19
Using Overlay Networks for Proximity-based Discovery Steven Czerwinski Anthony Joseph Sahara Winter Retreat January 13, 2004
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 0 times |

Using Overlay Networks for Proximity-based Discovery
Steven CzerwinskiAnthony Joseph
Sahara Winter RetreatJanuary 13, 2004

This Talk• Goals
– Build a decentralized, self-organizing discovery service
– Describe how P2P overlay networks are leveraged– Compare against traditional approaches
• Investigating using infrastructure resources to augment client / server architectures– REAP and MINNO showed code & data migration helps– Need a way to find infrastructure resources
• Outline– Background on proximity-based discovery– Compass architecture– Experimental results
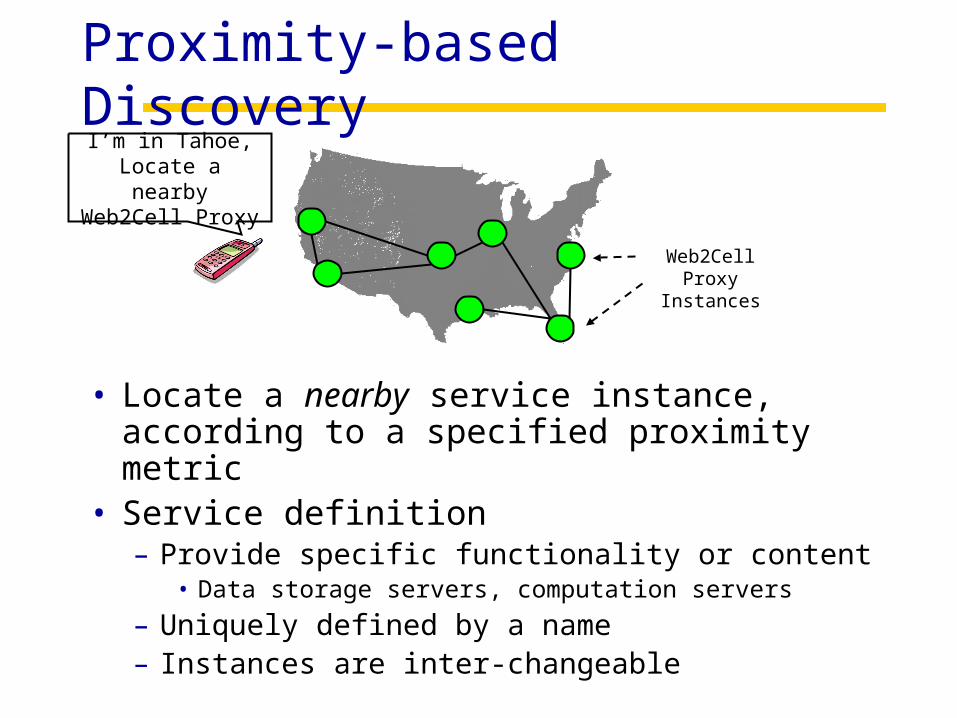
Proximity-based Discovery
• Locate a nearby service instance, according to a specified proximity metric
• Service definition– Provide specific functionality or content
• Data storage servers, computation servers
– Uniquely defined by a name– Instances are inter-changeable
Web2Cell Proxy Instances
I’m in Tahoe, Locate a nearby Web2Cell Proxy

Motivation
• Applications requiring discovery
• Benefits of using overlay networks– Does not rely on manual configuration or
