- 78 - THEORY OF AUTomATA AND ITS APPLICATION TO PSYCHOLOGY P. Suppes Contents Lecture 1. Introduction (language). Lecture 2. Register machines. Lecture 3. Models for the performance of elementary arithmetic computations. Linear regression models. Automaton mo- l dels. Register machines. Lecture 4. Language-processing. Classical model-theoretic seman- tics. Model-theoretic semantics for context-free languages. Application to "Erica". Lecture 5. From theory to corpus. Procedural semantics. The com- plexity of semantics. Institute for Mathematical Studies in the Social Sciences, Stan- ford University, Stanford, Calif. 94305, U.S.A.
Transcript
- 78 -
THEORY OF AUTomATA AND ITS APPLICATION TO PSYCHOLOGY
P. Suppes
Contents
Lecture 1. Introduction (language).
Lecture 2. Register machines.
Lecture 3. Models for the performance of elementary arithmetic
computations. Linear regression models. Automaton mol
Lecture 5. From theory to corpus. Procedural semantics. The com
plexity of semantics.
Institute for Mathematical Studies in the Social Sciences, Stan
ford University, Stanford, Calif. 94305, U.S.A.
patguest
Typewritten Text
G.J. Dalenoort (Ed.), Process Models for Psychology. Lecture Notes of the NUFFIC International Summer Course, 1972. Rotterdam: Rotterdam University Press, 1973, pp. 78-123.
- 79 -
THEORY OF AUTOmATA AND ITS APPLICATION TO PSYCHOLOGY
P. Suppes
Lecture 1
1.1 I NTRODUCT I ON
Suppes
The first three lectures w~ll deal with language processlng.
The objectlve is to understand natural language, especially of
children. The emphasis ~s on granlmar and sefTIantics wi th the maln
accent on semantics. The semantics will mainly be concerned ulith
model-thBoret~c semantics. By model-theoretic semantics is meant
the set-thooretical eccount of the maenlng of a sentence that
makes use of standard techniques of modern logic and mathematics.
Another topic will be procedural semantics. The central question
here is how a semantic tree actually can be computed. The last
two lectures will deal with process models ln young student's
learning and performing elementary mathemetlcs
1.2
The ideas underlying model theoretic-semantics in mathematical
logic go back to Frege, they have been developed especIally by
the work of Tarski and hlS students, amonq whom I mention ~on
tague, who contributed substantially to the applicatIon of model
theory to natural language. most of model theory is not concerned
with natural language. The semantical approaches developed by
linguists or others whose viewpoint is that of generative grammar
have been lacking in the formal precision of model-theoretic se
mantlcs. my objective is to combine the viewpoint of model-theo
retIC semantics on the one hand and generative grammar, especial
ly the work of Chomsky, on the other. The tools of model-theory
th respect to the responsibility for the contents of these 1ecturessee page Vll. Summarized by L. Noordman, H. Schouwenburg.
Suppes - 80 -
wlil be brought to bear on the analysls of natural language.
A number of examples will give you an intuitive idea of the ap
plicatlon of model theory. Let us take as an instance the simple
noun phrase square table. That noun phrase can be represented by a
simple tree,
NP /'" AdJ
I square table
abbreviations: NP noun phrase
rig. 1.1
N noun
Adj= adjective t
called a derivation tree of a particular noun phrase grammar. This
grammar has (except for insertion of lexical ltems) as yet only one
pro due t ion r u 1 e: f~ P ~ Ad J + N. How is the s em ant i c s 0 f t his no un
phrase to be formalized? ~ith each production rule of the grammar
there is associated a semantic function and thus we may convert
each derlvatlon tree for a given terminal utterance to a semantic
tree by assigning a denotation to each node of the tree. The de
notation of each node of the tree is shown after the colon follow
ing the label of the node.
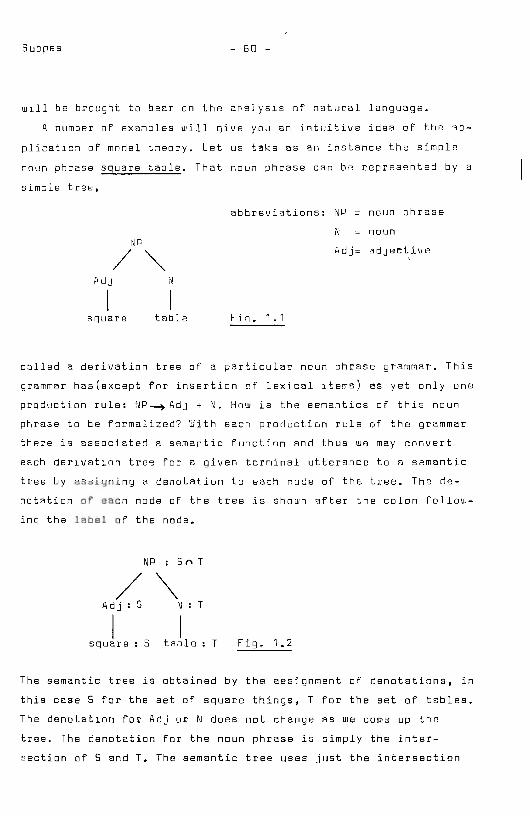
NP : 5" T
/'" Adj: S N T
I I square Stable T Fig. 1.2
The semantic tree is obtained by the assignment of denotations, in
this case S for the set of square things, T for the set of tables.
The denotatlon for Adj or N does not change as we come up the
tree. The denotation for the noun phrase is simply the inter
section of 5 and T. The semantic tree uses just the intersection
- 81 - Suppes
and 1dentity functions. The word order in the correspond1ng French
example table carree is reversed
NP : 5 r. T
/~ r~ : T Adj T
I I table T carree 5 Fig. 1.3
The root of the tree, the denotation, is Just the same. The se
mantic part of the tree is more like the English than the gramma
tical surface.
In order to study how to analyse denotation, an apparatus w1ll
be Introduced that is a modification of the claSSIcal semantic
theory. It is important to note that grammar and semantics go hand
in hand: the semantic analys1s is not a separate analys1s, it 1S
built on the same tree.
The noun phrase the square table is a slightly more elaborate
and compl1cated example. will give an analysis of the def1n1te
article in this example. A grammar with the following rules:
NP
AdJ
Adj
AdJ
yields
~ AdjP + N
P4 Adj P
p~ AdJ
p~ Det
this tree:
+ Adj abbreviatIons: AdJ P
Det
NP
/~ Adj P N
/'''''-Adj P Adj
I D
I
adjectIval phrase
determiner
the square table Fig. 1.4
Suppes - 82 -
The denotation of this noun phrase presents a problem: the and
sguare have to be put together, but it is much more natural to
think of the modifying square table as expressed in the grammati
cal tree:
NP : <j)<C,S n T)
/~ Oet : C NP I : Sf'lT
/"" Adj : 5 N T
I I the: C square: 5 table: T • 1.5
The denotation of the is C: the set of objects in the circum
stances, as determined by the context in wh1ch the phrase 1S
used. The semantic function for putting Oet and NP' together 1S a
function ,(C,SoT) defined as follows:
if ICnSoTI = 1 the intersection of C,S and T if the cardinality of CnSnT = 1
I CnS nT I a , .i. e. the fun c t ion is em p t y if the cardinality is zero
f if ICn51'\TI > 1 •• i.e. the function is too full 1f the cardinality 1S greater than 1
where e and f are two abstract Fregean objects.
Not all noun phrases can be analysed in this way. One can find
many counter-examples. we have to deal especially with two kinds
of counter-examples for the analysis of NP:
The denotation of the NP
is not the intersection of the set of alleged things and the
set of dictators.
two flowers. The denotation of this NP is nat the intersection
of two and the set of flowers.
