UNIVERSIT ´ E DE MONTR ´ EAL UNIFIED KERNEL/USER-SPACE EFFICIENT LINUX TRACING ARCHITECTURE DAVID GOULET D ´ EPARTEMENT DE G ´ ENIE INFORMATIQUE ET G ´ ENIE LOGICIEL ´ ECOLE POLYTECHNIQUE DE MONTR ´ EAL M ´ EMOIRE PR ´ ESENT ´ E EN VUE DE L’OBTENTION DU DIPL ˆ OME DE MA ˆ ITRISE ` ES SCIENCES APPLIQU ´ EES (G ´ ENIE INFORMATIQUE) AVRIL 2012 David Goulet, 2012.
Transcript
UNIVERSITE DE MONTREAL
UNIFIED KERNEL/USER-SPACE EFFICIENT LINUX TRACING ARCHITECTURE
DAVID GOULET
DEPARTEMENT DE GENIE INFORMATIQUE ET GENIE LOGICIEL
With a set of design goals and use cases to address, this section explains in detail the
work done to design an efficient tracing infrastructure. This resulted in the lttng-tools
project, based on the LTTng tracer family (Desnoyers et Dagenais, 2006) (Desnoyers, 2012),
an important benefit of this research to the tracing and open source communities.
The lttng-tools project regroups three components which now allow large scale de-
ployment of applications instrumented with the LTTng user space tracer alongside with the
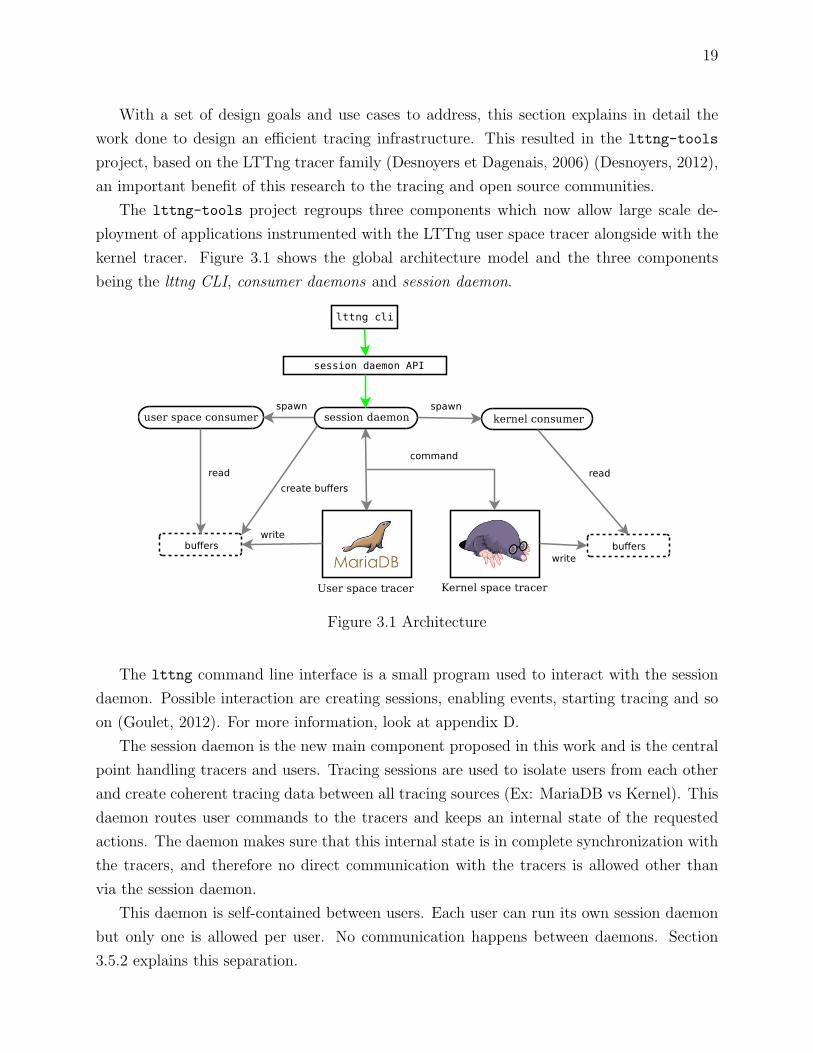
kernel tracer. Figure 3.1 shows the global architecture model and the three components
being the lttng CLI, consumer daemons and session daemon.
Figure 3.1 Architecture
The lttng command line interface is a small program used to interact with the session
daemon. Possible interaction are creating sessions, enabling events, starting tracing and so
on (Goulet, 2012). For more information, look at appendix D.
The session daemon is the new main component proposed in this work and is the central
point handling tracers and users. Tracing sessions are used to isolate users from each other
and create coherent tracing data between all tracing sources (Ex: MariaDB vs Kernel). This
daemon routes user commands to the tracers and keeps an internal state of the requested
actions. The daemon makes sure that this internal state is in complete synchronization with
the tracers, and therefore no direct communication with the tracers is allowed other than
via the session daemon.
This daemon is self-contained between users. Each user can run its own session daemon
but only one is allowed per user. No communication happens between daemons. Section
3.5.2 explains this separation.
20
Consumer daemons extract data from buffers containing recorded data and write it to
disk for later analysis. There are two separate consumer daemons, one handling user space
and the second one the kernel. A single consumer daemon handles all the user space (and
similarly for kernel space) tracing sessions for a given session daemon. It is the session daemon
that initiates the execution of the user space and kernel consumer daemons and feeds them
with tracing commands. The session daemon implements our proposed architecture.
For illustration purposes, here is a small example on how you start tracing the kernel
using this new architecture.
# lttng create mysession
# lttng enable-event sched_switch --kernel
# lttng start
...
# lttng stop
First, a session is created using the lttng command line interface which send command
to the session daemon. We then enable the event sched switch for the kernel domain (–
kernel). So, the daemon receives the command, maintain an internal state for the session and
finally enables the event on the tracer. Following this, the start action basically spawn the
kernel consumer and start tracing for every session. Upon the stop command, the consumer
stays alive but the tracer stops recording data.
The next section describes important tracing concepts for the global understanding of
the model. The following section presents the session daemon internal algorithms, key to its
efficiency.
