ABSTRACTWith the rate of errors that can silently effect an application’sstate/output expected to increase on future HPC machines, numer-ous application-level detection and recovery schemes have beenproposed. Recovery is more efficient when errors are contained andaffect only part of the computation’s state. Containment is usuallyachieved by verifying all information leaking out of a staticallydefined containment domain, which is an expensive procedure. Al-ternatively, error propagation can be analyzed to bound the domainthat is affected by a detected error. This paper investigates howsilent data corruption (SDC) due to soft errors propagates throughthree HPC applications: HPCCG, Jacobi, and CoMD. To allow formore detailed view of error propagation, the paper tracks propaga-tion at the instruction and application variable level. The impactof detection latency on error propagation is shown along with anapplication’s ability to recover. Finally, the impact of compiler opti-mizations are explored along with the impact of local problem sizeon error propagation.
KEYWORDSSilent Data Corruption; Error Propagation; Reliability; Error Detec-tion; Error Recovery
ACM Reference format:Jon Calhoun,Marc Snir, Luke N. Olson, andWilliamD. Gropp. 2017. Towardsa More Complete Understanding of SDC Propagation. In Proceedings ofHPDC ’17, Washington, DC, USA, June 26–30, 2017, 12 pages.https://doi.org/http://dx.doi.org/10.1145/3078597.3078617
1 INTRODUCTIONMachine errors both hard and soft are expected to increase [42]as the number of components in processors increases and as chip
technologies, such as smaller feature sizes [9] or near-threshold-voltage [26], are introduced to reduce power consumption. Thisplaces increased demands on both fabrication quality and on theunderlying system and numerical software stacks.
Energetic particles from cosmic radiation can invert the state oftransistors [3, 34]. Manufacturing defects can lead to the same effect.One consequence is that these faults produce soft errors that cancause a silent data corruption (SDC) — i.e., an erroneous deviationin system/application state. Corrupted state can be masked by theapplication causing no change in the output, or in extreme cases,can lead to corruption in the output. Modern hardware supportsredundancy and techniques such as error correcting codes (ECC)to detect soft errors and to prevent them from affecting the compu-tation state. As soft error rates increase, hardware may not provideadequate protection [43], allowing for corrupted state to impactapplication state. To combat this, software based SDC detectionschemes have been developed, with many leveraging applicationproperties and heuristics [10, 12, 25]. Others have taken applicationagnostic approaches [5, 6, 8] or leverage various forms of redun-dancy [19, 28, 37].
Global checkpoint-restart is the de-facto fault tolerance protocolused by HPC applications to recover from fail-stop failures. Thelimited bandwidth of persistent storage is the main performancebottleneck of checkpointing methods. Current versions mitigatestorage bandwidth issues by leveraging the memory hierarchy [7,35] and use compression techniques [40].
Another way to limit the impact of storage bandwidth is to avoidthe need for global checkpointing and global restart. Checkpoint-restart schemes often coordinate checkpointing and global restart:at checkpoint time, all processors are synchronized and the appli-cation state is saved, while at restart time, the entire applicationstate is restored. This results in bursts of I/O that slow down check-point and recovery. Various schemes have been proposed to supportuncoordinated checkpointing and localized restarts [21, 22, 47]. Sim-ilarly, application specific recovery reconstructs lost data from theremaining correct data [1].
Most recovery schemes assume that a corruption is limited to asubset of values — e.g., values in the memory of one compute node.This condition is easy to satisfy with fail-stop failures, but may notbe valid in the case of SDC detection with high latency. One solutionis to verify all state outside of a corrupted subset [14]. However, such
checks are expensive. An alternative is to determine the propagationof corruption when a detection occurs and to restrict recovery tothe potentially impacted state. In this case, some corruption canbe ignored as it is attenuated by the algorithm; in other scenarios,corrupted values may permanently influence the solution.
Prior work has explored how deviations from bit-flips in floating-point computation impact on convergence properties [16, 17]. Otherwork has used corruption propagation in the development of low-level instruction based detection schemes that check invariants orcreate SDC detectors inside the compiler [23, 38] or utilize codereplication to detect corruption in instructions that are likely leadto and propagate corrupted state [18, 27, 28], and understandinglong latency crashes [30, 45]. This paper combines the latency ofprogrammatic systems of corruption — e.g., segfaults, detection,control flow divergence, with corruption propagation in state vari-ables to discuss the impact of detection latency on recovery options.In the context of tracking corruption propagation inside applica-tions, [2] looks at state corruption propagation in MPI codes bytracking number of incorrect memory addresses, but does not re-late corruption back to application level data structure nor explorecompiler optimizations and the impact of local problem size oncorruption propagation. [31] quantifies corruption in different GPUand host memories in GPGPU programs. This papers focus on MPIapplications and tracks corruption in state variables and across MPIprocesses.
A detailed view of corruption propagation offers a measure ofan application’s ability to withstand soft errors. Moreover, it alsohelps application developers identifywhere to place detectors and toidentify locations for data recovery. This paper makes the followingcontributions:• the impact of detection latency on recovery options;• the data structures critical to corruption and the risk of ob-taining invalid results;• the influence of compiler optimizations on state corruptionpropagation; and• the analysis of problem size and inter-node corruption prop-agation.
The remainder of this paper is structured as follows. Section 2discusses corruption propagation for sparse matrix-vector multi-plication and motivates the need to investigate state corruptionpropagation in application codes. Section 3 details the design andoverview of the corruption propagation tool and how it tracks prop-agation at a micro and macro-level. Error propagation results arepresented in Section 4 along with a discussion on detection andrecovery options. Related work is discussed in Section 5.
2 MOTIVATION2.1 Sparse Matrix-Vector MultiplicationSparse matrix-vector multiplication (SpMV) is the core computekernel in many HPC applications. To understand corruption propa-gation, it is helpful to view a SpMV as of series of inner-productsbetween the rows of the matrix and the input vector or more simplyas an unstructured series of multiplications and additions.
In Figure 1, one element of the input vector is corrupted (redsquare). The corrupted value spreads through three inner products(rows), resulting in the corruption (red squares) in the output vector.
If this SpMV is used as part of an iterative method or solver, thenthe corrupted values propagate further as the output vector is usedin other parts of the method and with repeated application of theSpMV. Consequently, corruption in element i of the input vectorinfluences element j of the output vector if row j in column i isnon-zero. Thus, the propagation of corrupted values with densematrices is more rapid than with sparse matrices [13].
x x
x x x
x x x
x x x
x x
=
Figure 1: Propagation of corrupted state via a sparse matrix-vector multiplication.
One important caveat of corruption propagation for a SpMV isthat corruption is modeled through the algorithm and not by thecode as executed on a computer. A complete analysis of corruptionpropagation for the SpMV requires investigating the effect of cor-ruptions of loads, stores, address calculations, branching, looping,etc. This is often complex as deep inspection of the code is neededin order consider all paths of execution. The corruption propagationtool presented in this paper allows for tracking the propagation ofcorruption at the level of application variables and with load/storegranularity.
3 TRACKING PROPAGATIONFigure 2 details the flow of a fault occurring in a system that tran-sitions to a failure. Once a fault is activated, error is present inthe system. In this paper, error resulting from an activated faultis referred to as state corruption or corruption to avoid confusionwith numerical errors in HPC applications. The location of theinitial corrupted value is critical to identifying corruption propa-gation. During the execution the remaining program instructions,the corruption can be masked due to programmatic or algorithmicproperties, can lead to a system detectable event such as a segmen-tation fault, or can propagate to corrupt more of the program stateand become a silent data corruption (SDC). SDC detection schemesrely on a portion of the application state being corrupted, or a largemagnitude in the deviation to detect simulation divergence.
