UFC DEMA UNIVERSIDADE FEDERAL DO CEAR ´ A DEPARTAMENTO DE ESTAT ´ ISTICA E MATEM ´ ATICA APLICADA Inferˆ encia Estat´ ıstica Paramˆ etrica Ronald Targino Nojosa NOTAS DE AULA Vers˜aopreliminar Janeiro/2006
Transcript
UFC DEMA
UNIVERSIDADE FEDERAL DO CEARADEPARTAMENTO DE ESTATISTICA E MATEMATICA APLICADA
1.1 Histogramas correspondentes as distribuicoes amostrais de X para diferentes tamanhosde amostra em diferentes populacoes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Histogramas para a variavel Y segundo diferentes valores do parametro λ. . . . . . . . 101.3 Densidades Qui-quadrado para diferentes graus de liberdade. . . . . . . . . . . . . . . 121.4 Densidades F para diferentes combinacoes de graus de liberdade. . . . . . . . . . . . . 151.5 Esperanca e Variancia da F de Snedecor para diferentes combinacoes dos graus de
liberdade. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.6 Percentis da distribuicao F de Snedecor com graus de liberdade m=30 e n=10. . . . . 181.7 Funcoes densidades Normal padrao, t para diferentes graus de liberdade(k) e Cauchy. . 20
Neste capıtulo iniciamos o estudo de alguns problemas de estatıstica matematica. O conhecimentoadquirido nas disciplinas de Probabilidade sera extremamente util para no desenvolvimento destecapıtulo.
Suponha que estejamos interessados em alguma caracterıstica numerica de uma colecao de ele-mentos, chamada populacao. Por razoes de tempo e/ou custo nos nao desejamos ou nao estamosapitos a examinar individualmente cada um dos elemento que compoem a populacao. Nosso objetivoe tirar conclusoes sobre uma caracterıstica populacional desconhecida com base em informacoes deuma amostra extraıda da populacao. Seja X uma variavel aleatoria que descreve a populacao sob in-vestigacao, e F a funcao de distribuicao de X. Estaremos diante de uma entre duas possibilidades. OuX tem uma funcao de distribuicao com forma funcional conhecida (exceto talvez por um parametro θ,que pode ser um vetor), ou X tem uma funcao distribuicao totalmente desconhecida para nos (excetotalvez que F seja contınua, por exemplo). Um trabalho do estatıstico sera o de decidir, com baseem informacoes da amostra(aleatoria), que membro (ou membros) da famılia {Fθ; θ ∈ Θ } pode(oupodem) representar a funcao de distribuicao de X. Problemas desse tipo sao chamados problemas deinferencia estatıstica parametrica e serao abordados nos proximos capıtulos. Neste capıtulo a enfasesera para as distribuicoes amostrais. No caso em que nada e conhecido sobre a forma funcional dafuncao de distribuicao de X, o problema de inferencia esta no domınio da estatıstica nao-parametricae nao fara parte deste texto. A seguir apresentamos algumas definicoes importantes.
Definicao 1.1.1. (Populacao Alvo) A totalidade dos elementos que estao sob investigacao e sobre osquais se deseja obter informacoes sera denominada populacao alvo.
Definicao 1.1.2. (Amostra Aleatoria) Considere que as variaveis aleatorias X1, X2, . . . , Xn tenhamdensidade conjunta f(x1, x2, . . . , xn) que possa ser fatorada como f(x1, x2, . . . , xn) = f(x1) . . . f(xn),em que f(xi) e a densidade de cada Xi, i = 1, 2, . . . , n. Deste modo, define-se X1, X2, . . . , Xn comouma amostra aleatoria de tamanho n proveniente da populacao de densidade f .
Definicao 1.1.3. (Populacao Amostrada1) Seja X1, X2, . . . , Xn uma amostra aleatoria provenientede uma populacao com funcao de distribuicao F . Entao, essa populacao sera chamada populacaoamostrada.
Definicao 1.1.4. (Parametro) Parametro e uma medida numerica (funcao dos elementos popula-cionais) que descreve uma caracterıstica da populacao.
1Quando usarmos a palavra populacao sem um adjetivo (alvo ou amostrada), ela significara populacao amostrada.
1.1 Introducao 2
Definicao 1.1.5. (Estatıstica) Qualquer funcao das variaveis aleatorias observadas, t(X1, X2, . . . , Xn),que nao dependa de parametros desconhecidos, e chamada uma estatıstica.
Definicao 1.1.6. (Estimador) Um estimador e definido como uma estatıstica cujo valor e usado paraestimar um parametro θ.
Definicao 1.1.7. (Estimativa) Um valor particular de um estimador, t(x1, x2, . . . , xn), e chamadouma estatimativa de θ.
Definicao 1.1.8. (Espaco Parametrico) O conjunto Θ de todos os valores possıveis do parametro θde uma funcao de distribuicao F e chamado espaco parametrico.
Por simplificacao, denotamos a funcao de distribuicao de uma variavel aleatoria X por F . Claroque associado a essa funcao teremos um parametro θ (possivelmente um vetor). Poderıamos, entao,agora, denota-la por Fθ para uma melhor compreensao da definicao abaixo.
Definicao 1.1.9. (Famılia de Distribuicoes) O conjunto {Fθ; θ ∈ Θ} e chamado famılia de funcoes dedistribuicao de uma variavel aleatoria . Falaremos de famılia de funcoes de densidade de probabilidadese a variavel aleatoria for contınua, e de famılia de funcoes de probabilidade se variavel aleatoria fordiscreta.
A escolha da famılia de distribuicoes e passo importante na inferencia classica. Estabelecida afamılia, isto e, admitindo um modelo como verdadeiro, poderemos decidir que inferencias podemser feitas sobre o parametro em estudo (Capıtulos 2 e 3 ) ou verificar se os dados observados saocompatıveis com o modelo adotado (Capıtulo 4). Um questionamento pertinente, neste ponto, e:Quais criterios devemos usar para a escolha de um bom modelo. Murteira (1988) apresenta algumasregras2 devidas a Cox e Hinkley (1974):
(i) O modelo deve, sempre que possıvel, estabelecer uma ligacao com os conhecimentos teoricossobre o sistema em questao e com o trabalho experimental anteriormente realizado.
(ii) A forma do modelo de ser tal que os respectivos parametros tenham uma interpretacao clara.
(iii) O modelo deve ser parcimonioso, isto e, o modelo deve ter um numero de parametros tao reduzidoquanto possıvel.
(iv) O modelo deve ser acessıvel a aplicacao de procedimentos estatısticos correntes ou que naocarecam de uma teoria estatıstica muito elaborada.
No Capıtulo 4 retomaremos esse questionamento.
Exemplo 1.1.1. Seja X ∼ Binomial(n, p), p desconhecido. Entao, Θ ={p ; 0 < p < 1} e a famıliade possıveis funcoes de probabilidade de X e {Binomial(n, p); 0 < p < 1}.
Exemplo 1.1.2. Seja X ∼ Normal(µ, σ2). Se µ e σ2 sao desconhecidos, Θ ={(µ, σ2);−∞ <µ < ∞, σ2 > 0}. Se µ = µ0 e σ2 e desconhecido, Θ ={(µ0, σ2); σ2 > 0} ou, simplesmente, Θ={σ2; σ2 > 0} = (0, ∞).
Exemplo 1.1.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Exponencial(θ),em que θ e desconhecido. Entao, X−1, X, (X1 +Xn)/2, 1/3, X1, mınimo{X1, . . . , Xn} sao possıveisestimadores para para o parametro θ.
2Os autores reconhecem a dificuldade em apontar regras precisas
1.1 Introducao 3
Definicao 1.1.10. (Distribuicao Amostral) Sejam X1, X2, . . . , Xn uma amostra aleatoria de tamanhon. A distribuicao da amostra X1, X2, . . . , Xn e definida como a distribuicao conjunta de X1, X2, . . . ,Xn.
Definicao 1.1.11. (Distribuicao Amostral de uma Estatıstica) A distribuicao de probabilidade de umaestatıstica e chamada distribuicao amostral da estatıstica.
Exemplo 1.1.4. Seja X ∼ Bernoulli(p). A distribuicao conjunta para uma amostra de tamanhon = 2 proveniente de X e f(x1, x2) = f(x1)f(x2) = px1+x2(1 − p)2−x1−x2, 0 < x1 < 1, 0 < x2 < 1.Note que essa distribuicao amostral e diferente da distribuicao amostral da estatıstica S = X1 + X2
que e dada por f(s) =(2s
)ps(1−p)2−s, s = 0, 1, 2. Note que f(x1, x2) nos da a distribuicao da amostra
na ordem de extracao. Por exemplo, f(0, 1) = p(1 − p) refere-se a probabilidade de ocorrer primeiroum 0(zero) e depois um 1(um).
Distribuicao Amostral
A distribuicao amostral de uma estatıstica T = T (X1, X2, . . . , Xn ) pode ser definida a partir dadistribuicao conjunta da amostra. Sendo X1, X2, . . . , Xn uma amostra aleatoria de uma populacaocom funcao densidade de probabilidade ou funcao de probabilidade f(x1, x2, . . . , xn; θ), a funcao dedistribuicao acumulada de T , denotada por G(t; θ), e definida, respectivamente, para os casos davariavel aleatoria ser contınua ou discreta, por
G(t; θ) = P (T ≤ t) =
∫· · ·∫
A
n∏
i=1
f(xi; θ)dxi (1.1)
ou
G(t; θ) = P (T ≤ t) =∑
A
n∏
i=1
f(xi; θ), (1.2)
em que A = {(x1, . . . xn)/T (x1 . . . xn) ≤ t}.
O uso direto das expressoes acima podem exigir calculos extensivos. A distibuicao da estatısticaT tambem pode ser obtida atraves da Funcao Geradora de Momentos, da Funcao Caracterıstica, doMetodo de Inducao Matematica e, quando nao se consegue chegar a solucao analıtica, do Metodo deMonte Carlo ou de Simulacao. A seguir sao apresentados alguns exemplos.
Exemplo 1.1.5. (Usando a Funcao Distribuicao) Se X1, . . . , Xn sao variaveis aleatorias indepen-dentes e identicamente distribuıdas segundo uma distribuicao Exponencial(θ), a funcao de distribuicaoda estatıstica T = mınimo{X1, X2, . . . , Xn} e dada por
G(t) = P (T ≤ t) = P (mınimo{X1, X2, . . . , Xn} ≤ t) = 1 − P (mınimo{X1, X2, . . . , Xn} > t)
Portanto, T ∼ Exponencial(nθ).Nota: O maximo nao se distribui exponencialmente.
A funcao geradora de momentos apresenta-se de forma importante nesse texto. Uma das suaspropriedades mais importantes e expressa no teorema abaixo.
Teorema 1.1. (Unicidade da Funcao Geradora de Momentos) Se as funcoes geradoras de momentosde duas variaveis aleatorias X e Y sao identicas para todo t em um intervalo aberto contendo t = 0,entao, as distribuicoes de probabilidade de X e Y devem ser identicas.
Exemplo 1.1.6. (Usando a Funcao Geradora de Momentos) Se X1, . . . , Xn sao variaveis aleatoriasindependentes e identicamente distribuıdas segundo uma Exponencial(θ), a funcao geradora de mo-mentos de X e dada por
E(etX) =
∫ ∞
0etxθe−θxdx =
θ
θ − t
∫ ∞
0(θ − t)e−(θ −t)xdx =
θ
θ − t.
E a funcao geradora de momentos da estatıstica S =n∑
i=1
Xi e
E(etS) = E(etPn
i=1 Xi) =n∏
i=1
E(etXi) =[E(etX1)
]n=
(θ
θ − t
)n
.
Portanto, S tem distribuicao Gama(n, θ). Ja a estatıstica X tera distribuicao Gama(n, nθ). Vejaabaixo.
E(etX) = E(etn
Pni=1 Xi) =
n∏
i=1
E(etn
Xi) =[E(e
tn
X)]n
=
(θ
θ − tn
)n
=
(nθ
nθ − t
)n
.
1.2 Momentos
Os momentos de uma variavel aleatoria ou de uma distribuicao sao os valores esperados de potenciasda variavel aleatoria, e podem ser usados para auxiliar a caracterizacao da distribuicao. Dois momentosmuito utilizados sao a esperanca e a variancia. A esperanca e uma medida de posicao da distribuicao,e a variancia e uma medida de dispersao dos valores da variavel aleatoria.
Definicao 1.2.1. (Momento) Para k = 1, 2, . . ., o k-esimo momento da variavel aleatoria X, deno-tado por µ′
k, e definido como µ′k = E(Xk), se a esperanca existe.
Definicao 1.2.2. (Momento Central) Para k = 1, 2, . . ., o k-esimo momento central em relacao aE(X) = µ da variavel aleatoria X, denotado por µk, e definido como µk = E(X − E(X))k.
Observacoes:
(i) µ1 = 0 e µ2 = V (X);
(ii) Se k e ımpar e a funcao densidade de probabilidade de X e simetrica em relacao a µ,µk = 0.
1.2 Momentos 5
[Texto complementar: Funcao geradora de Momentos]
Teorema 1.2. Sejam X1, X2, . . . , Xn uma amostra aleatoria da distribuicao da variavel aleatoria Xcom media µ, variancia σ2 e funcao de distribuicao F (x). Entao,
(i) E(X) = µ; (ii) V (X) =σ2
n; (iii) E(X)3 =
µ′3 + 3(n − 1)µ′
2µ + (n − 1)(n − 2)µ3
n2;
(iv) E(X)4 =µ′
4 + 4(n − 1)µ′3µ + 3(n − 1)µ′
22 + 6(n − 1)(n − 2)µ′
2µ2 + (n − 1)(n − 2(n − 3)µ4
n3
Demonstracao
Sera demonstrado o caso (ii), os demais ficarao como exercıcio.V (X) = V (
∑ni=1 Xi/n) = [
∑ni=1 V (Xi)]/n2 = σ2/n.
Vejamos outra maneira de demonstrar este resultado.
V (X) = µ2(X) = E(X − µ)2 = 1n2 E[
∑ni=1(Xi − µ)]2
= 1n2 E[
∑ni=1(Xi − µ)2 +
∑ni=1
∑nj=1
i6=j
(Xi − µ)(Xj − µ)]
= 1n2 [∑n
i=1 E(Xi − µ)2 +∑n
i=1
∑nj=1
i6=j
E[(Xi − µ)(Xj − µ)]]
= 1n2 [∑n
i=1 σ2 + 0] = σ2
n
Nota:
(i) (∑n
i=1 ai)2 =
∑ni=1 a2
i + 2∑n−1
i=1
∑nj=1
i<j
aiaj =∑n
i=1 a2i +
∑ni=1
∑nj=1
i6=j
aiaj
(ii) (∑n
i=1 ai)3 =
∑ni=1 a3
i + 3∑n
i=1
∑nj=1
i6=j
a2i aj +
∑ni=1
∑nj=1
∑nk=1
i6=j, i6=k, j 6=k
aiajak
(iii) (∑n
i=1 ai)4 =
∑ni=1 a4
i + 4∑n
i=1
∑nj=1
i6=j
aia3j + 3
∑ni=1
∑nj=1
i6=j
a2i a
2j +
6∑n
i=1
∑nj=1
∑nk=1
i6=j, i6=k, j 6=k
a2i ajak +
∑ni=1
∑nj=1
∑nk=1
∑nl=1
i6=j 6=k 6=l
aiajakal
Teorema 1.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria da distribuicao da variavel aleatoria Xcom media µ, variancia σ2 e funcao de distribuicao F (x). Entao, o terceiro e o quarto momentoscentrais de X, em relacao a µ, denotados, respectivamente, por µ3(X) e µ4(X), sao definidos como
(i) µ3(X) = E[(X − µ)3] =E[(X − µ)3]
n2=
µ3
n2(ii) µ4(X) = E[(X − µ)4] =
µ4
n3+
3(n − 1)µ22
n3
Demonstracao
Sera demonstrado o caso (i). A demonstracao do (ii) e obtida de forma semelhante.
µ3(X) = E[(X − µ)3] =1
n3E[∑n
i=1(Xi − µ)]3 =
=1
n3[∑n
i=1 E(Xi − µ)3 + 3∑n
i=1
∑nj=1 E(Xi − µ)2E(Xj − µ)+
+∑n
i=1
∑nj=1
∑nk=1 E(Xi − µ)E(Xj − µ)E(Xk − µ)] =
1
n2E(X1 − µ)3 =
=1
n2E(X − µ)3 =
µ3
n2.
1.2 Momentos 6
Definicao 1.2.3. (Momento Amostral) Sejam X1, X2, . . . , Xn uma amostra aleatoria da distribuicaoda variavel aleatoria com funcao de distribuicao F (x). O k-esimo momento amostral, denotado porm′
k, e definido como
m′k =
1
n
n∑
i=1
Xki .
Tambem, o k-esimo momento central amostral, em relacao a X, denotado por mk, e definido como
mk =1
n
n∑
i=1
(Xi − X)k.
Teorema 1.4. (Momento Amostral) Sejam X1, X2, . . . , Xn uma amostra aleatoria da distribuicaoda variavel aleatoria X com funcao de distribuicao F (x). Entao, para k = 1, 2, . . .,
E(m′k) = µ′
k e V (m′k) =
[µ′2k − (µ′
k)2]
n.
Demonstracao
Observacoes:
(a) O valor esperado de um momento amostral e igual ao correspondente momentopopulacional;
(b) Os valores observaveis dos momentos amostrais tendem a estar mais concentrados emtorno do correspondente momento populacional a medida que o tamanho da amostracresce.
Exemplo 1.2.1. Se Xi, i = 1, 2, . . . , n, sao variaveis aleatorias independentes e identicamente dis-tribuıdas segundo uma Poisson(θ), a funcao de probabilidade de m′
1 e dada por
P (X = x) = P (S = nx) =[e−nθ(nθ)nx
]/(nx)!,
em que S =∑n
i=1 Xi e S ∼ Poisson(nθ). Portanto, m′1 assume os valores 0, 1
n , 2n , . . . com as
respectivas probabilidades e−nθ, nθe−nθ, (nθ)2
2 e−nθ, . . ..
Exemplo 1.2.2. Se X e uma variavel aleatoria com distribuicao Exponencial(θ) e funcao densidadede probabilidade f(x) = θ exp(−θx)I(x)
(0,∞)
, o k-esimo momento de X, k = 1, 2, . . ., e dado por
µ′k = E(Xk) =
∫ ∞
0xkθ exp(−θx)dx = Γ(k + 1)/θk.
O primeiro momento e o segundo momento central sao E(X) = θ−1 e V (X) = θ−2, respectivamente.Note que (a− b)4 =
∑ni=1
(4i
)ai(−b)4−i =
∑ni=1(−1)i
(4i
)aib4−i. Usando este resultado obtemos E(X −
µ)4 = E[∑n
i=1(−1)i(4i
)Xi(µ)4−i
]= µ4 − 4µ4 + 6µ2E(X2) − 4µE(X3) + E(X4) = 9/θ4.
Nos exemplos acima, obtivemos a distribuicao exata para o momento amostral. Quando isso naoe possıvel, podemos basear as inferencias em distribuicoes aproximadas ou recorrer a metodos desimulacao.
[Texto complementar: Serie de Taylor]
1.3 Teorema Central do Limite 7
1.3 Teorema Central do Limite
O Teorema Central do Limite (TCL) e um dos mais importantes resultados na Estatıstica Mate-matica. Procura-se expressar nesse teorema o fato de que a media aritmetica de n variaveis aleatoriasindependentes e identicamente distribuıdas, denotada por X, tem uma distribuicao cuja forma tendepara uma forma limite que nao depende da distribuicao das variaveis. A ilustracao abaixo mostra adistribuicao da populacao X e os histogramas correspondentes as distribuicoes amostrais de X paradiferentes tamanhos de amostra. Note que a forma do histograma alisado aproxima-se daquele dadistribuicao normal.
População 1 n=3
Amostras n=10 n=30
População 2
População 3
Figura 1.1: Histogramas correspondentes as distribuicoes amostrais de X para diferentes tamanhosde amostra em diferentes populacoes.
Para estudar essa forma limite, pensamos em transformar X de tal modo que a distribuicao limiteseja unica. Um dispositivo a ser usado e a padronizacao, que estabelece uma funcao linear de X ou Sque tem media zero e variancia um:
Z =S − nµ
σ√
n=
X − µ
σ/√
n.
Verificamos facilmente que E(Z) = 0 e V (Z) = 1. Fixando a media e a variancia, a variavel aleatoriaZ tem distribuicao cuja forma pode ser examinada quando n tende ao infinito. O teorema abaixoformaliza esse procedimento.
Teorema 1.5. (Teorema Central do Limite - Lindeberg and Levy) Sejam X1, X2, . . . , Xn variaveisaleatorias independentes e identicamente que formam uma amostra de tamanho n proveniente deuma distribuicao com media µ e variancia σ2, 0 < σ2 < ∞. Entao, a variavel aleatoria Z =∑n
i=1 Xi − nµ
σ√
n=
X − µ
σ/√
ntem distribuicao limite que e normal com media zero e variancia um, isto e,
limn→∞
P
[√n(X − µ)
σ≤ z
]= Φ(z), (1.3)
1.3 Teorema Central do Limite 8
para cada numero z fixado. Φ(·) denota a funcao de distribuicao de uma variavel aleatoria normalpadrao.
Demonstracao
Suponha que a funcao geradora de momentos da distribuicao de X, denotada por MX(t),exista para t, tal que −h < t < h, h > 0. Entao,
MZ(t) = E[exp(tZ)] = E
[exp
(t
∑ni=1 Xi − nµ
σ√
n
)]= E
[exp
(t√n
∑ni=1
Xi − µ
σ
)]
= E[exp
(t√n
∑ni=1 Yi
)]=
n∏
i=1
E
[exp
(t√n
Yi
)]=
n∏
i=1
[MYi
(t/√
n)]
=[MY (t/
√n)]n
.
Na ultima igualdade acima, usamos o fato de que as variaveis Yi, i = 1, 2, . . . , n, saoidenticamente distribuıdas, e, portanto, todos as MYi
(t/√
n) sao identicas, sendo denotadas porMY (t/
√n).
Desde que MX(t) exista, a funcao MY (t) = E[exp t (X−µ)σ ] existira para −h < t < h, h > 0. Se
expandirmos MY (t) em serie de Taylor (Maclaurin) , teremos:
MY (t) = MY (0) + M ′Y (0)t + M ′′
Y (0)t2
2!+ M ′′′
Y (0)t3
3!+ . . .
Note que
MY (0) = 1,
M ′Y (0) = E
[(X−µ
σ ) exp (tX−µσ )
]∣∣∣t=0
= 0,
M ′′Y (0) = E
[(X−µ
σ )2 exp (tX−µσ )
]∣∣∣t=0
= 1,
M ′′′Y (0) = E
[(X−µ
σ )3 exp (tX−µσ )
]∣∣∣t=0
= µ3/σ3.
Assim, MY (t) = 1 +t2
2!+
µ3t3
σ33!+ . . . . Agora, substituindo t por t/
√n em MY (t), teremos a
expansao para MY (t/√
n):
MY (t/√
n) = 1 +t2
2n+
µ3t3
6σ3n3/2+ . . . = 1 +
t2/2
n+ o(1/n).
Consequentemente, MZ(t) =
[1 +
t2/2
n+ o(1/n)
]n
e limn→∞
MZ(t) = et2/2. A notacao o(1/n)
deve ser entendida da seguinte forma: se f(k) = o(k), entao f(k)/k −→ 0 quando k −→ 0.Vemos que, para o tamanho da amostra tendendo ao infinito, Z tem a mesma funcao geradorade momentos de uma variavel aleatoria com distribuicao normal padrao. Portanto, adistribuicao de Z sera aproximadamente N(0, 1). Essa conclusao tem por base o teorema e olema seguintes. O grau de aproximacao dependera tambem da particular distribuicao davariavel aleatoria.
[Demonstrar usando Funcao Caracterıstica]
Teorema 1.6. (Teorema da Continuidade) Seja Xn uma variavel aleatoria com funcao distribuicaoFXn(x) e funcao geradora de momentos MXn(t) que existe para −h < t < h, h > 0, e para todo n. Seexiste uma funcao de distribuicao FX(x), com correspondente funcao geradora de momentos MX(t),definida para |t| ≤ h1 < h, tal que lim
n→∞MXn(t) = MX(t), entao Xn tem uma distribuicao limite com
funcao de distribuicao FX(t).
1.3 Teorema Central do Limite 9
Lema 1. Para a ∈ IR, limn→∞
[1 +
a
n+ o
(1
n
)]n
= limn→∞
[1 +
a
n
]n= ea.
Exemplo 1.3.1. Sejam X1, X2, . . . , Xn variaveis aleatorias independentes e identicamente distribuı-das segundo Bernoulli(p) e S =
∑ni=1 Xi. Temos que MS(t) = (1 − p + pet)n, para todo t. Se nos
tomarmos n −→ ∞ de tal forma que np = λ permaneca constante, entao, pelo Lema 1,
limn→∞
(1 − p + pet)n = limn→∞
[1 − λ
n+
λ
net
]n
= eλ(et−1), para todo t,
que e a funcao geradora de momentos de uma variavel aleatoria Poisson(λ). Portanto, a funcao dedistribuicao binomial aproxima-se da funcao de distribuicao Poisson nas condicoes impostas.
Exemplo 1.3.2. Seja X ∼ Poisson(λ). Fazendo uso do Teorema 1.6 para determinar a distribuicaolimite da variavel Y = (X − λ)/
√λ temos:
MY (t) = E[exp(tY )] = E[exp(tX − λ√
λ)] = exp(−t
√λ)E[exp(
t√λ
X)] = exp(−t√
λ) exp{λ[exp(t√λ
)−1]}.
Vamos expandir exp( t√λ) em serie de Taylor .
Funcao: f(t) = exp(t/√
λ).
