The Use of Trust in Social Machines Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science (M.S.) in Exact Humanities by Arpit Merchant 201156117 [email protected]Center for Exact Humanities (CEH) International Institute of Information Technology Hyderabad - 500 032, INDIA July, 2017
Transcript
The Use of Trust in Social Machines
Thesis submitted in partial fulfillmentof the requirements for the degree of
It is certified that the work contained in this thesis, titled “The Use of Trust in Social Machines”by Arpit Merchant, has been carried out under my supervision and is not submitted elsewherefor a degree.
Date Adviser: Prof. Navjyoti Singh
To Lata Merchant
(the bravest person I have ever known)
Acknowledgments
First and foremost I would like to thank my mother, Lata Merchant. I will never be able toexpress fully my gratitude in these pages for the unwavering support, belief and love that shegave me. Her tolerance towards my whims, her happiness at even the smallest of victories andher unlimited reservoir of courage inspired me to push through the challenges presented by thethesis and I would not be here if not for her. I love you, mummy. Forever and always.
Being away from home for five years, especially during the difficult moments was made a lit-tle easier because I knew I could rely on my sister Priyal, my dad Drumil and my grandparentsMinaben and Niti. Thank you so much for being there for me and for taking care of everything.This thesis would never have been completed if not for you. This thesis is dedicated to you,my family.
I would like to specially thank Prof. Navjyoti Singh for the guidance, support, and nurturingthat he provided me with during my undergraduate and graduate studies. He taught me howto explore different perspectives of a problem, how to look at the bigger picture and how topursue your dreams. Having him as my adviser was a truly unique experience that I willalways remember. I learned a great deal from it.
I want to express my gratitude to my friend and colleague Tushant Jha. I remember beingstuck with my work on countless occasions and going to him for advice and stimulating dis-cussions on pretty much every topic under the sun. It was one such occasion that led us to writeand submit a paper together (which got accepted). That ended up becoming the centerpiece ofmy thesis and I am so glad to have had his help. I would also like to thank Darshit Shah, VatikaHarlalka and Anurag Ghosh who helped me with some of the work contained in this thesis.
IIIT, Hyderabad provided me with a wonderful environment for research and for the friends Imade who stuck by me through everything. I am immensely grateful to Sindhu and Shivani forthe ‘30-second elevator pitch’ and the rest of EHD2k11 for being the perfect branch-mates with
v
vi
whom I cribbed, procrastinated, had fun and worked because we were all in the same boat. Iwant to sincerely thank Mohit Goel and my other dual-degree friends: Anirudh Tiwari, ManishShukla, Arnav Sharma, Naman Govil, Piyush Bansal, Vanshdeep Singh and Tejas Shah for theall amazing fun times and for being there for me when I needed it the most. I also especiallythank Srishti Aggarwal for making the year just that much more serene, beautiful and special.And lastly, I’d like to thank the other members of the Coffee Club, Akanksha Srivastava andAbhirath Batra for the caffeine-charged antics we pulled over the years.
Abstract
Trust is a complex human attitude that forms a vital, yet common component of nearlyevery aspect of human social behaviour. As a concept, it has been studied in various disci-plines of humanities in a myriad of different ways, while its use in computer science domainshas met with limited degrees of success. Over the years, it has been observed however, thattrust-aware models offer relevance, transparency and usability in real-world applications. Withcomputational systems becoming increasingly intelligent, and web-based social networks hav-ing become ubiquitous in today’s global society, contemporary new dimensions of trust haveemerged. The transformation of the internet into a social web has made it important to under-stand what trust means in the online world. In this thesis, we aim to extend a formal theory oftrust in the context of social media (in an attempt to bridge the gap between its understandingin the humanities and computer science) and explore its viability in designing better socio-technical systems.
We first detail the intricate nature of trust based on theories in philosophical literature. Wediscuss how trustworthiness of the trustee, risks, expectations of the trustor, motives, incentivesand skills factor into the attitude that is trust. We discuss ontological and epistemological per-spectives such as where trust exists, how do we know what we trust and where its value comesfrom. We also study its relation to the utilitarian moral theory to see how we can maximizebenefits through good actions. Grounded in these ideas, we argue for the important role playedby it in the effective working of large-scale social networks. We outline a novel multi-classtaxonomical framework comprising of personal, social and functional elements of trust. Weidentify how individual traits of users, collective behaviours of communities and the structuralcapabilities of the technologies, all contribute to the creation of trust. We expound on the in-tricate relationships between these three elements and show how institutions, digital semioticsand value-aligned technologies form strong theoretical and philosophical underpinnings in thedesign of these systems.
vii
viii
Having built the framework, we then depict its feasibility and relevance to real-world sys-tems through a case study of Wikipedia. We investigate how the different elements of trustmanifest themselves in Wikipedia. We illustrate themes such as purpose, content, systems de-sign, tasks, etc. and demonstrate the usefulness of the taxonomy in understanding where andhow trust originates, and why readers and editors alike have faith in Wikipedia. And lastly,we use elements of the framework along with machine learning and tensor factorization meth-ods to propose a novel, hybrid, trust-based recommendation model to suggest a personalizedlist of items to users. We present experimental evaluations of our model on a dataset of TEDvideos and show that it outperforms standard existing collaborative filtering and trust-basedapproaches. Moreover, subjectively speaking, it scores high on user satisfaction based on pop-ularity, diversity and freshness.
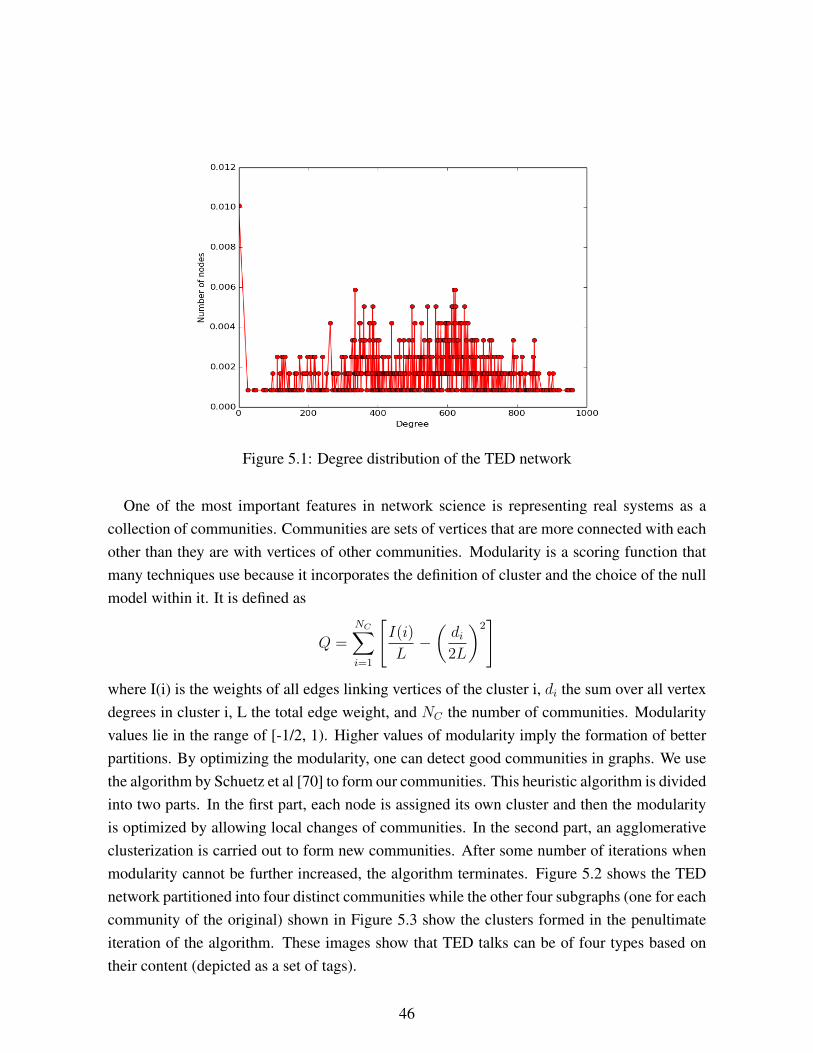
5.1 Degree distribution of the TED network . . . . . . . . . . . . . . . . . . . . . 465.2 TED Network Graph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475.3 The subcommunities of the four clusters of the TED video graph in Fig 5.2.
Each of these subcommunities can be further subclassified as can be seen fromthe coloured clusters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.4 Subjective evaluation of Global Trust (Blue), Social Trust (Red), Random (Yel-low) and Hybrid (Green) models based on popularity, diversity and freshnesscriteria to gauge user satisfaction. . . . . . . . . . . . . . . . . . . . . . . . . 49
xi
List of Tables
Table Page
4.1 Trust Constructs of Wikipedia as a Social Machine . . . . . . . . . . . . . . . 32
5.1 Accuracy of three baseline approaches, competing methods and the Hybridmodel proposed in this work. These models are evaluated for the top-10 andtop-20 recommendation tasks. . . . . . . . . . . . . . . . . . . . . . . . . . . 48
xii
Chapter 1
Introduction
Your corn is ripe today; mine will be so tomorrow. ’Tis profitable for us
both that I shou’d labour with you today, and that you shou’d aid me
tomorrow. I have no kindness for you, and know that you have as little for
me. I will not, therefore, take any pains on your account; and should I
labour with you on my account, I know I shou’d be disappointed, and that
I shou’d in vain depend upon your gratitude. Here then I leave you to
labour alone: You treat me in the same manner. The seasons change; and
both of us lose our harvests for want of mutual confidence and security.
— David Hume, Treatise on Human Nature, III, Section 5
Trust is an extremely important, yet common notion that everyone uses. We depend on itfor our relationships with people, for advice, for getting jobs done, etc. Trust is also dangeroussince when it is betrayed it results in the loss of the expected outcome as well as the belief andrespect on the trustee. We rely on trust every day and the very idea of a society implies theexistence of trust within its members.
Trust is not a new object of inquiry and indeed has been studied for centuries as is illustratedby the opening quote of this chapter. Hume (1740) discusses a social world that is borne out ofnatural trustworthiness. Human beings are naturally selfish, or at the very least endowed withconfined generosity, he says. One does not easily agree to perform actions for strangers unlessone expects to get something of value in return. We are not capable of solving every singletask by ourselves and neither do we wish to. So we rely on others to assist us while we tooreciprocate in some manner. We only go so far as to fulfill the basic requirements and we do
1
not act for their gratitude. Help from the other is the need of the hour and lack of cooperationcan be detrimental to all participants. These exchanges are not restricted to monetary valueonly and as such can range from social to cultural and even political capital and barter. Andsince generally most such transactions do not end at the same time, one of the parties mustnecessarily remain in uncertainty of the other finishing their task. This is the birth of trustbetween them.
Where does this trust then reside? How is trust maintained? In Leviathan (1651), Hobbesdiscusses interpersonal relations. He says that when one relies on one’s ability to know thetruth and of the other’s honesty, the discourse shifts to the belief or opinion of the veracityof each other. Saying ”I believe him. I trust him. I rely on him.” speaks to the virtue ofthe other as much as it does on one’s expectation of said virtue. And we tend to increase ordecrease trust based on repeated interactions over time and evaluation of new information asit speaks to our expectations. However, Hobbes also maintains that simply personal beliefsare not adequate for the progress of society and argues for the necessity of a higher authoritythat enforces contracts. And so the dominant paradigm of trust shifts from interpersonal, andexpands to include governments, independent third parties and in today’s world, even artificialintelligence.
This is not to say that nobility and friendship are rendered inconsequential. One may stillperform services for those one loves without regard for a reciprocal advantage or recompensefor services rendered. On the contrary, by acting selflessly onerous, one lays down the res-olution that that is convention in the particular relationship and there would be no motive orobligation henceforth. As a result, after these signs are instituted, a promise or treaty is forgedand one becomes bound by these engagements. And thus when we say ”I have faith in him.”,it speaks of trust. It should be noted that this applies not just to two individuals, but in fact toany two entities and on very large, global and even universal scales.
These ideas laid the foundation for the study of trust and through investigations in differentfields such as sociology, polity and economics, trust has evolved into a pervasive, complexentity lending meaningful influences. With the extensive integration of computer science intonearly every other domain and in particular social networks, it has become extremely importantto study the evolution of the notions of trust in order to understand the schemes of actions andorigins of real, natural and artificial operations in the modern world.
2
1.1 Trust in Computer Science
Trust is a widely used term in computer science whose definition varies according to domainand researcher. While trust is fundamentally a human notion, it can be used to design policiesand protocols so as to create a multi-stage process wherein the input data is verified to be trust-worthy, the internal mechanisms are made cooperative and the final output deemed reliable.We present below some illustrative examples of its applications.
Crytography relies on the safe and secure transmission of data from one entity to another.When Alice wants to send some information securely to Bob, she needs a trustworthy androbust transmission protocol to withstand eavesdropping as well as vandalism, trust that theinformation will reach the correct destination and trust that only the intended recipient Bob isable to decipher the message. On the other hand, Bob needs to be able to trust that the sourceof the information was indeed Alice and that it was not corrupted in the middle.
