Page 1
1 University of MichiganElectrical Engineering and Computer Science
Modulo Scheduling for Highly Customized Datapaths to Increase
Hardware Reusability
Kevin Fan, Hyunchul Park,Manjunath Kudlur, Scott Mahlke
Advanced Computer Architecture LaboratoryUniversity of Michigan
April 8, 2008
Page 2
2 University of MichiganElectrical Engineering and Computer Science
Introduction
• Emerging applications have high performance, cost, energy demands– H.264, wireless, software radio,
signal processing– 10-100 Gops required– 200 mW power budget
• Applications dominated by tight loops processing large amounts of streaming data
iPhone board
Page 3
3 University of MichiganElectrical Engineering and Computer Science
Loop Accelerators
C Code HardwareLoop
LD +/- *
Page 4
4 University of MichiganElectrical Engineering and Computer Science
FPGAs
Hardware Implementations
• Customization gets order-of-magnitude performance and efficiency wins– Viterbi: 100x speedup vs. ARM9
General PurposeProcessors
DSPsCGRAs
Loop Accelerators,ASICs
Efficiency, Performance
Fle
xibi
lity
MultifunctionLoop Accelerators
Page 5
5 University of MichiganElectrical Engineering and Computer Science
What About Programmability?
• Software changes – bug fixes, evolving standards• dct_8x8() from H.264 reference implementation
Version 13.0 Version 13.1 Version 13.2
for (coeff_ctr = 0; coeff_ctr < 64; coeff_ctr++) {
i=pos_scan[coeff_ctr][0];
j=pos_scan[coeff_ctr][1];
run++;
ilev=0;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
MCcoeff = MC(coeff_ctr);
runs[MCcoeff]++;
}
m7 = &curr_res[block_y + j][block_x];
level = iabs (m7[i]);
if (img->AdaptiveRounding)
{
fadjust8x8[j][block_x+i] = 0;
}
if (level != 0)
{
nonzero = TRUE;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
*coeff_cost += MAX_VALUE;
img->cofAC[b8+pl_off][MCcoeff][0][scan_poss[MCcoeff] ] = isignab(level,m7[i]);
img->cofAC[b8+pl_off][MCcoeff][1][scan_poss[MCcoeff]++] = runs[MCcoeff];
++scan_pos;
runs[MCcoeff]=-1;
}
else
{
*coeff_cost += MAX_VALUE;
ACLevel[scan_pos ] = isignab(level,m7[i]);
ACRun [scan_pos++] = run;
run=-1; // reset zero level counter
}
level = isignab(level, m7[i]);
ilev = level;
}
}
for (coeff_ctr = 0; coeff_ctr < 64; coeff_ctr++) {
i=pos_scan[coeff_ctr][0];
j=pos_scan[coeff_ctr][1];
run++;
ilev=0;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
MCcoeff = MC(coeff_ctr);
runs[MCcoeff]++;
}
m7 = &curr_res[block_y + j][block_x];
level = iabs (m7[i]);
if (img->AdaptiveRounding)
{
fadjust8x8[j][block_x+i] = 0;
}
if (level != 0)
{
nonzero = TRUE;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
*coeff_cost += MAX_VALUE;
img->cofAC[pl_off][MCcoeff][0][scan_poss[MCcoeff] ] = isignab(level,m7[i]);