multicast– No need for special discovery servers– Better scalability and fault tolerance
Application Area
Discovery target Publication
App-Level Multicast
Node participating in session Zhuang [2001]
Data Staging Nodes available for push-based caching
Flinn [2003]
Object Replication
Instance of content object Rhea [2003]
P2P networks Nodes to acts as gateways for joining
Castro [2002]
Protocol optimizers
Nodes to run mobile procedures Czerwinski [2001]
Server selection Nodes hosting a particular content set
Hanna [2001]

Overlays Applied to Discovery• Recast problem as object location & leverage
DOLRs– Servers = objects, Instances = object replicas
• Nodes hosting service instances…– Compute key by hashing service name– Publish: store instance information along the path to
root
• Clients making queries– Compute key by hashing service name– Query: search on path to root, returning first instance
• Proximity-based discovery arises from local convergence property– Paths to same root starting from nearby nodes quickly
converge– Overlay must use PNS (Proximity Neighbor Selection)
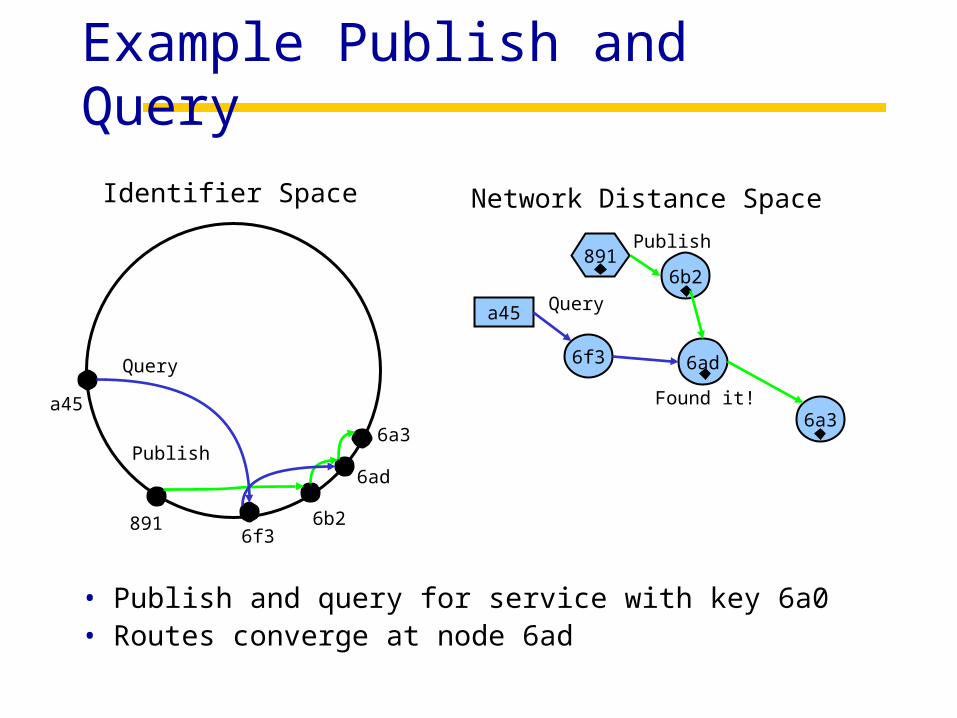
Example Publish and Query
Identifier Space Network Distance Space
a45
8916f3
6b2
6ad
6a3
Query
Publish
6f3
6b2
6ad
6a3
• Publish and query for service with key 6a0• Routes converge at node 6ad
a45
891Publish
Query
Found it!

