Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Michael Salim [email protected]Argonne National Laboratory Lemont, Illinois, USA Thomas Uram [email protected]Argonne National Laboratory Lemont, Illinois, USA J. Taylor Childers [email protected]Argonne National Laboratory Lemont, Illinois, USA Venkat Vishwanath [email protected]Argonne National Laboratory Lemont, Illinois, USA Michael E. Papka [email protected]Argonne National Laboratory Lemont, Illinois, USA Department of Computer Science, Northern Illinois University DeKalb, Illinois, USA ABSTRACT Massive upgrades to science infrastructure are driving data ve- locities upwards while stimulating adoption of increasingly data- intensive analytics. While next-generation exascale supercomput- ers promise strong support for I/O-intensive workflows, HPC re- mains largely untapped by live experiments, because data transfers and disparate batch-queueing policies are prohibitive when faced with scarce instrument time. To bridge this divide, we introduce Balsam: a distributed orchestration platform enabling workflows at the edge to securely and efficiently trigger analytics tasks across a user-managed federation of HPC execution sites. We describe the architecture of the Balsam service, which provides a workflow management API, and distributed sites that provision resources and schedule scalable, fault-tolerant execution. We demonstrate Balsam in efficiently scaling real-time analytics from two DOE light sources simultaneously onto three supercomputers (Theta, Sum- mit, and Cori), while maintaining low overheads for on-demand computing, and providing a Python library for seamless integration with existing ecosystems of data analysis tools. 1 INTRODUCTION Department of Energy (DOE) supercomputers have been success- fully leveraged by scientists for large-scale simulation in diverse fields, from understanding the evolution of the universe to dis- covering new materials. With the rise of data-intensive science, this landscape is changing to include high-throughput comput- ing (HTC) workloads, typically comprising a large collection of jobs with a mix of interdependencies that govern the concurrency available to be exploited. A leading cause of this paradigm shift is experimental science: a range of experimental facilities are un- dergoing upgrades, or have recently completed upgrades, that will increase their data-taking rate, in some cases by as much as two orders of magnitude [22, 28, 39]. This change necessitates access to computing resources beyond the experimental facility [27, 36], to accommodate the real-time demands of experimental data analysis. Such workloads have been explored in a variety of past workflow systems [17], job description approaches [35], and methods of map- ping jobs to compute resources [20]. Computational workloads from experimental facilities are uniquely driven by their coupling to ongoing experiments, leading to these features: significant data rates that vary over time, from constant to bursty; the need for near real-time processing to guide researchers operating the experiment to maximize the scientific utility of the instrument. For instance, to probe nanoscale dynamics in materials such as amorphous ice, X-ray photon-correlation spectroscopy (XPCS) experiments collect frames of X-ray speckle pattern data on cycles of minutes or tens of minutes [32], evaluate the fidelity of the acquired time series by analyzing auto-correlation of pixelwise intensities, and perform repeated measurements across the experimental parameter space (e.g. sample position, temperature, pressure). Today, XPCS detectors routinely collect megapixel frames at rates of 60 Hz (∼ 120 MB/sec), but with recent advances in detector technology, frame rates of 11.8 kHz (∼ 24 GB/sec) [21] exacerbate the challenge of real-time analy- sis: with limited computing resources, turnaround times of days or weeks preclude human-in-the-loop decision making or data-driven exploration of the parameter space. Addressing this scientific bottle- neck requires a multi-faceted approach to automated data reduction and analytics [21], as well as infrastructure to support the demands of data movement, storage, and large-scale computing and shrink analysis times from days or weeks to minutes. In the regime of near-real-time analysis, where turnaround times on the order of 1-10 minutes are short enough to restore human- in-the-loop decision making for XPCS and similar experiments, a promising approach consists in distributing analysis workloads from the experiment across multiple remote computing facilities to avoid excessive batch queueing delays or (un)planned computing outages [1, 6, 9, 39]. Our development of Balsam aims to support this approach with implementation in a few key areas: an application programming interface (API) for remote access to supercomputing facilities; close interaction with job schedulers to inject jobs op- portunistically and bundle as ensembles to maximize throughput; interaction with data transfer mechanisms to move input (output) data to (from) remote locations, bundling transfers as needed; user- domain deployment, simplifying deployment while adhering to security requirements; and, distribution of jobs across multiple compute facilities simultaneously, with direction to a specific facil- ity based on job throughput. arXiv:2105.06571v2 [cs.DC] 2 Jul 2021
Transcript
Toward Real-time Analysis of Experimental Science Workloadson Geographically Distributed Supercomputers
Michael Salimmsalimanlgov
Argonne National LaboratoryLemont Illinois USA
Thomas Uramturamanlgov
Argonne National LaboratoryLemont Illinois USA
J Taylor Childersjchildersanlgov
Argonne National LaboratoryLemont Illinois USA
Venkat Vishwanathvenkatanlgov
Argonne National LaboratoryLemont Illinois USA
Michael E Papkapapkaanlgov
Argonne National LaboratoryLemont Illinois USA
Department of Computer ScienceNorthern Illinois University
DeKalb Illinois USA
ABSTRACTMassive upgrades to science infrastructure are driving data ve-locities upwards while stimulating adoption of increasingly data-intensive analytics While next-generation exascale supercomput-ers promise strong support for IO-intensive workflows HPC re-mains largely untapped by live experiments because data transfersand disparate batch-queueing policies are prohibitive when facedwith scarce instrument time To bridge this divide we introduceBalsam a distributed orchestration platform enabling workflows atthe edge to securely and efficiently trigger analytics tasks acrossa user-managed federation of HPC execution sites We describethe architecture of the Balsam service which provides a workflowmanagement API and distributed sites that provision resourcesand schedule scalable fault-tolerant execution We demonstrateBalsam in efficiently scaling real-time analytics from two DOE lightsources simultaneously onto three supercomputers (Theta Sum-mit and Cori) while maintaining low overheads for on-demandcomputing and providing a Python library for seamless integrationwith existing ecosystems of data analysis tools
1 INTRODUCTIONDepartment of Energy (DOE) supercomputers have been success-fully leveraged by scientists for large-scale simulation in diversefields from understanding the evolution of the universe to dis-covering new materials With the rise of data-intensive sciencethis landscape is changing to include high-throughput comput-ing (HTC) workloads typically comprising a large collection ofjobs with a mix of interdependencies that govern the concurrencyavailable to be exploited A leading cause of this paradigm shiftis experimental science a range of experimental facilities are un-dergoing upgrades or have recently completed upgrades that willincrease their data-taking rate in some cases by as much as twoorders of magnitude [22 28 39] This change necessitates access tocomputing resources beyond the experimental facility [27 36] toaccommodate the real-time demands of experimental data analysisSuch workloads have been explored in a variety of past workflowsystems [17] job description approaches [35] and methods of map-ping jobs to compute resources [20] Computational workloads
from experimental facilities are uniquely driven by their couplingto ongoing experiments leading to these features significant datarates that vary over time from constant to bursty the need for nearreal-time processing to guide researchers operating the experimentto maximize the scientific utility of the instrument For instanceto probe nanoscale dynamics in materials such as amorphous iceX-ray photon-correlation spectroscopy (XPCS) experiments collectframes of X-ray speckle pattern data on cycles of minutes or tensof minutes [32] evaluate the fidelity of the acquired time series byanalyzing auto-correlation of pixelwise intensities and performrepeated measurements across the experimental parameter space(eg sample position temperature pressure) Today XPCS detectorsroutinely collect megapixel frames at rates of 60 Hz (sim 120 MBsec)but with recent advances in detector technology frame rates of 118kHz (sim 24 GBsec) [21] exacerbate the challenge of real-time analy-sis with limited computing resources turnaround times of days orweeks preclude human-in-the-loop decision making or data-drivenexploration of the parameter space Addressing this scientific bottle-neck requires a multi-faceted approach to automated data reductionand analytics [21] as well as infrastructure to support the demandsof data movement storage and large-scale computing and shrinkanalysis times from days or weeks to minutes
In the regime of near-real-time analysis where turnaround timeson the order of 1-10 minutes are short enough to restore human-in-the-loop decision making for XPCS and similar experimentsa promising approach consists in distributing analysis workloadsfrom the experiment across multiple remote computing facilities toavoid excessive batch queueing delays or (un)planned computingoutages [1 6 9 39] Our development of Balsam aims to support thisapproach with implementation in a few key areas an applicationprogramming interface (API) for remote access to supercomputingfacilities close interaction with job schedulers to inject jobs op-portunistically and bundle as ensembles to maximize throughputinteraction with data transfer mechanisms to move input (output)data to (from) remote locations bundling transfers as needed user-domain deployment simplifying deployment while adhering tosecurity requirements and distribution of jobs across multiplecompute facilities simultaneously with direction to a specific facil-ity based on job throughput
arX
iv2
105
0657
1v2
[cs
DC
] 2
Jul
202
1
Conferencersquo17 July 2017 Washington DC USA Salim et al
We demonstrate this functionality in the context of jobs flowingfrom two experimental facilities the Advanced Photon Source (APS)at Argonne National Laboratory and the Advanced Light Source(ALS) at Lawrence Berkeley Laboratory to three DOE computefacilities the Argonne Leadership Computing Facility (ALCF) theOak Ridge Leadership Computing Facility (OLCF) and NERSC Bal-sam sites were deployed at each facility to bridge the site schedulerto the Balsam service The Balsam service exposes an API for intro-ducing jobs and acts as a distribution point to the registered Balsamsites Using the API jobs were injected from the light source facil-ities simultaneously executed at the computing sites and resultsreturned to the originating facility Monitoring capabilities provideinsight into the backlog at each Balsam site and therefore a basisfor making scheduling decisions across compute facilities to opti-mize throughput While the current work emphasizes light sourceworkloads Balsam is easy to adopt and agnostic to applicationsmaking this approach applicable to diverse scientific domains
2 RELATEDWORKWorkflow management framework (WMF) development has a richhistory and remains an active field of research and developmentAs an open-source Python WMF Balsam [2] is similar to other sys-tems with Python-driven interfaces for managing high-throughputworkflows on supercomputers On the other hand some unique fea-tures of Balsam arise from requirements in orchestrating distributedworkloads submitted from remote users and run on multiple HPCsites We now discuss these requirements and contrast Balsam withsome contemporary HPC-oriented WMFs with Python APIs anddistributed execution capabilities
Distributed science workflows must invariably handle data andcontrol flow across networks spanning administrative domainsChallenging barriers to WMF adoption in multi-user HPC envi-ronments lie in deploying distributed clientserver infrastructuresand establishing connectivity among remote systems For instanceFireworks [29] Balsam [33] and the RADICAL-Pilot Ensem-ble Toolkit (EnTK) [19 31] are three widely-used WMFs at DOEsupercomputing facilities that expose Python APIs to define andsubmit directed acyclic graphs (DAGs) of stateful tasks to a data-base Like Balsam these WMFs possess various implementations ofa common pilot job design whereby tasks are efficiently executedon HPC resources by a process that synchronizes state with theworkflow database Because the database is directly written by useror pilot job clients users of Fireworks RADICAL or Balsam typ-ically deploy and manage their own MongoDB servers [10] (plusRabbitMQ for EnTK or PostgreSQL [13] for Balsam) The serverdeployments are repeated on a per-project basis and require pro-visioning resources on ldquogatewayrdquo nodes of an HPC systemrsquos localnetwork Next connecting to the database for remote job submis-sion requires an approach such as SSH port forwarding [33] orpasswordless SSHGSISSH [31] These methods are non-portableand depend on factors such as whether the compute facility man-dates multi-factor authentication (MFA)
By contrast the Balsam service-oriented architecture shifts ad-ministrative burdens away from individual researchers by routingall user user agent and pilot job client interactions through ahosted multi-tenant web service Because Balsam execution sites
communicate with the central service only as HTTP clients deploy-ments become a simple user-space pip package installation on anyplatform with a modern Python installation and outbound internetaccess As a consequence of the ubiquity of HTTP data transportBalsam works ldquoout of the boxrdquo on supercomputers spanning theALCF OLCF and NERSC facilities against a cloud-hosted Balsamservice
The Balsam REST API [3] defines the unifying data model andservice interactions upon which all Balsam components and userworkflows are authored In the context of REST interfaces to HPCresources Balsam may be compared with the Superfacility con-cept [27] which envisions a future of automated experimentaland observational science workflows linked to national comput-ing resources through a set of Web APIs Implementations such asthe NERSC Superfacility API [11] and the Swiss National Super-computing Centrersquos FirecREST API [25] expose methods such assubmitting and monitoring batch jobs moving data between re-mote filesystems and checking system availability However thesefacility services alone do not address workflow management orhigh-throughput execution instead they provide web-interfacedabstractions of the underlying facility analogous to modern cloudstorage and infrastructure services By contrast Balsam providesan end-to-end high-throughput workflow service with APIs forefficiently submitting fine-grained tasks (as opposed to batch jobscripts) along with their execution and data dependencies Thusfrom a front-end view Balsammay be viewed as an implementationof the Workflow as a Service (WFaaS) [38] concept with a backendarchitecture adapted to shared HPC environments
funcX [24] is an HPC-oriented instantiation of the function-as-a-service (FaaS) paradigm where users invoke Python functions inremote containers via an API web service funcX endpoints whichare similar to Balsam sites (32) run on the login nodes of targetHPC resources where Globus Auth is used for authentication anduser-endpoint association The funcX model is tightly focused onPython functions and therefore advocates decomposing workflowsinto functional building blocks Each function executes in a con-tainerized worker process running on one of the HPC computenodes By contrast Balsam provides a generalized model of appli-cations with executables that may or may not leverage contain-ers per-task remote data dependencies programmable error- andtimeout-handling and flexible per-task resource requirements (egtasks may occupy a single core or specify a multi-node distributedmemory job with some number of GPU accelerators per MPI rank)In the context of end-to-end distributed science workflows funcXis used as one tool in a suite of complementary technologies suchas Globus Automate [23] to set up event-based triggers of Globusdata transfers and funcX invocations Balsam instead provides aunified API for describing distributed workflows and the user siteagents manage the full lifecycle of data and control flow
Implicit dataflow programming models such as Parsl [18] andDask [26] are another powerful option for authoring dynamicworkflows directly in the Python language These libraries leveragethe concept of Python futures to expose parallelism in the Pythonscript and distribute computations across HPC resources In thiscontext the ephemeral workflow state resides in the executing
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Globus Transfer
ALCF-Theta
OLCF-Summit
NERSC-Cori
CobaltLSF
Slurm
TransferModule
Scheduler Module
Balsam Site 1
TransferModule
Scheduler Module
TransferModule
Scheduler Module
Balsam Site 2
Balsam Site 3
APS Clients
GridFTP
HTTPS
Balsam API Service
sites
apps
jobs
HTTPS HTTP
S
Figure 1 Simplified Balsam architecture Clients at the Advanced PhotonSource (APS) submit scientific workloads by creating Job resources at a spe-cific execution site through the Balsam REST API [3] Pilot jobs at Balsamsites on the ALCF-Theta OLCF-Summit and NERSC-Cori supercomputersfetch the appropriate Jobs for execution All Balsam components indepen-dently communicate with the API service endpoints as HTTPS clients Forinstance the Transfer Module fetches pending TransferItems from the APIbundles the corresponding files and orchestrates out-of-band data transfersvia Globus the Scheduler Module synchronizes API BatchJob resources withthe userrsquos resource allocations on the local batch scheduler
