Tutorials Monday, September 7, 2009: Learning from Multi-label Data G. Tsoumakas (Aristotle University of Thessaloniki), M. L. Zhang (Hohai University), Z.-H. Zhou (Nanjing University) Language and Document Analysis: Motivating Latent Variable Models W. Buntine (Helsinki Institute of IT, NICTA) Methods for Large Network Analysis V. Batagelj (University of Ljubljana) Friday, September 11,2009: Evaluation in Machine Learning P. Cunningham (University College Dublin) Transfer Learning for Reinforcement Learning Domains A. Lazaric (INRIA Lille), M. Taylor (University of Southern California) Graphical Models T. Caetano (NICTA) Tutorial Chair: C. Archambeau (University College London)
Transcript
Tutorials
Monday, September 7, 2009:
Learning from Multi-label DataG. Tsoumakas (Aristotle University of Thessaloniki), M. L. Zhang (Hohai University), Z.-H. Zhou (Nanjing University)
Language and Document Analysis: Motivating Latent Variable ModelsW. Buntine (Helsinki Institute of IT, NICTA)
Methods for Large Network AnalysisV. Batagelj (University of Ljubljana)
Friday, September 11,2009:
Evaluation in Machine LearningP. Cunningham (University College Dublin)
Transfer Learning for Reinforcement Learning DomainsA. Lazaric (INRIA Lille), M. Taylor (University of Southern California)
Graphical ModelsT. Caetano (NICTA)
Tutorial Chair: C. Archambeau (University College London)
Learning from Multi-Label Data
Tutorial at
ECML/PKDD’09
Bled, Slovenia
7 September, 2009
Min-Ling Zhang
College of Computer and
Information Engineering,
Hohai University, China
Zhi-Hua Zhou
LAMDA Group, National Key Laboratory
forNovel Software Technology,
Nanjing University, China
Grigorios Tsoumakas
Department of
Informatics, Aristotle
University of
Thessaloniki, Greece
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Data with multiple target variables What can the type of targets be?
Numerical Ecological modeling and environmental applications Industrial applications (automobile)
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Contents Introduction
What is multi-label learning Applications and datasets Evaluation in multi-label learning (various multi-label metrics)
Overview of existing multi-label learning techniques Problem transformation learning methods Algorithm adaptation methods
Advanced topics Learning in the presence of Label Structure Multi-instance multi-label learning
The Mulan open-source software
a2
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
What is Multi-Label LearningSettings:
d-dimensional input space (numerical or nominal features)
output (label) space of q labels
Inputs:S : multi-label training set with m examples
where is the d-dimensional instance
is the set of labels associated withOutputs:
h : a multi-label predictor
f : a ranking predictor where given an instance ,labels in are ordered according to
or
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Multi-Label Learning Tasks Setting
Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x
Classification Produce a bipartition of the set of labels into a relevant
and an irrelevant set Px: {λ1, λ4}, Nx: {λ2, λ3, λ5}
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Multi-Label Learning Tasks Setting
Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x
Ranking Produce a ranking of all labels according to relevance to
the given instance Let r(λ) denote the rank of label λ r(λ3) < r(λ2) < r(λ4) < r(λ5) < r(λ1)
It can also be learned from data containing Single labels, total rankings of labels and pairwise
preferences over the set of labels
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Multi-Label Learning Tasks Setting
Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x
Classification and Ranking Produce both a bipartition and a ranking of all labels These should be consistent: )()(', ΄rrNP xx
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Applications and Datasets (Semi) automated annotation of large object
collections for information retrieval Text/web, image, video, audio, biology
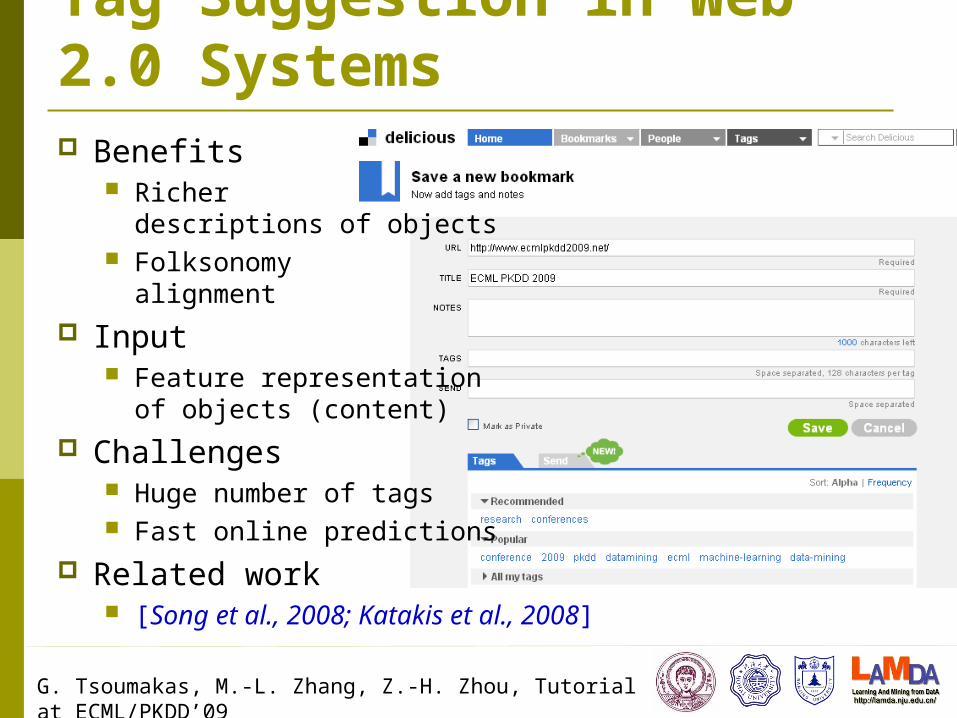
Tag suggestion in Web 2.0 systems Query categorization Drug discovery Direct marketing Medical diagnosis
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Text News
An article concerning the Antikythera Mechanism can be categorized to
Science/Technology, History/Culture Reuters Collection Version I [Lewis et al., 2004]
804414 newswire stories indexed by Reuters Ltd 103 topics organized in a hierarchy, 2.6 on average 350 industries (2-level hierarchy post-produced) 296 geographic codes
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Text Research articles
A research paper on an ensemble method for multi-label classification can be assigned to the areas
OHSUMED [Hersh et al., 1994] Medical Subject Headings (MeSH) ontology
ACM-DL [Veloso et al., 2007] ACM Computing Classification System (1st:11, 2nd:81 labels) 81251 Digital Library articles
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Text EUR-Lex collection [Loza Mencia and Furnkranz, 2008]
19596 legal documents of the European Union (EU) Hierarchy of 3993 EUROVOC labels, 5.4 on average
EUROVOC is a multilingual thesaurus for EU documents 201 subject matters, 2.2 on average 412 directory codes, 1.3 on average
WIPO-alpha collection [Fall et al., 2003]
