46
Using Emerging Patterns to Analyze Gene Expression Data Jinyan Li BioComputing Group Knowledge & Discovery Program Laboratories for Information Technology Singapore
| Date post: | 03-Jan-2016 |
| Category: |
Documents |
| Upload: | elmer-leonard |
| View: | 213 times |
| Download: | 0 times |

Using Emerging Patterns to Analyze Gene Expression Data
Jinyan Li
BioComputing Group
Knowledge & Discovery Program
Laboratories for Information Technology
Singapore

Outline
• Introduction
• Brief history of decision trees and emerging patterns
• Basic ideas for decision trees and EPs
• Advanced topics
• Comparisons using gene expression data
• Summary

Introduction
• Decision trees and emerging patterns both classification rules
• Sharp discrimination power (no or little uncertainty)
• Advantage over black-box learning models
• Decision trees not the best (on accuracy)
• EP-based classifiers: competitive to the best

Brief History of Decision Trees
CLS (Hunt etal. 1966)--- cost driven
ID3 (Quinlan, 1986 MLJ) --- Information-driven
C4.5 (Quinlan, 1993) --- Pruning ideas
CART (Breiman et al. 1984) --- Gini Index

Brief history of emerging patterns
General EP (Dong & Li, 1999 Sigkdd)
CAEP (Dong etal, DS99), JEP-C (Li etal, KAIS00)EP-space (Li etal, ICML00), DeEPs (Li etal, MLJ)
PCL (Li & Wong, ECML02)

Basic definitions
• Relational data
• Attributes (color, gene_x), attribute values (red, 200.1), attribute-value pair (equivalently, condition, item)
• Patterns, instances
• Training data, test data

A simple datasetOutlook Temp Humidity Windy classSunny 75 70 true PlaySunny 80 90 true Don’tSunny 85 85 false Don’tSunny 72 95 true Don’tSunny 69 70 false PlayOvercast 72 90 true PlayOvercast 83 78 false PlayOvercast 64 65 true PlayOvercast 81 75 false PlayRain 71 80 true Don’tRain 65 70 true Don’tRain 75 80 false PlayRain 68 80 false PlayRain 70 96 false Play
9 Play samples
5 Don’t
A total of 14.

A decision tree
outlook
windyhumidity
Play
Play
PlayDon’t
Don’t
sunny
overcast
rain
<= 75> 75 false
true
24
3
2NP-complete problem
3

C4.5
• A heuristic
• Using information gain to select the most discriminatory feature (for tree and sub-trees)
• Recursive subdivision over the original training data

Characteristics of C4.5 trees
• Single coverage of training data (elegance)
• Divide-and-conquer splitting strategy
• Fragmentation problem
• Locally reliable but globally un-significant rules
Missing many globally significant rules; mislead the system.

Emerging Patterns (1)
• An emerging pattern is a set of conditions usually involving several genes, with which most of a class satisfy but none of the other class satisfy.
• Real example:
{gene(37720_at) > 215, gene(38028_at)<=12}.
73% vs 0%• EPs are multi-gene discriminators.
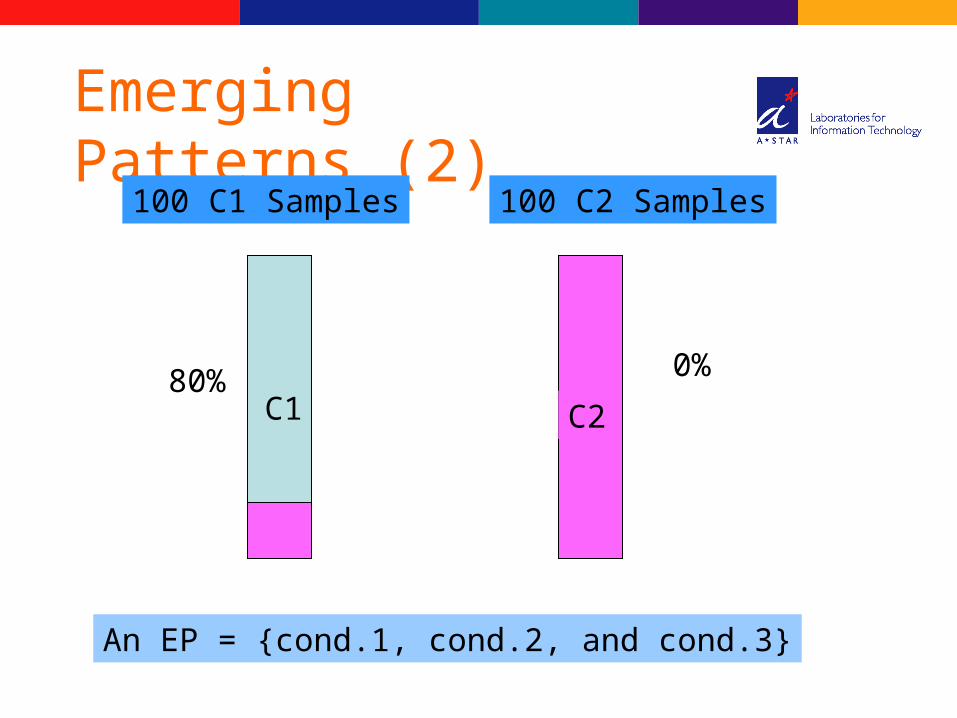
Emerging Patterns (2)
An EP = {cond.1, cond.2, and cond.3}
C1 C2
100 C1 Samples 100 C2 Samples
80% 0%

