57
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017

Tokenization and Sentence Segmentation
Yan ShaoDepartment of Linguistics and Philology, Uppsala University
29 March 2017

Outline
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 2/49

Tokenization
Why do we need to segment a text in NLP?Because a piece of text is more than a long string of characters, itcontains basic linguistic units that we are interested in:
Words (that we must deal with lexicons)Sentences (that separate unit of sense)Paragraphs...
For a human:
Bob eats apples.
For a computer:01000010011011110110001000100000011001010110000101110100011100110010000001100001011100000111000001101100011001010111001100101110
Grundläggande textanalys 3/49
Tokenization
Why do we need to segment a text in NLP?Because a piece of text is more than a long string of characters, itcontains basic linguistic units that we are interested in:
Words (that we must deal with lexicons)Sentences (that separate unit of sense)Paragraphs...
For a human:
Bob eats apples.
For a computer:01000010011011110110001000100000011001010110000101110100011100110010000001100001011100000111000001101100011001010111001100101110
Grundläggande textanalys 3/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 4/49

Tokenization
DefinitionSegmenting text into linguistic units, such as words, punctuationsand numbers.
For example: Bob eats apples.Contains 4 tokens: Bob|eats|apples|.
Grundläggande textanalys 5/49

Warm Up QUIZ
QuestionCan you tell me how many tokens contains this extract (counteverything that is bold):The wolf said: "Little pig, little pig, let me come in."
1 112 153 174 19
Grundläggande textanalys 6/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 7/49

Tokenization
Is tokenization trivial?“11:45 p.m. Ugh. First day of New Year has been day of horror.Can’t quite believe I am once again starting the year in a singlebed in my mom’s house. [...]When I got to the Alconburys’ andrang their entire-tune-of-town-hall-clock-style doorbell I was still ina strange world of my own–nauseous, vile-headed, acidic. ”
What if...Should we rely only on spaces?
Grundläggande textanalys 8/49

Tokenization
Is tokenization trivial?“11:45 p.m. Ugh. First day of New Year has been day of horror.Can’t quite believe I am once again starting the year in a singlebed in my mom’s house. [...]When I got to the Alconburys’ andrang their entire-tune-of-town-hall-clock-style doorbell I was still ina strange world of my own–nauseous, vile-headed, acidic. ”
What if...Should we rely only on spaces?
Grundläggande textanalys 8/49

Hyphens
True hyphens:Lexical hyphen:
"anti-discriminatory""twenty-two"
Sententially determined hyphenation:"their entire-tune-of-town-hall-clock-style doorbell""New York-based"
End-of-line hyphens as line breakers:Word segmentation and part-of-speech (POS) tag-ging are core steps for higher-level natural lan-guage processing (NLP) tasks.
Grundläggande textanalys 9/49

It is indeed tricky...There is not a straight forward way to deal with hyphensContext dependant: twenty-two vs New York-basedTask dependent: New York-based cannot be tokenized thesame way if we do Part-of-Speech, Information Retrieval,translation...Language dependent problem
Grundläggande textanalys 10/49

Tokenization
Some other special tokens:C++Email addresses ([email protected])Phone number (778-782-3054)City names (San Francisco, New York)date 23/05/14, 23-May-2014Compounds (statsminister)...
Can be processed withRule-based system, dictionary, etcMachine learning approaches
Grundläggande textanalys 11/49

Apostrophe
Mr. O’Neill thinks that the boys’ stories about Chile’s capitalaren’t amusing.
The rules for apostrophes are:Language specificContext sensitive:"O’Neill" vs "Chile"+"’s"
Grundläggande textanalys 12/49

Apostrophe
How is it dealt in softwares?Here is an example of how some apostrophes are handled in a wellknown tagger:
Figure: Regex for clitics in TreeTagger’s tokenizer
Grundläggande textanalys 13/49

Chinese Word Segmentation
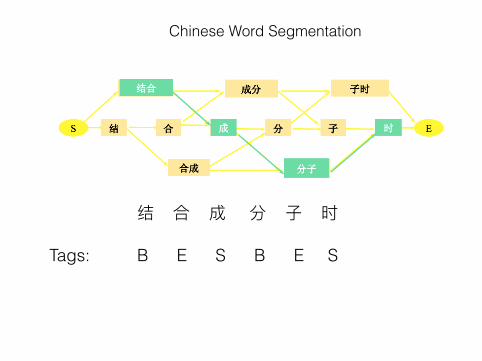
结合成分⼦子时
Meaning: When combined into moleculars
结合 combine 合成 compose 成分 component 分⼦子 molecular ⼦子时 midnight
结 joint, end… 合 add, close… 成 finish, success… 分 divide, minute… ⼦子 son, child, seed… 时 time, when…
结合 (combine) 成 (finish) 分⼦子 (molecular) 时 (when)
possible ways 25 = 32
Chinese Word Segmentation
结 合 成 分 ⼦子 时
B E S B E STags:

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 14/49

Is this text tokenized?
The wolf said : " Little pig , let me come in . "
NoteFor machine translation purpose
Grundläggande textanalys 15/49

Is this text tokenized?
The wolf said : " Little pig , let me come in . "
NoteFor machine translation purpose
Grundläggande textanalys 15/49

Is this text tokenized?
The wolf said: "Little pig, let me come in."
Grundläggande textanalys 16/49

Is this text tokenized?
<tok>The</tok> <tok>wolf</tok> <tok>said</tok><tok>:</tok> <tok>"</tok> <tok>Little</tok><tok>pig</tok> <tok>,</tok> <tok>little</tok><tok>pig</tok> <tok>,</tok> <tok>let</tok><tok>me</tok> <tok>come</tok> <tok>in</tok><tok>.</tok> <tok>"</tok>
Notetokenization separators for XML document
Grundläggande textanalys 17/49

Is this text tokenized?
<tok>The</tok> <tok>wolf</tok> <tok>said</tok><tok>:</tok> <tok>"</tok> <tok>Little</tok><tok>pig</tok> <tok>,</tok> <tok>little</tok><tok>pig</tok> <tok>,</tok> <tok>let</tok><tok>me</tok> <tok>come</tok> <tok>in</tok><tok>.</tok> <tok>"</tok>
Notetokenization separators for XML document
Grundläggande textanalys 17/49

Is this text tokenized?Thewolfsaid:"Littlepig,letmecomein."
Notetokenization separators for tagging purpose
Grundläggande textanalys 18/49

Is this text tokenized?Thewolfsaid:"Littlepig,letmecomein."Notetokenization separators for tagging purpose
Grundläggande textanalys 18/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 19/49

Evaluation
Choose between two tokenizers based on some observations:1 Observation 1: Tokenizer 1 systematically tokenizes wrong the
punctuations (for instance it gives the token ‘cheese!’ instead of thetokens ‘cheese’ and ‘!’) whereas Tokenizer 2 only gets wrong ontokenizing some hyphens which is a less recurrent mistake.
2 Observation 2: Tokenizer 1 divides the text into 1150 tokens whereasTokenizer 2 divides into 1100 and manually checked the text has 1000tokens. 1100 is closer to 1000.
Grundläggande textanalys 20/49

Evaluation
How can we explicitly evaluate the accuracy of a tokenizer?Take a simple example, non-ambiguous: I eat an apple.Manually create the gold standard tokenization of thisexample. I | eat | an | apple | .
Grundläggande textanalys 21/49

Evaluation
How can we explicitly evaluate the accuracy of a tokenizer?Take a simple example, non-ambiguous: I eat an apple.Manually create the gold standard tokenization of thisexample. I | eat | an | apple | .
Grundläggande textanalys 21/49

Evaluation
Now we have some output of several tokenizers.a I|eat|an|apple.b I|eat|a|n|apple.c I|eat|a|n|a|p|p|l|e.d I|eat an apple.
All of them are wrong, but some are worse that others.
Grundläggande textanalys 22/49

Evaluation
Standard Evaluation Matrix for most NLP tasksRecall: number of tokens that are right / number of tokens to beproduced according to the gold standard.Precision: number of tokens that are right / number of tokensthat were automatically generated.F1-score: 2×Recall×Precision / (Recall + Precision)
Grundläggande textanalys 23/49

Evaluation
Gold standard: I|eat|an|apple|.1 I|eat|a|n|a|p|p|l|e.2 I|eat an apple.
1 Recall=2/ 5 =40% Precision=2/(2+7)=2/9=22%2 Recall=1/ 5 =20% Precision=1/(1+1)=1/2=50%
Grundläggande textanalys 24/49

Evaluation
Gold standard: I|eat|an|apple|.
a I|eat|an|apple.b I|eat|a|n|apple.c I|eat|a|n|a|p|p|l|e.d I|eat an apple..
Recall: ?
Precision: ?
F1-score: ?
Grundläggande textanalys 25/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 26/49

Summary
Tokenization is:a basic task that almost every NLP task requiresfor Western European languages relatively well handled (andspecific problems through other languages: germanic, orientaletc.)
Tokenization is a universal task (as many in NLP)The accuracy has a significant impact on the higher-leveltasks.
Grundläggande textanalys 27/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 28/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 29/49