World Intellectual Patents Organization (WIPO) 75000 patents 4 level hierarchy of ~5000 categories
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Text Aviation safety reports (tmc2007)
Competition of SIAM Text Mining 2007 Workshop 28596 NASA aviation safety reports in free text form 22 problem types that appear during flights 2.2 annotations on average
Free clinical text in radiology reports (medical) Computational Medicine Center's 2007 Medical NLP
Challenge [Pestian et al., 2007]
978 reports, 45 labels, 1.3 labels on average
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Web Email
Enron dataset UC Berkeley Enron Email Analysis Project 1702 examples, 53 labels, 3.4 on average 2 level hierarchy
Web pages Hierarchical classification schemes
Open Directory Project Yahoo! Directory [Ueda & Saito, 2003]
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Image and Video Application
Automated annotation for retrieval Datasets
Scene [Boutell et al., 2004] 2407 images, 6 labels, 1.1 on average
Mediamill [Snoek et al., 2006] 85 hours of video data containing Arabic, Chinese, and US
broadcast news sources, recorded during November 2004 43907 frames, 101 labels, 4.4 on average
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Image and Video
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Audio Music and meta-data db of the HiFind company
450000 categorized tracks since 1999 935 labels from 16 categories (340 genre labels)
Annotation 25 annotators (musicians, music journalists) + supervisor Software-based annotation takes 8 min per track on average 37 annotation per track on average
A subset was used in [Pachet & Roy, 2009] 32,978 tracks, 632 labels, 98 acoustic features
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Audio Categorization of music into emotions
Relevant works [Li & Ogihara, 2003; 2006; Wieczorkowska et al., 2006]
Dataset emotions in [Trohidis et al., 2008] 593 tracks, 6 labels, 1.9 on average {happy, calm, sad, angry, quiet, amazed}
Some applications Song selection in mobile devices, music therapy Music recommendation systems, TV and radio programs
Acoustic data [Streich & Buhmann, 2008]
Construction of hearing aid instruments Labels: Noise, Speech, Music
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Biology Applications
Automated annotation of proteins with functions Annotation hierarchies
The Functional Catalogue (FunCat) A tree-shaped hierarchy of annotations for the functional
description of proteins from several living organisms The Gene Ontology (GO)
A directed acyclic graph of annotations for gene products
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Biology Datasets
Yeast [Elisseeff & Weston, 2002] 2417 examples, 14 labels (1st FunCat level), 4.2 on average
Two major activities of hypertension drugs Angiotensin converting enzyme inhibitor Neutral endopeptidase inhibitor
Compounds producing both these 2 specific activities found to be an effective new type of drug
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Other Direct marketing [Zhang et al., 2006]
A direct marketing company sends offers to clients for products of categories they potentially are interested
Historical data of clients and product categories that they got interested (multiple categories)
Data from Direct Marketing Association 19 categories
Classification and Ranking Send only relevant products, send top X products
Medical diagnosis A patient may be suffering from multiple diseases at the
same time, e.g. {obesity, hypertension}
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Evaluation Metrics: Label-BasedBasic Strategy:
Calculate classic single-label metric on each label independently, and then
combine metric values over all labels through micro- or macro-averaging
For the i-th possible label:
TNiFNiNO
FPiTPiYESclassifier output
NOYES
actual outputlabel λi
Contingency table for λi
……
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Evaluation Metrics: Label-Based (Cont’)
Combining single-label metrics:
micro-averaging: obtain final metric value by summing over corresponding decisions in each contingency table:
E.g.:
macro-averaging: obtain final metric value by averaging over the results of different labels:
E.g.:
Label-based multi-label metrics are easy to compute, but ignore the relationships between different labels!
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Evaluation Metrics: Instance-BasedBasic Strategy:
Calculate metric value for each instance by addressing relationships among different class labels (especially the ranking quality), and then return the mean value over all instances
Five popular instance-based multi-label metrics [Schapire & Singer,
MLJ00]: Given the learned predictor h(·) or f(·,·), and a test set
(1) Hamming loss
Evaluates how many times an instance-label pair is misclassified
(2) One-errorEvaluates how many times the top-ranked label is not in the set of proper labels of the instance
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ignore Simply ignore all multi-label examples
Major information loss!
Ex # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # Label set
3 { 1λ }
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Select one of the labels Most frequent label (Max) Less frequent label (Min) Random selection
Information loss!
