64
UGUR HALICI Dept. EEE, NSNT, Middle East Technical University 11.03.2015

UGURHALICI
Dept.EEE,NSNT,MiddleEastTechnicalUniversity
11.03.2015

Outline
• Biological‐arKficialneuron• Networkstructures
• MulKlayerPerceptron– BackpropagaKonalgorithm
• DeepNetworks– ConvoluKonalNeuralNetworks(CNN)– StackedAutoencoders– DeepBoltzmannMachine
1

BiologicalNeuron
• It is estaimated that the human central nervous system iscomprised of about 1,3x1010 neurons and that about 1x1010 ofthemtakesplaceinthebrain
• Aneuronhasaroughlysphericalcellbodycalledsoma
• The extensions around the cell body like bushy tree are calleddendrites, which are responsible from receiving the incomingsignalsgeneratedbyotherneurons.
2

BiologicalNeuron
• The signals generated in soma are transmiWed to other neuronsthroughanextensiononthecellbodycalledaxon.
• Anaxon,havingalengthvaryingfromafracKonofamillimetertoameter in human body, prolongs from the cell body at the pointcalledaxonhillock.
3

BiologicalNeuron
• Attheotherend,theaxonisseparatedintoseveralbranches,attheveryendofwhichtheaxonenlargesandformsterminalbuWons.
• TerminalbuWonsareplacedinspecialstructurescalledthsynapseswhicharethejuncKonstransmiYngsignalsfromoneneurontoanother.
• Aneurontypicallydrive103to104synapKcjuncKons
4

BiologicalNeuron
• The transmissionof a signal fromoneneuron to another throughsynapses is a complex chemical process in which specifictransmiWersubstancesare releasedfromthesendingsideofthejuncKon.
• The effect is to raise or lower the electrical potenKal inside thebodyof thereceivingcell,dependingonthetypeandstrengthofthesynapses.
• If this potenKal reaches a threshold, the neuron fires and sendpulsesthroughtheaxon.
• ItisthischaracterisKcthatthearKficialneuronmodelproposedbyMcCullochandPiWs(1943)aWemptreproduce.
5

ArKficialNeuronModel:Perceptron
• TheneuronmodelshowninFigureiscalledperceptronanditiswidelyusedinarKficialneuralnetworkswithsomeminormodificaKonsonit.
• IthasNinput,denotedasu1,u2,...uN.
6

ArKficialNeuronModel:Perceptron
• EachlineconnecKngtheseinputstotheneuronisassignedaweight,whicharedenotedasw1,w2,..,wNrespecKvely.
• WeightsinthearKficialmodelcorrespondtothesynapKcconnecKonsinbiologicalneurons.
• θrepresentthresholdinarKficialneuron.
• Theinputsandtheweightsarerealvalues.
7

ArKficialNeuronModel:NeuronAcKvaKon
TheacKvaKonisgivenbytheformula:
• AnegaKvevalueforaweightindicatesaninhibitoryconnecKonwhilea posiKvevalueindicatesanexcitatoryone.
• Althoughinbiologicalneurons,θhasanegaKvevalue,itmaybeassignedaposiKvevalueinarKficialneuronmodels.IfθisposiKve,itisusuallyreferredasbias.ForitsmathemaKcalconvenience,(+)signisusedintheacKvaKonformula.
8

ArKficialNeuronModel:NeuronOutput
• TheoutputvalueoftheneuronisafuncKonofitsacKvaKoninananalogytothefiringfrequencyofthebiologicalneurons:
• OriginallytheneuronoutputfuncKonf(a)inMcCullochPiWsmodelproposedasthresholdfuncKon,howeverlinear,rampandsigmoidfuncKonsarealsowidelyusedoutputfuncKons.
9
a)thresholdfunc0onb)rampfunc0on,c)sigmoidfunc0on,d)Gaussianfunc0on

ArKficialNeuronModel:NeuronOutput• Linear:
• Threshold:
• Ramp:
• Sigmoid:
10
Note:tanh(a)=2*sigmoid(a)-1