Python program tasks are not tied to an external persistent data-base This has obvious implications for provenance and fault toler-ance of workflows where per-workflow checkpointing is necessaryin systems such as Parsl The Balsam service provides durable taskstorage for each user site so that workflows can be centrally addedmodified and tracked over the span of a long-term project
3 IMPLEMENTATIONBalsam [2] (Figure 1) provides a centralized service allowing usersto register execution sites from any laptop cluster or supercom-puter on which they wish to invoke computation The sites runuser agents that orchestrate workflows locally and periodicallysynchronize state with the central service Users trigger remotecomputations by submitting jobs to the REST API [3] specifyingthe Balsam execution site and location(s) of data to be ingested
31 The Balsam ServiceBalsam [2] provides a centrally-hosted multi-tenant web serviceimplemented with the FastAPI [7] Python framework and Post-greSQL [13] relational database backend The service empowersHPC users to manage distributed Balsam sites and orchestrate work-flowswithin or across sites The centralized architecture as opposedto per-user databases enables remote Balsam sites to communicatewith the service as HTTPS clients This client-driven pattern iseffective in many HPC environments where outbound internetconnectivity is common (or easily enabled by proxy) but otherchannels or inbound connections are often restricted requiringnon-portable solutions and involvement of system administratorsWe now discuss concepts in the REST API (refer to OpenAPI schemaonline [3]) which defines the complete set of interactions uponwhich Balsam is built
The Balsam User is the root entity in the Balsam relationaldata model (eg all Sites are associated with their ownerrsquos userID) and the service uses JSON Web Tokens (JWT) to identify theauthenticated user in each HTTP request Access Tokens are is-sued by Balsam upon authentication with an external provider wehave implemented generic Authorization Code and Device CodeOAuth2 flows [12] permitting users to securely authenticate withany OAuth2 provider The Device Code flow enables secure loginfrom browserless environments such as supercomputer login nodesThe Balsam Python client library and balsam login command lineinterface manage interactive login flows and storeretrieve accesstokens in the userrsquos simbalsam configuration directory In the nearfuture we anticipate integrating the Balsam OAuth2 system with afederated identity provider as laid out in the DOE distributed dataand computing ecosystem (DCDE) plan [34]
The Balsam Site is a user-owned endpoint for remote execu-tion of workflows Sites are uniquely identified by a hostname andpath to a site directory mounted on the host The site directory is aself-contained project space for the user which stores configura-tion data application definitions and a sandboxed directory whereremote datasets are staged into per-task working directories priorto executionfrom balsamsite import ApplicationDefinition
class EigenCorr(ApplicationDefinition)
Runs XPCS -Eigen on an (H5 IMM) file pair from a
remote location
corr_exe = softwarexpcs -eigen2buildcorr
command_template = fcorr_exe inph5 -imm inpimm
environment_variables =
HDF5_USE_FILE_LOCKING FALSE
parameters =
cleanup_files = [hdf imm h5]
transfers =
h5_in
required True
direction in
local_path inph5
description Input HDF5 file
recursive False
imm_in
required True
direction in
local_path inpimm
description Input IMM file
recursive False
h5_out
required True
direction out
local_path inph5 output is input
modified in-place
description Output H5 file
recursive False
Listing 1 XPCS-Eigen corr ApplicationDefinition class which we evaluatewith benchmark datasets in Section 4
As part of its security model Balsam does not permit directinjection of arbitrary commands or applications through its API
Conferencersquo17 July 2017 Washington DC USA Salim et al
Instead users write ApplicationDefinition classes in Python mod-ules stored inside the site directory (see example Listing 1) Thesemodules serve as flexible templates for the permissible workflowsthat may run at each Balsam site BalsamApps registered with theAPI merely index the ApplicationDefinitions in each site with a 11correspondence The ApplicationDefinition provides a declarativedefinition of the application configuration via special attributes suchas the command_template which is interpreted as a shell commandwhere adjustable parameters are enclosed in double-curly bracesThe transfers attribute defines named slots for files or directoriesto be staged in or out prior to (or after) execution ApplicationDefi-nition metadata are automatically serialized and synchronized withthe corresponding REST API App resource Thus a sitersquos Apps be-come discoverable via the web API but maliciously submitted Appdata does not impact the execution of local ApplicationDefinitions
A Balsam Job (used interchangeably with task) represents asingle invocation of a Balsam App at a particular site The jobcontains application-specific parameters (such as command linearguments) resource requirements (like the number of computenodes or MPI ranks per node) and locations of data to be stagedin or out beforeafter app execution Jobs can also specify parentjob dependencies so that a user may submit DAGs of Balsam jobsto the API Each job references a specific App and is thereforetransitively bound to run at a single site upon creation (Jobrarr Apprarr Site) Jobs carry persistent states (enumerated in the REST APIdocumentation [3]) and metadata events generated from eventsthroughout their lifecycle Files or directories that need to be stagedin or out are associated with each Balsam Job and therefore passedto the API during job creation calls However the service trackseach of these TransferItems as a standalone unit of transfer betweensome Balsam Site and remote destination (defined with a protocol-specific URI such as Globus endpoint ID and path)
The Balsam job represents a fine-grained unit of work (task)while many tasks are executed inside a pilot job that efficientlyscales on the HPC compute nodes The pilot job and its associated re-source allocation is termed aBalsamBatchJob Balsam BatchJobscan be automatically created by the Site agent (autoscaling) or man-ually requested through the REST API By default a BatchJob ata Balsam site continuously fetches any locally-runnable Jobs andefficiently ldquopacksrdquo them onto idle resources Balsam launcher pi-lot jobs establish an execution Session with the service whichrequires sending a periodic heartbeat signal to maintain a leaseon acquired jobs The session backend guarantees that concurrentlaunchers executing jobs from the same site do not acquire andprocess overlapping jobs The Session further ensures that criticalfaults causing ungraceful launcher termination do not cause jobsto be locked in perpetuity the stale heartbeat is detected by theservice and affected jobs are reset to allow subsequent restarts
A major feature of Balsam is the Python SDK which is heav-ily influenced by and syntactically mirrors a subset of the Djangoobject relational model (ORM) [5] Rather than generating SQLand interfacing to a database backend the Balsam SDK generatesRESTful calls to the service APIs and lazily executes network re-quests through the underlying API client library The SDK pro-vides a highly consistent interface to query (bulk-)create (bulk-)update and delete the Balsam resources described in the preced-ing sections For instance Jobobjectsfilter(tags=experiment
XPCS state=FAILED) produces an iterable query of all BalsamJobs that failed and contain the experimentXPCS tag Upon itera-tion the lower-level REST Client generates the GET jobs HTTPrequest with appropriate query parameters The returned BalsamJobs are deserialized as Job objects which can be mutated andsynchronized with the API by calling their save() method
32 Balsam Site ArchitectureEach Balsam site runs an authenticated user agent that performsREST API calls to the central service to fetch jobs orchestrate theworkflow locally and update the centralized state
Indeed the Balsam service plays a largely passive bookkeepingrole in the architecture where actions are ultimately client-drivenThis design is a largely practical choice made to fit the infrastruc-ture and security constraints of current DOE computing facilitiesOperationally speaking a user must (1) log in to a site by the stan-dard SSH authentication route (2) authenticate with the Balsamservice to obtain an access token stored at the HPC site and (3)initialize the Balsam site agent in a directory on the HPC storagesystem The Balsam site is therefore an ordinary user process andinterfaces with the HPC system as such the architecture does notrequire elevated privileges or integration with specialized gatewayservices Typically the Balsam site consists of a few long-runninglightweight processes on an HPC login node the only requirementsare a Python installation (version ge 37) and outbound internetaccess (ie the user is able to perform HTTP requests such as curlhttpsapigithubcom) The Balsam launchers (pilot jobs) alsofetch jobs directly from the REST API therefore outbound curlfunctionality is needed from the head node where batch job scriptsbegin executing These requirements are satisfied by default on theSummitOLCF and CoriNERSC machines on ThetaALCF thedefault site configuration indicates that an HTTP proxy should beused in launcher environments
Site configurations comprise a YAML file and job template shellscript that wraps the invocation of the pilot job launcher Theseconfigurations are easily modified and a collection of default con-figurations is included directly as part of the Balsam software TheYAML file configures the local Balsam site agent as a collection ofindependent modules that run as background processes on a hostwith gateway access to the sitersquos filesystems and HPC scheduler (egan HPC login node) These modules are Python components writ-ten with the Balsam SDK (described in the previous section) whichuses locally stored access tokens to authenticate and exchange datawith the REST API services
The Balsammodules are architected to avoid hardcoding platform-dependent assumptions and enable facile portability across HPCsystems Indeed the majority of Balsam component implementa-tions are platform-independent and interactions with the underly-ing diverse HPC fabrics are encapsulated in classes implementinguniform platform interfaces Below we touch on a few of the keyBalsam site modules and the underlying platform interfaces
The Balsam Transfer Module queries the API service for pend-ing TransferItems which are files or directories that need to bestaged in or out for a particular Balsam job The module batchestransfer items between common endpoints and issues transfer tasks
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
to the underlying transfer interface For instance the Globus trans-fer interface enables seamless interoperation of Balsam with GlobusTransfer for dispatching out-of-band transfer tasks The transfermodule registers transfer metadata (eg Globus task UUIDs) withthe Balsam API and polls the status of transfer tasks synchronizingstate with the API For example to enable the Transfer Module withGlobus interoperability the user adds a local endpoint ID and alist of trusted remote endpoint IDs to the YAML configuration Theuser can also specify the maximum number of concurrent transfertasks as well as the maximum transfer batch size which is a criticalfeature for bundling many small files into a single GridFTP transferoperation The Transfer Module is entirely protocol-agnostic andadding new transfer interfaces entails implementing two methodsto submit an asynchronous transfer task with some collection offiles and poll the status of the transfer
The Scheduler Module uses an underlying scheduler platforminterface to query local batch scheduler queues (eg qstat) andsubmit resource allocations (qsub) for pilot jobs onto the queueInterfaces to Slurm Cobalt and LSF are provided to support DOEOffice of Science supercomputing systems at NERSC ALCF andOLCF respectively The interface provides the necessary abstrac-tions for interacting with the scheduler via subprocess calls andenables one to easily support other schedulers
The Balsam Scheduler Module is then platform-agnostic andserves to synchronize API BatchJobs with the local resource man-ager We emphasize that this module does not consider when orhow many resources are needed instead it provides a conduit forBatchJobs created in the Balsam service API to become concretepilot job submissions in a local queue The Scheduler Module YAMLconfiguration requires only specifying the appropriate schedulerinterface (eg Slurm) an API synchronization interval the localqueue policies (partitions) and the userrsquos project allocations
A separate concern is automating queue submission (ie BatchJobcreation) in real-time computing scenarios users maywish to allowthe site to automatically scale resources in response to a workloadwith changing resource requirements over time
The Elastic Queue Module allows users to flexibly controlauto-scaling behavior at a particular Balsam site by configuringa number of settings in the YAML file the appropriate schedulerqueue project allocation and pilot job mode are specified alongwith minimummaximum numbers of compute nodes and min-imummaximum walltime limits The user further specifies themaximum number of auto-queued jobs the maximum queueingwait time (after which BatchJobs are deleted from the queue) anda flag indicating whether allocations should be constrained to idle(backfill) node-hour windows
At every sync period (set in the YAML configuration) the ElasticQueue module queries the Balsam API for the aggregate resourcefootprint of all runnable Jobs (howmany nodes could I use right now)as well as the aggregate size of all queued and running BatchJobs(how many nodes have I currently requested or am I running on) Ifthe runnable task footprint exceeds the current BatchJob footprinta new BatchJob is created to satisfy the YAML constraints as wellas the current resource requirements
The Elastic Queue Modulersquos backfill mode enables remote usersto automatically tap unused cycles on HPC systems thereby in-creasing overall system utilization which is a key metric for DOE
ALCFTheta
APS
OLCFSummit
NERSCCori
ALS
ESNet
100+ Gbps Argonne National Laboratory
Oak Ridge National Laboratory
Lawrence Berkeley National Laboratory
100+ Gbps100+ Gbps
10-40 Gbps
10-40 Gbps
100+ Gbps
100+ Gbps
100+ Gbps
Figure 2 Connectivity between the geographically distributed Balsam sites(Theta at ALCF Cori at NERSC Summit at OLCF) and X-ray sources (APS atArgonne ALS at LBNL) All networks are interconnected via ESNet
leadership-class facilities with minimal perturbations to the sched-uling flow of larger-scale jobs By and large other mechanismsfor ensuring quality-of-service to experimentalists are dictated byDOE facility policies and therefore tangential to the current workHowever we expect that Balsam autoscaling can seamlessly uti-lize on-demand or preemptible queues such as the realtime queueoffered on Cori at NERSC
The Balsam launcher is a general pilot job mechanism thatenables efficient and fault-tolerant execution of Balsam jobs acrossthe resources allocated within an HPC batch job Launchers relyon two platform interfaces the ComputeNode interface definesavailable cores GPUs and MAPN (multiple applications per node)capabilities for the platformrsquos compute nodes The interfaces alsoincludes method for detecting available compute nodes within anallocation and logically tracking assignment of granular tasks toresources The AppRun interface abstracts the application launcherand is used to execute applications in an MPI implementation-agnostic fashion
4 EVALUATIONIn this section we evaluate the performance characteristics of Bal-sam in remote workload execution and ability to dynamically dis-tribute scientific workloads among three DOE supercomputingplatforms We study two benchmark workflows in which a fullround-trip analysis is performed data is first transferred from aclient experimental facility to the supercomputerrsquos parallel filesystem computation on the staged data occurs on dynamicallyprovisioned nodes and results are finally transferred back from thesupercomputer to the clientrsquos local file system
Our experiments address the following questions (1) How effec-tively does scientific throughput scale given the real-world over-heads in wide-area data transfers and in Balsam itself (2) Is thetotal round-trip latency consistently low enough to prove usefulin near real-time experimental analysis scenarios (3) Does Balsamcomplete workloads reliably under conditions where job submis-sion rates exceed available computing capacity andor resourcesbecome unavailable mid-run (4) Can simultaneously provisionedresources across computing facilities be utilized effectively to dis-tribute an experimental workload in real-time (5) If so can theBalsam APIs be leveraged to adaptively map jobs onto distributedresources to improve overall throughput
41 Methodology411 Systems Figure 2 depicts the geographically distributed su-percomputing systems comprising of a) Theta [15] A Cray XC40
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
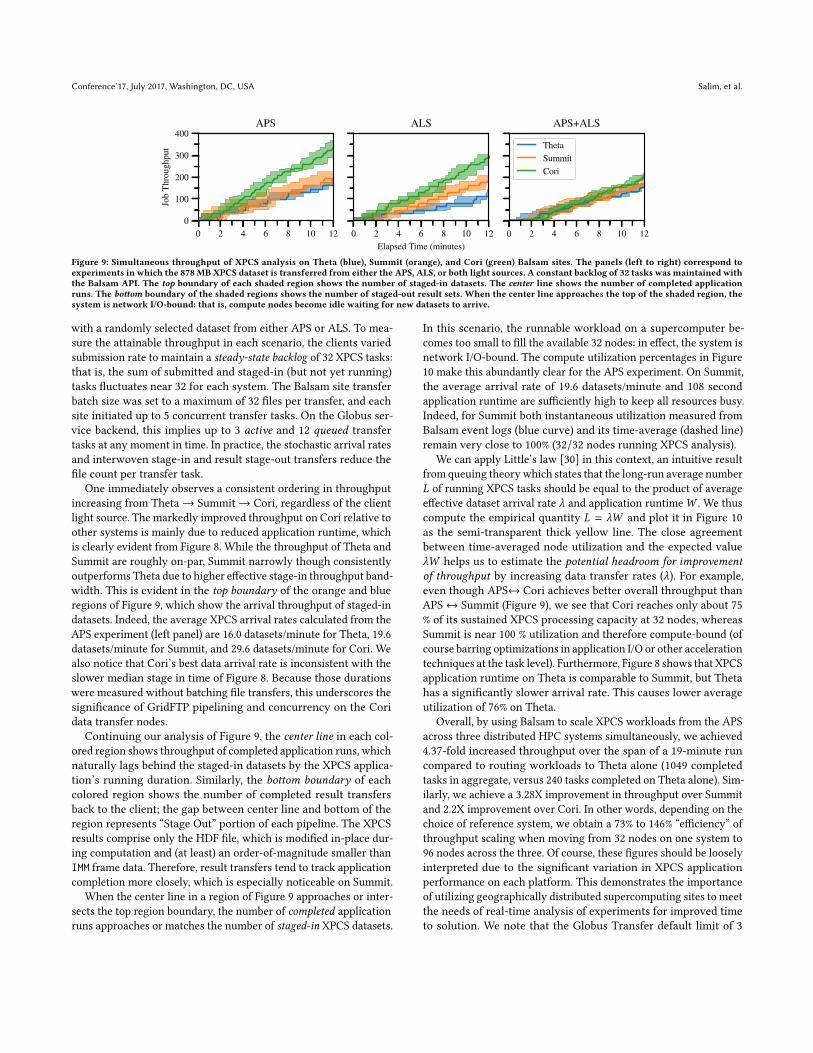
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
We demonstrate this functionality in the context of jobs flowingfrom two experimental facilities the Advanced Photon Source (APS)at Argonne National Laboratory and the Advanced Light Source(ALS) at Lawrence Berkeley Laboratory to three DOE computefacilities the Argonne Leadership Computing Facility (ALCF) theOak Ridge Leadership Computing Facility (OLCF) and NERSC Bal-sam sites were deployed at each facility to bridge the site schedulerto the Balsam service The Balsam service exposes an API for intro-ducing jobs and acts as a distribution point to the registered Balsamsites Using the API jobs were injected from the light source facil-ities simultaneously executed at the computing sites and resultsreturned to the originating facility Monitoring capabilities provideinsight into the backlog at each Balsam site and therefore a basisfor making scheduling decisions across compute facilities to opti-mize throughput While the current work emphasizes light sourceworkloads Balsam is easy to adopt and agnostic to applicationsmaking this approach applicable to diverse scientific domains