Select Min, Max and Random
Ex # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # Label
1 4λ
2 4λ
3 1λ
4 4λ
Ex # Label
1 1λ
2 3λ
3 1λ
4 2λ
Ex # λ4
1 4λ
2 3λ
3 1λ
4 2λ
Max Min Random
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Copy and Copy-Weight (Entropy) Replace each example with examples
(xi,λj) , one for each Copy-weight requires learners that take the weights of
examples into account Weights examples by
No information loss Increased examples O(mc)
Ex # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # Label
1a 1λ
1b 4λ
2a 3λ
2b 4λ
3 1λ
4a 2λ
4b 3λ
4c 4λ
Ex # Label Weight
1a 1λ 0,50
1b 4λ 0,50
2a 3λ 0,50
2b 4λ 0,50
3 1λ 1,00
4a 2λ 0,33
4b 3λ 0,33
4c 4λ 0,33
),( ii Yx iY),( jix ij Y
iY
1
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
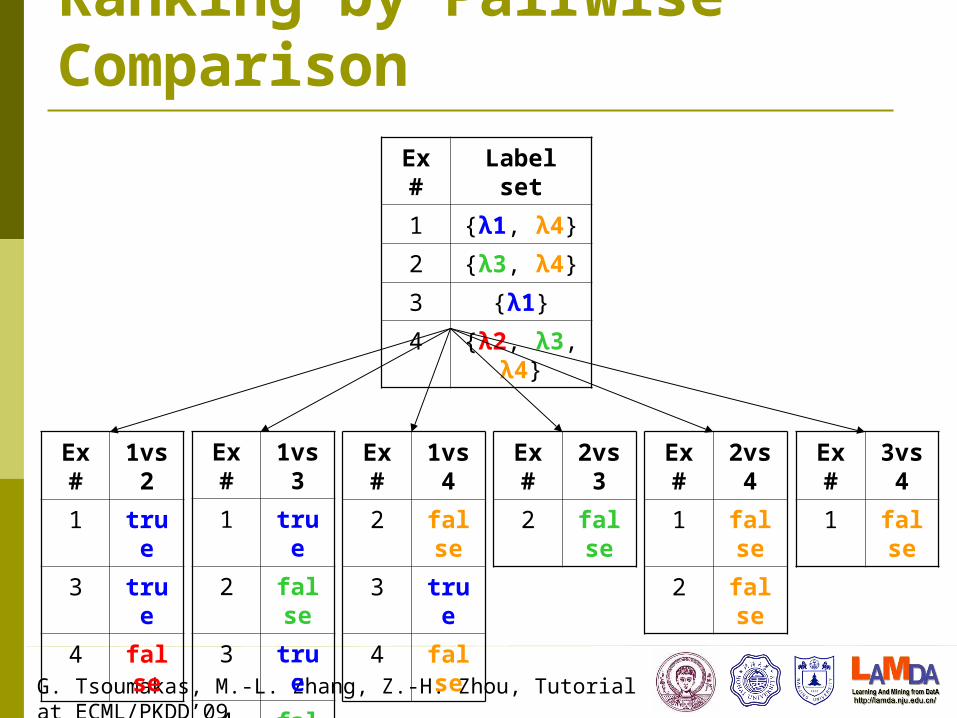
Ranking by Pairwise Comparison How it works [Hullermeier et al., 2008]
It learns q(q-1)/2 binary models, one for each pair of labels
Each model is trained based on examples that are annotated by at least one of the labels, but not both
It learns to separate the corresponding labels Given a new instance, all models are invoked and a
ranking is obtained by counting the votes received by each label
qjiji 1,,
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ranking by Pairwise ComparisonEx # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # 1vs2
1 true
3 true
4 false
Ex # 1vs3
1 true
2 false
3 true
4 false
Ex # 1vs4
2 false
3 true
4 false
Ex # 2vs3
2 false
Ex # 2vs4
1 false
2 false
Ex # 3vs4
1 false
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
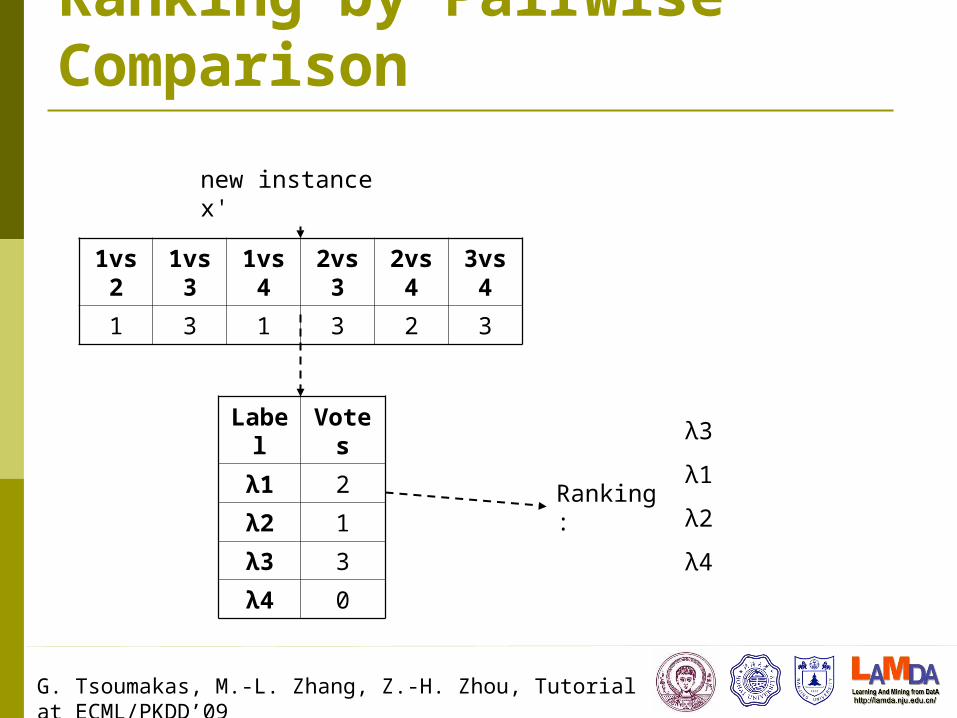
Ranking by Pairwise Comparison
1vs2 1vs3 1vs4 2vs3 2vs4 3vs4
1 3 1 3 2 3
new instance x'
Ranking:
Label Votes
λ1 2
λ2 1
λ3 3
λ4 0
λ3
λ1
λ2
λ4
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ranking by Pairwise Comparison Time complexity
Training: O(mqc) Testing: Needs to query q2 binary models
Space complexity Needs to maintain q2 binary models in memory
Pairwise decision tree/rule learning models might be simpler than one-vs-rest
Perceptrons/SVMs store a constant number of parameters
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Calibrated Label Ranking How it works [Furnkranz et al., 2008]
Extends ranking by pairwise comparison by introducing an additional virtual label λV, with the purpose of separating positive from negative labels
Pairwise models that include the virtual label correspond to the models of binary relevance
All examples are used When a label is true, the virtual label is considered false When a label is false, the virtual label is considered true
The final ranking includes the virtual label, which acts as the split point between positive/negative labels
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ranking by Pairwise ComparisonEx # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # 1vs2
1 true
3 true
4 false
Ex # 1vs3
1 true
2 false
3 true
4 false
Ex # 1vs4
2 false
3 true
4 false
Ex # 2vs3
2 false
Ex # 2vs4
1 false
2 false
Ex # 3vs4
1 false
Ex # 1vsV
1 true
2 false
3 true
4 false
Ex # 2vsV
1 false
2 false
3 false
4 true
Ex # 3vsV
1 false
2 true
3 false
4 true
Ex # 4vsV
1 true
2 true
3 false
4 true
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ranking by Pairwise Comparison
1vs2 1vs3 1vs4 2vs3 2vs4 3vs4
1 1 1 2 2 4
new instance x'
Label Votes
λ1 4
λ2 2
λ3 0
λ4 1
λV 3
Ranking:
λ1
λV
λ2
λ4
λ3
1vsV 2vsV 3vsV 4vsV
1 V V V
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ranking by Pairwise Comparison Benefits
Improved ranking performance Classification and ranking (consistent)
Limitations Space complexity (as in RPC)
A solution for perceptrons [Loza Mencıa & Furnkranz, 2008] Querying q2 + q models at runtime
QWeighted algorithm [Loza Mencia et al., 2009]
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