Related problems in information security can oftentimes be modeled as strategic interactionsbetween the attackers and defenders in various situations. Attackers try to breach the securitywhile the defenders attempt to take appropriate precautions to prevent damage to the systems.In such cases, groups of attackers and defenders cooperate amongst themselves to competeagainst the opposite groups to maximize their utility [37]. Here, privacy which is the abilityto control what information the players reveal about themselves, becomes vital in adapting theframeworks to real-world scenarios. These players need to disclose some private information inorder to establish trust. This causes a tension between security and trust in computer networks.One of the most popular class of models involves designing strategies for rational users that tryto establish data-centric trust in the presence of rational adversaries.
Human beings don’t always have all the information and the logical capabilities to decide onan optimal strategy in any given particular situation. Game theory is one of the most remark-able mathematical theories for modeling human interactions especially because it can capturecomplex situations such as bounded/limited rationality and incomplete information [74]. Itprovides tools for analyzing the decision making process when agents compete for shared re-sources. Each agent has his/her own set of preferences and here we rank the preferences byassigning different weights to the different factors that people take into account while choosinga strategy. This choice of weight may be aimed at maximizing one’s own personal payoff, butis founded upon principles of altruism, fairness and trustworthiness. For instance, in an itera-tive game, where the goal is to optimize over multiple rounds, agents increase or decrease the
3
weight they assigned to other agents in the previous round based on the outcome of the roundand how well their trust and expectations were rewarded or penalized [61].
In the case of distributed systems, most users and large organizations in particular, hesitatebefore using an anonymity infrastructure that they do not have control over. Using the Internetis also not a very good viable option because, on such an open network a system that handlesthe traffic for one organization will not be able to hide the traffic entering or leaving thatorganization. Instead, we have to distribute trust by asking each party to run a node on ashared infrastructure. Such a decentralized model would allow the smaller organizations to beable to participate easily as well [76].
Trust is being increasingly modeled and studied in social networks and the semantic web ingeneral, as well [38]. It has found applications in designing systems such as Epinions1 whichis a consumer review site where users can express explicit trust ratings about other reviewersand their reviews. And various trust propagation metrics have been developed to understandhow trust spreads amongst users in online networks.
Thus it is safe to say, that Trust is an important and popular field of study.
1.2 Motivation
Trust in different domains of computer science, as we saw in the previous section, has beenused in very specific ways that are suited well to resolve the issues that arise in those fields.The definition of trust in distributed systems may not necessarily work in game theory andvice versa. However, the last decade has seen the internet and the world wide web transformfrom being a tool to something more, something that has permeated nearly every aspect of ourlives. The individual fields of computer science are no longer in vacuum within themselves.Interdisciplinary and transdisciplinary connections between them have sprung up and led toholistic applications of tools and techniques of one field in some other field. As a result, everysingle system has already undergone or is currently undergoing a paradigm shift. Somethingas mundane as hailing taxis on the road has changed to using a technological device that usesthe internet to speak nothing of wireless monetary transactions, ordering food, connectingwith other people and other fundamental human actions. We have moved towards an intricateintegration of people and technology so much so that it is becoming difficult to talk about
1http://www.epinions.com/
4
one without referencing the other. And now with advances in machine learning and artificialintelligence, we have technologies that aid humans in ways that only other humans could inthe past. For example, recommender systems on movie streaming services such as Netflix havecreated not just an online library but also a personally tailored library assistant who can suggestnew titles based on past history.
A prime example and consequence of this transformation are social media sites. Social me-dia sites are a dime a dozen today with mainstream ones such as Facebook, Google+ that allowpeople to connect with one another to Quora and Stack Overflow that serve as question-answerplatforms to information collection and dissemination sites such as Wikipedia, Wordpress,Twitter, etc. These are not static or even simply dynamic websites. People and these tech-nological platforms have both evolved by coming together to define new norms of governance,rules of engagement, traditions and etiquette. Moreover, these massive entities interact witheach other in different ways that feel seamless. People today, get their news from Facebookand Twitter, refer to Wikipedia for their dose of knowledge and as such use these networks asa lens to see the world. Thus, these socio-technical systems have become societies with realpeople on a global scale.
As a result, it has become increasingly important to understand how these systems are built,their underlying design principles and motivations, and their impact on the people (and thereal world). Computational Social Science, Social Computing and Social Network Analysisemerged as fields of study that deal with these very issues by using the theories developed inhumanities to inform ideas in computer science and also use tools from computer science toextend knowledge in the humanities. Intuitively, even at first glance, one can observe that thedefinitions of trust in traditional fields of computer science are extremely narrow as comparedto the abstract human notion we know it to be. Clearly, these definitions fall utterly short whenapplied in the context of social networks.
Our motivation in this thesis, is to find out what it trust means in online social networks(OSNs) so that we can understand what factors cause the gain or loss of trust between the usersand the systems themselves, understand what actions to perform in order to influence the effectof those factors, and finally evaluate how we can use trust information to design systems thatallow for healthier, more effective communication and interaction.
5
1.3 Results and Structure of This Thesis
The presentation of the results of this thesis is divided into two main parts. The first part fo-cuses on humanities aspect of trust and the use of the relevant theories towards a holistic modelof trust in social networks and social machines. The second part is concerned with the appli-cations of the model to a case of study of Wikipedia and for the design of a recommendationsystem.
Chapter 2 - Philosophy of Trust. We start by providing basic definitions of trust, as well asdescribing some of the theories and concepts that are used in the rest of the thesis and/or formthe basis of our model. We introduce the notion of trustworthiness and detail a discussion of thefundamental difference and nature of its relationship to trust. We portray the ontological andepistemological foundations of trust. We introduce the two different values of trust that makeit such a powerful attitude. Finally, we explain the connection between trust and the utilitarianmoral theory which plays a crucial role in our solution to the problem of trust.
Chapter 3 - Multidimensional Framework for Trust in Social Machines. We turn our at-tention to Social Machines (SMs) (a term coined by Tim Berners-Lee) which are a naturalgeneralization of social networks. We define the problem of trust in the context of SMs. Wedevelop a novel taxonomical framework for understanding the different ways in which trustmanifests itself in SMs by building on past work. We provide solutions to the problem of trustbased on the role of institutions, digital semiotics and value-alignment.
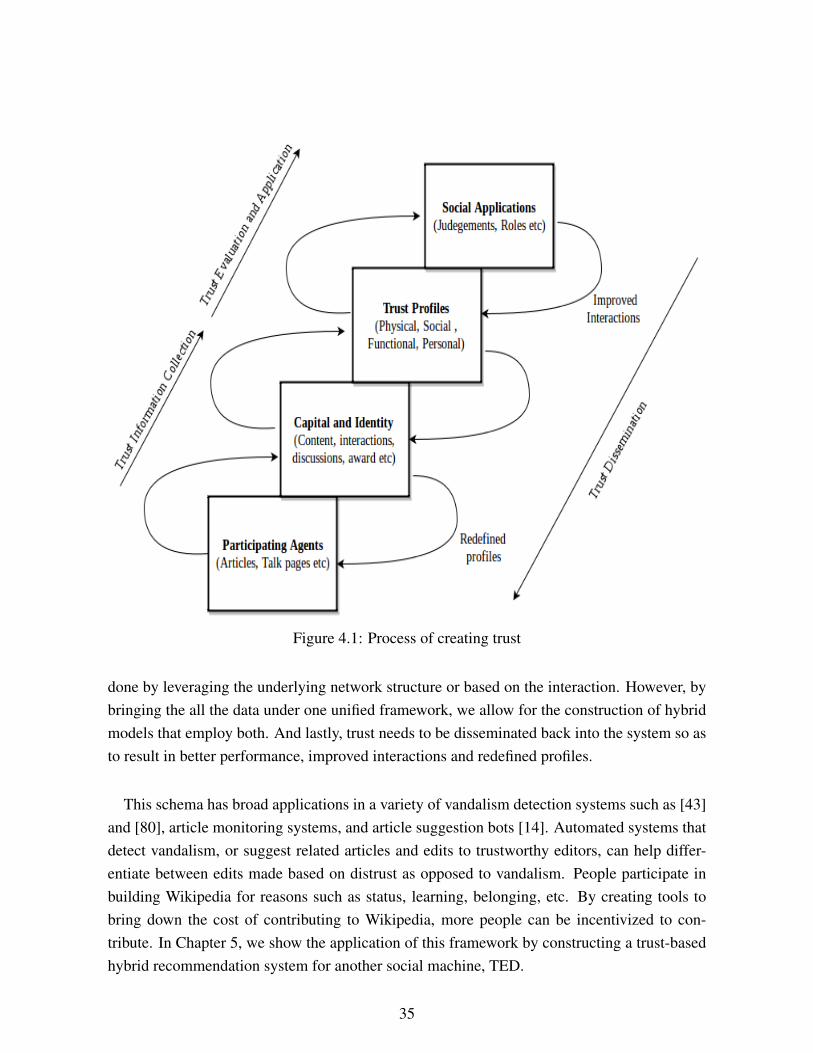
Chapter 4 - In Wikipedia We Trust: A Case Study. Next, we turn our attention to seeinghow this framework can capture all the various aspects of a social network through a case studyof Wikipedia. We identify the different agents, trust mechanisms, and categories. We considerthe system design goals, incentives and motivation to demonstrate the usefulness of the taxon-omy. And lastly, we discuss the process of creation of trust and the idea of distrust.
Chapter 5 - Hybrid Trust Aware Model for Personalized Top-N Recommendation. Wegive a new recommendation model based on the trust framework defined earlier, for the task ofrecommending a personalized list of N items to users. Our model produces recommendationsbased on a hybrid of global and local trust parameters combined using an extended sparse lin-ear method. We experimentally evaluate it on a real world dataset of TED videos and improvethe current scores by upto 19%.
6
Chapter 6 - Conclusions. We summarize what was achieved in this thesis, and discuss thepossible avenues for further research.
7
Chapter 2
Philosophy of Trust
Trust is important and yet also very risky. And so questions such as when is trust justified,when and why it should exist, and what its value is, are of particular significance. Thus,before we can begin to model and understand trust in the context of online social networks,it is necessary to obtain a coherent idea of its important features. In this chapter, we detail acomplex philosophical answer that explores these various aspects of trust.
2.1 Trust and Trustworthiness
The primary distinction between trust and trustworthiness is that the former is an attitudethat we display towards somebody (or something), while the latter is the property or charac-teristic of that somebody (or something). In the ideal situation, only a trustworthy entity istrusted. But in most regular cases, that does not occur. People end up trusting something thatis not trustworthy or do not trust something that is trustworthy. Moreover, a person A rarelytrusts person B completely. Realistically, A trusts B in some context or set of contexts X. Thenecessary and sufficient conditions for trust to exist between A and B for X involve trustwor-thiness of B, a certain level of optimism and faith on B and the amount of associated risk thatA is willing to take [54].
Lets first look at Trustworthiness, which itself depends on numerous factors. Firstly, itrepresents not just reliance but also a sense of betrayal. A relies on B to perform some action(s)and if they are not performed satisfactorily, A would not just be disappointed, but would alsofeel betrayed [26]. Trustworthiness thus invokes a deeper emotion. Secondly, it depends onthe competence of the trustee. To be clear, we don’t need the trustee to be competent in everyway, but we do require them to possess the various skills and abilities in the given context to
8
perform the given action. For example, driving a car safely requires a certain level of hand-eyecoordination, alertness and an understanding of the traffic rules, and obviously in that situation,the trustee need not know how to (say) cook well. Along with B’s competence, his commitmenttowards completing the task is also just as important. This condition can either arise from theeffort required on the trustee’s part and his willingness based on other commitments, duration,personal cost and impact of the outcome. Trustworthiness is dependent just as much on whetherthe trustee will act as it is dependent on how he will act.
Apart from these, Hardin [32] argues that conditions, restraints, motives and incentives alsoplay a role in determining trustworthiness. People can be compelled by norms and constraintsimposed either by themselves, by the trustee or by external forces such as society. Theseconstraints can be beneficial or can be detrimental to how trustworthy the trustee can be. Forinstance, one can publicly declare that one will never drink alcohol thereby placing oneselfat risk of public reproach in the event of failure to abide. Or this could be imposed by thetrustor (via a contract) or by government (via law). But notice that this is a partial account oftrustworthiness because this sort of person (to continue the previous example) would not drinkalcohol and drive, only because he believes he would face legal sanctions if he did not comply.While this action may be predictable, the person is not necessarily trustworthy. And so he hasthe power to betray the trustor. This is where personal motives and incentives come into thepicture. When the self-interests and the personal value of the outcome for the trustee alignwith those of the tasks he is expected to perform, the possibility of the breakdown of trust isreduced.