A thlrd example, deal1ng with adverbs, is: the very tall man. The
adverb very is an lntensifier. The denotation of cannot
be represented by the intersection of very and tall. Another in
teresting example is two red flowers. One could add a new rule:
AdjP-7Car to the grammar of noun phrases given earlier, Car
- 83 - Suppes
standing for cardinal. But this would give the same problem as ~n
the example the square table. The following grammar can be de
vised:
NP ~ Car + NP t
NP I ~ AdjP + N
AdjP ~ AdjP + Adj
AdJP-+ AdJ
It is to be noted that NP I Npr. NP' is used in order to avoid re
cursion on cardinal numbers that would allow sentences like two
three flowers.
To this grammar has to be added the Fraga-Russell definition
of 2: 2 is the set of all pair sets. The tree for two red flowers
is:
NP : 2 np(RnF)
/~ Car f\ip t
: RnF
I" AdjP : R N : F
+.R I two: 2 red: R flowers r F 1.9. 1.6
What about the semantics for the special rule NP---", Car.;. NP I,?
P(RnF) ~s the power set of RnF i.e. the family of all subsRts of
RnF. The denotation of the root NP is:
the intersection of the set of all pair sets and the power set
P (RnF)
It is not suggested that this model is a model of what is ln
the child's head. ~ child, a speaker, or a listener of Engl~sh ~s
not exam~ning in any sense the entire set 2 or the large set
P(RnF): these rules are not meant to be a part of procedural se
mantics.
The analysls given so far does not deal w~th all problems of
semant~cs. It has to be kept in mind that we are at the moment
Suppes - 84 -
dealing only with extensional semantics. Later on we will talk
about intensional semantics. In order to illustrate the difference
we can use a famous example of Frege's:
9 = the number of planets premiss
premiss 2 it is mathematlcally or logically necessary that
9 > 7
conclusion it 18 mathematically or logically ne~essary that
the number of planets is greater than 7
The problem is that what is cal18d in ~rem1ss 1 extensional iden
tity has been used for substitution into a non-extenslonal con-
text.
As an illustratlon of the application of the analysls to sen-
tences, let us take the example:
mar has the following production rules:
S --7' NP + VP
NP ~ as before
VP --7' TV + NP
NP~ PN
The gram-
where 5 stands for sentence, VP for verb phrase, TV for transltlv8
verb, and PN for proper name. The derivation tree looks llke:
5 : F (q,( C ,R n B) ,f:l' , J )
~ ------- ~ NP : <1>( C, R f"I 8) VP : H' 'J
/ ~ /' "'" Det:C NP':Rn8 TV:H NP:J
I~ I AdJP : R N: B PN : J
A1 j : R I
the: C red: R ball: !:J hi t : H John: J Fig. 1.7
The int8r8sti~g part of the tree is the denotation of each node. H
is a binary relation denoted by the two-place predicate hit. H'IJ
is the converse of H, restricted to J, denoting in this way a unit
- 85 - Suppes
set (in the present case). The denotation of S is the Frege
function:
={true if A :S B
F(A,B) false otherwise
(In the notation HI IJ, we would be more explicit if we wrote
H"{J}, but I idenb.fy unit sets with thelr members, l..e., {J}
J) •
Jhat I now would like to do is to glve a simple example from
actual data taken from a corpus collected by Roger Brown and his
aSSoclates. That corpus 1S known as Adam I, i.e. the early years
of a boy Adam who lS about 24 months old. I shall give a noun
phrase grammar for Adam I. Instead of uSlng simpllcity as the
cr1terlon for a grammar of a corpus, I prefer a much more con
servat1ve crlterion. without gIving an account of the mechanisms
by which a chlld lS generatlng the speech, we can probablilstl
cally predlct the utterance types by assigning probabilistic pa
rameters to the varlOUS productlon rules. One of the byproducts
one can expect from thls is a pretty good account of the length
of the utterances. The grammar for the noun phrase of Adam I has
7 product10n rules. The probabillty of uSlng each rule in a de
rivation as well as the set-theoretlcal semantic functlons are
lndlcated for each rule.
Noun-Phrase Grammar for Adam I
Production Rule [...rob('lbility SemantIc Functlon
1 • NP -'> N a1
Identlty
2. i\lp ~ AdjP a2
Identlty
3. I~P -'> Ad jP + N a3
Intersection
4. r~p ~Pro a4
Identlty
5. rJP ~NP + NP a5
Choice functlon
6. AdjP -4AdjP + Adj b1
Intersection
7. AdjP ~Adj b2
Identity
11 u 1 e 5, the c h 0 1. C e fun c t 1. 0 n, i s a r u let 0 ex pre ssp 0 sse s s ion. Pro
stands for pronoun. From a probabillstic viewpoint, the grammar
Suppes - 86 -
has five independent parameters, because the a's sum to one and
the b's sum to one. These parameters may be estimated from the
data by a maximum likelihood method. The basic grammatical data
are shown in the table • The first column gives the types of noun
phrases actually occurring in the corpus in decreasing order of
frequency. Some obvious abbreviations are used to shorten nota
t1on: A for Adj, P for Pro. The grammar defined genefates an in
finite number of utterances, but, of course, all except a small
finite number have a small probabil1ty of being generated. The
second column lists the numerical observed frequencies of the ut
terances (with 1mmediate repetition of utterances deleted from
the frequency count). The third column lists the theoretical or
predicted frequenc1es when a maximum-l1kelihood estimate of the
five parameters is made. The fourth column lists the observed
frequency with which the "standard" semant1c function shown above
seems to provide the correct interpretation for the five most
frequent types.
The fit with the data is far from perfect. I only want to 11-
lustrate the method. The point 1S that if we can produce a gram
mar that also has semantic functions that we are satisfied with,
then this fit is a direct way of BV81uat1ng the grammar.
The number of parameters in the analysis of a whole corpus 18
usually very large. One thing we are trying to do is to reduce
the number of parameters. The other thing, which is linguist1cal
ly much more interesting, IS the use of probab1lities for proba
bilistic disambiguation: to select one of two trees as the denot
ation of an ambiguous sentence.
- 87 - Suppes
TABLE
Probabilistic Noun-Phrase Grammar for Adam I
~Joun Observed Theoretical Stand. semantic
phrase frequency frequency function
N 1445 1555.6 1445
P 388 350.1 388
NN 231 113.7 154
AN 135 114.0 91
A 114 121.3 114
PN 31 25.6
NA 19 8.9
N Nr~ 12 8.3
AA 10 7. 1
NAN 8 8,3
AP 6 2.0
PPN 6 .4
A r~N 5 8.3
.4AN 4 6.6
rA 4 2.0
MJIl. 3 .7
Il. P ~J 3 • 1
AAA 2 .4
APA 2 .0
PJPP 2 .4
PAA 2 • 1
PAN 2 1 .9
Suppes - SB -
THEORY OF ~UTomATA AND ITS APPLICATION TO PSYCHOLOGY
P. Suppes
Lecture 2
2.1 RECISTER mACHINES
The formal presentation of the model-theoretlc semantics Wh1Ch
we were talking about in the previous lecture, w1ll be given
after the presentation of register machines. Register machines,
which have a set of instructions, are 1ntultively much closer in
conceptual organization to actual computers than are Tur1ng ma
ch1nes. It is my hope that they can be applied ln psychological
research by introducing psychologically appropriate instructions.
~e begin wlth some notation:
cn> 1S the content of a register n before carrying out an in
struction,
enl>ls the content after carry1ng out an instruction.
