72
Time Series II 1
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | dwayne-kimes |
| View: | 217 times |
| Download: | 0 times |

1
Time Series II

2
SyllabusNov 4 Introduction to data mining
Nov 5 Association Rules
Nov 10, 14 Clustering and Data Representation
Nov 17 Exercise session 1 (Homework 1 due)
Nov 19 Classification
Nov 24, 26 Similarity Matching and Model Evaluation
Dec 1 Exercise session 2 (Homework 2 due)
Dec 3 Combining Models
Dec 8, 10 Time Series Analysis
Dec 15 Exercise session 3 (Homework 3 due)
Dec 17 Ranking
Jan 13 Review
Jan 14 EXAM
Feb 23 Re-EXAM

3
Last time…
• What is time series?
• How do we compare time series data?

4
Today…
• What is the structure of time series data?
• Can we represent this structure compactly and accurately?
• How can we search streaming time series?
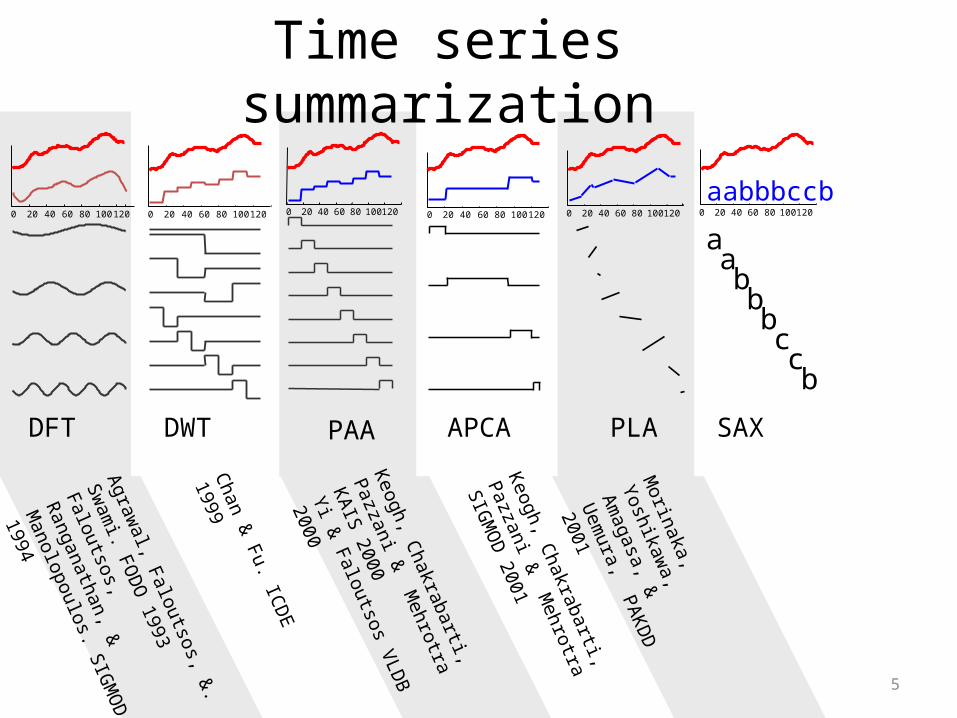
5
0 20 40 60 80 100 120 0 20 40 60 80 100 120 0 20 40 60 80 100120 0 20 40 60 80 100 120 0 20 40 60 80 100120
Keogh, Chakrabarti,
Pazzani & M
ehrotra KAIS
2000
Yi & Faloutsos V
LDB 2000
Keogh, Chakrabarti,
Pazzani & M
ehrotra
SIGM
OD
2001
Chan &
Fu. ICD
E
1999
Agraw
al, Faloutsos, &.
Swam
i. FOD
O 1993
Faloutsos, Ranganathan,
& M
anolopoulos. SIGM
OD
1994
Morinaka,
Yoshikawa,
Am
agasa, &
Uem
ura, PAKD
D
2001
DFT
DWT
APCAPAA PLA
0 20 40 60 80 100120
aabbbccb
aabbbccb
SAX
Time series summarization

6
• We can reduce the length of time series
• We should not lose any information
• We can process it faster
Why Summarization?
7
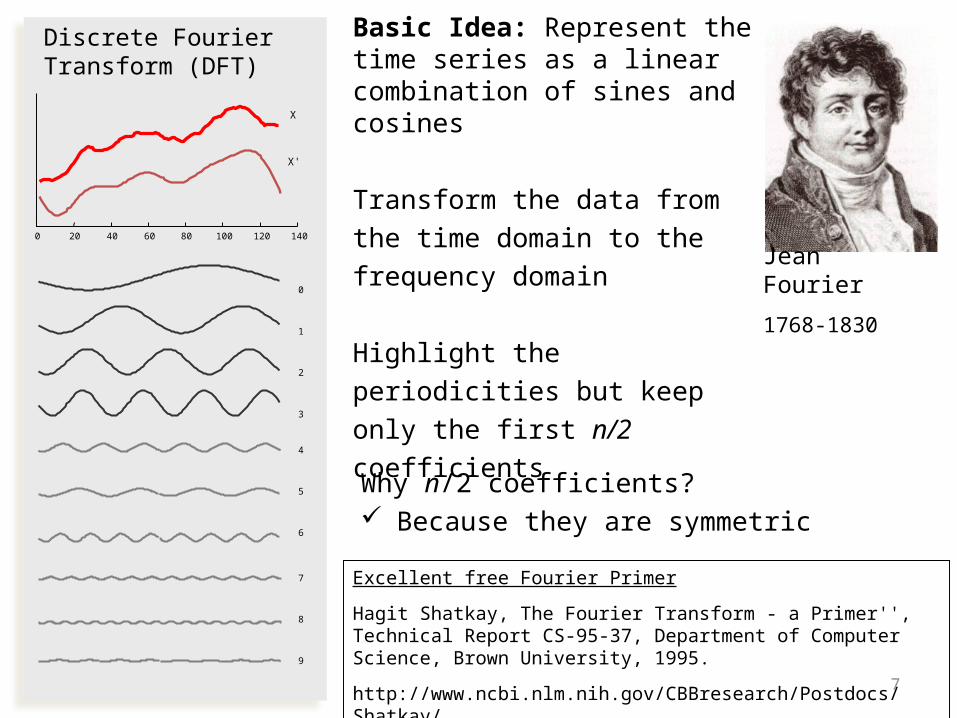
Jean Fourier
1768-1830
0 20 40 60 80 100 120 140
0
1
2
3
X
X'
4
5
6
7
8
9
Discrete Fourier Transform (DFT)
Excellent free Fourier Primer
Hagit Shatkay, The Fourier Transform - a Primer'', Technical Report CS-95-37, Department of Computer Science, Brown University, 1995.
http://www.ncbi.nlm.nih.gov/CBBresearch/Postdocs/Shatkay/
Basic Idea: Represent the time series as a linear combination of sines and cosines
Transform the data from the time domain to the frequency domain
Highlight the periodicities but keep only the first n/2 coefficientsWhy n/2 coefficients? Because they are symmetric

8
A: several real sequences are periodic
Q: Such as?
A: sales patterns follow seasons
economy follows 50-year cycle (or 10?)
temperature follows daily and yearly cycles
Many real signals follow (multiple) cycles
Why DFT?