How it works Each different set of labels in a multi-label training set
becomes a different class in a new single-label classification task
Given a new instance, the single-label classifier of LP outputs the most probable class (a set of labels)
Label Powerset (LP)
Ex # Label set
1 { 1λ , 4λ }
2 { 3λ , 4λ }
3 { 1λ }
4 { 2λ , 3λ , 4λ }
Ex # Label
1 1001
2 0011
3 1000
4 0111
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
c P(c|x) 1λ 2λ 3λ 4λ
1001
0,7 1 0 0 1
0011
0,2 0 0 1 1
1000
0,1 1 0 0 0
0111
0 0 1 1 1
ΣP(c|x)λj
0,8 0,0 0,2 0,9
c P(c|x) 1λ 2λ 3λ 4λ
1001
0,1 1 0 0 1
0011
0,3 0 0 1 1
1000
0,4 1 0 0 0
0111
0,2 0 1 1 1
ΣP(c|x)λj
0,5 0,2 0,5 0,6
Label Powerset (LP) Ranking
It is possible if a classifier that outputs scores (e.g. probabilities) is used [Read, 2008]
Are the bipartition and ranking always consistent?
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Label Powerset (LP) Complexity
Depends on the number of distinct labelsets that exist in the training set
It is upper bounded by min(m,2q) It is usually much smaller, but still larger than q
Limitations High complexity Limited training examples for many classes Cannot predict unseen labelsets
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Label Powerset (LP)
Dataset m q
Labelsets
Bound Actual Diversity
emotions 593 6 64 27 0,42
enron 1702 53 1702 753 0,44
hifind 32971 632 32971 32734 0,99
mediamill 43907 101 43907 6555 0,15
medical 978 45 978 94 0,10
scene 2407 6 64 15 0,23
tmc2007 28596 22 28596 1341 0,05
yeast 2417 14 2417 198 0,08
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Pruned Sets How it works [Read, 2008; Read et al., 2008]
Follows the transformation of LP, but it also … Prunes examples whose labelsets (classes) occur less
times than a small user-defined threshold p (e.g. 2 or 3) Deals with the large number of infrequent classes
Re-introduces pruned examples along with subsets of their labelsets that do exist more times than p
Strategy A: Rank subsets by size/number of examples and keep the top b of those
Strategy B: Keep all subsets of size greater than b
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Pruned Sets p=3 Strategy A, b=2
Strategy B, b=1
Labelset Count
1λ 16
2λ 14
2,λ 3λ 12
1,λ 4λ 8
3,λ 4λ 7
1,λ 2,λ 3λ
2
Subsets Size Count
2,λ 3λ 2 12
1λ 1 16
λ2 1 14
Subsets Size
2,λ 3λ 2
1λ 1
λ2 1
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Random k-Labelsets How it works [Tsoumakas & Vlahavas, 2007]
Randomly break a large set of labels into a number (n) of subsets of small size (k), called k-labelsets
For each of them train a multi-label classifier using the LP method
Given a new instance, query models and average their decisions per label
Thresholding to obtain final model
Benefits Computationally simpler sub-problems More balanced training sets Can predict unseen labelsets
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Random k-Labelsets
model 3-labelsets
predictions
1λ 2λ 3λ 4λ 5λ 6λ
h1 { 1, 2, λ λ6λ }
1 0 - - - 1
h2 { 2, 3, λ λ4λ }
- 1 1 0 - -
h3 { 3, 5, λ λ6λ }
- - 0 - 0 1
h4 { 2, 4, λ λ5λ }
- 0 - 0 0 -
h5 { 1, 4, λ λ5λ }
1 - - 0 1 -
h6 { 1, 2, λ λ6λ }
1 0 1 - - -
h7 { 1, 2, λ λ6λ }
0 - - 1 - 0
average votes 3/4 1/4 2/3 1/4
1/3 2/3
final prediction 1 0 1 0 0 1
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Random k-Labelsets Comments
The mean number of votes per label is nk/q The large it is, the higher the effectiveness It characterizes RAkEL as an ensemble method
How to set parameters k and n? k should be small enough to deal with LP's problems n should be large enough to obtain more votes Proposed default parameters
k=3, n=2q (6 votes per label)
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ensembles of Pruned Sets How it works [Read et al., 2008]
Constructs n pruned sets models by sampling the training set (e.g. 63%)