Two levels of corruption propagation are considered:macro tracks deviations in the state variables through the simula-
tion; andmicro tracks deviations in the loads, stores, and other low-level
operations.In order to track corruption propagation at both the micro andmacro level, an LLVM-based [29] instrumentation tool is devel-oped to emulate lock-step execution of a correctly executed gold
Fault Error FailureActivation Propagation
Figure 2: Logical flow of error propagation from initial faultto subsequent failure.
a = ld a ptr
b = add a, 2
c = cmp b, 0
br c, if, else
a f = ld a ptr f
b f = add a f, 2
c f = cmp b f, 0
br c f, if, else
(a) Code is duplicatedforming two sets gold(green code) and faulty(red code).
a = ld a ptr
a f = ld a ptr f
b = add a, 2
b f = add a f, 2
c = cmp b, 0
c f = cmp b f, 0
br c, if, else
br c f, if, else
a f = ld a ptr f
b = add a, 2
b f = add a f, 2
c = cmp b, 0
c f = cmp b f, 0
br c, if, else
br c f, if, else
(b) gold and faulty codeis interleaved to emulatelock-step execution.
a = ld a ptr
a f = chkLd(a ptr f, a ptr, a)
b = add a, 2
b f = add a f, 2
c = cmp b, 0
c f = cmp b f, 0
br c, if, else
br c f, if, else
(c) All loads and stores infaulty are replaced withinstrumentation calls totrack corruption propaga-tion at a load/store level ofaccuracy.
a = ld a ptr
a f = chkLd(a ptr f, a ptr, a)
b = add a, 2
b f = add a f, 2
c = cmp b, 0
c f = cmp b f, 0
checkDiverged(c, c f)
br c, if, else
(d) faulty branches are re-placed with an instrumen-tation call to check for con-trol flow divergence.
a = ld a ptr
a f = chkLd(a ptr f, a ptr, a)
a f crpt = crpt(a f)
b = add a, 2
b f = add a f crpt, 2
b f crpt = crpt(b f)
c = cmp b, 0
c f = cmp b f crpt, 0
checkDiverged(c, c f)
br c, if, else
(e) faulty instructions arerun though the fault in-jector FlipIt [11] to instru-ment them for fault injec-tion.
Figure 4: Overview of the code transformation for micro-level propagation tracking.
*.c *.bc *.bc *.oclang clang
FlipIt
LLVM Corruption
Propagation Pass
Figure 3: Overview of the instrumentation process thattransforms source code to be able to track propagation andinject faults.
along with a faulty execution faulty. Optimized LLVM IR code isrun though a compiler pass to instrument it to track corruptionpropagation and to inject faults before being compiled to objectcode — see Figure 3. Figure 4 illustrates the instrumentation pro-cess performed in the compiler pass. Source code is instrumented(Section 3.1) after compiler optimizations are performed to mitigatethe impact of instrumentation on the object code generated. AnAPI call at natural points in the application — e.g., end of an itera-tion — tracks propagation of application level memory allocationsat the macro-level. At the micro-level, the LLVM compiler pass addsinstrumentation to track propagation at a load/store granularityand relates loads/stores to application level memory allocations.
After replication, there exists two distinct sets of instructions:one for the gold application (green) and one for the faulty applica-tion (red). Instructions for the gold application forms a referenceset of loads, stores, and correct program behavior that the faultyapplication instructions are compared against. Replicating all in-structions creates separate memory images for both the gold andfaulty applications. Thus, these two sets of instructions do not sharethe same data.
3.1 Micro-level Propagation TrackingAt the micro-level, loads and stores are monitored for deviationssince these operations directly impact the state variables. Storescommit erroneous values to state variables, while loads allow forreuse and propagation of corrupted data. Examining corruptionpropagation at the micro-level allows a fine grain view of how cor-ruption propagates inside the application. This is useful to assess
the bound on a pointer reference leading to a segmentation fault,to determine the number of loads and stores that are perturbed, toquantify the deviation when a corruption is masked by the appli-cation, and to examine the impact of compiler optimizations at afine-grain level.
Because instructions from gold and faulty are interleaved, cor-responding operations — i.e. loads and stores — are next to eachother allowing for straightforward comparison of both the valuesand the addresses. To simplify the comparison, all loads and storesin faulty are replaced with an instrumentation call, see Figure 4c. Inaddition to determining if a loaded or stored value deviates from theexpected gold value, the deviation can be calculated (with additionalcomputational cost) along with information on the associated allo-cation. The latter requires the base address and size of all memoryallocations to be logged by instrumenting memory allocation callsand by inserting the base address and size into a table. Informationthat relates the gold and faulty allocations is also logged since it isused to assess macro-level propagation.
Algorithms 1 and 2 detail the logic of the instrumentation calls forloads and stores, respectively. The function call to checkInMemorydetermines whether an address is contained in a logged memory al-location of the faulty application. The information collected insidethe function logDeviation of Algorithm 3 accumulates informa-tion into the same variables for both loads and stores; however, inpractice a vector of statistics exists for loads and stores. If a storeis outside an allocated memory region of the faulty application,then the address and value are added into an outside store hashtable to allow subsequent loads to read the incorrectly written valueand to prevent overwriting of data used by the gold application.Conversely, if a load from faulty occurs outside an allocated mem-ory region, the load proceeds only if the address does not exist inthe outside store hash table. If the address is found in the outsidestore hash table, the faulty address is de-referenced in an effortto generate a segmentation fault, but execution proceeds with thevalue from the store hash table.
Once a fault is injected, it propagates to registers and mem-ory locations based on data-dependencies. Periodically, these data-dependencies flow to a comparison used in a branch. Control flow
Algorithm 1: Logic for load instrumentation function call.1 Function chkLd(fptr, gptr, gvalue)2 inMemory← checkInMemory(fptr)3 if !inMemory then4 inStoreTable← checkInStoreTable(fptr)5 if inStoreTable then6 fvalue← readStoreTable(fptr)7 else8 fvalue← *fptr
Algorithm 2: Logic for store instrumentation function call.1 Function chkSt(fptr, fvalue, gptr, gvalue)2 inMemory← checkInMemory(fptr)3 logDeviation(fptr, gptr, fvalue, gvalue, inMemory)4 if !inMemory then5 writeStoreTable(fptr, fvalue)6 else7 fptr← *fvalue
8 return
Algorithm 3: Logic for logging information on deviation ofload or store at the micro-level.1 Function logDeviation(fptr, gptr, fvalue, gvalue, inMemory)2 dev← abs(fvalue - gvalue)3 if dev != 0 then4 if !inMemory then5 numAccessOut← numAccessOut + 16 maxDeviation← max(maxDeviation, dev)7 numDevAccess← numDevAccess + 18 return
in the lock-step execution relies on the values from the gold ap-plication — see Figure 4d. Comparisons in faulty remain, but thebranching instruction is replaced with an instrumentation call tolog information about this branching deviation. Due to lock-stepstyle execution, micro-level propagation tracking is unable to ac-curately resolve control flow divergence. Resolving this requires acoarser view of propagation tracking: macro-propagation tracking.
To resolve control flow divergence and to handle regions of codenot open to instrumentation— e.g., MPI_Send, MPI_Recv— functioncalls are duplicated. For functions that modify global state and yielda different result when called by both the gold and faulty code — e.g.,rand(), MPI_Init()— the return value is duplicated allowing boththe gold and faulty codes to proceed with the intended value/action.
For functions open to instrumentation, the LLVM pass createsa new version of that function with an extended interface. Thefunction’s argument list is duplicated providing arguments for thegold and faulty code. In addition, the return type is modified toreturn a structure containing two elements: the return value forboth the gold and the faulty code. Code contained inside the originalfunction is duplicated and combined as shown in Figure 4. faulty
code depends on and consumes the faulty arguments, and the goldcode depends on and consumes the gold arguments.
After the gold and faulty code has been merged and all instru-mentation is complete, faulty instructions are passed to FlipIt [11],an LLVM based fault injector, to instrument the faulty instructionsfor fault injection — see Figure 4e. For instructions that have been re-placed with instrumentation calls, FlipIt is instructed to only injectfaults in arguments belonging to the faulty code. Arguments com-ing from gold will never suffer fault injection in instrumentationcalls.
