15
Time Indexed Hierarchical Relative Entropy Policy Search Florentin Mehlbeer June 19, 2013 1 / 15

Time Indexed Hierarchical Relative EntropyPolicy Search
Florentin Mehlbeer
June 19, 2013
1 / 15

Structure
Introduction
Reinforcement Learning
Relative Entropy Policy Search
Hierarchical Relative Entropy Policy Search
Time Indexed Hierarchical Relative Entropy Policy Search
Evaluation
Conclusion
References
2 / 15

IntroductionExample: Texas Hold’em Poker
I Every player gets 2 (pocket-)cards initiallyI In 3 steps 5 (community-)cards are shown: Flop (3), Turn (1),
River (1)I Betting rounds between the stagesI Remaining player having the best cards (pocket cards +
community cards) wins the chips
Question: Optimal strategy?3 / 15

Reinforcement LearningProblem Statement
I Given a set of states S = {s1, s2, . . . , sn} and actionsA = {a1, a2, . . . , am} find a policy π (a|s) : V × A→ [0, 1]maximizing the expected return J (π)
I Reward Ras is collected for every state transition
I Transition probabilities Pas→t
4 / 15

Reinforcement LearningPolicy Iteration of Actor-Critic Methods
I State-value function V π : S → R yields (approximate)expected future return for every state s ∈ S
I Therefore V π1 (s) ≥ V π2 (s) ∀s ∈ S iff π1 is better than π2
while not converged
1. Policy EvaluationEstimate current policy π by calculating its state-valuefunction V π
2. Policy Improvement
I Generate samples by executing the current policy π andobserve rewards
I Compute error (critic)I Adjust the policy’s probabilities accordingly
5 / 15

Relative Entropy Policy SearchProblem Statement
Maximize the expected return
maxp
J (π) = maxp
∑s∈S,a∈A
µ (s)π (a|s)︸ ︷︷ ︸p(s,a)
Ras
so that in every iteration
D (p‖q) = p (s, a) logp (s, a)
q (s, a)≤ ε
Analytical solution yields
p (s, a) =q (s, a) exp
(1η δ (s, a)
)∑
b∈A q (s, b) exp(1η δ (s, b)
)
6 / 15

Relative Entropy Policy SearchAlgorithm
while not converged doObtain N samples (si , ai , ti , ri ) using current policy πkfor i = 1→ N do
δ (si , ai )← δ (si , ai ) + [ri + V (ti )− V (si )]end for
(η,V )← Solve Optimization problem
πk+1 (a|s) = p(s,a)∑b∈A p(s,b)
end while
7 / 15

Hierarchical Relative Entropy Policy SearchIdea
I Goal: Versatile solutions with hierarchical structure
I Introduce high level actions called ”options”O = {o1, o2, . . . , on}
I Option = Sequence of actions
I Execute 1 option per episode
I 2 policies needed
I Supervisory Policy: π (o|s)I Sub-policy: π (a|o, s)
8 / 15

Hierarchical Relative Entropy Policy SearchApproach
I Goal: Determine p (s, a, o)I Problem: Marginals q (s, a) can be sampled onlyI Idea: Treat both policies as one mixture-of-options policy
π (a|s) =∑o∈O
π (o|s)π (a|o, s)
and compute responsibilities p (o|s, a) ≈ p (o|s, a) = q (o|s, a)I Additional constraint: Bound Entropy of responsibilities
−∑
s∈S,a∈Ap (s, a)
∑o∈O
p (o|s, a) log p (o|s, a) ≤ κ
Analytical solution yields
p (s, a, o) =q (s, a) p (o|s, a)1+η/ξ exp
(1η δ (s, a)
)∑
b∈A q (s, b) p (o|s, b)1+η/ξ exp(1η δ (s, b)
)9 / 15

Hierarchical Relative Entropy Policy SearchAlgorithm
while not converged doObtain N samples (si , ai , ti , ri ) using current policy πkfor i = 1→ N do
δ (si , ai )← δ (si , ai ) + [ri + V (ti )− V (si )]end for
(η, ξ,V )← Solve Optimization problem
πk+1 (o|s) =∑
a∈A p(s,a,o)∑t∈S,a∈A p(t,a,o)
πk+1 (a|o, s) = p(s,a,o)∑b∈A p(s,b,o)
end while
10 / 15

Time Indexed Hierarchical Relative Entropy Policy SearchIdea and approach
Idea
I Sequences of L options to reach a certain goal
I Execute 1 sequence per episode
I Each option takes 1 of the L time steps
Approach
I Expected return
J (π) =∑s∈S
µL+1 (s) r (s) +L∑
l=1
∑s∈S ,a∈A
µl (s)πl (a|s)
I Known constraints for each l
11 / 15

Time Indexed Hierarchical Relative Entropy Policy SearchAlgorithm
while not converged dofor l = 1→ L do
Obtain N samples (sl ,i , al ,i , tl ,i , rl ,i ) using cur. policy πk,lfor i = 1→ N do
δl (sl ,i , al ,i )← δl (sl ,i , al ,i ) + [rl ,i + V (tl ,i )− V (sl ,i )]end for
end for
(η, ξ,V)← Solve Optimization problemfor l = 1→ L do
πk+1,l (o|s) =∑
a∈A pl (s,a,o)∑t∈S,a∈A pl (t,a,o)
πk+1,l (a|o, s) = pl (s,a,o)∑b∈A pl (s,b,o)
end forend while
12 / 15
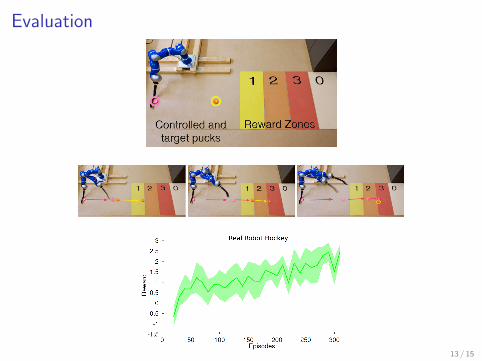
Evaluation
13 / 15

Conclusion
I Reinforcement Learning: Improving and executing a policyiteratively
I REPS solves RL Problem while bounding the KL-Divergenceof 2 subsequent state-action distributions
I Extension to HiREPS introducing options
I Time Indexed HiREPS: Sequencing of options
I Applications in sequencing motor tasks
14 / 15

References
[ 1 ] R. Sutton, A. Barto; Reinforcement Learning: AnIntroduction; 2005
[ 2 ] J. Peters, K. Mulling, Y. Altun; Relative Entropy PolicySearch; 2010
[ 3 ] C. Daniel, G. Neumann, J. Peters; Hierarchical RelativeEntropy Policy Search; 2012
[ 4 ] C. Daniel, G. Neumann, O. Kroemer, J. Peters; LearningSequential Motor Tasks; 2013
[ 5 ] R. Sutton, D. Precup, S. Singh; Between MDPs andSemi-MDPs: A Framework for Temporal Abstraction inReinforcement Learning; 1999
15 / 15

