Serie: f(0) + f (1)(0)t + f (2)(0)t2
2!+ f (3)(0)
t3
3!+ f (4)(0)
t4
4!+ · · · .
f(0) = 1
f (1)(0) =∂f(t)
∂t
∣∣∣t=0
= λ− 12 exp(t/
√λ)∣∣∣t=0
= λ− 12 .
f (2)(0) =∂2f(t)
∂t2
∣∣∣t=0
= λ−1 exp(t/√
λ)∣∣∣t=0
= λ−1.
f (3)(0) =∂3f(t)
∂t3
∣∣∣t=0
= λ− 32 exp(t/
√λ)∣∣∣t=0
= λ− 32 .
f (4)(0) =∂4f(t)
∂t4
∣∣∣t=0
= λ−2 exp(t/√
λ)∣∣∣t=0
= λ−2.
Substituindo em MY (t), temos
MY (t) = exp(−t√
λ) exp{λ[(1 + λ− 12 t + λ−1 t2
2+ λ− 3
2t3
3!+ λ−2 t4
4!+ · · · ) − 1]}
= exp(−t√
λ + t√
λ +t2
2+
t3
3!√
λ+
t4
4!λ+ · · · ) = exp(
t2
2+
t3
3!√
λ+
t4
4!λ+ · · · ).
Segue que limλ→∞
MY (t) = exp(t2/2), que e a funcao geradora de momentos de uma variavela aleatoria
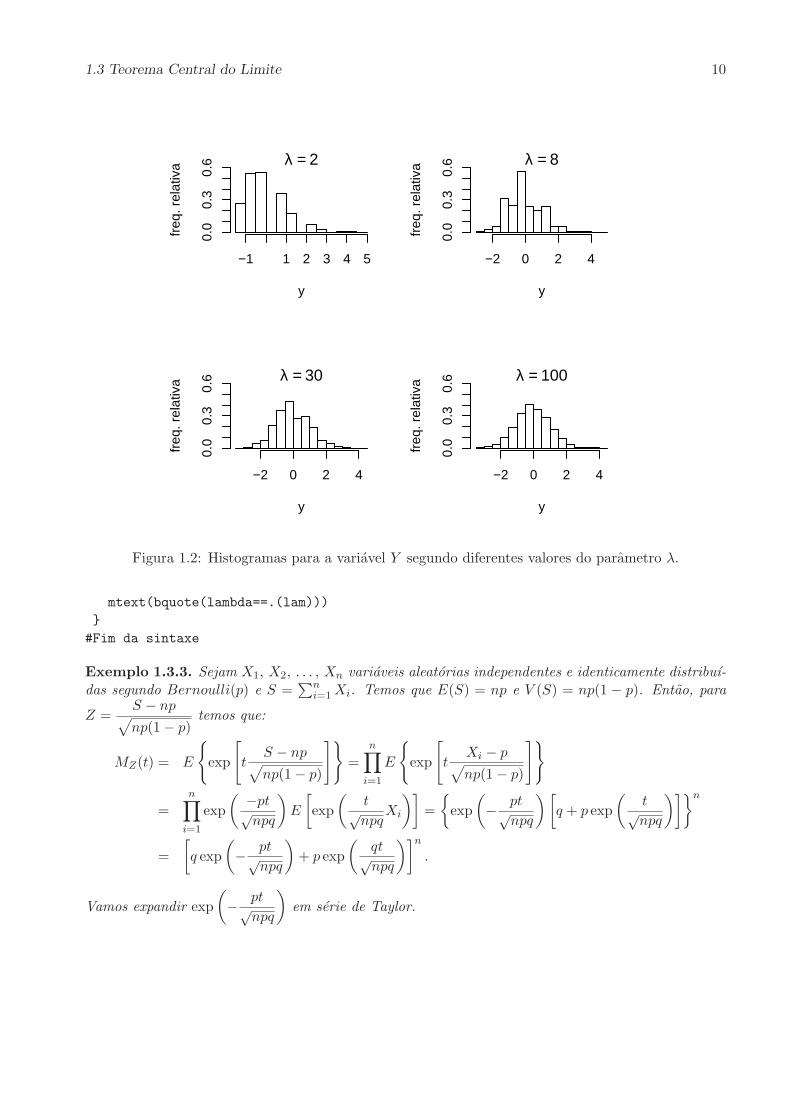
normal padrao. A Figura 1.2 apresenta histogramas de valores simulados para a variavel aleatoriaY segundo diferentes valores do parametro λ. O codigo do Programa R usado para gerar a figura eapresentado abaixo.
Figura 1.2: Histogramas para a variavel Y segundo diferentes valores do parametro λ.
mtext(bquote(lambda==.(lam)))
}
#Fim da sintaxe
Exemplo 1.3.3. Sejam X1, X2, . . . , Xn variaveis aleatorias independentes e identicamente distribuı-das segundo Bernoulli(p) e S =
∑ni=1 Xi. Temos que E(S) = np e V (S) = np(1 − p). Entao, para
Z =S − np√np(1 − p)
temos que:
MZ(t) = E
{exp
[t
S − np√np(1 − p)
]}=
n∏
i=1
E
{exp
[t
Xi − p√np(1 − p)
]}
=n∏
i=1
exp
( −pt√npq
)E
[exp
(t√npq
Xi
)]=
{exp
(− pt√
npq
)[q + p exp
(t√npq
)]}n
=
[q exp
(− pt√
npq
)+ p exp
(qt√npq
)]n
.
Vamos expandir exp
(− pt√
npq
)em serie de Taylor.
1.3 Teorema Central do Limite 11
Funcao: f(t) = exp
(− pt√
npq
).
Serie: f(0) + f (1)(0)t + f (2)(0)t2
2!+ f (3)(0)
t3
3!+ f (4)(0)
t4
4!+ · · · .
f(0) = 1
f (1)(0) =∂f(t)
∂t
∣∣∣t=0
= − p√npq
.
f (2)(0) =∂2f(t)
∂t2
∣∣∣t=0
=p2
npq.
f (3)(0) =∂3f(t)
∂t3
∣∣∣t=0
= − p3
(npq)32
.
f (4)(0) =∂4f(t)
∂t4
∣∣∣t=0
=p4
(npq)2.
Procedendo com a expansao para exp
(qt√npq
), e substituindo as funcoes pelas series em MZ(t),
temos:
MZ(t) =
{q
(1 − pt√
npq+
p2t2
2npq− p3t3
3!(npq)32
+ · · ·)
+ p
(1 +
qt√npq
+q2t2
2npq+
q3t3
3!(npq)32
+ · · ·)}n
=
[1 +
(p2q + pq2
npq
)t2
2+
(p3q + pq3
(npq)32
)t3
3!+ · · ·
]n
=
[1 +
t2
2n+ o
(1n
)]n
.
Segue, do Lema 1, que limn→∞
MZ(t) = exp
(t2
2
). Pelo Teorema 1.5, concluımos que a distribuicao
limite para Z e Normal(0, 1).
O teorema abaixo aplica-se a uma sequencia de variaveis aleatorias X1, X2, . . . , Xn que sao inde-pendentes, mas nao necessariamente identicamente distribuıdas.
Teorema 1.7. (Teorema Central do Limite - Liapounov) Sejam X1, X2, . . . , Xn variavel aleatoriaindependentes com E(Xi) = µi e V (Xi) = σ2
i , i = 1, 2, · · · , n. Suponha que E(|Xi − µi|3) < ∞ e que
limn→∞
∑ni=1 E(|Xi − µi|3)(∑n
i=1 σ2i )
32
= 0. (1.4)
Entao, para cada numero z fixado,
limn→∞
P (Z ≤ z) = limn→∞
P
∑n
i=1 Xi −∑n
i=1 µi(∑n
i=1 σ2i
) 12
≤ z
= Φ(z), (1.5)
em que Φ(·) denota a funcao de distribuicao de uma variavel aleatoria normal padrao.
A distincao entre o teorema de Lindeberg e Levy e o teorema de Liapounov e que o primeiro seaplica a uma sequencia de variaveis aleatorias independentes e identicamente distribuıdas. E parasua aplicacao e suficiente assumir apenas que a variancia de cada variavel aleatoria seja finita. Osegundo, aplica-se a uma sequencia de variaveis aleatorias independentes que nao necessariamentesejam identicamente distribuıdas. E para sua aplicabilidade deve ser assumido que o terceiro momentocentral de cada variavel aleatoria seja finito e que a condicao expressa na Equacao 1.4 seja satisfeita.
Metodo Delta
[Refazer!]
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 12
2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
0.4
x
dens
idad
e
k=1k=2k=3k=5k=10
Figura 1.3: Densidades Qui-quadrado para diferentes graus de liberdade.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student
1.4.1 Distribuicao Qui-quadrado (χ2)
A famılia de distribuicoes qui-quadrado e uma subcolecao de famılias da distribuicao gama. Vere-mos nesta secao a definicao da distribuicao qui-quadrado, algumas propriedades matematicas, algunsresultados importantes e o emprego dessa distribuicao na determinacao das distribuicoes amostrais deestimadores da variancia quando a amostra e proveniente de uma populacao com distribuicao normal.
Definicao 1.4.1. (Distribuicao qui-quadrado) Se X e uma variavel aleatoria com funcao densidadede probabilidade
f(x; k) =(1/2)k/2
Γ(k/2)x(k/2)−1e−x/2I(x)
(0,∞)
,
entao, define-se a distribuicao de X como uma distribucao qui-quadrado com k graus de liberdade,k > 0, k ∈ Z.
Se a variavel aleatoria X tem distribuicao qui-quadrado com k graus de liberdade (χ2(k)), sua
esperanca, variancia e funcao geradora de momentos sao, respectivamente,
E(X) = k, V (X) = 2k e MX(t) =
(1
1 − 2t
)k/2
, t < 1/2.
Na Figura 1.3 sao apresentados graficos da funcao densidade de qui-quadrado para diferentes valoresdo parametro k. Observe que para k = 2, a densidade e a da distribuicao exponencial. Quando kcresce, a media se afasta para a direita e a variancia aumenta. Quando k → ∞, a forma da curvaaproxima-se daquela da densidade normal. O codigo do Programa R usado para gerar a figura eapresentado abaixo.
Teorema 1.8. Se Xi, i = 1, 2, · · · , k, sao variaveis aleatorias independentes e distribuıdas segundonormais de media µi e variancias σ2
i , entao
U =k∑
i=1
(Xi − µi
σi
)2
=k∑
i=1
Z2i
tem distribuicao qui-quadrado com k graus de liberdade.
Demonstracao
MU (t) = E(etU ) =k∏
i=1
E(etZ2i ) =
k∏
i=1
∫ ∞
−∞etz2
i1√2π
e−12z2i dzi =
k∏
i=1
∫ ∞
−∞
1√2π
e−( 12−t)z2
i dzi.
Completando o integrando de tal modo a obter a densidade de uma Normal(0, 1(1−2t)), resulta
MU (t) =k∏
i=1
1√1 − 2t
=
(1√
1 − 2t
)k
=
(1
1 − 2t
) k2
, t <1
2,
que e a funcao geradora de momentos de uma variavel aleatoria com distribuicao χ2(k).
O Teorema 1.8 declara que a soma do quadrado de variaveis aleatorias com distribuicao normalpadrao tem uma distribuicao qui-quadrado com o numero de graus de liberdade igual ao numero determos da soma.
Exemplo 1.4.1. (DeGroot, 2002) Quando o movimento de uma partıcula microscopica em um lıquidoou um gas e observado, verifica-se que o movimento e irregular porque a partıcula colide frequente-mente com outras partıculas. O modelo probabilıstico para esse movimento, que e conhecido comomovimento Browniano, e o seguinte: um sistema de coordenadas e escolhido em um lıquido ou umgas. Suponha que a partıcula esta na origem desse sistema de coordenadas para o tempo t = 0, e sejam(X, Y, Z) as coordenadas da partıcula para qualquer tempo t > 0. As variaveis aleatorias X, Y e Zsao independentes e identicamente distribuıdas e cada uma delas tem uma distribuicao normal commedia µ e variancia σ2t. Para encontrar a probabilidade, para o tempo t = 2, de que a partıcula estejanuma esfera cujo centro e a origem e o raio e 4σ precisamos determinar a P (X2 + Y 2 + Z2 ≤ (4σ)2).Para t = 2, cada uma das variaveis X/
√2σ, Y/
√2σ e Z/
√2σ tera distribuicao normal padrao. Deste
modo, a variavel aleatoria W = (X2 + Y 2 + Z2)/(2σ2) tera distribuicao qui-quadrado com tres grausde liberdade. Segue que P (X2 + Y 2 + Z2 ≤ (4σ)2) = P (W < 8) = 0.9540.
Nota:
A funcao densidade de probabilidade de uma variavel aleatoria X com distribuicao gama deparametros α e β, (α > 0 e β > 0), e definida por
f(x; α, β) =βα
Γ(α)xα−1e−βxI(x)
(0,∞)
.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 14
O k-esimo momento de X e dado por
E(Xk) =
∫ ∞
0xkf(x; α, β)dx =
βα
Γ(α)
Γ(α + k)
βα+k=
Γ(α + k)
βkΓ(α), k = 1, 2, · · · .
Em particular, E(X) =α
βe V (X) =
α
β2. A funcao geradora de momentos e dada por
MX(t) =
∫ ∞
0etxf(x; α, β)dx =
βα
Γ(α)
∫ ∞
0xα−1e−(β−t)xdx =
βα
Γ(α)
Γ(α)
(β − t)α=
(β
β − t
)α
, t < β.
Note que para β = 12 , temos MX(t) =
(1/2
1/2 − t
)α
=
(1
1 − 2t
)α
, que corresponde a funcao
geradora de momentos de uma variavel aleatoria com distribuicao qui-quadrado com 2α grausde liberdade. Em suma, χ2
(k) corresponde a uma Gama(k2 , 1
2), ou seja, a distribuicaoqui-quadrado e um caso particular da distribuicao gama. Usando ainda a funcao geradora demomentos, prova-se facilmente que, se X ∼ Gama(α, β), a
b X ∼ Gama(α, baβ), a e b constantes
positivas.
Teorema 1.9. Se as variaveis aleatorias X1, X2, . . . , Xn sao independentes e Xi, i = 1, 2, · · · , k,tem distribuicao qui-quadrado com ni graus de liberdade, entao, a variavel aleatoria S =
∑ni=1 Xi tem
distribuicao χ2 com n1 + n2 + · · · + nk graus de liberdade.
Demonstracao
[Texto complementar: Mood, 1974]
Agora, vamos determinar a distribuicao da estatıstica S2 = (n − 1)−1∑n
i=1(Xi − X)2, que pos-teriormente sera usada como estimador para a variancia de populacoes normais, σ2. Vimos que avariavel aleatoria U = (n−1)
σ2 S2 tem distribuicao qui-quadrado com n− 1 graus de liberdade. Partindoda funcao de distribuicao de S2, temos:
G(s) = P (S2 ≤ s) = P (σ2U
n − 1≤ s) = P (U ≤ (n − 1)s
σ2) =
∫ (n−1)s
σ2
0
(12)
n−12
Γ(n−12 )
un−1
2−1e−
u2 du =
=
∫ s
0
(12)
n−12
Γ(n−12 )
[(n − 1)y
σ2
]n−32
e−(n−1)
2σ2 y (n − 1)
σ2dy =
∫ s
0
(n−12σ2 )
n−12
Γ(n−12 )
yn−3
2 e−(n−1)
2σ2 ydy.
Portanto, a funcao densidade de probabilidade de S2 tem distribuicao Gama(n−12 , n−1
2σ2 ).
1.4.2 Distribuicao F de Snedecor
A famılia de distribuicoes F e utilizada em duas diferentes situacoes de testes de hipoteses. Aprimeira, quando o interesse for testar hipoteses sobre as variancias de duas diferentes populacoesnormais. A segunda situacao, que nao faz parte desse texto, refere-se a testes de hipoteses paramedias de mais de duas populacoes normais. A distribuicao F e a distribuicao da razao de duasvariaveis aleatorias qui-quadrado independentes divididas pelos seus respectivos graus de liberdade.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 15
Definicao 1.4.2. (Distribuicao F) Se X e uma variavel aleatoria com funcao densidade de probabil-idade
f(x; m, n) =Γ(
m2 + n
2
)
Γ(
m2
)Γ(
n2
)(m
n
)m/2 x(m−2)/2
(1 + mx
n
)(m+n)/2I(x)(0,∞)
, (1.6)
entao, define-se a distribuicao de X como uma distribuicao F com m e n graus de liberdade, Fm,n.
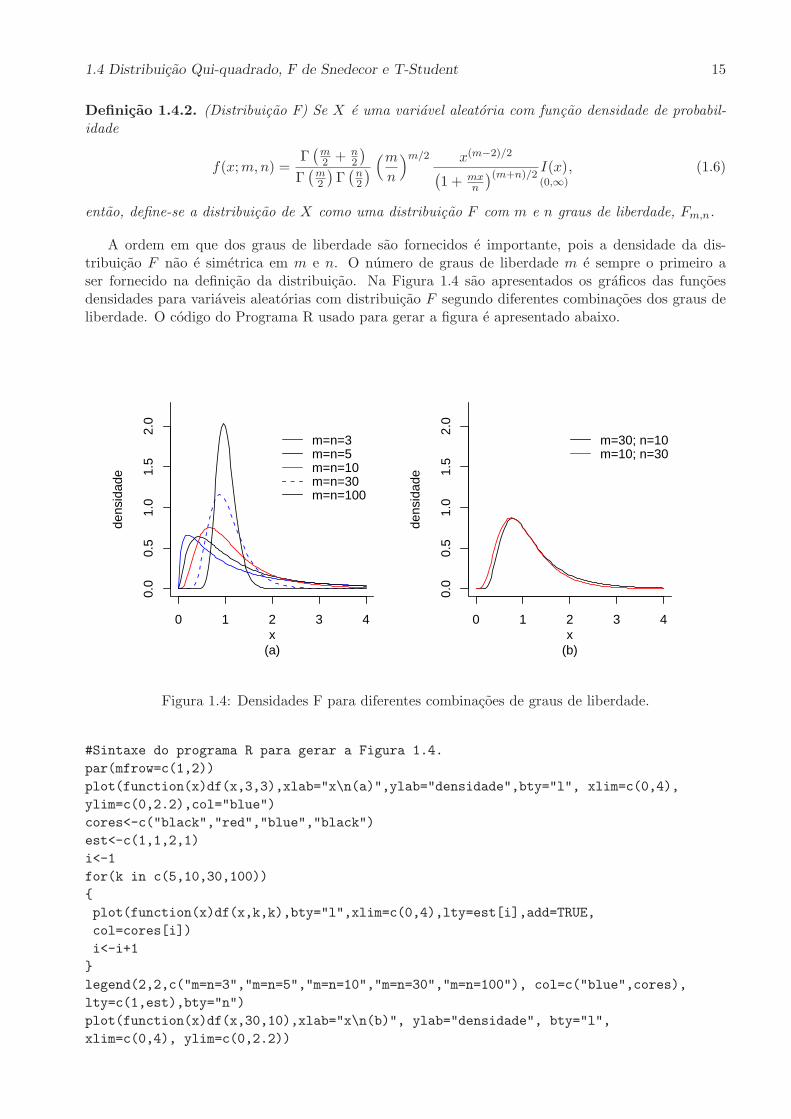
A ordem em que dos graus de liberdade sao fornecidos e importante, pois a densidade da dis-tribuicao F nao e simetrica em m e n. O numero de graus de liberdade m e sempre o primeiro aser fornecido na definicao da distribuicao. Na Figura 1.4 sao apresentados os graficos das funcoesdensidades para variaveis aleatorias com distribuicao F segundo diferentes combinacoes dos graus deliberdade. O codigo do Programa R usado para gerar a figura e apresentado abaixo.
0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
x(a)
dens
idad
e
m=n=3m=n=5m=n=10m=n=30m=n=100
0 1 2 3 4
0.0
0.5
1.0
1.5
2.0
x(b)
dens
idad
e
m=30; n=10m=10; n=30
Figura 1.4: Densidades F para diferentes combinacoes de graus de liberdade.
No problema de comparacao das variancias de duas populacoes normais, faz-se necessario o co-nhecimento da distribuicao da razao de variaveis aleatorias qui-quadrado. Para ilustrar, sejam σ2
1 eσ2
2 as duas variancias sujeitas a comparacao de acordo com as hipoteses σ21 = σ2
2 versus σ21 6= σ2
2.Note que essas hipoteses podem ser escritas como (σ2
1/σ22) = 1 versus (σ2
1/σ22) 6= 1. No sentido de
obter um estimador para a razao das variancias, aceita-se a razao das variancias amostrais s21/s2
2
como um estimador pertinente. Vimos, anteriormente, que a variavel aleatoria (n−1)S2/σ2 apresentadistribuicao de qui-quadrado com n − 1 graus de liberdade. Com essas duas informacoes, vamos embusca da distribuicao da variavel aleatoria
Y = U/V,
em que U e V sao variaveis aleatorias independentes com distribuicao de qui-quadrado com m e ngraus de liberdade, respectivamente. Para essas duas variavel aleatoria a funcao densidade conjuntae dada por
fU,V (u, v) =(12)(m/2+n/2)
Γ(m2 )Γ(n
2 )u(m/2)−1v(n/2)−1e−(u/2+v/2)I(v)
(0,∞)
I(u)(0,∞)
.
A funcao de distribuicao de Y e dada por
FY (y) = P (Y < y) = P (U/V < y) =
∫ ∫
v>0, u/v< y
f(u, v)du dv =
∫ ∞
0
∫ vy
0f(u, v)du dv =
=2−(m+n)/2
Γ(m2 )Γ(n
2 )
∫ ∞
0e−v/2vn/2−1
∫ vy
0e−u/2um/2−1du dv.
Sendo fY (y) =∂
∂yFY (y), a funcao densidade de probabilidade de Y , temos que
fY (y) =2−(m+n)/2
Γ(m2 )Γ(n
2 )
∫ ∞
0e−v/2vn/2−1
[e−vy/2(vy)(m/2−1)v
]dv =
=2−(m+n)/2
Γ(m2 )Γ(n
2 )ym/2−1
∫ ∞
0vn/2+m/2−1e−[(1+y)/2]vdv
=2−(m+n)/2
Γ(m2 )Γ(n
2 )ym/2−1 Γ(m
2 + n2 )
(1+y2
)n/2+m/2=
Γ(m2 + n
2 )
Γ(m2 )Γ(n
2 )ym/2−1(1 + y)−(m/2+n/2)I(y)
(0,∞)
. (1.7)
Definamos, agora, a variavel aleatoria
X =U/m
V/n=
n
mY.
Note que, dessa forma, X = S2u/σ2
u
S2v/σ2
v(e sob a hipotese de que as variancias populacionais σ2
u e σ2v sao
iguais, X = S2u/S2
v , que e o estimador citado para a razao das variancias populacionais). Partindo dafuncao de distribuicao de X, para determinar sua funcao densidade de probabilidade , temos FX(x) =P (X ≤ x) = P (Y ≤ m
n x) = FY ( nmx). Assim, fX(x) = m
n fY ( nmx) que resulta
fX(x) =m
n
Γ(m2 + n
2 )
Γ(m2 )Γ(n
2 )
(mx
n
)m/2−1 (1 +
mx
n
)−(m/2+n/2)=
Γ(m2 + n
2 )
Γ(m2 )Γ(n
2 )
(m
n
)m/2 xm/2−1
(1 + mx
n
)(m+n)/2I(x)(0,∞)
.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 17
Verificamos que essa densidade e a mesma expressa na Equacao 1.6. Concluımos, assim, queuma variavel aleatoria X com distribuicao F de Snedecor defini-se como a razao de duas variaveisaleatorias independentes com distribuicao de qui-quadrado, cada uma dividida pelos respectivos grausde liberdade. O valor esperado e a variancia para X com distribuicao F com m e n graus de liberdade,sao dados por
E(X) =n
n − 2e V (X) =
2n2(m + n − 2)
m(n − 2)2(n − 4).
Para a demonstracao desses resultados, podemos proceder a mudanca de variavel y = w/(1 − w) nadensidade da Equacao 1.7. Essa mudanca de variavel resultara uma densidade beta e, sem dificuldades,obteremos E(Y ) = m/(n− 2) e consequentemente E(X) = E( n
mY ) = n/(n− 2). A variancia pode serobtida de forma similar.
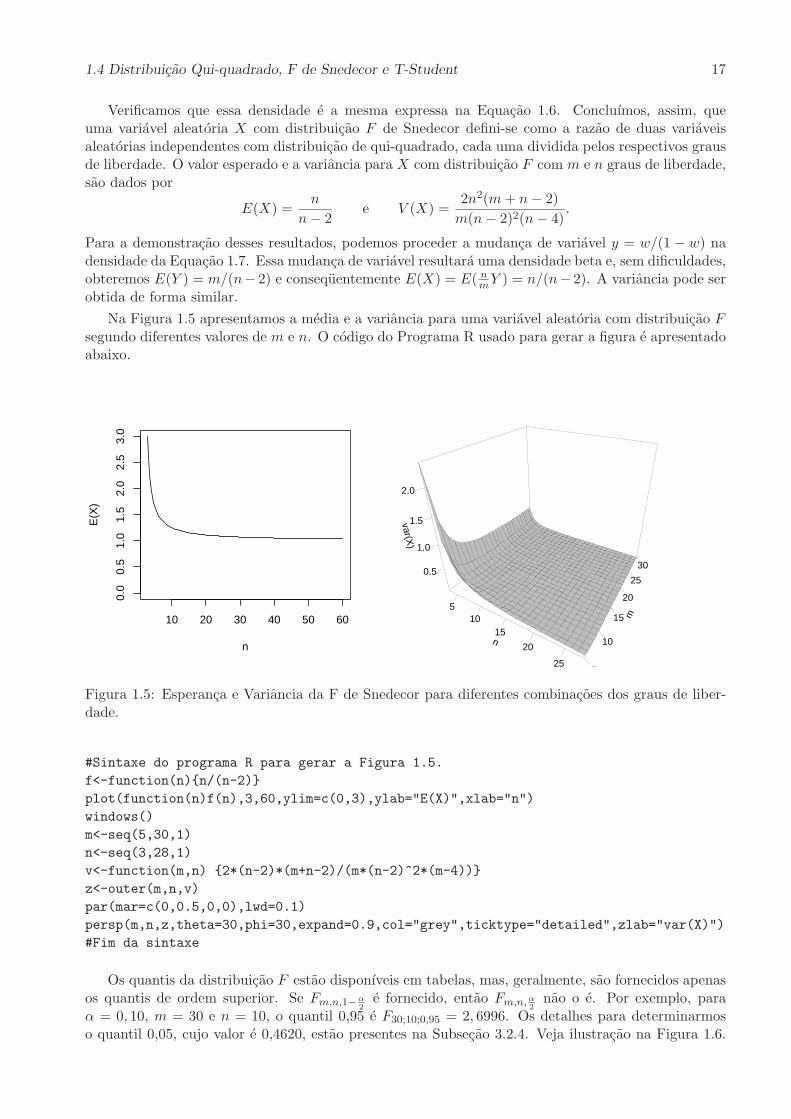
Na Figura 1.5 apresentamos a media e a variancia para uma variavel aleatoria com distribuicao Fsegundo diferentes valores de m e n. O codigo do Programa R usado para gerar a figura e apresentadoabaixo.