Defln1tion: An Unlimited Register reachine (URm) has
(1) a denumerable sequence of reg1sters numbered 1,2, 3, ••• ,
each of WhlCh can store any natural number, but each program
uses only a finite number of registers and
~i) six bas1c instructions
(a) P (n) add 1, en I> = en> + 1 ,
(b) D(n) substract 1, < n '> en> - 1 if < n> f. 0
(c) D(n) clear register, <n '> = D,
(d) C(m,n) copy from register m to n, <n I> m,
(e) J [L ~ Jump to label L 1 ,
(n J (n) [L1] jump to label L1 if <n~ = 0
In programs we use ( e) and (f) in the form J [3] jump to label (3) •
If jump 1S to a nonexistent labeled line, the machine stops. Thus
L1 is a variable for the labeled line to jump to. crhe six instruct
ions (a)-(f) are not a m1nimal set.)
As an example, the following program puts "half" of the number that
is in register in register 2, and the remainder in register 3.
1. J(1)t~ Go to line 2 if <1) f. D. Else to line B (i.e. stop)
2. D(1) Substract 1 from number in register 1
- 89 - Suppes
3. P(2) Add 1 to number in reglster 2
4. J(1)[8]
5. D (1 )
6. P(3)
7. J (11 Jump to llne 1
The definltion of a program of a URm is as follows:
A program for a URm is a finite sequence of lnstructions anyone
of which may be labeled. It can be proved that any partial recur
sive function can be computed by a URm by considerlng how a par
tial recursive function is defined. (Shepherdson and Sturgls,
1963)
many equ1valences are known:
A number-theoretic function is computable by a Turing I'lachlne
i ff 1 tis par t i a 11 y r e cur s i v e
iffit 1S lambda-deflneable
iffit is computable by a Register machine
We now will talk about an URm over an arbitrary finite alpha
bet V and about part1al recursive functions over such an alphabet.
The set V is finite, and as usual V* is the set of all finite se
quences of elements of V; 1n the present context, we shall call lIE the elements of V words. In the follow1ng, variables a
1 range
over V, and var1ables x, y, x1
' ••• , xn
' etc., over V*. Also, xa i is the concatenation of x and a
i" The definition of a part1al re
cursive function is in this case as follows:
Definition: A function is partial recurS1Ve iff it can be obtained
from the functions of I, II, and III by a finite number of ap
plications of IV, V and VI.
1.
II.
III.
I V •
Sa. (x1
) = x1
a i (Successor Function) 1
On(x1
, ••• , xn
)
U~(x1' •.• , xn)
~ (Constant Function, ~ = empty string)
x. (Projection Function) 1
If h1 , g1' ••• 9m
are part1al recurSive, so is the funct
ion f such that f(x 1 , ••• , xn) = h(9 1 (x 1 , ••• , x n ), ••• ,
g (x 1 ' ••• , x )) (Compos1tion) m n V. If g, h, are part1al recurS1ve so is the funct10n f such
Suppes - 90 -
that f(~, x2 ' ••• , xn) = g(x 2 , ••• , xn)
f(za., x2 ' ••• , x) == h.(z, f(z, x2 ' ••• , x), x2 ' ••• , x) ~ n l n n
i = 1, ••. , s. (Primitive Recursion)
VI. Let ~~y mean the shortest word composed Just of a i • If g is
part~al recursive so is the functlon f such that
f(x 1 , •.. , xn ) = ~iY g(x 1 , ••• , xn ' y) =.0 In other words, the value of the function f(x 1 , ••• , x n ) for the
arguments x1 ' •• 0' xn is the shortest word y composed Just of a l such that g(x 1 , ••• , xn ' y) == O.
~e define in 8 fashion as before a URM over V. The basic instruct-
ions can be reduced to three:
(a I ) p(i)(n) place a. on the right-hand end of <n>, l
( b I ) D(n) delete the left most letter of < n> if < n> J 0,
(c I ) J(i)(n) [L1] jump to label L 1 if <n> begins wlth a .• ~
A machine like this can generate or recognize a type 0 phrase-struc
ture grammar.
want to examine some simple examples that illustrate the
general remarks, and also try to say in what sense we can regard
the production rules of a grammar as the primitive instructions
of some reg~ster machine.
A simple illustration of what I have in mlnd ~n talklng about
proving that a program is correct, can be given by using a very
simple stack machine, proposed by a student of mine, Alex Can
nara, and being investigated by him as a teaching device. The
simple instructions will be almost self-explanatory. Thus the
first line of the program is PUSH X, which places X at the top of
the pushdown stack. The second, SQUARE, pushes X down and places on
the top of the stack X2. Instructions llke ADD and mULTIPLY operate
on the top two expressions on the stack, and each places the result
on the top of the stack. The instruction SUBTRACT subtracts the
second item in the stack from the top item, and places the result
on the top of the stack. Finally DIVIDE divides the top ~tem on the
stack by the second item and of course places the result on the top
of the stack. Now let me write a simple program to compute
(X 2 _ y2 )/2 XV. In the right-hand column I show the content of the
- 91 - Suppes
more general purposes it would be necessary to keep track of the
content at each line of all the positions in the stack.
PROGRAm ~EXT ITEW IN STACK
PUSH X X
SQUARE x2
PUSH Y Y x2
SQUARE y2 x2
SUBTRACT _ X2
PUSH 2 2 y2 _ X2
DIVIDE 2/(y2 _ X2 )
PUSH X X 2/(y2 _ X2 )
mUL TIPLY x( (y2 _ X2))
PUSH Y y x( (y2 _ X2»
mUL TI PL Y Y(X(2;{y 2 _ X 2 ) ) )
PUSH -1 -1 Y (x (2;{y2 _ x2»))
IVIDE _1/Y(X(2/(Y 2 _ X2)))
To shaw that this simple program is correct we would need to
prove the trivial theorem:
YX2/(
whlch is obvious to us, but well mIght not be to a 13-year old
student of algebra. moreover, in the special case of rational
functions, e.g., there is an algorithm for deciding If two ex
pressions denote the same function. On the ather hand, in gen
eral the proof of correctness of a program cannot be given by an
algorit~m, and the proof of correctness can be non-obvious.
In several of our informal discussions have tried to make
the point that the concept of a procedure and the concept of
proving the procedure correct have well-anchored historical roots
in Greek mathematics. In Euclid, for example, constructions are
procedures. The surprising fact ~s the clear and explicit recog
n~tion by Greek mathematicians that constructions and proofs of
their correctness are given a d~fferent status - are classified
Suppes - 92 -
separately - from the proofs of propositions. Euclid's construct
ions may be regarded as a process model of geometry. The r~gorous
examination of the foundations of geometry at the end of the
nineteenth century bv Hilbert and others took an unfortunate turn
in obliterating this distinction. In Hilbert's axiomatlzation of
geometry and all the others of the same period constructlons were
eliminated as formal objects to be studled explicitly. In other
wards, no explicit aXloms about constructions were given, al
though intultive talk about constructions was frequent. A good
example would be Hilbert's discussion of constructive geometry
over a Pythagorean field at the end of hlS book on geometry. (A
field is Pythagorean If for each a and each b ln the field'there 222 is a c in the field such that a + b = c ). In terms of the mo-
dern history of procedures prior to the advent of computers, the
explicit consideration of mathematical proofs as objects, espe
clally in Hilbert's proof theory, was a fundamental step, one not
taken by the ancient Greeks.
I now turn to the second point wanted to plck up from our
earlier construction. This concerns the sense in which a grammar
may be looked at as defining procedures or programs. I shall look
at the question from the standpoint of reg1ster mach1nes and try
interpreting the production rules of the grammar as the prlmitlve
instructions of the machine. (fy examples will be slmple context
free grammars but the approach is equally applicable to any
phrase-structure grammar.) If we attempt to apply the s1mple In
terpretation just described, we at once encounter a difficulty.
To ll1ustrate it, let us consider the following Simple grammar.