Compass Architecture
• Built on Bamboo– Proximity metric is estimated RTT
• Publish messages are periodic for soft-state• Tracks fixed number of instances per service
– Memory consumption depends on number of unique services
– Lottery used for eviction– Tickets based on estimated network distance
• Publish messages are aggregated / batched– One message per publish period per service
• To break ties when fulfilling queries– Lottery used for selecting among multiple instance
entries– Tickets based on inverse estimated network distance
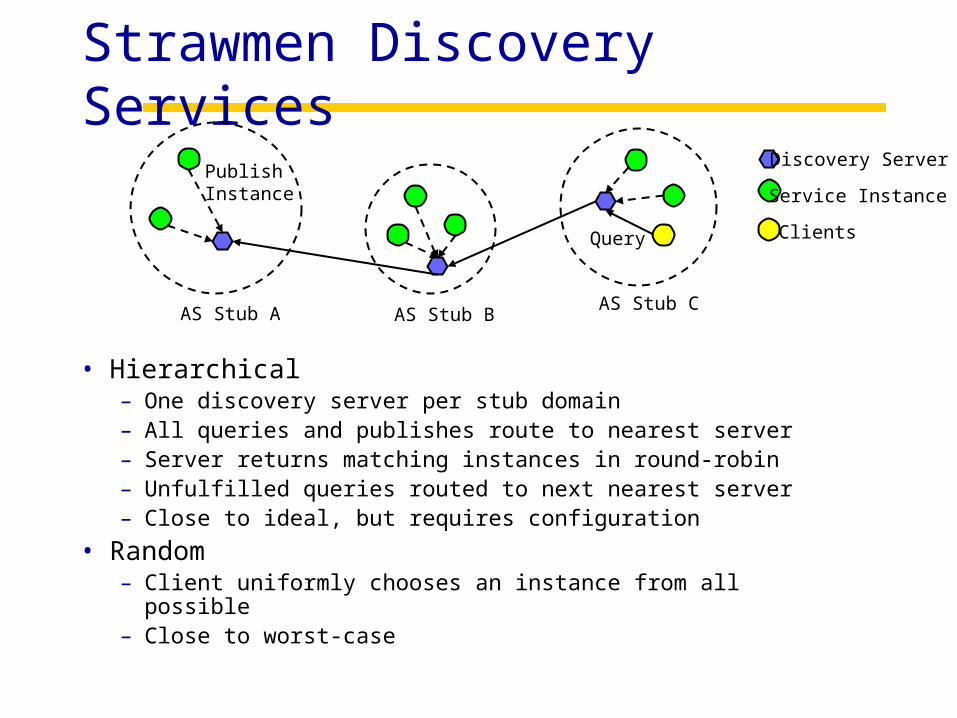
Strawmen Discovery Services
• Hierarchical– One discovery server per stub domain– All queries and publishes route to nearest server– Server returns matching instances in round-robin– Unfulfilled queries routed to next nearest server– Close to ideal, but requires configuration