Given a new instance, queries models and averages their decisions (each decision concerns all labels)
Thresholding to obtain final model
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
From Ranking to Classification BR can output numerical scores for each label
E.g. perceptrons, SVMs, decision trees, kNN, Bayes We use an intuitive threshold to go from these scores to
0/1 decisions (e.g. 0 in perceptrons, SVMs, 0.5 in probabilistic/confidence outputs)
The same applies to RPC, EPS, RAkEL and ranking via single-label classification
Are there general approaches to deliver
classification from a ranking?
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
From Ranking to Classification Thresholding strategies
RCut, PCut, SCut, RTCut, SCutFBR [Yang, 2001] A study of SCutFBR [Fan and Lin, 2007]
Learning the number of labels Based on the ranking [Elisseeff and Weston, 2002] Based on the content [Tang et. al, 2009]
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Thresholding Strategies: RCut How it works
Given a document, it sorts the labels by score and selects the top k labels, where k inside [1,q]
How to set the parameter k? It can be specified by the user
Typically it is set to the label cardinality of the training set It can be globally tuned using a validation set
Comments What if the number of labels per example varies? It does not perform well in practice [Tang et. al, 2009]
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Thresholding Strategies: PCut How it works
For each label λj , sort test instances based on score and assign λj to the top kj= k P(λj) test instances
P(λj) is the prior probability of a document belonging to λj (estimated on the training set)
k is a proportionality constant to trade-off false positives and false negatives
It can be globally tuned as in RCut
Comments It requires the prediction scores for all test instances, so
it is not suitable for online decisions
jj )( jj kPk
)( jP j
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Thresholding Strategies: SCut How it works
For each label λj , tune a threshold based on a validation set
Comments In contrast to RCut and PCut it tunes a separate
parameter for each label Requires a validation phase, whose complexity is linear
with respect to q Overfits when the binary learning problem is
unbalanced (few positive labels) Too high or too low thresholds
j
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Thresholding Strategies: RTCut How it works
Given a document, it sorts the labels by synthetic score and selects those above a threshold t
It is optimized using a validation set Synthetic score
1)}({max
)()()(
jLj
jjj s
srss
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Thresholding Strategies: SCutFBR How it works
When the SCut threshold is too high macro-F1 is hurt When the SCut threshold is too low both macro and
micro-F1 are hurt (prefer to increase the threshold) Solution: When the calculated threshold is below a
given value fbr then… SCutFBR.0
Set the threshold to infinity SCutFBR.1
Set the threshold to the largest score during validation
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Learning the Number of Labels [Elisseeff and Weston, 2002]
Input: a q-dimensional feature space with the obtained scores for each label
Output: The threshold t that minimizes the symmetric difference between predicted and true sets
Learning: linear least squares [Tang et. al, 2009]
Input: original feature space, scores, sorted scores Output: the size of the labelset Learning: multi-class classification, with a cut-off
parameter
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Decision tree Multi-label C4.5 [Clare & King, PKDD01]
Neural network BP-MLL [Zhang & Zhou, TKDE06]
Lazy (kNN) ML-kNN [Zhang & Zhou, PRJ07]
......