10 20 30 40 50 60
0.0
0.5
1.0
1.5
2.0
2.5
3.0
n
E(X
)
n
510
15
20
25
m
5
10
15
20
25
30
var(X)
0.5
1.0
1.5
2.0
Figura 1.5: Esperanca e Variancia da F de Snedecor para diferentes combinacoes dos graus de liber-dade.
Os quantis da distribuicao F estao disponıveis em tabelas, mas, geralmente, sao fornecidos apenasos quantis de ordem superior. Se Fm,n,1−α
2e fornecido, entao Fm,n, α
2nao o e. Por exemplo, para
α = 0, 10, m = 30 e n = 10, o quantil 0,95 e F30;10;0,95 = 2, 6996. Os detalhes para determinarmoso quantil 0,05, cujo valor e 0,4620, estao presentes na Subsecao 3.2.4. Veja ilustracao na Figura 1.6.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 18
0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
f2f1
Figura 1.6: Percentis da distribuicao F de Snedecor com graus de liberdade m=30 e n=10.
O codigo do Programa R usado para gerar a figura e apresentado abaixo. Para o momento, faz-senecessario apenas que estabelecamos a distribuicao de Y = 1/X, em que X tem distribuicao F comm e n graus de liberdade. Partindo das funcoes de distribuicao, temos:
FY (y) = P (Y < y) = P (X ≥ 1/y) = 1 − FX(1/y)
e, usando a igualdade fY (y) =∂FY (y)
∂y, concluımos que
fY (y) =1
y2fX(1/y) =
Γ(m2 + n
2 )
Γ(m2 )Γ(n
2 )
( n
m
)n/2 xn/2−1
(1 + nx
m
)(m+n)/2I(y)(0,∞)
. (1.8)
Portanto, Y = 1/X tem distribuicao F com n e m graus de liberdade.
A distribuicao t e outra distribuicao de ampla aplicacao em problemas de inferencia estatıstica. Adenominacao t de Student deve-se a W. S. Gosset que publicou seus estudos dessa distribuicao em 1908
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 19
sob o pseudonimo de Student. Uma variavel aleatoria com distribuicao t e resultante da razao entreuma variavel aleatoria com distribuicao normal padrao e a raiz quadrada de uma variavel aleatoriacom distribuicao qui-quadrado dividida pelos seus graus de liberdade (variaveis independentes). Dessaforma, o quadrado de uma t apresenta distribuicao F com 1 e n graus de liberdade, no numerador eno denominador, respectivamente.
Definicao 1.4.3. (Distribuicao t de Student) Se X e uma variavel aleatoria com funcao densidadede probabilidade
f(x; k) =Γ(
k+12
)
Γ(
k2
) 1√kπ
1(1 + x2
k
)(k+1)/2I(x)(0,∞)
, (1.9)
entao, define-se a distribuicao de X como uma distribucao t de Student com k graus de liberdade, tk.
Teorema 1.10. Se Z tem distribuicao normal padrao, U tem distribuicao qui-quadrado com k grausde liberdade e Z e U sao independentes, entao T = Z/
√U/k tem uma distribuicao t de Student com
k graus de liberdade.
Demonstracao
A funcao densidade de probabilidade conjunta de Z e U e dada por
fZ,U (z, u) =1√2π
(12)k/2
Γ(k2 )
uk/2−1e−(u+z2)/2 I(z)(−∞,∞)
I(u)(0,∞)
.
Usando a transformacao t = z/√
u/k e w = u, o jacobiano e
J =
∣∣∣∣∣∣∣∣
∂t
∂z
∂t
∂u
∂w
∂z
∂w
∂u
∣∣∣∣∣∣∣∣=
∣∣∣∣∣∣∣
1√uk
−12
z√
k
u32
0 1
∣∣∣∣∣∣∣=
1√uk
.
Dessa forma, fT,W (t, w) = fZ, U (g−11 (t, w), g−1
2 (t, w))|J |−1, em que g−11 (t, w) = t
√w/
√k e
g−12 (t, w) = w sao as funcoes inversas, e |J |−1 =
√w/k. Explicitando, temos
f(t, w) =1√2π
(12)k/2
Γ(k2 )
wk/2−1e−[w+(t2w)/k]/2(w/k)1/2 I(t)(−∞,∞)
I(w)(0,∞)
.
Para obter a funcao densidade de probabilidade de T , integramos a densidade conjunta acimaem relacao a w. Deste modo,
f(t) = f(t; k) =Γ(
k+12
)
Γ(
k2
) 1√kπ
1(1 + t2
k
)(k+1)/2I(t)
(−∞,∞)
Nas secoes anteriores, mostramos que se X1, X2, . . . , Xn e uma amostra aleatoria proveniente de
uma populacao normal com media µ e variancia σ2, entao Z =(X − µ)
σ/√
ntem distribuicao normal
padrao, U =
∑ni=1(Xi − X)2
σ2tem distribuicao de qui-quadrado com n− 1 graus de liberdade e Z e U
sao independentes. Do Teorema 1.10, concluımos que
X − µ
σ/√
n√[∑ni=1(Xi − X)2
σ2
]/(n − 1)
=X − µ
s/√
n
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 20
tem distribuicao t de Student com n − 1 graus de liberdade.
Observacoes:
(i) Se o numero de graus de liberdade e igual a 1, a distribuicao t equivale a distribuicaoCauchy.
(ii) A distribuicao t aproxima-se da distribuicao normal padrao quando o numero de graus deliberdade cresce.
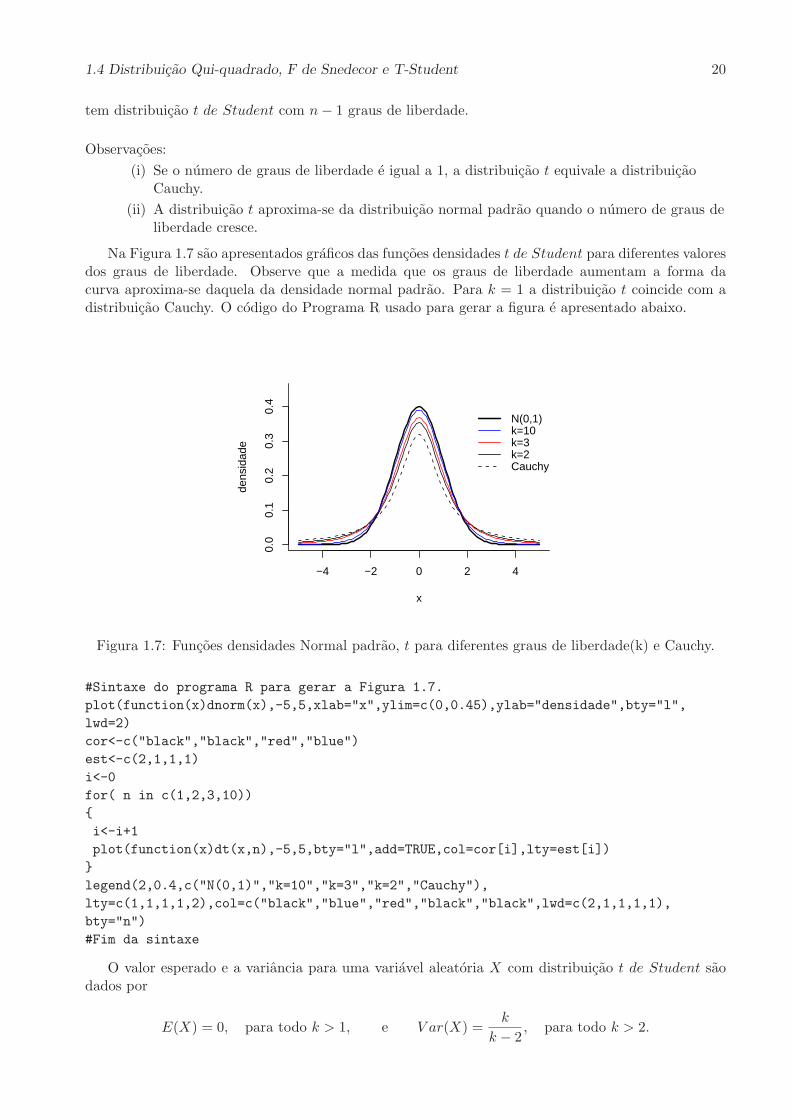
Na Figura 1.7 sao apresentados graficos das funcoes densidades t de Student para diferentes valoresdos graus de liberdade. Observe que a medida que os graus de liberdade aumentam a forma dacurva aproxima-se daquela da densidade normal padrao. Para k = 1 a distribuicao t coincide com adistribuicao Cauchy. O codigo do Programa R usado para gerar a figura e apresentado abaixo.
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
dens
idad
e
N(0,1)k=10k=3k=2Cauchy
Figura 1.7: Funcoes densidades Normal padrao, t para diferentes graus de liberdade(k) e Cauchy.
O valor esperado e a variancia para uma variavel aleatoria X com distribuicao t de Student saodados por
E(X) = 0, para todo k > 1, e V ar(X) =k
k − 2, para todo k > 2.
1.4 Distribuicao Qui-quadrado, F de Snedecor e T-Student 21
1.4.4 Distribuicoes Nao-centrais
[Inserir!]
Capıtulo 2
Estimacao Pontual
2.1 Introducao
Neste capıtulo introduzimos conceitos basicos da estimacao estatıstica e abordamos o metodo deestimacao de maxima verossimilhanca, devido a Ronald A. Fisher, o metodo dos momentos, devido aKarl Pearson, e o metodo dos mınimos quadrados.
O cenario deste capıtulo sera composto de experimentos aletatorios em que a caracterıstica deinteresse nos elementos populacionais pode ser representada por uma variavel aleatoria X cuja funcaode distribuicao tenha forma conhecida, mas seja desconhecido o parametro θ, do qual a funcao depende.Claro esta que se θ fosse conhecido, a funcao distribuicao estaria completamente especificada, e naoseria necessario fazer inferencia sobre este parametro. A estimacao do parametro θ, ou de algumafuncao desse parametro, g(θ), sera feita com base nos valores observados das variaveis aleatoriasX1, X2, . . . , Xn
1.
Na Estimacao Pontual trataremos de dois “problemas”: primeiro, encontrar meios para obterestatısticas para serem usados como estimadores; segundo, selecionar criterios para definir e encontraro “melhor”estimador. A seguir apresentamos algumas definicoes importantes.
Definicao 2.1.1. (Estatıstica) Uma funcao das variaveis aleatorias observadas, t(X1, X2, . . . , Xn),que nao dependa de parametros desconhecidos, e chamada uma estatıstica.
Definicao 2.1.2. (Estimador) Um estimador e definido como uma estatıstica cujo valor e usado paraestimar um parametro θ.
Definicao 2.1.3. (Estimativa) Um valor particular de um estimador, t(x1, x2, . . . , xn), e chamadouma estatimativa de θ.
Definicao 2.1.4. (Espaco Parametrico) O conjunto Θ de todos os valores possıveis do parametro θde uma funcao distribuicao F e chamado espaco parametrico.
Exemplo 2.1.1. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma distribuicaoGama(α, β). Se α e conhecido, entao θ = β e o parametro de interesse(desconhecido) e o espacoparametrico e Θ = {β; β > 0}. Agora, se β e conhecido, teremos θ = α e Θ = {α; α > 0}. Caso osdois parametros sejam desconhecidos, teremos θ = (α, β) e Θ = {(α, β); α > 0 e β}.
Exemplo 2.1.2. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma distribuicaoN(µ, σ2), σ2 conhecida. Como estimador para a media populacional µ podemos usar X = 1
n
∑ni=1 Xi.
Considerando a amostra de tamanho n = 5 e os valores observados x1, x2, x3, x4 e x5, a estimativapara µ e dada pela media amostral observada x = 1
5
∑5i=1 xi.
1Considera-se tambem o caso onde as variaveis nao necessariamente sao independentes ou identicamente distribuıdas
2.2 Metodos de Estimacao 23
2.2 Metodos de Estimacao
Nesta secao estudaremos procedimentos para a obtencao de estimadores. Serao abordados osmetodos dos Momentos, da Maxima Verossimilhanca e dos Mınimos Quadrados. Nas secoes seguintesserao apresentados conceitos e propriedades que permitirao avaliar o desempenho dos estimadores, oque nos dara condicoes de escolher o “melhor” estimador para um determinado parametro.
2.2.1 Metodo dos Momentos
O metodo dos momentos foi proposto por Karl Pearson em 1894. Considerando r parametros haserem estimados, o metodo dos momentos consiste em igualarmos os r momentos nao-centrais popula-cionais aos r momentos nao-centrais amostrais e tomarmos a solucao do sistema de equacoes, digamosθ1, θ2, . . . , θr, como estimativas dos parametros. Os estimadores serao Θ1, Θ2, . . . , Θr que sao, natu-ralmente, funcoes dos momentos amostrais, e, sendo estes estimadores consistentes para os momentospopulacionais, os estimadores pelo metodo dos momentos sao, em condicoes bastantes gerais, consis-tentes. Pode-se demostrar ainda que esses estimadores apresentam distribuicao assintotica normal.
Definicao 2.2.1. (Metodo dos Momentos) Sejam X1, X2, . . . , Xn variaveis aleatorias independentese identicamente distribuıdas cada uma possuindo funcao de distribuicao F (x; θ1, θ2, . . . , θr). Se osmomentos relevantes existirem, os Estimadores pelo Metodo dos Momentos(EMM) de θ1, θ2, . . . , θr
sao as solucoes das equacoesµ′
k = m′k, k = 1, 2, . . . , r,
onde, µ′k = E(Xk) e m′
k =1
n
n∑
i=1
Xki .
Observacoes:
(i) Os EMM nao sao, em regra, assintoticamente eficientes;
(ii) O metodo nao conduz a estimadores unicos, isto e, momentos diferentes podem levar aestimadores diferentes;
(iii) Em muitos casos os estimadores sao obtidos sem dificuldades de calculo;
(iv) Os EMM’s sao consistentes e apresentam distribuicao normal assintotica.
Exemplo 2.2.1. Sejam X1, X2, . . . , Xn uma amostra aleatoria de X com fdp f(x; θ) = θe−θx, 0 <x < ∞. Para estimar θ pelo metodo dos momentos, note que ha apenas um paramero (r = 1)
e, assim, apenas uma equacao e necessaria: µ′1 = m′
1. Segue que E(X) =1
n
∑ni=1 xi, resultando
1/θ = x. Portanto, o estimador pelo metodo dos momentos para θ e Θ = 1/X. Para a amostraobservada x1, x2 . . . , xn , a estimativa e dada por θ = 1/x.
Exemplo 2.2.2.
Exemplo 2.2.3.
Exemplo 2.2.4.
Exemplo 2.2.5.
2.2 Metodos de Estimacao 24
2.2.2 Metodo da Maxima Verossimilhanca
O Metodo da Maxima Verossimilhanca(MMV) foi introduzido por Ronald A. Fisher em 1912. Oforte apelo intuitivo, sua aplicabilidade em muitos casos e a existencia de propriedades desejaveis paraos estimadores resultantes do metodo sao razoes para o seu amplo uso dentre os metodos de estimacao.
Definicao 2.2.2. (Funcao de Verossimilhanca) Sejam X1, X2, . . . , Xn variaveis aleatorias (nao nec-essariamente independentes ou identicamente distribuıdas) com funcao de distribuicao conjunta de-notada por F (x∼; θ) = F (x1, x2, . . . , xn; θ). A funcao de verossimilhanca2 e definida por
L(θ) = L(θ;x∼) = f(x∼; θ),
onde f(., θ) e funcao densidade no caso contınuo e funcao de probabilidade no caso discreto, e θ edesconhecido.
A ideia do metodo e “olhar”para a funcao densidade de probabilidade (ou funcao de probabilidade)conjunta da amostra nao mais como funcao da amostra, mas, sim, como funcao do parametro θ,considerando a amostra observada x1, x2 . . . , xn fixa. Essa funcao passa a ser denominada funcao deverossimilhanca. O metodo da maxima verossimilhanca procura estabelecer valor para o parametro θque mais provavelmente resultou as observacoes x1, x2 . . . , xn . Em geral, este valor e uma funcao daamostra.
Definicao 2.2.3. (Estimador de Maxima Verossimilhanca) Seja L(θ) a funcao de verossimilhancapara as variaveis aleatorias X1, X2, . . . , Xn . Se θ = ϕ(x1, x2, . . . , xn) e um valor de θ, em Θ , quemaximiza L(θ), entao Θ = ϕ(X1, X2, . . . , Xn) e o estimador de maxima verossimilhanca(EMV) de θe θ e a estimativa de maxima verossimilhanca de θ para a amostra x1, x2 . . . , xn .
A verossimilhanca expressa a plausibilidade para diferentes valores de θ, fixada a amostra x1, x2, . . . ,xn; e informa a preferencia por um dentre diversos valores possıveis para o parametro. O valor queresulta a maior verossimilhanca e denominado estimativa de maxima verossimilhanca.
Muitas funcoes de verossimilhanca satisfazem condicoes de regularidade que permitem obter orespectivo maximo por derivacao. Nestes casos a estimativa de maxima verossimilhanca resulta de
∂L(θ;x∼)
∂θ= 0. (2.1)
A estimativa de maxima verossimihanca(EMV) nao coincide necessariamente com alguma solucaoda Equacao 2.1. Mesmo que essa equacao tenha solucao unica, nao significa que ela seja a EMV,que pode ate mesmo nao existir. O fato de operarmos derivando produtorios (Equacao 2.1) tornatrabalhosa a obtencao do maximo para L(θ). Para remediar essa dificuldade, fazemos uso da funcaologarıtmica que e uma funcao monotona crescente3, e, assim, L(θ) e l(θ) = log L(θ) tem seus maximospara o mesmo valor de θ. Desse modo, podemos obter o EMV de θ atraves da equacao
∂l(θ)
∂θ=
∂l(θ;X∼ )
∂θ= 0. (2.2)
Definicao 2.2.4. (Funcao de Log-verossimilhanca) A funcao de log-verossimilhanca e definida comoo logaritmo natural da funcao de verossimilhanca: l(θ) = log L(θ).
Definicao 2.2.5. (Funcao escore) A funcao escore, denotada por U(θ), e definida como a primeiraderivada da funcao de log-verossimilhanca com respeito a θ:
U(θ) =∂
∂θlog f(x∼; θ). (2.3)
2Alguns autores definem L(θ) = c.f(x∼
; θ), onde c e qualquer constante positiva, nao dependente de θ. Diz-se entaoque a verossimilhanca e proporcional a probabilidade de ocorrencia da amostra
3L(θ1; x∼
) < L(θ2; x∼
) ⇔ log L(θ1; x∼
) < log L(θ2; x∼
), ∀ θ1, θ2 ∈ Θ
2.2 Metodos de Estimacao 25
Muito frequentemente trabalhamos com variaveis aleatorias independentes, e as funcoes de veros-similhanca e de log-verossimilhanca reduzem-se, respectivamente, a
L(θ) =n∏
i=1
f(xi; θ) e l(θ) =n∑
i=1
log f(xi; θ).
No desenvolvimento para a obtencao da estimativa de maxima verossimilhanca, θ, precisamosdeterminar o maximo de l(θ) (ou de L(θ)) para todos os valores possıveis de θ, o que pode ser feitopor diferenciacao de l(θ) em relacao a θ, como exposto anteriormente. Entretanto, e possıvel queesse procedimento resulte um mınimo relativo ou um ponto de inflexao ao inves do maximo desejado.Assim, e necessario verificar efetivamente se o maximo foi encontrado, o que pode ser feito (talvez)avaliando o sinal da derivada segunda de l(θ).
Definicao 2.2.6. (Funcao de Informacao) A funcao de informacao (observada), denotada por I(θ),e definida como menos a derivada segunda da funcao de log-verossimilhanca em relacao θ:
I(θ) = −∂2l(θ)
∂θ2. (2.4)
Observacoes:
(i) O EMV pode nao existir ou nao ser unico;
(ii) O EMV deve assumir vlor no espaco parametrico;
(iii) I(θ) pode ser interpretada como a quantidade de informacao observada sobre θ contida naamostra.
Exemplo 2.2.6. Suponha que desejemos estimar o parametro θ de uma populacao representada pelavariavel aleatoria X com distribuicao Exponencial(θ). Uma amostra aleatoria X1, X2, . . . , Xn de Xe selecionada. Teremos:
Funcao de Verossimilhanca: L(θ;x∼) = f(x∼; θ) =n∏
i=1
f(xi; θ) =n∏
i=1
θe−θxi = θne−θPn
i=1 xi
n∏
i=1
I(θ)(0,∞)
.
Funcao de Log-Verossimilhanca: l(θ;x∼) = log L(θ;x∼) = n log θ − θn∑
i=1
xi.
Funcao Escore: U(θ) =∂l(θ; x)
∂θ=
n
θ−
n∑
i=1
xi.
Igualando a funcao escore a zero e resolvendo em relacao a θ, temos:n
θ−
n∑
i=1
xi = 0 ⇒ θ =1
x.
Funcao de Informacao (observada): I(θ) = −∂2l(θ;x∼)
∂θ2=
n
θ2> 0, pois θ > 0.
Vemos que a funcao de verossimilhanca tem um maximo relativo para θ =1
x. Verificamos ainda
que limθ→0 L(θ, x∼) = 0 e limθ→∞ L(θ, x∼) = 0, isto e, nao ha ponto de maximo nas fronteiras. Portanto,
θ resulta maximo absoluto para L(θ, x∼). Na Figura 2.1 sao mostrados os graficos para L(θ) e l(θ) versusθ, este ultimo chamado curva suporte. Em muitos casos esses graficos sao uteis para a verificacao doponto de maximo. O codigo do Programa R usado para gerar a figura e apresentado em seguida.
#Sintaxe do programa R para gerar a Figura 2.1.
set.seed(123) # Semente aleatoria
amostra<-rexp(10,1) # Amostra de tamanho 10 de uma Exponencial(1)
Resumindo o procedimento para encontrarmos θ pelo metodo da maxima verossimilhanca, devemosdeterminar a raız da equacao U(θ) = 0 e verificarmos se I(θ) > 0. Em muitos exemplos, a solucao daequacao U(θ) = 0 pode ser encontrada algebricamente. Para outros, sera necessario resolver a equacaoatraves de metodos numericos como, por exemplo, o de Newton-Raphson. Se o parametrico for umconjunto discreto, calculamos l(θ) para os diversos θ ∈ Θ, e o valor correspondente ao maximo de l(θ)sera o EMV, θ.
Exemplo 2.2.7. (Kalbfleisch, 1985) Um laboratorio esta avaliando se a agua de um rio esta propriapara banho. O interesse no estudo e a concentracao de coliformes(bacteria) na agua. O numero decoliformes e determinado para cada uma de n amostras(volume unitario) de agua do rio, resultandoos valores observados x1, x2 . . . , xn . O problema se resume a estimar µ, o numero medio de co-liformes por unidade de volume de agua no rio. Nos iremos supor que os coliformes distribuem-sealeatoriamente e uniformemente na agua do rio, de modo que a suposicao de um processo de Poissonseja atendida. Deste modo, a probabilidade de observarmos xi coliformes em uma amostra de umaunidade de volume da agua e dada pela distribuicao de Poisson com parametro µ:
f(xi; µ) = µxie−µ/xi!, xi = 0, 1, 2, . . . .
2.2 Metodos de Estimacao 27
Sendo volumes disjuntos independentes, a probabilidade de observamos x1, x2 . . . , xn e
f(x∼; µ) =n∏
i=1
f(xi; µ) =n∏
i=1
µxie−µ/xi! =µPn
i=1 xie−nµ
x1!x2! . . . xn!.
Da Definicao 2.2.2, a funcao de verossimilhanca e dada por c.f(x∼; µ), onde c e qualquer constantepositiva nao dependente de µ. Por simplificacao, escolhemos c = 1/(x1!x2! . . . xn!). Deste modo, asfuncoes de verossimilhanca e de log-verossimilhanca sao, respectivamente,
L(µ) = µPn
i=1 xie−nµ e l(µ) =
n∑
i=1
xi log(µ) − nµ, para 0 ≤ µ < ∞.
As funcoes Escore e de Informacao sao
U(µ) =
∑ni=1 xi
µ− n e I(µ) =
∑ni=1 xi
µ2.
Essas funcoes independem da escolha para a constante c.