9
How does it work?
• Decomposes signal to a sum of sine and cosine waves
• How to assess ‘similarity’ of x with a (discrete) wave?
0 1 n-1 time
valuex ={x0, x1, ... xn-1}
s ={s0, s1, ... sn-1}

10
• Consider the waves with frequency 0, 1, … • Use the inner-product (~cosine similarity)
0 1 n-1 time
value
freq. f=0
0 1 n-1 time
value
freq. f=1 sin(t * 2 /p n)
Freq=1/period
How does it work?

11
0 1 n-1
time
value
freq. f=2
Consider the waves with frequency 0, 1, … Use the inner-product (~cosine similarity)
How does it work?

12
‘basis’ functions
0 1 n-1
01 n-1
0 1 n-1sine, freq =1
sine, freq = 2
0 1 n-1
0 1 n-1
cosine, f=1
cosine, f=2
How does it work?

13
• Basis functions are actually n-dim vectors,
orthogonal to each other
• ‘similarity’ of x with each of them: inner
product
• DFT: ~ all the similarities of x with the basis
functions
How does it work?

14
Since: ejf = cos(f) + j sin(f), with j=sqrt(-1)
we finally have:
)/2exp(*/1
)1(
)/2exp(*/1
1
0
1
0
ntfjXnx
j
ntfjxnX
n
tft
n
ttf
inverse DFT
How does it work?

15
Each Xf is an imaginary number:
Xf = a + b j
• α is the real part• β is the imaginary part
• Examples:– 10 + 5j– 4.5 – 4j
How does it work?

16
SYMMETRY property of imaginary numbers:Xf = (Xn-f )*
( “*”: complex conjugate: (a + b j)* = a - b j )
Thus: we use only the first n/2 numbers
How does it work?
17
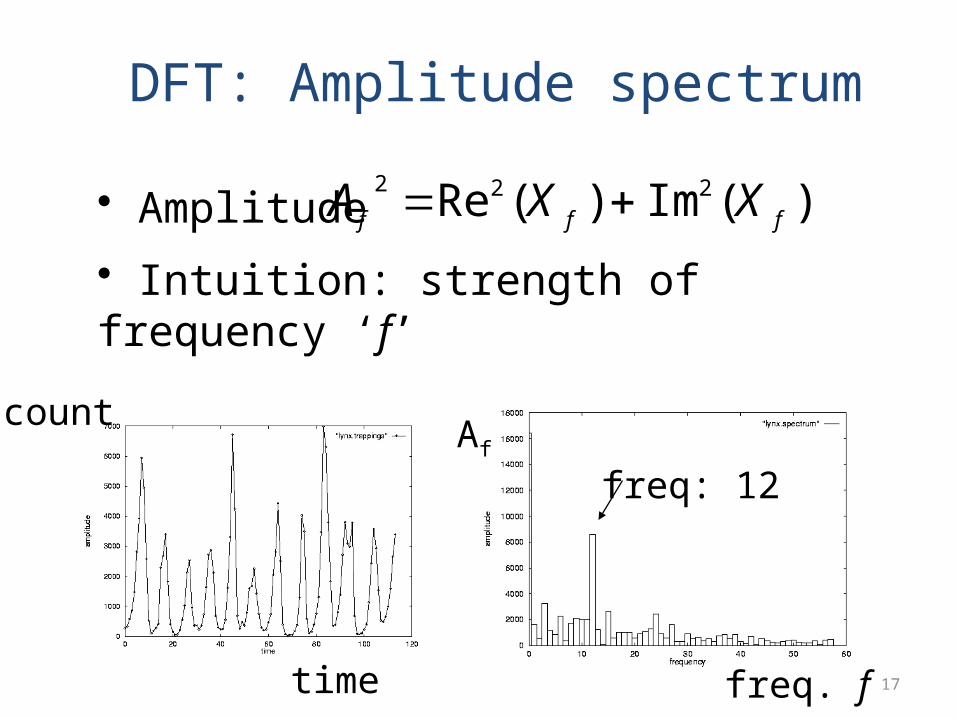
DFT: Amplitude spectrum
• Amplitude
• Intuition: strength of frequency ‘f’
)(Im)(Re 222
fff XXA
time
count
freq. f
Af
freq: 12

18
50 100 150 200 250
-5
0
5
Reconstruction using 1coefficients
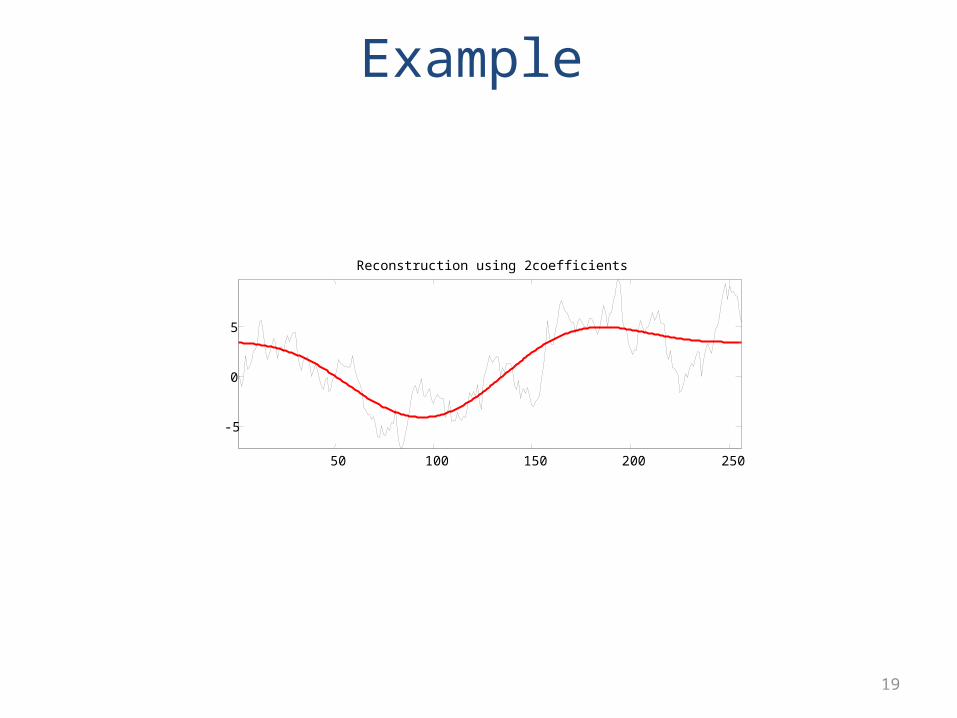
Example
19
50 100 150 200 250
-5
0
5
Reconstruction using 2coefficients
Example
20
50 100 150 200 250
-5
0
5
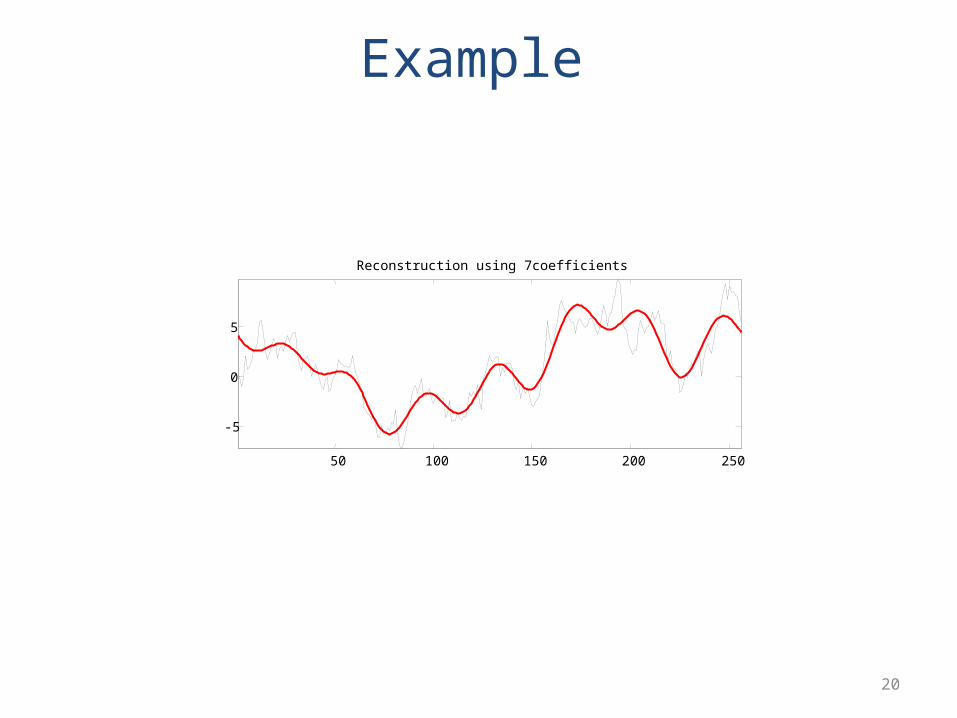
Reconstruction using 7coefficients
Example