3.5.1 Tracing concepts
One of the goals of the lttng-tools project is to bring LTTng’s tracers under one umbrella
and creating an abstraction layer between the user and the tracers, hence the importance of
the rendez-vous point concept.
Domains
First, we introduce the notion of tracing domains which is essentially, a type of tracer or
tracer/feature tuple. We currently implement two domains in lttng-tools:
– UST
Global user space domain. Channels and events registered in that domain are enabled on all current
and future registered user space applications.
21
– KERNEL
Three more domains are not yet implemented but are good examples of the tracer/feature
concept. They are UST PID for specific PID tracing, UST EXEC NAME based on application
name and UST PID FOLLOW CHILDREN which is the same as tracing a PID but follows spawned
children.
Session
One of the key new features is the concept of tracing session. It is an isolated container
used to separate tracing sources and users from each other. It takes advantage of the session
feature offered by the tracer.
Each tracing session has a human readable name (Ex.: myapps) and a directory path
where all trace data is written. It also contains the user UID/GID, in order to handle
permissions on the trace data and also determine who can interact with it. We use credentials
passing through UNIX socket (Rochkind, 2004) (Linux, 2008) for that purpose.
More importantly, it has pointers to each possible tracer session (kernel and user space).
Each of them contains the list of domains which contain a list of channels. Appendix A
shows the code snippet for the tracing session data structure.
Event
In earlier LTTng tracers (version 0.x) (Desnoyers et Dagenais, 2006), the term tracepoint
was used and represented a probe in the code recording information. Here, to abstract
different domains, the term event is used which relates to a TRACE EVENT statement in your
application code or in the Linux kernel instrumentation.
Using the command line tool lttng D, you can enable and disable events for a specific
tracing session on a per domain basis. An event is always bound to a channel and associated
tracing context (Desnoyers, 2012).
Channel
Channels existed in the earlier LTTng tracers but were hardcoded and specified by the
tracer. In the new LTTng 2.0 version, channels are now definable by the user and completely
customizable (size of buffers, number of subbuffer, read timer, etc.).
A channel contains a list of user specified events (e.g. system calls and scheduling
switches) and context information (e.g. process id and priority). Channels are created
on a per domain basis, thus each domain contains a list of channels that the user creates.
22
Each event type in a session can belong to a single channel. For example, if event A is
enabled in channel 1, it cannot be enabled in channel 2. However, event A can be enabled
in channel 2 (or channel 1 but not both) of another session.
3.5.2 Session daemon
The session daemon handles all interactions between the users, consumers and tracers.
Here is the list of the daemon’s roles. Each role is explained in depth to illustrate how are
satisfied the requirements exposed in section 3.3.
– Rendez-vous point:
Handles user, consumer and tracer interactions, being the synchronization component
across the tracing toolchain.
– Act as a tracing registry:
1. User space tracer registration (application register)
2. Tracing sessions management (user command)
Unlike the DPCL(Pase, 1998) project using a super daemon, our session daemons coexist
and act independently, never exchanging data, managing their instrumented applications
with the same credentials and handling their own consumers.
It is possible for multiple users to run a session daemon at the same time on the same
machine. Figure 3.2 shows the interaction between all the components in a multi-user envi-
ronment. It should be noted that the two session daemons of the figure never communicate.
Such separation is crucial for usability. It allows any user to compile its own session dae-
mon, run it and be able to trace his or her applications independently. Having two session
daemons communicating would be useless since the information of another user is irrelevant.
Section 3.5.2 explains the efficient mechanism behind applications and tracing sessions
management.
For kernel tracing, the session daemon must run with privileged credentials (UID = 0).
For obvious security reasons, only allowed users can gather kernel traces. A tracing group
is defined, similar to SystemTap groups (Prasad et al., 2005), where everyone in that group
can communicate with the session daemon running as root. This is achieved by using Unix
sockets (Rochkind, 2004) and having read and write permissions for the tracing group.
In summary, the session daemon grants access to tracing resources by running under
various credentials and allowing interactions only from users who possess enough rights to
do so. Unprivileged users cannot access other user’s traces and only allowed users can
control the kernel tracer. Moreover, the rendez-vous point concept allows it to provide a
23
Figure 3.2 Multi-user scenario
new set of features that tracers themselves cannot provide such as application registration,
and synchronization of every tracer available on the system.
The next two sections explains the user and kernel space tracer interactions with the
session daemon, looking in depth at application registration and kernel features. Following
this, the tracing registry, the core of the session daemon, is described.
Kernel tracer
While the kernel tracer is the most complex entity in terms of code and algorithms, it
is the simplest to handle. For the session daemon, this tracer is a single tracing source.
You cannot have two kernels running concurrently, as opposed to user space tracers where
multiple instrumented applications provide multiple tracing sources.
Managing the kernel tracer requires a different approach from user space tracing. The
traced data is entirely controlled by the kernel. For security reasons, we can assume that
they are not directly accessible by user space, at least not writable. As we saw in previous
projects (Desnoyers et Dagenais, 2006) (Yaghmour et Dagenais, 2000) (Prasad et al., 2005),
the kernel exposes a transport pipeline (Ex: character device or anonymous file descriptor)
and a user space daemon simply extracts data through this mechanism.
Mostly for security purposes, and buffering differences between tracers, the lttng-tools
24
project implemented a separate consumer for the kernel tracer. It is spawned and updated
by the session daemon. At startup, the session daemon loads every LTTng kernel module
and opens file /proc/lttng for upcoming interactions. As mention earlier, only a privileged
session daemon can communicate with the kernel tracer, and only users in the tracing group
can interact with it.
One specific feature of the kernel tracer is CPU hotplug. It is explained in section 3.5.2.
The kernel notifications are handled by a thread that polls the kernel file descriptor notifies
the consumer of the newly created per-cpu channel to consume.
User-space tracer
The user space tracer brings the possibility of multiple concurrent tracing sources. With
the LTTng 2.0 UST tracer, instrumented applications register with the session daemon at
the beginning of their execution.
Since the tracer functionality relies on a running session daemon, the registration mech-
anism is crucial and, thus, has to be very efficient. Two challenging situations occur, where
the session daemon is either running or not running. The most important premise is that
the application runtime behaviour should not be altered by the user space tracer waiting for
the session daemon. Thus, the user space tracer needs to follow this algorithm in a separate
thread, since condition at line 1 might not be satisfied at first:
Require: New process (thread)
1: if connect succeed then
2: register
3: receive possible command(s)
4: begin normal program execution
5: else
6: begin normal program execution
7: wait for notification (passive blocking)
8: end if
Line 1 tests the condition by connecting to the session daemon application socket. On
success, the application sends basic information used by the application registry 3.5.2 on line
3. Then, it waits for commands (Ex: create session, enabling events, etc.) and finally begins
the normal execution of the program (C main()).