Productlon Rules
s~ r~p + VP
NP~r~
NP~Adj + N
VP~TV + NP
Inst
S
NP1
NP2
VP
ons
Each production we interpret as an instruction of a machine with
a single register. (~e shall generate or parse only one sentence
- 93 - Suppes
at a t1me.) Thus, the first production now reads: "Replace S by
NP VP" and 1S denoted by S. l:Je also have an inltlal LOAD instruct
lon for placing a nonterminal symbol in the register. Now let us
look flrst at the derlvatlon in the grammar of the sentence
cows eat grass. For brev1ty I shall derive only the grammatical
structure and not make the flnal lexical substitutions. Thus we
begin the der1vatlon an the left and the attempted program an the
nght.
Derlvation
1. S
2. NP VP
3. NP TV NP
4. A dJ N TV NP
Program
Load 5
5
VP
?
At line 4 of the derivation we do not have a correct instruction
to add to our program on the right. It is clear from the deriv
atlon that NP2 1S used, but if we write NP2 as our instruction on
the rlght, we do not know, looking simply at the reglster machlne,
whether after the execution of the lnstruction the content of the
register is AdJ N TV NP or NP TV Adj N, unless of course we apply
NP2 to both occurrences of NP, which would be an unambiguous 1n
struction, but not the one we want. Consequently wlthout some
minor changes there 1S a d1fficulty of such a direct lnterpret
ation of the production rules. The minor change we must make is to
add an index to each lnstructlon. For example NP1(i) means that
instruction NP1 is to be applied to the ith occurrence of NP in
the register reading from left to right. Thus, our four lnstruct
ions are now S(i),NP1(1), NP2(i) and VP(i), and the program cor
responding to the derivation reads:
LOAD S
S (1)
VP(1)
NP2(1)
NP 1 ( 1 )
If we want to have a general register machine for generating or
Suppes - 94 -
parsing any language that is over a vocabulary V and that has a
phrase-structure grammar (not necessarily context-free), we can
use the general register machine over V described earlier and
write subroutines for each of the production rules of the gram
mar, which are by defin~tion of a phrase-structure grammar not
only partial recurs~ve but primitive recurs~ve.
Finally, I note that the usual definition of a language L( )
generated by a phrase-structure grammar G (a string of terminal
words is in L(G) if it is derivable from 5 in G) can be replaced
by the closely associated definition: a string of terminal words
1S in L(G) if there is a program with a slngle initial LOAD in
struct~on in the form LOAD 5 and the content of the reg1ster of
the machine is the string after the program lS run.
- 95 -
THEORY OF AUTomATA ~ND ITS APPLICATION TO PSYCHOLOGY
P. Suppes
Lecture 3
Today I shall talk about process models for students perform
ance ln elementary arithmetic. Process models In thlS domain can
be very much sImpler than process models of language performance.
Elementary mathematics provides one of the best examples as an
i~troduction to detailed process models. mathematics is a unl
versal set of skills; all children in the world are taught the
skills embodied in arithmetic. There has been historically a very
large Ilterature on the teachlng of elementary mathematics. Be
ginning in about 1910 there is a very good empirical literature
on how students come to perform the algorlthms of arithmetic. The
most influential single person is perhaps Edward Thorndlke, who
published Educational Psychology (1913), The Psychology of Arith
metlc (1922), and The PsycholoGY of Algebra.
Thorndlke tried to give a theoretIcal account of what the stu
dents are learning in terms of his concept of bonds, which is
like conditioning, and in terms of the law of effect. At that
time there was not a close connection between the psychologIcal
theory and the formal theory of algorlthms; the theory of algo
rithms in a mathematical sense was not very well developed. A
very large number of empirical studles has been made by many In
vestIgators In the 1920's. They were interested in empirIcal
questions and not so much ln psychological theory. The same was
true for Brown and others in the 1930's. Brown e.g. dld very nIce
studies on subtraction. The tradition of psychologists belng In
terested ln these topics stopped around 1930 WIth people like
Hull and Tolman.
At Stanford a few years ago we started the study of student's
performance In ele~entary mathematics ln a computer setting. Stu
dents are presented exerCIses at a teletype terminal. Two mea
sures of studentfs performance have been used: response probabil-
Suppes - 96 -
ity - the probability of a correct answer and response latency.
I only will talk about response probability. For simpllcity I
shall restrict the analysis to column addition, although the me
thods are extended also to other kinds of arithmetlc operations.
Three kinds of models in this domain will be reviewed: linear
regression models, automaton models and register machines.
3.1 LINEAR REGRESSION mODELS
The first question was to identify the structural features of
problems or exercises that will predict their relatlve difflcul
ty. These features are the independent variables ln the regres
sion models. Let Pl be the observed proportion of correct res
ponses on exsrClse 1; let f .. be the value of feature j on pro-1J
blem i and let ~ be the regresslon coefficient for feature j. A J
linear regression equat10n is
L a j J
In order to preserve the probabillty as the structural features
are combined, the following transformation was made:
Z. 1
log
The regression model we used is
Zi = j a j f ij + a a
The additions had the form:
abc
d e f
Lower case letters are used for simple digits. There are approx-6 imately 10 such problems. These have to be reduced to a small
number of independent variables (structural features). The fea
tures were identified and quantif~ed independently from the
data. The following structural features were defined for column
- 97 - Suppes
addition: SUMR IS the number of columns in the largest addend. For
three-row exerC1ses SUMR is defined as 1.5 t1mes the number of
columns, plus .5 if a column sum is 20 or more. For example:
SUMR [;1"
[ ~1_{1.5 if de < 20
SUMR -E - 2 1f de > 20 de
The second structural feature is CAR which represents the number
of tImes the sum of a column exceeds nine. For example:
CAR
CAR
Cl\R
[;] " 0
[~ ~J "{~ if b + d < 9
otherwise
[ ~ ~J = t1 1 f b +
-h- 2lfb+ 9 c
d + f < 9,
d + f> 9,
a+c+e>9
a+c+e>9
The third structural feature is VF: vertical format. The vertical
exercises with one digit response were given value D.
multicolumn exerCises with multidigit responses and one-column ad
dItion exerC1ses with a response of 11 were given the value of 1.
One-column addit10n exerCises W1th a multidig1t response other
than 11 were glven the value 3. For example:
vr [;] 0
v{~l 3
[a b CJ VF~ 9 h 1
Suppes - 98 -
The following regression equation was obtained for the mean res
ponse data of 63 students.
Zi = .53 SUMRi
+ .93 CARi
+ .31 vri
- 4.06
The multiple R was .74 and R2 = .54.
The regression models are not process models. They do not provide
even a schematic analysis of the algorithmic steps the student
uses to find an answer. They are only rough-end-ready models that
can be used if one does not understand the processes very well.
Automaton models, on the other hand, are process models. Their
use represents a natural extension of the regression analysis.
3.2 AUTOMATON mODELS
For the exercises in column addition we may restrict ourselves
to finite automata. We will start with a definition of determinis
tic automata.
A structure = <A, VI' Va' m, 0, sO> is a finite
(deterministic) automaton if and only if
(1) A 1S a finite, nonempty set (the set of the states of the
automaton)
(ii) VI is a f1nite, nonempty set (the input vocabulary)
Vo is a finite, nonempty set (the output vocabulary)
(iii) m is a function from the Cartesian product
(m defines the transition table; this tells
wo rks)
(iv) 0 1S a function from the Cartesian product
A x VI to Va (Q is the output function)
(v) sOc A (sO is the initial state).
(i) and (ii) are the finiteness conditions.
A x VI to A
how the machine
As an example, we may characterize an automaton that will perform
two-row column addition:
A {O,H where 0:: no carry, 1 a carry
VI {(m,n): 0 < m,n < 9} a column of two digits is processed
at a time
- 99 - Suppes
Vo = {0,1, ••• ,9} the output consists of the single digits
{01 if m + n + k _>< 9
9 where k is a state (0 or 1)
m (k,(m,n)) if m + n + k and (m,n) is an input pair
Q (k,(m,n))
So ::: 0
(k+m+n) mod 10
Thus the automaton operates by adding first the column of ones,
storing a~ internal state 0 if there is no carry, 1 l.f there is a
carry, with as output the sum of the column modulus 10, and then
moving on to the input of the column of tens, etc. The initial
internal state So is 0, because at the beginning of the exercise
there is no carry. This model is not interesting, because it is a
deterministic model: all problems will be solved correctly. Let
us now turn to a probabilistic automaton.