21
50 100 150 200 250
-5
0
5
Reconstruction using 20coefficients
Example
22
DFT: Amplitude spectrum
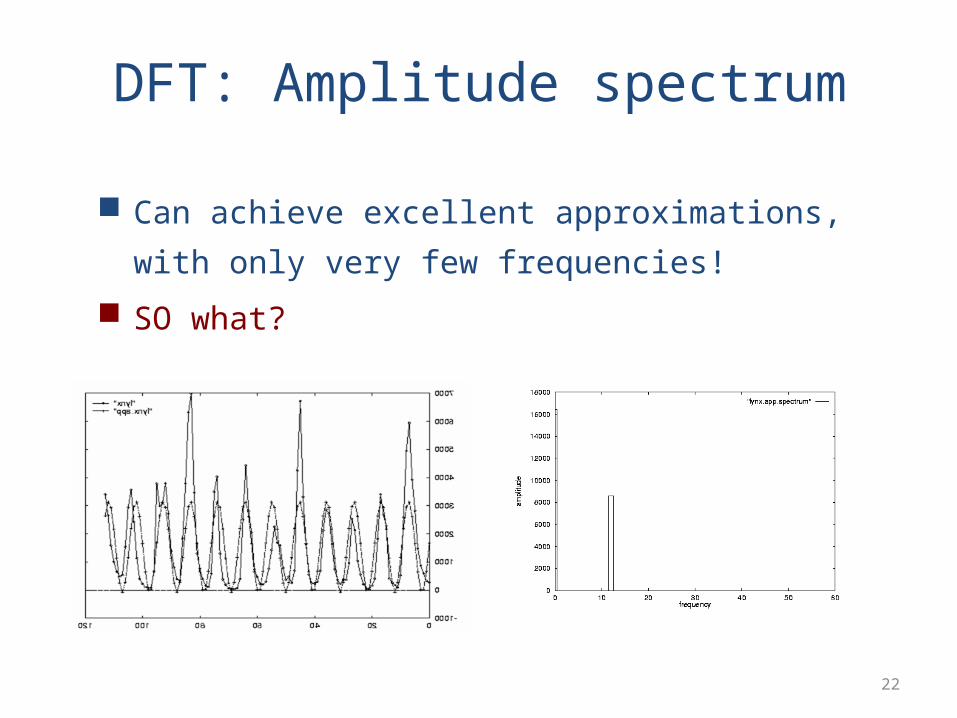
Can achieve excellent approximations, with only very few
frequencies!
SO what?

23
DFT: Amplitude spectrum
Can achieve excellent approximations, with only very few
frequencies!
We can reduce the dimensionality of each time series by
representing it with the k most dominant frequencies
Each frequency needs two numbers (real part and
imaginary part)
Hence, a time series of length n can be represented using
2*k real numbers, where k << n

0 20 40 60 80 100 120 140
C
0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 …
RawData
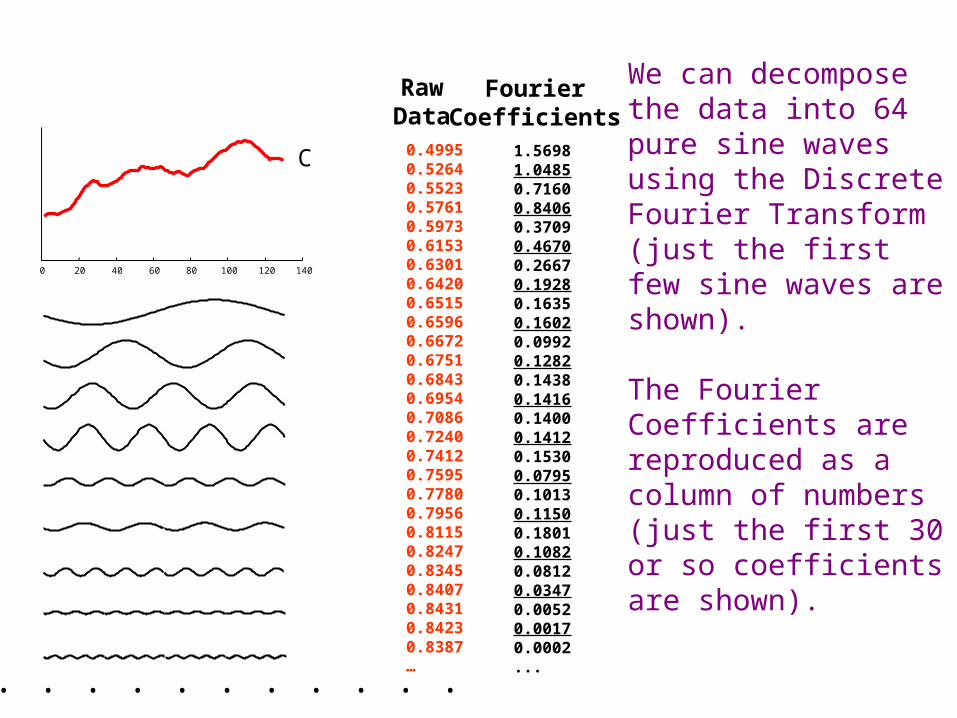
The graphic shows a time series with 128 points.
The raw data used to produce the graphic is also reproduced as a column of numbers (just the first 30 or so points are shown).
n = 128
0 20 40 60 80 100 120 140
C
. . . . . . . . . . . . . .
1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928 0.1635 0.1602 0.0992 0.1282 0.1438 0.1416 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ...
FourierCoefficients
0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 …
RawData
We can decompose the data into 64 pure sine waves using the Discrete Fourier Transform (just the first few sine waves are shown).
The Fourier Coefficients are reproduced as a column of numbers (just the first 30 or so coefficients are shown).