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
AdaBoost.MHDescription:
The core of a successful multi-label text categorization system BoosTexter [Schapire & Singer, MLJ00]
Basic Strategy:Map the original multi-label learning problem into a binary learning problem, which is then solved by traditional AdaBoost algorithm [Freund
& Schapire, JCSS97]
Example transformation:
Transform each multi-label training
example
into
binar
y
labeled
examples: concatenation of xi and each
label y
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
AdaBoost.MH (Cont’)Training procedure:
Classical AdaBoost is employed to learn from the transformed
binary-labeled examples iteratively
Weak hypotheses (base learners):
Has the basic form of decision stump (one-level
decision tree)
In each boosting round, the choices of weak hypothesis as well as its combination weight is optimized towards the minimization of empirical hamming loss
for text categorization task, each possible term w (e.g. bigram) specifies a weak hypothesis as follows:
E.g.:
where x is a text document,
and c0y and c1y are predicted
outputs
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Generative (Bayesian) ApproachDescription:
Modeling the generative procedure of multi-label texts [McCallum,
AAAI99w] [Ueda & Saito, NIPS03]
Basic Assumption:The word distribution given a set of labels is determined by a mixture (linear combination) of word distributions, one for each single label
Settings:
word distribution given a single label
word vocabulary
word distribution given a set of labels
q-dimensional mixture weight for Y
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
[assuming word independence]
Generative (Bayesian) Approach (Cont’)
MAP (Maximum A Posteriori) Principle:
Given a test document x*, its associated label set Y* is determined as:
The parameters and are learned by EM-style procedure
Here, the two generative approaches are specific to text applications instead of general-purpose multi-label learning methods
[applying Bayesian rule]
Directly estimated from training set by frequency counting
Prior probability Mixture of word
distributions
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Rank-SVMDescription:
A maximum margin approach for multi-label learning, implemented with
kernel trick to incorporate non-linearity [Elisseeff & Weston, NIPS02]
Basic Strategy:Assume one classifier for each individual label, and define “multi-label margin” on the whole training set, which is then minimized under QP (quadratic programming) framework
Classification system:
q linear classifiers , each with weight wk and bias bk:
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Rank-SVM (Cont’)Margin definition:
margin for a multi-label example
labels in should be ranked higherthan labels not in
margin for the training set S:
QP formulation (ideal case):
Solved by introducing slack variables and then optimized in its dual form (with incorporation of kernel trick)
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Multi-Label C4.5Description:
An extension of popular C4.5 decision tree to deal with multi-label data [Clare & King, PKDD01]
Basic Strategy:Define “multi-label entropy” over a set of multi-label examples, based on which the information gain of selecting a splitting attribute is calculated, and then a decision tree is constructed recursively in the same way of C4.5
Multi-label entropy:
Given a set of multi-label examples , let p(y) denote the
probability that an example in S has label y, then the multi-label entropy is:
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
BP-MLLDescription:
An extension of popular BP neural networks to deal with multi-label data [Zhang & Zhou, TKDE06]
Basic Strategy:Define a novel global error function capturing the characteristics of multi-label learning, i.e. labels belonging to an example should be ranked higher than those not belonging to that example
Network architecture:
Single-hidden-layer feed forward neural network
Adjacent layers are fully connected
Each input unit corresponds to a dimension of input space
Each output unit corresponds to an individual label
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
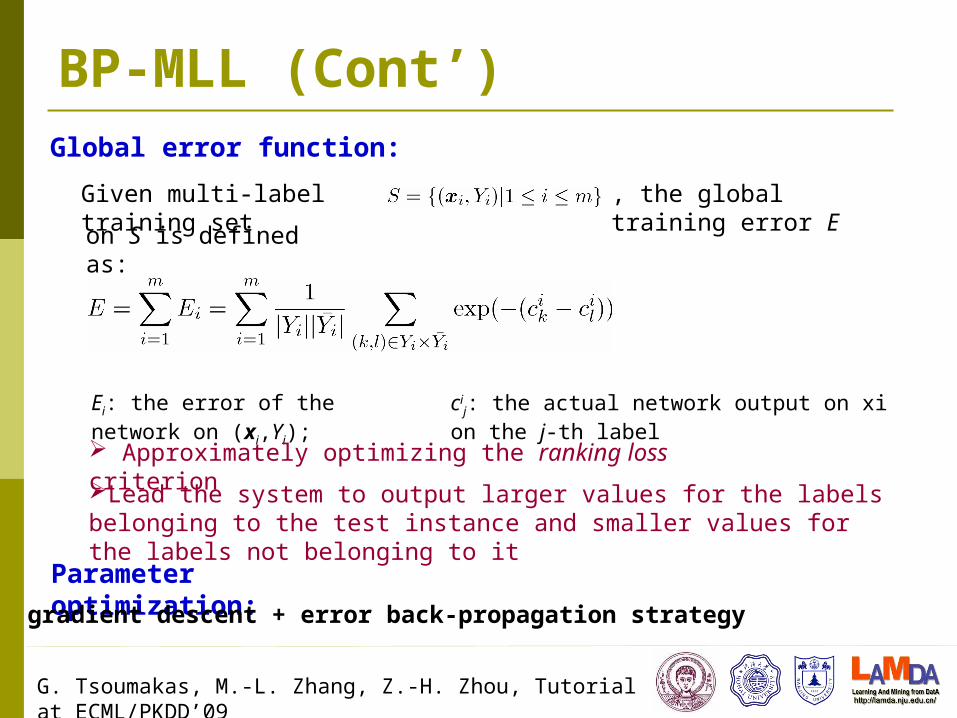
BP-MLL (Cont’)Global error function:
Given multi-label training set , the global training error E
on S is defined as:
Ei: the error of the network on (xi,Yi); cij: the actual network output on xi on the j-th label
Approximately optimizing the ranking loss criterion
Lead the system to output larger values for the labels belonging to the test instance and smaller values for the labels not belonging to it
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
ML-kNNDescription:
An extension of popular kNN to deal with multi-label data [Zhang & Zhou,
PRJ07]Basic Strategy:
Based on statistical information derived from the neighboring examples (i.e. membership counting statistic), the MAP principle is utilized to determine the label set of an unseen example
Settings:
the k nearest neighbors of x identified in the training set
the event that an example having (not) the l-th label
the event that there are exactly j examples in N(x) having the l-th label
q-dimensional membership counting vector, where the l-th dimension
counts the number of examples in N(x) having the l-th label
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
ML-kNN (Cont’)
Procedure:
Given a test example x, its associated label set Y is determined as:
Identify its k nearest neighbors in the training set, i.e. N(x)
Compute its membership counting vector based on N(x)
Determine the label set using MAP principle based on
Probabilities needed:
directly estimated from the training set based on frequency counting
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Contents Introduction
What is multi-label learning Applications and datasets Evaluation in multi-label learning (various multi-label metrics)
Overview of existing multi-label learning techniques Problem transformation learning methods Algorithm adaptation methods
Advanced topics Learning in the presence of Label Structure Multi-instance multi-label learning
The Mulan open-source software
a2
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Hierarchy Types and Implications Trees
Singe parent per label When an object is labeled with a node, it is also labeled
with its parent (paths) Path types
Annotation paths end at a leaf (full path) Annotation paths end at internal nodes (partial paths)
Directed acyclic graphs (DAGs) Multiple parents per label When an object is labeled with a node
It is also labeled with all its parents (multiple inheritance) It is also labeled with at least one of its parents
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
A Simple Approach Ignore hierarchies
Simple binary relevance Should be used as a baseline Learn leaf models only, in the case of full paths!