NetworkArchitectures
• NeuralcompuKngisanalternaKvetoprogrammedcompuKng,whichisamathemaKcalmodelinspiredbybiologicalmodels.
• ThiscompuKngsystemismadeupofanumberofarKficialneuronsandahugenumberofinterconnecKonsbetweenthem.
• AccordingtothestructureoftheconnecKons,weidenKfydifferentclassesofnetworkarchitectures.
11
a)layeredfeedforwardneuralnetworkb)nonlayeredrecurrentneuralnetwork(therearaealsobackwardconnecKons)

FeedforwardNeuralNetworks
• Infeedforwardneuralnetworks,theneuronsareorganizedintheformoflayers.
• Theneuronsinalayergetinputfromthepreviouslayerandfeedtheiroutputtothenextlayer.
• InthiskindofnetworksconnecKonstotheneuronsinthesameorpreviouslayersarenotpermiWed.
12
inputhiddenoutputlayerlayerlayer

FeedforwardNeuralNetworks
• Thelastlayerofneuronsiscalledtheoutputlayerandthelayersbetweentheinputandoutputlayersarecalledthehiddenlayers.
• Theinputlayerismadeupofspecialinputneurons,transmiYngonlytheappliedexternalinputtotheiroutputs.
13
inputhiddenoutputlayerlayerlayer

FeedforwardNeuralNetworks
• Inanetwork,ifthereisonlythelayerofinputnodesandasinglelayerofneuronsconsKtuKngtheoutputlayerthentheyare calledsinglelayernetwork.
• Ifthereareoneormorehiddenlayers,suchnetworksarecalledmul3layernetworks(ormul3layerperceptron)
14

BackpropagaKonAlgorithm
• ThebackpropagaKonalgorithmlooksfortheminimumoftheerrorfunc3oninweightspaceusingthemethodofgradientdescent.
• SincethismethodrequirescomputaKonofthegradientoftheerrorfuncKonateachiteraKonstep,theerrorfuncKonshouldbedifferenKable.
• ErrorfuncKonmaybechosenasmeansquareerrorbetweentheactualanddesiredoutputsforasetofsamples.(othererrorfuncKonsareavailableintheliteraturedependingonthestructureofthenetwork)
15

BackpropagaKonAlgorithm
• ThecombinaKonofweightswhichminimizestheerrorfuncKonisconsideredtobeasoluKonofthelearningproblem.
• Thenetworkistrainedbyusingasetofsamplestogetherwiththeirdesiredoutput,calledtrainingset.
• Usuallythereisanothersetcalledtestset,againconsistsofsamplestogetherwithdesiredoutputs,formeasuringperformance
16

TheBackpropagaKonAlgorithm
17
Step 0. Initialize weights: to small random values;
Step 1. Apply a sample: apply to the input a sample vector uk having desired output vector yk;
Step 2. Forward Phase: Starting from the first hidden layer and propagating towards the output layer: 2.1. Calculate the activation values for the units at layer L as: 2.1.1. If L-1 is the input layer 2.1.2. If L-1 is a hidden layer
2.2. Calculate the output values for the units at layer L as:
in which use index io instead of hL if it is an output layer

TheBackpropagaKonAlgorithm
18
Step 4. Output errors: Calculate the error terms at the output layer as:
Step 5. Backward Phase Propagate error backward to the input layer through each layer L using the error term
in which, use ioinstead of i(L+1) if L+1 is an output layer;

TheBackpropagaKonAlgorithm
19
Step 6. Weight update: Update weights according to the formula
Step7. Repeat steps 1-6 until the stop criterion is satisfied, which may be chosen as the mean of the total error
is sufficiently small.

DeepLearning:MoKvaKon
• Shallowmodels(SVMs,one‐hidden‐layerNNets,boosKng,etc…)areunlikelycandidatesforlearninghigh‐levelabstracKonsneededforAI
• Supervisedtrainingofmany‐layeredNNetsisadifficultopKmizaKonproblemsincetherearetoomanyweightstobeadjustedbutlabeledsamplesarelimited.
• ThereisahugecollecKonofunlabeleddata,itishardtolabelthem.• Unsupervisedlearningcoulddo“local‐learning”(eachmoduletries
itsbesttomodelwhatitsees)
20