0 20 40 60 80 100 120 140
C 1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928
TruncatedFourier
Coefficients
C’
We have
discarded
of the data.16
15
1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928 0.1635 0.1602 0.0992 0.1282 0.1438 0.1416 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ...
FourierCoefficients
0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 …
RawData
n = 128N = 8Cratio = 1/16

0 20 40 60 80 100 120 140
C
SortedTruncated
FourierCoefficients
C’
1.5698 1.0485 0.7160 0.8406 0.3709 0.1670 0.4667 0.1928 0.1635 0.1302 0.0992 0.1282 0.2438 0.2316 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ...
FourierCoefficients
0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 …
RawData
1.5698 1.0485 0.7160 0.8406 0.2667 0.1928 0.1438 0.1416
Instead of taking the first few coefficients, we could take the best coefficients

28
Discrete Fourier Transform…recap Pros and Cons of DFT as a
time series representation
Pros:
• Good ability to compress most
natural signals
• Fast, off the shelf DFT algorithms
exist O(nlog(n))
Cons:
• Difficult to deal with sequences of
different lengths
0 20 40 60 80 100 120 140
0
1
2
3
X
X'
4
5
6
7
8
9
29
Piecewise Aggregate Approximation (PAA)
0 20 40 60 80 100 120 140
X
X'
x1
x2
x3
x4
x5
x6
x7
x8
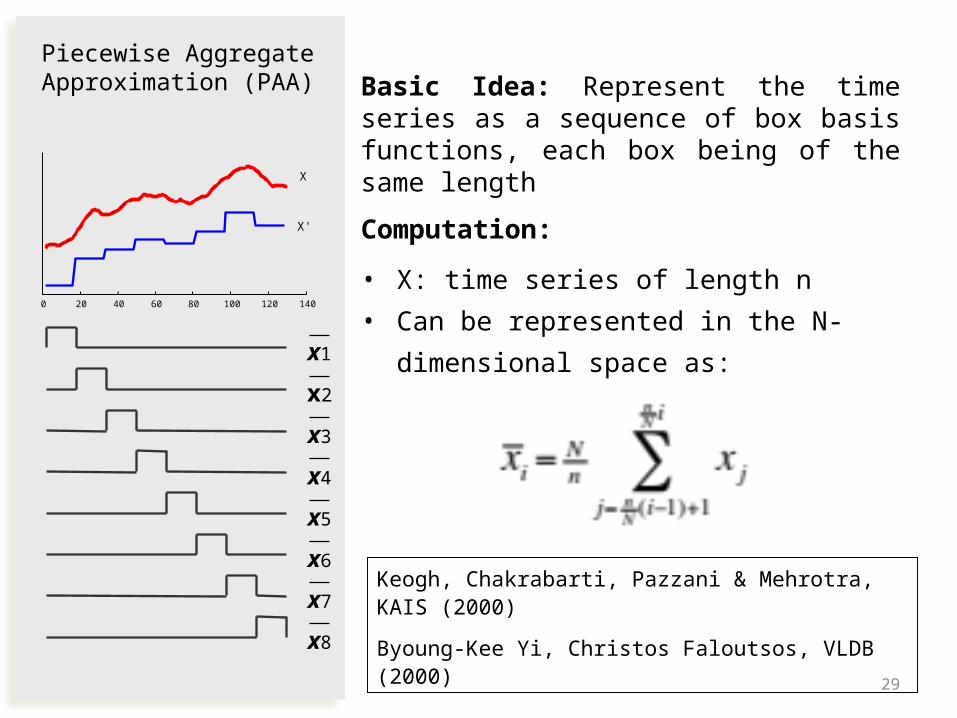
Basic Idea: Represent the time series as a sequence of box basis functions, each box being of the same length
Keogh, Chakrabarti, Pazzani & Mehrotra, KAIS (2000)
Byoung-Kee Yi, Christos Faloutsos, VLDB (2000)
Computation:
• X: time series of length n
• Can be represented in the N-
dimensional space as:
30
Piecewise Aggregate Approximation (PAA)
0 20 40 60 80 100 120 140
X
X'
x1
x2
x3
x4
x5
x6
x7
x8
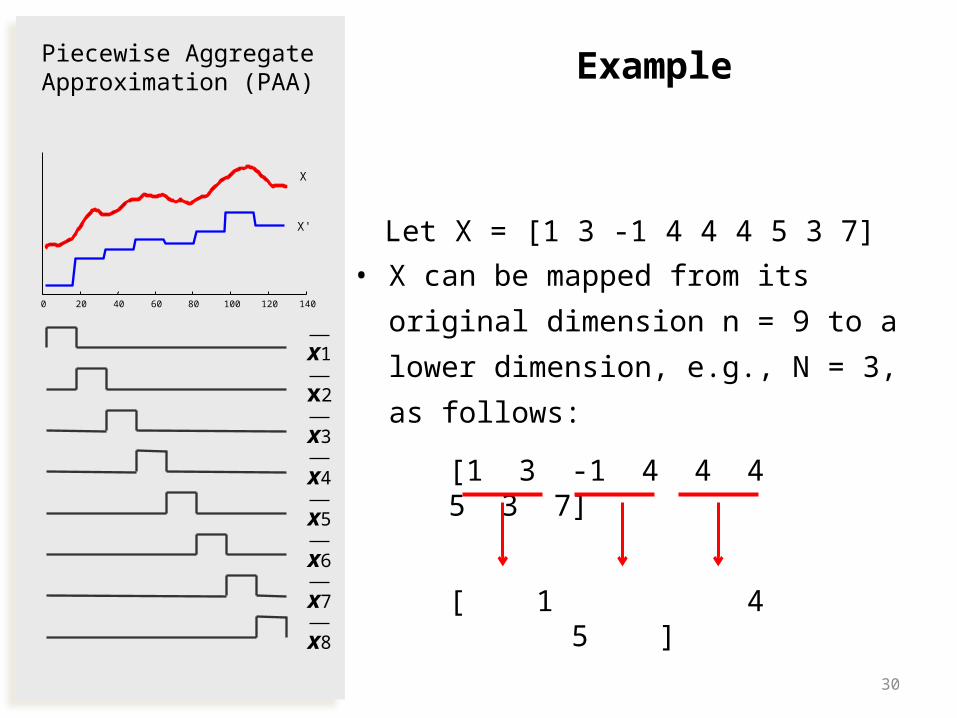
Example
Let X = [1 3 -1 4 4 4 5 3 7]
• X can be mapped from its original
dimension n = 9 to a lower
dimension, e.g., N = 3, as follows:
[1 3 -1 4 4 4 5 3 7]
[ 1 4 5 ]
31
0 20 40 60 80 100 120 140
X
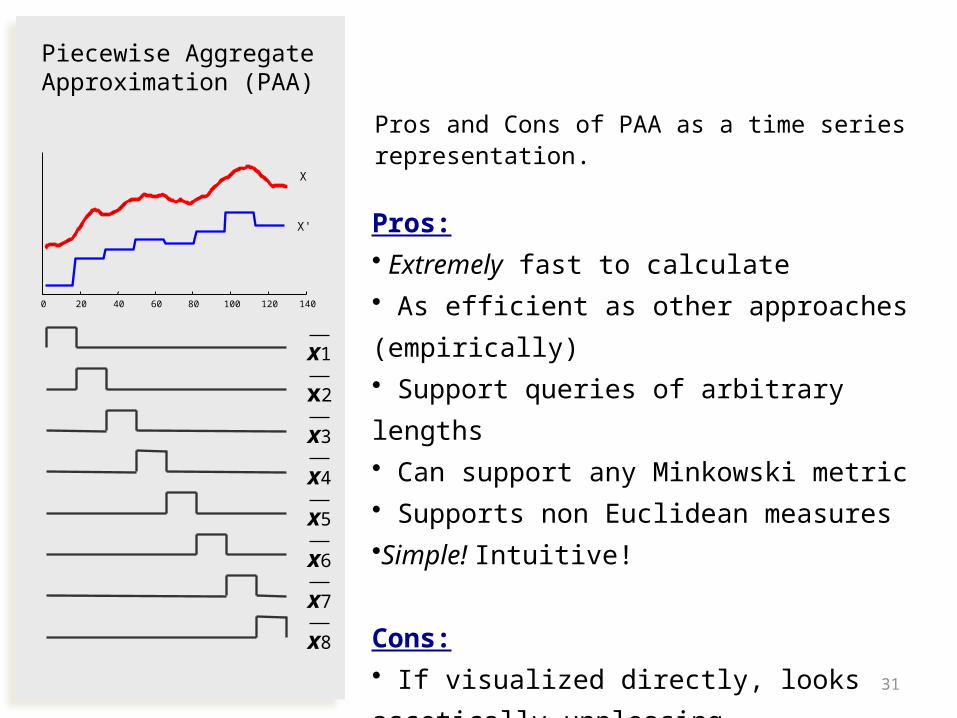
X' Pros: • Extremely fast to calculate• As efficient as other approaches
(empirically)• Support queries of arbitrary lengths• Can support any Minkowski metric• Supports non Euclidean measures•Simple! Intuitive!
Cons: • If visualized directly, looks ascetically
unpleasing
Pros and Cons of PAA as a time series representation.
Piecewise Aggregate Approximation (PAA)
x1
x2
x3
x4
x5
x6
x7
x8