People trust other people when they believe that the trustee is trustworthy (due to all theunderlying factors as described above), the risk of relying on the trustee to act in a certain wayis low and the trustee is motivated by goodwill to act in that way [33]. Individually, none ofthese are sufficient to warrant trust, but taken together they completely capture the nature oftrust. Risk accounts for the notion of expectation and level of optimism displayed by the trustorsince it restricts the inferences that one will make about the actions of the other. This raises thecriticism that trust leads to a feeling of betrayal and not mere disappointment. But the inclusionof goodwill as a contributing factor alleviates the critique since by trusting, the presumption isthat one is committed to common decency.
It should be noted that recent work [25] on trust has questioned (1) the role of motives, (2)the idea of trustworthiness as a virtue, (3) the nature of betrayal when trust is broken and (4)different forms of trust in pluralism. However, it is also important to acknowledge that we do
9
have a more holistic understanding of trust that includes the grounds for when it is justified,well-grounded and plausible.
2.2 Ontology and Epistemology of Trust
Ontology is the study of what exists and where. A classical philosophical field of study, itbroadly questions what there is, the features and relations of entities that do exist and what isinvolved in settling the question of what there is. Epistemology is a closely related field thatstudies knowledge, and is concerned with questions such as what do we know, how do we knowwhat we know and what are the sources of knowledge. The central ontological question abouttrust is ”Where does trust exist?” and the central epistemological question is ”When should onetrust and when should one not trust?
We trust a wide variety of people in a wide variety of ways every single day and in somany of the cases we don’t know anything about any of them. It is not possible to analyzelogically every bit of knowledge that we obtain. For example, we don’t know the doctor in theemergency room but we trust her to treat the patient to the best of her ability. While trust hereis unavoidable, it certainly involves risk. The rationality in trusting here, lies in the fact thatalthough we don’t have any evidence of the trustworthiness of the individual in question, weallow it to engender in them. Clearly, there is a bit of tension between rationality and trust.Baker [6] argues for this by saying that trust does indeed exist and that it is rational. Not inthe doctor as an individual but in our knowledge of the profession of medicine, the codes ofconduct as established in society and law, and in the reputation of the hospital (or institutionin general) to perform capably. This redirection of trust, he says is the logical answer to theontological question of trust. We extend this argument further in Chapter 3 in the context ofsocial machines.
Further, philosophers such as Russell Hardin [32] and Victoria McGeer [51] discuss theepistemology of trust as an open or a closed system. Hardin argues that rational trust is alwayspartial (open) in the sense that one never fully trusts anyone. One has some measure of thetrustworthiness of the other under certain conditions and uses that to estimate and justify theirtrust in the other and after the completion of the task, updates the personal information for usein future interactions. This is how trust exists according to the internalist school of thought. Onthe other hand, there is the reliabilist or externalist school of thought (as supported by McGeer,et al.) that says that trust is not always internal or specific to the trustor and in fact, there exist
10
reasons for trusting that are external to the trustor. They argue that while it makes sense tohave good, personal reasons for placing trust in something, there are numerous situations toovaried in nature that may influence the trustor without his/her knowledge. These could includenon-verbal or visual signals, body language and “gut feelings”.
Apart from these, the social, political, economic and cultural surroundings also have a sig-nificant influence on the way we trust. There is no universal set of ground rules that must besatisfied in order for us to trust in something. Paradigmatically, we take the stance that bothinternal and external forces shape our behaviour. We have the natural right to trust the waywe want as long as it coheres with our personal sensibilities and we have the natural right tochange the way we trust as per our judgments. However, there are some markers to the waywe trust that are common, generally speaking, across all peoples, which can be gleaned fromrationally reflecting on the grounds for trust and improving the trustworthiness of factors onwhich it could be based.
2.3 Value of Trust
When Alice tells Bob that she trusts him, a very obvious follow up question to ask might be“How much does she trust him?”. That is, what is the value of her trust in Bob and can it bequantified? As we have already seen, trust manifests in different ways for different people. Butwhile the exact value of trust between Alice and Bob would depend on the situation at hand,philosophers have discussed the value it could have in a sense to justify the field of inquiry intotrust. Generally speaking, trust can have intrinsic and extrinsic value.
The intrinsic value of trust for the trustor and trustee is that it allows them to interact witheach other in a cooperative manner and sustain meaningful relationships [26]. The value herecomes not just from that of the goods traded between them but also from gain of autonomy, ex-perience, maturity and mutual respect for the other which makes it instrumentally worthwhile.It is important to note that very little is known about the value of trust in and of itself and mostdiscussion in humanities has focused on measuring it through its impact on the value of thegoods it produces. For instance, kids trust their parents to take care of them because they tendto be vulnerable and it can be essential for them to do so. In such cases, trustor is dependent onthe trustee and powerless to enforce any sort of contract on them while the reverse is not true.But it is precisely because of trust in oneself that the self-motivation to act in a caring manner
11
towards the child arises, along with the knowledge that doing so, will aid the child in importantways and enable growth.
On the other hand, the extrinsic value of trust [51] is the scientific, moral (and almost allother forms of) knowledge that is gained through cooperative relationships. If everyone wereto keep reinventing the wheel, we would not have a car. That is to say, we do not experiment,discover and verify every single piece of information that comes our way. Instead we trust theknowledge generated by others (for example, we trust the fact that the earth revolves around thesun although we may not have validated that for ourselves) to proceed with our own objectives.The vast quantity of knowledge generated over the centuries is available to the trustor andtrustee and their interactions serve to add to this knowledge which others can use to informtheir interactions. This value of trust is of great significance for the progress of society as awhole. Moreover, the extrinsic value of trust lies in the impact it has on transactions betweensocieties and even groups of societies; especially in today’s globalized world, this is of practicalmerit.
2.4 Trust and Utilitarian Moral Theory
Utilitarianism is one of the most important moral theories whose core idea is that whether anaction is right or wrong depends on the outcome or consequences of that action. It argues thatthe purpose of morality is to increase happiness, pleasure, etc and reduce pain, unhappinessin order to make life better. And so the basic tenet of utilitarian moral theory is to maximizethe benefits through good actions. Act utilitarianism prescribes a course of action on a case-by-case basis. What is right in one situation need not be right in another. This theory becamepopular because it allowed for exceptions to rules and therefore more flexibility in maximizingevery single action. For example, “You should not lie except when lying would spare yourloved ones from pain.” is an acceptable moral code as opposed to Immanuel Kant who argued“You should never lie.” which is absolute.
However, this led to thinkers such as Jeremy Bentham, John Rawls and John Mill raisingthe following three points; (i) for whom is the benefit being maximized, individual self-interestor groups of individuals or everyone? (ii) how can we foresee or predict the consequences ofactions and (iii) how do we determine the set of moral codes for judging actions? In trying toanswer each of these questions, we run into expectation effects. That is, consider if everyoneonly performed actions guided by self-interest, then other people would not be able to rely
12
upon them for anything. People would not be able to trust each other. If a doctor can save fivepeople by transplanting the organs of one healthy person (in turn killing the healthy person),then act utilitarianism would imply that the doctor should save the five. However, that wouldcause a complete breakdown of trust in the medical profession. More generally, lying, breakingpromises and violating the law when it leads to good results would lead to a society where noone trusts anyone and all benefits that cooperation would have yielded would be lost.
Trust, thus forms a vital guiding principle (although certainly not the only one) in the designof the set of moral codes. It informs the choice of rules and exceptions allowed so that people’sbehaviour can have some consistency and predictability. And through wide general acceptanceof trust-based systems, people can trust other people to obey rules. Trust would allow peopleto come up with reasonably accurate expectations of the others’ intentions and thus lead toimproved cooperation. As a result, rough estimates of potential consequences can be madeleading to social stability. Rule utilitarianism came up as a response to these criticisms ofthe act-based theory wherein actions are judged to be morally good if they conform to somejustified moral rule and the moral rule itself is justified if its inclusion in the moral code (asinformed by trust) would evaluate to more utility.
13
Chapter 3
Multi-Dimensional Framework for Trust in Social Machines
Trust plays an important role in the effective working of Social Machines by allowing forcooperative behaviour amongst their human and digital components. A detailed study of trusthelps in gaining insights into the working of social machines, and allows designers to createbetter systems which are able to engage more people and allow for efficient operations. Inthis chapter, we undertake a discussion on the variety of ways in which trust can be observedin Social Machines by outlining a three class taxonomy (personal, social and functional). Webuild upon earlier observations in past literature while seeking a broader definition. We discussthe problem of trust, that of promoting trust amongst the trustworthy in social machines, andpresent the various insights, challenges and frontiers that arise in response. This includes therole of institutions, communication processes and value aligned technologies in social, personaland functional trust respectively. And lastly we present the emergence of a fourth class of trustthat comes out of the Internet of Things and Web 2.0, physical trust.
3.1 The Problem of Trust
What is the problem we wish to solve when we attempt to construct a Social Machine?
Social Machines are the building blocks of today’s networked systems. Internet websitestoday are no longer simply static pages that one reads. There is active participation from both,the users and the softwares. Based on the actions performed by the user, the website softwarereacts in a specific manner. With recent advances in machine learning, recommender systems,data mining, etc, the response from the software is intelligent even, to a certain extent. Forexample, if (say) John has already viewed several videos related to (say) Baseball on Youtube,the website can suggest similar videos to him in the future. This evolves over time as changes
14
wrought by past events form patterns in actions and the software adapts to accommodate thenew trends. This leap from static to dynamic and intelligent software led to Tim Berners-Leecoining the term Social Machine [10]. A Social Machine is a complex techno-social systemcomprised of various individuals or groups of individuals and digital components connectedthrough a networked platform, in a predefined mode of interaction for a particular purpose. Inrecent years, there has been an increasing interest in studying web systems as social machines([21], [45], [72], [79]).
In our study, we refer to the complete structure of a website along with its users, the contentcreated by both, the users and the site through interactions with each other, as well as theunderlying information processing systems together as a social machine. As an illustrativeexample, consider Wikipedia, an online, collaborative, free-access encyclopedia created byJimmy Wales and Larry Sanger1. Any person can create, edit, modify and read an article onWikipedia. A “Talk” page associated with each article allows editors to discuss, coordinateand debate the related issues. In case of disputes, resolution is reached through communityconsensus and vandalism is restricted through internalized benefits. Editors in good standingcan be upgraded to the post of administrators if recommended by the community. This large-scale interaction of humans with machines combines democratic and hierarchical elements toform interleaving social and digital processes (We delve further into this in Chapter 4 with alook at a specific example). Similarly, Google Plus, Facebook, Github, Twitter, etc. can all beunderstood through the social machines paradigm. Furthermore, this definition is extensibleand can be applied to other systems, as Buregio et al [12] show by constructing Government asa social machine.
The central problem in the construction of a Social Machine (SM) is thus, generation of co-operative behavior between its human and digital components. SMs require complementationof purposes and actions of different actors. And cooperation allows for systematic integra-tion of the merits of the components that constitute it. While cooperative behaviour, as gametheory has shown, leads to more effective systems, it might not always be rational under vari-ous restrictions due to the distributed nature of the system, possibility of malicious actions etc[61]. In these cases, promoting cooperation requires that there exists trust between the vari-ous components. Trust provides the incentives that can ensure mutual guarantees of successfulinteractions and intended benefits.
1https://www.wikipedia.org/
15
The problem therefore, in the context of Social Machines boils down to taking design deci-sions that foster trust. Trustworthiness is the property of an entity to act in the manner in whichit is expected to act whereas trust is the attitude or belief towards an entity that it will act in theexpected manner [63]. If trust is placed on an untrustworthy agent or if trust is not placed on atrustworthy agent, then the design of the system is crucially flawed. The solution is thus to getthe different components to work together and we posit that by creating a set of incentives andregulations such that trust is placed on that which is trustworthy, better results can be achievedeffectively. This is why an analysis of what trust depends on, how it changes, and its natureand complexity is useful in the study of social machines.
To be precise, a unified definition of trust is elusive due to the vast diversity of its constituentfacets [53]. The observation and analysis of human behaviour on the web is a hard problem be-cause it involves computational formalization of abstract human notions such as trust. A modelthat is based on realistic assumptions of trust as a sociological and psychological concept, andcan yet be formally specified and rigorously evaluated would lead to a powerful framework fordecision making [59]. A complex series of collective reasoning goes into establishing a mea-sure of trust among a group of strangers, reasoning which is difficult for a machine to grasp.And this might vary from person to person. In order for online systems to exhibit a similarlevel of response, sophisticated theoretical foundations are required. Krukow et al. [42], arguefor the need for such a “hybrid” framework of computational trust. In this chapter, we define ataxonomy of trust that aims to capture the different elements of trust in the SM paradigm andargue for an extended framework that incorporates those elements presented by new techno-logical advancements.
The rest of the chapter is organized as follows. In Section 3.2, we summarize the relatedworks. Section 3.3 presents the new taxonomy of trust and describes the three classes. Section3.4 provides solutions to the problem of trust from the perspective of institutions, informationand the value alignment problem. Section 3.5 presents the emergence of a fourth class (physicaltrust) in the taxonomy of trust, through the context of the Internet of Things. And lastly inSection 3.6, we present our conclusions and directions for future work.