DeepLearning:Overview
• DeeplearningisusuallybestwheninputspaceislocallystructuredspaKallyortemporally:images,language,etc.vsarbitraryinputfeatures
• Incurrentmodels,layersojenlearninanunsupervisedmodeanddiscovergeneralfeaturesoftheinputspace
• Thenfinallayerfeaturesarefedintosupervisedlayer(s)– AndenKrenetworkisojensubsequentlytunedusingsupervised
trainingoftheenKrenet,usingtheiniKalweighKngslearnedintheunsupervisedphase
• Couldalsodofullysupervisedversions,etc.(earlyBPaWempts)
21

DeepLearning:Overview
• MulKplelayersworktobuildanimprovedfeaturespace– Firstlayerlearns1storderfeatures
(e.g.edges…)– 2ndlayerlearnshigherorderfeatures
(combinaKonsoffirstlayerfeatures,combinaKonsofedges,etc.)
– furtherlayerslearnmorecomplexfeatures
22

ConvoluKonalNeuralNetworks(CNN)
• Fukushima(1980)–Neo‐Cognitron• LeCun(1998)–ConvoluKonalNeuralNetworks
– SimilariKestoNeo‐Cognitron
CommonCharacterisKcs:• Aspecialkindofmul3‐layerneuralnetworks.
• Implicitlyextractrelevantfeatures.
• Afeed‐forwardnetworkthatcanextracttopologicalproperKesfromanimage.
• LikealmosteveryotherneuralnetworksCNNsaretrainedwithaversionoftheback‐propaga3onalgorithm.
23

ConvoluKonalNeuralNetworks
ConvNet(Y.LeCunandY.Bengio1995)
• Neural network with specialized connectivity structure
• Feed-forward:- Convolve input (apply filter)- Non-linearity (rectified linear)- Pooling (local average or max)
• Train convolutional filters byback-propagating classification error
Normalization
Pooling
Non-linearity
Convolution Filters (Learned)
Input image
Feature maps
convolution layer
subsampling layer
24

ConvoluKonalNeuralNetworks
ConvoluKonandSubsamplinglayersrepeatedmanyKmes
25
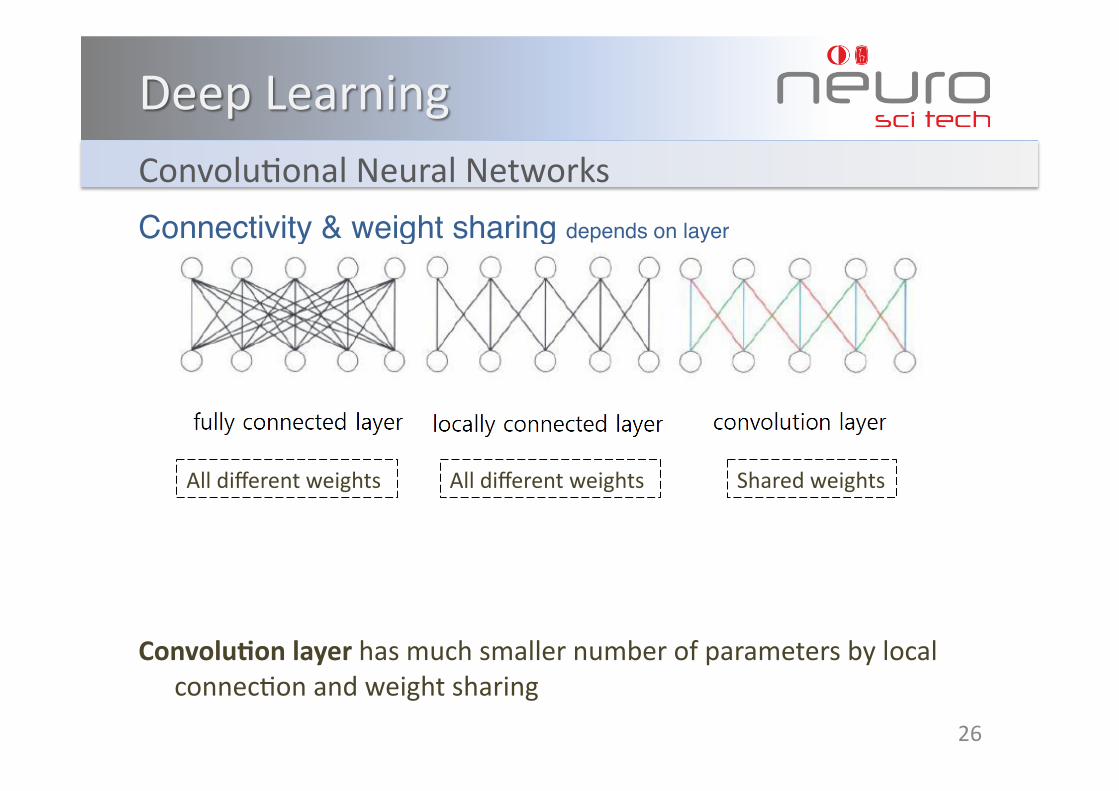
ConvoluKonalNeuralNetworks
Connectivity & weight sharing depends on layer
Convolu3onlayerhasmuchsmallernumberofparametersbylocalconnecKonandweightsharing
Alldifferentweights Alldifferentweights Sharedweights
26