Igualando a funcao Escore a zero e resolvendo para µ, temos como estimativa de maxima ve-orssimilhanca µ =
∑ni=1 xi/n = x, se
∑ni=1 xi > 0. Note que I(µ) > 0, pois µ > 0. Ainda, L(0) = 0
e limµ→∞ L(µ) = 0, o que indica a obtencao de maximo absoluto. Para∑n
i=1 xi = 0, a equacaoU(µ) = 0 nao tem solucao e o maximo ocorre no limite do espaco parametrico: µ = 0. Em ambosos casos o estimador de maxima verosimilhanca e X. Assim, para maximizarmos a probabilidade deocorrencia dos dados x1, x2 . . . , xn , a media populacional µ tera como estimador a media amostralx.
Exemplo 2.2.8. Considere um sistema em que uma operacao realiza-se com “sucesso”ou “falha”,e seja p a probabilidade de “sucesso” da operacao. Oito realizacoes da operacao foram executadas,fornecendo o seguinte resultado: 1, 0, 1, 1, 1, 0, 1, 1, onde o valor 1 representa “sucesso”e o valor0, “fracaso”. Assumindo independencia nas realizacoes, e denotando por X a variavel aleatoria queregistra a ocorrencia de sucesso, teremos uma distribuicao Bernoulli(p) para X. A probabilidadeda sequencia observada e p
Pni=1 xi(1 − p)n−
Pni=1 xi = p6(1 − p)2. Esta funcao de p sera a funcao
de verossimilhanca, que sera positiva para 0 < p < 1 e zero para p = 1 ou p = 0, portanto, omaximo ocorre no interior do intervalo [0, 1]. Para obtermos a estimativa de maxima verossimilhanca,resolvemos a equacao
∂L(p)
∂p=
∂
∂pp6(1 − p)2 = 0
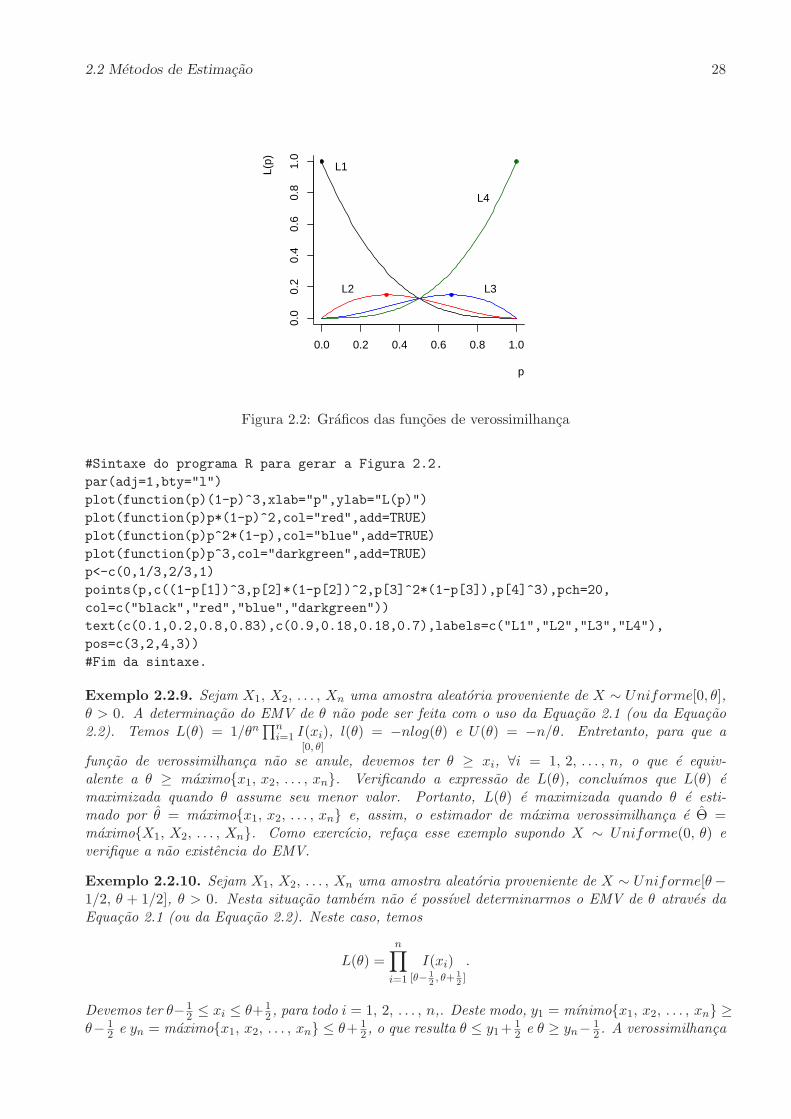
em relacao a p. A solucao e p = 6/8 = 3/4, que e a frequencia relativa de sucessos nas oito realizacoes.O valor maximo para a verossimlhanca e L(p) = (3/4)6(1/4)2 ∼= 0.0111.
Note que a funcao de verossimilhanca depende da amostra x1, x2 . . . , xn apenas atraves da esta-tıstica
∑ni=1 xi. Considere, agora, por simplicidade, uma amostra de tamanho n = 3. Neste caso, a
estatıstica∑n
i=1 xi pode assumir um dos quatro valores: 0, 1, 2, 3. Abaixo sao apresentadas as funcoesde verossimilhanca para essas quatro possibilidades.
L0 = L(p ;∑n
i=1 xi = 0) = (1 − p)3
L1 = L(p ;∑n
i=1 xi = 1) = p(1 − p)2
L2 = L(p ;∑n
i=1 xi = 2) = p2(1 − p)
L3 = L(p ;∑n
i=1 xi = 3) = p3
Na Figura 2.2 sao apresentadas as curvas para essas funcoes. Note que o ponto onde o maximo decada uma das curva e atingido, para 0 ≤ p ≤ 1, e o mesmo: p = x. Para as quatro curvas, os valorespara x sao 0, 1/3, 2/3 e 1, respectivamente. O codigo do Programa R usado para gerar a figura eapresentado em seguida.
2.2 Metodos de Estimacao 28
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
p
L(p) L1
L2 L3
L4
Figura 2.2: Graficos das funcoes de verossimilhanca
Exemplo 2.2.9. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Uniforme[0, θ],θ > 0. A determinacao do EMV de θ nao pode ser feita com o uso da Equacao 2.1 (ou da Equacao2.2). Temos L(θ) = 1/θn
∏ni=1 I(xi)
[0, θ]
, l(θ) = −nlog(θ) e U(θ) = −n/θ. Entretanto, para que a
funcao de verossimilhanca nao se anule, devemos ter θ ≥ xi, ∀i = 1, 2, . . . , n, o que e equiv-alente a θ ≥ maximo{x1, x2, . . . , xn}. Verificando a expressao de L(θ), concluımos que L(θ) emaximizada quando θ assume seu menor valor. Portanto, L(θ) e maximizada quando θ e esti-mado por θ = maximo{x1, x2, . . . , xn} e, assim, o estimador de maxima verossimilhanca e Θ =maximo{X1, X2, . . . , Xn}. Como exercıcio, refaca esse exemplo supondo X ∼ Uniforme(0, θ) everifique a nao existencia do EMV.
Exemplo 2.2.10. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Uniforme[θ−1/2, θ + 1/2], θ > 0. Nesta situacao tambem nao e possıvel determinarmos o EMV de θ atraves daEquacao 2.1 (ou da Equacao 2.2). Neste caso, temos
L(θ) =n∏
i=1
I(xi)[θ− 1
2, θ+ 1
2]
.
Devemos ter θ−12 ≤ xi ≤ θ+1
2 , para todo i = 1, 2, . . . , n,. Deste modo, y1 = mınimo{x1, x2, . . . , xn} ≥θ− 1
2 e yn = maximo{x1, x2, . . . , xn} ≤ θ+ 12 , o que resulta θ ≤ y1+ 1
2 e θ ≥ yn− 12 . A verossimilhanca
2.2 Metodos de Estimacao 29
e, entao, expressa porL(θ) = I(θ)
[yn− 12, y1+ 1
2]
.
Sendo a verossimilhanca constante no intervalo [yn − 12 , y1 + 1
2 ] e nula para θ > y1 + 12 ou θ < yn − 1
2 ,concluımos que qualquer valor no intervalo citado e uma estimativa de maxima verossimilhanca de θ.Por exemplo, (y1 + yn)/2.
Exemplo 2.2.11. (Kalbfleisch, 1985) Para cada um de duzentos dias de trabalho, uma amostraaleatoria de dez itens foi selecionada de uma linha de producao e avaliada quanto as imperfeicoes. Osresultados foram:
Numero de itens com defeito 0 1 2 3 ≥ 4 TotalFrequencia observada 133 52 12 3 0 200
Para determinarmos o EMV de θ, a probabilidade de que um item seja defeituoso, iremos suporque o numero de itens defeituosos na amostra de tamanho dez, denotado por X, tenha distribuicaobinomial. Deste modo, a probabilidade de x itens defeituosos em dez e px = P (X = x) =
(10x
)θx(1 −
θ)10−x, x = 1, 2, . . . , 10. A probabilidade de quatro ou mais itens defeituosos sera dada por p4+ =1 − p0 − p1 − p2 − p3. Note que esse experimento apresenta as caracterısticas de um experimentomultinomial, pois o resultado de uma unica observacao pertencera a uma de cinco categorias, comprobabilidades pi, i = 0, 1, . . . , 4+. A probabilidade de observarmos a tabela de frequencia dada e
f(x∼; θ) =200
133! 52! 12! 3! 0!p1330 p52
1 p122 p3
3p04+ = w.p133
0 p521 p12
2 p33p
04+
A verossimilhanca sera entao
L(θ) = cf(x∼, θ) = cw
[(10
0
)θ0(1 − θ)10
]133[(10
1
)θ(1 − θ)9
]52[(10
2
)θ2(1 − θ)8
]12[(10
3
)θ3(1 − θ)7
]3
.
Escolhendo a constante c de modo conveniente para a simplificacao de L(θ), temos que:
L(θ) =[(1 − θ)10
]133 [θ(1 − θ)9
]52 [θ2(1 − θ)8
]12 [θ3(1 − θ)7
]3= θ85(1 − θ)1915.
A funcao de verossimilhanca e da forma apresentada no Exemplo 2.2.8, com∑n
i=1 xi/n = 85 e n =
200. Deste modo, o estimador de maxima verossimilhanca e dado por θ = 85/2000 = 0.0425.
No quadro abaixo sao apresentadas as estimativas para as probabilidades e frequencias esperadaspara cada uma das cinco classes.
As estimativas para a probabilidade e a frequencia esperada para a primeira classe (numero deitens com defeito igual a zero) sao, respectivamente, p0 =
(100
)θ0(1 − θ)10 = 0, 6477 e a estimativa
da frequencia esperada para essa classe e np0 = 200(0, 6477) = 129, 54. Os demais resultados foramobtidas de modo similar.
Em muitos problemas, o interesse nao esta em estimar o parametro θ, mas, sim, uma funcao dele.Por exemplo, estimar P (X = 0) = e−θ, se X ∼ Poisson(θ). O teorema seguinte nos ajudara emsituacoes como esta.
2.2 Metodos de Estimacao 30
Teorema 2.1. (Princıpio da invariancia) (i) Suponha que Θ = W (X1, X2, . . . , Xn) e o estimadorde maxima verossimilhanca de θ que caracteriza f(x; θ). Se g(·) e uma funcao biunıvoca(isto e,g(θ1) = g(θ2) se, e somente se, θ1 = θ2), entao o EMV de g(θ) e g(Θ). (ii) Este resultado podegeneralizar-se em dois sentidos: primeiro, para θ vetor, e ,segundo, abandonando-se a condicao defuncao biunıvoca para g(·).
Demonstracao
(i) Sendo g(·) uma funcao biunıvoca, podemos escrever θ = g−1(g(θ)), pois g(·) e invertıvel.Assim, L(θ;x∼) = L(g−1(g(θ));x∼), de modo que θ maximiza os dois lados desta igualdade.
Portanto, θ = g−1(g(θ)) e g(θ) = g(θ), ou seja, a EMV de g(θ) e g(θ) e o EMV de g(θ) e g(Θ).
(ii) Ainda que varios valores de θ correspondam a um unico valor de g(θ), θ (que maximizaL(θ), por hipotese) e um dos valores de θ que conduzem g(·) a g(θ), e, portanto, g(θ)corresponde ao maximo de L(·).
Exemplo 2.2.12. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Bernoulli(θ),θ ∈ [0, 1]. O estimador de maxima verossimilhanca de θ e . . . . Para obtermos o EMV de V (X) =θ(1 − θ), fazemos . . .
Exemplo 2.2.13. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Exponencial(θ),com funcao densidade de probabilidade f(x; θ) = θ exp (−θx), x > 0, θ > 0. Para determinarmos oEMV da P (X > 1), note que . . .
Exemplo 2.2.14. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Normal(µ, σ2,µ ∈ IR, σ2 > 0. Vamos determinarmos o EMV de g(θ) = σ2 + µ2. Inicialmente . . .. Veja o exemplo2.2.15.
[Texto complementar: Distribuicao do EMV em grandes amostras]
Funcao de verossimilhanca com dois ou mais parametros
Abordaremos, agora, situacoes em que o modelo probabilıstico para a variavel em estudo envolvedois ou mais parametros desconhecidos. Para uma funcao de verossimilhanca contendo r parametros,os estimadores de maxima verossimilhanca dos parametros θ1, θ2, . . . , θr serao as variaveis aleatoriasΘ1, Θ2, . . . , Θr, e θ1, θ2, . . . , θr serao os valores em Θ que maximizam L(θ∼;x∼). O ponto onde a funcaode verossimilhanca atinge seu maximo pode ser obtido pela solucao das r equacoes:
∂L(θ∼;x∼)
∂θ1= 0,
∂L(θ∼;x∼)
∂θ2= 0, . . . ,
∂L(θ∼;x∼)
∂θr= 0. (2.5)
A estimativa de maxima verossimilhanca nao coincidira necessariamente com alguma solucao dosistema. Mesmo que o sistema tenha solucao unica, nao significa que ela seja a EMV, que pode atemesmo nao existir.
Na obtencao do estimador de maxima verossimilhanca duas verificacoes sao importantes: (i) ver-ificar se a solucao esta em Θ e (ii) verificar se a solucao e maximo local de l(θ∼). Para esta ultima
verificacao, e suficiente que U(θ∼) = U(θ∼) = U(θ)∣∣∣θ∼ = θ∼
= 0 e que a matriz de informacao observada
J(θ∼) = −∂U(θ∼)
∂θ∼= −
∂2l(θ∼, x∼)
∂θ∼∂θ∼′
∣∣∣θ∼ = θ∼
seja positiva definida.
2.2 Metodos de Estimacao 31
Neste texto, daremos atencao a modelos com dois parametros.
Suponha que o modelo probabilıstico para um experimento envolva dois parametros, θ1 e θ2. Aestimativa de maxima verossimilhanca de (θ1, θ2) e o par de valores parametricos (θ1, θ2) que maximizaas funcoes de verossimilhanca e de log-verossimilhanca.
No caso de um parametro, θ pode ser obtido resolvendo a equacao U(θ) = 0. Agora, a funcaoescore e um vetor com dois componentes:
U(θ∼) = U(θ1, θ2) =
[U1(θ1, θ2)
U2(θ1, θ2)
]=
∂l(θ∼, x∼)
∂θ1
∂l(θ∼, x∼)
∂θ2
Para encontrarmos (θ1, θ2), resolvemos o par de equacoes simultaneas: U1(θ1, θ2) = 0 e U2(θ1, θ2) =0. Entretanto, se o maximo ocorrer no limite do espaco parametrico, as estimativas nao serao obtidasdessas equacoes.
A condicao para o maximo relativo no caso uniparametrico foi J(θ) = −∂U(θ)
∂θ= −
∂2l(θ, x∼)
∂θ2> 0.
Agora, a funcao de informacao observada e uma matrix simetrica dois-por-dois:
J(θ∼) = J(θ1, θ2) =
[J11(θ1, θ2) J12(θ1, θ2)
J21(θ1, θ2) J22(θ1, θ2)
]=
−∂2l(θ∼, x∼)
∂θ21
−∂2l(θ∼, x∼)
∂θ1∂θ2
−∂2l(θ∼, x∼)
∂θ1∂θ2−
∂2l(θ∼, x∼)
∂θ22
Para um maximo relativo a matriz J(θ∼) = J(θ1, θ2) deve ser positiva definida, o que pode ser verificado
por J11 > 0, J22 > 0 e J11J22 − J12J21 > 0, onde Jij = Jij(θ1, θ2).
Como no caso uniparametrico, a verossimilhanca e invariante sob transformacoes um-a-um dosparametros. Frequentemente, esse tipo de transformacao traz simplificacao no calculo do maximo. Atransformacao inversa pode entao ser aplicada para obter os estimadores de maxima verossimilhancapara os parametros originais. E ainda, segue da propriedade de invariancia que, se ω = g(θ1, θ2), entaoo estimador de maxima verossimilhanca de ω e ω = g(θ1, θ2).
Exemplo 2.2.15. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma distribuicaoNormal de media µ e variancia σ2. Vamos determinar os estimadores de maxima verossimilhancapara µ e σ2.
Solucao: Feito em sala de aula!
Em alguns casos, nao e possıvel obter (θ1, θ2) de forma algebrica, isto e, obter uma expressaopara os estimadores. Nos exemplos abaixo, veremos o uso do metodo de Newton-Raphson (metodo deNewton ou das tangentes, no caso uniparametrico) que e um procedimento iterativo para a solucaode equacoes.
Suponha que seja possıvel resolver uma das equacoes, digamos U1(θ1, θ2) = 0, e assim obter umaexpressao algebrica para θ1em funcao de θ2. Seja θ1(θ2) a solucao dessa equacao. Esse e o esti-mador de maxima verossimilhanca de θ1dado θ2; isto e, θ1(θ2) e o valor de θ1que maximiza l(θ1, θ2;x∼)
quando o valor de θ2 e suposto conhecido. Substituindo θ1 por θ1(θ2) na segunda equacao resultaU2(θ1(θ2), θ2) = 0, que pode, entao, ser resolvida para θ2 como no caso uniparametrico. O exemplo aseguir esclarece esse procedimento.
Exemplo 2.2.16. (Kalbfleisch, 1985) Suponha que para um teste de resistencia de um componentemetalico, 23 amostras(corpos de prova) foram avaliadas resultando nos valores
De estudos anteriores admite-se que a resistencia apresenta aproximadamente uma distribuicao deWeibull, cuja densidade e dada por f(x; α, β) = αβxβ−1 exp (−αxβ), 0 < x < ∞, onde α > 0 e β > 0.Nosso objetivo e determinar (α, β) com base na amostra observada.
Solucao:Funcao densidade de probabilidade conjunta:
f(x∼; α, β) =n∏
i=1
f(xi; α, β) = (αβ)n
(n∏
i=1
xi
)(β−1)
exp (−αn∑
i=1
xβi )
n∏
i=1
I(x)(0,∞)
Funcao de log-verossimilhanca: l(α, β;x∼) = n log(α) + n log(β) + (β − 1)n∑
i=1
log(xi) − αn∑
i=1
xβi
Funcao Escore: U(α, β) =
[U1(α, β)
U2(α, β)
]=
∂l(α, β;x∼)
∂α
∂l(α, β;x∼)
∂β
=
n
α−
n∑
i=1
xβi
n
β+
n∑
i=1
log(xi) − αn∑
i=1
xβi log(xi)
.
A equacao U1(α, β) = 0 pode ser resolvida algebricamente para α, resultando α(β) = n/∑n
i=1 xβi . Essa
e a estimativa de maxima verossimilhanca de α quando β e suposto conhecido.
Para obter β, substituımos α pela sua estimativa α(β) na equacao U2(α, β) = 0 e resolvemos emrelacao a β. Assim, teremos
U2(α(β), β) =n
β+
n∑
i=1
log(xi) −(
n/n∑
i=1
xβi
)n∑
i=1
xβi log(xi).
A equacao U2(α(β), β) = 0 nao pode ser resolvida algebricamente. Uma solucao e usar o metodoiterativo de Newton (veja detalhes no Apendice):
β(t+1) = β(t) − U2(α(β(t)), β(t))
U ′2(α(β(t)), β(t))
, em que U ′2(α(β(t)), β(t)) =
∂U2(α(β), β)
∂β
∣∣∣∣∣β=β(t)
.
No procedimento iterativo de Newton, obtemos uma nova estimativa β(t+1) a partir de uma anteriorβ(t), via a equacao acima. O superescrito (t) significa a t-esima iteracao do procedimento. O processoe repetido ate a distancia entre β(t+1) e β(t) se tornar suficientemente pequena. Faz-se necessario,obviamente, um valor inicial para o parametro β(t). (acrescentar detalhes!!)
A derivada da funcao U2 em relacao a β e
∂U2(α(β), β)
∂β= − n
β2− n
∑ni=1 xβ
i (log xi)2
∑ni=1 xβ
i
+n(∑n
i=1 xβi log xi)
2
(∑n
i=1 xβi )2
.
Agora, usando os dados do exemplo temos n = 23 e∑n
i=1 log xi = 95, 46. Assumindo o valor 1como valor inicial para a estimativa (β(0) = 1), obtemos:
Iteracao 1(t=0)
2.3 Propriedades dos Estimadores 33
∑ni=1 xβ(0)
i = 1.661, 160,∑n
i=1 xβ(0)
i log xi = 7.312, 526,∑n
i=1 xβ(0)
i (log xi)2 = 32.572, 030,
U2(α(β(0)), β(0)) = 17, 213, U ′2(α(β(0)), β(0)) = −28, 287 e β(1) = 1, 6085.
Iteracao 2(t=1)
∑ni=1 xβ(1)
i = 25.204, 740,∑n
i=1 xβ(1)
i log xi = 11.4257, 600,∑n
i=1 xβ(1)
i (log xi)2 = 523.008, 800,
U2(α(β(1)), β(1)) = 5, 496, U ′2(α(β(1)), β(1)) = −13, 506 e β(2) = 2, 0155.
Apos algumas iteracoes obtemos o valor 2,1021 como estimativa de maxima verossimilhanca para oparametro β e, consequentemente, a estimativa de maxima verossimilhanca para o parametro α e
α = n/∑n
i=1 xβi = 9, 515 × 10−5.
Para o modelo Weibull, podemos substituir α por θ−β. O parametro θ e interpretado como osexagesimo terceiro quantil da distribuicao. Como a transformacao de (α, β) para (θ, β) e um-a-um,
a estimativa de maxima verossimilhanca de θ e, pela propriedade de invariancia, θ = α−1/β = 81, 88.
Abaixo e apresentado o codigo do programa R para obter as estimativas de maxima verossimilhancapara esse exemplo. A funcao fitdistr retorna as estimativas e os respectivos erros-padrao.
#Sintaxe do programa R para o exemplo com a distribuic~ao Weibull.
O exemplo seguinte ilustra o caso onde nao e possıvel adequar o problema de modo a trabalharcom apenas uma equacao.
Exemplo 2.2.17.
2.2.3 Metodo dos Mınimos Quadrados
[Inserir!]
2.3 Propriedades dos Estimadores
Em muitas situacoes, temos disponıvel mais de um estimador para o mesmo parametro. Investigaras propriedades dos estimadores nos ajuadara a decidir qual deles escolher. Considere θ o parametrode interesse e T = t(X1, X2, . . . , Xn) um estimador.
2.3 Propriedades dos Estimadores 34
2.3.1 Estimadores Nao-Viesados
O conceito de estimador nao-viesado tem base na ideia de que um “bom” estimador deve fornecerestimativas que tenham como valor medio o proprio valor do parametro, isto e, a media da distribuicaodo estimador e igual ao parametro (desconhecido). Com menos formalidade, dizemos que, ao usarmosos valores de um estimador T como estimativa para θ, em media “acertamos” o valor deste ultimo.
Definicao 2.3.1. (Estimador nao-viesado) Um estimador T e dito nao-viesado para θ se E(T ) = θ,∀ θ ∈ Θ .
Definicao 2.3.2. O vies de um estimador T , denotado por B(T ), e definido por E(T ) − θ.
Definicao 2.3.3. Um estimador T e dito ser assintoticamente nao-viesado se limn→∞
B(T ) = 0, ∀ θ ∈Θ .
Observacoes:
(i) O vies e o que chamamos de erro sistematico verificado quando usamos T para estimar θ;
(ii) Estimadores nao-viesados podem nao existir;
(iii) Se T e um estimador nao-viesado para θ, g(T ) e geralmente viesado para g(θ), a menosque g seja uma funcao linear;
Exemplo 2.3.1. Sejam X1, X2, . . . , Xn variaveis aleatorias independentes e identicamente distri-buıdas segundo uma distribuicao N(µ, σ2), µ e σ2 desconhecidos. Verifica-se facilmente que X e umestimador nao-viesado para µ: E(X) = 1
nE(∑n
i=1 Xi) = 1n nE(Xi) = µ. Nas definicoes acima, θ
denota o parametro de interesse e T o seu estimador; neste exemplo µ = θ e X = T . Para estimar σ2,o estimador S2 e tambem um estimador nao-viesado. Note: E(S2) = 1
n−1E[∑n
i=1(Xi−X)]2 e, segundo
o exposto no texto complementar da Subsecao 1.4.1, segue que σ2
n−1E[∑n
i=1(Xi −X)/σ]2 = σ2. Agora,
para exemplificar a observacao (iii), verificaremos que S e viesado para σ. Seja Y = (n − 1)S2/σ2.Sabemos que Y ∼ χ2
(n−1)4 e, portanto, E[Y ] = n − 1. Agora,
E(√
Y ) =
∫ ∞
0y
12
(12
)n−12
Γ(
n−12
) y(n−12
)−1 e−y2 dy =
(12
)n−12
Γ(
n−12
) Γ(
n2
)(
12
)n2
∫ ∞
0
(12
)n2
Γ(
n2
)y n2−1e−
y2 dy =
√2 Γ(n
2 )
Γ(n−12 )
.
