54
Copyright ©2011 Brooks/Cole, Cengage Learning Understanding Sampling Distributions: Statistics as Random Variables Chapter 9 1

Copyright ©2011 Brooks/Cole, Cengage Learning
Understanding
Sampling
Distributions:
Statistics as
Random Variables
Chapter 9
1

Copyright ©2011 Brooks/Cole, Cengage Learning 2
A statistic is a numerical value computed from a
sample. Its value may differ for different samples.
e.g. sample mean , sample standard deviation s,
and sample proportion .
A parameter is a numerical value associated with
a population. Considered fixed and unchanging.
e.g. population mean m, population standard
deviation s, and population proportion p.
x
p̂
9.1 Parameters, Statistics,
and Statistical Inference

Copyright ©2011 Brooks/Cole, Cengage Learning 3
Statistical Inference
Statistical Inference: making conclusions about
population parameters on basis of sample statistics.
Two most common procedures:
Confidence intervals: an interval of values that the
researcher is fairly sure will cover the true,
unknown value of the population parameter.
Hypothesis tests: uses sample data to attempt to
reject a hypothesis about the population.

Copyright ©2011 Brooks/Cole, Cengage Learning 4
9.2 From Curiosity to Questions
about Parameters
The Big Five Parameters

Copyright ©2011 Brooks/Cole, Cengage Learning 5
Paired Differences
Paired data (or paired samples): when pairs of variables
are collected. Only interested in population (and sample)
of differences, and not in the original data.
• Each person measured twice. Two measurements of same
characteristic or trait are made under different conditions.
• Similar individuals are paired prior to an experiment. Each
member of a pair receives a different treatment.
Same response variable is measured for all individuals.
• Two different variables are measured for each individual.
Interested in amount of difference between two variables.

Copyright ©2011 Brooks/Cole, Cengage Learning 6
Independent Samples
Two samples are called independent samples
when the measurements in one sample are not
related to the measurements in the other sample.
• Random samples taken separately from two
populations and same response variable is recorded.
• One random sample taken and a variable recorded,
but units are categorized to form two populations.
• Participants randomly assigned to one of two
treatment conditions, and same response variable
is recorded.

Copyright ©2011 Brooks/Cole, Cengage Learning 7
Familiar Examples Translated into
Questions about Parameters
Situation 1. Estimating the proportion falling into a
category of a categorical variable.
Example research questions:
What proportion of American adults believe there is
extraterrestrial life? In what proportion of British
marriages is the wife taller than her husband?
Population parameter: p = proportion in the population
falling into that category.
Sample estimate: = proportion in the sample falling
into that category. p̂

Copyright ©2011 Brooks/Cole, Cengage Learning 8
Familiar ExamplesSituation 2. Estimating the difference between two
populations with regard to the proportion falling into a category of a qualitative variable.
Example research questions:
How much difference is there between the proportions that
would quit smoking if taking the antidepressant buproprion
(Zyban) versus if wearing a nicotine patch?
How much difference is there between men who snore
and men who don’t snore with regard to the proportion
who have heart disease?
Population parameter: p1 – p2 = difference between the two population proportions.
Sample estimate: = difference between the two sample proportions.
21ˆˆ pp

Copyright ©2011 Brooks/Cole, Cengage Learning 9
Familiar Examples
Situation 3. Estimating the mean of a quantitative variable.
Example research questions:
What is the mean time that college students watch TV
per day? What is the mean pulse rate of women?
Population parameter: m = population mean for the variable
Sample estimate: = sample mean for the variablex

Copyright ©2011 Brooks/Cole, Cengage Learning 10
Familiar Examples
Situation 4. Estimating the mean of paired differences
for quantitative variables.
Example research questions:
What is the mean difference in weights for freshmen at the
beginning and end of the first semester?
What is the mean difference in age between husbands and
wives in Britain?
Population parameter: m d = population mean of differences
Sample estimate: = mean of differences for paired sampled