On connection failure, we immediately begin the program execution since we cannot wait
for an unknown period of time. Finally, on line 7, we wait for notification, which is the more
25
complex part.
Figure 3.3 shows the three possible scenarios for the session daemon notification process.
Three applications begin waiting respectively before, during and after the notify (wake) of
the session daemon which indicates that it is ready to receive registration.
App1 and app3 are clearly able to register since the state of the wake is not racing with
the wait process and the registration. However, app2 is a more problematic case which
requires careful synchronization in order to avoid starvation on the tracer side and the
possible wait/wake race shown in figure 3.4. This model is based on the fact that there are
n > 0 wait processes and 1 waker.
Figure 3.3 UST registration synchronization
Figure 3.4 UST registration wait/wake race
This issue shows that a shared IPC is needed as a way to synchronize applications and
a session daemon. A persistent memory location with the session daemon state (flag) is
needed to ensure coherent state over time for all user space tracers. Commonly, this is called
a semaphore (Abraham Silberschatz et Gagne, 2008) and we use it to synchronize processes.
We elected to use a shared memory area (SHM) (Manpages, 2008) where we put the
semaphore. The second important consideration is that if no session daemon is available,
26
the user space tracer should wait passively in a separate thread, hence not altering the
execution behaviour of the application. A futex object (Drepper, 2011) was chosen.
A futex() system call provides a way for a program to wait passively on a value at
a given address. It can also use a method to wake anyone waiting on that value. This
mechanism is typically used to implement locking scheme in a shared memory area. Thus,
it provides a passive blocking call for the session daemon state variable and the contention
dealt by the kernel.
Overall, there are two critical concepts for the wait/wake scheme:
1. Persistent memory area with a state flag (using a semaphore)
2. Waiting has to be passive (no CPU usage)
Figure 3.5 illustrates the data flow between the application and the tracer at this stage.
The SHM area is created either by the user space tracer or the session daemon, whoever
comes first, at a hardcoded path, and contains a futex object used to wake every process
waiting on it.
The user space tracer waits on the futex and the session daemon, once spawned and
ready for registration, notifies all waiting applications by atomically setting the state flag
and waking the futex (FUTEX WAKE).
After this notification, instrumented applications register to the session daemon. At any
point in time, if the session daemon dies, the same process is done all over again. The user
space tracer returns waiting on the global futex which is reset atomically by the session
daemon when quitting. If an application cannot connect to a daemon and the state of the
flag indicates to register, the application will reset it.
There is a potential race at the user space level when two applications try to create the
SHM area. The kernel ensures (Love, 2010) that only one shared memory segment is created
with the same path, so if one creation fails with an already exist error message, the user
space tracer retries immediately to wait on the futex.
This design is important because it avoids starvation on the tracer side by using futex
synchronization. The tracer is either waiting or registering. There is absolutely no window
where it could wait forever. It would be unacceptable for an instrumented application to
never register hence not be traceable. Moreover, this registration phase is only done once
and before the main() of the application is called. Little extra time is added to the program
execution 3.6.
Figure 3.5 shows that once the session daemon wakes the futex, all applications, which
can be numerous, immediately try to register by connecting to a socket (ust sock) created by
27
Figure 3.5 User space tracer registration
the session daemon and sending the registration data. The kernel allows us to queue multiple
requests for connections with the listen() syscall. However, once accepted, handling the
registration should be very fast.
Figure 3.6 illustrate the detailed scheme used to dispatch a registration to a thread pool
without locks. Once the instrumented application sends its information, it is immediately
enqueued in a wait-free queue provided by the URCU library (Desnoyers et al., 2010) and
the next registration waiting on the socket can be handled. The dispatcher thread is the
next step.
The dispatch thread is using the dequeue blocking call of the wait-free queue and, once
the node is popped, it is written on a pipe (Rochkind, 2004) (a fast data IPC available for
Linux, see section 3.6 for detailed benchmark). There is one pipe per thread in the thread
pool and the dispatcher is going in a round-robin to assign the request to a thread. The
registration request is the same size and time regardless of the application so the dispatch
policy is pretty simple. Once the registration is completed, i.e. adding an entry in the
lockless registry 3.5.2, a registration done packet is sent back and the socket is kept open
and used for later commands.
This socket is added to a central application management thread which polls every user
space socket and monitors events. This is how the session daemon can detect an unregister-
ation. If the socket is closed on the application side, the session daemon picks it and handles
the cleanup. This mechanism is particularly interesting for two reasons.
First, for any application dying unexpectedly, for instance a segmentation fault, the kernel
closes the socket automatically so the in-process library (tracer) does not have to notify the
session daemon (and in this example won’t be able to do so anyway).
Secondly, command synchronization is based on the availability of the socket. Any com-
mand failing on the user space tracer (with a write error on the socket) automatically cleans
28
Figure 3.6 Session lock with the lockless hash table issue
up the application session registry of newly created data structure protected by RCU mech-
anisms. It is however very important to close the socket on the session daemon side after
releasing application and registry data structure memory, or else an application could regis-
ter during that time, and the socket number be reused. This would create incoherent data
in the registry having a session assigned to the application but non existent in the tracer.
By monitoring this socket, we are able to remove synchronization primitives between the
user and the tracer since it is correct, by design, for the command to fail on the tracer side,
even if the data is coherent on the session daemon.
Tracing registry
The tracing registry stores tracing sessions and application information using lockless
data structures. Figure 3.7 is a representation of the registry tree for tracing session objects
3.5.1.
A tracing session contains two tracer types, the first level nodes of the registry hierarchy,
with the tracing session itself being the root node. Those nodes contain per domain channel
hash tables. For example, the UST PID domain is a hash table indexed by PID and each
bucket contains a hash table of channels. The UST and KERNEL domains are actually a single
29
structure containing a hash table of channels. Indeed, those domains are global and only
one element is possible.