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Hierarchical Binary Relevance Training [Koller & Sahami, 1997; Cesa-Bianchi et al., 2006]
One binary model at each node, using only those examples that are annotated with the parent node
Predictions are formed top-down A node can predict true only if its parent predicted so What about probabilities? p( )=λ p( |λ par( )λ p(par( ))λ
When thresholding, the threshold for a node should not be higher than that of its parent
Comments Handles both partial and full paths
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Hierarchical Multi-Label Learning Generalization of HBR [Tsoumakas et al., 2008]
Training and testing follows same approach as HBR One multi-label learner is trained at each internal node If BR is used at each node, then we get HBR
TreeBoost.MH [Esuli et al., 2008]
Instantiation using AdaBoost.MH
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Other Approaches Predictive Clustering Trees [Blockeel et al., 2008]
B-SVM [Cesa-Bianchi et al., 2006]
Train similarly to HBR Bottom-up Bayesian combination of probabilities
Bayesian networks [Barutcuoglu et al., 2006]
Train independent binary classifiers for each label Combine them using a Bayesian network to correct
inconsistencies
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
MIML
instance label
instance
instance
……
……
object
label
label
……
……
Multi-Instance
Multi-Label
Learning (MIML)[Zhou & Zhang, NIPS06]
Traditional
Supervised
Learning (SISL)
instance label
object
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Ambiguous Object
Sunset ?
Clouds ?
Trees ?
Countryside ?
……
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Sports ?Tour ?
Entertainment ?Economy ?
……
Ambiguous Object
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
To Address the Ambiguity
Sports ?
Tour ?
Entertainment ?Economy ?……
Multip
le
labels
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
output space
MLL addresses
the output
ambiguity
Multi-Label Learning (MLL)
instance label
object
label
label
……
……
A real-world object is represented by a single instance
The instance is associated with multiple labels
The MLL Setting:
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
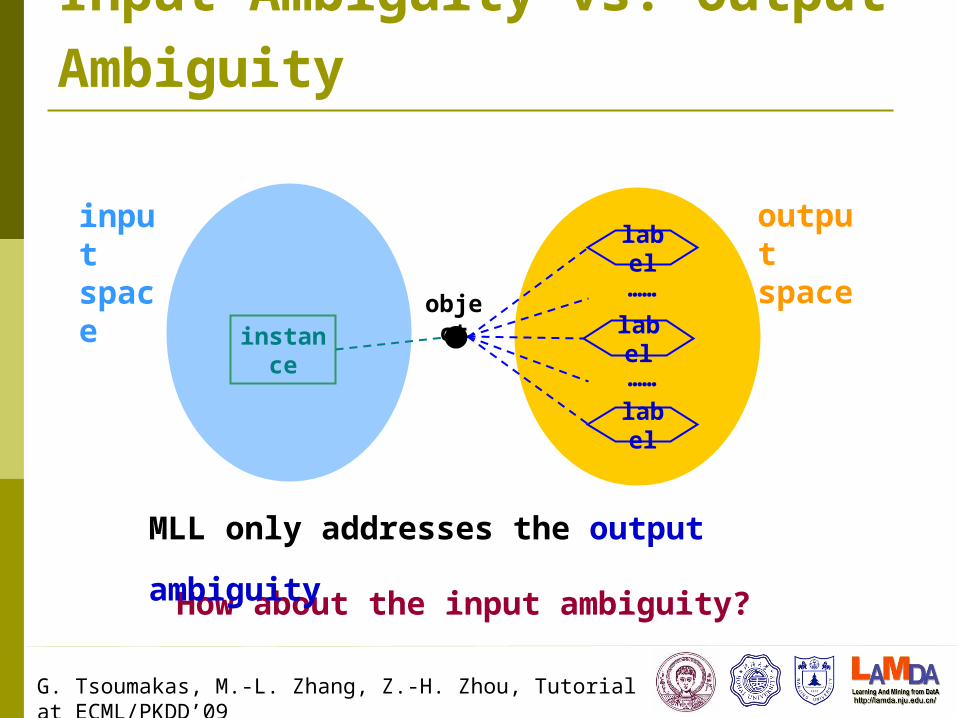
input space
How about the input ambiguity?
output space
MLL only addresses the output
ambiguity
Input Ambiguity vs. Output Ambiguity
instance label
object
label
label
……
……
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
input space
MIL addresses
the input
ambiguity
Multi-Instance Learning (MIL)
A real-world object is represented by multiple instances
The instance is associated a single label
The MIL Setting:
instance label
instance
instance
……
……
object
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Limitations of MLL and MIL
Are MLL and MIL sufficient for learning ambiguous data?
Input and output ambiguities usually occur simultaneously!