Symbolic ApproXimation (SAX)
• similar in principle to PAA– uses segments to represent data series
• represents segments with symbols (rather than real numbers)– small memory footprint
32
33
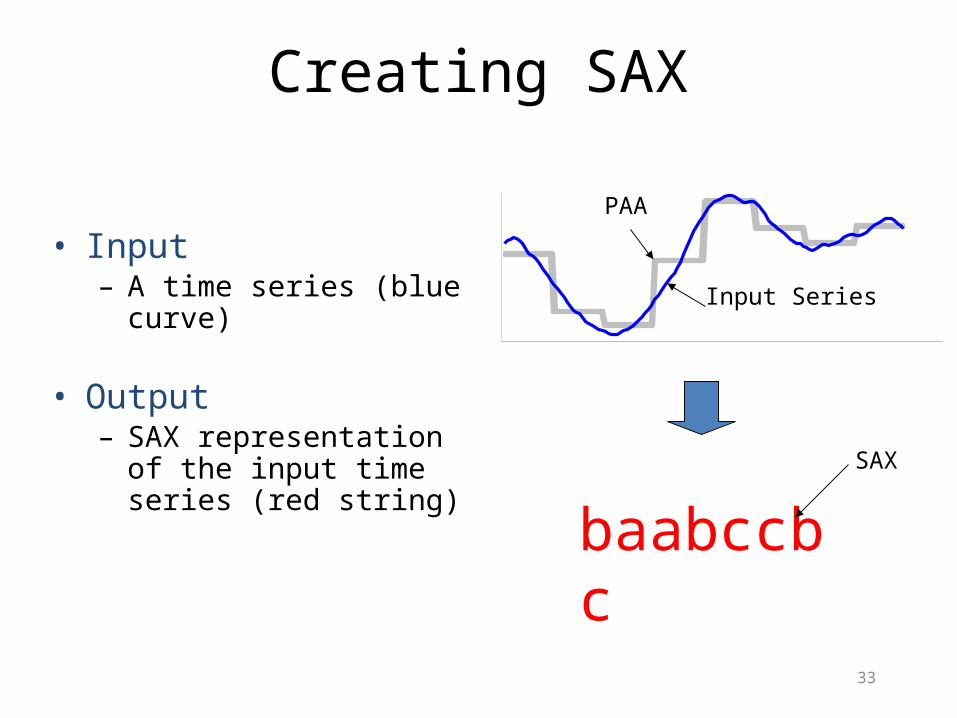
Creating SAX
• Input– A time series (blue curve)
• Output – SAX representation of the
input time series (red string)
baabccbc
Input Series
PAA
SAX
34
-3
-2
-1
0
1
2
3
4 8 12 160
A time series T
4 8 12 160
PAA(T,4)
-3
-2
-1
0
1
2
3
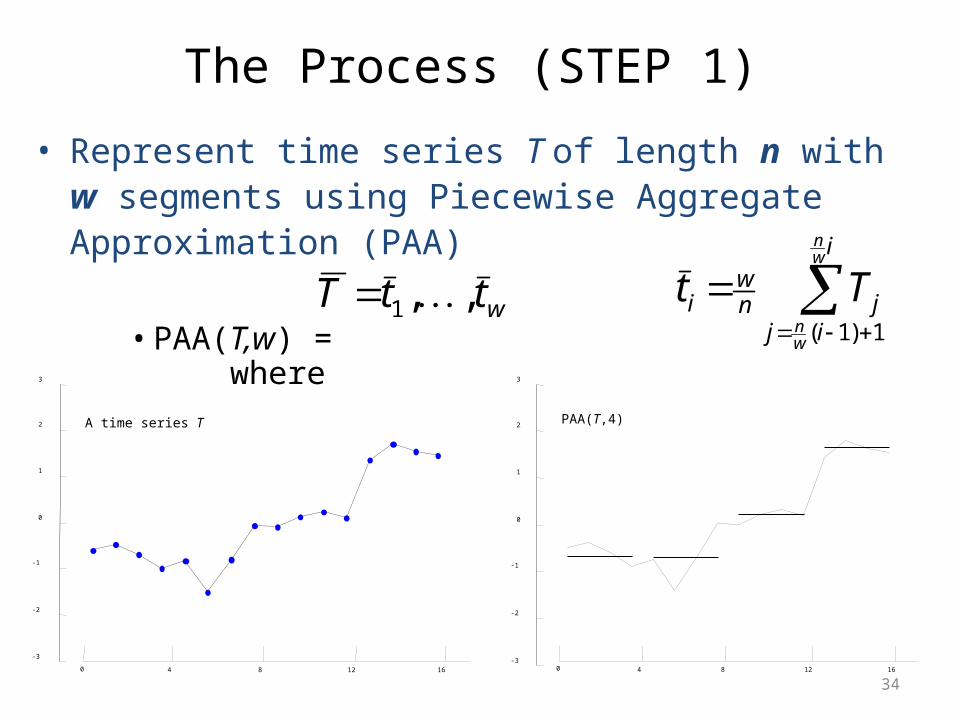
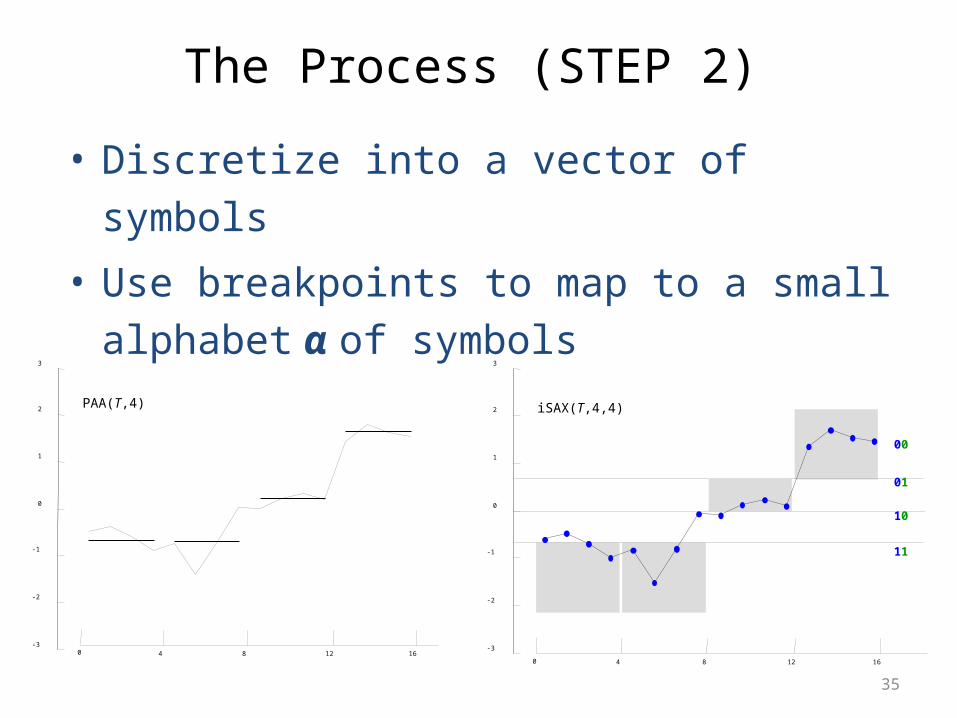
The Process (STEP 1)
• Represent time series T of length n with w segments using Piecewise Aggregate Approximation (PAA)
• PAA(T,w) = where wttT ,,1
i
ijjn
wi
wn
wn
Tt1)1(
35
4 8 12 160
PAA(T,4)
-3
-2
-1
0
1
2
3
The Process (STEP 2)
• Discretize into a vector of symbols
• Use breakpoints to map to a small alphabet α of
symbols
-3
-2
-1
0
1
2
3
4 8 12 160
00
01
10
11
iSAX(T,4,4)