Figure 3.7 Tracing registry
The main goal of this structure is to be efficient for lookups and insertions. Each user
command specifies at least a session name and a domain. Lookups for the session, a channel
and an event are all O(1). Thus, every client command is efficiently handled.
The insertion process is trivial, beginning with a lookup by key given by the user (Ex:
channel name), to see if the object already exists and adding it to the right hash table found
using the tracing session name and domain. The cost of adding an element is basically the
time to hash the key, see section 3.6 for performance results.
However, a special use case arises for the kernel tracer. Channels are allocated on a per
CPU basis, meaning that the number of data structures allocated is set to the number of
enabled CPUs. Linux supports CPU hotplug, the kernel then informs the session daemon
of added or removed CPUs, and the channel hash table has to be updated accordingly.
We currently use a per-session pthread mutex (Rochkind, 2004) to synchronize the channel
hash table between the thread handling client commands and the thread handling CPU
hotplug. As future work, the user space lockless notification mechanism developed during
this research, explained in section 3.5.2, will be implemented.
30
The tracing registry also keeps track of registered applications. With LTTng UST 2.0
tracer (Desnoyers, 2012), applications register at startup with the session daemon, trying to
connect to a socket and send information such as UID, GID, PID and library version used
to validate the compatibility of the tracer against the session daemon. That bidirectional
Unix socket (Linux, 2008) is kept open for future tracing commands requested by the user.
The transmitted information is stored in an application structure (See appendix A for
the code reference) which is kept in two lockless hash tables where one is indexed by PID
and the second one is indexed by socket file descriptor number. Upon registration, we get
the PID of the application and a new socket file descriptor value. An add unique operation
is done using the PID as key to insert the application into the registry. When an application
unregisters, the only notification we have is the socket application being closed. Therefore,
the session daemon needs to be able to find the application using two different informations,
PID and socket number. In a previous implementation, the second table simply mapped
from socket to PID, leading to a race when a process was removed between the access to the
socket to PID table and the access to the PID table, as shown in figure 3.8. The important
point is that every lookup to the registry has to be done in a single operation to avoid such
races in this lockless design.
Figure 3.8 Two lockless hash table node
This registration process is of prime importance, creating the user space tracer rendez-
vous point allowing the session daemon to provide features that the tracer itself cannot
provide. It allows the user to list what are the available applications to trace.
Furthermore, for user space tracing, events that measure and record bootstrap proce-
dures for an application are extremely common. With the tracing registry, all events are
31
first defined in the session daemon and then dispatched to the appropriate domain (tracer).
This enables preregistered channels/events for a session, before the application has started.
Since a tracing session is independent of the tracer lifetime, those pending events are auto-
matically enabled on the tracer when it becomes available (by registering).
Multiple tracing sources case
User-space tracing is more involved since, unlike the Kernel, we have multiple tracing
sources (applications). This brings different synchronization issues between client commands
and application commands. The typical scenario is:
1. Tracing is started
2. The enable-event command, when completed, assures the user that the data will be
recorded if the user space tracer hits the event.
Figure 3.9 shows the two possible race conditions that can happen where the enable event
begins before the registration and the second one begins after.
For example, a script could be enabling several events, while in parallel an application to
trace would be started. Several events would be enabled before the application starts and
registers with the session daemon, while others would be enabled after the registration.
The two cases are valid and have to apply to the registering application. This example
can be extended to all commands and illustrates the concept of data coherency between the
user and the tracer.
user1
app
user2 enable_event
register
enable_event
time
Figure 3.9 Possible race with register before
In order to maintain a good performance, even with a large number of registering ap-
plications, an efficient synchronization mechanism, shown in figure 3.10, was developed to
address the previous race conditions. Every list of objects is actually a lockless hash table
from the user space RCU library (Desnoyers et al., 2010). Every reading and deletion uses
32
RCU (McKenney et Walpole, 2007), thus completely eliminating the use of locks for every
operation, as long as we have a single writer.
Figure 3.10 Lockless shadow-copy mechanism on application registration
When an application registers, it is quickly added to the registered application hash table.
It then triggers a shadow copy of all UST sessions of all tracing sessions (from the registry)
to its application session structure. The application session structure thereafter contains
all applicable sessions, channels and events for the application, which can then be activated
accordingly. The UST sessions thus represent user tracing commands, while the application
session represents the application tracing state.
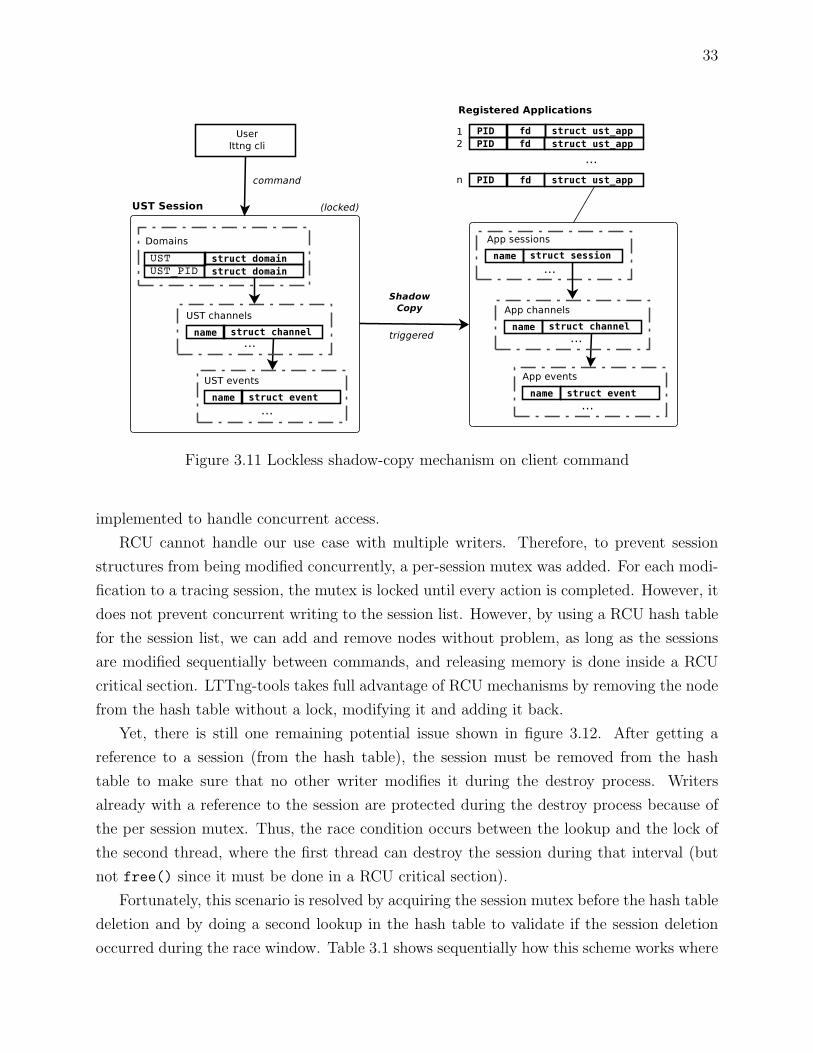
Figure 3.11 illustrate the concept of shadow copy on a user command. The UST session
reference is acquired, modifications are done on that session and the shadow copy is triggered
for each user space application session. An important point to understand is that every
addition, modification or deletion is first done onto the UST session and then applied to
the application session. Upon registration, the UST session hash table is used to trigger the
shadow copy.