2 RELATEDWORKWorkflow management framework (WMF) development has a richhistory and remains an active field of research and developmentAs an open-source Python WMF Balsam [2] is similar to other sys-tems with Python-driven interfaces for managing high-throughputworkflows on supercomputers On the other hand some unique fea-tures of Balsam arise from requirements in orchestrating distributedworkloads submitted from remote users and run on multiple HPCsites We now discuss these requirements and contrast Balsam withsome contemporary HPC-oriented WMFs with Python APIs anddistributed execution capabilities
Distributed science workflows must invariably handle data andcontrol flow across networks spanning administrative domainsChallenging barriers to WMF adoption in multi-user HPC envi-ronments lie in deploying distributed clientserver infrastructuresand establishing connectivity among remote systems For instanceFireworks [29] Balsam [33] and the RADICAL-Pilot Ensem-ble Toolkit (EnTK) [19 31] are three widely-used WMFs at DOEsupercomputing facilities that expose Python APIs to define andsubmit directed acyclic graphs (DAGs) of stateful tasks to a data-base Like Balsam these WMFs possess various implementations ofa common pilot job design whereby tasks are efficiently executedon HPC resources by a process that synchronizes state with theworkflow database Because the database is directly written by useror pilot job clients users of Fireworks RADICAL or Balsam typ-ically deploy and manage their own MongoDB servers [10] (plusRabbitMQ for EnTK or PostgreSQL [13] for Balsam) The serverdeployments are repeated on a per-project basis and require pro-visioning resources on ldquogatewayrdquo nodes of an HPC systemrsquos localnetwork Next connecting to the database for remote job submis-sion requires an approach such as SSH port forwarding [33] orpasswordless SSHGSISSH [31] These methods are non-portableand depend on factors such as whether the compute facility man-dates multi-factor authentication (MFA)
By contrast the Balsam service-oriented architecture shifts ad-ministrative burdens away from individual researchers by routingall user user agent and pilot job client interactions through ahosted multi-tenant web service Because Balsam execution sites
communicate with the central service only as HTTP clients deploy-ments become a simple user-space pip package installation on anyplatform with a modern Python installation and outbound internetaccess As a consequence of the ubiquity of HTTP data transportBalsam works ldquoout of the boxrdquo on supercomputers spanning theALCF OLCF and NERSC facilities against a cloud-hosted Balsamservice
The Balsam REST API [3] defines the unifying data model andservice interactions upon which all Balsam components and userworkflows are authored In the context of REST interfaces to HPCresources Balsam may be compared with the Superfacility con-cept [27] which envisions a future of automated experimentaland observational science workflows linked to national comput-ing resources through a set of Web APIs Implementations such asthe NERSC Superfacility API [11] and the Swiss National Super-computing Centrersquos FirecREST API [25] expose methods such assubmitting and monitoring batch jobs moving data between re-mote filesystems and checking system availability However thesefacility services alone do not address workflow management orhigh-throughput execution instead they provide web-interfacedabstractions of the underlying facility analogous to modern cloudstorage and infrastructure services By contrast Balsam providesan end-to-end high-throughput workflow service with APIs forefficiently submitting fine-grained tasks (as opposed to batch jobscripts) along with their execution and data dependencies Thusfrom a front-end view Balsammay be viewed as an implementationof the Workflow as a Service (WFaaS) [38] concept with a backendarchitecture adapted to shared HPC environments
funcX [24] is an HPC-oriented instantiation of the function-as-a-service (FaaS) paradigm where users invoke Python functions inremote containers via an API web service funcX endpoints whichare similar to Balsam sites (32) run on the login nodes of targetHPC resources where Globus Auth is used for authentication anduser-endpoint association The funcX model is tightly focused onPython functions and therefore advocates decomposing workflowsinto functional building blocks Each function executes in a con-tainerized worker process running on one of the HPC computenodes By contrast Balsam provides a generalized model of appli-cations with executables that may or may not leverage contain-ers per-task remote data dependencies programmable error- andtimeout-handling and flexible per-task resource requirements (egtasks may occupy a single core or specify a multi-node distributedmemory job with some number of GPU accelerators per MPI rank)In the context of end-to-end distributed science workflows funcXis used as one tool in a suite of complementary technologies suchas Globus Automate [23] to set up event-based triggers of Globusdata transfers and funcX invocations Balsam instead provides aunified API for describing distributed workflows and the user siteagents manage the full lifecycle of data and control flow
Implicit dataflow programming models such as Parsl [18] andDask [26] are another powerful option for authoring dynamicworkflows directly in the Python language These libraries leveragethe concept of Python futures to expose parallelism in the Pythonscript and distribute computations across HPC resources In thiscontext the ephemeral workflow state resides in the executing
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Globus Transfer
ALCF-Theta
OLCF-Summit
NERSC-Cori
CobaltLSF
Slurm
TransferModule
Scheduler Module
Balsam Site 1
TransferModule
Scheduler Module
TransferModule
Scheduler Module
Balsam Site 2
Balsam Site 3
APS Clients
GridFTP
HTTPS
Balsam API Service
sites
apps
jobs
HTTPS HTTP
S
Figure 1 Simplified Balsam architecture Clients at the Advanced PhotonSource (APS) submit scientific workloads by creating Job resources at a spe-cific execution site through the Balsam REST API [3] Pilot jobs at Balsamsites on the ALCF-Theta OLCF-Summit and NERSC-Cori supercomputersfetch the appropriate Jobs for execution All Balsam components indepen-dently communicate with the API service endpoints as HTTPS clients Forinstance the Transfer Module fetches pending TransferItems from the APIbundles the corresponding files and orchestrates out-of-band data transfersvia Globus the Scheduler Module synchronizes API BatchJob resources withthe userrsquos resource allocations on the local batch scheduler
Python program tasks are not tied to an external persistent data-base This has obvious implications for provenance and fault toler-ance of workflows where per-workflow checkpointing is necessaryin systems such as Parsl The Balsam service provides durable taskstorage for each user site so that workflows can be centrally addedmodified and tracked over the span of a long-term project
3 IMPLEMENTATIONBalsam [2] (Figure 1) provides a centralized service allowing usersto register execution sites from any laptop cluster or supercom-puter on which they wish to invoke computation The sites runuser agents that orchestrate workflows locally and periodicallysynchronize state with the central service Users trigger remotecomputations by submitting jobs to the REST API [3] specifyingthe Balsam execution site and location(s) of data to be ingested
31 The Balsam ServiceBalsam [2] provides a centrally-hosted multi-tenant web serviceimplemented with the FastAPI [7] Python framework and Post-greSQL [13] relational database backend The service empowersHPC users to manage distributed Balsam sites and orchestrate work-flowswithin or across sites The centralized architecture as opposedto per-user databases enables remote Balsam sites to communicatewith the service as HTTPS clients This client-driven pattern iseffective in many HPC environments where outbound internetconnectivity is common (or easily enabled by proxy) but otherchannels or inbound connections are often restricted requiringnon-portable solutions and involvement of system administratorsWe now discuss concepts in the REST API (refer to OpenAPI schemaonline [3]) which defines the complete set of interactions uponwhich Balsam is built
The Balsam User is the root entity in the Balsam relationaldata model (eg all Sites are associated with their ownerrsquos userID) and the service uses JSON Web Tokens (JWT) to identify theauthenticated user in each HTTP request Access Tokens are is-sued by Balsam upon authentication with an external provider wehave implemented generic Authorization Code and Device CodeOAuth2 flows [12] permitting users to securely authenticate withany OAuth2 provider The Device Code flow enables secure loginfrom browserless environments such as supercomputer login nodesThe Balsam Python client library and balsam login command lineinterface manage interactive login flows and storeretrieve accesstokens in the userrsquos simbalsam configuration directory In the nearfuture we anticipate integrating the Balsam OAuth2 system with afederated identity provider as laid out in the DOE distributed dataand computing ecosystem (DCDE) plan [34]
The Balsam Site is a user-owned endpoint for remote execu-tion of workflows Sites are uniquely identified by a hostname andpath to a site directory mounted on the host The site directory is aself-contained project space for the user which stores configura-tion data application definitions and a sandboxed directory whereremote datasets are staged into per-task working directories priorto executionfrom balsamsite import ApplicationDefinition
class EigenCorr(ApplicationDefinition)
Runs XPCS -Eigen on an (H5 IMM) file pair from a
remote location
corr_exe = softwarexpcs -eigen2buildcorr
command_template = fcorr_exe inph5 -imm inpimm
environment_variables =
HDF5_USE_FILE_LOCKING FALSE
parameters =
cleanup_files = [hdf imm h5]
transfers =
h5_in
required True
direction in
local_path inph5
description Input HDF5 file
recursive False
imm_in
required True
direction in
local_path inpimm
description Input IMM file
recursive False
h5_out
required True
direction out
local_path inph5 output is input
modified in-place
description Output H5 file
recursive False
Listing 1 XPCS-Eigen corr ApplicationDefinition class which we evaluatewith benchmark datasets in Section 4
As part of its security model Balsam does not permit directinjection of arbitrary commands or applications through its API
Conferencersquo17 July 2017 Washington DC USA Salim et al
Instead users write ApplicationDefinition classes in Python mod-ules stored inside the site directory (see example Listing 1) Thesemodules serve as flexible templates for the permissible workflowsthat may run at each Balsam site BalsamApps registered with theAPI merely index the ApplicationDefinitions in each site with a 11correspondence The ApplicationDefinition provides a declarativedefinition of the application configuration via special attributes suchas the command_template which is interpreted as a shell commandwhere adjustable parameters are enclosed in double-curly bracesThe transfers attribute defines named slots for files or directoriesto be staged in or out prior to (or after) execution ApplicationDefi-nition metadata are automatically serialized and synchronized withthe corresponding REST API App resource Thus a sitersquos Apps be-come discoverable via the web API but maliciously submitted Appdata does not impact the execution of local ApplicationDefinitions
A Balsam Job (used interchangeably with task) represents asingle invocation of a Balsam App at a particular site The jobcontains application-specific parameters (such as command linearguments) resource requirements (like the number of computenodes or MPI ranks per node) and locations of data to be stagedin or out beforeafter app execution Jobs can also specify parentjob dependencies so that a user may submit DAGs of Balsam jobsto the API Each job references a specific App and is thereforetransitively bound to run at a single site upon creation (Jobrarr Apprarr Site) Jobs carry persistent states (enumerated in the REST APIdocumentation [3]) and metadata events generated from eventsthroughout their lifecycle Files or directories that need to be stagedin or out are associated with each Balsam Job and therefore passedto the API during job creation calls However the service trackseach of these TransferItems as a standalone unit of transfer betweensome Balsam Site and remote destination (defined with a protocol-specific URI such as Globus endpoint ID and path)
The Balsam job represents a fine-grained unit of work (task)while many tasks are executed inside a pilot job that efficientlyscales on the HPC compute nodes The pilot job and its associated re-source allocation is termed aBalsamBatchJob Balsam BatchJobscan be automatically created by the Site agent (autoscaling) or man-ually requested through the REST API By default a BatchJob ata Balsam site continuously fetches any locally-runnable Jobs andefficiently ldquopacksrdquo them onto idle resources Balsam launcher pi-lot jobs establish an execution Session with the service whichrequires sending a periodic heartbeat signal to maintain a leaseon acquired jobs The session backend guarantees that concurrentlaunchers executing jobs from the same site do not acquire andprocess overlapping jobs The Session further ensures that criticalfaults causing ungraceful launcher termination do not cause jobsto be locked in perpetuity the stale heartbeat is detected by theservice and affected jobs are reset to allow subsequent restarts
A major feature of Balsam is the Python SDK which is heav-ily influenced by and syntactically mirrors a subset of the Djangoobject relational model (ORM) [5] Rather than generating SQLand interfacing to a database backend the Balsam SDK generatesRESTful calls to the service APIs and lazily executes network re-quests through the underlying API client library The SDK pro-vides a highly consistent interface to query (bulk-)create (bulk-)update and delete the Balsam resources described in the preced-ing sections For instance Jobobjectsfilter(tags=experiment
XPCS state=FAILED) produces an iterable query of all BalsamJobs that failed and contain the experimentXPCS tag Upon itera-tion the lower-level REST Client generates the GET jobs HTTPrequest with appropriate query parameters The returned BalsamJobs are deserialized as Job objects which can be mutated andsynchronized with the API by calling their save() method
32 Balsam Site ArchitectureEach Balsam site runs an authenticated user agent that performsREST API calls to the central service to fetch jobs orchestrate theworkflow locally and update the centralized state
Indeed the Balsam service plays a largely passive bookkeepingrole in the architecture where actions are ultimately client-drivenThis design is a largely practical choice made to fit the infrastruc-ture and security constraints of current DOE computing facilitiesOperationally speaking a user must (1) log in to a site by the stan-dard SSH authentication route (2) authenticate with the Balsamservice to obtain an access token stored at the HPC site and (3)initialize the Balsam site agent in a directory on the HPC storagesystem The Balsam site is therefore an ordinary user process andinterfaces with the HPC system as such the architecture does notrequire elevated privileges or integration with specialized gatewayservices Typically the Balsam site consists of a few long-runninglightweight processes on an HPC login node the only requirementsare a Python installation (version ge 37) and outbound internetaccess (ie the user is able to perform HTTP requests such as curlhttpsapigithubcom) The Balsam launchers (pilot jobs) alsofetch jobs directly from the REST API therefore outbound curlfunctionality is needed from the head node where batch job scriptsbegin executing These requirements are satisfied by default on theSummitOLCF and CoriNERSC machines on ThetaALCF thedefault site configuration indicates that an HTTP proxy should beused in launcher environments
Site configurations comprise a YAML file and job template shellscript that wraps the invocation of the pilot job launcher Theseconfigurations are easily modified and a collection of default con-figurations is included directly as part of the Balsam software TheYAML file configures the local Balsam site agent as a collection ofindependent modules that run as background processes on a hostwith gateway access to the sitersquos filesystems and HPC scheduler (egan HPC login node) These modules are Python components writ-ten with the Balsam SDK (described in the previous section) whichuses locally stored access tokens to authenticate and exchange datawith the REST API services
The Balsammodules are architected to avoid hardcoding platform-dependent assumptions and enable facile portability across HPCsystems Indeed the majority of Balsam component implementa-tions are platform-independent and interactions with the underly-ing diverse HPC fabrics are encapsulated in classes implementinguniform platform interfaces Below we touch on a few of the keyBalsam site modules and the underlying platform interfaces
The Balsam Transfer Module queries the API service for pend-ing TransferItems which are files or directories that need to bestaged in or out for a particular Balsam job The module batchestransfer items between common endpoints and issues transfer tasks
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
to the underlying transfer interface For instance the Globus trans-fer interface enables seamless interoperation of Balsam with GlobusTransfer for dispatching out-of-band transfer tasks The transfermodule registers transfer metadata (eg Globus task UUIDs) withthe Balsam API and polls the status of transfer tasks synchronizingstate with the API For example to enable the Transfer Module withGlobus interoperability the user adds a local endpoint ID and alist of trusted remote endpoint IDs to the YAML configuration Theuser can also specify the maximum number of concurrent transfertasks as well as the maximum transfer batch size which is a criticalfeature for bundling many small files into a single GridFTP transferoperation The Transfer Module is entirely protocol-agnostic andadding new transfer interfaces entails implementing two methodsto submit an asynchronous transfer task with some collection offiles and poll the status of the transfer