Copyright ©2011 Brooks/Cole, Cengage Learning 11
Situation 5. Estimating the difference between two
populations with regard to the mean
of a quantitative variable.
Example research questions:
How much difference is there in average weight loss for
those who diet compared to those who exercise to lose
weight? How much difference is there between the mean
foot lengths of men and women?
Population parameter: m1 – m2 = difference between the
two population means.
Sample estimate: = difference between the two
sample means.
Familiar Examples
21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 12
9.3 SD Mod 0: An Overview
of Sampling Distribution
The distribution of possible values of a statistic for
repeated samples of the same size from a population
is called the sampling distribution of the statistic.
Statistics as Random Variables
Each new sample taken
value of the sample statistic will change.
Many statistics of interest have sampling distributions
that are approximately normal distributions

Copyright ©2011 Brooks/Cole, Cengage Learning 13
Example 9.2 Mean Hours of Sleep
for College Students
Survey of n = 190 college students.
“How many hours of sleep did you get last night?”
Sample mean = 7.1 hours.
If we repeatedly took
samples of 190 and each
time computed the sample
mean, the histogram of the
resulting sample mean
values would look like the
histogram at the right:

Copyright ©2011 Brooks/Cole, Cengage Learning 14
Standard Deviation and
Standard Error of a Statistic
• Standard deviation of a sampling distribution
measures the variation among possible values of the
sample statistic over all possible random samples.
We include the name of the statistic being studied,
e.g. the standard deviation of the mean.
• Standard error describes the estimated value of the
standard deviation of a statistic. We include the name
of the statistic, e.g. the standard error of the mean.

Copyright ©2011 Brooks/Cole, Cengage Learning 15
9.4 SD Mod 1: Sampling Distribution
for One Sample Proportion
• Suppose (unknown to us) 40% of a population
carry the gene for a disease, (p = 0.40).
• We will take a random sample of 25 people from
this population and count X = number with gene.
• Although we expect (on average) to find 10 people
(40%) with the gene, we know the number will
vary for different samples of n = 25.
• In this case, X is a binomial random variable
with n = 25 and p = 0.4.

Copyright ©2011 Brooks/Cole, Cengage Learning 16
Many Possible Samples
Four possible random samples of 25 people:
Sample 1: X =12, proportion with gene =12/25 = 0.48 or 48%.
Sample 2: X = 9, proportion with gene = 9/25 = 0.36 or 36%.
Sample 3: X = 10, proportion with gene = 10/25 = 0.40 or 40%.
Sample 4: X = 7, proportion with gene = 7/25 = 0.28 or 28%.
Note:• Each sample gave a different answer, which did not
always match the population value of 40%.
• Although we cannot determine whether one sample will
accurately reflect the population, statisticians have
determined what to expect for most possible samples.

Copyright ©2011 Brooks/Cole, Cengage Learning 17
Sampling Distribution
for a Sample Proportion
Let p = population proportion of interest
or binomial probability of success.
Let = sample proportion or proportion of successes.
If numerous random samples or repetitions of the same size n
are taken, the distribution of possible values of is
approximately a normal curve distribution with
• Mean = p
• Standard deviation = s.d.( ) =
This approximate distribution is sampling distribution of .
p̂
p̂
p̂
p̂n
pp )1(

Copyright ©2011 Brooks/Cole, Cengage Learning 18
The Normal Curve Approximation
Rule for Sample Proportions
Normal Approximation Rule can be applied in two situations:
Situation 1: A random sample is taken from a population.
Situation 2: A binomial experiment is repeated numerous times.
In each situation, three conditions must be met:
1: The Physical SituationThere is an actual population or repeatable situation.
2: Data CollectionA random sample is obtained or situation repeated many times.
3: The Size of the Sample or Number of TrialsThe size of the sample or number of repetitions is relatively large,
np and np(1-p) must be at least 5 and preferable at least 10.

Copyright ©2011 Brooks/Cole, Cengage Learning 19
Examples for which Rule Applies
• Election Polls: to estimate proportion who favor a candidate; units = all voters.
• Television Ratings: to estimate proportion of households watching TV program; units = all households with TV.
• Consumer Preferences: to estimate proportion of consumers who prefer new recipe compared with old; units = all consumers.
• Testing ESP: to estimate probability a person can successfully guess which of 5 symbols on a hidden card; repeatable situation = a guess.