The last element to examine is how to modify a tracing session in a multi-threaded
environment. Multiple users can modify the same session concurrently. Many concurrent
commands may be issued using lttng command line, modify the tracing session information
and trigger actions in application tracers. At this time, lttng-tools does not handle client
commands using a thread pool scheme, but its synchronization model was designed and
33
Figure 3.11 Lockless shadow-copy mechanism on client command
implemented to handle concurrent access.
RCU cannot handle our use case with multiple writers. Therefore, to prevent session
structures from being modified concurrently, a per-session mutex was added. For each modi-
fication to a tracing session, the mutex is locked until every action is completed. However, it
does not prevent concurrent writing to the session list. However, by using a RCU hash table
for the session list, we can add and remove nodes without problem, as long as the sessions
are modified sequentially between commands, and releasing memory is done inside a RCU
critical section. LTTng-tools takes full advantage of RCU mechanisms by removing the node
from the hash table without a lock, modifying it and adding it back.
Yet, there is still one remaining potential issue shown in figure 3.12. After getting a
reference to a session (from the hash table), the session must be removed from the hash
table to make sure that no other writer modifies it during the destroy process. Writers
already with a reference to the session are protected during the destroy process because of
the per session mutex. Thus, the race condition occurs between the lookup and the lock of
the second thread, where the first thread can destroy the session during that interval (but
not free() since it must be done in a RCU critical section).
Fortunately, this scenario is resolved by acquiring the session mutex before the hash table
deletion and by doing a second lookup in the hash table to validate if the session deletion
occurred during the race window. Table 3.1 shows sequentially how this scheme works where
34
Figure 3.12 Session lock with the lockless hash table issue
each column is a different thread doing modification and removal concurrently (th1 and th2
are from 3.12).
Table 3.1 Scheme to avoid race condition between look up and lock
Modify (th1) Removal (th2)
lookup()
lookup()
lock session()
ht del()
unlock session()
call rcu(free session)
lock session()
lookup()
session unavailable
There is also the possibility of using a simple deleted flag on the node and testing it
atomically instead of acquiring a mutex. However, it was implemented that way to take
advantage of the pthread mutex lock blocking call.
In summary, the tracing registry is the backbone of LTTng tracing, being a rendez-vous
point for all tracing components, thus ensuring data coherency between the user, the tracers
and the consumers.
35
3.6 Experimental results
This section presents the experimental results of all lttng-tools mechanisms. Section 3.6.1
shows the different benchmarks done, as of today, on the lttng-tools 2.0 stable version:
– User space tracer notification
– User space tracer registration
– Performance baseline
This section also includes performance results on studied Linux IPC. Those results are
the performance baseline of the implementation and a discussion follows on possible avenues
to improve this baseline.
Finally, section 3.6.2 compares our work to studied user space application synchronization
mechanisms presented in section 3.3.
3.6.1 Benchmarks
First, Table 3.2 describes the test setup hardware used for the benchmark. After that,
for each subsection, the methodology is explained first and results are presented in a table.
Every measurement was taken using the precise cpu cycle count before and after each
tested section. See appendix B to see how the cpu frequency is measured before running the
benchmarks. For the IPC section, the Linux command time is also used for comparison.
Linux IPC
As aforementioned, this study analyzed the different possible IPCs (Kay A. Robbins,
2003) of the Linux operating system in order to determine the fastest and most efficient for
Table 3.2 Test setup specification
CPU Intel Core i7 920 @ 2.67GHzRAM 6 GB
OS Linux ubuntu 10.04.4Kernel 3.2.0
Version lttng-tools 2.0-stableVersion lttng-ust 2.0-stable
Version libc6 2.11.1-0ubuntu7.8
36
our application.
Shared memory area is of course the fastest IPC between processes since, once initialized,
there is no system call to access the data. Nevertheless, this requires more synchronization,
often ending up using a system call to deal with contention.
Asynchronous bidirectional communication between threads and processes is crucial for
lttng-tools. For this reason, we experimented with pipes and sockets, testing outbound and
inbound data transmission. Tables 3.3 and 3.4 show the write and read average time for the
pipe IPC along with the standard deviation. Tables 3.5 and 3.6 present the send and recv
average time. The standard deviation is also available.
Benchmarks were run 1000 times for each with different message sizes ranging from very
few bytes (16) to four times the size of a Linux memory page of 4096 bytes. For each result,
the received data is validated against the sent data.