img->cofAC[pl_off][MCcoeff][1][scan_poss[MCcoeff]++] = runs[MCcoeff];
++scan_pos;
runs[MCcoeff]=-1;
}
else
{
*coeff_cost += MAX_VALUE;
ACLevel[scan_pos ] = isignab(level,m7[i]);
ACRun [scan_pos++] = run;
run=-1; // reset zero level counter
}
level = isignab(level, m7[i]);
ilev = level;
}
}
for (coeff_ctr = 0; coeff_ctr < 64; coeff_ctr++) {
i=pos_scan[coeff_ctr][0];
j=pos_scan[coeff_ctr][1];
run++;
ilev=0;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
MCcoeff = MC(coeff_ctr);
runs[MCcoeff]++;
}
m7 = &curr_res[block_y + j][block_x];
level = iabs (m7[i]);
if (img->AdaptiveRounding)
{
fadjust8x8[j][block_x+i] = 0;
}
if (level != 0)
{
nonzero = TRUE;
if (currMB->luma_transform_size_8x8_flag && input->symbol_mode == CAVLC)
{
*coeff_cost += MAX_VALUE;
img->cofAC[pl_off][MCcoeff][0][scan_poss[MCcoeff] ] = isignab(level,m7[i]);
img->cofAC[pl_off][MCcoeff][1][scan_poss[MCcoeff]++] = runs[MCcoeff];
++scan_pos;
runs[MCcoeff]=-1;
}
else
{
*coeff_cost += MAX_VALUE;
ACLevel[scan_pos ] = isignab(level,m7[i]);
ACRun [scan_pos++] = run;
run=-1; // reset zero level counter
}
level = isignab(level, m7[i]);
ilev = level;
}
}
Page 6
6 University of MichiganElectrical Engineering and Computer Science
FPGAs
Programmable Loop Accelerator
• Reusable hardware → reduced NRE costs• Generalize accelerator without losing efficiency
General PurposeProcessors
DSPsCGRAs
Loop Accelerators,ASICs
Efficiency, Performance
Fle
xibi
lity
MultifunctionLoop Accelerators
ProgrammableLoop Accelerators
Page 7
7 University of MichiganElectrical Engineering and Computer Science
Flexible Accelerators
HardwareLoop 1
SynthesisSystem
Loop 2
Compiler
• Generalize accelerator architecture• Map new loops to existing hardware
Page 8
8 University of MichiganElectrical Engineering and Computer Science
Loop Accelerator Architecture
Point-to-point Connections
+
… …
&
… …
MEM
… …
LocalMem
FSM
Controlsignals
CRF
BR
• Hardware realization of modulo scheduled loop• Parameterized execution resources, storage, connectivity
Page 9
9 University of MichiganElectrical Engineering and Computer Science
Programmable Accelerator Architecture
Point-to-point Connections
+/-
… …
&/|
… …
MEM
… …
LocalMem
ControlMemory
Controlsignals
CRF
BR
RR RRRRRR
Literals
Bus
• ~50% area overhead vs. non-programmable accelerator
• Generalize architectural features that limit programmability
Page 10
10 University of MichiganElectrical Engineering and Computer Science
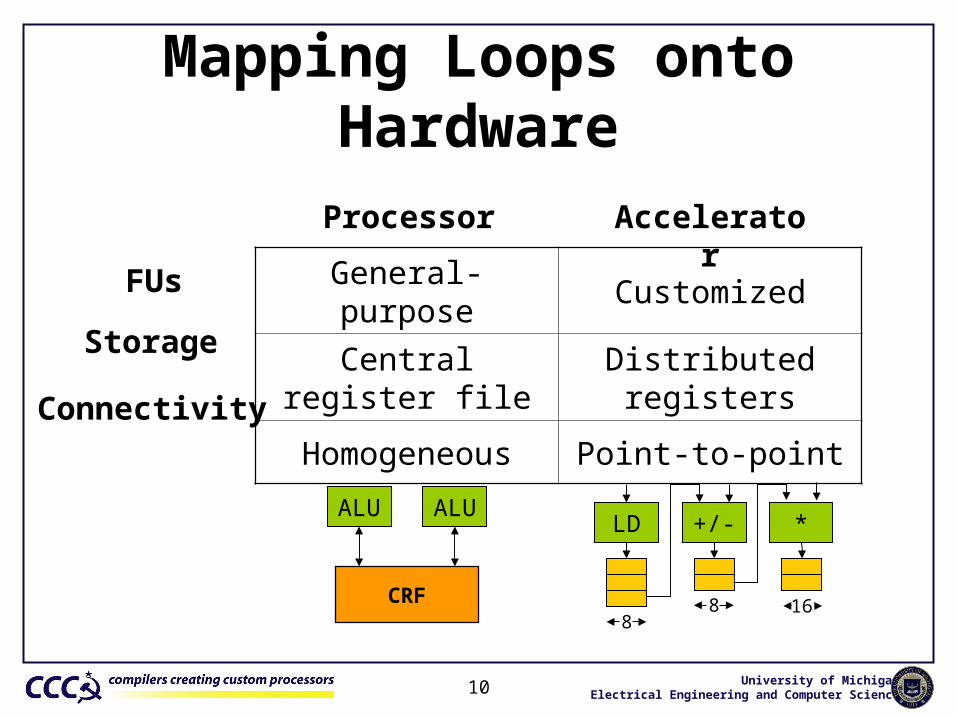
Mapping Loops onto Hardware
General-purpose Customized
Central register file Distributed registers
Homogeneous Point-to-point
Processor Accelerator
FUs
Storage
Connectivity
ALU ALU
CRF
LD +/- *
88 16
Page 11
11 University of MichiganElectrical Engineering and Computer Science