Copyright ©2011 Brooks/Cole, Cengage Learning 20
Example 9.4 Possible Sample Proportions
Favoring a Candidate
Suppose 40% all voters favor Candidate C. Pollsters take a sample of n = 2400 voters. Rule states the sample proportion who favor X will have approximately a normal distribution with
Histogram at right
shows sample
proportions resulting
from simulating this
situation 400 times.
mean = p = 0.4 and s.d.( ) = p̂ 01.02400
)4.01(4.0)1(
n
pp

Copyright ©2011 Brooks/Cole, Cengage Learning 21
s.d.( ) = .
Estimating the Population Proportion
from a Single Sample Proportion
In practice, we don’t know the true population proportion p,
so we cannot compute the standard deviation of ,
In practice, we only take one random sample, so we only have one sample proportion . Replacing p with in the standard deviation expression gives us an estimate that is called the standard error of .
p̂
p̂ p̂
p̂
p̂n
pp )1(
s.e.( ) = .p̂n
pp )ˆ1(ˆ
If = 0.39 and n = 2400, then the standard error is 0.01. So
the true proportion who support the candidate is almost surely
between 0.39 – 3(0.01) = 0.36 and 0.39 + 3(0.01) = 0.42.
p̂

Copyright ©2011 Brooks/Cole, Cengage Learning 22
9.5 SD Mod 2: Sampling Distribution
for Diff in Two Sample Proportions
For the populations:
p1 = population proportion for the first population.
p2 = population proportion for the second population.
Parameter: p1 – p2 = difference in popul proportions.
For the samples:
= sample proportion for sample from first popul.
= sample proportion for sample from second popul.
Statistic: = difference in sample proportions.
1p̂
2p̂
21ˆˆ pp

Copyright ©2011 Brooks/Cole, Cengage Learning 23
Conditions
Sampling distribution of difference in two independent sample
proportions is approximately normal when:
Condition 1: Sample proportions are available for two
independent samples, randomly selected from the two
populations of interest.
Condition 2: All of the quantities n1p1, n1(1 – p1), n2p2, and
n1(1 – p2) are at least 10. These quantities represent the
expected numbers of successes and failures in each sample.

Copyright ©2011 Brooks/Cole, Cengage Learning 24
Sampling Distribution for the
Difference in Two Sample Proportions
Mean = p1 – p2
Standard deviation = s.d.( )
=
When we don’t know the populations proportions, we use the
sample proportions, resulting in:
Standard error = s.e.( ) =
2
22
1
11 )1()1(
n
pp
n
pp
21ˆˆ pp
2
22
1
11 )ˆ1(ˆ)ˆ1(ˆ
n
pp
n
pp
21
ˆˆ pp

Copyright ©2011 Brooks/Cole, Cengage Learning 25
Example 9.6 Men, Women, Death Penalty
Suppose 37% of women and 27% of men oppose death penalty,
p1 = .37 and p2 = .27, for a difference p1 – p2 = .37 – .27 = .10
For independent random samples of 1017 women and 885 men,
the sampling distribution of is approx normal with
mean .10 and standard deviation:
021.885
)27.1(27.
1017
)37.1(37.
21ˆˆ pp
Note: 2008 survey gave observed
difference of .36 – .285 = .075,
which is not unusual.

Copyright ©2011 Brooks/Cole, Cengage Learning 26
9.6 SD Mod 3: Sampling Distribution
for One Sample Mean
• Suppose we want to estimate the mean weight lossfor all who attend clinic for 10 weeks. Suppose (unknown to us) the distribution of weight loss is approximately N(8 pounds, 5 pounds).
• We will take a random sample of 25 people from this population and record for each X = weight loss.
• We know the value of the sample mean will varyfor different samples of n = 25.
• What do we expect those means to be?