Sendo E(√
Y ) =√
n−1σ E(S), segue que E(S) =
√2 Γ(n
2 )σ√n − 1 Γ(n−1
2 )= kσ. Portanto, pela definicao 2.3.1,
S e um estimador viesado para σ. Se fizermos 1kS, teremos um estimador nao-viesado para σ. O
quadro abaixo mostra o valor da constante 1/k para diferentes tamanhos de amostra. Para n = 100,a constante e aproximadamente 1(um).
Exemplo 2.3.2. Sejam X1, X2, . . . , Xn variaveis aleatorias independentes e identicamente distribuıdassegundo uma Normal(µ, σ2), µ e σ2 desconhecidos. Para verificar que σ2 e um estimador viesado para
σ2, note que E(σ2) = E(Pn
i=1(Xi−X)2
n ) = E(n−1n S2) = (n−1)σ2
n . Como E(σ2) 6= σ2, σ2 e viesado parao parametro σ2. O vies do estimador e
B(σ2) =(n − 1)σ2
n− σ2 = −σ2
n.
4χ2(n−1) equivale a uma Gama(n−1
2, 1
2)
2.3 Propriedades dos Estimadores 35
Segundo a Definicao 2.3.3, este estimador e assintoticamente nao-viesado. Para obtermos um esti-mador nao-viesado para σ2 que seja funcao de σ2, facamos T ′ = n
n−1 σ2. Note que T ′ = S2 e, como
visto no exemplo acima, S2 e um estimador nao-viesado para σ2.
Exemplo 2.3.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria de X ∼ Poisson(θ). Se considerar-mos os estimadores T = X e T ′ = S2 para θ, resulta que E(T ) = E(X) = 1
n
∑ni=1 E(Xi) = E(X) = θ
e E(T ′) = E(S2) = σ2 = V (X) = θ. Assim, X e S2 sao estimadores nao-viesados para θ. Note queo estimador da forma aX + (1 − a)S2, 0 ≤ a ≤ 1, e nao-viesado para θ. Vemos aqui um exemplo deinfinitos estimadores nao-viesados para um parametro.
Exemplo 2.3.4. Seja X uma unica observacao proveniente de uma populacao com distribuicaoPoisson(θ), θ > 0, e seja g(θ) = e−3θ. Considerando g(θ) o parametro de interesse, vamos veri-ficar se T = (−2)X e um estimador nao-viesado para g(θ). Calculando a esperanca do estimador,temos:
E(T ) =∞∑
x=0
(−2)x e−θθx
x!= e−θ
∞∑
x=0
(−2θ)x
x!= e−θe−2θ = e−3θ.
Logo, (−2)X e um estimador nao-viesado para g(θ). Entretanto, se x for par, a estimativa serapositiva e, se x for ımpar, a estimativa sera negativa, o que e um absurdo, pois g(θ) so pode assumirvalores positivos. Concluımos que (−2)X e um estimador inadmissıvel.
Exemplo 2.3.5. Seja X uma unica observacao proveniente de uma populacao com distribuicaoBernoulli(θ), θ > 0, e seja g(θ) = θ2. Considerando g(θ) o parametro de interesse, vamos verificar seexiste um estimador nao-viesado para g(θ). Denotemos por T um possıvel estimador nao-viesado deg(θ), deste modo E(T ) = θ2. Lembrando que T e funcao de variaveis aleatorias, neste caso apenasX, vamos usar T (X) para representar o estimador. Como X so assume os valores 0 ou 1, temos queE[T (X)] = T (1)P (X = 1) + T (0)P (X = 0) = T (1)θ + T (0)(1− θ) = [T (1)− T (0)] θ + T (0), ∀ θ ∈ Θ .Para que T seja nao-viesado, devemos ter [T (1)− T (0)] θ + T (0) = θ2, o que e impossıvel, pois T naopode depender de θ.
Exemplo 2.3.6. Seja X uma variavel aleatoria com distribuicao Poisson(θ), θ > 0. Considerandog(θ) = eθ o parametro de interesse, vamos determinar um estimador nao-viesado para g(θ). De-
notemos esse estimador por T (X). Deste modo E[T (X)] = eθ, o que implica∑∞
x=0 T (x)θx
x!= e2θ.
Expandindo o membro direito dessa ultima igualdade em serie de potencia em θ resulta
∞∑
x=0
T (x)θx
x!=
∞∑
x=0
(2θ)x
x!.
As duas series de potencia somente serao iguais se os correspondentes coeficientes de θx o forem.Portanto, T (x) = 2x, para x = 0, 1, 2, . . ., e o estimador nao-viesado e T (X) = 2X .
Erro Quadratico Medio
Sendo T um estimador para θ, as estimativas por ele produzidas podem variar de uma amostrapara outra. Assim, o risco de obtermos uma estimativa muito afastada (com erro consideravel) de θsera tanto menor quanto maior for a concentracao de probabilidade em torno de θ. A qualidade deum estimador nao pode ser avaliada atraves de uma unica estimativa; interessa sim, investigar seusresultados em sucessivas amostras.
A colecao de estimativas produzidas por T tem comportamento probabilıstico regido pela dis-tribuicao de probabilidade do estimador, ou seja, pela distribuicao amostral de T . Ve-se aqui aimportancia do estudo, no capıtulo anterior, das distribuicoes por amostragem.
O erro quadratico medio(EQM) e uma medida de qualidade do estimador, sendo uma composicaode outras duas medidas, uma medindo a precisao, a variancia, e outra medindo o erro sistematico, ovies.
2.3 Propriedades dos Estimadores 36
Definicao 2.3.4. (Erro Quadratico Medio) O erro quadratico medio (EQM) de um estimador T doparametro θ e definido por E[(T − θ)2].
Outra medida de mesmo proposito do EQM e o erro absoluto medio definido por E[|T − θ|]. Estee menos utilizado, visto as facilidades de calculo e de interpretacao do EQM. Podemos citar ainda aideia de concentracao. Um estimador T e mais concentrado do que um outro estimador U , para omesmo parametro θ, se, para todo θ ∈ Θ , P (θ − ǫ < T < θ + ǫ) ≥ P (θ − ǫ < U < θ + ǫ) qualquer queseja ǫ > 0. Se a desigualdade se verifica para um estimador U arbitrario, dizemos que T e o estimadormais concentrado. Neste texto, faremos uso apenas do EQM.
Como comentado anteriormente, o EQM e uma composicao da variancia e do vies do estimador.Para estimadores nao-viesados, o EQM coincide com a variancia do estimador, pois B(T ) = 0. Nabusca de um bom estimador e desejavel obter um que tenha EQM uniformemente mınimo, isto e, umestimador T tal que sendo U um outro estimador qualquer verifica-se
E[(T − θ)2] ≤ E[(U − θ)2], ∀ θ ∈ Θ. (2.6)
Estimadores com esta propriedade sao raros. O que se verifica sao situacoes em que um estimadore melhor do que outro, ou seja, apresenta erro quadratico medio menor, apenas para certos valoresde θ ∈ Θ. Isso nos leva a necessidade de estabelecer outras propriedades que somem mais condicoespara a busca de “bons”estimadores. Entretanto, se estivermos tratando com estimadores da classedos nao-viesados, a Desigualdade 2.6 expressa-se pelas variancias dos estimadores e sendo ela estritapara pelo menos um θ, isto e , V (T ) < V (U), o estimador T e dito ser um estimador nao-viesado devariancia uniformemente mınima para θ. Estes estimadores serao abordados com mais detalhes aindaneste capıtulo.
Minimizando o Erro Quadratico Medio
Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de distribuicao de media θ e varianciaσ2. Considere um experimento aleatorio em que o valor t de um estimador T = t(X1, X2, . . . , Xn)deva ser predito antes da sua observacao. Como medida de qualidade do estimador usaremos o erroquadratico medio e obviamente buscaremos predizer t de modo que seja mınimo o valor esperado doquadrado do erro T − t, isto e, minimizando o EQM de T em realcao a t. Desenvolvendo o EQM,temos
E[(T − t)]2 = E(T 2) − 2tE(T ) + t2.
Derivando o segundo membro em relacao a t e igualando o resultado a zero, temos
t = E(T ).
Assim, o valor a ser usado como estimativa de t e o valor esperado de T , o que traduz
mınimot
{E[(T − t)2]} = E[(T − E(T )]2 = V (T ).
Por fim, ressaltamos que o erro quadratico medio fornece um limite para a probabilidade do erroabsoluto de estimacao exceder um certo valor ǫ, o que pode ser visto pela desigualdade de Chebychev:
P (|T − θ| > ǫ) ≤ E[(T − θ)2]
ǫ2, ∀ ǫ > 0.
2.3 Propriedades dos Estimadores 37
Exemplo 2.3.7. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Poisson(θ).Para obtermos o EQM do estimador X, note que E(X) = E(
∑ni=1 Xi)/n = E(X) = θ, e assim
EQM(X) = V (X) = θ/n, pois X e nao-viesado.
Exemplo 2.3.8. Sendo X1, X2, . . . , Xn uma amostra aleatoria de uma disribuicao Uniforme[0, θ ],θ > 0, o estimador T = 2X e nao-viesado para θ, pois E(2X) = 2E(
∑ni=1 X)/n = θ e seu erro
quadratico medio e EQM(2X) = V (2X) = 4V (X)/n = θ2/3n. Um outro estimador para θ seriaM = maximo{X1, . . . , Xn}. Para obtermos o valor esperado deste estimador vamos determinarinicialmente sua distribuicao. Seja G(m) a funcao distribuicao de M e g(m) a sua funcao densidadede probabilidade . Temos:
G(m) = P (M ≤ m) = [P (X1 ≤ m)]n = [FX(m)]n
e
g(m) =n
θ
(m
θ
)n−1, 0 ≤ m ≤ θ.
Assim, o valor esperado de M e dado por E(M) =
∫ θ
0n(m
θ
)ndm =
n
n + 1θ. M e viesado para θ.
O seu erro quadratico medio e
EQM(M) = V (M) + B(M)2 = E(M2) − E(M)2 + B(M)2
=nθ2
n + 2− n2θ2
(n + 1)2+
θ2
(n + 1)2=
2θ2
(n + 2)(n + 1)2.
Se desejarmos um estimador sem vies, podemos tomar uma funcao de M que resulte um estimadornao-viesado. Vemos facilmente que U = (n + 1)M/n e esse estimador. Comparando os estimadoresnao-viesados, temos que o erro quadratico medio de U e EQM(U) = (n + 1)2θ2/[(n + 1)2 − 1], que emaior que EQM(T ), ∀ θ ∈ Θ. Portanto, T e melhor(no sentido do EQM) que U para estimar θ.
Exemplo 2.3.9. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ N(µ, σ2), µ eσ2 desconhecidos. Nos exemplos 2.3.1 e 2.3.2, vimos que S2 e nao-viesado e σ2 e viesado para σ2. Oserros quadraticos medios para esses dois estimadores sao
EQM(S2) = V (S2) =σ4
(n − 1)V
((n − 1)S2
σ2
)=
2σ4
n − 1
e
EQM(σ2) = V (σ2) + [B(σ2)]2 =
(n − 1
n
)2
V (S2) +
(−σ2
n
)2
=2(n − 1)σ4
n2+
σ4
n2=
(2n − 1)σ4
n2.
Sendo (2n − 1)/n2 menor que 2/(n − 1), qualquer que seja n > 1, resulta EQM(σ2) < EQM(S2).Apesar do erro quadratico medio de σ2 ser inferior ao de S2, o seu valor esperado indica que eleassume valores que tendem a ser, em media, inferiores ao parametro de interesse σ2. Por essa razao,a chamada variancia corrigida, S2, e o estimador que e usado, sobretudo em pequenas amostras.
Exemplo 2.3.10. No exemplo anterior comparamos em termos de erro quadratico medio os esti-
madores S2 e σ2, ambos apresentando a seguinte forma: k∑n
i=1
(Xi − X
)2, onde k = 1/(n − 1) para
S2 e k = 1/n para σ2. Muitos sao os estimadores com essa forma; determinaremos o valor de k, k > 0,tal que o estimador correspondente tenha erro quadratico medio mınimo, quaisquer que sejam µ e σ2.
Denotando esse estimador por S2 e usando o resultado de que a variavel aleatoria
∑ni=1(Xi − X)2
σ2
tem distribuicao de qui-quadrado com (n − 1) graus de liberdade, teremos
Para amostras grandes, fica claro a pouca diferenca entre os tres estimadores.
2.3.2 Estimadores Consistentes
O conceito de consistencia considera o desempenho do estimador em funcao do tamanho da amos-tra. O uso da notacao indexada Tn indica que o estimador esta associado a uma amostra de tamanhon. Por exemplo, se o estimador e a media amostral, teremos T1 = X1, T2 = (X1 + X2)/2, T3 =(X1 +X2 +X3)/3, · · · . Quando aumentamos o tamanho da amostra, esperamos, naturalmente, maior“eficiencia” do estimador. Esta e a ideia de consistencia. Abordaremos a consistencia sob dois aspec-tos: a consistencia em probabilidade e a consistencia em media quadratica.
Definicao 2.3.5. Sejam T1, T2, . . . , Tn, . . . uma sequencia de estimadores de θ, onde Tn = t(X1,X2, . . . , Xn). A sequencia {Tn} e chamada consistente em probabilidade5 para θ, se, para todo ǫ > 0,
limn→∞
P [ |Tn − θ| ≥ ǫ] = 0, para todo θ ∈ Θ.
Observacoes:
(i) Em geral usamos a desigualdade de Chebychev para a verificacao dessa propriedade;
(ii) Consistencia nao implica nao-vies assintotico;
(iii) As condicoes limn→∞
E(Tn) = θ e limn→∞
V (Tn) = 0 sao suficientes para que Tn seja um
estimador consistente de θ.
Desigualdades
Colocar em apendice!!!
Teorema 2.2. Seja X uma variavel aleatoria e g(.) uma funcao nao-negativa cujo domınio e a retareal. Se E[g(X)] existe, entao, para todo ǫ > 0,
P [ g(X) ≥ ǫ] ≤ E[g(X)]
ǫ.
5A consistencia em probabilidade tambem e denominada consistencia simples ou fraca
2.3 Propriedades dos Estimadores 39
Demonstracao
Caso Discreto.
Seja P (X = xk) = pk, k = 1, 2, . . . . Entao,
E(g(X)) =∑k
g(xk)pk =∑
k: g(xk)≥ǫ
g(xk)pk +∑
k: g(xk)<ǫ
g(xk)pk
≥ ∑k: g(xk)≥ǫ
g(xk)pk ≥ ∑k: g(xk)≥ǫ
ǫ pk = ǫ∑
k: g(xk)≥ǫ
pk
= ǫ∑
k: g(xk)≥ǫ
P (X = xk) = ǫ P [ g(X) ≥ ǫ].
Caso Contınuo.
E(g(X)) =∫k
g(x)f(x)dx =∫
k: g(x)≥ǫ
g(x)f(x)dx +∫
k: g(x)<ǫ
g(x)f(x)dx
≥∫
k: g(x)≥ǫ
g(x)f(x)dx ≥∫
k: g(x)≥ǫ
ǫ f(x)dx = ǫ∫
k: g(x)≥ǫ
f(x)dx
= ǫ P [ g(X) ≥ ǫ].
Portanto, para ambos os casos, P [ g(X) ≥ ǫ] ≤ E[g(X)]
ǫ.
Teorema 2.3. (Desigualdade de Markov) Seja X uma variavel aleatoria qualquer, entao, para todot > 0,
P (|X| ≥ ǫ) ≤ E |X|tǫt
, ∀ ǫ > 0.
Demonstracao
P (|X| ≥ ǫ) = P(|X|t ≥ ǫt
)≤ E |X|t
ǫt.
Teorema 2.4. (Desigualdade de Chebychev) Se X e integravel, isto e, E(X) existe, entao
P [|X − E(X)| ≥ ǫ] ≤ E[X − E(X)]2
ǫ2, ∀ ǫ > 0.
Demonstracao
P (|X − E(X)| ≥ ǫ) = P{
[X − E(X)]2 ≥ ǫ2}≤ E[X − E(X)]2
ǫ2=
V (X)
ǫ2.
Exemplo 2.3.11. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma distribuicaoBernoulli(1, θ). Usando a desigualdade de Chebychev para verificar a consistencia do estimador Xtemos que
P(∣∣X − θ
∣∣ ≥ ǫ)≤ E[X − θ]2
ǫ2=
V (X)
ǫ2=
V (X)
nǫ2=
θ(1 − θ)
nǫ2.
Portanto, limn→∞
P( ∣∣X − θ
∣∣ ≥ ǫ)
= 0 e, assim, X e estimador consistente para θ.
Observacoes:
2.3 Propriedades dos Estimadores 40
(i) Sendo X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma distribuicao de media θ
e variancia σ2, o estimador X e consistente para θ, pois P(∣∣X − θ
∣∣ ≥ ǫ)≤ V (X)
nǫ2.
(ii) Sendo Tn um estimador consistente, entao qualquer outro estimador Wn definido porWn = (n − a)Tn/(n − b), onde a e b sao constantes, tambem sera consistente.
Exemplo 2.3.12. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ N(µ, σ2). S2
e estimador consistente em probabilidade para σ2. No Capıtulo 1, vimos que (n − 1)S2/σ2 tem dis-
tribuicao Gama(n−12 , 1
2). Consequentemente, S2 ∼ Gama(n−12 , n−1
2σ2 ), com E(S2) = σ2 e V (S2) = 2σ4
n−1(ver primeira lista de exercıcios). Usando a desigualdade de Chebychev, temos:
P (|S2 − σ2| ≥ ǫ) ≤ V (S2)
ǫ2=
2σ4
(n − 1)ǫ2.
Como limn→∞
P[ ∣∣S2 − σ2
∣∣ ≥ ǫ]
= 0, S2 e consistente para σ2.
Definicao 2.3.6. Sejam T1, T2, . . . , Tn, . . . uma sequencia de estimadores de θ. Essa sequencia echamada consistente em erro quadratico medio6 se, e somente se, lim
n→∞E[(
Tn − θ2)]
= 0, para todo
θ ∈ Θ .
Observacoes:
(i) Consistencia em erro quadratico medio implica consistencia em probabilidade, mas naonecessariamente o inverso;
(ii) Consistencia em erro quadratico medio implica que o vies e a variancia do estimadortendem a zero quando o tamanho da amostra tende ao infinito;
(iii) Nao consistencia em erro quadratico medio nao implica nao consistencia em probabilidade.
Exemplo 2.3.13. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma distribuicao Normal(µ, σ2).Considere os seguintes estimadores: X para µ e S2 e σ2 para σ2. Vimos no exemplo 2.3.1 que Xe S2 sao nao-viesados e, portanto, EQM(X) = V (X) e EQM(S2) = V (S2). Pela desigualdade deChebychev e os resultados do exemplo 2.3.10 verificamos facilmente que ambos os estimadores saoconsistentes em media quadratica, consequentemente consistentes em probabilidade. Dos exemplos2.3.2 e 2.3.10 temos que σ2 e assintoticamente nao-viesado e lim
n→∞V (σ2) = 0, portanto σ2 tambem e
consistente em media quadratica e em probabilidade.
Exemplo 2.3.14. Sejam X1, X2, . . . , Xn um amostra aleatoria de X ∼ Exponencial(θ). ConsidereTn = nY , onde Y = mınimo{X1, X2, . . . , Xn}, um estimador para E(X) = 1/θ. No exemplo 1.1.5,vimos que Y tem distribuicao Exponencial(nθ) e, portanto, E(Tn) = nE(Y ) = 1/θ e V (Tn) =n2V (Y ) = 1/θ2. Sendo Tn nao-viesado, EQM(Tn) = V (Tn). Concluımos que Tn nao e estimadorconsistente em erro quadratico medio para E(X), pois lim
n→∞E[Tn − (1/θ)]2 = 1/θ2 6= 0.
Exemplo 2.3.15. Considere um experimento que consiste em uma sucessao ilimitada de lancamentosde uma moeda equilibrada. Em tal experimento, a frequencia relativa da “face cara”ao fim de nlancamentos sera denotada por Xn. Suponha, entao, uma sucessao de variaveis aleatorias {Xn} emque
P(Xn = x
)= P (S = nx) =
(n
nx
)(1/2)n x(1/2)n−nx I(x)
{0, 1n
, 2n
,..., 1}.
6Outra denominacao e consistente em media quadratica.
2.3 Propriedades dos Estimadores 41
Abaixo procuramos ilustrar a consistencia de Xn em relacao a 1/2. Iniciamos com a distribuicaoamostral de Xn para alguns valores de n.
2) ≤ −0, 1) = P (X30 ≥ 0, 6) + P (X30 ≤ 0, 4) =0, 3616
Para n = 100,P (|X100 − 1
2 | ≥ ǫ) = P ((X100 − 12) ≥ 0, 1) + P ((X100 − 1
2) ≤ −0, 1) = P (X100 ≥ 0, 6) + P (X100 ≤0, 4) ∼= 0, 0569
Para n = 400,P (|X400 − 1
2 | ≥ ǫ) = P ((X400 − 12) ≥ 0, 1) + P ((X400 − 1
2) ≤ −0, 1) = P (X400 ≥ 0, 6) + P (X400 ≤0, 4) ∼= 0, 0000
Ao prosseguir com valores de n cada vez maiores, mais proximo sera a probabilidade de zero. Eimportante ressaltar que Xn
p→ 12 nao significa ser limn→∞ Xn = 1
2 , no sentido da analise. Nessesentido para qualquer ǫ > 0 poderıamos determinar um numero inteiro n(ǫ), funcao de ǫ, tal quen > n(ǫ) implicasse |Xn − 1
2 | < ǫ. Mas isso nao e possıvel, pois, por maior que seja n, pode ocorrer|Xn − 1
2 | ≥ ǫ. A sucessao numerica de probabilidade, P (|Xn = 12 | ≥ ǫ) e que tende a zero no sentido
da analise, isto e, com qualquer ǫ > 0 e γ > 0, arbitrariamente pequenos, e possıvel determinar uminteiro n0 = n(ǫ, γ), tal que n > n0 implique P (|Xn − 1
2 | ≥ ǫ) ≤ γ.
2.3.3 Estimadores Eficientes
Na Subsecao 2.3.1 discutimos sobre precisao de estimadores e vimos que a restricao a classe deestimadores nao-viesados permite obter um estimador com erro quadratico medio uniformemente
2.3 Propriedades dos Estimadores 42
mınimo. Nesta subsecao, definimos estimadores eficientes e introduzimos uma medida que quantificaa informacao contida em uma amostra sobre um determinado parametro desconhecido.
Definicao 2.3.7. (Estimadores Eficientes) Sejam Tn e T ′n dois estimadores para o parametro θ. Di-
remos que Tn e mais eficiente que T ′n se
E[(Tn − θ)2] ≤ E[(T ′n − θ)2], (2.7)
∀ θ ∈ Θ, com desigualdade estrita para algum θ.
Exemplo 2.3.16.
Exemplo 2.3.17.
Tratando de estimadores da classe dos nao-viesados, a Desigualdade 2.7 representa-se pelas vari-ancias. Deste modo, o estimador de maxima eficiencia sera o de variancia uniformemente mınima.Com os procedimentos seguintes, buscamos estabelecer uma cota inferior para a variancia de todos osestimadores nao-viesados para um parametro θ.
Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de f(., θ), onde θ ∈ Θ, sendo Θ umintervalo aberto nos IR. Seja T = t(X∼ ) = t(X1, X2, . . . , Xn) um estimador nao-viesado para g(θ).
Suponha que o suporte da distribuicao {x, f(x; θ)} seja independente de θ e que, para todo θ ∈ Θ,
(i)∂
∂θlog f(x; θ) existe para todo x.
(ii)∂
∂θ
∫. . .
∫f(x∼; θ)dx∼ =
∫. . .
∫∂
∂θf(x∼; θ)dx∼, se f e uma fdp;
∂
∂θ
∑. . .∑
f(x∼; θ) =∑
· · ·∑ ∂
∂θf(x∼; θ), se f e uma fp.
(iii)∂
∂θ
∫. . .
∫t(x∼)f(x∼; θ)dx∼ =
∫. . .
∫t(x∼)
∂
∂θf(x∼; θ)dx∼, se f e uma
fdp;
∂
∂θ
∑. . .∑
t(x∼)f(x∼; θ) =∑
· · ·∑
t(x∼)∂
∂θf(x∼; θ), se f e uma
fp.
(iv) 0 < E
[(∂
∂θlog f(X; θ)
)2]
< ∞.
As condicoes (i) ate (iv) sao chamadas condicoes de regularidade. Quando essas condicoes acimase verificam dizemos estar presentes a um caso regular de estimacao e o estimador T e dito regular.A condicao (i) garante a existencia de ∂
∂θ log f(x; θ); as condicoes (ii) e (iii) permitem permutar asoperacoes de derivacao em relacao ao parametro e de integracao sobre o espaco da amostra; a condicao(iv) nos diz que ∂
∂θ log f(X; θ) possui variancia finita e positiva. Segue algumas definicoes importantes.
Definicao 2.3.8. (Funcao escore) A funcao escore, denotada por U(θ), e definida como a primeiraderivada da funcao de log-verossimilhanca com respeito a θ:
U(θ) =∂
∂θlog f(x∼; θ).
Resultado 1 : A esperanca da funcao escore e igual a zero.
E
[∂ log f(X∼ ; θ)
∂θ
]=
∫∂ log f(x∼; θ)
∂θf(x∼; θ)dx∼ =
∫1
f(x∼; θ)
∂f(x∼; θ)
∂θf(x∼; θ)dx∼
=
∫∂f(x∼; θ)
∂θdx∼ =
∂
∂θ
∫f(x∼; θ)dx∼ = 0 (2.8)
2.3 Propriedades dos Estimadores 43
Definicao 2.3.9. (Informacao de Fisher) A quantidade
I∼F (θ) = E
[(∂ log f(X∼ ; θ)
∂θ
)2]
e denominada informacao de Fisher de θ.
Resultado 2 : Admitindo a existencia da derivda segunda da funcao de log-verossimilhanca,
E
[(∂ log f(X∼ ; θ)
∂θ
)2]
= −E
(∂2 log f(X∼ ; θ)
∂θ2
).