Scheduling Example
ADDER1 ADDER2MEM
0
1
2
3
4
II=2
Time+2 +3
+4 +5
LD1
LD1
+2 +3
LD1
+2 +3
+4
+4LD1
+3 +2
+3 +2
+4
+4
+5
+5
+5 ?
Page 12
12 University of MichiganElectrical Engineering and Computer Science
Modulo Scheduling for LAs
• Large search space, few solutions• Op-centric approaches unable to find solutions• Satisfiability Modulo Theory (SMT) formulation to
solve linear and SAT constraints simultaneously
MoveInsertion
SMTScheduling
RegisterAllocation
LoopControl SignalsMachine
descriptionIncrement II
Page 13
13 University of MichiganElectrical Engineering and Computer Science
SMT Formulation
• Boolean variables Xi,f,t are true if operation i is scheduled on FU f at time slot t.
• Integer variables Si represent stage of operation i.
( Xi,fi,ti Xj,fj,tj ) ( )
sched_time(j) sched_time(i) + lat(i) – dist(i,j) II
i
j
lat(i)
dist(i,j)
Sj II + tj Si II + ti + lat(i) – dist(i,j) II
• More details in paper
Page 14
14 University of MichiganElectrical Engineering and Computer Science
Measuring Programmability
• How well can different loops be mapped onto the same hardware?
• Performance matters – how much does II increase?• Need set of loops with different degrees of similarity
FU FU
Hardware
Loop LoopLoop
LoopLoop
Loop
?
Page 15
15 University of MichiganElectrical Engineering and Computer Science
Graph Perturbation
• Synthetically generated graphs• More perturbations → less similar to original graph• Iteratively apply random transformations:
Add edge between existing operationsAdd edge with new producerAdd edge with new consumer
Remove edge
Page 16
16 University of MichiganElectrical Engineering and Computer Science
0
2
4
6
8
10
12
14
16
18
20
dcac dequant fft fir fmradio turbo fsed sobel heat lu
# P
ert
urb
ati
on
s
≥3
<3
<2
<1
Results – Perturbed Graphs
AverageII increase
4 8 7 2 4 4 44 6 9
MPEG4 Signal processing Image Math
Base II
Page 17
17 University of MichiganElectrical Engineering and Computer Science
Results – Restricted Datapath
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
# Perturbations
II in
cre
as
e r
ati
o
PLA
No RRF
No Bus
No Mux
Page 18
18 University of MichiganElectrical Engineering and Computer Science
Conclusion
• Increase flexibility of customized hardware without sacrificing performance, efficiency
• Successfully map loops to heterogeneous hardware• Compile times of 5 minutes – 1 hour• Software changing faster than hardware →
patchable ASIC
Page 19
19 University of MichiganElectrical Engineering and Computer Science
Questions?
Page 20
20 University of MichiganElectrical Engineering and Computer Science
Page 21
21 University of MichiganElectrical Engineering and Computer Science
Results – Cross Compilation