Copyright ©2011 Brooks/Cole, Cengage Learning 27
Many Possible Samples
Four possible random samples of 25 people:
Sample 1: Mean = 8.32 pounds, standard deviation = 4.74 pounds.
Sample 2: Mean = 6.76 pounds, standard deviation = 4.73 pounds.
Sample 3: Mean = 8.48 pounds, standard deviation = 5.27 pounds.
Sample 4: Mean = 7.16 pounds, standard deviation = 5.93 pounds.
Note:• Each sample gave a different answer, which did not always
match the population mean of 8 pounds.
• Although we cannot determine whether one sample mean will
accurately reflect the population mean, statisticians have
determined what to expect for most possible sample means.

Copyright ©2011 Brooks/Cole, Cengage Learning 28
The Normal Curve Approximation
Rule for Sample Means
Let m = mean for population of interest.
Let s = standard deviation for population of interest.
Let = sample mean.
If numerous random samples of the same size n are taken, the
distribution of possible values of is approximately a normal
curve distribution with
• Mean = m
• Standard deviation = s.d.( ) =
This approximate distribution is sampling distribution of .
x
x
xn
s
x

Copyright ©2011 Brooks/Cole, Cengage Learning 29
The Normal Curve Approximation
Rule for Sample Means
Normal Approximation Rule can be applied in two situations:
Situation 1: The population of measurements of interest is
bell-shaped and a random sample of any size is measured.
Situation 2: The population of measurements of interest is
not bell-shaped but a large random sample is measured.
Note: Difficult to get a Random Sample? Researchers usually
willing to use Rule as long as they have a representative sample
with no obvious sources of confounding or bias.

Copyright ©2011 Brooks/Cole, Cengage Learning 30
Examples for which Rule Applies
• Average Weight Loss: to estimate average weight loss; weight assumed bell-shaped; population = all current and potential clients.
• Average Age At Death: to estimate average age at which left-handed adults (over 50) die; ages at death not bell-shaped so need n 30; population = all left-handed people who live to be at least 50.
• Average Student Income: to estimate mean monthly income of students at university who work; incomes not bell-shaped and outliers likely, so need large random sample of students; population = all students at university who work.

Copyright ©2011 Brooks/Cole, Cengage Learning 31
Example 9.8 Hypothetical Mean
Weight LossSuppose the distribution of weight loss is approximately N(8 pounds, 5 pounds) and we will take a random sample of n = 25 clients. Rule states the sample mean weight loss will have a normal distribution with
Histogram at right shows
sample means resulting
from simulating this
situation 400 times.
mean = m = 8 pounds and s.d.( ) = poundx 125
5
n
s
Empirical Rule:
It is almost certain that
the sample mean will be
between 5 and 11 pounds.