De f 1 nit ion: A s t r u c t u r e U::: < A, V I' V 0' p, q, sO> is a fl.nite
probabilistic (or stochastic) automaton if and only if
(i) A lS a finite, nonempty set
(il) VI and Vo are finite, nonempty sets
(iii) p is a function on A x VI x A to (o,D such that for each s
in A and a l.n VI p is a probability density over A, i.e. s,o (a) for each s· in A, p (s') > 0
s,o -(b) E p (s') = 1
s'EA s,o
(iv) q l.S a function on A x VI x Vo to [0,1J such that for each
s ln A and a in VI' q is a probability density over Vo s,o
(v) sOfA
The number of possible parameters l.n this case is unl.nterestingly
large: each transition m(k,(m,n)) may be replaced by a probabilis
tic transition 1 - £k ' and each output Q(k,(m,n)) by 10 proba-,m,n
bl.lities for a total of 2200 parameters.
what kind of assumptions can be made in order to reduce the
number of parameters? A three-parameter automaton model l.S easily
defined. The fl.rst parameter, y lS simply the probability of an
output error. Conversely, the probability of a correct output is
P(Q(k,(m,n)) = (k+m+n) mod 10) ::: 1 - y
Suppes - 100 -
The second parameter, E, is the probabilIty of an error when there
is no carry:
P(m,(k,(m,n)) = 0 Ik+m+n ~ 9) 1 - E
The second parameter, T'I, is the probability of an error when there
is a carry:
P(IYl,(k,(m,n)) 1 I k+m+n > 9) :::: 1 - T'I
In other words, if there is no carry, the probabilIty of a correct
transition is 1 - E and if there is a carry, the probability of
such a transItIon is 1 - n. We assume that these errors are con
stant, independently of the partIcular combInation of k+m+n. So
this is a drastIc reduction of the number of the parameters. Con
sider now problem i with Ci
carrIes and Dl digits. If we Ignore the
probability of two errors leading to a correct response, then the
probabilIty of a correct answer is Just
D. C. D.-C -1 P(correct answer to problem i) = (1-y) 1 (1-n) 1 (1-£) 1 1
We may get a direct comparison with the linear regression model if
we take the logarithm of both sides to obtain:
og(1-y) + C 10g(1-n) + (D -C -1)109(1-£) 1 I 1
and estimate log (1-y), 10g(1 n) and 10g(1-£) by regression with
the additive constant set equal to zero. We also may use some other
approach to make estlmates, such as minimumX 2 or maXImum likeli
hood methods. The automaton model naturally suggests a more de
tailed analysis of the data. Unlike the regresslon model, the auto
maton provides an immediate analysis of the digit-by-digit res
ponses. We can find the general maXImum likelihood 8stlmates of Y,
E and n when the response data are given in this more explicit
form. Let there be n digit-responses in a block of responses. For
1 ~ i S n let X be the random variable that assumes the value 1 if I
the i th respo'nse is correct and 0 otherwise. I t is then easy to see
that
- 101 - Suppes
f1
-
Y
)
if i is a onesl-column digit,
p(x 1 ) (1-y)(1-&) 1.f it 1.S not a onas'-column d1.git and :;::
there carry to the ith d1.git, 1.S no
(1-y)(1-n) if there is a carry to the ith digit
Similarly for the same three alternatives
p( 0)
For a string of actual digit responses x1
' ••• , xn we can wr1te
the likelihood functlon as:
where a the number of correct responses, the number of 1.n
correct responses in the onesl-column, c = the number of correct
responses not ln the ones'-column when the internal state 18 0,
d the number of correct responses when the internal state 1.S 1,
e the number of lncorrect responses not ln the onesl-column
when the internal state is 0, and f
ponses when the 1.nternal state is
the number of lncorrect res
(In the model statistical In-
dependence of responses is assured by the correctlon procedure).
I tis m 0 r e con v e n i e n t toe s t 1 mat e y t 1 -V, £ I = 1 -£ and n I = 1 - n • fil a k -
ing this change, taklng the logarithm of both sides of the likell
hood function, and dlfferentlating with respect to each of the va
rlables, we obtain three equations that determine the maXimum
likellhood estimates of y', e:' and n'
OL a fn' oy I V' -y 1-Y 'n I 0,
OL E- ey' 0 O£ I £ I 1-y'e:'
oL .sL. fy t 0 on I n t 1-V 'n I
Solving these equations we obtain as estimates:
A' V
Suppes
" .. , 11
c(a+b-c-d) (c+e)(a-c-d) f
d(a+b-c-d) (d+f) (a-c-d) •
- 102 -
The estimates for the same data already described are:
y .0430
£ .0085
n .0578
The fit with the data is pretty good but by no means exact. The
fit can be improved by replacing the parameter E by two parameters:
EO in case there is no carry also in the preceding column and E 1
in case there is a carry in the preceding column. (as an illustra
tion, consider 457 135 592
The estimates are
.0000
.0928
This model of EO and £1' as well as the data analysis for both
automata is due to Alex Cannara.
The central criticism of the automaton models is that they are
informationally inadequate to the problem. They do not give any
account of how the student is processing the format of the problem.
The way of handling the problem is abstract in the sense that the
definit~on of the input for the automaton is not closely related to
the input the student is faced with perceptually. The type of mo
dels to be discussed next, on the other hand, is more perceptually
adequate.
3.3 REGISTER mACHINES*
The programs written for a register machine deal with the pro-
* This research is a Joint effort with Lindsay Flannery.
- 103 - Suppes
cessing of the perceptual format of the problems. The informa
tional part in this case is more realistic. However, what is not
realistic in these models, is the highly schematic character of
the perceptual processing. The introduction of perceptual pro
cesses in the model will be illustrated by an example of a sub
routine of the program. We have a two-dimensional array. The
square at the top at the right hand side is called (1,1). The
instructions are stated in the column at the right hand side.
5 <op>
9 <55>
14 <NSS>
Attend (1,1)
Read in
Attend (+1. 0)
Read in
+
5
9
, +
The instruction "Read inti means that the content of the square
(1,1) in this case has to be stored in a stimulus-supported re
g1ster 55; "Attend (+1, 0)" means that one has to go to the
square one row below the previous square that is in the same co
lumn as that square. The number 5 will be transferred to an ope
rating reglster OP and the number 9 will be stored in a stimulus
supported register. The response -14- will be put in a non-sti
mulus-supported register NSS. The numbers 5 and 9 have visual
support; the number 14 has no visual support.
In solvlng a problem e.g. making the addition
l 516
~4932
21543
214
the student is not surveying the whole array. The problem is that,
when he has finished a column, he has to determine whether there is
anything to the left of that column. Let me describe what we call
the vertical scan subroutine that is used in all these vertical
Suppes - 104 -
format problems. That subroutine is indicated as
V SCAN (0, • IF • , 9,_) .
RD READIN
J~lP(O, ••• ,9,_) S8 FIN
Attend (+1.-1) READIN
JIYlP ( - ) ss FIN
Attend (+0, + 1 )
JIY1P RD
FIN END
The first operat10n 1S "read 1n" wherever we are. We jump to FIN
1f we get anything because all we want to do is to find out 1f
there lS something. If we get something we put 1t in a stimulus
supported reg1ster. If we do not get anything we go down a row
and move to the right: Attend (+1,-1). ~e read in, if we get some
thing, we put 1t in a stimulus-supported register and do a jump to
FIN. Otherwise we stay in the same row and go to the left: Attend
(+0.+1) and make an unconditional Jump to READ.