The Scheduler Module uses an underlying scheduler platforminterface to query local batch scheduler queues (eg qstat) andsubmit resource allocations (qsub) for pilot jobs onto the queueInterfaces to Slurm Cobalt and LSF are provided to support DOEOffice of Science supercomputing systems at NERSC ALCF andOLCF respectively The interface provides the necessary abstrac-tions for interacting with the scheduler via subprocess calls andenables one to easily support other schedulers
The Balsam Scheduler Module is then platform-agnostic andserves to synchronize API BatchJobs with the local resource man-ager We emphasize that this module does not consider when orhow many resources are needed instead it provides a conduit forBatchJobs created in the Balsam service API to become concretepilot job submissions in a local queue The Scheduler Module YAMLconfiguration requires only specifying the appropriate schedulerinterface (eg Slurm) an API synchronization interval the localqueue policies (partitions) and the userrsquos project allocations
A separate concern is automating queue submission (ie BatchJobcreation) in real-time computing scenarios users maywish to allowthe site to automatically scale resources in response to a workloadwith changing resource requirements over time
The Elastic Queue Module allows users to flexibly controlauto-scaling behavior at a particular Balsam site by configuringa number of settings in the YAML file the appropriate schedulerqueue project allocation and pilot job mode are specified alongwith minimummaximum numbers of compute nodes and min-imummaximum walltime limits The user further specifies themaximum number of auto-queued jobs the maximum queueingwait time (after which BatchJobs are deleted from the queue) anda flag indicating whether allocations should be constrained to idle(backfill) node-hour windows
At every sync period (set in the YAML configuration) the ElasticQueue module queries the Balsam API for the aggregate resourcefootprint of all runnable Jobs (howmany nodes could I use right now)as well as the aggregate size of all queued and running BatchJobs(how many nodes have I currently requested or am I running on) Ifthe runnable task footprint exceeds the current BatchJob footprinta new BatchJob is created to satisfy the YAML constraints as wellas the current resource requirements
The Elastic Queue Modulersquos backfill mode enables remote usersto automatically tap unused cycles on HPC systems thereby in-creasing overall system utilization which is a key metric for DOE
ALCFTheta
APS
OLCFSummit
NERSCCori
ALS
ESNet
100+ Gbps Argonne National Laboratory
Oak Ridge National Laboratory
Lawrence Berkeley National Laboratory
100+ Gbps100+ Gbps
10-40 Gbps
10-40 Gbps
100+ Gbps
100+ Gbps
100+ Gbps
Figure 2 Connectivity between the geographically distributed Balsam sites(Theta at ALCF Cori at NERSC Summit at OLCF) and X-ray sources (APS atArgonne ALS at LBNL) All networks are interconnected via ESNet
leadership-class facilities with minimal perturbations to the sched-uling flow of larger-scale jobs By and large other mechanismsfor ensuring quality-of-service to experimentalists are dictated byDOE facility policies and therefore tangential to the current workHowever we expect that Balsam autoscaling can seamlessly uti-lize on-demand or preemptible queues such as the realtime queueoffered on Cori at NERSC
The Balsam launcher is a general pilot job mechanism thatenables efficient and fault-tolerant execution of Balsam jobs acrossthe resources allocated within an HPC batch job Launchers relyon two platform interfaces the ComputeNode interface definesavailable cores GPUs and MAPN (multiple applications per node)capabilities for the platformrsquos compute nodes The interfaces alsoincludes method for detecting available compute nodes within anallocation and logically tracking assignment of granular tasks toresources The AppRun interface abstracts the application launcherand is used to execute applications in an MPI implementation-agnostic fashion
4 EVALUATIONIn this section we evaluate the performance characteristics of Bal-sam in remote workload execution and ability to dynamically dis-tribute scientific workloads among three DOE supercomputingplatforms We study two benchmark workflows in which a fullround-trip analysis is performed data is first transferred from aclient experimental facility to the supercomputerrsquos parallel filesystem computation on the staged data occurs on dynamicallyprovisioned nodes and results are finally transferred back from thesupercomputer to the clientrsquos local file system
Our experiments address the following questions (1) How effec-tively does scientific throughput scale given the real-world over-heads in wide-area data transfers and in Balsam itself (2) Is thetotal round-trip latency consistently low enough to prove usefulin near real-time experimental analysis scenarios (3) Does Balsamcomplete workloads reliably under conditions where job submis-sion rates exceed available computing capacity andor resourcesbecome unavailable mid-run (4) Can simultaneously provisionedresources across computing facilities be utilized effectively to dis-tribute an experimental workload in real-time (5) If so can theBalsam APIs be leveraged to adaptively map jobs onto distributedresources to improve overall throughput
41 Methodology411 Systems Figure 2 depicts the geographically distributed su-percomputing systems comprising of a) Theta [15] A Cray XC40
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Globus Transfer
ALCF-Theta
OLCF-Summit
NERSC-Cori
CobaltLSF
Slurm
TransferModule
Scheduler Module
Balsam Site 1
TransferModule
Scheduler Module
TransferModule
Scheduler Module
Balsam Site 2
Balsam Site 3
APS Clients
GridFTP
HTTPS
Balsam API Service
sites
apps
jobs
HTTPS HTTP
S
Figure 1 Simplified Balsam architecture Clients at the Advanced PhotonSource (APS) submit scientific workloads by creating Job resources at a spe-cific execution site through the Balsam REST API [3] Pilot jobs at Balsamsites on the ALCF-Theta OLCF-Summit and NERSC-Cori supercomputersfetch the appropriate Jobs for execution All Balsam components indepen-dently communicate with the API service endpoints as HTTPS clients Forinstance the Transfer Module fetches pending TransferItems from the APIbundles the corresponding files and orchestrates out-of-band data transfersvia Globus the Scheduler Module synchronizes API BatchJob resources withthe userrsquos resource allocations on the local batch scheduler
Python program tasks are not tied to an external persistent data-base This has obvious implications for provenance and fault toler-ance of workflows where per-workflow checkpointing is necessaryin systems such as Parsl The Balsam service provides durable taskstorage for each user site so that workflows can be centrally addedmodified and tracked over the span of a long-term project
3 IMPLEMENTATIONBalsam [2] (Figure 1) provides a centralized service allowing usersto register execution sites from any laptop cluster or supercom-puter on which they wish to invoke computation The sites runuser agents that orchestrate workflows locally and periodicallysynchronize state with the central service Users trigger remotecomputations by submitting jobs to the REST API [3] specifyingthe Balsam execution site and location(s) of data to be ingested
31 The Balsam ServiceBalsam [2] provides a centrally-hosted multi-tenant web serviceimplemented with the FastAPI [7] Python framework and Post-greSQL [13] relational database backend The service empowersHPC users to manage distributed Balsam sites and orchestrate work-flowswithin or across sites The centralized architecture as opposedto per-user databases enables remote Balsam sites to communicatewith the service as HTTPS clients This client-driven pattern iseffective in many HPC environments where outbound internetconnectivity is common (or easily enabled by proxy) but otherchannels or inbound connections are often restricted requiringnon-portable solutions and involvement of system administratorsWe now discuss concepts in the REST API (refer to OpenAPI schemaonline [3]) which defines the complete set of interactions uponwhich Balsam is built
The Balsam User is the root entity in the Balsam relationaldata model (eg all Sites are associated with their ownerrsquos userID) and the service uses JSON Web Tokens (JWT) to identify theauthenticated user in each HTTP request Access Tokens are is-sued by Balsam upon authentication with an external provider wehave implemented generic Authorization Code and Device CodeOAuth2 flows [12] permitting users to securely authenticate withany OAuth2 provider The Device Code flow enables secure loginfrom browserless environments such as supercomputer login nodesThe Balsam Python client library and balsam login command lineinterface manage interactive login flows and storeretrieve accesstokens in the userrsquos simbalsam configuration directory In the nearfuture we anticipate integrating the Balsam OAuth2 system with afederated identity provider as laid out in the DOE distributed dataand computing ecosystem (DCDE) plan [34]
The Balsam Site is a user-owned endpoint for remote execu-tion of workflows Sites are uniquely identified by a hostname andpath to a site directory mounted on the host The site directory is aself-contained project space for the user which stores configura-tion data application definitions and a sandboxed directory whereremote datasets are staged into per-task working directories priorto executionfrom balsamsite import ApplicationDefinition
class EigenCorr(ApplicationDefinition)
Runs XPCS -Eigen on an (H5 IMM) file pair from a
remote location
corr_exe = softwarexpcs -eigen2buildcorr
command_template = fcorr_exe inph5 -imm inpimm
environment_variables =
HDF5_USE_FILE_LOCKING FALSE
parameters =
cleanup_files = [hdf imm h5]
transfers =
h5_in
required True
direction in
local_path inph5
description Input HDF5 file
recursive False
imm_in
required True
direction in
local_path inpimm
description Input IMM file
recursive False
h5_out
required True
direction out
local_path inph5 output is input
modified in-place
description Output H5 file
recursive False
Listing 1 XPCS-Eigen corr ApplicationDefinition class which we evaluatewith benchmark datasets in Section 4
As part of its security model Balsam does not permit directinjection of arbitrary commands or applications through its API
Conferencersquo17 July 2017 Washington DC USA Salim et al
Instead users write ApplicationDefinition classes in Python mod-ules stored inside the site directory (see example Listing 1) Thesemodules serve as flexible templates for the permissible workflowsthat may run at each Balsam site BalsamApps registered with theAPI merely index the ApplicationDefinitions in each site with a 11correspondence The ApplicationDefinition provides a declarativedefinition of the application configuration via special attributes suchas the command_template which is interpreted as a shell commandwhere adjustable parameters are enclosed in double-curly bracesThe transfers attribute defines named slots for files or directoriesto be staged in or out prior to (or after) execution ApplicationDefi-nition metadata are automatically serialized and synchronized withthe corresponding REST API App resource Thus a sitersquos Apps be-come discoverable via the web API but maliciously submitted Appdata does not impact the execution of local ApplicationDefinitions
A Balsam Job (used interchangeably with task) represents asingle invocation of a Balsam App at a particular site The jobcontains application-specific parameters (such as command linearguments) resource requirements (like the number of computenodes or MPI ranks per node) and locations of data to be stagedin or out beforeafter app execution Jobs can also specify parentjob dependencies so that a user may submit DAGs of Balsam jobsto the API Each job references a specific App and is thereforetransitively bound to run at a single site upon creation (Jobrarr Apprarr Site) Jobs carry persistent states (enumerated in the REST APIdocumentation [3]) and metadata events generated from eventsthroughout their lifecycle Files or directories that need to be stagedin or out are associated with each Balsam Job and therefore passedto the API during job creation calls However the service trackseach of these TransferItems as a standalone unit of transfer betweensome Balsam Site and remote destination (defined with a protocol-specific URI such as Globus endpoint ID and path)
The Balsam job represents a fine-grained unit of work (task)while many tasks are executed inside a pilot job that efficientlyscales on the HPC compute nodes The pilot job and its associated re-source allocation is termed aBalsamBatchJob Balsam BatchJobscan be automatically created by the Site agent (autoscaling) or man-ually requested through the REST API By default a BatchJob ata Balsam site continuously fetches any locally-runnable Jobs andefficiently ldquopacksrdquo them onto idle resources Balsam launcher pi-lot jobs establish an execution Session with the service whichrequires sending a periodic heartbeat signal to maintain a leaseon acquired jobs The session backend guarantees that concurrentlaunchers executing jobs from the same site do not acquire andprocess overlapping jobs The Session further ensures that criticalfaults causing ungraceful launcher termination do not cause jobsto be locked in perpetuity the stale heartbeat is detected by theservice and affected jobs are reset to allow subsequent restarts
A major feature of Balsam is the Python SDK which is heav-ily influenced by and syntactically mirrors a subset of the Djangoobject relational model (ORM) [5] Rather than generating SQLand interfacing to a database backend the Balsam SDK generatesRESTful calls to the service APIs and lazily executes network re-quests through the underlying API client library The SDK pro-vides a highly consistent interface to query (bulk-)create (bulk-)update and delete the Balsam resources described in the preced-ing sections For instance Jobobjectsfilter(tags=experiment
XPCS state=FAILED) produces an iterable query of all BalsamJobs that failed and contain the experimentXPCS tag Upon itera-tion the lower-level REST Client generates the GET jobs HTTPrequest with appropriate query parameters The returned BalsamJobs are deserialized as Job objects which can be mutated andsynchronized with the API by calling their save() method
32 Balsam Site ArchitectureEach Balsam site runs an authenticated user agent that performsREST API calls to the central service to fetch jobs orchestrate theworkflow locally and update the centralized state
Indeed the Balsam service plays a largely passive bookkeepingrole in the architecture where actions are ultimately client-drivenThis design is a largely practical choice made to fit the infrastruc-ture and security constraints of current DOE computing facilitiesOperationally speaking a user must (1) log in to a site by the stan-dard SSH authentication route (2) authenticate with the Balsamservice to obtain an access token stored at the HPC site and (3)initialize the Balsam site agent in a directory on the HPC storagesystem The Balsam site is therefore an ordinary user process andinterfaces with the HPC system as such the architecture does notrequire elevated privileges or integration with specialized gatewayservices Typically the Balsam site consists of a few long-runninglightweight processes on an HPC login node the only requirementsare a Python installation (version ge 37) and outbound internetaccess (ie the user is able to perform HTTP requests such as curlhttpsapigithubcom) The Balsam launchers (pilot jobs) alsofetch jobs directly from the REST API therefore outbound curlfunctionality is needed from the head node where batch job scriptsbegin executing These requirements are satisfied by default on theSummitOLCF and CoriNERSC machines on ThetaALCF thedefault site configuration indicates that an HTTP proxy should beused in launcher environments
Site configurations comprise a YAML file and job template shellscript that wraps the invocation of the pilot job launcher Theseconfigurations are easily modified and a collection of default con-figurations is included directly as part of the Balsam software TheYAML file configures the local Balsam site agent as a collection ofindependent modules that run as background processes on a hostwith gateway access to the sitersquos filesystems and HPC scheduler (egan HPC login node) These modules are Python components writ-ten with the Balsam SDK (described in the previous section) whichuses locally stored access tokens to authenticate and exchange datawith the REST API services
The Balsammodules are architected to avoid hardcoding platform-dependent assumptions and enable facile portability across HPCsystems Indeed the majority of Balsam component implementa-tions are platform-independent and interactions with the underly-ing diverse HPC fabrics are encapsulated in classes implementinguniform platform interfaces Below we touch on a few of the keyBalsam site modules and the underlying platform interfaces
The Balsam Transfer Module queries the API service for pend-ing TransferItems which are files or directories that need to bestaged in or out for a particular Balsam job The module batchestransfer items between common endpoints and issues transfer tasks
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
to the underlying transfer interface For instance the Globus trans-fer interface enables seamless interoperation of Balsam with GlobusTransfer for dispatching out-of-band transfer tasks The transfermodule registers transfer metadata (eg Globus task UUIDs) withthe Balsam API and polls the status of transfer tasks synchronizingstate with the API For example to enable the Transfer Module withGlobus interoperability the user adds a local endpoint ID and alist of trusted remote endpoint IDs to the YAML configuration Theuser can also specify the maximum number of concurrent transfertasks as well as the maximum transfer batch size which is a criticalfeature for bundling many small files into a single GridFTP transferoperation The Transfer Module is entirely protocol-agnostic andadding new transfer interfaces entails implementing two methodsto submit an asynchronous transfer task with some collection offiles and poll the status of the transfer