36
Symbol Mapping
• Each average value from the PAA vector is replaced
by a symbol from an alphabet
• An alphabet size, a of 5 to 8 is recommended
– a,b,c,d,e
– a,b,c,d,e,f
– a,b,c,d,e,f,g
– a,b,c,d,e,f,g,h
• Given an average value we need a symbol

37
Symbol Mapping
This is achieved by using the normal distribution from statistics:
– Assuming our input series is normalized we can use
normal distribution as the data model
– We divide the area under the normal distribution into ‘a’
equal sized areas where a is the alphabet size
– Each such area is bounded by breakpoints

38
SAX Computation – in pictures
0 20 40 60 80 100 120
C
C
0
-
-
0 20 40 60 80 100 120
bbb
a
cc
c
a
baabccbc
This slide taken from Eamonn’s Tutorial on SAX

39
Finding the BreakPoints
• Breakpoints for different alphabet sizes can be structured as a lookup table
• When a=3– Average values below -0.43 are
replaced by ‘A’– Average values between -0.43
and 0.43 are replaced by ‘B’– Average values above 0.43 are
replaced by ‘C’
a=3 a=4 a=5
b1 -0.43
-0.67
-0.84
b2 0.43 0 -0.25
b3 0.67 0.25
b4 0.84

40
The GEMINI Framework• Raw data: original full-dimensional space • Summarization: reduced dimensionality space• Searching in original space costly• Searching in reduced space faster:
– Less data, indexing techniques available, lower bounding
• Lower bounding enables us to– prune search space: through away data series based on
reduced dimensionality representation– guarantee correctness of answer
• no false negatives• false positives: filtered out based on raw data

41
GEMINI
Solution: Quick filter-and-refine:
• extract m features (numbers, e.g., average)
• map into a point into m-dimensional feature space
• organize points
• retrieve the answer using a NN query
• discard false alarms

42
Generic Search using Lower Bounding
query
simplifiedquery
Simplified DB Original DBAnswerSuperset
Verify against original
DB
Final Answer
set
No false negatives!!
Remove false positives!!

43
GEMINI: contractiveness
• GEMINI works when:
Dfeature(F(x), F(y)) <= D(x, y)
• Note that, the closer the feature distance to the actual one, the better

44
Streaming Algorithms
• Similarity search is the bottleneck for most time series data mining
algorithms, including streaming algorithms
• Scaling such algorithms can be tedious when the target time series
length becomes very large!
• This will allow us to solve higher-level time series data mining
problems: e.g., similarity search in data streams, motif discovery, at
scales that would otherwise be untenable

45
Fast Serial Scan• A streaming algorithm for fast and exact search in
very large data streams:
query
data stream

46
Z-normalization• Needed when interested in detecting trends and not
absolute values
• For streaming data:– each subsequence of interest should be z-normalized before
being compared to the z-normalized query– otherwise the trends lost
• Z-normalization guarantees:– offset invariance– scale/amplitude invariance
A
BC