Boundary emerging patterns
• Definition: A boundary EP is an EP whose proper subsets are not EPs.
• Boundary EPs separate EPs from non- EPs • Distinguish EPs with high frequency from
EPs with low frequency.• Boundary EPs are of our greatest interests.

EP rules derived
• A total of 12 EPs, some important ones of them never discovered by C4.5.
• Examples: {Humi <=80, windy = false} -> Play (5:0).
• A total of 5 rules in the decision tree induced by C4.5.
• C4.5 missed many important rules.

Characteristics of EP approach
• Each EP is a tree with only one branch• A cluster of trees: EPs combined (loss of
elegance)• Globally significant rules• Exponential number in size (need to focus
on very important feature if large number of features exist.)

Usefulness of Emerging Patterns in Classification
• PCL (Prediction by Collective Likelihood of Emerging Patterns).
• Accurate
• Easily understandable.

Spirit of the PCL Classifier (1)
Top-Ranked EPs inPositive class
Top-Ranked EPs inNegative class
EP_1 (90%)EP_2 (86%) . .EP_n (68%)
EP_1 (100%)EP_2 (95%) . .EP_n (80%)
The idea of summarizing multiple top-ranked EPs is intendedto avoid some rare tie cases.

Spirit of the PCL Classifier (2)
Score_p = EP’_1_p / EP_1_p + … + EP’_k_p / EP_k_p
Most freq. EP from posi. classin the test sample
Most freq. EP of posi class
Similarly, Score_n = EP’_1_n / EP_1_n + … + EP’_k_n / EP_k_n
If Score_p > Score_n, then positive class, otherwise negative class.
K=10,Ideal Score_p = 10Score_n = 0

C4.5 and PCL
• Differences:– C4.5 is a greedy search
algorithm using the divide-and-conquer idea.
– PCL is a global search algorithm.
– Leaves in C4.5 are allowed to contain mixed samples, however PCL does not.
– Multiple trees used by PCL, but single tree used by C4.5.
• Similarities:– Both can provide high-
level rules.

Advanced topics
• Bagging, boosting and C4.5
• Convexity of EP spaces (ICML00, Li etal).
• Decomposition of EP spaces into a series of P-spaces and a small convex space (ECML02, Li and Wong).
• DeEPs (to appear in MLJ, Li etal).
• Version spaces (Mitchell, 1982 AI).

Gene Expression Profiles
• Huge number of features
• Most of them can be ignored when for classification
• Many good discriminating feautures
• Number of instances relatively small

Expression data in this talk
• Prostate disease, 102 instances, Cancer Cell v.1, issue 1, 2002
• ALL disease, 327 instances, Cancer Cell, v.1, issue 2, 2002
• MLL disease, 72 instances, Nature Genetics, Jan., 2002
• Breast cancer, 98 instances, Nature, Jan. 2002

Classification models in this talk
• K-nearest neighbor (simplest)
• C4.5 (decision tree based, easily understandable)• Bagged and Boosted C4.5
• Support Vector Machines (black box)
• Our PCL classifier

Our Work Flow
Original Training Data
Feature selection
Establishing Classification Model
Giving a Test Sample
Making a Prediction

Selecting Discriminatory Genes
• T-statistics and MIT-correlation.– Based on expression average and deviation
between two classes of cell.
• Entropy-based discretization methods, including Chi-Square statistics, and CFS.– Based on clear boundaries in the expression
range of a gene.

An Ideal Gene ExpressionRange
• Expression values are two-end distributed.
C1 C2Xyz.x

Results on Prostate Dataset
52 tumor samples and 50 normal samples, each representedby ~12,500 numeric values.
Two Problems: -1- What is the main difference? How to use rules to represent the difference?
-2- What’s the LOOCV accuracy by PCL and C4.5?

C4.5 Tree32598_at
40707_at33886_at
Tumor
Tumor
Normal
Normal
<=29 >29
<= 10> 10 <= -6
> -6
> 5
34950_at
Normal
<=5
3+1
63+1

Emerging patternsPatterns Frequency (T) Frequency(N){9, 36} 38 instances 0{9, 23} 38 0{4, 9} 38 0{9, 14} 38 0{6, 9} 38 0{7, 21} 0 36{7, 11} 0 35{7, 43} 0 35{7, 39} 0 34{24, 29} 0 34
Reference number 9: the expression of 37720_at > 215.Reference number 36: the expression of 38028_at <= 12.