The basic idea of the application of the register mach1nes 1S
the quest10n what mean1ngful instructions - in terms of behav10r
and internal processes of the students - to have as prlmitives.
There 1S some hopeof behaviorally checking these primit1ves. As a
check of the model we can look at the eye-movements. How far from
the actual eye-movements is this subroutine. If we want to account
for the eye-movements, the program becomes much more elaborate.
Another feature that lS miSSing 1n the model are the latencies.
One of the things that has been fairly extenslvely studied over 50
years is not only the accuracy but also the speed of children do-
1ng these exercises. This model does not give any account of the
latenc18s. The third feature that 1S omitted is learning. In the
case of process models with children, arithmetic offers one of the
best possib1l1ties for actually getting a detailed grip on learn
ing. We can ask the question what kind of verbal reinforcements
can be given by the teacher in order to enlarge the internal pro-
- 105 - Suppes
gram of the student. f 1n classifying geometrlc figures the ver
bal reJ.nforcement con:Hsts of "correct" and "not correct", the
learn1ng 1S extremely slow. What 1S needed 1S close correspond
enC8 between the verbal lnstruction to the student - 1n thlS e
the reinforcement - and what he 1 to do. iuch close corres-
pondence 18 pract1cal 1n the case of arithmetlc.
- 106 -
THEORY OF AUTomATA AND ITS APPLICATION TO PSYCHOLOGY
P. Suppes
Today I will turn to models for natural language processing.
The studies of natural languages, especially of procedural seman
tics are as yet in a much less empirical stage than the studies
in arithmetic. I shall talk about classical model-theoretic se
mantics; semantics for context free languages, about some ap
plications to Erica, a corpus of a young girl, and about procedu
ral semantics.
4.1 CLASSICAL mODEL-THEORETIC SEMANTICS
I return to the semantics of natural languages by first re
viewing the classical semantics of mathematical logic, because
the ideas develop grew out of this earlier development. Some
linguists have claimed that the semantics of natural languages
should be represented in first-order logic. According to Quine
e .• , the two 8ssential features of natural languages are pre
dication and quantification. I restrict myself to theories with
standard formalization. (An axiomatic base for all of classical
mathematics can be given by such a theory, namely, axiomatic set
theory.)
Theories with standard formalization consist of the following
ingredients:
(i) First-order predicate lOgIC with identity, including the
logical notation of sentential connectives, quantifiers, va
riables, identity symbol and parentheses.
(ii) The non-logical primitive symbolS of the theory, which fall
Into three classes: relation or predicate symbols, operation sym
bols, and IndiVIdual constants or names.
(iii) The axioms of the theory, when the theory is axiomatically
built.
- 107 - Suppes
Definitions of neill symbols are treated as special kinds of axioms.
Roughly speaking, definitions are axioms that add no new content
to the theory. (Technically they must satisfy crlteria of elimina
bility and non-creativity).
Here are some simple examples of theories with standard forma
lization:
1. Group theory
Primitive symbols: binary operation symbol 9, unary operation sym
bol -1, and individual constant 8. (It is important to distinguish ~ -
between the binary operation symbol 0 in a formal context and the
operation 0 in the possible realization. The symbol is a symbol of
the language or theory of groups. The operation itself is a non
linguistic object. In a given case of a possible realization we
think of the symbol as denoting the relation. But, and this is
fundamental, the operation symbol only denotes an operation relat
ive to a given possible realization.)
Axiom:
(~x)(Yy)(Vz)(xo(yoz)
(Vx)(x 0 e = x)
(Vx)(x 0 x- 1 = e)
(xoy)oz)
2. Elementary Euclidean geometry
Primitive symbols: Ternary relation symbol B for betweenness, qua
ternary relation symbol E for equldistance: xy E uv if the dis
tance between x and y is equal to the distance between u and v.
Axioms: Several standard verSlons which I shall omit.
3. Axiomatic set th
Prlmitive symbol: binary relatlon symbol e of membership.
Axioms: Zermelo-fraenkel axioms, for example.
The next step is to move on to the semantics of a theory with
standard formalization. \Ue first deflne the concept of a possible
of a theory_ As an example, consider group theory as
defined above. The primitive symbols are given in the fixed order
stated above. A possible realization of group theory is a relat--1
ional structure U <At 0, ,e> where A is a non-empty set, 0
Suppes
is a binary operatlon on A,
- 108 -
i.e., -1
a function from A x A to A,
18 a unary Function fram A to A, and 8 is an element of A.
Finally, we say that a possible realization of the theory of
groups is a of the theory of groups iITall the axioms are
satisfied in the possible realization. (I omit a technical defi
nition of satisfaction. Another intuitive way of formulating the
matter 1S thlS: in a model of a theory all the axioms hold or ~
In usual mathematical terminology, a model of the theory of
groups is a group, But such terminology 18 not always used, for
example, it 1S not ordinarily so used in geometry or in set
theory, although we do often speak of spaces in geometry.
Glven the apparatus I have briefly descrlbed, there are many
addltional general concepts that have been formulated and that
may be intensely studied, under the general heading of the theory
of models, which is Just the study of semantics of theories wlth
standard formalization.
For the sentences of the language of a theory, independent of
the axioms of the theory, perhaps the most important relat10n be-
tween them is that of A sentence S1 in the
language of a theory is a logical consequence of a sentence iff
51 holds in any poss~ble realization of the theory in which
holds. To show, for example, that associativity of a binary oper
at10n is not a consequence of lts being commutative, we can give
a possible realization in WhlCh the binary operation is commut
stlve but not associative.
What is important about first-order languages, or the lan
guages of theories with standard formal1zation is that we can
exactly m~rror the semantic concept of log~cal consequence in the
syntactic concept of derivation. In other words, we can give
purely syntactic rules of loglcal ~nference such that 51 is de
rivable from S2 by means of the rules of inference if and only if
S1 is a logical consequence of • It is generally agreed that
such an intimate connection between syntax and semantics probably
does not exist for natural languages. We can grant this claim,
- 109 - Suppes
and yet go on to use the lack of almost any study of the relatlon
bet~een syntax (Inference) and semantics (logical consequence) in
natural languages as a point of crIticism of most contemporary
theories of the semantlcs of natural language. However, this is
not a topic, as seductlve as It is, that I can explore here.
It might be thought that only axiomatIC theories can be use
fully studied In the theory of models, but the example of th
concept of logIcal consequence, applying as It does very broadly
to the language of the theory, shows that thIS is not necessarIly
the case. In many instances, rather than aXiomatlzing the theory,
we characterize the valid sentences of the theory by statIng that
a valId sentence is one that holds in a particular possible rea
lization of the theory. For example, the valld sentences of ele
mentary Euclidean geometry may be defined to be Just those that
hold in the standard numerical interpretation of betweenness and
equidlstance In the Cartesian plane Re x Ref where Re is the set
of real numbers.
Because the semantics of first-order logic is well understood,
it is natural that some people have proposed using fIrst-order
logic as the "base structure" of a generative grammar. The dIffi
culty with this approach is that we have no algorithms for trans
lating ordinary language into logical notatIon, and we must re
peatedly appeal directly to the intuitive meaning of the natural
language expressions in order to make the translation. For this
and many other reasons it seems desirable to develop mOdel-theo
retic semantics dIrectly for natural language.