The Scheduler Module uses an underlying scheduler platforminterface to query local batch scheduler queues (eg qstat) andsubmit resource allocations (qsub) for pilot jobs onto the queueInterfaces to Slurm Cobalt and LSF are provided to support DOEOffice of Science supercomputing systems at NERSC ALCF andOLCF respectively The interface provides the necessary abstrac-tions for interacting with the scheduler via subprocess calls andenables one to easily support other schedulers
The Balsam Scheduler Module is then platform-agnostic andserves to synchronize API BatchJobs with the local resource man-ager We emphasize that this module does not consider when orhow many resources are needed instead it provides a conduit forBatchJobs created in the Balsam service API to become concretepilot job submissions in a local queue The Scheduler Module YAMLconfiguration requires only specifying the appropriate schedulerinterface (eg Slurm) an API synchronization interval the localqueue policies (partitions) and the userrsquos project allocations
A separate concern is automating queue submission (ie BatchJobcreation) in real-time computing scenarios users maywish to allowthe site to automatically scale resources in response to a workloadwith changing resource requirements over time
The Elastic Queue Module allows users to flexibly controlauto-scaling behavior at a particular Balsam site by configuringa number of settings in the YAML file the appropriate schedulerqueue project allocation and pilot job mode are specified alongwith minimummaximum numbers of compute nodes and min-imummaximum walltime limits The user further specifies themaximum number of auto-queued jobs the maximum queueingwait time (after which BatchJobs are deleted from the queue) anda flag indicating whether allocations should be constrained to idle(backfill) node-hour windows
At every sync period (set in the YAML configuration) the ElasticQueue module queries the Balsam API for the aggregate resourcefootprint of all runnable Jobs (howmany nodes could I use right now)as well as the aggregate size of all queued and running BatchJobs(how many nodes have I currently requested or am I running on) Ifthe runnable task footprint exceeds the current BatchJob footprinta new BatchJob is created to satisfy the YAML constraints as wellas the current resource requirements
The Elastic Queue Modulersquos backfill mode enables remote usersto automatically tap unused cycles on HPC systems thereby in-creasing overall system utilization which is a key metric for DOE
ALCFTheta
APS
OLCFSummit
NERSCCori
ALS
ESNet
100+ Gbps Argonne National Laboratory
Oak Ridge National Laboratory
Lawrence Berkeley National Laboratory
100+ Gbps100+ Gbps
10-40 Gbps
10-40 Gbps
100+ Gbps
100+ Gbps
100+ Gbps
Figure 2 Connectivity between the geographically distributed Balsam sites(Theta at ALCF Cori at NERSC Summit at OLCF) and X-ray sources (APS atArgonne ALS at LBNL) All networks are interconnected via ESNet
leadership-class facilities with minimal perturbations to the sched-uling flow of larger-scale jobs By and large other mechanismsfor ensuring quality-of-service to experimentalists are dictated byDOE facility policies and therefore tangential to the current workHowever we expect that Balsam autoscaling can seamlessly uti-lize on-demand or preemptible queues such as the realtime queueoffered on Cori at NERSC
The Balsam launcher is a general pilot job mechanism thatenables efficient and fault-tolerant execution of Balsam jobs acrossthe resources allocated within an HPC batch job Launchers relyon two platform interfaces the ComputeNode interface definesavailable cores GPUs and MAPN (multiple applications per node)capabilities for the platformrsquos compute nodes The interfaces alsoincludes method for detecting available compute nodes within anallocation and logically tracking assignment of granular tasks toresources The AppRun interface abstracts the application launcherand is used to execute applications in an MPI implementation-agnostic fashion
4 EVALUATIONIn this section we evaluate the performance characteristics of Bal-sam in remote workload execution and ability to dynamically dis-tribute scientific workloads among three DOE supercomputingplatforms We study two benchmark workflows in which a fullround-trip analysis is performed data is first transferred from aclient experimental facility to the supercomputerrsquos parallel filesystem computation on the staged data occurs on dynamicallyprovisioned nodes and results are finally transferred back from thesupercomputer to the clientrsquos local file system
Our experiments address the following questions (1) How effec-tively does scientific throughput scale given the real-world over-heads in wide-area data transfers and in Balsam itself (2) Is thetotal round-trip latency consistently low enough to prove usefulin near real-time experimental analysis scenarios (3) Does Balsamcomplete workloads reliably under conditions where job submis-sion rates exceed available computing capacity andor resourcesbecome unavailable mid-run (4) Can simultaneously provisionedresources across computing facilities be utilized effectively to dis-tribute an experimental workload in real-time (5) If so can theBalsam APIs be leveraged to adaptively map jobs onto distributedresources to improve overall throughput
41 Methodology411 Systems Figure 2 depicts the geographically distributed su-percomputing systems comprising of a) Theta [15] A Cray XC40
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
Instead users write ApplicationDefinition classes in Python mod-ules stored inside the site directory (see example Listing 1) Thesemodules serve as flexible templates for the permissible workflowsthat may run at each Balsam site BalsamApps registered with theAPI merely index the ApplicationDefinitions in each site with a 11correspondence The ApplicationDefinition provides a declarativedefinition of the application configuration via special attributes suchas the command_template which is interpreted as a shell commandwhere adjustable parameters are enclosed in double-curly bracesThe transfers attribute defines named slots for files or directoriesto be staged in or out prior to (or after) execution ApplicationDefi-nition metadata are automatically serialized and synchronized withthe corresponding REST API App resource Thus a sitersquos Apps be-come discoverable via the web API but maliciously submitted Appdata does not impact the execution of local ApplicationDefinitions
A Balsam Job (used interchangeably with task) represents asingle invocation of a Balsam App at a particular site The jobcontains application-specific parameters (such as command linearguments) resource requirements (like the number of computenodes or MPI ranks per node) and locations of data to be stagedin or out beforeafter app execution Jobs can also specify parentjob dependencies so that a user may submit DAGs of Balsam jobsto the API Each job references a specific App and is thereforetransitively bound to run at a single site upon creation (Jobrarr Apprarr Site) Jobs carry persistent states (enumerated in the REST APIdocumentation [3]) and metadata events generated from eventsthroughout their lifecycle Files or directories that need to be stagedin or out are associated with each Balsam Job and therefore passedto the API during job creation calls However the service trackseach of these TransferItems as a standalone unit of transfer betweensome Balsam Site and remote destination (defined with a protocol-specific URI such as Globus endpoint ID and path)
The Balsam job represents a fine-grained unit of work (task)while many tasks are executed inside a pilot job that efficientlyscales on the HPC compute nodes The pilot job and its associated re-source allocation is termed aBalsamBatchJob Balsam BatchJobscan be automatically created by the Site agent (autoscaling) or man-ually requested through the REST API By default a BatchJob ata Balsam site continuously fetches any locally-runnable Jobs andefficiently ldquopacksrdquo them onto idle resources Balsam launcher pi-lot jobs establish an execution Session with the service whichrequires sending a periodic heartbeat signal to maintain a leaseon acquired jobs The session backend guarantees that concurrentlaunchers executing jobs from the same site do not acquire andprocess overlapping jobs The Session further ensures that criticalfaults causing ungraceful launcher termination do not cause jobsto be locked in perpetuity the stale heartbeat is detected by theservice and affected jobs are reset to allow subsequent restarts
A major feature of Balsam is the Python SDK which is heav-ily influenced by and syntactically mirrors a subset of the Djangoobject relational model (ORM) [5] Rather than generating SQLand interfacing to a database backend the Balsam SDK generatesRESTful calls to the service APIs and lazily executes network re-quests through the underlying API client library The SDK pro-vides a highly consistent interface to query (bulk-)create (bulk-)update and delete the Balsam resources described in the preced-ing sections For instance Jobobjectsfilter(tags=experiment
XPCS state=FAILED) produces an iterable query of all BalsamJobs that failed and contain the experimentXPCS tag Upon itera-tion the lower-level REST Client generates the GET jobs HTTPrequest with appropriate query parameters The returned BalsamJobs are deserialized as Job objects which can be mutated andsynchronized with the API by calling their save() method
32 Balsam Site ArchitectureEach Balsam site runs an authenticated user agent that performsREST API calls to the central service to fetch jobs orchestrate theworkflow locally and update the centralized state
Indeed the Balsam service plays a largely passive bookkeepingrole in the architecture where actions are ultimately client-drivenThis design is a largely practical choice made to fit the infrastruc-ture and security constraints of current DOE computing facilitiesOperationally speaking a user must (1) log in to a site by the stan-dard SSH authentication route (2) authenticate with the Balsamservice to obtain an access token stored at the HPC site and (3)initialize the Balsam site agent in a directory on the HPC storagesystem The Balsam site is therefore an ordinary user process andinterfaces with the HPC system as such the architecture does notrequire elevated privileges or integration with specialized gatewayservices Typically the Balsam site consists of a few long-runninglightweight processes on an HPC login node the only requirementsare a Python installation (version ge 37) and outbound internetaccess (ie the user is able to perform HTTP requests such as curlhttpsapigithubcom) The Balsam launchers (pilot jobs) alsofetch jobs directly from the REST API therefore outbound curlfunctionality is needed from the head node where batch job scriptsbegin executing These requirements are satisfied by default on theSummitOLCF and CoriNERSC machines on ThetaALCF thedefault site configuration indicates that an HTTP proxy should beused in launcher environments
Site configurations comprise a YAML file and job template shellscript that wraps the invocation of the pilot job launcher Theseconfigurations are easily modified and a collection of default con-figurations is included directly as part of the Balsam software TheYAML file configures the local Balsam site agent as a collection ofindependent modules that run as background processes on a hostwith gateway access to the sitersquos filesystems and HPC scheduler (egan HPC login node) These modules are Python components writ-ten with the Balsam SDK (described in the previous section) whichuses locally stored access tokens to authenticate and exchange datawith the REST API services
The Balsammodules are architected to avoid hardcoding platform-dependent assumptions and enable facile portability across HPCsystems Indeed the majority of Balsam component implementa-tions are platform-independent and interactions with the underly-ing diverse HPC fabrics are encapsulated in classes implementinguniform platform interfaces Below we touch on a few of the keyBalsam site modules and the underlying platform interfaces
The Balsam Transfer Module queries the API service for pend-ing TransferItems which are files or directories that need to bestaged in or out for a particular Balsam job The module batchestransfer items between common endpoints and issues transfer tasks
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
to the underlying transfer interface For instance the Globus trans-fer interface enables seamless interoperation of Balsam with GlobusTransfer for dispatching out-of-band transfer tasks The transfermodule registers transfer metadata (eg Globus task UUIDs) withthe Balsam API and polls the status of transfer tasks synchronizingstate with the API For example to enable the Transfer Module withGlobus interoperability the user adds a local endpoint ID and alist of trusted remote endpoint IDs to the YAML configuration Theuser can also specify the maximum number of concurrent transfertasks as well as the maximum transfer batch size which is a criticalfeature for bundling many small files into a single GridFTP transferoperation The Transfer Module is entirely protocol-agnostic andadding new transfer interfaces entails implementing two methodsto submit an asynchronous transfer task with some collection offiles and poll the status of the transfer
The Scheduler Module uses an underlying scheduler platforminterface to query local batch scheduler queues (eg qstat) andsubmit resource allocations (qsub) for pilot jobs onto the queueInterfaces to Slurm Cobalt and LSF are provided to support DOEOffice of Science supercomputing systems at NERSC ALCF andOLCF respectively The interface provides the necessary abstrac-tions for interacting with the scheduler via subprocess calls andenables one to easily support other schedulers
The Balsam Scheduler Module is then platform-agnostic andserves to synchronize API BatchJobs with the local resource man-ager We emphasize that this module does not consider when orhow many resources are needed instead it provides a conduit forBatchJobs created in the Balsam service API to become concretepilot job submissions in a local queue The Scheduler Module YAMLconfiguration requires only specifying the appropriate schedulerinterface (eg Slurm) an API synchronization interval the localqueue policies (partitions) and the userrsquos project allocations
A separate concern is automating queue submission (ie BatchJobcreation) in real-time computing scenarios users maywish to allowthe site to automatically scale resources in response to a workloadwith changing resource requirements over time
The Elastic Queue Module allows users to flexibly controlauto-scaling behavior at a particular Balsam site by configuringa number of settings in the YAML file the appropriate schedulerqueue project allocation and pilot job mode are specified alongwith minimummaximum numbers of compute nodes and min-imummaximum walltime limits The user further specifies themaximum number of auto-queued jobs the maximum queueingwait time (after which BatchJobs are deleted from the queue) anda flag indicating whether allocations should be constrained to idle(backfill) node-hour windows
At every sync period (set in the YAML configuration) the ElasticQueue module queries the Balsam API for the aggregate resourcefootprint of all runnable Jobs (howmany nodes could I use right now)as well as the aggregate size of all queued and running BatchJobs(how many nodes have I currently requested or am I running on) Ifthe runnable task footprint exceeds the current BatchJob footprinta new BatchJob is created to satisfy the YAML constraints as wellas the current resource requirements
The Elastic Queue Modulersquos backfill mode enables remote usersto automatically tap unused cycles on HPC systems thereby in-creasing overall system utilization which is a key metric for DOE
ALCFTheta
APS
OLCFSummit
NERSCCori
ALS
ESNet
100+ Gbps Argonne National Laboratory
Oak Ridge National Laboratory
Lawrence Berkeley National Laboratory
100+ Gbps100+ Gbps
10-40 Gbps
10-40 Gbps
100+ Gbps
100+ Gbps
100+ Gbps
Figure 2 Connectivity between the geographically distributed Balsam sites(Theta at ALCF Cori at NERSC Summit at OLCF) and X-ray sources (APS atArgonne ALS at LBNL) All networks are interconnected via ESNet
leadership-class facilities with minimal perturbations to the sched-uling flow of larger-scale jobs By and large other mechanismsfor ensuring quality-of-service to experimentalists are dictated byDOE facility policies and therefore tangential to the current workHowever we expect that Balsam autoscaling can seamlessly uti-lize on-demand or preemptible queues such as the realtime queueoffered on Cori at NERSC
The Balsam launcher is a general pilot job mechanism thatenables efficient and fault-tolerant execution of Balsam jobs acrossthe resources allocated within an HPC batch job Launchers relyon two platform interfaces the ComputeNode interface definesavailable cores GPUs and MAPN (multiple applications per node)capabilities for the platformrsquos compute nodes The interfaces alsoincludes method for detecting available compute nodes within anallocation and logically tracking assignment of granular tasks toresources The AppRun interface abstracts the application launcherand is used to execute applications in an MPI implementation-agnostic fashion
4 EVALUATIONIn this section we evaluate the performance characteristics of Bal-sam in remote workload execution and ability to dynamically dis-tribute scientific workloads among three DOE supercomputingplatforms We study two benchmark workflows in which a fullround-trip analysis is performed data is first transferred from aclient experimental facility to the supercomputerrsquos parallel filesystem computation on the staged data occurs on dynamicallyprovisioned nodes and results are finally transferred back from thesupercomputer to the clientrsquos local file system