Copyright ©2011 Brooks/Cole, Cengage Learning 32
s.d.( ) = .
Standard Error of the Mean
In practice, the population standard deviation s is rarely
known, so we cannot compute the standard deviation of ,
In practice, we only take one random sample, so we only have the sample mean and the sample standard deviation s. Replacing s with s in the standard deviation expression gives us an estimate that is called the standard error of .
x
s.e.( ) = .
For a sample of n = 25 weight losses,
the standard deviation is s = 4.74 pounds.
So the standard error of the mean is 0.948 pounds.
xn
s
xn
s
x
x
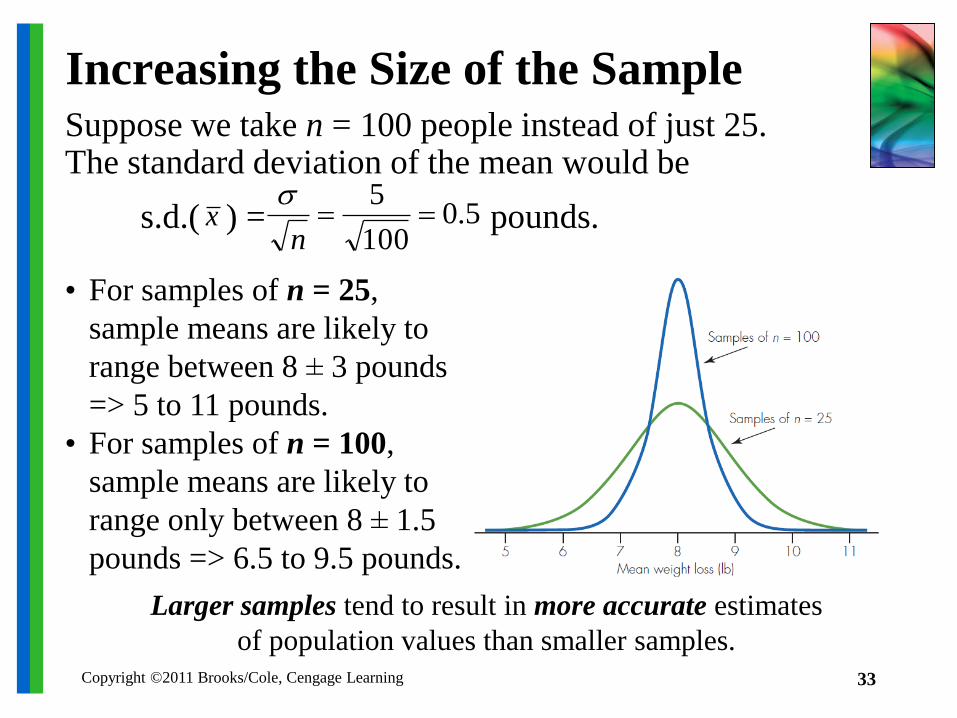
Copyright ©2011 Brooks/Cole, Cengage Learning 33
Increasing the Size of the SampleSuppose we take n = 100 people instead of just 25. The standard deviation of the mean would be
• For samples of n = 25,
sample means are likely to
range between 8 ± 3 pounds
=> 5 to 11 pounds.
• For samples of n = 100,
sample means are likely to
range only between 8 ± 1.5
pounds => 6.5 to 9.5 pounds.
s.d.( ) = pounds.x 5.0100
5
n
s
Larger samples tend to result in more accurate estimates
of population values than smaller samples.

Copyright ©2011 Brooks/Cole, Cengage Learning 34
9.7 SD Mod 4: Sampling Distribution
for Sample Mean of Paired Differences
Let md = mean for population of differences.
Let sd = standard deviation for population of differences.
Let = mean for the sample of differences.
Let sd = standard deviation for sample of differences.
If numerous random samples of the same size n are taken, the
distribution of possible values of is approximately a normal
curve distribution with
• Mean = md
• Standard deviation = s.d.( ) =
This approximate distribution is sampling distribution of .
d
n
ds
d
d
d

Copyright ©2011 Brooks/Cole, Cengage Learning 35
The Normal Curve Approximation Rule
for Sample Mean of Paired Differences
Normal Approximation Rule can be applied in two situations:
Situation 1: The population of differences is
bell-shaped and a random sample of any size is measured.
Situation 2: The population of differences is not bell-shaped
but a large random sample is measured.
Note: Difficult to get a Random Sample? Researchers usually
willing to use Rule as long as they have a representative sample
with no obvious sources of confounding or bias.

Copyright ©2011 Brooks/Cole, Cengage Learning 36
s.d.( ) = .
Standard Error of the Mean Difference
Standard deviation of :
Standard error of :
s.e.( ) = .
The standard error is used to estimate the standard deviation.
n
ds
n
sd
d
d
d
d

Copyright ©2011 Brooks/Cole, Cengage Learning 37
Example 9.9 No “Freshman 15”
How likely to see a mean weight gain of 4.2 pounds or larger
(for a random sample of 60 freshman) if there is no average
weight gain in the population of all such students? Suppose
the standard deviation for the population of weight gains is
known to be 7 pounds. The sampling distribution of is …
• Approximately normal
• mean = md = 0 pounds
• s.d.( ) = pounds9.0904.060
7
n
ds
Empirical Rule: 95%
of the possible sample
means will be between
-1.8 and 1.8 pounds.
d
d