47
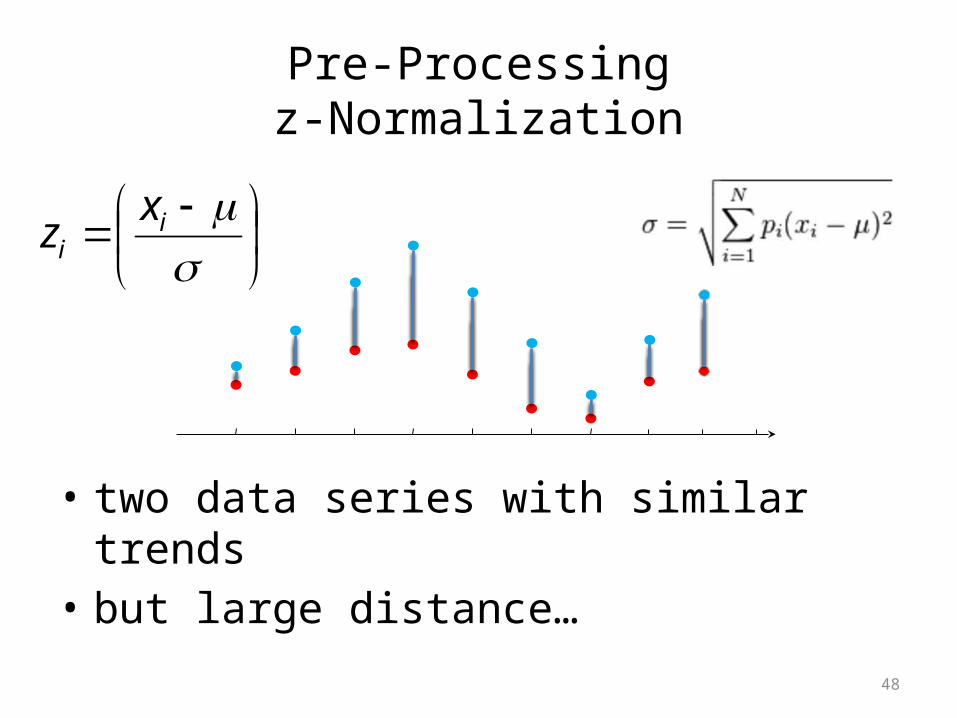
Pre-Processingz-Normalization
• data series encode trends• usually interested in identifying similar trends
• but absolute values may mask this similarity
48
Pre-Processingz-Normalization
• two data series with similar trends• but large distance…
v1v2
ii
xz

49
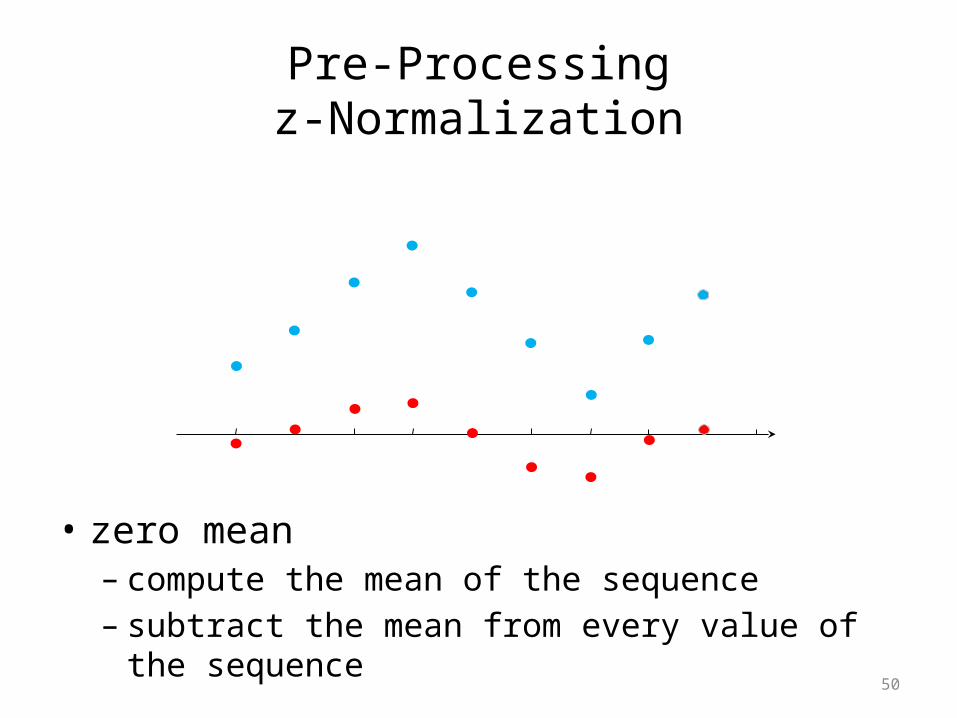
Pre-Processingz-Normalization
• zero mean– compute the mean of the sequence– subtract the mean from every value of the sequence
v1v2
50
Pre-Processingz-Normalization
• zero mean– compute the mean of the sequence– subtract the mean from every value of the sequence

51
Pre-Processingz-Normalization
• zero mean– compute the mean of the sequence– subtract the mean from every value of the sequence

52
Pre-Processingz-Normalization
• zero mean– compute the mean of the sequence– subtract the mean from every value of the sequence

53
Pre-Processingz-Normalization
• zero mean• standard deviation one
– compute the standard deviation of the sequence– divide every value of the sequence by the stddev

54
Pre-Processingz-Normalization
• zero mean• standard deviation one
– compute the standard deviation of the sequence– divide every value of the sequence by the stddev

55
Pre-Processingz-Normalization
• zero mean• standard deviation one
– compute the standard deviation of the sequence– divide every value of the sequence by the stddev

56
Pre-Processingz-Normalization
• zero mean• standard deviation one

57
Pre-Processingz-Normalization
• when to z-normalize– interested in trends
• when not to z-normalize– interested in absolute values

58
Proposed Method: UCR Suite
• An algorithm for similarity search in large data streams
• Supports both ED and DTW search
• Works for both z-normalized and un-normalized data
series
• Combination of various optimizations

59
Squared Distance + LB• Using the Squared Distance
• Lower Bounding– LB_Yi– LB_Kim– LB_Keogh
CU
L Q
LB_Keogh
𝐸𝐷ሺ𝑄,𝐶ሻ=ඨ ሺ𝑞𝑖 − 𝑐𝑖ሻ2𝑛𝑖=1
2

60
• Lower Bounding– LB_Yi
– LB_Kim
– LB_Keogh
A
B
CD
max(Q)
min(Q)
CU
LQ
Lower Bounds

61
Early Abandoning• Early Abandoning of ED
• Early Abandoning of LB_Keogh
CQ
We can early abandon at this point
CU
L
UQ
LU, L is an envelope of Q
bsfcqCQEDn
i ii 1
2)(),(

62
CQ
CU
L
Fully calculated LBKeogh
About to begin calculation of DTW
Partial calculation of DTW
Partial truncation of LBKeogh
K = 0 K = 11
Early Abandoning• Early Abandoning of DTW• Earlier Early Abandoning of DTW using LB Keogh
C
Q
R (Warping Windows)
Stop if dtw_dist ≥ bsf
dtw_dist

63
CQ
CU
L
Fully calculated LBKeogh
About to begin calculation of DTW
Partial calculation of DTW
Partial truncation of LBKeogh
K = 0 K = 11
Early Abandoning• Early Abandoning of DTW• Earlier Early Abandoning of DTW using LB_Keogh
C
Q
R (Warping Windows)
(partial)dtw_dist
(partial)lb_keogh
Stop if dtw_dist +lb_keogh ≥ bsf

64
Z-normalization
• Early Abandoning Z-Normalization – Do normalization only when needed (just in time)– Every subsequence needs to be normalized before it is
compared to the query– Online mean and std calculation is needed– Keep a buffer of size m and compute a running mean and
standard deviation
ii
xz

65
The Pseudocode

66
Reordering• Reordering Early Abandoning
– We don’t have to compute ED or LB from left to right– Order points by expected contribution
CC
Q Q1
32 4
65
7
983
51 42
Standard early abandon ordering Optimized early abandon ordering
- Order by the absolute height of the query point- This step is performed only once for the query and can save about 30%-50%
of calculations
Idea