Sentence Segmentation Introduction
Sentence SegmentationSentence segmentation find sentence boundaries between wordsin different sentences. Since most written languages havepunctuation marks which occur at sentence boundaries, sentencesegmentation is frequently referred to as sentence boundarydetection, sentence boundary disambiguation, or sentenceboundary recognition. All these terms refer to the same task:determining how a text should be divided into sentences for furtherprocessing.
Grundläggande textanalys 30/49

Why sentence segmentation?
Preprocessing step for higher-level taskUseful for: Syntactical Parsing, Information Extraction,Machine Translation, Text AlignmentNot (very) trivial
The basic algorithm [.?!][ ()"]+[A-Z](which means “select every punctuation followed by a space and anupper-case.”) provokes 6.5% errors on the Brown corpus and WSJ
Grundläggande textanalys 31/49

Sentence Segmentation
Dot ’.’ is ambiguousDecimal ex. 6.22Abreviations (your result will be influenced by the number ofthem)Named entity: Web sites, IP address (www.mywebsite.com,94.23.225.162:3128, etc.)
Grundläggande textanalys 32/49

Sentence Segmentation
Different sentence segmentation approachesMachine learning based:
Unsupervised they can be trained on any language and genre.Supervised they require annotation of a training set. We willcover some rule-based methods
Grundläggande textanalys 33/49

Sentence Segmentation
Rule based systemsTake the local context of the punctuation into account:
regular expressions [.?!][ ()"]+[A-Z]or finite states transducershttp://www-igm.univ-mlv.fr/~unitex/
Grundläggande textanalys 34/49

Rule based systems
Rule based systemsMoreover:
A list of frequent starting words (The, He, However ...)A list of abbreviations (Mr. , Av., a.m., A.S.A.P)
Grundläggande textanalys 35/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 36/49

Is this sentence segmented?
Welcome! Can I help you? I’m fine.
Grundläggande textanalys 37/49

Is this sentence segmented?
Welcome!Can I help you?I’m fine.
Grundläggande textanalys 38/49

Is this sentence segmented?
Welcome!CanIhelpyou?I’mfine.
Grundläggande textanalys 39/49

Is this sentence segmented?
Welcome!
CanIhelpyou?
I’mfine.
Grundläggande textanalys 40/49

Is this sentence segmented?
<sent><tok>Welcome</tok><tok> !</tok></sent><sent><tok> Can </tok> <tok> I</tok><tok> help </tok><tok> you</tok><tok>?</tok></sent>
Grundläggande textanalys 41/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 42/49

Summary
Similarly to tokenization, there is no universal way for sentencesegmentation
Language specificGenre specific
Grundläggande textanalys 43/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 44/49

Summary
Two NLP preprocessing:- Tokenization- Sentence segmentationThey vary across different genres, NLP tasks, as well aslanguagesSome ambiguities are common and need to be handle such ashyphenation and dotsTheir accuracies have significant impacts on higher-level NLPtasks. (Parsing for instance).Foster [2010]
Grundläggande textanalys 45/49

Table of Contents
1 TokenizationIntroductionExerciseEvaluationSummary
2 Sentence segmentationIntroductionExerciseSummary
3 Summary
4 Practical Guidance
Grundläggande textanalys 46/49

Practical Guidance
How to solve a problem in the lab sessions1 Make sure you understand what you need to do on it (e.g.,
Tokenise)2 Make some simple example(s) (e.g., I eat an apple)3 Solve the simple samples by hand. (e.g., I|eat|an|apple|.)4 If you think everything is clear, make the program that do the
task.5 Test your program on your examples before applying to the
real data6 If the output is correct, apply to the real data for further
testing.
Grundläggande textanalys 47/49

Practical Guidance
How to write a good lab reportGive a global overview of the results ( %, numbers)Exemplify enough to make your point.Give a consistent information presentation to the reader (ex.Write all examples in italic, put data into tables forcomparisons etc.)Target your answer to the question.Make sure the information you provide is meaningful and clearout of its context.
Grundläggande textanalys 48/49

References
Jennifer Foster. “cba to check the spelling”: Investigating ParserPerformance on Discussion Forum Posts. In Proceedings of theNAACL-HLT, pages 381–384. Association for ComputationalLinguistics, 2010. URLhttp://aclweb.org/anthology/N10-1060.
Ruslan Mitkov. The Oxford Handbook of ComputationalLinguistics, volume 0 of Oxford Handbooks in Linguistics.Oxford University Press, 2003. URL http://books.google.com/books?hl=en&lr=&id=OaClhre-vW4C&pgis=1.
Grundläggande textanalys 49/49

















