45
Welcome
| Date post: | 27-May-2015 |
| Category: |
Documents |
| Upload: | ben-stopford |
| View: | 11,692 times |
| Download: | 0 times |
Welcome

Remember when it looked like this. They were all pretty much alike?

It used to be easy…

Now it’s quite
c0nfuZ1nG!


But it’s also quite
exciting!

We Lose: Joe Hellerstein (Berkeley) 2001
“Databases are commoditised and cornered to slow-moving, evolving, structure intensive, applications that require schema evolution.“ … “The internet companies are lost and we will remain in the doldrums of the enterprise space.” … “As databases are black boxes which require a lot of coaxing to get maximum performance”

What Happened?

The Web

With a lot of users.

we changed scale

we changed tack

New Approach to Data Access Simple
Pragmatic
Solved an insoluble problem
Unencumbered by tradition (good & bad)

With this came a Different Focus
Tradition • Global consistency • Schema driven • Reliable Network • Highly Structured
No SQL • Local consistency • Schemaless • Unreliable Network • Semi-structured/
Unstructured
NoSQL / Big Data technologies really focus on load and volume problems by avoiding the complexities associated with traditional transactional storage

The ‘Relational Camp’ had been busy too
Realisation that the traditional architecture was insufficient for
various modern workloads

End of an Era Paper - 2007
“Because RDBMSs can be beaten by more than an order of magnitude on the standard OLTP benchmark, then there is no market where they are competitive. As such, they should be considered as legacy technology more than a quarter of a century in age, for which a complete redesign and re-architecting is the appropriate next step.” – Michael Stonebraker

No Longer a One-Size-Fits-All

There is a new and impressive breed
• Products ~ 5 years old • Shared nothing (sharded) • Designed for SSD’s & 10GE • Large address spaces (256GB+) • No indexes (column oriented) • Dropping traditional tenets (referential integrity
etc) • Surprisingly quick for big queries when
compared with incumbent technologies.

Both types of solution have clear value
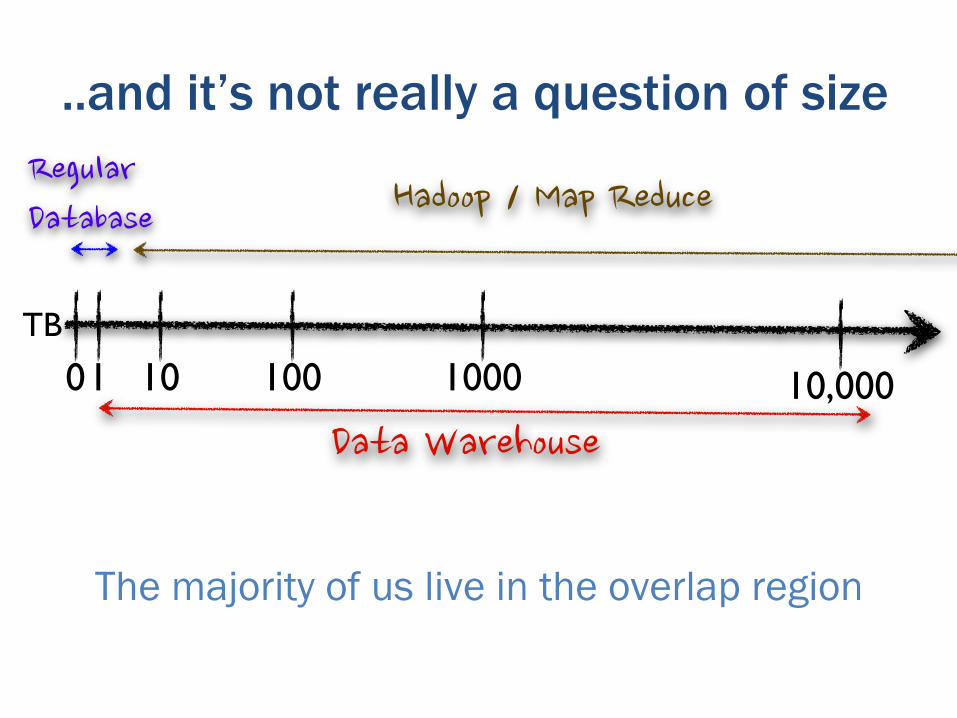
..and it’s not really a question of size
������������
����������������������������
1001010 1000 10,000
TB
The majority of us live in the overlap region