3.2 Macro-level Propagation TrackingMacro-level propagation tracking targets the deviation of high-levelstate variables, data structures, and propagation across processboundaries. To facilitate tracking propagation of corruption in statevariables, the base address of all memory allocations along with theallocation’s length are stored in a table. During compilation, theLLVM corruption propagation pass inserts an instrumentation callafter the memory allocation in the gold and faulty code that logsboth allocations into the table. Furthermore, this instrumentationcall creates a relationship between the two allocations allowingfor comparison of indices when computing propagation statistics.Algorithm 4 details the logic used when comparing two memoryallocations. By default, only the percent of elements corrupted,ℓ2-norm, and max-norm between the gold and faulty memory allo-cations is logged for post run analysis.
Comparing the state of all allocated variables is expensive; there-fore, comparison points are placed at natural termination points —e.g., end of an iteration. These locations correspond to locationswhere SDC checks are often placed and checkpointing occurs. Ini-tially, corruption is confined to the process in which the fault oc-curred. As the application progresses, inter-process communicationallows corruption to propagate beyond the process suffering thefault. Understanding how fast this occurs and which processes arelikely to have corrupted data allows for only a subset of processesto recover by checkpoint-restart or a more tailored algorithmicsolution.
Unlike micro-level propagation tracking, macro-level propaga-tion tracking is able to resolve divergence in control flow graph byexecuting functions to completion once for the gold arguments andlastly for the faulty arguments. Control flow may diverge insidethe function, but at the point the function call returns both the gold
and faulty applications are at the same point in the control flowgraph. Thus, comparing the states of the gold and faulty memoryallocations is safe and meaningful.
4 EXPERIMENTAL RESULTS4.1 Testing Methodology
4.1.1 System. Results are collected on Blue Waters, a Cray su-percomputer managed by the National Center for SupercomputingApplications and supported by the National Science Foundationand the University of Illinois. Each compute node has 2 AMD 6276Interlagos CPUs and 64 GB of RAM. Clang and LLVM version 3.5.2compile and instrument the source code.
4.1.2 Fault Injection. The fault model used in this paper assumesthat transient faults arise in processor logic during execution. Thatis, the fault manifests as a single bit-flip in the result register ofthe instruction. In addition, it is assumed that register files andmemories such as SRAM and DRAM are sufficiently protected byerror correcting codes (ECC) or more advance features such asChipkill [15], and that faults are not injected in these locations. TheLLVM corruption propagation pass uses the open-source LLVMbased fault injector FlipIt [11] to instrument instruction from thefaulty application, allowing for faults to be injected dynamically atruntime.
This paper does not inject faults into the initialization of the ap-plications. Instead, faults are injected during the main computation.The selected applications use MPI, and in the tests, MPI processrank 3 is selected to experience a single bit-flip error during theexecution of a unique, random dynamic LLVM instruction. Instruc-tions selected for fault injection are classified into the followingcategories based on its use in code: floating-point arithmetic (Arith-FP), fixed-point integer arithmetic (Arith-Fix), pointer and addresscalculation (Pointer), and branching, comparisons, and control flow(Control). Latency, in number of instructions, counts dynamicallyexecuted LLVM instructions.
Although a single MPI process suffers a fault, all MPI processesstill track propagation via the methods outlined in Section 3 inorder to determine if propagation occurs between nodes.
Each application is run 1500 times with a different random faulteach time. The kernels WAXPY and SpMV are run 1500 times peroptimization level each with a different random fault.
4.1.3 Applications. Jacobi: This defines Jacobi relaxation ona unit square with fixed boundaries using a 5-point stencil and1-D row partitioning of parallel processes. This test uses 4 MPIprocesses with 4096 grid points per process. Instrumentation yieldsa 102× slowdown. Jacobi relaxation does not guarantee a reductionin the residual, however unexpected large jumps often indicatethe presence of state corruption. This paper flags any increasein the residual by an order of magnitude as SDC. The stoppingtolerance use for Jacobi is 1e−3, and the floating-point comparisontolerance when tracking propagation is set to 1e−5. Finally, macro-level propagation results are logged at the end of each iteration.
CoMD: CoMD1 is a molecular dynamics mini-app created andmaintained by the Exascale Co-Design Center for Materials inExtreme Environments (ExMatEx). CoMD is parallelized with MPI1https://github.com/exmatex/CoMD
and uses a link-cell structure to determine the interaction regionsfor the atoms. This test uses 16MPI processes to simulate themotionand interaction of 32000 atoms over 500 time-steps, where forcesbetween atoms are computed using the Embedded-Atom Method(EAM). Instrumentation results in a 33× slowdown and SDC isdetected by ensuring that the total energy is within five standarddeviations of the ensemble mean. Macro-level propagation resultsare logged at the end of each iteration. Deviations smaller than1e−10 are considered insignificant to accuracy of CoMD.
HPCCG:HPCCG2 is a conjugate gradient (CG) benchmark fromthe Mantevo Suite that simulates a 3D chimney domain using a 27-point finite difference matrix. This test is run with 16 MPI processesand a local block size of nx = ny = nz = 13 and instrumentationresults in a 460× slowdown. As with Jacobi, the CG algorithm doesnot guarantee a reduction in the residual. Here, any increase in theresidual by an order of magnitude is flagged as SDC. Macro-levelpropagation results are logged at the end of each iteration. Theconvergence tolerance used for HPCCG is 1e−7 — when trackingcorruption propagation, deviations smaller than 1e−10 are ignored.
4.2 Micro-level Propagation4.2.1 Latency of Detection. Each injected fault starts as a single-
bit error in the result register of an instruction. As the programexecutes, the single-bit error propagates to other registers andmemory locations. Depending on the type of instruction the faultis injected into, the latency to detection often varies. The analysisin this paper looks at three triggers to failure: segmentation fault,detection, and control flow divergence. Table 1 shows the break-down of each symptom based on instruction type across the testsin Section 4.1.3.
Segmentation faults account for 30–35% of all injected faults ineach application. From Table 1, the majority (over 50%) of segmen-tation faults are triggered by Pointer instructions. Figure 5 showsthe segmentation fault latency for each application in number ofLLVM instructions executed after an injection. A significant num-ber (90%) of segmentation faults occur within 4 LLVM instructions.Of the runs with a segmentation fault within 4 LLVM instructions,61% percent are classified as Pointer, 32% percent are classified asArith-Fix, 0% percent are classified as Arith-FP, and 13% percent areclassified as Control. Looking at the remaining segmentation faults,16% percent are classified as Pointer, 8% percent are classified asArith-Fix, 0% percent are classified as Arith-FP, and 76% percent areclassified as Control. Short latencies are attributed to corruption ofaddress calculation — e.g., corrupting an address or offset, beforea load or a store. Longer latencies are the result of corruption inthe loop induction variables. The instructions used to check a loopconditional increases the segmentation fault latency slightly beforethe induction variable is used as part of a load/store during thesubsequent iteration. Segmentation fault latencies for these appli-cations are consistent with those reported for the Linux kernel [20]and other benchmarks [30].
Figure 6 shows the bit locations that generated a segmentationfault. The results highlight that most segmentation faults occur dueto a bit-flip near the most-significant bit (MSB). Bit-flips in bits nearthe least-significant bit (LSB) lead to incorrect indexing and using
2https://mantevo.org/packages.php
Table 1: Breakdown of failure symptom by instruction type.
Failure SymptomInstruction Segmentation Detection Control Flow
0 1 1e+1 1e+2 1e+3 1e+4 1e+5 1e+6Number of LLVM Instructions Until Crash
Jacobi
CoMD
HPCCG
App
licat
ion
Figure 5: Latency (number of LLVM instructions) until a seg-mentation fault.
LSB 8 16 24 32 40 48 56 MSBBit Location
Jacobi
CoMD
HPCCG
App
licat
ion
Figure 6: Bit positions where injected fault resulted in a seg-mentation fault.
incorrect data. Flipping bits 0–2 result in unaligned data access fordouble precision arrays and can cause significant deviation in theload/store, but rarely generates a segmentation fault. As the localproblem size grows, the amount of allocated memory also increases.As a result, the number of segmentation faults decreases for loworder bits by replacing them with load/store on incorrect addresses.