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
For Example…
An image usually contains multiple regions each can be represented by an instance
The image can
simultaneously
belong to multiple
classesElephantLion
GrasslandAfrica
……
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
An document usually contains multiple sections each can be represented by an instance
The document can
simultaneously
belong to multiple
categories
Scientific novelJules Verne’s writingBook on traveling……
For Example…
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
So, Why Not MIML?
instance label
instance
instance
……
……
object
label
label
……
……
Multi-Instance
Multi-Label
Learning (MIML)[Zhou & Zhang, NIPS06]
Traditional supervised learning, multi-label
learning and multi-instance learning are all
degenerated versions of MIML
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
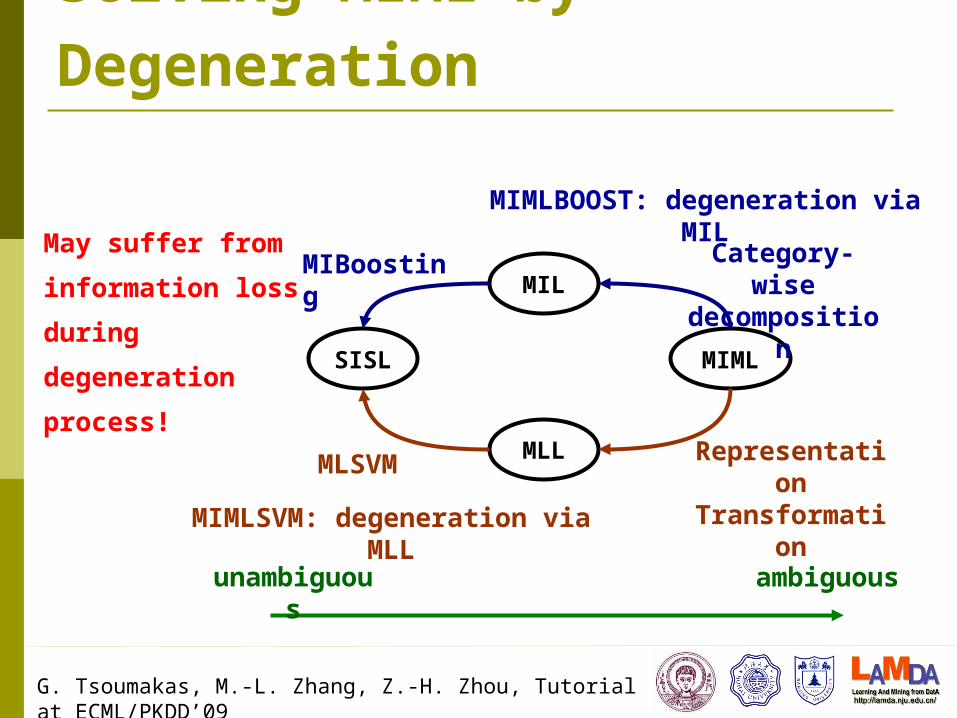
Solving MIML by Degeneration
MIL
unambiguous
ambiguous
MIMLBOOST: degeneration via MIL
MLL
SISL
MIML
Category-wise
decomposition
MIBoosting
Representation
Transformation
MLSVM
MIMLSVM: degeneration via MLL
May suffer from
information loss
during
degeneration
process!
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
Contents Introduction
What is multi-label learning Applications and datasets Evaluation in multi-label learning (various multi-label metrics)
Overview of existing multi-label learning techniques Problem transformation learning methods Algorithm adaptation methods
Advanced topics Learning in the presence of Label Structure Multi-instance multi-label learning
The Mulan open-source software
a2
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09
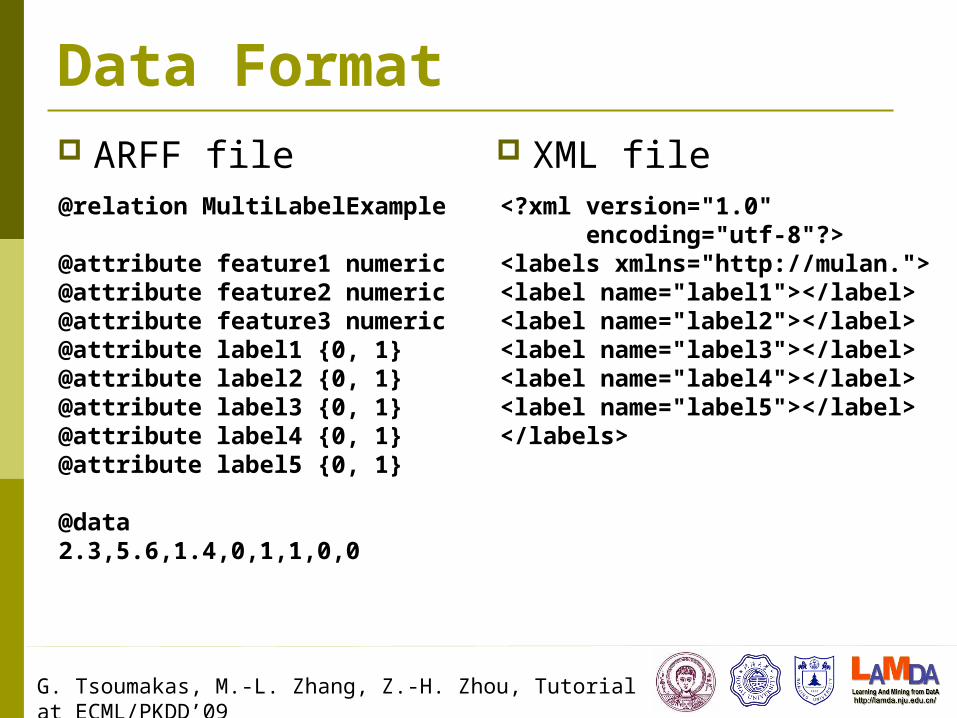
Mulan It is built on top of Weka
Well established code and user base Data format Main packages Examples
G. Tsoumakas, M.-L. Zhang, Z.-H. Zhou, Tutorial at ECML/PKDD’09