• Random– Client uniformly chooses an instance from all
possible– Close to worst-case
AS Stub A AS Stub BAS Stub C
Discovery Server
Service Instance
Clients
PublishInstance
Query

Experiments• Used Modelnet to emulate wide-area topology
– Transit-stub topology generated by INET
• Nodes– 500 clients and 500 instance generators– 100 services, divided into 4 density classes (.1,.5,1,5 per AS
stub)– Emulated on cluster with 40 physical hosts
• Trials– 30 minute warm-up period followed by 1 hour of queries– Gateways are chosen in stub to speed warm-up
• Client load generators– Clients issue two queries per minute– Queries generated randomly
• Metric: Instance penalty– Distance from client to discovered instance minus client to
hierarchical’s instance
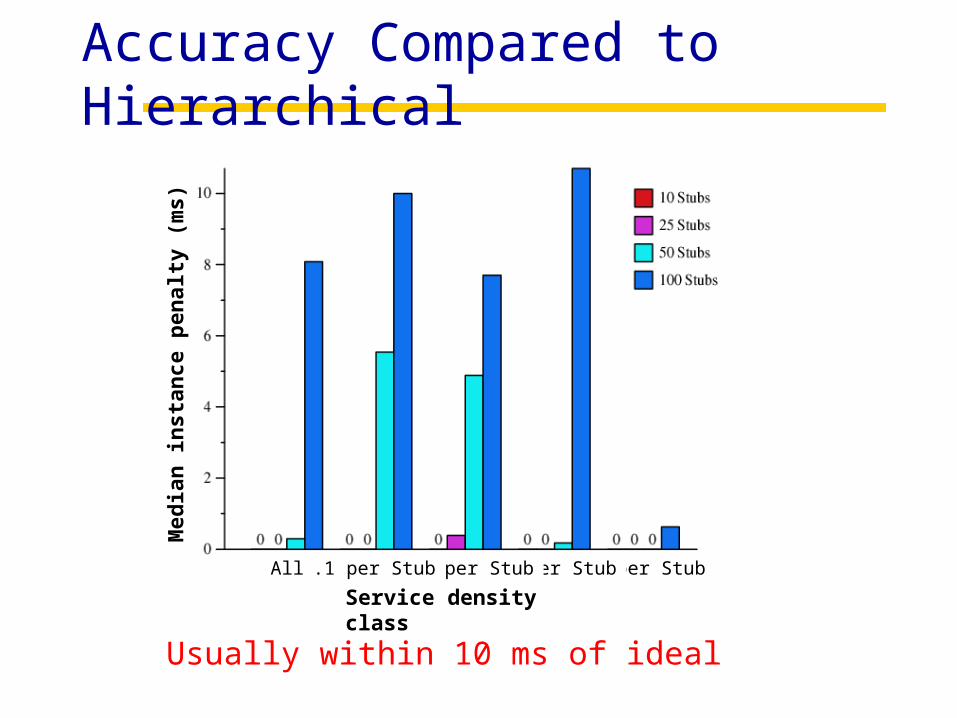
Accuracy Compared to Hierarchical
Usually within 10 ms of ideal
Service density class
Med
ian
inst
ance
pen
alty
(m
s)
All 5 per Stub1 per Stub.5 per Stub.1 per Stub
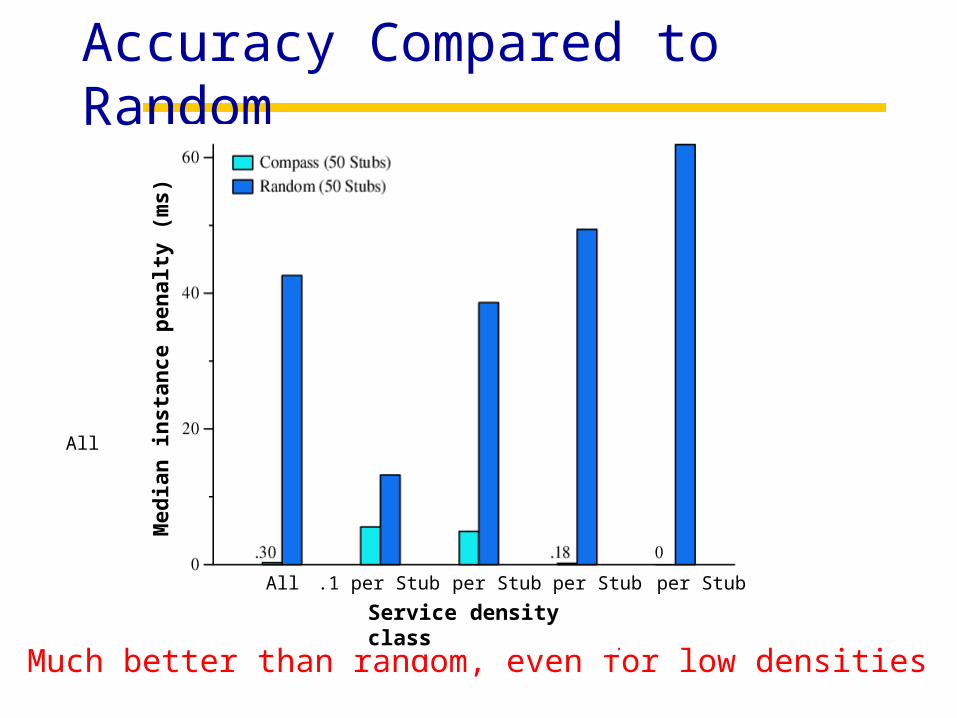
Accuracy Compared to Random
Much better than random, even for low densities
Med
ian
inst
ance
pen
alty
(m
s)
Service density class
All
All 5 per Stub1 per Stub.5 per Stub.1 per Stub
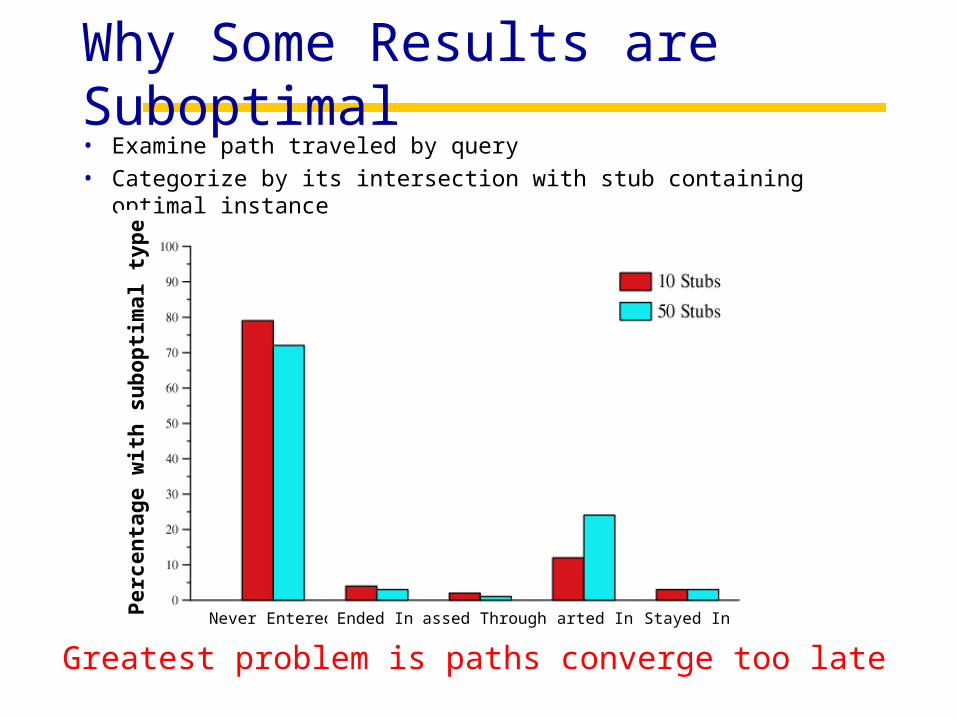
Why Some Results are Suboptimal
Greatest problem is paths converge too late
• Examine path traveled by query• Categorize by its intersection with stub containing optimal
instance
Per
cen
tage
wit
h s
ub
opti
mal
typ
e
Never Entered Started InPassed ThroughEnded In Stayed In
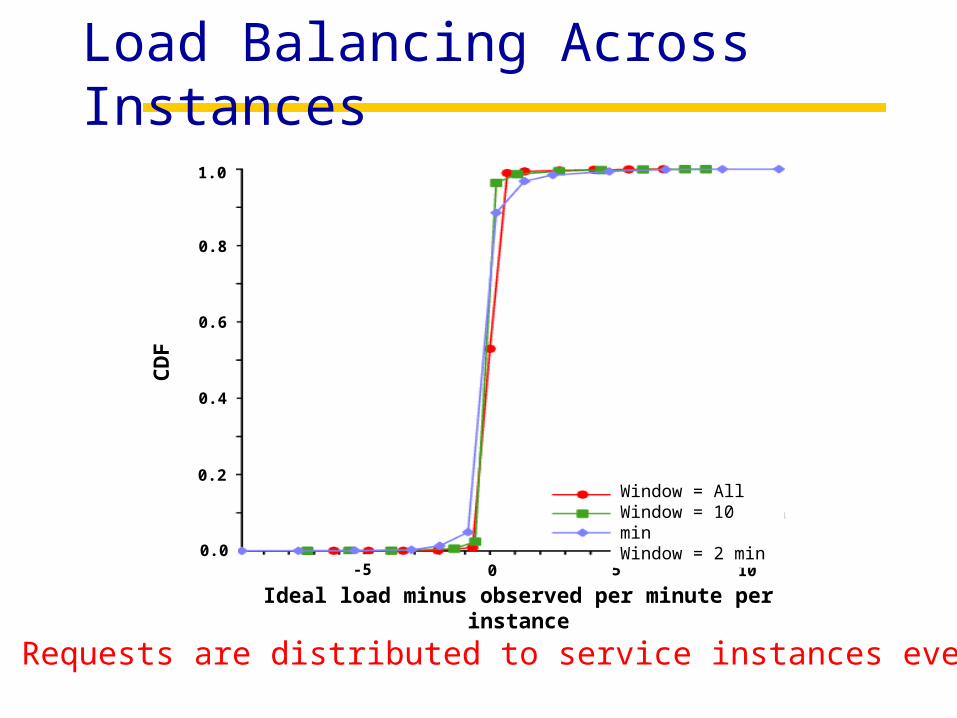