Segmentation faults are an excellent detector that allow littlecorruption propagation in most cases. Since segmentation faultsoccur in only 30–35% of the tests most faults allow for propagationand SDC. Typical HPC SDC detectors check for errors at a coarsegranularity (thousands or millions of instructions) by looking for
1e+5 1e+6 1e+7 1e+8 1e+9Number of LLVM Instructions Until Detection
Jacobi
CoMD
HPCCG
App
licat
ion
Figure 7: Latency (number of LLVM instructions) until SDCdetection.
latent errors that have corrupted the state of application level vari-ables to cause a noticeable deviation. Overall the lightweight SDCdetectors added to tests (Section 4.1.3) detect data corruption in 11%of Jacobi runs, 1% of HPCCG runs, and 2% of CoMD runs. Breakingdown which faults are detected by instruction type, Table 1, showsmost detected faults occur in Arith-FP instructions. Figure 7 showsthe latency in number of LLVM instructions executed before thedetection occurs. Compared to detection via segmentation faults,detection latency of specially designed detectors is much larger.
Each test checks for SDC at the end of each iteration. Convertingdetection latency from LLVM instructions executed to iterationsexecuted shows all runs with detection for CoMD and HPCCGare within 2 iterations of injection. Detected SDC in Jacobi hasa longer maximal latency at 492 iterations. Faults that cause anorder of magnitude differences in floating-point values are detectedduring the following iteration. Without SDC detectors 100% ofHPCCG runs and 56% of Jacobi would require extra iterations toconverge to the correct solution. All CoMD runs with detectionappear as outliers when forming an ensemble distribution at thefinal time-step if no SDC detectors are present.
If checkpoint-restart routines are used to recover from the de-tected SDC, then for runs with a high latency of detection, a dominoeffect of needing to roll back older and older checkpoints is possibleif recovery proceeds from frequently taken in-memory checkpoints;this is common for multi-level checkpointing schemes [7, 35]. At thetime of detection, if the extent of corruption is known in terms ofstate variables and processes, then forward-recovery schemes offerthe best solution to avoid the domino effect of checkpoint-restart(backward-recovery).
4.2.2 Abnormal Behavior. HPC applications commonly iterateover and compute on vectors of data. Faults in Pointer and Arith-Fixinstructions often lead to corruption in pointers used in load/storeoperations, and can lead to segmentation faults. However, corrup-tion of loop control variables can lead to divergence in the controlflow graph. Control flow divergence in loops (see Figure 8) resultsin an early loop exit; consequently, elements of a vector may notbe updated or computed. Control flow divergence occurs in 3% ofJacobi runs, 6% of HPCCG runs, and 20% of CoMD runs. UnlikeHPCCG and Jacobi where data distribution is static, CoMD hasatoms that migrate between processes that dynamically modify the
1 1e+2 1e+4 1e+6 1e+8 1e+10Number of LLVM Instructions Until Control Flow Divergence
Jacobi
CoMD
HPCCG
App
licat
ion
Figure 8: Latency (number of LLVM instructions) until con-trol flow diverges.
data distribution. The extreme latencies for control flow divergencein CoMD are due to corruption of the atom positions that modifiesthe control flow of the atom exchange routine as atoms migrate in-correctly (inter-process corruption propagation). In the remainingcases, most control flow diverges within the injected loop struc-ture, leaving some vector entries unmodified. To ensure correctexecution of these loops, instruction duplication techniques such asIPAS [28] and FlipBack [36] or low-cost invariant checks [23], offerthe ability to ensure correct control flow with minor overheads.
An optimization to lower the overhead of algorithmic based SDCdetection schemes is to assume static data — e.g., the matrix in alinear solver is sufficiently protected that it does not need explicitchecks for consistency and leaving SDC checks to inspect dynamicdata. With a fault model that only allows for corruption in Arith-FPvalues, this is a valid assumption, however once corruption occurin Arith-Fix and Pointer type instructions, static data can be writtenby errant store instructions. Although very rare (less than 0.1%of runs) it does have the ability to make a convergent algorithmnon-convergent or converge to a different solution. To mitigatecorruption of static data, checksums can be employed to ensureconsistency or pages containing static data can be marked read-onlyafter initialization to ensure no errant stores corrupt the data.
4.2.3 Effect of Compiler Optimizations. The ratios of the dif-ferent instruction types impact the probability of different failuresymptoms. Table 2 shows the percentage of dynamic LLVM in-structions for each application classified as a given instruction type.Across all applications, instructions classified as Arith-FP comprisesthe majority dynamic instructions followed by instruction typesPointer and Arith-Fix that are used to compute addresses. Finally,Control flow makes up the smallest classification percentage.
Instruction mix depends on the data structures, compiler, andoptimization level. Two key operations in the HPCCGmini-app andother linear solvers are the sparse matrix-vector multiply (SpMV)and scaled vector addition (WAXPBY). The impact of compiler opti-mizations on these small kernels helps identify the impact on thefull mini-app and production application.
WAXPY: A WAXPY operation, Algorithm 5 scales two input vectorsx and y when performing the vector addition operation. Compil-ing without any optimizations (-O0) produces verbose and explicitcode as every load and store references memory. Register allocatingvariables i and N along with hoisting loads outside the loop with-O1 reduces address calculation and loads/stores that often leadto segmentation faults, see Section 4.2. Furthermore, optimizationlevels -O2 and -O3 unroll and vectorize the loop, further reducingthe need for control flow instructions. For this kernel, -O2 and -O3produces identical code. To support higher level optimizations suchas loop unrolling and vectorization, extra instructions are added toensure correctness for all sizes of N. Table 4 summarizes the impactof compiler optimizations. Vectorization increases the number ofinteger operations which causes an increase in runs that experiencea segmentation fault. Loop unrolling removes branching instruc-tions and instructions that update the loop induction variable whichremoves locations where corruption of loop induction variables arepossible lowering control flow divergence.
Algorithm 5: Scaled Vector Addition (WAXPBY).1 for i← 0 to N do2 w[i]← a * x[i] + b * y[i]
Table 3: Dynamic LLVM instruction percentage for WAXPBYkernel.
Optimizations Arith-Fix Pointer Control Arith-FP
O0 31% 23% 15% 31%O1 8% 23% 23% 46%
O2/O3 17% 40% 3% 40%
SpMV: The SpMV kernel, Algorithm 6, is more complicatedthan that of WAXPBY both mathematically and in machine code.Because the SpMV uses a sparse matrix representation (compressedsparse row in Algorithm 6), the level of indirection needed to accessentries of the matrix increases. Each increase in indirection involvesa pointer dereference; therefore, with more address manipulationsand loads/stores, the number of dynamic instructions of Arith-Fixand Pointer are higher than with WAXPBY, as shown in Table 5. This
also implies that common symptoms of these types of operationswill be more prevalent.
Algorithm 6: Sparse Matrix-Vector Multiplication.1 for i← 0 to num_row do2 tmp← 03 for jj← A_i[i] to A_i[i+1] do4 tmp← tmp + A_data[jj] * x_data[A_j[jj]]
5 y_data[i] ← tmp
With the baseline optimization level -O0, the code is explicit andverbose. Higher levels of optimizations retain the base addresses ofthe arrays A_i, A_j, A_data in register temporaries along with loopinduction variables and hoists loads with -O1. Optimization levels-O2 and -O3 do not vectorize this kernel. Instead, the inner mostloop is unrolled removing comparisons and branching instructionsalong with hoisting the load of num_row to outside the loops.
Table 6 shows that without vectorization, the rate of segmenta-tion faults remains around 30% of executions, which is consistentwith WAXPBY and the applications. Loop unrolling fails to reducedivergence in control flow compared to WAXPBY. Control flow forthe inner most loop is more complex than with WAXPBY resultingin more locations in which a fault can occur that influences controlflow.
4.3 Macro-level PropagationAfter a fault occurs, an erroneous value is present in the applica-tion state. Over time, as this value is used/reused, the corruptionpropagates to infect larger portions of the application state. MostHPC SDC detectors ensure correctness of application level variables.Knowing which application variables are corrupted and the extentof corruption can assist in placement of detection and recoveryschemes.