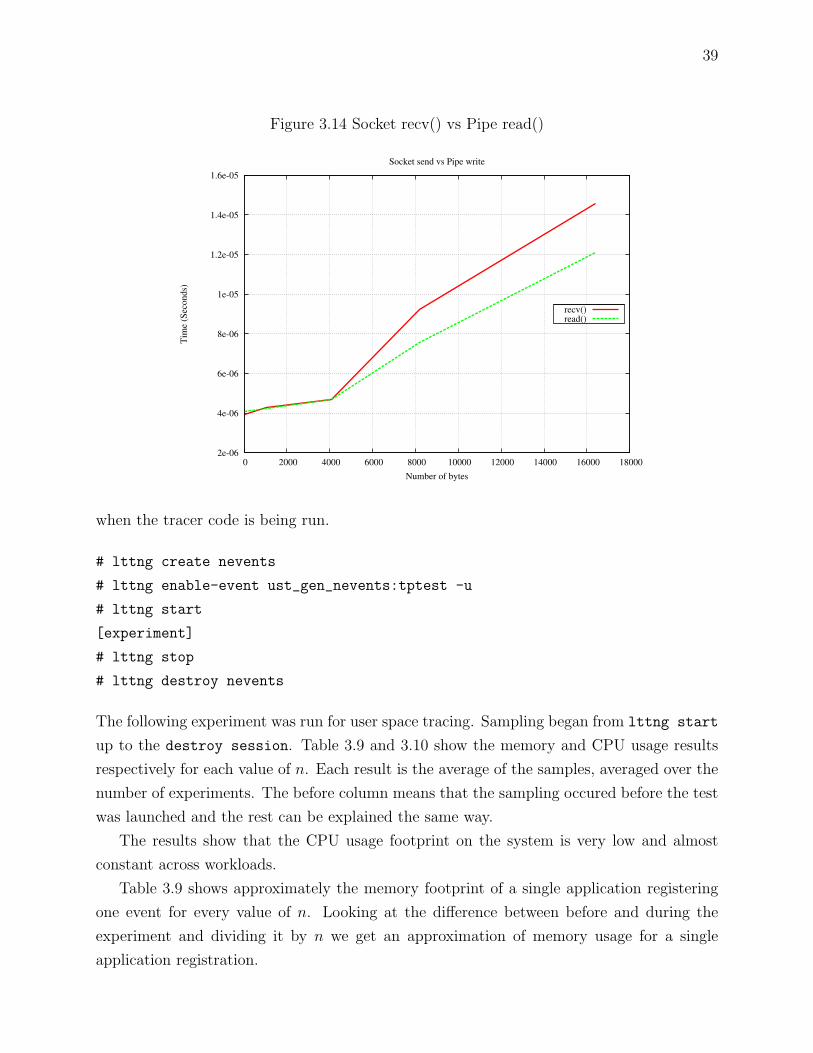
The overall difference between those two mechanisms are shown in figure 3.13 and 3.14.
Table 3.3 write to pipe
Bytes Time Deviation
16 3.3197×10−6 sec. 0.16344×10−6 sec.1024 3.4067×10−6 sec. 1.09235×10−6 sec.4096 3.4127×10−6 sec. 0.24667×10−6 sec.8192 3.9786×10−6 sec. 0.31152×10−6 sec.16384 5.5347×10−6 sec. 0.17899×10−6 sec.
Table 3.4 read from pipe
Bytes Time Deviation
16 4.1076×10−6 sec. 0.4876×10−6 sec.1024 4.2581×10−6 sec. 0.4925×10−6 sec.4096 4.6689×10−6 sec. 0.0858×10−6 sec.8192 7.5881×10−6 sec. 0.6682×10−6 sec.16384 12.1067×10−6 sec. 2.9066×10−6 sec.
The croocked line in figure 3.13 and 3.14 which occurs at 4096 and 8192 are page faults
triggered by the kernel hence creating a longer time to manage the data.
These results demonstrate the very thin difference between the two. In addition, Unix
sockets allow two key features that are used across the lttng-tools code base: passing process
37
Table 3.5 send to socket
Bytes Time Deviation
16 2.3662×10−6 sec. 0.26949×10−6 sec.1024 2.4888×10−6 sec. 0.09812×10−6 sec.4096 2.7906×10−6 sec. 0.07993×10−6 sec.8192 4.1098×10−6 sec. 0.18246×10−6 sec.16384 6.0743×10−6 sec. 0.26255×10−6 sec.
Table 3.6 recv from socket
Bytes Time Deviation
16 3.9375×10−6 sec. 0.26938×10−6 sec.1024 4.2832×10−6 sec. 0.12567×10−6 sec.4096 4.6800×10−6 sec. 0.31030×10−6 sec.8192 9.2137×10−6 sec. 0.39677×10−6 sec.16384 14.5910×10−6 sec. 1.99072×10−6 sec.
credentials and file descriptors over the socket. Using sockets is therefore a good choice for
bidirectional communication, because of these very useful extra features.
UST notification
This performance measurement was done 1000 times and the average time of all runs is
presented. The notification process implies more fine-grained measurements.
The context of this benchmark is that the session daemon starts and notifies applications.
For the session daemon part, table 3.7 shows the step by step procedure and breakdown in
time. The following results show the notification procedure on the session daemon side only.
UST registration
This benchmark was run 1000 times over an eight hour period and measure each steps
of a single instrumented application registration. Table 3.8 break down the time step by
step for each important registration procedure (Refer to section 3.5.2 to understand the each
step).
We end up with a baseline of 0.1526 millisecond on average for one single application
registration. At this point in time, the lttng-tools session daemon does not handle application
The following experiment was run for user space tracing. Sampling began from lttng start
up to the destroy session. Table 3.9 and 3.10 show the memory and CPU usage results
respectively for each value of n. Each result is the average of the samples, averaged over the
number of experiments. The before column means that the sampling occured before the test
was launched and the rest can be explained the same way.
The results show that the CPU usage footprint on the system is very low and almost
constant across workloads.
Table 3.9 shows approximately the memory footprint of a single application registering
one event for every value of n. Looking at the difference between before and during the
experiment and dividing it by n we get an approximation of memory usage for a single
application registration.
40
Table 3.7 UST notification time breakdown
Step Time
1 Memory mapping for the shared page 4.3458×10−6 sec.2 Setting read-only permissions 4.6256×10−6 sec.3 Open shm and truncate it to fit a memory page 9.6669×10−6 sec.4 Futex wake call 4.9137×10−6 sec.
Total 23.552×10−6 sec.
Table 3.8 UST registration time breakdown
Step Time
1 Receiving and enqueue data 36.394×10−6 sec.2 Dequeue and write to pipe 11.564×10−6 sec.3 Read from pipe 2.6511×10−6 sec.4 Add app to registry 32.535×10−6 sec.5 Send register done 69.441×10−6 sec.
Total 152.58×10−6 sec.