ConvoluKonalNeuralNetworks
Convolution layer: filters • DetectthesamefeatureatdifferentposiKonsintheinputimage
features
Filter (kernel)
Feature map
Input
27

ConvoluKonalNeuralNetworks
Nonlinearity Tanh
Sigmoid:1/(1+exp(‐x))
RecKfiedlinear(ReLU):max(0,x)‐Simplifiesbackprop‐Makeslearningfaster‐Makefeaturesparse
→ PreferredopKon
28

ConvoluKonalNeuralNetworks
Sub-sampling layer SpaKalPooling:AverageorMax
RoleofPooling‐InvariancetosmalltransformaKons‐reducetheeffectofnoisesandshijordistorKon
Max
Average
29

ConvoluKonalNeuralNetworksNormalizaKon
ContrastnormalizaKon(between/acrossfeaturemap)‐Equalizesthefeaturesmap
Feature maps before contrast normalization
Feature mapsafter contrast normalization
30

ConvoluKonalNeuralNetworksL5Net:ConvoluKonNetworkbyLeCunforHandwriWenDigitRecogniKon
• C1,C3,C5:ConvoluKonallayer.(5×5ConvoluKonmatrix.)
• S2,S4:Subsamplinglayer.(byfactor2)
• F6:Fullyconnectedlayer.
About187,000connecKon.
About14,000trainableweight.31

ConvoluKonalNeuralNetworksL5Net:ConvoluKonNetworkbyLeCunforHandwriWenDigitRecogniKon
32
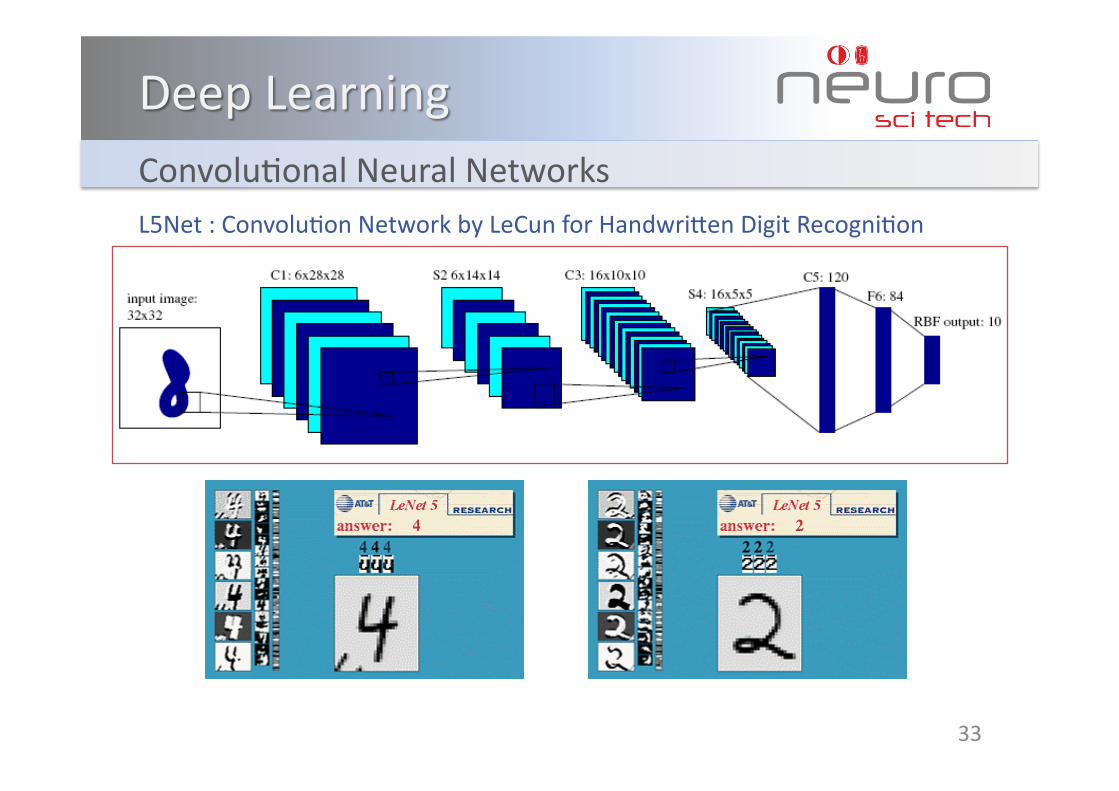
ConvoluKonalNeuralNetworksL5Net:ConvoluKonNetworkbyLeCunforHandwriWenDigitRecogniKon
33