Demonstracao
Resultado 3 : A informacao (total) de Fisher de θ, I∼F (θ), correspondente a amostra observada e asoma das informacoes (individuais) de Fisher, IF (θ), das n observacoes da amostra.
Demonstracao
Sendo f(x∼; θ) =n∏
i=1
f(xi; θ), onde x∼ = (x1, x2, . . . , xn), temos que
I∼F (θ) = −E
[∂2 log f(X∼ ; θ)
∂θ2
]= −E
[∂2 log
∏ni=1 f(Xi; θ)
∂θ2
]= −E
[∂2∑n
i=1 log f(Xi; θ)
∂θ2
]
= −E
[n∑
i=1
∂2 log f(Xi; θ)
∂θ2
]= −
n∑
i=1
E
[∂2 log f(Xi; θ)
∂θ2
]= n
{−E
[∂2 log f(X1; θ)
∂θ2
]}
= nIF (θ) (2.9)
Observacoes:
(i) A informacao de Fisher de θ e igual a variancia da funcao escore:
I∼F (θ) = E
[(∂ log f(X∼ ; θ)
∂θ
)2]
= V
(∂ log f(X∼ ; θ)
∂θ
), pois E
[(∂ log f(X∼ ; θ)
∂θ
)]= 0.
(ii) I∼F (θ) pode ser interpretado como a quantidade (esperada) de informacao sobre θ contidana amostra.
(iii) As condicoes de regularidade nao sao atendidas quando a distribuicao da(s) variavel(is) e aUniforme.
Exemplo 2.3.18. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente da densidade f(x; θ) =(e−θθx)/x!, x = 0, 1, 2, . . . . A funcao de log-verossimilhanca e
log[f(x∼; θ)
]= log
n∏
i=1
e−θθxi
xi!=
n∑
i=1
log
(e−θθxi
xi!
)= −nθ + log θ
n∑
i=1
xi −n∑
i=1
log xi!.
A funcao escore e dada por U(θ) = −n +
∑ni=1 xi
θ. E a informacao de Fisher e
−E
(∂2 log f(X∼ ; θ)
∂θ2
)= −E
(−∑n
i=1 Xi
θ2
)=
n
θ.
Note que: quanto maior for o tamanho da amostra mais informacoes teremos sobre θ.
2.3 Propriedades dos Estimadores 44
Exemplo 2.3.19. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao Xcom distribuicao Normal(µ, σ2), σ2 conhecido. Teremos θ = µ. A funcao de log-verossimilhanca e
log[f(x∼; µ)
]= log(2πσ2)−n exp
[−
n∑
i=1
(xi − µ)2/(2σ2)
]= −n log(2πσ2) −
n∑
i=1
(xi − µ)2/(2σ2).
A funcao escore e dada por U(θ) =1
σ2
n∑
i=1
(xi − µ) =n(x − µ)
σ2. A derivada da funcao escore e
∂U(µ)
∂µ= − n
σ2, e, assim, a informacao de Fisher e I∼F (µ) =
n
σ2.
Definicao 2.3.10. (Eficiencia Relativa) A eficiencia relativa do estimador T com respeito ao esti-mador T ′ e dada por
ER(T, T ′) =E[(T ′ − θ)2
]
E[(T − θ)2
] .
Quando ER(T, T ′) > 1, dizemos que T e mais eficiente que T ′.
Definicao 2.3.11. (Eficiencia Absoluta) Se T e um estimador nao-viesado para θ, definimos aeficiencia absoluta de T por
EA(T ) =1/I∼F
(θ)
V (T ).
Quando EA(T ) = 1, dizemos que T e um estimador eficiente para θ.
Se as relacoes acima sao verificadas somente quando o tamanho da amostra tende ao infinito,passamos a falar em estimadores assintoticamente mais eficientes.
O teorema seguinte estabelece uma cota inferior para a variancia dos estimadores nao-viesadospara g(θ).
Teorema 2.5. (Desigualdade da Informacao) Atendidas as condicoes de regularidade
V (T ) ≥ [g′(θ)]2
E
[(∂ log f(X∼ ; θ)
∂θ
)2] , (2.10)
onde T e estimador nao-viesado para g(θ). A igualdade e verificada se, e somente se, existe umafuncao k(θ, n) tal que
∂
∂θlog
[n∏
i=1
f(xi; θ)
]= k(θ, n)[t(x∼) − g(θ)]. (2.11)
Demonstracao
Feito em sala de aula.A Equacao 2.11 e util para a obtencao de um ENVVUM.
Definicao 2.3.12. (Estimador Nao-Viesado de Variancia Uniformemente Mınima) Sejam X1, X2,X3, . . . , Xn uma amostra aleatoria da variavel aleatoria X com densidade f(x; θ). Um estimadorT = t(X1, X2, . . . , Xn) de g(θ) e dito ser um Estimador Nao-Viesado de Variancia UniformementeMınima (ENVVUM) de g(θ) se, e somente se,
2.4 Estatısticas Suficientes 45
(i) E(T ) = g(θ), isto e, T e um estimador nao-viesado para g(θ), e
(ii) V (T ) ≤ V (U) para qualquer outro estimador U nao-viesado de g(θ).
O uso direto da definicao acima nao e operacional, pois, podem existir inumeros estimadoresnao-viesados para um certo parametro. Verificar se a variancia do estimador proposto coincide como LICR e um meio para estabelecer um ENVVUM, mas, em muitos casos, o limite inferior para avariancia dos estimadores nao-viesados e maior que o LICR, isto e, um ENVVUM pode existir semque, necessariamente, sua variancia coincida com o LICR.
Observacoes:
(i) A quantidade[g′(θ)]2
nIF (θ)e chamada de Limite Inferior de Cramer-Rao (LICR) para a
variancia de estimadores nao viesdos de g(θ).
(ii) O Teorema 2.5 fornece um limite inferior para a variancia de estimadores nao-viesados.Um pesquisador que use um estimador nao-viesado cuja variancia coincida (ou estejaproxima) do LICR, estara usando um bom estimador nao-viesado (Mood, 1974).
(iii) Se e possıvel encontrar um estimador nao-viesado cuja variancia coincida com o LICR,entao tal estimador e dito ser um Estimador Nao-Viesado de Variancia UniformementeMınima (ENVVUM).
Exemplo 2.3.20. Sejam X1, X2, . . . , Xn amostra aleatoria proveniente de f(x; θ) = θ exp (−θx),x > 0, θ > 0. Vamos determinar LICR para a variancia dos estimadores nao-viesados de g(θ) = θ.Usando a Expressao 2.10 . . . finalmente [g′(θ)]2/[nIF (θ)] = θ2/n . De modo similar, o LICR para avariancia dos estimadores nao-viesados de g(θ) = 1/θ e dado por 1/(nθ2) . Agora, usando a Expressao2.11, temos que o ENVVUM de g(θ) = 1/θ e X, pois ∂
∂θ log [∏n
i=1 f(xi; θ)] =∑n
i=1∂∂θ [log(θ) − θxi] =∑n
i=1
(1θ − xi
)= −n(x − 1
θ ). E o ENVVUM para θ? Bem, nao o obteremos usando a Expressao2.11; precisamos de outros conhecimentos. Para nao ficarmos sem resposta, um possıvel candidatoa estimador nao-viesado de θ e 1/X. Mas, E(1/X) = nθ/(n − 1) e assim, eliminando o seu vies,ficamos com (n − 1)/(nX) que denotaremos por T ∗. Usando o Teorema 2.15 concluımos que T ∗ eENVVUM de θ.
Exemplo 2.3.21.
Exemplo 2.3.22.
2.4 Estatısticas Suficientes
Usamos as informacoes de uma amostra X1, X2, . . . , Xn para fazer inferencias sobre um parametrodesconhecido θ. Com a ideia de reducao ou sumarizacao dos dados procuramos, numa primeira analise,substituir os dados por estatısticas - por exemplo, media aritmetica, mediana, desvio-padrao, mınimo,maximo - que reflitam caracterısticas importantes do conjunto de dados. Nesta secao, abordaremosde forma introdutoria o princıpio da suficiencia, um dos princıpios de reducao de dados (veja Cassela& Berger, 1990).
Uma estatıstica suficiente para um parametro θ ou para a famılia {Fθ; θ ∈ Θ } de possıveis dis-tribuicoes de X∼ e uma estatıstica que condensa toda a informacao que a amostra X1, X2 . . . , Xn
contem sobre o parametro em estudo. Qualquer informacao amostral, alem do valor da estatısticasuficiente, nao contem nenhuma informacao adicional sobre θ. Uma estatıstica suficiente condensa osdados sem perder informacao sobre o parametro. Nesta secao, continuamos em busca dos melhoresestimadores.
2.4 Estatısticas Suficientes 46
“Princıpio da Suficiencia: Se T (X∼ ) e uma estatıstica suficiente para θ, entao qualquer inferenciasobre θ dependera da amostra X∼ somente atraves do valor de T (X∼ ). Isto e, se x∼ e x∼
′ sao dois pontosamostrais tal que T (x∼) = T (x∼
′), entao teremos a mesma inferencia sobre θ, independentemente deobservarmos x∼ ou x∼
′.”
Definicao 2.4.1. (Estatıstica Suficiente) Uma estatıstica T = t(X1, X2, . . . , Xn) diz-se suficientepara um parametro θ, ou para a famılia {Fθ; θ ∈ Θ } de possıveis distribuicoes de X∼ , quando a dis-
tribuicao condicional de X1, X2, . . . , Xn dado um valor t de T nao depende7 de θ, ∀ θ ∈ Θ.
Exemplo 2.4.1. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao Bernoulli(θ). Asestatısticas seguintes sao suficientes para θ: (i) T =
∑ni=1 Xi e (ii) U = X1X2 + X3, supondo n = 3.
Exemplo 2.4.2. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao Poisson(θ). Aestatıstica T =
∑ni=1 Xi e suficiente para θ.
A definicao de estatıstica suficiente dada acima
(i) permite apenas que possamos verificar se determinada estatıstica e ou nao suficiente;
(ii) nao auxilia na busca de uma estatıstica suficiente;
(iii) pode tornar trabalhoso verificar a suficiencia, principalmente no caso contınuo;
(iv) exige a determinacao da distribuicao da estatıstica T .
Teorema 2.6. (Criterio da Fatoracao de Neyman) Sejam X1, X2, . . . , Xn uma amostra aleatoria dadistribuicao da variavel aleatoria X com funcao densidade de probabilidade (ou funcao de probabili-dade) f(x, θ), onde o parametro θ pode ser um vetor. A estatıstica T e suficiente para θ se, e somentese, a densidade conjunta de X1, X2, . . . , Xn, denotada por f(x∼; θ), fatorar como
f(x∼; θ) = L(θ;x∼) = h(x∼)g(t(x∼); θ),
onde h(x∼) e uma funcao que so depende de x1, x2, . . . , xn e g(t(x∼); θ) e uma funcao que depende deθ e de x1, x2, . . . , xn somente atraves da funcao t. As funcoes h e g sao funcoes nao-negativas.
Demonstracao
Observacoes:
(i) Funcao um-a-um de uma estatıstica suficiente tambem e suficiente;
(ii) X1, X2, . . . , Xn e uma estatıstica suficiente;
(iii) Se θ e unidimensional, nem sempre havera uma estatıstica suficiente tambemunidimensional.
Redigir como exemplos!!!!!
Exemplo 2.4.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao Poisson(θ). En-contre uma estatıstica suficiente para θ.
Exemplo 2.4.4. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao Bernoulli(θ). Amedia amostral e uma estatıstica suficiente para θ.
7Expressao analıtica e domınio das variaveis.
2.4 Estatısticas Suficientes 47
Exemplo 2.4.5. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comf.d.p. dada por f(x; θ) = θxθ−1 I(x)
(0,1). Obtenha uma estatıstica suficiente para θ. Justifique o fato de
que∑n
i=1 log Xi e uma estatıstica suficiente para θ.
Exemplo 2.4.6. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comf.d.p. dada por f(x; θ) = e−(x−θ) I(x)
(θ,∞), θ > 0. (a) Encontre uma estatıstica suficiente para θ. (b)
Use a definicao para verificar que Y1 = mınimo(X1, X2, . . . , Xn) e suficiente para θ.
Exemplo 2.4.7. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao normal de media µ e variancia 1. Encontre uma estatıstica suficiente para µ.
Exemplo 2.4.8. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao uniforme no intervalo (0, θ), θ > 0. Encontre uma estatıstica suficiente para θ.
Exemplo 2.4.9. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao uniforme no intervalo (θ − 1, θ + 1), θ > 0. Encontre uma estatıstica suficiente para θ.
O conceito de suficiencia estende-se sem dificuldade ao caso em que a funcao densidade de proba-bilidade (ou funcao de probabilidade) envolve k parametros. E o caso do modelo normal com mediaµ e variancia σ2. A representacao para o vetor de parametros e θ∼ = (µ, σ2)′, µ e σ2 desconhecidos.Entretanto, desde que nao haja prejuızo na compreensao, usaremos a notacao θ para representar o(s)parametro(s).
Teorema 2.7. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao X de densidadef(x, θ). As estatısticas T1(X∼ ), T2(X∼ ), . . . , Tr(X∼ ) sao conjuntamente suficiente para θ se, e somente se,a distribuicao condicional de X1, X2, . . . , Xn dado T1 = t1, T2 = t2, . . . , Tr = tr nao depende de θ.
Teorema 2.8. (Criterio da Fatoracao para o caso multiparametrico) Sejam X1, X2, . . . , Xn umaamostra aleatoria de tamanho n de uma populacao com densidade f(x; θ), onde o parametro θ podeser um vetor. Um conjunto de estatısticas T1(X∼ ), T2(X∼ ), . . . , Tr(X∼ ) e conjuntamente suficiente para θse, e somente se, a densidade conjunta de X1, X2, . . . , Xn , f(x∼; θ), fatorar como
onde a funcao h nao envolve o parametro θ e a funcao g(t1, t2, . . . , tr; θ) depende de x1, x2 . . . , xn
somente atraves das funcoes t1, t2, . . . , tr.
Teorema 2.9. Se T1(X∼ ), T2(X∼ ), . . . , Tr(X∼ ) e conjuntamente suficiente para θ, entao qualquer conjuntode funcoes um-a-um de T1, T2, . . . , Tr tambem e conjuntamente suficiente.
Por exemplo, se for verificado que∑n
i=1 Xi e suficiente par θ, entao X tambem sera suficiente paraθ; se T1 = (
∑ni=1 Xi,
∑ni=1 X2
i ) for conjuntamente suficiente para θ, entao T2 = (X,∑n
i=1(Xi−X)2) =
(X,∑n
i=1 X2i − nX
2) = (X, S2) tambem sera conjuntamente suficiente para θ. Note, entretanto, que
X2
e∑n
i=1(Xi − X)2 nao sao, em geral, conjuntamente suficiente, pois nao sao funcoes um-a-um de∑ni=1 Xi e
∑ni=1 X2
i . O parametro θ citado pode ser um vetor.
De acordo com o teorema acima, ha inumeros conjuntos de estatısticas suficientes. Os teoremas quetrazem o criterio da fatoracao fornecem um metodo relativamente facil para decidir se uma estatısticae suficiente ou se um conjunto de estatısticas e conjuntamente suficiente. Entretanto, uma particularestatıstica pode ser suficiente, mas nao sermos habeis o bastante para fatorar a denidade conjunta naforma adequada. Esses teoremas tambem sao uteis para encontrarmos estatısticas suficientes.
[Redigir como exemplos!!]
2.4 Estatısticas Suficientes 48
Exemplo 2.4.10. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao normal de media µ e variancia σ2. Mostrar que
∑ni=1 Xi e
∑ni=1 X2
i sao conjuntamentesuficientes para θ∼ = (µ, σ2)′. X e S2 tambem sao conjuntamente suficientes para θ∼ = (µ, σ2)′?
Exemplo 2.4.11. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao uniforme no intervalo[θ1, θ2]. Mostrar que Y1 e Yn sao conjuntamente suficientes para θ.
Exemplo 2.4.12. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao uniforme no intervalo[θ1, θ2]. Mostrar que Y1 e Yn sao conjuntamente suficientes para θ.
Exemplo 2.4.13. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao uniforme no intervalo[0, θ]. Mostrar que Yn e suficientes para θ.
Teorema 2.10. Se T e uma estatıstica suficiente e se existe um estimador de maxima verossilhancapara θ, entao esse estimador e uma funcao de T .
Demonstracao
Observacoes:
(i) O teorema acima nao diz que o estimador de maxima verossimilhaca e necessariamentesuficiente, embora se verifique que seja suficiente com muita frequencia;
(ii) Todo estimador mais eficiente e necessariamente estimador de maxima verossimilhanca(EMV), o que nao implica que qualquer EMV seja necessariamente mais eficiente. Noteque σ2 e um EMV, mas nao e eficiente.
Teorema 2.11. (Criterio de Fisher-Neyman) Se X1, X2, . . . , Xn representa uma amostra aleatoria deuma populacao com funcao densidade de probabilidade (ou funcao de probabilidade) f(x; θ) e T = t(X∼ )uma estatıstica com funcao densidade de probabilidade (ou funcao de probabilidade) g(t(X∼ )|θ). Entao,T e suficiente se, e somente se,
f(x∼; θ) =n∏
i=1
f(xi, θ) = g(t(X∼ )|θ)h(x∼),
onde, para cada valor fixo de t(x∼), a funcao h(x∼) nao depende de θ.
Demonstracao
Colorario 2.11.1. (Teorema de Fisher-Neyman) Sejam X1, X2, . . . , Xn uma amostra aleatoria deuma populacao com densidade f(x; θ), θ ∈ Θ. Se T e uma estatıstica suficiente para θ, tem-se queh(T ) tambem e suficiente para θ e, ainda, T e suficiente para g(θ). A funcao h deve ser uma funcaomensuravel, invertıvel e independente de θ, e a funcao g, mensuravel e invertıvel.
Demonstracao
[Redigir como exemplos!!]
2.4 Estatısticas Suficientes 49
Exemplo 2.4.14. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao com distribuicaopoisson de parametro θ. Encontre uma estatıstica suficiente para θ2.
Exemplo 2.4.15.
[Texto complementar: Estatıstica Suficiente Minimal, Ancilar, Completa e Famılia Exponencial]
Agora, de modo mais direto, continuamos nossa busca por estimadores nao-vieados de varianciauniformemente mınima. O primeiro resultado mostra como a suficiencia e util nessa busca.
Teorema 2.12. (Rao-Blackwell) Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de umapopulacao X com densidade f(x; θ), e S1 = s1(X1, X2, . . . , Xn), S2 = s2(X1, X2, . . . , Xn), . . . , Sr =sr(X1, X2, . . . , Xn) um conjunto de estatısticas conjuntamente suficientes para g(θ). Seja T =t(X1, X2, . . . , Xn) um estimador nao-viesado de g(θ). Defina T ∗ como T ∗ = E(T |S1, S2, . . . , Sr).Entao,
(i) T ∗ e uma estatıstica e e funcao das estatısticas suficientes S1, S2, . . . , Sr: T ∗= t∗(S1, S2, . . . , Sr).
(ii) E(T ∗) = g(θ); isto e, T ∗ e um estimador nao-viesado de g(θ).
(iii) V (T ∗) ≤ V (T ) para todo θ, e V (T ∗) < V (T ) para algum θ, a menos que T seja igual a T ∗ comprobabilidade um.
Demonstracao
Esse teorema nos diz que: dado um estimador nao-viesado T , outro estimador nao-viesado que sejafuncao de uma estatıstica suficiente podera ser obtido e sua variancia nao sera maior que a de T . Oteorema de Rao-Blackwell nao fornece um estimador nao-viesado de variancia uniformmente mınima.Precisaremos da definicao de estatıstica completa.
Definicao 2.4.2. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao Xcom densidade f(x; θ), θ ∈ Θ, e T = t(X1, X2, . . . , Xn) uma estatıstica. A famılia de densidades deT e dita ser completa se, e somente se, para todo θ, E[g(T )] = 0 implicar P [g(T ) = 0] = 1, onde g(T )e uma estatıstica. A estatıstica T e dita ser completa se, e somente se, sua famılia de densidades ecompleta.
Outra forma de declarar que uma estatıstica T e completa e: Uma estatıstica T e completa se,e somente se, o unico estimador de zero que e funcao de T e uma estatıstica que e identicamentezero com probabilidade 1. A definicao de estatıstica completa sera util na obtencao do estimadornao-viesado de variancia uniformemente mınima de g(θ).
Exemplo 2.4.16. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdistribuicao Poisson (θ), θ > 0. Vimos que T =
∑ni=1 Xi e uma estatıstica suficiente para θ. T tambem
e completa. Vejamos: Pela definicao de completividade, E[g(T )] = 0 ⇒ g(T ) = 0 com probabilidade1(um). Assim, E[g(T )] =
∑∞t=0 g(t)[e−nθ(nθ)t]/t! = 0, para todo θ, implica
∑∞t=0 g(t)θt/t! = 0.
Dessa forma g(t)/t! = 0 para todo inteiro t nao-negativo. Portanto, a funcao g devera satisfazerP [g(T ) = 0] = 1 para todo θ. Entao T e uma estatıstica completa.
2.4 Estatısticas Suficientes 50
Teorema 2.13. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao comdensidade f(x; θ), θ ∈ Θ, onde Θ e um intervalo. Se f(x; θ) = ec(θ)T (x)+d(θ)+s(x), ou seja, f(x; θ)pertence a famılia exponencial uniparametrica, entao
∑ni=1 T (Xi) e uma estatıstica suficiente completa
minimal.
Teorema 2.14. Suponha que a variavel aleatoria X tenha distribuicao pertencente a famılia expo-nencial p-parametrica. A estatıstica
T (X∼ ) =
(n∑
i=1
T1(Xi),
n∑
i=1
T2(Xi), . . . ,
n∑
i=1
Tp(Xi)
)
e suficiente para θ, e sera completa se o domınio de variacao de (c1(θ), c2(θ), . . . , cp(θ)) contiver umretangulo p-dimensional.
No caso uniparametrico, e necessario que o domınio de variacao de c(θ) contenha um intervalo nareta. No caso bidimensional, um quadrado, e assim por diante.
[Redigir como exemplos!!!!!]
Exemplo 2.4.17. Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacao com distribuicaonormal de media µ e variancia σ2, µ ∈ IR, σ2 > 0. (a) Mostre que T (X∼ ) = (
∑ni=1 Xi,
∑ni=1 X2
i ) e
conjuntamente suficiente para θ∼ = (µ, σ2)′. (b) T e completa?
Exemplo 2.4.18.
Teorema 2.15. (Lehmann-Scheffe) Sejam X1, X2, . . . , Xn uma amostra aleatoria de uma populacaocom densidade f(x; θ). Se S = S(X1, X2, . . . , Xn) e uma estatıstica suficiente e completa e se T ∗ =t∗(S), uma funcao de S, e um estimador nao-viesado de g(θ), entao T ∗ e um estimador nao-viesadode variancia uniformemente mınima de g(θ).
Demonstracao
Importante:
(i) Se uma estatıstica suficiente e completa S existe e se ha um estimador nao-viesado parag(θ), entao existe um estimador nao-viesado de variancia uniformemente mınima de g(θ).
(ii) O ENVVUM e o unico estimador nao-viesado de g(θ) que e uma funcao de S.
Observacoes:
(i) Para algumas funcoes do parametro nao ha estimador nao-viesado;
(ii) Estimadores nao-viesados de variancia uniformemente mınima podem nao existir;
(iii) E possıvel encontrar um ENVVUM mesmo quando uma estatıstica suficiente mınima naoe completa.
Capıtulo 3
Estimacao Intervalar
3.1 Introducao
Na estimacao pontual (capıtulo anterior) nao e possıvel julgarmos a magnitude do erro cometidopor atribuirmos ao parametro a estimativa observada, pois, sendo o estimador uma variavel aleatoria,as estimativas irao variar de uma amostra para outra. Seria, entao, razoavel estabelecermos umintervalo1 que contivesse, com uma certa confianca, o parametro desconhecido. Esta e a ideia daestimacao intervalar que tambem sera util na tomada de decisao (Capıtulo 4), auxiliando na rejeicaoou nao de valores tidos como aceitaveis para o parametro em estudo.
Exemplo 3.1.1. Um engenheiro esta estudando a resistencia de um determinado material sob certascondicoes. Apos um levantamento, assumiu que a distribuicao da variavel aleatoria X, que denotaa resistencia do material, e normalmente distribuıda com variancia de nove unidades. O interesse eestimar o parametro θ, a resistencia media. Como estimador decidiu usar a media amostral X. Emuma amostra de dez pecas obteve os seguintes resultados: 9,77; 7,39; 7,29; 8,15; 11,08; 13,44; 3,67;8,60; 9,32; 5,94 unidades. A estimativa pontual para θ e dada por x=8,465. Claro que, para umaoutra amostra, o estimador assumiria, com probabilidade 1(um), um outro resultado. A estimativaintervalar para θ e dada por [6,605; 10,325]. Nas proximas secoes esclareceremos a interpretacao dointervalo de confianca e veremos como determinar esse intervalo.
O objetivo geral deste capıtulo e estabelecer um estimador (ou uma estimativa) intervalar parag(θ), uma funcao de θ, a partir de uma amostra aleatoria X1, X2, . . . , Xn da densidade f(x; θ) para-metrizada por θ.
Definicao 3.1.1. (Intervalo de Confianca) Sejam X1, X2, . . . , Xn uma amostra aleatoria da densi-dade f(x; θ). Seja T1 = t1(X1, X2, . . . , Xn) e T2 = t2(X1, X2, . . . , Xn) tal que T1 ≤ T2 e P (T1 ≤g(θ) ≤ T2) ∼= 1−α, onde (1−α) nao depende de θ. Entao, o intervalo aleatorio [T1, T2] e chamado umintervalo de 100(1 − α)% de confianca para g(θ). T1 e T2 sao chamados de limite inferior e superiorde confianca para g(θ), respectivamente. (1 − α) e chamado de nıvel de confianca.