4.3.1 Jacobi. Each iteration of Jacobi refines a solution u toimprove the solution accuracy resulting in an updated solutionin a separate vector unew . These two vectors represent the twokey data structures and is the focus when measuring corruption
Table 5: Dynamic LLVM instruction classification percent-age for SpMV kernel.
Figure 9: Average percentage of corrupted elements of iter-ative solution u for Jacobi.
propagation. Figure 9 shows the average percentage of elementsthat are corrupted due to an injected fault (intensity of color) acrossall MPI processes (y-axis) in the iterations following the injectioniteration (x-axis) for the solution variable u. The variable unew isnot shown as it is qualitatively similar to u. All runs are aggregatedto align the iteration where injection occurs. This allows corruptionpercentages in all remaining iterations to be averaged over all runs.All faults are injected on rank 3, and as time evolves corruptionpropagation occurs inside this process indicated by the increase inthe intensity of color on the horizontal row for rank 3. Overtime,corruption propagates inside rank 3 and reaches the region of thearray that is communicated via a halo-exchange corrupting process2. This process continues until all processes are corrupted or thecorruption is attenuated. Because Jacobi converges to a solution,over time the corruption in the variables is removed. When trackingpropagation in u, comparisons are made between the memory of ufrom the gold and faulty applications. As Jacobi continues to iterate,error does not appear to reduce because as error due to the faultis removed from the faulty u it is being compared to an ever moreaccurate u from the gold application. Only with extra iterations onfaulty (beyond what is run for gold) do the two solution vectorsconverge.
After a fault, corruption appears immediately on rank 3. Ascorruption propagates inside rank 3, it corrupts values set to process2 in a halo exchange the speed of this corruption depends on thestencil size. This problem uses a 5-point stencil, and the averageworst case propagation latency occurs when an element interior to alocal domain is corrupted. This requires n/2 iterations were n is thelocal block size. SDC detected in Jacobi is within 492 iterations ofinjection. For any reasonable local block size, once SDC is detected itcan be confined to a process and its immediate neighbors; allowinga customized local recovery scheme to be applied.
4.3.2 HPCCG. Conjugate Gradient (CG) — see Algorithm 7 — isa popular solver for systems of linear equations. This algorithmrelies on four key variables: the iterative solution xk , search di-rections pk that are used to update xk , residual vector rk , and thematrix-vector product A ∗ p.
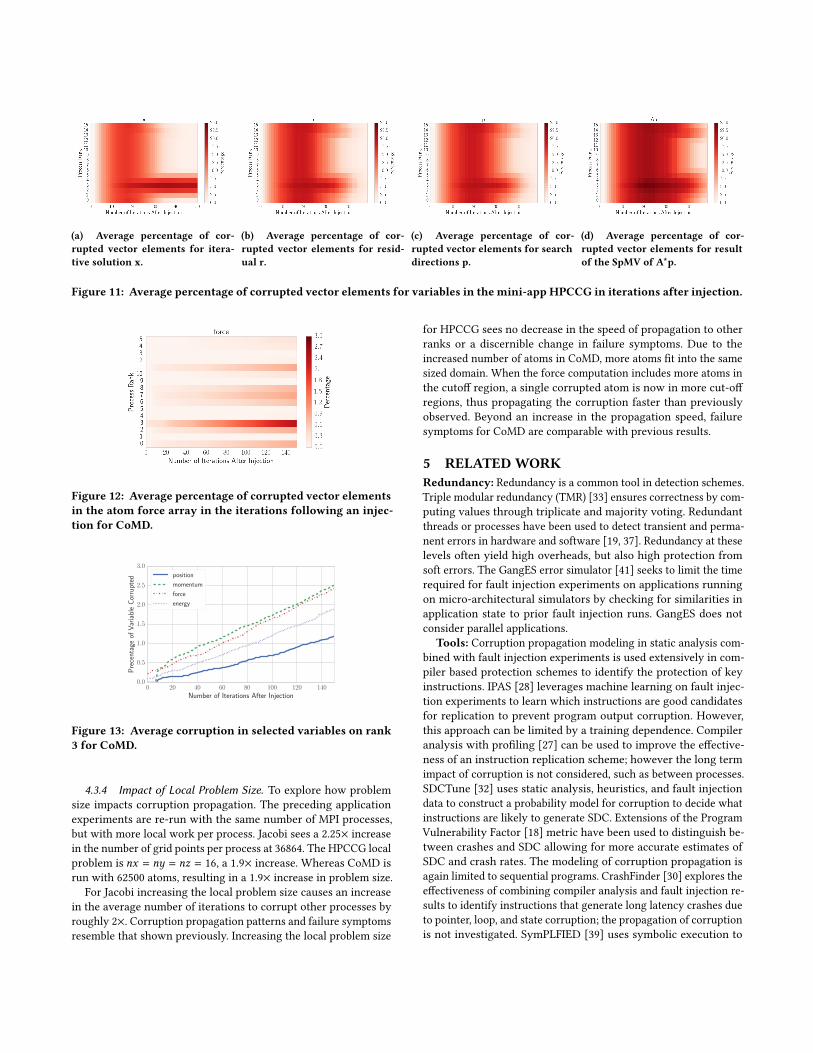
As with Jacobi, propagation results for HPCCG are aggregatedto align the iteration in which injection occurs. Figure 11 showscorruption propagation in the form of the average percentage of
Algorithm 7: Conjugate Gradient Method.1 r0 = b − Ax02 p0 = r03 k = 04 while ∥ rk ∥2< tol do
5 αk =rTk rk
pTk Apk6 xk+1 = xk + αkpk7 rk+1 = rk − αkApk
8 βk =rTk+1rk+1rTk rk
9 pk+1 = rk+1 + βkpk10 k = k + 1
elements corrupted (color) per variable across all MPI processes (y-axis) for subsequent iterations after injection (x-axis). As corruptionpropagates locally inside each variable, the horizontal color for thatrow grows darker. As corruption is removed, the color lightens.Propagation between processes can be seen by looking at the colorprogression of columns at each iteration.
Initially, the average percentage of elements corrupted in eachvector is small. However, as HPCCG continues to iterate, corruptionbegins to propagate both internally and externally of the corruptedprocess, rank 3. The most severe corruption is confined to rank 3and the neighboring processes across the majority of the iterations.Dependencies between the four variables in Figure 11 are due acorruption in the variables r , p, or Ap, which leads to corruption inthe solution vectorx . Furthermore, the SpMVpropagates corruptionas shown in the corresponding corruption in p and Ap on everyprocesses of each iteration. Data dependencies in updating othervectors further propagates corruption in Ap to all other variables.Ensuring the correctness of p limits corruption propagation fromthe SpMV in Ap and subsequently corruption propagating to r andx .
To see corruption propagation between variables more closely,Figure 10 shows the average percentage of elements from eachvariable corrupted on rank 3. As with Jacobi, the iterative solution xincreases in error initially, but over time does not appear to removeerror due to soft error corruption. This error is reduced at eachiteration, however the iteration does not converge back to gold x .Errors in r closely follow those in p as both are used in updatingthe other through a WAXPBY. As corruption in p grows and subsides,Ap reflects and propagates the corruption accordingly.
The search direction p is central to corruption propagation asit is used in updating the other variables. Ensuring that p is com-puted correctly helps ensure that the other variables are computedcorrectly. Because CG uses inner-products, if masking does notoccur, then corruption in input vectors propagates to all processesin one iteration. Therefore, some form of corruption is residentin all variables within 3 iterations for runs that did not producea segmentation fault. Local recovery is still possible, though it iscomplicated by the presence of corruption on multiple processes.