3.2 Related Work
Trust as a concept, has been studied in a wide variety of disciplines such as philosophy,economics, psychology, sociology and cognitive sciences [53]. Rousseau [68] summarizes
16
contemporary definitions of trust as “...a psychological state comprising the intention to acceptvulnerability based upon positive expectations of the intentions and behaviours of others.” Du-mouchel [22], on the other hand defines trust as an action. “To trust is to act and not simply toexpect because it is the act, not the expectation, that gives the other agent power over the personwho trusts.” Actions are concrete as they can be observed and their impact can be measuredthrough other actions. As discussed here and detailed in Chapter 2, there are a multitude ofdefinitions of trust and exploring the scope of these definitions is important because it allowsus to encapsulate relevant conceptions of trust in this context of Social Machines.
Shadbolt, et al. [72] argue for a classification framework for social machines through con-structs such as participants, contributions and motivations (which we discuss specifically fromthe point of view of Wikipedia, later in Chapter 4). They show that a wide array of web systemstoday fall within this framework and thus it is important to carry out an analysis of the growthand behaviour of these systems. Trust is a common notion across these systems and as suchplays a pivotal role in defining the governance and use of their functions.
O’Hara [64] discusses some of the challenges of trust in social machines and provides aframework to discuss it. He defines trust as a 6-tuple:
X trusts Y :=def Tr 〈X, Y, Z, I(R,c), Deg, Warr〉where (3.1)
• X and Y are the trustor and trustee respectively.
• Z is the agent making claims R about Y’s intentions, capacities and behaviours.
• c is the context in which the event(s) is/are occurring.
• R are the claims made in context c.
• I(R,c) is the interpretation of claims R by trustor X in context c.
• Trust is seen as the belief held by X that Y will comply with the claims made by Z.
• Deg denotes the degree of this belief
• Warr denotes the warrant for such belief, rational or irrational.
This model is only directly applicable to trust that arises from trustworthiness of systemsthat comply with some claims and guarantees of the designer. However, we observe that trustbetween people, groups of people, and software systems is also essential to any SM. Such trust
17
is also interesting since, unlike the former, this type of trust usually does not have any Z makingclaims about the system. Instead, it is deeply rooted in the understanding of individuals aboutthe social context and norms, and the mental model they hold of their environment [39].
3.3 Taxonomy of Trust in SMs
A complex system is a system that is composed of a large number of parts that interact witheach other and give rise to collective behaviours. The study of systems involves understandinghow changes in some aspect of it can affect some other seemingly unrelated aspect of it [58].In our study of trust in a complex system, we consider emergence and evolution as two keycomponents. Emergence is the idea that the system as a whole is more than the sum of itsparts. Evolution is the property that events from the past accumulate and have an impact onthe future events. The complexity of the nature of trust makes it very difficult to capture itsessence succinctly, however the tools and techniques of complex systems allow for it to bestudied more effectively.
We present below a threefold model of trust in this techno-social setting based on the lo-cus of the trustee in the relationship. We use a bottom up approach to agglomeratively addcomponents to build a system itself and model the interactions. We make an obvious distinc-tion between trust that is vested in the software and digital components of system, calling itFunctional Trust, from the trust that exists between an individual and his peer in the system,which we call Personal Trust. We further talk about a third class, Social Trust, that exists inmembers of the community with respect to its collective behaviour, we claim is distinct fromboth Personal and Functional aspects.
3.3.1 Personal Trust
Any careful survey of the living world around us shows that there is an incredibly diversevariety of individuals. Apart from the notion of biological individuality, there are philosophicalproblems concerning various aspects of people. These can be stated in the form of questionssuch as What makes something a unique individual?, What is the nature of such a uniqueindividual being? as posited by Leibniz. All of these together contribute to the particular andspecific nature of each person. No two individuals ever go through the exact same situationsin the exact same sequence at the exact same time and location. That portion of one’s identitythat presuppposes no application, the absolute identity, forms the basis of personal elements
18
of trust in our framework. Moreover, the fundamental biological and cognitive processes inthe human brain also determine the perceptual and motor operations. This is encapsulated in awell-studied architecture called ACT-R put forth by John Robert Anderson [5].
Put differently, this element of trust in social machines represents the unique features andattributes of the agents themselves. The personality of the individual based on traits such asopenness, conscientiousness, neuroticism, extraversion, agreeableness[8] affect how one givesand perceives the receipt of trust. These psychological and other cognitive determinants oftrust such as desires and interests of the agent, are valuable characteristics that define theirnature [73]. The personal beliefs that individuals hold, colour the way they interact with otherindividuals. And this trust that one has, is different from peer to peer.
Such trust is vested in one’s personality, whose existence is independent of any specificSM. In particular, the trust that the trustor has on the trustee on different SMs is stronglycorrelated (since there is one common individual behind each of these accounts) and trust ona single platform as such cannot be seen in isolation. Each account is a unique entity in itselfwith its own history. These accounts not only interact with accounts of others, but also maycommunicate with each other in a variety of ways for a variety of reasons. For example, onecan use one’s (say) Google ID to log into (say) Facebook. Each of these SMs are unique interms of their computational processes, the nature of the relationship between humans andmachines, their software design and the obtained results. Yet the underlying personality traitsbehind each of the actions on the various SMs are common. One’s online identity is the sumof one’s behaviour across these different SMs.
3.3.2 Social Trust
In stark contrast to Leibniz, Geach [27] describes the relative (cross-world) identity of anindividual as that which is brought into application when he/she interacts with someone orsomething else. In modal discourse, this is the identity that is different across different worldsand situations, based on interpretations. Based on our personal predispositions to our surround-ings we make decisions and take actions. These directly influence and are in turn influenced bythe nature of our method of trust. Societal and cultural relations, geographical and historicalcontexts, political scenarios and economic climates therefore play a vital role to an understand-ing of the nature of trust.
19
Let us say X and Y are cousins and also students studying in the same department. Theyare both added onto the respective Family and Department groups on Whatsapp. Actions oftrust can be seen to differ considerably in both the groups despite each of them being the samepeople on the same platform. This, as we observe, is a consequence of different communityroles in which they interpret each other in both cases. This notion of roles in society givesrise to collective behaviour and that impacts how one forms and develops relationships [24].Moreover, this extends to trusting in the unknown when one does not have enough informationto form one’s own opinion and instead chooses to trust what the community (or a particularindividual, for that matter) does.
There is thus an element of trust comprising of the sociological conditions such as geo-spatial locations of people, the surrounding environment, standard of living, routine habits,etc [77]. Culture and traditions that one grows up with influence the way one thinks. Onebecomes more attuned to those around that belong to similar backgrounds. One identifies morewith them and that impacts the manner, speed and nature of trust that develops with them.Additionally, the position of an individual in a society is based on the role(s) that the individualplays [57]. Every society (online or offline) has a structure that governs the way the that itoperates. A structure might have multiple hierarchies within itself and each hierarchy can haveits own set of goals, capabilities and limitations [41]. These along with language and psycho-physical characteristics as perceived in the society together constitute the social elements oftrust.
3.3.3 Functional Trust
The functional element constitutes of the trust that the individual has on the software and thefunctionality of the system. Identifying the role and method of functioning of the underlyingstructure is an important characteristic of how and how much one trusts the system. Perhapsthe most important characteristic here is that the claims are rigorously defined while in Socialand Individual, there are no binding documents that outline the rules and regulations. One signs“I Agree” on most claims documents without reading them in their entirety. The individualshowever, place their trust not on detailed analyses of these claims but rather, they learn fromexperience just as they do in the case of the other elements as well.
This trust that individuals hold in the features of the software platform, can be seen in thecontext of guarantees and standards provided by the designer-administrator of the platform, andthe inherent assumptions such as privacy and/or absence of malicious code. It is interesting how
20
in many cases the latter, the inherent assumptions, are often not well defined. The differencein interpretation of such norms often leads to conflict and renegotiation of the terms of use ofthe social machine. This can especially be observed in how the framework of privacy settingsevolves over a period of time as a result of various issues and demands of the Social Machine.
Software systems are themselves inherently complex, and appearance and disappearance ofsoftware bugs is a regular feature of their engineering cycle. Functional trust also captures thetrust in the correctness of programs that constitute various digital components of the SM. Thistrust can manifest itself in two forms, depending on the organizational style of the software ad-ministration, i.e. open source and closed source. In open source, trust for program is redirectedto trust in the developer community and institutions. On the other hand, in closed source, truston the functionalities as well as their correctness both, is redirected to trust in the firm(s) thatcontrol the digital components.
3.4 Solving The Problem of Trust
The problem of trust, in the context of design of Social Machines as also discussed byO’Hara [64], is the promotion of trust amongst the human and artificial actors of the SocialMachine which are trustworthy, i.e. which will work towards the mutually accepted and un-derstood purpose and not behave in a malicious fashion. The hardness of this problem arisesfrom the problems of cooperation and rational behaviour, as established by Hollis in his Trustwithin Reason [34]. The establishment of trust with parties that do not have pre-existing Per-sonal Trust is especially crucial for social machines that involve collaborative participation insome efforts, eg. Wikipedia, Quora, etc. Two common solutions, as also pointed out pastliterature, include signalling amongst honest agents to establish cooperative behaviour, and es-tablishment of trustworthy institutions that allow honest participation and penalize maliciousbehaviour. The scope of signalling between honest peers helps them gain more information andestablish common context between them. Institutions aid in the founding of trust by boilingit down to displacement or redirection of trust from between the peers to towards the commu-nity and the procedures and structures established amongst them. Also, while signalling andinstitutions help in building trust amongst peers with the aid of technology, many new chal-lenges appear when dealing with trust between humans and complex software systems. Withthe emergence of intelligent systems and their presence in SMs, for which making claims andguarantees is inherently impossible with the state-of-art, new foundations for Functional trustbecome necessary.
21
3.4.1 The Role of Institutions
Institutions play an important role in aligning interests and displacement of trust in socialmachines, by redirecting trust to hierarchies and procedures established in the community.The role of institutions in the functioning of society and economy has been a well-establishedconcept in political science and anthropology [18], including a detailed discussion by FrancisFukuyama in Trust: The Social Virtues and the Creation of Prosperity. Fukuyama [25] andsubsequent discussions by Cesar Hidalgo [29], point to the importance of ’trust’ in establish-ment of economic cooperation and distribution and use of information towards shared goals. Ithas been pointed out how this trust results in emergence of institutions [23], since it is only inthe presence of institutions that individuals are able to substitute their trust towards a multitudeof peers, many of whom might be unknown to him/her, with a trust towards the institutionsthrough which they interact. Institutions, thus, play a role in simplifying the act of trusting.
For instance, while using Wikipedia, despite the absence of personal knowledge about con-tributors to an article, individuals have a tendency to trust the facts. This is motivated primarilyby an institutional trust vested on the overall techno-social institution of Wikipedia, which en-tails its review process as well as a dedicated community. This example in fact, helps us closelyanalyze the birth of institutional trust, as can be observed in how it essentially involves a com-bination of social trust in the community as well as functional trust in moderation privilegesand other features that support the requisite procedures.
The definition of what constitutes an institution is just as ambiguous [71] in a Social Machineas it is elsewhere. While at a certain level, a complete social machine can be called an institu-tion, on the other hand, merely the moderation system or the upvote system can also be calledan institution in itself. Institutions emerge at various levels in Social Machines. While some in-stitutions might simply be elements of interaction that occur as software features, for instanceupvote systems (Quora, Stack Overflow, etc), others might be more complicated hierarchieswhich are intentionally designed and supported, such as Wikipedia moderation system. How-ever, in some cases they might even emerge unexpectedly in the form of some organizationalfeature that was not originally intended by the designer. Of course in this case, the designersand administrators usually take notice of such emergent behaviour and have an incentive toevolve the technology front of the social machine to accommodate for them.
22
3.4.2 Virtual Spaces and Digital Semiosis
The use of signalling or implicit communication of honest intentions has been a well es-tablished concept in evolutionary game theory, to combat the negativities of game-theoreticrational behaviour in restrictive settings. Signalling has been argued as one of the foundationsof cooperative behaviour in evolutionary biology [16, 15], and is also seen as an act to com-pensate information asymmetry in economic theory ([75], [3]). However, signalling is not anexotic action that requires exquisite planning and effort, but in fact is prevalent in day-to-dayhuman conversation as well, in form of body language and gestures, vocal paralanguage (voice,pitch, rhythm, etc.), and conversational implicatures. This, therefore, extends to virtual spacesof communication and interaction created within Social Machines as well, both at textual andsymbolic level.
Social Machines that are built on textual communication allow greater linguistic flexibilityto establish institutions and trust. An easy way to analyze such communication is to borrowthe framework of literary theorist I A Richards, as outlined in Malinowski [46], that claimsfour layers of interpretation of text: 1) Surface Meaning or Sense, 2) Emotive Meaning orFeeling, 3) Tone or Attitude, and 4) Intention. Digital communication and conversation canalso be seen at these four levels. The Emotive and Attitude layers also emerge as a resultof paralinguistic features that emerge in digital communication, such as common practice ofinterpreting implicit anger and shouting for a text written with all uppercase letters. It canalso be observed, then, that trust also plays different roles at different layers. For instance, itis possible for an individual to trust some controversial fact shared publicly by her peer, eventhough she might still suspect some ill intentions behind it. Consequently, the manner in whicheach of the layers influences personal trust between peers also differs.