Copyright ©2011 Brooks/Cole, Cengage Learning 38
9.8 SD Mod 5: Sampling Distribution
for Difference in Two Sample Means
Let m1 = population mean for first population.
Let m2 = population mean for second population.
Parameter: m1 – m2 = difference in population means.
Let = sample mean for sample from first population.
Let = sample mean for sample from second population.
Statistic: = difference in sample means.
Let s1 = population standard deviation for first population.
Let s2 = population standard deviation for second population.
Let s1 = sample std deviation for sample from first population.
Let s2 = sample std deviation for sample from second population.
1x
2x
21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 39
Conditions for Sampling Distribution
of to be Approx Normal
An important condition in this situation is that the two samples
must be independent. How?
• Take separate random samples from each of two populations
such as men and women.
• Take a random sample from a population and divide the
sample into two groups based on a categorical variable such
as smoker and nonsmoker.
• Randomly assign participants in a randomized experiment to
two treatment groups such as exercise or diet.
21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 40
In addition to independent samples,
one of the following two situations must hold:
Situation 1: The populations of measurements are both
bell-shaped and random samples of any size are measured.
Situation 2: Large random samples are measured from each
population. Arbitrary definition of large is both samples are
at least 30, but extreme outliers or extreme skewness in
either sample may require even larger samples.
Conditions for Sampling Distribution
of to be Approx Normal21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 41
s.d.( ) = .
Standard Error of the Mean Difference
Standard deviation of :
Standard error of :
The standard error is used to estimate the standard deviation.
2
2
2
1
2
1
nn
ss
21 xx
21 xx
s.e.( ) = .21 xx 2
2
2
1
2
1
n
s
n
s
21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 42
Example 9.10 Who Are the Speed Demons?What’s the fastest you’ve ever driven a car? ____ mph.
Mean for 87 males = 107 mph, mean for 102 females = 88 mph.
Is this 19 mph difference large enough to convince of real difference
in populations? Suppose standard deviations for each population of
speeds is known to be 15 mph. The sampling distribution of is:
• Approximately normal
• mean = m1 – m2 = 0 mph
• s.d.( ) =
Note: difference of 19 mph almost
impossible in this scenario. Thus,
true difference in population means
almost surely much greater than 0.
21 xx
2.2102
15
87
15 22
2
2
2
1
2
1 nn
ss21 xx

Copyright ©2011 Brooks/Cole, Cengage Learning 43
9.9 Preparing for Statistical
Inference: Standardized Statistics
If conditions are met, these standardized
statistics have, approximately, a standard
normal distribution N(0,1).

Copyright ©2011 Brooks/Cole, Cengage Learning 44
Example 9.11 Unpopular TV Shows
Networks cancel shows with low ratings. Ratings based
on random sample of households, using the sample
proportion watching show as estimate of population
proportion p. If p < 0.20, show will be cancelled.
Suppose in a random sample of 1600 households, 288 are
watching (for proportion of 288/1600 = 0.18). Is it likely
to see = 0.18 even if p were 0.20 (or higher)?
p̂
p̂
00.2
1600
20.0120.0
20.018.0
1
ˆ
)(
n
p)p(
ppz
The sample proportion of 0.18 is about
2 standard deviations below the mean of 0.20.

Copyright ©2011 Brooks/Cole, Cengage Learning 45
Student’s t-Distribution:
Replacing s with s
If sample size n is small, this standardized statistic will not have a N(0,1) distribution but rather a t-distribution with n – 1 degrees of freedom (df).
Dilemma: we generally don’t know s. Using s we have:
More on t-distributions in Chapters 11 and 13.
s
xn
n
x
xds
xt
)(
/).(.
m
s
mm

Copyright ©2011 Brooks/Cole, Cengage Learning 46
Example 9.12 Standardized Mean Weights
Claim: mean weight loss is m = 8 pounds.
Sample of n =25 people gave a sample mean weight loss of = 8.32 pounds and a sample standard deviation of s = 4.74 pounds.
Is the sample mean of 8.32 pounds reasonable to expect if m = 8 pounds?
34.025
74.4832.8
ns
xt
m
The sample mean of 8.32 is only about one-third
of a standard error above 8, which is consistent
with a population mean weight loss of 8 pounds.
x