67
Reordering
Intuition- The query will be compared to many data stream points during a search - Candidates are z-normalized:
- the distribution of many candidates will be Gaussian, with a zero mean of zero
- the sections of the query that are farthest from the mean (zero) will on average have the largest contributions to the distance measure
Idea
• Reordering Early Abandoning – We don’t have to compute ED or LB from left to right– Order points by expected contribution

68
Different Envelopes
• Reversing the Query/Data Role in LB_Keogh– Make LB_Keogh tighter– Much cheaper than DTW– Online envelope calculation
CU
L
UQ
L
Envelop on Q Envelop on C
69
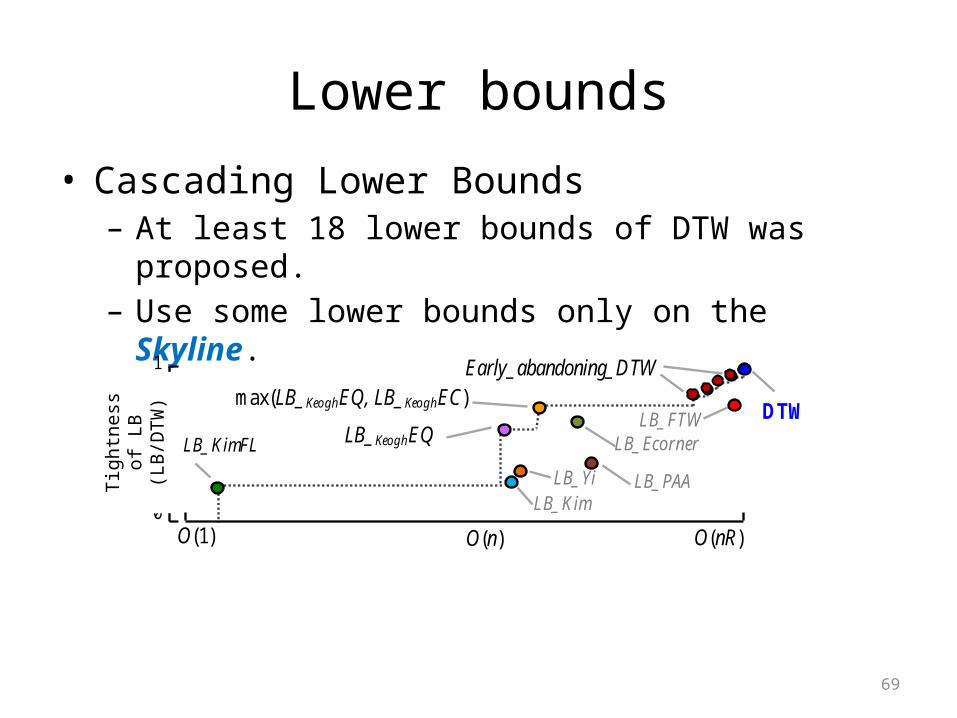
Lower bounds
• Cascading Lower Bounds– At least 18 lower bounds of DTW was proposed. – Use some lower bounds only on the Skyline.
0
1
O(1) O(n) O(nR)
LB_KimFL LB_KeoghEQ
max(LB_KeoghEQ, LB_KeoghEC)Early_abandoning_DTW
LB_KimLB_YiTi
ghtn
ess
of
low
er b
ound
LB_EcornerLB_FTW DTW
LB_PAA
Tigh
tnes
s of
LB
(LB/
DTW
)

70
Experimental Result: Random Walk
Million (Seconds)
Billion (Minutes)
Trillion (Hours)
UCR-ED 0.034 0.22 3.16
SOTA-ED 0.243 2.40 39.80
UCR-DTW 0.159 1.83 34.09
SOTA-DTW 2.447 38.14 472.80
• Random Walk: Varying size of the data
Code and data is available at: www.cs.ucr.edu/~eamonn/UCRsuite.html
71
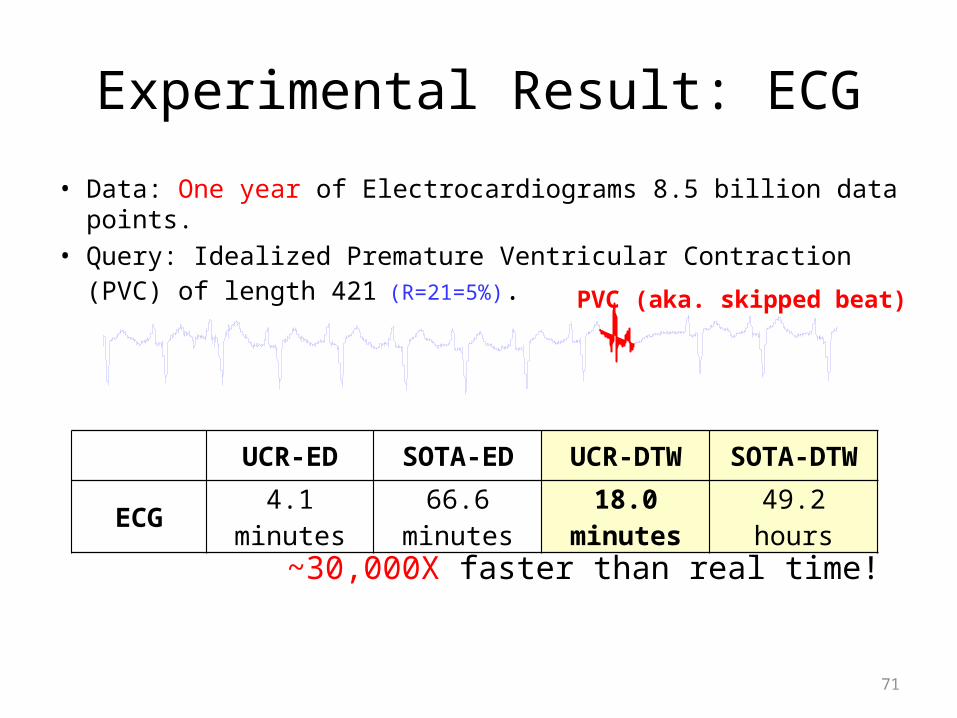
• Data: One year of Electrocardiograms 8.5 billion data points.• Query: Idealized Premature Ventricular Contraction (PVC) of
length 421 (R=21=5%).
UCR-ED SOTA-ED UCR-DTW SOTA-DTW
ECG 4.1 minutes 66.6 minutes 18.0 minutes 49.2 hours
Experimental Result: ECG
PVC (aka. skipped beat)
~30,000X faster than real time!

72
Up next…Nov 4 Introduction to data mining
Nov 5 Association Rules
Nov 10, 14 Clustering and Data Representation
Nov 17 Exercise session 1 (Homework 1 due)
Nov 19 Classification
Nov 24, 26 Similarity Matching and Model Evaluation
Dec 1 Exercise session 2 (Homework 2 due)
Dec 3 Combining Models
Dec 8, 10 Time Series Analysis
Dec 15 Exercise session 3 (Homework 3 due)
Dec 17 Ranking
Jan 13 No Lecture
Jan 14 EXAM
Feb 23 Re-EXAM

