Even in physical conversation, body language, gestures and other forms of non-verbal com-munication also play a huge role in enabling signalling. Semiosis, or production of meaningwith use of signs and symbols, manifests itself in social machines in form of domain spe-cific non-linguistic structures, such as ’likes’, ’pokes’, ’shares’ on Facebook. Many differentfeatures available on different SMs as means of symbolic interactions between peers providedifferent syntactic systems and established semantics. However, often such symbols can alsotake other meanings in different personal and social contexts, and consequently help in trustbuilding beyond the intended purposes. For instance, having a large following on Twitter isnot an indicator of trust in itself. But it is more likely for someone to believe his tweets tobe authentic information if the person has a record of being retweeted massively. And in So-cial Machines, where communities are expected to interact, the human-computer interaction
23
and symbolic elements of interaction must be designed, taking into cognizance the scope forsignalling and trust building.
3.4.3 Value Alignment of Technology
Functional Trust, as discussed, rests on the trustworthiness of digital components and theliability of the programmer or the designer. However, with a growth of artificially intelligentsystems, there is a rise of a new class of complex systems, for whom complete causal reason-ing about behaviour is not possible with the available knowledge [11]. For simple applicationslike recommendation engines to slightly more complicated ones like Business Decision Sup-port Systems, these systems, or artificial actors, deal with complex data and are expected tomake complex decisions towards their goals. As reasoning about epistemic qualities of theseprograms, such as about the bias present in presentation of information, becomes increasinglydifficult with newer technologies, new challenges appear at the frontier of functional trust.
This problem becomes more severe as there are a number of operations for which a SocialMachine must rely on such artificial actors. And the difficulty of building trust between humancomponents and artificial actors increases proportionally to the complexity of decisions andconsequences. This problem has been studied as the Value Alignment Problem in ArtificialGeneral Intelligence (AGI) and Singularity Studies communities, as the problem of providingbounds on whether the decision system shall not take an action against certain well-understoodvalues [69].
Even weak claims about these systems rely on deep results about the mathematical propertiesof the structures implemented. This can also be seen as redirection to trust over mathematicsas a field of knowledge, which can be seen as an institution and has also been called a SocialMachine in itself in a more generalized setting by Martin [49]. However, since precise guar-antees about the working of such complex systems cannot be reasoned about, designers andmost diligent individuals rely only on broad epistemic and mathematical fundamentals and sta-tistical evidence of performance. Some novel approaches have been taken, such as OpenAI2,that attempt at generation of trust by opening up the source code and the underlying scientificartifacts to the scrutiny of public. This can be seen as redirection of trust on the communityof a few diligent participants and their institutions of operation. Nevertheless, it is importantto note that most of the trust today for intelligent technologies is still rooted in trust towardsexpertise of the firm(s) that maintain them.
2https://openai.com/blog/introducing-openai/
24
3.5 Physical Trust and the Internet of Things
Computers, smart-phones and tablets are no longer the only devices through which one canconnect to the Web today. Internet of Things (IoT) is the network of physical technology thatsupports the collection and exchange of data and acts on it according to it’s instructions [19]. Itallows users to connect directly and control remotely the existing infrastructure. A wide rangeof tools from glasses, watches, electronic devices and appliances, even entire homes are nowcapable of joining a networked platform. With the diversification in instruments of interactionbetween users, technology and physical reality, these are a growing part of social machines andso we require the trust to be something beyond personal, social and functional. We refer to thisas physical trust.
This trust depends on three major factors namely, the security, autonomy and privacy thatthese devices can provide. Users of these devices assume that they are protected against cyberattacks and cannot be exploited remotely. The innovative software and hardware behind thesedevices is in its early stages of development and hence is vulnerable to liability. Many of themare incompatible with a host of technologies that are now pervasive. Their capability to beintegrated better is crucial to the notion that these devices are indeed more user-friendly anddon’t end up increasing the workload. These devices also collect data from their users. Sinceusers are limited in terms of their technical knowledge, they trust the manufacturers that thisdata is being used only for the better functioning of the device itself and not for profiling ormass collection and distribution without explicit and informed consent.
3.6 Conclusions
Trust plays an important role in the way we form relationships, build organizations, interactcooperatively and design responses. However, the definition of trust can vary depending onthe person, context, spatio-temporal locations and so on. And therein lies the problem. Trustoften acts in ways that are not easily perceivable at different levels of granularity. In scholarlyliterature, there is no consensus yet on a universally accepted definition of trust. That is becauseits properties, mechanisms and impact are not fully understood. In this chapter, we take a stepforward in understanding the role that trust plays in social machines.
In this globalized world that is well connected through various social machines, the defini-tions of trust that we have discussed in the previous sections and chapters are limiting in thefollowing four ways:
25
1. The trust that X places on Y, as defined by O’Hara (Section 3.2) is based solely on theclaims made by Z about Y’s trustworthiness in the given context. It fails to account forthe incentives of the agents to have implicit positive expectations of the others’ behaviourleading to trust without any claims of trustworthiness.
2. They do not incorporate the role of institutions and the idea of redirection of trust. Thatis to say, for instance even though X may not find Y to be trustworthy, X might expectY to behave in a particular manner because he/she chooses to redirecting his/her trustfrom Y into an institution that Y belongs to or is a part of. Apart from this, in manydaily situations, different agents have different goals that are of significance to themindividually. And with complex systems having numerous artificial and human agents,the trust that actions against certain accepted norms will not be taken, depends cruciallyon the alignment of the values of these different agents with different goals.
3. The warrant(s) for X to have various beliefs about Y are abstractly defined to be basedon past history, reciprocal agreements, reputation, etc. In order to understand and an-alyze these warrants and their degrees better, we propose the three solutions namely,institutions, digital semiosis and proofs of correctness. Each of them may have differentelements and variables within them depending on the social machine in question.
4. Lastly, these definitions talk about X, Y and Z as simply human agents. In the context ofsocial machines, this is inadequate since an agent can be a human, a basic unit of soft-ware, a group of humans, a collection of software units, a collection of social machinesand as such any combination thereof.
These are the problems that are addressed in our generalized understanding of trust and wecan summarize this succinctly as, trust is the attitude towards the trustworthiness of agent(s)and/or the towards the trustworthiness of institutions that they are a part of, and/or towards thetrustworthiness of the incentives and alignment of values that arises out of such actions, basedon the warrants provided by the personal, social and functional (and physical) elements of theuniversal system. This adds the following variables to the formulation by O’Hara.
E(P, S, F) represents the elements of trust coming from Personal, Social and Functional vari-ables that come into play based on the nature of relations that exist between X, Y and Z, Valrepresents the value set of all the agents involved, Incen represents the incentives for the agentsto perform actions that foster trust and Insti represents the institutions involved in the givensystem, with the rest of the symbols retaining their original definitions.
26
Personal (individual) traits of users, the collective social attitudes of communities and thestructural and functional capabilities of the technologies contribute to the formation of trust.We expound on the relationships of these three elements of trust and show how they can resultin strong theoretical underpinnings in the design of social machines and the critical analysis ofhuman and societal behaviour. We also show how social machines themselves can be seen asinstitutions, and how this viewpoint provides an outlook to Internet of Things, virtual spacesand their organizing principles. Further observations about the nature of trust will play a centralrole in understanding a world with increasing role of technology. Thus, this framework is animportant step not only for the present, but also for the future of foundational principles ofsocial machines.
Due to the vast variety of social machines, the precise manner in which our frameworkand solutions for solving the problem of trust arise also varies. For instance, Facebook iscompletely different from (say) TED in a myriad of ways. In TED, the social elements arisefrom the types of roles played by users such as viewers, speakers, etc while on Facebook,there is a single type of user who can act as a moderator and/or admin for various groups andpages. This structural difference is fundamental in the sense that everyone on Facebook is on asomewhat equal footing and a dialogue can happen back and forth easily, while on TED there isfar less opportunity for the same. Identifying these qualities for individual SMs and comparingand contrasting the precise differentiations between them is an important problem. The studyof closely associated notions such as Privacy, Bias and Security are left as potential avenuesfor further work.
27
Chapter 4
In Wikipedia We Trust: A Case Study
The multi-dimensional framework for trust in social machines established in the previous chap-ter is a theoretical argument towards the problem of trust in the online world and our solutionfor it. In this chapter, we present a case study of trust in Wikipedia (which we treat as a SocialMachine) to show the feasibility of the framework to real world systems. We demonstrate howthe various elements of trust manifest themselves, suggest measures to evaluate them and alsodefine the notion of distrust within the framework.
Wikipedia follows an open editing model that allows anyone to edit any entry. This has led toquestions about the credibility and quality of information on it. Yet, it remains one of the mostwidely visited online encyclopedias. Here, we present a discussion of the various factors thatinfluence the trust that users have on Wikipedia through a framework consisting of personal,social and functional elements. We further argue that digital signals and non-verbal cues alsoplay an important role in determining trust on the various agents of the system.
4.1 Introduction
Wikipedia is one of the largest online, collaborative and free access encyclopedias in theworld. The massive success and popularity of Wikipedia for creating, finding and consolidatinginformation is because it is publicly maintained and any reader can contribute to it. As oftoday, the English Wikipedia has over 5 million articles and an estimated 500 million uniqueusers each month. This large scale interaction between humans and software has led to thedevelopment of complex social and hierarchical processes that govern its functioning.
28
To capture the essence of such systems, Tim Berners-Lee coined the term Social Machine,[10] which can be defined as “a complex techno-social system comprising of various individ-uals or groups of individuals and digital components connected through a networked platformin a particular mode of interaction for a particular purpose” [56]. Wikipedia as a whole (in-cluding the users, articles, its metadata and the technology) can be seen through this lens of asocial machine and this allows for a systematic study of web systems [72]. In order for socialmachines to function smoothly, these various interacting human and digital components mustbehave in a cooperative manner which in turn requires trust.
Placing trust on that which is not trustworthy or not placing trust on that which is trustworthyis the source of apprehension about Wikipedia’s credibility as an information source [64]. Thesolution therefore, is to place trust on that which is trustworthy. There has been growing interestin studying this. Kittur [40] ask if it is possible to trust a wiki and show that its metadata impactsusers’ perception of trustworthiness of its content. McGuinness [52], design a managementframework for encoding, computing and visualizing trust in the case of Wikipedia authors andarticles. Dondio et al. [20] compute trust values of articles on Wikipedia through domainanalysis. Lucassen [44] study users’ trust in Wikipedia by evaluating article features whileAdler et al. [2] use revision histories and reputation of authors for this task. Javanmardi et al.[36] analyze the relation between user contribution and trust in Wikipedia.
However, we argue that trust has a very broad definition, only a narrow part of which hasbeen studied in literature thus far. Websites such as Epinions allow users to explicitly providetrust ratings which makes it easier to analyze the trustworthiness of its products. But the collab-orative environment of Wikipedia hides article information and is susceptible to vandalism. Sotrust has to be measured implicitly as well and in order to do that, it is necessary to identify allthe features as well as underlying processes that influence it. In this chapter, we present a clas-sification framework for trust in Wikipedia and posit that this can form the basis for enhancedapplications that can in turn help increase the quality of its content and ease of use.
4.2 Taxonomy of Trust in Wikipedia
In any Social Machine, there are multiple agents involved that trust each other to varyingdegrees. In the specific case of Wikipedia, the following agents play a part in developing thetrust network:
1. Wikipedia Articles
29
2. Article Talk Pages
3. Article Edit History
4. Readers
5. Editors
6. Moderators
7. Administrators
8. User Pages
9. Wikimedia Foundation
Each of these agents trust the others in the system in aspects as explained below.
4.2.1 Personal Trust
This part of trust in Wikipedia, and Social Machines in general, manifests itself as a result ofthe personal characteristics and traits of the agents themselves. The various human agents in thesystem trust each other to varying degrees based on their own personalities and background. Aneditor whose views align more closely with a certain reader may enjoy a higher level of trustfrom such a reader due to positive reinforcement of ideas. Similarly, agents sharing similarinterests may have a greater amount of mutual trust amongst them as compared to other agents.
On Wikipedia, readers of an article display such implicit Personal trust towards the correct-ness of the article and towards the editors, moderators and administrators that were involved inshaping the article.
4.2.2 Social Trust
Social trust is a consequence of the different community roles played by agents and howthey are interpreted by others. Within Wikipedia, two types of Social Trust mechanisms can befound:
1. Title Relation: People tend to place a greater trust in strangers that seem to hold a positionof authority. This level of implicit trust in a position is greater in the case of Wikipediaas attaining the positions of a moderator or administrator is demonstrably difficult. The
30
Personal trust in the general community of readers and editors of Wikipedia that choosetheir leaders gives rise to an implicit social trust of such elected leaders.