LOOCV accuracies
Classifier PCL C4.5 SVM 3-NN Single Bagged BoostedAccuracy 95.1 91.2 94.1 93.1 90.2 96.1Error rate 5 9 6 7 10 4

Subtype classificationof ChildhoodLeukemiaUsing Gene ExpressionProfiling
One of our important projects.

Collaborating Parties
• St. Jude Children’s Research Hospital, USA.– Mary E. Ross, Sheila A. Shurtleff, W. Kent Williams, Divyen Patel, Rami
Mahfouz, Fred G. Behm, Susana C. Raimondi, Mary V. Relling, Anami Patel, Cheng Cheng, Dario Campana, Ching-Hon Pui, William E. Evans, Clayton Naeve, and James R. Downing
• NUH, Singapore.– Eng-Juh Yeoh
• University of Mississippi, USA.– Dawn Wilkins, Xiaodong Zhou
• LIT, Singapore.– Jinyan Li, Huiqing Liu, Limsoon Wong

Important Motivations
• Leukemia is a heterogeneous disease (T-ALL, E2A-PBX1, TEL-AML1, BCR-ABL, MLL, and Hyperdip>50).
• Response is different.• Leukemia is 80%
curable if subtype is correctly diagnosed.
• Correct diagnosis needs many different tests and experts.
• Tests and experts not commonly available in a single hospital, especially in less advanced countries.
• So, developing new methods is needed.

ALL Data Description
Subtype Training Testing
T-ALL 28 15E2A-PBX1 18 9TEL-AML1 52 27BCR-ABL 9 6MLL 14 6Hyperdip50 42 22Others 52 27
Total 215 112
A sample = {gene_1, gene_2, …, gene_12558}

Central questions
• Diagnosis: Classification of more than six subtypes of the leukemia disease
• Prognosis: Prediction of outcome of therapy

Classification StrategyA new sample
T-ALL? Yes T-ALL predicted noE2A-PBX1? Yes E2A-PBX1 predicted noTEL-AML1? Yes TEL-AML1 predicted noBCR-ABL? Yes BCR-ABL predicted noMLL? Yes MLL predicted noHyperdip50? Yes Hyperdip50 predicted no

Total Mis-classifications of the 112 Test Samples
Feature Selection SVM NB k-NN C4.5 PCL
Top20-ChiSquare 6 8 7 14 4Entropy 5 7 4 14 5Top20-mit 7 7 9 14 4
Overall, we achieved 96% accuracy level in the prediction.

An Excellent Publication
Cancer Cell, March ‘02• Lead article• Cover page

Other Questions for the Childhood Leukemia
• Can one subtype separating from other subtypes?
• Can we do classification in parallel, rather than using a tree structure?

Test Error Rates
Datasets PCL C4.5(112 test instances) Single Bagged BoostedBCR-ABL vs others 1:0 4:4 6:0 4:4E2A-PBX1 vs others 0:0 0:0 0:0 0:0Hyperdip50 vs others 2:2 4:7 4:2 4:7MLL vs others 0:2 2:2 1:0 2:2T-ALL vs others 0:0 1:0 1:0 1:0TEL-AML1 vs others 2:0 2:2 2:1 2:2
Parallel classification 7 27 20 10
Overall, PCL is better than C4.5 (single, bagged, or boosted).

MLL Distinction from Conventional ALL
• Armstrong, etal, Nature Genetics, Jan. 2002
• 3 classes, 57 training samples, 15 test instances.
• Much smaller than the St.Jude’s data.
• Independently obtained data.

Test Error Rates by PCL and C4.5
Datasets PCL C4.5 Single Bagged Boosted
ALL vs others 0:0 1:2 0:0 1:2AML vs others 0:0 1:0 0:0 0:0MLL vs others 0:1 0:0 0:0 0:0ALL vs AML 0:0 0:0 1:0 0:0ALL vs MLL 0:0 0:0 0:0 0:0AML vs MLL 0:0 0:0 0:0 0:0

Relapse Study on Breast Cancer
• Veer etal, Nature, Jan. 2002• 78 training samples, 19 test data for relapse
study.

Test Error Rates by Classifiers
Dataset PCL C4.5 SVM 3-NN Single Bagged Boosted
Relapse vsNon-relapse 3:3 5:0 5:2 2:4 6:2 7:3(12:7)
Accuracy not good; may need other more sophisticated methods;Gene expression may be not sufficient for relapse study.

Summary
• Discussed similarities and differences between decision trees and emerging patterns.
• Discussed advanced topics such as bagging, boosting, convexity.
• Performance comparison using 4 gene expression datasets.
• Overall, PCL is better that C4.5 (single, bagged, or boosted) on accuracy and rules.

Thank you!
May 27, 2002

