4.2 mODEL-THEORETIC SEmANTICS FOR CONTEXT-FREE lANGUAGES
I now shall describe in a more technical way the applIcation
of model-theory to natural languages. Some standard grammatical
concepts are defined in the Interest of completeness. First, if V
is a set, V* IS the set of all finite sequences whose elements
are members of V. I shall often refer to these finite sequences
28 The empty sequence, 0, IS in V*; we define V+ V* -{O}.
Suppes - 110 -
A structure G <V,VN,p,s> is a phrase-structure grammar if and
only if V and P are finite, nonempty sets, VN
is a subset of V, S
is in VN and P ~ V* X V+. Following the usual terminology, VN is
the nonterminal vocabulary and VT = V - VN the terminal vocabula
ry. 5 is the start symbol of the single axiom from which we de
rive strings or words in the language generated by G. The set P
is the set of production or rewrite rules. If <a, $> EP, we write
a"" $ t which we read: from a we may produce or derive B (immediat
el y) •
A phrase-structure grammar G = <V,VN,P,S> is context-free if
and only if P ~ VN
X V+, Le., if a'" B is in P then CI €VN
and
B €V+.
The standard definition of derivations is as follows. Let
G <V,VN,p,S> be a phrase-structure grammar.
a production of P, and y and 0 are strings in
First, if a'" a is
V*, then yao===> YfHl.
'" .!... D Gl.' f We say that a is derivable from a in G, in symbols, ~ ~p G
there are strings a 1 , ••• ,a n in V* such that a a 1 , a 1 t- Cl 2' ••• ,
a 1 ~ tI = 8. The sequence 6 <a 1, ••• ,a n> is a derivation in G. n- G n The language L(G) generated by G is {a: a EV~ & 5 ~a}. I n other
G words, L(G) is the set of all strings made up of terminal vocabu-
lary and derived from S.
The semantic concepts developed also require use of the con
cept of a derivation tree of a grammar. The relevant notions are
set forth in a series of definitions. Certain familiar set-theo
retical notions about relations are also needed. To begin with, a
is an ordered pair < T , R > such that T is a non
empty set and R is a binary relation on T, i.e., R ~ TxT. R is
a of T if and only if R is reflexive, antisym-
metric and transitive on T. R is a strict simple ordering of T if
and only if R is asymmetric, transitive and connected on T. We
also need the concept of R-immediate predecessor. For x and y l.n
T, xJy if and only if xRy, not yRx and for every z if z I y and
zRy then zRx. In the language of formal grammars, we say that if
xJy then x directly dominates y, or y is the direct descendant of
x.
- 111 - Suppes
Using these notions, we define in succession tree, ordered tree
and labeled ordered tree. A binary structure <T,R> is a tree if
and only if (i) T is flnite, (ii) R is a partial ordering of T,
(iii) there is an R-first element of T, i.e., there is an x such
that for every y, xRy, and (iv) If xJz and yJz then x = y. If xRy
in a tree, we say that y is a descendant of x. Also the R-first
element of a tree is called the root of the tree, and an element
of T that has no descendants is called a leaf. Ue call any element
of T a node, and we shall sometlmes refer to leaves as termlnal
nodes.
A ternary structure <T,R,L> is an ordered tree if and only If
(i) L is a binary relation on T, (ii) <T,R> is a tree, (iii) for
each x in T, L is a strict simple ordering of {y : xJy}, (iv) if
xLy and yRz then xLz, and (v) if xLy and xRz then zLy. It is cus
tomary to read xLy as "x is to the left of y". Having this order
ing is fundamental to generating termlnal strlngs and not just
sets of termlnal words. The terminal string of an ordered labeled
tree lS just the sequence of labels <f(x1), ••• ,f(x
n» of the
leaves of the tree as ordered by L. Formally, a quinary structure
<T,V,R,L,f> is a labeled ordered tree if and only if (i) V is a
nonempty set, (ii) <T,R,L> is an ordered tree, and (iii) f is a
function from T into V. The function f is the labeling functlon
and f(x) is the label of node x.
The deflnition of a derivation tree is relatlve to a given con
text-free grammar.
Deflnition. Let G = <V,VN,p,S> be a context-free grammar and
let T = <T,V,R,L,f> be a labeled ordered tree. T is a derivation
tree of G if and only if
(i) If x is the root of T, f(x) = 5;
(ii) If xRy and x I y then f(x) is in VN
;
(iii) If Y1'."'Yn are all the direct descendants of x, i.e.,
={y: xJy} 1,0, and y.Ly. if i < j, then l J
< f ( x ) ,< f ( y 1 ) , ••• , f ( Y n »> is a production in P.
Suppes - 112 -
Je now turn to semantics proper by Introducing the set t of
set-theoretical functIons. Ue shall let the domains of these
functions be n-tuples of any sets (with some approprIate restrIC
tion understood to avoid set-theoretical paradoxes).
Let <V,VN
,P,5> be a context-free grammar. Let 4) be
a function defined on P which assigns to each production p in P a
finite, possibly empty set of set-theoretical functIons subject
to the restriction that f the right member of production p has n
terms of V, then any function of 4) (p) has n arguments. Then
~ <V,VN,P,s,t> is a potentIally denoting context-free grammar.
If for each p in P, t(R) has exactly one member then G is said to
be simple.
The simplicity and abstractness of the definltion may be mis
leading. In the case of a formal language, 8.g., a context-free
programming language, the creators of the language speCIfy the
semantics by defining t. matters are mare complicated in apply
ing the same idea of capturing the semantlcs by such a function
for fragments of a natural language.
A clear separation of the generallty of • and an evaluation
function v is lntended. The functions in • should be constant
.over many different uses of a word, phrase or statement. The
valuation v, on the other hand, can change sharply from one oc
casion of use to the next. To provide for any finite composltion
of functions, or other ascensions in the natural hierarchy of
sets and functions built up from a domain of individuals, the
familY~'(D) of sets with closure properties stronger than needed
in any particular application is defined. The abstract objects T
(for truth) and F (for falSity) are excluded as elements of~'(D).
In this definition ~A is the power set of A, i.e., the set of all
subsets of A.
Definition. Let D be a nonempty set. Then~I(D) is the smal-
lest family of sets such that
(1) DE.lt"(D),
(ii) if A, BeX'(D) then A U Be:;re'(D),
(iii) if At:: )tIeD) then .!PA e;Jt' (D) ,
- 113 - Suppes
We defineJl'(D) =Jl'(D) U {T,F}, with T f/..;e'(D), F ¢Je.'(D) and
T .; F.
A model structure for G is defined Just for terminal words and
phrases. The meaning or denotation of nonterminal symbols changes
from one derivation or derivation tree to another.
Definition. Let D be a nonempty set, let G = <V,VN,P,S> be a +
phrase-structure grammar, and let v be a partial function on VT to }teD) such that if v is defined for a in V; and if y 1S a sub
sequence of a, then v 1S not defined for y. Then o1J::: <D,v> 1S a
model structure for G. If the domain of v is exactly VT , then ~
is s1.mple.
We also refer to v as a valuat10n function for G.
I now define semantic trees that assign denotat10ns to nonter
m1nal symbols 1.n a derivat1.on tree. The definit1.on is for simple
potentIally denoting grammars and for simple model structures. In
other words, there 1S a unique function for each production, and
the valuation function is defined just on VT
' and not on phrases +
of Vr Definition. Let G = <V,VN,p,s,t> be a simple, potentially de
noting context-free grammar, let.;/) = < D,v> be a simple model
s t r u c t u ref 0 r G, Ie t '?T' = < T , V , R , L ,f> be a de r i vat ion t r e e 0 f
<V,V N,P,5> such that if x is a terminal node then f(x) € VT
and
let tP be a function from f to dt(D) such that
(i) if <x,f(x» E f and f(x) € VT
then 1/J(x,f(x)) = v(f(x)),
(li) if <x,f(x» c f, f(x) E VN' and Y1""'Yn are all the direct
descendants of x with y.Ly if i < J, then 1. J
t/I(x,f(x)) = (1P(Y1,f(Y1)), ••• ,lJi(Yn,f(Yn))'
where <p = t (p) and p is the production < fex) ,<f(Y1)"" ,f(Yn»>'
The n ~ = < T , V , R , L , f , tV> is a s 1. m pIe s em ant i c t r e e of G and ~.