Our experiments address the following questions (1) How effec-tively does scientific throughput scale given the real-world over-heads in wide-area data transfers and in Balsam itself (2) Is thetotal round-trip latency consistently low enough to prove usefulin near real-time experimental analysis scenarios (3) Does Balsamcomplete workloads reliably under conditions where job submis-sion rates exceed available computing capacity andor resourcesbecome unavailable mid-run (4) Can simultaneously provisionedresources across computing facilities be utilized effectively to dis-tribute an experimental workload in real-time (5) If so can theBalsam APIs be leveraged to adaptively map jobs onto distributedresources to improve overall throughput
41 Methodology411 Systems Figure 2 depicts the geographically distributed su-percomputing systems comprising of a) Theta [15] A Cray XC40
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
to the underlying transfer interface For instance the Globus trans-fer interface enables seamless interoperation of Balsam with GlobusTransfer for dispatching out-of-band transfer tasks The transfermodule registers transfer metadata (eg Globus task UUIDs) withthe Balsam API and polls the status of transfer tasks synchronizingstate with the API For example to enable the Transfer Module withGlobus interoperability the user adds a local endpoint ID and alist of trusted remote endpoint IDs to the YAML configuration Theuser can also specify the maximum number of concurrent transfertasks as well as the maximum transfer batch size which is a criticalfeature for bundling many small files into a single GridFTP transferoperation The Transfer Module is entirely protocol-agnostic andadding new transfer interfaces entails implementing two methodsto submit an asynchronous transfer task with some collection offiles and poll the status of the transfer
The Scheduler Module uses an underlying scheduler platforminterface to query local batch scheduler queues (eg qstat) andsubmit resource allocations (qsub) for pilot jobs onto the queueInterfaces to Slurm Cobalt and LSF are provided to support DOEOffice of Science supercomputing systems at NERSC ALCF andOLCF respectively The interface provides the necessary abstrac-tions for interacting with the scheduler via subprocess calls andenables one to easily support other schedulers
The Balsam Scheduler Module is then platform-agnostic andserves to synchronize API BatchJobs with the local resource man-ager We emphasize that this module does not consider when orhow many resources are needed instead it provides a conduit forBatchJobs created in the Balsam service API to become concretepilot job submissions in a local queue The Scheduler Module YAMLconfiguration requires only specifying the appropriate schedulerinterface (eg Slurm) an API synchronization interval the localqueue policies (partitions) and the userrsquos project allocations
A separate concern is automating queue submission (ie BatchJobcreation) in real-time computing scenarios users maywish to allowthe site to automatically scale resources in response to a workloadwith changing resource requirements over time
The Elastic Queue Module allows users to flexibly controlauto-scaling behavior at a particular Balsam site by configuringa number of settings in the YAML file the appropriate schedulerqueue project allocation and pilot job mode are specified alongwith minimummaximum numbers of compute nodes and min-imummaximum walltime limits The user further specifies themaximum number of auto-queued jobs the maximum queueingwait time (after which BatchJobs are deleted from the queue) anda flag indicating whether allocations should be constrained to idle(backfill) node-hour windows
At every sync period (set in the YAML configuration) the ElasticQueue module queries the Balsam API for the aggregate resourcefootprint of all runnable Jobs (howmany nodes could I use right now)as well as the aggregate size of all queued and running BatchJobs(how many nodes have I currently requested or am I running on) Ifthe runnable task footprint exceeds the current BatchJob footprinta new BatchJob is created to satisfy the YAML constraints as wellas the current resource requirements
The Elastic Queue Modulersquos backfill mode enables remote usersto automatically tap unused cycles on HPC systems thereby in-creasing overall system utilization which is a key metric for DOE
ALCFTheta
APS
OLCFSummit
NERSCCori
ALS
ESNet
100+ Gbps Argonne National Laboratory
Oak Ridge National Laboratory
Lawrence Berkeley National Laboratory
100+ Gbps100+ Gbps
10-40 Gbps
10-40 Gbps
100+ Gbps
100+ Gbps
100+ Gbps
Figure 2 Connectivity between the geographically distributed Balsam sites(Theta at ALCF Cori at NERSC Summit at OLCF) and X-ray sources (APS atArgonne ALS at LBNL) All networks are interconnected via ESNet
leadership-class facilities with minimal perturbations to the sched-uling flow of larger-scale jobs By and large other mechanismsfor ensuring quality-of-service to experimentalists are dictated byDOE facility policies and therefore tangential to the current workHowever we expect that Balsam autoscaling can seamlessly uti-lize on-demand or preemptible queues such as the realtime queueoffered on Cori at NERSC
The Balsam launcher is a general pilot job mechanism thatenables efficient and fault-tolerant execution of Balsam jobs acrossthe resources allocated within an HPC batch job Launchers relyon two platform interfaces the ComputeNode interface definesavailable cores GPUs and MAPN (multiple applications per node)capabilities for the platformrsquos compute nodes The interfaces alsoincludes method for detecting available compute nodes within anallocation and logically tracking assignment of granular tasks toresources The AppRun interface abstracts the application launcherand is used to execute applications in an MPI implementation-agnostic fashion
4 EVALUATIONIn this section we evaluate the performance characteristics of Bal-sam in remote workload execution and ability to dynamically dis-tribute scientific workloads among three DOE supercomputingplatforms We study two benchmark workflows in which a fullround-trip analysis is performed data is first transferred from aclient experimental facility to the supercomputerrsquos parallel filesystem computation on the staged data occurs on dynamicallyprovisioned nodes and results are finally transferred back from thesupercomputer to the clientrsquos local file system
Our experiments address the following questions (1) How effec-tively does scientific throughput scale given the real-world over-heads in wide-area data transfers and in Balsam itself (2) Is thetotal round-trip latency consistently low enough to prove usefulin near real-time experimental analysis scenarios (3) Does Balsamcomplete workloads reliably under conditions where job submis-sion rates exceed available computing capacity andor resourcesbecome unavailable mid-run (4) Can simultaneously provisionedresources across computing facilities be utilized effectively to dis-tribute an experimental workload in real-time (5) If so can theBalsam APIs be leveraged to adaptively map jobs onto distributedresources to improve overall throughput
41 Methodology411 Systems Figure 2 depicts the geographically distributed su-percomputing systems comprising of a) Theta [15] A Cray XC40
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
system at the ALCF with 4392 compute nodes having 64 13 GHzIntel Xeon Phi (Knightrsquos Landing) cores per node each with 192GB memory b) Summit [14] An IBM AC922 system at the OLCFwith 4608 nodes each node with two IBM Power 9 processors andsix Nvidia V100 GPUs together with 512GB DDR4 and 96GB HBM2memory c) Cori (Haswell Partition) [4] The Haswell partitionof Cori a Cray XC40 system at NERSC consists of X nodes eachwith two 23 GHz 16-core Intel Haswell processor with 128 GBmemory
The APS light source is located at Argonne and the ALS at LBNLAll three sites are interconnected via ESNet
412 Balsam The Balsam service comprising both relational data-base and web server frontend was deployed on a single AWSt2xlarge instance For the purpose of this experiment user lo-gin endpoints were disabled and JWT authentication tokens weresecurely generated for each Balsam site Moreover inbound con-nectivity was restricted to traffic from the ANL ORNL and NERSCcampus networks
Three Balsam sites were deployed across the login nodes ofTheta Summit and Cori Balsam managed data transfers via theGlobus Online [8] interface between each compute facility anddata transfer nodes at the Argonne Advanced Photon Source (APS)and Berkeley Lab Advanced Light Source (ALS) Data staging wasperformed with Globus endpoints running on dedicated data trans-fer nodes (DTNs) at each facility All application IO utilized eachsystemrsquos production storage system (Lustre on Theta IBM Spec-trum Scale on Summit and the project community filesystem (CFS)on Cori) The ALCF internal HTTPS proxy was used to enable out-bound connections from the Theta application launch nodes to theBalsam service Outbound HTTPS requests were directly supportedfrom Cori and Summit compute nodes
Since DOE supercomputers are shared and perpetually oversub-scribed resources batch queueing wait times are inevitable for realworkflows Although cross-facility reservation systems and real-time queues offering a premium quality of service to experimentswill play an important role in real-time science on these systems weseek to measure Balsam overheads in the absence of uncontrollabledelays due to other users In the following studies we therefore re-served dedicated compute resources to more consistently measurethe performance of the Balsam platform
413 Applications We chose two applications tomeasure through-put between facilities in multiple scenarios Thematrix diagonaliza-tion (MD) benchmark which serves as a proxy for an arbitrary fine-grained numerical subroutine entails a single Python NumPy callto the eigh function which computes the eigenvalues and eigenvec-tors of a Hermitian matrix The input matrix is transferred over thenetwork from a client experimental facility and read from storageafter computation the returned eigenvalues are written back todisk and transferred back to the requesting clientrsquos local filesystemWe performed the MD benchmark with double-precision matrixsizes of 50002 (200 MB) and 120002 (115 GB) which correspond toeigenvalue (diagonal matrix) sizes of 40 kB and 96 kB respectivelyThese sizes are representative of typical datasets acquired by theXPCS experiments discussed next
TheX-ray photon correlation spectroscopy (XPCS) technique presentsa data-intensive workload in the study of nanoscale materials dy-namics with coherent X-ray synchrotron beams which is widelyemployed across synchrotron facilities such as the Advanced Pho-ton Source (APS) at Argonne and the Advanced Light Source (ALS)at Lawrence Berkeley National Lab We chose to examine XPCSbecause XPCS analysis exhibits a rapidly growing frame rates withmegapixel detectors and on the order of 1 MHz acqusition rates onthe horizon XPCS will push the boundaries of real-time analysisdata-reduction techniques and networking infrastructure [6] Inthis case we execute XPCS-Eigen [16] C++ package used in theXPCS beamline and the corr analysis which computes pixel-wisetime correlations of area detector images of speckle patterns pro-duced by hard X-ray scattering in a sample The input comprisestwo files a binary IMM file containing the sequence of acquiredframes and an HDF file containing experimental metadata and con-trol parameters for the corr analysis routine corrmodifies the HDFfile with results in-place and the file is subsequently transferred backto the Balsam client facility For the study we use an XPCS datasetcomprised of 823 MB of IMM frames and 55 MB of HDF metadataThis 878 MB payload represents roughly 7 seconds of data acquisi-tion at 120 MBsec which is a reasonably representative value forXPCS experiments with megapixel area detectors operating at 60Hz and scanning samples for on the order of tens of seconds perposition [21 32] All the XPCS and MD runs herein were executedon a single compute node (ie without distributed-memory paral-lelism) and leverages OpenMP threads scaling to physical cores pernode (64 on Theta 42 on Summit 32 on Cori)
414 Evaluation metrics The Balsam service stores Balsam Jobevents (eg job created data staged-in application launched) withtimestamps recorded at the job execution site We leverage thisBalsam EventLog API to query this information and aggregate avariety of performance metrics
bull Throughput timelines for a particular job state (eg numberof completed round-trip analyses as a function of time)
bull Number of provisioned compute nodes and their instanta-neous utilization (measured at the workflow level by numberof running tasks)
bull Latency incurred by each stage of the Balsam Job life-cycle
415 Local cluster baselines at experimental beamlines For anexperimental scientist to understand the value of Balsam to offloadanalysis of locally acquired data a key question to consider is thegreater capacity of remotely distributed computing resources worththe cost of increased data transfer times and the time to solution Wetherefore aim to measure baseline performance in a pipeline thatis characteristic of data analysis workflows executing on an HPCcluster near the data acquisition source as performed in productionat the beamlines today[37] In this case the imaging data is firstcopied from the local acquisition machine storage to the beamlinecluster storage and analysis jobs are launched next to analyze thedata To that end we simulated ldquolocal clusterrdquo scenarios on theTheta and Cori supercomputers by submitting MD benchmarkruns continuously onto an exclusive reservation of 32 computenodes (or a fraction thereof) and relying on the batch schedulernot Balsam to queue and schedule runs onto available resources
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
The reservations guaranteed resource availability during each runso that measurements did not incur queuing delays due to otherusers on the system Instead of using Globus Online to trigger datamovement transfers were invoked in the batch job script as filecopy operations between a data source directory and a temporarysandbox execution directory on the same parallel filesystem Thuswe consider the overall tradeoff between increased data transfertime and reduced application startup time when adopting a remoteWMF such as Balsam
42 Comparison to local cluster workflowsFigure 3 depicts the scalability of Balsam task throughput whenremotely executing the MD application on Theta or Cori with inputdatasets stored at the APS These measurements are compared withthe throughput achieved by the ldquolocal clusterrdquo pipeline in whichthe same workload is repeatedly submitted onto an exclusive reser-vation of compute nodes via the local batch scheduler as describedin section 415 We consider both Theta which uses the Cobaltscheduler and Cori which uses the Slurm scheduler Note that onboth machines the Balsam workflow entails staging matrix data infrom the APS Globus endpoint and transferring the output eigen-values in the reverse direction back to APS While the local clusterbaseline does not use pilot jobs and is at a disadvantage in terms ofinflated scheduler queueing times the local runs simply read datafrom local storage and are also significantly advantaged in termsof reduced transfer overhead This is borne out in the ldquoStage Inrdquoand ldquoStage Outrdquo histograms of figure 4 which show that local datamovement times for the small (200 MB) MD benchmark are one tothree orders of magnitude faster than the corresponding Globustransfers invoked by Balsam
Despite added data transfer costs Balsam efficiently overlapsasynchronous data movement with high-throughput task executionyielding overall enhanced throughput and scalability relative to thelocal scheduler-driven workflows On Theta throughput increasesfrom 4 to 32 nodes with 85 to 100 efficiency depending on thesizes of transferred input datasets On the other hand the top panelsof Figure 3 show that Cobalt-driven task throughput is non-scalablefor the evaluated task durations on the order of 20 seconds (smallinput) or 15 minutes (large input) The Cobalt pipeline is in effectthrottled by the scheduler job startup rate with a median per-jobqueuing time of 273 seconds despite an exclusive reservation ofidle nodes In contrast to Cobalt on Theta the bottom panels ofFigure 3 show that Slurm on Cori is moderately scalable for high-throughput workloads For the smaller MD dataset Slurm achieves66 efficiency in scaling from 4 to 32 nodes for the larger datasetefficiency increases to 85 The improvement over Cobalt is dueto the significantly reduced median Slurm job queuing delay of27 seconds (see blue ldquoQueueingrdquo duration histograms in figure4) Here too Balsam scales with higher efficiency than the localbaseline (87 for small dataset 97 for large dataset) despite thewide geographic separation between the APS and NERSC facilities
Provided adequate bandwidth tapping remote resources clearlyenables one to scale workloads beyond the capacity of local infras-tructure but this often comes at the price of unacceptably highturnaround time with significant overheads in data movement andbatch queuing Table 1 quantifies the Balsam latency distributions
Table 1 APS harr Theta Balsam analysis pipeline stage durations (in sec) forthe matrix diagonalization benchmark The latency incurred by each stage isreported as the mean plusmn standard deviation with the 95th percentile durationin parenthesis Jobswere submitted toBalsamAPI at a steady rate to a 32-nodeallocation (20 and 036 jobssec for small and large datasets respectively)
Time to Solution 527 plusmn 176 (1030) 1611 plusmn 238 (2050)Overhead 341 plusmn 123 (663) 721 plusmn 225 (1122)
that were measured from submitting 1156 small and 282 large MDtasks from APS to Theta at rates of 20 and 036 jobssecond re-spectively We note a mean 341 second overhead in processing thesmall MD dataset and 95th percentile overheads of roughly 1 or 2minutes in processing the small or large MD datasets respectivelyOn average 84 to 90 of the overhead is due to data transfer timeand not intrinsic to Balsam (which may for instance leverage directmemory-to-memory transfer methods) Notwithstanding room forimprovement in transfer rates turnaround times on the order of 1minute may prove acceptable in near-real-time experimental sce-narios requiring access to large-scale remote computing resourcesThese latencies may be compared with other WMFs such as funcX[24] and RADICAL-Pilot [31] as part of future work