ConvoluKonalNeuralNetworks
DeepFace:Taigmanvd,CVPR2014
Face Alignment
Representation(CNN)
34

StackedAuto‐Encoders
• Bengio(2007)–AjerDeepBeliefNetworks(Hinton,2006)• Stackmany(sparse)auto‐encodersinsuccessionandtrainthem
usinggreedylayer‐wisetraining(forexampleBackpropogaKon)• DropthedecodeoutputlayereachKme
35

StackedAuto‐Encoders
• Dosupervisedtrainingonthelastlayerusingfinalfeatures
outputlayer
z1
z2
z3
36

StackedAuto‐Encoders
• UsingSojmaxclassifierattheoutputlayerresultsinbeWerperformance
z1
z2
z3
y1
y2
y3
€
P(y = 1 0 0[ ] x)
€
P(y = 0 1 0[ ] x)
€
P(y = 0 0 1[ ] x)
€
yi =ezi
ez jj∑
∂yi∂zi
= yi (1− yi)
37

StackedAuto‐Encoders
Touseso>maxinBackpropaga3onlearning
€
yi =ezi
ez jj∑
∂yi∂zi
= yi (1− yi)
E = − t j lnj∑ y j
∂E∂zi
=∂E∂y j
∂y j
∂zij∑ = yi − ti
targetvalue
The output units use a non-local non-linearity:
The natural cost function is the negative log probability of the right answer
Use gradient of E for updating the weights in the previous layers in Backpropagation
38

StackedAuto‐Encoders
• ThendosupervisedtrainingontheenKrenetworktofine‐tuneallweights
z1
z2
z3
y1
y2
y3
€
P(y = 1 0 0[ ] x)
€
P(y = 0 1 0[ ] x)
€
P(y = 0 0 1[ ] x)
39

StackedAuto‐EncoderswithSparseEncoders
• AutoencoderswillojendoadimensionalityreducKon– PCA‐likeornon‐lineardimensionalityreducKon
• Thisleadstoa"dense"representaKonwhichisniceintermsofuseofresources(i.e.numberofnodes)– Allfeaturestypicallyhavenon‐zerovaluesforanyinputandthe
combinaKonofvaluescontainsthecompressedinformaKon
40

StackedAuto‐EncoderswithSparseEncoders
• However,thisdistributedrepresentaKoncanojenmakeitmoredifficultforsuccessivelayerstopickoutthesalientfeatures
• AsparserepresentaKonusesmorefeatureswhereatanygivenKmeasignificantnumberofthefeatureswillhavea0value– ThisleadstomorelocalistvariablelengthencodingswhereaparKcular
node(orsmallgroupofnodes)withvalue1signifiesthepresenceofafeature(smallsetofbases)
• Thisiseasierforsubsequentlayerstouseforlearning• Forsparseencoding:
– Usemorehiddennodesintheencoder
– UseregularizaKontechniqueswhichencouragesparseness(e.g.asignificantporKonofnodeshave0outputforanygiveninput)
41

StackedAuto‐Encoders:Denoising
• De‐noisingAuto‐Encoder– StochasKcallycorrupttraininginstanceeachKme,butsKlltrainauto‐
encodertodecodetheuncorruptedinstance,forcingittolearncondiKonaldependencieswithintheinstance
– BeWerempiricalresults,handlesmissingvalueswell
42