Definicao 3.1.2. (Intervalo de Confianca Unilateral) Sejam X1, X2, . . . , Xn uma amostra aleatoriada densidade f(x; θ). Seja T1 = t1(X1, X2, . . . , Xn) uma estatıstica tal que P (g(θ) ≥ T1) ∼= (1 − α),entao T1 e chamado limite unilateral inferior de confianca para g(θ). De forma similar, seja T2 =t1(X1, X2, . . . , Xn) uma estatıstica tal que P (g(θ) ≤ T2) ∼= (1 − α), entao T2 e chamado limiteunilateral superior de confianca para g(θ).
Na estimacao intervalar fazemos uso de pivos ou quantidade pivotais para estabelecer os Intervalosde Confianca.
1Poderıamos ate falar em intervalo de valores, mas preferimos a interpretacao dada na Subsecao 3.2.1.
3.1 Introducao 52
Definicao 3.1.3. (Quantidade Pivotal) Sejam X1, X2, . . . , Xn uma amostra aleatoria da densidadef(x; θ). Seja Q = q(X1, X2, . . . , Xn; θ), isto e, Q e uma funcao de X1, X2, . . . , Xn e θ. Se adistribuicao de Q nao depende de θ, entao Q e uma Quantidade Pivotal.
Exemplo 3.1.2. Sejam X1, X2, . . . , Xn amostra aleatoria de X ∼ N(θ, 9).
(i) X − θ e uma quantidade pivotal?Como X ∼ N(θ, 9), entao X ∼ N(θ, 9
n) e (X − θ) ∼ N(0, 9n). Portanto, pela definicao, (X − θ)
e uma quantidade pivotal;
(ii)(X − θ)
3√n
e uma quantidade pivotal? Sim, pois(X − θ)
3√n
∼ N(0, 1).
Metodo da Quantidade Pivotal
Se Q = q(X1, X2, . . . , Xn; θ) e uma quantidade pivotal com uma certa funcao densidade de prob-abilidade, entao para 0 < (1 − α) < 1 deve existir q1 e q2, dependente de α, tal que P (q1 ≤ Q ≤q2) = 1 − α. Agora, se para cada possıvel amostra, q1 ≤ q(x1, x2, . . . , xn; θ) ≤ q2, se e somentese t1(x1, x2, . . . , xn) ≤ g(θ) ≤ t2(x1, x2, . . . , xn), entao [T1, T2] e um intervalo de 100(1 − α)% deconfianca para g(θ), onde Ti = ti(X1, X2, . . . , Xn), i = 1, 2.
Observacoes:
(i) q1 e q2 sao independentes de θ ja que Q o e.
(ii) Para (1 − α) fixo, existem muitos pares q1 e q2 tal que P (q1 ≤ Q ≤ q2) = 1 − α.Trabalhando com intervalos de confianca aleatorios, procuramos q1 e q2 tal que ocomprimento medio do intervalo seja o menor possıvel.
(iii) Nem sempre sera possıvel invertermos ou pivotearmos uma desigualdadeq1 ≤ q(x1, x2, . . . , xn; θ) ≤ q2, isto e, reescreve-la comot1(x1, x2, . . . , xn) ≤ g(θ) ≤ t2(x1, x2, . . . , xn).
Exemplo 3.1.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria de X ∼ N(θ, 1). Para estabelecermos
um intervalo de confianca para g(θ) = θ partimos da quantidade pivotal Q =(X − θ)
1√n
. Usando o
metodo da quantidade pivotal temos:
q1 ≤ Q ≤ q2 = q1 ≤ X − θ1√n
≤ q2
= q11√n≤ X − θ ≤ q2
1√n
= −X + q11√n≤ −θ ≤ X + q2
1√n
= X − q21√n≤ θ ≤ X − q1
1√n
Portanto, [X − q21√n
; X − q13√n
] e um intervalo de confianca 100(1 − α)% para θ.
Pergunta: Como determinar q1 e q2?Resposta: O comprimento do intervalo e dado por L = (q2−q1)/
√n; entao, o comprimento do intervalo
sera mınimo quando (q2 − q1) for mınimo sob a restricao P (q1 ≤ Q ≤ q2) = Φ(q2) − Φ(q1) = (1 − α),o que ocorre quando q1 = −q2. Na secao seguinte mais detalhes sao apresentados, o que tornara maisclaro esta ultima igualdade.
3.2 Amostragem em Populacao Normal 53
Finalizando o metodo da quantidade pivotal, informamos que nem sempre existira uma quanti-dade pivotal para um certo problema, e, mesmo existindo, esta pode nao ser inversıvel. SegundoMood(1974), se X1, X2, . . . , Xn e uma amostra aleatoria proveniente da densidade f(x; θ), a qualcorresponde a funcao de distribuicao F (x; θ), contınua em x, entao, a transformada integral de Xi,F (Xi; θ), i = 1, 2, . . . , n, tem uma distribuicao uniforme no intervalo (0, 1). Daı, Wi = − log F (Xi; θ)tem distribuicao Exponencial de parametro 1(um), Y =
∑ni=1 Wi = −∑n
i=1 log F (Xi; θ) tem dis-tribuicao Gama (n, 1) e 2Y tem distribuicao χ2
2n. Agora, note que:
P [q1 ≤ Q ≤ q2] = P [q1 ≤ F (Xi; θ) ≤ q2] = P [− log q2 ≤ − log F (Xi; θ) ≤ − log q1]
= (sem perda de generalidade)P [− log q2 ≤ −∑ni=1 log F (Xi; θ) ≤ − log q1]
= P{− log q2 ≤ − log[∏n
i=1 F (Xi; θ)] ≤ − log q1}
= P [q1 ≤∏ni=1 F (Xi; θ) ≤ q2], para 0 < q1 < q2 < 1.
Concluımos que −∑ni=1 log F (Xi; θ) ou
∏ni=1 F (Xi; θ) e uma quantidade pivotal. Dessa forma,
tendo a populacao uma funcao de distribuicao contınua, uma quantidade pivotal existe. Vale ressaltarque essa quantidade pivotal pode nao ser viavel para a determinacao do intervalo de confianca.Nas duas secoes seguintes varios exemplos sao apresentados. Como texto complementar sugerimosParametros de locacao e de escala, Mood(1974).
3.2 Amostragem em Populacao Normal
Nesta secao estaremos considerando uma amostra aleatoria, X1, X2, . . . , Xn , proveniente de umapopulacao normal com media θ e variancia σ2.
3.2.1 Intervalo de Confianca para a Media
Consideramos inicialmente a variancia populacional σ2 conhecida. Abaixo apresentamos o desen-volvimento para a obtencao do intervalo de confianca 100(1 − α)% para a media θ.
Usando o metodo da quantidade pivotal tomemos como pivo Q =√
n(X − θ)/σ, que tem dis-tribuicao normal padrao. A restricao a ser considerada e
P (q1 ≤ Q ≤ q2) = 1 − α. (3.1)
Segue: P (q1 ≤ Q ≤ q2) = (1 − α) = P (q1 ≤ √n(X − θ)/σ ≤ q2) = P (X − q2σ/
√n ≤ µ ≤
X − q1σ/√
n) = 1 − α. Buscamos, agora, determinar q1 e q2 de tal modo que o comprimento dointervalo, dado por L = (q2 − q1)σ/
√n, seja mınimo. Vamos reescrever a expressao para L usando
uma unica icognita. Interpretemos q2 como uma funcao de q1 e denotemos por q2(q1). Agora, buscamoso mınimo para
L = [q2(q1) − q1]σ/√
n, (3.2)
sujeito a restricao
∫ q2(q1)
q1
f(q)dq = 1 − α. (3.3)
Derivando a Equacao 3.2 em relacao a q1, temos que
∂L
∂q1=
[∂q2(q1)
∂q1− 1
]σ√n
. (3.4)
3.2 Amostragem em Populacao Normal 54
Para determinarmos ∂q2(q1)∂q1
, derivamos2 ambos os membros da equacao 3.3 em relacao a q1. Vejamos:
∂
∂q1
∫ q2(q1)
q1
f(q)dq = 0 ⇒ f(q2(q1))∂q2(q1)
∂q1− f(q1)
∂q1
∂q1= 0 ⇒ ∂q2(q1)
∂q1=
f(q1)
f(q2(q1)).
Agora, aplicando este resultado em (3.4) e igualando-a a zero, temos que
f(q1)
f(q2(q1))= 1. (3.5)
Pela simetria da distribuicao, q1 = q2(q1) satisfaz (3.5), mas nao a restricao (3.3). Assim, a solucaodesejada e −q1 = q2(q1). Como q1 e q2(q1) sao valores de Q que tem distribuicao normal padrao,usamos q1 = −zα/2 e q2(q1) = zα/2, o que resulta
[X − zα
2
σ√n
, X + zα2
σ√n
](3.6)
como intervalo de confianca 100(1 − α)% para a media populacional θ.
Podemos, agora, planejar nosso experimento de tal modo que tenhamos um nıvel de confianca eum comprimento de intervalo determinados. Para um nıvel de confianca (1 − α) e um comprimentomaximo 2e, onde e = zα
2(σ/
√n) e o erro maximo de estimativa, escolheremos o menor tamanho de
amostra n tal que
n ≥z2
α2σ2
e2.
Isto significa que se estimarmos θ por X, tomando uma amostra de tamanho n ≥ z2α2σ2/e2, teremos
(1 − α) de confianca de que o erro em nossa estimativa e no maximo e.
Exemplo 3.2.1. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao normalde media θ e variancia 16. Sejam T1 = t1(X1, X2, . . . , X25) = X−1, 568 e T2 = t2(X1, X2, . . . , X25)=X +1, 568. O intervalo aleatorio [T1, T2] e um intervalo de confianca para o parametro θ. O seu nıvelde confianca e dado por P (X−1, 568 ≤ θ ≤ X +1, 568) = P (1, 96 ≤ Z ≤ 1, 96) = 0, 95. Se desejarmosum intervalo com 99% de confianca e comprimento maximo de 3,136 (portanto, e = 1, 568) teremosque usar uma amostra de tamanho n ≥ 43,178, ou seja, usaremos n = 44.
Vamos definir a metade do comprimento do intervalo como uma medida de precisao
da estimacao. No exemplo acima, para uma amostra de tamanho 25 e precisao de 1,568, obtivemosum intervalo com confianca de 95%. Para aumentarmos o nıvel de confianca para 99%, mantendo aprecisao, vimos ser necessario usar uma amostra de tamanho 44. Caso nao fosse possıvel aumentarmoso tamanho da amostra, para aumentarmos o nıvel de confianca para 99% seria necessaria diminuirmosa precisao para 2,06. Verifique este resultado. Concluımos que, neste caso, a precisao e inversamenterelacionada com o nıvel de confianca. Abaixo sao apresentados comentarios sobre a relacao entretamanho da amostra n, precisao e, nıvel de confianca 100(1 − α)% e desvio-padrao σ.
. Fixados σ e nıvel de confianca, para obtermos intervalos de menor comprimento e necessarioaumentarmos n;
. Fixados σ e e, para obtermos intervalos de maior nivel de confianca e necessario aumentarmosn;
. Fixados σ e n, para obtermos intervalos de maior nivel de confianca e necessario diminuirmos aprecisao.
2 ∂∂x
Z u(x)
v(x)
f(t)dt = f(u(x))∂u(x)
∂x− f(v(x))
∂v(x)
∂x
3.2 Amostragem em Populacao Normal 55
Interpretacao do Intervalo de Confianca
Voltando ao Exemplo 3.1.1, a estimativa intervalar [6,605; 10,325] foi obtida usando o intervaloaleatorio (3.6). O nıvel de confianca, neste caso 95%, esta associado ao intervalo aleatorio e naoao intervalo numerico obtido (estimativa intervalar). Assim, nao e apropriado falar que o intervalo[6,605; 10,325] contem a media populacional com uma confianca de 95%. Fazendo uso da interpretacaofrequentista, de cada cem intervalos construıdos a partir do intervalo aleatorio em (3.6), 95% delesdevem conter a media populacional. O intervalo numerico [6,605; 10,325] pode ser ou nao um dos quecontem a media θ.
Para o caso da variancia populacional σ2 ser desconhecida, o desenvolvimento e feitode forma similar. Sabemos que
√n(X − θ)/σ tem distribuicao normal padrao e (n − 1)S2/σ2, em
que S2 =∑n
i=1(Xi − X)2/(n − 1), tem distribuicao qui-quadrado com (n − 1) graus de liberdade.Eliminamos o problema de σ2 ser desconhecida usando a distribuicao t-Student (veja Subsecao 1.4.3).A quantidade pivotal sera, portanto, Q =
√n(X − θ)/S que tem distribuicao t-Student com (n − 1)
graus de liberdade. O intervalo de confianca para a media populacional θ e dado por[X − t(n−1), α
2
S√n
, X + t(n−1), α2
S√n
].
O comprimento desse intervalo e L = 2t(n−1), α2
S√n, que, por ser aleatorio, pode ser arbitrariamente
amplo. Note que minimizar o comprimento medio desse intervalo resulta em minimizar E(L) =2t(n−1), α
2
kσ√n, em que k e uma constante dependente do tamanho da amostra (veja Subsecao 2.3.1).
Como, entao, podemos determinar um intervalo de comprimento medio mınimo? A resposta poderarser obtida com o estudo da Inferencia Estatıstica Sequencial, mas nao abordaremos este topico nestetexto.
Exemplo 3.2.2. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao nor-mal de media θ e variancia desconhecida σ2. Sejam T1 = t1(X1, X2, . . . , X9) = X − S/2 e T2 =t2(X1, X2, . . . , X9) = X + S/2. O intervalo aleatorio [T1, T2] e um intervalo de confianca para oparametro θ. O seu nıvel de confianca e dado por P (X − S/2 ≤ θ ≤ X + S/2) = P (−1, 5 ≤ t8 ≤1, 5) = 0, 828. Voce devera usar o programa R para verificar atraves de uma simulacao este resultado.
3.2.2 Intervalo de Confianca para a Variancia
Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao normal com media θe variancia σ2, ambos os parametros desconhecidos. Sabemos que Q = (n− 1)S2/σ2 ∼ χ2
(n−1). Entao,Q e uma quantidade pivotal.
Assim, temos que P (q1 ≤ Q ≤ q2) = P (q1 ≤ (n − 1)S2/σ2 ≤ q2) = P ((n − 1)S2/q2 ≤ σ2 ≤(n − 1)S2/q1), em que q1 e q2 sao dados por P (q1 ≤ Q ≤ q2) = 1 − α. Geralmente, q1 e q2 sao sele-cionados de tal modo que P (Q < q1) = P (Q > q2) = α/2, resultando no chamado intervalo simetrico.Note que q1 = χ2
(n−1);(1−α2) e q2 = χ2
(n−1);α2. Este intervalo nao sera o intervalo de comprimento
mınimo3.
[(n − 1)S2
χ2(n−1);(1−α
2)
,(n − 1)S2
χ2(n−1);α
2
](3.7)
Quando determinamos um intervalo de confianca para θ, estamos determinando, em verdade, umafamılia completa de intervalos de confianca, isto e, para um certo estimador intervalar de θ com con-fianca 100(1 − α)%, um estimador intervalar de g(θ) com confianca 100(1 − α)% pode ser obtido,
3O intervalo de comprimento mınimo pode ser obtido por tentativa e erro ou por integracao numerica. Em um estudode simulacao verificou-se que, praticamente, nao ha diferenca entre o interval simetrico e o mınimo quando o tamanhoda amostra e superior a 18.
3.2 Amostragem em Populacao Normal 56
onde g(θ) e uma funcao estritamente monotona. De forma mais direta, sendo [T1, T2] um intervalo deconfianca 100(1−α)% para θ, entao [g(T1), g(T2)] sera um intervalo de confianca 100(1−α)% para g(θ).
O intervalo de confianca 100(1 − α)% para o desvo-padrao populacional σ sera dado por
[√(n − 1)S2
χ2(n−1);(1−α
2)
,
√(n − 1)S2
χ2(n−1);α
2
].
Intervalo de confianca para σ2 com media populacional conhecida.Agora, consideramos X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao normalcom media θ conhecida e variancia desconhecida σ2. O procedimento para estabelecermos o intervalode confianca para σ2 e o mesmo exposto acima, com a quantidade pivotal sendo Q = nσ2/σ2, em queσ2 =
∑ni=1(Xi − θ)2/n. Q distribui-se segundo uma χ2
n.
Os intervalos de confianca 100(1 − α)% para σ2 e σ sao, respectivamente,
[nσ2
χ2n;(1−α
2)
,nσ2
χ2n;α
2
]e
[√nσ2
χ2n;(1−α
2)
,
√nσ2
χ2n;α
2
].
Exemplo 3.2.3. Suponha que uma amostra de tamanho n = 10 retirada de uma populacao normalforneca variancia s2 = 2, 25. Os limites de confianca 80% para a variancia populacional sao dados 4
por [ 20,2514,684 , 20,25
4,168 ] = [1, 379; 4,858]. Verifique que o intervalo de confianca 90% e [1,197, 6,090].
Exemplo 3.2.4. Seja X uma amostra de tamanho 1 proveniente de N(0, σ2), σ2 > 0. A probabili-dade do intervalo aleatorio [ |X|, |8X| ] conter o desvio padrao populacional σ e dado por P (|X| ≤ σ ≤|8X|) = P (σ
8 ≤ |X| ≤ σ) = P (σ8 ≤ X ≤ σ) + P (−σ ≤ X ≤ −σ
8 ) = 2P (18 ≤ Z ≤ 1) ∼= 0, 5832. Para
obter o comprimento esperado do intervalo fazemos: E(|X|) =∫∞−∞ |X|f(x)dx =
∫ 0−∞−xf(x)dx +
∫∞0 xf(x)dx = 2
∫∞0
x√2πσ
exp[−12(x
σ )2]dx =∫∞0
σ√2π
exp(−u2 )du = 2σ√
2π= σ
√2π . Portanto, o compri-
mento esperado do intervalo aleatorio e E(7|X|) = 7σ√
2π∼= 5, 59σ.
Exemplo 3.2.5. Sejam X1, X2, . . . , Xn uma amostra de tamanho 8 proveniente de uma distribuicaoN(θ, σ2), θ conhecido e σ2 > 0. A probabilidade do intervalo aleatorio [Y/20, Y/3], em que Y =∑8
i=1(Xi − θ)2, conter a variancia σ2 e dado por P (Y/20 ≤ σ2 ≤ Y/3). Sendo Y/σ2 ∼ χ28, segue
P (Y/20 ≤ σ2 ≤ Y/3) = P (3 ≤ Y/σ2 ≤ 20) ∼= 0, 924. O comprimento do intervalo e L = (Y/3 −Y/20) ∼= 0, 283Y ; seu comprimento esperado e E(0, 283Y ) = 2, 624σ2.
3.2.3 Intervalo de Confianca para Diferenca de Duas Medias
Considere duas amostras independentes X1, X2, . . . , Xn e Y1, Y2, . . . , Ym de tamanhos n e mextraıdas, respectivamente, de duas distribuicoes independentes N(θX , σ2
X) e N(θY , σ2Y ). Denotemos
as medias amostrais por X e Y e as variancias amostrais por S2X e S2
Y . Estas quatro estatısticassao mutuamente independentes. Veja a Subsecao 1.4.1 para a independencia entre X e S2. Temos,entao, que X e Y sao independentes e normalmente distribuıdas com medias θX e θY e varianciasσ2
X/n e σ2Y /m, respectivamente. Sendo X − Y uma combinacao linear de variaveis aleatorias normais
4Na tabela, v = (n − 1) e P = α/2 ou (1 − α/2), onde P e a area a direita do ponto.
3.2 Amostragem em Populacao Normal 57
independentes, sua distribuicao tambem sera normal com valor esperado θX − θY e variancia σ2X/n +
σ2Y /m e
(X − Y ) − (θX − θY )√σ2
X
n+
σ2Y
m
(3.8)
tera distribuicao normal de media 0 variancia 1. Caso as variancias populacionais sejam conheci-
das, esta variavel pode ser usada como quantidade pivotal para estabelecer um intervalo de confiancapara a diferenca de medias (θ1 − θ2). E de acordo com o procedimento apresentado na Subsecao 3.2.1,temos que [
(X − Y ) − zα2
√σ2
X
n+
σ2Y
m, (X − Y ) + zα
2
√σ2
X
n+
σ2Y
m
]
e o intervalo de confianca 100(1 − α)% para a diferenca de medias (θ1 − θ2).
Quando nao sao conhecidas as variancias populacionais, temos dois casos a serem considerados:Primeiro, quando, mesmo sendo desconhecidas as variancias populaiconais, podemos considera-lasiguais; segundo, quando essas variancias sao desconhecidas e diferentes. Notemos que ha tres casos naestimacao intervalar para a diferenca de medias.
Vejamos o desenvolvimento para o caso em que σ2X e σ2
Y sao desconhecidas, mas podem
ser consideradas iguais.
Lembrando do exposto na Subsecao 1.4.3, a distribuicao t-Student e definida como a razao entreuma Normal Padrao e a raiz quadrada de uma Qui-quadrado dividida pelos seus graus de liberdade:
tk = Z/
√χ2
k
k . Vamos usar uma variavel aleatoria Q com distribuicao t-Student como nossa quantidade
pivotal. O numerador para Q sera a Expressao 3.8 e o denominador sera
√(Pn
i=1 Xi−X)2+Pm
j=1(Yj−Y )2
σ2(n+m−2),
o que resulta na quantidade pivotal Q =(X−Y )−(θ1−θ2)
Sp
q1n
+ 1m
, onde Sp =(n−1)S2
X+(m−1)S2Y
n+m−2 . Abaixo,
mostramos o desenvolvimento para se chegar a essa quantidade pivotal.
Do exposto no inıcio desta subsecao e considerando σ2X = σ2
Y = σ2, temos que:
X ∼ N(θ1, σ2) e Y ∼ N(θ2, σ2).
Consequentemente, para amostras de tamanho n e m extraıdas, respectivamente, dessas duas dis-tribuicoes, as distribuicoes para as medias amostrais sao
X ∼ N(θ1, σ2/n) e Y ∼ N(θ2, σ
2/m).
E, como visto na Subsecao 1.4.1,
(n − 1)S2X
σ2=
∑ni=1
(Xi − X
)
σ2∼ χ2
n−1,(m − 1)S2
Y
σ2=
∑mj=1
(Yj − Y
)
σ2∼ χ2
m−1
e
(X − Y
)∼(
θ1 − θ2;σ2
n+
σ2
m
).
3.2 Amostragem em Populacao Normal 58
Um resultado importante neste desenvolvimento e a distribuicao de U =
∑ni=1
(Xi − X
)
σ2+
∑mj=1
(Yj − Y
)
σ2.
Se considerarmos uma variavel aleatoria W com distribuicao de probabilidade qui-quadrado de n
graus de liberdade5, χ2n, sua funcao geradora de momentos (fgm) sera dada por MW (t) =
( 12
12−t
)n2
=(
11−2t
)n2, para t < 1
2 . Da mesma forma, se R ∼ χ2m sua fgm sera MR(t) =
(1
1−2t
)m2, para t < 1
2 .
Sendo W e R variaveis aleatorias independentes, a fgm de (W + R) sera MW+R(t) = MW (t)MR(t) =(1
1−2t
)n+m2
. Portanto, W + R ∼ χ2n+m. Note que a variavel aleatoria U e a soma de duas variaveis
aleatorias com distribuicoes χ2n−1 e χ2
m−1, respectivamente. Logo, U tera distribuicao de qui-quadradocom n + m − 2 graus de liberdade: U ∼ χ2
n+m−2. A quantidade pivotal sera, entao,
Q =
(X − Y ) − (θX − θY )√σ2
n+
σ2
m√√√√[(∑n
i=1 Xi − X)2
+∑m
j=1
(Yj − Y
)2]/σ2
(n + m − 2)
,
que tem disribuicao de t-Student com n + m − 2 graus de liberdade. Simplificando temos:
Q =
(X − Y
)− (θX − θY )√(
1
n+
1
m
) ∑ni=1
(Xi − X
)2+∑m
j=1
(Yj − Y
)2
n + m − 2
=
=(X − Y ) − (θX − θY )√(
1
n+
1
m
)S2
p
=(X − Y ) − (θX − θY )
Sp
√(1
n+
1
m
) ,
em que
S2p =
(n − 1)
∑ni=1
(Xi − X
)2
n − 1+ (m − 1)
∑mj=1
(Yj − Y
)2
m − 1n + m − 2
=(n − 1) S2
X + (m − 1)S2Y
n + m − 2,
ou seja, S2p e a variancia amostral ponderada (pelos graus de liberdade) das duas variancias amostrais.
Note ainda que(n + m − 2)S2
p
σ2∼ χ2
n+m−2.
Agora, usando o metodo da quantidade pivotal e o fato de q1 = −q2, pois Q tem distribuicaosimetrica, temos:
P (q1 ≤ Q ≤ q2) = P
−tn+m−2;α
2≤ (X − Y ) − (θX − θY )
Sp
√1n + 1
m
≤ tn+m−2;α2
= P((X− Y ) − tn+m−2;α
2Sp
√1n + 1
m ≤ θX− θY ≤ (X− Y ) + tn+m−2;α2Sp
√1n + 1
m
).
5Equivale a uma Gama�
n2, 1
2
�
3.2 Amostragem em Populacao Normal 59
Portanto, [(X − Y ) − tn+m−2;α
2Sp
√1
n+
1
m; (X − Y ) + tn+m−2;α
2Sp
√1
n+
1
m
]
e um intervalo de confianca 100(1 − α)% para (θX − θY ).
Para o caso em que as variancias σ2X e σ2
Y sao desconhecidas e nao podem ser conside-
radas iguais, as discussoes serao apresentadas no proximo capıtulo.
