much slower than attached
processors– Communication channels are typically slow
• Acceleration comes from parallelism
• The rest of this talk considers FPGA/custom hardware implementations
6th Jun 2007 | Ashley Brown # 8
The ProblemThe Problem
• Double precision floating point on FPGAs uses a lot of area
• Density is improving: but still want to squeeze more in!– Re-using hardware can reduce concurrency
• Scientific applications: typically 64-bit floating point
• Often full precision is (believed to be) required– Is this really the case?
• We have more options than single or double
6th Jun 2007 | Ashley Brown # 9
Current Solutions for F.P. minimisationCurrent Solutions for F.P. minimisation
• Finding ‘minimal precision’:– Tools such as BitSize– Select precision for some operands, tool calculates
the rest– Test vectors used to gauge errors
• Reducing hardware area:– Replacing floating point by fixed point, transparent
to user (Cheung et al.)– Solution above is dangerous in scientific
computations– Works in this case as trigonometric functions have
defined ranges
6th Jun 2007 | Ashley Brown
Current Solutions for F.P. minimisation (2)Current Solutions for F.P. minimisation (2)
• Approach by Dongarra et al– Inspired by Cell single precision f.p. performance– Use single precision most of the time with an
iterative refinement algorithm– When approaching convergence, switch to double
precision to finish off– Works on Cell and with SSE instructions
• Strodzka’s mixed-precision approach– Split loop into low and high preceision loops– Low precision computation loop– High precision correction loop
• Most expensive step: shifting for add/subtract– Operand alignment– Normalisation
• Set limits on alignment to reduce hardware size– Trap to software to perform other alignments
• Provisional results: only shift-by-4 required for some applications
subtract
s exp significand s exp significand
shift right
neg
abs
add
Align operandsImplicit leading ‘1’ must shifted in on left.
Swap OperandsSmallest operand gets shifted.
Compare ExponentsFractional parts must be aligned according to exponent different.
Add
Select ExponentLargest exponent used.
neg
s exp significand
exp significandNormaliseNormalise result, adjusting exponent as necessary.
6th Jun 2007 | Ashley Brown # 18
Alternative Representations #1: Custom Floating Alternative Representations #1: Custom Floating PointPoint
• No need to use 64- or 32-bit
• Use a compromise instead, maybe 48-bit is enough?
1 mantissa(52)exp(11)
1 mantissa(23)exp(8)
1 mantissa(38)exp(9)
IEEE Single
Custom
IEEE Double
• Can we drop the sign bit?
• Reduce hardware
• Reduce communications
subtract
s exp significand s exp significand
shift right
neg
abs
add
Align operandsImplicit leading ‘1’ must shifted in on left.
Swap OperandsSmallest operand gets shifted.
Compare ExponentsFractional parts must be aligned according to exponent different.
Add
Select ExponentLargest exponent used.
neg
s exp significand
exp significandNormaliseNormalise result, adjusting exponent as necessary.
6th Jun 2007 | Ashley Brown # 19
Alternative Representations #2: Fixed PointAlternative Representations #2: Fixed Point
• For very narrow ranges, fixed point may be an option
• Must be treated with extreme care
• Dual fixed-point format provides another possibility– Two different formats: different fixed point positions– 1 bit reserved to switch between formats
subtract
s exp significand s exp significand
shift right
neg
abs
add
Align operandsImplicit leading ‘1’ must shifted in on left.
Swap OperandsSmallest operand gets shifted.
Compare ExponentsFractional parts must be aligned according to exponent different.
Add
Select ExponentLargest exponent used.
neg
s exp significand
exp significandNormaliseNormalise result, adjusting exponent as necessary.
6th Jun 2007 | Ashley Brown # 20
FloatWatchFloatWatch
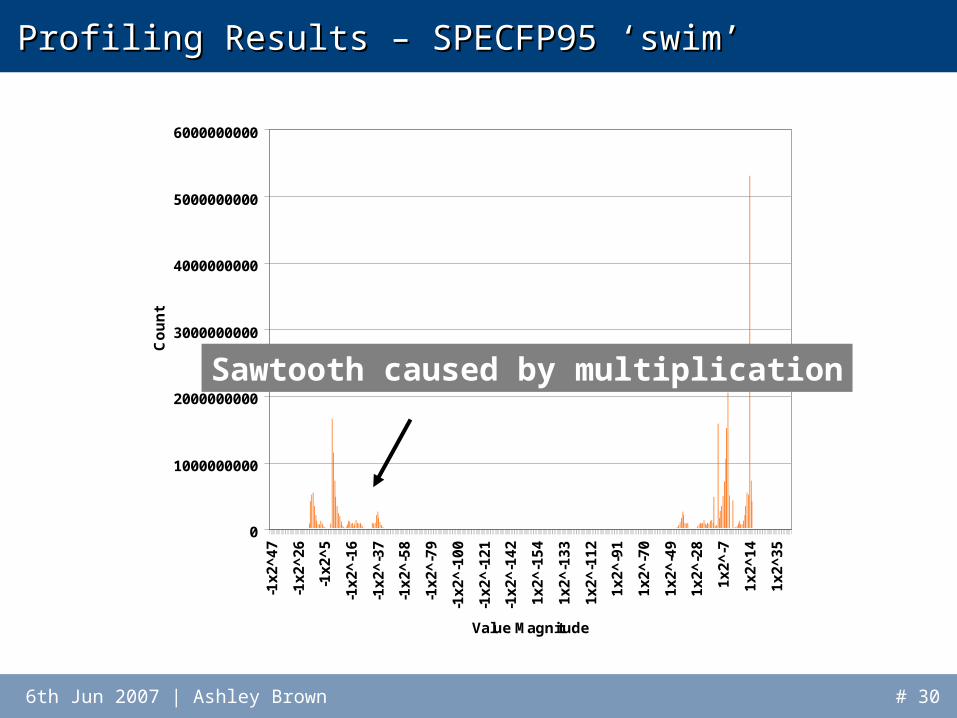
• Valgrind-based value profiler
• Can return a number of metrics:– Floating point value
ranges– Variation between 32-bit
and 64-bit F.P. executions
– Difference in magnitude between F.P. operations
• Each metric has uses for optimisation!