More a question of utility … which this tends to lead to
composite offerings

Compose Solutions
�������������
���������
�� ������� ����
������� �������������
�

So what does this mean for the enterprise?
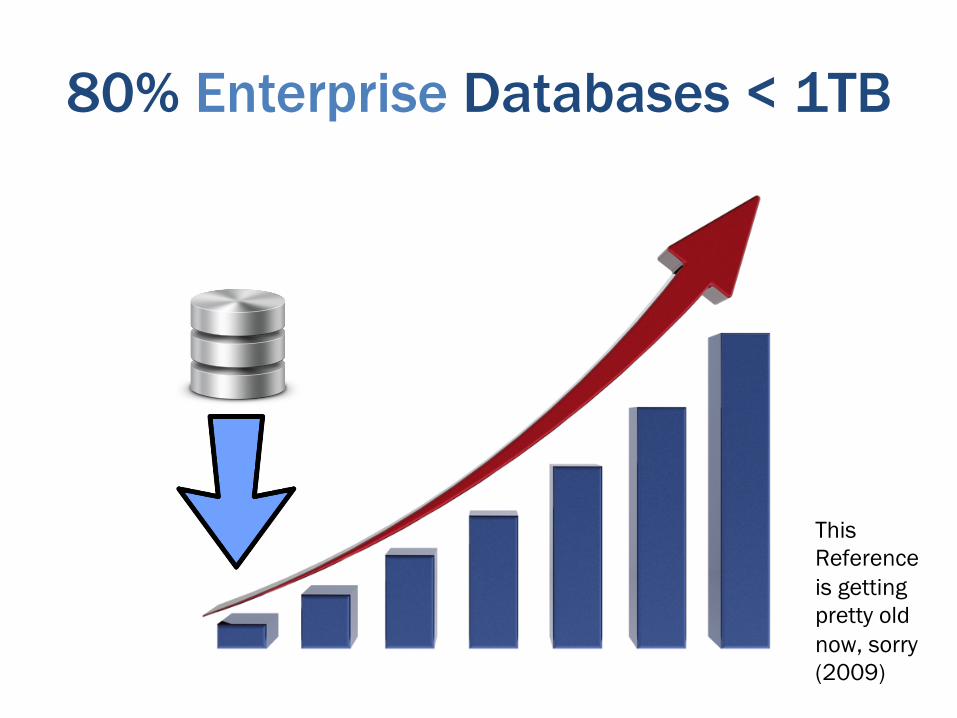
80% Enterprise Databases < 1TB
This Reference is getting pretty old now, sorry (2009)

Yet we often have a lot of them
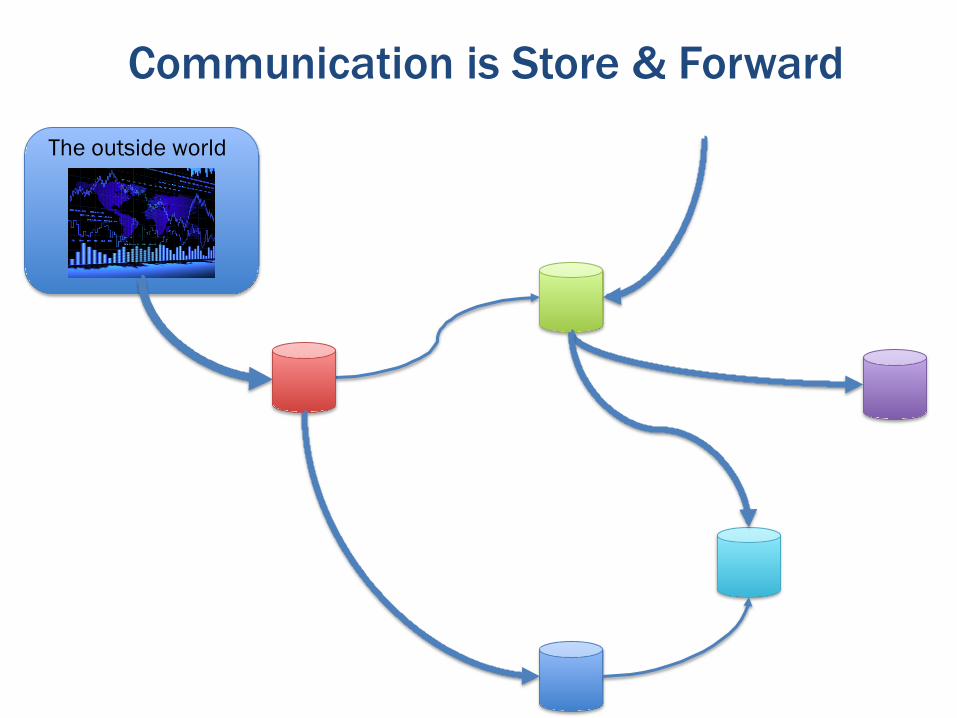
Communication is Store & Forward
The outside world

Sometimes we’re a bit more organized!