Para finalizar esta subsecao, suponha que (X1, Y1), (X2, Y2), . . . , (Xn, Yn) e uma amostra aleatoriaproveniente de uma distribuicao normal bivariada com parametros ρ = Cov(X, Y )/(σXσY ), θX ,θY , σ2
X e σ2Y . Para estabelecer um intervalo de confianca para θY − θX , facamos Di = Yi − Xi,
i = 1, 2, . . . , n. Entao as variaveis aleatorias D1, D2, . . . , Dn sao independentes e identicamente dis-tribuıdas segundo uma distribuicao normal de media θD = θY −θX e variancia σ2
D = σ2Y +σ2
X−2ρσY σX .Interpretando D1, D2, . . . , Dn como nossa amostra aleatoria, “caımos”no caso de estimacao de umamedia populacional, θD, com variancia populacional desconhecida apresentado na pagina 55. Portantoo intervalo de confianca 100(1 − α)%sera dado por
[D − t(n−1);α
2
SD√n
, D + t(n−1);α2
SD√n
]
onde SD =√Pn
i=1(Di−D)(n−1) . Este intervalo e conhecido como intervalo de confianca para diferencas
de medias para observacoes emparelhadas. Deixamos para explorar esses intervalos no contextodo proximo capıtulo.
3.2.4 Intervalo de Confianca para a Razao de Variancias
Considere duas amostras aleatorias independentes X1, X2, . . . , Xn e Y1, Y2, . . . , Ym extraıdas,respectivamente, de duas distribuicoes independentes N(θX , σ2
X) e N(θY , σ2Y ). Vimos na Secao 1.4.2
que a variavel aleatoriaχ2
m/m
χ2n/n
tem distribuicao F com m e n graus de liberdade; e o uso do estimardor
S2X/S2
Y para σ2X/σ2
Y .
Buscando uma quantidade pivotal para para σ2X/σ2
Y , segue que:
(n − 1)S2X
σ2X
∼ χ2(n−1),
(m − 1)S2Y
σ2Y
∼ χ2(m−1)
e[(n − 1)S2
X
σ2X
]/(n − 1)
[(m − 1)S2
Y
σ2Y
]/(m − 1)
=S2
X/σ2X
S2Y /σ2
Y
∼ F(n−1),(m−1).
Usaremos, portanto, Q =S2
X/σ2X
S2Y /σ2
Y
como quantidade pivotal para σ2X/σ2
Y . Assim, P (q1 ≤ Q ≤ q2) =
1 − α se, e somente se, P
(q1 ≤ S2
X
S2Y
σ2Y
σ2X
≤ q2
)= P
(1
q2
S2X
S2Y
≤ σ2X
σ2Y
≤ 1
q1
S2X
S2Y
)= 1 − α. Considerando
um intervalo simetrico, ou seja, P (Q < q1) = P (Q > q2) = α/2, teremos q1 = Fn−1, m−1, 1−α2
eq2 = Fn−1, m−1, α
2. Definamos, entao,
[1
Fn−1; m−1; α2
S2X
S2Y
,1
Fn−1; m−1; 1−α2
S2X
S2Y
](3.9)
3.3 Amostragem em Populacoes Diversas 60
como o intervalo de confianca 100(1 − α)% para σ2X/σ2
Y .
Geralmente, as tabelas para a distribuicao F so apresentam valores cujas areas(probabilidades) asua direita sao no maximo 0,10. Na Expressao 3.9 precisamos do valor Fn−1; m−1; 1−α
2que e o valor
da distribuicao Fn−1; m−1 cuja area a direita desse valor e 1 − α2 . Para α = 0, 10, devemos ter o valor
de Fn−1; m−1 cuja area a direita desse valor e 0, 95. As tabelas disponıveis nao fornecem esse valordiretamente. Para o determinarmos, usaremos o seguinte resultado apresentado na Subsecao 1.4.2:para uma variavel aleatoria X com distribuicao Fn−1,m−1, seu inverso, isto e, 1/X, tem distribuicaoFm−1,n−1. Segue desses resultados, que
P (X ≤ xn−1, m−1, p) = p ⇐⇒ P
(1
X≥ 1
xn−1, m−1, p
)= p,
onde xn−1, m−1, p e o p-quantil da distribuicao Fn−1;m−1. Assim, P (1/X ≤ 1/(xn−1, m−1, p)) = 1 − p.Como 1/X ∼ Fm−1;n−1, temos que 1/(xn−1, m−1, p) = xm−1, n−1, 1−p. Concluımos, assim, que seq1 = Fn−1, m−1; 1−α
2, entao 1/q1 = Fm−1, n−1, α
2.
Substituindo este resultado na Expressao 3.9 temos:
[1
Fn−1; m−1; α2
S2X
S2Y
, Fm−1; n−1; α2
S2X
S2Y
]. (3.10)
O intervalo aleatorio para a razao de variancias, assim definido, permite o uso das tabelas disponveisnos ınumeros livros que abordam este topico.
Exemplo 3.2.6. Para construir um intervalo de confianca 98% para o quociente das variancias deduas populacoes normais, X e Y, extraımos, independentemente, uma amostra de cada populacao. Otamanho da amostra da populacao X foi n = 41, resultando o desvio-padrao sX = 6,57; e o tamanhoda amostra da populacao Y foi m = 31, resultando o desvio-padrao sY = 5,43. Entao, s2
X/s2Y =
1, 4644, F40, 30, 0,01 = 2,30 e F30, 40, 0,01 = 2,20. O intervalo de confianca 98% e [0,6367, 3,2217]. Paran = m = 21, o intervalo e [0,4981, 4,3053]; para n = 31 e m = 21, [0,7873, 3,0899].
3.3 Amostragem em Populacoes Diversas
Nesta secao estaremos considerando uma amostra aleatoria, X1, X2, . . . , Xn , proveniente de umapopulacao com media θ e variancia σ2.
3.3.1 Intervalo para uma Proporcao
Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de uma populacao Bernoulli (θ). Oparametro θ e a media da distribuicao, ou seja, a proporcao de resultados com uma determinadacaracterıstica na amostra de tamanho n.
Para estabelecermos o intervalo de confianca para θ, abordaremos o caso em que n e suficien-temente grande, permitindo, assim, o uso do teorema central do limite. Para pequenas amostrasapresentaremos o uso da desigualdade de Chebychev.
Consideramos inicialmente o caso em que a amostra e grande6 o suficiente para que possamos fazeruso da aproximacao normal para a distribuicao do estimador X do parametro θ. Com essa condicao,
6De modo geral e aceitavel n > 30.
3.3 Amostragem em Populacoes Diversas 61
X tera distribuicao aproximadamente normal de media θ e variancia θ(1 − θ)/n. Consequentemente,(X − θ)/
√θ(1 − θ)/n tera distribuicao normal padrao. Usando esta ultima variavel aleatoria como
quantidade pivotal para θ, resulta
P (q1 ≤ Q ≤ q2) = P
[−zα
2≤ (X − θ)√
θ(1 − θ)/n≤ zα
2
](3.11)
= P[X − zα
2
√θ(1 − θ)/n ≤ θ ≤ X + zα
2
√θ(1 − θ)/n
]= 1 − α.
Note que os limites desse intervalo dependem de θ que e desconhecido. Sendo θ(1− θ) a varianciade X, um estimador usual seria S2, a variancia amostral de X1, X2, . . . , Xn . Desenvolvendo S2 temos:
S2 =
∑ni=1(Xi − X)2
n − 1=
(∑ni=1 X2
i − nX2)
(n − 1)=
(∑ni=1 Xi − nX2
)
(n − 1)=
(nX − nX2
)
(n − 1)=
n
n − 1
[X(1 − X)
].
Substituindo θ(1 − θ) na Equacao 3.11 por n[X(1 − X)]/(n − 1), resulta o intervalo
P
[X − zα
2
√X(1 − X)/(n − 1) ≤ θ ≤ X + zα
2
√X(1 − X)/(n − 1)
]= 1 − α.
Entretanto, como n e grande, S2 esta proxima de σ2 = (n − 1)S2/n, e, assim, usando σ2 como esti-mador para θ(1 − θ), terıamos σ2 = X(1 − X) e o intervalo de confianca 100(1 − α)% para θ sendodefinido como
P
[X − zα
2
√X(1 − X)/n ≤ θ ≤ X + zα
2
√X(1 − X)/n
]= 1 − α. (3.12)
Analisando a Equacao 3.11, poderıamos ainda estabelecer uma alternativa para o intervalo dadoem 3.12. Desde que 0 < θ < 1, o maior valor para a variancia de X, θ(1−θ), e 1
4(Verifique!). Podemos,entao, usar este limite superior como estimativa para a variancia de X. Estaremos, assim, estabele-cendo um intervalo de comprimento maximo, ja que sera maximo o erro-padrao de X,
√θ(1 − θ)/n.
O intervalo de confianca 100(1 − α)% para θ sera
P
[X − zα
2
√1
4n≤ θ ≤ X + zα
2
√1
4n
]= 1 − α. (3.13)
Exemplo 3.3.1. Um pesquisdor esta investigando certo tipo de falha no sistema de freios de carrosde alta performance. Tais falhas podem ter sido responsaveis por um grave acidente ocorrido em umacorrida. De 950 carros selecionados aleatoriamente, sete tinham falhas no sistema de freios.
Suponha que o pesquisador nao tivesse nenhum dado alem do contido nesse texto preliminar e quepretendesse estabelecer um intervalo de confianca 99% para a proporcao θ de sistemas de freios quetenham tais falhas. Para esse fim, fez uso do intervalo (3.13), pois, por garantia, optou por admitirmaxima variancia para o estimador X, o que resulta em um intervalo de maximo comprimento.O resultado foi [, ]. A interpretacao do intervalo nos diz: Dos intervalos construıdos nas mesmascondicoes e segundo a definicao em (3.13), espera-se que 99% deles contenham a verdadeira proporcaode sistemas de freios que apresentam tal falha. O intervalo [, ] pode ser um desses.
Agora, suponha que seja plausıvel usar a informacao do enunciado para fornecer uma estimativapara a variancia de X (ou para o erro-padrao de X). Assim, fazendo uso do intervalo em (3.12) oresultado e [, ]. A interpretacao do intervalo e feita de forma analoga. Note que este intervalo temamplitude inferior ao primeiro.
3.3 Amostragem em Populacoes Diversas 62
Abordando o problema de determinacao de tamanho de amostra, poderiamos perguntar: Quaogrande a amostra deve ser para produzir uma estimativa de θ diferente do valor verdadeiro por nomaximo 0,008 e com confianca de 99%, independente do valor verdadeiro de θ? Considerando o erromaximo de estimativa e = 0, 008 e a varianca maxima para o estimador X, temos que e ≤ zα
2
√1/(4n)
e, portanto, da desigualdade n ≥ z2α2/(4e2) podemos obter o menor tamanho de amostra que satisfaz
as exigencias. Um outro modo para estabelecer o tamanho da amostra e fazer uso de informacoes quepossam nos dar uma estimativa preliminar para θ. Se isso e possıvel, a expressao para o erro seriae = zα
2
√X(1 − X)/n. Sendo essa estimativa preliminar o valor para o estimador X que e igual a
7/950 e zα2
∼= 2,575 o tamanho da amostra sera n = 758. Verifique que a utilizacao da estimativapreliminar para θ reduz sensıvelmente o tamanho da amostra. Isto e esperado, pois estamos usandouma informacao a mais no calculo do tamanho da amostra.
Para o caso em que n e pequeno, isto e, o tamanho da amostra nao e grande o suficiente parafazermos uso do teorema central do limite, podemos recorrer a desigualdade de Chebychev7: Se Y eintegravel, isto e, E(Y ) existe, entao
P [ |Y − E(Y )| ≥ ǫ ] ≤ V (Y )/ǫ2, ∀ ǫ > 0
ouP[|Y − E(Y )| ≥ ǫ
√V (Y )
]≤ 1/ǫ2, ∀ ǫ > 0.
Sendo X uma variavel aleatoria como disribuicao Bernoulli(θ), E(X) = θ e V (X) = θ(1 − θ). Amedia amostral X tem valor esperado E(X) = θ e variancia V (X) = θ(1 − θ)/n. Segue que
P[|X − θ)| ≥ ǫ
√θ(1 − θ)/n
]≤ 1/ǫ2. (3.14)
Sendo θ(1 − θ) ≤ 14 , e tomando o complementar da equacao acima, resulta
P[X − ǫ/(2
√n ) < θ < X + ǫ/(2
√n )]
> 1 − 1/ǫ2.
Vemos que e possıvel escolhermos n e ǫ de tal modo a atender as necessidades na determinacao dointervalo. Desenvolvendo um pouco mais, a partir de 3.14, temos:
P[|X − θ)| < ǫ
√θ(1 − θ)/n
]> 1 − 1/ǫ2,
deste modoP[|X − θ)|2 < ǫ2θ(1 − θ)/n
]> 1 − 1/ǫ2.
Agora, |X − θ|2 < ǫ2θ(1 − θ)/n se, e somente se, (1 + ǫ2/n)θ2 − (2X + ǫ2/n)θ + X2 < 0. Estadesigualdade e satisfeita se (1 + ǫ2/n)θ2 − (2X + ǫ2/n)θ + X2 = 0. As duas raizes para esta equacaosao
θ1 =X
1 + (ǫ2/n)+
(ǫ2/n) − ǫ√
(4/n)X(1 − X) + (ǫ2/n2)
2[1 + (ǫ2/n)]
e
θ2 =X
1 + (ǫ2/n)+
(ǫ2/n) + ǫ√
(4/n)X(1 − X) + (ǫ2/n2)
2[1 + (ǫ2/n)]
Segue queP (θ1 < θ < θ2) > 1 − 1/ǫ2.
7Podemos usar a desigualdade de Chebychev independentemente do tamanho da amostra, mas ressaltamos que seuuso produz intervalos de amplitude muito grande.
3.3 Amostragem em Populacoes Diversas 63
Quando n e grande, usamos a seguinte aproximacao:
θ1∼= X − ǫ
√X(1 − X)
ne θ2
∼= X + ǫ
√X(1 − X)
n.
Par finalizar a subsecao, proceda a comparacao entre este intervalo e o intervalo (3.12).
3.3.2 Intervalo para Diferenca de Proporcoes
Considere duas amostras independentes X1, X2, . . . , Xn e Y1, Y2, . . . , Ym de tamanhos n e mextraıdas, respectivamente, de duas distribuicoes independentes Bernoulli(θX) e Bernoulli(θY ). Combase em amostras grandes (n > 30 e m > 30), temos as seguintes variaveis aleatorias e suas dis-tribuicoes aproximadas:
X − θX√θX(1 − θX)
n
∼ N(0, 1),Y − θY√θY (1 − θY )
m
∼ N(0, 1) e(X − Y ) − (θX − θY )√
θX(1 − θX)
n+
θY (1 − θY )
m
∼ N(0, 1).
Para determinar um intervalo de confianca 100(1 − α)% para θX − θY , teremos como quantidadepivotal
Q =(X − Y ) − (θX − θY )√
θX(1 − θX)
n+
θY (1 − θY )
m
,
e, tomando o intervalo simetrico, temos
P (q1 ≤ Q ≤ q2) = P (−zα2≤ (X − Y ) − (θX − θY )√
θX(1 − θX)
n+
θY (1 − θY )
m
≤ zα2) = 1 − α.
Consequentemente, e independente de θX e θY ,
P
[(X−Y) − zα
2
√θX(1−θX)
n+
θY (1 − θY)
m≤θX−θY ≤(X −Y) + zα
2
√θX(1−θX)
n+
θY (1−θY)
m
]=1−α.
Note que os limites de confianca dependem de θX e θY que sao desconhecidos. Podemos usar osestimadores X(1− X) e Y (1− Y ) para as variancias de X e Y , respectivamente (ver Subsecao 3.3.1).O intervalo procurado e
[(X − Y ) − zα
2
√X(1 − X)
n+
Y (1 − Y )
m, (X − Y ) + zα
2
√X(1 − X)
n+
Y (1 − Y )
m
].
Deixamos para explorar esses intervalos no contexto do proximo capıtulo.
3.3.3 Intervalo para um Parametro de Interesse
Nesta subsecao apresentamos atraves de exemplos o uso do metodo da quantidade pivotal paraestabelecer intervalos de confianca para parametros em distribuicoes diversas. Abordamos tambem aconstrucao de intervalos de comprimento mınimo e intervalos aproximados baseados na distribuicaoassintotica do estimador de maxima verossimilhanca.
3.3 Amostragem em Populacoes Diversas 64
Exemplo 3.3.2. Seja X uma variavel aleatoria com distribuicao Weibull(θ, β). Na figura abaixo emostramos curvas correspondentes a funcao densidade de probabilidade de X que e dada por f(x; θ, β) =θβx(β−1) exp[−θxβ], x > 0, θ > 0, β > 0. Suponha o parametro β = 3 e o θ desconhecido. Para estab-elecermos um intervalo de confianca 100(1−α)% para θ, uma amostra aleatoria de tamanho n prove-niente de X foi selecionada. Notemos primeiramente que se U ∼ Uniforme(0, 1), entao (1 − U) ∼Uniforme(0, 1). Pelo metodo da transformacao integral, F (X) ∼ U(0, 1) e, consequentemente,1 − F (X) ∼ U(0, 1). Pelo metodo da quantidade pivotal, ver Secao 3.1, Q′ = −∑n
i=1 log[1 − F (Xi)]e uma quantidade pivotal. Temos que F (x) = 1 − exp(−θx3), x > 0. Assim, Q′ =
∑ni=1 θX3
i temdistribuicao Gama(n, 1) e Q = 2Q′ tem distribuicao χ2
2n. Q = 2θ∑n
i=1 X3i sera nossa quantidade
pivotal. Segue:
q1 ≤ Q ≤ q2 ⇐⇒ q1
2∑n
i=1 X3i
≤ θ ≤ q2
2∑n
i=1 X3i
.
Portanto,
[q1
2∑n
i=1 X3i
,q2
2∑n
i=1 X3i
]e o intervalo de confianca 100(1 − α)% para θ. Considerando
o intervalo simetrico, isto e, P [Q < q1] = P [Q > q2] = α2 , teremos q1 = χ2
2n; 1−α2
e q2 = χ22n; α
2.
Usando o programa R para gerar uma amostra de tamanho 20 de X ∼ Weibull(12 , 3) obtivemos∑n
i=1 x3i = 39,989. Para uma confianca de 95%, obtemos χ2
40;0,975 = 24,433 e χ240;0,025 = 59,342. O
intervalo de confianca 95% para θ e, entao, dado por [0,305, 0,742]. Como exercıcio, simule, porexemplo, 1000 intervalos desse tipo e verifique o percentual deles que contem o valor 1
2 .
Exemplo 3.3.3. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente da densidade f(x; θ) =θxθ−1I(x)
(0, 1)
. Para obtermos um intervalo de confianca 100(1 − α)% para θ notemos que a funcao dis-
tribuicao de X e dada por F (x; θ) = xθI(x)(0, 1)
+ I(x)[ 1,∞)
e que Q = −∑ni=1 log F (Xi) e uma quantidade
pivotal. Assim,
q1 ≤ Q ≤ q2 ⇐⇒ q1 ≤ −θn∑
i=1
log Xi ≤ q2.
O intervalo de confianca 100(1 − α)% para θ e, entao [q1
−∑ni=1 log Xi
,q2
−∑ni=1 log Xi
]. Sabemos que
Q em distribuicao Gama(n, 1). Usando um intervalo simetrico, q1 e q2 sao tais que P (Q < q1) =P (Q > q2) = α
2 . E posıvel, ainda, trabalhar com a distribuicao de Qui-quadrado conforme feito noexemplo anterior. Voce devera usar o programa R para ilustrar este exemplo.
Nota:Se Y ∼ Beta(a, b), a > 0, b > 0, a funcao densidade de probabilidade de Y e dada por
f(y; a, b) =1
B(a, b)ya−1(1 − y)b−1I(y)
(0,1)
, onde B(a, b) =∫ 10 ya−1(1 − y)b−1dy =
Γ(a)Γ(b)
Γ(a + b).
Outra maneira de encontrarmos uma quantidade pivotal para um parametro θ e determinarmosuma funcao de uma estatıstica suficiente S, g(S), tal que sua distribuicao seja independente de θ.
Exemplo 3.3.4. Sejam X1, X2, . . . , Xn uma amostra aleatoria proveniente de X ∼ Uniforme(0, θ),θ > 0. Pelo Criterio da Fatoracao de Neyman, Yn = maximo{X1, X2, . . . , Xn} e uma estatısticasuficiente para θ, e sua funcao densidade de probabilidade e g
Yn(y) = nθ−nyn−1, 0 < y < θ. Buscamos,
agora, uma funcao de Yn cuja distribuicao seja independente de θ. Seja Z = Yn/θ. Verifica-sefacilmente que a funcao de distribuicao de Z e H(z) = zn e sua fpp e h(z) = nzn−1, 0 < z < 1.Usaremos Z como nossa quantidade pivotal. Note que Z tem distribuicao Beta(n, 1). Segue: z1 ≤Yn/θ ≤ z2 ⇔ Yn/z2 ≤ θ ≤ Yn/z1. Assim,
[Yn/z2, Yn/z1] (3.15)
3.3 Amostragem em Populacoes Diversas 65
e um intervalo de confianca para θ. Para determinarmos z1 e z2, usamos o fato de que P (z1 ≤ Yn/θ ≤z2) =
∫ z2
z1nzn−1dz = zn
2 − zn1 = 1 − α. Verificando a ultima igualdade, notamos que existem infinitos
pares(z1 e z2) que a satisfazem. Poderıamos, entao, arbitrar um valor para z2 e determinar o valorde z1. Contudo, vejamos como fica o intervalo simetrico: devemos ter
∫ 1b nzn−1dz =
∫ a0 nzn−1dz = α
2 ;
isto resulta z1 =(
α2
) 1n e z2 =
(1 − α
2
) 1n . Agora, seja L o comprimento do intervalo em (3.15).
Para estabelecermos o intervalo de menor comprimento devemos minimizar L = (Yn/z1 − Yn/z2).Considere ainda que possamos escrever z1 como funcao de z2 e vamos denotar por z1(z2). O compri-mento fica dado, entao, por L = (Yn/z1(z2) − Yn/z2) e buscamos o mınimo para L sujeito a restricao∫ z2
z1(z2)h(z)dz = zn
2 − z1(z2)n = 1 − α. Tomando a derivada de L em relacao a z2, temos
∂L
∂z2=
[− 1
z1(z2)2
∂z1(z2)
∂z2+
1
z22
]Yn.
Da condicao∫ z2
z1(z2)h(z)dz = 1 − α, resulta ∂
∂z2
∫ z2
z1(z2)h(z)dz = h(z2)
∂z2∂z2
− h(z1(z2))∂z1(z2)
∂z2= 0, o que
implica∂z1(z2)
∂z2=
zn−12
z1(z2)n−1 . Deste modo,
∂L
∂z2=
[− 1
z1(z2)2
zn−12
z1(z2)n−1
+1
z22
]Yn =
[z1(z2)
n+1 − zn+12
z1(z2)n+1z2
2
]Yn.
Desde que ∂L∂z2
< 0, para todo z2, pois z1(z2) < z2, a funcao L e decrescente como funcao de z2 e seumınimo e obtido para z2 maximo, ou seja, z2 = 1. Substituindo esse valor na restricao zn
2 − z1(z2)n =
1 − α, temos que z1(z2) = α1n . Concluımos que o intervalo de confianca 100(1 − α)% de menor
comprimento para o parametro θ e dado por
[Yn,
Yn
α1n
].
[Texto complementar: Intervalo Baseado na Distribuicao Assintotica do Estimador de
Maxima Verossimilhanca]
Referencias Bibliograficas
[1] DeGroot, M. H. and Schervish, M. J. (2002). Probability and Statistics, 3rd edition. Addison-Wesley, New York.
[2] Hogg, R. V. and Craig, A. T. (1970). Introduction to Mathematical Statistics, 3rd edition. Macmil-lan, New York.
[3] James, B. R. (1981). Probabilidade: Um Curso em Nıvel Intermediario. Projeto Euclides, Impa,Rio de Janeiro.
[4] Kalbfleisch, J. G. (1985). Probability and Statistical Inference, 2d edition. Springer-Verlag, NewYork.
[5] Lehmann, E. L. (1983). Theory of Point Estimation. John Wiley & Sons, Inc., New York.
[6] Mood, A. M., Graybill, F. A. and Boes, D. C. (1974). Introduction to the Theory Statistics, 3rdedition. McGraw-Hill, New York.
[7] Murteira, B. J. F. (1990). Probabilidades e Estatıstica, 3a edicao. McGraw-Hill, Lisboa.
[8] Murteira, B. J. F. (1988). Estatıstica: Inferencia e Decisao. Estudos Gerais-Serie Universitaria,Lisboa.
[9] Rohatgi, V. K. (1976). An Introduction to Probability Theory and Mathematical Statistics. JohnWiley & Sons, Inc., New York.
Indice Remissivo
Amostra Aleatoria, 1
Curva suporte, 25
Desigualdadede Chebychev, 39, 60, 62de Markov, 39
DistribuicaoAmostral, 3Amostral de uma Estatıstica, 3Bernoulli, 60Exponencial, 6F de Snedecor, 59, 60Poisson, 6Qui-quadrado, 12, 14Weibull, 64
Erro de Estimativa, 54Estatıstica Suficiente, 46Estimador
Consistente, 38De Maxima Verossimilhanca, 24, 48Eficiente, 42, 44, 48Nao-Viesado, 34Nao-Viesado
De Variancia Uniformemente Mınima, 44,45
Famılia Exponencial, 50Funcao
De Informacao, 25, 31De Log-verossimilhanca, 24De Verossimilhanca, 24Escore, 24, 31Geradora de Momentos, 4, 8
Intervalo de Confianca, 51
Limite Inferior de Cramer-Rao, 45
Metodo de Newton-Raphson, 31Momento, 4Momento Amostral, 6