DeepBoltzmanMachine:BoltzmanMachine(BM)
• BoltzmanmachineisarecurrentneuralnetworkhavingstochasKcneuronsanditsdynamicisdefinedintermsofenergiesofjointconfiguraKonsofthevisibleandhiddenunits
hidden units
visible units
43

DeepBoltzmanMachine:StochasKcNeuron
StochasKcneuronhaveastateof1or0whichisastochasKcfuncKonoftheneuron’sbias,b,andtheinputitreceivesfromotherneurons.
whereTisacontrolparameterhavinganalogyintemperature.
€
p(si = 1) = 1
1+ exp(−bi − s jw ji) /Tj∑
= 1
1+ exp(−ΔEi /T)
44

DeepBoltzmanMachine:StochasKcNeuron
0.5
00
1
€
bi + s jw jij∑
45
hightempraturelowtemprature
€
p(si = 1) = 1
1+ exp(−bi − s jw ji) /Tj∑

DeepBoltzmanMachine:BMStateUpdate
InaBoltzmannmachine,atrialforastatetransiKonisatwo‐stepprocess.
1. Givenastateofvisibleandhiddenunits(v,h),firstaunitjisselectedasacandidatetochangestate.TheselecKonprobabilityusuallyhasuniformdistribuKonovertheunits.
2. Thenthechosenunitwillhaveastateof1or0acccordingtoformulagivenbefore
46

DeepBoltzmanMachine:BMEnergy
biasofuniti
weightbetweenunitsiandj
EnergywithconfiguraKonvonthevisibleunitsandhonthehiddenunits
binarystateofunitiinjointconfiguraKonv,h
indexeseverynon‐idenKcalpairofiandjonce
47

StackedDeepBoltzmanMachine:BMEnergy
• The probability of a jointconfiguraKon over both visibleandhiddenunitsdependson theenergy of that joint configuraKoncompared with the energy of allotherjointconfiguraKons. (T: temprature, it drops in p(v,h)equaKonwhenitissetasT=1)
• TheprobabilityofaconfiguraKonof the visible units is the sum ofthe probabiliKes of all the jointconfiguraKonsthatcontainit.
€
p(v,h) =e−E (v,h ) /T
e−E (u,g ) /Tu,g∑
€
p(v) =
e−E(v,h ) /Th∑e−E(u,g ) /T
u,g∑
parKKonfuncKon
48

DeepBoltzmanMachine:BMLearning
• EverythingthatoneweightneedstoknowabouttheotherweightsandthedatainordertodomaximumlikelihoodlearningiscontainedinthedifferenceoftwocorrelaKons.
€
∂log p(v)∂wij
= sis j v− sis j free .
Derivative of log probability of one training vector
Expected value of product of states at thermal equilibrium when the training vector is clamped on the visible units
Expected value of product of states at thermal equilibrium when nothing is clamped
49

DeepBoltzmanMachine:RestrictedBM(RBM)
• InrestrictedBoltzmanmachinetheconnecKvityisrestrictedtomakeinferenceandlearningeasier.– Onlyonelayerofhiddenunits.– NoconnecKonsbetweenhiddenunits.
• InanRBM,thehiddenunitsarecondiKonallyindependentgiventhevisiblestates.Itonlytakesonesteptoreachthermalequilibriumwhenthevisibleunitsareclamped.– Sowecanquicklygettheexactvalueof
<sisj>tobeusedintraining
hidden
i
j
visible
50

DeepBoltzmanMachine:SingleRBMLearning
Start with a training vector on the visible units.
Then alternate between updating all the hidden units in parallel and updating all the visible units in parallel.
i
j
i
j
i
j
i
j
t=0t=1t=2t=infinity
afantasy
51

DeepBoltzmanMachine:SingleRBMLearning
Contras3vedivergencelearning:Aquickwaytotrain(learn)anRBM
• Startwithatrainingvectoronthevisibleunits.• Updateallthehiddenunitsinparallel• Updatetheallthevisibleunitsinparalleltogeta“reconstrucKon”.• Updatethehiddenunitsagain.
Thisisnotfollowingthegradientoftheloglikelihood.Butitworkswell.
€
Δwij = ε ( <sis j>0 − <sis j>
1)
i
j
i
j
t=0t=1
52