Load Balancing Across Instances
Requests are distributed to service instances evenly
CD
F
Ideal load minus observed per minute per instance-5 0 5 10
0.0
0.2
0.4
0.6
0.8
1.0
Window = AllWindow = 10 minWindow = 2 min
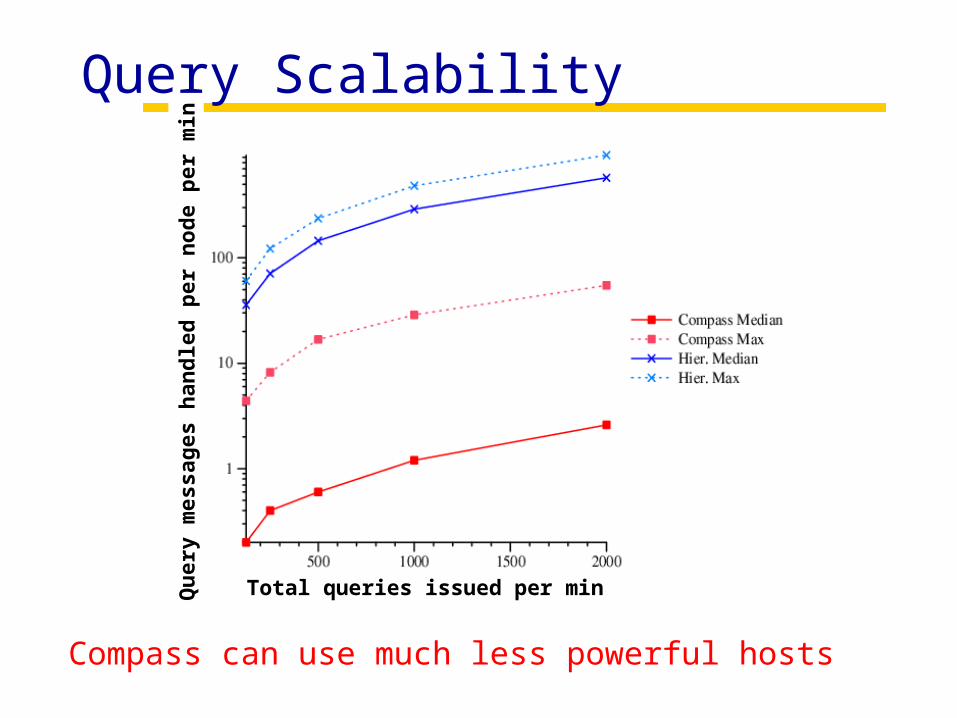
Query Scalability
Compass can use much less powerful hosts
Qu
ery
mes
sage
s h
and
led
per
nod
e p
er m
in
Total queries issued per min

Conclusions
• Overlay networks work well for discovery– Median latency usually less than 10 ms from
ideal– Load is distributed evenly among service
instances– Reduces query load by 1/200th– No need for manual configuration
• Future work– Investigate larger network topology– Incorporate virtual coordinates– Integrate into REAP and MINNO research

Backup Slides

What About Security?