4.3.3 CoMD. Molecular dynamics codes such as CoMD do notconverge to the same solution with each execution of the programas with HPCCG and Jacobi. Instead, a single run is combined with
0 10 20 30 40 50Number of Iterations After Injection
0
5
10
15
20
25
Pre
cent
age
ofE
lem
ents
Cor
rupt
ed
x
r
p
Ap
Figure 10: Average corruption in selected variables on rank3 for HPCCG.
many other runs to form a statistical ensemble to analyze the dis-tribution of key properties such as energy. This implies that smalldeviations can be masked if they do not modify the distribution.The key variables in CoMD for propagation analysis are: atom po-sitions, atom momenta, atom forces, and atom energy. CoMD alsodiffers from the other applications in how it stores its data. Becauseatoms migrate between processes, arrays are over allocated leavingspace for other atoms from remote processes. This slack space is notcontiguous within the arrays because it is allocated per local celland not collectively for the entire local domain. The unused regionsof the atoms complicate tracking propagation. Without modifyingthe data layout of CoMD this paper factors out the unused atomstorage by using the number of atoms per process instead of thememory allocation size when computing corruption statistics.
Figure 12 shows the average percentage of corruption in the keyvariables of CoMD. For simplicity, only the force variable is shown.The remaining variables have a similar propagation pattern in termsof percentage of elements and ranks corrupted. Unlike HPCCG,where the SpMV rapidly propagates corruption between processes,the propagation in CoMD resembles Jacobi with corruption slowlypropagating to neighboring domain regions. Although slow, thecorruption propagation increases monotonically as time evolveswhich leads to an increased likelihood of the run becoming anoutlier for large numbers of iterations. Over the iterations after aninjection, 1% of the runs are classified as outliers when looking atthe energy distribution at the final iteration. All of these outliersare caught by the SDC check.
The communication pattern in CoMD consists of point-to-pointmessages as atoms migrate from process to process. A single atomcontributes to the force calculation of neighboring atoms. Thisregion of influence is small and needs many iterations for the cor-ruption to spread beyond the initially corrupted region of influence.This accounts for slow rate of propagation inside CoMD. Althoughcorruption can propagate to neighbor processes, it requires tensto hundreds of iterations before corruption of an atom propagatesto all processes. Corruption that impacts the simulation’s energydistribution are detected within two iterations which allows forlittle inter-process propagation. Containment domains can be estab-lished around the process triggering the SDC detector and nearestneighbors to allow for partial recovery.
(a) Average percentage of cor-rupted vector elements for itera-tive solution x.
(b) Average percentage of cor-rupted vector elements for resid-ual r.
(c) Average percentage of cor-rupted vector elements for searchdirections p.
(d) Average percentage of cor-rupted vector elements for resultof the SpMV of A*p.
Figure 11: Average percentage of corrupted vector elements for variables in the mini-app HPCCG in iterations after injection.
Figure 12: Average percentage of corrupted vector elementsin the atom force array in the iterations following an injec-tion for CoMD.
0 20 40 60 80 100 120 140Number of Iterations After Injection
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Pre
cent
age
ofV
aria
ble
Cor
rupt
ed
position
momentum
force
energy
Figure 13: Average corruption in selected variables on rank3 for CoMD.
4.3.4 Impact of Local Problem Size. To explore how problemsize impacts corruption propagation. The preceding applicationexperiments are re-run with the same number of MPI processes,but with more local work per process. Jacobi sees a 2.25× increasein the number of grid points per process at 36864. The HPCCG localproblem is nx = ny = nz = 16, a 1.9× increase. Whereas CoMD isrun with 62500 atoms, resulting in a 1.9× increase in problem size.
For Jacobi increasing the local problem size causes an increasein the average number of iterations to corrupt other processes byroughly 2×. Corruption propagation patterns and failure symptomsresemble that shown previously. Increasing the local problem size
for HPCCG sees no decrease in the speed of propagation to otherranks or a discernible change in failure symptoms. Due to theincreased number of atoms in CoMD, more atoms fit into the samesized domain. When the force computation includes more atoms inthe cutoff region, a single corrupted atom is now in more cut-offregions, thus propagating the corruption faster than previouslyobserved. Beyond an increase in the propagation speed, failuresymptoms for CoMD are comparable with previous results.
5 RELATEDWORKRedundancy: Redundancy is a common tool in detection schemes.Triple modular redundancy (TMR) [33] ensures correctness by com-puting values through triplicate and majority voting. Redundantthreads or processes have been used to detect transient and perma-nent errors in hardware and software [19, 37]. Redundancy at theselevels often yield high overheads, but also high protection fromsoft errors. The GangES error simulator [41] seeks to limit the timerequired for fault injection experiments on applications runningon micro-architectural simulators by checking for similarities inapplication state to prior fault injection runs. GangES does notconsider parallel applications.
Tools: Corruption propagation modeling in static analysis com-bined with fault injection experiments is used extensively in com-piler based protection schemes to identify the protection of keyinstructions. IPAS [28] leverages machine learning on fault injec-tion experiments to learn which instructions are good candidatesfor replication to prevent program output corruption. However,this approach can be limited by a training dependence. Compileranalysis with profiling [27] can be used to improve the effective-ness of an instruction replication scheme; however the long termimpact of corruption is not considered, such as between processes.SDCTune [32] uses static analysis, heuristics, and fault injectiondata to construct a probability model for corruption to decide whatinstructions are likely to generate SDC. Extensions of the ProgramVulnerability Factor [18] metric have been used to distinguish be-tween crashes and SDC allowing for more accurate estimates ofSDC and crash rates. The modeling of corruption propagation isagain limited to sequential programs. CrashFinder [30] explores theeffectiveness of combining compiler analysis and fault injection re-sults to identify instructions that generate long latency crashes dueto pointer, loop, and state corruption; the propagation of corruptionis not investigated. SymPLFIED [39] uses symbolic execution to
abstract the state of corrupted values in the program to find hard-to-detect fault injection locations that random fault-injection mayreveal; this is limited to sequential integer programs.
Characterization: A study of the numerical impact of a singlebit-flip on matrix-vector computations and GMRES is presentedin [16, 17], respectively. An analysis of long latency crashes [45],shows corruptions in memory have long fault activation timesleading to long latencies for crashes compared to corruption inregisters, but does not investigate the extent of corruption prop-agation at the time of detection and the ability to recover locally.The impact of soft errors on the Linux kernel is determined [20],but does not quantify the corruption of system state variables todetermine how to prevent propagation for long latency crashes.Y-branches [44] explores how control flow divergence impacts ap-plications correctness and performance. Control flow re-convergesif the architectural state exactly matches a golden copy; however,for applications that can remove/mask corruption over-time, thismay underestimate the number Y-branches.
Characterizations of corruption in floating-point computationinside HPC applications is presented in [2]. Corruption is trackedbased on terms of number of incorrect memory accesses and doesnot relate this to application level variables. A similar study [31],quantifies corruption in GPU and host memories for GPU bench-marks, but does not look at how corruption propagation in a dis-tributed memory environment.
Recovery: Establishing a bound on the subset of total programstate that is corrupted allows for localized recovery. Containmentdomains [14] surround code regions, using verification to ensurecorrectness. Identifying the location of code containment remainsopen. Similarly, transactional semantics [24] can be used for MPI,but not on application variables thatmay be corrupted. Esoftcheck [46],uses compiler analysis to remove redundant SDC detectors to main-tain high reliability, but does not consider the latency of detectionand how it effects propagation. An analytic version of this problemwhich investigates optimal placement of detectors of different capa-bilities to verify a checkpoint is corruption free is presented in [4],but considers a fixed recovery time that does not change based onhow much state is corrupted.
6 CONCLUSIONAs HPC systems trend toward larger numbers of smaller compo-nents at lower voltages, the rate of errors due to hardware faults isexpected to increase. To mitigate these issues in HPC applications,many SDC detection and recovery schemes have been proposed.This paper explores how state corruption due to a soft error propa-gates at a micro (instruction level) and macro (application variable)level for three applications: Jacobi, HPCCG, and CoMD.
At a micro-level, latency of segmentation faults, divergence ofcontrol flow and detection are investigated. In addition, the im-pact of compiler optimizations is explored on two kernels: WAXPBYand SpMV. Results show that the majority of segmentation faultsoccur shortly after a fault occurs allowing for little propagation.Deviations in control flow predominantly occur as premature looptermination in loops where the fault occurs.