(1475− 1192)/n = 283 kB (3.1)
(8255− 1192)/n = 70.63 kB (3.2)
(59936− 1192)/n = 58.744 kB (3.3)
We end up with a memory footprint of less than 58 kilobytes per registered application
since n = 1 shows the amount of memory needed for data structures handling application
registration. Since the process event was enabled by the user, a shadow copy was triggered,
increasing the memory usage. Also, channel streams are on a per CPU basis and contain a
trace directory path of 4096 bytes. More cores, more memory.
3.6.2 Comparison
This section takes a look at the dispatching mechanism performance. Section 3.6.1 shows
the time it takes, once an application has established a connection, to dispatch and handle
41
Table 3.9 Memory usage of lttng-sessiond (size kB)
This chapter presents the conclusion of this research. The proposed tracing architecture
and the lttng-tools project are first summarized. Then, some limitations of the current
implementation are presented. Finally, we discuss possible improvements as future work.
5.1 Summary of the work
This main accomplishment presented here is the unified tracing architecture, combining
user and kernel space control, and enabling the implementation of the lttng-tools project.
It provides a command line user interface, a tracing control library, user and kernel tracing
consumers and, the pivotal part of this architecture, the session daemon.
We have presented a tracing registry and algorithms that provide lockless interactions.
This registry enables tracing sessions and aggregates user and kernel tracer information
under one umbrella. Moreover, this registry is extended to registering applications, allowing
user space tracing to record early event(s) during the bootstrap process, and trace events
to be pre-enabled before the program lifetime. With registration, users are also able to list
available traceable applications.
The notification process of waiting applications is also an important realization. Using a
shared semaphore (implemented with futex and SHM), we were able to address race condi-
tions on registration and insure that no starvation occurs on the application side (user space
tracer). This scheme also enables applications to register in any state of the runtime, i.e.
the program continues to work even if the session daemon is not available or is restarting.
Finally, we proposed a fast dispatch mechanism to handle application registration which
can possibly be extended to thread pooling and larger workloads. We have shown that the
CPU usage on the system is quite low during that process. This design takes advantage of
multi-processor systems by creating three different processes to optimize the request dispatch
and avoid wait periods on Linux IPC or I/O.
50
5.2 Limitations
Since the model allows to enable events on non registered applications, when the tracer
registers, all tracing sessions are checked for pending events and enabled on the tracer side if
it applies. This process takes the lock on the global session list to stop any modification and
iterate. Assuming a large number of applications registering at the same time, this causes
an important latency on the client side, since the global list is locked. Consequently, if the
client request is very long, it will penalize every application.
The per session mutex is definitely a bottleneck to performance. Fine-grained locking
could be done to address such problem. This would require precise measurements and
synchronization checks.
The proposed model was not validated on other user space domains such as per PID
events. The problem with this domain is that a PID can be reused for two different appli-
cations. If the tracing session has multiple events and channels enabled for a specific PID,
if the application dies it is detected and the shadow copy is cleaned up. However, on a per
PID basis, we would also need to clean the tracing session which only the client side can do
securely in the current synchronization model.
5.3 Future work
As short term future work, one possible improvement would be to implement a thread
pool design, for both application registration and user commands management, and validate
its scalability.
The previous issues on per PID tracing is a more complex problem with the current
scheme. Nonetheless, it would be very useful to allow LTTng to behave like strace.
The data protection issues are also important. There are mostly two ways to approach
this problem. Either the transport layer is the secure channel or, upon extraction, the data
itself is encrypted.
Furthermore, network streaming and remote control is still to be investigated. This
would require to at least add one thread in the architecture, which will potentially bring
synchronization issues and an in-depth review of the underlying algorithms.
51
LIST OF REFERENCES
ABRAHAM SILBERSCHATZ, P. B. G. et GAGNE, G. (2008). Operating System Concepts
(8th ed.). John Wiley & Sons. Inc.
APPAVOO, J., WISNIEWSKI, R. W. et XENIDIS, J. (2002). K42’s performance monitor-
ing and tracing infrastructure. IBM Research.
BLIGH, M., DESNOYERS, M. et SCHULTZ, R. (2007). Linux kernel debugging on google-
sized clusters. Proceedings of the Linux Symposium.
CANTRILL, B. M., SHAPIRO, M. W. et LEVENTHAL, A. H. (2004). Dynamic instru-
mentation of production systems. USENIX.
CORBET, J. (2007). Kernel markers. Linux Weekly News.
DEROSE, L., JR., T. H. et HOLLINGSWORTH, J. K. (2001). The dynamic probe class
library - an infrastructure for developing instrumentation for performance tools. Parallel
and Distributed Processing Symposium., Proceedings 15th International.
DESNOYERS, M. (2009). Low-Impact Operating System Tracing. These de doctorat, Ecole
Polytechnique de Montreal.
DESNOYERS, M. (2012). Man page lttng-ust.3. Efficios Inc.
DESNOYERS, M. et DAGENAIS, M. (2006). The lttng tracer : A low impact performance
and behavior monitor for gnu/linux. Ottawa Linux Symposium.
DESNOYERS, M., MCKENNEY, P. E., STERN, A. S., DAGENAIS, M. R. et WALPOLE,
J. (2010). User-level implementations of read-copy update. IEEE Transaction on Parallel
and Distributed Systems.
DON DOMINGO, W. C. (2010). SystemTap Beginners Guide - Introduction to SystemTap.
RedHat.
DREPPER, U. (2011). Futexes are tricky. Red Hat Inc.
FIELDING, R. et KAISER, G. (1997). The apache http server project. Internet Computing,
IEEE, 1, Issue 4.
FITZPATRICK, B. (2004). Distributed caching with memcached. Linux Journal,
2004, Issue 124.
FOURNIER, P.-M., DESNOYERS, M. et DAGENAIS, M. R. (2009). Combined tracing of
the kernel and applications with lttng. Linux Symposium, Ottawa.
GOULET, D. (2012). lttng.1. Efficios Inc.
52
GREGG, B. et MAURO, J. (2011). DTrace : Dynamic Tracing in Oracle Solaris, Mac OS
X and FreeBSD. Prentice Hall.
HOLLINGSWORTH, J. K., MILLER, B. P. et CARGILLE, J. (1994). Dynamic program
instrumentation for scalable performance tools. Scalable High Performance Computing
Conference.
INTEL (2010). Intel 64 and IA-32 Architectures Software Developer Manuals.
KAY A. ROBBINS, S. R. (2003). Unix Systems Programming Communication Concurrency
And Threads. Prentice Hall.