• Security still unresolved in overlay networks
• Malicious nodes could– Drop all queries and publish messages– Mount DoS by constantly returning target as
answer to queries– Publish false instances to lure clients
• Duplicate pointers would dropping messages
• Integrating PKI would prevent false instances
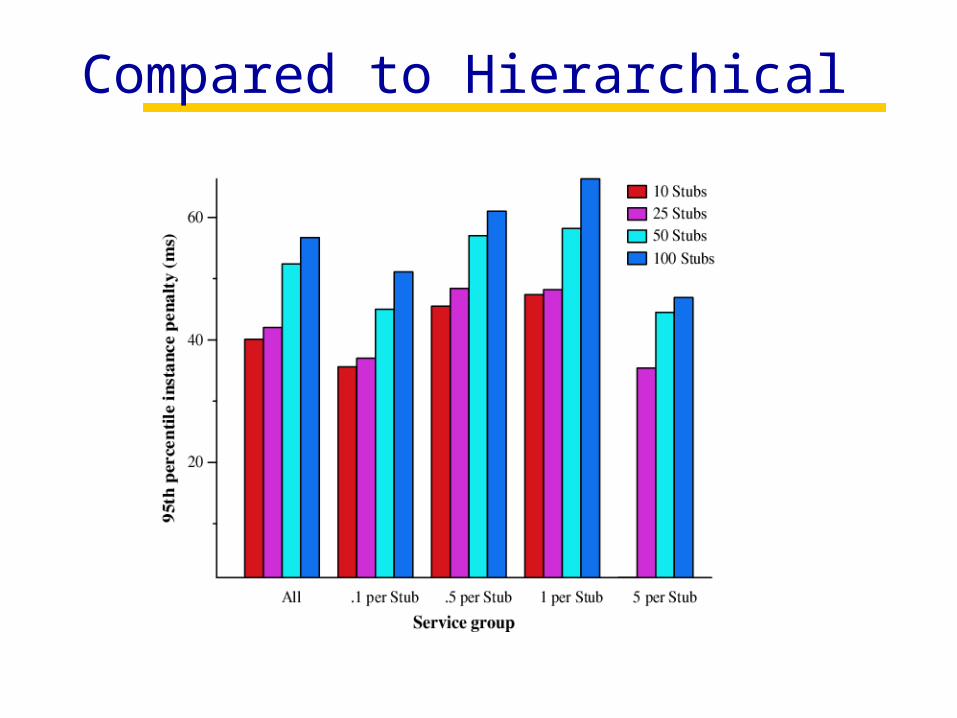
Compared to Hierarchical
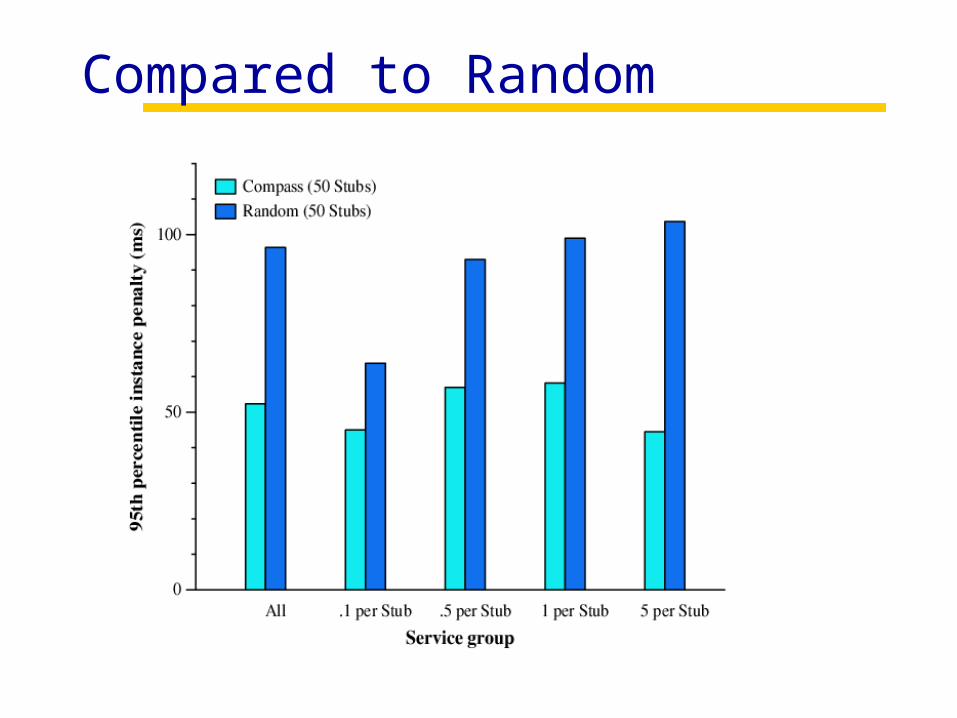
Compared to Random

