Macro-level results highlight the speed and intensity of corrup-tion on the processes where the failure occurs and between other
processes. Corruption results for critical data structures are dis-cussed along with the ability to define regions of containment forlocal recovery. Finally, increasing the local problem size increasesthe latency of inter-process corruption propagation in Jacobi, whiledecreases the latency in CoMD (and does not influence the latencyfor HPCCG).
Latencies are useful in determining the effectiveness of a de-tection scheme — i.e., short latencies limit corruption propagationand can lower recovery costs. However, low cost recovery in aparallel application requires knowing the corrupted processes anddata structures. Tracking propagation at the macro-level enablesdiscovery of the variables that are most susceptible to corruption, itidentifies the speed of corruption between processes, and indicatedwhether operations reduce or amplify corruption. The probabilityof corruption is valuable in developing more precise SDC detectors.
ACKNOWLEDGMENTWe would like to our reviewers and shepherd for their helpful andinsightful comments on improving the quality of this paper.
This work was sponsored by the Air Force Office of ScientificResearch under grant FA9550-12-1-0478. This work was supportedin part by the Office of Advanced Scientific Computing Research,Office of Science, U.S. Department of Energy award DE-FG02-13ER26138/DE-SC0010049. This material is based upon work sup-ported by the National Science Foundation under Grant No. SHF-1617488. This research is part of the BlueWaters sustained-petascalecomputing project, which is supported by the National ScienceFoundation (awards OCI–0725070 and ACI–1238993) and the stateof Illinois. Blue Waters is a joint effort of the University of Illinoisat Urbana-Champaign and its National Center for SupercomputingApplications.
REFERENCES[1] E. Agullo, L. Giraud, A. Guermouche, J. Roman, and M. Zounon. Towards resilient
parallel linear krylov solvers: recover-restart strategies. Rapport de rechercheRR-8324, INRIA, July 2013.
[2] R. A. Ashraf, R. Gioiosa, G. Kestor, R. F. DeMara, C.-Y. Cher, and P. Bose. Under-standing the propagation of transient errors in HPC applications. In Proceedingsof the International Conference for High Performance Computing, Networking,Storage and Analysis, SC ’15, pages 72:1–72:12, New York, NY, USA, 2015. ACM.
[3] R. C. Baumann. Radiation-induced soft errors in advanced semiconductor tech-nologies. Device and Materials Reliability, IEEE Transactions on, 5(3):305–316,Sept. 2005.
[4] L. Bautista-Gomez, A. Benoit, A. Cavelan, S. K. Raina, Y. Robert, and H. Sun.Which verification for soft error detection? In HiPC, pages 2–11. IEEE ComputerSociety, 2015.
[5] L. Bautista-Gomez and F. Cappello. Detecting silent data corruption for extreme-scale MPI applications. In Proceedings of the 22Nd European MPI Users’ GroupMeeting, EuroMPI ’15, pages 12:1–12:10, New York, NY, USA, 2015. ACM.
[6] L. Bautista-Gomez and F. Cappello. Exploiting spatial smoothness in HPC ap-plications to detect silent data corruption. In Proceedings of the 2015 IEEE 17thInternational Conference on High Performance Computing and Communications,2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and2015 IEEE 12th International Conf on Embedded Software and Systems, HPCC-CSS-ICESS ’15, pages 128–133, Washington, DC, USA, 2015. IEEE ComputerSociety.
[7] L. Bautista-Gomez, S. Tsuboi, D. Komatitsch, F. Cappello, N. Maruyama, andS. Matsuoka. FTI: high performance fault tolerance interface for hybrid systems.In Proceedings of 2011 International Conference for High Performance Computing,Networking, Storage and Analysis, SC ’11, pages 32:1–32:32, New York, NY, USA,2011. ACM.
[8] E. Berrocal, L. Bautista-Gomez, S. Di, Z. Lan, and F. Cappello. Lightweight silentdata corruption detection based on runtime data analysis for HPC applications.In Proceedings of the 24th International Symposium on High-Performance Parallel
and Distributed Computing, HPDC ’15, pages 275–278, New York, NY, USA, 2015.ACM.
[9] S. Borkar. Designing reliable systems from unreliable components: The challengesof transistor variability and degradation. IEEE Micro, 25(6):10–16, Nov. 2005.
[10] P. G. Bridges, K. B. Ferreira, M. A. Heroux, and M. Hoemmen. Fault-tolerantlinear solvers via selective reliability. CoRR, abs/1206.1390, 2012.
[11] J. Calhoun, L. Olson, and M. Snir. FlipIt: An LLVM based fault injector for HPC.In Proceedings of the 20th International Euro-Par Conference on Parallel Processing(Euro-Par ’14), 2014.
[12] J. Calhoun, L. Olson, M. Snir, and W. D. Gropp. Towards a more fault resilientmultigrid solver. In Proceedings of the Symposium on High Performance Computing,HPC ’15, pages 1–8, San Diego, CA, USA, 2015. Society for Computer SimulationInternational.
[13] J. Calhoun, M. Snir, L. Olson, and M. Garzaran. Understanding the propagation oferror due to a silent data corruption in a sparse matrix vector multiply. In Proceed-ings of the 2015 IEEE International Conference on Cluster Computing, CLUSTER’15, pages 541–542, Washington, DC, USA, 2015. IEEE Computer Society.
[14] J. Chung, I. Lee, M. Sullivan, J. H. Ryoo, D. W. Kim, D. H. Yoon, L. Kaplan, andM. Erez. Containment domains: A scalable, efficient, and flexible resiliencescheme for exascale systems. In Proceedings of the International Conference onHigh Performance Computing, Networking, Storage and Analysis, SC ’12, pages58:1–58:11, Los Alamitos, CA, USA, 2012. IEEE Computer Society Press.
[15] T. J. Dell. A white paper on the benefits of chipkillcorrect ECC for PC servermain memory. Technical report, IBM Microelectronics Division, 1997.
[16] J. Elliott, M. Hoemmen, and F. Mueller. Evaluating the impact of SDC on theGMRES iterative solver. In Proceedings of the 2014 IEEE 28th International Paralleland Distributed Processing Symposium, IPDPS ’14, pages 1193–1202, Washington,DC, USA, 2014. IEEE Computer Society.
[17] J. Elliott, F. Mueller, M. Stoyanov, and C. Webster. Quantifying the impact ofsingle bit flips on floating point arithmetic. Technical report, Oak Ridge NationalLaboratory, August 2013.
[18] B. Fang, Q. Lu, K. Pattabiraman, M. Ripeanu, and S. Gurumurthi. ePVF: anenhanced program vulnerability factor methodology for cross-layer resilienceanalysis. 2016 46th Annual IEEE/IFIP International Conference on DependableSystems and Networks (DSN), 00:168–179, 2016.
[19] D. Fiala, F. Mueller, C. Engelmann, R. Riesen, K. Ferreira, and R. Brightwell. De-tection and correction of silent data corruption for large-scale high-performancecomputing. In Proceedings of the International Conference on High PerformanceComputing, Networking, Storage and Analysis, SC ’12, pages 78:1–78:12, Los Alami-tos, CA, USA, 2012. IEEE Computer Society Press.
[20] W. Gu, Z. Kalbarczyk, R. K. Iyer, and Z.-Y. Yang. Characterization of linux kernelbehavior under errors. In DSN, pages 459–468. IEEE Computer Society, 2003.
[21] A. Guermouche, T. Ropars, E. Brunet, M. Snir, and F. Cappello. Uncoordinatedcheckpointing without domino effect for send-deterministic MPI applications.In Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International,pages 989–1000. IEEE, 2011.
[22] A. Guermouche, T. Ropars, M. Snir, and F. Cappello. Hydee: Failure containmentwithout event logging for large scale send-deterministic MPI applications. InParallel & Distributed Processing Symposium (IPDPS), 2012 IEEE 26th International,pages 1216–1227. IEEE, 2012.