43 Optimizing the data stagingFigure 5 shows the effective cross-facility Globus transfer ratesachieved in this work summarized over a sample of 390 transfertasks from the APS in which at least 10 GB of data were trans-mitted We observed data rates from the APS to ALCF-Theta datatransfer nodes were significantly lower than those to the OLCFand NERSC facilities and needs further investigation To adapt tovarious bandwidths and workload sizes the Balsam sitersquos transfermodule provides an adjustable transfer batch size parameter whichcontrols the maximum number of files per transfer task Whenfiles are small relative to the available bandwidth batching files isessential to leveraging the concurrency and pipelining capabilitiesof GridFTP processes underlying the Globus Transfer service [40]On the other hand larger transfer batch sizes yield diminishingreturns on effective speed increase the duration of transfer tasksand may decrease opportunities for overlapping computation withsmaller concurrent transfer tasks
These tradeoffs are explored for the small and large MD datasetsbetween the APS and a Theta Balsam site in Figure 6 As expectedfor the smaller dataset (each file is 200 MB) the aggregate job stage-in rate steadily improves with batch size but then drops when batchsize is set equal to the total workload size of 128 tasks We attributethis behavior to the limited default concurrency of 4 GridFTP pro-cesses per transfer task which is circumvented by allowing Balsamto manage multiple smaller transfer tasks concurrently For thelarger MD dataset (each 115 GB) the optimal transfer batch sizeappears closest to 16 files
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
100
101
102
1421 23 23
52101
198419
200 MB dataset
1018 22 20
3157
116221
115 GB dataset
Cobalt (Local)Relish (APS$Theta)
1220 21 23
4575
124
305
The
ta
Combined dataset
4 8 16 32Nodes
100
101
102
Thr
ough
put(
jobs
min
)
69141
197364
160323
5961113
4 8 16 32Nodes
1736
59116
2446
80
187
Slurm (Local)Relish (APS$Cori)
4 8 16 32Nodes
2962
100188
3674
152285
Cor
i
Balsam
Balsam
Figure 3 Weak scaling of matrix diagonalization throughput on Theta (top row) and Cori (bottom) Average rate of task completion is compared between localBatchQueue andBalsamAPSharrALCFNERSCpipelines at various node counts The left and center panels show runswith 50002 and 120002 input sizes respectivelyThe right panels show runs where each task submission draws uniformly at random from the two input sizes To saturate Balsam data stage-in throughput thejob source throttled API submission to maintain steady-state backlog of up to 48 datasets in flight Up to 16 files were batched per Globus transfer task
Figure 4 Unnormalized histogram of latency contributions from stages inthe Cobalt Batch Queuing (top) Slurm Batch Queuing (center) and APS harrTheta Balsam (bottom) analysis pipelines in the 200 MB matrix diagonaliza-tion benchmark Jobs were submitted to Balsam API at a steady rate of 2jobssecond onto a 32-node allocation The Queueing time represents delaybetween job submission to Slurm or Cobalt (using an exclusive node reserva-tion) and application startup Because Balsam jobs execute in a pilot launcherthey do not incur a queueing delay instead the Run Delay shows the elapsedtime between Globus data arrival and application startup within the pilot
44 Autoscaling and fault toleranceThe Balsam site provides an elastic queueing capability which au-tomates HPC queuing to provision resources in response to time-varying workloads When job injection rates exceed the maximumattainable compute nodes in a given duration Balsam durably ac-commodates the growing backlog and guarantees eventual execu-tion in a fashion that is tolerant to faults at the Balsam service
0 250 500 750 1000 1250Effective Rate (MBsec)
APSrarr ALCF
APSrarr OLCF
APSrarr NERSC
Figure 5 Effective cross-facility Globus transfer rates The transfer durationis measured from initial API request to transfer completion the rate factorsin average transfer task queue time and is lower than full end-to-end band-width The boxes demarcate the quartiles of transfer rate to each facility col-lected from 390 transfer tasks where at least 10 GB were transmitted
8 16 32 64 128Transfer Batch Size
0
25
50
75
100
Arr
ival
Rat
e(j
obs
min
)
757 783855 887
555
190 214 190 18095
200 MB115 GB
Figure 6 APS dataset arrival rate for matrix diagonalization benchmark onTheta averaged over 128 Balsam Jobs The Balsam site initiates up to threeconcurrent Globus transfers with a varying number of files per transfer(transfer batch size) For batch sizes of 64 and 128 the transfer is accomplishedin only two (12864) or one (128128) Globus transfer tasks respectively Thediminished rate at batch size 128 shows that at least two concurrent transfertasks are needed to utilize the available bandwidth
site launcher pilot job or individual task level Figure 7 shows thethroughput and node utilization timelines of an 80-minute exper-iment between Theta and the APS designed to stress test theseBalsam capabilities
In the first phase (green background) a relatively slow API sub-mission rate of 10 small MD jobsecond ensures that the completedapplication run count (green curve) closely follows the injected jobcount (blue curve) with an adequately-controlled latency The gray
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0
1000
2000
3000
Job
Cou
nt
SubmittedStaged InRun Done
0 20 40 60 80Elapsed Time (minutes)
0
8
16
24
32
Nod
eC
ount
Figure 7 Elastic scaling during a Balsam stress test using theAPSharrThetama-trix diagonalization benchmark with 200 MB dataset Three traces in the toppanel show the count of jobs submitted to the API jobs for which the inputdataset has been staged and completed application runs The bottom time-line shows the count of elastically-provisioned Theta compute nodes (gray)and count of running analysis tasks (blue) During the first 15 minutes (greenregion) jobs are submitted at a steady rate of 10 jobssecond In the second15 minutes (yellow region) jobs submitted at a rate of 30 jobssecond causethe task backlog to grow because datasets arrive faster than can be handledwith themaximumelastic scaling capacity (capped at 32 nodes for this experi-ment) In the third phase (red region) a randomly-chosen Balsam launcher isterminated every two minutes In the final stage of the run Balsam recoversfrom the faults to fully process the backlog of interrupted jobs
trace in the bottom panel shows the number of available computenodes quickly increasing to 32 obtained via four resource alloca-tions in 8-node increments As an aside we mention that the nodecount and duration of batch jobs used to provision blocks of HPCresources is adjustable within the Balsam site configuration In factthe elastic queuing module may opportunistically size jobs to fillidle resource gaps using information provided by the local batchscheduler In this test however we fix the resource block size at 8nodes and a 20 minutes maximum wall-clock time
In the second phase (yellow background) the API submission ratetriples from 10 to 30 small MD jobssecond Meanwhile the avail-able node count briefly drops to 0 as the 20 minute limit expires foreach of the initially allocated resource blocks Application through-put recovers after the elastic queuing module provisions additionalresources but the backlog between submitted and processed tasksquickly grows larger In the third phase (red background) we sim-ulate faults in pilot job execution by randomly terminating oneof the executing batch jobs every two minutes thereby causingup to 8 MD tasks to timeout The periodically killed jobs coupledwith large scheduler startup delays on Theta causes the number ofavailable nodes to fluctuate between 16 and 24 Additionally theBalsam site experiences a stall in Globus stage-ins which exhauststhe runnable task backlog and causes the launchers to time-outon idling Eventually in the fourth and final region the adverseconditions are lifted and Balsam processes the full backlog of tasksacross several additional resource allocations We emphasize thatno tasks are lost in this process as the Balsam service durablytracks task states in its relational database and monitors the heart-beat from launchers to recover tasks from ungracefully-terminated
APSrarrTheta
APSrarrCori
APSrarrSummit
ALSrarrTheta
ALSrarrCori
ALSrarrSummit
Light Source Supercomputer
0
25
50
75
100
125
150
Med
ian
Lat
ency
(sec
onds
)
Stage In Run Delay Run Stage Out
Figure 8 Contribution of stages in the Balsam Job life-cycle to total XPCSanalysis latency With at most one 878 MB dataset in flight to each computefacility the bars reflect round-trip time to solution in the absence of pipelin-ing or batching data transfers The greenRun segments represent themedianruntime of theXPCS-Eigen corr calculation The blue and red segments repre-sent overheads in Globus data transfers Orange segment represents the delayin Balsam application startup after input dataset has been staged
sessions These features enable us to robustly support bursty exper-imental workloads while providing a fault-tolerant computationalinfrastructure to the real-time experiments
45 Simultaneous execution on geographicallydistributed supercomputers
We evaluate the efficacy of Balsam in distributing XPCS (section413) workloads from one or both of the APS andALS national X-rayfacilities on to the Theta Cori and Summit supercomputing systemsin real time By starting Balsam sites on the login (or gateway orservice) nodes of three supercomputers a user transforms theseindependent facilities into a federated infrastructure with uniformAPIs and a Python SDK to securely orchestrate the life-cycle ofgeographically-distributed HPC workflows
Figure 8 shows the median time spent in each stage of a remoteBalsam XPCS corr analysis task execution with 878 MB datasetThe overall time-to-solution from task submission to returnedcalculation results ranges from 86 seconds (APSharrCori) to a maxi-mum of 150 seconds (ALSharrTheta) Measurements were performedwith an allocation of 32 nodes on each supercomputer and withoutpipelining input data transfers (ie a maximum of one GridFTPtransfer in flight between a particular light source and computefacility) These conditions minimize latencies due to Globus trans-fer task queueing and application startup time From Figure 8 itis clear that data transfer times dominate the remote executionoverheads consisting of stage in run delay and stage out Howeverthese overheads are within the constraints needed for near-real-time execution We emphasize that there is significant room fornetwork performance optimizations and opportunities to interfacethe Balsam transfer service with performant alternatives to disk-to-disk transfers Moreover the overhead in Balsam applicationlaunch itself is consistently in the range of 1 to 2 seconds (1 to 3of XPCS runtime depending on the platform)
Figure 9 charts the simultaneous throughput of XPCS analysesexecuting concurrently on 32 compute nodes of each system ThetaCori and Summit The three panels correspond to separate experi-ments in which (1) XPCS is invoked from APS datasets alone (2)XPCS is invoked from ALS datasets alone or (3) XPCS is invoked
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6 8 10 120
100
200
300
400
Job
Thr
ough
put
APS
0 2 4 6 8 10 12Elapsed Time (minutes)
ALS
0 2 4 6 8 10 12
APS+ALS
ThetaSummitCori
Figure 9 Simultaneous throughput of XPCS analysis on Theta (blue) Summit (orange) and Cori (green) Balsam sites The panels (left to right) correspond toexperiments in which the 878 MB XPCS dataset is transferred from either the APS ALS or both light sources A constant backlog of 32 tasks was maintained withthe Balsam API The top boundary of each shaded region shows the number of staged-in datasets The center line shows the number of completed applicationruns The bottom boundary of the shaded regions shows the number of staged-out result sets When the center line approaches the top of the shaded region thesystem is network IO-bound that is compute nodes become idle waiting for new datasets to arrive
with a randomly selected dataset from either APS or ALS To mea-sure the attainable throughput in each scenario the clients variedsubmission rate to maintain a steady-state backlog of 32 XPCS tasksthat is the sum of submitted and staged-in (but not yet running)tasks fluctuates near 32 for each system The Balsam site transferbatch size was set to a maximum of 32 files per transfer and eachsite initiated up to 5 concurrent transfer tasks On the Globus ser-vice backend this implies up to 3 active and 12 queued transfertasks at any moment in time In practice the stochastic arrival ratesand interwoven stage-in and result stage-out transfers reduce thefile count per transfer task
One immediately observes a consistent ordering in throughputincreasing from Thetararr Summit rarr Cori regardless of the clientlight source The markedly improved throughput on Cori relative toother systems is mainly due to reduced application runtime whichis clearly evident from Figure 8 While the throughput of Theta andSummit are roughly on-par Summit narrowly though consistentlyoutperforms Theta due to higher effective stage-in throughput band-width This is evident in the top boundary of the orange and blueregions of Figure 9 which show the arrival throughput of staged-indatasets Indeed the average XPCS arrival rates calculated from theAPS experiment (left panel) are 160 datasetsminute for Theta 196datasetsminute for Summit and 296 datasetsminute for Cori Wealso notice that Corirsquos best data arrival rate is inconsistent with theslower median stage in time of Figure 8 Because those durationswere measured without batching file transfers this underscores thesignificance of GridFTP pipelining and concurrency on the Coridata transfer nodes
Continuing our analysis of Figure 9 the center line in each col-ored region shows throughput of completed application runs whichnaturally lags behind the staged-in datasets by the XPCS applica-tionrsquos running duration Similarly the bottom boundary of eachcolored region shows the number of completed result transfersback to the client the gap between center line and bottom of theregion represents ldquoStage Outrdquo portion of each pipeline The XPCSresults comprise only the HDF file which is modified in-place dur-ing computation and (at least) an order-of-magnitude smaller thanIMM frame data Therefore result transfers tend to track applicationcompletion more closely which is especially noticeable on Summit
When the center line in a region of Figure 9 approaches or inter-sects the top region boundary the number of completed applicationruns approaches or matches the number of staged-in XPCS datasets
In this scenario the runnable workload on a supercomputer be-comes too small to fill the available 32 nodes in effect the system isnetwork IO-bound The compute utilization percentages in Figure10 make this abundantly clear for the APS experiment On Summitthe average arrival rate of 196 datasetsminute and 108 secondapplication runtime are sufficiently high to keep all resources busyIndeed for Summit both instantaneous utilization measured fromBalsam event logs (blue curve) and its time-average (dashed line)remain very close to 100 (3232 nodes running XPCS analysis)
We can apply Littlersquos law [30] in this context an intuitive resultfrom queuing theorywhich states that the long-run average number119871 of running XPCS tasks should be equal to the product of averageeffective dataset arrival rate _ and application runtime119882 We thuscompute the empirical quantity 119871 = _119882 and plot it in Figure 10as the semi-transparent thick yellow line The close agreementbetween time-averaged node utilization and the expected value_119882 helps us to estimate the potential headroom for improvementof throughput by increasing data transfer rates (_) For exampleeven though APSharr Cori achieves better overall throughput thanAPS harr Summit (Figure 9) we see that Cori reaches only about 75 of its sustained XPCS processing capacity at 32 nodes whereasSummit is near 100 utilization and therefore compute-bound (ofcourse barring optimizations in application IO or other accelerationtechniques at the task level) Furthermore Figure 8 shows that XPCSapplication runtime on Theta is comparable to Summit but Thetahas a significantly slower arrival rate This causes lower averageutilization of 76 on Theta
Overall by using Balsam to scale XPCS workloads from the APSacross three distributed HPC systems simultaneously we achieved437-fold increased throughput over the span of a 19-minute runcompared to routing workloads to Theta alone (1049 completedtasks in aggregate versus 240 tasks completed on Theta alone) Sim-ilarly we achieve a 328X improvement in throughput over Summitand 22X improvement over Cori In other words depending on thechoice of reference system we obtain a 73 to 146 ldquoefficiencyrdquo ofthroughput scaling when moving from 32 nodes on one system to96 nodes across the three Of course these figures should be looselyinterpreted due to the significant variation in XPCS applicationperformance on each platform This demonstrates the importanceof utilizing geographically distributed supercomputing sites to meetthe needs of real-time analysis of experiments for improved timeto solution We note that the Globus Transfer default limit of 3
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
0 2 4 6 8 10 120
25
50
75
100
Com
pute
Util
izat
ion
()
APSharr Theta
0 2 4 6 8 10 12Elapsed time (minutes)
APSharr Cori
0 2 4 6 8 10 12
APSharr Summit
Littlersquos lawTime-averagedInstantaneous
Figure 10 Compute node utilization on each Balsam site corresponding to the APS experiment in Figure 9 The solid line shows the instantaneous node utilizationmeasured via Balsam events as a percentage of the full 32-node reservation on each system The dashed line indicates the time-averaged utilization which shouldcoincide closely with the expected utilization derived from the average data arrival rate and application runtime (Littlersquos law) The data arrival rate on Summit issufficiently high that compute nodes are busy near 100 of the time By contrast Theta and Cori reach about 75 utilization due to a bottleneck in effective datatransfer rate