DeepBoltzmanMachine:SingleRBMLearning
UsinganRBMtolearnamodelofadigitclass
i
j
i
j
t=0t=1
100 hidden units (features)
256 visible units (pixels)
Reconstructions by model trained on 2’s
Data
Reconstructions by model trained on 3’s
53

DeepBoltzmanMachine:Pre‐trainingDBMTrainingadeepnetworkbystackingRBMs• Firsttrainalayeroffeaturesthatreceiveinputdirectlyfromthe
pixels.• ThentreattheacKvaKonsofthetrainedfeaturesasiftheywere
pixelsandlearnfeaturesinasecondhiddenlayer.
• Thendoitagainforthenextlayers
54

DeepBoltzmanMachine:Pre‐trainingDBMCombiningRBMstomakeaDeepBM
€
W1Train this RBM first
Then train this RBM
copy binary state h1 for each v
Compose the two RBM models to make a single DBN model
When only downward connections are used, it’s not a Boltzmann machine but Deep Belief Network
€
W1
€
W2
€
W2
€
W1T
55

DeepBoltzmanMachine:Pre‐trainingDBMInordertouseDBMforrecogniKon
(discriminaKon):
• intopRBMusealsolabelunits:L‐ useKlabelnodesiffthereareKclasses
‐ alabelvectorisobtainedbyseYngthenodeinLcorrespondingtotheclassofthedatato“1”,whilealltheothersare“0”
• trainthetopRBMtogetherwithlabelunits
• Themodellearnsajointdensityforlabelsandimages.
• ApplypaWernatboWomlayerandthenobserveLabelatthetoplayer 3 layer DBM
€
h3
€
W1
€
v€
W2
€
W3
€
W1T
€
W2T
€
L
56
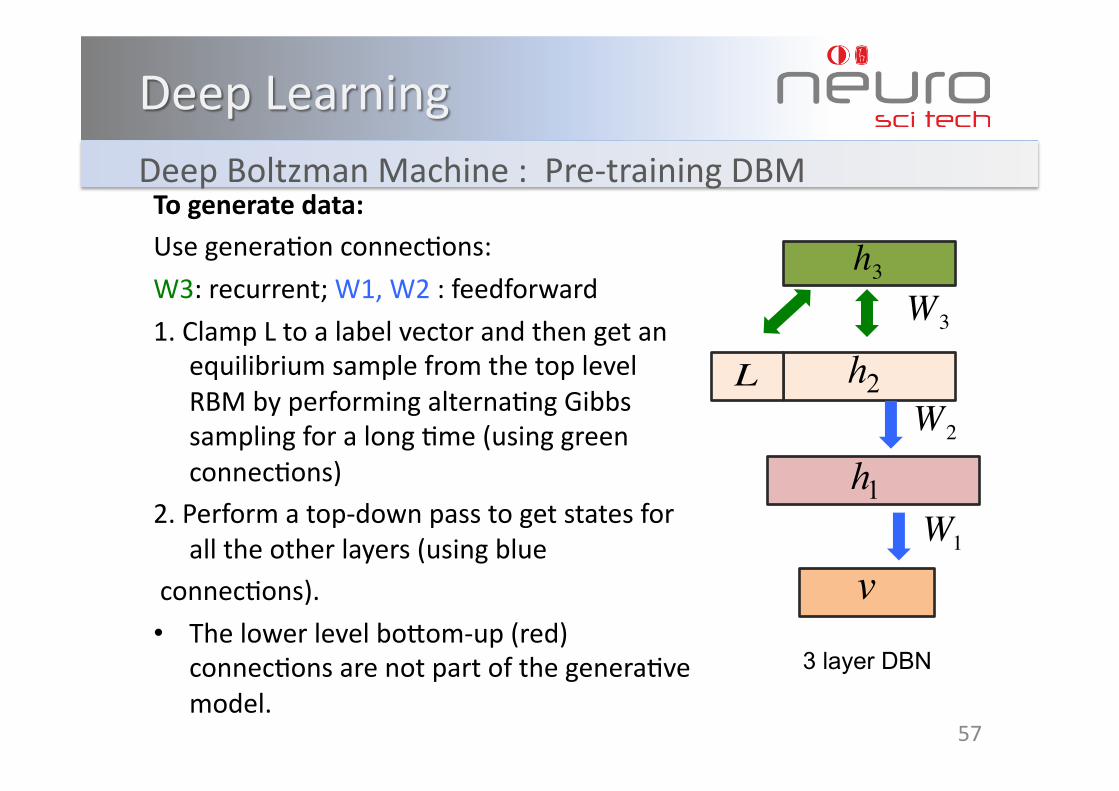
DeepBoltzmanMachine:Pre‐trainingDBMTogeneratedata:UsegeneraKonconnecKons:
W3:recurrent;W1,W2:feedforward
1.ClampLtoalabelvectorandthengetanequilibriumsamplefromthetoplevelRBMbyperformingalternaKngGibbssamplingforalongKme(usinggreenconnecKons)
2.Performatop‐downpasstogetstatesforalltheotherlayers(usingblue
connecKons).
• ThelowerlevelboWom‐up(red)connecKonsarenotpartofthegeneraKvemodel.
€
h3
3 layer DBN €
W1
€
v€
W2
€
W3
€
L
57