[23] S. K. S. Hari, S. V. Adve, and H. Naeimi. Low-cost program-level detectors forreducing silent data corruptions. In Proceedings of the 2012 42Nd Annual IEEE/IFIPInternational Conference on Dependable Systems and Networks (DSN), DSN ’12,pages 1–12, Washington, DC, USA, 2012. IEEE Computer Society.
[24] A. Hassani, A. Skjellum, P. V. Bangalore, and R. Brightwell. Practical resilientcases for fa-mpi, a transactional fault-tolerant mpi. In Proceedings of the 3rdWorkshop on Exascale MPI, ExaMPI ’15, pages 1:1–1:10, New York, NY, USA, 2015.ACM.
[25] L. Jaulmes, M. Casas, M. Moretó, E. Ayguadé, J. Labarta, and M. Valero. Exploitingasynchrony from exact forward recovery for DUE in iterative solvers. In Proceed-ings of the International Conference for High Performance Computing, Networking,Storage and Analysis, SC ’15, pages 53:1–53:12, New York, NY, USA, 2015. ACM.
[26] H. Kaul, M. Anders, S. Hsu, A. Agarwal, R. Krishnamurthy, and S. Borkar. Near-threshold voltage (NTV) design: Opportunities and challenges. In Proceedings ofthe 49th Annual Design Automation Conference, DAC ’12, pages 1153–1158, NewYork, NY, USA, 2012. ACM.
[27] D. S. Khudia, G. Wright, and S. Mahlke. Efficient soft error protection for com-modity embedded microprocessors using profile information. In Proceedings ofthe 13th ACM SIGPLAN/SIGBED International Conference on Languages, Compilers,Tools and Theory for Embedded Systems, LCTES ’12, pages 99–108, New York, NY,USA, 2012. ACM.
[28] I. Laguna, M. Schulz, D. F. Richards, J. Calhoun, and L. Olson. IPAS: intelligentprotection against silent output corruption in scientific applications. In Proceed-ings of the 2016 International Symposium on Code Generation and Optimization,CGO 2016, pages 227–238, New York, NY, USA, 2016. ACM.
[29] C. Lattner and V. Adve. LLVM: a compilation framework for lifelong programanalysis & transformation. In Proceedings of the 2004 International Symposium on
Code Generation and Optimization (CGO’04), Palo Alto, California, Mar 2004.[30] G. Li, Q. Lu, and K. Pattabiraman. Fine-grained characterization of faults causing
long latency crashes in programs. In DSN, pages 450–461. IEEE Computer Society,2015.
[31] G. Li, K. Pattabiraman, C.-Y. Cher, and P. Bose. Understanding error propagationin GPGPU applications. In Proceedings of the International Conference for HighPerformance Computing, Networking, Storage and Analysis, SC ’16, pages 21:1–21:12, Piscataway, NJ, USA, 2016. IEEE Press.
[32] Q. Lu, K. Pattabiraman, M. S. Gupta, and J. A. Rivers. SDCTune: a model forpredicting the sdc proneness of an application for configurable protection. InProceedings of the 2014 International Conference on Compilers, Architecture andSynthesis for Embedded Systems, CASES ’14, pages 23:1–23:10, New York, NY,USA, 2014. ACM.
[33] R. E. Lyons andW. Vanderkulk. The use of triple-modular redundancy to improvecomputer reliability. IBM J. Res. Dev., 6(2):200–209, Apr. 1962.
[34] T. C. May and M. H. Woods. Alpha-particle-induced soft errors in dynamicmemories. Electron Devices, IEEE Transactions on, 26(1):2–9, Jan. 1979.
[35] A. Moody, G. Bronevetsky, K. Mohror, and B. R. d. Supinski. Design, modeling,and evaluation of a scalable multi-level checkpointing system. In Proceedingsof the 2010 ACM/IEEE International Conference for High Performance Computing,Networking, Storage and Analysis, SC ’10, pages 1–11, Washington, DC, USA,2010. IEEE Computer Society.
[36] X. Ni and L. V. Kale. FlipBack: automatic targeted protection against silentdata corruption. In Proceedings of the International Conference for High Perfor-mance Computing, Networking, Storage and Analysis, SC ’16, pages 29:1–29:12,Piscataway, NJ, USA, 2016. IEEE Press.
[37] X. Ni, E. Meneses, N. Jain, and L. V. Kale. ACR: automatic checkpoint/restartfor soft and hard error protection. In ACM/IEEE International Conference forHigh Performance Computing, Networking, Storage and Analysis, SC ’13. IEEEComputer Society, Nov. 2013.
[38] K. Pattabiraman, R. K. Iyer, and Z. T. Kalbarczyk. Automated derivation ofapplication-aware error detectors using static analysis: The trusted illiac approach.IEEE Transactions on Dependable and Secure Computing, 8:44–57, 2009.
[39] K. Pattabiraman, N. M. Nakka, Z. T. Kalbarczyk, and R. K. Iyer. SymPLFIED:symbolic program-level fault injection and error detection framework. IEEETransactions on Computers, 62(11):2292–2307, 2013.
[40] N. Sasaki, K. Sato, T. Endo, and S. Matsuoka. Exploration of lossy compressionfor application-level checkpoint/restart. In Proceedings of the 2015 IEEE Interna-tional Parallel and Distributed Processing Symposium, IPDPS ’15, pages 914–922,Washington, DC, USA, 2015. IEEE Computer Society.
[41] S. K. Sastry Hari, R. Venkatagiri, S. V. Adve, and H. Naeimi. GangES: gangerror simulation for hardware resiliency evaluation. In Proceeding of the 41stAnnual International Symposium on Computer Architecuture, ISCA ’14, pages61–72, Piscataway, NJ, USA, 2014. IEEE Press.
[42] M. Snir, R. W. Wisniewski, J. A. Abraham, S. V. Adve, S. Bagchi, P. Balaji, J. Belak,P. Bose, F. Cappello, B. Carlson, A. A. Chien, P. Coteus, N. A. DeBardeleben,P. C. Diniz, C. Engelmann, M. Erez, S. Fazzari, A. Geist, R. Gupta, F. Johnson,S. Krishnamoorthy, S. Leyffer, D. Liberty, S. Mitra, T. Munson, R. Schreiber,J. Stearley, and E. V. Hensbergen. Addressing failures in exascale computing.International Journal of High Performance Computing Applications, 28(2):127 –171, May 2014.
[43] V. Sridharan, N. DeBardeleben, S. Blanchard, K. B. Ferreira, J. Stearley, J. Shalf,and S. Gurumurthi. Memory errors in modern systems: The good, the bad, andthe ugly. In Proceedings of the Twentieth International Conference on ArchitecturalSupport for Programming Languages and Operating Systems, ASPLOS ’15, pages297–310, New York, NY, USA, 2015. ACM.
[44] N.Wang, M. Fertig, and S. Patel. Y-branches: When you come to a fork in the road,take it. In Proceedings of the 12th International Conference on Parallel Architecturesand Compilation Techniques, PACT ’03, pages 56–, Washington, DC, USA, 2003.IEEE Computer Society.
[45] K. S. Yim, Z. T. Kalbarczyk, and R. K. Iyer. Quantitative analysis of long-latencyfailures in system software. In Proceedings of the 2009 15th IEEE Pacific RimInternational Symposium on Dependable Computing, PRDC ’09, pages 23–30,Washington, DC, USA, 2009. IEEE Computer Society.
[46] J. Yu, M. J. Garzaran, and M. Snir. ESoftCheck: removal of non-vital checks forfault tolerance. In Proceedings of the 7th Annual IEEE/ACM International Sympo-sium on Code Generation and Optimization, CGO ’09, pages 35–46, Washington,DC, USA, 2009. IEEE Computer Society.
[47] G. Zheng, L. Shi, and L. V. Kalé. FTC-Charm++: an in-memory checkpoint-basedfault tolerant runtime for Charm++ and MPI. In Cluster Computing, 2004 IEEEInternational Conference on, pages 93–103. IEEE, 2004.