Copyright ©2011 Brooks/Cole, Cengage Learning 47
Sampling for a Long, Long Time:
The Law of Large Numbers
LLN: the sample mean will eventually get
“close” to the population mean m no matter how
small a difference you use to define “close.”
LLN = peace of mind to casinos, insurance companies.
• Eventually, after enough gamblers or customers,
the mean net profit will be close to the theoretical mean.
• Price to pay = must have enough $ on hand to pay the
occasional winner or claimant.
x
9.10 Generalizations beyond
the Big Five

Copyright ©2011 Brooks/Cole, Cengage Learning 48
The Central Limit Theorem (CLT)
The Central Limit Theorem states that if n is sufficiently large, the sample means of random samples from a population with mean m and finite standard deviation s are approximately normally distributed with mean m and standard deviation . n
s
Technical Note:
The mean and standard deviation given in the CLT
hold for any sample size; it is only the “approximately
normal” shape that requires n to be sufficiently large.

Copyright ©2011 Brooks/Cole, Cengage Learning 49
Example 9.14 California Decco Losses
California Decco lottery game: mean amount lost per ticket over millions of tickets sold is m = $0.35; standard deviation s = $29.67 => large variability in possible amounts won/lost, from net win of $4999 to net loss of $1.
mean (loss) = m = $0.35and s.d.( ) = x 09.0$100000
67.29$
n
s
Empirical Rule: mean loss is almost surely between
$0.08 and $0.62 total loss for the 100,000 tickets is
likely between $8,000 to $62,000!
There are better ways to invest $100,000.
Suppose store sells 100,000 tickets in a year. CLT
distribution of possible sample mean loss per ticket
is approximately normal with …

Copyright ©2011 Brooks/Cole, Cengage Learning 50
Sampling Distribution for Any Statistic
Every statistic has a sampling distribution, but the appropriate distribution may not always be normal, or even approximately bell-shaped.
Construct an approximate sampling distribution for a statistic by actually taking repeated samples of the same size from a population and constructing a relative frequency histogram for the values of the statistic over the many samples.

Copyright ©2011 Brooks/Cole, Cengage Learning 51
Example 9.15 Winning the Lottery
by Betting on Birthdays
Pennsylvania Cash 5 lottery game:Select 5 numbers from integers 1 to 39. Grand prize won if match all 5 numbers. One strategy = 5 numbers bet correspond to birth days of month for 5 family members => no chance to win if highest number drawn is 32 to 39. What is the probability of this?
Statistic of interest = H = highest of five integers
randomly drawn without replacement from 1 to 39.
e.g. if numbers selected are 3, 12, 22, 36, 37 then H = 37.

Copyright ©2011 Brooks/Cole, Cengage Learning 52
Example 9.15 Winning the Lottery
by Betting on Birthdays
Value of H for 1560 games
Highest number over 31 occurred in 72% of the games.
Most common value of H = 39 in 13.5% of games.

Copyright ©2011 Brooks/Cole, Cengage Learning 53
Case Study 9.1 Do Americans Really Vote
When They Say They Do?
Election of 1994:
• Time Magazine Poll: n = 800 adults (two days after election),
56% reported that they had voted.
• Info from Committee for the Study of the American Electorate:
only 39% of American adults had voted.
If p = 0.39 then sample proportions for samples of size n = 800 should vary approximately normally with …
mean = p = 0.39 and s.d.( ) = p̂ 017.0800
)39.01(39.0)1(
n
pp

Copyright ©2011 Brooks/Cole, Cengage Learning 54
Case Study 9.1 Do Americans Really Vote
When They Say They Do?
0.10017.0
39.056.0
z
If respondents were telling the truth, the sample percent
should be no higher than 39% + 3(1.7%) = 44.1%,
nowhere near the reported percentage of 56%.
If 39% of the population voted, the standardized score
for the reported value of 56% is …
It is virtually impossible to obtain a standardized score of 10.

