2. Interaction Relation: History and context between different agents also affects the amountof trust they have in each other. Suppose two editors are frequently in dispute over thelayout of an article, and the community (or moderators) more often than not side withthe same editor in all disputes, he shall have a lower level of trust for his opponent thanother editors on the website. Similarly, the trust the community and other editors placein this editor will have increased over time for that range of topics.
4.2.3 Functional Trust
Functional trust is a realization of the implicit trust a user places in the software and func-tionality of the underlying system. Hence, it is a product not only of the historical reliabilityof the system, but also the underlying ideology. In the case of Wikipedia, we can classify theFunctional Trust that the users have into two categories:
1. System Characteristics: As mentioned earlier, the fundamental nature of a free-editingwiki necessarily brings up the question of trust amongst its users. Anyone may edit thecontents of an article on Wikipedia with data / facts that are provably wrong. While themany eyeballs theory [66] states in spirit that such edits will eventually be caught andrectified, the duration for which they remain live may be disconcertingly long for certainmore astute readers. Such readers would have a low level of trust in the contents of aWikipedia Article that is not adequately cited with verifiable claims. This trust metric isdirectly derived from the structure of Wikipedia that allows free and anonymous editingto everybody.
2. Website Safety: The users of the Wikipedia website also place an implicit trust in themaintainers and developers of the website at the Wikimedia Foundation. This is theusers’ trust in the stability, availability and security of the website. Users expect Wikipediato be online and available whenever they feel like looking at it. They also expect the web-site not to maliciously attack their machines, despite having no technical knowledge ofserver maintenance or personal acquaintance of the developers running the website.
Looking at Wikipedia as a social machine, it is our aim to present the notion of trust in it as aunion of different classifying factors, each with distinct properties. To that end we build, defineand present Table 4.1 below which shows the our own consolidated constructs by illustratingthree themes: (i) purpose, content and tasks, (ii) incentives and motivation and (iii) systemdesign and goals.
31
Table 4.1: Trust Constructs of Wikipedia as a Social Machine
Purpose, Content and Tasks
Create and Produce content (text, audio, images, etc)Subjective assessment of contextMass consumption of contentGovernance and Community leadershipDomain specific tasks and challengesRoles fulfilled by participants
• reader• editor• moderator• administrator
Participation is carried out through• web browsers• mobile devices• applications
Incentives and Motivation
Tangible rewards• badges and stars (eg )• competition prizes
Non-tangible incentives• to give and receive knowledge and informations• to be part of social community• for benefit of society
System Design and Goals
Generally accessible to a wide, diverse audienceSeparation of powersSocial governance for high quality standardsWebsite safety, securitySystem Characteristics
32
The first set corresponds to the actions of the participants individually and collectively withinthe system. It also pertains to the geo-spatial locations and medium, and technologies used forproblem solving, content creation, subjective appraisal. The second set of constructs pertainsto the motivation and reasons for the growth and popularity of the system and the participants.These can be intrinsic such as fun, knowledge-gain and learning, philanthropy as well as ex-trinsic in terms of monetary gains, rewards, reputation, etc. Lastly, the third set of constructsdiscusses the nature of various interactions between participants that arise due to the varietyof roles that any single participant may play. These can be machine-generated or can developnaturally as the system evolves and may even result in a hierarchical structure. Autonomy andanonymity (ensured partly ensured by system safety and security and partly by the inherentnature of the social elements of the system) are also valuable contributors.
4.2.4 Digital Signalling
In real world settings, when two individuals (say) Rory and Lorelai interact with each other,non-verbal cues play an important part in determining trust. Similarly, in the online world,apart from textual information, audio-visual elements play a role. The number, quality andrelevance of image and audio files, animations, etc add to the authenticity of the source mate-rial. The same is also true for references cited. Apart from these, Wikipedia has the feature ofawarding badges or stars to authors for their contributions (eg. Teahouse Badge1). The articleson Wikipedia are likewise awarded designations through symbols such as a plus sign in a greencircle that indicate that it is a well-written, neutral entry or that it lacks references and so on.These are important signals that add to or reduce the trust on the particular entity.
The second aspect of digital signalling is that of implicit and explicit trust. For example,when a Barnstar is awarded to an editor by others, it explicitly denotes that that editor is trustedby the community. On the other hand, when editors adds to the existing content of an article,they implicitly show that they trust the previous edits and agree with them. Such actions canbe represented as interaction relations between the various agents [47] thus can be capturedwithin this taxonomy.
In this section, we discuss the soundness, completeness and applicability of the schemaproposed above. We also briefly discuss the notion of distrust.
4.3.1 Usefulness of the Taxonomy
While certain kinds of interactions between various agents may be shared among the threeelements of Trust namely, Personal, Social and Functional, there are some distinct interactionsthat cannot. We argue that the elements of trust as defined previously, are distinct and uniquefrom each other. They are also complete in the sense that other notions of trust are capturedby some combination of two or more of these facets. For instance, trust coming from the nor-mative behaviour of agents can be seen as derived from social and personal trust. By definingthe articles, as dynamic agents themselves, the trust coming purely from the information andcontent is also captured. One trusts the various devices (phones, tablets, laptops, etc.) throughwhich Wikipedia can be accessed and trusts Wikipedia’s system to behave in the same manneracross these devices. We argue that the former is independent of the website and is the func-tionality of the device while the latter is captured by a combination of the Interaction Relationand System Characteristics. The soundness of the taxonomy in understanding trust is explainedbelow.
In Figure 4.1, we capture the process of creation of trust in the Wikipedia community. Thefirst step is to identify the participating agents, in this case the ones listed in Section 4.2. Thistypically contains the personal profiles and backgrounds of participants, personal identity, etc.The second step is to collect trust information based on (i) attitudes, (ii) experiences, (iii) be-haviours and (iv) technology. The positive, negative, both or neutral views of an agent towardsother agents represents their attitude towards it and it derives from either direct experience orobservational learning. Experiences describe the perceived nature of the frequent interactionsand these usually have a feedback mechanism that influences the future updates. Behavioursdenote the pattern observed in the interactions and experiences and in the context of humanagents, the changes over time in the nature of communications (for instance) capture an in-teresting aspect of trust in the online community. And lastly, the technology employed in thedaily use by agents and the way it changes reflects the popularity and support it received (or didnot receive). All this combined, provides a holistic view of the information that is indicative oftrust in the social machine. Once we have all the trust information that we can have, we need tohave models to sift through the data, classify it and then evaluate it. This evaluation is usually
34
Figure 4.1: Process of creating trust
done by leveraging the underlying network structure or based on the interaction. However, bybringing the all the data under one unified framework, we allow for the construction of hybridmodels that employ both. And lastly, trust needs to be disseminated back into the system so asto result in better performance, improved interactions and redefined profiles.
This schema has broad applications in a variety of vandalism detection systems such as [43]and [80], article monitoring systems, and article suggestion bots [14]. Automated systems thatdetect vandalism, or suggest related articles and edits to trustworthy editors, can help differ-entiate between edits made based on distrust as opposed to vandalism. People participate inbuilding Wikipedia for reasons such as status, learning, belonging, etc. By creating tools tobring down the cost of contributing to Wikipedia, more people can be incentivized to con-tribute. In Chapter 5, we show the application of this framework by constructing a trust-basedhybrid recommendation system for another social machine, TED.
35
4.3.2 Trust and Distrust
Govier [30] defines distrust as lack of confidence in the other, a concern that the other mayact so as to harm one, that he does not care about ones welfare or intends to act harmfully, oris hostile. Some of the primary cognitive components of distrust are misbehaviour, suspicion,insincerity, and also when expectations are violated. One identifies distrust through the relevantcontextual information and indicators based on different situations. For instance, when articleson Wikipedia are repeatedly vandalized by an individual, there is suspicion that the next editis most likely also vandalism and therefore worthless. This leads to a natural distrust of theindividual.
The notion of distrust can also be captured under each of the elements of the taxonomy asthe negation or absence of trust. For instance, when an editor makes an edit to overwrite theexisting content of a Wikipedia article, he/she expresses distrust in the actions of the previousauthor and the validity of the content itself. The quality of interactions between agents par-ticularly through their social behaviour on Wikipedia can be used to identify the loss or gainof trust. There are various aspects through which distrust can be identified such as transactioncosts, breach of contract, unresolved questions and behaviour in choices. Each of these arebarriers to trust and can result in tensions. We leave an empirical study of this idea for futurework.
4.4 Conclusions
With the growing use and popularity of online wikis, it is important to study the natureand process by which trust is formed and evolves on these systems. The Social Machinesparadigm allows for a holistic view of Wikipedia as a techno-social system. We present athree-fold taxonomy that outlines the different relations (personal, social and functional) thatexist, thereby facilitating a systematic framework for analyzing trust. We also discuss the roleplayed by digital signals and non-verbal signs.
Our early efforts described here provide theoretical foundations that can improve contentand user experience on Wikipedia. The advent of Internet of Things and Web 2.0 has broughtin a variety of devices and technologies that can interact with the internet. The physical trust,or trust in the proper functioning of these devices also contributes to trust. Future work first andforemost, includes carrying out empirical analyses of trust in Wikipedia based on ideas outlinedin the previous three chapters. This could involve building applications to compute trust ratings
36
for different agents of the system, trust-based automated systems to detect vandalism, poorquality content, and even recommendation engines for authors (about articles they might beinterested in editing) based on this taxonomy. This is needed to understand how well ourfindings generalize on the large-scale. And lastly, we only briefly discuss the idea of distrustas measured by the quality of interactions between agents. Further study and experimentalevaluation in particular, is required to identify the variety of ways in which it can manifestitself and observe the framework in action.
37
Chapter 5
Hybrid Trust-Aware Model for Personalized Top-N
Recommendation
Due to the large quantity and diversity of content being easily available to users, recommendersystems (RS) have become an integral part of nearly every online system. They allow users toresolve the information overload problem by proactively generating high-quality personalizedrecommendations. Trust metrics help leverage preferences of similar users and have led toimproved predictive accuracy which is why they have become an important consideration inthe design of RSs. We argue that there are additional aspects of trust as a human notion, that canbe integrated with collaborative filtering techniques to suggest to users items that they mightlike. In this chapter, we present an approach for the top-N recommendation task that computesprediction scores for items as a user specific combination of global and local trust models tocapture differences in preferences. Our experiments show that the proposed method improvesupon the standard trust model and outperforms competing top-N recommendation approacheson real world data by upto 19%.
5.1 Introduction
In recent years, more content is being produced every hour than can be possibly consumedby any single individual. In 2016, on Youtube alone, more than 500 hours of videos wereuploaded every minute! While this means that there is a really large variety of items for viewersto choose from, the sheer amount makes it extremely hard for them to easily find something thatthey would actually like watching. Recommender Systems (RS) have proved to be an importantresponse to this information overload problem by helping to locate the sought content quickly.
38
Top-N RSs provide users with a ranked list of N relevant items to encourage views and havethus become ubiquitous across domains.
It is widely established that Collaborative Filtering (CF) based strategies have been success-fully deployed in solving the Top-N recommendation task ([65], [62]). Collaborative filteringis based on the notion that we rely on the community to provide suggestions. It is a methodof processing or filtering information obtained through collaboration between various agents,information sources and other metadata. Neighborhood methods and latent space models rep-resent users and items in a common latent feature space and identify similar users and items,and are common approaches used for collaborative filtering [13].
However, such RSs share an inherent drawback in choosing recommendation partners basedon similar ratings histories with the active user and/or recommendation items with similar con-tent features to the active item. Apart from similarity, trustworthiness of users is an importantconsideration in providing a high quality set of recommendations. Indeed trust-based RSs haveproven to improve predictive accuracy of standard CF frameworks [50]. However, the previoustrust-based models are limiting in that they estimate only a single model for all users based ona narrow definition of user trust. We argue, that there are additional aspects to trust that canfurther enhance the performance of these RSs. Specifically, personal trust that arises from theunique features and attributes of the individual users, social trust which comes from contexts,social groups and communal habits, and functional trust which is based on the role and methodof functioning of the underlying system [55].
In this chapter, we are interested in combining a holistic view of trust with collaborativefiltering to improve the ability of the RS to make accurate and trustworthy predictions. Wepropose a Top-N recommendation approach that extends the sparse linear method [60] bycombining context-aware global and local trust models in the personalized setting. To dothis, we leverage the taxonomic framework in [55] to collect personal, social and functionaltrust information and solve an optimization problem following a tensor factorization processto strengthen the coupling between user and item features. Our experimental evaluation of theproposed method on a TED1 dataset shows that it has upto 19% higher accuracy as comparedto competing methods along with better diversity and popularity which are desirable for usersatisfaction.
1https://www.ted.com/
39
The rest of the chapter is organized as follows: Section 2 presents the related work. Section3 describes the proposed method. Section 4 presents the experimental evaluation and Section5 presents the performance analysis. Finally, Section 6 provides concluding remarks.
5.2 Related Work
Trust has been defined across various categories and there are numerous methods on how toview and measure trust ([81], [48]). Trust-based systems are generating an increasing amountof interest and have made several notable advancements to the state-of-the-art in social networkanalysis, community detection and recommender systems [73]. Here we present a few notableworks in the field.