The function", assigns a denotation to each node of a semantic
tree. We now have two parts, on the one hand we have the models
with the denotations of the terminal words or termlnal phrases,
on the other hand we have the semantic functions that put to
gether the structure of the sentence by saying what the denotat
ions are of the nodes in the tree as we come up in the structural
Suppes - 114 -
of the tree has a denotation the result is as illustrated in the
simple description I gave in the first lecture.
4.3 APPLICP.TImJS TO "ERICA"
now llke to give so~e examples from the corpus [rlca, taken
from the dissertatlon of Bob S~ith. [rlca was about 30 months old
at the time of the recordings. We have 23 hours of recordings.
There are approxlmately 27.000 words by [rlca and approximately
50.000 words by adults. '~e start with the domain. The subsets of
tne domain are adjectives, nouns, possessive adjectives, personal
pronouns, proper names, pronouns. There were 2039 types ln the
corpus. S8~ of the types fall wlthln these categories. The most
lnteresting part of the corpus from a semantlc point of view' are
the verbs. There were 4 kinds of verbs in [rlca: auxlliarles, mo
diflers, transltlve and lntransltlve verbs, and linking verbs
like to be. Leavlng the llnking verbs aside 812 dlfferent verbs
occurred l.e. 26~ of the different types. In order to lllustrate
how we write the semantic rules of utterances I shall take the
following sentence form: pronoun, linklng verb, nOlln. If [pro-
noun] lndicates the denotation of a pronoun, [I'J] the denotation
of a noun and f indicates the llnklng verb, the semantlc rule of
thlS sentence is: If [pronoun] f [11] then True, else False.
- 115 -
THEORY OF AUTo~ATA A~D ITS ~PPLICATIO~ TO PSYCHOLOGY
~. Suppes
Lecture 5
The four topics I would like to discuss today are:
1. from theory to corpus
2. procedural semantiCS
3. intenSional semantics and meaning
4. the complexity of semantics
The first topic concerns the question of how one actually applies
the ideas developed in the earlier lectures to a corpus. The
other tOPiCS are especially relevant to a theory of how psycho
logically we use language.
5.1 FRO~ ThE08Y TO CORPUS
How do we make the semantiC analysiS that we have discussed.
shall diSCUSS in a very simplified way how we get to work on an
actual corpus. Suppose that we have sampled 509 noun phrases ut
tered by a child in a controlled situation. The question of how
noun phrases are identified Will be Ignored at the moment. Let
us further assume that we h2ve written a simple grammar for noun
phrases as we have discussed earlier. ThiS grammar has, say, 3S
production rules. ]e associate with each of these production
rules a semantiC function. Juppose the vocabulary consists of 105
termInal words. In the controlled experiment I have in ~Ind, t~e
meanIng of the majOrity of these words is independent of the
particular SItuation; we know the denotation of these indIVidual
words. Suppose there is a residue of 25 fu~ctlon words and SO~8
others - lIke the, not, to, of - whose meaninq 1S not 1ndependent
of the sltuation. So we have to postUlate a meaning for these
words.
In the k1nd of controlled situation I am talking about, it IS
SummarIzed by L. Noordman.
Suppes - 116 -
not difficult to determine the denotation of each one of the noun
phrases. Two investigators will easily agree on the denotation of
the noun phrases, for example, on that of red book, if there are
some objects in front of the child.
We now have an ordinary type of theoretical analysis. Je know
the denotation of the 509 term~nal phrases; we know the denotat
ion of most of the words. We have a hypothesis concerning the
grammar, the semantic functions and some of the special words. ~e
can construct theoretical denotations from the semantic functions
and from the words we agreed on. The quest10n is: do these theo
retical denotations match the denotations the investigators
agreed on.
This description of the analysis of child's speech is somewhat
simplified. It only indicates how we test in f1rst approximation
the grammar and semantics we have wr1tten with the agreed-upon
denotations of a given collection of sp~ech.
The work may be more complicated for several reasons. There
may be discrepancies between the meaning of adult's speech and
child's speech. Sometimes adults will not agree on the denotation
of the utterances of the child. Moreover the investigation may
not have an appropriate analysis for manvutterances in a corpus,
although they agree on the denotation of these utterances. I
shall come back to this issue when talking about intensional se
mantics.
5.2 PROCEDURAL SEMANTICS
The analysis of semantics I have given in the previous lec
tures was in terms of set-theoretical notions; one failure of
this analysis 1S that it is not procedurally oriented. I would now
like to talk about procedural semantics. Uhat I have to say about
semantics is not at the stage of the analysis of performance in
arithmetic. I' would like to make a parallel between arithmetic
and semantics. In the case of arithmetic we used a register ma
chine to describe the process, we should like to have a s1milar
- 117 - Suppes
machine, to be called al~st machine, for the analysis of seman
tics. It is very clear what the intension is in the case of the
reglster ~achines for arithmetic. We have a clear formal con
ception of ths algorithms that the student is learning. The
point is to try to get an understanding of how in deta~l a stu
dent has internalised these algorithms. One test of our under
standing is whether we can successfully give an account of the
learning and performance of the student. We would like to do the
same thing in the case of semantics. Let us conslder the tree
for the red table or the tree for two red flowers as given
earlier. The question that arises repeatedly is: in what sense
are these denotations e.g. the power set 2oP(RnF) in the case of
two red flowers, represented in the head. It is not suggested
that the operatl0ns on sets constitute the operations in the
head of the child. The model-theoretic concepts however repre
sent a character~sation of the semantics of sentences which in
itself is algorlthmlc and well understood. In fact we take a
step forward in the representation of the semantics of sentences
by reducing it to such a representation. The next question is
how the semantics mlght be processed. ille can talk about list re
presentation: internally we have a list for each term~nal node.
The ~dea of a list machine is to compute the list for a node -
e.g. for red table; RnT - from the two underlying lists. In this
way one computes the root of the tree in the case of speech re
cognition. We replace sets and operations on sets by lists. We
can write a simple context-free grammar for lists:
SI-?(S)
5 -io 5S
5 ~ (5)
S ~ atom
The last rule is a lexical rewrite rule.
As a first approximation, we can say that the child is inter
nally representing the semantics as lists. And just as we had a
hierarchydt(D) indicating set-theoretical denotations, we have a
corresponding definition for a list hierarchy:oC(D) indicating
Suppes - 118 -
operations performed on lists. We now have psychologically and
conceptually a number of detailed fine-grained operations suggest
ing how we internally manipulate semantic representations.
In setting up procedures - lists in this case - one can work
with a higher order language such as LISP. Another approach, that
is psychologlcally oriented, is to postulate a simple register ma
chine and to see how closely we can tailor its instructions and
ltS operations to the actual behavior of the child. These ap
proaches are not mutually exclusive. \Ue have not yet applied in
detail this kind of machine to the language-learnlng of the child.
would like to make an additional re~ark about procedural 8e
mantlcs. Learning skills llke baseball-catching are often con
trasted wlth language-learning. It is sometlmes said that in the
case of e.g. learning to catch a baseball in contrast to learning
a language there s a possibility of looking lnto the procedures
the chlld is setting up in learnlng the skill. There are training
sessions; there is a clear improvement in performance, while
everybody learns the language without trainlng sessions. nut we
~ave to keep in mind the following facts. A child between 2 and
yearls old produces approximately 300 utterances per hour, With 6
hours a day there are approximately 500,000 utterances a year.
The nu~ber of utterances of adults to Children is about 1,000,000.
~8ople learn to catch baseballs In far ress trials. What I want
to emphasize is that there is a tremendous amount of experience
lnvolved in language-learning.
5.3 INTEfJSIONAL S IeS
A second range of problems that cannot be handled in exten
sional set-theoretical semantlcs concerns the analysis of inten