But most of our data is not that accessible
Exposed
Core Operational
Data
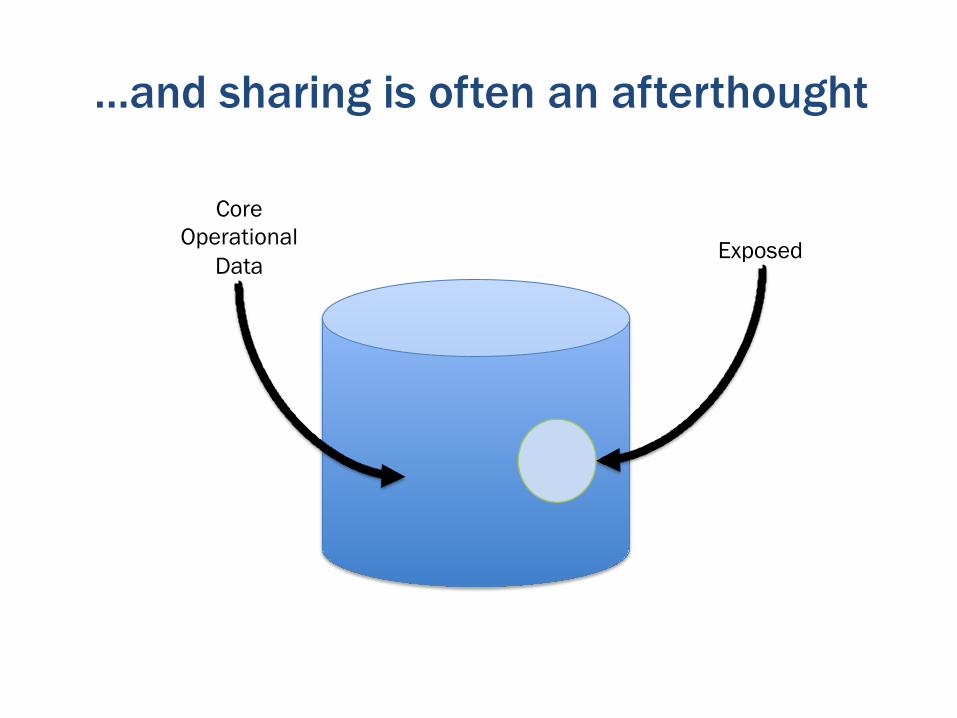
…and sharing is often an afterthought
Exposed
Core Operational
Data

Services can help

But as data is getting bigger and heavier

..it can make it hard to join data together

So we often we turn to some form of Enterprise Data Warehouse
(or maybe data virtualization)

Big data tech sometimes provides a composite solution (or ETL)
�������������
���������
�� ������� ����
������� �������������
�

Ability to model data is much more of a gating factor than raw size
Dave Campbell (Microsoft – VLDB Keynote 2012)
Importing data into a standard model is a slow and painful processs

An alternative is to use a Late Bound Schema

Combining structured & unstructured approaches in a layered fashion makes the process more nimble
Structured Standardisation
Layer
Raw Data
Late Bound Schema

We take this kind of approach
• Grid of machines • Late bound schema • Sharded, immutable data • Low latency (real time) and high throughput
(grid) use cases • All data is observable (an event) • Interfaces: Standardised (safe) or Raw
(uayor)

Both Raw & Standardised data is available
Object/SQL Standardisation
Raw Data
RelationalAnalytics
Operational (real time / MR)

This helps to loosen the grip of the single schema, whilst also providing a more iterative
approach to standardisation

Support for both one standardised and many bespoke models in the same technology
Standardised Model
Raw Facts from different systems

Next step: to centralise common processing tasks
Standardised Model
Risk Calculation

Are we back to the mainframe?

Thanks
http://www.benstopford.com

