AneuralnetworkmodelofdigitrecogniKon&modeling• handwriWendigitsas28x28
imagesfordigits0,1,2..9
• 10classesso10labelunits
seemoviesat:
hWp://www.cs.toronto.edu/~hinton/digits.html
2000 top-level units
500 units
500 units
28 x 28 pixel image
10 label units
58

AneuralnetworkmodelofdigitrecogniKon:finetuning• FirstlearnonelayerataKme
bystackingRBMs:Treatthisas“pre‐training”thatfindsagoodiniKalsetofweightswhichcanthenbefine‐tunedbyalocalsearchprocedure.
2000 top-level units
500 units
500 units
28 x 28 pixel image
2000 top-level units
500 units
500 units
28 x 28 pixel image
• Then add a 10-way softmax at the top and do backpropagation
10 softmax units
59

MoreApplicaKonexamplesonDeepNeuralNetworks
SpeechRecogniKonBreakthroughfortheSpoken,TranslatedWordhWps://www.youtube.com/watch?v=Nu‐nlQqFCKg
PublishedonNov8,2012MicrosojChiefResearchOfficerRickRashiddemonstratesaspeechrecogniKonbreakthroughviamachinetranslaKonthatconvertshisspokenEnglishwordsintocomputer‐generatedChineselanguage.ThebreakthroughispaWernedajerdeepneuralnetworksandsignificantlyreduceserrorsinspokenaswell
60

• June2012,Googledemonstratedoneofthelargestneuralnetworksyet,withmorethanabillionconnecKons.AteamledbyStanfordcomputerscienceprofessorAndrewNgandGoogleFellowJeffDeanshowedthesystemimagesfrom10millionrandomlyselectedYouTubevideos.Onesimulatedneuroninthesojwaremodelfixatedonimagesofcats.Othersfocusedonhumanfaces,yellowflowers,andotherobjects.Byusingthepowerofdeeplearning,thesystemidenKfiedthesediscreteobjectseventhoughnohumanshadeverdefinedorlabeledthem.
hWps://www.youtube.com/watch?v=‐rIb_MEiylw
61
MoreApplicaKonexamples

ClosingRemarks
“Thebasicidea—thatsojwarecansimulatetheneocortex’slargearrayofneuronsinanarKficial“neuralnetwork”—isdecadesold,andithasledtoasmanydisappointmentsasbreakthroughs.ButbecauseofimprovementsinmathemaKcalformulasandincreasinglypowerfulcomputers,computerscienKstscannowmodelmanymorelayersofvirtualneuronsthaneverbefore.
WithmassiveamountsofcomputaKonalpower,machinescannowrecognizeobjectsandtranslatespeechinrealKme.ArKficialintelligenceisfinallygeYngsmart.”
RobertD.HofonApril23,2013,MITTechnologyreview
62

Credits
Deeplearningnetwork:hWp://deeplearning.net/
CourseraOpenCourse:NeuralNetworksbyGeofreyHintonhWps://www.coursera.org/course/neuralnets
METUEE543:Neurocomputers,LectureNotesbyUgurHalıcıhWp://www.eee.metu.edu.tr/~halici/courses/543LectureNotes/
543index.html
DeeplearningtutorialatStanford
hWp://ufldl.stanford.edu/tutorial/
63

