KEW, N. (2007). Apache Modules Book, The Application Development with Apache. Pren-
tice Hall.
LINUX (2008). Man page unix.7. Linux.
LOVE, R. (2010). Linux Kernel Development, 3rd Edition. Addison-Wesley, troisieme
edition.
MANPAGES (2008). Man page shm overview.7. Linux man-pages project.
MCKENNEY, P. E. et WALPOLE, J. (2007). What is rcu, fundamentally ? Linux Weekly
News, http ://lwn.net/Articles/262464/.
PASE, D. M. (1998). Dynamic Probe Class Library (DPCL) : Tutorial and Reference Guide.
IBM Corp.
PETROVIC, J. (2008). Using memcached for data distribution in industrial environment.
Systems, 2008. ICONS 08. Third International Conference on Systems.
PRASAD, V., COHEN, W. et EIGLER, F. C. (2005). Locating system problems using
dynamic instrumentation. Proceedings of the Ottawa Linux Symposium.
ROCHKIND, M. J. (2004). Advanced UNIX Programming, 2nd Edition. Addison-Wesley.
WIKIPEDIA (2011). Pulseaudio. referal from http ://pulseaudio.org.
YAGHMOUR, K. et DAGENAIS, M. R. (2000). The linux trace toolkit. Linux Journal.
YLONEN, T., CORP, S. C. S., LONVICK, C. et INC., C. S. (2006). RFC 4251 : The
Secure Shell (SSH) Protocol Architecture.
53
APPENDIX A
LTTng-Tools session code snippet
Tracing session code
Listing A.1 lttng-sessiond/session.h
1 /*
2 * This data s t r u c tu r e conta in s in fo rmat ion needed to i d e n t i f y a t r a c i ng
3 * s e s s i o n f o r both LTTng and UST.
4 */
5 struct l t t s e s s i o n {6 char name [NAMEMAX] ;
7 char path [PATHMAX] ;
8 struct l t t k e r n e l s e s s i o n * k e r n e l s e s s i o n ;
9 struct l t t u s t s e s s i o n * u s t s e s s i o n ;
10 /*
11 * Protect any read/wr i t e on t h i s s e s s i o n data s t r u c tu r e . This l o ck
12 * must be acqu i red * be f o r e * us ing any pub l i c f unc t i on s dec l a r ed
13 * below . Use s e s s i o n l o c k ( ) and s e s s i o n un l o c k ( ) f o r that .
14 */
15 pthread mutex t l ock ;
16 struct c d s l i s t h e a d l i s t ;
17 int enabled ; /* enabled / s t a r t ed f l a g */
18 int id ; /* s e s s i o n unique i d e n t i f i e r */
19 /* UID/GID of the user owning the s e s s i o n */
20 u id t uid ;
21 g i d t g id ;
22 } ;
54
UST application code
Listing A.2 lttng-sessiond/ust-app.h
1 /*
2 * Reg i s t e r ed t r a c e ab l e app l i c a t i o n s . Libust r e g i s t e r s to the
3 * s e s s i o n daemon .
4 */
5 struct ust app {6 p id t ppid ;
7 u id t uid ; /* User ID that owns the apps */
8 g i d t g id ; /* Group ID that owns the apps */
9 int b i t s p e r l o n g ;
10 int compatible ; /* I f the l t tng−ust t r a c e r v e r s i on does not match the
11 supported ve r s i on o f the s e s s i o n daemon , t h i s f l a g i s
12 s e t to 0 (NOT compatible ) e l s e 1 . */
13 struct l t t n g u s t t r a c e r v e r s i o n ve r s i on ;
14 u in t 32 t v major ; /* Verion major number */
15 u in t 32 t v minor ; /* Verion minor number */
16 char name [ 1 7 ] ; /* Process name ( shor t ) */
17 struct l t t n g h t * s e s s i o n s ;
18 struct l t t ng h t node u l ong pid node ;
19 struct l t t ng h t node u l ong sock node ;
20 } ;
55
APPENDIX B
CPU frequency acquisition code
CPU frequency sampling code
Listing B.1 benchmark/benchmark.c
1 c y c l e s t g e t c y c l e s (void )
2 {3 /*
4 * URCU macro us ing the cpu cy c l e counter :
5 * #de f i n e r d t s c l l ( va l ) \6 * do { \7 * unsigned i n t a , d ; \8 * asm v o l a t i l e (” rd t s c ” : ”=a” ( a ) , ”=d” ( d ) ) ; \9 * ( va l ) = ( ( unsigned long long ) a ) \
10 * | ( ( ( unsigned long long ) d ) << 32 ) ; \11 * } whi le (0 )
12 */
13 return c a a g e t c y c l e s ( ) ;
14 }15
16 u in t 64 t g e t cpu f r e q (void )
17 {18 struct t imezone tz ;
19 struct t imeva l tv s ta r t , tvstop ;
20 c y c l e s t c be f o r e , c a f t e r ;
21 unsigned long microseconds ;
22
23 memset(&tz , 0 , s izeof ( tz ) ) ;
24
25 gett imeofday(&tvs ta r t , &tz ) ;
26 c b e f o r e = g e t c y c l e s ( ) ;
27 gett imeofday(&tvs ta r t , &tz ) ;
28
29 s l e e p ( 1 ) ;
30
31 gett imeofday(&tvstop , &tz ) ;
56
32 c a f t e r = g e t c y c l e s ( ) ;
33 gett imeofday(&tvstop , &tz ) ;
34
35 microseconds = ( ( tvstop . t v s e c − t v s t a r t . t v s e c ) * 1000000) +
36 ( tvstop . tv us e c − t v s t a r t . t v u s e c ) ;
37
38 return ( u i n t 64 t ) ( ( c a f t e r − c b e f o r e ) / microseconds ) ;

















































































![Event Tracing and Pstore - Linaro · Trace events can be filtered in the kernel in number of ways which are described in linux kernel documentation [1], some of them below: Filter](https://static.documents.pub/doc/80x56/5ec55f35333851662b469cb3/event-tracing-and-pstore-linaro-trace-events-can-be-filtered-in-the-kernel-in.jpg)