Adali et al [1] measured the behavioural trust in social networks based on conversationsand propagation of information. Trifunavic [78] proposed a trust model for opportunistic net-works using explicit and implicit social trust. Based on the taxonomic framework by [55],we are interested in three categories of trust; Context-specific Social trust wherein a user Amight trust user B when it comes to some specific situation, but not necessarily in some other.System-based Functional trust which describes the trust in the system as a whole and its inter-personal elements. And lastly the Personal trust by the user in the capabilities of the formertwo categories to provide quality recommendations.
O’Donovan and Smyth [62] devised algorithms for computing Profile-Level and Item-LevelTrust based on trust statements provided by users about other users. Massa and Avesani [50]showed how trust weight, computed through a local trust metric obtained from trust values, canbe integrated with collaborative filtering to improve accuracy. In her PhD thesis, Golbeck [28]studied online social networks and defined a trust metric called TidalTrust, that in a breadth-first manner computed trust propagation based on how much a user trusted other users’ filmratings. While their work is based on explicit trust statements and/or values provided by users,in our work we derive trust values implicitly from comments and ratings. It is interesting tonote that our findings are similar to those obtained by aforementioned works and are reportedin Section 5. To be sure, another way to model trust in social networks is via a PartiallyObservable Markov Decision Process (POMDP) [67].
Pappas et al [65] compare Content Based (CB), Collaborative Filtering and hybrid methodsbased on semantic vector spaces to recommend TED talks in a personalized setting. They show
40
that CB methods are outperformed by the CF methods, but hybrid methods do well too. Theyleave the impact of comments and user behaviours for future study. We utilize local and globaltrust metrics at the user and item level that outperform competing approaches to solving thepersonalized Top-N recommendation task.
5.2.1 SLIM Method
In the SLIM method by Ning et al [60], ratings are predicted for the all unrated items t for auser u as a sparse aggregation of his/her past ratings:
rut = rTu st (5.1)
where is the row vector of R corresponding to user u and st is estimated by solving the follow-ing optimization problem:
minst
1
2||rt −Rst||22 +
α
2||st||22 + β||st||1
s.t. st ≥ 0
stt = 0
(5.2)
where α and β are regularization parameters, the first constraint is to ensure that only non-negative ratings are predicted and the second constraint ensures that an item t is not used toweigh itself. SLIM has been proven to be a very effective method for the top-N recommen-dation task. But this only considers a single local model for all users based on item-itemsimilarity. In order to capture the different preferences of different users, we extend SLIM toutilize both local and global trust models to generate recommendations.
5.3 Proposed Approach
5.3.1 Formalization
The goal is to recommend ”talks” to the user based on knowledge obtained from the oneshe/she has already viewed, and other trusted members of the community. Let first define U =
u1, u2, . . . , un to be a set of users and T = t1, t2, . . . , tm be a set of talks. Let R be theuser-talk favourites matrix of size n×m that shows the rating provided by users for talks thatthey have viewed and liked. If a user u marks a talk t as “favourite”, then the correspondingentry rut of the matrix is 1 and 0 otherwise for the unrated talks. Let <u denote the set of itemsmarked as favourite by user u.
41
5.3.2 Estimating Contextual Social Trust
Social trust between users depends on the nature of interactions between them and the con-text. For instance, Alice may trust Bob when it comes to recommending talks related to (say)Technology but may not trust Bob as much when it comes to talks related to (say) Psychology.To compute social trust between users u and v in the context of a particular talk t, we carry outsentiment analysis of their comments on t (Our exact model would not work if comments arenot available. However, if feedback in any other form is available, it could be adapted for thecurrent purposes.). We denote the sparse user-user-talk tensor Y ∈ Yn×n×m by:
Y tu,v =
ptu,v − ntu,v
ptu,v + ntu,v
(5.3)
where ptu,v and ntu,v are the number of comments of similar and opposite relative polarity re-
spectively, made by u and v on t. Similar to Hu et al [35], we transform the counts Y tu,v into
contextual social trust values S = (Stu,v)u,v,t given by the equation St
u,v = 1+α log(1+Y tu,v/ε).
α and ε are scaling parameters which are empirically determined.
The observed values in S are formed by the information provided by the users and estimatingthe unknown values boils down to a Tensor Completion (TC) problem. Analogous to MatrixFactorization (MF), the aim is to factorize the tensor into three matrices U ∈ Rn×dU , V ∈Rn×dV , A ∈ Rn×dA and a central tensor J ∈ RdU×dV ×dA such that F = J ⊗ U ⊗ V ⊗ A
approximates S. That is, it minimizes the loss function between the observed and estimatedvalues. We define the loss function as:
L(F, S) :=1
||J ||1
∑u,v,t
Dtu,vL(F t
u,v, Stu,v) (5.4)
whereD ∈ 0, 1n×n×m is a binary tensor taking the value 1 when Stu,v is observed and L is the
pointwise loss function given by L(F tu,v, S
tu,v) = 1
2(F t
u,v − Stu,v)
2. We also add the Frobeniusnorm as a regularization term for improving the generalization performance and to preventoverfitting and it is given by:
and similarly also for tensor J. The regularization weights λU , λV and λA control the sparsity ofthe corresponding matrices U, V and A. Thus combining Equations (5.4) and (5.5), the overallminimization problem becomes:
H(U, V,A, S) := L(F, S) + Ω(U, V,A) + Ω(J) (5.6)
The optimization problem of Equation 5.6 can be solved using HOSVD-decomposition [17]and stochastic gradient descent.
42
5.3.3 Computing Global Trust
To compute the global trust value of a talk t, we first construct a network graph G =
(V,E,W ) of the underlying system, where each vertex v ∈ V is a talk and there exists anedge between two talks if they share at least one tag in common. The weights assigned to eachedge represent the total number of tags that two talks have in common. We now compute, foreach talk t:
b(t) =1
|V |(|V | − 1)
∑(i,j)∈Ei 6=j
σij(t)
σij(5.7)
where σij is the number of shortest paths from i to j and σij(t) is the number of shortest pathsfrom i to j that are internal to t. b(t) roughly denotes how easy it is to be able to reach fromtalk t to some talk t’. That is, Equation 5.7 estimates the influence of t in the graph. We alsocalculate for each t, its PageRank score c(t) given by:
c(t) = α∑j
djtc(j)
L(j)+
1− αn
(5.8)
where L(j) =∑
t djt is the number of neighbours of node j. The motivation behind it is that itprovides an estimate of how important the node is and what the probability of visiting the nodein a random walk is.
Combining the global importance and influence of talk t in the network graph, we define theglobal trust of t as:
G(t) =2× b(t)× c(t)b(t) + c(t)
(5.9)
5.3.4 Hybrid Trust Recommendation
In this subsection, we present our Hybrid Trust-Aware method for personalized top-N rec-ommendation. We compute the social and global trust values as described in Subsections 3.2and 3.3 respectively. Putting it all together, the predicted rating rut for user u for talk t will beestimated by:
rut =∑l∈<u
guG(l)× slt +∑v∈Tu
(1− gu)F tu,v × arg min
l∈<v
slt (5.10)
where gu is the personal trust for user u which controls the interplay between the social andglobal terms. Its value lies in the interval [0, 1] where 0 denotes that only the social part plays arole in the prediction and 1 denotes that only the global part is used. gu is initially set to 0.5 toensure equal weightage to both parts and it is updated during training to reflect the behaviour
43
of the user. G(l) represents the global trust for talk l as obtained from Equation 5.9 and F tu,v
represents the social trust between users u and v for talk t as seen in Section 3.2. And lastly, sltrepresents the item-item Jaccard similarity coefficient between the lth item rated by u and thetarget item t.
We then compute the predicted rating rut for every unrated talk t for a user u according toEquation 5.10, sort the values and recommend the top-N talks with the highest ratings to theuser.
5.4 Experimental Evaluation
5.4.1 Dataset
We evaluate our method on a real-world TED dataset2 collected by Pappas et al [65] whichthey have released under the same Creative Commons license as TED. The dataset is based ona snapshot of the TED website taken in September, 2012. It includes 1.2k talks, 69k users, over100k instances of talks marked as favourites and over 200k comments. Each talk is character-ized by a unique ID, title, number of views, name of the speaker, etc. Additionally, metadatasuch as related tags (e.g. “Technology”, “Science”) and related talks that have been manuallyassigned (by the TED staff) for each talk are also made available.
5.4.2 Evaluation Methodology
For the top-N personalized recommendation task, for each user u, we randomly select 80%of his/her favourites to place into the training set (M) and the remaining 20% form the test (E)set. The set of users is selected on the basis of the minimal number of favourites available.After these splits have been constructed, the model is trained on the training set and the recom-mendation quality is measured on the test set. We use the widely popular Precision and Recallmeasures for the top-N list.
Precision(E,N) =|Top(u,N) ∩ t|(u, t) ∈ E|
N(5.11)
Recall(E,N) =|Top(u,N) ∩ t|(u, t) ∈ E|
|t|(u, t) ∈ E|(5.12)
2https://www.idiap.ch/dataset/ted
44
We repeat the experiments 10 times with new training and test samples and report averageprecision and recall values.
Additionally, we carry out a more subjective evaluation of user satisfiability using the fol-lowing metrics to show the relative advantages and weaknesses of our model:
1. Popularity - computes the number of other users who have viewed the talk.
2. Newness - computes the average of the release dates of the recommended talks.
3. Diversity - measures the distribution of themes covered by the talks.
Furthermore, we compare our model with three baseline approaches namely, Random whereintalks recommended to the user are chosen uniformly at random from all available talks, Con-tent Based (CB) algorithm that given a similarity function recommends N most similar itemsto those in the user’s favourites list, and the standard Resnick prediction method. We also com-pare with related recommender methods from literature; Profile-Level Trust in [62], TaRS [50]and ESA [65].
We perform all our experiments on a computer equipped with a 64-bit Intel Core-i3 processorand a 4GB RAM. We write the code in Python and use Gephi [9] and Networkx [31], whichare tools designed to analyze large networks. And for the estimated rating prediction, we useTensorFlow and Scikit-Learn libraries.
5.4.3 Results
We construct the network graph G = (V,E) defined in Section 3.3 for the TED dataset with|V | = 1203 and |E| = 306977. Its characteristic path length is 1.55 which is small compared tothe size of the graph and its diameter is 3 which indicates that on average, it is possible to reachany talk from any talk in relatively few steps. The degree distribution of the graph yields anexponent of λ = 1.03 with an estimated xmin = 0.0008. (Fig 5.1 shows the degree distributionof the graph. It is a plot of the probability P(k) that a vertex will have degree k, versus k. Wefit our distribution using the comparison function of the Powerlaw [4] toolbox and find that thedistribution is exponential.) Since the distribution is exponential, the value of λ is invariant tothe size of the network. And the average clustering coefficient is 0.702. Taken together, we canconclude that the graph is scale free and exhibits small-world properties based on the work byBarabasi and Albert [7].
45
Figure 5.1: Degree distribution of the TED network
One of the most important features in network science is representing real systems as acollection of communities. Communities are sets of vertices that are more connected with eachother than they are with vertices of other communities. Modularity is a scoring function thatmany techniques use because it incorporates the definition of cluster and the choice of the nullmodel within it. It is defined as
Q =
NC∑i=1
[I(i)
L−(di2L
)2]
where I(i) is the weights of all edges linking vertices of the cluster i, di the sum over all vertexdegrees in cluster i, L the total edge weight, and NC the number of communities. Modularityvalues lie in the range of [-1/2, 1). Higher values of modularity imply the formation of betterpartitions. By optimizing the modularity, one can detect good communities in graphs. We usethe algorithm by Schuetz et al [70] to form our communities. This heuristic algorithm is dividedinto two parts. In the first part, each node is assigned its own cluster and then the modularityis optimized by allowing local changes of communities. In the second part, an agglomerativeclusterization is carried out to form new communities. After some number of iterations whenmodularity cannot be further increased, the algorithm terminates. Figure 5.2 shows the TEDnetwork partitioned into four distinct communities while the other four subgraphs (one for eachcommunity of the original) shown in Figure 5.3 show the clusters formed in the penultimateiteration of the algorithm. These images show that TED talks can be of four types based ontheir content (depicted as a set of tags).
46
Figure 5.2: TED Network Graph
(a) (b)
(c) (d)
Figure 5.3: The subcommunities of the four clusters of the TED video graph in Fig 5.2. Eachof these subcommunities can be further subclassified as can be seen from the coloured clusters.
47
Table 5.1: Accuracy of three baseline approaches, competing methods and the Hybrid modelproposed in this work. These models are evaluated for the top-10 and top-20 recommendationtasks.