64 128 256 512Compute Nodes
050
100150200250300
Thr
ough
put(
task
sm
in)
411813
1620
2957
Figure 11 Weak scaling of XPCS benchmark throughput with increasing Bal-sam launcher job size on Theta We consider how throughput of the sameXPCS application increases with compute node count when the network datatransfer bottleneck is removed An average of two jobs per Theta node werecompleted at each node count with 90 efficiency at 512 nodesconcurrent transfer tasks per user places a significant constrainton peak throughput achievable by a single user This issue is par-ticularly evident in the right-most panel of Figure 9 where Balsamis managing bi-directional transfers along six routes As discussedearlier the clients in this experiment throttled submission to main-tain a steady backlog of 32 jobs per site Splitting this backlog inhalf between two remote data sources (APS and ALS) decreasesopportunities for batching transfers and reduces overall benefitsof pipeliningconcurrency in file transfers Of course this is tosome extent an artifact of the experimental design real distributedclients would likely use different Globus user accounts and wouldnot throttle task injection to maintain a steady backlog Neverthe-less increasing concurrency limits on data transfers could providesignificant improvements in global throughput where many Balsamclientndashexecution site endpoint pairs are concerned
Although we have established the limiting characteristics ofXPCS data transfers on Balsam scalability one may consider moregenerally the scalability of Balsam on large-scale HPC systemsFigure 11 shows the performance profile of the XPCS workload onTheta when wide-area-network data movement is taken out of theequation and the input datasets are read directly from local HPCstorage As more resources are made available to Balsam launchersthe rate of XPCS processing weak-scales with 90 efficiency from64 to 512 Theta nodes This efficiency is achieved with the mpipilot job mode where one aprun process is spawned for each XPCSjob We anticipate improved scaling efficiency with the serial jobmode This experiment was performed with a fixed number of XPCStasks per compute node however given the steady task throughputwe expect to obtain similar strong scaling efficiency in reducingtime-to-solution for a fixed large batch of analysis tasks Finallylaunchers obtain runnable jobs from the Balsam Session API whichfetches a variable quantity of Jobs to occupy available resources
Theta Summit Cori0
10
20
30
Ave
rage
Thr
ough
put(
jobs
min
)
152 151 160155 163185
Round RobinShortest Backlog
Figure 12 Throughput of client-driven task distribution strategies for theXPCS benchmark with APS data source Using round-robin distributionXPCS jobs are evenly distributed alternating among the three Balsam sitesUsing the shortest-backlog strategy the client uses the Balsam API to adap-tively send jobs to the site with the smallest pending workload In both sce-narios the client submits a batch of 16 jobs every 8 seconds
Because runnable Jobs are appropriately indexed in the underlyingPostgreSQL database the response time of this endpoint is largelyconsistent with respect to increasing number of submitted Jobs Wetherefore expect consistent performance of Balsam as the numberof backlog tasks grows
46 Adaptive workload distributionThe previous section focused on throughputs and latencies in theBalsam distributed system for analysing XPCS data on Theta Sum-mit and Cori execution sitesWe now relax the artificial steady back-log constraint and instead allow the APS client to inject workloadsin a more realistic fashion jobs are submitted at a constant averagerate of 20 jobssecond spread across batch-submission blocks of 16XPCS jobs every 80 seconds This workload represents a plausibleexperimental workflow in which 14 GB batches of data (16 datasetstimes 878 MBdataset) are periodically collected and dispatched forXPCS-Eigen analysis remotely It also introduces a scheduling prob-lem wherein the client may naively distribute workloads evenlyamong available execution sites (round-robin) or leverage the Bal-sam Job events API to adaptively route tasks to the system withshortest backlog lowest estimated time-to-solution etc Here weexplore a simplified variant of this problem where XPCS tasksare uniformly-sized and each Balsam site has a constant resourceavailability of 32 nodes
Figure 12 compares the average throughput of XPCS datasetanalysis from the APS when distributing work according to one oftwo strategies round-robin or shortest-backlog In the latter strategy
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Conferencersquo17 July 2017 Washington DC USA Salim et al
0 2 4 6minus40
minus20
0
20
40
∆ SBminus
RR
Theta
0 2 4 6Elapsed Time (min)
Summit
0 2 4 6
Cori
Figure 13 Difference in per-site job distribution between the consideredstrategies Each curve shows the instantaneous difference in submitted taskcount between the shortest-backlog and round-robin strategies (Δ119878119861minus119877119877 ) overthe span of six minutes of continuous submission A negative value indicatesthat fewer jobs were submitted at the same point in time during the round-robin run relative to the shortest-backlog run
0 5 10Elapsed Time (minutes)
0
100
200
300
Job
Cou
nt
Round Robin
Staged InRun DoneStaged Out
0 5 10
Shortest Backlog
Figure 14 Throughput of data staging and application runs onCori comparedbetween round-robin and shortest-backlog strategiesMore frequent task sub-missions to Cori in the adaptive shortest-backlog strategy contribute to 16higher throughput relative to round-robin strategy
the client uses the Balsam API to poll the number of jobs pend-ing stage-in or execution at each site the client then submits eachXPCS batch to the Balsam site with the shortest backlog in a first-order load-levelling attemptWe observed a slight 16 improvementin throughput on Cori when using the shortest-backlog strategyrelative to round-robin with marginal differences for Theta andSummit The submission rate of 20 jobssecond or 120 jobsminutesignificantly exceeds the aggregate sustained throughput of ap-proximately 58 jobsminute seen in the left panel of Figure 9 Wetherefore expect a more significant difference between the distri-bution strategies when job submission rates are balanced with theattainable system throughput
Nevertheless Figure 13 shows that with the shortest-backlogstrategy the APS preferentially submits more workloads to Summitand Cori and fewer workloads to Theta which tends to accumulatebacklog more quickly owing to slower data transfer rates Thisresults in overall increased data arrival rates and higher throughputon Cori (Figure 14) despite overloaded pipelines on all systems
5 CONCLUSIONIn this work we describe the Balsamworkflow framework to enablewide-area multi-tenant distributed execution of analysis jobs onDOE supercomputers A key development is the introduction of acentral Balsam service that manages job distribution fronted by aprogrammatic interface Clients of this service use the API to injectand monitor jobs from anywhere A second key development isthe Balsam site which consumes jobs from the Balsam service andinteracts directly with the scheduling infrastructure of a clusterTogether these two form a distributed multi-resource executionlandscape
The power of this approach was demonstrated using the BalsamAPI to inject analysis jobs from two light source facilities to theBalsam service targeting simultaneous execution on three DOEsupercomputers By strategically combining data transfer bundlingand controlled job execution Balsam achieves higher throughputthan direct-scheduled local jobs and effectively balances job dis-tribution across sites to simultaneously utilize multiple remotesupercomputers Utilizing three geographically distributed super-computers concurrently we achieve a 437-fold increased through-put compared to routing light source workloads to Theta Otherkey results include that Balsam is a user-domain solution that canbe deployed without administrative support while honoring thesecurity constraints of facilities
REFERENCES[1] [nd] Advanced Light Source Five Year Strategic Plan https
summit[15] [nd] Theta httpswwwalcfanlgovalcf-resourcestheta[16] [nd] XPCS-Eigen httpsgithubcomAdvancedPhotonSourcexpcs-eigen[17] Malcolm Atkinson Sandra Gesing Johan Montagnat and Ian Taylor 2017 Sci-
entific workflows Past present and future Future Generation Computer Systems75 (Oct 2017) 216ndash227 httpsdoiorg101016jfuture201705041
[18] Yadu Babuji Anna Woodard Zhuozhao Li Daniel S Katz Ben Clifford RohanKumar Luksaz Lacinski Ryan Chard Justin M Wozniak Ian Foster MichaelWilde and Kyle Chard 2019 Parsl Pervasive Parallel Programming in Python In28th ACM International Symposium on High-Performance Parallel and DistributedComputing (HPDC) httpsdoiorg10114533076813325400 babuji19parslpdf
[19] V Balasubramanian A Treikalis O Weidner and S Jha 2016 Ensemble ToolkitScalable and Flexible Execution of Ensembles of Tasks In 2016 45th InternationalConference on Parallel Processing (ICPP) IEEE Computer Society Los AlamitosCA USA 458ndash463 httpsdoiorg101109ICPP201659
[20] Krzysztof Burkat Maciej Pawlik Bartosz Balis Maciej Malawski Karan VahiMats Rynge Rafael Ferreira da Silva and Ewa Deelman 2020 Serverless Contain-ers ndash rising viable approach to Scientific Workflows arXiv201011320 [csDC]
[21] Stuart Campbell Daniel B Allan Andi Barbour Daniel Olds Maksim RakitinReid Smith and Stuart B Wilkins 2021 Outlook for Artificial Intelligence andMachine Learning at the NSLS-II Machine Learning Science and Technology 2 1(3 2021) httpsdoiorg1010882632-2153abbd4e
[22] Joseph Carlson Martin J Savage Richard Gerber Katie Antypas Deborah BardRichard Coffey Eli Dart Sudip Dosanjh James Hack Inder Monga Michael EPapka Katherine Riley Lauren Rotman Tjerk Straatsma Jack Wells HarutAvakian Yassid Ayyad Steffen A Bass Daniel Bazin Amber Boehnlein GeorgBollen Leah J Broussard Alan Calder Sean Couch Aaron Couture Mario Cro-maz William Detmold Jason Detwiler Huaiyu Duan Robert Edwards JonathanEngel Chris Fryer George M Fuller Stefano Gandolfi Gagik Gavalian DaliGeorgobiani Rajan Gupta Vardan Gyurjyan Marc Hausmann Graham HeyesW Ralph Hix Mark ito Gustav Jansen Richard Jones Balint Joo Olaf KaczmarekDan Kasen Mikhail Kostin Thorsten Kurth Jerome Lauret David LawrenceHuey-Wen Lin Meifeng Lin Paul Mantica Peter Maris Bronson Messer Wolf-gang Mittig Shea Mosby Swagato Mukherjee Hai Ah Nam Petr navratil WitekNazarewicz Esmond Ng Tommy OrsquoDonnell Konstantinos Orginos FrederiquePellemoine Peter Petreczky Steven C Pieper Christopher H Pinkenburg BradPlaster R Jefferson Porter Mauricio Portillo Scott Pratt Martin L Purschke
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers
46 Adaptive workload distribution
5 Conclusion
References
Toward Real-time Analysis of Experimental Science Workloads on Geographically Distributed Supercomputers Conferencersquo17 July 2017 Washington DC USA
Ji Qiang Sofia Quaglioni David Richards Yves Roblin Bjorn Schenke RoccoSchiavilla Soren Schlichting Nicolas Schunck Patrick Steinbrecher MichaelStrickland Sergey Syritsyn Balsa Terzic Robert Varner James Vary StefanWild Frank Winter Remco Zegers He Zhang Veronique Ziegler and MichaelZingale [nd] Nuclear Physics Exascale Requirements Review An Office ofScience review sponsored jointly by Advanced Scientific Computing Researchand Nuclear Physics June 15 - 17 2016 Gaithersburg Maryland ([n d])httpsdoiorg1021721369223
[23] K Chard and I Foster 2019 Serverless Science for Simple Scalable and ShareableScholarship In 2019 15th International Conference on eScience (eScience) IEEEComputer Society Los Alamitos CA USA 432ndash438 httpsdoiorg101109eScience201900056
[24] Ryan Chard Yadu Babuji Zhuozhao Li Tyler Skluzacek Anna Woodard BenBlaiszik Ian Foster and Kyle Chard 2020 funcX A Federated Function ServingFabric for Science Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing httpsdoiorg10114533695833392683
[25] Felipe A Cruz and Maxime Martinasso 2019 FirecREST RESTful API on CrayXC systems arXiv191113160 [csDC]
[26] Dask Development Team 2016 Dask Library for dynamic task scheduling httpsdaskorg
[27] B Enders D Bard C Snavely L Gerhardt J Lee B Totzke K Antypas SByna R Cheema S Cholia M Day A Gaur A Greiner T Groves M KiranQ Koziol K Rowland C Samuel A Selvarajan A Sim D Skinner R Thomasand G Torok 2020 Cross-facility science with the Superfacility Project at LBNLIn 2020 IEEEACM 2nd Annual Workshop on Extreme-scale Experiment-in-the-Loop Computing (XLOOP) IEEE Computer Society Los Alamitos CA USA 1ndash7httpsdoiorg101109XLOOP51963202000006
[28] Salman Habib Robert Roser Richard Gerber Katie Antypas Katherine Riley TimWilliams Jack Wells Tjerk Straatsma A Almgren J Amundson S Bailey DBard K Bloom B Bockelman A Borgland J Borrill R Boughezal R Brower BCowan H Finkel N Frontiere S Fuess L Ge N Gnedin S Gottlieb O GutscheT Han K Heitmann S Hoeche K Ko O Kononenko T LeCompte Z Li ZLukic W Mori P Nugent C K Ng G Oleynik B OrsquoShea N PadmanabhanD Petravick F J Petriello J Power J Qiang L Reina T J Rizzo R Ryne MSchram P Spentzouris D Toussaint J L Vay B Viren F Wurthwein andL Xiao [nd] ASCRHEP Exascale Requirements Review Report ([n d])httpswwwostigovbiblio1398463
[29] Anubhav Jain Shyue Ping Ong Wei Chen Bharat Medasani Xiaohui Qu MichaelKocher Miriam Brafman Guido Petretto Gian-Marco Rignanese Geoffroy Hau-tier Daniel Gunter and Kristin A Persson 2015 FireWorks a dynamic workflowsystem designed for high-throughput applications Concurrency and ComputationPractice and Experience 27 17 (2015) 5037ndash5059 httpsdoiorg101002cpe3505CPE-14-0307R2
[30] John D C Little and Stephen C Graves 2008 Littles Law In Building IntuitionSpringer US 81ndash100 httpsdoiorg101007978-0-387-73699-0_5
[31] Andre Merzky Matteo Turilli Manuel Maldonado Mark Santcroos and ShantenuJha 2018 Using Pilot Systems to Execute Many Task Workloads on Supercom-puters arXiv151208194 [csDC]
[32] Fivos Perakis Katrin Amann-Winkel Felix Lehmkuumlhler Michael Sprung DanielMariedahl Jonas A Sellberg Harshad Pathak Alexander Spaumlh Filippo Cav-alca Daniel Schlesinger Alessandro Ricci Avni Jain Bernhard Massani FloraAubree Chris J Benmore Thomas Loerting Gerhard Gruumlbel Lars G M Pet-tersson and Anders Nilsson 2017 Diffusive dynamics during the high-to-lowdensity transition in amorphous ice Proceedings of the National Academy ofSciences 114 31 (2017) 8193ndash8198 httpsdoiorg101073pnas1705303114arXivhttpswwwpnasorgcontent114318193fullpdf
[33] M Salim T Uram J T Childers V Vishwanath andM Papka 2019 Balsam NearReal-Time Experimental Data Analysis on Supercomputers In 2019 IEEEACM1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP)26ndash31 httpsdoiorg101109XLOOP49562201900010
[34] Mallikarjun (Arjun) Shankar and Eric Lancon 2019 Background and Roadmapfor a Distributed Computing and Data Ecosystem Technical Report httpsdoiorg1021721528707
[35] Joe Stubbs Suresh Marru Daniel Mejia Daniel S Katz Kyle Chard MaytalDahan Marlon Pierce and Michael Zentner 2020 Toward Interoperable Cy-berinfrastructure Common Descriptions for Computational Resources and Ap-plications In Practice and Experience in Advanced Research Computing ACMhttpsdoiorg10114533117903400848
[36] S Timm G Cooper S Fuess G Garzoglio B Holzman R Kennedy D Grassano ATiradani R Krishnamurthy S Vinayagam I Raicu H Wu S Ren and S-Y Noh2017 Virtual machine provisioning code management and data movementdesign for the Fermilab HEPCloud Facility Journal of Physics Conference Series898 (oct 2017) 052041 httpsdoiorg1010881742-65968985052041
[37] Siniša Veseli Nicholas Schwarz and Collin Schmitz 2018 APS Data ManagementSystem Journal of Synchrotron Radiation 25 5 (Aug 2018) 1574ndash1580 httpsdoiorg101107s1600577518010056
[38] Jianwu Wang Prakashan Korambath Ilkay Altintas Jim Davis and DanielCrawl 2014 Workflow as a Service in the Cloud Architecture and Sched-uling Algorithms Procedia Computer Science 29 (2014) 546ndash556 httpsdoiorg101016jprocs201405049
[39] Theresa Windus Michael Banda Thomas Devereaux Julia C White Katie Anty-pas Richard Coffey Eli Dart Sudip Dosanjh Richard Gerber James Hack InderMonga Michael E Papka Katherine Riley Lauren Rotman Tjerk StraatsmaJack Wells Tunna Baruah Anouar Benali Michael Borland Jiri Brabec EmilyCarter David Ceperley Maria Chan James Chelikowsky Jackie Chen Hai-PingCheng Aurora Clark Pierre Darancet Wibe DeJong Jack Deslippe David DixonJeffrey Donatelli Thomas Dunning Marivi Fernandez-Serra James FreericksLaura Gagliardi Giulia Galli Bruce Garrett Vassiliki-Alexandra Glezakou MarkGordon Niri Govind Stephen Gray Emanuel Gull Francois Gygi AlexanderHexemer Christine Isborn Mark Jarrell Rajiv K Kalia Paul Kent Stephen Klip-penstein Karol Kowalski Hulikal Krishnamurthy Dinesh Kumar Charles LenaXiaosong Li Thomas Maier Thomas Markland Ian McNulty Andrew MillisChris Mundy Aiichiro Nakano AMN Niklasson Thanos Panagiotopoulos RonPandolfi Dula Parkinson John Pask Amedeo Perazzo John Rehr Roger RousseauSubramanian Sankaranarayanan Greg Schenter Annabella Selloni Jamie SethianIlja Siepmann Lyudmila Slipchenko Michael Sternberg Mark Stevens MichaelSummers Bobby Sumpter Peter Sushko Jana Thayer Brian Toby Craig TullEdward Valeev Priya Vashishta V Venkatakrishnan C Yang Ping Yang andPeter H Zwart [nd] Basic Energy Sciences Exascale Requirements Review AnOffice of Science review sponsored jointly by Advanced Scientific ComputingResearch and Basic Energy Sciences November 3-5 2015 Rockville Maryland([n d]) httpsdoiorg1021721341721
[40] Esma Yildirim JangYoung Kim and Tevfik Kosar 2012 How GridFTP PipeliningParallelism and Concurrency Work A Guide for Optimizing Large Dataset Trans-fers In 2012 SC Companion High Performance Computing Networking Storageand Analysis IEEE httpsdoiorg101109sccompanion201273
Abstract
1 Introduction
2 Related Work
3 Implementation
31 The Balsam Service
32 Balsam Site Architecture
4 Evaluation
41 Methodology
42 Comparison to local cluster workflows
43 Optimizing the data staging
44 Autoscaling and fault tolerance
45 Simultaneous execution on geographically distributed supercomputers