6th Jun 2007 | Ashley Brown # 21
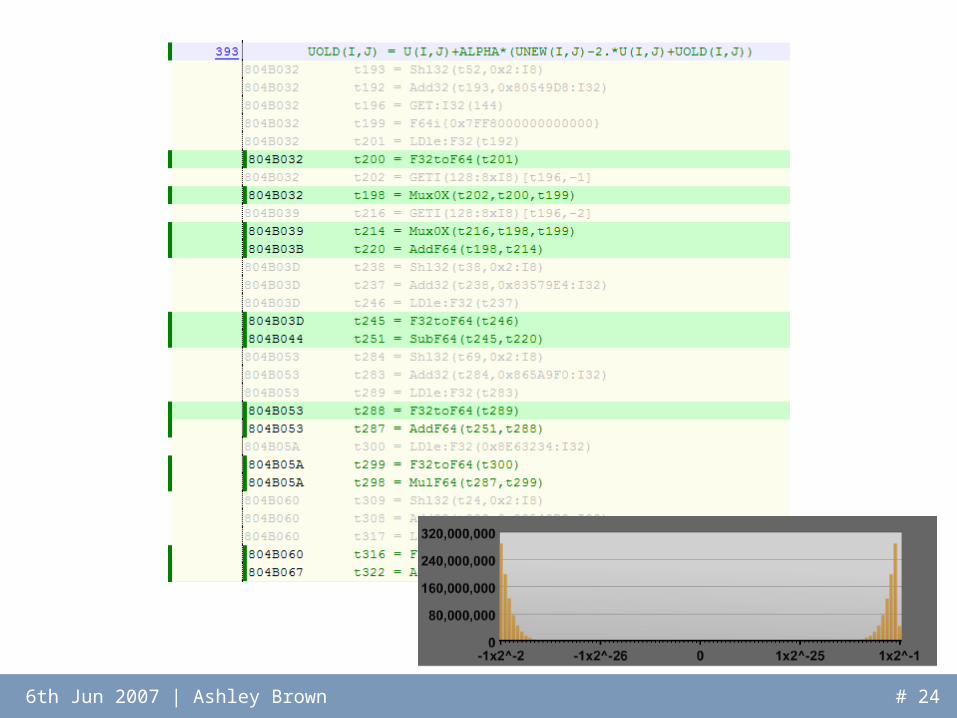
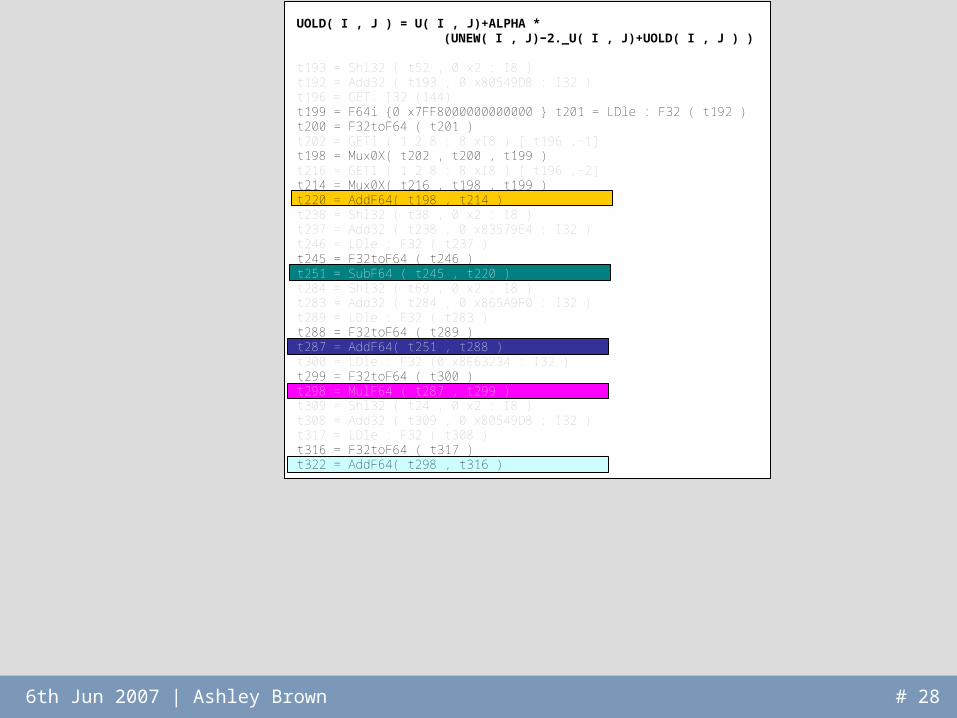
FloatWatchFloatWatch
• Operates on x86 binaries under Valgrind– x86 machine code
converted to simplified SSA– FloatWatch inserts
instrumentation code after floating point operations
• Dynamic modification of acceleration hardware– Exploit reconfigurability of FPGAs– Reconfigure device to meet application requirements
• Important considerations:– What happens to data already on the chip?
# 35
6th Jun 2007 | Ashley Brown # 36
““Pipeline Prediction”Pipeline Prediction”
• Similar concept to branch prediction
• Build a selection of pipelines with different performance characteristics– Slow but generic version– Fast version with limited range, reduced operand