Model Random CB Resnick TaRS ESA HybridPrecision@10 0.028 0.026 0.043 0.085 0.132 0.158
Table 5.1 shows the mean average precision and recall values for the Hybrid model and theother baseline and competing methods for the personalized recommendation task. We onlymeasure precision and recall for top-10 and top-20 talks since most users do not scroll beyondthese many recommendations. As can be seen from Table 5.1, the Hybrid method outperformsthe baseline methods as well as the competing methods in terms of accuracy. While CB is ableto provide talks with similar content, it fails to identify those talks that are not similar that auser would like. On the other hand, while the CF-based Resnick method is able to suggesttalks viewed as popular in the community, trusted users are found to better predictors and soit is worth the extra effort to find them. The Hybrid model conveys to the user that the talkswere recommended to him/her by these specific users who have successfully recommendedtalks to other users based on their trustworthiness which in turn causes the user to trust futurerecommendations.
Figure 5.4 compares the popularity, newness and diversity of the recommendations and itis a more subjective evaluation which we argue is equally important as accuracy. The Hybridmodel scores high on diversity and mediocre on newness and popularity. We compare this withmodels based on Global trust only, Social trust only and the Random method. The Randommethod outperforms the Hybrid model on diversity as can be expected but the Hybrid modelperforms better than the Global and Social trust metric only models. This suggests that Hybridcan discover talks to recommend even if they are not very popular or newly added.
48
Figure 5.4: Subjective evaluation of Global Trust (Blue), Social Trust (Red), Random (Yellow)and Hybrid (Green) models based on popularity, diversity and freshness criteria to gauge usersatisfaction.
49
5.5 Conclusions
In this chapter, we address the personalized top-N recommendation problem. The modelwe propose combines a three-dimensional (personal, social and functional) view of trust withcollaborative filtering to recommend trusted content suggested by trusted fellow users. Ex-perimental results depict that the model outperforms standard CB and CF methods as well ascompeting trust-based approaches. While our model is evaluated only on a dataset of TEDtalks, we believe the results are promising enough to be applied to other domains as well.
50
Chapter 6
Conclusions
In this thesis, we developed a new framework to understand trust in the online world for avariety of social networks. This framework draws upon a diverse set of theories and conceptsfrom fundamental philosophical literature such as ontology, epistemology and utilitarian moraltheory among others. The paradigm that played a key role in establishing our framework wasthat there are multiple and distinct dimensions associated with properties of the users, sociolog-ical groups and the technological systems themselves, each of which significantly contribute tothe creation of trust. In particular, we were able to extrapolate the role of institutions, signalsand value-alignment to provide solutions to the problem of trust.
These ideas led not only to a study of the manifestation of trust in Wikipedia, but alsorevealed the generic nature of the framework insofar as its applicability to every kind of socialmachine is concerned. They also allowed us to motivate and make progress on a trust-basedrecommendation task for personalized suggestions of items to users.
To be sure, there are certain limitations of our work. First, we have not conclusively dis-cussed the completeness of the three-pronged taxonomic framework we proposed. There couldbe other elements to trust that we have so far not investigated that are independent of Personal,Social and Physical. Second, we fall short of providing an extensive experimental analysis ofthe solutions to the problem of trust, particularly in the case of Wikipedia. And lastly, our rec-ommender system relies on a narrow analysis of user comments and feedback for computingsocial trust. This model demonstrates the importance and effectiveness of trust-based models,but can be significantly improved.
51
We believe that the research presented in this thesis opens up a lot of interesting avenues topursue. We describe them below:
Extending the Multi-Dimensional Framework of Trust - We presented personal, social andfunctional elements of trust and only briefly touched upon the emergence of a fourth element,namely physical taking into account the growing trend and popularity of Internet of Thingsand other wearable and sensory devices. This represents one promising approach to extendingthe framework. We also wonder if it is possible to utilize the insights gained from our workto demonstrably obtain a complete (in the sense of necessary and sufficient) understanding oftrust in social networks. One another direction of research would be to add to philosophicalliterature in the digital humanities and social computing domains based on investigations ofonline societies.
Further Study of the Generic Nature of the Framework - As our ultimate goal is to de-velop a full understanding of trust and its impact on the everyday workings of socio-technicalsystems, one could consider taking a more principled approach that involves empirical experi-ments for a qualitative and quantitative analysis. A particular direction in this vein could focuson applying the framework to different kinds of social machines and establishing its efficacyin studying human and societal behaviour in the changing landscape of the technological world.
Applying the Framework to Design Trustworthy Intelligent Systems - Given the benefitsof using trust-based features to inform the design of systems as presented in this thesis, anatural direction to pursue is to understand further, the extent to which this paradigm canbe applied. More sophisticated recommendation engines, anti-vandalism bots, modules thatenforce socio-judicial norms of governance and more generally, building of intelligent systemsthat enable participating entities to show trustworthiness would lead to a deeper understandingof our society.
52
Related Publications
1. The Use of Trust in Social Machines, Arpit Merchant, Tushant Jha, Navjyoti Singh,Theory and Practice of Social Machines, World Wide Web Conference (WWW), 2016.
2. In Wikipedia We Trust, Arpit Merchant, Darshit Shah, Navjyoti Singh, Wiki Workshop,International Conference on Web and Social Media (ICWSM), 2016.
3. Hybrid Trust-Aware Model for Personalized Top-N Recommendation, Arpit Mer-chant, Navjyoti Singh, ACM India’s KDD Conference on Data Sciences (CoDS), 2017.[Best Poster Award]
53
Bibliography
[1] S. Adali, R. Escriva, M. K. Goldberg, M. Hayvanovych, M. Magdon-Ismail, B. K. Szymanski,
W. Wallace, G. Williams, et al. Measuring behavioral trust in social networks. In Intelligence and
Security Informatics (ISI), 2010 IEEE International Conference on, pages 150–152. IEEE, 2010.
[2] B. T. Adler, K. Chatterjee, L. De Alfaro, M. Faella, I. Pye, and V. Raman. Assigning trust to
wikipedia content. In Proceedings of the 4th International Symposium on Wikis, page 26. ACM,
2008.
[3] G. Akerlof. The market for ’lemons’: Quality uncertainty and the market mechanism. Springer,
1995.
[4] J. Alstott, E. Bullmore, and D. Plenz. powerlaw: a python package for analysis of heavy-tailed
distributions. 2014.
[5] J. R. Anderson. The architecture of cognition. Psychology Press, 2013.
[6] J. Baker. Trust and rationality. 1987.
[7] A.-L. Barabasi and R. Albert. Emergence of scaling in random networks. science, 286(5439):509–
512, 1999.
[8] M. R. Barrick and M. K. Mount. The big five personality dimensions and job performance: A
meta-analysis. 1991.
[9] M. Bastian, S. Heymann, and M. Jacomy. Gephi: An open source software for exploring and
manipulating networks, 2009.
[10] T. Berners-Lee, M. Fischetti, and M. L. Foreword By-Dertouzos. Weaving the Web: The original
design and ultimate destiny of the World Wide Web by its inventor. HarperInformation, 2000.
[11] N. Bostrom. Superintelligence: Paths, dangers, strategies. OUP Oxford, 2014.
[12] V. Buregio, K. Brito, N. Rosa, M. Neto, V. Garcia, and S. Meira. Towards government as a social
machine. In Proceedings of the 24th International Conference on World Wide Web Companion,
pages 1131–1136. International World Wide Web Conferences Steering Committee, 2015.
54
[13] E. Christakopoulou and G. Karypis. Local item-item models for top-n recommendation. In Pro-
ceedings of the 10th ACM Conference on Recommender Systems, pages 67–74. ACM, 2016.
[14] D. Cosley, D. Frankowski, L. Terveen, and J. Riedl. Suggestbot: using intelligent task routing
to help people find work in wikipedia. In Proceedings of the 12th international conference on
Intelligent user interfaces, pages 32–41. ACM, 2007.
[15] S. R. Dall, L.-A. Giraldeau, O. Olsson, J. M. McNamara, and D. W. Stephens. Information and
its use by animals in evolutionary ecology. Trends in ecology & evolution, 20(4):187–193, 2005.
[16] R. Dawkins and J. R. Krebs. Animal signals: information or manipulation. Behavioural ecology:
An evolutionary approach, 2:282–309, 1978.
[17] L. De Lathauwer, B. De Moor, and J. Vandewalle. A multilinear singular value decomposition.
SIAM journal on Matrix Analysis and Applications, 21(4):1253–1278, 2000.
[18] H. Demsetz. Information and efficiency: another viewpoint. The Journal of Law & Economics,
12(1):1–22, 1969.
[19] J. Donath. The social machine: designs for living online. MIT Press, 2014.
[20] P. Dondio, S. Barrett, S. Weber, and J. M. Seigneur. Extracting trust from domain analysis: A case
study on the wikipedia project. In Autonomic and Trusted Computing, pages 362–373. Springer,
2006.
[21] B. R. Duffy. Fundamental issues in affective intelligent social machines. Open Artificial Intelli-
gence Journal, 2:21–34, 2008.
[22] P. Dumouchel. Trust as an action. European journal of Sociology, 46(03):417–428, 2005.
[23] E. Durkheim. The rules of sociological method: and selected texts on sociology and its method.
Simon and Schuster, 2014.
[24] M. Foddy, M. J. Platow, and T. Yamagishi. Group-based trust in strangers the role of stereotypes
and expectations. Psychological Science, 20(4):419–422, 2009.
[25] F. Fukuyama. Trust: The social virtues and the creation of prosperity. World and I, 10:264–268,
1995.
[26] D. Gambetta. Trust: Making and breaking cooperative relations. 1988.
[27] P. T. Geach. Reference and generality. 1964.
[28] J. Golbeck, B. Parsia, and J. Hendler. Trust networks on the semantic web. Springer, 2003.
[29] M. C. Gonzalez, C. A. Hidalgo, and A.-L. Barabasi. Understanding individual human mobility
patterns. Nature, 453(7196):779–782, 2008.
55
[30] T. Govier. Is it a jungle out there? trust, distrust and the construction of social reality. Dialogue:
Canadian Philosophical Review/Revue canadienne de philosophie, 33(2):237–252, 1994.
[31] A. A. Hagberg, D. A. Schult, and P. J. Swart. Exploring network structure, dynamics, and function
using NetworkX. In Proceedings of the 7th Python in Science Conference (SciPy2008), pages 11–
15, Pasadena, CA USA, Aug. 2008.
[32] R. Hardin. Trust and trustworthiness. Russell Sage Foundation, 2002.
[33] J. Hardwig. The role of trust in knowledge. The Journal of Philosophy, 88(12):693–708, 1991.
[34] M. Hollis. Trust within reason. Cambridge University Press, 1998.
[35] Y. Hu, Y. Koren, and C. Volinsky. Collaborative filtering for implicit feedback datasets. In 2008
Eighth IEEE International Conference on Data Mining, pages 263–272. Ieee, 2008.
[36] S. Javanmardi, Y. Ganjisaffar, C. Lopes, and P. Baldi. User contribution and trust in wikipedia.
In Collaborative Computing: Networking, Applications and Worksharing, 2009. CollaborateCom
2009. 5th International Conference on, pages 1–6. IEEE, 2009.
[37] M. L. Katz and C. Shapiro. Network externalities, competition, and compatibility. The American
economic review, 75(3):424–440, 1985.
[38] D. Kempe, J. Kleinberg, and E. Tardos. Maximizing the spread of influence through a social
network. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge
discovery and data mining, pages 137–146. ACM, 2003.
[39] D. E. Kieras and S. Bovair. The role of a mental model in learning to operate a device*. Cognitive
science, 8(3):255–273, 1984.
[40] A. Kittur, B. Suh, and E. H. Chi. Can you ever trust a wiki?: impacting perceived trustworthiness
in wikipedia. In Proceedings of the 2008 ACM conference on Computer supported cooperative
work, pages 477–480. ACM, 2008.
[41] R. M. Kramer. Trust and distrust in organizations: Emerging perspectives, enduring questions.
Annual review of psychology, 50(1):569–598, 1999.
[42] K. Krukow, M. Nielsen, and V. Sassone. Probabilistic computational trust. 2009.
[43] S. Kumar, F. Spezzano, and V. S. Subrahmanian. VEWS: A wikipedia vandal early warning
system. CoRR, abs/1507.01272, 2015.
[44] T. Lucassen and J. M. Schraagen. Trust in wikipedia: how users trust information from an un-
known source. In Proceedings of the 4th workshop on Information credibility, pages 19–26. ACM,
2010.
56
[45] M. Luczak-Roesch, R. Tinati, and N. Shadbolt. When resources collide: Towards a theory of
coincidence in information spaces. In Proceedings of the 24th International Conference on World
Wide Web Companion, pages 1137–1142. International World Wide Web Conferences Steering
Committee, 2015.
[46] B. Malinowski, F. G. Crookshank, C. K. Ogden, and I. A. Richards. The Meaning of Meaning; a
Study of the Influence of Language Upon Thought and of the Science of Symbolism. Kegan Paul,
Trench, Trubner; Harcourt, Brace, 1923.
[47] S. Maniu, B. Cautis, and T. Abdessalem. Building a signed network from interactions in wikipedia.
In Databases and Social Networks, pages 19–24. ACM, 2011.
[48] S. P. Marsh. Formalising trust as a computational concept. 1994.
[49] U. Martin and A. Pease. Mathematical practice, crowdsourcing, and social machines. In Intelligent